Out-of-distribution Detection in
Medical Image Analysis: A survey
Abstract
Computer-aided diagnostics has benefited from the development of deep learning-based computer vision techniques in these years. Traditional supervised deep learning methods assume that the test sample is drawn from the identical distribution as the training data. However, it is possible to encounter out-of-distribution samples in real-world clinical scenarios, which may cause silent failure in deep learning-based medical image analysis tasks. Recently, research has explored various out-of-distribution (OOD) detection situations and techniques to enable a trustworthy medical AI system. In this survey, we systematically review the recent advances in OOD detection in medical image analysis. We first explore several factors that may cause a distributional shift when using a deep-learning-based model in clinic scenarios, with three different types of distributional shift well defined on top of these factors. Then a framework is suggested to categorize and feature existing solutions, while the previous studies are reviewed based on the methodology taxonomy. Our discussion also includes evaluation protocols and metrics, as well as the challenge and a research direction lack of exploration.
Index Terms:
trustworthy AI, medical image analysis, out-of-distribution detection.I Introduction
Traditional supervised machine learning methods are established based on the naive assumption that the test and training samples are drawn from the same distribution, i.e., in-distribution. However, it doesn’t always hold true in the real world, where out-of-distribution samples may be encountered during inference. For deep learning-based medical image analysis tasks such as disease recognition or organ segmentation, models trained in-house may fail on out-of-distribution samples silently, leading to severe outcomes such as misdiagnosis. Therefore, a trustworthy model must be able to say “I don’t know” when encounter an OOD sample and then take the control to the human expert instead of suggesting an error-prone prediction.
To this end, out-of-distribution (OOD) detection in medical image analysis has recently developed and drawn attention in the research community. Existing research is conducted across a range of medical fields, while the evaluations encompass various out-of-distribution settings. Besides, several similar tasks are also explored, such as anomaly detection and uncertainty quantification. However, to our best knowledge, there is no systematic framework that clearly describes and groups these cases, and the terminology used in the literature is diverse and sometimes confusing.
In this survey, we focus on out-of-distribution (OOD) detection in two widely studied medical image analysis tasks, namely supervised medical image classification and medical image segmentation, since most of the previous techniques have been developed for them. Our contributions include:
-
•
Problem formulation: We first explore several factors that may lead to a distributional shift in real clinical scenarios, as well as define and interpret three types of distributional shifts based on these factors, which naturally expands the general OOD detection framework [1] to the field of medical image analysis;
-
•
Solution framework: A proper solution framework is proposed to organize the related research from two aspects, namely methodology taxonomy and association with base task model;
-
•
Study review: We systematically review the existing studies based on the methodology taxonomy, with a focus on technical details and experiment settings;
-
•
Evaluation protocols and metrics: The evaluation protocols, metrics, and test samples corresponding to three proposed OOD types used in the previous studies are summarized;
-
•
Challenges and future directions: We also discuss a challenge in this area and identify a research direction that deserves more attention in future work.
II Preliminary
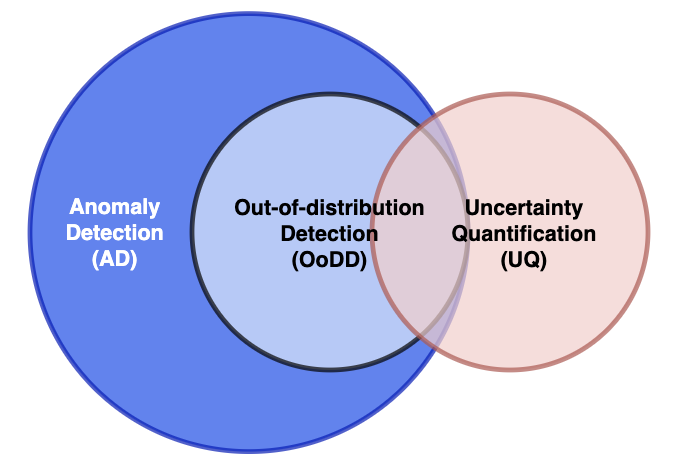
In order to reduce ambiguity and claim the scope of this survey, we first clarify three similar concepts that are easily confused with each other, namely out-of-distribution (OOD) detection, Anomaly Detection (AD), and uncertainty quantification (UQ). The relationship between them is illustrated in Fig1. Besides, it is necessary to clarify the in-distribution before formulating an out-of-distribution (OOD) detection task. To this end, we briefly introduce supervised medical image classification and medical image segmentation in this section. To help readers with no professional background, we also prepare some basic knowledge of several biomedical image types that appear in the involved studies.
II-A Out-of-distribution (OOD) detection
A supervised deep learning model is trained with a set of instance-label pairs to learn match patterns behind them, in the hope that it will generalize well to similar instances. Given a trained model, we term its original learning objective the base task for clarity. Denote the input space and the label (semantic) space , an in-distribution is a joint distribution over the product space and is realized by the base task training data pairs. Apart from the base task, a trustworthy model should be capable of identifying the test samples beyond the training in-distribution, namely out-of-distribution (OOD) detection. Due to the distributional mismatch, the OOD sample may exceed the model’s perception and thus be an inappropriate input. OOD detection allows marking these problematic inputs and adopting other resorts to handle them properly.
II-B Anomaly Detection (AD)
Anomaly Detection (AD) is a general concept referring to the identification of deviation from normal data [2]. OOD detection can be viewed as a special case of AD when treating the in-distribution samples as normal data. In the research community of deep learning-based medical image analysis, the term Anomaly Detection mostly refers to the detection of pathology that deviates from normal healthy images[3][4][5][6]. We term this case AD-based pathology detection for clarity. In general, it is achieved through supervised or semi-supervised learning. Supervised learning is to train a classification model with an extremely unbalanced dataset containing both healthy and pathological (abnormal) samples. In contrast, semi-supervised approaches use only healthy samples to train a model capturing the normal pattern and then score the normality during inference to detect pathologies[3]. AD-based pathology detection is a base task in itself, whereas OOD detection serves as an adjunct to identify unsuitable inputs given a model dedicated to some base task. Thus, we excluded AD-based pathology detection from our survey though some literature [7][8] call it ”out-of-distribution detection” as well.
II-C Uncertainty quantification (UQ)
Uncertainty quantification (UQ) is a task that measures predictive uncertainty (PU), i.e., how confident the model feels about the prediction w.r.t. a given input. UQ methods are developed to identify the uncertain sample that requires human review, as well as enable the discovery of the model’s deficiency[9]. Although these techniques are widely utilized to detect OOD samples in medical image analysis [10] [11] [12] [13] [14] [15] [16], we argue UQ and OOD detection are not equivalent and interchangeable concepts.
Conventionally, predictive uncertainty (PU) can be factorized into two parts: (1) aleatoric uncertainty (AU) and (2) epistemic uncertainty (EU). The aleatoric uncertainty, also known as data uncertainty, is irreducible as it arises from the inherent properties of data, such as class overlap and noises. In contrast, epistemic uncertainty comes from the lack of knowledge in terms of the underlying model or data, which can be reduced by improving the model’s structure, using more training data, or adding valid regularization [17]. Thus, the predictive uncertainty (PU) is modeled as the sum of AU and EU [18]:
However, another perspective [19] [20] accounted for predictive uncertainty (PU) into three divisions: (1) aleatoric uncertainty (AU), (2) model uncertainty (MU), and (3) distributional uncertainty (DU). Here model uncertainty measures the match between the model and training data, while distributional uncertainty arises from the distributional mismatch between the test sample and training set. We argue both model uncertainty (MU) and distributional uncertainty (DU) belong to epistemic uncertainty (EU) as they can be reduced by feeding more data representative of in-distribution samples or OOD samples. Therefore, the predictive uncertainty can be rewritten as:
In other words, high uncertainty may occur in either an in-distribution sample that is hard to predict due to its intrinsic nature (e.g., class overlap) or model deficiency, or an OOD sample. However, most learning-based deterministic UQ methods such as the confidence branch [21], DUQ [22], and Evidential Deep Learning [23] only learn to quantify the uncertainty from in-distribution data, without explicitly considering distributional uncertainty. [24] argued that some prevalent UQ methods fail to detect OOD, including Maximum Softmax Probability [25], MC Dropout [26], and Deep Ensembles [27]. Besides, recent research [28] [29] [30] suggested that UQ methods have performance degeneration when distributional shift happens [9].
Another difference between UQ and OOD detection lies in their evaluation protocols. In fact, the evaluation of UQ is not straightforward simply due to no ground truth of “uncertainty”. Alternatively, it is often achieved by the evaluation of downstream tasks, including OOD detection [9]. However, UQ can also be evaluated by tasks without involving OOD samples, such as calibration, error detection, segmentation quality control, etc [9]. Thus, any research dedicated to UQ without considering OOD detection is beyond our scope. For those, please refer to [9].
II-D Supervised medical image segmentation
Supervised medical image classification has been widely applied to a range of computer-aided diagnostic tasks such as distinguishing between malignant and benign lesions, identification of specific pathology, or rating the disease risks [31]. Let denote the input space and the label (semantic) space, a medical image together with its semantic label lies on the product space . A supervised medical image classification algorithm aims to learn a map from training set , where is a binary indicator or one-hot encoder representative of a pre-defined class. In this case, the in-distribution is the joint distribution over characterized by image-label pairs in the training set.
II-E Medical image segmentation
Medical image segmentation refers to the process of identifying and delineating regions of interest such as lesions, organs, and other substructures. It is achieved by determining the set of pixels (voxels) that belong to these regions rather than the background [31], thereby can be viewed as pixel (voxel)-level classification. Let denote the pixel (voxel) space and the label (semantic) space, any pixel (voxel) together with its semantic label lies on the product space . Based on a training set where is a mask indicating label for each pixel within input , a medical image segmentation algorithm aims to learn a map for each pixel (voxel), pixels (voxels) with same predicted label form a mask for that category. In this case, the in-distribution is the joint distribution over characterized by pixel (voxel)-label pairs in the training set.
II-F Biomedical images
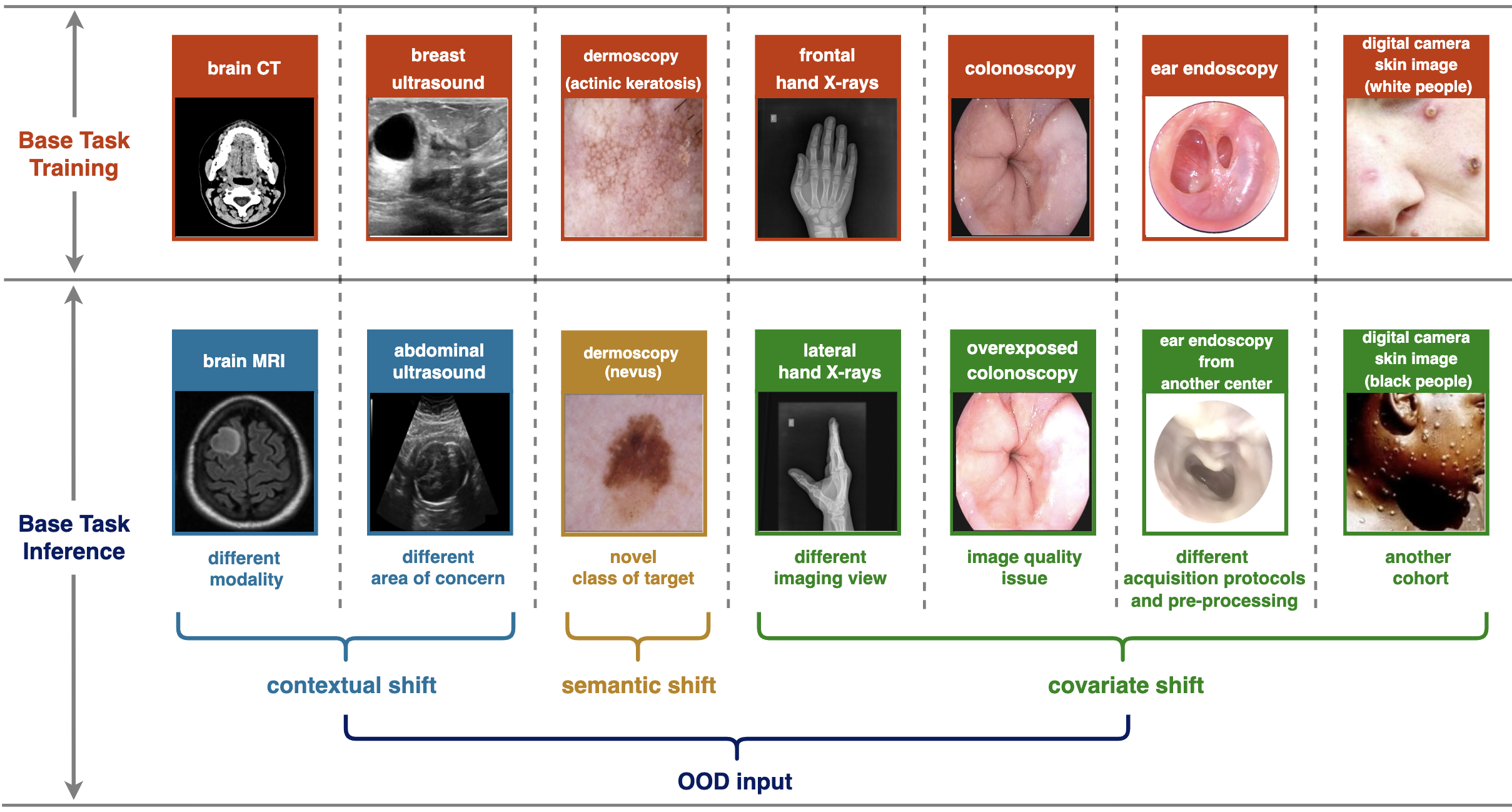
OOD detection in medical image analysis is studied across a range of medical modalities and image types. We simply introduce some relevant biomedical images to give the reader a primer picture. Please find the example in Fig2.
X-ray images: X-rays can penetrate through the tissues but would be scattered when encountering bones, which leads to different light exposure in their corresponding imaging area. As the film of X-rays is a negative image (i.e., the darker regions reflect the higher light exposure), the region of bones looks lighter than that of tissues[4]. Common X-ray images include chest X-ray (CXR) images, Musculoskeletal X-ray images, Mammography images, etc.
Fundus images: A fundus image is a two-dimensional projection of the fundus obtained by a monocular camera, which is appropriate for widespread screening purposes due to the non-invasive acquired manner [32]. Fundus images can be used for the diagnosis of common eye diseases, such as glaucoma, cataract, and diabetic retinopathy (DR)[32].
Dermoscopy images: Dermoscopy is a high-resolution skin imaging technique that allows visualization of deeper skin structures by reducing surface reflectance [33]. The image is captured by skin surface microscopy, which is equipped with high-quality magnifying lens and powerful lighting system. Dermoscopy images are often used to examine pigmented skin lesions, such as Melanoma and Moles.
Stained histology slides:
A histology slide is a glass slide with the tissue samples fixed upon it, which is typically stained, sectioned, and examined under a microscope[34]. The objective of staining is to color different structures within cells. For example, Hematoxylin, a basic dye employed in this procedure, imparts a bluish color to the nuclei, whereas eosin, another histological stain, imparts a pinkish hue to the cell’s nucleus[34]. It is frequently used for diagnosis or classification of cancers.
Optical-coherence tomography (OCT): Optical coherence tomography (OCT) is a technique that allows for the non-contact imaging of the surface and internal microstructure of samples in three dimensions[35], which has been popularly used in the diagnosis of retinal diseases such as age-related macular degeneration (AMD)[12].
Computed tomography (CT): The Computed tomography (CT) scan is computer-generated cross-sectional images produced through rotating X-rays around a specified body part, which has been proven useful in preventative medicine and cancer screening[36]. It is capable of capturing features in each cross-section and thereby eliminates the superimposition of images in plain films (e.g., X-ray images), [36].
Magnetic resonance imaging (MRI): MRI is a non-invasive imaging technique that maps the internal anatomy structures within the body[37], such as organs, bones, muscles, and blood vessels. Compared with CT scans, the advantage of MRI is it uses radio frequency (RF) radiation instead of electromagnetic radiation, which reduces the exposure-related risk[37].

III Related Work
[38] first discovered the phenomenon that deep neural networks would make an overconfident prediction to out-of-distribution (OOD) data. Since then, out-of-distribution (OOD) detection has been an active field in the research community.[25] pioneered OOD detection, proposing to use Maximum Probability Score (MSP) as a simple baseline. [39] found that simply adding a perturbation to the input in fast gradient sign direction and using temperature scaling improved the OOD detection. [40] suggested modeling the training data features with class conditional Gaussian distribution and testing the OOD sample using Mahalanobis distance. Later, a range of methods and techniques are developed to address this issue, such as Outlier Exposure [41], energy score [42], gradient-based GradNorm score [43], and generation-based VOS [44].
Some aspects other than downstream OOD detection methods also attracted some attention. [45] and [46] focused on the effect of network backbone, demonstrating using a vision transformer (ViT) pre-trained with large-scale datasets can significantly improve the simple MSP [41] and Mahalanobis-based method [40].[47] tried to leverage the multi-modal representation learning, extending the pre-trained language-vision model CLIP to detect OOD. Besides, [48] argued most works evaluated their methods only on the small, low-resolution datasets, and scaled the OOD detection for datasets with 10-100 times larger label space than previous works.
In order to systematically review the recent studies in OOD detection and other related tasks, [1] proposed a well-defined framework named generalized out-of-distribution detection. However, they overlook the studies about OOD detection in medical image analysis. Although [49] reviewed some works in medical image OOD detection, their work is excessively incomprehensive. Besides, it lacks the exploration of problem formulation, a well-organized solution framework, and the discussion of evaluation protocols, challenges, and future directions, as compared to our work.
In addition to OOD detection, some surveys are conducted in medical Anomaly Detection (AD) [3][4]. These works only consider AD as a base task while missing the situation where it functions as an auxiliary to improve the reliability of a deep learning-based model, namely OOD detection. [9] systematically reviewed the uncertainty quantification (UQ) in deep learning-based medical image analysis. Despite some overlaps between UQ and OOD detection, they are not equivalent concepts and should be treated differently, as we argued in II-C.
IV Problem formulation and taxonomy
Distributional shifts can occur across a variety of factors. [50] argued that not all distribution shifts should be considered in OOD detection. Instead, a distributional shift should be taken into account only when it occurs on the factors of interest. Let’s take object recognition as an example. Usually, the model is trained to classify the identity of the foreground object into several pre-defined semantic classes while not caring about the background. In this case, an image with a pre-defined object located in a novel background should not be an OOD sample. However, the opposite is true in a scene classification task. Motivated by this view, we first analyze the factors on which the distributional shift may happen in clinical scenarios. On top of these factors, we borrow two names from generalized OOD detection framework[1], semantic shift, and covariate shift, together with contextual shift to characterize three distributional types in medical image analysis. Please note the three terminologies are used hereafter to reduce confusion, though they may have different names, such as “far OOD”, “near OOD”, and “domain shift” in literature.
IV-A Distributional shift factors
Referring to [51] and domain expert’s opinion, we summarize seven distributional shift factors of importance in medical image analysis:
Modality: Medical image modality often depends on the acquisition equipment, encompassing but not limited to Magnetic Resonance Imaging (MRI), Computed Tomography (CT), X-ray, and stained histology slides. Two distinct medical image modalities differ in imaging principles. As a result, the geometric nature and appearance can vary dramatically across two modalities, even for the same object.
Area of concern: Generally, a medical image classification or segmentation task should be dedicated to a fixed area, such as the brain, chest, skin, or lymph node tissue. Different areas are incomparable due to the differences in their intrinsic anatomical natures.
Imaging view: For some medical images, a shift in imaging views may cause a difference. For example, a posteroanterior (PA) Chest X-ray image is acquired by placing X-rays at the rear of the patient, while an anteroposterior (AP) Chest X-ray image is acquired oppositely. The two exhibit explicable variations due to the patient’s positioning and the cone-beam geometry[52].
Image quality: The existence of image quality issues, such as blurry, poor contrast, and overexposed, may lead to a distributional shift. This arises from incorrect operation or the poor performance of imaging equipment.
Acquisition protocols and pre-processing: The acquisition protocols and pre-processing of medical images tend to vary among medical sites/centers as the principles they follow may be different from each other.
Class of target: The target in medical images is an analogy to the semantic object in natural image datasets such as CIFAR-10 or ImageNet. Specifically, it can be a disease, pathology, or cell in medical image classification, as well as a lesion, organ, tissue, or other anatomical structures of interest in medical image segmentation. The input image sometimes contains a novel class of the target, resulting in a distributional shift in semantics.
Cohort: A cohort refers to a group of individuals or patients who share certain characteristics and are studied together for research or clinical purposes. This group is often selected based on specific criteria, such as age, gender, medical condition, or treatment received. A novel cohort that is unseen in the training set also leads to a distributional shift. For example, a pediatric chest X-ray is OOD to adult chest X-ray image, or a chest X-ray containing artificial implants is OOD to implant-free chest X-ray image.
| Modality |
|
|
|
|
|
|
||||||||||||
| contextual shift | ✓ | ✓ | ||||||||||||||||
| semantic shift | ✓ | |||||||||||||||||
| covariate shift | ✓ | ✓ | ✓ | ✓ |
IV-B OOD detection in medical image analysis
A generalized OOD detection framework [1] is discussed with respect to a deep learning-based visual recognition model. [1] suggested dichotomizing distributional shift into covariate (sensory) shift and semantic shift. The former refers to the shift that occurs only in the marginal distribution . while the latter means a novel class of object, which leads to the distributional shift in both and . For example, given a deep learning-based classification model trained with RGB images to distinguish between dog and cat, covariate and semantic shift instances can be a sketch of the dog and an RGB image of the frog, respectively.
Despite a perfect fit for natural object recognition, we argue this framework is not appropriate to describe distributional shift cases in medical image analysis. Let’s assume the base task is to distinguish between Lung Opacity and Pleural Effusion based on chest X-ray image, and a set of corresponding chest X-ray image with normal contrast is used to train a deep learning model. Now we consider two different OOD samples: (1) A chest CT slice obtained from a patient with Lung Opacity, and (2) A poor-contrast chest X-ray image obtained from a patient with Lung Opacity. Based on the definition in [1], both two can be categorized into covariate shift. However, they differ in the degree of deviation from in-distribution. The former is completely incomparable to in-distribution samples due to the mismatch in modality. In contrast, the latter retains a lot of features representative of in-distribution samples, thereby still having a chance to be predicted correctly. In order to properly adapt the generalized OOD detection framework[1] to clinal scenarios, we propose a taxonomy for OOD detection in medical image analysis and define each category based on the factors discussed before (see Table I), in the hope that it can well describe all the cases considered in previous studies.
IV-B1 Contextual shift
The context of a medical image can be roughly described from two aspects, the modality (e.g., X-ray images, CT-scans, histology slides…), and the area of concern (e.g., an organ, tissue…). We define contextual shift sample as the input image having inconsistent modality and\or area of concern with the training set. Note the non-medical image is a case of contextual shift to any medical images. Usually, a medical image classification or medical image segmentation task only targets a specific context, which means the modality and area of concern are typically consistent across the training set. However, there is an exception in [53] where the model is trained across multiple similar modalities (i.e., CT and MRI) and different organs (e.g., liver, heart…), namely multi-task segmentation. In this case, contextual shift means the input image has a different modality and\or area of concern from that of any training samples. The context specifies in which situation the trained model will be correctly used, or in other words, the correct input type. Thus, contextual shift will inevitably lead to a meaningless prediction. For example, it makes no sense to input a chest CT slice into a lung pathology classifier trained with X-ray images, and a tumor segmentation model trained on brain CT must fail to segment COVID-19 lung lesion shown in chest CT. Such a distributional shift often arises from man-made input errors or malicious attacks and should be rejected without any hesitation.
IV-B2 Semantic shift
Following the definition in [1], we define semantic shift as the input image containing a novel class of target. It is common in supervised medical image classification, such as an image with a rare disease that is not defined in the label set. However, we argue semantic shift detection in medical image segmentation is meaningful only when the segmentation object is a lesion instead of organ, tissue, or other anatomical structures whose semantic classes are constant. For example, in [54] the base task is to segment pulmonary Covid-19 lesions in chest CT scans while a set of OOD samples are pulmonary lesions caused by non-Covid pneumonia, bacterial pneumonia, fungal pneumonia, etc. This can be seen as semantic shift in medical image segmentation. A semantic shift arises from incomplete knowledge or a lack of available samples in the training stage. Other than the indication of an erroneous input, the identification of semantic shift samples can benefit the model as well. Once detected, they can be annotated by an oracle (e.g., a physician) and stored in a database. By resorting to continual learning techniques, these samples can be used to update the model’s knowledge throughout its entire life span.
| base task | In-distribution Data | contextual Shift | semantic shift | covariate shift | |
| supervised medical image classification | Chest X-ray (CXR) images | [51][10][55][52] | [51][11] | [51][52] | |
| Musculoskeletal X-ray images | [10][55] | ||||
| Mammography images | [56] | ||||
| Fundus images | [51][10][57] | [51] | [51][57] | ||
| Dermoscopy \digital camera skin images | [58][59] | [60][61][58][59][62] [63] | [58][62] | ||
| Stained Histology Slides | [51][15] | [51][13][14][15] | [15] | ||
| Optical Coherence Tomography (OCT) | [12] | [12] | |||
| Abdomen CT | [64] | ||||
| Chest CT | [55] | ||||
| Head CT | [55] | ||||
| Breast MRI | [55] | ||||
| medical image segmentation | Chest CT | [54] | [54] | [65][54] | |
| Head CT | [66][64] | [66][64] | |||
| Liver T1 MRI | [67] | ||||
| Brain cortical plate T2 MRI | [53] | ||||
| Prostate T2 MRI | [16] | ||||
| Laparoscopic Cholecystectomy images | [68] | ||||
| Endoscopic Surgical images | [68] | ||||
|
[53] | [53] |
IV-B3 Covariate shift
Even without contextual and semantic shifts, an input sample can still deviate far from the training set in covariates [1]. For supervised medical image classification or medical image segmentation, covariates can be explained as imaging view, image quality, acquisition protocols and pre-processing, and subject group, as the shift in these factors would not change the class of target. We define covariate shift as an input image in which at least one covariate is different from that of any training sample. Covariate shift often results from the inconsistency between data acquisition sources, such as different centers and cohorts. Unlike modality and area of concern, covariates should be diverse across training samples in order to learn a robust model that can generalize well in real clinical cases. Thus, the identification of covariate shift samples can also improve the model’s generalization through continuous learning.
The three distributional shifts are illustrated in Fig3). They were considered in previous studies across a wide range of biomedical image types and we summarize the corresponding reference in Table II. Now OOD detection in medical image analysis can be formulated as follows. Given a medical image classification\segmentation model trained with the training set , OOD detection is to find a score function and a threshold-based detector
| (1) |
so that if deviates far from the training samples in terms of context, semantics of target, or covariates.
V Solution framework
There are various methods developed to achieve OOD detection in these years. While most of them were initially evaluated in natural image recognition, some have been adapted to the field of medical image analysis. In addition, several studies considered achieving OOD detection in medical image analysis by resorting to UQ techniques. To establish a clear understanding of recent advances in this area, we proposed a solution framework to well organize the existing research from two perspectives, namely methodology taxonomy and association with base task, shown in Table III.
V-A Methodology taxonomy
First, the methodology of OOD detection in medical image analysis are summarized into five categories based on their principles:
Post-hoc feature process: These methods view the intermediate layer of the base task model as a feature extractor and achieve OOD detection in the latent feature space rather than the output space. Specifically, the representation of each sample is obtained by forwarding the input with the pre-trained model, and some processes are then conducted on these representations to estimate OOD-ness. The idea is motivated by the fact that a sample far away from the training in-distribution can still obtain a high softmax score[38][69]. These methods were broadly adopted to address OOD detection in medical image analysis due to their ability to obtain OOD scores posterior to the base task training.
Learning-free UQ: As mentioned in the preliminary, the distributional shift is one of the sources of epistemic uncertainty. Thus, uncertainty quantification (UQ) is often treated as the solution to OOD detection in medical image analysis, with low uncertainty indicating a high probability of being OOD. From the view of Bayesian Neural Networks (BNNs), the model parameters are also random variables, which induces a natural factorization of predictive uncertainty as below[19]:
where , , and are pre-defined class, input, and the training set, respectively. The aleatoric (data) uncertainty (AU) is described by the posterior distribution over class labels given an input and a fixed set of model parameters, while the epistemic uncertainty (EU) is captured by the posterior distribution over model parameters given a training set[19]. This framework can be explained as a distribution over all the possible predictive categorical distributions. However, it is intractable to obtain the true model posterior in practice. An alternative is to approximate it through a set of point estimates of predictions generated by MC-dropout [26] or explicit ensembles [27][14]. Subsequently, the uncertainty is directly quantified by checking the statistics or metrics computed on this set. We term these methods ”learning-free” as they do not consider uncertainty estimation as a training objective. Note that the distributional shift is not explicitly taken into account in these methods, which means the OOD detection is achieved by implicitly modeling the distributional uncertainty (DU) through the epistemic uncertainty (EU) [19].
Learning-based deterministic UQ: These methods explicitly consider uncertainty modeling during training, which is typically achieved by optimizing a special loss function. Instead of using the statistic or the metric computed on a set of predictions, they output a single deterministic uncertainty in an inference run. However, as there is no available ODD during training, the concept of uncertainty, or confidence, is only learned from in-distribution samples. Thus, we argue that using these methods to detect OOD is equivalent to viewing the hard-to-classify in-distribution sample as a proxy of OOD, with the implicit assumption that the response to the former can generalize to the latter.
OOD-aware training: Introducing a few OOD samples into the training set, these methods attempt to directly learn the discrimination between in-distribution and OOD samples from supervision signals. Furthermore, the model is typically trained in a multi-task fashion, combining the losses of the base task and OOD detection in a certain ratio.
Unsupervised stand-alone detectors: These methods train a model in an unsupervised manner (i.e., no labels are available during training) using only in-distribution data and anticipate that the model would respond differently to OOD samples. Besides, the model is dedicated to OOD detection and typically stands alone, which means its network architecture, training process, and inference are completely separated from those of the base task. Thus, one can distinguish them from post-hoc feature process based on whether the features retrieved from the base task model are utilized.
In section V and VI, the studies related to OOD detection in supervised medical image classification and medical image segmentation are systematically reviewed based on our taxonomy.
V-B Association with base task model
In addition to the methodology taxonomy, the association between OOD methods and base task model also constitutes a concern in our framework, as it reveals how easily an OOD detection solution can be deployed given a pre-trained model. Specifically, there are three cases in the existing research:
Model Reuse: In this case, there is no additional training process to the base task. Instead, the pre-trained model is only reused to obtain the intermediate feature or final output. Therefore, these methods are able to serve as a plug-and-play tool to equip any pre-trained model.
Retraining: In this case, the pre-trained base task model is retrained from scratch to obtain both the base task prediction and OOD score in a single inference run. Thus, these solutions cannot be directly deployed into a pre-trained model.
Independent Training: These methods require one or multiple training processes independent of the base task. Despite additional computational overhead, one can directly combine them with a pre-trained model to establish a trustworthy system.
Note that the term ”training” here only refers to a process involving backpropagation, a simple model fit such as logistic regression or decision tree is not considered a training process.
| Base task | Methodology category | Methodology |
|
Retraining |
|
Reference | ||
|---|---|---|---|---|---|---|---|---|
| Supervised medical image classification | Post-hoc feature process | Simple binary classifier | ✓ | [51] | ||||
| Mahalanobis | ✓ | [51] [11] [12] [61] [52] [56] | ||||||
| Cosine similarity | ✓ | [12] | ||||||
| Isolation Forests | ✓ | [60] | ||||||
| Extreme Value Theorem | ✓ | [59] | ||||||
| Gram matrix | ✓ | [58] | ||||||
| Subset Scaning | ✓ | [62] | ||||||
| Learning-free UQ | MSP | ✓ | [51] [10] [11] [12] [61][52] [62] [56] | |||||
| Entropy | ✓ | [14] [15] [56] | ||||||
| Temperature Scaling | ✓ | [11] [12] [15] | ||||||
| ODIN | ✓ | [51] [11] [12] [52] [62] | ||||||
| MC-dropout | ✓ | [11] [12] [13] [14] [15] [56] [63] | ||||||
| Test-time Augmentation | ✓ | [12] [63] | ||||||
| Deep Ensemble | ✓ | [11] [12] [13] [14] [15] | ||||||
| M-head CNN | ✓ | [14] [15] | ||||||
| Learning-based deterministic UQ | Evidential Deep Learning | ✓ | [12] [56] | |||||
| Confidence Branch | ✓ | [10] | ||||||
| OOD-aware training | Outlier Exposure | ✓ | [70] [12] [61] | |||||
| Reject Bucket | ✓ | [12] [61] | ||||||
| Dirichlet Prior Network | ✓ | [57] | ||||||
| Unsupervised stand-alone detectors | Autoencoder | ✓ | [51] | |||||
| Variational Autoencoder | ✓ | [51] | ||||||
| Diffusion Models | ✓ | [55] | ||||||
| Medical image segmentation | Post-hoc feature process | Mahanlanobis | ✓ | [65] [54] [67] [53] | ||||
| Spectrum Decomposition | ✓ | [53] | ||||||
| Learning-free UQ | MSP | ✓ | [65] [54] [68] | |||||
| Entropy | ✓ | [16] | ||||||
| KL from Uniform | ✓ | [54] | ||||||
| Temperature Scaling | ✓ | [65] [54] | ||||||
| MC-dropout | ✓ | [65] [54] [53] [68] | ||||||
| Test-time Augmentation | ✓ | [54] | ||||||
| Deep Ensemble | ✓ | [53] [68] | ||||||
| OOD-aware training | EDL+RL | ✓ | [68] | |||||
| Outlier Exposure | ✓ | [53] | ||||||
| Unsupervised stand-alone detectors | Density Estimation | ✓ | [66] | |||||
| Latent Diffusion Models | ✓ | [64] |
VI OOD detection in supervised medical image classification
Research about OOD detection in medical image analysis mostly focuses on supervised medical image classification. While most adapted general OOD detection methods to medical fields, several techniques were first proposed to tackle specific clinical problems. Following the solution taxonomy described in V-A, we review the related studies in each category. Each subsection is organised as follows: the principle of the involved technique is first introduced and then followed by its application in medical image analysis.
VI-A Post-hoc feature process
One of these methods is feature-based binary classifier. A simple classifier, such as SVM, logistic regression, or KNN, is fitted by distinguishing between in-distribution and OOD samples in a validation set, where the input is the low-dimensional penultimate layer features extracted by base task networks. Feature-based binary classifier was evaluated in [51], where medical OOD detection is benchmarked by comparing a variety of OOD methods across several medical image domains, including (1) chest X-ray image, (2) fundus images, and (3) stained histology slides of lymph nodes. Besides, all three distributional types are considered in their evaluation settings. Surprisingly, the logistic binary classifier outperformed all the other methods in the results that aggregate all evaluations, despite its simplicity.
Another representative method is Mahalanobis-based method, which was initially proposed by [40] to detect OOD input for a classification task. Mahalanobis distance between a data point and a distribution with mean and covariance matrix is defined as:
Through multiplication with the inverse of , Mahalanobis distance rescales into a covariance-free space where the outlier degree can be estimated more reasonably. Besides, it can also be viewed as a monotonic function of log-likelihood of Multivariate Gaussian Distribution, with a large indicating low density. [40] models the layer-wise feature of training samples as class-conditional Gaussian Distribution with tied covariance. For layer , the feature map is global-average-pooled into a vector , then the confidence score is defined as the negated squared between the test sample and closet class centroid:
where and is the empirical covariance and empirical mean for class estimated over training set. To further improve OOD detection performance, the input is preprocessed by adding a perturbation in gradient-sign direction similar to ODIN [39]:
Finally, the weighted sum over all layers is used to detect OOD, where the weights are estimated by fitting a logistic regression on the validation set.
[11] compared a couple of OOD methods in semantic shift detection across natural images and chest X-ray image, noting that the performance of Mahalanobis-based method drops sharply in the latter. The author attributes this to the less separation among classes for X-ray images than for natural images, which is substantiated by the T-SNE of intermediate layer features. Besdies, it is commonly observed that Mahalanobis-based method tends to perform pretty well in contextual shift detection but poorly in semantic shift detection. In [51], it is demonstrated to be quite effective for all OOD types except for novel disease classes. A similar trend is also shown in OCT (Optical coherence tomography)-based retina disease classification [12] and skin disease classification [60][58][61], where Mahalanobis-based method is used to compare with their proposed approaches. [52] proved Mahalanobis-based method with some modifications [40] performed pretty well in covariate shift detection of chest X-ray (CXR). They argued that Mahalanobis distance computed on the convolutional layer is linearly increased with the number of channels, thereby dividing the layer-wise score by this number to prevent the deep layer from weighing more. Besides, they estimate the mean of each class and common covariance using a validation set (only in-distribution) instead of the training set. In their experiments, the base task model is trained on posteroanterior (front to back) adult CXR, with the anteroposterior (back to front), lateral, pediatric CXR, and Non-CXR being OOD samples for evaluation.
Cosine similarity is also utilized to detect OOD in feature space [12]. For two vectors , , it is given by
which only measures the difference in direction without considering magnitude. Similar to [40], the class centroid is empirically estimated over the penultimate layer representations of training samples. Given an input with its representation , the OOD score is defined as below [12]:
where is the centroid of class . [12] explored the semantic shift detection and contextual shift detection in OCT-based retina disease classification, with novel retina disease types absent in the training set and fundus images being corresponding OOD instances. They compared a series of prevalent OOD methods and metrics, finding that all methods can be significantly improved by simply using cosine similarity as a metric.
[60] applied a popular Outlier Detection algorithm, Isolation Forests (IF), to the intermediate layer features of a trained CNN classifier, named Deep Isolation Forests. An Isolation Forest consists of multiple independent decision trees, with each of them constructed by iteratively splitting the nodes with randomly sampled feature and split point. The normality is then defined as:
where is the mean of path length that traversal in each tree, is the average path length over the training set. The intuition is an outlier may contain extreme feature value that deviates from normal samples and therefore can be easily isolated by a decision tree at the early stage. Taking a similar strategy to [12], [60] constructed an IF for each class and is used as In-distribution score. The evaluation is conducted eight times on semantic shift detection in skin lesion classification, with each lesion class being OOD in turn. Compared with some popular OOD detection methods, Deep Isolation Forests performed best in five of eight runs, suggesting it is a promising method for semantic shift detection in medical image classification.
Extreme Value Theorem (EVT) is first applied to open set recognition by [71]. [59] considered this method to equip a CNN-based skin disease classifier. After training, the penultimate activations (i.e., logits) are first extracted. For any pre-defined class , the mean activation vector is estimated over correctly classified training samples, and then a Weibull distribution is fitted on the largest distance between and the associated samples to estimate the probability of input being an outlier with respect to class , noted as . During inference, OpenMax redistributes the logits and forms a new logit for the rejection (OOD) class. Specifically, the rejection logit is the weighted sum over the top highest logits :
where the weight is estimated by the per-class Weibull distribution. Besides, the is scaled to keep the total logits unchanged:
Finally, the probability of being OOD or each pre-defined class is explicitly output by performing SoftMax over . The author [59] simply evaluated this method on 10 images containing novel types of skin diseases absent in the training set (i.e., semantic shift detection) and 10 natural images (i.e., contextual shift detection), observing 80% and 100% OOD samples are detected in two situations, respectively.
[58] focused on skin disease classification, evaluating the Gram matrix-based method proposed by [72] in several OOD detection settings, where the healthy skin image, the corrupted skin image, and the natural image/histology image are OOD samples, respectively. For an image , the activation map from the layer can be represented as a matrix , where is the flattened feature feature map of the channel. Then gram matrix of the layer is given by:
where encodes the correlation between feature map pairs and is derived by taking the power of , with higher order focusing more on the prominent activations. After the classification model training, the upper bound (i.e., max) and lower bound (i.e., min) of each are estimated across the training set. During inference, the deviation from the training set interval is computed for each order and each layer, with their aggregation viewed as a signal of abnormality to detect OOD. The experiments demonstrate that the Gram matrix-based method performed better than Mahalanobis-based method in an unbiased evaluation setting, where the validation set (containing both in-distribution and OOD samples) is unavailable for hyperparameter-tuning.
[62] also explored skin disease classification and proposed to apply subset scanning [73] to OOD detection. Given a trained model, an input, and a layer, they search a subset of all nodes on the layer, where the divergence between input’s activations and in-distribution activations is maximized. The anomalousness is then quantified by a log-likelihood ratio statistic (e.g., the Berk-Jones test statistic), and the sum over all layers is thresholded to detect OOD. Besides, the author also found the ODIN perturbations [39] further improved this method. The evaluation is conducted on both semantic shift detection and covariate shift detection, where unseen skin disease images and skin disease images collected with different acquisition protocols are used, respectively. Although subset scanning is most effective in covariate shift detection as compared to MSP and ODIN, it is even inferior to MSP in semantic shift detection.
VI-B Learning-free uncertainty quantification
A basic learning-free UQ method is Maximum Softmax Probability (MSP) [25], which simplifies the model posterior as a single point estimate. A threshold is determined based on the validation set, and the input with MSP lower than the threshold is detected as OOD. Despite underperformance, MSP is widely used as the baseline in a range of studies[51][10][11][12][15][52][62][61] due to its simplicity. Besides, a variant is also used in [14] [15], where the uncertainty, or OOD-ness, is quantified by the entropy of softmax probability. [74] suggested calibrating the prediction through temperature scaling. When training is done, softmax score is rescaled by divining a coefficient from logits vector :
where temperature is tuned on the validation set. In this way, only the magnitude of MSP is scaled while the predicted class remains unchanged. Due to implementation simplicity, it is commonly evaluated in medical image OOD detection [11] [12] [15] for comparison.
Later, ODIN [39] is proposed to improve MSP so that it is more distinguishable between in-distribution and OOD samples. After model training, the input is first added a perturbation in the opposite way of fast gradient sign method (FGSM)[75]:
where is the magnitude and is the original MSP with temperature . Then the MSP of new input is computed and thresholded to detect OOD samples. The temperature, , perturbation magnitude , and threshold are tuned on a validation set containing both in-distribution samples and OOD samples to reach a 95% TPR (i.e., keeping the MSP of 95% of in-distribution samples higher than the threshold ). Moving the input in a fast gradient sign direction w.r.t MSP, the perturbation inflates the score to be higher. Further, the effect is experimentally shown to be more influential to in-distribution samples than to OOD, which promotes a larger gap between them. ODIN is also broadly evaluated [51] [11] [12] [52][62] for OOD detection in medical image classification. [11] experimentally demonstrated ODIN is the more effective than Mahalanobis-based method, MC-Dropout, and Deep Ensemble on semantic shift detection in lung X-ray pathology classification. Besides, they also concluded that the improvement mainly comes from perturbation instead of temperature scaling. [12] found that replacing MSP with cosine similarity dramatically improved the performance of ODIN on both semantic shift detection and contextual shift detection.
Dropout [76] is a popular regularization technique for deep neural networks, which randomly zeros out a fraction of layer nodes during training to alleviate over-fitting. Another UQ method prevalently used for OOD detection is MC-Dropout [26], which utilizes dropout during inference to generate a set of predictions. Given an test sample , MC-Dropout approximates the distribution over all possible predictions through a set of point estimates generated by applying randomly sampled dropout masks. Then the expected prediction for the class is estimated by the sample mean:
and the variance for the class is estimated by the sample variance:
In [11][12][15][14][13][56] where MC-dropout is evaluated for OOD detection upon medical image classification, three OOD scores are often used, including the MSP of expected prediction:
the entropy of expected prediction:
and the average of class variance:
[11] evaluate MC-dropout in semantic shift detection, with the MSP of expected prediction being the in-distribution score. The experiments reflect it is effective for natural images but unsatisfactory for chest X-ray image. [12] evaluated MC-dropout with all three score functions, demonstrating all of them are significantly surpassed by the cosine similarity-based method on both semantic and contextual shift detection in OCT-based retina disease classification. [13] evaluated MC-dropout in semantic shift detection on stained histology slides. In their setting, the base task is the detection of adenocarcinoma in hematoxylin and eosin (H&E) lymph node sections from breast cancer, with squamous cell carcinoma (SCC) from head and neck cancer being OOD. The performance of MC-dropout is unsatisfactory and even worse than the baseline (MSP) in all evaluation metrics.
Test-time augmentation (TTAUG) is also a simple strategy to mimic distribution over predictions, which utilizes a series of augmentations to generate different versions of input and feed them into the trained model to get a set of point estimates . [12] also evaluated this method with the same OOD score as MC-dropout. The results show it is reliable for contextual shift detection but unsatisfactory for semantic shift detection. [63] suggested a combination of TTAUG and MC dropout. They first process the test sample with different augmentations and then forward each version with a sampled dropout mask. Besides, a novel metric named Bhattacharyya Coefficient (BC) [77] is considered, which measures the overlap between the prediction distribution (i.e., ) of the top two classes with the highest expected prediction . The experiment is conducted on semantic shift detection in skin disease classification, demonstrating the combination is more effective than either using TTAUG or MC-dropout alone. Besides, the mean of class variance is shown to be the optimal metric, superior to Bhattacharyya Coefficient.
Ensemble is a strategy that involves combining multiple base models to create a more accurate and robust model. Another way to approximate the distribution over predictions is the explicit networks ensemble, named Deep Ensemble (DE) [27]. During training, a set of networks are trained in parallel:
These networks share identical architecture but have random weight initializations and random training data shuffling to keep the variation among them. During inference, the input is fed into all the models to obtain a set of predictions . Similar to MC-dropout, the expected prediction for class is estimated by the sample mean:
and the variance of prediction for class is estimated by the sample variance:
Three OOD scores for MC-dropout are also commonly used for DE. With MSP of expected prediction being in-distribution score, DE is shown to perform slightly better than the baseline but significantly worse than ODIN on semantic shift detection in chest X-ray disease classification [11]. [12] tried three scores for DE on semantic shift detection in OCT-based retina disease classification, finding all of them are less effective than ODIN and cosine similarity. [13][15][14] both test DE semantic shift detection about lymph nodes histology slides, with the first using MSP of expected predictions and the latter two using the entropy of expected predictions. As compared to the baseline (MSP), DE shows a significant superiority in citethagaard2020 but only a limited improvement in [15] and [14].
A disadvantage of Deep Ensemble is the huge computational overhead caused by multiple independent training and inference runs. To address the issue, [14] proposed a variant named multi-head CNN. It consists of a CNN backbone followed by several randomly initialized output heads, which generate a set of predictions in a single pass while reducing the computational burden by sharing the weights in the early-stage layer. Besides, the author suggested a loss function called meta loss, which is defined as the weighted sum of the cross entropies over all heads:
where is the softmax output of head, is the cross entropy loss. The weight of each head is determined in the following manner:
where is a small value to assign the winning head (with the minimum loss) the largest weight. In this way, the most gradient signals are distributed to that head to encourage specialization and promote the diversity of the ensemble. [14] evaluated M-head CNN on semantic shift detection in stained histology slides-based breast cancer metastasis identification, where the novel class, diffuse large B-cell lymphoma, is treated as OOD. They show 10-head CNN outperforms baseline, MC-dropout, and standard Deep Ensemble by a large margin in FPR 95. [15] further evaluated this method in covariate shift detection and contextual shift detection about lymph node histology slides, with three settings being (in-distribution vs. OOD): (1) prostate biopsies without colorectal tissue vs. prostate biopsies containing colorectal tissue; (2) lymph node tissue vs. prostate biopsies; and (3) prostate biopsies vs. lymph node tissue. However, M-head CNN has no obvious advantage over other methods in these evaluations.
VI-C Learning-based deterministic uncertainty quantification
A classic method under this category is Evidential Deep Learning (EDL) [23]. EDL is inspired by Subjective Logic [78], which formalizes the Dempster–Shafer Theory of Evidence (DST) with Dirichlet distribution. Similar to DPN [19] [79] [20], it explicitly models the distribution over all possible predictions as a Dirichlet distribution parameterized by concentration parameters :
where is the K-dimensional multimodal beta function, and is the vector lies on the probability simplex, satisfying . Further, the Dirichlet distribution is explained from the view of DST. Denote the collected evidence supporting class as , the is associated with concentration parameter through and then the total evidence is Dirichlet strength (also known as precision) . The belief mass assigned to class is defined as the ratio between per-class evidence and total evidence, given as , while the uncertainty mass is computed so that all masses sum up to one, obtaining
In this framework, a Dirichlet corresponds to a belief mass assignment (or, opinion), which is based on the evidence observed from data. Besides, the aleatoric uncertainty (AU) and epistemic uncertainty (EU) can be separately quantified as the mean of Dirichlet distribution, i.e., the expected categorical prediction:
and the (epistemic) uncertainty mass:
which is inversely proportional to the total amount of evidence. An observation without any evidence found corresponds to the maximum epistemic uncertainty , while sufficient evidence could reduce the epistemic uncertainty to trivial.
Given a classification network, the softmax layer is replaced with a ReLU activation layer to generate the evidence for an instance , noted as . Then a Dirichlet distribution is parameterized by
, with each prediction being viewed as drawn from this distribution. The total evidence, or Dirichlet strength, is given by . However, the loss for can not be directly computed as the the sampling process is undifferentiable. Alternatively, the expectation of loss with respect to the Dirichlet distribution is used to train the network:
where is the label and is the predicted probability vector, while is the expectation of , given by . Besides, to prevent the evidence of incorrect class from being increased, a regularizer is added to the above loss:
where and the weight increasing gradually until the epoch. This is equivalent to forcing the evidence to be zero except for the evidence supporting the correct class . Training with this loss assures the uncertainty is reduced only when the evidence in favor of the ground truth class is found enough, or in other words, high uncertainty is reflected by the lack of correct evidence.
[12] compared EDL with other methods on both semantic and contextual shift detection in OCT-based retina disease classification. The experiment showed its performance is quite terrible in both evaluations and even worse than the baseline (MSP) in semantic shift detection, suggesting the uncertainty estimation learned from the in-distribution cannot generalize well to OOD samples. [56] directly applied the subjective logic-based UQ framework in EDL to a general pre-trained classification network, without replacing the softmax with ReLU and retraining with a special loss. Instead, they manually rescale the logits into a specified non-negative range to be the evidence and qualify the uncertainty with . Besides, the author also suggested using Mahalanobis-based method as a complementary to further improve the OOD detection. They artificially generate a linear transition from the in-distribution sample, i.e., Full-Field Digital Mammography (FFDM) images, to the OOD sample, i.e., 2D views synthesized from 3D tomosynthesis acquisitions (S-View), in order to mimic a series of samples that gradually deviate from in-distribution. The uncertainty mass is observed to be most effective at the middle degree of transition and degenerates thereafter. In contrast, Mahalanobis distance is more indicative of OOD in the last half, substantiating the two are complementary with each other. In their experiment, three breast imaging classification tasks are considered: (1) risk assessment (high vs. low risk), (2) breast density stratification according to BI-RADS scores, and (3) glandular vs. conjunctive patch-tissue classification. However, the covariate shift detection is evaluated in a non-straightforward way. Rather than measuring the detection performance, they mix the covariate shiftsamples and normal samples, compare the base classification task performance when deleting the most uncertain samples with different threshold levels, and see if improvements are observed by doing so. The results show the proposed method is effective and comparable to EDL[23] and MC-dropout[26] while requires no retraining and model modification.
Another learning-based deterministic UQ method is the confidence branch [21], which adds a branch parallel to the classification head to explicitly output the confidence estimation. Specifically, the confidence branch takes the global feature as input and outputs confidence estimation through multiple fully connected layers followed by a sigmoid activation function. During training, the model is allowed to correct its classification prediction by asking for hints, which is achieved by interpolation between the prediction and the ground truth label:
where confidence decides the degree to request a hint. To avoid the model lazily learning confidence to be a constant zero, the access to hints is penalized by a loss:
Finally, it is added to the base task loss, leading to the total loss as below:
where is a hyperparameter to balance the two losses. Minimizing this loss forces the model to access the hint only when it has no confidence about its prediction, which is equivalent to measuring the confidence by the model’s willingness to request hints. Further, four tricks are used to improve the methods. First, the is adjusted dynamically through the training process, which is achieved by setting a fixed budget and increasing (decreasing) the when () after each weight update. Then the access to ground truth, i.e., the interpolation, is adopted at only half of the batches, allowing the model to have a chance of 50% to learn the classification from the error without answer disclosure. This can be explained as preventing the model from losing the ability to correctly classify. Besides, augmentations are used to create more hard-to-classify examples from which the pattern of low confidence is learned. Finally, the ODIN [39] is used w.r.t the hint loss , which is experimentally found to enlarge the gap between in-distribution and OOD samples.
[10] utilized confidence branch to detect the contextual shifts in supervised medical image classification, evaluated the performance across multiple modalities and areas of concern, and compared to MSP and Outlier Exposure (OE). The results show it outperforms MSP by a large margin in all the evaluations while beating the OE in part of the evaluations as well, suggesting it is a promising solution to contextual shift detection. However, their performance on harder tasks, i.e., covariate shift detection and semantic shift detection, requires further exploration.
VI-D OOD-aware Training
Outlier Exposure (OE) was pioneered by [41] to tackle OOD detection. They proposed to introduce OOD samples into the training set to heuristically learn the discrimination between In-distribution and OOD samples, in the hope that the effect can generalize to the unseen samples. In the case of classification, the author referred to [80], using the cross-entropy from logits to uniform distribution to penalize the OOD samples. This can be interpreted as forcing the model to evenly distribute the propensities to all predefined classes for an OOD sample. As a result, no decision should be made based on the result. Thus, the final loss function is rewritten as below:
where is cross entropy and is uniform distribution. During inference, the entropy over the predicted probability vector is used as the OOD score. [10] evaluated Outlier Exposure in contextual shift detection. Three datasets involving chest X-ray images, Musculoskeletal X-ray images (including elbow, finger, forearm, hand, humerus, shoulder and wrist), and fundus images are used as the in-distribution training set in turn, with the remaining two being test OOD samples. To simulate real clinical scenarios where the knowledge of possible OOD is incomplete, the exposed OOD instances (used for training) are only sampled from another hand X-ray dataset, with the unused instances being test OOD as well. Although OE outperforms MSP by a large margin, it slightly sacrifices classification accuracy as compared to the standard base task model.
The abstention class approach [81], also known as the reject bucket [12], explicitly outputs the probability of being OOD through an extra class head, which is learned by introducing a few OOD samples as positive instances. [12] explored few-shot OE and reject bucket, proving that just a small number of OOD exposures can aid semantic shift detection while maintaining the high accuracy of in-distribution retina disease classification. In addition, reject bucket is superior to standard OE in semantic shift detection in this case. [61] focus on semantic shift detection upon skin lesion classification, using a variant of reject bucket to detect the skin lesion classes beyond the training set. Specifically, they add several extra output heads, with each of them corresponding to a rare skin lesion class. Then a few instances of these rare classes are added to the original training set as exposed OOD samples. Besides, each training instance is associated with a fine-grain label specifying skin lesion class and a coarse-grain binary label indicating OOD or in-distribution. During training, the total loss is defined as the sum of fine-grain loss and coarse-grain loss:
While is the normal cross entropy over skin lesion class labels, is a binary cross entropy over coarse-grain labels, where the probability of being OOD is computed as the sum over all rare class heads. The experiment demonstrates it outperforms single reject bucket [81] by around 3 points in AUROC.
The idea of OE is also shown in Dirichlet Prior Network (DPN) [19], where the OOD training samples are used to model their behavior as distinct from in-distribution data. Recall most uncertainty quantification (UQ) methods approximate distribution over all possible predictions through a set of point estimates. For K-classification problem, each of the point estimates is a categorical distribution over K-dimensional probability simplex. Given an input , DPN explicitly models such an ensemble by a parameterized Dirichlet distribution over all possible predictive categorical distributions:
where is the gamma function, is concentration parameter, and is precision controlling the sharpness of Dirichlet distribution. Thus, the final prediction is the expectation of Dirichlet distribution, given as:
For an in-distribution input of class , each point estimate of prediction, i.e., a categorical distribution , should have much larger than others. Besides, all the point estimates for this input should be consistent with each other. Thus, the Dirichlet distribution is expected to be significantly sharper at the corner (of probability simplex) associated with the ground truth. For those input of class but with high data uncertainty, each point estimate may be flatter due to the inherent class overlap but all the point estimates should be still consistent, corresponding to a Dirichlet distribution sharper at the center. As for an OOD input, each point estimate is flat while all the point estimates should be inconsistent with each other, which can be described by a Dirichlet distribution uniformly spread across the whole simplex. These behaviors can be modeled by minimizing Kullback-Leibler Divergence between the output Dirichlet distribution and a “template” with the expected nature, which is done in a multi-task fashion[19]:
Here, the OOD template sets all concentration parameters , while the template of in-distribution is shaped by the concentration parameter , where
and is a hyperparameter set to be large (e.g., 100). During inference, the measurement of Mutual Information (MI) is used to detect OOD, which isolates the epistemic uncertainty by removing aleatoric (data) uncertainty from the total uncertainty:
Given a test input, the higher MI reflects a flatter Dirichlet distribution, thus indicating it is likely to be an OOD sample.
Later, [79] suggested replacing the KL divergence with reverse KL divergence, while [20] proposed an alternative loss function for DPN to more effectively differentiate the OOD sample from the in-distribution sample of high data uncertainty:
|
|
|
|
where is the logit associated with class . For in-distribution data, the cross entropy is used to force the mean of Dirichlet Distribution, i.e., the expected prediction, to be consistent with the class label. For OOD sample, it is used to shape the expected prediction to be uniformly distributed over all classes. Besides, encourages a larger precision for in-distribution samples and penalizes the precision for OOD samples, which can be seen from the following and noting sigmoid is a monotonically increasing function:
Thus, minimizing the loss function results in an unimodal Dirichlet distribution for in-distribution and a multimodal Dirichlet distribution for OOD, respectively. [57] designed a diabetic retinopathy (DR) screening pipeline capable of covariate shift detection and contextual shift detection, which is achieved by a combination of two DPNs. During training, in-distribution training samples are identical for both DPN, while the instances from another retina image dataset and non-retinal images are OOD training samples, respectively. During inference, the first DPN outputs the DR screen prediction (DR or healthy), as well as identifies input suffering covariate shift, while the other directly rejects the images of no interest (i.e., non-retina images).
VI-E Unsupervised stand-alone detectors
A representative unsupervised stand-alone detector is the reconstruction error-based method. [82] proposed to train an autoencoder (AE) [83] [84] on normal data for anomaly detection. Specifically, an AE is used to compress the normal data into the low-dimensional latent space and then recover their original dimension to get a reconstruction. Then the difference between input and reconstruction, reconstruction error, is minimized to train an AE. Intuitively, reconstruction error can be used to measure the degree of abnormality as AE trained on normal data cannot capture unfamiliar patterns caused by the deviation, leading to low-quality reconstruction.
A variant is [85], which replaces the AE with variational autoencoder (VAE) [86] to reconstruct the normal data and estimate the anomaly score via reconstruction probability. While most literature simply explains the principle of VAE-based anomaly detection as the intuition that deviation leads to a poor reconstruction, we try to give a more thorough explanation.
In short, VAE models the probability density of a sample as a continuous form of Gaussian Mixture:
which explains the generation of as the following process: the latent variable is first sampled from a standard Gaussian distribution , while the is then sampled from a Gaussian distribution determined by . Given a training set, the density estimation can be achieved via maximum likelihood estimation (MLE). The logarithm likelihood of an input can be factorized as below:
where is an arbitrary probability density. As always holds true, the first term is the variational lower bound of , noted as . Thus, the objective of VAE, i.e., maximum likelihood estimation (MLE), can be achieved by directly maximizing . Further, the variational lower bound can be factored into two parts:
Given an training sample , VAE simulates via a Gaussian distribution where mean and variance is generated by the encoder . Then the first term of variational lower bound is derived as:
where is the dimension of . Besides, a set of latent variables are sampled from and fed into the decoder to generate a set of mean and variance , with each pair parameterized a Gaussian distribution associated with the sampled . Then the is a mimic of while the expectation is a mimic of the second term of variational lower bound:
During training, gradually converge to the prior as the Kullback-Leibler Divergence between them is minimized. Then the following equation can be seen as an approximation of the true density at the position of input :
which is termed reconstruction probability in [85]. Thus, a low reconstruction probability reflects the input lies in the low-density region of normal data, which suggests a high possibility of being an anomaly. A simplification is using the expectation of the difference , namely the reconstruction error of VAE, to be the anomaly score as is inversely proportional to .
As we mentioned in the preliminary, OOD detection is a special case of anomaly detection, where the “normal data” are the samples sharing the same distribution as the base task training set. Therefore, construction-based anomaly detection methods can be easily adapted to OOD detection by training an AE or VAE only on the in-distribution data. [51] evaluate both AE and VAE in all three OOD detection settings w.r.t. multi-class medical image classification. Overall, both methods perform well in contextual shift detection and covariate shift detection, while they lose as compared to the two post-hoc feature process methods, binary classifier, and Mahalanobis-based method. Besides, both of them fail to detect semantic shift, which is thought to be harder than the other two types. We speculate the reason as the natural heterogeneity in the multi-class training set makes it hard to capture the pattern of all pre-defined classes, resulting in an undesirable reconstruction even for in-distribution samples and thereby an ambiguous distinction from OOD samples.
However, the reconstruction quality of AE or VAE is closely related to the dimension of information bottleneck (e.g., latent space), which is selected before training and determined during inference, leaving a costly process to tune this key hyperparameter. To address this issue, Denoising Diffusion Probabilistic Models (DDPM) [87] were recently utilized to achieve anomaly detection [6] and OOD detection [55] due to their capability to generate a set of reconstructions from diverse noise levels. The score function, i.e., reconstruction quality, can be measured by considering a range of bottleneck choices in a single inference run. For a given input , the forward process generates a series of via iteratively adding the noise, which is also known as the diffusion process:
where follows standard Gaussian distribution and diffusion rate controls the variance of added noise. By simply setting increases along with the forward step , converges to standard Gaussian . It can be easily derived from the following expression:
where .
Then can be expressed as the integration over a chain generated by T-step diffusion process:
which explains the generation of as a Markov process containing steps: is firstly drawn from the standard Gaussian distribution , and the is generated by denoising at each step. Similar to VAE, DDPM is also trained via the maximization of the variational lower bound:
which is achieved by denoising the instances generated by forward diffusion steps in practice, and the reconstruction error reflects the density at the input position for the same reason as VAE. [55] trained DDPM only on the in-distribution data to detect OOD samples. During inference, they generated reconstructions for a test sample by denoising from randomly sampled steps, and the average of similarities between reconstruction and input is used as the input score. Specifically, the similarity metric is computed as the sum of MSE, and LPIPS [70] which measures the distances in intermediate layer features. Besides, the faster sample strategy, PLMS sampler [88], is adopted to speed up the inference. The author evaluated the method on the simplest OOD detection task in medical image classification, i.e., contextual shift detection across multiple modalities and organs (Hand X-ray, Abdomen CT, Chest X-ray, Chest CT, Breast MRI, and Head CT), finding it performs almost perfectly. However, the covariate and semantic shift detection in medical image classification remain unexplored in their work.
VII OOD detection in medical image segmentation
Medical image segmentation, as one of the pivot tasks in computer-aided diagnostics, was recently empowered by emerging deep learning models such as U-net [89]. However, the available training samples for medical image segmentation, especially for those with 3D modalities such as CT and MRI, are quite rare due to the vast annotation cost. As a result, it is common to encounter distributional shift when applying the segmentation models to real clinical samples. The segmentation model trained on a specific dataset may silently output a meaningless or low-quality segmentation mask for the input from a different distribution. Recently, a range of research has paid attention to OOD detection in medical image segmentation. In this section, we also review them following the methodology taxonomy described in V-A.
VII-A Post-hoc Feature Process
Similar to supervised medical image classification, most OOD detection methods in medical image segmentation distinguish between OOD sample and in-distribution sample based on the intermediate features extracted from the segmentation network instead of the final output. Mahalanobis-based method [40] is popularly utilized due to its applicability.[65] focus on lung lesion segmentation in chest Computed Axial Tomography (CAT) scans of COVID-19 patients, finding that a patch-based nnU-net [90], even trained on a multi-center dataset, may still output an unreliable lesion mask on other datasets. Inspired by [40], they extracted the features of all training patches from the encoder, downsampled them by average pooling, and then computed the mean and covariance to estimate a Gaussian Distribution. For the test sample, the low-dimension feature of each patch is extracted in the same way as above, and the Mahalanobis distance to the Gaussian Distribution, serving as the per-patch uncertainty estimation, is computed to finally combine into an image-level uncertainty mask in the same way as the prediction mask. Finally, the average over all voxels is thresholded to determine OOD samples. In the experiment, datasets different from the training set in patient groups and acquisition protocols are viewed as OOD samples, and the result shows Mahalanobis-based method outperforms MSP, temperature scaling, and MC-dropout by a large margin in both Detection error and FPR. [54] compared this method to others on a broader collection of OOD samples, including (1) training set data with artificial transformation (covariate shift); (2) chest CAT scans from patients suffering other lung diseases than COVID-19 (semantic shift), and (3) Spleen and Colon CT scans (contextual shift). Compared to other methods, Mahalanobis-based method stands the best across all evaluations. [67] explored OOD detection for liver segmentation in T1-weighted liver magnetic resonance imaging exams (MRIs). Similar to [54] and [65], they applied the Mahalanobis-based method on the bottleneck features of Swin UNETR [91]. Besides, they explore four dimensionality reduction methods to reduce the feature dimension, including average pooling, PCA, UMAP [92], and t-SNE [93]. In evaluation setting, the OOD samples come from either T1-weighted liver MRI that is hard to segment or T1-weighted liver MRI with poor image quality, which belongs to covariate shiftin our framework. The experiment substantiates that PCA with 256 principal components improves Mahalanobis-based method most.
[53] suggested a multitask learning strategy for 3D organ segmentation to tackle the insufficiency of annotated training samples. Specifically, the model is trained on a mixture of CT scans and MRIs across multiple organs, including the brain cortical plate, liver, kidney, left atrium, prostate, pancreas, hippocampus, and spleen. Then they proposed to detect OOD samples using spectral analysis of the feature map extracted from the final convolutional layer. Given the feature map of size denoting height, width, depth, and channel respectively, the spectral decomposition is conducted on the flattened feature maps of size :
where is a diagonal matrix containing the singular values of , also known as spectrum. The normalized spectrum:
is shown to be distinguishable between in-distribution and OOD samples, and the OOD score is finally computed by the Euclid distance from the test sample to its nearest neighbor within the training set. The author considers both contextual shift detection and covariate shift detection in evaluation settings (in-distribution vs. OOD): (1) the training dataset mixing brain cortical plate-T2 MRI, prostate-MRI, heart-MRI, liver-CT, and liver-MRI vs. pancreas CT, spleen CT, and hippocampus MRI,; (2) brain cortical plate-T2 MRI from newborns vs. brain cortical plate-T2 MRI from the young and the older. Experiment results reveal spectrum is superior to other popular OOD methods in detection accuracy and AUROC, including MC-Dropout, Deep Ensemble, ODIN, Mahalanobis-based method, and Outlier Exposure.
VII-B Learning-free uncertainty quantification
The fact that segmentation can be viewed as pixel (voxel)-level classification naturally induces a simple way to estimate the uncertainty of the whole predicted segmentation mask. That is, the uncertainty of each pixel (voxel) is estimated in the same manner as image classification, while the image-level uncertainty is often represented through the aggregation over all pixels (voxels). In this way, traditional UQ methods can be directly used for a segmentation task. In related literature [65] [54] [53], it is very common to evaluate the learning-free UQ methods as a comparison to their proposed method, due to the simplicity of implementation. [65] demonstrated MC-dropout is inferior to Mahalanobis-based method but outperforms other leraning-free UQ methods by a large margin, including MSP, temperature scaling, and a variant of MSP measuring the Kullback-Leibler Divergence from softmax score to uniform distribution [94][80]. On the basis of [65], [54] adopted more evaluations to mimic all three distributional shifts, while adding test-time augmentation (TTAUG) into comparison. Although not as good as Mahalanobis-based method, TTAUG is superior to other UQ methods across all evaluations, suggesting it is a promising solution to OOD detection. [16] found the average of per-pixel entropies w.r.t the foreground probability is able to effectively distinguish samples from two different prostate segmentation datasets, which can be seen as a mimic of the covariate shiftsetting. Besides, they also observed a negative correlation between this score and the Dice coefficients [95], concluding it can serve as a measurement of segmentation quality during inference, with high average entropy indicating a low-quality segmentation and thereby an OOD sample.
VII-C OOD-aware training
For OOD detection in medical image segmentation, it is also possible to model distinct behaviors for in-distribution and OOD samples by explicitly introducing OOD supervision. [68] suggested using a reinforcement learning strategy to tune an Evidential Deep Learning (EDL) [23] model. Specifically, a segmentation network is adapted to the EDL model by replacing the softmax layer with softplus function. In this way, the logit is explained as the evidence supporting the corresponding class, which is further used to parameterize a Dirichlet distribution serving as the conjugate prior over the predicted categorical distribution :
where . Then the model is trained by minimizing the expectation of cross entropy associated with each possible point estimate, which is computed by integrating out over the Dirichlet. In this way, the aleatoric uncertainty (AU) and epistemic uncertainty (EU) can be separately expressed as the expected categorical prediction, , and the total evidence, , with the former being the uncertainty (confidence) estimation of in-distribution sample while the latter being the uncertainty estimation of OOD sample.
To further improve the uncertainty estimation, [68] proposed tuning a policy network on the validation set, where the OOD samples are synthesized by corrupting the in-distribution samples. The policy network is first initialized by the pre-trained EDL network , and then optimized through maximizing a reinforcement learning objective:
The second term penalizes the policy network from deviating far from the original pre-trained EDL network , while the first term is a reward function that encourages some desirable behaviors for in-distribution and OOD samples. Specifically, the reward for in-distribution is defined as the negative logarithm of the calibration metric, Expected Calibration Error (ECE), which measures how well the confidence aligns with the practical predicted accuracy:
where , , and denotes aleatoric uncertainty (AU) estimation, ground truth, and prediction, is the set of in-distribution samples falling into the bin, and is the total number of in-distribution samples. ECE groups the in-distribution samples into bins according to confidence estimation, computes the difference between confidence mean and accuracy within each bin, and finally averages over all bins. For OOD samples, the reward is the ratio of the epistemic uncertainty (EU) between themselves and their in-distribution counterparts (the version before corruption):
where is the epistemic uncertainty (EU) estimation, is the pixel, and the EU of the whole image is estimated via the aggregation over all pixels. It is obvious the maximization of such reward functions improves the calibration of the in-distribution sample while encouraging a high EU for OOD samples. In order to allow a more efficient tuning under the constraints of the second penalty term, the author suggested a fine-grained parameter update scheme. Specifically, the update step of each parameter is weighted by its importance to the model outputs, which can be computed by the diagonal element of the fisher information matrix [96]. In their evaluation, two in-distribution tasks are carried out, including the segmentation of four different soft tissues in laparoscopic cholecystectomy images and the segmentation of the submucosal tissue, mucosa tissue, muscle tissue, and blood vessel in endoscopic surgical images. In evaluation, the in-distribution images are corrupted to mimic the situation of covariate shift. The experiments showed the proposed method obtains a significant improvement when compared with a series of UQ methods, such as MC-dropout [26], Deep Ensemble [27], and DUQ [22].
VII-D Unsupervised stand-alone detectors
Similar to the case of classification, an unsupervised stand-alone OOD detector for medical image segmentation is typically a generative model trained only on in-distribution samples, with training and inference isolated to the base task.
Rather than measuring reconstruction errors, another generative model-based approach is to directly estimate the likelihood of the input being in-distribution. Given a sequence, , its probability can be factorized into a chain of conditional probabilities:
Representing the 3D volumes with a sequence, [25] estimated the probability density of in-distribution volumes by multiplication of the conditional probabilities along this chain. The first thing is to learn an efficient compression, which can represent the input with a relatively short sequence while keeping useful information as much as possible. Inspired by the high-resolution image synethsis[97], the author achieved this goal through VQGAN [97], where a discrete codebook is learned to encode the rich information of image constituents, and the 3D volumes are then represented as a sequence of entries drawn from the codebook. Specifically, the input volume is first fed into an encoder to produce a feature map , which is further quantized by replacing each voxel (i.e., patch for the whole volume) with its nearest codebook entry in terms of the norm, obtaining a new spatial representation encoded by :
where maps the index of encoder output to the index of codebook . Then a decoder is responsible for recovering the volume size from the quantized spatial representation , obtaining the reconstruction . Besides, a discriminator is added to distinguish between real and reconstructions to push the limit of compression. Finally, the VQGAN is trained end-to-end in an adversarial manner with the total loss:
where the first term computes the reconstruction error and the second computes the classification loss of the discriminator. In order to estimate the probability density of input, the spatial quantized representation is flattened into a sequence , and the likelihood of each patch, , is predicted in an autoregressive manner via a transformer [98] and is optimized via Maximum Likelihood Estimation (MLE). The author evaluated this method in two OOD detection settings w.r.t segmenting Intracerebral Haemorrhages (ICH) in head CT, with manually corrupted in-distribution ICH head CT and 3D volumes (including CT and MRI) of other organs respectively simulating covariate shiftand contextual shift. They show the proposed method performs well in all evaluations except for subtle corruption such as low-level noising and left-to-right flip. However, we argue this is not a concern as the model should be robust to these slight covariate shifts instead of rejection.
Despite the effectiveness of [66], [64] argued that transformer-based likelihood estimation suffers several disadvantages including sensitivity to compression level, high memory requirements, and disability to output an input-size OOD score map. To tackle the issues, they considered detecting OOD with the reconstruction error of a DDPM trained only on in-distribution samples. As directly applying DDPM for 3D volume leads to dramatically increased computational overhead, the author proposed Latent Diffusion Models (LDMs), which conducts the forward process, i.e., adding noises, and reconstructions, i.e., denoising, on the downsampled latent representation compressed by VQGAN [88]. During inference, the denoised representation is then decoded to recover the input size, and the reconstruction errors (or, similarity) are computed in the original input space instead of downsampled feature space. The experiment is conducted in the same way as [25], and the results showed LDMs outperforms [66] in both contextual and covariate shift detection. Besides, the proposed method successfully addresses the three disadvantages of [66], suggesting it is a promising solution to OOD detection especially for high-resolution 3D volumes.
VIII Evaluation protocols
Given a medical image classification or segmentation task, the training, hyperparameter tuning, and evaluation of the model are conducted on three distinct parts of in-distribution dataset, , , and . When considering OOD detection, the test set should consist of both held-out parts from the in-distribution dataset and the datasets standing for OOD samples, namely , read
In addition, some OOD samples should be added to the validation set in order to determine score threshold and other hyperparameters, read
Note it is more reasonable to maintain the difference between and to simulate the realistic clinic scenarios where OOD samples are hard to expect.
In evaluation, the contextual shift is often simulated by non-medical image datasets, such as ImageNet, or medical images with different modality and/or area of concern from in-distribution samples, while the semantic shiftis naturally represented by the medical images within the in-distribution context but containing class of target such as diseases/lesions of novel classes. For covariate shift, the image quality issues and differences in acquisition protocols\pre-processing are conventionally mimicked by corrupting or transforming the in-distribution instances, while the different imaging view and subject groups are tested using corresponding instances.
Labeling the OOD as positive and in-distribution negative, the performance of an OOD detection method can be measured through binary classification evaluation metrics, including accuracy, detection errors, sensitivity (TPR), specificity (TNR), AUROC, AUPR, and FPR95. Note the first four involve a fixed detection threshold, which is determined by keeping most (typically 95%) of the in-distribution validation instances correctly identified. [68] evaluated their method with two brand-new metrics, Pixel Ratio, and Box Ratio [99]. Specifically, Pixel Ratio is defined as the ratio between the score of a manually corrupted version (randomly adding a white noise box to an image, i.e., a mimic of covariate shift) and its in-distribution counterpart, where the score is computed by aggregating the score of all pixels. Box Ratio is defined in the same way, except that the score is the sum of the pixels located within the corrupted box. In addition, the evaluation of the OOD detection method should also take the base task evaluation into account so that accurate detection is not achieved at the cost of sacrificing the model performance. Besides, [56] adopted an indirect way to evaluate covariate shift detection. In each run, they kept a specified proportion of samples with the lowest uncertainty estimations and tested the base task performance over them. Ideally, an improvement should be observed when the proportion decreases, which demonstrates the real uncertain samples, or the covariate shiftsamples, are successfully scored higher than those certain ones.
IX Challenges and future directions
The existing research has shown success in contextual and covariate shift detection, while methods for semantic shift detection in supervised medical image classification remain underperformance across multiple modalities and medical departments. [51] evaluated a range of OOD detection methods, reporting a random-guess level accuracy and AUROC for all of them on semantic shift detection about front-view chest X-ray image. [11] observed a significant drop in semantic shift detection performance from natural image recognition to the disease recognition of chest X-ray image. [61] showed the best approach in unseen skin disease detection achieving around 80% in AUROC. The experiments in [60] also reflected an undesirable result for semantic shift detection in skin disease classification, with the AUROC of their proposed method varying from 63% to 76% as the test OOD disease changes. Similarly, [62] reported the best performance is 73% and 81% in AUROC when detecting two different OOD skin disease types. [15] demonstrated the highest AUROC to be 71% and 81% for two evaluations of semantic shift detection about stained histology slides. In natural image object recognition, semantic shift detection is caused by the existence of novel class instances that typically appear in a local area. However, this is not the case in some medical scenes, where the disease or lesion is typically reflected by scattered anomalies in the images. Besides, it is even difficult for a human to distinguish between semantic shiftsamples and in-distribution in some medical image modalities (e.g., endoscopic images), as their difference often lies subtle.
Another challenge lies in multi-label settings. Although a range of literature has explored OOD detection in supervised medical image classification, they simply assume the underlying base task to be Single Label Classification (SLC). However, it is common for multiple diseases to be present in a single medical image, which corresponds to a multi-label setting. In reality, it is impractical to train a recognition model for each disease given the huge training and annotation costs. Instead, an alternative is to train a multi-label classification (MLC) model [100][101][102] capable of recognizing several pre-defined diseases in a single inference run, which was recently utilized for computer-aided diagnostics [103][104][105]. Generally, an MLC model is a neural network followed by multiple binary classification heads, each of which is responsible for judging the existence of a pre-defined class. However, most of these methods can not correctly handle out-of-distribution input during inference. In multi-label settings, a semantic shiftinstance can be either an image with only novel class instances or one with a mix of pre-defined class instances and novel class instances. For convenience, we term the first case simple OOD and the second hybrid OOD. Compared with simple OOD, it is rather difficult to distinguish a hybrid one from in-distribution samples due to the partial overlaps in their semantics. Although semantic shift detection in general image MLC has drawn attention in the research community [106][107][108][103], they only evaluated their methods against the simple OOD. Besides, [109][110] focus on the incremental learning of streaming data, where the data with new labels should be detected in each inference run. However, to our best knowledge only[111][112] and [103] explored unseen disease detection in multi-label settings, suggesting there is a research gap in this area.
References
- [1] J. Yang, K. Zhou, Y. Li, and Z. Liu, “Generalized out-of-distribution detection: A survey,” arXiv preprint arXiv:2110.11334, 2021.
- [2] G. Pang, C. Shen, L. Cao, and A. V. D. Hengel, “Deep learning for anomaly detection: A review,” ACM computing surveys (CSUR), vol. 54, no. 2, pp. 1–38, 2021.
- [3] M. E. Tschuchnig and M. Gadermayr, “Anomaly detection in medical imaging-a mini review,” in Data Science–Analytics and Applications: Proceedings of the 4th International Data Science Conference–iDSC2021. Springer, 2022, pp. 33–38.
- [4] T. Fernando, H. Gammulle, S. Denman, S. Sridharan, and C. Fookes, “Deep learning for medical anomaly detection–a survey,” ACM Computing Surveys (CSUR), vol. 54, no. 7, pp. 1–37, 2021.
- [5] Y. Lu and P. Xu, “Anomaly detection for skin disease images using variational autoencoder,” arXiv preprint arXiv:1807.01349, 2018.
- [6] J. Wyatt, A. Leach, S. M. Schmon, and C. G. Willcocks, “Anoddpm: Anomaly detection with denoising diffusion probabilistic models using simplex noise,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 650–656.
- [7] A. R. Venkatakrishnan, S. T. Kim, R. Eisawy, F. Pfister, and N. Navab, “Self-supervised out-of-distribution detection in brain ct scans,” arXiv preprint arXiv:2011.05428, 2020.
- [8] L. Gao and S. Wu, “Response score of deep learning for out-of-distribution sample detection of medical images,” Journal of biomedical informatics, vol. 107, p. 103442, 2020.
- [9] B. Lambert, F. Forbes, S. Doyle, H. Dehaene, and M. Dojat, “Trustworthy clinical ai solutions: a unified review of uncertainty quantification in deep learning models for medical image analysis,” Artificial Intelligence in Medicine, p. 102830, 2024.
- [10] O. Zhang, J.-B. Delbrouck, and D. L. Rubin, “Out of distribution detection for medical images,” in Uncertainty for Safe Utilization of Machine Learning in Medical Imaging, and Perinatal Imaging, Placental and Preterm Image Analysis: 3rd International Workshop, UNSURE 2021, and 6th International Workshop, PIPPI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, October 1, 2021, Proceedings 3. Springer, 2021, pp. 102–111.
- [11] C. Berger, M. Paschali, B. Glocker, and K. Kamnitsas, “Confidence-based out-of-distribution detection: a comparative study and analysis,” in Uncertainty for Safe Utilization of Machine Learning in Medical Imaging, and Perinatal Imaging, Placental and Preterm Image Analysis: 3rd International Workshop, UNSURE 2021, and 6th International Workshop, PIPPI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, October 1, 2021, Proceedings 3. Springer, 2021, pp. 122–132.
- [12] T. Araújo, G. Aresta, U. Schmidt-Erfurth, and H. Bogunović, “Few-shot out-of-distribution detection for automated screening in retinal oct images using deep learning,” Scientific Reports, vol. 13, no. 1, p. 16231, 2023.
- [13] J. Thagaard, S. Hauberg, B. van der Vegt, T. Ebstrup, J. D. Hansen, and A. B. Dahl, “Can you trust predictive uncertainty under real dataset shifts in digital pathology?” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part I 23. Springer, 2020, pp. 824–833.
- [14] J. Linmans, J. van der Laak, and G. Litjens, “Efficient out-of-distribution detection in digital pathology using multi-head convolutional neural networks.” in MIDL, 2020, pp. 465–478.
- [15] J. Linmans, S. Elfwing, J. van der Laak, and G. Litjens, “Predictive uncertainty estimation for out-of-distribution detection in digital pathology,” Medical Image Analysis, vol. 83, p. 102655, 2023.
- [16] A. Mehrtash, W. M. Wells, C. M. Tempany, P. Abolmaesumi, and T. Kapur, “Confidence calibration and predictive uncertainty estimation for deep medical image segmentation,” IEEE transactions on medical imaging, vol. 39, no. 12, pp. 3868–3878, 2020.
- [17] K. Zou, Z. Chen, X. Yuan, X. Shen, M. Wang, and H. Fu, “A review of uncertainty estimation and its application in medical imaging,” Meta-Radiology, p. 100003, 2023.
- [18] M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khosravi, U. R. Acharya et al., “A review of uncertainty quantification in deep learning: Techniques, applications and challenges,” Information fusion, vol. 76, pp. 243–297, 2021.
- [19] A. Malinin and M. Gales, “Predictive uncertainty estimation via prior networks,” Advances in neural information processing systems, vol. 31, 2018.
- [20] J. Nandy, W. Hsu, and M. L. Lee, “Towards maximizing the representation gap between in-domain & out-of-distribution examples,” Advances in neural information processing systems, vol. 33, pp. 9239–9250, 2020.
- [21] T. DeVries and G. W. Taylor, “Learning confidence for out-of-distribution detection in neural networks,” arXiv preprint arXiv:1802.04865, 2018.
- [22] J. Van Amersfoort, L. Smith, Y. W. Teh, and Y. Gal, “Uncertainty estimation using a single deep deterministic neural network,” in International conference on machine learning. PMLR, 2020, pp. 9690–9700.
- [23] M. Sensoy, L. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,” Advances in neural information processing systems, vol. 31, 2018.
- [24] D. Ulmer and G. Cinà, “Know your limits: Uncertainty estimation with relu classifiers fails at reliable ood detection,” in Uncertainty in Artificial Intelligence. PMLR, 2021, pp. 1766–1776.
- [25] D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” arXiv preprint arXiv:1610.02136, 2016.
- [26] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in international conference on machine learning. PMLR, 2016, pp. 1050–1059.
- [27] B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” Advances in neural information processing systems, vol. 30, 2017.
- [28] C. Tomani, S. Gruber, M. E. Erdem, D. Cremers, and F. Buettner, “Post-hoc uncertainty calibration for domain drift scenarios,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 124–10 132.
- [29] Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. Dillon, B. Lakshminarayanan, and J. Snoek, “Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,” Advances in neural information processing systems, vol. 32, 2019.
- [30] M. Minderer, J. Djolonga, R. Romijnders, F. Hubis, X. Zhai, N. Houlsby, D. Tran, and M. Lucic, “Revisiting the calibration of modern neural networks,” Advances in Neural Information Processing Systems, vol. 34, pp. 15 682–15 694, 2021.
- [31] X. Chen, X. Wang, K. Zhang, K.-M. Fung, T. C. Thai, K. Moore, R. S. Mannel, H. Liu, B. Zheng, and Y. Qiu, “Recent advances and clinical applications of deep learning in medical image analysis,” Medical Image Analysis, vol. 79, p. 102444, 2022.
- [32] T. Li, W. Bo, C. Hu, H. Kang, H. Liu, K. Wang, and H. Fu, “Applications of deep learning in fundus images: A review,” Medical Image Analysis, vol. 69, p. 101971, 2021.
- [33] M. E. Celebi, N. Codella, and A. Halpern, “Dermoscopy image analysis: overview and future directions,” IEEE journal of biomedical and health informatics, vol. 23, no. 2, pp. 474–478, 2019.
- [34] H. A. Alturkistani, F. M. Tashkandi, and Z. M. Mohammedsaleh, “Histological stains: a literature review and case study,” Global journal of health science, vol. 8, no. 3, p. 72, 2016.
- [35] B. E. Bouma, J. F. de Boer, D. Huang, I.-K. Jang, T. Yonetsu, C. L. Leggett, R. Leitgeb, D. D. Sampson, M. Suter, B. J. Vakoc et al., “Optical coherence tomography,” Nature Reviews Methods Primers, vol. 2, no. 1, p. 79, 2022.
- [36] P. R. Patel and O. De Jesus, “Ct scan,” 2021.
- [37] G. Katti, S. A. Ara, and A. Shireen, “Magnetic resonance imaging (mri)–a review,” International journal of dental clinics, vol. 3, no. 1, pp. 65–70, 2011.
- [38] A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 427–436.
- [39] S. Liang, Y. Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” arXiv preprint arXiv:1706.02690, 2017.
- [40] K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” Advances in neural information processing systems, vol. 31, 2018.
- [41] D. Hendrycks, M. Mazeika, and T. Dietterich, “Deep anomaly detection with outlier exposure,” arXiv preprint arXiv:1812.04606, 2018.
- [42] W. Liu, X. Wang, J. Owens, and Y. Li, “Energy-based out-of-distribution detection,” Advances in neural information processing systems, vol. 33, pp. 21 464–21 475, 2020.
- [43] R. Huang, A. Geng, and Y. Li, “On the importance of gradients for detecting distributional shifts in the wild,” Advances in Neural Information Processing Systems, vol. 34, pp. 677–689, 2021.
- [44] X. Du, Z. Wang, M. Cai, and Y. Li, “Vos: Learning what you don’t know by virtual outlier synthesis,” arXiv preprint arXiv:2202.01197, 2022.
- [45] S. Fort, J. Ren, and B. Lakshminarayanan, “Exploring the limits of out-of-distribution detection,” Advances in Neural Information Processing Systems, vol. 34, pp. 7068–7081, 2021.
- [46] R. Koner, P. Sinhamahapatra, K. Roscher, S. Günnemann, and V. Tresp, “Oodformer: Out-of-distribution detection transformer,” arXiv preprint arXiv:2107.08976, 2021.
- [47] S. Esmaeilpour, B. Liu, E. Robertson, and L. Shu, “Zero-shot out-of-distribution detection based on the pre-trained model clip,” in Proceedings of the AAAI conference on artificial intelligence, vol. 36, no. 6, 2022, pp. 6568–6576.
- [48] R. Huang and Y. Li, “Mos: Towards scaling out-of-distribution detection for large semantic space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8710–8719.
- [49] H. Chen, J. Cao, and M. Yi, “Out of distribution detection for medical images,” in International Conference on Computer Vision, Application, and Algorithm (CVAA 2022), vol. 12613. SPIE, 2023, pp. 95–102.
- [50] F. Ahmed and A. Courville, “Detecting semantic anomalies,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 3154–3162.
- [51] T. Cao, C.-W. Huang, D. Y.-T. Hui, and J. P. Cohen, “A benchmark of medical out of distribution detection,” arXiv preprint arXiv:2007.04250, 2020.
- [52] E. Calli, B. Van Ginneken, E. Sogancioglu, and K. Murphy, “Frodo: An in-depth analysis of a system to reject outlier samples from a trained neural network,” IEEE Transactions on Medical Imaging, vol. 42, no. 4, pp. 971–981, 2022.
- [53] D. Karimi and A. Gholipour, “Improving calibration and out-of-distribution detection in deep models for medical image segmentation,” IEEE Transactions on Artificial Intelligence, vol. 4, no. 2, pp. 383–397, 2022.
- [54] C. González, K. Gotkowski, M. Fuchs, A. Bucher, A. Dadras, R. Fischbach, I. J. Kaltenborn, and A. Mukhopadhyay, “Distance-based detection of out-of-distribution silent failures for covid-19 lung lesion segmentation,” Medical image analysis, vol. 82, p. 102596, 2022.
- [55] M. S. Graham, W. H. Pinaya, P.-D. Tudosiu, P. Nachev, S. Ourselin, and J. Cardoso, “Denoising diffusion models for out-of-distribution detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2947–2956.
- [56] M. Tardy, B. Scheffer, and D. Mateus, “Uncertainty measurements for the reliable classification of mammograms,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2019, pp. 495–503.
- [57] J. Nandy, W. Hs, and M. L. Le, “Distributional shifts in automated diabetic retinopathy screening,” in 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021, pp. 255–259.
- [58] A. G. Pacheco, C. S. Sastry, T. Trappenberg, S. Oore, and R. A. Krohling, “On out-of-distribution detection algorithms with deep neural skin cancer classifiers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 732–733.
- [59] Y. Yasin, D. J. Rumala, M. H. Purnomo, A. A. P. Ratna, A. N. Hidayati, I. Nurtanio, R. F. Rachmadi, and I. K. E. Purnama, “Open set deep networks based on extreme value theory (evt) for open set recognition in skin disease classification,” in 2020 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM). IEEE, 2020, pp. 332–337.
- [60] X. Li, C. Desrosiers, and X. Liu, “Deep neural forest for out-of-distribution detection of skin lesion images,” IEEE Journal of Biomedical and Health Informatics, vol. 27, no. 1, pp. 157–165, 2022.
- [61] A. G. Roy, J. Ren, S. Azizi, A. Loh, V. Natarajan, B. Mustafa, N. Pawlowski, J. Freyberg, Y. Liu, Z. Beaver et al., “Does your dermatology classifier know what it doesn’t know? detecting the long-tail of unseen conditions,” Medical Image Analysis, vol. 75, p. 102274, 2022.
- [62] H. Kim, G. A. Tadesse, C. Cintas, S. Speakman, and K. Varshney, “Out-of-distribution detection in dermatology using input perturbation and subset scanning,” in 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI). IEEE, 2022, pp. 1–4.
- [63] M. Combalia, F. Hueto, S. Puig, J. Malvehy, and V. Vilaplana, “Uncertainty estimation in deep neural networks for dermoscopic image classification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 744–745.
- [64] M. S. Graham, W. H. L. Pinaya, P. Wright, P.-D. Tudosiu, Y. H. Mah, J. T. Teo, H. R. Jäger, D. Werring, P. Nachev, S. Ourselin et al., “Unsupervised 3d out-of-distribution detection with latent diffusion models,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 446–456.
- [65] C. Gonzalez, K. Gotkowski, A. Bucher, R. Fischbach, I. Kaltenborn, and A. Mukhopadhyay, “Detecting when pre-trained nnu-net models fail silently for covid-19 lung lesion segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part VII 24. Springer, 2021, pp. 304–314.
- [66] M. S. Graham, P.-D. Tudosiu, P. Wright, W. H. L. Pinaya, U. Jean-Marie, Y. H. Mah, J. T. Teo, R. Jager, D. Werring, P. Nachev et al., “Transformer-based out-of-distribution detection for clinically safe segmentation,” in International Conference on Medical Imaging with Deep Learning. PMLR, 2022, pp. 457–476.
- [67] M. Woodland, N. Patel, M. Al Taie, J. P. Yung, T. J. Netherton, A. B. Patel, and K. K. Brock, “Dimensionality reduction for improving out-of-distribution detection in medical image segmentation,” in International Workshop on Uncertainty for Safe Utilization of Machine Learning in Medical Imaging. Springer, 2023, pp. 147–156.
- [68] H. Yang, C. Chen, Y. Chen, H. C. Yip, and D. QI, “Uncertainty estimation for safety-critical scene segmentation via fine-grained reward maximization,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [69] M. Hein, M. Andriushchenko, and J. Bitterwolf, “Why relu networks yield high-confidence predictions far away from the training data and how to mitigate the problem,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 41–50.
- [70] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595.
- [71] A. Bendale and T. E. Boult, “Towards open set deep networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1563–1572.
- [72] C. S. Sastry and S. Oore, “Detecting out-of-distribution examples with gram matrices,” in International Conference on Machine Learning. PMLR, 2020, pp. 8491–8501.
- [73] C. Cintas, S. Speakman, V. Akinwande, W. Ogallo, K. Weldemariam, S. Sridharan, and E. McFowland, “Detecting adversarial attacks via subset scanning of autoencoder activations and reconstruction error,” in Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, 2021, pp. 876–882.
- [74] C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” in International conference on machine learning. PMLR, 2017, pp. 1321–1330.
- [75] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
- [76] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” The journal of machine learning research, vol. 15, no. 1, pp. 1929–1958, 2014.
- [77] P. Van Molle, T. Verbelen, C. De Boom, B. Vankeirsbilck, J. De Vylder, B. Diricx, T. Kimpe, P. Simoens, and B. Dhoedt, “Quantifying uncertainty of deep neural networks in skin lesion classification,” in Uncertainty for Safe Utilization of Machine Learning in Medical Imaging and Clinical Image-Based Procedures: First International Workshop, UNSURE 2019, and 8th International Workshop, CLIP 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, October 17, 2019, Proceedings 8. Springer, 2019, pp. 52–61.
- [78] A. Jøsang and A. Jøsang, “Principles of subjective logic,” Subjective Logic: A Formalism for Reasoning Under Uncertainty, pp. 83–94, 2016.
- [79] A. Malinin and M. Gales, “Reverse kl-divergence training of prior networks: Improved uncertainty and adversarial robustness,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [80] K. Lee, H. Lee, K. Lee, and J. Shin, “Training confidence-calibrated classifiers for detecting out-of-distribution samples,” arXiv preprint arXiv:1711.09325, 2017.
- [81] S. Thulasidasan, S. Thapa, S. Dhaubhadel, G. Chennupati, T. Bhattacharya, and J. Bilmes, “A simple and effective baseline for out-of-distribution detection using abstention,” 2020.
- [82] O. Lyudchik, “Outlier detection using autoencoders,” Tech. Rep., 2016.
- [83] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,” nature, vol. 323, no. 6088, pp. 533–536, 1986.
- [84] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science, vol. 313, no. 5786, pp. 504–507, 2006.
- [85] J. An and S. Cho, “Variational autoencoder based anomaly detection using reconstruction probability,” Special lecture on IE, vol. 2, no. 1, pp. 1–18, 2015.
- [86] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [87] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [88] L. Liu, Y. Ren, Z. Lin, and Z. Zhao, “Pseudo numerical methods for diffusion models on manifolds,” arXiv preprint arXiv:2202.09778, 2022.
- [89] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241.
- [90] F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,” Nature methods, vol. 18, no. 2, pp. 203–211, 2021.
- [91] A. Hatamizadeh, V. Nath, Y. Tang, D. Yang, H. R. Roth, and D. Xu, “Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,” in International MICCAI Brainlesion Workshop. Springer, 2021, pp. 272–284.
- [92] L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,” arXiv preprint arXiv:1802.03426, 2018.
- [93] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.
- [94] D. Hendrycks, M. Mazeika, S. Kadavath, and D. Song, “Using self-supervised learning can improve model robustness and uncertainty,” Advances in neural information processing systems, vol. 32, 2019.
- [95] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in 2016 fourth international conference on 3D vision (3DV). Ieee, 2016, pp. 565–571.
- [96] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- [97] P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883.
- [98] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [99] K. Zepf, S. Wanna, M. Miani, J. Moore, J. Frellsen, S. Hauberg, A. Feragen, and F. Warburg, “Laplacian segmentation networks: Improved epistemic uncertainty from spatial aleatoric uncertainty,” arXiv preprint arXiv:2303.13123, 2023.
- [100] J. Lanchantin, T. Wang, V. Ordonez, and Y. Qi, “General multi-label image classification with transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 478–16 488.
- [101] S. Liu, L. Zhang, X. Yang, H. Su, and J. Zhu, “Query2label: A simple transformer way to multi-label classification,” arXiv preprint arXiv:2107.10834, 2021.
- [102] R. You, Z. Guo, L. Cui, X. Long, Y. Bao, and S. Wen, “Cross-modality attention with semantic graph embedding for multi-label classification,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 709–12 716.
- [103] D. Zhang and B. Taneva-Popova, “A theoretical analysis of out-of-distribution detection in multi-label classification,” in Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, 2023, pp. 275–282.
- [104] J. Lin, Q. Cai, and M. Lin, “Multi-label classification of fundus images with graph convolutional network and self-supervised learning,” IEEE Signal Processing Letters, vol. 28, pp. 454–458, 2021.
- [105] B. Chen, J. Li, G. Lu, H. Yu, and D. Zhang, “Label co-occurrence learning with graph convolutional networks for multi-label chest x-ray image classification,” IEEE journal of biomedical and health informatics, vol. 24, no. 8, pp. 2292–2302, 2020.
- [106] S. Basart, M. Mantas, M. Mohammadreza, S. Jacob, and S. Dawn, “Scaling out-of-distribution detection for real-world settings,” in International Conference on Machine Learning, 2022.
- [107] H. Wang, W. Liu, A. Bocchieri, and Y. Li, “Can multi-label classification networks know what they don’t know?” Advances in Neural Information Processing Systems, vol. 34, pp. 29 074–29 087, 2021.
- [108] L. Wang, S. Huang, L. Huangfu, B. Liu, and X. Zhang, “Multi-label out-of-distribution detection via exploiting sparsity and co-occurrence of labels,” Image and Vision Computing, vol. 126, p. 104548, 2022.
- [109] Y. Zhu, K. M. Ting, and Z.-H. Zhou, “Multi-label learning with emerging new labels,” IEEE Transactions on Knowledge and Data Engineering, vol. 30, no. 10, pp. 1901–1914, 2018.
- [110] Y. Zhang, Y. Wang, X.-Y. Liu, S. Mi, and M.-L. Zhang, “Large-scale multi-label classification using unknown streaming images,” Pattern Recognition, vol. 99, p. 107100, 2020.
- [111] S. Shi, I. Malhi, K. Tran, A. Y. Ng, and P. Rajpurkar, “Chexseen: Unseen disease detection for deep learning interpretation of chest x-rays,” arXiv preprint arXiv:2103.04590, 2021.
- [112] A. Wollek, T. Willem, M. Ingrisch, B. Sabel, and T. Lasser, “Out-of-distribution detection with in-distribution voting using the medical example of chest x-ray classification,” Medical Physics, 2023.