References.bib
Advancing Long-Term Multi-Energy Load Forecasting with Patchformer: A Patch and Transformer-Based Approach
Abstract
In the context of increasing demands for long-term multi-energy load forecasting in real-world applications, this paper introduces Patchformer, a novel model that integrates patch embedding with encoder-decoder Transformer-based architectures. To address the limitation in existing Transformer-based models, which struggle with intricate temporal patterns in long-term forecasting, Patchformer employs patch embedding, which predicts multivariate time-series data by separating it into multiple univariate data and segmenting each of them into multiple patches. This method effectively enhances the model’s ability to capture local and global semantic dependencies. The numerical analysis shows that the Patchformer obtains overall better prediction accuracy in both multivariate and univariate long-term forecasting on the novel Multi-Energy dataset and other benchmark datasets. In addition, the positive effect of the interdependence among energy-related products on the performance of long-term time-series forecasting across Patchformer and other compared models is discovered, and the superiority of the Patchformer against other models is also demonstrated, which presents a significant advancement in handling the interdependence and complexities of long-term multi-energy forecasting. Lastly, Patchformer is illustrated as the only model that follows the positive correlation between model performance and the length of the past sequence, which states its ability to capture long-range past local semantic information.
Keywords Long-term multi-energy load forecasting Transformer-based model Patch embedding
1 Introduction
1.1 Background
The development of Integrated Multi-Energy Systems (IMES) marks a significant evolution in the energy sector, which reflects a shift towards more diversified, efficient, and sustainable energy management practices. IMES encompasses a blend of various energy sources and forms, including electricity, gas, heat, cooling and renewables, and it integrates into a cohesive system. This integration facilitates a more holistic energy production, distribution, and consumption framework. The evolution of IMES reflects a growing recognition of the need for more resilient and adaptable energy systems, especially in the face of escalating global energy demands and the need for improving collective technical, economic, and environmental performance [mancarella2016modelling]. IMES has become an important strategic development direction in the energy field to deal with the global challenges in the fossil energy crisis, climate changes and environmental pollution. Central to the effective operation of IMES is the role of energy forecasting. Precise prediction plays a crucial role in overseeing these complex systems, guaranteeing that energy generation and supply correspond with demand trends. This alignment is essential for maximising the economic and environmental benefits of IMES as well as for their operational efficiency. Accurate load forecasting contributes to the economic and environmental sustainability of energy systems by optimising resource allocation and lowering operating costs. For instance, [ranaweera1997economic] shows that the annual economic loss could be up to 10 million pounds when every percentage point increases in the error of electricity load forecasting in the United Kingdom. In addition, [wang2020multi] also illustrates that when the forecasting error is decreased by 1%, the total energy consumption of 58 million MW/h can be saved in one year in China. Moreover, effective energy load forecasting promotes the integration of renewable energy sources, assisting in the reduction of carbon/ greenhouse gas emissions and furthering the aims of sustainable energy from an environmental standpoint. The prediction’s reliability and accuracy are critical for the development of future energy systems to be sustainable and able to satisfy energy demands economically.
1.2 Literature Review
The methods of time-series forecasting can be categorised into two groups: 1) traditional methods represented by time-series analysis and regression analysis. 2) artificial intelligence methods represented by machine learning and deep learning. Autoregressive integrated moving-average (ARIMA) [box2015time, box1974some] is one of the most popular models in the former group. It predicts the data by obtaining the fitting equations for time series data and other variables. However, the traditional forecasting methods are mainly based on linear analysis and have limited capacity to deal with nonlinear problems [wang2020multi]. The latter group of time-series forecasting methods includes various machine learning and deep learning techniques, such as Recurrent Neural Networks (RNN) [rangapuram2018deep], Long Short-Term Memory (LSTM) networks [elsworth2020time], Gated Recurrent Units (GRU) [zhang2017time, jo2021improved], and Transformer-based methods [kitaev2020reformer, zhou2021informer, wu2021autoformer, zhou2022fedformer, nie2023a], which have significantly enhanced forecasting capabilities. Among these, Transformer-based models stand out for their ability to handle large datasets and capture complex temporal relationships in multivariate data, offering substantial improvements over other techniques. This is due to their parallelisability and attention mechanism. In particular, the vanilla transformer model [vaswani2017attention] uses a scaled dot product attention mechanism to calculate the point-wise correlation between two different data points. However, applying the full attention mechanism to long-term time-series forecasting (LTTSF) is computationally expensive due to its quadratic complexity in terms of the length of input sequence , which makes it challenging to handle long-term sequences. To overcome this issue, many improved models for LTTSF have been developed. For instance, Reformer [kitaev2020reformer] has been designed to enhance the efficiency for training on long sequences by introducing the Locality-Sensitive Hashing attention to reduce the computational complexity from to . Informer model [zhou2021informer], which also achieves complexity, introduces a ProbSparse self-attention mechanism, self-attention distilling, and a generative style decoder. These features collectively enhance the model’s efficiency and prediction capacity, making it a robust solution for LTTSF. Although the computational complexity has been reduced, the above models still use the point-wise attention mechanism to understand the correlation between two data points. This may not be the preferred mechanism in time-series forecasting compared to natural language processing (NLP). It is because, unlike a word in a sequence sentence, a single time step in a time series does not have semantic meaning. Therefore, the point-wise correlation cannot capture the input sequence’s local semantic information or pattern, which results in poor LTTSF performance. A few models have been developed to address the problem. For instance, Autoformer [wu2021autoformer] incorporates a decomposition architecture with an Auto-Correlation mechanism calculated by Fast Fourier Transforms (FFT) based on series periodicity. It focuses on discovering dependencies and aggregating representations at the sub-series level. This mechanism is more efficient and accurate than traditional self-attention mechanisms, especially for long-term forecasting. Similarly, FEDformer [zhou2022fedformer] also introduces the seasonal-trend decomposition and Frequency Enhanced Attention block with Discrete Fourier Transform (DFT) to capture the sub-series level correlation in time-series sequences. Moreover, inspired by the Vision Transformer (ViT) [dosovitskiy2021an] which truncates each image into patches before feeding it into the vanilla transformer model, and the following influential work BEiT [bao2022beit], PatchTST [nie2023a] segments time series into subseries-level patches as input tokens, which is designed to retain local semantic information, and employs channel-independence, where each channel contains a single univariate time series sharing the same embedding and Transformer weights which benefits for multivariate time-series forecasting. This design enhances long-term forecasting accuracy significantly compared to state-of-the-art Transformer models, reduces computation and memory usage, and allows the model to attend to a more extended history. This paper proposes a novel Transformer-based model which integrates the patch embedding mechanism and vanilla transformer’s encode-decoder architecture to improve the LTTSF performance.
The methods for load forecasting also consist of both traditional and artificial intelligence methods. For instance, [lee2011short, fang2016evaluation] apply ARIMA and its variant seasonal autoregressive integrated moving-average (SARIMA) for load forecasting problems. [shi2017deep] proposes a novel pooling-based deep RNN for household load forecasting, which batches a group of customers’ load profiles in a pool of inputs. [kong2017short] introduces an LSTM RNN-based framework to forecast the highly volatile and uncertain electric load of an individual energy customer. A novel short-term load forecasting method based on attention mechanism, rolling update and bi-directional long short-term memory (Bi-LSTM) neural network is proposed for short-term electricity load forecasting in [wang2019bi]. One of the characteristics of multi-energy data is the interdependence among each energy. Forecasting models have been built to capture the interdependence to enhance the forecasting accuracy in the literature. For instance, [wang2020multi] proposes an encoder-decoder model based on LSTM, considering the high-dimensional temporal dynamic characteristic. To capture the cross-coupling characteristic, a coupling feature matrix for multi-energy load is established. [zhang2021short] presents a convolutional neural network (CNN)-Seq2Seq model with an attention mechanism based on a multi-tasking learning method for a short-term multi-energy load forecasting, which considering temperature, humidity, wind speed, and the coupling relationship of multi-energy. An improved multi-energy forecasting method, which uses a CNN-Attention-LSTM model based on federated learning to predict multi-energy load in the integrated energy microgrid is proposed in [zhang2022federated]. In time-series forecasting literature, the prediction length for LTTSF typically ranges from 96 to 720 time steps with hourly data [nie2023a, wu2021autoformer, zhou2022fedformer, zhang2022crossformer]. On the other hand, short-term energy load forecasting literature usually predicts for a few days or weeks [kuo2018high, wang2019bi, zhang2021short, cen2024multi], while long-term energy load forecasting literature extends to months or years [mohammed2022adaptive, khuntia2018long, lindberg2019long]. However, the daily or monthly data used in energy load prediction may have fewer time steps to predict than LTTSF literature. To predict multi-energy load with hourly data, this paper follows the definition of long-term in LTTSF literature. Furthermore, long-term multi-energy load forecasting has witnessed a paradigm shift in recent years with the development of Transformer-based models. Many Transformer-based models are developed for multi-energy load forecasting in the literature. For instance, A one-encoder multi-decoder multi-task model is developed in [wang2022transformer] to capture the joint relationships among different energies. A similar idea is also adopted in [wang2023probabilistic] with the novel Bayesian multi-head attention mechanism. Despite the growing body of research on Transformer-based models in multi-energy forecasting, a research gap remains in the literature. To the best of our knowledge, there has been no exploration of Transformer-based models that incorporate patch embedding techniques in long-term multi-energy load forecasting, which has shown great promise in other domains, such as NLP and computer vision (CV), for its ability to capture local contextual information and reduce computational complexity. [cen2024multi] proposes a PatchTCN-TST model, which applies a patching approach but only for short-term multi-load energy forecasting. The absence of patch embedding-based Transformer models in long-term multi-energy load forecasting is a significant neglect. Such models have the potential to enhance the model’s ability to process and learn from multivariate time series data, capture local and global semantic information, and provide a deep understanding of energy consumption patterns. This approach could lead to more accurate and robust forecasting models, which are essential for effective energy management and planning in the face of increasing demand and the growing complexity of future energy systems.
1.3 Contributions
This paper introduces a novel Transformer-based model that integrates patch embedding techniques for long-term multi-energy load forecasting. This model, which we have named the Patchformer, is designed to address the specific challenges of forecasting energy loads over extended periods. By processing the multivariate time series data into multiple univariate data and segmenting individual univariate data into patches, the Patchformer offers a unique approach to understanding and predicting energy consumption patterns. We believe this model represents an advancement in energy forecasting, filling a critical gap in the existing literature and improving the accuracy and efficiency across long-term forecasting models. The key contributions of this paper are outlined as follows:
-
•
Innovative Model Architecture: The Patchformer is designed to integrate the Patch Embedding block from PatchTST and the encoder-decoder structure from the vanilla transformer model. This Patch Embedding block treats each channel of the multivariate time series as a distinct univariate input and segments it into subseries-level patches. This approach captures local semantic information within each univariate time series and learns inter-channel relationships more effectively via a channel-independent approach, where each channel shares the same embedding and Transformer weights, enhancing efficiency in multivariate time-series forecasting. In addition, with its multi-head attention mechanisms, the encoder-decoder structure facilitates the importation of comprehensive information from the encoder to the decoder, potentially improving forecasting accuracy.
-
•
First of its kind for Long-Term Multi-Energy Load Forecasting: To the best of our knowledge, the Patchformer is the first Transformer-based model employing a patch embedding method for long-term multi-energy load forecasting. This approach effectively addresses the complexities of predicting multi-energy load over extended periods and captures the interdependence among different energies (e.g., electricity, gas and heat) and other energy-related products (e.g., greenhouse gas (GHG)).
-
•
Comprehensive Numerical Analysis: Experiments show the Patchformer model achieves better performance against other state-of-the-art Transformer-based models for multivariate long-term forecasting in the Multi-Energy dataset and six other benchmark datasets. In addition, the model also procures higher accuracy in univariate long-term forecasting when predicting the load of electricity and gas. Moreover, the numerical analysis also illustrates the positive effect of the interdependence among energies and energy-related products on the performance of the forecasting in the Multi-Energy dataset across Patchformer and other models via comparing the model accuracy between predicting the electricity, gas load and GHG emissions all at once and the average of the individual predictions. Lastly, the experiment demonstrates the distinct positive correlation between Patchformer’s performance and the past sequence length, which shows its ability to capture long-range past local semantic information.
1.4 Paper Organisation
The remainder of this paper is organised as follows. Section 2 illustrates the proposed Patchformer mode architecture in detail. In Section 3, numerical analysis has been developed and evaluated the performance of the Patchformer as well as other state-of-the-art Transformer-based models in different types of datasets, including one novel multi-energy dataset and six public benchmark datasets. In addition, the multi-energy analysis is also illustrated in the section. Lastly, Section 4 concludes the paper and discusses future work.
2 Model Architecture
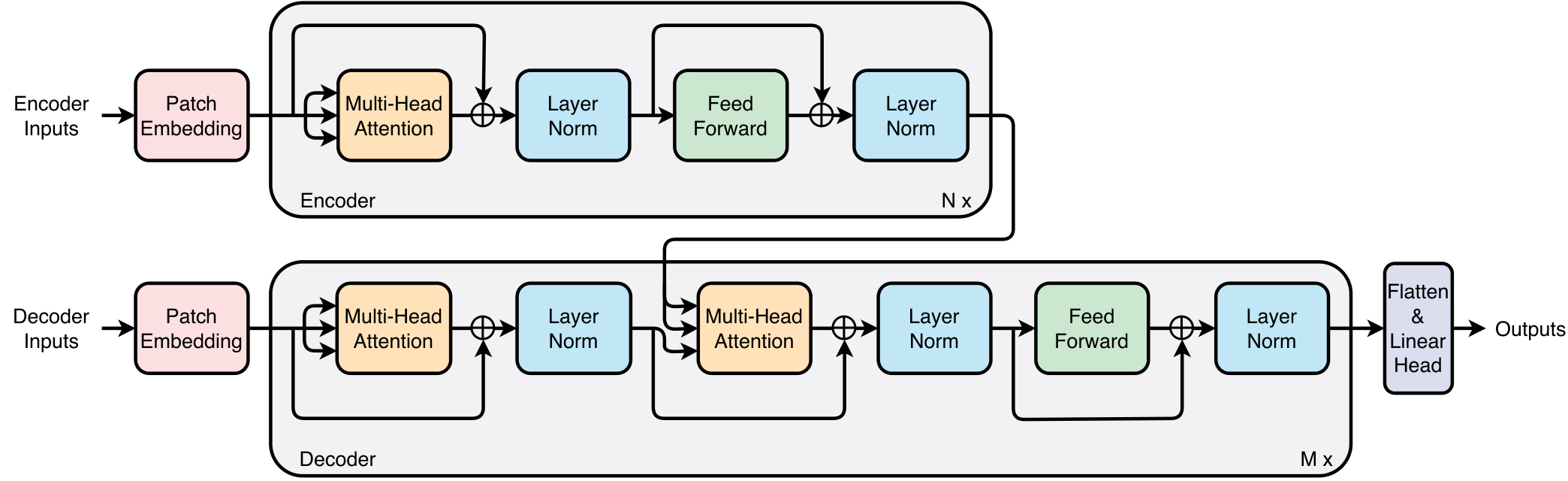
This section introduces the Patchformer model architecture, which is shown in Figure 1. Section 2.1 gives a high-level overview of the Patchformer model. Section 2.2 presents one of the core concepts of the model, which is the patching embedding approach. Section 2.3,2.4 and 2.5 depict each of the building blocks for the encoder and decoder. Finally, the structure of the encoder, decoder, and linear head are illustrated in Section 2.6,2.7 and 2.8, respectively.
2.1 Model Overview
The model consists of an encoder and a decoder, while the maximum number of layers in the encoder and decoder are and , respectively. For the multivariate time-series forecasting, the past time sequence is denoted as with a total of length and channels . represents a data point at time and channel . The future/prediction time sequence is represented as with the total length . Through the encoder, the information of its inputs is imported into the decoder to provide extra past information for the decoder to predict future sequences.
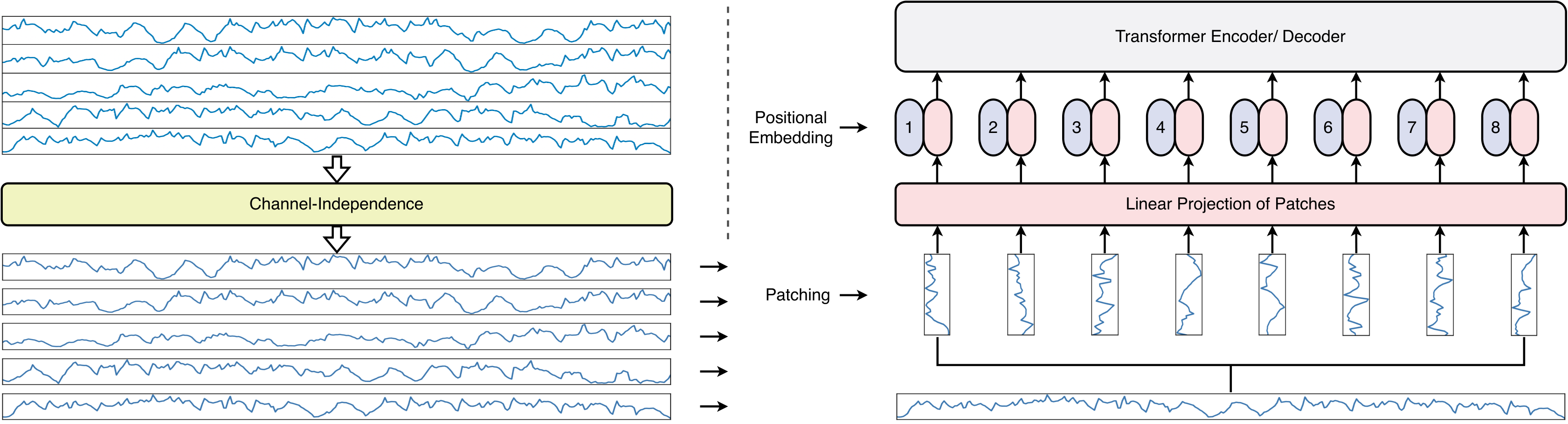
2.2 Patch Embedding
The past multivariate time sequence is split as univariate time sequences before patching, which is the representation of the channel-independence. Each is then segmented into multiple patches by the patch length and stride which is similar to the idea in CNN. Therefore, the total number of patches is calculated by . Notice that the patching method always pads extra time steps with the last value of the past time sequence to ensure all time-series data are in patches [nie2023a]. After patching, a one-dimensional univariate time series data is converted to a two-dimensional matrix in which each row represents a patch. In addition, value embedding which projects from dimensional space into dimensional space and positional embedding is applied to optimise the patch representation and ordering. Figure 2 shows the procedure of the patch embedding approach. Lastly, the patch embedding block can be represented as which are illustrated as follows:
| (1) | ||||
where is a learnable weight for value embedding and denotes positional embedding. is the patch embedded output.
2.3 Multi-Head Attention Block
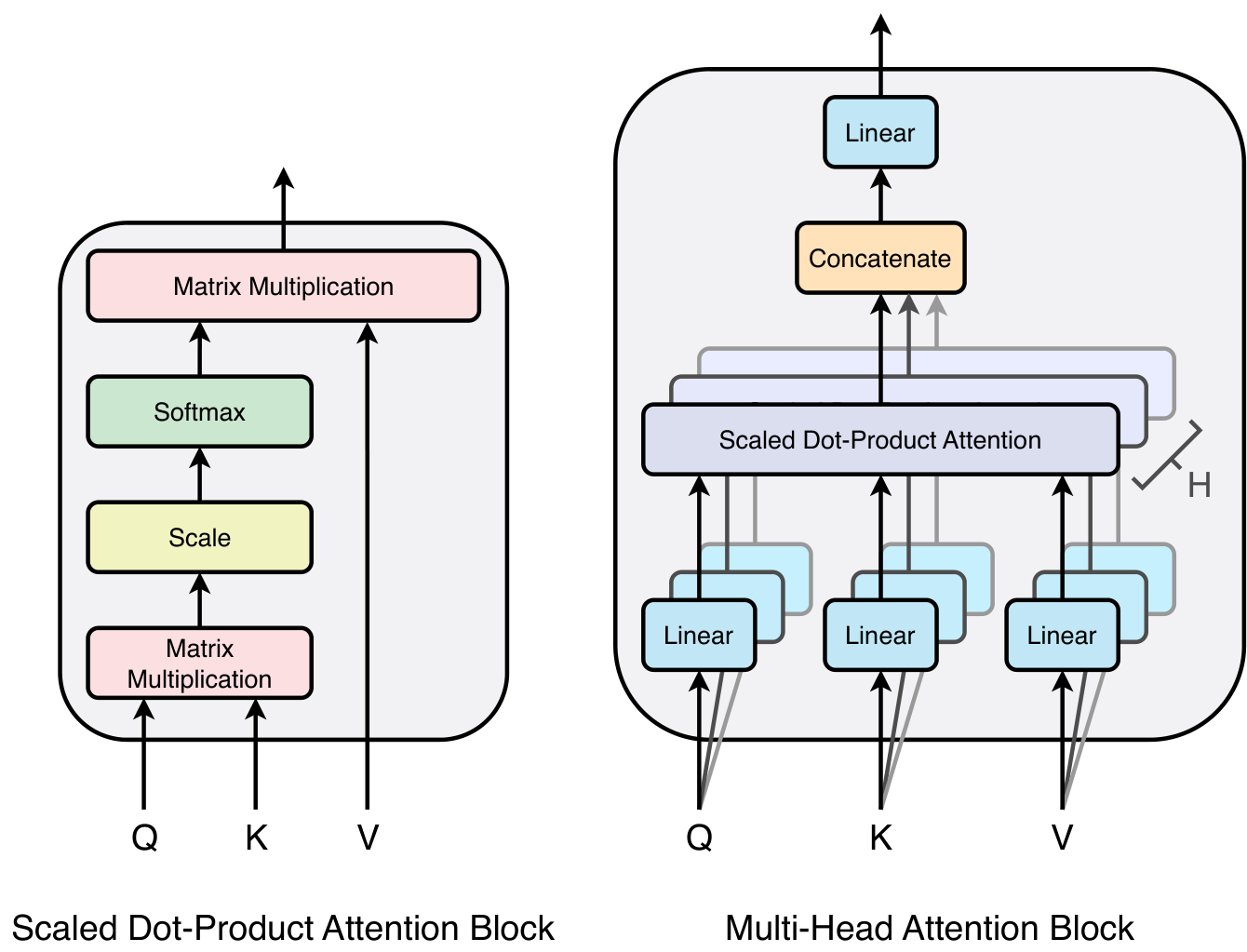
The Patchformer employs the vanilla transformer’s multi-head attention mechanism [vaswani2017attention] to learn the complex local semantic information among patches. Figure 3 shows the scaled dot product attention and multi-head attention mechanisms. In particular, the attention layer is used to calculate the attention score by applying the softmax function to the dot product of the similarity between Query and Key . The result of the dot product is then scaled by . The attention score is calculated by the product between the scaled dot product and Value . All the , and are computed from the dot product between input and , and , respectively. The multi-head attention block consists of attention layers, namely, heads, which obtain the multi-head attention score by calculating the dot product between the concatenated attention scores and . The multi-head attention block are formulated as follows:
| (2) | ||||
where the trainable weights and result in and . Lastly, the multi-head attention output is obtained by projecting the row-wise concatenation among all heads with weight .
2.4 Layer Normalisation Block
Layer normalisation is a technique designed to normalise the inputs across the features for each data sample in a mini-batch. Unlike batch normalisation, which normalises across the batch dimension, layer normalisation performs normalisation for each individual sample. For a given sub-layer output , layer normalisation first computes the mean and standard deviation for each data sample independently. The output of the sub-layer is then normalised by subtracting the mean and dividing by the standard deviation. After normalisation, the process applies two learnable parameters, typically denoted as and , which scale and shift the normalised value, respectively. These are trainable parameters which are learned during the training process. The layer normalisation is denoted as and the detailed process is shown below:
| (3) | ||||
Layer normalisation helps stabilise the training process and enables the training of deeper models by mitigating the vanishing or exploding gradient problems. It can lead to faster convergence in training, which is crucial for complex models like transformers that have a large number of parameters.
2.5 Feed Forward Block
The Feed Forward block includes two fully connected feed-forward networks (FFNs) with the ReLU activation function in between.
| (4) |
where the weights in the FFNs are and , respectively. denote the bias terms of the FFNs. The feed forward block is summarised by with the output dimension unchanged compared to its input.
2.6 Encoder
With all the above blocks, the Patchformer encoder can be summarised as below:
| (5) | ||||
where the and represent the outputs of the first and the second layer normalisation blocks, respectively. In addition, the output of the -th encoder layer and which is converted from the encoder inputs .
2.7 Decoder
Patchformer decoder’s input consists of two parts. The first part comes from the second half of the encoder’s inputs , denoted as to provide the most recent past information to the decoder. The second part of are all zeros. The detailed formulation is shown below:
| (6) |
where is used as a placeholder to form the decoder input.
After Patch Embedding, , is obtained as the input for the decoder. Notice that the inner and encoder-decoder multi-head attentions are designed to capture the local semantic information among input patches. By adopting the encoder’s output , the decoder can be summarised as follows:
| (7) | ||||
where represents the outputs for the -th decoder layer. In addition, . denote the outputs of layer normalisation blocks in the -th decoder layer, respectively.
2.8 Flatten and Linear Head
The Flatten and Linear Head block is designed first to flatten the output of the decoder from dimension to . Second, the final prediction sequence is obtained by converting the output dimension again to . The detailed formulations are shown below:
| (8) | ||||
where , . The final prediction time sequence is obtained by a linear transformation with weight .
3 Numerical Analysis
In this section, the performance comparison and evaluation between the proposed Patchformer and other state-of-the-art models: Autoformer [wu2021autoformer], Crossformer [zhang2022crossformer], and Transformer [vaswani2017attention] and multi-energy analysis are discussed in detail. Firstly, the datasets which contain a novel Multi-Energy dataset, six public benchmark datasets and experimental setup are introduced in Section 3.1. The performance of multivariate forecasting for Patchformer and other models across different datasets are discussed in Section 3.2. Sections 3.3-3.5 analyse the Patchformer performance on the Multi-Energy dataset from various perspectives in detail. In particular, Section 3.3 studies the univariate forecasting performance among Patchformer and other models on the Multi-Energy dataset by predicting electricity, gas load and GHG emission. In addition, the effect of the interdependence among electricity, gas load and GHG emission on the performance of the LTTSF on the Multi-Energy dataset is illustrated in Section 3.4. Lastly, in Section 3.5, the forecasting performance is compared between Patchformer and other models with different past sequence lengths.
3.1 Datasets and Experimental Setup
The proposed Patchformer model is evaluated on seven datasets, including the novel and comprehensive Multi-Energy dataset [multi-energy] and other six datasets that are well known and have been utilised as benchmarks, publicly available on [wu2021autoformer]. Here is the description of the seven datasets: Multi-Energy dataset records energy-related data collected on the Temple campus at Arizona State University, which includes hourly electricity, gas, and heat load demand, renewable energy generation, and GHG emissions for each building from 24 July 2015 to 12 September 2020. Exchange dataset collects the daily exchange rate of eight different countries from 1 January 1990 to 10 October 2010. Weather dataset is a collection of 21 meteorological indicators (e.g., air temperature, humidity and precipitation) every 10 minutes in the entire year of 2020. and ETTh1 and ETTh2 datasets record the hourly data (e.g., load and oil temperature) from two different electricity transformers from 1 July 2016 to 26 June 2018. Similarly, and ETTm1 and ETTm2 datasets collect every 15 minutes data from the two electricity transformers in the same time period. The statistics of the seven datasets are shown in Table 1, which shows the total number of input features and length of the time-series observations. The Patchformer and other models are written in PyTorch and run on Ubuntu 22.04.3 LTS x86_64 with Intel Xeon (8) @ 2.000GHz and 52GB of RAM. The GPU uses NVIDIA Tesla V100 SXM2 16GB.
Moreover, in this section, the mean squared error (MSE) and mean absolute error (MAE) are applied as experimental evaluation indicators to reflect the forecasting accuracy of the proposed Patchformer and other comparison models. The definitions of the two evaluation indexes are formulated as follows:
| (9) | ||||
where is the total number of the data. The actual and predicted values are denoted as and at the -th time step of the dataset, respectively.
Datasets Multi-Energy Exchange Weather ETTh1 ETTh2 ETTm1 ETTm2 Features 19 8 21 7 7 7 7 Length 49415 7588 52696 17420 17420 69680 69680
Models Hyperparameters Patchformer patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 8, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 Autoformer topK = 5, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 Crossformer topK = 5, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 Transformer encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 8, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Multi-Energy | 96 | 0.062 | 0.135 | 0.061 | 0.150 | 0.067 | 0.150 | 0.063 | 0.147 | |
| 192 | 0.073 | 0.149 | 0.075 | 0.161 | 0.086 | 0.172 | 0.079 | 0.161 | ||
| 336 | 0.090 | 0.167 | 0.083 | 0.173 | 0.165 | 0.243 | 0.153 | 0.217 | ||
| 720 | 0.121 | 0.193 | 0.140 | 0.215 | 0.221 | 0.274 | 0.257 | 0.273 | ||
| Exchange | 96 | 0.089 | 0.217 | 0.153 | 0.285 | 0.256 | 0.367 | 0.550 | 0.579 | |
| 192 | 0.190 | 0.321 | 0.277 | 0.383 | 0.468 | 0.508 | 0.934 | 0.734 | ||
| 336 | 0.387 | 0.471 | 0.471 | 0.513 | 0.975 | 0.763 | 1.328 | 0.904 | ||
| 720 | 1.071 | 0.769 | 1.107 | 0.818 | 1.620 | 1.029 | 2.565 | 1.336 | ||
| Weather | 96 | 0.175 | 0.231 | 0.342 | 0.385 | 0.177 | 0.242 | 0.353 | 0.412 | |
| 192 | 0.213 | 0.274 | 0.321 | 0.374 | 0.222 | 0.289 | 0.574 | 0.542 | ||
| 336 | 0.263 | 0.311 | 0.347 | 0.384 | 0.276 | 0.338 | 0.631 | 0.584 | ||
| 720 | 0.339 | 0.369 | 0.415 | 0.418 | 0.372 | 0.411 | 0.850 | 0.686 | ||
| ETTh1 | 96 | 0.425 | 0.444 | 0.529 | 0.487 | 0.419 | 0.439 | 0.773 | 0.684 | |
| 192 | 0.484 | 0.477 | 0.509 | 0.486 | 0.539 | 0.517 | 0.886 | 0.744 | ||
| 336 | 0.549 | 0.512 | 0.508 | 0.494 | 0.709 | 0.638 | 0.966 | 0.770 | ||
| 720 | 0.603 | 0.566 | 0.542 | 0.520 | 0.721 | 0.622 | 1.016 | 0.800 | ||
| ETTh2 | 96 | 0.342 | 0.387 | 0.375 | 0.410 | 0.790 | 0.612 | 2.633 | 1.291 | |
| 192 | 0.473 | 0.459 | 0.443 | 0.449 | 1.830 | 1.041 | 5.961 | 2.007 | ||
| 336 | 0.475 | 0.478 | 0.501 | 0.496 | 1.863 | 1.088 | 5.811 | 1.948 | ||
| 720 | 0.600 | 0.538 | 0.496 | 0.499 | 2.833 | 1.447 | 2.964 | 1.399 | ||
| ETTm1 | 96 | 0.364 | 0.393 | 0.512 | 0.485 | 0.362 | 0.403 | 0.725 | 0.620 | |
| 192 | 0.411 | 0.421 | 0.539 | 0.494 | 0.388 | 0.422 | 0.870 | 0.703 | ||
| 336 | 0.437 | 0.447 | 0.587 | 0.523 | 0.617 | 0.579 | 1.062 | 0.790 | ||
| 720 | 0.499 | 0.482 | 0.650 | 0.535 | 0.931 | 0.722 | 1.063 | 0.789 | ||
| ETTm2 | 96 | 0.214 | 0.308 | 0.230 | 0.314 | 0.250 | 0.333 | 0.469 | 0.500 | |
| 192 | 0.321 | 0.380 | 0.281 | 0.340 | 0.888 | 0.694 | 1.438 | 0.891 | ||
| 336 | 0.373 | 0.415 | 0.338 | 0.373 | 1.451 | 0.850 | 1.154 | 0.818 | ||
| 720 | 0.592 | 0.529 | 0.459 | 0.441 | 2.678 | 1.148 | 2.675 | 1.208 | ||
3.2 Multivariate Forecasting on Different Datasets
In this section, the performance of multivariate forecasting among different models on the above-mentioned seven datasets is compared. Multivariate forecasting considers the historical data of several variables to forecast one or more of these variables while taking into account the interdependence between multiple input variables. The same number of input and output variables is applied to analyse the performance of the multivariate forecasting in this section. The hyperparameters used in the section are shown in Table 2. The prediction and past sequence length are set to be and , respectively. The evaluation results are shown in Table 3. Patchformer consistently outperformed competing models at prediction sequence lengths of 192, 336 and 720 on the Multi-Energy dataset introduced in this paper. Notably, at the 720-step forecast, the Patchformer achieved an MSE of 0.121 and an MAE of 0.193, which is 15.70% and 11.40% less than the second-best scores, respectively. It indicates its capability to capture the complex interdependencies among the multiple energy vectors over long-term horizons. In addition, at the extended horizon of 96, 192 and 336 steps, the Patchformer’s performance remains competitive, with all the best MSE and MAE, except for two second-best MSE at 96 and 336 steps, demonstrating the model’s robustness in long-term forecasting. Its superiority in the multi-energy forecasting domain is critical for modern IMES systems.
For benchmark datasets in multivariate time series forecasting, the Patchformer exhibited varying degrees of efficacy. In the Exchange Rate dataset, the Patchformer performs the best across all prediction lengths and is optimal at shorter horizons but showed a significant decline as the prediction length increased, with the MSE rising sharply to 1.071 at the 720-step horizon. This suggests a potential vulnerability in the Patchformer’s architecture when dealing with the non-stationary and volatile nature of financial time series over long-term periods.
In Weather forecasting, the Patchformer maintained competitiveness and the best performance across all horizons, with the best MSE and MAE for all prediction steps. This indicates the Patchformer’s adeptness at modelling environmental time series data, which often have clearer temporal patterns and seasonality.
With the ETTh1, ETTh2, ETTm1, and ETTm2 datasets, which contain the data from electricity transformers, including load and oil temperature, the Patchformer displays either the best or second-best MSE and MAE for all prediction lengths, which indicates the model’s robustness and reliability. In particular, Patchformer obtains the best MSE and MAE for all different prediction lengths on the ETTm1 dataset, except for MSE at 96 and 192 steps, which are relatively close to the best results obtained by Crossformer.
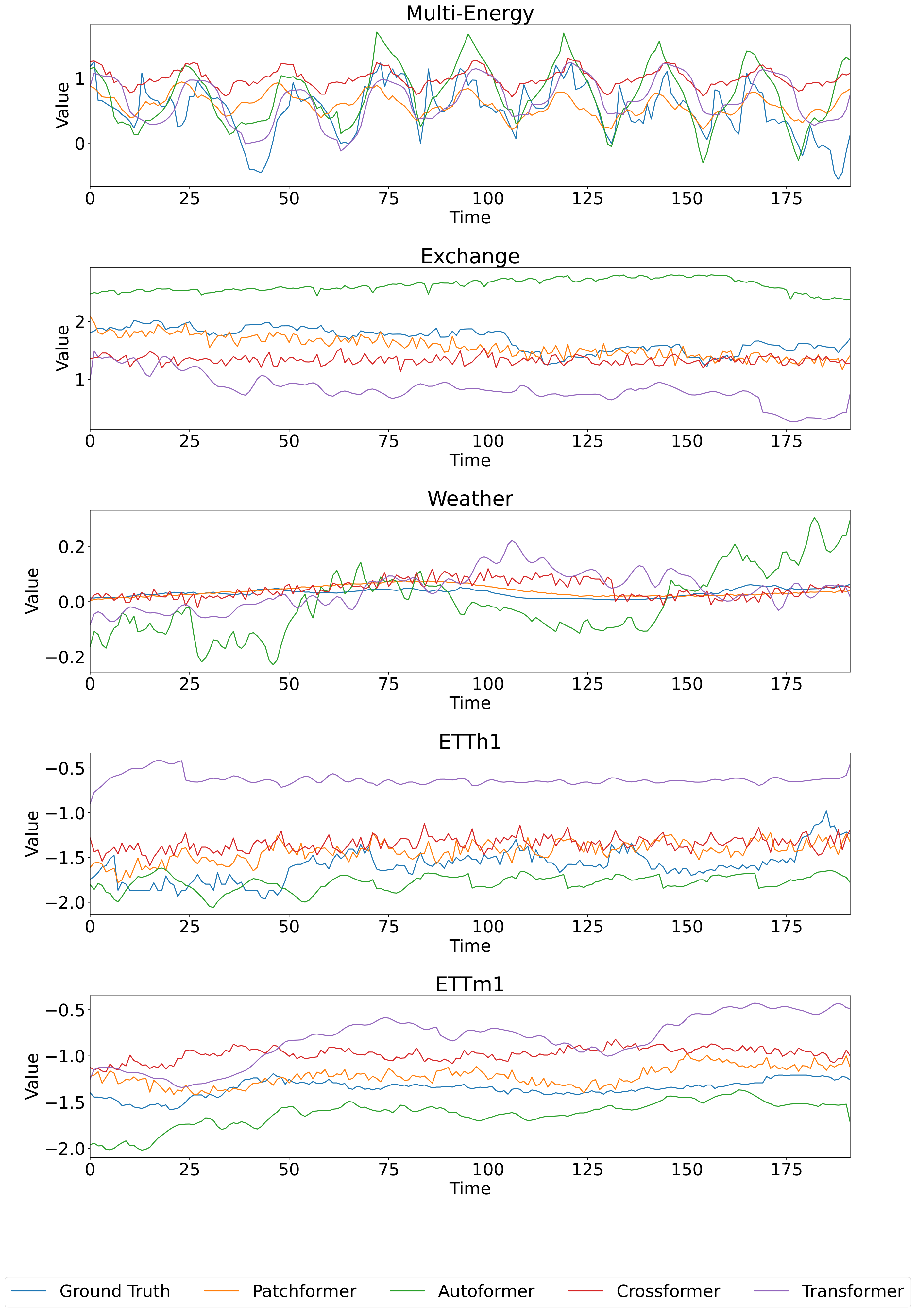
Figure 4 visualises the time-series predictions of the four models on Multi-Energy, Exchange, Weather, ETTh1 and ETTm1 datasets. In particular, the predicted values of the electricity load on the Multi-Energy dataset are visualised to show the models’ performance. As a result, the Patchformer exhibits strong performance across multiple datasets since it efficiently captures the trend and is closest to the ground truth. The experimental results indicate that the Patchformer can handle long-term predictions efficiently, especially in domains where the data has explicit seasonality patterns. With high volatility and irregular patterns, such as financial markets, the Patchformer’s long-term forecasting performance can be improved in future work.
3.3 Univariate Forecasting
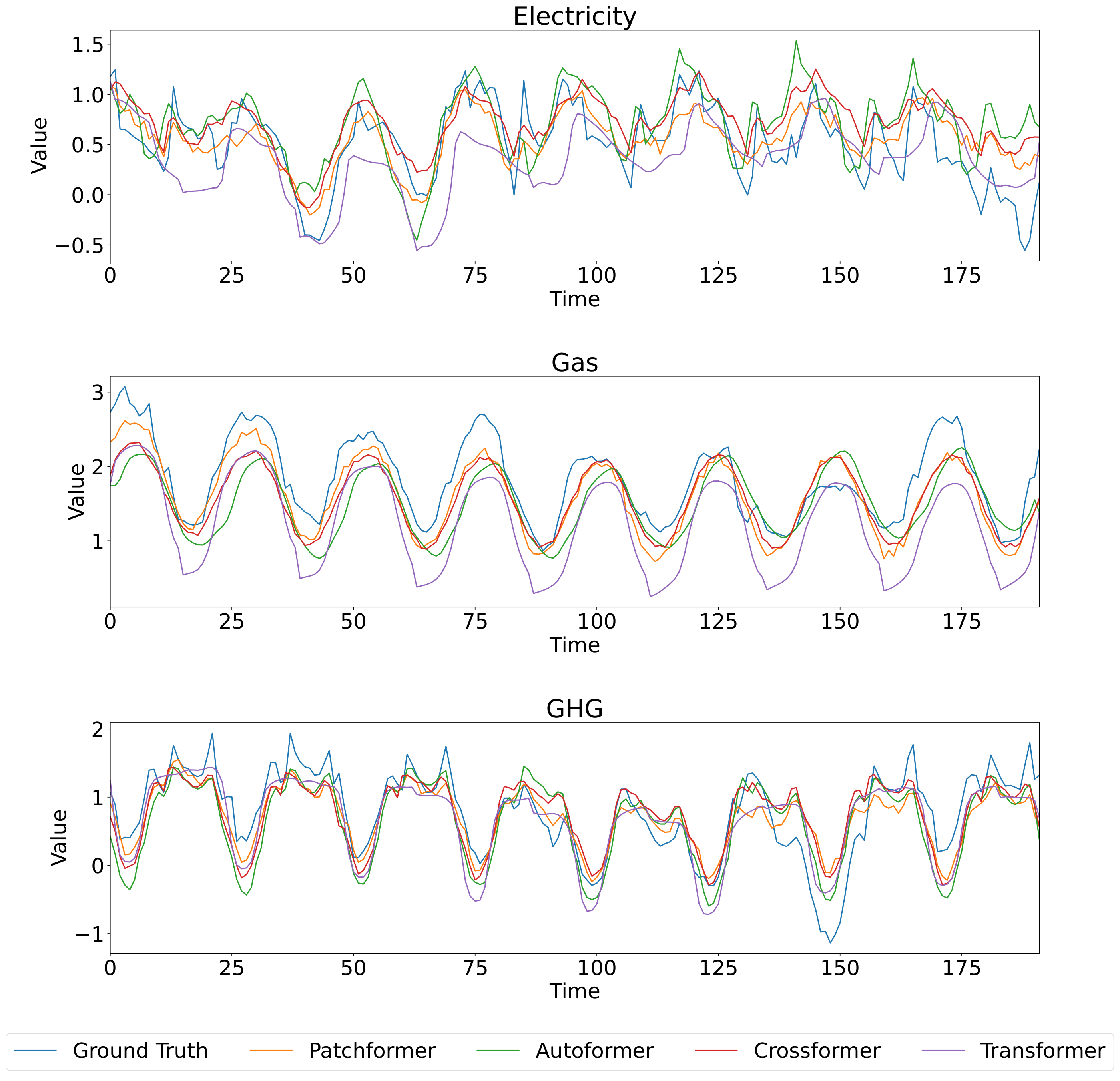
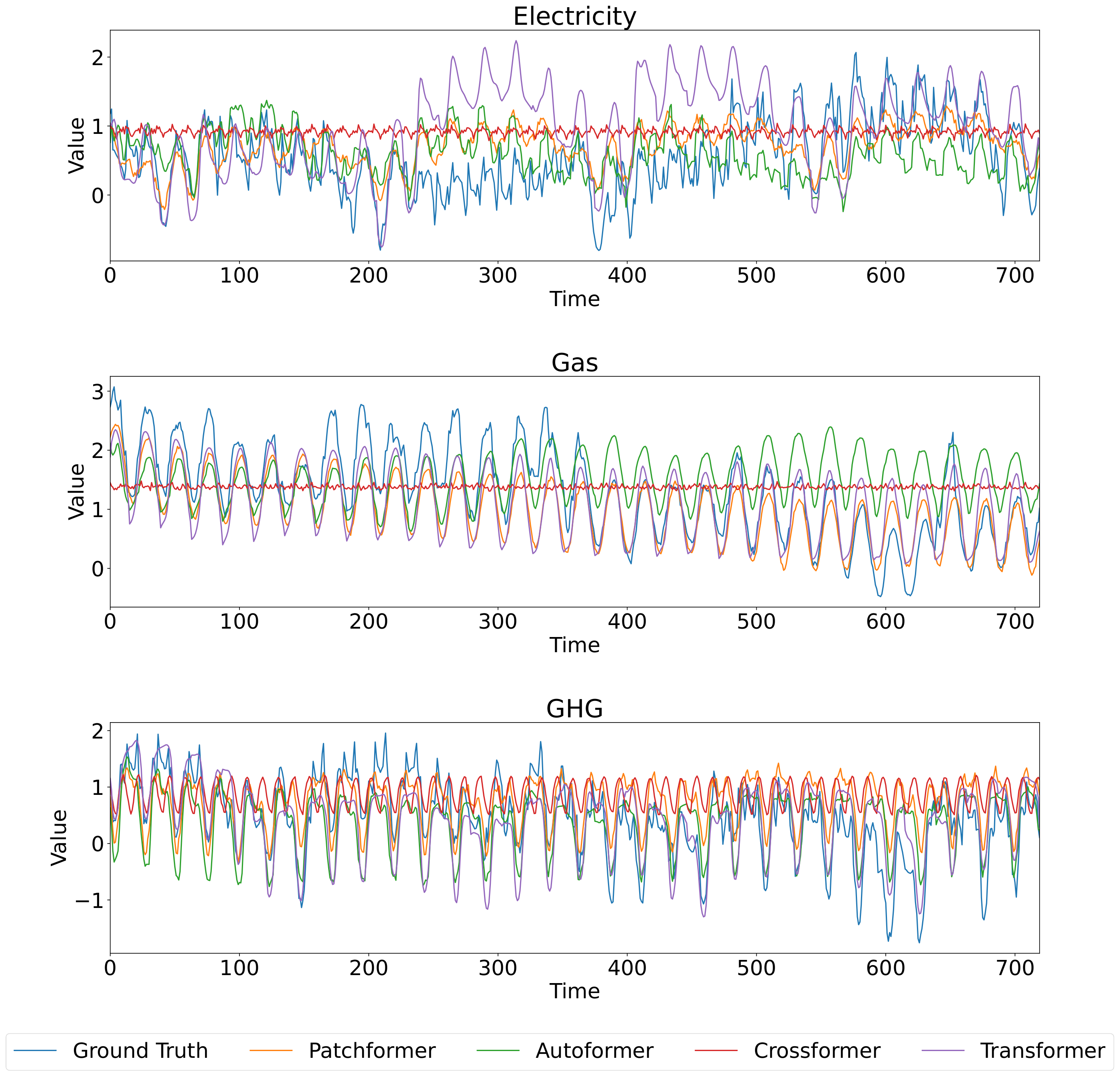
In addition to multivariate forecasting, this section presents univariate forecasting results with Patchformer and other comparing models on the Multi-Energy dataset. Univariate forecasting focuses on forecasting the future values of that single variable based on its own historical data. The output is the prediction of future values of the same single variable without considering any other input variables. The features chosen to be analysed are electricity and gas load demand, as well as GHG emissions. The hyperparameters of Patchformer among different prediction lengths are shown in Table 4. The past sequence length for all models is fixed at 336 time steps, and the forecasting horizons are 96, 192, 336, and 720 time steps. Table 5 shows univariate forecasting results. Patchformer outperforms all other models on electricity and gas forecasting as it receives the best MSE and MAE results across all prediction lengths. For the forecasting results on the GHG dataset, Patchformer has room for improvement, which implies there may not be a single model that universally outperforms others across all metrics, electricity and gas demand, GHG emissions, and prediction lengths. In addition, Figures 5 and 6 visualise 336 steps past sequence length forecasting with all models on Electricity, Gas and GHG in the Multi-Energy dataset when the prediction lengths are 192 and 720 steps, respectively. The time-series patterns among Electricity, Gas and GHG are shown to be different in both figures. Also, it is fairly obvious to observe that the predictions of Patchformer are the closest to the ground truth value when predicting electricity and gas in Figures 5 and 6, which indicates the excellent performance of Patchformer. Furthermore, from Figure 6, the prediction of Crossformer is stated as relatively consistent across time while other models fluctuate dramatically.
Prediction Length Hyperparameters 96 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 2048, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 192 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 256, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 1024, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 336 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 2048, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 720 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 128, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 1024, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Electricity | 96 | 0.114 | 0.262 | 0.176 | 0.326 | 0.116 | 0.264 | 0.154 | 0.304 | |
| 192 | 0.148 | 0.300 | 0.230 | 0.372 | 0.151 | 0.306 | 0.186 | 0.336 | ||
| 336 | 0.181 | 0.332 | 0.291 | 0.427 | 0.227 | 0.375 | 0.226 | 0.369 | ||
| 720 | 0.272 | 0.412 | 0.290 | 0.428 | 0.340 | 0.472 | 0.497 | 0.556 | ||
| Gas | 96 | 0.071 | 0.195 | 0.114 | 0.262 | 0.074 | 0.196 | 0.101 | 0.232 | |
| 192 | 0.084 | 0.221 | 0.121 | 0.269 | 0.095 | 0.230 | 0.120 | 0.262 | ||
| 336 | 0.106 | 0.244 | 0.193 | 0.340 | 0.130 | 0.273 | 0.118 | 0.264 | ||
| 720 | 0.143 | 0.293 | 0.335 | 0.439 | 0.270 | 0.405 | 0.169 | 0.307 | ||
| GHG | 96 | 0.141 | 0.290 | 0.242 | 0.368 | 0.135 | 0.285 | 0.172 | 0.323 | |
| 192 | 0.202 | 0.354 | 0.217 | 0.369 | 0.159 | 0.312 | 0.184 | 0.335 | ||
| 336 | 0.280 | 0.413 | 0.226 | 0.373 | 0.225 | 0.377 | 0.266 | 0.399 | ||
| 720 | 0.426 | 0.518 | 0.311 | 0.442 | 0.550 | 0.583 | 0.317 | 0.449 | ||
3.4 Multi-Energy Forecasting Comparison
In this section, the effect of the interdependence among energy-related products on the performance of the time-series forecasting in the Multi-Energy dataset is discussed. The features in the dataset chosen to be analysed are electricity and gas load demand, as well as GHG emissions, since they are highly interrelated in nature. The prediction, past sequence length and hyperparameters of the Patchformer model are identical to Section 3.3. The forecasting results are shown in Table 6, in which All-at-Once means to predict electricity and gas load and GHG emission simultaneously, whereas Electricity, Gas and GHG are predicted individually. The feature Average is calculated by the mean of the features Electricity, Gas and GHG. In Table 6, Patchformer outperforms all other three models across all features selected from the Multi-Energy dataset as it achieves the most best MSE and MAE results than other models. In addition, the Patchformer forecasting results at 336 and 720 prediction lengths when predicting electricity, gas load, and GHG emission all at once are better than predicted individually. Furthermore, the difference of Patchformer MSE and MAE between All-at-Once and Average at 96 and 192 prediction lengths are insignificant (MSE: 2.65% and 1.36%, MAE: 1.96% and 0.34%). Moreover, the results of All-at-Once are generally better than Average for all other models, especially Autoformer and Transformer. Overall, the pattern in which predicting multi-energy results all at once is better than predicting them individually demonstrates the interdependence among electricity, gas load and GHG emission can be captured by Patchformer and other models and improve the forecasting performance.
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| All-at-Once | 96 | 0.113 | 0.255 | 0.139 | 0.286 | 0.130 | 0.274 | 0.146 | 0.282 | |
| 192 | 0.147 | 0.292 | 0.156 | 0.304 | 0.173 | 0.318 | 0.233 | 0.357 | ||
| 336 | 0.179 | 0.324 | 0.187 | 0.336 | 0.368 | 0.467 | 0.318 | 0.408 | ||
| 720 | 0.255 | 0.389 | 0.234 | 0.378 | 0.499 | 0.540 | 0.471 | 0.501 | ||
| Electricity | 96 | 0.115 | 0.263 | 0.154 | 0.306 | 0.134 | 0.284 | 0.186 | 0.321 | |
| 192 | 0.145 | 0.297 | 0.161 | 0.311 | 0.230 | 0.375 | 0.255 | 0.374 | ||
| 336 | 0.178 | 0.330 | 0.209 | 0.355 | 0.246 | 0.391 | 0.491 | 0.518 | ||
| 720 | 0.311 | 0.440 | 0.289 | 0.427 | 0.584 | 0.599 | 0.539 | 0.554 | ||
| Gas | 96 | 0.073 | 0.198 | 0.111 | 0.253 | 0.088 | 0.216 | 0.101 | 0.233 | |
| 192 | 0.085 | 0.221 | 0.131 | 0.281 | 0.114 | 0.253 | 0.159 | 0.294 | ||
| 336 | 0.101 | 0.241 | 0.128 | 0.279 | 0.174 | 0.315 | 0.192 | 0.320 | ||
| 720 | 0.137 | 0.287 | 0.196 | 0.330 | 0.382 | 0.467 | 0.210 | 0.338 | ||
| GHG | 96 | 0.139 | 0.288 | 0.171 | 0.323 | 0.154 | 0.305 | 0.188 | 0.333 | |
| 192 | 0.206 | 0.355 | 0.211 | 0.362 | 0.212 | 0.359 | 0.360 | 0.453 | ||
| 336 | 0.312 | 0.438 | 0.225 | 0.370 | 0.311 | 0.439 | 0.432 | 0.492 | ||
| 720 | 0.439 | 0.522 | 0.273 | 0.411 | 0.682 | 0.643 | 0.551 | 0.565 | ||
| Average | 96 | 0.109 | 0.250 | 0.145 | 0.294 | 0.125 | 0.268 | 0.159 | 0.295 | |
| 192 | 0.145 | 0.291 | 0.168 | 0.318 | 0.185 | 0.329 | 0.258 | 0.374 | ||
| 336 | 0.197 | 0.336 | 0.187 | 0.335 | 0.244 | 0.382 | 0.371 | 0.443 | ||
| 720 | 0.296 | 0.416 | 0.252 | 0.389 | 0.549 | 0.570 | 0.433 | 0.486 | ||
3.5 Different Length of Past Time Sequences
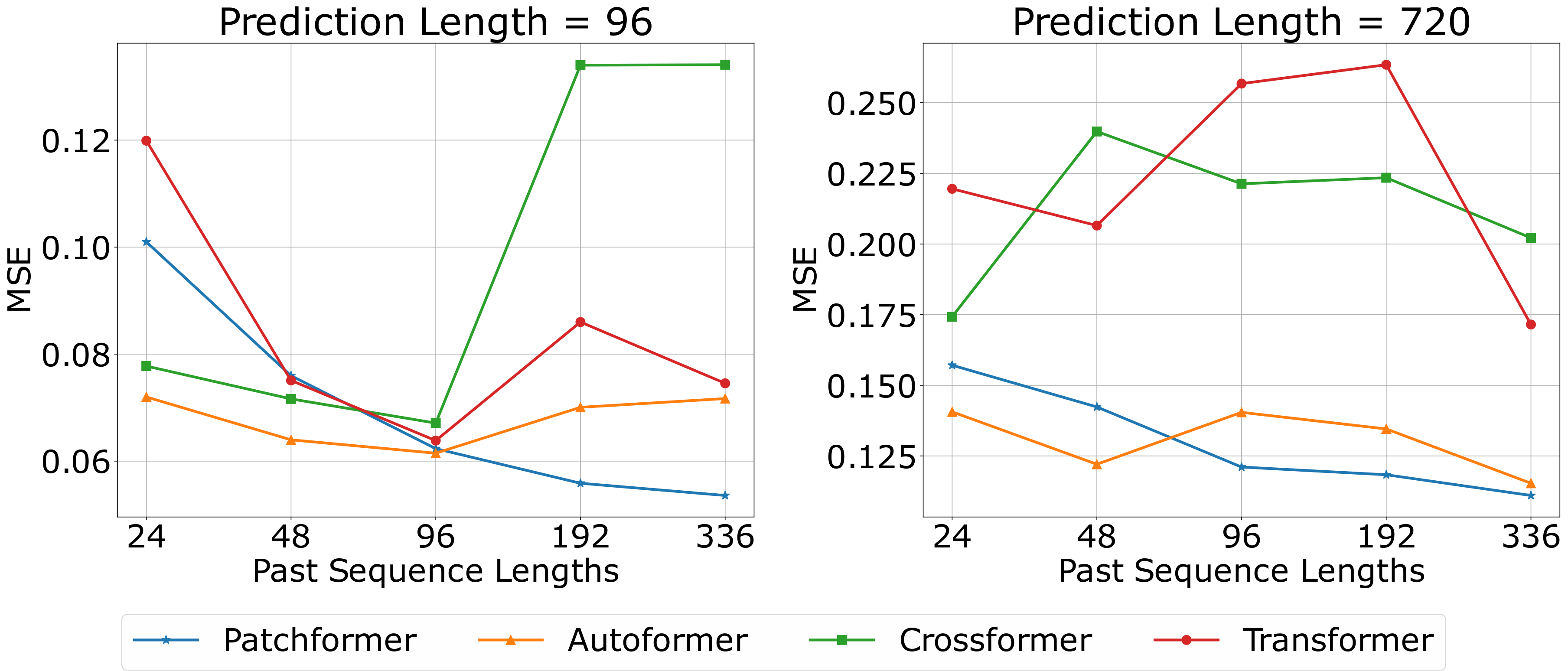
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Pred: 96 | 24 | 0.101 | 0.170 | 0.072 | 0.155 | 0.078 | 0.158 | 0.120 | 0.182 | |
| 48 | 0.076 | 0.150 | 0.064 | 0.147 | 0.072 | |||||