FlashSpeech: Efficient Zero-Shot Speech Synthesis
Abstract
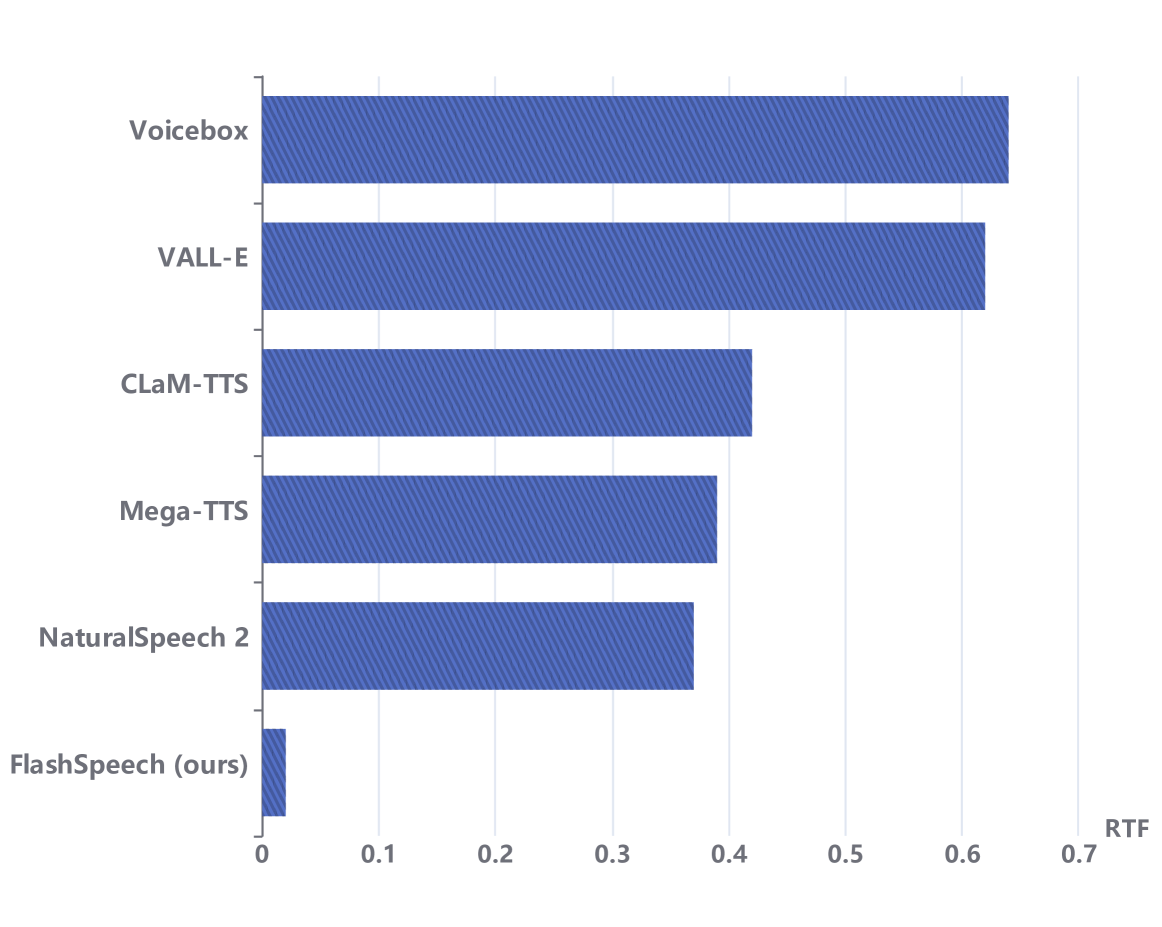
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
1 Introduction
In recent years, the landscape of speech synthesis has been transformed by the advent of large-scale generative models. Consequently, the latest research efforts have achieved notable advancements in zero-shot speech synthesis systems by significantly increasing the size of both datasets and models. Zero-shot speech synthesis, such as text-to-speech (TTS), voice conversion (VC) and Editing, aims to generate speech that incorporates unseen speaker characteristics from a reference audio segment during inference, without the need for additional training. Current advanced zero-shot speech synthesis systems typically leverage language models (LMs) Wang et al. (2023a); Yang et al. (2023); Zhang et al. (2023); Kharitonov et al. (2023); Wang et al. (2023b); Peng et al. (2024); Kim et al. (2024) and diffusion-style models Shen et al. (2024); Kim et al. (2023b); Le et al. (2023); Jiang et al. (2023b) for in-context speech generation on the large-scale dataset. However, the generation process of these methods needs a long-time iteration. For example, VALL-E Wang et al. (2023a) builds on the language model to predict 75 audio token sequences for a 1-second speech, in its first-stage autoregressive (AR) token sequence generation. When using a non-autoregressive (NAR) latent diffusion model Rombach et al. (2022) based framework, NaturalSpeech 2 Shen et al. (2024) still requires 150 sampling steps. As a result, although these methods can produce human-like speech, they require significant computational time and cost. Some efforts have been made to accelerate the generation process. Voicebox Le et al. (2023) adopts flow-matching Lipman et al. (2022) so that fewer sampling steps (NFE111NFE: number of function evaluations.: 64) can be achieved because of the optimal transport path. ClaM-TTS Kim et al. (2024) proposes a mel-codec with a superior compression rate and a latent language model that generates a stack of tokens at once. Although the slow generation speed issue has been somewhat alleviated, the inference speed is still far from satisfactory for practical applications. Moreover, the substantial computational time of these approaches leads to significant computational cost overheads, presenting another challenge.
The fundamental limitation of speech generation stems from the intrinsic mechanisms of language models and diffusion models, which require considerable time either auto-regressively or through a large number of denoising steps. Hence, the primary objective of this work is to accelerate inference speed and reduce computational costs while preserving generation quality at levels comparable to the prior research. In this paper, we propose FlashSpeech as the next step towards efficient zero-shot speech synthesis. To address the challenge of slow generation speed, we leverage the latent consistency model (LCM) Luo et al. (2023), a recent advancement in generative models. Building upon the previous non-autoregressive TTS system Shen et al. (2024), we adopt the encoder of a neural audio codec to convert speech waveforms into latent vectors as the training target for our LCM. To train this model, we propose a novel technique called adversarial consistency training, which utilizes the capabilities of pre-trained speech language models Chen et al. (2022b); Hsu et al. (2021); Baevski et al. (2020) as discriminators. This facilitates the transfer of knowledge from large pre-trained speech language models to speech generation tasks, efficiently integrating adversarial and consistency training to improve performance. The LCM is conditioned on prior vectors obtained from a phoneme encoder, a prompt encoder, and a prosody generator. Furthermore, we demonstrate that our proposed prosody generator leads to more diverse expressions and prosody while preserving stability.
Our contributions can be summarized as follows:
-
•
We propose FlashSpeech, an efficient zero-shot speech synthesis system that generates voice with high audio quality and speaker similarity in zero-shot scenarios.
-
•
We introduce adversarial consistency training, a novel combination of consistency and adversarial training leveraging pre-trained speech language models, for training the latent consistency model from scratch, achieving speech generation in one or two steps.
-
•
We propose a prosody generator module that enhances the diversity of prosody while maintaining stability.
-
•
FlashSpeech significantly outperforms strong baselines in audio quality and matches them in speaker similarity. Remarkably, it achieves this at a speed approximately 20 times faster than comparable systems, demonstrating unprecedented efficiency.
2 Related work
2.1 Large-Scale Speech Synthesis
Motivated by the success of the large language model, the speech research community has recently shown increasing interest in scaling the sizes of model and training data to bolster generalization capabilities, producing natural speech with diverse speaker identities and prosody under zero-shot settings. The pioneering work is VALL-E Wang et al. (2023a), which adopts the Encodec Défossez et al. (2022) to discretize the audio waveform into tokens. Therefore, a language model can be trained via in-context learning that can generate the target utterance where the style is consistent with prompt utterance. However, generating audio in such an autoregressive manner Wang et al. (2023b); Peng et al. (2024)can lead to unstable prosody, word skipping, and repeating issues Ren et al. (2020); Tan et al. (2021); Shen et al. (2024). To ensure the robustness of the system, non-autoregressive methods such as NaturalSpeech2 Shen et al. (2024) and Voicebox Le et al. (2023) utilize diffusion-style model (VP-diffusion Song et al. (2020) or flow-matching Lipman et al. (2022)) to learn the distribution of a continuous intermediate vector such as mel-spectrogram or latent vector of codec. Both LM-based methods Zhao et al. (2023) and diffusion-based methods show superior performance in speech generation tasks. However, their generation is slow due to the iterative computation. Considering that many speech generation scenarios require real-time inference and low computational costs, we employ the latent consistency model for large-scale speech generation that inference with one or two steps while maintaining high audio quality.
2.2 Acceleration of Speech Synthesis
Since early neural speech generation models Tan et al. (2021) use autoregressive models such as Tacotron Wang et al. (2017) and TransformerTTS Li et al. (2019), causing slow inference speed, with computation, where is the sequence length. To address the slow inference speed, FastSpeech Ren et al. (2020, 2019) proposes to generate a mel-spectrogram in a non-autoregressive manner. However, these models Ren et al. (2022) result in blurred and over-smoothed mel-spectrograms due to the regression loss they used and the capability of modeling methods. To further enhance the speech quality, diffusion models are utilized Popov et al. (2021a); Jeong et al. (2021); Popov et al. (2021b) which increase the computation to , where T is the diffusion steps. Therefore, distillation techniques Luo (2023) for diffusion-based methods such as CoMoSpeech Ye et al. (2023), CoMoSVC Lu et al. (2024) and Reflow-TTS Guan et al. (2023) emerge to reduce the sampling steps back to , but require additional pre-trained diffusion as the teacher model. Unlike previous distillation techniques, which require extra training for the diffusion model as a teacher and are limited by its performance, our proposed adversarial consistency training technique can directly train from scratch, significantly reducing training costs. In addition, previous acceleration methods only validate speaker-limited recording-studio datasets with limited data diversity. To the best of our knowledge, FlashSpeech is the first work that reduces the computation of a large-scale speech generation system back to .
2.3 Consistency Model
The consistency model is proposed in Song et al. (2023); Song and Dhariwal (2023) to generate high-quality samples by directly mapping noise to data. Furthermore, many variants Kong et al. (2023); Lu et al. (2023); Sauer et al. (2023); Kim et al. (2023a) are proposed to further increase the generation quality of images. The latent consistency model is proposed by Luo et al. (2023) which can directly predict the solution of PF-ODE in latent space. However, the original LCM employs consistency distillation on the pre-trained latent diffusion model (LDM) which leverages large-scale off-the-shelf image diffusion models Rombach et al. (2022). Since there are no pre-trained large-scale TTS models in the speech community, and inspired by the techniques Song and Dhariwal (2023); Kim et al. (2023a); Lu et al. (2023); Sauer et al. (2023); Kong et al. (2023), we propose the novel adversarial consistency training method which can directly train the large-scale latent consistency model from scratch utilizing the large pre-trained speech language model Chen et al. (2022b); Hsu et al. (2021); Baevski et al. (2020) such as WavLM for speech generation.
3 FlashSpeech
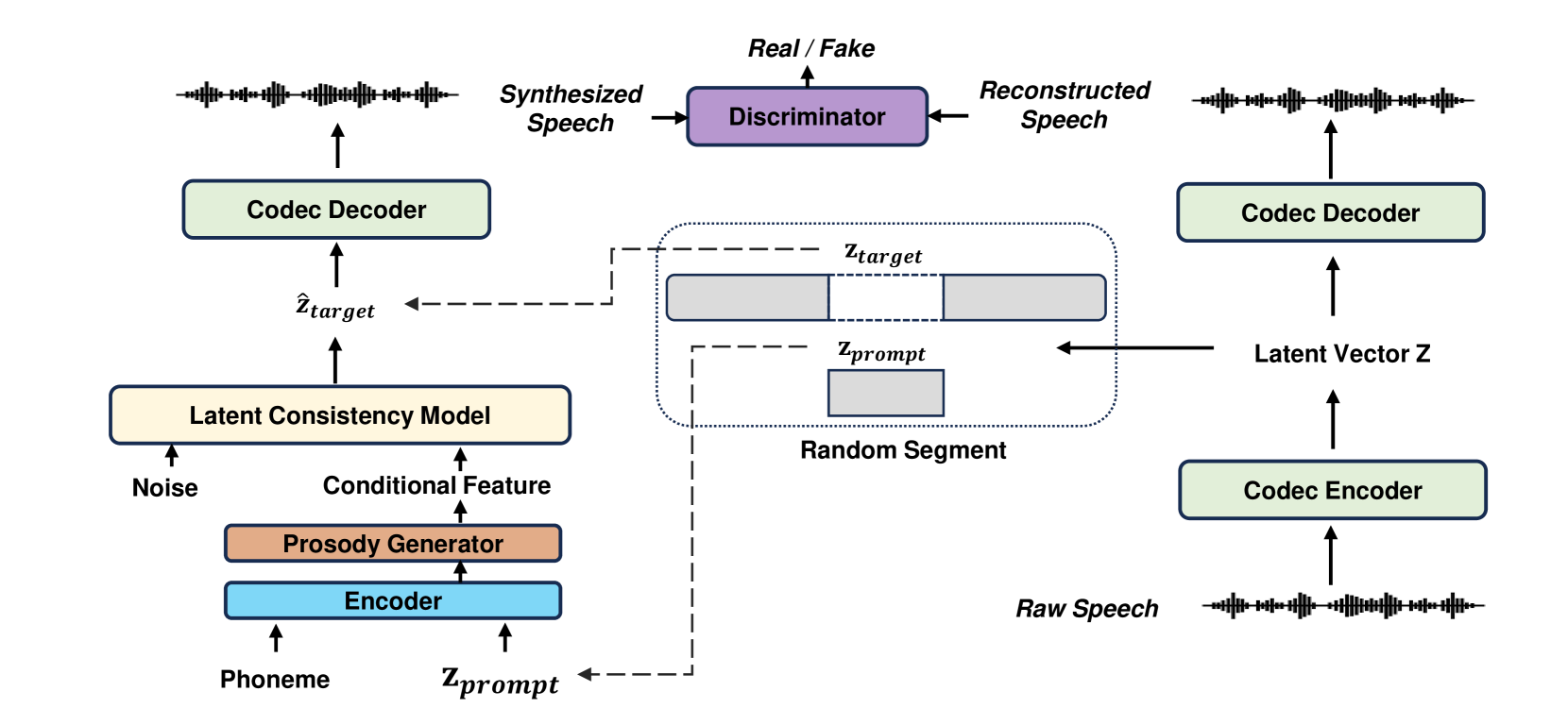
3.1 Overview
Our work is dedicated to advancing the speech synthesis efficiency, achieving computation cost while maintaining comparable performance to prior studies that require or computations. The framework of the proposed method, FlashSpeech, is illustrated in Fig. 2. FlashSpeech integrates a neural codec, an encoder for phonemes and prompts, a prosody generator, and an LCM, which are utilized during both the training and inference stages. Exclusively during training, a conditional discriminator is employed. FlashSpeech adopts the in-context learning paradigm Wang et al. (2023a), initially segmenting the latent vector z, extracted from the codec, into and . Subsequently, the phoneme and are processed through the encoder to produce the hidden feature. A prosody generator then predicts pitch and duration based on the hidden feature. The pitch and duration embeddings are combined with the hidden feature and inputted into the LCM as the conditional feature. The LCM model is trained from scratch using adversarial consistency training. After training, FlashSpeech can achieve efficient generation within one or two sampling steps.
3.2 Latent Consistency Model
The consistency model Song et al. (2023) is a new family of generative models that enables one-step or few-step generation. Let us denote the data distribution by . The core idea of the consistency model is to learn the function that maps any points on a trajectory of the PF-ODE to that trajectory’s origin, which can be formulated as:
| (1) |
where is the consistency function and represents the data perturbed by adding zero-mean Gaussian noise with standard deviation . is a fixed small positive number. Then can then be viewed as an approximate sample from the data distribution . To satisfy property in equation (1), following Song et al. (2023), we parameterize the consistency model as
| (2) |
where is to estimate consistency function by learning from data, is a deep neural network with parameter , and are are differentiable functions with and to ensure boundary condition. A valid consistency model should satisfy the self-consistency property Song et al. (2023)
| (3) |
where and following Karras et al. (2022); Song et al. (2023); Song and Dhariwal (2023). Then the model can generate samples in one step by evaluating
| (4) |
from distribution .
As we apply a consistency model on the latent space of audio, we use the latent features which are extracted prior to the residual quantization layer of the codec,
| (5) |
where is the speech waveform. Furthermore, we add the feature from the prosody generator and encoder as the conditional feature , our objective has changed to achieve
| (6) |
During inference, the synthesized waveform is transformed from via the codec decoder. The predicted is obtained by one sampling step
| (7) |
or two sampling steps
| (8) | |||||
| (9) |
where means the intermediate step, is set to 2 empirically. is sampled from a standard Gaussian distribution.
3.3 Adversarial Consistency Training
A major drawback of the LCM Luo et al. (2023) is that it needs to pre-train a diffusion-based teacher model in the first stage, and then perform distillation to produce the final model. This would make the training process complicated, and the performance would be limited as a result of the distillation. To eliminate the reliance on the teacher model training, in this paper, we propose a novel adversarial consistency training method to train LCM from scratch. Our training procedure is outlined in Fig. 3, which has three parts:
3.3.1 Consistency Training
To achieve the property in equation (3), we adopt following consistency loss
| (10) |
where represents the noise level at discrete time step , is the distance function, and are the student with the higher noise level and the teacher with the lower noise level, respectively. The discrete time steps denoted as are divided from the time interval , where the discretization curriculum increases correspondingly as the number of training steps grows
| (11) |
where , is the current training step and is the total training steps. and are hyperparameters to control the size of . The distance function uses the Pseudo-Huber metric Charbonnier et al. (1997)
| (12) |
where is an adjustable constant, making the training more robust to outliers as it imposes a smaller penalty for large errors than loss. The parameters of teacher model are
| (13) |
which are identical to the student parameters . This approach Song and Dhariwal (2023) has been demonstrated to improve sample quality of previous strategies that employ varying decay rates Song et al. (2023). The weighting function refers to
| (14) |
which emphasizes the loss of smaller noise levels. LCM through consistency training can generate speech with acceptable quality in a few steps, but it still falls short of previous methods. Therefore, to further enhance the quality of the generated samples, we integrate adversarial training.
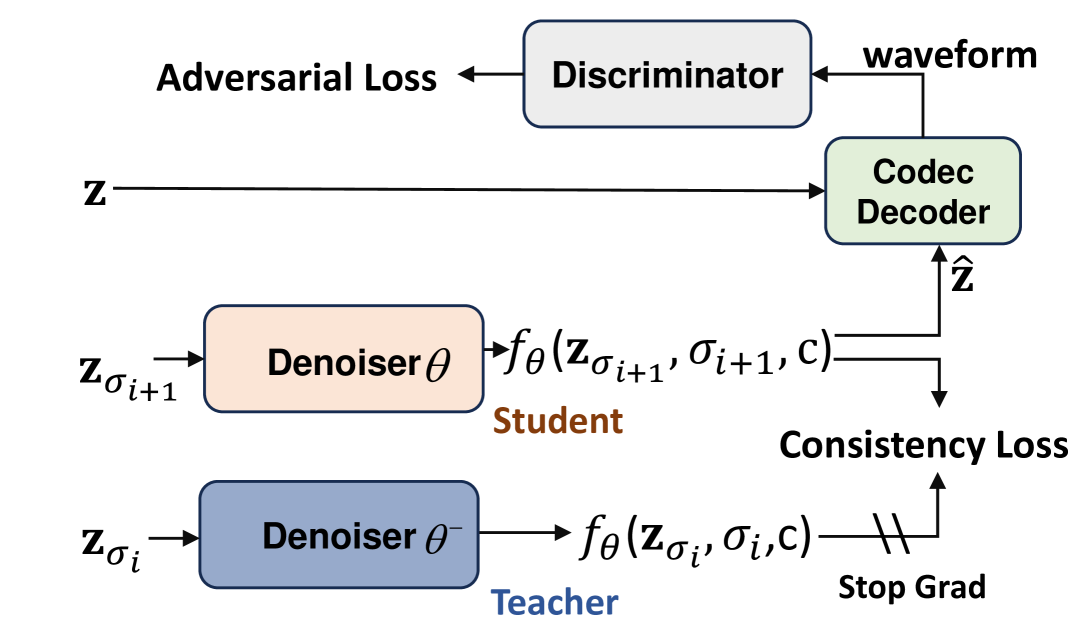
3.3.2 Adversarial Training
For the adversarial objective, the generated samples and real samples are passed to the discriminator which aims to distinguish between them, where refers to the trainable parameters. Thus, we employ adversarial training loss
| (15) |
In this way, the error signal from the discriminator guides to produce more realistic outputs. For details, we use a frozen pre-trained speech language model and a trainable lightweight discriminator head to build the discriminator. Since the current is trained on the speech waveform, we covert both and to ground truth waveform and predicted waveform using the codec decoder. To further increase the similarity between prompt audio and generated audio, our discriminator is conditioned on the prompt audio feature. This prompt feature is extracted using on prompt audio and applies average pooling on the time axis. Therefore,
| (16) |
where and refer to feature extracted through for ground truth waveform and predicted waveform. The discriminator head consists of several 1D convolution layers. The input feature of the discriminator is conditioned on via projection Miyato and Koyama (2018).
3.3.3 Combined Together
Since there is a large gap on the loss scale between consistency loss and adversarial loss, it can lead to instability and failure in training. Therefore, we follow Esser et al. (2021) to compute the adaptive weight with
| (17) |
where is the last layer of the neural network in LCM. The final loss of training LCM is defined as This adaptive weighting significantly stabilizes the training by balancing the gradient scale of each term.
3.4 Prosody Generator
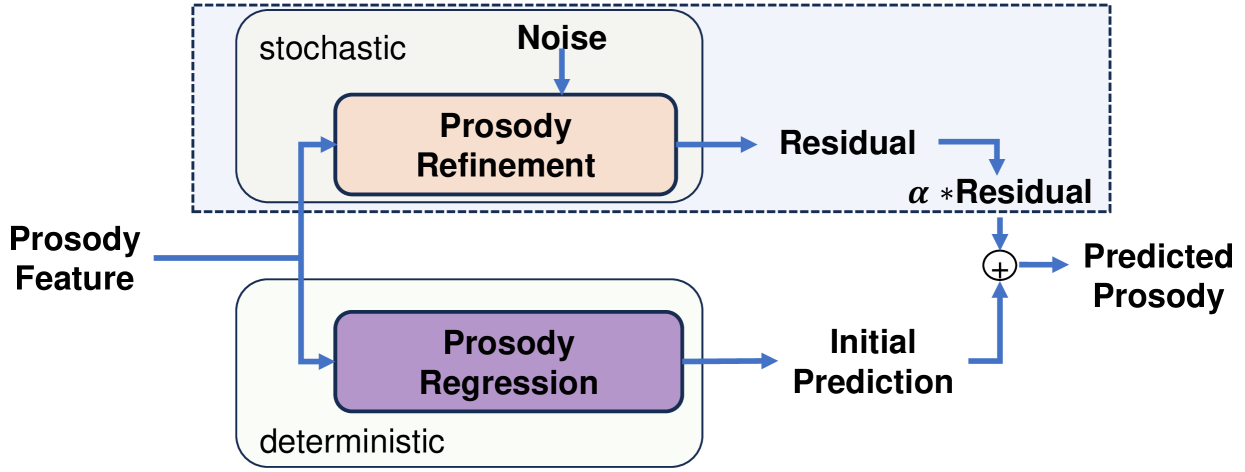
3.4.1 Analysis of Prosody Prediction
Previous regression methods for prosody prediction Ren et al. (2020); Shen et al. (2024), due to their deterministic mappings and assumptions of unimodal distribution, often fail to capture the inherent diversity and expressiveness of human speech prosody. This leads to predictions that lack variation and can appear over-smoothed. On the other hand, diffusion methods Le et al. (2023); Li et al. (2023) for prosody prediction offer a promising alternative by providing greater prosody diversity. However, they come with challenges regarding stability, and the potential for unnatural prosody. Additionally, the iterative inference process in DMs requires a significant number of sampling steps that may also hinder real-time application. Meanwhile, LM-based methods Jiang et al. (2024a); Wang et al. (2023a) also need a long time for inference. To alleviate these issues, our prosody generator consists of a prosody regression module and a prosody refinement module to enhance the diversity of prosody regression results with efficient one-step consistency model sampling.
3.4.2 Prosody Refinement via Consistency Model
As shown in 4, our prosody generator consists of two parts which are prosody regression and prosody refinement. We first train the prosody regression module to get a deterministic output. Next, we freeze the parameters of the prosody regression module and use the residual of ground truth prosody and deterministic predicted prosody as the training target for prosody refinement. We adopt a consistency model as a prosody refinement module. The conditional feature of the consistency model is the feature from prosody regression before the final projection layer. Thus, the residual from a stochastic sampler refines the output of a deterministic prosody regression and produces a diverse set of plausible prosody under the same transcription and audio prompt. One option for the final prosody output can be represented as:
| (18) |
where denotes the final prosody output, represents the residual output from the prosody refinement module, capturing the variations between the ground truth prosody and the deterministic prediction, is the initial deterministic prosody prediction from the prosody regression module. However, this formulation may negatively affect prosody stability, a similar observation is found in Vyas et al. (2023); Le et al. (2023). More specifically, higher diversity may cause less stability and sometimes produce unnatural prosody. To address this, we introduce a control factor that finely tunes the balance between stability and diversity in the prosodic output:
| (19) |
where is a scalar value ranging between 0 and 1. This adjustment allows for controlled incorporation of variability into the prosody, mitigating issues related to stability while still benefiting from the diversity offered by the prosody refinement module.
3.5 Applications
This section elaborates on the practical applications of FlashSpeech. We delve into its deployment across various tasks such as zero-shot TTS, speech editing, voice conversion, and diverse speech sampling. All the sample audios of applications are available on the demo page.
3.5.1 Zero-Shot TTS
Given a target text and reference audio, we first convert the text to phoneme using g2p (grapheme-to-phoneme conversion). Then we use the codec encoder to convert the reference audio into . Speech can be synthesized efficiently through FlashSpeech with the phoneme input and , achieving high-quality text-to-speech results without requiring pre-training on the specific voice.
3.5.2 Voice Conversion
Voice conversion aims to convert the source audio into the target audio using the speaker’s voice of the reference audio. Following Shen et al. (2024); Preechakul et al. (2022), we first apply the reverse of ODE to diffuse the source audio into a starting point that still maintains some information in the source audio. After that, we run the sampling process from this starting point with the reference audio as and condition . The condition uses the phoneme and duration from the source audio and the pitch is predicted by the prosody generator. This method allows for zero-shot voice conversion while preserving the linguistic content of the source audio, and achieving the same timbre as the reference audio.
3.5.3 Speech Editing
Given the speech, the original transcription, and the new transcription, we first use MFA (Montreal Forced Aligner) to align the speech and the original transcription to get the duration of each word. Then we remove the part that needs to be edited to construct the reference audio. Next, we use the new transcription and reference to synthesize new speech. Since this task is consistent with the in-context learning, we can concatenate the remaining part of the raw speech and the synthesized part as the final speech, thus enabling precise and seamless speech editing.
3.5.4 Diverse Speech Sampling
FlashSpeech leverages its inherent stochasticity to generate a variety of speech outputs under the same conditions. By employing stochastic sampling in its prosody generation and LCM, FlashSpeech can produce diverse variations in pitch, duration, and overall audio characteristics from the same phoneme input and audio prompt. This feature is particularly useful for generating a wide range of speech expressions and styles from a single input, enhancing applications like voice acting, synthetic voice variation for virtual assistants, and more personalized speech synthesis. In addition, the synthetic data via speech sampling can also benefit other tasks such as ASR Rossenbach et al. (2020).
4 Experiment
| Model | Data | RTF | Sim-O | Sim-R | WER | CMOS | SMOS |
|---|---|---|---|---|---|---|---|
| GroundTruth | - | - | 0.68 | - | 1.9 | 0.11 | 4.39 |
| VALL-E reproduce | Librilight | 0.62 | 0.47 | 0.51 | 6.1 | -0.48 | 4.11 |
| NaturalSpeech 2 | MLS | 0.37 | 0.53 | 0.60 | 1.9 | -0.31 | 4.20 |
| Voicebox reproduce | Librilight | 0.66 | 0.48 | 0.50 | 2.1 | -0.58 | 3.95 |
| Mega-TTS | G+W | 0.39 | - | - | 3.0 | - | - |
| CLaM-TTS |
MLS+G+L
+V+LJ |
0.42 | 0.50 | 0.54 | 5.1 | - | - |
| FlashSpeech (ours) | MLS | 0.02 | 0.52 | 0.57 | 2.7 | 0.00 | 4.29 |
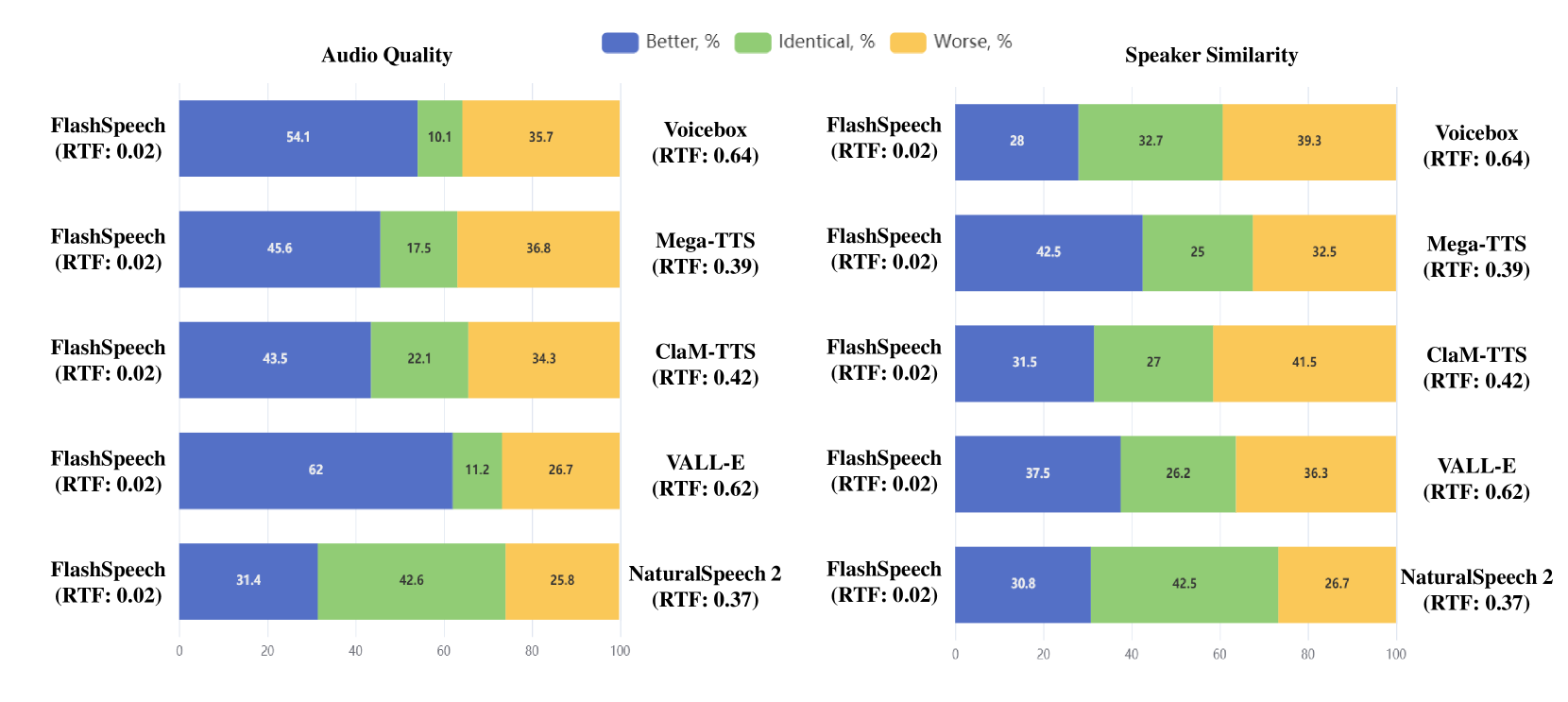
In the experimental section, we begin by introducing the datasets and the configurations for training in our experiments. Following this, we show the evaluation metrics and demonstrate the comparative results against various zero-shot TTS models. Subsequently, ablation studies are conducted to test the effectiveness of several design choices. Finally, we also validate the effectiveness of other tasks such as voice conversion. We show our speech editing and diverse speech sampling results on our demo page.
4.1 Experimental Settings
4.1.1 Data and Preprocessing
We use the English subset of Multilingual LibriSpeech (MLS) Pratap et al. (2020), including 44.5k hours of transcribed audiobook data and it contains 5490 distinct speakers. The audio data is resampled at a frequency of 16kHz. The input text is transformed into a sequence of phonemes through grapheme-to-phoneme conversion Sun et al. (2019) and then we use our internal alignment tool aligned with speech to obtain the phoneme-level duration. We adopt a hop size of 200 for all frame-level features. The pitch sequence is extracted using PyWorld222https://github.com/JeremyCCHsu/Python-Wrapper-for-World-Vocoder. we adopt Encodec Défossez et al. (2022) as our audio codec. We use a modified version 333https://github.com/yangdongchao/UniAudio/tree/main/codec and train it on MLS. We use the dense features extracted before the residual quantization layer as our latent vector .
4.1.2 Training Details
Our training consists of two stages, in the first stage we train LCM and the prosody regression part. We use 8 H800 80GB GPUs with a batch size of 20k frames of latent vectors per GPU for 650k steps. We use the AdamW optimizer with a learning rate of 3e-4, warm up the learning rate for the first 30k updates and then linear decay it. We deactivate adversarial training with = 0 before 600K training iterations. For hyper-parameters, we set in Equation (12) to 0.03. In equation (10), where , . For N(k) in Equation (11), we set . After 600k steps, we activate adversarial loss, and N(k) can be considered as fixed to 1280. We crop the waveform length fed into the discriminator into minimum waveform length in a minibatch. In addition, the weight of the feature extractor WavLM and the codec decoder are frozen.
In the second stage, we train 150k steps for the prosody refinement module with consistency training in Equation (10). Different from the above setting, we empirically set , . During training, only the weight of the prosody refinement part is updated.
4.1.3 Model Details
The model structures of the prompt encoder and phoneme encoder are followShen et al. (2024). The neural function part in LCM is almost the same as the Shen et al. (2024). We rescale the sinusoidal position embedding in the neural function part by a factor of 1000. As for the prosody generator, we adopt 30 non-casual wavenet Oord et al. (2016) layers for the neural function part in the prosody refinement module and the same configurations for prosody regression parts in Shen et al. (2024). And we set for the prosody refinement module empirically. For the discriminator’s head, we stack 5 convolutional layers with weight normalization Salimans and Kingma (2016) for binary classification.
4.2 Evaluation Metrics
We use both objective and subjective evaluation metrics, including
-
•
RTF: Real-time-factor (RTF) measures the time taken for the system to generate one second of speech. This metric is crucial for evaluating the efficiency of our system, particularly for applications requiring real-time processing. We measure the time of our system end-to-end on an NVIDIA V100 GPU following Shen et al. (2024).
-
•
Sim-O and Sim-R: These metrics assess the speaker similarity. Sim-R measures the objective similarity between the synthesized speech and the reconstruction reference speech through the audio codec, using features embedding extracted from the pre-trained speaker verification model Wang et al. (2023a); Kim et al. (2024)444https://github.com/microsoft/UniSpeech/tree/main/downstreams/speaker_verification. Sim-O is calculated with the original reference speech. Higher scores in Sim-O and Sim-R indicate a higher speaker similarity.
-
•
WER (Word Error Rate): To evaluate the accuracy and clarity of synthesized speech from the TTS system, we employ the Automatic Speech Recognition (ASR) model Wang et al. (2023a) 555https://huggingface.co/facebook/hubert-large-ls960-ft to transcribe generated audio. The discrepancies between these transcriptions and original texts are quantified using the Word Error Rate (WER), a crucial metric indicating intelligibility and robustness.
-
•
CMOS, SMOS, UTMOS: we rank the comparative mean option score (CMOS) and similarity mean option score (SMOS) using mturk. The prompt for CMOS refers to ’Please focus on the audio quality and naturalness and ignore other factors.’. The prompt for SMOS refers to ’Please focus on the similarity of the speaker to the reference, and ignore the differences of content, grammar or audio quality.’ Each audio has been listened to by at least 10 listeners. UTMOS Saeki et al. (2022) is a Speech MOS predictor666https://github.com/tarepan/SpeechMOS to measure the naturalness of speech. We use it in ablation studies which reduced the cost for evaluation.
-
•
Prosody JS Divergence: To evaluate the diversity and accuracy of the prosody prediction in our TTS system, we include the Prosody JS Divergence metric. This metric employs the Jensen-Shannon (JS) divergence Menéndez et al. (1997) to quantify the divergence between the predicted and ground truth prosody feature distributions. Prosody features, including pitch, and duration, are quantized and their distributions in both synthesized and natural speech are compared. Lower JS divergence values indicate closer similarity between the predicted prosody features and those of the ground truth, suggesting a higher diversity of the synthesized speech.
4.3 Experimental Results on Zero-shot TTS
Following Wang et al. (2023a), We employ LibriSpeech Panayotov et al. (2015) test-clean for zero-shot TTS evaluation. We adopt the cross-sentence setting in Wang et al. (2023a) that we randomly select 3-second clips as prompts from the same speaker’s speech. The results are summarized in table 1 and figure 5.
4.3.1 Evaluation Baselines
-
•
VALL-E Wang et al. (2023a): VALL-E predicts codec tokens using both AR and NAR models. RTF777In CLaM-TTS and Voicebox, they report the inference time for generating 10 seconds of speech. Therefore, we divide by 10 to obtain the time for generating 1 second of speech (RTF). is obtained from Kim et al. (2024); Le et al. (2023). We use our reproduced results for MOS, Sim, and WER. Additionally, we do a preference test with their official demo.
-
•
Voicebox Le et al. (2023): Voicebox uses flow-matching to predict maksed mel-spectrogram. RTF is from the original paper. We use our reproduced results for MOS, Sim, and WER. We also implement a preference test with their official demo.
-
•
NaturalSpeech2 Shen et al. (2024): NaturalSpeech2 uses a latent diffusion model to predict latent features of codec. The RTF is from the original paper. the Sim, WER and samples for MOS are obtained through communication with the authors. We also do a preference test with their official demo.
-
•
Mega-TTS Jiang et al. (2023a)888Since we do not find any audio samples for Mega-TTS2 Jiang et al. (2024b) under the 3-second cross-sentence setting, we are not able to compare with them.: Mega-TTS uses both language model and GAN to predict mel-spectrogram. We obtain RTF from mobilespeech Ji et al. (2024) and WER from the original paper. We do a preference test with their official demo.
-
•
ClaM-TTS Kim et al. (2024): ClaM-TTS uses the AR model to predict mel codec tokens. We obtain the objective evaluation results from the original paper and do a preference test with their official demo.
4.3.2 Generation Quality
FlashSpeech stands out significantly in terms of speaker quality, surpassing other baselines in both CMOS and audio quality preference tests. Notably, our method closely approaches ground truth recordings, underscoring its effectiveness. These results affirm the superior quality of FlashSpeech in speech synthesis. our method.
4.3.3 Generation Similarity
Our evaluation of speaker similarity utilizes Sim, SMOS, and speaker similarity preference tests, where our methods achieve 1st, 2nd, and 3rd place rankings, respectively. These findings validate our methods’ ability to achieve comparable speaker similarity to other methods. Despite our training data (MLS) containing approximately 5k speakers, fewer than most other methods (e.g., Librilight with about 7k speakers or self-collected data), we believe that increasing the number of speakers in our methods can further enhance speaker similarity.
4.3.4 Robustness
Our methods achieve a WER of 2.7, placing them in the first echelon. This is due to the non-autoregressive nature of our methods, which ensures robustness.
4.3.5 Generation Speed
FlashSpeech achieves a remarkable approximately 20x faster inference speed compared to previous work. Considering its excellent audio quality, robustness, and comparable speaker similarity, our method stands out as an efficient and effective solution in the field of large-scale speech synthesis.
4.4 Ablation Studies
4.4.1 Ablation studies of LCM
We explored the impact of different pre-trained models in adversarial training on UTMOS and Sim-O. As shown in the table 2, the baseline, which employs consistency training alone, achieved a UTMOS of 3.62 and a Sim-O of 0.45. Incorporating adversarial training using wav2vec2-large999https://huggingface.co/facebook/wav2vec2-large, hubert-large101010https://huggingface.co/facebook/hubert-large-ll60k, and wavlm-large111111https://huggingface.co/microsoft/wavlm-large as discriminators significantly improved both UTMOS and Sim-O scores. Notably, the application of adversarial training with Wavlm-large achieved the highest scores (UTMOS: 4.00, Sim-O: 0.52), underscoring the efficacy of this pre-trained model in enhancing the quality and speaker similarity of synthesized speech. Additionally, without using the audio prompt’s feature as a condition the discriminator shows a slight decrease in performance (UTMOS: 3.97, Sim-O: 0.51), highlighting the importance of conditional features in guiding the adversarial training process.
As shown in table 3, the effect of sampling steps (NFE) on UTMOS and Sim-O revealed that increasing NFE from 1 to 2 marginally improves UTMOS (3.99 to 4.00) and Sim-O (0.51 to 0.52). However, further increasing to 4 sampling steps slightly reduced UTMOS to 3.91 due to the accumulation of score estimation errors Chen et al. (2022a); Lyu et al. (2024). Therefore, we use 2 steps as the default setting for LCM.
| Method | UTMOS | Sim-O |
|---|---|---|
| Consistency training baseline | 3.62 | 0.45 |
| + Adversarial training (Wav2Vec2-large) | 3.92 | 0.50 |
| + Adversarial training (Hubert-large) | 3.83 | 0.47 |
| + Adversarial training (Wavlm-large) | 4.00 | 0.52 |
| - prompt projection | 3.97 | 0.51 |
| NFE | UTMOS | Sim-O |
|---|---|---|
| 1 | 3.99 | 0.51 |
| 2 | 4.00 | 0.52 |
| 4 | 3.91 | 0.51 |
4.4.2 Ablation studies of Prosody Generator
In this part, we investigated the effects of a control factor, denoted as , on the prosodic features of pitch and duration in speech synthesis, by setting another influencing factor to zero. Our study specifically conducted an ablation analysis to assess how influences these features, emphasizing its critical role in balancing stability and diversity within our framework’s prosodic outputs.
Table 4 elucidates the effects of varying on the pitch component. With set to 0, indicating no inclusion of the residual output from prosody refinement, we observed a Pitch JSD of 0.072 and a WER of 2.8. A slight modification to resulted in a reduced Pitch JSD of 0.067, maintaining the same WER. Notably, setting to 1, fully incorporating the prosody refinement’s residual output, further decreased the Pitch JSD to 0.063, albeit at the cost of increased WER to 3.7, suggesting a trade-off between prosody diversity and speech intelligibility.
Similar trends in table 5 are observed in the duration component analysis. With , the Duration JSD was 0.0175 with a WER of 2.8. Adjusting to 0.2 slightly improved the Duration JSD to 0.0168, without affecting WER. However, fully embracing the refinement module’s output by setting yielded the most significant improvement in Duration JSD to 0.0153, which, similar to pitch analysis, came with an increased WER of 3.9. The results underline the delicate balance required in tuning to optimize between diversity and stability of prosody without compromising speech intelligibility.
| Pitch JSD | WER | |
|---|---|---|
| 0 | 0.072 | 2.8 |
| 0.2 | 0.067 | 2.8 |
| 1 | 0.063 | 3.7 |
| Duration JSD | WER | |
|---|---|---|
| 0 | 0.0175 | 2.8 |
| 0.2 | 0.0168 | 2.8 |
| 1 | 0.0153 | 3.9 |
4.5 Evaluation Results for Voice Conversion
In this section, we present the evaluation results of our voice conversion system, FlashSpeech, in comparison with state-of-the-art methods, including YourTTS 121212https://github.com/coqui-ai/TTS Casanova et al. (2022) and DDDM-VC 131313https://github.com/hayeong0/DDDM-VC Choi et al. (2024). We conduct the experiments with their official checkpoints in our internal test set.
| Method | CMOS | SMOS | Sim-O |
|---|---|---|---|
| YourTTS Casanova et al. (2022) | -0.16 | 3.26 | 0.23 |
| DDDM-VC Choi et al. (2024) | -0.28 | 3.43 | 0.28 |
| Ours | 0.00 | 3.50 | 0.35 |
Our system outperforms both YourTTS and DDDM-VC in terms of CMOS, SMOS and Sim-O, demonstrating its capability to produce converted voices with high quality and similarity to the target speaker. These results confirm the effectiveness of our FlashSpeech approach in voice conversion tasks.
4.6 Conclusions and Future Work
In this paper, we presented FlashSpeech, a novel speech generation system that significantly reduces computational costs while maintaining high-quality speech output. Utilizing a novel adversarial consistency training method and an LCM, FlashSpeech outperforms existing zero-shot TTS systems in efficiency, achieving speeds about 20 times faster without compromising on voice quality, similarity, and robustness. In the future, we aim to further refine the model to improve the inference speed and reduce computational demands. In addition, we will expand the data scale and enhance the system’s ability to convey a broader range of emotions and more nuanced prosody. For future applications, FlashSpeech can be integrated for real-time interactions in applications such as virtual assistants and educational tools.
References
- (1)
- Baevski et al. (2020) Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Casanova et al. (2022) Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and Moacir A Ponti. 2022. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In Proc. Intl. Conf. Machine Learning (ICML).
- Charbonnier et al. (1997) Pierre Charbonnier, Laure Blanc-Féraud, Gilles Aubert, and Michel Barlaud. 1997. Deterministic edge-preserving regularization in computed imaging. IEEE Transactions on image processing 6, 2 (1997), 298–311.
- Chen et al. (2021) Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, et al. 2021. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio. arXiv preprint arXiv:2106.06909 (2021).
- Chen et al. (2022a) Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R Zhang. 2022a. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. arXiv preprint arXiv:2209.11215 (2022).
- Chen et al. (2022b) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. 2022b. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 16, 6 (2022), 1505–1518.
- Choi et al. (2024) Ha-Yeong Choi, Sang-Hoon Lee, and Seong-Whan Lee. 2024. Dddm-vc: Decoupled denoising diffusion models with disentangled representation and prior mixup for verified robust voice conversion. In Proc. AAAI Conf. Artif. Intell. (AAAI).
- Défossez et al. (2022) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2022. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438 (2022).
- Esser et al. (2021) Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recogn (CVPR).
- Guan et al. (2023) Wenhao Guan, Qi Su, Haodong Zhou, Shiyu Miao, Xingjia Xie, Lin Li, and Qingyang Hong. 2023. Reflow-tts: A rectified flow model for high-fidelity text-to-speech. arXiv preprint arXiv:2309.17056 (2023).
- Hsu et al. (2021) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio, Speech, Lang. Process. 29 (2021), 3451–3460.
- Ito and Johnson (2017) Keith Ito and Linda Johnson. 2017. The LJ Speech Dataset. https://keithito.com/LJ-Speech-Dataset/.
- Jeong et al. (2021) Myeonghun Jeong, Hyeongju Kim, Sung Jun Cheon, Byoung Jin Choi, and Nam Soo Kim. 2021. Diff-tts: A denoising diffusion model for text-to-speech. arXiv preprint arXiv:2104.01409 (2021).
- Ji et al. (2024) Shengpeng Ji, Ziyue Jiang, Hanting Wang, Jialong Zuo, and Zhou Zhao. 2024. MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech. arXiv:2402.09378
- Jiang et al. (2024a) Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun MA, and Zhou Zhao. 2024a. Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis. In Proc. Intl. Conf. Learning Representations (ICLR).
- Jiang et al. (2024b) Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, and Zhou Zhao. 2024b. Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis. arXiv:2307.07218
- Jiang et al. (2023a) Ziyue Jiang, Yi Ren, Zhenhui Ye, Jinglin Liu, Chen Zhang, Qian Yang, Shengpeng Ji, Rongjie Huang, Chunfeng Wang, Xiang Yin, et al. 2023a. Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias. arXiv preprint arXiv:2306.03509 (2023).
- Jiang et al. (2023b) Ziyue Jiang, Qian Yang, Jialong Zuo, Zhenhui Ye, Rongjie Huang, Yi Ren, and Zhou Zhao. 2023b. FluentSpeech: Stutter-Oriented Automatic Speech Editing with Context-Aware Diffusion Models. In Findings of the Association for Computational Linguistics: ACL 2023.
- Karras et al. (2022) Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. 2022. Elucidating the design space of diffusion-based generative models. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Kharitonov et al. (2023) Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour. 2023. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. arXiv preprint arXiv:2302.03540 (2023).
- Kim et al. (2023a) Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. 2023a. Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion. In Proc. Intl. Conf. Learning Representations (ICLR).
- Kim et al. (2024) Jaehyeon Kim, Keon Lee, Seungjun Chung, and Jaewoong Cho. 2024. CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech. In Proc. Intl. Conf. Learning Representations (ICLR).
- Kim et al. (2023b) Sungwon Kim, Kevin J Shih, Rohan Badlani, Joao Felipe Santos, Evelina Bakhturina, Mikyas T Desta, Rafael Valle, Sungroh Yoon, and Bryan Catanzaro. 2023b. P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Koizumi et al. (2023) Yuma Koizumi, Heiga Zen, Shigeki Karita, Yifan Ding, Kohei Yatabe, Nobuyuki Morioka, Michiel Bacchiani, Yu Zhang, Wei Han, and Ankur Bapna. 2023. Libritts-r: A restored multi-speaker text-to-speech corpus. arXiv preprint arXiv:2305.18802 (2023).
- Kong et al. (2023) Fei Kong, Jinhao Duan, Lichao Sun, Hao Cheng, Renjing Xu, Hengtao Shen, Xiaofeng Zhu, Xiaoshuang Shi, and Kaidi Xu. 2023. ACT: Adversarial Consistency Models. arXiv preprint arXiv:2311.14097 (2023).
- Le et al. (2023) Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. 2023. Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Li et al. (2019) Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, and Ming Liu. 2019. Neural speech synthesis with transformer network. In Proc. AAAI Conf. Artif. Intell. (AAAI).
- Li et al. (2023) Xiang Li, Songxiang Liu, Max WY Lam, Zhiyong Wu, Chao Weng, and Helen Meng. 2023. Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model. arXiv preprint arXiv:2305.16749 (2023).
- Lipman et al. (2022) Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. 2022. Flow Matching for Generative Modeling. In Proc. Intl. Conf. Learning Representations (ICLR).
- Lu et al. (2023) Haoye Lu, Yiwei Lu, Dihong Jiang, Spencer Ryan Szabados, Sun Sun, and Yaoliang Yu. 2023. Cm-gan: Stabilizing gan training with consistency models. In ICML 2023 Workshop on Structured Probabilistic Inference and Generative Modeling.
- Lu et al. (2024) Yiwen Lu, Zhen Ye, Wei Xue, Xu Tan, Qifeng Liu, and Yike Guo. 2024. CoMoSVC: Consistency Model-based Singing Voice Conversion. arXiv preprint arXiv:2401.01792 (2024).
- Luo et al. (2023) Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. 2023. Latent consistency models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023).
- Luo (2023) Weijian Luo. 2023. A comprehensive survey on knowledge distillation of diffusion models. arXiv preprint arXiv:2304.04262 (2023).
- Lyu et al. (2024) Junlong Lyu, Zhitang Chen, and Shoubo Feng. 2024. Sampling is as easy as keeping the consistency: convergence guarantee for Consistency Models.
- Menéndez et al. (1997) ML Menéndez, JA Pardo, L Pardo, and MC Pardo. 1997. The jensen-shannon divergence. Journal of the Franklin Institute 334, 2 (1997), 307–318.
- Miyato and Koyama (2018) Takeru Miyato and Masanori Koyama. 2018. cGANs with Projection Discriminator. In Proc. Intl. Conf. Learning Representations (ICLR).
- Oord et al. (2016) Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016).
- Panayotov et al. (2015) Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: an asr corpus based on public domain audio books. In Proc. IEEE Intl. Conf. Acoustics, Speech, Signal Process. (ICASSP). IEEE.
- Peng et al. (2024) Puyuan Peng, Po-Yao Huang, Daniel Li, Abdelrahman Mohamed, and David Harwath. 2024. VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild. arXiv preprint arXiv:2403.16973 (2024).
- Popov et al. (2021a) Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. 2021a. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. In Proc. Intl. Conf. Machine Learning (ICML).
- Popov et al. (2021b) Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Sergeevich Kudinov, and Jiansheng Wei. 2021b. Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme. In Proc. Intl. Conf. Learning Representations (ICLR).
- Pratap et al. (2020) Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. 2020. Mls: A large-scale multilingual dataset for speech research. arXiv preprint arXiv:2012.03411 (2020).
- Preechakul et al. (2022) Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, and Supasorn Suwajanakorn. 2022. Diffusion autoencoders: Toward a meaningful and decodable representation. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recogn (CVPR).
- Ren et al. (2020) Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2020. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proc. Intl. Conf. Learning Representations (ICLR).
- Ren et al. (2019) Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2019. Fastspeech: Fast, robust and controllable text to speech. Proc. Conf. Neural Information Processing Systems (NeurIPS) (2019).
- Ren et al. (2022) Yi Ren, Xu Tan, Tao Qin, Zhou Zhao, and Tie-Yan Liu. 2022. Revisiting Over-Smoothness in Text to Speech. In Proc. Assoc. for Computational Linguistics (ACL.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recogn (CVPR).
- Rossenbach et al. (2020) Nick Rossenbach, Albert Zeyer, Ralf Schlüter, and Hermann Ney. 2020. Generating synthetic audio data for attention-based speech recognition systems. In Proc. IEEE Intl. Conf. Acoustics, Speech, Signal Process. (ICASSP).
- Saeki et al. (2022) Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. Utmos: Utokyo-sarulab system for voicemos challenge 2022. arXiv preprint arXiv:2204.02152 (2022).
- Salimans and Kingma (2016) Tim Salimans and Diederik P. Kingma. 2016. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks. arXiv:1602.07868
- Sauer et al. (2023) Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. 2023. Adversarial diffusion distillation. arXiv preprint arXiv:2311.17042 (2023).
- Shen et al. (2024) Kai Shen, Zeqian Ju, Xu Tan, Eric Liu, Yichong Leng, Lei He, Tao Qin, sheng zhao, and Jiang Bian. 2024. NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers. In Proc. Intl. Conf. Learning Representations (ICLR).
- Song and Dhariwal (2023) Yang Song and Prafulla Dhariwal. 2023. Improved Techniques for Training Consistency Models. In Proc. Intl. Conf. Learning Representations (ICLR).
- Song et al. (2023) Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. 2023. Consistency models. In Proc. Intl. Conf. Machine Learning (ICML).
- Song et al. (2020) Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-Based Generative Modeling through Stochastic Differential Equations. In Proc. Intl. Conf. Learning Representations (ICLR).
- Sun et al. (2019) Hao Sun, Xu Tan, Jun-Wei Gan, Hongzhi Liu, Sheng Zhao, Tao Qin, and Tie-Yan Liu. 2019. Token-level ensemble distillation for grapheme-to-phoneme conversion. In Proc. Interspeech.
- Tan et al. (2021) Xu Tan, Tao Qin, Frank Soong, and Tie-Yan Liu. 2021. A survey on neural speech synthesis. arXiv preprint arXiv:2106.15561 (2021).
- Vyas et al. (2023) Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. 2023. Audiobox: Unified audio generation with natural language prompts. arXiv preprint arXiv:2312.15821 (2023).
- Wang et al. (2023a) Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023a. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111 (2023).
- Wang et al. (2017) Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, et al. 2017. Tacotron: Towards End-to-End Speech Synthesis. In Proc. Interspeech.
- Wang et al. (2023b) Zhichao Wang, Yuanzhe Chen, Lei Xie, Qiao Tian, and Yuping Wang. 2023b. Lm-vc: Zero-shot voice conversion via speech generation based on language models. IEEE Signal Processing Letters (2023).
- Yamagishi et al. (2019) Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. 2019. CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit (version 0.92).
- Yang et al. (2023) Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, et al. 2023. Uniaudio: An audio foundation model toward universal audio generation. arXiv preprint arXiv:2310.00704 (2023).
- Ye et al. (2023) Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu, and Yike Guo. 2023. CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model. In Proc. ACM Multimedia (ACM MM).
- Zhang et al. (2022) Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, et al. 2022. Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. In Proc. IEEE Intl. Conf. Acoustics, Speech, Signal Process. (ICASSP).
- Zhang et al. (2023) Ziqiang Zhang, Long Zhou, Chengyi Wang, Sanyuan Chen, Yu Wu, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv preprint arXiv:2303.03926 (2023).
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223 (2023).