MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
Abstract.
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demands innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
1. Introduction
Recently, the large language model (LLM), a breakthrough in the field of artificial intelligence, has provided a novel way for people to access information through interactive communication. Although it has become an indispensable tool for tasks such as content creation, semantic understanding and conversational AI, it still exhibits certain limitations. One such limitation is the model’s tendency to produce hallucinated or fabricated content, as it generates responses based on patterns observed in the training data rather than verifying factual accuracy. Furthermore, it struggles with real-time knowledge updates, as it can only provide information available up until the time of its last training. This makes it less reliable for retrieving the latest, dynamic information. Therefore, integrating an external up-to-date knowledge base with large language models is of paramount importance to enhance their performance and reliability. This combination not only mitigates the limitations of hallucination and knowledge update but also broadens the model’s applicability across various domains, making it more versatile and valuable. Consequently, information retrieval systems, like the Bing search engine (microsoft, 0a), continue to play a vital role in the new LLM-based information systems, such as Webgpt (Nakano et al., 2021) and new Bing (microsoft, 0b).
For modern information retrieval systems, the core is the large semantic understanding model, such as a neural indexer model (Wang et al., 2022) or dual embedding model (Huang et al., 2013; Shen et al., 2014; Palangi et al., 2016; Hu et al., 2014; Devlin et al., 2018; Qiao et al., 2019; Reimers and Gurevych, 2019; Shan et al., 2021; Xiong et al., 2020), which can capture users’ intents as well as the rich meanings of a document with better tolerance for out of vocabulary words, spelling errors, and synonymous expressions. Training a high-quality large semantic understanding model requires a vast amount of data to achieve sufficient knowledge coverage. The larger the dataset, the better the model is likely to perform, as the model can learn more complex and sophisticated patterns and correlations.
High-quality human-labeled data is as important as data scale. Recent research, such as InstructGPT (Ouyang et al., 2022) and LLAMA-2 (Touvron et al., 2023), has demonstrated the crucial role of labeled data for training large foundation models. These models rely on large volumes of training data to learn generalizable features, while human-labeled data enable the model to learn the specific tasks it is designed for. This also applies to large semantic understanding models.
Moreover, information-rich data is also crucial for training large semantic understanding models effectively. The use of multi-modal datasets can help models understand complex relationships between different types of data and transfer knowledge between them. For example, using images and text in a multi-modal data set can help models learn about image concepts and their corresponding text descriptions, providing a more holistic representation of the data.
| Dataset | #Documents | #Queries | Web | Multi-lingual docs | Rich-info docs | Multi-lingual queries |
|---|---|---|---|---|---|---|
| Robust04 | 528K | 250 | - | - | - | - |
| ClueWeb09 | 1B | - | ✓ | ✓ | - | - |
| ClueWeb12 | 733M | - | ✓ | - | - | - |
| GOV2 | 25M | 50 | - | - | - | - |
| Common Crawl (One Dump) | 3.1B | - | ✓ | ✓ | - | - |
| Natural Questions | 28M | 320K | - | - | - | - |
| MS MARCO | 3.2M | 100K | - | - | - | - |
| MS MARCO Ranking v2 | 11M | 1M | - | - | - | - |
| ORCAS | 3.2M | 10M | - | - | - | - |
| CLIR | 23.9M | 2.8M | - | ✓ | - | - |
| MS MARCO Web Search (w. ClueWeb22) | 10B | 10M | ✓ | ✓ | ✓ | ✓ |
The emerging large, real and rich data requirements motivate us to create a new MS MARCO Web Search dataset, the first large-scale information-rich web dataset with millions of real clicked query-document labels. MS MARCO Web Search incorporates the largest open web document dataset, ClueWeb22 (Overwijk et al., 2022), as our document corpus. ClueWeb22 includes about 10 billion high-quality web pages, sufficiently large to serve as representative web-scale data. It also contains rich information from the web pages, such as visual representation rendered by web browsers, raw HTML structure, clean text, semantic annotations, language and topic tags labeled by industry document understanding systems, etc. MS MARCO Web Search further contains 10 million unique queries from 93 languages with millions of relevant labeled query-document pairs collected from the search log of the Microsoft Bing search engine to serve as the query set. This large collection of multi-lingual information-rich real web documents, queries and labeled query-document pairs enables various kinds of downstream tasks and encourages several new research directions that previous datasets cannot well support, for example, generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models, etc. As the first large, real and rich web dataset, MS MARCO Web Search will serve as a critical data foundation for future AI and systems research.
MS MARCO Web Search offers a retrieval benchmark which implements several state-of-the-art embedding models, retrieval algorithms, and retrieval systems originally developed on existing datasets. We compare the quality of their results and system performance on our new MS MARCO Web Search dataset as the benchmark baselines for web scale information retrieval. The experiment results demonstrate that embedding models, retrieval algorithms, and retrieval systems are all critical components in web information retrieval. And interestingly, simply improving only one component may bring negative impacts to the end-to-end retrieval result quality and system performance. We hope that this retrieval benchmark can facilitate future innovations in data-centric techniques, embedding models, retrieval algorithms, and retrieval systems to maximize end-to-end performance.
2. Background and Related Work
2.1. Web Scale Information Retrieval
In traditional information retrieval, user queries and documents are represented as a list of keywords, and the retrieval is done based on keyword matching. However, simple keyword matching faces many challenges. First, it cannot clearly understand users’ intents. In particular, it cannot estimate users’ positive and negative sentiment and may return opposite results by mistake. Second, it cannot combine synonymous expressions, reducing the diversity of results (Guo et al., 2022). Third, it cannot handle spelling errors and will return irrelevant results. Therefore, query alteration is employed to address the above challenges. Unfortunately, it is difficult to cover all kinds of query alterations, especially those newly-appeared alterations.
With the great success of deep learning in natural language processing, both queries and documents can be more meaningfully represented as semantic embedding vectors. Since embedding-based retrieval solves the above three challenges, it has been widely used in modern information systems to facilitate new state-of-the-art retrieval quality and performance. Numerous prior studies have concentrated on deep embedding models, from DSSM (Huang et al., 2013), CDSSM (Shen et al., 2014), LSTM-RNN (Palangi et al., 2016), and ARC-I (Hu et al., 2014) to transformer-based embedding models (Devlin et al., 2018; Reimers and Gurevych, 2019; Qiao et al., 2019; Shan et al., 2021; Xiong et al., 2020; Chen et al., 2024; Xiao et al., 2023). They have shown impressive gains with brute-force nearest neighbor embedding search on some small datasets as compared with traditional keyword matching.
Due to the extremely high computational cost and query latency of brute-force vector search, there are many research approaches focusing on large-scale approximate vector nearest neighbor search (ANN) algorithms and systems design (Jégou et al., 2011; Johnson et al., 2019; Baranchuk et al., 2018; Babenko and Lempitsky, 2014; Kalantidis and Avrithis, 2014, 2014; Babenko and Lempitsky, 2016; Subramanya et al., 2019; Guo et al., 2020; Ren et al., 2020; Chen et al., 2021). They can be divided into partition-based and graph-based solutions. Partition-based solutions, such as SPANN (Chen et al., 2021), divide the whole vector space into a large number of clusters and only do fine-grained search on a small number of the closest clusters to a query in online search. Graph-based solutions, such as DiskANN (Subramanya et al., 2019), construct a neighbor graph for the whole dataset and do the best-first traversal from some fixed starting points when a query comes in. Both of these approaches work well on some uniform-distributed datasets.
Unfortunately, when applying embedding-based retrieval in the web scenario, several new challenges emerge. First, web scale data volumes require large models, high embedding dimensions, and a large-scale labeled training dataset to guarantee sufficient knowledge coverage. Second, performance gains of state-of-the-art embedding models verified on small datasets cannot be directly transferred to a web scale dataset (see section 4.4). Third, embedding models need to co-work with ANN systems in order to serve large scale data volumes efficiently. However, different training data distributions may affect the accuracy and system performance of an ANN algorithm, which will greatly reduce the result accuracy as compared to embedding models with brute-force search. Distill-VQ (Xiao et al., 2022) has verified that CoCondenser (Gao and Callan, 2022) embedding model with Faiss-IVFPQ ANN index achieves different result accuracy on MSMarco (Nguyen et al., 2016) and NQ (Kwiatkowski et al., 2019) datasets. Moreover, even the same training data distribution will also result in different embedding vector distributions, which will lead to different ranking trends of the embedding models in brute-force search (KNN) and approximate nearest neighbor search (ANN) (see section 4.6).
2.2. Existing Datasets
To encourage innovation in the information retrieval area, the community has collected several datasets for public benchmarking (summarized in Table 1).
There are many public web datasets for traditional information retrieval tasks, such as Robust04 (Rob, [n. d.]), ClueWeb09 (Clarke et al., 2009), ClueWeb12 (Callan, 2012), GOV2 (Clarke et al., 2004), ClueWeb22 (Overwijk et al., 2022) and Common Crawl (com, [n. d.]). Unfortunately, these datasets have, at most, hundreds of labeled queries, far from enough to learn a good deep learning enhanced retrieval model.
Recently, several new datasets have been published for research on deep learning enhanced retrieval (Nguyen et al., 2016; Kwiatkowski et al., 2019; Sasaki et al., 2018). MS MARCO (Nguyen et al., 2016) is one of the most popular datasets for embedding model investigation. It provides 100K questions collected from Bing’s search questions paired with human generated answers contextualized within web documents. MS MARCO Ranking v2 (Soboroff, 2021) expands the size of the document and question sets to 11 million and 1 million, respectively. ORCAS (Craswell et al., 2020) provides 10 million unique queries and 18 million clicked query-document pairs for MS MARCO documents. Natural Questions (Kwiatkowski et al., 2019), a sub-million-scale question answering dataset collected from Google’s search queries with human annotated answers in Wikipedia articles, was repurposed for embedding-based retrieval by extracting passages from Wikipedia as candidate answers (Karpukhin et al., 2020). CLIR (Sasaki et al., 2018), a million-scale cross-language information retrieval dataset collected from Wikipedia, has been used to train cross-lingual embedding models (Xu et al., 2021). However, none of these datasets meet the emerging large, real and rich requirements. These datasets focus on English-only question answering tasks. None of them has the desired web-scale data with highly-skewed multi-lingual queries which can be short, ambiguous and often not formulated as natural language questions. Further, they only provide the raw text of queries and answers, which limits the potential of future cross-modal knowledge transfer research. Finally, they only focus on evaluating the quality of embedding models using brute-force search, which cannot reflect end-to-end retrieval challenges.
ANN benchmark (Aumüller et al., 2017) and Billion-scale ANN benchmark (big, [n. d.]) provide multiple high-dimensional vector datasets to evaluate the result accuracy and system performance for embedding-based retrieval algorithms. Unfortunately, they cannot measure model quality and thus cannot reflect the end-to-end retrieval performance.
Therefore, a large-scale information-rich web dataset with real document and query distribution that can reflect real-world challenges is still lacking.
3. MS MARCO Web Search Dataset
In this paper, we present MS MARCO Web Search, a large-scale dataset for research on web information retrieval. MS MARCO Web Search dataset consists of a high quality set of web pages that mirrors the highly-skewed web document distribution, a query set that reflects the real web query distribution, and a large-scale query-document label set for embedding model training and evaluation.
3.1. Document Preparation
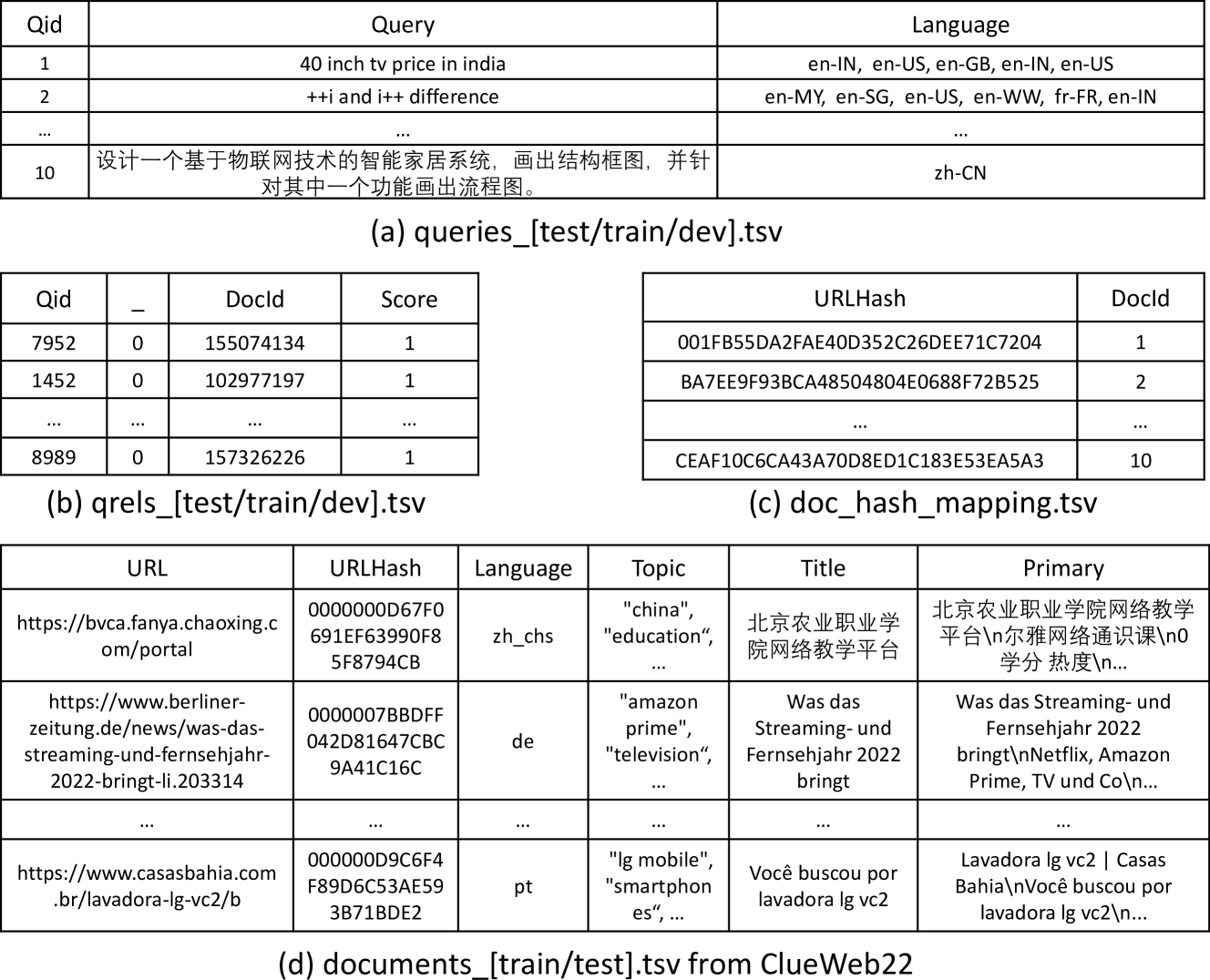
We use ClueWeb22 (Callan, 2012) as our document set since it is the largest and newest open web document dataset for our purpose. It meets the requirements of large scale, high quality and realistic document distributions crawled and processed by a commercial web search engine with rich information. Compare to Common Crawl (com, [n. d.]) which only crawls 35 million registered domains and covers 40+ languages, ClueWeb22 closely mimics the realistic crawl selection of a commercial search engine with 207 languages. It has 10 billion high-quality web pages with rich affiliated information, such as url, language tag, topic tag, title and clean text, etc. Figure 2 (d) gives an example of the data structures provided by ClueWeb22.
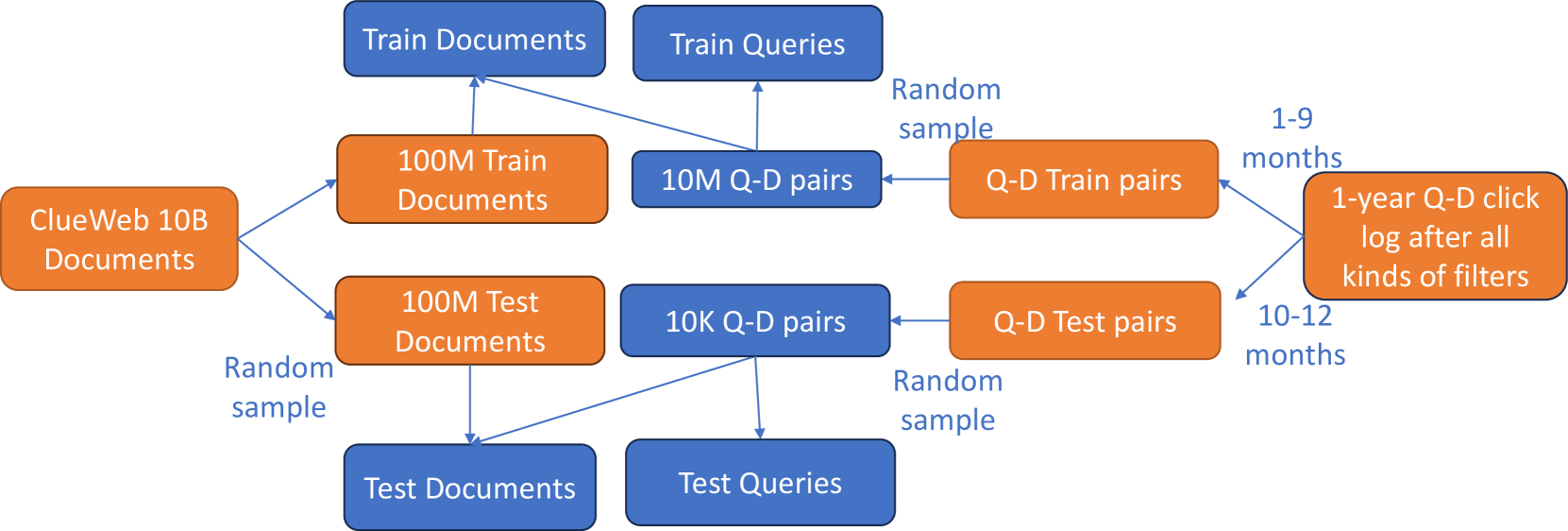
To make training cost-effective for both academia and industry, we provide a 100 million and a 10 billion document set. The 100 million document set is a random subset of the 10 billion document set. In order to evaluate model generalization ability in a small-scale dataset, two 100 million non-overlapping document sets are provided, one for training and the other for testing. The whole process is shown in the left part of figure 1.
3.2. Query Selection and Labeling
To generate large scale high quality queries and query-document relevance labels, we sample query-document clicks from one year of Bing search engine’s logs. The initial query set gets filtered to remove queries that are rarely triggered, contain personally identifiable information, offensive content, adult content and those having no click connection to the ClueWeb22 document set. The resulting set includes queries triggered by many users, which reflects the real query distribution of a commercial web search engine.
The queries are split into train and test sets based on time, which is similar to real-world web scenarios training an embedding model using past data and serving future incoming web pages and queries. We sample around 10 million query-document pairs from the train set and 10 thousand query-document pairs from the test set. The documents in the query-document train and test sets are then merged into the 100 million train document set and test document set respectively (shown in right part of figure 1). To enable quality verification of the model during training, we split a dev query-document set from the train query-document set. Since the train and dev sets share the same document set, the dev set can be used to quickly verify the training correctness and model quality during training. For the 10B dataset, we use the same train, dev, and test queries but sample more query-document pairs.
3.3. Dataset Analysis
| Scale | Train | Dev | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Document | Query | Q-D | Document | Query | Q-D | Document | Query | Q-D | |
| Set-100M | 109969872 | 9206475 | 9346695 | 109969872 | 9253 | 9402 | 100924960 | 9374 | 9374 |
| Set-10B | 10B | 9206475 | 62302553 | 10B | 9253 | 63314 | 10B | 9374 | 40511 |
We have constructed two scales of the datasets: Set-100M and Set-10B. Table 2 gives the detailed statistics of the datasets. The example files of MS MARCO Web Search Set-100M are shown in figure 2.
3.3.1. Language Distribution Analysis
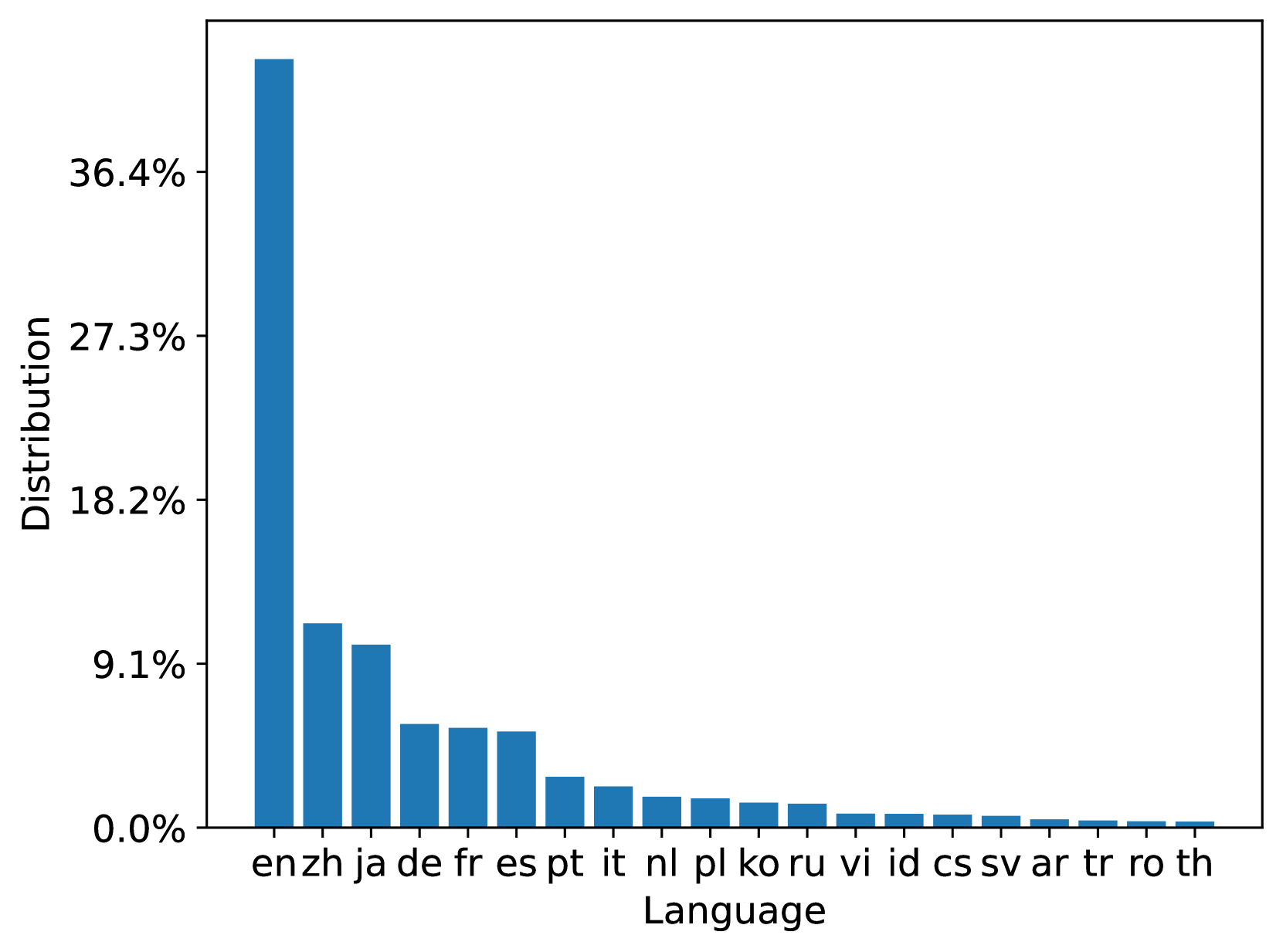
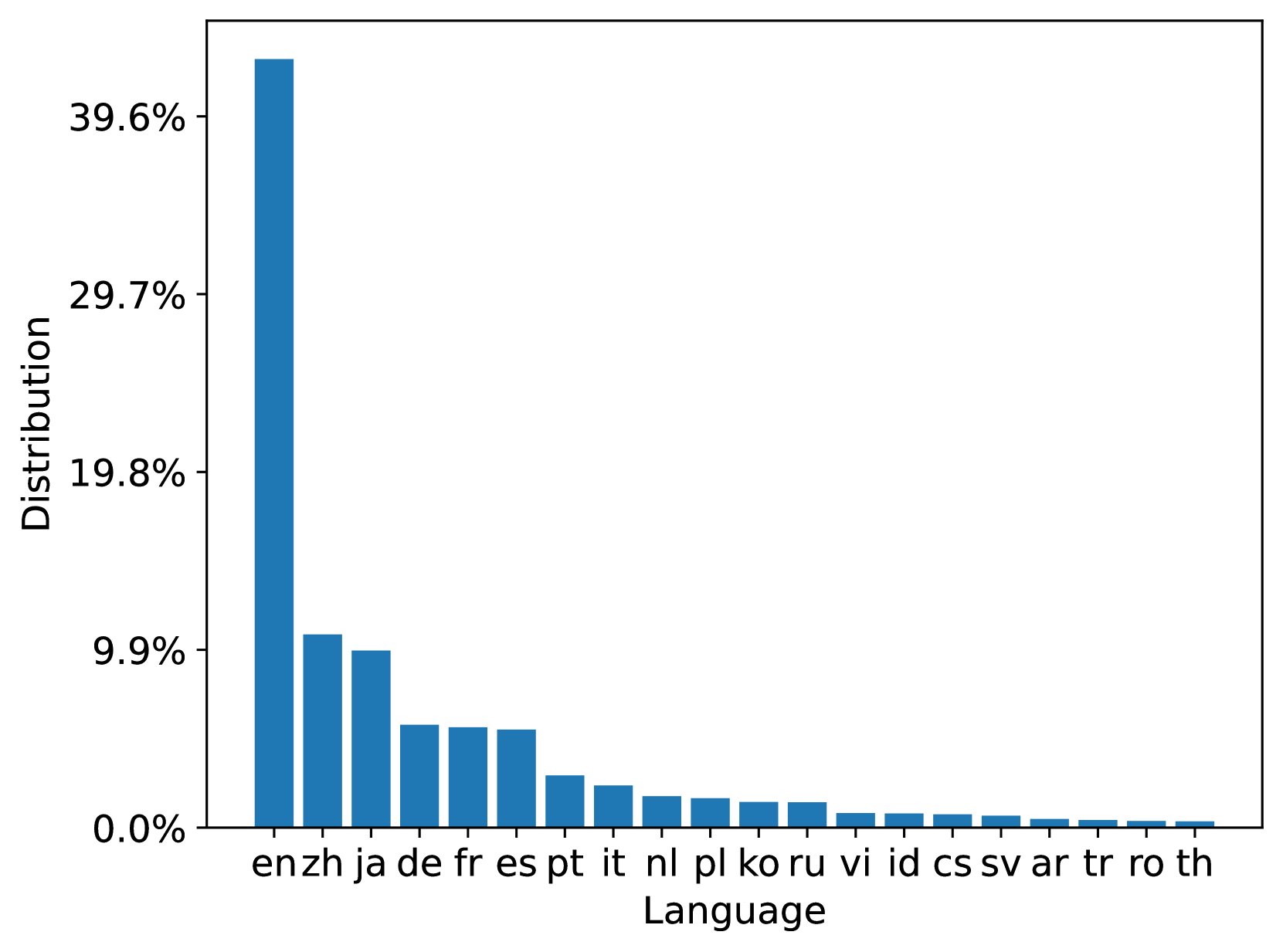
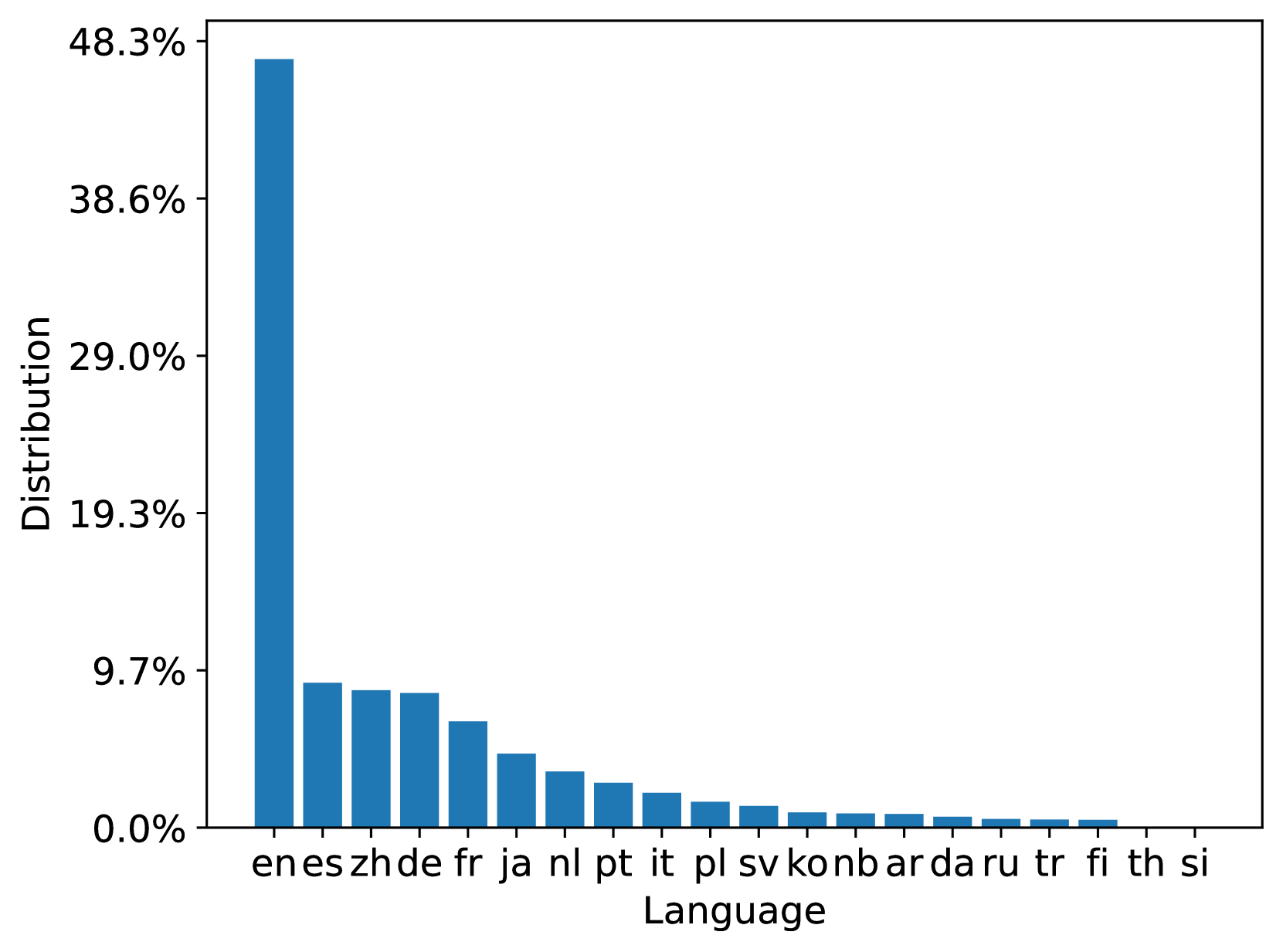
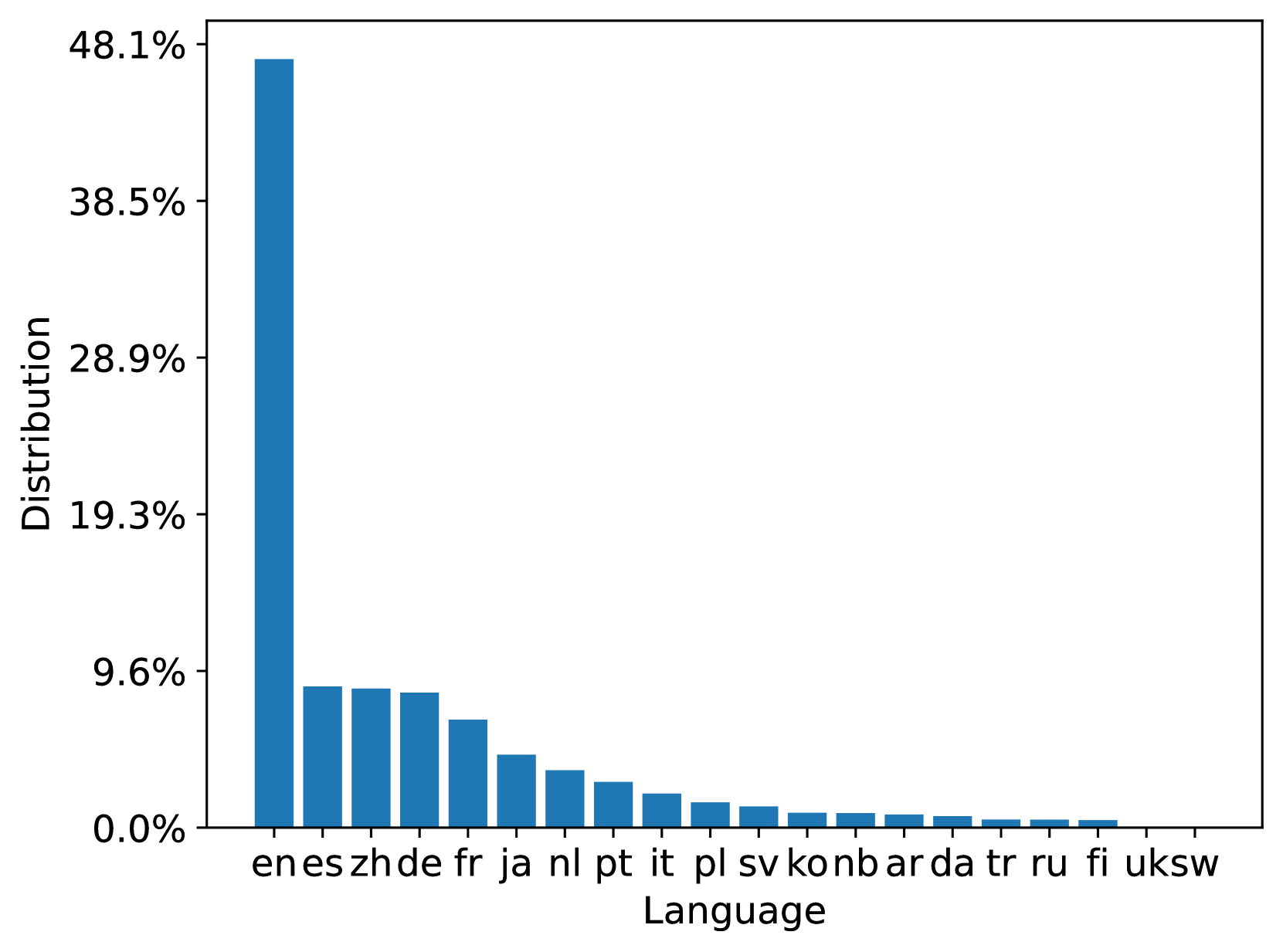
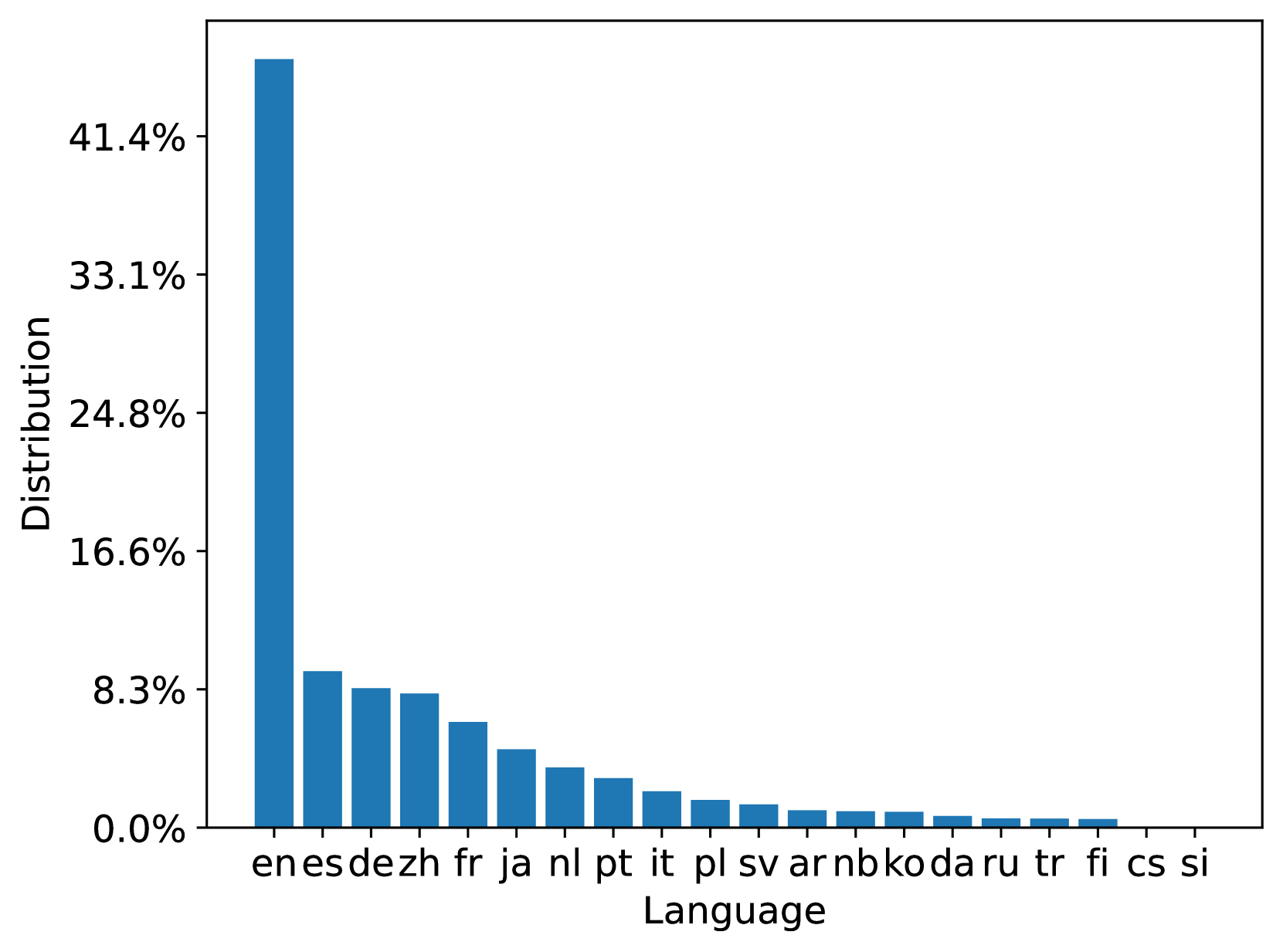
MS MARCO Web Search is a multi-lingual dataset with its queries and document both from a commercial web search engine. We analyze the 20 most popular languages among 93 and 207 languages in both queries and documents in the 100M dataset respectively; the 10B dataset has a similar distribution. Figure 3 summarizes the document language distribution in the train and test document sets. We can see that both train and test document sets are aligned with the original ClueWeb22 document distribution. Figure 4 summarizes the query language distribution in the train, dev, and test query sets. From the distribution, we can see that the language distribution of the queries in the web scenario is high-skewed which may lead to model bias. It encourages research on data-centric techniques for training data optimization.
3.3.2. Data Skew Analysis
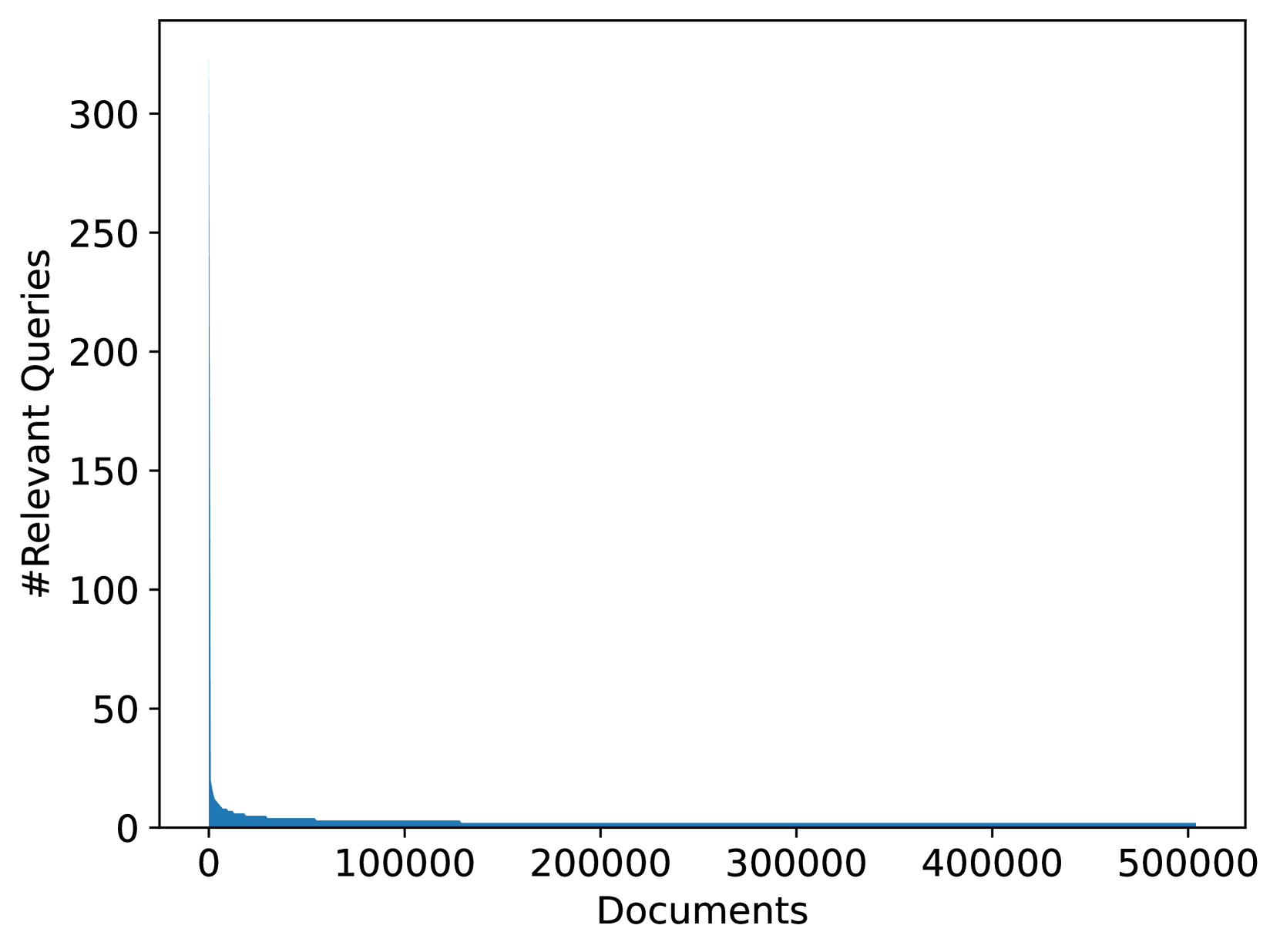
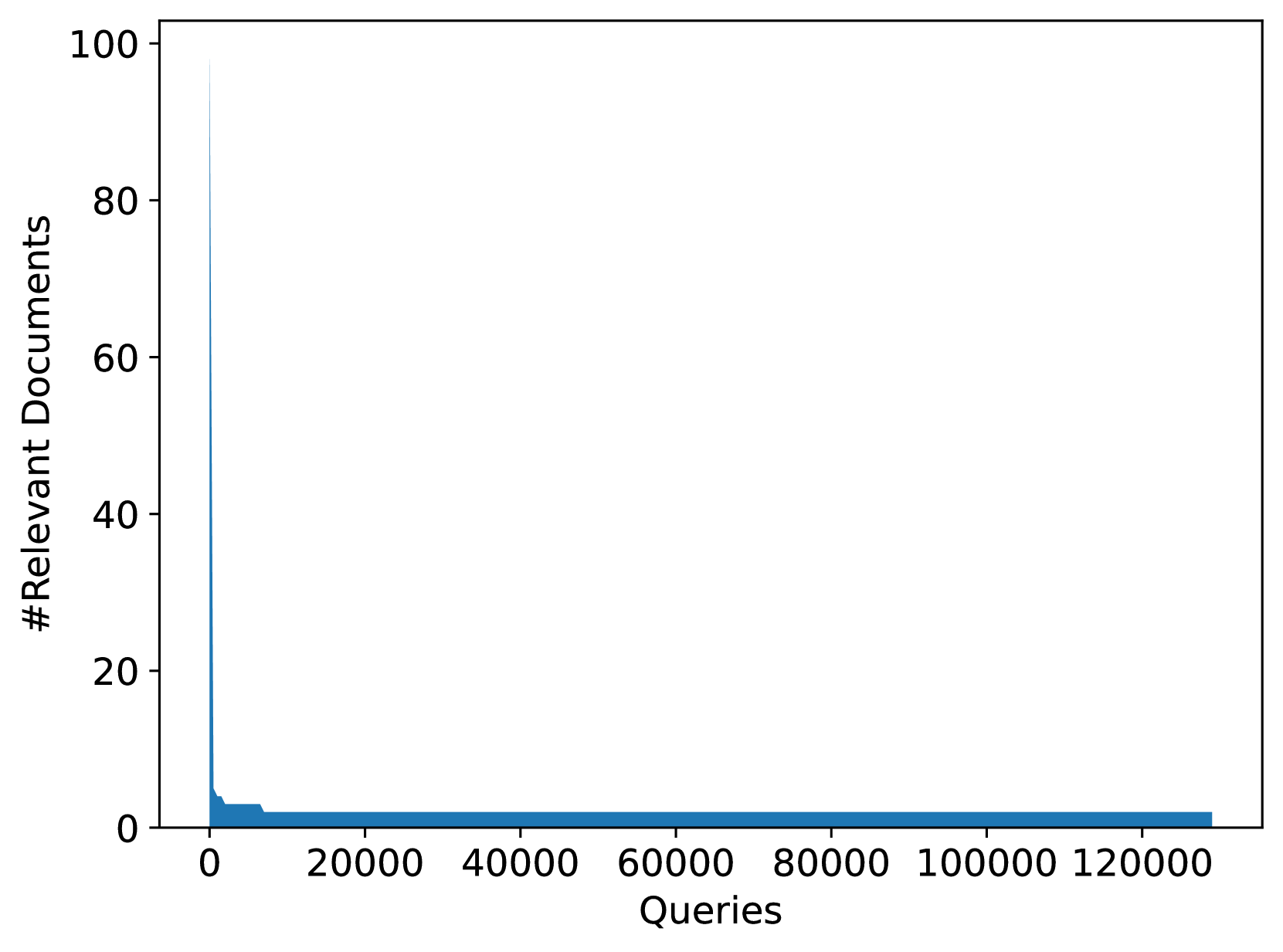
We analyze the query-document label distribution in the training data. Figure 5 shows documents and the number of relevant queries associated with them. From the figure, we can see that there are only a few documents with multiple labels: only 7.77% of the documents have relevant labeled queries and 0.46% of documents have more than one labeled relevant query. Figure 5 summarizes the queries and their relevant documents. From the figure, we can see that only 1.4% of queries have multiple relevant documents. This highly skewed nature of the dataset is consistent with what is observed while training models for web-scale information retrieval. Our intention is to keep this skew to make models trained on this dataset applicable to real-world scenarios.
3.3.3. Test-Train Overlap Analysis
| Total | QTrain, CTrain | QTrain, CTrain | QTrain, CTrain | QTrain, CTrain |
|---|---|---|---|---|
| 9374 | 82 | 1468 | 178 | 7646 |
As introduced in (Lewis et al., 2021), there exists large test-train overlap in some popular open-domain QA datasets, which cause many popular open-domain models to simply memorize the queries seen at the training stage. Subsequently, they perform worse on novel queries. The work (Zhan et al., 2022) observes this phenomenon in the MSMARCO dataset. To better evaluate model generalizability, we minimize the overlap between the train and test sets by splitting the query-document pairs into train and test sets by time. This means the test query-document pairs have no time overlap with the train query-document pairs, which introduces a large portion of novel queries. This can be verified in the table 3. We summarize the test query-document pairs into four categories:
-
•
QTrain, DTrain: Both query and document have appeared in the train set,
-
•
QTrain, DTrain: Query has not been seen in the train set, but the relevant document has been seen in the train set,
-
•
QTrain, DTrain: Query has been seen in the train set, but the document is a new web page that has not been seen in the train set,
-
•
QTrain, DTrain: Both query and document are novel content which have never been seen in the train set.
We can see from the table 3 that 82% of query-document pairs are novel content in the test set which have not been seen in the train set. Therefore, MS MARCO Web Search dataset is capable of offering effective assessments of models based on memory capacity and generalizability by dividing the test set into four categories for a more detailed comparison.
3.4. New Challenges Raised by MS MARCO Web Search
Based on the MS MARCO Web Search datasets, we raise three challenge tasks in large embedding model and retrieval system design.
3.4.1. Large-scale Embedding Model Challenge
As introduced before, the large-scale web data volume requires large embedding models to guarantee sufficient knowledge coverage. It requires balancing the following two goals: good model generalization ability and efficient train/inference speed.
3.4.2. Embedding Retrieval Algorithm Challenge
Embedding models need to co-work with the embedding retrieval system to serve a web scale dataset. In this challenge, we take the embedding vectors generated by our best baseline model as the ANN vector set. The goal of this challenge is to call for ANN algorithm innovations to minimize the accuracy gap between approximate search and brute-force search while still preserving good system performance.
3.4.3. End-to-end Retrieval System Challenge
In the web scenario, the result quality and system performance of the end-to-end retrieval system are the most important metrics in comparing different solutions. This challenge task encourages any kind of solutions, including an embedding model plus ANN system (Lu et al., 2020), inverted index solution (Dai and Callan, 2019; Zhuang et al., 2021; Bevilacqua et al., 2022), hybrid solution (Seo et al., 2019; Guo et al., 2022; Lassance and Clinchant, 2023), neural indexer (Wang et al., 2022; Tay et al., 2022), and large language model (Touvron et al., 2023) etc.
| Baselines | MS MARCO Web Search | NQ | MS MARCO Passage | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MRR@10 | recall@1 | recall@5 | recall@10 | recall@20 | recall@100 | recall@20 | recall@100 | recall@50 | recall@1K | |
| DPR | 0.542 | 45.12% | 66.04% | 72.10% | 76.80% | 87.54% | 78.4% | 85.4% | - | - |
| ANCE | 0.633 | 54.18% | 75.53% | 80.53% | 84.17% | 91.17% | 81.9% | 87.5% | 81.1% | 95.9% |
| SimANS | 0.649 | 55.86% | 76.84% | 81.78% | 85.23% | 91.98% | 86.2% | 90.3% | 88.7% | 98.7% |
| Baselines | ANN recall@1 | ANN recall@10 | ANN recall@100 | QPS | P50 latency | P90 latency | P99 latency |
|---|---|---|---|---|---|---|---|
| SPANN | 87.97% | 80.55% | 69.84% | 625 | 10.411 ms | 10.873 ms | 11.334 ms |
| DiskANN | 91.46% | 87.07% | 69.73% | 2691 | 21.968 ms | 37.841 | 69.462 ms |
| Baselines | MRR@10 | recall@1 | recall@5 | recall@10 | recall@20 | recall@100 |
|---|---|---|---|---|---|---|
| Elasticsearch BM25 | 0.296 | 22.30% | 39.04% | 46.00% | 52.42% | 63.87% |
| DPR | 0.467 | 39.21% | 56.66% | 61.27% | 64.69% | 70.28% |
| ANCE | 0.580 | 49.87% | 68.59% | 72.94% | 75.86% | 80.18% |
| SimANS | 0.585 | 50.63% | 68.79% | 73.14% | 75.85% | 79.82% |
| Baselines | QPS | P50 latency | P90 latency | P99 latency |
|---|---|---|---|---|
| Elasticsearch BM25 | 149 | 312.025 ms | 1065.141 ms | 3745.546 ms |
| DPR/ANCE/SimANS | 625 | 21.924 ms | 23.017 ms | 34.217 ms |
4. Benchmark Results
In this section, we provide initial benchmark results for some state-of-the-art embedding models, ANN algorithms, and popular retrieval systems on the MS MARCO Web Search 100M dataset as baselines. For the 10B dataset, we leave it for open exploration.
4.1. Environment Setup
We use the Azure Standard_ND96asr_v4 Virtual Machine for model training and performance testing. It contains 96 vCPU cores, 900 GB memory, 8 A100 40GB GPUs with NVLink 3.0.
4.2. Baseline Methods
4.2.1. State-of-the-art Embedding Models
We take the following three state-of-the-art multi-lingual models as the initial baseline models:
-
•
DPR (Karpukhin et al., 2020) is based on a BERT pre-trained model and a dual-encoder architecture, whose embedding is optimized for maximizing the inner product score of a query and its relevant passage. The negative training examples are selected by BM25 retrieved documents.
-
•
ANCE (Xiong et al., 2020) improves embedding-based retrieval performance by selecting hard negative training examples from the entire document set using an asynchronously updated approximate nearest neighbor index.
-
•
SimANS (Zhou et al., 2022) avoids over indexing on false negatives by selecting ambiguous samples rather than the hardest ones.
We aspire for the MS MARCO Web Search dataset to establish itself as a new standard benchmark for retrieval, enticing more baseline models to assess and experiment with it.
4.2.2. State-of-the-art ANN Algorithms
For embedding retrieval algorithms, we choose the state-of-the-art disk-based ANN algorithms DiskANN (Jayaram Subramanya et al., 2019) and SPANN (Chen et al., 2021) as the baselines. DiskANN is the first disk-based ANN algorithm that can effectively serve billion-scale vector search with low resource cost. It adopts the neighborhood graph solution which stores the graph and the full-precision vectors on the disk, while putting compressed vectors (e.g., through Product Quantization (Jegou et al., 2010)) and some pivot points in memory. During the search, a query follows the best-first traversal principle to start the search from a fixed point in the graph.
SPANN adopts a hierarchical balanced clustering technique to fast partition the whole dataset into a large number of posting lists which are kept in the disk. It only stores the centroids of the posting lists in memory. To speed up the search, SPANN leverages a memory index to fast navigate the query to closest centroids, and then loads the corresponding posting lists from disk into memory for further fine-grained search. With several techniques like postings expansion with a maximum length constraint, boundary vector replication and query-aware dynamic pruning, it achieves state-of-the-art performance in multiple billion-scale datasets in terms of memory cost, result quality, and search latency.
4.2.3. End-to-end Retrieval Systems
BM25 (Robertson and Walker, 1994) is the most widely used ranking function in the web information retrieval area to estimate the relevance score of a document given a query. It ranks a set of documents based on a probabilistic retrieval framework and has been integrated into the Elasticsearch system to serve all kinds of search scenarios.
4.3. Evaluation Metrics
We evaluate all the baselines on both result quality and system performance aspects. For result quality, we take Mean Reciprocal Rank (MRR) and recall as the evaluation metrics:
-
•
MRR: the average of the multiplicative inverse of the rank of the first correct result, which is widely used for evaluating the model quality.
-
•
Recall: the average percentage of ground truth items recalled during the search. For the embedding model challenge and the end-to-end retrieval system challenge, we use our test query-document labels as the ground truth. For the embedding retrieval algorithm challenge, we use the brute-force vector search results as the ground truth (ANN recall) to evaluate the ANN algorithm performance.
For system performance, we evaluate the following metrics under limited resource cost to align with industry scenarios:
-
•
Throughput: All queries are provided at once, and we measure the wall clock time between the ingestion of the vectors and when all the results are output using all the threads in a machine. Then the throughput is calculated as the processed queries per second (QPS).
-
•
Latency: we measure the 50, 90 and 99 percentile query latency at certain QPS.
4.4. Evaluation of Embedding Models
In this experiment, we measure the MRR and recall of all the baseline embedding models. From the result, we can see that SimANS with the ambiguous samples as negative training examples performs the best on MS MARCO Web Search 100M dataset. The ranking of the baseline models is aligned with the model evolution trend in the literature. Nonetheless, when compared with the evaluation results in Natural Question (NQ) (Kwiatkowski et al., 2019) and MS MARCO Passage Ranking (Nguyen et al., 2016), the gap in performance between ANCE and SimANS in MS MARCO Web Search becomes less significant.
We also evaluate the system performance for the three baseline embedding models. Since they use the same model architecture and the same number of parameters, their serving time cost is similar. At the peak of 698 QPS, the latency percentiles of 50, 90, and 99 are 9.896 ms, 10.018 ms, and 11.430 ms, respectively.
4.5. Evaluation of ANN Algorithms
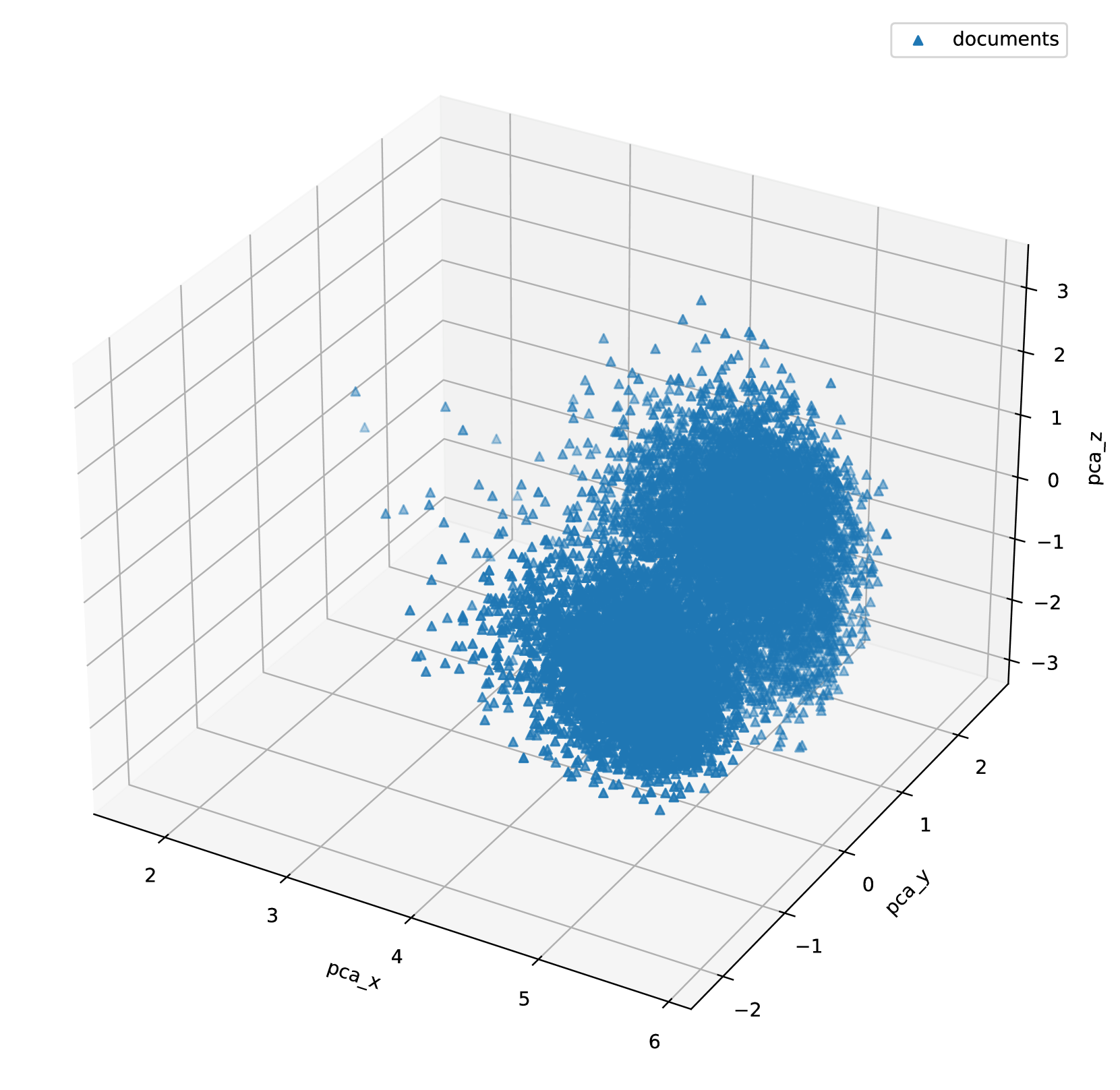
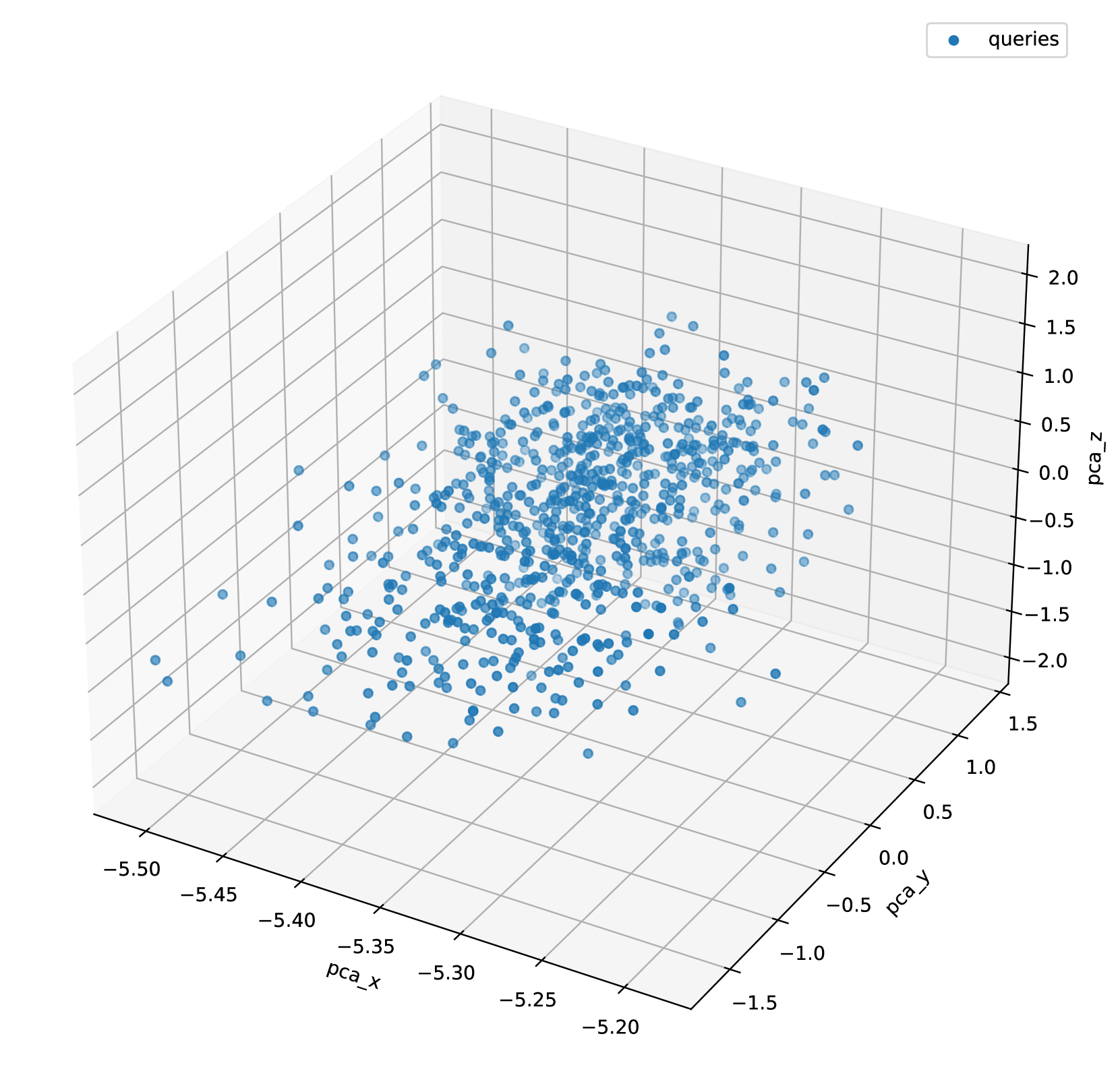
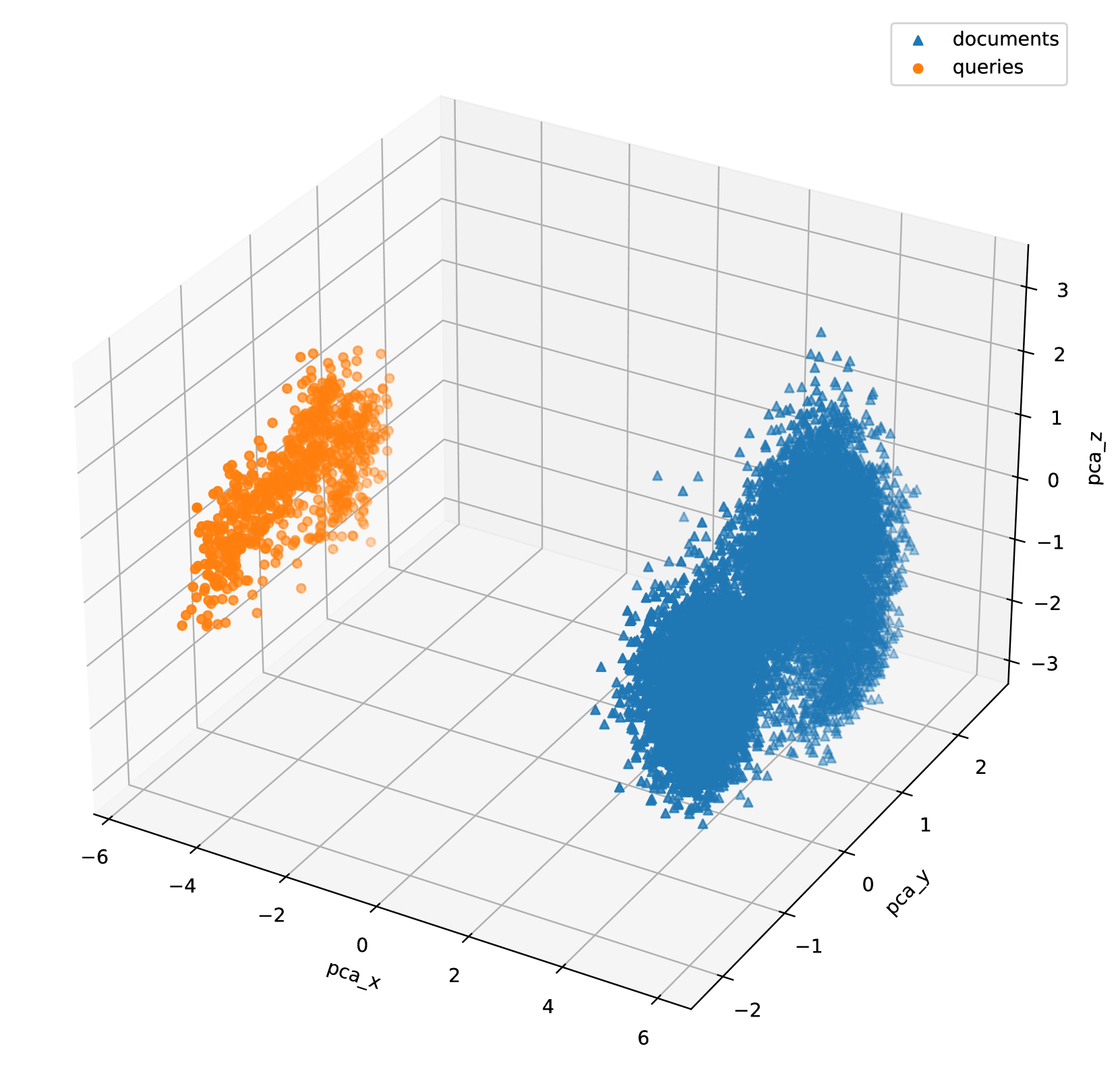
In this experiment, we evaluate the ANN performance with vectors generated by the best baseline model. We build both DiskANN and SPANN indices and evaluate both their serving performance and result quality. Here we only focus on evaluating the gap between ANN and KNN. Therefore, we use the brute-force search results as the ground truth to measure recall. Table 5 summarizes the recall and system performance of the two baselines. From the results, we can see that it is difficult to achieve high recall when the number of return results K is large. One of the reasons is that the distributions of queries and documents are highly-skewed and far away from each other (see figure 6). We also observe this phenomenon in DPR and ANCE embeddings.
4.6. Evaluation of End-to-end Performance
In this section, we evaluate the end-to-end performance of the three baseline embedding models plus SPANN index and the widely-used Elasticsearch BM25 solution. Table 6 and table 7 demonstrate the result quality and system performance of all these baseline systems, respectively. Compared with table 4, we can see that after using the ANN index, the final result quality drops a lot. For example, the metric recall@100 drops more than 10 points for all baseline models. There exists large quality gaps between the ANN and KNN results (see table 5). Moreover, we notice that using the ANN index will change the model ranking trend. SimANS achieves the best results for all the result quality metrics with brute-force search. However, when using the SPANN index, it performs worse than ANCE in recall@20 and recall@100. We further analyze the phenomenon in detail and find that SimANS has a larger gap between the average distance of query to the top100 documents relative to the average distance of document to the top100 documents than ANCE. The gap in SimANS and ANCE are 103.35 and 73.29, respectively. This will cause inaccurate distance bound estimation for a query to the neighbors of a document. As a result, ANN cannot perform well because it relies on distance estimated according to the triangle inequality. Both result quality and system performance results of the end-to-end evaluation call for more innovations on the end-to-end retrieval system design.
5. Potential Biases and Limitations
As discussed in section 3.3.1, The language distribution of documents and queries in the web scenario is high-skewed. This will lead to language bias on data and models. ClueWeb22 (Callan, 2012) demonstrates that there also exists topic distribution skew in the web scenario. Therefore, domain bias also may happen in data and models.
To protect user privacy and content health, we remove queries that are rarely triggered (triggered by less than K users, where K is a high value), contain personally identifiable information, offensive content, adult content and queries that have no click connection to the ClueWeb22 document set. As a result, the query distribution is slightly different from the real web query distribution.
6. Future Work and Conclusions
MS MARCO Web Search is the first web dataset that effectively meets the criteria of being large, real, and rich in terms of data quality. It is composed of large-scale web pages and query-document labels sourced from a commercial search engine, retaining rich information about the web pages that is widely employed in industry. The retrieval benchmark offered by MS MARCO Web Search comprises three challenging tasks that require innovation in both the areas of machine learning and information retrieval system research. We hope MS MARCO Web Search can serve as a benchmark for modern web-scale information retrieval, facilitating future research and innovation in diverse directions.
References
- (1)
- big ([n. d.]) [n. d.]. Billion-scale ANNS Benchmarks. https://big-ann-benchmarks.com/.
- com ([n. d.]) [n. d.]. Common Crawl.
- Rob ([n. d.]) [n. d.]. Robust04. https://trec.nist.gov/data/robust/04.guidelines.html.
- Aumüller et al. (2017) Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2017. ANN-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. In International conference on similarity search and applications. Springer, 34–49.
- Babenko and Lempitsky (2014) Artem Babenko and Victor Lempitsky. 2014. The inverted multi-index. IEEE transactions on pattern analysis and machine intelligence 37, 6 (2014), 1247–1260.
- Babenko and Lempitsky (2016) Artem Babenko and Victor Lempitsky. 2016. Efficient indexing of billion-scale datasets of deep descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2055–2063.
- Baranchuk et al. (2018) Dmitry Baranchuk, Artem Babenko, and Yury Malkov. 2018. Revisiting the inverted indices for billion-scale approximate nearest neighbors. In Proceedings of the European Conference on Computer Vision (ECCV). 202–216.
- Bevilacqua et al. (2022) Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers. Advances in Neural Information Processing Systems 35 (2022), 31668–31683.
- Callan (2012) Jamie Callan. 2012. The lemur project and its clueweb12 dataset. In Invited talk at the SIGIR 2012 Workshop on Open-Source Information Retrieval.
- Chen et al. (2024) Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216 (2024).
- Chen et al. (2021) Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search. Advances in Neural Information Processing Systems 34 (2021), 5199–5212.
- Clarke et al. (2004) Charles Clarke, Nick Craswell, and Ian Soboroff. 2004. Overview of the TREC 2004 Terabyte Track. In TREC.
- Clarke et al. (2009) Charles LA Clarke, Nick Craswell, and Ian Soboroff. 2009. Overview of the TREC 2009 Web Track.. In Trec, Vol. 9. 20–29.
- Craswell et al. (2020) Nick Craswell, Daniel Campos, Bhaskar Mitra, Emine Yilmaz, and Bodo Billerbeck. 2020. ORCAS: 20 million clicked query-document pairs for analyzing search. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2983–2989.
- Dai and Callan (2019) Zhuyun Dai and Jamie Callan. 2019. Context-aware sentence/passage term importance estimation for first stage retrieval. arXiv preprint arXiv:1910.10687 (2019).
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Gao and Callan (2022) Luyu Gao and Jamie Callan. 2022. Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2843–2853.
- Guo et al. (2022) Jiafeng Guo, Yinqiong Cai, Yixing Fan, Fei Sun, Ruqing Zhang, and Xueqi Cheng. 2022. Semantic models for the first-stage retrieval: A comprehensive review. ACM Transactions on Information Systems (TOIS) 40, 4 (2022), 1–42.
- Guo et al. (2020) Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. In Proceedings of the 37th International Conference on Machine Learning (ICML). 3887–3896.
- Hu et al. (2014) Baotian Hu, Zhengdong Lu, Hang Li, and Qingcai Chen. 2014. Convolutional neural network architectures for matching natural language sentences. Advances in neural information processing systems 27 (2014).
- Huang et al. (2013) Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2333–2338.
- Jayaram Subramanya et al. (2019) Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node. Advances in Neural Information Processing Systems 32 (2019).
- Jegou et al. (2010) Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence 33, 1 (2010), 117–128.
- Jégou et al. (2011) Hervé Jégou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. 2011. Searching in one billion vectors: re-rank with source coding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 861–864.
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data (2019).
- Kalantidis and Avrithis (2014) Yannis Kalantidis and Yannis Avrithis. 2014. Locally optimized product quantization for approximate nearest neighbor search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2321–2328.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906 (2020).
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7 (2019), 453–466.
- Lassance and Clinchant (2023) Carlos Lassance and Stéphane Clinchant. 2023. Naver Labs Europe (SPLADE)@ TREC Deep Learning 2022. arXiv preprint arXiv:2302.12574 (2023).
- Lewis et al. (2021) Patrick Lewis, Pontus Stenetorp, and Sebastian Riedel. 2021. Question and Answer Test-Train Overlap in Open-Domain Question Answering Datasets. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 1000–1008.
- Lu et al. (2020) Wenhao Lu, Jian Jiao, and Ruofei Zhang. 2020. Twinbert: Distilling knowledge to twin-structured compressed BERT models for large-scale retrieval. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2645–2652.
- microsoft (0a) microsoft. 0a. Bing search. https://www.bing.com/.
- microsoft (0b) microsoft. 0b. New Bing. https://www.bing.com/new.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. 2021. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332 (2021).
- Nguyen et al. (2016) Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A human generated machine reading comprehension dataset. In CoCo@ NIPS.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Overwijk et al. (2022) Arnold Overwijk, Chenyan Xiong, and Jamie Callan. 2022. ClueWeb22: 10 billion web documents with rich information. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3360–3362.
- Palangi et al. (2016) Hamid Palangi, Li Deng, Yelong Shen, Jianfeng Gao, Xiaodong He, Jianshu Chen, Xinying Song, and Rabab Ward. 2016. Deep sentence embedding using long short-term memory networks: Analysis and application to information retrieval. IEEE/ACM Transactions on Audio, Speech, and Language Processing 24, 4 (2016), 694–707.
- Qiao et al. (2019) Yifan Qiao, Chenyan Xiong, Zhenghao Liu, and Zhiyuan Liu. 2019. Understanding the Behaviors of BERT in Ranking. arXiv preprint arXiv:1904.07531 (2019).
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019).
- Ren et al. (2020) Jie Ren, Minjia Zhang, and Dong Li. 2020. HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory. In In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vol. 33.
- Robertson and Walker (1994) Stephen E Robertson and Steve Walker. 1994. Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval. In SIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University. Springer, 232–241.
- Sasaki et al. (2018) Shota Sasaki, Shuo Sun, Shigehiko Schamoni, Kevin Duh, and Kentaro Inui. 2018. Cross-lingual learning-to-rank with shared representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 458–463.
- Seo et al. (2019) Minjoon Seo, Jinhyuk Lee, Tom Kwiatkowski, Ankur Parikh, Ali Farhadi, and Hannaneh Hajishirzi. 2019. Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 4430–4441.
- Shan et al. (2021) Xuan Shan, Chuanjie Liu, Yiqian Xia, Qi Chen, Yusi Zhang, Kaize Ding, Yaobo Liang, Angen Luo, and Yuxiang Luo. 2021. GLOW: Global Weighted Self-Attention Network for Web Search. In 2021 IEEE International Conference on Big Data (Big Data). IEEE, 519–528.
- Shen et al. (2014) Yelong Shen, Xiaodong He, Jianfeng Gao, Li Deng, and Grégoire Mesnil. 2014. Learning semantic representations using convolutional neural networks for web search. In Proceedings of the 23rd international conference on world wide web. 373–374.
- Soboroff (2021) Ian Soboroff. 2021. Overview of TREC 2021. In 30th Text REtrieval Conference. Gaithersburg, Maryland.
- Subramanya et al. (2019) Suhas Jayaram Subramanya, Rohan Kadekodi, Ravishankar Krishaswamy, and Harsha Vardhan Simhadri. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node. In Proceedings of the 33rd International Conference on Neural Information Processing Systems. 13766–13776.
- Tay et al. (2022) Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. 2022. Transformer memory as a differentiable search index. Advances in Neural Information Processing Systems 35 (2022), 21831–21843.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
- Wang et al. (2022) Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al. 2022. A neural corpus indexer for document retrieval. Advances in Neural Information Processing Systems 35 (2022), 25600–25614.
- Xiao et al. (2022) Shitao Xiao, Zheng Liu, Weihao Han, Jianjin Zhang, Defu Lian, Yeyun Gong, Qi Chen, Fan Yang, Hao Sun, Yingxia Shao, et al. 2022. Distill-vq: Learning retrieval oriented vector quantization by distilling knowledge from dense embeddings. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1513–1523.
- Xiao et al. (2023) Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighof. 2023. C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597 (2023).
- Xiong et al. (2020) Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. 2020. Approximate nearest neighbor negative contrastive learning for dense text retrieval. arXiv preprint arXiv:2007.00808 (2020).
- Xu et al. (2021) Linlong Xu, Baosong Yang, Xiaoyu Lv, Tianchi Bi, Dayiheng Liu, and Haibo Zhang. 2021. Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval. arXiv preprint arXiv:2111.01992 (2021).
- Zhan et al. (2022) Jingtao Zhan, Xiaohui Xie, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma. 2022. Evaluating Interpolation and Extrapolation Performance of Neural Retrieval Models. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2486–2496.
- Zhou et al. (2022) Kun Zhou, Yeyun Gong, Xiao Liu, Wayne Xin Zhao, Yelong Shen, Anlei Dong, Jingwen Lu, Rangan Majumder, Ji-Rong Wen, and Nan Duan. 2022. SimANS: Simple Ambiguous Negatives Sampling for Dense Text Retrieval. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track. 548–559.
- Zhuang et al. (2021) Shengyao Zhuang, Hang Li, and G. Zuccon. 2021. Deep Query Likelihood Model for Information Retrieval. In ECIR.