SimPO: Simple Preference Optimization
with a Reference-Free Reward
Abstract
Direct Preference Optimization (DPO) is a widely used offline preference optimization algorithm that reparameterizes reward functions in reinforcement learning from human feedback (RLHF) to enhance simplicity and training stability. In this work, we propose SimPO, a simpler yet more effective approach. The effectiveness of SimPO is attributed to a key design: using the average log probability of a sequence as the implicit reward. This reward formulation better aligns with model generation and eliminates the need for a reference model, making it more compute and memory efficient. Additionally, we introduce a target reward margin to the Bradley-Terry objective to encourage a larger margin between the winning and losing responses, further enhancing the algorithm’s performance. We compare SimPO to DPO and its latest variants across various state-of-the-art training setups, including both base and instruction-tuned models like Mistral and Llama3. We evaluated on extensive instruction-following benchmarks, including AlpacaEval 2, MT-Bench, and the recent challenging Arena-Hard benchmark. Our results demonstrate that SimPO consistently and significantly outperforms existing approaches without substantially increasing response length. Specifically, SimPO outperforms DPO by up to 6.4 points on AlpacaEval 2 and by up to 7.5 points on Arena-Hard. Our top-performing model, built on Llama3-8B-Instruct, achieves a remarkable 44.7 length-controlled win rate on AlpacaEval 2—surpassing Claude 3 Opus on the leaderboard, and a 33.8 win rate on Arena-Hard—making it the strongest 8B open-source model.000Code and models can be found at https://github.com/princeton-nlp/SimPO.
1 Introduction
Learning from human feedback is crucial in aligning large language models (LLMs) with human values and intentions [47], ensuring they are helpful, honest, and harmless [5]. Reinforcement learning from human feedback (RLHF) [15, 58, 69] is a popular method for fine-tuning language models to achieve effective alignment. While the classical RLHF approach [58, 66] has shown impressive results, it presents optimization challenges due to its multi-stage procedure, which involves training a reward model and then optimizing a policy model to maximize that reward [12].
Recently, researchers have been exploring simpler offline algorithms. Direct Preference Optimization (DPO) [62] is one such approach. DPO reparameterizes the reward function in RLHF to directly learn a policy model from preference data, eliminating the need for an explicit reward model.It has gained widespread practical adoption due to its simplicity and stability. In DPO, the implicit reward is formulated using the log ratio of the likelihood of a response between the current policy model and the supervised fine-tuned (SFT) model. However, this reward formulation is not directly aligned with the metric used to guide generation, which is approximately the average log likelihood of a response generated by the policy model. We hypothesize that this discrepancy between training and inference may lead to suboptimal performance.

| Model | LC (%) | WR (%) | Len. |
| GPT-4 Turbo (04/09) | 55.0 | 46.1 | 1802 |
| GPT-4 Turbo (11/06) | 50.0 | 50.0 | 2049 |
| Llama3-Instruct-8B-SimPO | 44.7 | 40.5 | 1825 |
| Claude 3 Opus | 40.5 | 29.1 | 1388 |
| Llama3-Instruct-8B-DPO | 40.3 | 37.9 | 1837 |
| Llama3-Instruct-70B | 34.4 | 33.2 | 1919 |
| Llama3-Instruct-8B | 26.0 | 25.3 | 1899 |
| GPT-3.5 Turbo (06/13) | 22.7 | 14.1 | 1328 |
In this work, we propose SimPO, a simple yet effective offline preference optimization algorithm (Figure 1). The core of our algorithm aligns the reward function in the preference optimization objective with the generation metric. SimPO consists of two major components: (1) a length-normalized reward, calculated as the average log probability of all tokens in a response using the policy model, and (2) a target reward margin to ensure the reward difference between winning and losing responses exceeds this margin. In summary, SimPO has the following properties:
-
•
Simplicity: SimPO does not require a reference model making it more lightweight and easier to implement compared to DPO, and other reference-dependent approaches.
-
•
Significant performance advantage: Despite its simplicity, SimPO significantly outperforms DPO and its latest variants (e.g., a recent reference-free objective ORPO [38]). The performance advantage is consistnt across various training setups and extensive instruction-following benchmarks, including AlpacaEval 2 [51, 24] and the challenging Arena-Hard [50] benchmark. It achieves up to a 6.4 point improvement on AlpacaEval 2 and a 7.5 point improvement on Arena-Hard.
-
•
Minimal length exploitation: SimPO does not significantly increase response length compared to the SFT or DPO models (Table 1), indicating minimal length exploitation [24, 67, 78].
Extensive analysis shows that SimPO utilizes preference data more effectively, leading to a more accurate likelihhod ranking of winning and losing responses on a held-out validation set, which in turn translates to a better policy model. As shown in Table 1, we produce a top-performing model, built on top of Llama3-8B-instruct, that achieves a notable 44.7 length-controlled win rate on AlpacaEval 2, outperforming Claude 3 Opus on the leaderboard, and a 33.8 win rate on Arena-Hard, making it the strongest 8B open-source model to date.
2 SimPO: Simple Preference Optimization
In this section, we first introduce the background of DPO (§2.1). Then we identify the discrepancy between DPO’s reward and the likelihood metric used for generation, and propose an alternative reference-free reward formulation that mitigates this issue (§2.2). Finally, we derive the SimPO objective by incorporating a target reward margin term into the Bradley-Terry model (§2.3).
2.1 Background: Direct Preference Optimization (DPO)
DPO [62] is one of the most popular offline preference optimization methods. Instead of learning an explicit reward model [58], DPO reparameterizes the reward function using a closed-form expression with the optimal policy:
| (1) |
where is the policy model, is the reference policy, typically the supervised fine-tuned (SFT) model, and is the partition function. By incorporating this reward formulation into the Bradley-Terry (BT) ranking objective [10], , DPO expresses the probability of preference data with the policy model rather than the reward model, yielding the following objective:
| (2) |
where are preference pairs consisting of the prompt, the winning response, and the losing response from the preference dataset .
2.2 A Simple Reference-Free Reward Aligned with Generation
Discrepancy between reward and generation for DPO.
Using Eq. (1) as the implicit reward expression have the following drawbacks: (1) the requirement of a reference model during training incurs additional memory and computational costs, and (2) there is a discrepancy between the reward being optimized during training and the generation metric used for inference. Specifically, during generation, the policy model is used to generate a sequence that approximately maximizes the average log likelihood, defined as follows:
| (3) |
Direct maximization of this metric during decoding is intractable, and various decoding strategies can be used to approximate it, such as greedy decoding [30], beam search [31, 49], nucleus sampling [35], and top- sampling [26, 36, 61]. Additionally, this metric is commonly used for ranking options in multiple-choice tasks within language models [11, 37, 58]. In DPO, for any triple , satisfying the reward ranking does not necessarily mean that the likelihood ranking is met. In fact, only roughly of the triples from a held-out set satisfy this condition when trained with DPO (see Figure 4(b)).
Length-normalized reward formulation.
Naturally, we consider replacing the reward formulation in DPO with in Eq. (3), so that it aligns with the likehood metric that guides generation. This results in a length-normalized reward:
| (4) |
where is a constant that controls the scaling of the reward difference. We find that normalizing the reward with response lengths is crucial; removing the length normalization term from the reward formulation results in a bias toward generating longer but lower-quality sequences (see Section 4.4 for more details). Consequently, this reward formulation eliminates the need for a reference model, enhancing memory and computational efficiency compared to reference-dependent algorithms.
2.3 The SimPO Objective
Target reward margin.
Additionally, we introduce a target reward margin term, , to the Bradley-Terry objective to ensure that the reward for the winning response, , exceeds the reward for the losing response, , by at least :
| (5) |
The margin between two classes is known to influence the generalization capabilities of classifiers [1, 9, 19, 27].111This margin is termed home advantage in Bradley-Terry models [1, 27]. In standard training settings with random model initialization, increasing the target margin typically improves generalization. In preference optimization, the two classes are the winning and losing responses for a single input. In practice, we observe that generation quality initially improves with an increasing target margin but degrades when the margin becomes too large (§4.3). One of DPO’s variants, IPO [6], also formulates a target reward margin similar to SimPO. However, its full objective is not as effective as SimPO (§4.1).
Objective.
In summary, SimPO employs an implicit reward formulation that directly aligns with the generation metric, eliminating the need for a reference model. Additionally, it introduces a target reward margin to help separating the winning and losing responses. In Appendix E, we provide a gradient analysis of SimPO and DPO to further understand the differences between the two methods.
3 Experimental Setup
Models and training settings.
We perform preference optimization with two families of models, Llama3-8B [2] and Mistral-7B [40] under two setups: Base and Instruct.
For the Base setup, we follow the training pipeline of Zephyr [75]. First, we train a base model (i.e., mistralai/Mistral-7B-v0.1, or meta-llama/Meta-Llama-3-8B) on the UltraChat-200k dataset [22] to obtain an SFT model. Then, we perform preference optimization on the UltraFeedback dataset [20] using the SFT model as the starting point. This setup provides a high level of transparency, as the SFT models are trained on open-source data.
For the Instruct setup, we use off-the-shelf instruction-tuned model (i.e., meta-llama/Meta-Llama-3-8B-Instruct, or mistralai/Mistral-7B-Instruct-v0.2) as the SFT models. These models have undergone extensive instruction-tuning processes, making them more powerful and robust than the SFT models in the Base setup. However, they are also more opaque because their RLHF procedure is not publicly disclosed. To mitigate the distribution shift between SFT models and the preference optimization process, we generate the preference dataset using the SFT models following [74]. Specifically, we use prompts from the UltraFeedback dataset and regenerate the chosen and rejected response pairs with the SFT models. For each prompt , we generate 5 responses using the SFT model with a sampling temperature of 0.8. We then use PairRM [41] to score the 5 responses, selecting the highest-scoring one as and the lowest-scoring one as . For simplicity, we generate data in a single pass instead of iteratively as in [74].
In summary, we have four setups: Llama3-Base, Llama3-Instruct, Mistral-Base, and Mistral-Instruct. We believe these configurations represent the state-of-the-art, placing our models among the top performers on various leaderboards. We encourage future research to adopt these settings for better and fairer comparisons of different algorithms.
Additionally, we find that tuning hyperparameters is crucial for achieving optimal performance with all the offline preference optimization algorithms, including SimPO. Generally, for SimPO, setting between 2.0 and 2.5 and between 0.5 and 1.5 leads to good performance across all setups. For more details, please refer to Appendix A.
Evaluation benchmarks.
We primarily assess our models using three of the most popular open-ended instruction-following benchmarks: MT-Bench [88], AlpacaEval 2 [51],222https://tatsu-lab.github.io/alpaca_eval/ and Arena-Hard v0.1 [50]. These benchmarks evaluate the models’ versatile conversational abilities across a diverse set of queries and have been widely adopted by the community (details in Table 2).
AlpacaEval 2 consists of 805 questions from 5 datasets, and MT-Bench covers 8 categories with 80 questions. The most recently released Arena-Hard is an enhanced version of an MT-Bench, incorporating 500 well-defined technical problem-solving queries. We report scores following each benchmark’s evaluation protocol. For AlpacaEval 2, we report both the raw win rate (WR) and the length-controlled win rate (LC) [24]. The LC metric is specifically designed to be robust against model verbosity. For Arena-Hard, we report the win rate (WR) against the baseline model. For MT-Bench, we report the average MT-Bench score with GPT-4 and GPT-4-Preview-1106 as the judge model.333GPT-4-Preview-1106 produces more accurate reference answers and judgments compared to GPT-4. For decoding details, please refer to Appendix A. We also evaluate on downstream tasks from the Huggingface Open Leaderboard benchmarks [8], with additional details in in Appendix B.
| # Exs. | Baseline Model | Judge Model | Scoring Type | Metric | |
| AlpacaEval 2 | 805 | GPT-4 Turbo | GPT-4 Turbo | Pairwise comparison | LC & raw win rate |
| Arena-Hard | 500 | GPT-4-0314 | GPT-4 Turbo | Pairwise comparison | Win rate |
| MT-Bench | 80 | - | GPT-4/GPT-4 Turbo | Single-answer grading | Rating of 1-10 |
| Method | Objective |
| DPO [62] | |
| IPO [6] | |
| KTO [25] | |
| ORPO [38] | |
| R-DPO [60] | |
| SimPO |
Baselines.
We compare SimPO with other offline preference optimization methods listed in Table 3.444Many recent studies [82, 70] have extensively compared DPO and PPO [66]. We will leave the comparison of PPO and SimPO to future work. IPO [6] is a theoretically grounded approach method that avoids DPO’s assumption that pairwise preferences can be replaced with pointwise rewards. KTO [25] learns from non-paired preference data. ORPO [38] introduces a reference-model-free odd ratio term to directly contrast winning and losing responses with the policy model and jointly trains with the SFT objective. R-DPO [60] is a modified version of DPO that includes an additional regularization term to prevent exploitation of length. We thoroughly tune the hyperparameters for each baseline and report best performance. We find that many variants of DPO do not empirically present an advantage over standard DPO. Further details can be found in Appendix A.
4 Experimental Results
In this section, we present main results of our experiments, highlighting the superior performance of SimPO on various benchmarks and ablation studies (§4.1). We provide an in-depth understanding of the following components: (1) length normalization (§4.2), (2) the margin term (§4.3), and (3) why SimPO outperforms DPO (§4.4). Unless otherwise specified, the ablation studies are conducted using the Mistral-Base setting.
4.1 Main Results and Ablations
| Method | Mistral-Base (7B) | Mistral-Instruct (7B) | ||||||||
| AlpacaEval 2 | Arena-Hard | MT-Bench | AlpacaEval 2 | Arena-Hard | MT-Bench | |||||
| LC (%) | WR (%) | WR (%) | GPT-4 Turbo | GPT-4 | LC (%) | WR (%) | WR (%) | GPT-4 Turbo | GPT-4 | |
| SFT | 8.4 | 6.2 | 1.3 | 4.8 | 6.3 | 17.1 | 14.7 | 12.6 | 6.2 | 7.5 |
| DPO [62] | 15.1 | 12.5 | 10.4 | 5.9 | 7.3 | 26.8 | 24.9 | 16.3 | 6.3 | 7.6 |
| IPO [6] | 11.8 | 9.4 | 7.5 | 5.5 | 7.2 | 20.3 | 20.3 | 16.2 | 6.4 | 7.8 |
| KTO [25] | 13.1 | 9.1 | 5.6 | 5.4 | 7.0 | 24.5 | 23.6 | 17.9 | 6.4 | 7.7 |
| ORPO [38] | 14.7 | 12.2 | 7.0 | 5.8 | 7.3 | 24.5 | 24.9 | 20.8 | 6.4 | 7.7 |
| R-DPO [60] | 17.4 | 12.8 | 8.0 | 5.9 | 7.4 | 27.3 | 24.5 | 16.1 | 6.2 | 7.5 |
| SimPO | 21.5 | 20.8 | 16.6 | 6.0 | 7.3 | 32.1 | 34.8 | 21.0 | 6.6 | 7.6 |
| Method | Llama3-Base (8B) | Llama3-Instruct (8B) | ||||||||
| AlpacaEval 2 | Arena-Hard | MT-Bench | AlpacaEval 2 | Arena-Hard | MT-Bench | |||||
| LC (%) | WR (%) | WR (%) | GPT-4 Turbo | GPT-4 | LC (%) | WR (%) | WR (%) | GPT-4 Turbo | GPT-4 | |
| SFT | 6.2 | 4.6 | 3.3 | 5.2 | 6.6 | 26.0 | 25.3 | 22.3 | 6.9 | 8.1 |
| DPO [62] | 18.2 | 15.5 | 15.9 | 6.5 | 7.7 | 40.3 | 37.9 | 32.6 | 7.0 | 8.0 |
| IPO [6] | 14.4 | 14.2 | 17.8 | 6.5 | 7.4 | 35.6 | 35.6 | 30.5 | 7.0 | 8.3 |
| KTO [25] | 14.2 | 12.4 | 12.5 | 6.3 | 7.8 | 33.1 | 31.8 | 26.4 | 6.9 | 8.2 |
| ORPO [38] | 12.2 | 10.6 | 10.8 | 6.1 | 7.6 | 28.5 | 27.4 | 25.8 | 6.8 | 8.0 |
| R-DPO [60] | 17.6 | 14.4 | 17.2 | 6.6 | 7.5 | 41.1 | 37.8 | 33.1 | 7.0 | 8.0 |
| SimPO | 22.0 | 20.3 | 23.4 | 6.6 | 7.7 | 44.7 | 40.5 | 33.8 | 7.0 | 8.0 |
| Method | Mistral-Base (7B) Setting | Mistral-Instruct (7B) Setting | ||||||||
| AlpacaEval 2 | Arena-Hard | MT-Bench | AlpacaEval 2 | Arena-Hard | MT-Bench | |||||
| LC (%) | WR (%) | WR (%) | GPT-4 Turbo | GPT-4 | LC (%) | WR (%) | WR (%) | GPT-4 Turbo | GPT-4 | |
| DPO | 15.1 | 12.5 | 10.4 | 5.9 | 7.3 | 26.8 | 24.9 | 16.3 | 6.3 | 7.6 |
| SimPO | 21.5 | 20.8 | 16.6 | 6.0 | 7.3 | 32.1 | 34.8 | 21.0 | 6.6 | 7.6 |
| w/o LN | 11.9 | 13.2 | 9.4 | 5.5 | 7.3 | 19.1 | 19.7 | 16.3 | 6.4 | 7.6 |
| 16.8 | 14.3 | 11.7 | 5.6 | 6.9 | 30.9 | 34.2 | 20.5 | 6.6 | 7.7 | |
SimPO consistently and significantly outperforms existing preference optimization methods.
As shown in Table 4, while all preference optimization algorithms enhance performance over the SFT model, SimPO, despite its simplicity, achieves the best overall performance across all benchmarks and settings. Notably, SimPO outperforms the best baseline by 3.6 to 4.8 points on the AlpacaEval 2 LC win rate and by 0.2 to 6.2 points on Arena-Hard across various settings. These consistent and significant improvements highlight the robustness and effectiveness of SimPO.
Benchmark quality varies.
Although all three benchmarks are widely adopted, we find that MT-Bench exhibits poor separability across different methods. Minor differences between methods on MT-Bench may be attributed to randomness, likely due to the limited scale of its evaluation data and its single-instance scoring protocol. This finding aligns with observations reported in [50]. In contrast, AlpacaEval 2 and Arena-Hard provide more meaningful distinctions between different methods. Additionally, Arena-Hard employs a different judge model from the baseline model, likely leading to fairer evaluations. We observe that the win rate on Arena-Hard is significantly lower than on AlpacaEval 2, indicating that Arena-Hard is a more challenging benchmark.
The Instruct setting introduces significant performance gains.
Across all benchmarks, we observe that the Instruct setting consistently outperforms the Base setting. This improvement is likely due to the higher quality of SFT models used for initialization and the generation of more high-quality preference data by these models.
Both key designs in SimPO are crucial.
In Table 5, we demonstrate results from ablating each key design of SimPO: (1) removing length normalization in Eq. (4) (i.e., w/o LN); (2) setting the target reward margin to be 0 in Eq. (6) (i.e., ). Removing the length normalization has the most negative impact on the results. Our examination reveals that this leads to the generation of long and repetitive patterns, substantially degrading the overall quality of the output (See Appendix D). Setting to 0 yields also leads to a performance degradation compared to SimPO, indicating that it is not the optimal target reward margin. In the following subsections, we conduct in-depth analyses to better understand both design choices.
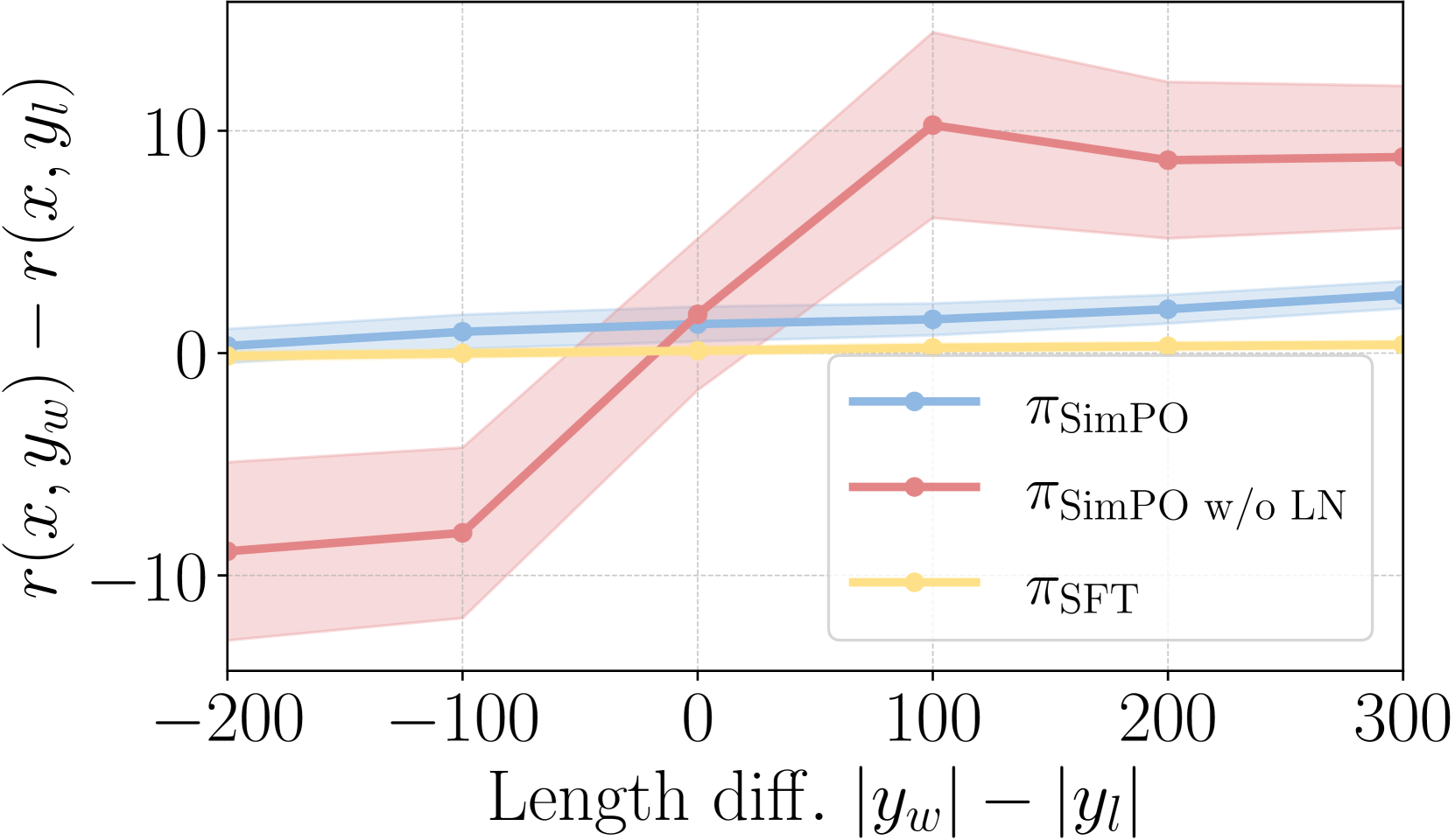
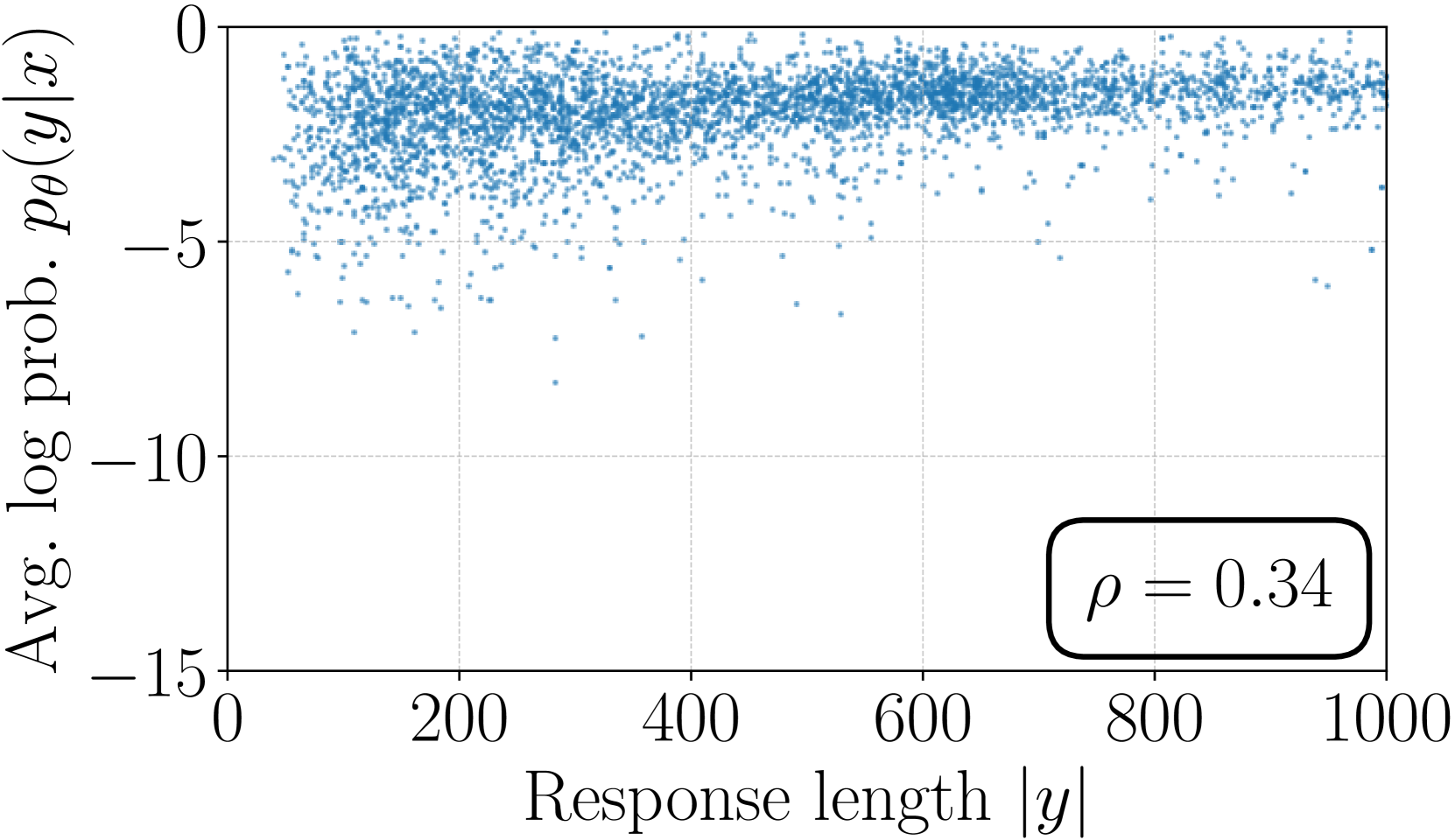
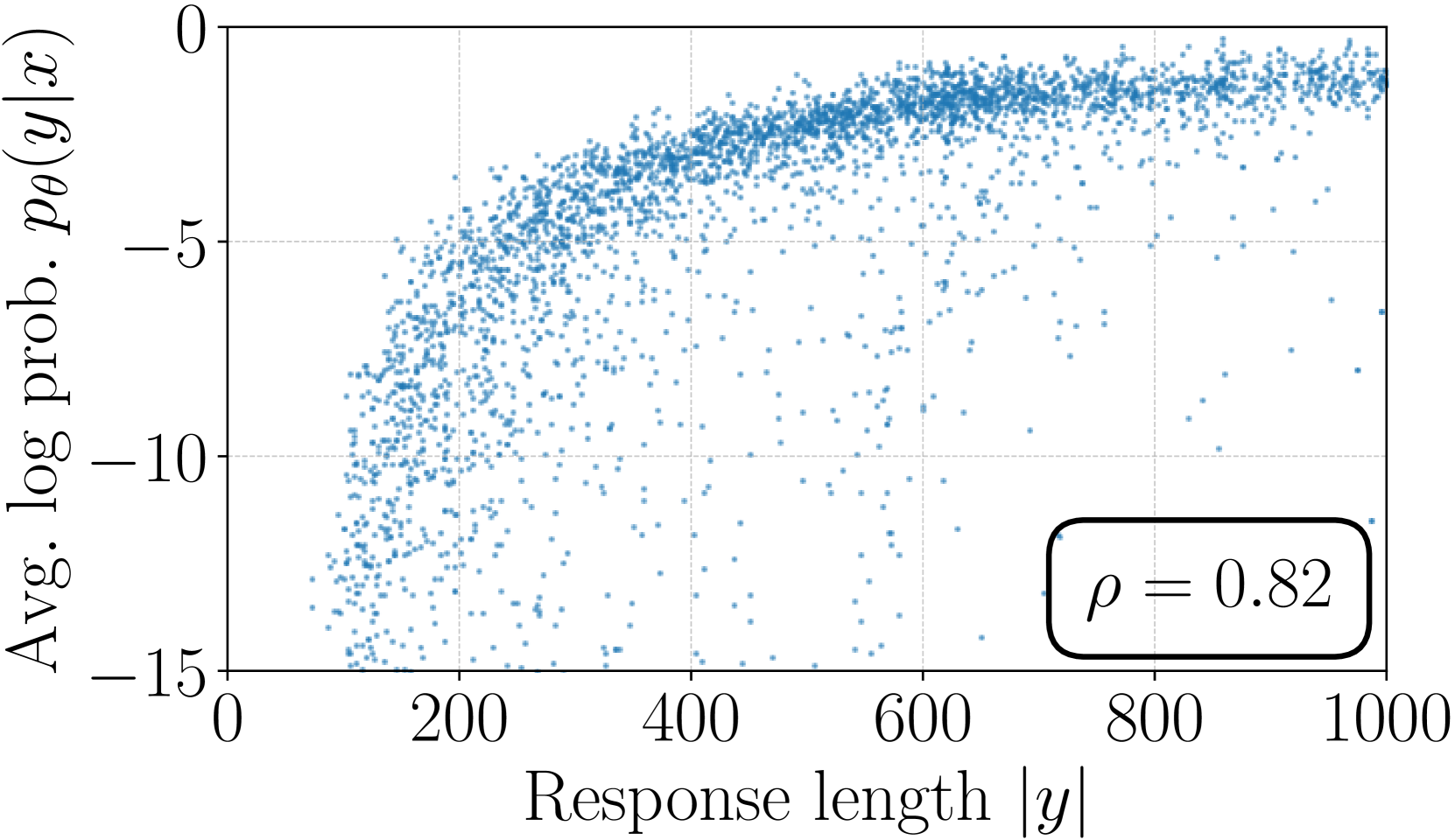
4.2 Length Normalization (LN) Prevents Length Exploitation
LN leads to an increase in the reward difference for all preference pairs, regardless of their length.
The Bradley-Terry objective in Eq. (5) essentially aims to optimize the reward difference to exceed the target margin . We investigate the relationship between the learned reward differences and the length difference between the winning and losing responses from the training set of UltraFeedback. We measure the difference of reward (; Eq. (4)) using the SFT model, the SimPO model, and a model trained with SimPO but without length normalization. We present the results in Figure 2(a) and observe that SimPO with LN consistently achieves a positive reward margin for all response pairs, regardless of their length difference, and consistently improves the margin over the SFT model. In contrast, SimPO without LN results in a negative reward difference for preference pairs when the winning response is shorter than the losing response, indicating that the model learns poorly for these instances.
Removing LN results in a strong positive correlation between the reward and response length, leading to length exploitation.
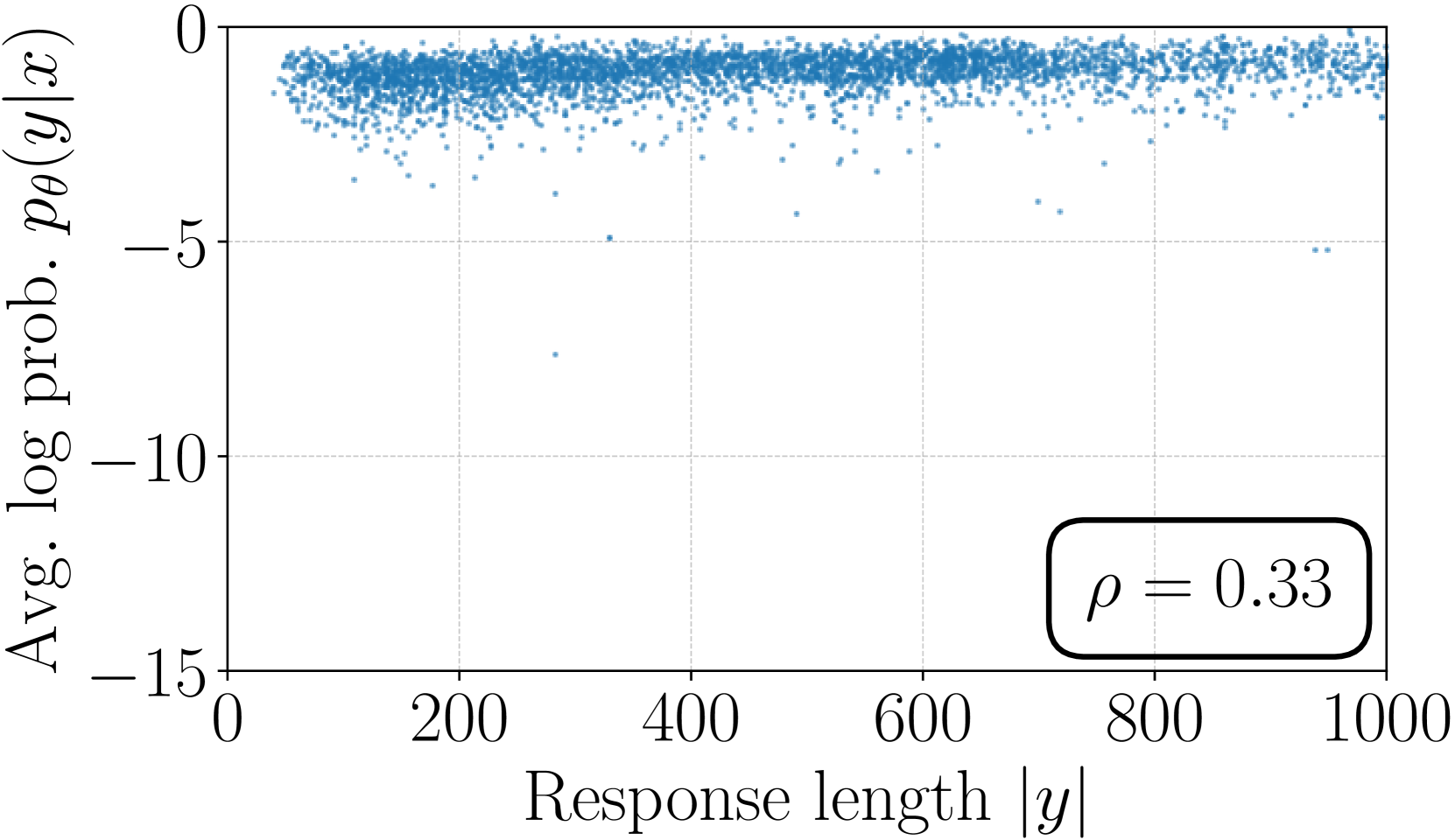
Figures 2(b) and 2(c) illustrate the average log likelihood ( in Eq. (3)) versus response length on a held-out set for models trained with SimPO and SimPO without LN. The model trained without LN exhibits a much stronger positive Spearman correlation between likelihood and response length compared to SimPO, indicating a tendency to exploit length bias and generate longer sequences (see Table 11). In contrast, SimPO results in a Spearman correlation coefficient similar to the SFT model (see Figure 5(a)).
4.3 The Impact of Target Reward Margin in SimPO
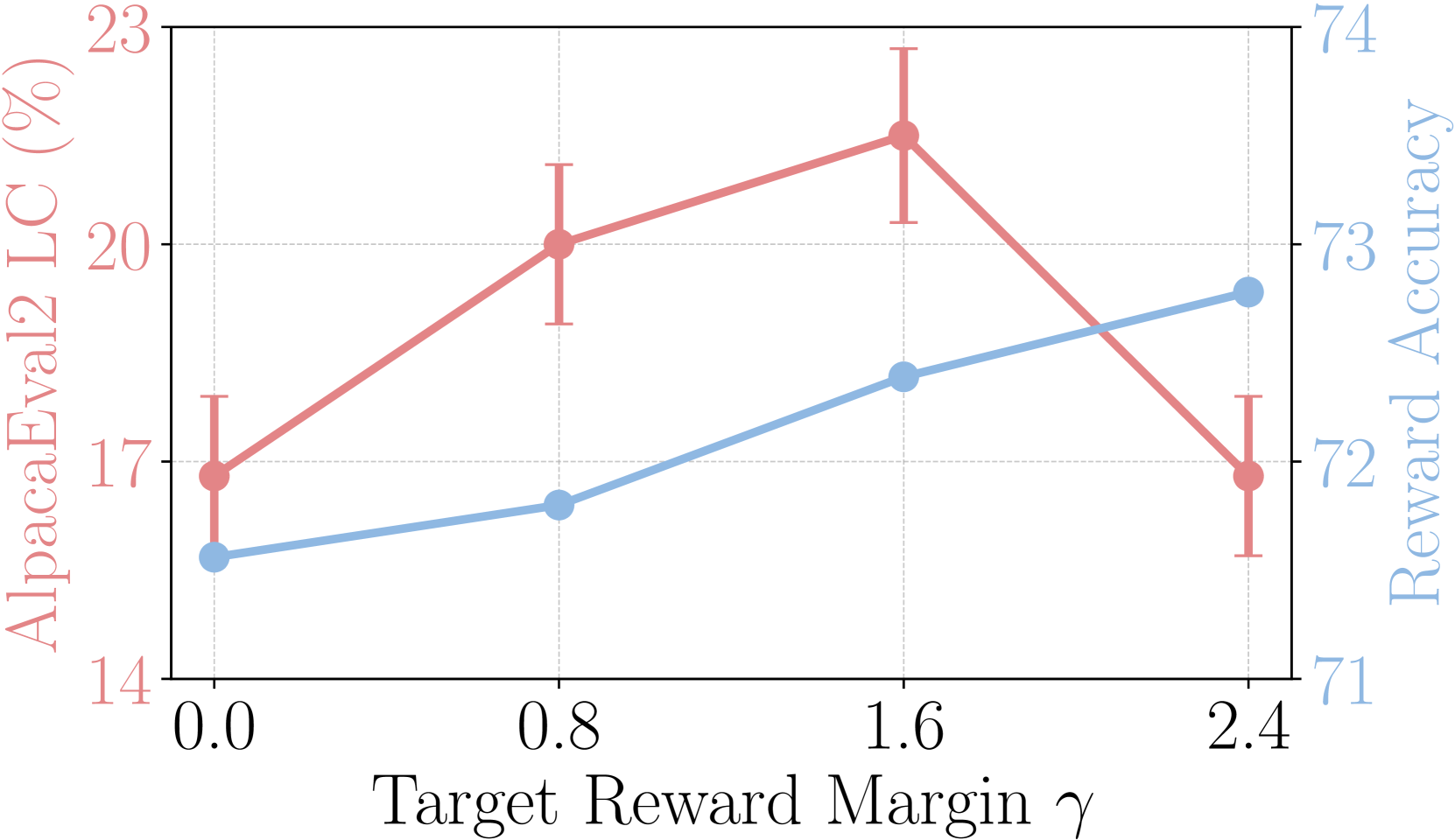
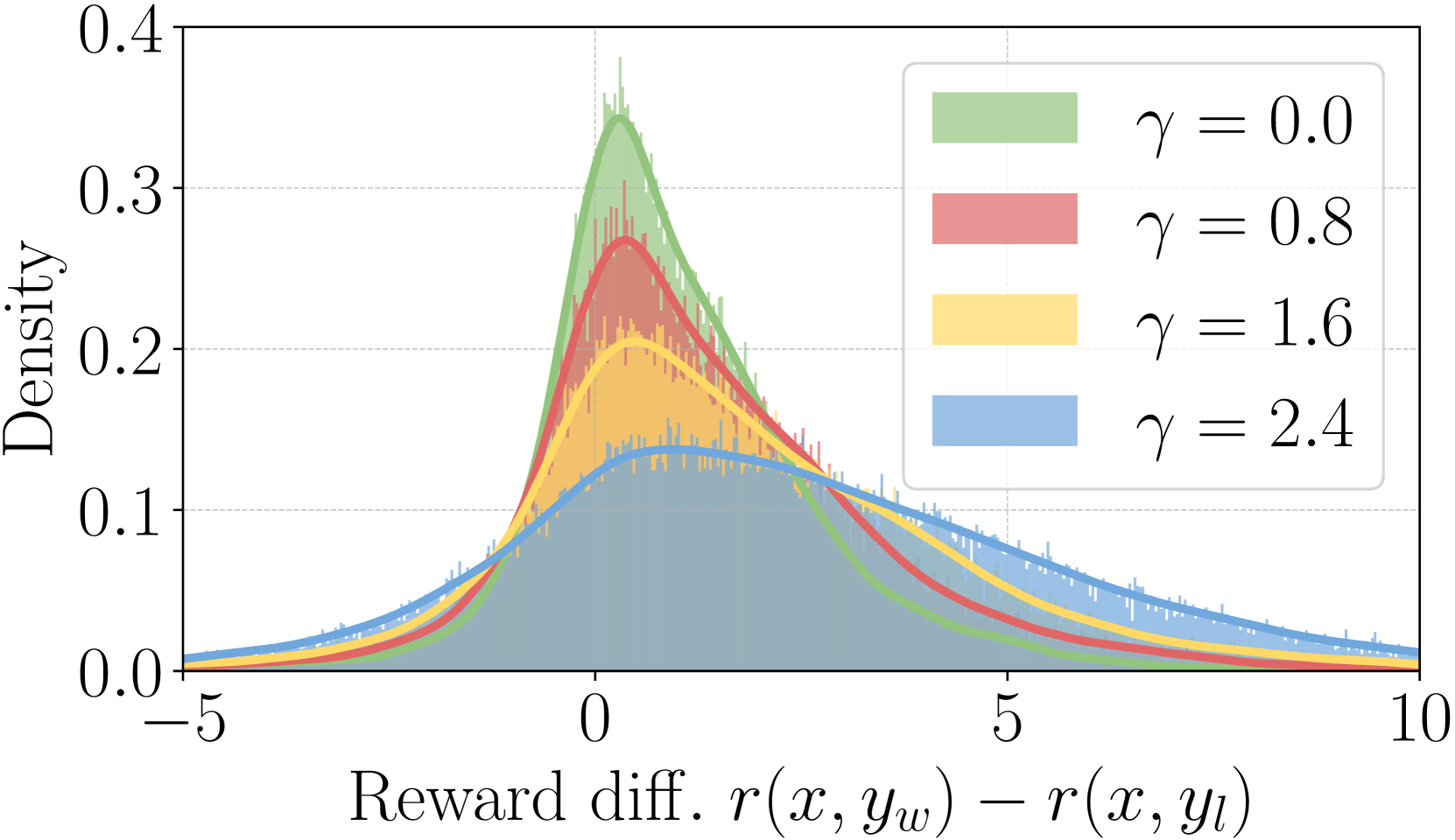
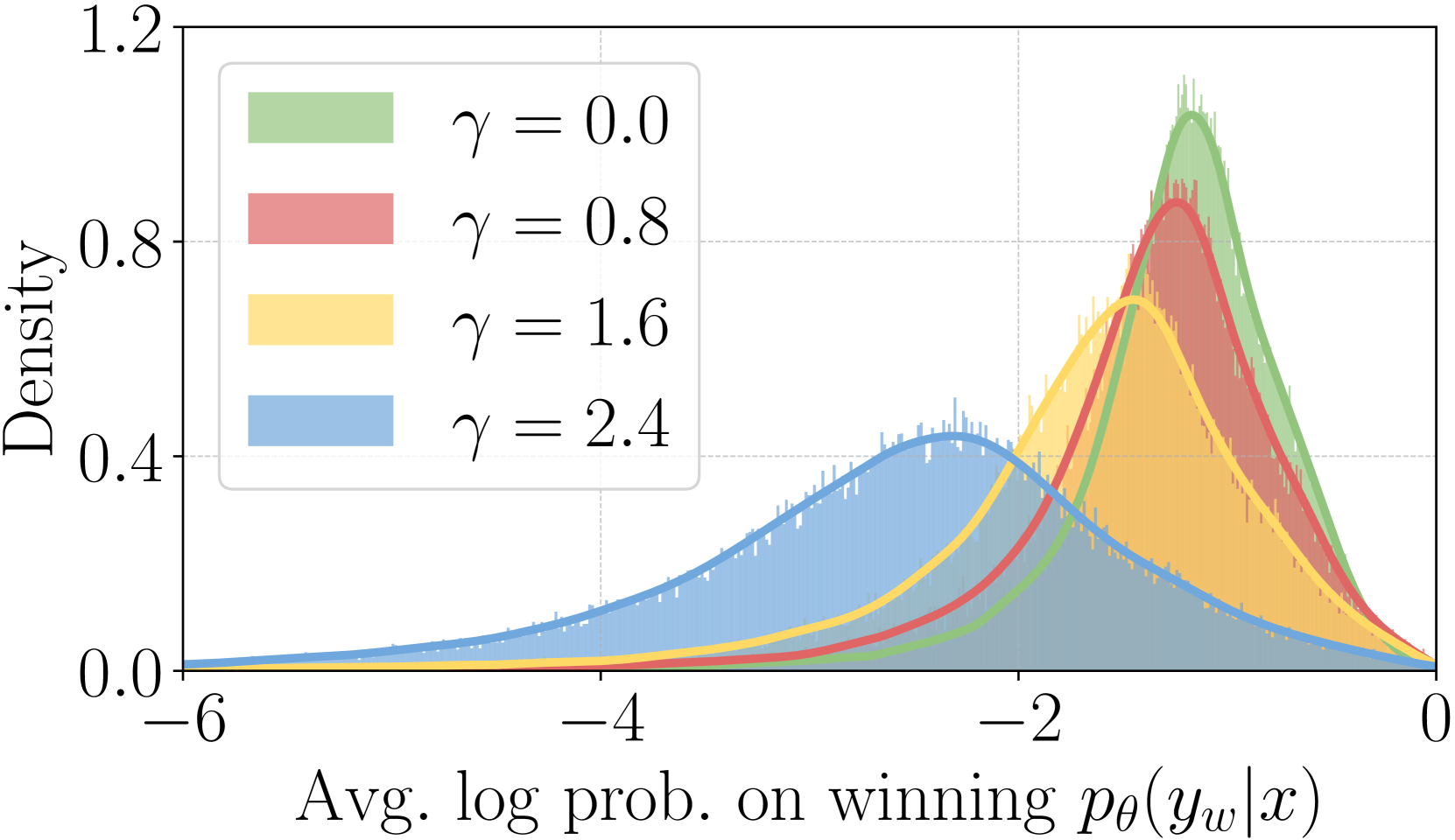
Influence of on reward accuracy and win rate.
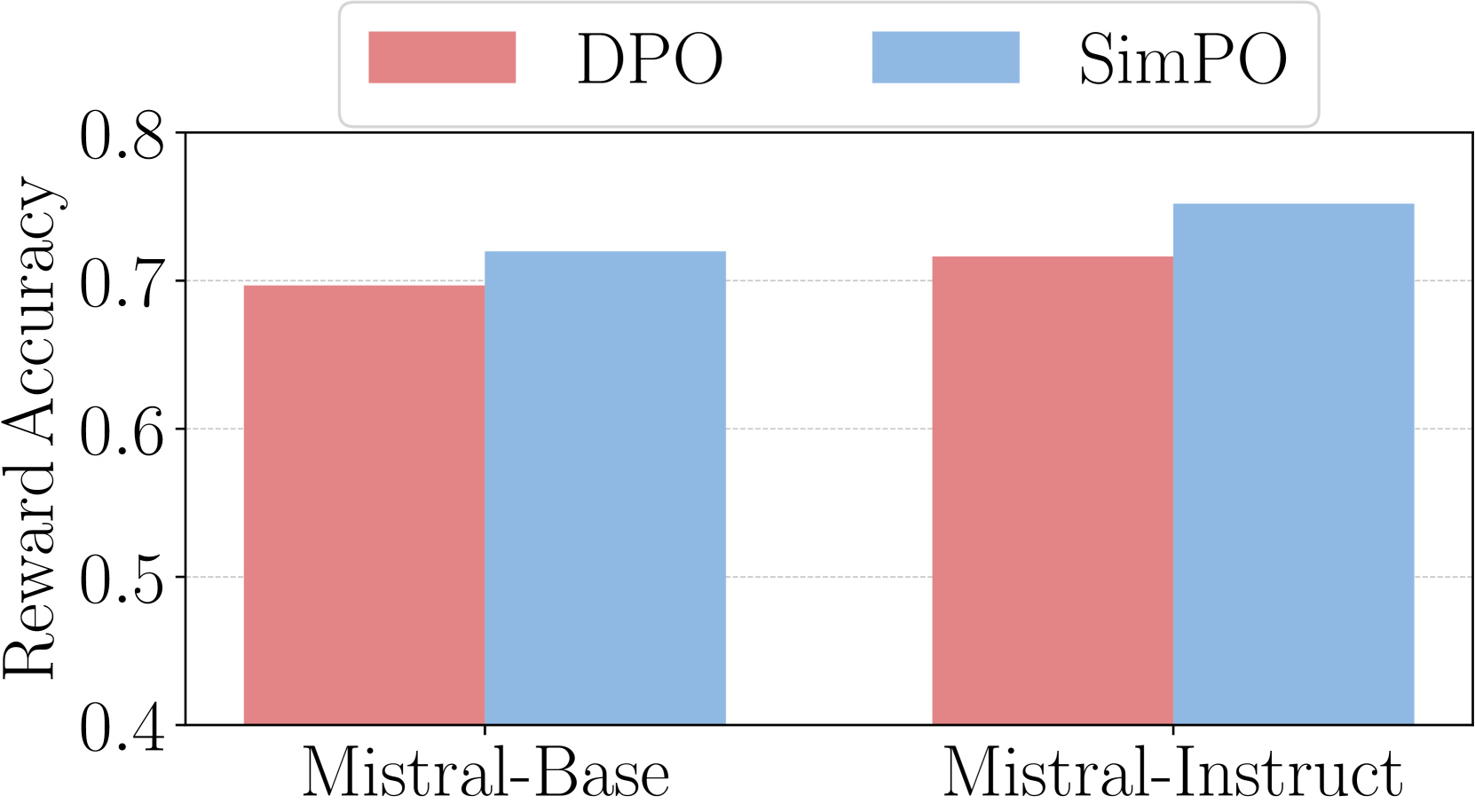
We investigate how the target reward margin in SimPO affects the reward accuracy on a held-out set and win rate on AlpacaEval 2, presenting the results in Figure 3(a). Reward accuracy is measured as the percentage of preference pairs where the winning response ends up having a higher reward for the wining response than the losing response (i.e., ). We observe that reward accuracy increases with on both benchmarks, indicating that enforcing a larger target reward margin effectively improves reward accuracy. However, the win rate on AlpacaEval 2 first increases and then decreases with , suggesting that generation quality is not solely determined by the reward margin.
Impact of on the reward distribution.
We visualize the distribution of the learned reward margin and the reward of winning responses under varying values in Figure 2(b) and Figure 2(c). Notably, increasing tends to flatten both distributions and reduce the average log likelihood of winning sequences. This initially improves performance but can eventually lead to model degeneration. We hypothesize that there is a trade-off between accurately approximating the true reward distribution and maintaining a well-calibrated likelihood when setting the value. Further exploration of this balance is deferred to future work.
4.4 In-Depth Analysis of DPO vs. SimPO
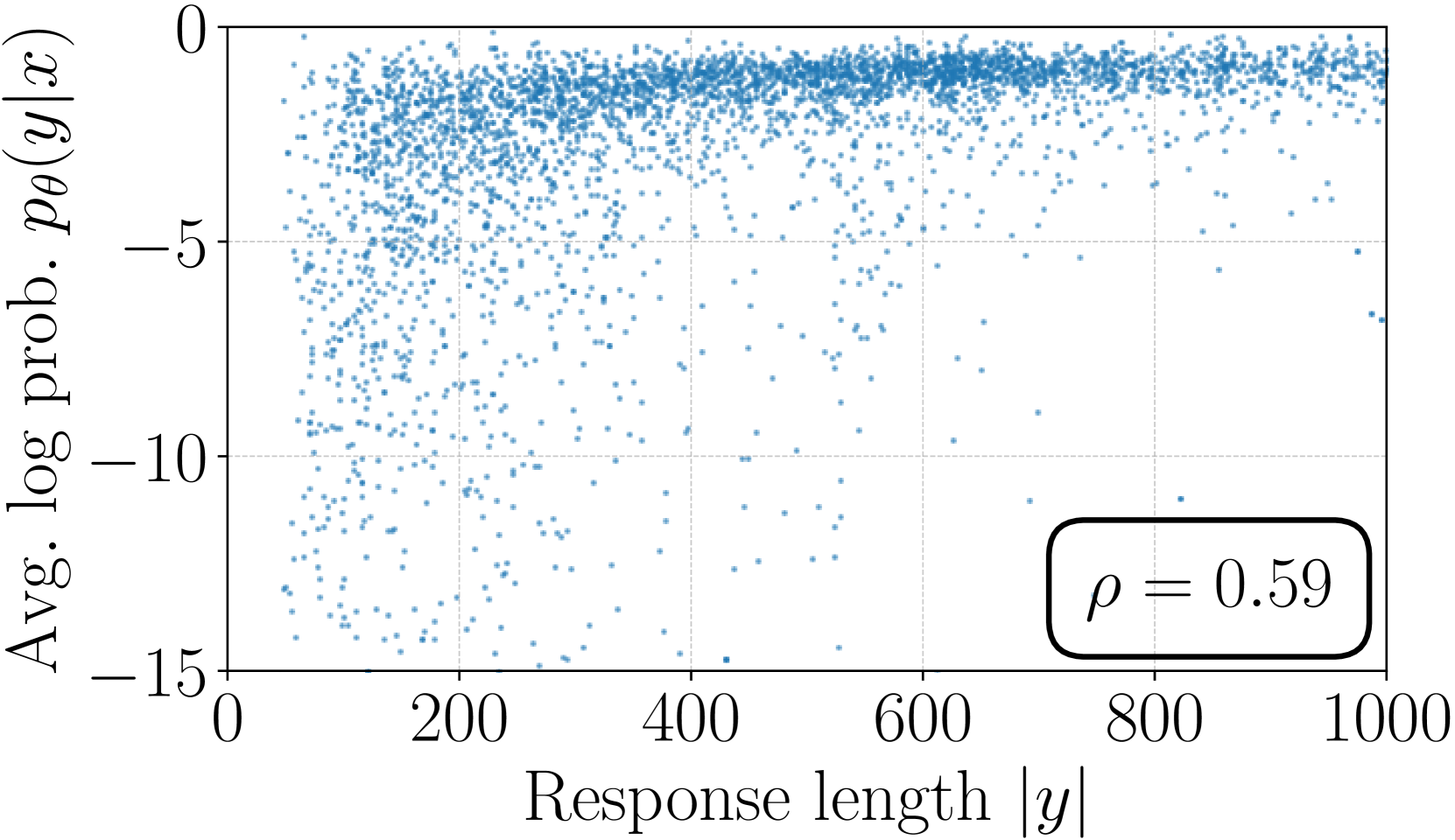
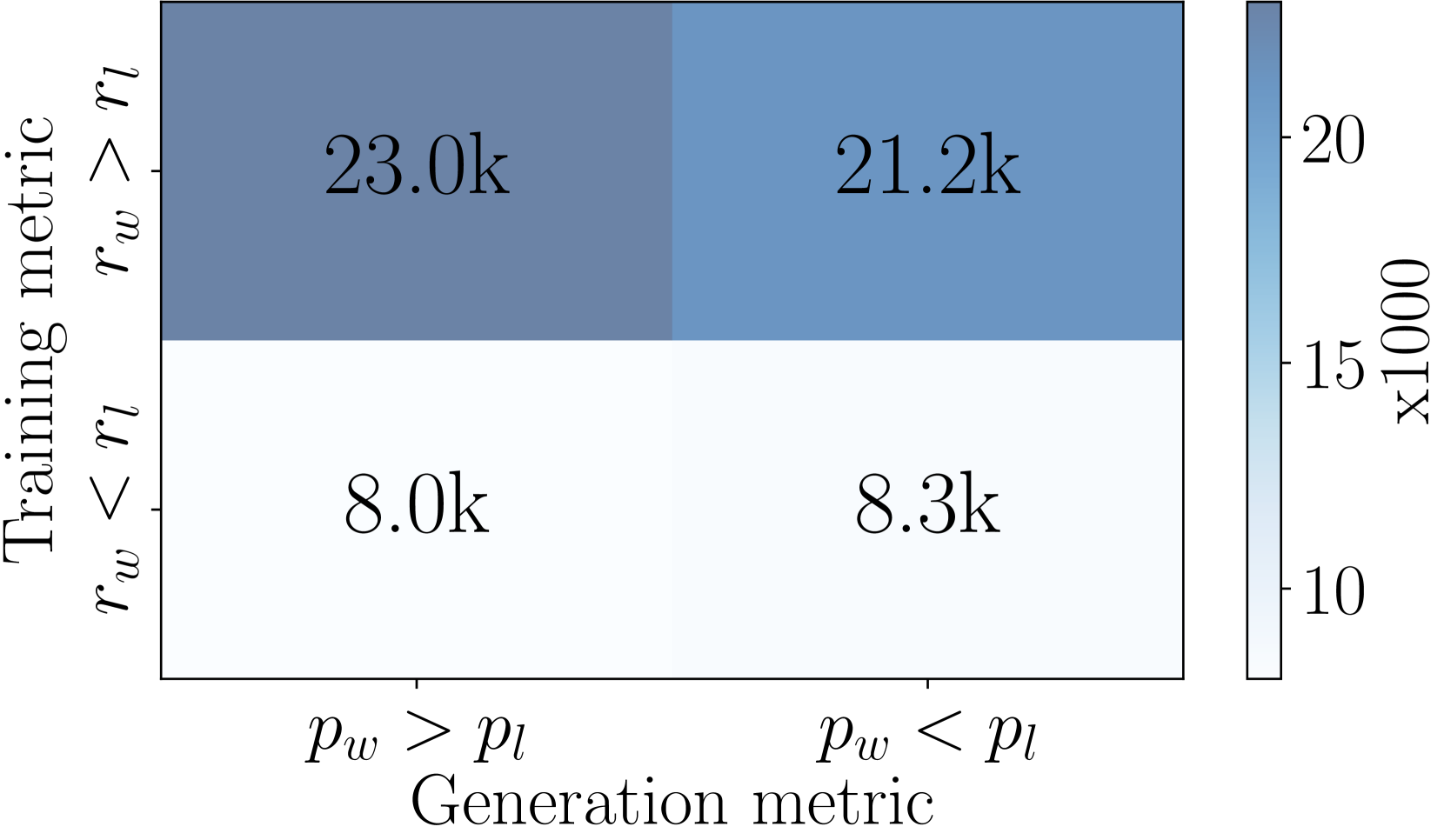
In this section, we compare SimPO to DPO in terms of (1) likelihood-length correlation, (2) reward formulation, (3) reward accuracy, and (4) algorithm efficiency. We demonstrate that SimPO outperforms DPO in terms of reward accuracy and efficiency.
| SimPO w/o LN | DPO | SimPO | |
| 0.82 | 0.59 | 0.34 |
DPO reward implicitly facilitates length normalization.
Although the DPO reward expression (with the partition function excluded), lacks an explicit term for length normalization, the logarithmic ratio between the policy model and the reference model can serve to implicitly counteract length bias. As shown in Table 6 and Figure 4(a), employing DPO reduces the Spearman correlation coefficient between average log likelihood and response length compared to the approach without any length normalization (referred to as “SimPO w/o LN”). However, it still exhibits a stronger positive correlation when compared to SimPO.555Note that this correlation does not fully reflect the generation length. Despite DPO showing a stronger correlation, the length of its generated responses is comparable to or even slightly shorter than those of the SimPO models. Please find more details in Appendix D.
DPO reward mismatches generation likelihood.
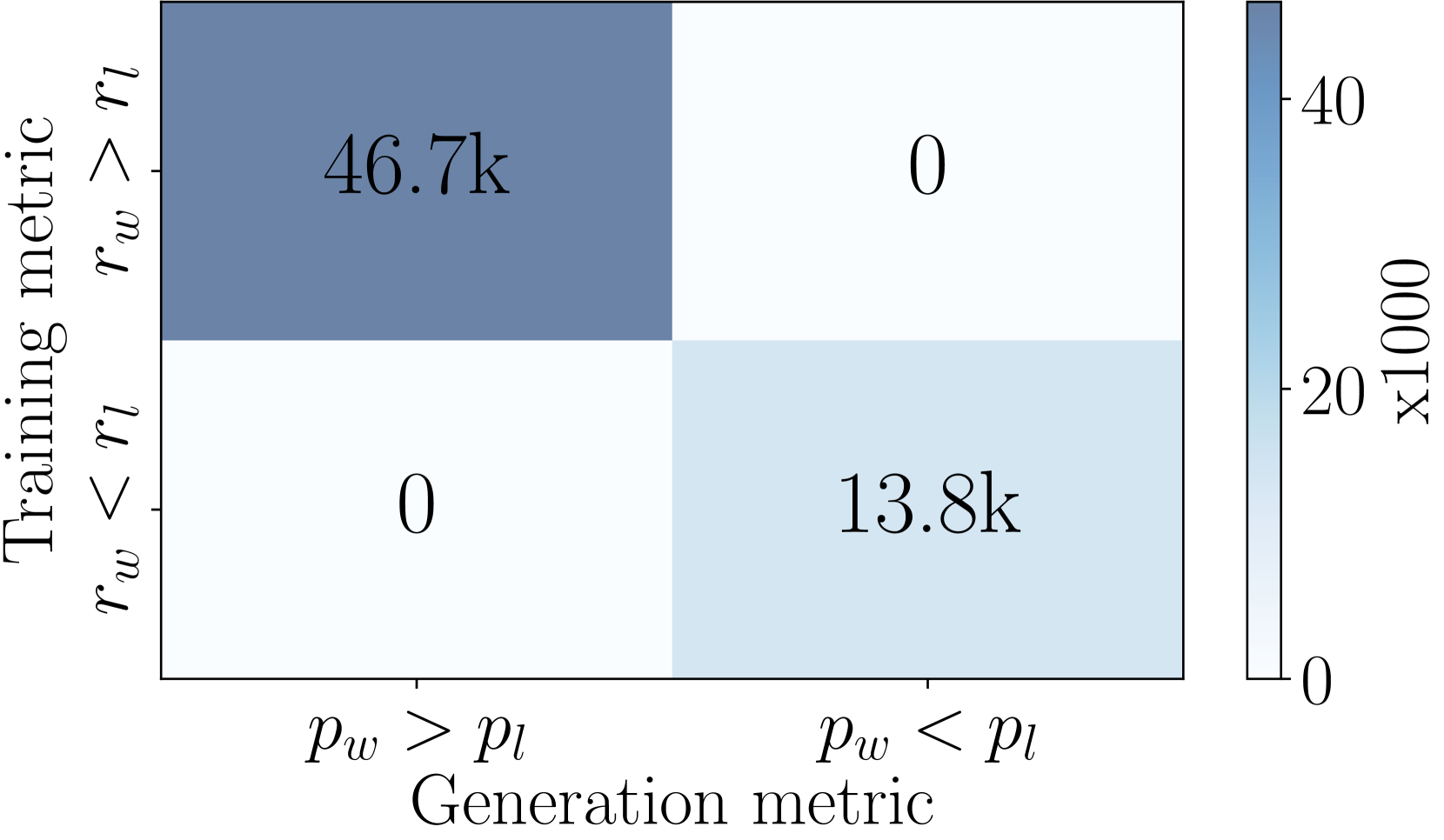
There is a divergence between DPO’s reward formulation, , and the average log likelihood metric, , which directly impacts generation. As shown in Figure 4(b), among the instances on the UltraFeedback training set where , almost half of the pairs have . In contrast, SimPO directly employs the average log likelihood (scaled by ) as the reward expression, thereby eliminating the discrepancy completely, as demonstrated in Figure 5(b).
DPO lags behind SimPO in terms of reward accuracy.
In Figure 4(c), we compare the reward accuracy of SimPO and DPO, assessing how well their final learned rewards align with preference labels on a held-out set. We observe that SimPO consistently achieves higher reward accuracy than DPO, suggesting that our reward design facilitates more effective generalization and leads to higher quality generations.
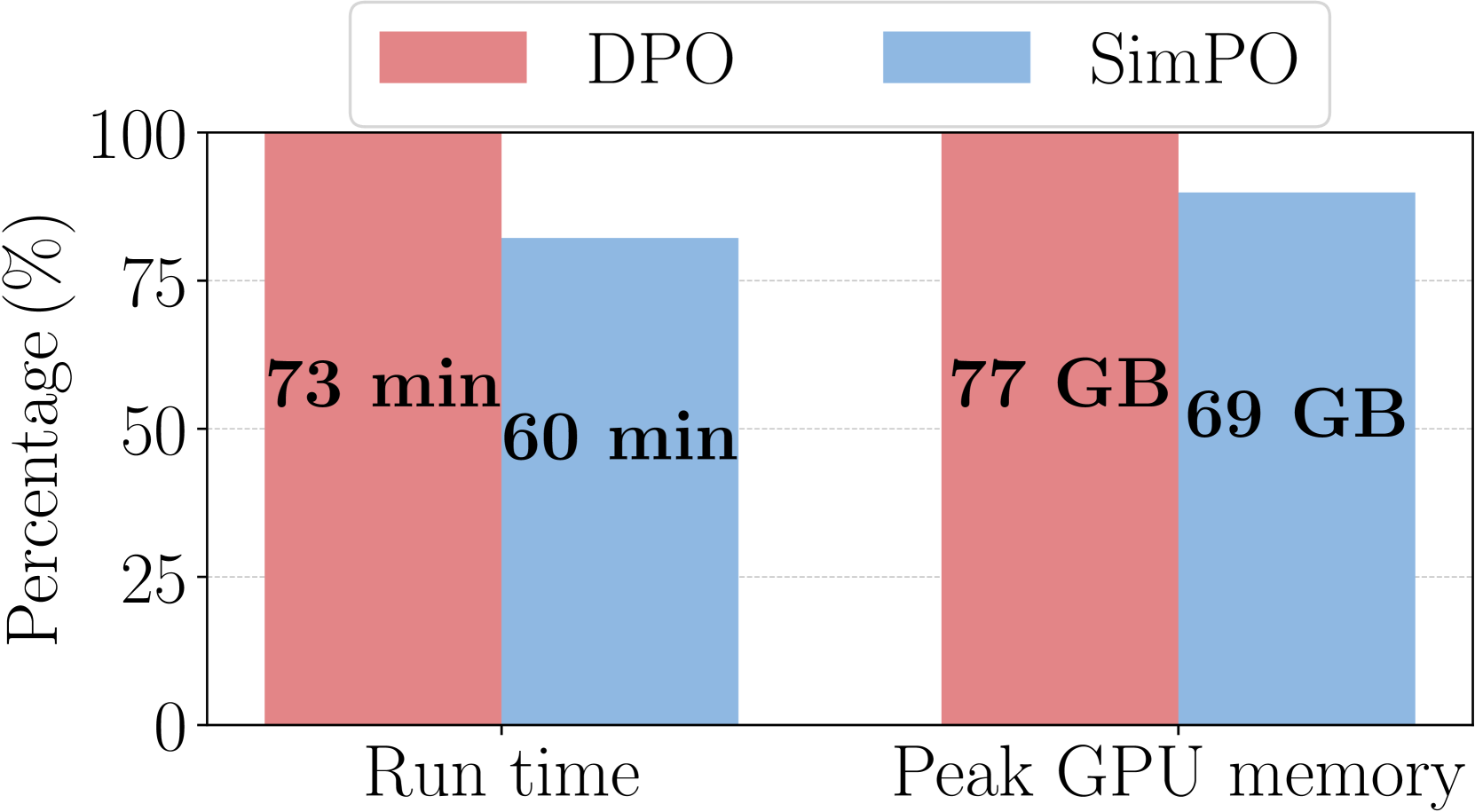
SimPO is more memory and compute-efficient than DPO.
Another benefit of SimPO is its efficiency as it does not use a reference model. Figure 4(d) illustrates the overall run time and per-GPU peak memory usage of SimPO and DPO in the Llama3-Base setting using 8×H100 GPUs. Compared to a vanilla DPO implementation,666DPO can be as memory efficient as SimPO if it were implemented to separate the forward passes of the reference model from the actual preference optimization. However, this implementation is not standard practice. SimPO cuts run time by roughly 20% and reduces GPU memory usage by about 10%, thanks to eliminating forward passes with the reference model.
5 Related Work
Reinforcemant learning from human feedback.
RLHF is a technique that aligns large language models with human preferences and values [15, 91, 58, 7]. The classical RLHF pipeline typically comprises three phases: supervised fine-tuning [90, 72, 29, 18, 44, 22, 77, 13, 79], reward model training [28, 56, 14, 52, 33, 46], and policy optimization [66, 4]. Proximal Policy Optimization (PPO) [66] is a widely used algorithm in the third stage of RLHF. The RLHF framework is also widely applied to various applications, such as mitigating toxicity [45, 3], ensuring safety [21], enhancing helpfulness [73], serching and navigating the web [57], and improving model reasoning abilities [32]. Recently, [12] has highlighted challenges across the whole RLHF pipeline from preference data collection to model training. Further research has also demonstrated that RLHF can lead to biased outcomes, such as verbose outputs from the model [24, 67, 78].
Preference optimization.
Given that online preference optimization algorithms are complex and difficult to optimize [89, 65], researchers have been exploring more efficient and simpler alternative offline algorithms. Direct Preference Optimization (DPO) [62] is a notable example. However, the absence of a reward model in DPO limits its ability to sample preference pairs from the optimal policy. To address this, researchers have explored augmenting preference data using a trained SFT policy [87] or a refined SFT policy with rejection sampling [55], enabling the policy to learn from data generated by the optimal policy. Further studies have extended this approach to an iterative training setup, continuously updating the reference model for optimization with either the most recent policy model or by generating preference pairs scored and selected by the evolving policy model [42, 63, 84]. Additionally, some studies have replaced the online RL objective with offline ranking objectives, allowing for comparisons among more than two instances from a broader perspective [23, 54, 68, 83]. Another line of work explores simpler preference optimization objectives without relying on a reference model [38, 81], similar to SimPO. Our work follows the pair-wise preference optimization setup without iterative training. We compare it to a series of offline algorithms, including DPO, IPO [6], KTO [25], ORPO [38], and R-DPO [60], and find that SimPO can outperform these methods in both efficiency and performance. Recently, [71] proposed a generalized preference optimization framework that unifies different offline algorithms, and SimPO can be seen as a special case of this framework.
6 Discussion
Conclusion.
In this work, we propose SimPO, a simple and effective preference optimization algorithm that consistently outperforms existing approaches across various training setups. By aligning the reward function with the generation likelihood and introducing a target reward margin, SimPO eliminates the need for a reference model and achieves strong performance without exploiting the length bias. Extensive analysis demonstrates that the key designs in SimPO are crucial and validates the efficiency and effectiveness of SimPO.
Limitations and future work.
First, despite the empirical success and intuitive motivation of SimPO, we lack a theoretical and rigorous understanding of why it works. Moreover, the introduction of a target reward margin requires us to tune an additional hyperparameter, future work could explore how to determine the optimal margin automatically. Second, SimPO is an offline preference algorithm and does not leverage iterative training or other orthogonal techniques. Future work could explore the integration of SimPO with these methods to further enhance model performance. Third, our experiments focus solely on the evaluation of helpfulness, neglecting other crucial aspects of model behavior such as safety, honesty, and fairness. Investigating the generalization of SimPO to these behaviors in future studies is important. Finally, we observe a performance drop on some downstream tasks, especially on the math benchmarks. We provide a more detailed discussion of the limitations and future directions in the next section.
Limitations
-
•
More in-depth theoretical analysis. Despite the empirical success and intuitive motivation of SimPO, a more rigorous theoretical analysis is necessary to fully understand the factors contributing to its effectiveness. Additionally, we introduce an additional hyperparameter, the target reward margin, which requires manual tuning. Future work could explore how to determine the optimal margin automatically and provide a more theoretical understanding of SimPO.
-
•
Safety and honesty. SimPO is designed to optimize the generation quality of language models by pushing the margin between the average log likelihood of the winning response and the losing response to exceed a target reward margin. However, it does not explicitly consider safety and honesty aspects, which are crucial for real-world applications. Future work should explore integrating safety and honesty constraints into SimPO to ensure that the generated responses are not only high-quality but also safe and honest. The dataset used in this work, UltraFeedback [20], primarily focuses on helpfulness, and future research may consider a more comprehensive study utilizing larger-scale preference datasets [39, 86] and evaluation benchmarks [76] that place a strong emphasis on safety aspects. Nonetheless, we observe that this method consistently achieves high TruthfulQA [53] performance compared to other objectives in Table 9, suggesting its potential for safety alignment.
-
•
Performance drop on math. We observed that preference optimization algorithms generally decrease downstream task performance, particularly on reasoning-heavy tasks like GSM8k, as shown in Table 9. SimPO occasionally results in performance comparable to or worse than DPO. We hypothesize that this may be related to the choice of training datasets, hyperparameters used for training, or a mismatch of chat templates used for downstream task evaluations. One explanation is that the preference optimization objective may not be effectively increasing the likelihood of preferred sequences despite increasing the reward margin. [59] first observed this phenomenon and point out that this can hinder learning from math preference pairs where changing one token can flip the label (e.g., changing to ). They propose a simple regularization strategy to add back a reference-model calibrated supervised fine-tuning loss to the preference optimization objective, and effectively mitigate this issue. Future work may consider integrating this regularization strategy into SimPO to improve performance on reasoning-heavy tasks.
Acknowledgments
The authors would like to thank Tianyu Gao, Tanya Goyal, Kaifeng Lyu, Sadhika Malladi, Eric Mitchell, Lewis Tunstall and members of the Princeton NLP group for their valuable feedback and discussions. We thank Niklas Muennighoff for his advice on training and reproducing training KTO models. Mengzhou Xia is supported by an Apple Scholars in AIML Fellowship. This research is also funded by the National Science Foundation (IIS-2211779) and a Sloan Research Fellowship.
References
- [1] Alan Agresti. Categorical data analysis, volume 792. John Wiley & Sons, 2012.
- [2] AI@Meta. Llama 3 model card. 2024.
- [3] Afra Amini, Tim Vieira, and Ryan Cotterell. Direct preference optimization with an offset. arXiv preprint arXiv:2402.10571, 2024.
- [4] Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems, 30, 2017.
- [5] Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Benjamin Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, John Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom B. Brown, Jack Clark, Sam McCandlish, Christopher Olah, and Jared Kaplan. A general language assistant as a laboratory for alignment. ArXiv, abs/2112.00861, 2021.
- [6] Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences. ArXiv, abs/2310.12036, 2023.
- [7] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- [8] Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. Open llm leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard, 2023.
- [9] Bernhard E Boser, Isabelle M Guyon, and Vladimir N Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory, pages 144–152, 1992.
- [10] Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39:324, 1952.
- [11] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020.
- [12] Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217, 2023.
- [13] Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. Alpagasus: Training a better alpaca with fewer data. In The Twelfth International Conference on Learning Representations, 2024.
- [14] Lichang Chen, Chen Zhu, Davit Soselia, Jiuhai Chen, Tianyi Zhou, Tom Goldstein, Heng Huang, Mohammad Shoeybi, and Bryan Catanzaro. Odin: Disentangled reward mitigates hacking in rlhf. arXiv preprint arXiv:2402.07319, 2024.
- [15] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- [16] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [17] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [18] Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023.
- [19] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine learning, 20:273–297, 1995.
- [20] Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. UltraFeedback: Boosting language models with high-quality feedback. In ICML, 2024.
- [21] Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback. arXiv preprint arXiv:2310.12773, 2023.
- [22] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. In EMNLP, 2023.
- [23] Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, SHUM KaShun, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023.
- [24] Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled AlpacaEval: A simple way to debias automatic evaluators. ArXiv, abs/2404.04475, 2024.
- [25] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model alignment as prospect theoretic optimization. ArXiv, abs/2402.01306, 2024.
- [26] Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, 2018.
- [27] David Firth and Heather Turner. Bradley-terry models in r: the bradleyterry2 package. Journal of Statistical Software, 48(9), 2012.
- [28] Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023.
- [29] Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. Koala: A dialogue model for academic research. Blog post, April, 1:6, 2023.
- [30] Ulrich Germann. Greedy decoding for statistical machine translation in almost linear time. In NAACL, 2003.
- [31] Alex Graves. Sequence transduction with recurrent neural networks. ArXiv, abs/1211.3711, 2012.
- [32] Alex Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. Teaching large language models to reason with reinforcement learning. arXiv preprint arXiv:2403.04642, 2024.
- [33] Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, and Roberta Railneau. Glore: When, where, and how to improve llm reasoning via global and local refinements. arXiv preprint arXiv:2402.10963, 2024.
- [34] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2020.
- [35] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In International Conference on Learning Representations, 2019.
- [36] Ari Holtzman, Jan Buys, Maxwell Forbes, Antoine Bosselut, David Golub, and Yejin Choi. Learning to write with cooperative discriminators. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1638–1649, 2018.
- [37] Ari Holtzman, Peter West, Vered Shwartz, Yejin Choi, and Luke Zettlemoyer. Surface form competition: Why the highest probability answer isn’t always right. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7038–7051, 2021.
- [38] Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model. ArXiv, abs/2403.07691, 2024.
- [39] Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset. ArXiv, abs/2307.04657, 2023.
- [40] Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L’elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7B. ArXiv, abs/2310.06825, 2023.
- [41] Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. LLM-Blender: Ensembling large language models with pairwise ranking and generative fusion. In ACL, 2023.
- [42] Dahyun Kim, Yungi Kim, Wonho Song, Hyeonwoo Kim, Yunsu Kim, Sanghoon Kim, and Chanjun Park. sDPO: Don’t use your data all at once. ArXiv, abs/2403.19270, 2024.
- [43] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [44] Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Minh Nguyen, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations-democratizing large language model alignment. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
- [45] Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Vinayak Bhalerao, Christopher Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. In International Conference on Machine Learning, pages 17506–17533. PMLR, 2023.
- [46] Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. Rewardbench: Evaluating reward models for language modeling, 2024.
- [47] Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, and Shane Legg. Scalable agent alignment via reward modeling: a research direction. arXiv preprint arXiv:1811.07871, 2018.
- [48] Hector Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In Thirteenth international conference on the principles of knowledge representation and reasoning, 2012.
- [49] Jiwei Li, Will Monroe, Alan Ritter, Dan Jurafsky, Michel Galley, and Jianfeng Gao. Deep reinforcement learning for dialogue generation. In Jian Su, Kevin Duh, and Xavier Carreras, editors, Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1192–1202, Austin, Texas, November 2016. Association for Computational Linguistics.
- [50] Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From live data to high-quality benchmarks: The Arena-Hard pipeline, April 2024.
- [51] Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. AlpacaEval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
- [52] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- [53] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, 2022.
- [54] Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mohammad Saleh, Simon Baumgartner, Jialu Liu, et al. LiPO: Listwise preference optimization through learning-to-rank. arXiv preprint arXiv:2402.01878, 2024.
- [55] Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J Liu, and Jialu Liu. Statistical rejection sampling improves preference optimization. In The Twelfth International Conference on Learning Representations, 2024.
- [56] Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- [57] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- [58] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022.
- [59] Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with dpo-positive. arXiv preprint arXiv:2402.13228, 2024.
- [60] Ryan Park, Rafael Rafailov, Stefano Ermon, and Chelsea Finn. Disentangling length from quality in direct preference optimization. ArXiv, abs/2403.19159, 2024.
- [61] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [62] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In NeurIPS, 2023.
- [63] Corby Rosset, Ching-An Cheng, Arindam Mitra, Michael Santacroce, Ahmed Awadallah, and Tengyang Xie. Direct nash optimization: Teaching language models to self-improve with general preferences. ArXiv, abs/2404.03715, 2024.
- [64] Sebastian Ruder. An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747, 2016.
- [65] Michael Santacroce, Yadong Lu, Han Yu, Yuanzhi Li, and Yelong Shen. Efficient RLHF: Reducing the memory usage of PPO. arXiv preprint arXiv:2309.00754, 2023.
- [66] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- [67] Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in RLHF. arXiv preprint arXiv:2310.03716, 2023.
- [68] Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference ranking optimization for human alignment. In AAAI, 2024.
- [69] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- [70] Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, Rémi Munos, Bernardo Ávila Pires, Michal Valko, Yong Cheng, et al. Understanding the performance gap between online and offline alignment algorithms. arXiv preprint arXiv:2405.08448, 2024.
- [71] Yunhao Tang, Zhaohan Daniel Guo, Zeyu Zheng, Daniele Calandriello, Rémi Munos, Mark Rowland, Pierre Harvey Richemond, Michal Valko, Bernardo Ávila Pires, and Bilal Piot. Generalized preference optimization: A unified approach to offline alignment. arXiv preprint arXiv:2402.05749, 2024.
- [72] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023.
- [73] Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine-tuning language models for factuality. In The Twelfth International Conference on Learning Representations, 2024.
- [74] Hoang Tran, Chris Glaze, and Braden Hancock. Iterative DPO alignment. Technical report, Snorkel AI, 2023.
- [75] Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of LM alignment. ArXiv, abs/2310.16944, 2023.
- [76] Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, Sang Truong, Simran Arora, Mantas Mazeika, Dan Hendrycks, Zi-Han Lin, Yuk-Kit Cheng, Sanmi Koyejo, Dawn Xiaodong Song, and Bo Li. DecodingTrust: A comprehensive assessment of trustworthiness in gpt models. In NeurIPS, 2023.
- [77] Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song, and Yang Liu. OpenChat: Advancing open-source language models with mixed-quality data. In ICLR, 2024.
- [78] Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Chandu, David Wadden, Kelsey MacMillan, Noah A Smith, Iz Beltagy, et al. How far can camels go? exploring the state of instruction tuning on open resources. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
- [79] Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. LESS: Selecting influential data for targeted instruction tuning. In ICML, 2024.
- [80] Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. arXiv preprint arXiv:2401.08417, 2024.
- [81] Jing Xu, Andrew Lee, Sainbayar Sukhbaatar, and Jason Weston. Some things are more cringe than others: Preference optimization with the pairwise cringe loss. arXiv preprint arXiv:2312.16682, 2023.
- [82] Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, and Yi Wu. Is DPO superior to PPO for llm alignment? a comprehensive study. arXiv preprint arXiv:2404.10719, 2024.
- [83] Hongyi Yuan, Zheng Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. RRHF: Rank responses to align language models with human feedback. In NeurIPS, 2023.
- [84] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024.
- [85] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguistics.
- [86] Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatGPT interaction logs in the wild. In The Twelfth International Conference on Learning Representations, 2024.
- [87] Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J. Liu. SLiC-HF: Sequence likelihood calibration with human feedback. ArXiv, abs/2305.10425, 2023.
- [88] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
- [89] Rui Zheng, Shihan Dou, Songyang Gao, Yuan Hua, Wei Shen, Binghai Wang, Yan Liu, Senjie Jin, Qin Liu, Yuhao Zhou, et al. Secrets of RLHF in large language models part I: PPO. arXiv preprint arXiv:2307.04964, 2023.
- [90] Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. LIMA: Less is more for alignment. NeurIPS, 2023.
- [91] Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
Appendix A Implementation Details
We find that hyperparameter tuning is crucial for achieving optimal performance of preference optimization methods. However, the importance of careful hyperparameter tuning may have been underestimated in prior research, potentially leading to suboptimal baseline results. To ensure a fair comparison, we conduct thorough hyperparameter tuning for all methods compared in our experiments.
General training hyperparameters.
| Method | Objective | Hyperparameter |
| DPO [62] | ||
| IPO [6] | ||
| KTO [25] | ||
| ORPO [38] | ||
| R-DPO [60] | ||
| SimPO | ||
| Setting | Learning rate | ||
| Mistral-Base | 2.0 | 1.6 | 3e-7 |
| Mistral-Instruct | 2.5 | 0.3 | 5e-7 |
| Llama3-Base | 2.0 | 1.0 | 6e-7 |
| Llama3-Instruct | 2.5 | 1.4 | 1e-6 |
For the Base training setups, we train SFT models using the UltraChat-200k dataset [22] with the following hyperparameters: a learning rate of 2e-5, a batch size of 128, a max sequence length of 2048, and a cosine learning rate schedule with 10% warmup steps for 1 epoch. All the models are trained with an Adam optimizer [43].
For the preference optimization stage, we conduct preliminary experiments to search for batch sizes in [32, 64, 128] and training epochs in [1, 2, 3]. We find that a batch size of 128 and a single training epoch generally yield the best results across all methods. Therefore, we fix these values for all preference optimization experiments. Additionally, we set the max sequence length to be 2048 and apply a cosine learning rate schedule with 10% warmup steps on the preference optimization dataset.
Method-specific training hyperparameters.
We have noticed that the optimal learning rate varies for different preference optimization methods and greatly influences the benchmark performance. Therefore, we individually search the learning rates in the range of [3e-7, 5e-7, 6e-7, 1e-6] for each method. Table 7 shows the detailed information on method-specific hyperparameters search ranges for baselines.777There is a discrepancy between the KTO runs in their original paper, where the original runs use a RMSProp optimizer [64]. We use an Adam optimizer [43] for all the experiments. Table 8 shows SimPO’s hyperparameters used under each setting.
Decoding hyperparameters.
For AlpacaEval 2, we use a sampling decoding strategy to generate responses, with a temperature of 0.7 for the Mistral-Base setting following zephyr-7b-beta,888https://github.com/tatsu-lab/alpaca_eval/blob/main/src/alpaca_eval/models_configs/zephyr-7b-beta/configs.yaml a temperature of 0.5 for the Mistral-Instruct setting following Snorkel-Mistral-PairRM-DPO, and a temperature of 0.9 for both Llama3 settings.999We grid search the temperature hyperparameter for the Llama3-Base setting with DPO over , and fix it for all different methods. For Arena-Hard, we use the default greedy decoding for all settings and methods. For MT-Bench, we follow the official decoding configuration which defines different sampling temperatures for different categories.
Computation environment.
All the training experiments in this paper were conducted on 8×H100 GPUs based on the alignment-handbook repo.101010https://github.com/huggingface/alignment-handbook
Appendix B Downstream Task Evaluation
To examine how preference optimization methods affect downstream task performance, we evaluate models trained with different methods on various tasks listed on the Huggingface Open Leaderboard [8]. These tasks include MMLU [34], ARC [16], HellaSwag [85], TruthfulQA [53], Winograd [48], and GSM8K [17]. We follow the established evaluation protocols and present the results for all models in Table 9. Generally, we find that preference optimization’s effect varies across tasks.
Knowledge is largely retained with a small loss.
Compared to the SFT checkpoint, we find that all preference optimization methods generally maintain MMLU performance with minimal decline. In this aspect, SimPO is largely comparable to DPO.
Reading comprehension and commonsense reasoning improves.
For ARC and HellaSwag, preference optimization methods generally improve performance compared to the SFT checkpoint. One hypothesis is that the preference optimization dataset contains similar prompts to these tasks, which helps the model better understand the context and improve reading comprehension and commonsense reasoning abilities.
Truthfulness improves.
Surprisingly, we find that preference optimization methods consistently improve TruthfulQA performance compared to the SFT checkpoint, and the improvement could be as high as over 10% in some cases. Similarly, we hypothesize that the preference dataset contains instances that emphasize truthfulness, which helps the model better understand the context and generate more truthful responses.
Math performance drops.
GSM8K is the benchmark that shows the most volatility across methods. Notably, except for ORPO, almost all approaches lead to consistent drops in one or more settings. We hypothesize that ORPO retains performance largely due to its supervised fine-tuning loss for regulation. [59] adds a reference-model calibrated supervised fine-tuning loss to the preference optimization objective, and find that it effectively solves the issue and maintains performance on math tasks as well.
Overall, identifying a pattern in downstream performance is challenging. Comprehensive analysis is difficult due to using different pretrained models, preference optimization datasets, and objectives. Recent works indicate that gradient-based approaches could be effective in finding relevant data for downstream tasks [79], and could possibly extended to understand the effect of preference optimization. We believe a thorough study on how preference optimization affects downstream performance would be valuable and call for a rigorous and more comprehensive analysis in future work.
| MMLU (5) | ARC (25) | HellaSwag (10) | TruthfulQA (0) | Winograd (5) | GSM8K (5) | Average | |
| Mistral-Base | |||||||
| SFT | 60.10 | 58.28 | 80.76 | 40.35 | 76.40 | 28.13 | 57.34 |
| DPO | 58.48 | 61.26 | 83.59 | 53.06 | 76.80 | 21.76 | 59.16 |
| IPO | 60.23 | 60.84 | 83.30 | 45.44 | 77.58 | 27.14 | 59.09 |
| KTO | 60.90 | 62.37 | 84.88 | 56.60 | 77.27 | 38.51 | 63.42 |
| ORPO | 63.20 | 61.01 | 84.09 | 47.91 | 78.61 | 42.15 | 62.83 |
| R-DPO | 59.58 | 61.35 | 84.29 | 46.12 | 76.56 | 18.12 | 57.67 |
| SimPO | 59.21 | 62.63 | 83.60 | 50.68 | 77.27 | 22.21 | 59.27 |
| Mistral-Instruct | |||||||
| SFT | 60.40 | 63.57 | 84.79 | 66.81 | 76.64 | 40.49 | 65.45 |
| DPO | 60.53 | 65.36 | 85.86 | 66.71 | 76.80 | 40.33 | 65.93 |
| IPO | 60.20 | 63.31 | 84.88 | 67.36 | 75.85 | 39.42 | 65.17 |
| KTO | 60.52 | 65.78 | 85.49 | 68.45 | 75.93 | 38.82 | 65.83 |
| ORPO | 60.43 | 61.43 | 84.32 | 66.33 | 76.80 | 36.85 | 64.36 |
| R-DPO | 60.71 | 66.30 | 86.01 | 68.22 | 76.72 | 37.00 | 65.82 |
| SimPO | 60.53 | 66.89 | 85.95 | 68.40 | 76.32 | 35.25 | 65.56 |
| Llama3-Base | |||||||
| SFT | 64.88 | 60.15 | 81.37 | 45.33 | 75.77 | 46.32 | 62.30 |
| DPO | 64.31 | 64.42 | 83.87 | 53.48 | 76.32 | 38.67 | 63.51 |
| IPO | 64.40 | 62.88 | 80.46 | 54.20 | 72.22 | 22.67 | 59.47 |
| KTO | 64.42 | 63.14 | 83.55 | 55.76 | 76.09 | 38.97 | 63.65 |
| ORPO | 64.44 | 61.69 | 82.24 | 56.11 | 77.51 | 50.04 | 65.34 |
| R-DPO | 64.19 | 64.59 | 83.90 | 53.41 | 75.93 | 39.27 | 63.55 |
| SimPO | 64.00 | 65.19 | 83.09 | 59.46 | 77.19 | 31.54 | 63.41 |
| Llama3-Instruct | |||||||
| SFT | 67.06 | 61.01 | 78.57 | 51.66 | 74.35 | 68.69 | 66.89 |
| DPO | 66.88 | 63.99 | 80.78 | 59.01 | 74.66 | 49.81 | 65.86 |
| IPO | 66.52 | 61.95 | 77.90 | 54.64 | 73.09 | 58.23 | 65.39 |
| KTO | 66.38 | 63.57 | 79.51 | 58.15 | 73.40 | 57.01 | 66.34 |
| ORPO | 66.41 | 61.01 | 79.38 | 54.37 | 75.77 | 64.59 | 66.92 |
| R-DPO | 66.74 | 64.33 | 80.97 | 60.32 | 74.82 | 43.90 | 65.18 |
| SimPO | 65.63 | 62.80 | 78.33 | 60.70 | 73.32 | 50.72 | 65.25 |
| AlpacaEval 2 | Arena-Hard | |||||||
| Models | LC (%) | WR (%) | STD (%) | Length | WR | 95 CI high | 95 CI low | Length |
| Mistral-Base | ||||||||
| SFT | 8.4 | 6.2 | 1.1 | 914 | 1.3 | 1.8 | 0.9 | 521 |
| DPO | 15.1 | 12.5 | 1.0 | 1477 | 10.4 | 11.7 | 9.4 | 628 |
| IPO | 11.8 | 9.4 | 0.9 | 1380 | 7.5 | 8.5 | 6.5 | 674 |
| KTO | 13.1 | 9.1 | 0.9 | 1144 | 5.6 | 6.6 | 4.7 | 475 |
| ORPO | 14.7 | 12.2 | 1.0 | 1475 | 7.0 | 7.9 | 5.9 | 764 |
| R-DPO | 17.4 | 12.8 | 1.0 | 1335 | 9.9 | 11.1 | 8.4 | 528 |
| SimPO | 21.4 | 20.8 | 1.2 | 1868 | 16.6 | 18.0 | 15.1 | 699 |
| Mistral-Instruct | ||||||||
| SFT | 17.1 | 14.7 | 1.1 | 1676 | 12.6 | 14.1 | 11.1 | 486 |
| DPO | 26.8 | 24.9 | 1.3 | 1808 | 16.3 | 18.0 | 15.2 | 518 |
| IPO | 20.3 | 20.3 | 1.2 | 2024 | 16.2 | 17.9 | 14.4 | 740 |
| KTO | 24.5 | 23.6 | 1.3 | 1901 | 17.9 | 20.3 | 16.1 | 496 |
| ORPO | 24.5 | 24.9 | 1.3 | 2022 | 20.8 | 22.5 | 19.1 | 527 |
| R-DPO | 27.3 | 24.5 | 1.3 | 1784 | 16.1 | 18.0 | 14.6 | 495 |
| SimPO | 32.1 | 34.8 | 1.4 | 2193 | 21.0 | 22.7 | 18.8 | 539 |
| Llama3-Base | ||||||||
| SFT | 6.2 | 4.6 | 0.7 | 1082 | 3.3 | 4.0 | 2.6 | 437 |
| DPO | 18.2 | 15.5 | 1.1 | 1585 | 15.9 | 18.1 | 14.1 | 563 |
| IPO | 14.4 | 14.2 | 1.1 | 1856 | 17.8 | 19.5 | 16.0 | 608 |
| KTO | 14.2 | 12.4 | 1.0 | 1646 | 12.5 | 14.2 | 10.9 | 519 |
| ORPO | 12.2 | 10.6 | 0.9 | 1628 | 10.8 | 12.3 | 9.6 | 639 |
| R-DPO | 17.6 | 14.4 | 1.1 | 1529 | 17.2 | 18.5 | 15.7 | 527 |
| SimPO | 22.0 | 20.3 | 1.2 | 1795 | 23.4 | 25.4 | 21.6 | 704 |
| Llama3-Instrct | ||||||||
| SFT | 26.0 | 25.3 | 1.3 | 1920 | 22.3 | 23.9 | 20.3 | 596 |
| DPO | 40.3 | 37.9 | 1.4 | 1883 | 32.6 | 34.8 | 30.3 | 528 |
| IPO | 35.6 | 35.6 | 1.4 | 1983 | 30.5 | 32.8 | 28.4 | 554 |
| KTO | 33.1 | 31.8 | 1.4 | 1909 | 26.4 | 28.7 | 24.3 | 536 |
| ORPO | 28.5 | 27.4 | 1.3 | 1888 | 25.8 | 27.4 | 23.8 | 535 |
| R-DPO | 41.1 | 37.8 | 1.4 | 1854 | 33.1 | 35.3 | 30.9 | 522 |
| SimPO | 44.7 | 40.5 | 1.4 | 1825 | 33.8 | 35.9 | 32.0 | 504 |
Appendix C Standard Deviation of AlpacaEval 2 and Arena-Hard
We present the standard deviation of AlpacaEval 2 and the 95% confidence interval of Arena-Hard in Table 10. All these metrics are reasonable and do not exhibit any significant outliers or instability.
Appendix D Generation Length Analysis
Length normalization decreases generation length and improves generation quality.
Removing length normalization from the SimPO objective results in an approach similar to Contrastive Preference Optimization (CPO) [80], which interpolates reward maximization with a supervised fine-tuning loss and has demonstrated strong performance in machine translation. However, without the supervised fine-tuning loss, the reward maximization objective without length normalization is suboptimal in preference optimization.
We analyze the generation length of models trained with or without length normalization on AlpacaEval 2 and Arena-Hard. As shown in Figure 5, length normalization significantly decrease the generation length by up to 25% compared to when it is not used in most cases. However, even though the generation length is shorter, the models with length normalization consistently achieve much higher win rates on both benchmarks. This suggests that length normalization can effectively control the verbosity of the generated responses, and meanwhile improve the generation quality.
Length is not a reliable indicator of generation quality.
We further analyze the generation length of models trained with different methods on AlpacaEval 2 and Arena-Hard, as shown in Table 10. Generally, we find that no single method consistently generates longer or shorter responses across all settings. Additionally, even though some methods may generate longer responses, they do not necessarily achieve better win rates on the benchmarks. This indicates that the length of the generated responses is not a reliable indicator of generation quality.
SimPO demonstrates minimal exploitation of response length.
We observe that SimPO has a shorter generation length compared to DPO in the Llalam3-Instruct case but exhibits a higher generation length in other settings, with up to 26% longer responses on AlpacaEval 2. Conversely, SimPO only increases length by only around 5% on Arena-Hard compared to DPO. It is fair to say that the generation length heavily depends on the evaluation benchmark. A stronger indicator is that SimPO consistently achieves a higher length-controlled win rate on AlpacaEval 2 compared to the raw win rate, demonstrating minimal exploitation of response length.
| Model | AlpacaEval 2 | Arena-Hard | ||||||
| Mistral-Base | Mistral-Instruct | Mistral-Base | Mistral-Instruct | |||||
| LC (%) | Length | LC (%) | Length | WR (%) | Length | WR (%) | Length | |
| SimPO | 21.5 | 1868 | 32.1 | 2193 | 16.6 | 699 | 21.0 | 539 |
| SimPO w/o LN | 11.9 | 2345 | 19.1 | 2067 | 9.4 | 851 | 16.3 | 679 |
Appendix E Gradient Analysis
We examine the gradients of SimPO and DPO to understand their different impact on the training process.
| (7) | ||||
where
represent the gradient weight in SimPO and DPO, respectively. It can be seen that the differences are twofold: (1) comparing the gradient weights and , SimPO’s gradient weight does not involve the reference model and has a straightforward interpretation: the weights will be higher for samples where the policy model incorrectly assigns higher likelihood to than ; (2) comparing the gradient updates, SimPO’s gradients on and are length-normalized, while DPO’s are not. This corresponds to the empirical findings [60] that DPO may exploit length bias: longer sequences with more tokens will receive larger gradient updates in DPO, dominating the training process.


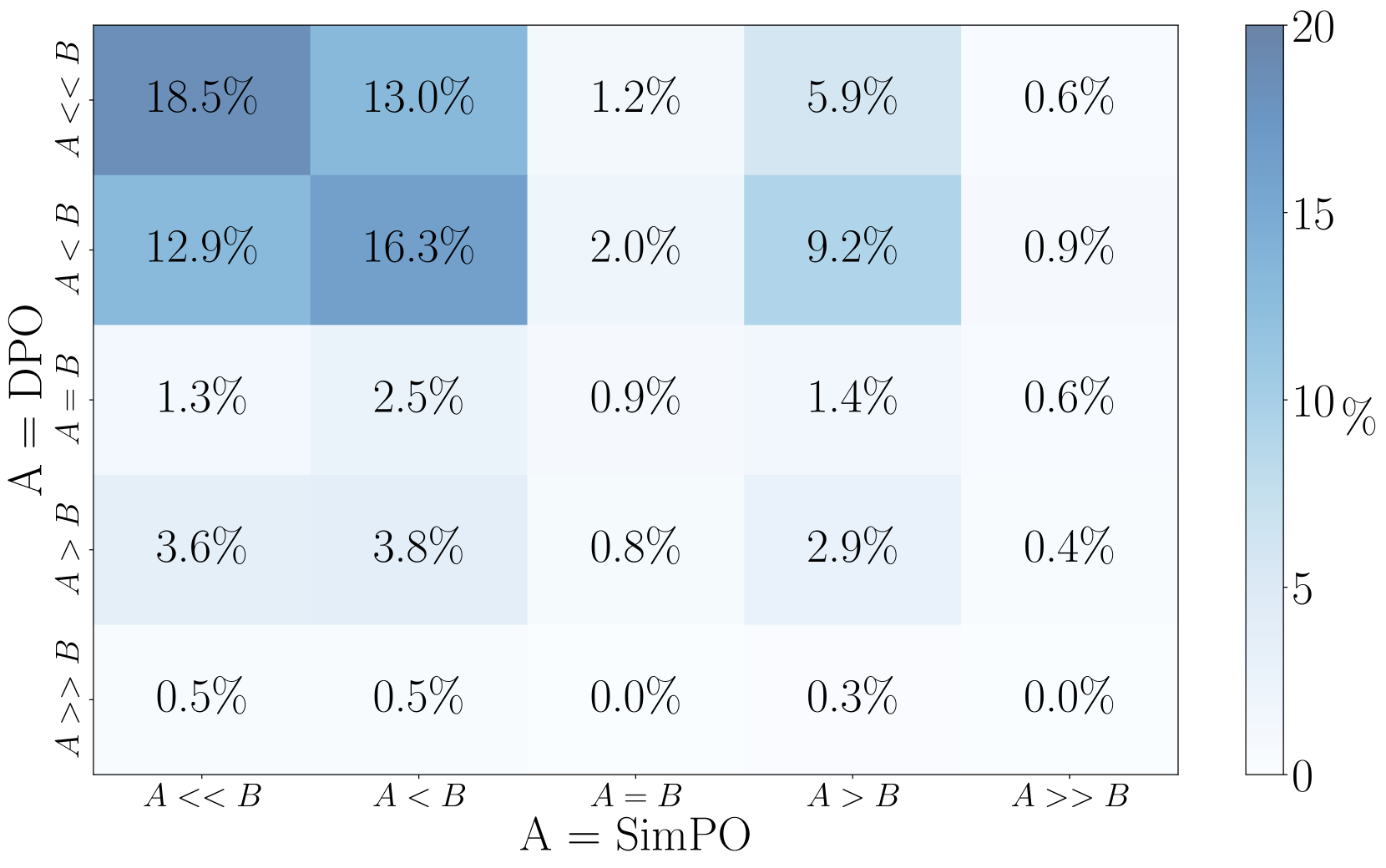
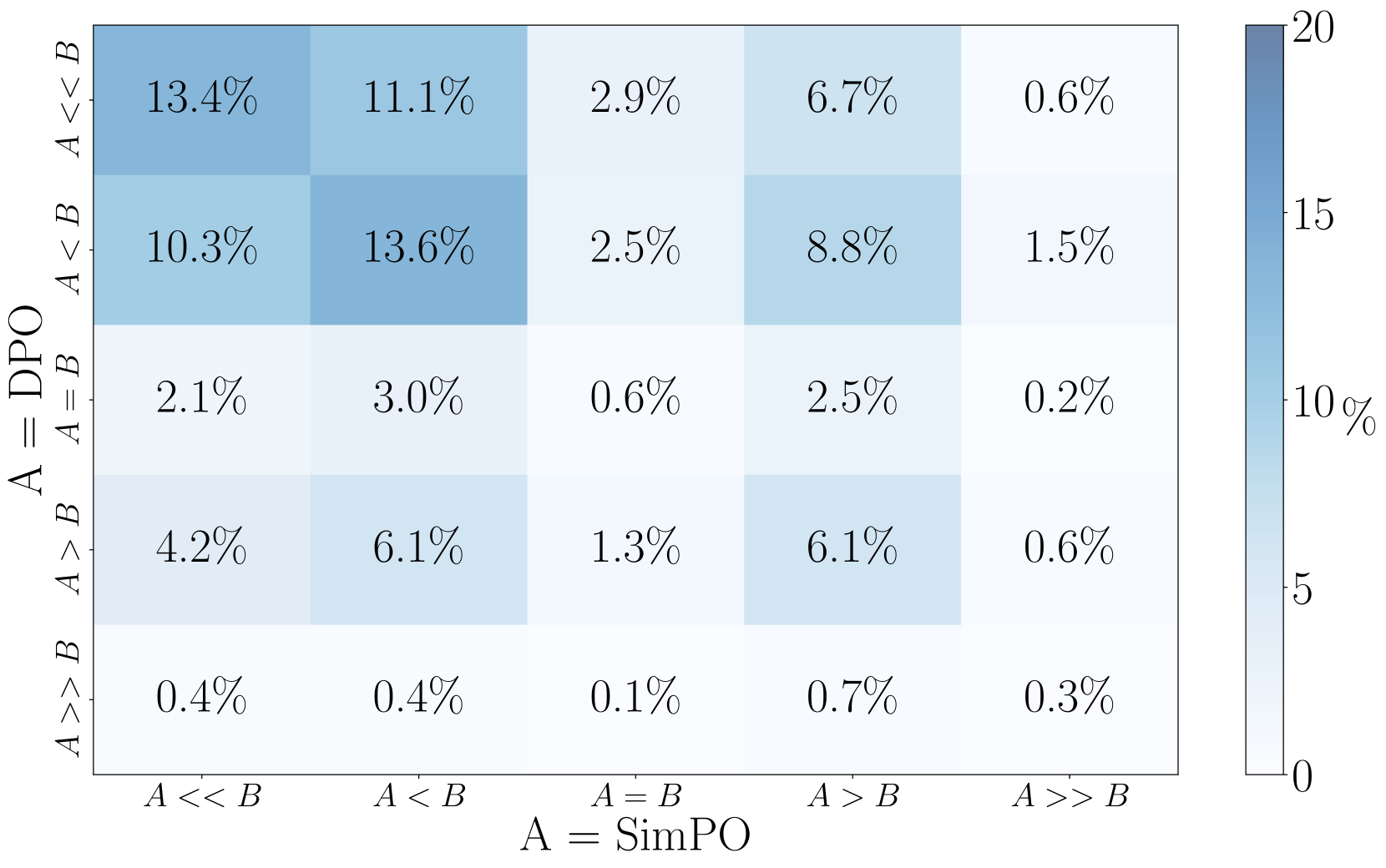
Appendix F Qualitative Analysis
We present the win rate heatmap of Mistral-Base and Mistral-Instruct on AlpacaEval 2 and Arena-Hard in Figure 6 and Figure 7, respectively. Based on this analysis, we present qualitative examples of responses generated by a SimPO model, a DPO model and the baseline model GPT-4-Preview-1106 on AlpacaEval 2.
Comparing SimPO with DPO.
In Figure 8 and Figure 9, we present an example where Mistral-Base-SimPO generates a better-structured answer compared to Mistral-Base-DPO. Given the question, "How can you determine if a person is genuinely interested in a conversation or simply being polite?", the DPO model generates a response with a long list of bullet points, making it difficult to understand the relationships between different points. In contrast, the SimPO model produces a well-structured answer with high-level categorization of different behaviors, followed by detailed suggestions for each category. This makes the answer more readable and easier to understand.
Comparing Instruct models with Base models when trained with SimPO.
In Figure 10, we present an example where Llama3-Instruct generates a more detailed and well-formatted answer compared to the baseline model, and as well as the Llama3-Base-SimPO model. Given the question: What language does Argentina people speak? Llama3-Base-SimPO only gives a very brief answer. GPT-4-Preview-1106 gives a more detailed answer in explaining how the Argentina Spanish differs from standard Spanish. However, the answer is not well formatted and a bit hard to parse. Llama3-Instruct-SimPO gives a detailed and well-formatted answer, which is easier to read and understand, and offers sufficient details.
| Input | Q: How can you determine if a person is genuinely interested in a conversation or simply being polite? |
| Mistral-Base DPO | As an AI, I dont́ have access to contextual information or nonverbal cues, but here are some general signs that may indicate whether someone is genuinely interested in a conversation or being polite: |
| 1. Active listening: A genuinely interested person will actively listen to what youŕe saying, ask questions, and provide feedback or comments. They may also maintain eye contact, nod, or use verbal cues like "uh-huh" or "I see" to show theyŕe engaged. | |
| 2. Follow-up questions: A genuine interest in the conversation often leads to follow-up questions. If someone is asking questions that show theyŕe interested in learning more about the topic, itś a good sign theyŕe engaged. | |
| 3. Body language: Nonverbal cues like leaning in, smiling, and mirroring your body language can indicate genuine interest. However, note that some people may have different body language styles, so this may not always be a reliable indicator. | |
| 4. Topic continuation: If the conversation flows naturally, and both parties are contributing equally, itś a sign of mutual interest. If one person dominates the conversation or keeps steering it back to their own interests, it may indicate a lack of genuine interest. | |
| 5. Time spent: If the conversation lasts longer than expected or planned, itś a sign that both parties are engaged and interested. | |
| 6. Follow-up actions: If someone shows genuine interest, they may follow up with you after the conversation, whether itś through a message, email, or phone call. | |
| Remember, however, that sometimes people may be polite or professional, even if theyŕe not genuinely interested. Itś essential to consider the context and the relationship you have with the person to determine their level of interest accurately. |
| Input | Q: How can you determine if a person is genuinely interested in a conversation or simply being polite? |
| Mistral-Base SimPO | Here are some indicators to consider: |
| 1. Engagement: | |
| - Active listening: Does the person maintain eye contact, nod, ask follow-up questions, and respond thoughtfully to what you say? Engaged individuals tend to show genuine interest by demonstrating attentiveness and participation in the conversation. | |
| - Initiative: Does the person take the lead in steering the conversation, expressing enthusiasm, sharing personal experiences, or asking questions beyond polite small talk? Someone who genuinely cares about the topic or connection may show initiative in keeping the discussion engaging. | |
| - Body language: Observe nonverbal cues such as leaning in, mirroring posture, facial expressions, and gestures that convey enthusiasm, curiosity, or openness. These signals suggest a deeper level of interest beyond mere politeness. | |
| 2. Content and depth: | |
| - Topic selection: Does the person show genuine curiosity or passion about the subject matter, asking relevant questions, sharing insights, or expressing opinions? If they seem invested in exploring the topic’s nuances, it indicates a genuine interest beyond mere politeness. | |
| - Level of detail: Does the person provide specific examples, personal anecdotes, or elaborate on their thoughts, indicating a deeper level of engagement and investment in the conversation? | |
| 3. Follow-up actions: | |
| - Continued communication: Does the person initiate further conversations, send follow-up messages, or suggest meeting up outside the initial interaction? Such actions suggest a genuine desire to maintain the connection and explore further topics, indicating a genuine interest beyond mere politeness. | |
| - Personalization: Does the person remember details discussed earlier, reference shared interests, or show interest in learning more about your life or experiences? Personalized interactions indicate a genuine interest in building a relationship beyond mere politeness. | |
| Overall, genuine interest in a conversation involves active participation, enthusiasm, depth, and follow-up actions that demonstrate a genuine desire to connect and engage beyond mere politeness. |
| Input | Q: what language does argentina people speak |
| Llama3-Base SimPO | The official language spoken in Argentina is Spanish, specifically Argentine Spanish, which shares similarities with other varieties of Spanish spoken in neighboring countries like Uruguay, Chile, and Paraguay. |
| Llama3-Instruct SimPO | In Argentina, the official language is Spanish. Specifically, the dialect spoken in Argentina is known as Rioplatense Spanish, which is a variation of Spanish with some unique characteristics and influences from Italian, German, and other immigrant languages. |
| Rioplatense Spanish is distinguished by: | |
| 1. Voseo: Instead of using tú (you) as the informal singular pronoun, Argentines use vos and its associated verb conjugations. | |
| 2. Lunfardo: A slang vocabulary derived from Italian, Corsican, and other immigrant languages, which has been incorporated into everyday speech. | |
| 3. Accent and pronunciation: Argentines tend to pronounce the "c" and "z" sounds with a soft "s" or "sh" sound, rather than a hard "th" sound like in standard Spanish. | |
| Overall, Argentine Spanish is known for its distinctive flavor and is widely understood throughout the Spanish-speaking world. However, it’s worth noting that there may be regional variations within Argentina, and some dialects may differ slightly from the standard Rioplatense variety. | |
| gpt4-turbo-1106-preview | The primary language spoken in Argentina is Spanish. Specifically, the variety of Spanish spoken there is known as Rioplatense Spanish, which is characterized by its unique accent and the use of the pronoun "vos" instead of "tú" for the second person singular. Additionally, there are various indigenous languages spoken in different regions of the country, as well as immigrant languages such as Italian, German, and English, but these are much less widespread than Spanish. |