How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study
Abstract
Meta’s LLaMA family has become one of the most powerful open-source Large Language Model (LLM) series. Notably, LLaMA3 models have recently been released and achieve impressive performance across various with super-large scale pre-training on over 15T tokens of data. Given the wide application of low-bit quantization for LLMs in resource-limited scenarios, we explore LLaMA3’s capabilities when quantized to low bit-width. This exploration holds the potential to unveil new insights and challenges for low-bit quantization of LLaMA3 and other forthcoming LLMs, especially in addressing performance degradation problems that suffer in LLM compression. Specifically, we evaluate the 10 existing post-training quantization and LoRA-finetuning methods of LLaMA3 on 1-8 bits and diverse datasets to comprehensively reveal LLaMA3’s low-bit quantization performance. Our experiment results indicate that LLaMA3 still suffers non-negligent degradation in these scenarios, especially in ultra-low bit-width. This highlights the significant performance gap under low bit-width that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, pushing the LLMs to lower bit-width with higher accuracy for being practical. Our project is released on https://github.com/Macaronlin/LLaMA3-Quantization and quantized LLaMA3 models are released in https://huggingface.co/LLMQ.
1 Introduction
Launched by Meta in February 2023, the LLaMA touvron2023llama series111 https://llama.meta.com represents a breakthrough in autoregressive large language models (LLMs) using the Transformer vaswani2017attention architecture. Right from its first version, with 13 billion parameters, it managed to outperform the much larger, closed-source GPT-3 model which boasts 175 billion parameters. On April 18, 2024, Meta introduced the LLaMA3 model, offering configurations of 8 billion and 70 billion parameters. Thanks to extensive pre-training on more than 15 trillion data tokens, the LLaMA3 models222 https://github.com/meta-llama/llama3 have achieved state-of-the-art (SOTA) performance across a broad range of tasks, establishing the LLaMA family as among the finest open-source LLMs available for a wide variety of applications and deployment scenarios.
Despite their impressive performance, deploying LLaMA3 models still poses significant challenges due to resource limitations in many scenarios. Fortunately, low-bit quantization has emerged as one of the most popular techniques for compressing LLMs. This technique reduces the memory and computational requirements of LLMs during inference, enabling them to run on resource-limited devices. Addressing the performance drop that occurs after compression is a major concern for current LLM quantization approaches. While numerous low-bit quantization methods have been proposed, their evaluations have primarily focused on the earlier and less capable LLaMA models (LLaMA1 and LLaMA2). Thus, LLaMA3 presents a new opportunity for the LLM community to assess the performance of quantization on cutting-edge LLMs and to understand the strengths and limitations of existing methods. In this empirical study, our aim is to analyze the capability of LLaMA3 to handle the challenges associated with degradation due to quantization.
Our study sets out two primary technology tracks for quantizing LLMs: Post-Training Quantization (PTQ) and LoRA-FineTuning (LoRA-FT) quantization, with the aim of providing a comprehensive evaluation of the LLaMA3 models’ quantization. We explore a range of cutting-edge quantization methods across technical tracks (RTN, GPTQ frantar2022gptq , AWQ lin2023awq , SmoothQuant xiao2023smoothquant , PB-LLM shang2023pb , QuIP chee2024quip , DB-LLM chen2024db , and BiLLM huang2024billm for PTQ; QLoRA dettmers2024qlora and IR-QLoRA qin2024accurate for LoRA-FT), covering a wide spectrum from 1 to 8 bits and utilizing a diverse array of evaluation datasets, including WikiText2, C4, PTB, CommonSenseQA datasets (PIQA, ARC-e, ARC-c, HellaSwag, Winogrande), and MMLU benchmark. The overview of our study is presented as Figure 1. These evaluations assess the capabilities and limits of the LLaMA3 model under current LLM quantization techniques and serve as a source of inspiration for the design of future LLM quantization methods. The choice to focus specifically on the LLaMA3 model is motivated by its superior performance among all current open-source instruction-tuned LLMs across a variety of datasets2, including 5-shot MMLU, 0-shot GPQA, 0-shot HumanEval, 8-shot CoT GSM-8K, and 4-shot CoT MATH. Furthermore, we have made our project and the quantized models available to the public on https://github.com/Macaronlin/LLaMA3-Quantization and https://huggingface.co/LLMQ, respectively. This not only aids in advancing the research within the LLM quantization community but also facilitates a broader understanding and application of effective quantization techniques.
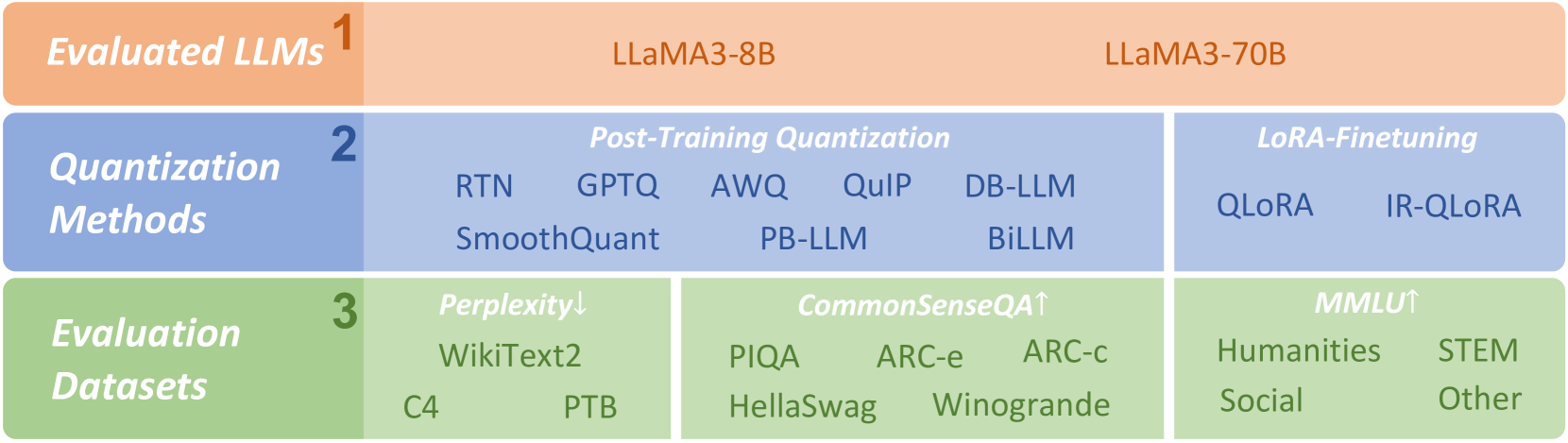
2 Empirical Evaluation
2.1 Experiment Settings
Evaluated LLMs. We obtain the pre-trained LLaMA3-8B and -70B through the official repository2.
Quantization methods. To evaluate the performance of low-bit quantized LLaMA3, we select representative LLM quantization methods with extensive influence and functionality, including 8 PTQ methods and 2 LoRA-FT methods. The implementations of our evaluated quantization methods follow their open-source repositories333 https://github.com/IST-DASLab/gptq, https://github.com/mit-han-lab/llm-awq, https://github.com/mit-han-lab/smoothquant, https://github.com/Cornell-RelaxML/QuIP, https://github.com/hahnyuan/PB-LLM, https://github.com/Aaronhuang-778/BiLLM, https://github.com/artidoro/qlora, https://github.com/htqin/IR-QLoRA. We also used eight NVIDIA A800 with 80GB GPU memory for quantitative evaluation.
| Method | #W | #A | #G | PPL | CommonSenseQA | |||||||
| WikiText2 | C4 | PTB | PIQA | ARC-e | ARC-c | HellaSwag | Wino | Avg. | ||||
| LLaMA3 | 16 | 16 | - | 6.1 | 9.2 | 10.6 | 79.9 | 80.1 | 50.4 | 60.2 | 72.8 | 68.6 |
| RTN | 4 | 16 | 128 | 8.5 | 13.4 | 14.5 | 76.6 | 70.1 | 45.0 | 56.8 | 71.0 | 63.9 |
| 3 | 16 | 128 | 27.9 | 1.1e2 | 95.6 | 62.3 | 32.1 | 22.5 | 29.1 | 54.7 | 40.2 | |
| 2 | 16 | 128 | 1.9E3 | 2.5E4 | 1.8E4 | 53.1 | 24.8 | 22.1 | 26.9 | 53.1 | 36.0 | |
| 8 | 16 | - | 6.2 | 9.5 | 11.2 | 79.7 | 80.8 | 50.4 | 60.1 | 73.4 | 68.9 | |
| 4 | 16 | - | 8.7 | 14.0 | 14.9 | 75.0 | 68.2 | 39.4 | 56.0 | 69.0 | 61.5 | |
| 3 | 16 | - | 2.2E3 | 5.6E2 | 2.0E3 | 56.2 | 31.1 | 20.0 | 27.5 | 53.1 | 35.6 | |
| 2 | 16 | - | 2.7E6 | 7.4E6 | 3.1E6 | 53.1 | 24.7 | 21.9 | 25.6 | 51.1 | 35.3 | |
| GPTQ | 4 | 16 | 128 | 6.5 | 10.4 | 11.0 | 78.4 | 78.8 | 47.7 | 59.0 | 72.6 | 67.3 |
| 3 | 16 | 128 | 8.2 | 13.7 | 15.2 | 74.9 | 70.5 | 37.7 | 54.3 | 71.1 | 61.7 | |
| 2 | 16 | 128 | 2.1E2 | 4.1E4 | 9.1E2 | 53.9 | 28.8 | 19.9 | 27.7 | 50.5 | 36.2 | |
| 8 | 16 | - | 6.1 | 9.4 | 10.6 | 79.8 | 80.1 | 50.2 | 60.2 | 72.8 | 68.6 | |
| 4 | 16 | - | 7.0 | 11.8 | 14.4 | 76.8 | 74.3 | 42.4 | 57.4 | 72.8 | 64.8 | |
| 3 | 16 | - | 13.0 | 45.9 | 37.0 | 60.8 | 38.8 | 22.3 | 41.8 | 60.9 | 44.9 | |
| 2 | 16 | - | 5.7E4 | 1.0E5 | 2.7E5 | 52.8 | 25.0 | 20.5 | 26.6 | 49.6 | 34.9 | |
| AWQ | 4 | 16 | 128 | 6.6 | 9.4 | 11.1 | 79.1 | 79.7 | 49.3 | 59.1 | 74.0 | 68.2 |
| 3 | 16 | 128 | 8.2 | 11.6 | 13.2 | 77.7 | 74.0 | 43.2 | 55.1 | 72.1 | 64.4 | |
| 2 | 16 | 128 | 1.7E6 | 2.1E6 | 1.8E6 | 52.4 | 24.2 | 21.5 | 25.6 | 50.7 | 34.9 | |
| 8 | 16 | - | 6.1 | 8.9 | 10.6 | 79.6 | 80.3 | 50.5 | 60.2 | 72.8 | 68.7 | |
| 4 | 16 | - | 7.1 | 10.1 | 11.8 | 78.3 | 77.6 | 48.3 | 58.6 | 72.5 | 67.0 | |
| 3 | 16 | - | 12.8 | 16.8 | 24.0 | 71.9 | 66.7 | 35.1 | 50.7 | 64.7 | 57.8 | |
| 2 | 16 | - | 8.2E5 | 8.1E5 | 9.0E5 | 55.2 | 25.2 | 21.3 | 25.4 | 50.4 | 35.5 | |
| QuIP | 4 | 16 | - | 6.5 | 11.1 | 9.5 | 78.2 | 78.2 | 47.4 | 58.6 | 73.2 | 67.1 |
| 3 | 16 | - | 7.5 | 11.3 | 12.6 | 76.8 | 72.9 | 41.0 | 55.4 | 72.5 | 63.7 | |
| 2 | 16 | - | 85.1 | 1.3E2 | 1.8E2 | 52.9 | 29.0 | 21.3 | 29.2 | 51.7 | 36.8 | |
| DB-LLM | 2 | 16 | 128 | 13.6 | 19.2 | 23.8 | 68.9 | 59.1 | 28.2 | 42.1 | 60.4 | 51.8 |
| PB-LLM | 2 | 16 | 128 | 24.7 | 79.2 | 65.6 | 57.0 | 37.8 | 17.2 | 29.8 | 52.5 | 38.8 |
| 1.7 | 16 | 128 | 41.8 | 2.6E2 | 1.2E2 | 52.5 | 31.7 | 17.5 | 27.7 | 50.4 | 36.0 | |
| BiLLM | 1.1 | 16 | 128 | 28.3 | 2.9E2 | 94.7 | 56.1 | 36.0 | 17.7 | 28.9 | 51.0 | 37.9 |
| SmoothQuant | 8 | 8 | - | 6.3 | 9.2 | 10.8 | 79.5 | 79.7 | 49.0 | 60.0 | 73.2 | 68.3 |
| 6 | 6 | - | 7.7 | 11.8 | 12.5 | 76.8 | 75.5 | 45.0 | 56.9 | 69.0 | 64.6 | |
| 4 | 4 | - | 4.3E3 | 4.0E3 | 3.6E3 | 54.6 | 26.3 | 20.0 | 26.4 | 50.3 | 35.5 | |
Evaluation datasets. For the PTQ methods, we evaluate quantized LLaMA3 on the WikiText2 merity2016pointer , PTB marcus1994penn , and a portion of the C4 dataset raffel2020exploring , using Perplexity (PPL) as the evaluation metric. Subsequently, we further conduct experiments on five zero-shot evaluation tasks (PIQA bisk2020piqa , Winogrande sakaguchi2021winogrande , ARC-e clark2018think , ARC-c clark2018think , and Hellaswag zellers2019hellaswag ) to fully validate the quantized performance of LLaMA3. For the LoRA-FT methods, we conduct the evaluation on the 5-shot MMLU benchmark hendrycks2020measuring while also validating the aforementioned 5 zero-shot datasets for the LoRA-FT methods.
For the fairness of our evaluation, we uniformly use WikiText2 as the calibration dataset for all quantization methods, with a sample size of 128 and a consistent token sequence length of 2048. Furthermore, for quantization methods requiring channel-wise grouping, we adopt a block size of 128 to balance performance and inference efficiency, which is a common practice in existing works.
| Method | #W | #A | #G | PPL | CommonSenseQA | |||||||
| WikiText2 | C4 | PTB | PIQA | ARC-e | ARC-c | HellaSwag | Wino | Avg. | ||||
| LLaMA3 | 16 | 16 | - | 2.9 | 6.9 | 8.2 | 82.4 | 86.9 | 60.3 | 66.4 | 80.6 | 75.3 |
| RTN | 4 | 16 | 128 | 3.6 | 8.9 | 9.1 | 82.3 | 85.2 | 58.4 | 65.6 | 79.8 | 74.3 |
| 3 | 16 | 128 | 11.8 | 22.0 | 26.3 | 64.2 | 48.9 | 25.1 | 41.1 | 60.5 | 48.0 | |
| 2 | 16 | 128 | 4.6E5 | 4.7E5 | 3.8E5 | 53.2 | 23.9 | 22.1 | 25.8 | 53.0 | 35.6 | |
| GPTQ | 4 | 16 | 128 | 3.3 | 6.9 | 8.3 | 82.9 | 86.3 | 58.4 | 66.1 | 80.7 | 74.9 |
| 3 | 16 | 128 | 5.2 | 10.5 | 9.7 | 80.6 | 79.6 | 52.1 | 63.5 | 77.1 | 70.6 | |
| 2 | 16 | 128 | 11.9 | 22.8 | 31.6 | 62.7 | 38.9 | 24.6 | 41.0 | 59.9 | 45.4 | |
| AWQ | 4 | 16 | 128 | 3.3 | 7.0 | 8.3 | 82.7 | 86.3 | 59.0 | 65.7 | 80.9 | 74.9 |
| 3 | 16 | 128 | 4.8 | 8.0 | 9.0 | 81.4 | 84.7 | 58.0 | 63.5 | 78.6 | 73.2 | |
| 2 | 16 | 128 | 1.7E6 | 1.4E6 | 1.5E6 | 52.2 | 25.5 | 23.1 | 25.6 | 52.3 | 35.7 | |
| QuIP | 4 | 16 | - | 3.4 | 7.1 | 8.4 | 82.5 | 86.0 | 58.7 | 65.7 | 79.7 | 74.5 |
| 3 | 16 | - | 4.7 | 8.0 | 8.9 | 82.3 | 83.3 | 54.9 | 63.9 | 78.4 | 72.5 | |
| 2 | 16 | - | 13.0 | 22.2 | 24.9 | 65.3 | 48.9 | 26.5 | 40.9 | 61.7 | 48.7 | |
| PB-LLM | 2 | 16 | 128 | 11.6 | 34.5 | 27.2 | 65.2 | 40.6 | 25.1 | 42.7 | 56.4 | 46.0 |
| 1.7 | 16 | 128 | 18.6 | 65.2 | 55.9 | 56.5 | 49.9 | 25.8 | 34.9 | 53.1 | 44.1 | |
| BiLLM | 1.1 | 16 | 128 | 17.1 | 77.7 | 54.2 | 58.2 | 46.4 | 25.1 | 37.5 | 53.6 | 44.2 |
| SmoothQuant | 8 | 8 | - | 2.9 | 6.9 | 8.2 | 82.2 | 86.9 | 60.2 | 66.3 | 80.7 | 75.3 |
| 6 | 6 | - | 2.9 | 6.9 | 8.2 | 82.4 | 87.0 | 59.9 | 66.1 | 80.6 | 75.2 | |
| 4 | 4 | - | 9.6 | 16.9 | 17.7 | 76.9 | 75.8 | 43.5 | 52.9 | 58.9 | 61.6 | |
2.2 Track1: Post-Training Quantization
As shown in Table 1 and Table 2, we provide the performance of low-bit LLaMA3-8B and LLaMA3-70B with 8 different PTQ methods, respectively, covering a wide bit-width spectrum from 1 to 8-bit.
Among them, Round-To-Nearest (RTN) is a vanilla rounding quantization method. GPTQ frantar2022gptq is currently one of the most efficient and effective weight-only quantization methods, which utilizes error compensation in quantization. But under 2-3 bits, GPTQ causes severe accuracy collapse when quantized LLaMA3. AWQ lin2023awq adopts an anomaly channel suppression approach to reduce the difficulty of weight quantization, and QuIP chee2024quip ensures the incoherence between weights and Hessian by optimizing matrix computation. Both of them can keep LLaMA3’s capability at 3-bit and even push the 2-bit quantization to promising.
The recent emergence of binarized LLM quantization methods has realized ultra-low bit-width LLM weight compression. PB-LLM shang2023pb employs a mixed-precision quantization strategy, retaining a small portion of significant weight full-precision while quantizing the majority of weights to 1-bit. DB-LLM chen2024db achieves efficient LLM compression through double binarization weight splitting and proposes a deviation-aware distillation strategy to further enhance 2-bit LLM performance. BiLLM huang2024billm further pushes the LLM quantization boundary to as low as 1.1-bit through residual approximation of salient weights and grouped quantization of non-salient weights. These LLM quantization methods specially designed for ultra-low bit-width can achieve higher accuracy of quantized LLaMA3-8B at 2-bit, far outperforms methods like GPTQ, AWQ, and QuIP under 2-bit (even 3-bit some cases).
We also perform LLaMA3 evaluation on quantized activations via SmoothQuant xiao2023smoothquant , which moves the quantization difficulty offline from activations to weights to smooth out activation outliers. Our evaluation shows that SmoothQuant can retain the accuracy of LLaMA3 with 8- and 6-bit weights and activations, but faces collapse at 4-bit.
Moreover, we find that the LLaMA3-70B model shows significant robustness for various quantization methods, even in ultra-low bit-width.
2.3 Track2: LoRA-FineTuning Quantization
Except for the PTQ methods, we also provide the performance of 4-bit LLaMA3-8B with 2 different LoRA-FT quantization methods as shown in Table 3, including QLoRA dettmers2024qlora and IR-QLoRA qin2024accurate .
On the MMLU dataset, the most notable observation with LLaMA3-8B under LoRA-FT quantization is that low-rank finetuning on the Alpaca alpaca dataset not only cannot compensate for the errors introduced by quantization, even making the degradation more severe. Specifically, various LoRA-FT quantization methods obtain worse performance quantized LLaMA3 under 4-bit compared with their 4-bit counterparts without LoRA-FT. This is in stark contrast to similar phenomena on LLaMA1 and LLaMA2, where, for the front one, the 4-bit low-rank finetuned quantized versions could even easily surpass the original FP16 counterpart on MMLU. According to our intuitive analysis, the main reason for this phenomenon is due to LLaMA3’s strong performance brought by its massive pre-scale training, which means the performance loss from the original model’s quantization cannot be compensated for by finetuning on a tiny set of data with low-rank parameters (which can be seen as a subset of the original model hu2021lora ; dettmers2024qlora ). Despite the significant drop from quantization that cannot be compensated by finetuning, 4-bit LoRA-FT quantized LLaMA3-8B significantly outperforms LLaMA1-7B and LLaMA2-7B under various quantization methods. For instance, with the QLoRA method, 4-bit LLaMA3-8B has an average accuracy of 57.0 (FP16: 64.8), exceeding 4-bit LLaMA1-7B’s 38.4 (FP16: 34.6) by 18.6, and surpassing 4-bit LLaMA2-7B’s 43.9 (FP16: 45.5) by 13.1 xu2023qa ; qin2024accurate . This implies that a new LoRA-FT quantization paradigm is needed in the era of LLaMA3.
A similar phenomenon occurs with the CommonSenseQA benchmark. Compared to the 4-bit counterparts without LoRA-FT, the performance of the models fine-tuned using QLoRA and IR-QLoRA also declined (e.g. QLoRA 2.8% vs IR-QLoRA 2.4% on average). This further demonstrates the strength of using high-quality datasets in LLaMA3, as the general dataset Alpaca does not contribute to the model’s performance in other tasks.
| Method | #W | MMLU | CommonSenseQA | |||||||||
| Hums. | STEM | Social | Other | Avg. | PIQA | ARC-e | ARC-c | HellaSwag | Wino | Avg. | ||
| LLaMA3 | 16 | 59.0 | 55.3 | 76.0 | 71.5 | 64.8 | 79.9 | 80.1 | 50.4 | 60.2 | 72.8 | 68.6 |
| NormalFloat | 4 | 56.8 | 52.9 | 73.6 | 69.4 | 62.5 | 78.6 | 78.5 | 46.2 | 58.8 | 74.3 | 67.3 |
| QLoRA | 4 | 50.3 | 49.3 | 65.8 | 64.2 | 56.7 | 76.6 | 74.8 | 45.0 | 59.4 | 67.0 | 64.5 |
| IR-QLoRA | 4 | 52.2 | 49.0 | 66.5 | 63.1 | 57.2 | 76.3 | 74.3 | 45.3 | 59.1 | 69.5 | 64.9 |
3 Conclusion
Meta’s recently released LLaMA3 models have rapidly become the most powerful LLM series, capturing significant interest from researchers. Building on this momentum, our study aims to thoroughly evaluate the performance of LLaMA3 across a variety of low-bit quantization techniques, including post-training quantization and LoRA-finetuning quantization. Our goal is to assess the boundaries of its capabilities in scenarios with limited resources by leveraging existing LLM quantization technologies. Our findings indicate that while LLaMA3 still demonstrates superior performance after quantization, the performance degradation associated with quantization is significant and can even lead to larger declines in many cases. This discovery highlights the potential challenges of deploying LLaMA3 in resource-constrained environments and underscores the ample room for growth and improvement within the context of low-bit quantization. The empirical insights from our research are expected to be valuable for the development of future LLM quantization techniques, especially in terms of narrowing the performance gap with the original models. By addressing the performance degradation caused by low-bit quantization, we anticipate that subsequent quantization paradigms will enable LLMs to achieve stronger capabilities at a lower computational cost, ultimately driving the progress of generative artificial intelligence, as represented by LLMs, to new heights.
References
- [1] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- [2] Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems, 36, 2024.
- [3] Hong Chen, Chengtao Lv, Liang Ding, Haotong Qin, Xiabin Zhou, Yifu Ding, Xuebo Liu, Min Zhang, Jinyang Guo, Xianglong Liu, et al. Db-llm: Accurate dual-binarization for efficient llms. arXiv preprint arXiv:2402.11960, 2024.
- [4] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [5] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- [6] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [7] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- [8] Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2021.
- [9] Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xiaojuan Qi. Billm: Pushing the limit of post-training quantization for llms. arXiv preprint arXiv:2402.04291, 2024.
- [10] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
- [11] Mitch Marcus, Grace Kim, Mary Ann Marcinkiewicz, Robert MacIntyre, Ann Bies, Mark Ferguson, Karen Katz, and Britta Schasberger. The penn treebank: Annotating predicate argument structure. In Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994, 1994.
- [12] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- [13] Haotong Qin, Xudong Ma, Xingyu Zheng, Xiaoyang Li, Yang Zhang, Shouda Liu, Jie Luo, Xianglong Liu, and Michele Magno. Accurate lora-finetuning quantization of llms via information retention. arXiv preprint arXiv:2402.05445, 2024.
- [14] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- [15] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- [16] Yuzhang Shang, Zhihang Yuan, Qiang Wu, and Zhen Dong. Pb-llm: Partially binarized large language models. arXiv preprint arXiv:2310.00034, 2023.
- [17] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [18] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [19] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [20] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- [21] Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, and Qi Tian. Qa-lora: Quantization-aware low-rank adaptation of large language models. arXiv preprint arXiv:2309.14717, 2023.
- [22] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.