ERATTA: Extreme RAG for Table To Answers with Large Language Models
Abstract
Large language models (LLMs) with retrieval augmented-generation (RAG) have been the optimal choice for scalable generative AI solutions in the recent past. However, the choice of use-cases that incorporate RAG with LLMs have been either generic or extremely domain specific, thereby questioning the scalability and generalizability of RAG-LLM approaches. In this work, we propose a unique LLM-based system where multiple LLMs can be invoked to enable data authentication, user query routing, data retrieval and custom prompting for question answering capabilities from data tables that are highly varying and large in size. Our system is tuned to extract information from Enterprise-level data products and furnish real time responses under 10 seconds. One prompt manages user-to-data authentication followed by three prompts to route, fetch data and generate a customizable prompt natural language responses. Additionally, we propose a five metric scoring module that detects and reports hallucinations in the LLM responses. Our proposed system and scoring metrics achieve confidence scores across hundreds of user queries in the sustainability, financial health and social media domains. Extensions to the proposed extreme RAG architectures can enable heterogeneous source querying using LLMs.
Index Terms:
Retrieval Augmented Generation, authentication, sustainability, hallucination, Unicorn, TextBisonI Introduction
Generative AI solutions using Large Language Models (LLMs) have been extremely popular since the launch of Open AI’s chatGPT-3 in late 2022 [1]. Most LLM solutions today can typically be categorized as Gen-AI applications, such as a chatbot-like experience with a virtual assistant for code, language and content generation [2]; or Gen-AI agents that are capable of automated orchestration to perform specific tasks such as booking tickets, writing blogs, articles and generating software automatically [3]. Most such solutions implement the retrieval augmented-generation (RAG) approach, wherein the most relevant data sources are first identified followed by the knowledge-graph method to isolate only relevant data entities that are collated with natural language instructions and answering guidelines and sent to the LLM to receive the required responses [4]. In this paper, we present a novel system architecture that maximizes the RAG impact through multiple LLM calls for tasks such as user authentication, query routing and natural language question-answering while ensuring accuracy standards by flagging hallucinations, security standards and low throughput.
The RAG approaches are scalable and efficient for knowledge retrieval with lower maintenance and operating costs when compared to LLM fine tuning [5]. For use-cases that require question-answering from large volumes of tabular data at Enterprise level, RAG approaches have been accurate and scalable as presented in [2]. The three major capabilities of RAG with LLMs for the Tables-to-answers use-cases are as follows: 1) user-access authentication for tabular data based on minimal user profile data, 2) semantic-selection of the most relevant data chunks from a knowledge-base, 3) code generation using textual prompts (also knows as seq2sql [6]).
The process of generating code (SQL, Python, C/C++) using LLMs to query tabular-data has several advantages. First, LLMs can accept data in tabular format which allows better manageability for ‘relevant data’ search to each user query when compared to semantic retrieval on textual data from vector databases as presented in the work [2]. Structured data tables eliminate the need to manage a complex retrieval engine and results ranking system. Second, passing data in smaller sub-tables to LLMs enables scalability on new data tables without the need for the an offline table to text generation and vector embedding process in [2]. For tabular data sets that are have high refresh rates such as stock market prices, inflation indices, carbon footprint etc., passing the relevant sub-tables ensures most accurate data-to-answers. Third, tabular data is structured and concise which minimizes the scope for data misrepresentation and hallucinations. It is noteworthy that LLMs have been found to be more accurate and stable for text-to-code generation than for text-to-text generation in terms of ‘fake responses’ or hallucinations. Thus, our novel system shown in Fig. 1 incorporates text to SQL code generation followed by passing shorter data tables to LLM prompts to enable a variety of table-to-answers that have been tested on Sustainability domain datasets.
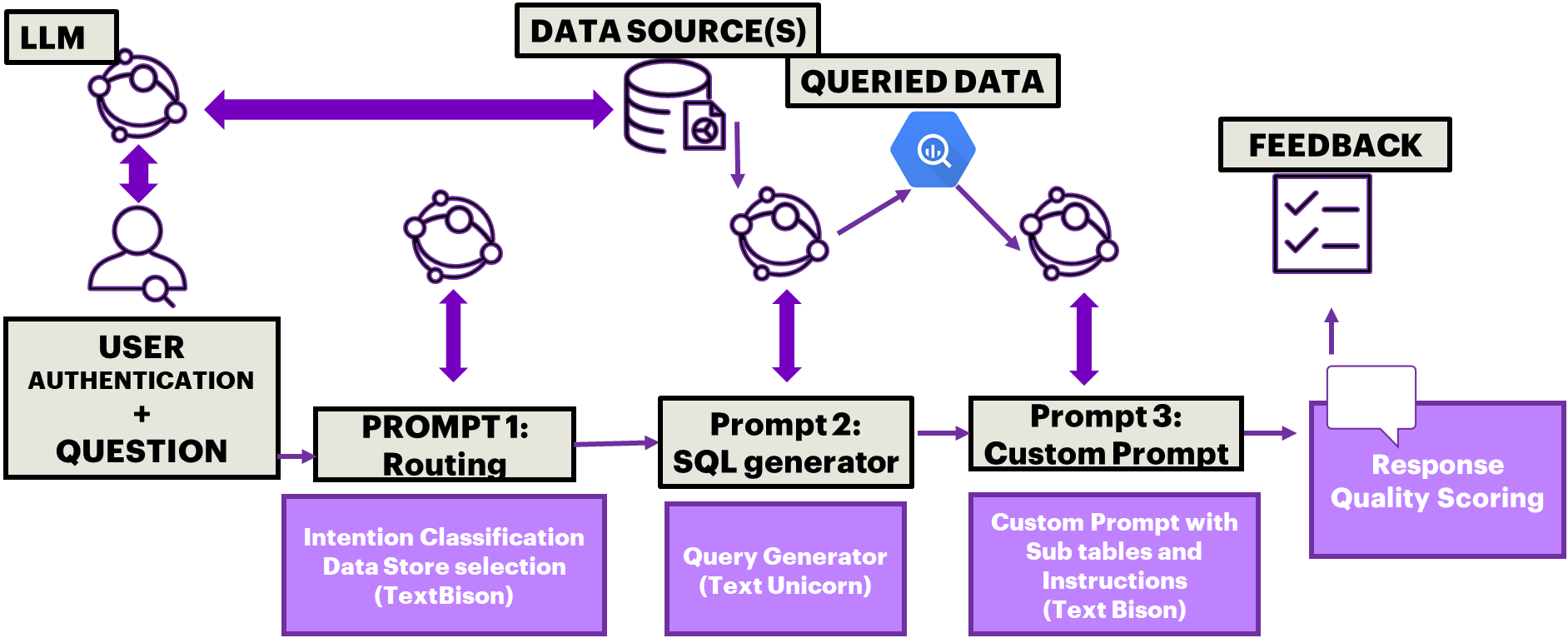
This paper makes three key contributions. First, we present three approaches to implement scalable RAG-based retrieval systems using LLMs: 1) User access to table authentication, 2) text to SQL code generation to identify relevant data sub-tables, 3) tabular data input to LLM prompts for hallucination minimized responses. Second, we present hallucination detection mechanisms on the RAG system to ensure accurate and reliable responses. Third, we present a multi-prompt system that can be extended to predictive and prescriptive categories of tables-to-answers. For each user question, the first LLM prompt routes the query and identifies the necessary data tables, the second LLM prompt generates several SQL queries to retrieve the relevant data, and the third LLM prompt constructs a coherent response in natural language. By focusing on smaller, sub-tables with labeled information, our system capitalizes on the LLM’s strengths in handling concise and well-defined datasets.
II Related Work
Generating responses from tabular data sources has been an area of focus for the past few decades. Early works such as [7] relied on the structure of tabular data in xml/html documents to parse and extract the required answers. Prior to the advent of LLMs, some major efforts in this domain included the development of algorithms known as ‘seq2sql’ models that can accept a sequence of input words and convert it into a corresponding SQL query. Some notable ‘seq2sql’ algorithms and their capabilities are shown in Table I.
| Model Name | Year | Core Capabilities |
| Bidirectional Attention | June, 2018 | - Three sub-modules were designed with deep learning models for inference. |
| for SQL Generation | - Bi-directional attention mechanisms and character embeddings were implemented with convolutional neural networks (CNNs). | |
| [8] | -Experimental evaluations were presented for the Wiki SQL dataset (87,726 hand annotated text and SQL). | |
| Seq2seq | 2018 | - This deep learning model used rewards from in-the-loop query execution over databases. |
| [9] | - The model leveraged the structure of SQL to prune the space of generated queries and learned an optimal generation policy. | |
| -Tested on 8,0654 hand-annotated examples of questions and SQL queries leading to 23-25% improvement in logical accuracy. | ||
| TypeSQL+TC | 2018 | -Utilized type information to better understand rare entities and numbers in natural language questions. |
| [10] | -Tested on Wiki SQL dataset and outperformed prior state-of-the-art by 5.5% in less time. | |
| Tranx | 2018 | -A transition-based neural semantic parser that mapped natural language (NL) utterances into formal meaning representations. |
| [11] | Highly generalizable system that can be applied to new representations by just writing a new abstract syntax description. | |
| Experimental verification performed for 4 semantic parsing and code generation tasks. | ||
| STAMP+RL | 2018 | -For typical seq2SQL models, inaccuracies occur due to mismatch between question words and table contents. |
| [12] | -Quality of generated SQL query was improved through content replication by column name, cells or SQL keywords. | |
| - Generation of‘WHERE’ clause was further improved by using column-cell relations. | ||
| PT-MAML | 2018 | -Adapted meta learning to solve the situation where the number of conditions in a text-to-SQL query vary significantly. |
| [13] | -This method decoded a text sequence guided by a fixed syntax pattern by tagging for schema and constant values. |
In this work, we extend the state-of-the-art by breaking down the tasks of data fetching from an input sequence of words into three stages, 1) query routing, 2) multiple-SQL generation, 3) SQL and text combination to yield accurate solutions to complex, multi-tabular queries.
III Data and Methods
In this work we propose an automated LLM-based user access authenticator and question-answering chatbot on sustainability-specific datasets containing information regarding carbon footprint, water/electricity consumption and renewable energy usage. The dataset comprises of 7 tables of sizes 50MB to 1.2 GB each with over 1000 rows and 50 columns of data in each table. Based on these tables, the user questions can be categorized into the following 7 major categories and their combinations as shown in Table II.
| Intention | Type | Example user-queries |
|---|---|---|
| 0 | Percent | What % of our offices are at 100% renewable electricity? |
| 1 | Change | What is the annual reduction of emissions globally? |
| 2 | Rank | Which country has the highest Emissions type 1 emissions? |
| 3 | Level | What is scope 1 emission levels for offices in Argentina? |
| 4 | Rank | Which city had the highest water consumption for Dec 2022? |
| 5 | Multi | Which countries reduced scope 3 emissions consistently in |
| the last 2 years and increased renewable electricity? | ||
| 6 | FAQ | What is included in business travel? |
The descriptions for the proposed Extreme RAG system components are presented below.
III-A Extreme RAG System Components
III-A1 Authentication RAG
This process is a scalable extension to an otherwise rule-based look-up that enables/maps tables to users based on the user-access restrictions. As shown in Fig. 1, upon each user login, there is a need to enable a database lookup to retain access only to the tables that the user can retrieve from and to withhold access to all remaining tables. For example, a user from ‘North America’ can only have access to power consumption information from North America. So only the tables with user-access are pre-loaded to the Postgres DB or BigQuery for future question answering while all remaining geo-location tables are skipped. On the other hand, a user specializing in renewable energy may require access to specific data tables across continents. For authenticating access for hundreds of thousands of users on thousands of data tables with varying schema, a custom prompt that outputs the access information in json/xml formats is the proposed scalable solution.
III-A2 Prompt 1: Routing a User Question
Once authenticated, each user question needs to be routed for its intention and appropriate data tables. The query routing is an essential step since the instructions to respond to the different categories of questions in Table I vary significantly. Query extension and query rewriting is then performed by converting the user query into its high-dimensional embedded format and matching it to at most five prior query samples in the vector space. Thus, the first query prompt maps the data sources that are pre-loaded to the user-access constraints to the query context and scope. The output of this prompt 1 is a comprehensive list of data sources relevant to the user query.
The routing prompt is trained on a specific template to identify table relevance. The result is a list of table names in Python list format, which can be easily integrated with other data-processing tasks. Although this can be envisioned as a standard classification task as in [2], LLMs are found to be more generalizable and scalable across a wide range of use queries and source tables with minimal training than standard supervised learning models.
Following the identification of these data sources, the proposed system proceeds to retrieve a list of data source configurations for each identified source. These data source configurations represent tabular metadata as in [13] and are important to isolate the appropriate SQL queries in Prompt 2.
III-A3 Prompt 2: Data Retrieval
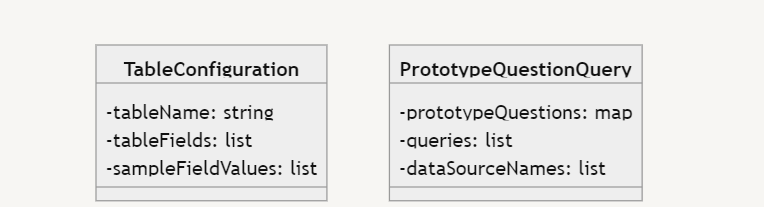
Once the appropriate data tables are mapped to a user query, the data retrieval prompt converts standard language to SQL code. This prompt takes in 3 inputs: 1) the rewritten and extended sub-queries, 2) a list of data source configurations (metadata) obtained by semantic matching of the queries with prototype questions, and 3) a sample question and its answer. Utilizing these inputs, Prompt 2 generates a complex, nested, SQL query. A query runner process runs this SQL query against the data sources specified by the previous step to fetch the required information in tabular form. Only the ‘relevant’ rows and fields from the pre-loaded tables are fetched and loaded into a specific BigQuery Table.
The metadata corresponding to the mapped tables, can be expressed as “Table Configurations” and the example questions can be specified as “Prototype Question configurations” as shown in Fig. 2. Here, Table Configurations represents an encapsulation (class) with properties for the table name, a list of relevant table fields, and a list of sample field values. Prototype Question Query similarly is another class that maps prior user questions to queries and data source names. The primary advantage of using these data structures in Prompt 2 is that it eliminates the need for code changes whenever the data domains change. For each new data source, the Table Configuration List is automatically updated, and with each new user query category, the Prototype Question Query list is updated. Thus, these data structures enable generalizability and scalability.
III-A4 Prompt 3: Answer Retrieval
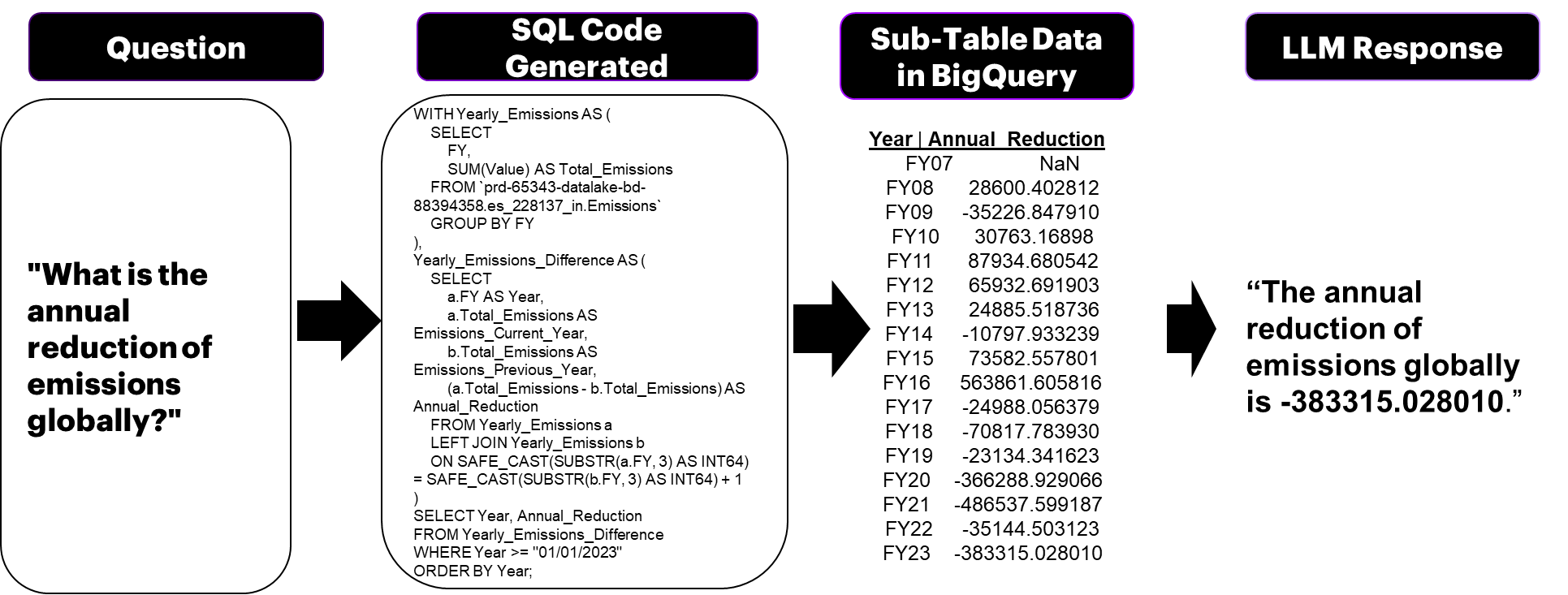
Finally, the third prompt per user query utilizes the re-written and extended questions and the tabular data loaded at the end of prompt 2 in BigQuery to generate a customized prompt that is then sent to the LLM for a natural language response. This step is an extension to the classical seq2sql models as it collects the SQL query outputs combines them with standard instructional guardrails and a sample question and answer to retrieve a natural language response. The style and format are specified as part of the prompt. It is noteworthy that per user-query the requirement is for all 3 prompts to complete under 15 seconds of run time to ensure real-time qualities. An example of the three prompts per user query is shown in Fig. 3.
III-B Quality Assurance
LLMs have been well known to be riddled with “fake-responses” or “hallucinations” [2] even after setting model paremeters like temperature and top-P to zero. We propose the following factual checks (flags) for each user query () in combination with the outcomes in prompts 2 and 3 to detect possible hallucinations for the Extreme-RAG responses generated by the proposed system. For these checks, “spacy”-based modules are used to extract and compare the textual named entities in the user questions (), with those in the response (), in the SQL queries () and the data loaded in BigQuery by Prompt 2 ().
-
1.
Number check: This flag in prompt 3 ensures that all numerical values mentioned in the answers are directly derived from the underlying data sources without any discrepancies or fabrications by the end of Prompt 2. This check is crucial for maintaining the factual accuracy of numerical data presented in responses as shown in (3).
-
2.
Entity Check: This flag verifies that all entities mentioned in the user query are accurately reflected in the response, ensuring the response’s relevance and completeness. This step is critical for confirming that the answer addresses all aspects of the query comprehensively, thereby enhancing user satisfaction and trust in the system. For example, in a user query regarding “water consumption rates in the USA”, this check ensures that the named entity “USA” is included in the response () and query () as shown in (2).
-
3.
Query Check: This flag confirms that all essential keywords and conditions stated in the user question are included in the SQL commands that are executed in Prompt 2. This step verifies the presence of specific filter words used in the user question () within the SQL queries (). This flag is configured using column metadata for each table and each filter check is added individually per data schema. This step ensures that the query accurately reflects the criteria and constraints specified in the question and can be envisioned by equation (2) wherein is changed to .
-
4.
Regurgitation check: This warning flag identifies if the response merely replicates information from the prompt 3 without paraphrasing. This step checks for word sequences where ten consecutive words from the prompt 3 are repeated. This step detects responses that fail to expand upon the query, which is essential for providing value-added insights to the user [2].
-
5.
Increase/Decrease Modifier check: This flag checks for consistency between the directional changes mentioned in the user query and that described in the prompt 3 response. This step ensures that the response accurately reflects the dynamics or trends requested by the user, critical for analyses involving changes over time or comparisons.
| (3) | |||
| (6) |
IV Experiments and Results
For validation of the proposed system we have deployed the proposed Extreme-RAG system to answer specific questions across domains and databases using the Vertex AI platform in Google cloud. Prompt 1 and 3 are built using TextBision002 while Prompt 2 is built using the Unicorn LLM. The proposed system is scalable and can be generalized to other cloud-based and on-prem LLMs as well.
IV-A Qualitative Response Analysis
We assess our Extreme RAG system on 100 random queries from multiple domains such as financial reporting, healthcare and social media and the user queries along with the SQL generated and the quality scores are shown in Table III. Here, we observe that although the prompt 3 contains instructions based on the sustainability dataset, using a new-domain for validation dataset results in similar response performances. For financial domain data tables and queries, the proposed system achieves highest confidence scores (all scores are 1). For healthcare related queries, we observe some numerical hallucinations in the patient ID numbers that leads to inaccurate numerical predictions (80% accuracy for metric). For the social media use case, the proposed system hallucinates numbers (that can be flagged by our scoring module) and the modifier flag returns a not applicable value of -1.
| Question | SQL command | |
|---|---|---|
| What was the revenue growth for the Northeast region in | SELECT region, SUM(revenue) AS revenue FROM financials WHERE region ‘Northeast’ | [1,1,1,1,1] |
| last quarter compared to the previous quarter? | AND (quarter ‘Last’ OR quarter ‘Previous’) GROUP BY quarter | |
| How many new patients were admitted to the oncology department | SELECT department, COUNT (patient-id) AS new-patients FROM hospital-admissions | [0.8,1,1,1,1] |
| this month and how does this compare to last month? | WHERE department ‘Oncology’ AND (month ‘This’ OR month ‘Last’) GROUP BY month | |
| What was the click-through rate (CTR) for the digital marketing campaign | SELECT platform, AVG (click-through-rate) AS CTR FROM marketing-data | [0,1,1,1,-1] |
| on social media platforms in January? | WHERE campaign ‘Digital Marketing’ AND platform ‘Social Media’ AND month ‘January’ |
IV-B Quantitative Response Analysis
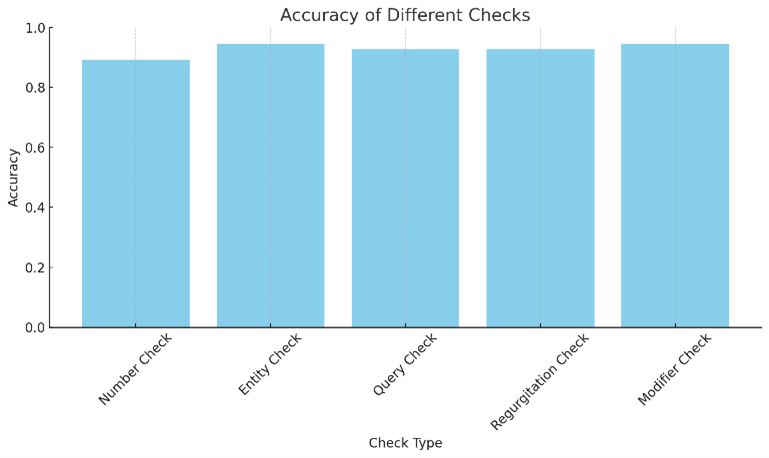
The quantitative responses on 500 sample variants of 60 queries generated on the sustainability datasets are shown in Fig. 4. We observe that all responses have average scores around 90%. The number check score is lowest at 89.09% followed by entity check and modifier checks at 94.55% each. Averaged query check and regurgitation check are around 92.73%. This shows the impact of the proposed Extreme-RAG system towards hallucination control and scalability.
IV-C Extreme RAG Extensions
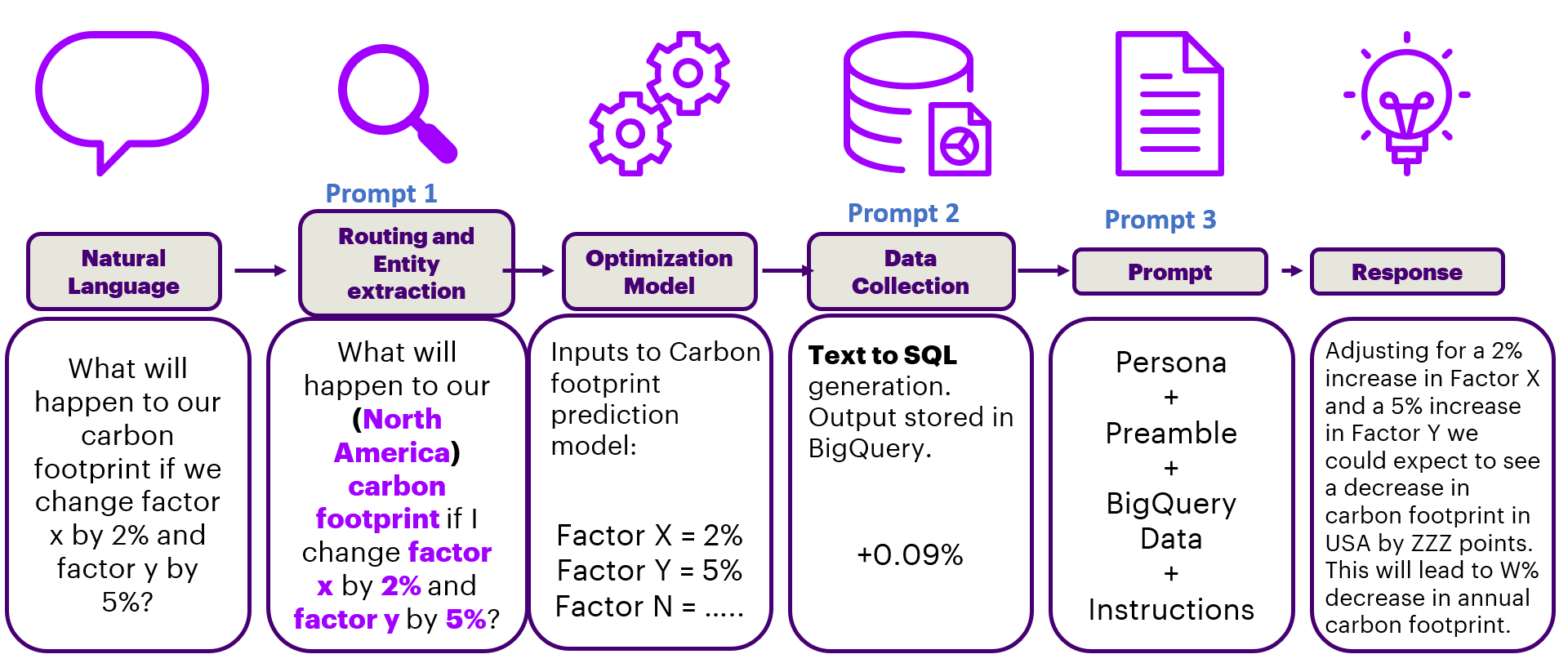
The proposed RAG architecture can further be extended to scenario planning and predictive capabilities using LLMs. Fig. 5 shows a sample flow where a real-time optimization/predictive algorithm is invoked based on the named entities extracted from prompt 1, and the result returned from the algorithm can then be saved into BigQuery followed by a prompt 3 that furnishes the response in natural language. Such extensions/modifications to the code generation LLM prompt (prompt 2) enhance the scalability of the proposed system.
V Conclusion
In this work, we propose a novel multi-LLM system that enables scalable tables-to-answers with an averaged accuracy of . The system flags hallucinations with a series of checks that constantly monitor the multi-LLM outputs. The proposed Extreme-RAG system enables several levels of checks to ensure the appropriate data subset is fetched from large Enterprise-level data tables while returning a natural language response in under 10 seconds per user query. Future works can be directed towards extending RAG approaches to heterogeneous data sources for automation and insight generation tasks.
Acknowledgement
The authors would like to thank Dike Effidua and Bharat Jethwani for all experimentation efforts and Priya Raman for all her leadership.
References
- [1] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [2] S. Roychowdhury, A. Alvarez, B. Moore, M. Krema, M. P. Gelpi, P. Agrawal, F. M. Rodríguez, Á. Rodríguez, J. R. Cabrejas, P. M. Serrano et al., “Hallucination-minimized data-to-answer framework for financial decision-makers,” in 2023 IEEE International Conference on Big Data (BigData). IEEE, 2023, pp. 4693–4702.
- [3] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–22.
- [4] T. Bui, O. Tran, P. Nguyen, B. Ho, L. Nguyen, T. Bui, and T. Quan, “Cross-data knowledge graph construction for llm-enabled educational question-answering system: A~ case~ study~ at~ hcmut,” arXiv preprint arXiv:2404.09296, 2024.
- [5] O. Ovadia, M. Brief, M. Mishaeli, and O. Elisha, “Fine-tuning or retrieval? comparing knowledge injection in llms,” arXiv preprint arXiv:2312.05934, 2023.
- [6] X. Zhang, F. Yin, G. Ma, B. Ge, and W. Xiao, “M-sql: Multi-task representation learning for single-table text2sql generation,” IEEE Access, vol. 8, pp. 43 156–43 167, 2020.
- [7] X. Wei, B. Croft, and A. McCallum, “Table extraction for answer retrieval,” Information retrieval, vol. 9, pp. 589–611, 2006.
- [8] G. Huilin, G. Tong, W. Fan, and M. Chao, “Bidirectional attention for sql generation,” in 2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis (ICCCBDA). IEEE, 2019, pp. 676–682.
- [9] Z. Li, J. Cai, S. He, and H. Zhao, “Seq2seq dependency parsing,” in Proceedings of the 27th International Conference on Computational Linguistics, 2018, pp. 3203–3214.
- [10] T. Yu, Z. Li, Z. Zhang, R. Zhang, and D. Radev, “Typesql: Knowledge-based type-aware neural text-to-sql generation,” arXiv preprint arXiv:1804.09769, 2018.
- [11] P. Yin and G. Neubig, “Tranx: A transition-based neural abstract syntax parser for semantic parsing and code generation,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing (Demo Track), 2018.
- [12] Y. Sun, D. Tang, N. Duan, J. Ji, G. Cao, X. Feng, B. Qin, T. Liu, and M. Zhou, “Semantic parsing with syntax-and table-aware sql generation,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 361–372.
- [13] P.-S. Huang, C. Wang, R. Singh, W.-t. Yih, and X. He, “Natural language to structured query generation via meta-learning,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, 2018.