EMERGE: Integrating RAG for Improved Multimodal EHR Predictive Modeling
Abstract
The integration of multimodal Electronic Health Records (EHR) data has notably advanced clinical predictive capabilities. However, current models that utilize clinical notes and multivariate time-series EHR data often lack the necessary medical context for precise clinical tasks. Previous methods using knowledge graphs (KGs) primarily focus on structured knowledge extraction. To address this, we propose EMERGE, a Retrieval-Augmented Generation (RAG) driven framework aimed at enhancing multimodal EHR predictive modeling. Our approach extracts entities from both time-series data and clinical notes by prompting Large Language Models (LLMs) and aligns them with professional PrimeKG to ensure consistency. Beyond triplet relationships, we include entities’ definitions and descriptions to provide richer semantics. The extracted knowledge is then used to generate task-relevant summaries of patients’ health statuses. These summaries are fused with other modalities utilizing an adaptive multimodal fusion network with cross-attention. Extensive experiments on the MIMIC-III and MIMIC-IV datasets for in-hospital mortality and 30-day readmission tasks demonstrate the superior performance of the EMERGE framework compared to baseline models. Comprehensive ablation studies and analyses underscore the efficacy of each designed module and the framework’s robustness to data sparsity. EMERGE significantly enhances the use of multimodal EHR data in healthcare, bridging the gap with nuanced medical contexts crucial for informed clinical predictions.
Keywords electronic health record, multimodal learning, large language model, retrieval-augmented generation
1 Introduction
The advent of Electronic Health Records (EHR) marks a pivotal advancement in the way patient data is gathered and analyzed, contributing to a more effective and informed healthcare delivery system for clinical prediction [1, 2, 3, 4, 5]. This advancement is largely attributed to the utilization of multimodal EHR data, which primarily includes clinical notes and multivariate time-series data from patient records [6, 7, 8]. Such data types are integral to healthcare prediction tasks, mirroring the holistic approach practitioners adopt by leveraging various patient data points to inform their clinical decisions and treatment strategies, rather than depending on a single data source [9]. Deep learning-based methods have become the mainstream approach, processing multimodal data to learn a mapping from heterogeneous inputs to output labels [10, 11, 6]. However, in contrast to healthcare professionals, who have a deep understanding of medical contexts through extensive experience and knowledge, neural networks trained from scratch lack these insights into medical concepts [12]. Without deliberate integration of external knowledge, these networks often lack the ability or sensitivity to recognize crucial disease entities or laboratory test results within the EHR, essential for accurate prediction tasks [13]. In response, some recent studies have begun incorporating knowledge graphs to infuse additional medical insights into their analyses [14, 15]. These graphs offer a supplementary layer of clinically relevant concepts, thereby enhancing the model’s ability to provide contextually meaningful representations and interpretable evidence [16]. Despite these advancements, significant limitations remain in fully linking external knowledge with multiple EHR modalities, underscoring the imperative need for continuous research to integrate multi-source insights and improve the multimodal EHR data predictive modeling.
Previous methods integrating external medical knowledge into EHR data analysis tend to extract knowledge from data modalities such as ICD disease codes, patient conditions, procedures, and drugs, neglecting the use of clinical notes and time-series data, which are more common and practical [17] (Limitation 1). Additionally, these methods primarily extract hierarchical and structured knowledge from clinical-context knowledge graphs. However, these medical concepts—entity names and their relationships into a graph have limited direct contribution to predictive tasks (Limitation 2). With Large Language Models (LLMs) like GPT-4 [18] demonstrating strong capabilities in diverse clinical tasks [13, 19, 20] and serving as large medical knowledge graphs (KGs) [21]. By prompting the LLM, GraphCare [22] constructs a GPT-KG using structured condition, procedure, and drug record data, represented as triples (entity 1, relationship, entity 2). It further employs graph neural networks for downstream tasks. However, this approach encounters the hallucination issue [23], where LLMs may generate incorrect or fabricated information. To mitigate this, GraphCare collaborates with medical professionals to scrutinize and remove potentially harmful content, a process that is both complex and labor-intensive, requiring significant expertise to validate and refine the generated triples. Moreover, directly generating the KG via LLMs introduces a domain gap since this task is likely untrained for the LLMs, leading to potentially lower accuracy compared to professional knowledge graphs built through established methodologies (Limitation 3).
To overcome these limitations, we propose utilizing LLMs in a Retrieval-augmented Generation (RAG) approach [24]. The RAG framework integrates structured time-series EHR data, unstructured clinical notes, and an established KG (PrimeKG [25]) with LLM’s semantic reasoning capabilities [26]. The LLMs are prompted to generate comprehensive summaries of patients’ health statuses, and these summaries are then fused for downstream tasks. Despite its apparent simplicity, applying this method to clinical tasks presents several technical challenges:
Challenge 1: How to extract entities from multimodal EHR data and match these entities with external KG consistently? Extracting entities from the diverse and complex formats of EHR data (including clinical notes and multivariate time-series data) is challenging. Moreover, unlike structured codes where it can directly compare the code-related entities’ embedding with KG’s entity, the entities extracted by LLM have hallucination issues. Accurately matching extracted entities with those in an external knowledge graph while eliminating the potential for hallucinations posed by LLMs is crucial for maintaining the integrity and reliability of the clinical prediction tasks [27].
Challenge 2: How to encode and incorporate long-text retrieved knowledge with task-relevant characteristics? The extracted textual knowledge likely contains too many tokens [28] for conventional language model inputs (e.g., BERT supports only 512 tokens [29]). However, with the development of long-context LLMs [30], it is feasible to leverage LLMs to distill this knowledge further. Additionally, simply integrating the retrieved knowledge may not be task-specific, creating a gap between the knowledge and downstream tasks [31, 32, 33]. Therefore, a task-relevant prompting strategy [34] is necessary during the LLM distillation process.
To these ends, We propose EMERGE framework to address the above limitations and challenges with the following approaches, which are our three-fold contributions:
-
1.
We design a RAG-driven multimodal EHR enhancement framework for clinical notes and time-series EHR data (Response to Limitation 1). EMERGE leverages the capabilities of LLMs and professionally labeled large medical knowledge graphs. We retrieve medical entities by prompting the LLM for clinical notes and using z-score-based filtering for time-series data, then match them in KG with post-validation and alignment to mitigate hallucination (Response to Limitation 3). In addition to triples of entities, we also include more knowledge by extending the entities’ definition and description. (Response to Limitation 2).
-
2.
Methodologically, we first compare LLM-generated entities with original clinical notes to ensure the entities appear in the raw text. We then compute their embeddings and cosine similarities among extracted entities and KG entities, aligning the entities through threshold-based filtering. This ensures that the overall entity extraction and matching process adheres to clinical standards with consistency guarantees (Response to Challenge 1). We prompt the long-context LLM to summarize the extracted knowledge into a distilled reflection of the patient’s health status, instructing the generated content is task-relevant. To integrate the extracted knowledge and consider heterogeneity, we design an adaptive multimodal fusion network with a cross-attention mechanism that attentively fuses each modality’s representation (Response to Challenge 2).
-
3.
Experimentally, our extensive experiments on the MIMIC-III and MIMIC-IV datasets, focusing on in-hospital mortality and 30-day readmission tasks, demonstrate EMERGE’s superior performance and the effectiveness of each designed module. Additionally, to meet practical clinical needs, we evaluate the model’s robustness with fewer training samples, showing EMERGE’s remarkable resilience against data sparsity. Moreover, a case study on the generated summaries reflects the framework’s soundness, also serving as an interpretable decision-making reference.
2 Related Work
2.1 Multimodal EHR Learning
The evolution of medical technology has enabled the analysis of various medical modalities—ranging from clinical notes and time-series laboratory test data to demographics, conditions, procedures, drugs, and medical imaging. Noteworthy efforts in multimodal learning for healthcare include MedGTX [35] and M3Care [6]. MedGTX introduces a pre-trained model for joint multi-modal representation learning of structured and textual EHR data by interpreting structured EHR data as a graph and employing a graph-text multi-modal learning framework. M3Care compensates for the missing modalities by imputing task-related information in the latent space through auxiliary information from similar patients. M3Care leverages a task-guided modality-adaptive similarity metric to effectively handle missing modalities without relying on unstable generative models. The work of Zhang et al. [8] further explored the irregularity of time intervals in time-series EHR data and clinical notes via a time attention mechanism. Notably, Xu et al. [9] introduced a joint learning approach from visit sequences and clinical notes, employing Gromov-Wasserstein Distance for contrastive learning and dual-channel retrieval to enhance patient similarity analysis. Lee et al. [36] proposed a unified framework for learning across all EHR modalities, eschewing separate imputation modules in favor of modality-aware attention mechanisms.
Although the methods mentioned above perform well across multiple joint modalities, a common drawback is their limited consideration of incorporating clinical background information, wherein external medical knowledge could provide significant insights into the EHR data. Furthermore, the absence of semantic medical knowledge renders the training-from-scratch pipeline more challenging to converge, especially when data is scarce in practical clinical settings.
2.2 Incorporating External Knowledge for EHR
Addressing the need to blend clinical background knowledge with EHR data, numerous studies have leveraged medical knowledge graphs (KGs) to enhance the EHR data representation learning process, thereby augmenting predictive performance. Techniques such as utilizing the ancestor information of nodes within KGs have been employed to refine medical representation learning, as seen in GRAM [10], which integrates hierarchical medical ontologies via a graph attention network. KAME [11] builds on this by embedding ontology information throughout the prediction process, enriching the contextual understanding of models. MedPath [14] employs graph neural networks to capture and integrate high-order connections from knowledge graphs into input representations, thereby enhancing the relevance and utility of external knowledge. MedRetriever [37] enhances health risk prediction and interpretability by leveraging unstructured medical text from authoritative sources. It combines EHR embeddings with features from target disease documents to retrieve relevant text segments. Collaborative graph learning models, such as CGL [38], explore patient-disease interactions and domain knowledge, while KerPrint [16] focus on addressing knowledge decay on multiple time visits. The advent of Large Language Models (LLMs) as comprehensive knowledge bases [21] offers new possibilities, exemplified by GraphCare [22], which creates a KG from structured EHR data for GNN learning, though it faces challenges related to content hallucination.
These efforts mostly concentrate on extracting knowledge from structured medical data, overlooking the rich semantic information embedded in unstructured EHR data. This oversight limits the potential for fully leveraging the depth of knowledge contained within EHRs, highlighting the need for methodologies that encompass both structured and unstructured data modalities.
3 Problem Formulation
3.1 EHR Datasets Formulation
The electronic health records (EHR) dataset comprises both structured and unstructured data, represented as multivariate time-series data and clinical notes, respectively. To facilitate analysis, these two modalities are initially processed separately, either from the raw data matrix or via a tokenization process. Specifically, the multivariate time-series data, denoted as , encapsulate information across visits and numeric or categorical features. Clinical notes, denoted as , contain recorded notes documenting the health status of each patient. Additionally, external knowledge graphs (KGs) are incorporated to enhance the personalized representation of each patient.
3.2 Predictive Objective Formulation
The prediction objective is conceptualized as a binary classification task, which involves predicting in-hospital mortality and 30-day readmission. By leveraging the comprehensive patient information derived from EHR data and KGs, the model aims to predict specific clinical outcomes. The prediction task is formulated as:
| (1) |
where represents the targeted prediction outcome.
For the in-hospital mortality prediction task, our objective is to determine the discharge status based on data from the initial 48-hour window of an ICU stay, where a status of 0 indicates the patient is alive and 1 indicates the patient is deceased. In the same vein, the 30-day readmission task aims to predict whether a patient will be readmitted within 30 days after discharge, with 0 indicating no readmission and 1 indicating readmission.
3.3 Notation Table
The notations and their descriptions used in this paper are presented in Table 1.
| Notations | Descriptions |
| Number of patients | |
| External knowledge graphs | |
| Time-series data of one patient | |
| Clinical note of one patient | |
| Retrieved textual knowledge of one patient | |
| Number of visits for a patient in time-series EHR data | |
| Number of features in time-series EHR data | |
| Representation of modality or fused hidden states | |
| Entity set extracted from a single time-series EHR data | |
| Entity set extracted from one clinical note | |
| Cosine similarity between two embedding vectors | |
| Threshold for identifying anomalies in time-series data | |
| Threshold for matching extracted entities with nodes in knowledge graph | |
| Z-score value for the -th feature at visit of one patient | |
| Parameter matrices of linear layers. Footnote denotes the name of the layer | |
| Fused final representation of the -th patient | |
| LM | Language Model (basically BERT-based model) |
| LLM | Large Language Model (basically GPT-based model) |
4 Methodology
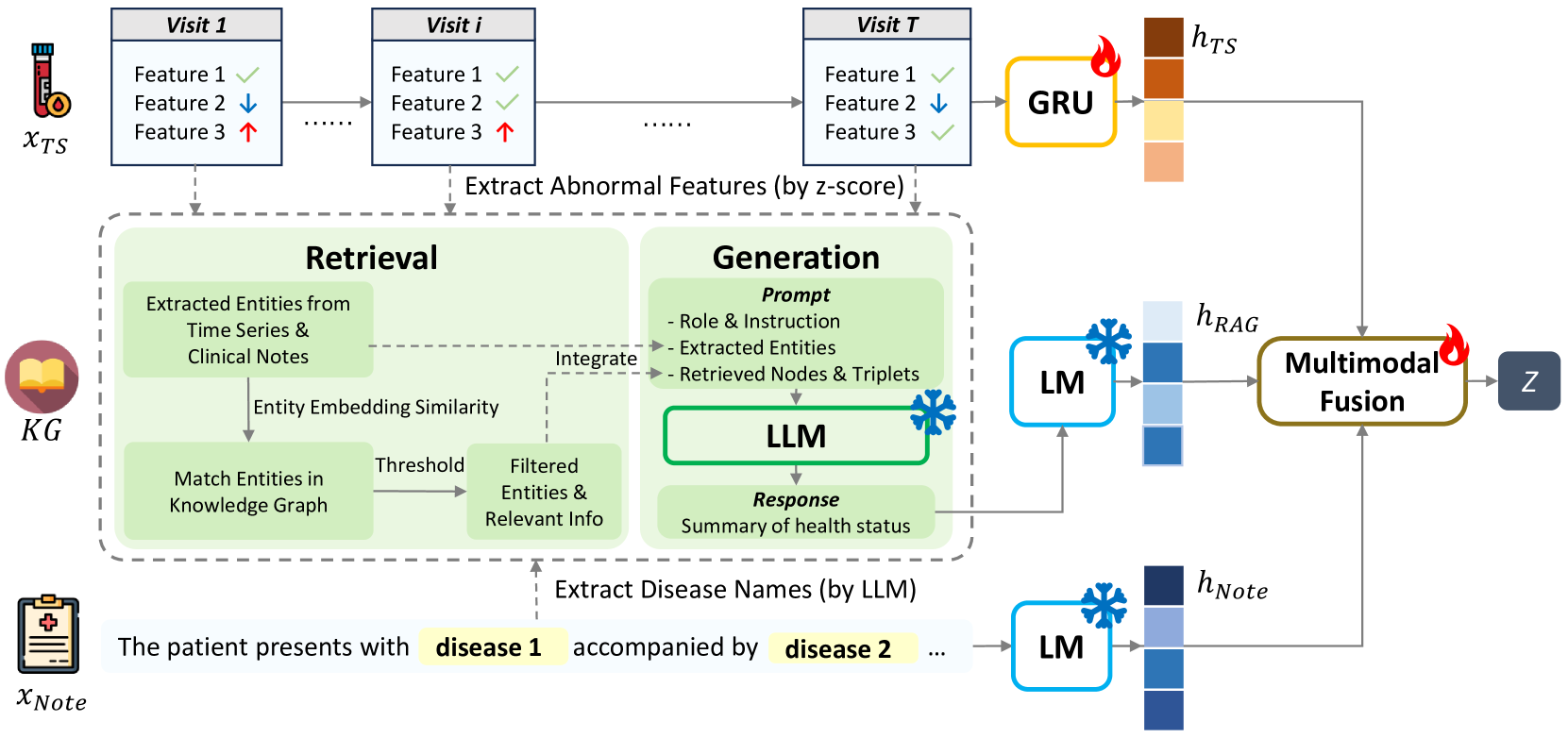
Figure 1 shows the overall framework architecture of EMERGE. It consists of three main modules:
-
•
Multimodal Embedding Extraction applies GRU as time-series data’s encoder and pretrained long-context language model for clinical notes.
-
•
RAG-Driven Enhancement Pipeline retrieves entities and links knowledge in established KG for both time-series and clinical notes modalities. We integrate entities triples relationships along with their definitions and descriptions along with disease relationships into a prompt. The prompt serves as the instruction for the LLM to generate the patient health status summary.
-
•
Multimodal Fusion Network incorporates the generated summaries and adaptively fuses multiple modalities for further downstream tasks.
4.1 Multimodal EHR Embedding Extraction
We delve into the techniques used for embedding extraction from multimodal EHR, emphasizing the transformation from raw, human-readable inputs, denoted as , to deep semantic embeddings for comprehensive analysis.
When dealing with time-series data, we employ the Gated Recurrent Unit (GRU) network as the encoder. GRU is a highly efficient variant of recurrent neural networks, capable of capturing the time dependencies in sequence data and encoding this temporally linked information. We extract the representation of time-series as below:
| (2) |
where is the time-series data and denotes the output of time-series encoder.
As for text records, we utilize medical domain language model to obtain text embeddings, represented as TextEncoder. Formally,
| (3) |
where is the textual clinical notes and denotes the note representation.
4.2 RAG-Driven Enhancement Pipeline
4.2.1 Extract Entities from Multimodal EHR Data
In order to exploit the expert information encapsulated within the knowledge graph, it is necessary to extract disease entities from both time-series data and clinical notes, and subsequently align them with the information present in the graph. The set of disease entities in the time-series data is denoted as , while those in the clinical notes data are denoted as . Naturally, we design two separate processes tailored to each modality.
Retrieval process for time-series data.
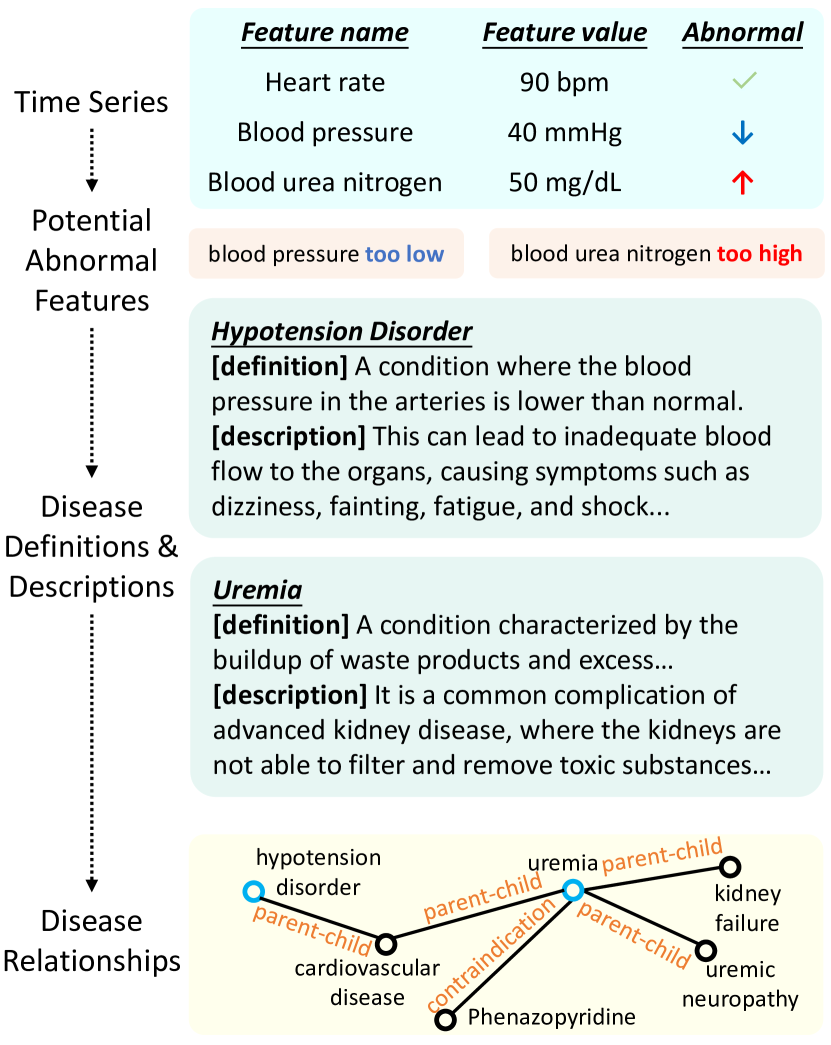
Time-series data is a structured format encompassing feature names and resultant values post clinical examination. Each feature name reflects specific aspects of an individual’s physical condition, highlighting the deviations from the reference range. As shown in Figure 2, the specified record showcases a low blood pressure and high blood urea nitrogen, significantly surpassing the normal range. This imply the potential risk of hypo-tension and uremia for the patient. Indeed, such feature names occur in diseases definitions and descriptions, typically indicating serious health threats.
For each patient, there are usually more than one entity (or abnormal feature), and some may be missing values. Consequently, our focus is primarily on non-empty values. For each feature , we can identify outliers through the z-score method [39], which measures anomalies by calculating the deviation of data points from the mean, using standard deviation as a unit as below:
| (4) |
where represents the z-score of the -th feature of a patient. Features over a specified threshold (such as 3- deviation) are identified as abnormal, indicating potential health issues.
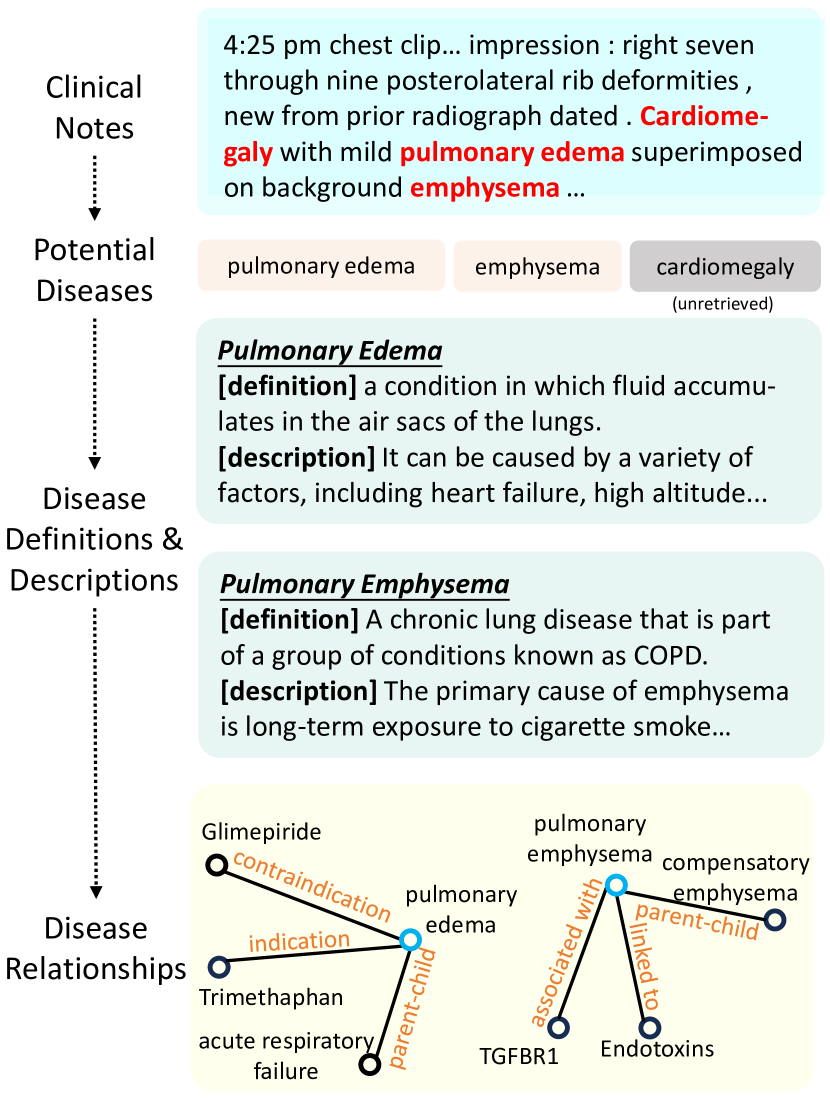
Retrieval process for clinical notes.
Contrary to structured data, clinical notes are presented in a textual format, which makes it challenging to comprehend and extract valuable information. However, LLMs have exhibited exceptional performance on natural language understanding tasks, including named entity recognition (NER). Therefore, we utilize an LLM to identify potential disease names that the patient may have, as shown in Figure 4. Moreover, we implement specified rules for effective post-processing.
-
1.
Entities Extraction: We employ an example and clear instruction in prompt, instructing LLM to concentrate on entities of disease that the patient may suffer from. The complete prompt template is in Figure 3. Sometimes there may be no entities yield in single invocation, so we utilize multiple rounds to incrementally expand the current extracted entity set as below:
(5) (6) where represents the prompt template. represents the entity set obtained in the -th round and represents the aggregate set.

Figure 3: Prompt template for extracting entities. -
2.
Entities Refinement: Considering the hallucination issue associated with LLM, we design a post-processing process to address it. This process consists of three primary steps: firstly, we discard entities that do not appear in the original text; secondly, we leverage LLM to filter entities not in disease type; and finally, we delete duplicated entities to prevent semantic redundancy.
(7) where denotes the illegal entity set, which we then remove from .
To ensure the quantity and quality of the extracted entities, we execute step 1 and step 2 iteratively until achieving convergence.
4.2.2 Retrieve Information from External KG
To ensure an accurate match between the extracted entities and nodes within the knowledge graph, we adapt a semantic-based dense vector retrieval approach. Initially, we utilize a sentence embedding model denoted as TextEncoder to encode all KG nodes, denoted as . Subsequently, for each entity in or , we deploy the same embedding model to encode them. This process ensures that all embeddings are aligned within the same vector space, as shown below:
| (8) | ||||
| (9) |
where and symbolize disease entities from and the extracted entity set. Respectively, and denote their corresponding embeddings.
When match relative nodes, we take current entity (including abnormal features and potential disease names) as the query. Then we compute the similarities between and each node in KG. The metric used for these calculation is cosine similarity, as shown below:
| (10) |
where and denote the embeddings of the entity and the node.
In our approach, we establish a threshold to gauge the requisite similarity between two embeddings. We focus on nodes that surpass this threshold, ensuring that only the most relevant matches are considered:
| (11) |
where is the threshold for similarity, and denotes the set of nodes that we exclusively accept as matches for the entity .
Subsequently, we can obtain the definitions and descriptions within the disease entities, each represented as a node of the graph. Furthermore, relationships between diseases, encapsulated within triples, act as the edges of the graph. These pieces of information elaborate on the severity of the diseases, the harm they pose to the human body, and their interconnections from various perspectives. They further clarify the entity information from the original notes, thereby enhancing LLM’s understanding of the patient’s health condition.
4.2.3 Summarize and Encode KG Knowledge
Drawing from the entities extracted from time-series and clinical notes, along with supplementary information about them, we have compiled extensive details about the patient’s medical condition. However, this content contains too many tokens for conventional language model inputs (such as BERT). As a countermeasure, we utilize retrieval-augmented generation to condense the aforementioned details, thereby attaining a concise representation of the patient’s health status.
The prompt template, as illustrated in Figure 5, begins by defining a role and instructions to guild the generation by the LLM. Subsequently, we enumerate all abnormal features derived from the time-series data, and disease names extracted from clinical notes, which reflect the patient’s health threats. To enhance the comprehension, we integrate retrieved disease definitions and descriptions, along with the relationships sampled from KG to form a comprehensive supplementary resource. Based on this augmented information, the LLM compiles a summary of the patient’s health status.
Finally, we employ a language model, denoted as TextEncoder, to encode the retrieval knowledge from external KG as below:
| (12) |
where symbolizes the sentence embedding of the summary, which we will combine with and to obtain a comprehensive representation of the patient’s health status.

4.3 Multimodal Fusion Network
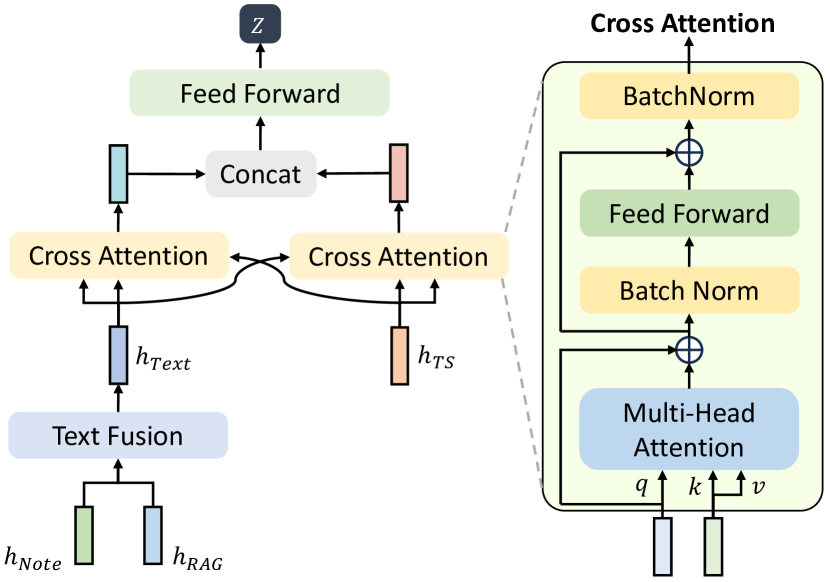
Currently, there are three learned hidden representations, denoted respectively as , , and . We first concatenate the hidden representations extracted from entities with those from the text, and then utilize a fusion network to combine and map them to a unified dimension:
| (13) |
To better integrate information from different modalities, we proposed an attention-based fusion network primarily consisting of cross-attention layers. First, the vector is computed from the hidden representation of the other modality, while the and vectors are computed from the hidden representations of the current modality:
| (14) | ||||
where , , are the , , vectors respectively, and , , are the corresponding projection matrices. Following this, we compute the attention outputs as follows:
| (15) | ||||
In addition, we apply residual connections and BatchNorm to every multi-head attention layer and FeedForward Network.
As a result, the outputs of the two cross-attention modules have carried information from both modalities. We further concatenate them and use MLP layer to obtain the fused information.
| (16) |
Finally, the fused representation is expected to predict downstream tasks. We pass through a two-layer MLP structure, with an additional dropout layer between two fully connected layers, to obtain the final prediction results :
| (17) |
The BCE Loss is selected as the loss function for the binary mortality outcome and readmission prediction task:
| (18) |
where is the number of patients within one batch, is the predicted probability and is the ground truth.
By converting these three different types of data into compatible embeddings, our model lays a solid groundwork for the multimodal analysis of EHR. This strategy of embedding extraction sets the stage for further analysis tasks under the RAG framework, allowing us to accurately and comprehensively understand and analyze the complex information in EHR.
5 Experimental Setups
5.1 Experimented Datasets and Utilized KG
Sourced from the EHRs of the Beth Israel Deaconess Medical Center, MIMIC-III and MIMIC-IV dataset is extensive and widely used in healthcare research. We adhere to the established EHR benchmark pipeline [40, 41] for preprocessing time-series data. 17 lab test features (include categorical features) and 2 demographic features (age and gender) are extracted. To minimize missing data, we consolidate every consecutive 12-hour segment into a single record for each patient, focusing on the first 48 records. And we follow Clinical-LongFormer[42]’s approach to extract and preprocess clinical notes, which includes minimal but essential steps: removing all de-identification placeholders to protect Protected Health Information (PHI), replacing non-alphanumeric characters and punctuation marks, converting all letters to lowercase for consistency, and stripping extra white spaces.
We excluded all patients without any notes or time-series data. We randomly split the dataset into training, validation, and test set with 7:1:2 percentage. The statistics of datasets is in Table 2.
| Dataset | Split | Samples | ||
| MIMIC-III | Train | 10776 (70.00%) | 1389 (12.89%) | 1787 (16.58%) |
| Val | 1539 (10.00%) | 193 (12.54%) | 258 (16.76%) | |
| Test | 3080 (20.00%) | 361 (11.72%) | 489 (15.88%) | |
| MIMIC-IV | Train | 13531 (70.00%) | 1608 (11.88%) | 2099 (15.51%) |
| Val | 1933 (10.00%) | 244 (12.62%) | 297 (15.36%) | |
| Test | 3867 (20.00%) | 448 (11.59%) | 599 (15.49%) |
The external knowledge base we utilized is PrimeKG [25], which integrates 20 high-quality resources to describe 17,080 diseases with 4,050,249 relationships representing ten major biological scales, including disease-associated entities. Futhermore, PrimeKG extracts textual features of disease nodes containing information about disease prevalence, symptoms, etiology, risk factors, epidemiology, clinical descriptions, management and treatment, complications, prevention, and when to seek medical attention, which are highly relevant to the clinical prediction tasks.
The median number of retrieved entities is 14 for MIMIC-III and 7 for MIMIC-IV, with an average effective extracted entity rate of 67.25% and 66.88%, respectively, from a total of 468,948 and 319,893 extracted entities for the two datasets.
When prompting the LLM to generate the summary, 4 patients in the MIMIC-III dataset were not successfully generated due to DeepSeek-v2 [43]’s strict content censor policy, which flagged “Content Exists Risk.” We replaced these with “None”.
5.2 Evaluation Metrics
We adopt the following evaluation metrics, which are widely used in binary classification tasks:
-
•
AUROC: This metric is our primary consideration in binary classification tasks due to its widespread use in clinical settings and its effectiveness in handling imbalanced datasets [44].
-
•
AUPRC: The AUPRC is particularly useful for evaluating performance in datasets with a significant imbalance between classes [45].
-
•
min(+P, Se): This composite metric represents the minimum value between precision (+P) and sensitivity (Se), providing a balanced measure of model performance [46].
All these three metrics are the higher the better.
5.3 Baseline Models
5.3.1 EHR Prediction Models
We include multimodal EHR baseline models (MPIM [8], UMM [36], MedGTX [35], VecoCare[9], M3Care [6]) and approaches that incorporating external knowledge from KG (GRAM [10], KAME [11], CGL [38], KerPrint [16], MedPath [14], MedRetriever [37]), and LLM facilitated model GraphCare [22] as our baselines.
-
•
MPIM [8] (ICML-2023) models the irregularity of time intervals in time-series EHR data and clinical notes via gating mechanism and apply interleaved attention mechanism for modality fusion.
-
•
UMM [36] (MLHC-2023) introduces Unified Multi-modal Set Embedding (UMSE) and Modality-Aware Attention (MAA) with Skip Bottleneck (SB) to handle challenges in data embedding and missing modalities in multi-modal EHR.
-
•
MedGTX [35] (CHIL-2022) introduces a pre-trained model for joint multi-modal representation learning of structured and textual EHR data by interpreting structured EHR data as a graph and employing a graph-text multi-modal learning framework.
-
•
VecoCare [9] (IJCAI-2023) addresses the challenges of synthesizing information from structured and unstructured EHR data using a Gromov-Wasserstein Distance-based contrastive learning and an adaptive masked language model.
-
•
M3Care [6] (KDD-2022) proposes an end-to-end model to handle missing modalities in multimodal healthcare data by imputing task-related information in the latent space using a task-guided modality-adaptive similarity metric.
-
•
GRAM [10] (KDD-2017) enhances EHRs with medical ontologies, using an attention mechanism to represent medical concepts by their ancestors in the ontology for improved predictive performance and interpretability.
-
•
KAME [11] (CIKM-2018) employs a knowledge attention mechanism to learn embeddings for nodes in a knowledge graph, improving the accuracy and robustness of health information prediction while providing interpretable disease representations.
-
•
CGL [38] (IJCAI-2021) proposes a collaborative graph learning model to explore patient-disease interactions and incorporate medical domain knowledge, integrating unstructured text data for accurate and explainable health event predictions.
-
•
KerPrint [16] (AAAI-2023) offers retrospective and prospective interpretations of diagnosis predictions through a time-aware KG attention method and an element-wise attention method for selecting candidate global knowledge, enhancing interpretability.
-
•
MedPath [14] (WWW-2021) employs graph neural networks to capture and integrate high-order connections from knowledge graphs into input representations, thereby enhancing the relevance and utility of external knowledge.
-
•
MedRetriever [37] (CIKM-2021) enhances health risk prediction and interpretability by leveraging unstructured medical text from authoritative sources. It combines EHR embeddings with features from target disease documents to retrieve relevant text segments.
-
•
GraphCare [22] (ICLR-2024) generates patient-specific knowledge graphs from external KGs and LLMs to improve healthcare predictions with a Bi-attention Augmented (BAT) GNN, demonstrating significant improvements in various healthcare prediction tasks.
5.3.2 Multimodal Fusion Methods
To examine the effectiveness of our fusion network, we consider fusion methods: Add [47], Concat [48, 49], Tensor Fusion (TF) [50], and MAG [51, 52].
-
•
Add [47]: Simply performs element-wise addition of features from different modalities to integrate information.
-
•
Concat [48, 49]: The representations are concated to do predictions.
-
•
Tensor Fusion (TF) [50]: It integrates information from multiple sources or modalities by creating a multimodal tensor representation that captures the interactions between these modalities.
-
•
MAG [51, 52]: It dynamically fuse information from different modalities by adaptively weighting and integrating the features from each modality based on their relevance and contribution to the task at hand.
5.4 Implementation Details
5.4.1 Hardware and Software Configuration
All runs are trained on a single Nvidia RTX 3090 GPU with CUDA 12.4. The server’s system memory (RAM) size is 128GB. We implement the model in Python 3.8.19, PyTorch 2.2.2 [53], PyTorch Lightning 2.2.4 [54], and pyehr [41].
5.4.2 Model Training and Hyperparameters
AdamW [55] is employed with a batch size of 256 patients. All models are trained for 100 epochs with an early stopping strategy based on AUPRC after 10 epochs without improvement. The learning rate and hidden dimensions are tuned using a grid search strategy on the validation set. The searched hyperparameter for EMERGE is: 128 hidden dimensions, 0.001 learning rate. The dropout rate is set to . Performance is reported in the form of mean±std by applying bootstrapping on all test set samples 10 times for the MIMIC-III and MIMIC-IV datasets, following practices in AICare [56]. The threshold for identifying anomalies in time-series data is set as 2 (z-score value=2). The threshold for matching entities in KG is set as 0.6 for MIMIC-III and 0.7 for MIMIC-IV.
5.4.3 Utilized (Large) Language Models
EMERGE utilizes both Language Models (LMs) and Large Language Models (LLMs) in the pipeline. For LMs, we use the frozen-parameter pretrained Clinical-LongFormer [42]’s [CLS] token [29] for extracting textual embeddings and BGE-M3 [57] as the text embedding model to compute entity embeddings. For LLMs, we deploy an offline Qwen-7B [58] to extract entities from clinical notes and call the DeepSeek-V2 Chat [43] API to generate summaries.
-
•
Clinical-LongFormer [42]: Pretrained on MIMIC-III clinical notes, it is a domain-enriched language model designed to handle long clinical texts by extending the maximum input sequence length from 512 to 4096 tokens. Adopting it to extract MIMIC text embeddings follows Zhang et al. [8].
-
•
BGE-M3 [57]: Targets multi-language and cross-language text vectorization using a vast, diverse dataset. It is specifically designed for feature extraction and retrieval, accepting up to 8192 tokens with a hidden dimension of 1024.
-
•
Qwen 1.5-7B Chat [58]: A large language model pretrained on 3TB of data, supporting extensive task adaptability. It can handle contexts up to 8192 tokens, making it capable of processing patients’ clinical notes records.
-
•
DeepSeek-V2 Chat [43]: DeepSeek-V2 is a Mixture-of-Experts language model with 236B parameters, of which only 21B are activated per token, featuring architectures like Multi-head Latent Attention and DeepSeekMoE for efficient inference and economical training.
6 Experimental Results and Analysis
6.1 Experimental Results
The performance of our EMERGE framework on in-hospital mortality and 30-day readmission prediction tasks on the MIMIC-III dataset is summarized in Table 3. EMERGE consistently outperforms the baseline models, indicating its superior practical applicability in real-world clinical settings.
| Methods | MIMIC-III Mortality | MIMIC-III Readmission | MIMIC-IV Mortality | MIMIC-IV Readmission | ||||||||
| AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | |
| MPIM | 85.24±1.12 | 50.52±2.56 | 50.59±2.33 | 78.65±1.51 | 48.26±2.84 | 46.94±1.97 | 89.45±0.59 | 60.10±1.67 | 57.62±1.41 | 79.13±0.78 | 47.67±1.95 | 49.52±1.99 |
| UMM | 84.01±1.10 | 49.76±2.21 | 49.41±2.45 | 77.46±1.36 | 47.81±2.55 | 47.27±1.91 | 87.82±0.73 | 53.84±2.35 | 55.40±1.98 | 78.75±0.63 | 48.63±1.45 | 49.58±1.29 |
| MedGTX | 85.97±1.04 | 49.36±3.05 | 48.20±2.27 | 78.60±1.17 | 46.44±2.69 | 45.99±2.60 | 88.77±0.73 | 58.33±2.31 | 58.25±1.59 | 78.82±1.32 | 47.48±1.88 | 49.54±1.76 |
| VecoCare | 83.43±1.49 | 47.28±2.68 | 47.92±2.22 | 76.93±1.82 | 46.18±2.76 | 47.22±2.63 | 88.01±0.68 | 55.37±2.20 | 55.35±1.72 | 79.17±1.20 | 51.58±1.93 | 51.42±1.48 |
| M3Care | 83.33±1.24 | 47.86±2.33 | 49.96±1.99 | 76.80±1.55 | 46.29±2.62 | 45.38±2.32 | 88.14±0.78 | 54.06±2.04 | 54.30±1.73 | 79.87±1.31 | 51.03±1.95 | 51.10±1.36 |
| GRAM | 84.70±1.34 | 49.21±4.45 | 49.64±2.85 | 77.84±1.49 | 47.97±3.68 | 46.95±2.12 | 87.75±0.65 | 54.01±2.93 | 54.62±2.63 | 79.53±1.01 | 50.13±2.53 | 50.80±1.67 |
| KAME | 84.59±1.11 | 49.48±3.37 | 49.51±2.33 | 78.04±1.34 | 48.23±3.21 | 47.41±2.50 | 87.76±0.67 | 55.74±2.37 | 54.79±1.44 | 78.91±1.01 | 47.62±1.66 | 49.63±1.28 |
| CGL | 84.20±1.16 | 47.64±3.47 | 47.67±2.61 | 77.47±1.33 | 46.68±3.33 | 47.73±2.25 | 88.42±0.94 | 56.64±2.21 | 54.80±1.62 | 78.95±0.90 | 47.74±1.66 | 49.16±1.24 |
| KerPrint | 85.29±1.21 | 51.23±3.48 | 50.88±2.24 | 78.81±1.68 | 47.92±2.45 | 47.32±2.52 | 88.28±0.60 | 57.90±1.80 | 55.12±1.46 | 79.84±1.03 | 53.55±1.61 | 52.34±1.64 |
| MedPath | 85.61±1.34 | 48.90±3.24 | 48.86±3.00 | 77.92±0.85 | 45.66±2.61 | 45.72±2.24 | 88.85±1.00 | 56.82±2.60 | 57.96±2.63 | 78.88±0.83 | 47.58±2.23 | 49.75±2.39 |
| MedRetriever | 85.62±1.47 | 49.99±3.06 | 49.03±2.54 | 77.77±0.90 | 46.81±2.36 | 46.89±2.08 | 89.01±0.42 | 57.75±1.60 | 58.16±1.32 | 79.15±0.90 | 48.26±1.08 | 49.49±1.18 |
| GraphCare | 85.85±0.95 | 50.16±2.20 | 49.15±2.57 | 78.70±1.19 | 47.19±2.33 | 46.82±2.04 | 89.13±0.57 | 60.85±2.01 | 59.16±1.85 | 79.18±1.15 | 48.55±1.86 | 49.64±1.58 |
| EMERGE | 86.25±1.50 | 52.08±2.87 | 51.42±2.40 | 79.06±1.05 | 48.59±2.52 | 47.86±2.58 | 89.50±0.57 | 63.11±2.12 | 59.95±1.49 | 80.61±1.09 | 57.28±2.01 | 54.50±1.71 |
6.2 Ablation Studies
6.2.1 Comparing Different Modality Fusion Strategies
To understand the contribution of each modality and the modality fusion approaches, we compare their performance, as illustrated in Table 4. The results reveal that: 1) Utilizing multiple modalities is better than using a single modality. 2) The RAG pipeline-generated summary exhibits stronger representation capability (by comparing the settings “Note only” vs. “RAG only”, and “TS+Note” vs. “TS+RAG”). This showcases the effectiveness of task-relevant generated summaries in facilitating prediction modeling. 3) EMERGE’s cross-attention-based adaptive multimodal fusion network outperforms other modality fusion strategies.
| Methods | MIMIC-III Mortality | MIMIC-III Readmission | MIMIC-IV Mortality | MIMIC-IV Readmission | ||||||||
| AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | |
| TS only | 84.57±1.50 | 46.53±3.14 | 48.89±2.92 | 77.17±1.36 | 43.87±2.72 | 46.21±2.83 | 87.96±0.65 | 55.62±2.00 | 55.02±2.01 | 79.03±1.17 | 51.79±1.93 | 51.02±1.66 |
| Note only | 66.50±1.40 | 19.62±0.68 | 23.22±1.23 | 64.76±1.00 | 24.64±0.76 | 27.07±0.51 | 69.47±1.03 | 27.70±1.26 | 30.90±1.30 | 66.40±0.97 | 29.52±1.31 | 32.39±1.61 |
| RAG only | 69.21±1.54 | 22.46±2.68 | 27.04±2.62 | 64.65±1.05 | 24.12±1.78 | 27.65±1.63 | 71.84±1.27 | 27.68±2.76 | 30.62±2.91 | 67.37±1.29 | 28.26±2.37 | 31.83±2.16 |
| TS+Note | 85.72±1.34 | 49.02±2.76 | 48.28±2.36 | 78.36±1.06 | 46.95±2.49 | 45.79±2.17 | 88.55±0.58 | 60.01±1.84 | 57.95±1.47 | 79.93±0.94 | 54.29±1.67 | 52.84±1.45 |
| TS+RAG | 86.21±1.29 | 51.15±3.24 | 50.62±2.78 | 78.24±0.90 | 46.94±2.54 | 47.11±2.46 | 89.49±0.58 | 62.49±2.19 | 58.75±2.20 | 80.55±1.12 | 55.64±2.07 | 52.38±1.77 |
| Note+RAG | 72.32±1.14 | 27.07±1.66 | 28.66±1.72 | 68.80±0.80 | 28.87±1.47 | 31.96±1.62 | 74.96±1.12 | 32.28±2.97 | 35.43±2.54 | 70.72±1.23 | 32.42±2.26 | 35.33±2.70 |
| TS+Text: Concat | 85.66±1.44 | 49.41±2.89 | 48.18±3.09 | 78.04±1.00 | 46.72±2.36 | 46.18±2.21 | 89.33±0.57 | 62.42±2.10 | 59.75±1.23 | 80.58±0.96 | 55.40±1.84 | 52.77±1.47 |
| TS+Text: TF | 85.55±1.42 | 50.30±2.92 | 50.11±3.24 | 77.83±1.15 | 46.73±2.50 | 46.70±2.59 | 89.08±0.57 | 59.47±2.28 | 59.53±1.53 | 80.34±0.96 | 53.01±1.87 | 51.81±1.35 |
| TS+Text: MAG | 86.09±1.47 | 49.14±2.51 | 49.12±2.92 | 77.69±0.89 | 44.86±2.04 | 45.76±1.67 | 89.56±0.62 | 62.64±2.04 | 60.16±1.52 | 80.66±1.08 | 56.62±1.96 | 53.97±1.71 |
| TS+Text: Ours | 86.25±1.50 | 52.08±2.87 | 51.42±2.40 | 79.06±1.05 | 48.59±2.52 | 47.86±2.58 | 89.50±0.57 | 63.11±2.12 | 59.95±1.49 | 80.61±1.09 | 57.28±2.01 | 54.50±1.71 |
6.2.2 Comparing Different Time-series Encoders
From Figure 7, we compare the performance of four different time-series encoders: GRU, LSTM, Transformer, and RNN, in encoding EHR data. The evaluation focuses exclusively on time-series data inputs, excluding any text inputs, to determine which model is most effective in handling such data. The GRU model consistently performs well, therefore we have selected GRU as the backbone encoder for time-series data in EMERGE.
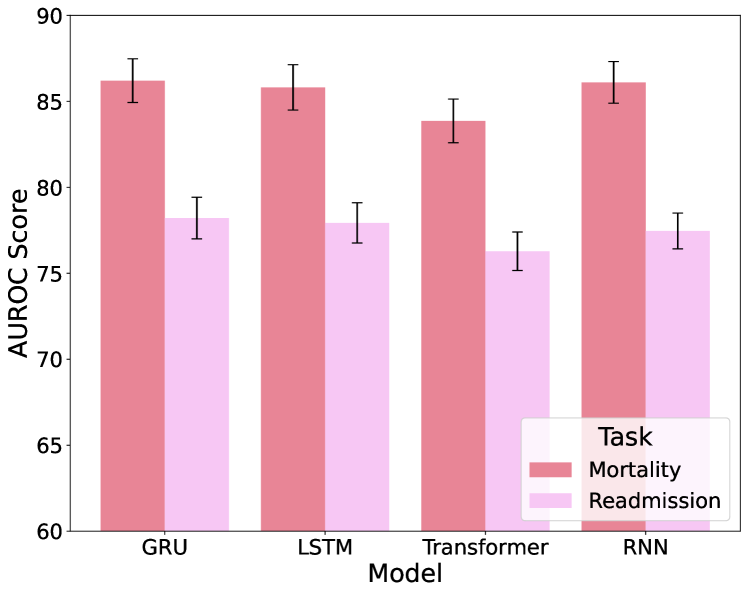
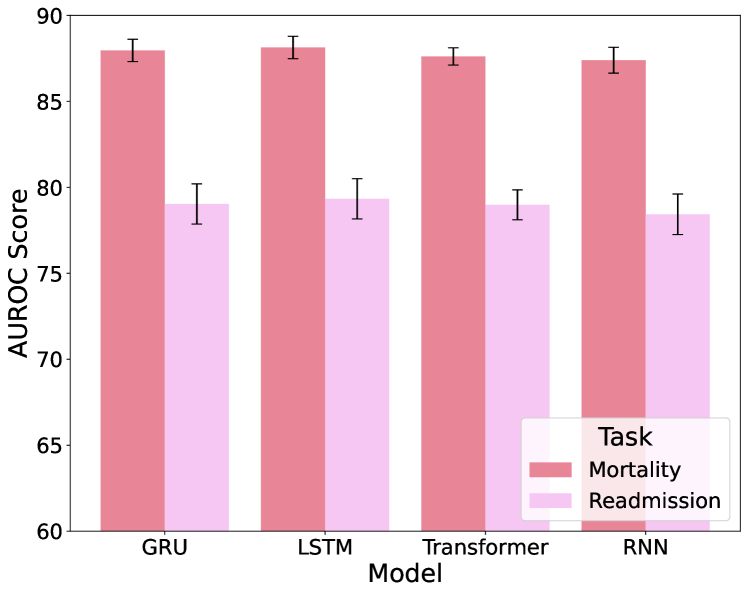
6.2.3 Comparing Different Text Fusion Approaches
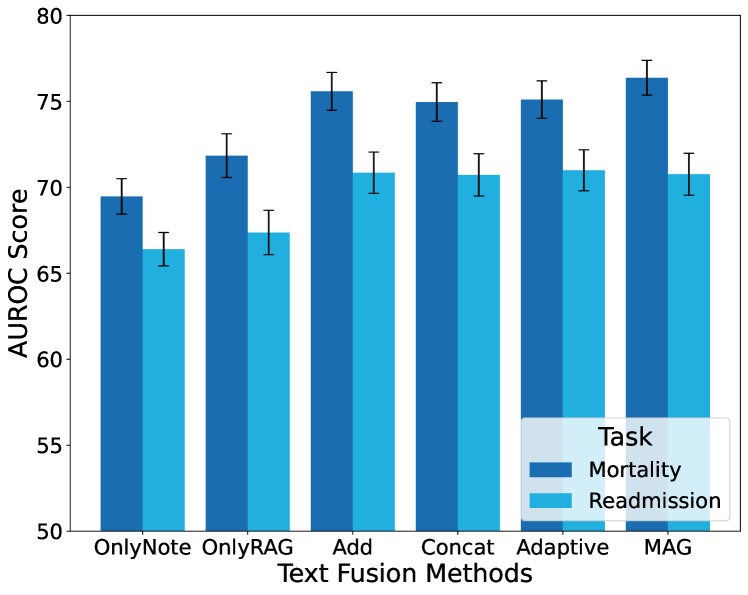
From Figure 8, similar as modality fusion, we conduct the comparison for multiple text fusion approaches: note only (“OnlyNote”), summary only (“OnlyRAG”), add, concat, adaptive concat, and MAG. The evaluation focuses exclusively on text inputs with no time-series data. The concat strategy performs the best on the MIMIC-III model and shows decent performance on MIMIC-IV. Considering its simplicity, we choose concat as the text fusion method.

6.2.4 Comparing Internal Design of Fusion Module
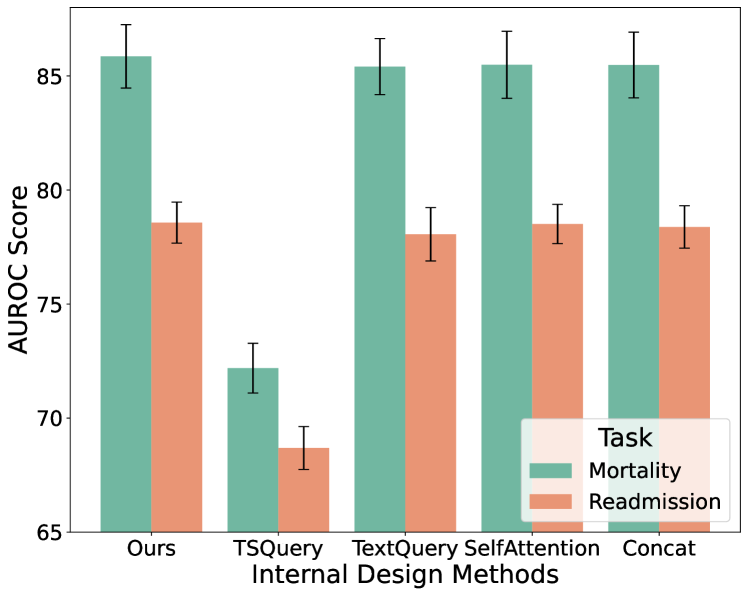
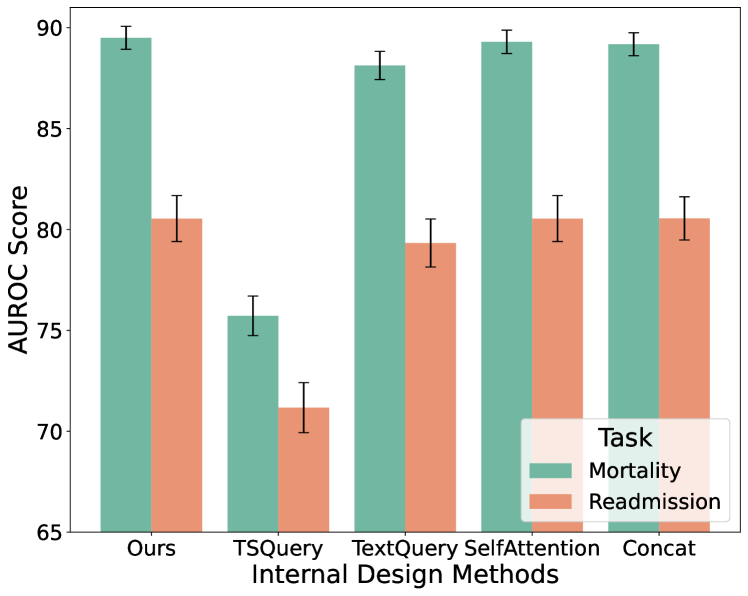
To explore in detail the role of the cross-attention mechanism for multimodal fusion in Figure 6, we provide experiments on alternative internal components in Figure 9: “Ours” represents the version in Figure 6, “TSQuery” can be regarded as the left branch with the time-series embedding serving as the query, “TextQuery” as the right branch, “SelfAttention” replaces the cross-attention and retains the concat and projection layer, and “Concat” does not include any attention module. The superior performance of our final employed fusion approach demonstrates the effectiveness of the cross-modality fusion approach in a bi-directional way.
6.3 Further Analysis
6.3.1 Sensitivity to Hidden Dimensions and Learning Rates
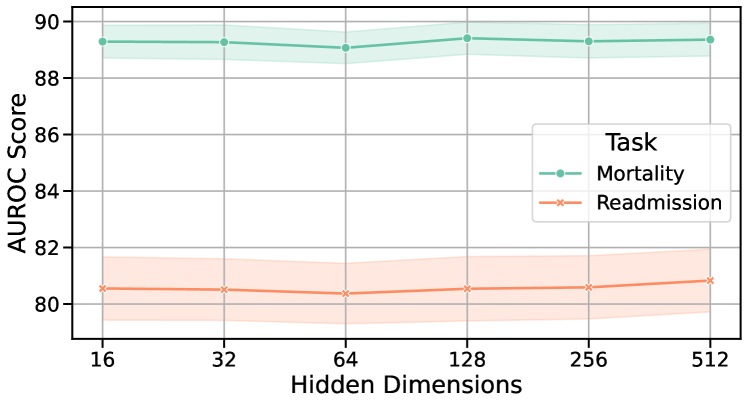
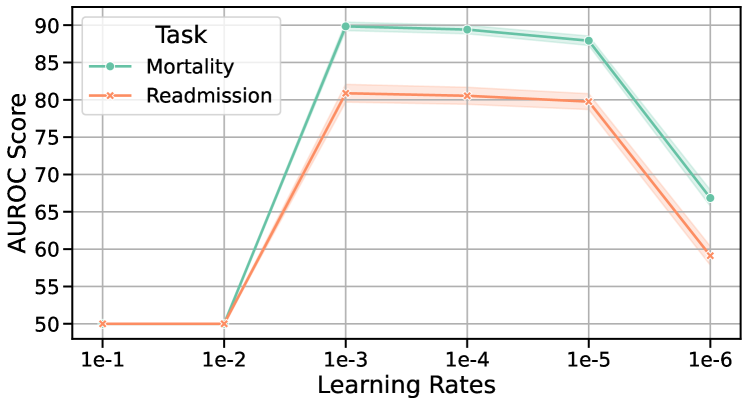
To assess the sensitivity of our EMERGE framework to different hidden dimensions and learning rates, we conducted experiments on the MIMIC-III and MIMIC-IV datasets, as shown in Figure 10. The results indicate that a hidden dimension of 128 and a learning rate of 1e-3 yield the best performance. The minimal variations across different settings demonstrate EMERGE’s low sensitivity to these hyperparameters.
6.3.2 Robustness to Data Sparsity
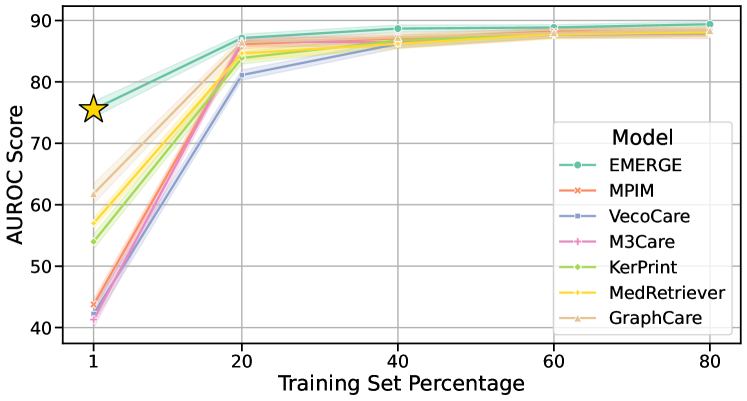
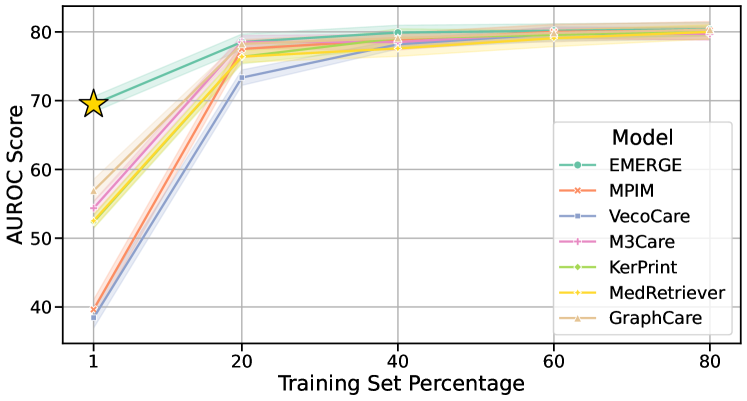
To evaluate the robustness of our EMERGE framework against data sparsity, we conduct experiments using 1%, 20%, 40%, 60%, and 80% of the training set. As depicted in Figure 11, EMERGE shows remarkable resilience, especially with only 1% (less than 150) of the training samples. This robustness is crucial in clinical settings where data collection is often challenging, making EMERGE valuable for clinical practice.
6.3.3 Case Study of Generated Summary
We include a case study in Figure 12, showcasing a comprehensive summary of the patient’s health status with EMERGE. It highlights a “high fraction of inspired oxygen”, which aligns with “fraction inspired oxygen too high” derived from time-series data, thus enabling further risk prediction. Disease entities such as adenocarcinoma, non-small cell lung cancer (NSCLC stage IV), among others, are all noted in the patient’s clinical records, demonstrating that the LLM meticulously follows the original data during the generation process. Additionally, the model conducts an analysis of the aforementioned diseases and concludes that there is a “complex medical history and the presence of multiple comorbidities”. It also forecasts a “high risk for in-hospital mortality, potential 30-day readmission” along with the auxiliary recommendation of “close monitoring and management”.

7 Conclusions
In this work, we propose EMERGE, an RAG-driven multimodal EHR data representation learning framework that incorporates time-series EHR, clinical notes data, and an external knowledge graph for healthcare prediction. The EMERGE framework comprehensively leverages LLMs’ semantic reasoning ability, long-context encoding capacity, and the medical context of the knowledge graph. The EMERGE framework achieves superior performance on two real-world datasets’ in-hospital mortality and 30-day readmission tasks against the latest baseline models. Extensive experiments showcase EMERGE’s effectiveness and robustness to data sparsity. EMERGE marks a step towards more effective utilization of multimodal EHR data in healthcare, offering a potent solution to enhance clinical representations with external knowledge and LLMs.
Ethical Statement
This study, involving the analysis of de-identified Electronic Health Records (EHR) from the MIMIC-III and MIMIC-IV datasets, upholds high ethical standards. It should be noted that in our use of the online API of the LLM to generate patient summaries, the content in the prompts is derived from publicly accessible knowledge graphs and only includes feature names from the MIMIC dataset. Therefore, privacy concerns are limited. Overall, our methodology aims to minimize harm and ensure unbiased, equitable findings, reflecting the complex nature of medical data. We rigorously adhere to these ethical values throughout our research.
References
- [1] Yinghao Zhu, Zixiang Wang, Long He, Shiyun Xie, Liantao Ma, and Chengwei Pan. Prism: Leveraging prototype patient representations with feature-missing-aware calibration for ehr data sparsity mitigation, 2024.
- [2] Zhongji Zhang, Yuhang Wang, Yinghao Zhu, Xinyu Ma, Tianlong Wang, Chaohe Zhang, Yasha Wang, and Liantao Ma. Domain-invariant clinical representation learning by bridging data distribution shift across emr datasets, 2024.
- [3] Liantao Ma, Yueying Wu, Junyi Gao, Wen Tang, Chunyan Su, Yinghao Zhu, Tianlong Wang, Weibin Liao, Xu Chu, Ewen Harrison, et al. Exploring the relationship between dietary intake and clinical outcomes in peritoneal dialysis patients. 2024.
- [4] Weibin Liao, Yinghao Zhu, Zixiang Wang, Xu Chu, Yasha Wang, and Liantao Ma. Learnable prompt as pseudo-imputation: Reassessing the necessity of traditional ehr data imputation in downstream clinical prediction. arXiv preprint arXiv:2401.16796, 2024.
- [5] Yinghao Zhu, Jingkun An, Enshen Zhou, Lu An, Junyi Gao, Hao Li, Haoran Feng, Bo Hou, Wen Tang, Chengwei Pan, and Liantao Ma. M3fair: Mitigating bias in healthcare data through multi-level and multi-sensitive-attribute reweighting method. arXiv preprint arXiv:2306.04118, 2023.
- [6] Chaohe Zhang, Xu Chu, Liantao Ma, Yinghao Zhu, Yasha Wang, Jiangtao Wang, and Junfeng Zhao. M3care: Learning with missing modalities in multimodal healthcare data. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, page 2418–2428, New York, NY, USA, 2022. Association for Computing Machinery.
- [7] Jiaqi Wang, Junyu Luo, Muchao Ye, Xiaochen Wang, Yuan Zhong, Aofei Chang, Guanjie Huang, Ziyi Yin, Cao Xiao, Jimeng Sun, and Fenglong Ma. Recent advances in predictive modeling with electronic health records, 2024.
- [8] Xinlu Zhang, Shiyang Li, Zhiyu Chen, Xifeng Yan, and Linda Ruth Petzold. Improving medical predictions by irregular multimodal electronic health records modeling. In International Conference on Machine Learning, pages 41300–41313. PMLR, 2023.
- [9] Yongxin Xu, Kai Yang, Chaohe Zhang, Peinie Zou, Zhiyuan Wang, Hongxin Ding, Junfeng Zhao, Yasha Wang, and Bing Xie. Vecocare: Visit sequences-clinical notes joint learning for diagnosis prediction in healthcare data. In Edith Elkind, editor, Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, pages 4921–4929. International Joint Conferences on Artificial Intelligence Organization, 8 2023. Main Track.
- [10] Edward Choi, Mohammad Taha Bahadori, Le Song, Walter F Stewart, and Jimeng Sun. Gram: graph-based attention model for healthcare representation learning. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 787–795, 2017.
- [11] Fenglong Ma, Quanzeng You, Houping Xiao, Radha Chitta, Jing Zhou, and Jing Gao. Kame: Knowledge-based attention model for diagnosis prediction in healthcare. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, pages 743–752, 2018.
- [12] Riccardo Miotto, Fei Wang, Shuang Wang, Xiaoqian Jiang, and Joel T Dudley. Deep learning for healthcare: review, opportunities and challenges. Briefings in bioinformatics, 19(6):1236–1246, 2018.
- [13] Yinghao Zhu, Zixiang Wang, Junyi Gao, Yuning Tong, Jingkun An, Weibin Liao, Ewen M. Harrison, Liantao Ma, and Chengwei Pan. Prompting large language models for zero-shot clinical prediction with structured longitudinal electronic health record data, 2024.
- [14] Muchao Ye, Suhan Cui, Yaqing Wang, Junyu Luo, Cao Xiao, and Fenglong Ma. Medpath: Augmenting health risk prediction via medical knowledge paths. In Proceedings of the Web Conference 2021, pages 1397–1409, 2021.
- [15] Junyi Gao, Chaoqi Yang, Joerg Heintz, Scott Barrows, Elise Albers, Mary Stapel, Sara Warfield, Adam Cross, and Jimeng Sun. Medml: fusing medical knowledge and machine learning models for early pediatric covid-19 hospitalization and severity prediction. Iscience, 25(9), 2022.
- [16] Kai Yang, Yongxin Xu, Peinie Zou, Hongxin Ding, Junfeng Zhao, Yasha Wang, and Bing Xie. Kerprint: local-global knowledge graph enhanced diagnosis prediction for retrospective and prospective interpretations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5357–5365, 2023.
- [17] Alvin Rajkomar, Eyal Oren, Kai Chen, Andrew M Dai, Nissan Hajaj, Michaela Hardt, Peter J Liu, Xiaobing Liu, Jake Marcus, Mimi Sun, et al. Scalable and accurate deep learning with electronic health records. NPJ digital medicine, 1(1):18, 2018.
- [18] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [19] Michael Wornow, Yizhe Xu, Rahul Thapa, Birju Patel, Ethan Steinberg, Scott Fleming, Michael A Pfeffer, Jason Fries, and Nigam H Shah. The shaky foundations of large language models and foundation models for electronic health records. npj Digital Medicine, 6(1):135, 2023.
- [20] Shuhua Shi, Shaohan Huang, Minghui Song, Zhoujun Li, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. Reslora: Identity residual mapping in low-rank adaption. arXiv preprint arXiv:2402.18039, 2024.
- [21] Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, and Xin Luna Dong. Head-to-tail: How knowledgeable are large language models (llm)? aka will llms replace knowledge graphs? arXiv preprint arXiv:2308.10168, 2023.
- [22] Pengcheng Jiang, Cao Xiao, Adam Richard Cross, and Jimeng Sun. Graphcare: Enhancing healthcare predictions with personalized knowledge graphs. In The Twelfth International Conference on Learning Representations, 2024.
- [23] Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023.
- [24] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [25] Payal Chandak, Kexin Huang, and Marinka Zitnik. Building a knowledge graph to enable precision medicine. Scientific Data, 10(1):67, 2023.
- [26] Boshi Wang, Xiang Yue, and Huan Sun. Can chatgpt defend its belief in truth? evaluating llm reasoning via debate. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11865–11881, 2023.
- [27] Fergus Imrie, Paulius Rauba, and Mihaela van der Schaar. Redefining digital health interfaces with large language models. arXiv preprint arXiv:2310.03560, 2023.
- [28] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2023.
- [29] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [30] Dawei Zhu, Nan Yang, Liang Wang, Yifan Song, Wenhao Wu, Furu Wei, and Sujian Li. Pose: Efficient context window extension of llms via positional skip-wise training. In The Twelfth International Conference on Learning Representations, 2024.
- [31] Jiaqi Bai, Hongcheng Guo, Jiaheng Liu, Jian Yang, Xinnian Liang, Zhao Yan, and Zhoujun Li. Griprank: Bridging the gap between retrieval and generation via the generative knowledge improved passage ranking. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM ’23, page 36–46, New York, NY, USA, 2023. Association for Computing Machinery.
- [32] Jiaqi Bai, Zhao Yan, Shun Zhang, Jian Yang, Hongcheng Guo, and Zhoujun Li. Infusing internalized knowledge of language models into hybrid prompts for knowledgeable dialogue generation. Knowledge-Based Systems, page 111874, 2024.
- [33] Jiaqi Bai, Ze Yang, Jian Yang, Hongcheng Guo, and Zhoujun Li. Kinet: Incorporating relevant facts into knowledge-grounded dialog generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1213–1222, 2023.
- [34] OpenAI. Prompt engineering. https://platform.openai.com/docs/guides/prompt-engineering, 2023. Accessed: 2024-05-20.
- [35] Sungjin Park, Seongsu Bae, Jiho Kim, Tackeun Kim, and Edward Choi. Graph-text multi-modal pre-training for medical representation learning. In Conference on Health, Inference, and Learning, pages 261–281. PMLR, 2022.
- [36] Kwanhyung Lee, Soojeong Lee, Sangchul Hahn, Heejung Hyun, Edward Choi, Byungeun Ahn, and Joohyung Lee. Learning missing modal electronic health records with unified multi-modal data embedding and modality-aware attention. arXiv preprint arXiv:2305.02504, 2023.
- [37] Muchao Ye, Suhan Cui, Yaqing Wang, Junyu Luo, Cao Xiao, and Fenglong Ma. Medretriever: Target-driven interpretable health risk prediction via retrieving unstructured medical text. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 2414–2423, 2021.
- [38] Chang Lu, Chandan K Reddy, Prithwish Chakraborty, Samantha Kleinberg, and Yue Ning. Collaborative graph learning with auxiliary text for temporal event prediction in healthcare. In Zhi-Hua Zhou, editor, Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 3529–3535. International Joint Conferences on Artificial Intelligence Organization, 8 2021. Main Track.
- [39] Alexander E Curtis, Tanya A Smith, Bulat A Ziganshin, and John A Elefteriades. The mystery of the z-score. Aorta, 4(04):124–130, 2016.
- [40] Junyi Gao, Yinghao Zhu, Wenqing Wang, Guiying Dong, Wen Tang, Hao Wang, Yasha Wang, Ewen M Harrison, and Liantao Ma. A comprehensive benchmark for covid-19 predictive modeling using electronic health records in intensive care. Patterns, 2024.
- [41] Yinghao Zhu, Wenqing Wang, Junyi Gao, and Liantao Ma. Pyehr: A predictive modeling toolkit for electronic health records. https://github.com/yhzhu99/pyehr, 2024.
- [42] Yikuan Li, Ramsey M Wehbe, Faraz S Ahmad, Hanyin Wang, and Yuan Luo. A comparative study of pretrained language models for long clinical text. Journal of the American Medical Informatics Association, 30(2):340–347, 2023.
- [43] DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model, 2024.
- [44] Matthew B. A. McDermott, Lasse Hyldig Hansen, Haoran Zhang, Giovanni Angelotti, and Jack Gallifant. A closer look at auroc and auprc under class imbalance. arXiv preprint arXiv:2401.06091, 2024.
- [45] Misuk Kim and Kyu-Baek Hwang. An empirical evaluation of sampling methods for the classification of imbalanced data. PLoS One, 17(7):e0271260, 2022.
- [46] Xinyu Ma, Yasha Wang, Xu Chu, Liantao Ma, Wen Tang, Junfeng Zhao, Ye Yuan, and Guoren Wang. Patient health representation learning via correlational sparse prior of medical features. IEEE Transactions on Knowledge and Data Engineering, 2022.
- [47] Aming Wu and Yahong Han. Multi-modal circulant fusion for video-to-language and backward. In IJCAI, volume 3, page 8, 2018.
- [48] Swaraj Khadanga, Karan Aggarwal, Shafiq Joty, and Jaideep Srivastava. Using clinical notes with time series data for icu management. arXiv preprint arXiv:1909.09702, 2019.
- [49] Iman Deznabi, Mohit Iyyer, and Madalina Fiterau. Predicting in-hospital mortality by combining clinical notes with time-series data. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4026–4031, 2021.
- [50] Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Tensor fusion network for multimodal sentiment analysis. arXiv preprint arXiv:1707.07250, 2017.
- [51] Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, Amir Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. Integrating multimodal information in large pretrained transformers. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2020, page 2359. NIH Public Access, 2020.
- [52] Bo Yang and Lijun Wu. How to leverage multimodal ehr data for better medical predictions? arXiv preprint arXiv:2110.15763, 2021.
- [53] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- [54] William A Falcon. Pytorch lightning. GitHub, 3, 2019.
- [55] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [56] Liantao Ma, Chaohe Zhang, Junyi Gao, Xianfeng Jiao, Zhihao Yu, Yinghao Zhu, Tianlong Wang, Xinyu Ma, Yasha Wang, Wen Tang, Xinju Zhao, Wenjie Ruan, and Tao Wang. Mortality prediction with adaptive feature importance recalibration for peritoneal dialysis patients. Patterns, 4(12), 2023.
- [57] Jianlv Chen and Shitao Xiao. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. https://synthical.com/article/9ffce599-0640-457c-bd1c-502cab06e8af, 1 2024.
- [58] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.