M3DM-NR: RGB-3D Noisy-Resistant Industrial Anomaly Detection via Multimodal Denoising
Abstract
Existing industrial anomaly detection methods primarily concentrate on unsupervised learning with pristine RGB images. Yet, both RGB and 3D data are crucial for anomaly detection, and the datasets are seldom completely clean in practical scenarios. To address above challenges, this paper initially delves into the RGB-3D multi-modal noisy anomaly detection, proposing a novel noise-resistant M3DM-NR framework to leveraging strong multi-modal discriminative capabilities of CLIP. M3DM-NR consists of three stages: Stage-I introduces the Suspected References Selection module to filter a few normal samples from the training dataset, using the multimodal features extracted by the Initial Feature Extraction, and a Suspected Anomaly Map Computation module to generate a suspected anomaly map to focus on abnormal regions as reference. Stage-II uses the suspected anomaly maps of the reference samples as reference, and inputs image, point cloud, and text information to achieve denoising of the training samples through intra-modal comparison and multi-scale aggregation operations. Finally, Stage-III proposes the Point Feature Alignment, Unsupervised Feature Fusion, Noise Discriminative Coreset Selection, and Decision Layer Fusion modules to learn the pattern of the training dataset, enabling anomaly detection and segmentation while filtering out noise. Extensive experiments show that M3DM-NR outperforms state-of-the-art methods in 3D-RGB multi-modal noisy anomaly detection.
Index Terms:
Anomaly Detection, Multi-modal Learning, Noisy Learning, Unsupervised Learning1 Introduction
Industrial anomaly detection aims to find the abnormal region of products and plays an important role in industrial quality inspection. Most existing industrial anomaly detection methods [1, 2] primarily focus on RGB images [3, 4] and use a vast number of normal examples for training. Consequently, current industrial anomaly detection methods predominantly rely on unsupervised approaches, meaning they train exclusively on normal RGB examples and only during inference are defect examples tested. These two factors contribute to two significant issues (Fig. 1-Top-Left). First, during the quality inspection of industrial products, human inspectors rely on both 3D shape and color characteristics to assess product quality. The 3D shape information is crucial for accurate defect detection in particular, and identifying defects using only RGB images proves difficult. With advancements in 3D sensor technology, recent MVTec-3D AD dataset that includes both 2D images and 3D point cloud data is proposed to alleviate this problem and has bolstered research in multi-modal industrial anomaly detection (Fig. 1-Top-Middle). Second, the presence of noise in the normal dataset is an unavoidable issue in real-world applications, particularly in industrial manufacturing where products are mass-produced daily. Most existing unsupervised AD methods [5, 6, 7] are prone to noisy data due to their exhaustive strategy to model the training set. However, noisy samples can easily mislead those overconfident AD algorithms, causing them to misclassify similar anomaly samples in the test set and generate incorrect locations. SoftPatch [8] is the first to introduce the setting for noisy industrial detection, but it explored only noisy industrial detection on RGB data.

For the first issue, the core idea for existing unsupervised anomaly detection is to find out the difference between normal representations and anomalies. Current 2D industrial anomaly detection methods can be mainly categorized into two categories: (1) Reconstruction-based methods. Image reconstruction tasks are widely used in anomaly detection methods [3, 12, 13, 14, 15, 16] to learn normal representation. Reconstruction-based methods are easy to implement for a single modal input (2D image or 3D point cloud). But for multi-modal inputs, it is hard to find a reconstruction target. (2) Pretrained feature extractor-based methods. An intuitive way to utilize the feature extractor is to map the extracted feature to a normal distribution and find the out-of-distribution one as an anomaly. Normalizing flow-based methods [6, 17, 18] use an invertible transformation to directly construct normal distribution, and memory bank-based methods[19, 5] store some representative features to implicitly construct the feature distribution. Compared with reconstruction-based methods, directly using a pretrained feature extractor does not involve the design of a multi-modal reconstruction target and is a better choice for the multi-modal task. Besides that, current multi-modal industrial anomaly detection methods [20, 18] directly concatenate the features of the two modalities together. However, when the feature dimension is high, the disturbance between multi-modal features will be violent and cause performance reduction.
Regarding the second issue of noisy anomaly detection, existing methods in noisy industrial detection have primarily focused on single-modality noisy anomaly detection using RGB images, with a lack of research on RGB-3D multi-modal noisy data. However, in practical industrial detection, noise often contaminates 3D data, and RGB-3D multi-modal data serve as an important reference for determining whether a sample is anomalous. The absence of exploration in RGB-3D multi-modal noisy data means that current methods are vulnerable to the multi-modal noisy data in real-world production environments. Furthermore, existing approaches employ a simplistic and naive strategy of patch-level denoising and sample re-weighting based on outlier-detection weights, leading to unsatisfying denoising effects and the persistence of noise in the dataset.

To solve the problems mentioned above, in this paper, we first delve into the RGB-3D multi-modal noisy industrial detection problem (Fig. 1-Top-Right). To address the challenges of RGB-3D multi-modal noisy data, we propose a novel three-stage multi-modal noise-resistant framework termed M3DM-NR, which performs denoising at both sample-level and patch-level, as shown in Fig. 2. This framework utilizes pretrained CLIP [21] and Point-BIND [22] models to extract aligned text, RGB, and 3D point cloud features to denoise multi-modal data through both cross-modal comparison and intra-modality comparison. To the best of our knowledge, we are the first to employ a multi-modal learning approach based on pre-trained CLIP and Point-BIND to solve the RGB-3D multi-modal noisy industrial anomaly detection problem. In this framework, Stage I selects a few normal samples from the training dataset as intra-modal reference samples and compute the suspected anomaly map to focus on abnormal regions by the proposed Intra-Modal Reference Selection. In Stage II, recognizing the fact that in industrial anomaly detection, anomalies often constitute only a small fraction of the entire sample, we thus propose a novel Enhanced Multi-modal Denoising module to rank the anomalies of each training sample by performing multi-scale feature comparison and weighting with a suspected reference, enabling the filtering of anomalous samples. In Stage III, to address the above problems concerning multi-modal anomaly detection, we propose a novel Multimodal Anomaly Detection via Hybrid Fusion scheme to Learn the pattern of the training dataset to conduct anomaly detection and segmentation while filtering out noise at the patch level. Different from the existing methods that directly concatenate the features of the two modalities, we propose a hybrid fusion scheme to reduce the disturbance between multi-modal features and encourage feature interaction. We propose Unsupervised Feature Fusion (UFF) to fuse multi-modal features, which is trained using a patch-wise contrastive loss to learn the inherent relation between multi-modal feature patches at the same position. To encourage the anomaly detection model to keep the single domain inference ability, we construct three memory banks separately for RGB, 3D and fused features. For the final decision, we construct Decision Layer Fusion (DLF) to consider all memory banks for anomaly detection and segmentation. Besides, we further propose a Point Feature Alignment (PFA) operation to better align 3D and 2D features and Noise Discriminative Coreset Selection to filter out noise at patch-level.
To evaluate our method, we conduct extensive experiments on the MVTec 3D-AD [10] and Eyecandies [23] datasets, comparing our method with existing RGB, 3D, and RGB-3D based industrial detection methods. Moreover, to further highlight the robustness of our method, we follow the experiment setting in SoftPatch [8] and conduct experiments under Non-Overlap and, more challenging, Overlap settings. The extensive experimental results and metrics (I-AUROC, P-AUROC, AUPRO) demonstrate that our method surpasses existing state-of-the-art approaches. Additionally, we performed a comprehensive ablation study, thoroughly validating the effectiveness of all novel modules proposed.
This is an extension of the previous conference version (M3DM [9] in CVPR’23). In the conference papar, we mainly proposed M3DM, a novel multi-modal industrial anomaly detection method with hybrid feature fusion, which outperforms the state-of-the-art detection and segmentation precision on MVTec 3D-AD [10]. In this extended journal version, we make the following four contributions:
-
•
We study a new RGB-3D multi-modal noisy industrial anomaly detection task and have substantially broadened our research to this practical setting, proposing a novel three-stage multi-modal noise-resistant framework termed M3DM-NR. It addresses reference selection, denoising, and final anomaly detection and segmentation, ensuring systematic and hierarchical processing.
-
•
We design three novel Initial Feature Extraction, Suspected References Selection, and Suspected Anomaly Map Computation modules in Stage I to select a few normal samples from the training dataset as intra-modal reference samples, and it generates suspected anomaly maps to focus on abnormal regions as the reference for the next stage.
-
•
To obtain cleaner training data, we propose an extra Stage II termed Enhanced Multi-modal Denoising to introduce multi-scale feature comparison and weighting methods to finely rank and denoise training samples.
-
•
We employ M3DM as Stage III to achieve final anomaly detection and segmentation. Extensive quantitative experiments across various settings demonstrate the performance of our approach over existing state-of-the-art methods in 3D-RGB multi-modal noisy anomaly detection. We also conduct massive ablation study to illustrate the effectiveness of each designed component.
2 Related Work
2.1 2D Industrial Anomaly Detection
Current anomaly detection can be mainly categorized into following three parts: 1) Data augmentation based methods [24, 25, 14, 26, 27, 28] propose to introduce pseudo anomalies to normal samples with the aim of improving the system’s ability to identify such anomalies during training. 2) Reconstruction based methods [29, 12, 13, 16, 15, 30, 31, 32, 33, 34] leverage auto-encoders and generative adversarial networks. Although these reconstruction methods may not accurately recover anomalous regions, comparing the reconstructed image with the original can pinpoint anomalies and facilitate decision-making. 3) Feature embedding based methods [35, 36, 6, 17, 5, 37, 38, 39] depend on pre-trained feature extractors, with additional detection modules that learn to identify abnormal areas using the extracted features or representations. Drawing parallels between 2D and 3D anomaly detection, our work expands the application of the memory bank approach to 3D and multi-modal contexts, yielding impressive outcomes.
2.2 3D Industrial Anomaly Detection
The first public 3D industrial anomaly detection dataset is the MVTec 3D-AD dataset [10], which includes both RGB information and point position data for each instance. Current 3D anomaly detection can be mainly categorized into following four parts: 1) Data augmentation-based methods [40, 41] draw inspirations from 2D anomaly detection strategies to generate pseudo RGB and 3D anomaly samples, enhancing the model’s capacity to identify anomalies. 2) Reconstruction-based methods [42, 40] utilize auto-encoders and generative adversarial networks trained to generate normal samples for both RGB and 3D data, irrespective of whether the input is normal or anomalous. This approach fails to reconstruct regions with anomalies effectively. By comparing these reconstructed samples with the originals, anomalies can be identified, thus aiding in decision-making. 3) Feature embedding-based methods [11, 9, 43, 44, 45, 46] rely on pre-trained feature extractors, supplemented with additional fusion modules that align and integrate multi-modal information. Detection modules then utilize these fused features or representations to identify abnormal areas, enhancing the system’s ability to detect anomalies. 4) Knowledge distillation-based methods [47, 18, 48] train a student network to reconstruct samples or extract features, where the disparity between the teacher and student networks serves as an indicator of anomalies. In our research, we adopt the feature embedding-based approach but diverge with a novel pipeline.
2.3 Learning with Noisy Data
Recognizing noisy labels is increasingly gaining attention in the realm of supervised learning. Yet, this concept has scarcely been ventured into within unsupervised anomaly detection, largely due to the absence of clear labels. In classification tasks, certain studies have suggested filtering pseudo-labeled data that carry a high confidence threshold to mitigate noise [49, 50]. Li et al. [51] employ a mixture model to identify noisy-labeled data, adopting a semi-supervised approach for training. In the field of object detection, strategies such as multi-augmentation [52], a teacher-student model [53], or contrastive learning [54] have been leveraged, drawing on the expertise of expert models to reduce noise. However, the prevailing methods for recognizing noisy labels depend heavily on labeled data for correcting inaccuracies. Our research diverges by aiming to enhance a model’s resistance to noise in an unsupervised manner, thereby eliminating the need for manual annotations. A recent review [55] examines the robustness of 30 AD algorithms, yet overlooks unsupervised approaches in the context of annotation errors. Pang et al. [56] address anomalies in video without relying on manually labeled data, exploiting information across consecutive frames, contrasting our focus on detecting anomalies in single images. Other studies [57, 58, 59] tackle the elimination of noisy and corrupted data in semantic anomaly detection. SoftPatch [8] proposed to filter out noise at patch-level using outlier detection, but the employed outlier detection method is rather naive and doesn’t produce very good results. In this paper, we introduce a method that utilizes a pretrained CLIP-based model to extract and align multi-modal information, enabling the effective filtration of noise at sample-level.
2.4 Multi-modal Learning
Among the recent successes of large pre-trained vision-language models (VLMs) [60, 61, 21], CLIP [21] stands out as the first to employ pre-training on web-scale image-text data, demonstrating unprecedented generality. Notable features include its language-driven zero-shot inference capabilities, which have significantly enhanced both effective robustness [62] and perceptual alignment [63]. Other studies [64, 65, 66] have also utilized the pre-trained CLIP model for downstream tasks, such as language-guided detection and segmentation, achieving promising results. Beyond aligning vision and language, Point-Bind [22] extends this alignment to include 3D modality. Recently, some recent works have attempted to apply the multimodal CLIP model to the AD domain [67, 68, 69, 70, 71]. Specific WinCLIP [67] leverages the robust multi-modal capabilities of the pre-trained CLIP model for effective zero-shot 2D anomaly detection.
In this paper, we utilize the Point-BIND’s aligned embedding space of image, language, and 3D modalities to effectively filter out noise at sample-level in the training set.
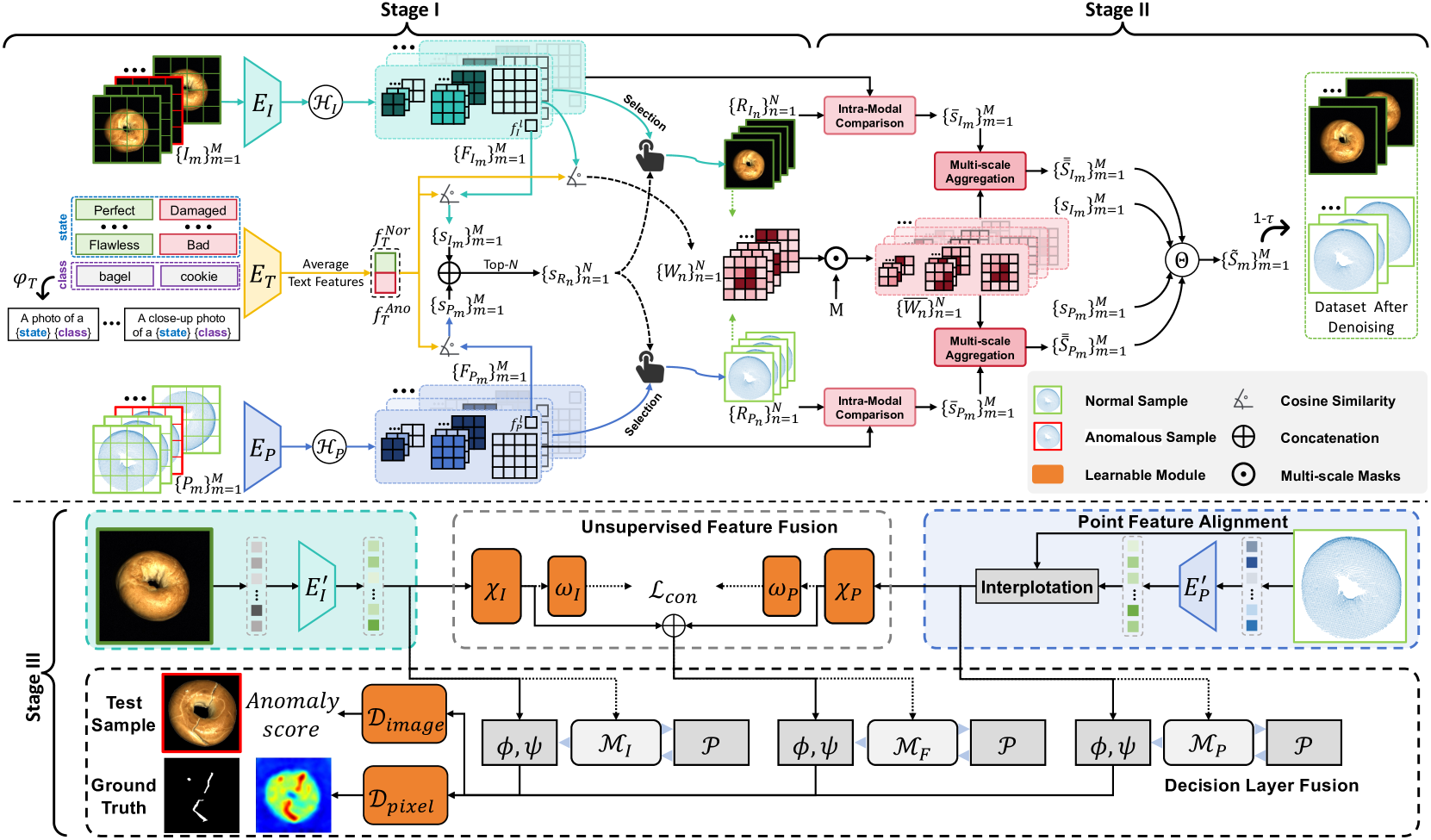
3 Methodology
As shown in Fig. 3, our proposed M3DM-NR framework takes RGB images and 3D point clouds as input to perform RGB-3D based multi-modal noisy anomaly detection and segmentation. Specifically, M3DM-NR consists of three stages to achieves this goal: 1) Intra-modal Reference Selection (Stage I in Sec. 3.1) selects a few normal samples from the training dataset as intra-modal reference samples, and the suspected anomaly map is computed to focus on abnormal regions. 2) Enhanced Multi-modal Denoising (Stage II in Sec. 3.2) ranks the anomalies of each training sample by performing multi-scale feature comparison and weighting with a suspected reference, enabling the filtering of anomalous samples. 3) Multimodal Anomaly Detection via Hybrid Fusion (Stage III in Sec. 3.3) learns the pattern of the training dataset to conduct anomaly detection and segmentation while filtering out noise at patch-level.
3.1 Stage I: Intra-modal Reference Selection
3.1.1 Initial Feature Extraction
Given image and point cloud pairs and , RGB-3D anomaly detection requires three modes of information input, so it contains three parts of feature pre-extraction algorithm:
Text prompt ensemble. The effectiveness of text descriptions is crucial for multimodal anomaly detection. Following APRIL-GAN [68], we employ a text prompt ensemble strategy to fully explore the textual representation of defects. Specifically, the proposed strategy includes several templates, each in the format “A photo of a state class”, where ‘state’ denotes predefined normal and abnormal state descriptions, and ‘class’ represents the class name. The output features are averaged using pooling to obtain the final descriptive features and .
Multi-scale image feature representation. For each image in the training dataset, we first use pretrained image encoder in CLIP model to extract corresponding feature :
| (1) |
Then, a multi-scale segmentation operation is used to segment into 3 different scales , denoted as:
| (2) |
where is the class token and is obtained by the following equation:
| (3) | ||||
is the multi-scale mask, where each is a binary mask that selects kernel size centered at , with specifically selects the entire point cloud. is the set of image patches at big, middle, or small scale, indicates the coordinate of patches in the original image, and denotes the element-wise multiplication.
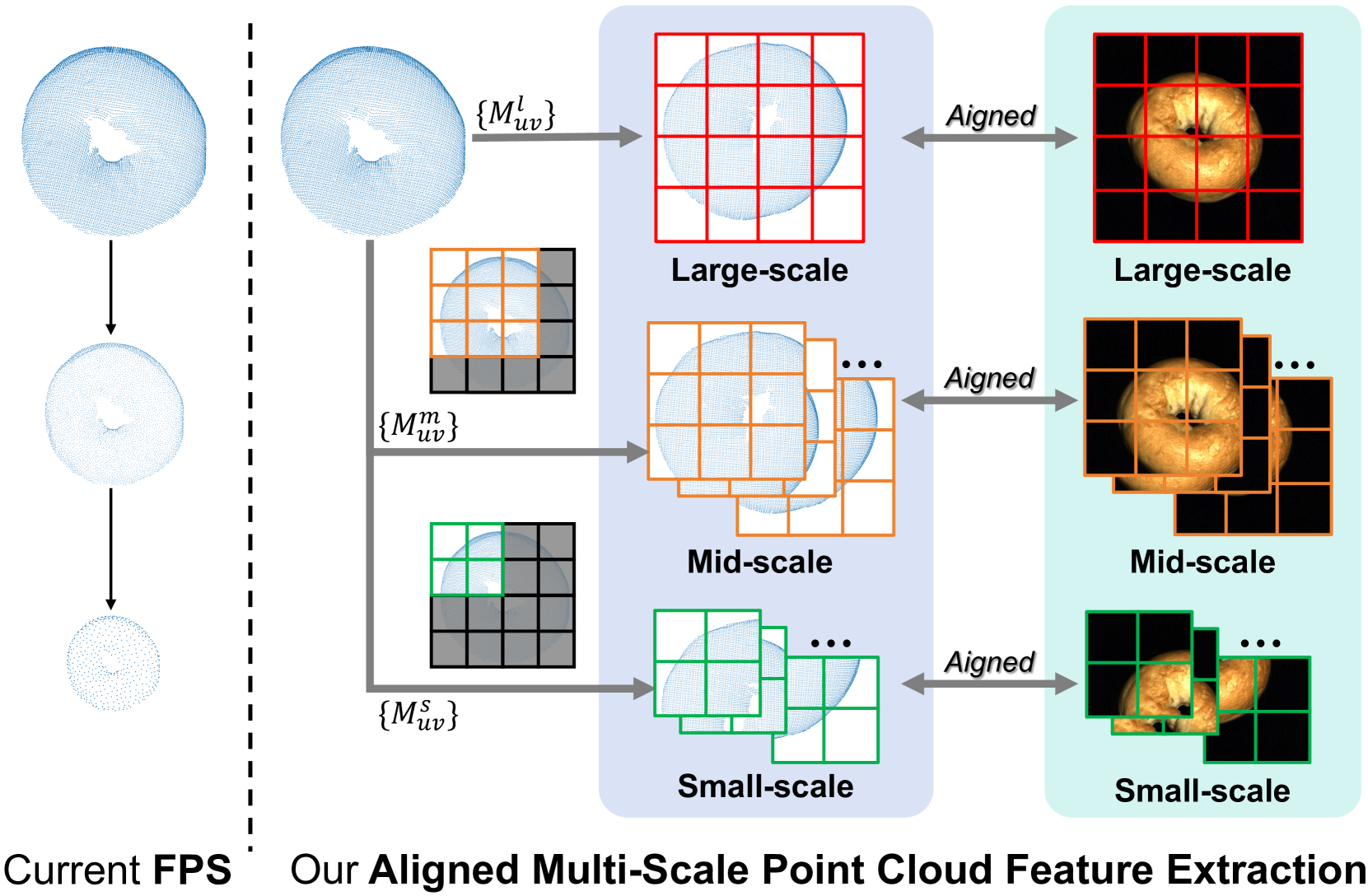
Aligned multi-scale point cloud feature extraction. As previous work [9] shown, in the MVTec 3D-AD [10] dataset, many anomalies cannot be detected through RGB images alone. For example, in the ‘potato’ category, an anomaly type named ‘cut’ can only be identified using 3D point cloud data. Thus, incorporating 3D point cloud data in the noise-filtering process is crucial. Therefore, we proposed to use 3D point cloud modality in noise detection.
However, we find that relying solely on the whole point cloud was insufficient during the experiments. In the MVTec 3D-AD dataset, defects often occupy only a small portion of the entire sample’s point cloud data, meaning that most areas of a sample are normal. Furthermore, existing works [72, 73, 22, 74] aligning point cloud encoders with CLIP focus on object classification tasks, which prioritize the global information of the object’s 3D point cloud data and overlook local details. Traditional multi-scale point cloud data segmentation based on FPS sampling (Fig. 4-Left) presents a full point cloud perspective with varying levels of sparsity but fails to specifically highlight local details. Yet, focusing on these details is crucial for detecting noise samples.
To address this problem, we propose a novel Aligned Multi-Scale Point Cloud Feature Extraction module, as shown in the right part of Fig. 4. This approach enhances the ability of localized noise detection by extracting local point cloud features aligned with the granularity of image patching. Specifically, for each point cloud in the training dataset, we segment into three scales, mirroring the approach used for image segmentation. Also, we generate 3 sets of masks , , and as aforementioned operation of image. By applying these three sets of masks to the entire point cloud, we obtain three distinct sets of point clouds at different scales:
| (4) |
Unlike images, in point cloud modality, only the points that do not fall on the backplane are meaningful. Consequently, some smaller patches of the point cloud may contain only a few meaningful points or none at all, making them insignificant or even obstructive for anomaly detection. To enhance efficiency, we identify and discard these non-contributory patches during the segmentation. This process results in filtered sets of point clouds:
| (5) |
where is a hyper-parameter representing the thresholds for the minimum number of points required in a point cloud patch to be considered meaningful.
These sets of point clouds constitute three distinct scales of point cloud representation. The granularity of these patches is aligned with that of image patches, enhancing the efficacy of subsequent multi-modal anomaly detection. We extract features from these multi-scale point cloud patches:
| (6) | ||||
where is the class token and is the feature map of -scale point cloud.
3.1.2 Suspected References Selection
We first try to identify noise samples in the training dataset solely by comparing the class tokens of text and RGB images. However, we observed that certain samples in the MVTec 3D-AD [10] dataset cannot be straightforwardly classified using only cross-modal comparison, i.e., text and image class tokens. For example, the ‘Foam’ category in MVTec 3D-AD includes a defect type labeled ‘color’, which defies classification with our text templates and necessitates comparison with an RGB reference image of a normal sample. Consequently, to achieve comprehensive anomaly classification, a language-guided zero-shot approach falls short, as some defects are only identifiable through intra-modal references, not merely by cross-modal comparison. Given that noise data constitutes a relatively small fraction of the entire training set, the majority of data are normal samples, we propose to select samples that are most representative of normality from the training set in Stage I. These samples will then serve as intra-modal references in Stage II to compensate for the shortcomings of cross-modal comparison. Specifically, is used to get suspected anomaly score by computing similarity with and as follows:
| (7) |
where denotes the cosine similarity. is calculated with , , and in the same way.
| (8) |
Final suspected score combines and together:
| (9) |
We select normal samples with the smallest as intra-modal references for the next Stage II that is identified as and in Fig. 3.
3.1.3 Suspected Anomaly Map Computation
Furthermore, we have observed that in industrial anomaly detection tasks, anomalies typically constitute only a small fraction of the entire sample. This means that focusing on all small local patch with uniform attention will not effectively facilitate optimal noise sample detection. Consequently, we propose using the preliminary suspected anomaly map obtained from Stage I as the attention map in Noise-Focused Aggregation within Stage II. This strategy allows for differentiated attention across all local patches, enabling our model to more precisely focus on specific local patches that may contain noise. To generate the preliminary suspected anomaly map, we follow WinCLIP [67], using Harmonic aggregation of windows and multi-scale aggregation to get the suspected anomaly map (). This suspected anomaly maps serve as the attention map to enhance the denoising process in Stage II.
3.2 Stage II: Enhanced Multi-modal Denoising
In industrial anomaly detection tasks, anomalies often occupy only a small portion of the entire sample. Therefore, after segmenting the sample into multi-scale patches, some patches will contain anomalies while others will not. Naturally, we aim to focus more on those patches containing anomalies and less on those without when computing the suspected anomaly score through intra-modality comparison, to enhance the accuracy of anomaly detection. This is achieved by assigning a weight to each patch based on the suspected anomaly map computed in Sec. 3.1.3, thereby allowing differential attention to patches based on their likelihood of containing anomalies. Specifically, this process is divided into four steps:
Intra-modal comparison. With intra-modal references selected during Stage I, we employ these image features and point cloud features for reference:
| (10) | ||||
where and are class tokens, while and are -scale feature maps. The intra-modality suspected anomaly score is determined by the cosine similarity between the feature vectors of the original query samples and those of intra-modal references:
| (11) | |||
where , , and .
Compute weights for local patches. We first compute weight for every local patch. Given the suspected anomaly map , we initially procure individual suspected anomaly maps for distinct patches by applying the masks generated in Sec. 3.1 to the whole suspected anomaly map.
| (12) |
In this way, we can determine the weight for each local patch at both middle and small scales. For large scale, the entire suspected anomaly map can be directly used as the weight.
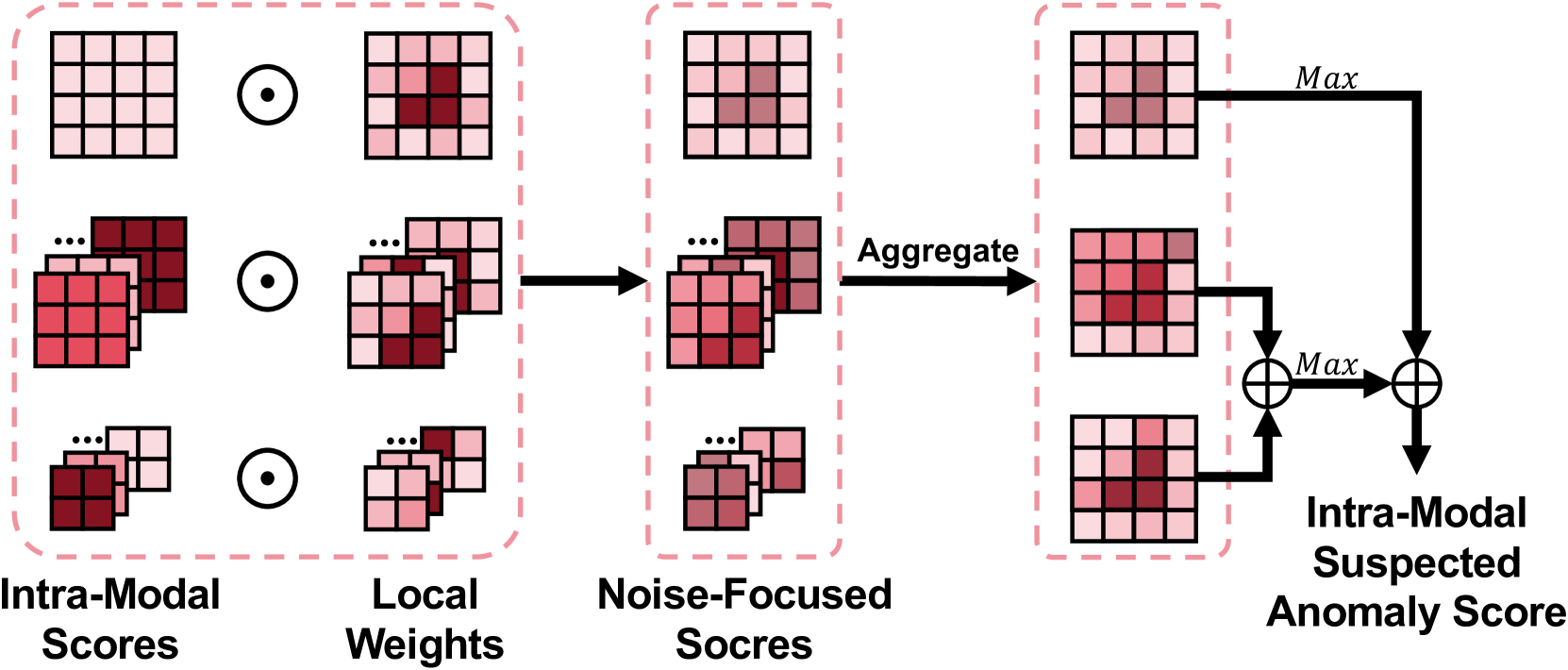
Multi-scale anomaly score aggregation. For each local patch, the suspected anomaly score is first distributed to every pixel of the local patch. Then at each pixel in the whole point cloud, we aggregate multiple scores from all overlapping local patches to improve anomaly classification. In order to focus more on those patches which contain anomalies, we re-weight the score using while aggregating multi-scale information. In this way, regions will be paid attention based on their likelihood of containing anomalies (Fig. 5-Left):
| (13) | |||
Final suspected anomaly score computation. The final suspected image anomaly score is computed using both cross-modal score calculated in Eq. 7 and intra-modality score calculated in Eq. 13:
| (14) |
Detailed explaination can be viewed in the right part of Fig. 5-Left. The final suspected point cloud anomaly score is computed using the same way:
| (15) |
Analogously, the final suspected anomaly score is calculated as a weighted combination of and , given by the equation:
| (16) |
where and are hyper-parameters controlling the extent to which RGB and point cloud modalities are integrated. Finally, we remove the samples with top percent scores.
3.3 Fused Anomaly Detection
As shown in Fig. 3, Stage III takes in the dataset filtered by Stage I&II as input and learns its pattern to conduct anomaly detection and segmentation. Besides, Stage III also filters out noise at patch-level in case some hard noise samples still exist in the training dataset.
3.3.1 Point Feature Alignment
Point Feature Interpolation. Post-FPS conducted within the Point Transformer (), the center points of the point cloud are unevenly distributed, leading to an imbalance in the density of point features. To address this, we interpolate the features back to the original point cloud. With point features corresponding to center points , we employ inverse distance weighting to interpolate the feature for each point in the input point cloud. The interpolation is mathematically represented as:
| (17) |
where is a small constant to prevent division by zero.
Point Feature Projection. After interpolation, we project the interpolated point features onto a 2D plane as using the point coordinates and camera parameters. Noting the sparsity of point clouds, we assign a value of 0 to any 2D plane position lacking a corresponding point. The resulting projected feature map matches the size of the RGB image.
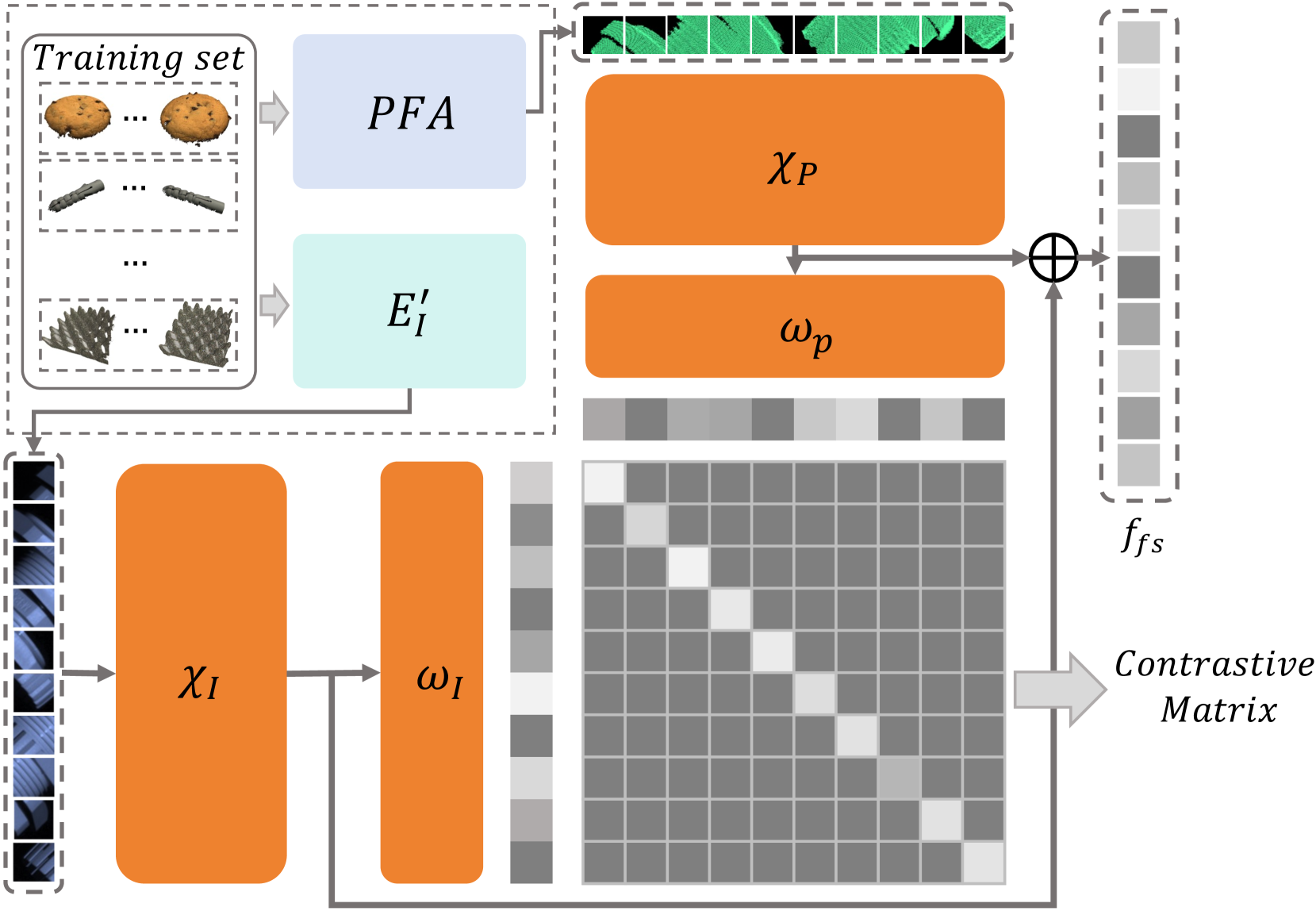
3.3.2 Unsupervised Feature Fusion
The interaction between multi-modal features can yield new information beneficial for industrial anomaly detection. For instance, as shown in Fig. 1, detecting a hole in a cookie necessitates the integration of both its black color and the shape depression. To decipher the intrinsic relationship between these modalities in the training data, we developed the Unsupervised Feature Fusion (UFF) module.
We introduce a patch-wise contrastive loss to train this module. Given RGB features and point cloud features , our goal is to promote a higher correlation of information between features from different modalities at identical spatial positions while minimizing this correlation for features at distinct positions.
The features of a sample are represented as , where denotes the index of the training sample, and represents the patch position. We employ MLP to derive interaction information between the two modalities and utilize fully connected layers to transform the processed features into query or key vectors, denoted as . For contrastive learning, we apply the InfoNCE loss:
| (18) |
where is the batch size. The UFF module, trained with collective training data from all categories in MVTec 3D-AD, is depicted in Fig. 6.
During inference, outputs of the MLP layers are concatenated to form a fused patch feature, denoted as .
3.3.3 Noise Discriminative Coreset Selection
In our experimental process, we found that, despite pre-processing the training data to remove noise at the sample level, some noise samples that closely resembled normal samples could not be eliminated. To address this, we conducted a second round of denoising at the patch level. Following Softpatch [8], we discard noise patches in coreset selection process. Initially, we calculated outlier scores for all patches. These scores were then aggregated to identify the noise patches, after which we just remove the patches with top percent scores. We implemented it using the Local Outlier Factor (LOF) method.
LOF is a local-density-based outlier detector. Inspired by Softpatch, we propose to use LOF in M3DM in two ways. Firstly, we will use LOF to rule out noise patches with the aim of making the training datset contain only normal samples. Secondly, we will use the LOF as the soft weight for patches to achieve more accurate anomaly detection.
The k-distance-based absolute local reachability density is first calculated as:
| (19) |
where is L2-norm, is the distance of kth-neighbor, is the set of k-nearest neighbors of and is the number of the set which usually equal k when without repeated neighbors. With the local reachability density of each patch, the overwhelming effect of large clusters is largely reduced. To normalize local density to relative density for treating all clusters equally, the relative density of image is defined below:
| (20) |
is the relative density of the neighbors over patch’s own, and represents as a patch’s confidence of inlier. Patches with top scores are removed before coreset selection.
3.3.4 Decision Layer Fusion
As depicted in Fig. 1, certain industrial anomalies, such as the protruding part of a potato, manifest exclusively in a single domain, making the correlation between multi-modal features less evident. Additionally, despite the advantages of Feature Fusion in enhancing multi-modal feature interaction, we observed some loss of information during the fusion process. Furthermore, we observed that, despite undergoing denoising at both the image and patch levels, some hard noise patches remain within the dataset. These hard noise elements can adversely affect the precision of anomaly scores during the final inference stage.
To address these issues, we propose utilizing multiple memory banks to preserve the original color feature (), point cloud feature (), and fusion feature (). These are denoted as , , and respectively. Besides, we propose to use obtained in Sec. 3.3.3 to re-weight the anomaly score during inference, which can down-weight noisy samples according to outlier scores. During inference, each bank contributes to predicting an anomaly score and a segmentation map. Two learnable One-Class Support Vector Machines (OCSVMs), and , are employed to finalize the anomaly score and the segmentation map . This procedure is referred to as Decision Layer Fusion (DLF) and can be mathematically represented as follows:
| (21) |
where and are scoring functions, defined as follows:
| (22) |
where , and is the weight parameter obtained in Sec. 3.3.3.
4 Experiment
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | 3D-ST[47] | 86.2 | 48.4 | 83.2 | 89.4 | 84.8 | 66.3 | 76.3 | 68.7 | 95.8 | 48.6 | 74.8 | ||
| FPFH[20] | 82.5 | 55.1 | 95.2 | 79.7 | 88.3 | 58.2 | 75.8 | 88.9 | 92.9 | 65.3 | 78.2 | |||
| AST[18] | 88.1 | 57.6 | 96.5 | 95.7 | 67.9 | 79.7 | 99.0 | 91.5 | 95.6 | 61.1 | 83.3 | |||
| M3DM[9] | 94.1 | 65.1 | 96.5 | 96.9 | 90.5 | 76.0 | 88.0 | 97.4 | 92.6 | 76.5 | 87.4 | |||
| Ours | 94.2 | 66.1 | 95.5 | 97.2 | 90.4 | 77.2 | 88.1 | 96.4 | 91.6 | 78.5 | 87.4 | |||
| RGB | PADiM[19] | 97.5 | 77.5 | 69.8 | 58.2 | 95.9 | 66.3 | 85.8 | 53.5 | 83.2 | 76.0 | 76.4 | ||
| PatchCore[5] | 87.6 | 88.0 | 79.1 | 68.2 | 91.2 | 70.1 | 69.5 | 61.8 | 84.1 | 70.2 | 77.0 | |||
| STFPM[76] | 93.0 | 84.7 | 89.0 | 57.5 | 94.7 | 76.6 | 71.0 | 59.8 | 96.5 | 70.1 | 79.3 | |||
| CS-Flow[6] | 94.1 | 93.0 | 82.7 | 79.5 | 99.0 | 88.6 | 73.1 | 47.1 | 98.6 | 74.5 | 83.0 | |||
| AST[18] | 94.7 | 92.8 | 85.1 | 82.5 | 98.1 | 95.1 | 89.5 | 61.3 | 99.2 | 82.1 | 88.0 | |||
| M3DM[9] | 94.4 | 91.8 | 89.6 | 74.9 | 95.9 | 76.7 | 91.9 | 64.8 | 93.8 | 76.7 | 85.0 | |||
| Ours | 94.2 | 91.7 | 89.4 | 73.9 | 96.1 | 77.8 | 93.3 | 64.9 | 92.8 | 77.7 | 85.1 | |||
| RGB + 3D | Voxel GAN[10] | 68.0 | 32.4 | 56.5 | 39.9 | 49.7 | 48.2 | 56.6 | 57.9 | 60.1 | 48.2 | 51.7 | ||
| PatchCore + FPFH[20] | 91.8 | 74.8 | 96.7 | 88.3 | 93.2 | 58.2 | 89.6 | 91.2 | 92.1 | 88.6 | 86.5 | |||
| AST[18] | 98.3 | 87.3 | 97.6 | 97.1 | 93.2 | 88.5 | 97.4 | 98.1 | 100.0 | 79.7 | 93.7 | |||
| M3DM [9] | 99.4 | 90.9 | 97.2 | 97.6 | 96.0 | 94.2 | 97.3 | 89.9 | 97.2 | 85.0 | 94.5 | |||
| Ours | 99.3 | 91.1 | 97.7 | 97.6 | 96.0 | 92.2 | 97.3 | 89.9 | 95.5 | 88.2 | 94.5 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | 3D-ST[47] | 95.0 | 48.3 | 98.6 | 92.1 | 90.5 | 63.2 | 94.5 | 98.8 | 97.6 | 54.2 | 83.3 | ||
| FPFH[20] | 97.3 | 87.9 | 98.2 | 90.6 | 89.2 | 73.5 | 97.7 | 98.2 | 95.6 | 96.1 | 92.4 | |||
| M3DM [9] | 94.3 | 81.8 | 97.7 | 88.2 | 88.1 | 74.3 | 95.8 | 97.4 | 95.0 | 92.9 | 90.6 | |||
| Ours | 94.2 | 81.8 | 97.8 | 88.3 | 88.0 | 74.3 | 95.8 | 97.4 | 95.0 | 92.9 | 90.6 | |||
| RGB | CFlow[6] | 85.5 | 91.9 | 95.8 | 86.7 | 96.9 | 50.0 | 88.9 | 93.5 | 90.4 | 91.9 | 87.1 | ||
| PatchCore[5] | 90.1 | 94.9 | 92.8 | 87.7 | 89.2 | 56.3 | 90.4 | 93.2 | 90.8 | 90.6 | 87.6 | |||
| PADiM[19] | 98.0 | 94.4 | 94.5 | 92.5 | 96.1 | 79.2 | 96.6 | 94.0 | 93.7 | 91.2 | 93.0 | |||
| M3DM [9] | 95.2 | 97.2 | 97.3 | 89.1 | 93.2 | 84.3 | 97.0 | 95.6 | 96.8 | 96.6 | 94.2 | |||
| Ours | 95.4 | 97.0 | 97.3 | 89.1 | 93.4 | 84.3 | 97.0 | 95.6 | 96.8 | 96.6 | 94.2 | |||
| RGB+3D | Voxel GAN[10] | 66.4 | 62.0 | 76.6 | 74.0 | 78.3 | 33.2 | 58.2 | 79.0 | 63.3 | 48.3 | 63.9 | ||
| PatchCore + FPFH[20] | 97.6 | 96.9 | 97.9 | 97.3 | 93.3 | 88.8 | 97.5 | 98.1 | 95.0 | 97.1 | 95.9 | |||
| M3DM [9] | 97.0 | 97.1 | 97.9 | 95.0 | 94.1 | 93.2 | 97.7 | 97.1 | 97.1 | 97.5 | 96.4 | |||
| Ours | 97.4 | 97.1 | 97.8 | 94.5 | 93.8 | 94.7 | 97.8 | 97.1 | 97.2 | 97.4 | 96.5 |
4.1 Experimental Setup
Dataset. 3D industrial anomaly detection is in the beginning stage. The MVTec-3D AD dataset is the first 3D industrial anomaly detection dataset. Our experiments were performed on the MVTec-3D dataset. MVTec-3D AD[10] dataset consists of 10 categories, a total of 2,656 training samples, and 1,137 testing samples. The 3D scans were acquired by an industrial sensor using structured light, and position information was stored in 3 channel tensors representing , and coordinates. Those 3 channel tensors can be single-mapped to the corresponding point clouds. Additionally, the RGB information is recorded for each point. Because all samples in the dataset are viewed from the same angle, the RGB information of each sample can be stored in a single image. Totally, each sample of the MVTec-3D AD dataset contains a colored point cloud.
We conduct both regular anomaly detection in Sec. 4.2 and noisy anomaly detection in Sec. 4.3. For noisy anomaly detection, in odrder to generate a noisy training set, we randomly select 10% anomalous samples from the test set and integrate them into the existing training samples. Additionally, we establish two distinct settings, Overlap and Non-Overlap, to assess the robustness of our model. In the Overlap setting, the anomalous samples added to the training dataset will also be included in the test dataset to demonstrate the risk that defects with similar appearance will severely exacerbate the performance of an anomaly detector trained with noisy data. Conversely, in the Non-Overlap setting, these samples will not be retested.
Data Pre-processing. Different from 2D data, 3D ones are easier to remove the background information. Following [20], we estimate the background plane with RANSAC[77] and any point within 0.005 distance is removed. At the same time, we set the corresponding pixel of removed points in the RGB image as 0. This operation not only accelerates the 3D feature processing during training and inference but also reduces the background disturbance for anomaly detection. Finally, we resize both the position tensor and the RGB image to size, which is matched with the feature extractor input size.
Feature Extractors. In Stage I&II, we use text and image encoder from LAION-2B based CLIP with ViT-H/14 and point cloud encoder from Point-BIND. In Stage III, we use the ViT-B/8 pretrained on ImageNet[78] with DINO[79] as the RGB image encoder and a Point Transformer[80, 81], which is pretrained on ShapeNet[82] dataset as the 3D point cloud encoder, use the layer output as our 3D point cloud feature.
Learnable Module Details. Stage I&II are traing-free and Stage III has 2 learnable modules: the Unsupervised Feature Fusion module and the Decision Layer Fusion module. 1) For UFF, and are 2 two-layer MLPs with hidden dimension as input feature. We use AdamW optimizer with the learning rate as 0.003 and cosine warm-up in 250 steps. Batch size as 16 and we report the best anomaly detection results under 750 UFF training steps. 2) For DLF, we use two linear OCSVMs [83] with SGD [84] optimizers, and the learning rate is set as and each class is trained for 1000 steps.
Evaluation Metrics. All evaluation metrics are exactly the same as in [10]. We evaluate the image-level anomaly detection performance with the area under the receiver operator curve (I-AUROC), and higher I-AUROC means better image-level anomaly detection performance. For segmentation evaluation, we use the per-region Overlap (AUPRO) metric, which is defined as the average relative Overlap of the binary prediction with each connected component of the ground truth. Similar to I-AUROC, the receiver operator curve of pixel level predictions can be used to calculate P-AUROC for evaluating the segmentation performance.
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | SIFT | 50.00.8 | 48.51.9 | 67.80.2 | 58.10.4 | 58.23.8 | 49.22.8 | 40.50.6 | 47.01.3 | 43.31.1 | 45.02.7 | 50.80.5 | ||
| FPFH | 53.42.8 | 40.93.2 | 71.41.2 | 62.70.8 | 64.52.4 | 38.50.3 | 46.82.6 | 45.31.5 | 52.21.5 | 51.54.2 | 52.70.3 | |||
| AST | 61.00.6 | 38.40.6 | 72.90.6 | 75.20.6 | 47.80.6 | 55.70.6 | 66.90.6 | 60.60.6 | 55.51.0 | 49.20.6 | 58.30.2 | |||
| Shape-Guided | 66.15.1 | 58.710.4 | 71.46.0 | 76.41.4 | 71.60.7 | 54.13.1 | 61.04.5 | 59.35.7 | 60.74.5 | 64.37.4 | 64.41.9 | |||
| M3DM | 74.00.7 | 56.71.8 | 72.21.7 | 74.50.6 | 77.40.7 | 62.30.6 | 56.21.9 | 64.10.5 | 72.50.5 | 74.31.8 | 68.40.7 | |||
| Ours | 93.51.6 | 71.81.3 | 93.80.7 | 91.12.3 | 78.02.7 | 67.23.2 | 79.91.4 | 79.92.2 | 87.90.4 | 79.83.5 | 82.30.4 | |||
| RGB | PaDim | 70.80.7 | 57.32.6 | 54.70.5 | 43.21.6 | 72.10.3 | 55.42.2 | 61.70.3 | 36.81.3 | 74.82.5 | 55.21.5 | 58.20.4 | ||
| PatchCore | 64.90.7 | 71.40.9 | 71.51.5 | 52.52.2 | 73.31.2 | 56.52.9 | 46.61.1 | 36.80.4 | 54.21.3 | 57.21.3 | 58.50.4 | |||
| AST | 57.60.6 | 62.20.0 | 50.70.0 | 47.50.6 | 58.80.0 | 56.00.0 | 54.60.0 | 43.70.6 | 42.80.0 | 44.60.6 | 51.80.2 | |||
| Shape-Guided | 62.74.4 | 64.39.3 | 66.97.3 | 57.316.4 | 72.10.9 | 51.53.2 | 52.910.0 | 50.311.1 | 50.59.4 | 58.29.3 | 58.75.8 | |||
| SoftPatch | 88.81.1 | 87.32.2 | 84.91.3 | 63.31.2 | 96.50.8 | 75.01.6 | 62.30.7 | 43.62.1 | 89.31.4 | 71.00.9 | 76.20.3 | |||
| M3DM | 64.11.4 | 62.12.1 | 65.50.9 | 53.62.1 | 70.70.9 | 57.01.2 | 54.72.0 | 42.12.3 | 53.81.1 | 58.30.9 | 58.20.5 | |||
| Ours | 90.30.4 | 87.53.4 | 86.51.8 | 67.14.6 | 86.10.6 | 79.22.8 | 84.42.3 | 54.66.2 | 90.02.2 | 73.11.1 | 79.90.4 | |||
| 3D+RGB | PatchCore+FPFH | 61.32.7 | 58.30.9 | 72.30.4 | 69.01.1 | 67.21.0 | 47.11.9 | 53.02.0 | 52.11.3 | 52.71.0 | 68.20.8 | 60.10.4 | ||
| AST | 65.30.6 | 69.50.6 | 73.80.6 | 83.10.0 | 68.10.6 | 64.40.6 | 64.70.6 | 64.10.6 | 49.70.6 | 55.80.0 | 65.80.0 | |||
| Shape-Guided | 69.10.7 | 67.21.4 | 76.30.5 | 71.30.8 | 71.80.3 | 58.00.3 | 62.00.3 | 60.40.7 | 55.30.3 | 67.80.6 | 65.90.2 | |||
| M3DM | 72.52.2 | 62.40.8 | 69.61.4 | 72.42.1 | 73.90.9 | 64.32.0 | 60.10.3 | 54.02.0 | 62.11.8 | 71.42.1 | 66.30.5 | |||
| Ours | 96.72.1 | 86.23.0 | 95.51.3 | 90.33.4 | 86.03.0 | 79.13.7 | 86.63.7 | 72.23.3 | 92.00.5 | 81.31.6 | 86.61.3 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | SIFT | 69.11.6 | 68.20.8 | 85.30.4 | 72.30.8 | 67.11.4 | 55.71.5 | 64.31.4 | 66.61.7 | 69.90.8 | 72.61.2 | 69.10.4 | ||
| FPFH | 70.51.6 | 73.70.6 | 88.50.2 | 72.60.8 | 72.62.7 | 56.72.4 | 66.71.6 | 75.02.2 | 65.51.8 | 77.21.3 | 71.90.4 | |||
| Shape-Guided | 74.60.6 | 83.72.2 | 98.10.1 | 81.95.4 | 88.60.1 | 80.46.7 | 88.97.3 | 88.20.0 | 88.73.6 | 93.75.5 | 86.71.7 | |||
| M3DM | 84.01.0 | 79.71.1 | 95.80.4 | 79.61.3 | 85.50.6 | 68.31.6 | 86.40.9 | 91.30.8 | 90.31.5 | 88.70.4 | 85.00.4 | |||
| Ours | 95.01.3 | 78.80.8 | 97.20.1 | 84.51.4 | 83.93.0 | 66.62.4 | 91.21.6 | 89.90.6 | 92.70.5 | 89.90.7 | 87.00.2 | |||
| RGB | PaDim | 77.92.7 | 79.93.8 | 91.80.2 | 72.21.3 | 90.00.7 | 92.41.9 | 91.41.2 | 92.61.2 | 91.31.3 | 92.20.8 | 87.20.7 | ||
| PatchCore | 67.11.7 | 73.30.0 | 77.00.3 | 72.10.8 | 69.91.2 | 59.12.4 | 61.71.2 | 64.31.1 | 56.11.6 | 73.11.2 | 67.40.8 | |||
| Shape-Guided | 67.50.6 | 73.90.7 | 81.20.1 | 72.10.1 | 76.10.6 | 56.00.0 | 62.50.2 | 71.61.0 | 64.70.5 | 73.80.1 | 69.90.1 | |||
| SoftPatch | 83.92.0 | 89.32.7 | 91.40.5 | 79.20.7 | 91.81.8 | 72.42.8 | 76.52.4 | 72.92.7 | 89.82.6 | 90.11.7 | 83.70.3 | |||
| M3DM | 68.61.7 | 72.70.8 | 77.40.3 | 70.50.6 | 68.61.3 | 59.81.4 | 64.91.4 | 65.01.4 | 57.00.8 | 75.11.2 | 68.00.7 | |||
| Ours | 93.11.6 | 91.91.3 | 96.10.4 | 82.11.8 | 81.55.6 | 73.91.0 | 90.42.1 | 84.31.4 | 94.21.0 | 90.20.6 | 87.80.5 | |||
| 3D+RGB | PatchCore+FPFH | 70.41.5 | 72.80.6 | 77.90.3 | 77.51.0 | 68.81.5 | 64.91.0 | 65.01.7 | 65.91.3 | 56.40.8 | 75.31.3 | 69.50.6 | ||
| Shape-Guided | 74.60.6 | 80.90.5 | 93.60.3 | 79.30.9 | 89.30.9 | 76.60.2 | 82.40.2 | 94.00.3 | 86.60.1 | 93.70.8 | 85.10.0 | |||
| M3DM | 69.01.4 | 72.50.8 | 77.80.4 | 72.81.0 | 68.01.5 | 61.30.7 | 65.21.5 | 65.31.4 | 57.20.8 | 75.31.2 | 68.40.6 | |||
| Ours | 95.91.3 | 92.01.2 | 96.70.4 | 90.41.1 | 84.62.3 | 83.41.7 | 91.92.7 | 85.81.7 | 94.50.3 | 91.40.5 | 90.70.2 |
4.2 Regular Anomaly Detection on MVTec 3D-AD
In the regular anomaly detection setting, we compare our method with several 3D-based, RGB-based, and hybrid multi-modal 3D/RGB methods on MVTec-3D. Tabs. I and II show the anomaly detection results record with I-AUROC and the segmentation results record with AUPRO respectively. We report the P-AUROC in P-AUROC for regular anomaly segmentation on MVTec 3D-AD. From Tabs. I and I, we can conclude that our M3DM-NR also maintains the regular anomaly detection ability.
4.3 Noisy Anomaly Detection on MVTec 3D-AD
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | SIFT | 68.81.1 | 65.02.6 | 86.10.3 | 72.90.6 | 79.75.2 | 69.13.9 | 61.31.0 | 69.71.9 | 74.61.9 | 59.33.6 | 70.70.6 | ||
| FPFH | 73.43.8 | 54.84.3 | 90.71.5 | 78.50.9 | 88.33.3 | 54.00.4 | 70.93.8 | 67.22.3 | 90.02.6 | 67.95.6 | 73.60.4 | |||
| AST | 82.80.6 | 51.90.6 | 91.30.6 | 92.31.2 | 64.31.2 | 78.50.2 | 98.32.9 | 90.30.3 | 94.71.7 | 63.31.2 | 80.80.9 | |||
| Shape-Guided | 90.20.9 | 67.50.1 | 91.40.3 | 92.11.2 | 80.810.1 | 67.74.1 | 86.57.4 | 87.11.0 | 89.61.3 | 83.36.7 | 83.62.0 | |||
| M3DM | 87.10.8 | 68.21.2 | 79.43.1 | 87.81.3 | 83.82.8 | 73.02.5 | 76.62.6 | 82.60.7 | 92.92.0 | 80.01.6 | 81.10.8 | |||
| Ours | 94.50.6 | 74.42.4 | 94.80.9 | 93.70.8 | 83.81.1 | 72.83.5 | 84.00.2 | 87.30.4 | 89.81.3 | 82.21.2 | 85.70.7 | |||
| RGB | PaDim | 93.01.0 | 73.33.3 | 66.30.7 | 52.42.0 | 88.31.0 | 72.23.2 | 84.31.3 | 50.72.2 | 91.92.7 | 68.62.2 | 74.10.6 | ||
| PatchCore | 89.20.9 | 95.21.4 | 90.81.9 | 65.92.8 | 97.51.0 | 77.44.7 | 70.61.7 | 54.60.6 | 93.52.2 | 75.41.7 | 81.00.7 | |||
| AST | 79.50.1 | 83.10.1 | 63.20.8 | 60.20.1 | 80.70.6 | 77.51.8 | 81.11.0 | 63.40.1 | 74.30.8 | 59.20.0 | 72.20.1 | |||
| Shape-Guided | 79.31.0 | 89.62.4 | 77.40.3 | 58.62.0 | 94.30.2 | 71.43.6 | 67.70.7 | 62.10.0 | 72.01.6 | 66.50.3 | 73.90.8 | |||
| SoftPatch | 90.60.2 | 91.81.7 | 87.60.4 | 67.80.8 | 98.00.6 | 78.04.8 | 70.60.7 | 55.31.5 | 93.42.7 | 75.61.2 | 80.90.4 | |||
| M3DM | 87.72.3 | 83.02.7 | 83.11.1 | 66.41.7 | 96.71.4 | 77.71.7 | 82.73.1 | 62.53.4 | 92.91.8 | 76.71.2 | 80.90.8 | |||
| Ours | 90.81.3 | 90.24.0 | 86.91.8 | 68.03.6 | 91.03.6 | 83.21.8 | 88.72.1 | 57.76.7 | 93.31.1 | 75.91.6 | 82.60.5 | |||
| 3D+RGB | PatchCore+FPFH | 81.14.0 | 77.81.4 | 91.70.5 | 84.51.6 | 91.81.3 | 64.82.6 | 79.53.1 | 77.31.9 | 90.91.6 | 89.81.1 | 82.90.8 | ||
| AST | 85.40.6 | 88.90.6 | 91.30.6 | 95.60.6 | 89.21.0 | 85.90.6 | 92.80.6 | 91.60.6 | 79.60.6 | 70.00.6 | 87.00.3 | |||
| Shape-Guided | 91.00.5 | 86.32.0 | 94.20.5 | 86.41.0 | 94.20.1 | 77.10.5 | 88.60.1 | 85.81.0 | 88.30.1 | 85.10.2 | 87.70.3 | |||
| M3DM | 96.62.2 | 85.71.9 | 88.42.5 | 86.43.1 | 96.11.3 | 86.35.4 | 85.10.6 | 76.52.3 | 94.81.3 | 79.32.4 | 87.50.5 | |||
| Ours | 98.10.8 | 91.02.6 | 96.80.8 | 94.22.0 | 93.70.8 | 90.62.0 | 92.91.6 | 81.92.0 | 95.31.4 | 84.72.4 | 91.91.0 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | SIFT | 86.40.0 | 70.20.0 | 90.30.0 | 86.10.0 | 90.60.0 | 60.30.0 | 85.00.0 | 95.30.0 | 93.80.0 | 86.30.0 | 84.40.0 | ||
| FPFH | 92.60.0 | 78.30.0 | 92.10.0 | 85.50.0 | 88.20.0 | 68.30.0 | 90.50.0 | 94.30.0 | 92.10.0 | 90.30.0 | 87.20.0 | |||
| Shape-Guided | 95.60.0 | 80.30.0 | 98.10.0 | 89.50.0 | 88.20.0 | 70.30.0 | 95.20.6 | 96.30.0 | 93.10.0 | 93.70.0 | 90.00.1 | |||
| M3DM | 93.70.5 | 81.10.3 | 97.60.2 | 86.30.4 | 87.91.3 | 75.34.6 | 95.40.2 | 96.90.4 | 94.60.4 | 92.70.3 | 90.10.6 | |||
| Ours | 95.80.3 | 81.20.4 | 97.60.1 | 86.60.7 | 88.01.1 | 73.04.0 | 95.50.4 | 96.50.1 | 94.20.6 | 93.50.8 | 90.20.5 | |||
| RGB | PaDim | 93.02.4 | 87.52.6 | 93.70.4 | 86.80.9 | 92.71.3 | 93.37.0 | 94.90.5 | 95.01.0 | 92.40.6 | 94.90.6 | 92.40.5 | ||
| PatchCore | 90.90.6 | 97.00.1 | 96.20.5 | 88.40.5 | 95.70.4 | 79.12.5 | 89.20.5 | 93.40.9 | 96.50.7 | 95.10.2 | 92.20.2 | |||
| Shape-Guided | 90.21.9 | 94.52.2 | 94.91.3 | 86.51.2 | 93.60.5 | 74.86.5 | 90.74.0 | 92.41.7 | 91.84.3 | 93.32.2 | 90.32.2 | |||
| SoftPatch | 93.20.3 | 96.10.1 | 96.40.1 | 89.70.7 | 95.30.5 | 78.41.7 | 90.00.3 | 93.50.7 | 96.20.7 | 94.70.5 | 92.30.2 | |||
| M3DM | 93.50.3 | 96.80.3 | 96.90.5 | 86.00.6 | 93.80.8 | 79.21.6 | 96.20.4 | 94.80.6 | 96.80.4 | 96.90.1 | 93.10.1 | |||
| Ours | 93.70.9 | 96.00.6 | 96.80.3 | 84.01.5 | 92.41.0 | 79.52.4 | 95.60.1 | 94.80.6 | 96.80.6 | 95.30.3 | 92.50.2 | |||
| 3D+RGB | PatchCore+FPFH | 96.60.4 | 96.11.2 | 97.70.5 | 92.63.2 | 92.51.4 | 89.10.5 | 96.50.2 | 96.70.2 | 95.31.1 | 97.20.1 | 95.00.4 | ||
| Shape-Guided | 93.50.1 | 94.00.2 | 97.50.3 | 93.00.3 | 95.50.1 | 93.10.8 | 95.30.1 | 97.90.1 | 95.60.1 | 97.20.2 | 95.20.1 | |||
| M3DM | 94.30.8 | 96.50.3 | 97.40.5 | 89.20.2 | 92.70.9 | 82.81.0 | 96.40.3 | 95.40.6 | 97.20.4 | 96.70.3 | 93.90.2 | |||
| Ours | 96.90.3 | 96.30.2 | 97.60.0 | 92.70.5 | 93.90.4 | 91.81.3 | 97.00.5 | 96.40.1 | 97.00.2 | 96.50.1 | 95.60.1 |
In the noisy anomaly detection setting, we compare our method with several 3D-based, RGB-based, and hybrid multi-modal 3D/RGB methods on MVTec-3D. Tabs. III and V show the anomaly detection results record with I-AUROC under Overlap and Non-Overlap settings respectively. Tabs. IV and VI show the segmentation results record with AUPRO under Overlap and Non-Overlap settings respectively. We report the P-AUROC in P-AUROC for noisy anomaly segmentation on MVTec 3D-AD.
Overlap and Non-Overlap Analysis. Compared to the Non-Overlap setting, our method significantly outperformed all baseline methods in the Overlap setting, especially in anomaly detection (I-AUROC). Specifically, our approach exceeded the second-best by 13.9%, 3.7%, and 20.3% in I-AUROC for the 3D, RGB, and 3D+RGB settings, respectively. This indicates the effectiveness of sample-level denoising in Stage I & II of our method, as most baseline methods struggled with anomalies existing in both the training and test datasets. This includes approaches like SoftPatch [8], which only perform denoising at the patch-level, whereas our method remained largely unaffected. This demonstrates the enhanced robustness of our proposed Stage I & II, especially in situations where defects with similar appearances existing in both the training and test datasets, i.e., a common scenario in real-world industrial settings.
3D-Based. On pure 3D anomaly detection, we get the highest I-AUROC and outperform M3DM [9] 13.9% in Overlap and Shape-Guided [44] 2.1% in Non-Overlap. For segmentation, we get the best result with AUPRO and outperform Shape-Guided 0.3% in Overlap and M3DM 0.1% in Non-Overlap. This shows our method has much better detection and segementation performance than the previous method, and with our PFA, the Point Transformer is the better 3D feature extractor for this task.
RGB-Based. Our I-AUROC in RGB domain is 3.7% higher than SoftPatch in Overlap and 1.7% higher than Softpatch and M3DM in Non-Overlap. For segmentation, we get the highest AUPRO score, 0.6% higher than PaDim in Overlap and second best score in Non-Overlap.
Hybrid 3D/RGB. On multi-modal 3D/RGB anomaly detection, we get the highest I-AUROC and outperform M3DM 20.3% in Overlap and Shape-Guided 4.2% in Non-Overlap. For segmentation, we get the best result with AUPRO and outperform Shape-Guided 0.6% in Overlap and Shape-guided 0.4% in Non-Overlap. These results are contributed by our fusion strategy and the high-performance 3D anomaly detection results.

| Stage I&II | Overlap | Non-Overlap | Noise-level | |||||||
| I-AUROC | P-AUROC | AUPRO | I-AUROC | P-AUROC | AUPRO | |||||
| ✗ | ✗ | ✗ | ✗ | 66.40.4 | 72.90.9 | 66.53.4 | 87.70.5 | 98.70.1 | 94.50.2 | 9.090.00 |
| ✓ | ✗ | ✗ | ✗ | 79.71.1 | 89.21.1 | 84.50.6 | 88.60.6 | 98.80.1 | 94.90.3 | 5.130.13 |
| ✓ | ✓ | ✗ | ✗ | 82.60.7 | 92.70.5 | 87.80.3 | 89.20.8 | 98.70.0 | 94.90.1 | 3.870.08 |
| ✓ | ✓ | ✓ | ✗ | 86.20.5 | 94.30.4 | 90.30.5 | 91.30.2 | 98.90.1 | 95.40.0 | 2.790.18 |
| ✓ | ✓ | ✓ | ✓ | 86.61.3 | 94.60.3 | 90.70.2 | 91.91.0 | 98.90.0 | 95.60.1 | 2.730.05 |
4.4 Visualization Results
In this section, we visualize anomaly segmentation results for all categories of MVTec-3D AD datasets under the overlap setting. As shown in Fig. 7, we visualize the heatmap results of our method and PatchCore + FPFH [20], M3DM [9] and Shape-Guided [44] with multi-modal inputs. Our method outperforms the previous ones by producing more accurate segmentation maps and exhibiting greater resilience to dataset noise. While the earlier approaches were often confounded by noise samples within the dataset, this is particularly noticeable in the Cable Gland, Dowel, Foam, and Peach results for PatchCore + FPFH, as well as the Foam and Rope results for Shape-Guided. More visualization results under the non-overlap setting is shown in Visualization results of Non-Overlap setiing.
4.5 Ablation Study
We conduct an ablation study on the main components introduced in Sec. 3, namely Stage I & II two-stage sample-level denoising, intra-modality reference, Aligned Multi-Scale Point Cloud Feature Extraction and Noise-Focused Aggregation. The results are displayed in Tab. VII. It was observed that the incremental inclusion of each component led to improvements in I-AUROC, P-AUROC, and AUPRO under both Overlap and Non-Overlap settings, particularly under the more challenging Overlap setting. Besides these metrics, the Noise-level metric also clearly demonstrates that the model’s capability for sample-level denoising progressively increased with the addition of each module.
Different Scales. We also conduct an ablation study on the feature scales extracted in the Aligned Multi-Scale Point Cloud Feature Extraction, with results presented in Tab. VIII. The model performance varies across different scale configurations. Notably, when incorporating all scales, all performance metrics peaked, demonstrating that multi-scale consideration can enhance model performance. When the small scale is excluded, our model performs nearly as well as the full configuration, indicating that omitting small-scale processing has a relatively minor impact. This could be attributed to small-scale patches often containing too few point cloud points, many of which might be deemed insignificant and discarded during segmentation.
| Methods |
|
|
|
|
Full | |||||||||
| Over | I-AUROC | 82.60.7 | 84.61.0 | 83.71.2 | 85.30.4 | 86.61.3 | ||||||||
| P-AUROC | 92.70.5 | 94.00.3 | 93.60.2 | 94.20.4 | 94.60.3 | |||||||||
| AUPRO | 87.80.3 | 89.80.3 | 89.40.4 | 90.20.2 | 90.70.2 | |||||||||
| N-Over | I-AUROC | 89.20.8 | 89.60.6 | 89.10.9 | 89.80.1 | 91.91.0 | ||||||||
| P-AUROC | 98.70.0 | 98.70.1 | 98.80.1 | 98.80.1 | 98.90.0 | |||||||||
| AUPRO | 94.90.1 | 95.00.2 | 95.40.2 | 95.40.2 | 95.60.1 | |||||||||
| Noise-level | 3.870.08 | 2.770.18 | 3.180.20 | 2.760.07 | 2.730.05 | |||||||||
| 128 | 256 | 512 | 1024 | ||
| Over | I-AUROC | 86.61.3 | 86.20.6 | 85.90.4 | 84.00.5 |
| P-AUROC | 94.60.3 | 94.30.7 | 94.40.1 | 93.40.4 | |
| AUPRO | 90.70.2 | 90.30.4 | 90.20.4 | 89.00.5 | |
| N-Over | I-AUROC | 91.91.0 | 91.40.9 | 91.00.2 | 89.40.5 |
| P-AUROC | 98.90.0 | 98.90.0 | 98.90.1 | 98.70.3 | |
| AUPRO | 95.50.1 | 95.50.1 | 95.40.1 | 95.00.3 | |
| Noise-level | 2.730.05 | 2.730.05 | 2.750.13 | 3.460.10 | |
Point Cloud Threshold. We also perform an ablation study on the hyper-parameter introduced, representing the thresholds for the minimum number of points required in a point cloud patch to be considered meaningful. The experimental results are shown in Tab. IX. Given that the point cloud encoder used in our experiments has a minimum group size of 128, we commence our testing from this threshold. The findings indicate that for most metrics, a threshold of 128 points is the most appropriate, aligning with expectations as a lower threshold would mean considering more patches for computing the anomaly score, potentially leading to better accuracy. Therefore, after balancing the considerations of computational complexity and the accuracy of RGB-3D multi-modal anomaly detection, we opted for a threshold of 128 in this paper.
and .
| 1.0 1.3 | 1.0 1.4 | 1.0 1.5 | 1.0 1.6 | 1.0 1.7 | ||
| Over | I-AUROC | 86.10.7 | 85.60.5 | 86.61.3 | 86.11.0 | 86.11.0 |
| P-AUROC | 94.30.7 | 94.20.7 | 94.60.3 | 94.20.7 | 94.20.0 | |
| AUPRO | 90.30.4 | 90.20.3 | 90.70.3 | 90.30.4 | 90.30.3 | |
| N-Over | I-AUROC | 91.30.5 | 90.70.8 | 91.91.0 | 91.21.1 | 91.10.8 |
| P-AUROC | 98.90.1 | 98.90.1 | 98.90.0 | 98.90.0 | 98.90.1 | |
| AUPRO | 95.40.2 | 95.40.1 | 95.50.1 | 95.40.2 | 95.50.2 | |
| Noise-level | 2.740.09 | 2.750.07 | 2.710.19 | 2.720.04 | 2.750.06 | |
| Ref Num | 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|---|
| Over | I-AUROC | 80.70.9 | 84.80.7 | 85.61.5 | 86.10.5 | 86.61.3 |
| P-AUROC | 89.41.3 | 93.50.4 | 93.80.3 | 93.90.2 | 94.60.3 | |
| AUPRO | 85.50.7 | 89.30.1 | 89.80.3 | 90.00.4 | 90.70.3 | |
| N-Over | I-AUROC | 88.70.9 | 90.60.4 | 91.00.9 | 91.50.4 | 91.91.0 |
| P-AUROC | 98.80.1 | 98.80.1 | 98.90.0 | 98.80.1 | 98.90.0 | |
| AUPRO | 94.90.4 | 95.50.2 | 95.50.1 | 95.40.1 | 95.50.1 | |
| Noise-level | 5.070.13 | 3.200.04 | 2.880.20 | 2.820.19 | 2.710.19 | |
To assess the extent to which RGB and Point Cloud modalities should be integrated, we conducted experiments with the hyper-parameters and , which control the level of integration. The results of these experiments are presented in Tab. X. We observed that the model achieves optimal performance across all metrics for both anomaly detection and segmentation with and . This indicates that enhancing the integration of the 3D Point Cloud modality can further improve performance. This outcome aligns with findings reported in Secs. 4.2 and 4.3, where most methods performed better using purely 3D data rather than solely RGB data. This suggests that the 3D Point Cloud data in the MVTec 3D-AD dataset [10] contains richer information and facilitates more effective anomaly detection compared to RGB data within the same dataset.
Number of Intra-Modal Reference Samples. To determine the appropriate number of intra-modal reference samples in Stage I, we conducted an ablation study on the quantity of these samples. The results are shown in Tab. XI. We conclude that increasing the number of intra-modal reference samples enhances the model’s performance. This improvement is logical, as more reference samples mean more normal cases for the model to learn from, naturally boosting performance. However, selecting too many intra-modal reference samples can lead to the inclusion of noise samples and increase computational complexity. Therefore, in practical implementation, we opted for 4 intra-modal reference samples, striking a balance between model performance and computational efficiency.
5 Conclusion
In this paper, we first delve into the RGB-3D multi-modal noisy anomaly detection problem and have introduced a novel framework, M3DM-NR, to address the challenging task of RGB-3D multi-modal noisy industrial anomaly detection. Our approach systematically tackles the issues of reference selection, denoising, and final anomaly detection and segmentation through a three-stage process. In Stage I, we developed the Initial Feature Extraction, Suspected References Selection, and Suspected Anomaly Map Computation modules to filter normal samples and generate suspected anomaly maps, providing a robust foundation for subsequent stages. Stage II, termed Enhanced Multi-modal Denoising, leverages multi-scale feature comparison and weighting methods to refine and denoise the training samples, ensuring cleaner data for model training. Finally, Stage III integrates Point Feature Alignment, Unsupervised Feature Fusion, Noise Discriminative Coreset Selection, and Decision Layer Fusion to achieve precise anomaly detection and segmentation while effectively filtering out noise at the patch level. Extensive experiments demonstrate that our M3DM-NR framework significantly outperforms existing state-of-the-art methods in both detection and segmentation precision for 3D-RGB multi-modal noisy anomaly detection. The ablation studies further validate the effectiveness of each component within our framework, highlighting the importance of our systematic and hierarchical approach.
Future Works. Our work not only advances the field of industrial anomaly detection but also sets a new benchmark for handling noisy multi-modal data. Future research can build upon our framework to explore additional modalities and further enhance the robustness and accuracy of anomaly detection systems in practical industrial settings. Future work could consider more realistic methods of injecting noise into the training set. Currently, the approach of using anomalous samples from the test set as noise in the training set is rather naive. Future research could explore how noise naturally occurs in normal samples within real industrial production environments and attempt to construct new multi-modal noisy industrial detection datasets. Additionally, future efforts could look into fine-tuning the CLIP model to better handle the task of multi-modal noisy industrial anomaly detection. The current method employs a training-free approach. The pre-trained CLIP model used in M3DM-NR is trained on a large-scale image dataset containing all categories of images. Subsequent work could consider fine-tuning the CLIP model on specific industrial detection datasets before using it for multi-modal noisy industrial anomaly detection.
References
- [1] Y. Cao, X. Xu, J. Zhang, Y. Cheng, X. Huang, G. Pang, and W. Shen, “A survey on visual anomaly detection: Challenge, approach, and prospect,” arXiv preprint arXiv:2401.16402, 2024.
- [2] J. Liu, G. Xie, J. Wang, S. Li, C. Wang, F. Zheng, and Y. Jin, “Deep industrial image anomaly detection: A survey,” Machine Intelligence Research, vol. 21, no. 1, pp. 104–135, 2024.
- [3] P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 9592–9600.
- [4] C. Wang, W. Zhu, B.-B. Gao, Z. Gan, J. Zhang, Z. Gu, S. Qian, M. Chen, and L. Ma, “Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,” in CVPR, 2024.
- [5] K. Roth, L. Pemula, J. Zepeda, B. Schölkopf, T. Brox, and P. Gehler, “Towards total recall in industrial anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 318–14 328.
- [6] D. Gudovskiy, S. Ishizaka, and K. Kozuka, “Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 98–107.
- [7] Y. Zheng, X. Wang, R. Deng, T. Bao, R. Zhao, and L. Wu, “Focus your distribution: Coarse-to-fine non-contrastive learning for anomaly detection and localization,” in 2022 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2022, pp. 1–6.
- [8] X. Jiang, J. Liu, J. Wang, Q. Nie, K. Wu, Y. Liu, C. Wang, and F. Zheng, “Softpatch: Unsupervised anomaly detection with noisy data,” Advances in Neural Information Processing Systems, vol. 35, pp. 15 433–15 445, 2022.
- [9] Y. Wang, J. Peng, J. Zhang, R. Yi, Y. Wang, and C. Wang, “Multimodal industrial anomaly detection via hybrid fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 8032–8041.
- [10] P. Bergmann, X. Jin, D. Sattlegger, and C. Steger, “The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization,” in Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, VISIGRAPP 2022, Volume 5: VISAPP, Online Streaming, February 6-8, 2022, G. M. Farinella, P. Radeva, and K. Bouatouch, Eds. SCITEPRESS, 2022, pp. 202–213. [Online]. Available: https://doi.org/10.5220/0010865000003124
- [11] E. Horwitz and Y. Hoshen, “Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2967–2976.
- [12] D. Gong, L. Liu, V. Le, B. Saha, M. R. Mansour, S. Venkatesh, and A. v. d. Hengel, “Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1705–1714.
- [13] V. Zavrtanik, M. Kristan, and D. Skočaj, “Reconstruction by inpainting for visual anomaly detection,” Pattern Recognition, vol. 112, p. 107706, 2021.
- [14] ——, “Draem-a discriminatively trained reconstruction embedding for surface anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 8330–8339.
- [15] H. Deng and X. Li, “Anomaly detection via reverse distillation from one-class embedding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 9737–9746.
- [16] P. Perera, R. Nallapati, and B. Xiang, “Ocgan: One-class novelty detection using gans with constrained latent representations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2898–2906.
- [17] J. Yu, Y. Zheng, X. Wang, W. Li, Y. Wu, R. Zhao, and L. Wu, “Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows,” arXiv preprint arXiv:2111.07677, 2021.
- [18] M. Rudolph, T. Wehrbein, B. Rosenhahn, and B. Wandt, “Asymmetric student-teacher networks for industrial anomaly detection,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 2592–2602.
- [19] T. Defard, A. Setkov, A. Loesch, and R. Audigier, “Padim: a patch distribution modeling framework for anomaly detection and localization,” in International Conference on Pattern Recognition. Springer, 2021, pp. 475–489.
- [20] E. Horwitz and Y. Hoshen, “An empirical investigation of 3d anomaly detection and segmentation,” arXiv preprint arXiv:2203.05550, 2022.
- [21] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [22] Z. Guo, R. Zhang, X. Zhu, Y. Tang, X. Ma, J. Han, K. Chen, P. Gao, X. Li, H. Li et al., “Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following,” arXiv preprint arXiv:2309.00615, 2023.
- [23] L. Bonfiglioli, M. Toschi, D. Silvestri, N. Fioraio, and D. De Gregorio, “The eyecandies dataset for unsupervised multimodal anomaly detection and localization,” in Proceedings of the Asian Conference on Computer Vision, 2022, pp. 3586–3602.
- [24] C.-L. Li, K. Sohn, J. Yoon, and T. Pfister, “Cutpaste: Self-supervised learning for anomaly detection and localization,” in CVPR, 2021.
- [25] G. Zhang, K. Cui, T.-Y. Hung, and S. Lu, “Defect-gan: High-fidelity defect synthesis for automated defect inspection,” in CACV, 2021.
- [26] Z. Liu, Y. Zhou, Y. Xu, and Z. Wang, “Simplenet: A simple network for image anomaly detection and localization,” in CVPR, 2023.
- [27] M. Yang, P. Wu, and H. Feng, “Memseg: A semi-supervised method for image surface defect detection using differences and commonalities,” Engineering Applications of Artificial Intelligence, 2023.
- [28] T. D. Tien, A. T. Nguyen, N. H. Tran, T. D. Huy, S. Duong, C. D. T. Nguyen, and S. Q. Truong, “Revisiting reverse distillation for anomaly detection,” in CVPR, 2023.
- [29] L. Chen, Z. You, N. Zhang, J. Xi, and X. Le, “Utrad: Anomaly detection and localization with u-transformer,” Neural Networks, 2022.
- [30] Y. Liang, J. Zhang, S. Zhao, R. Wu, Y. Liu, and S. Pan, “Omni-frequency channel-selection representations for unsupervised anomaly detection,” TIP, 2023.
- [31] J. Zhang, X. Chen, Y. Wang, C. Wang, Y. Liu, X. Li, M.-H. Yang, and D. Tao, “Exploring plain vit reconstruction for multi-class unsupervised anomaly detection,” arXiv preprint arXiv:2312.07495, 2023.
- [32] H. He, Y. Bai, J. Zhang, Q. He, H. Chen, Z. Gan, C. Wang, X. Li, G. Tian, and L. Xie, “Mambaad: Exploring state space models for multi-class unsupervised anomaly detection,” arXiv, 2024.
- [33] J. Zhang, X. Li, G. Tian, Z. Xue, Y. Liu, G. Pang, and D. Tao, “Learning feature inversion for multi-class unsupervised anomaly detection under general-purpose coco-ad benchmark,” arXiv, 2024.
- [34] H. He, J. Zhang, H. Chen, X. Chen, Z. Li, X. Chen, Y. Wang, C. Wang, and L. Xie, “Diad: A diffusion-based framework for multi-class anomaly detection,” arXiv preprint arXiv:2312.06607, 2023.
- [35] Q. Wan, L. Gao, X. Li, and L. Wen, “Unsupervised image anomaly detection and segmentation based on pretrained feature mapping,” TII, 2022.
- [36] Y. Cao, X. Xu, Z. Liu, and W. Shen, “Collaborative discrepancy optimization for reliable image anomaly localization,” TII, 2023.
- [37] J. Lei, X. Hu, Y. Wang, and D. Liu, “Pyramidflow: High-resolution defect contrastive localization using pyramid normalizing flow,” in CVPR, 2023.
- [38] M. Salehi, N. Sadjadi, S. Baselizadeh, M. H. Rohban, and H. R. Rabiee, “Multiresolution knowledge distillation for anomaly detection,” in CVPR, 2021.
- [39] Y. Cao, Q. Wan, W. Shen, and L. Gao, “Informative knowledge distillation for image anomaly segmentation,” KBS, 2022.
- [40] R. Chen, G. Xie, J. Liu, J. Wang, Z. Luo, J. Wang, and F. Zheng, “Easynet: An easy network for 3d industrial anomaly detection,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 7038–7046.
- [41] V. Zavrtanik, M. Kristan, and D. Skočaj, “Keep dræming: Discriminative 3d anomaly detection through anomaly simulation,” Pattern Recognition Letters, 2024.
- [42] W. Li and X. Xu, “Towards scalable 3d anomaly detection and localization: A benchmark via 3d anomaly synthesis and a self-supervised learning network,” arXiv preprint arXiv:2311.14897, 2023.
- [43] Y. Cao, X. Xu, and W. Shen, “Complementary pseudo multimodal feature for point cloud anomaly detection,” arXiv preprint arXiv:2303.13194, 2023.
- [44] Y.-M. Chu, L. Chieh, T.-I. Hsieh, H.-T. Chen, and T.-L. Liu, “Shape-guided dual-memory learning for 3d anomaly detection,” 2023.
- [45] Y. Tu, B. Zhang, L. Liu, Y. Li, C. Xu, J. Zhang, Y. Wang, C. Wang, and C. R. Zhao, “Self-supervised feature adaptation for 3d industrial anomaly detection,” arXiv preprint arXiv:2401.03145, 2024.
- [46] B. Zhao, Q. Xiong, X. Zhang, J. Guo, Q. Liu, X. Xing, and X. Xu, “Pointcore: Efficient unsupervised point cloud anomaly detector using local-global features,” arXiv preprint arXiv:2403.01804, 2024.
- [47] P. Bergmann and D. Sattlegger, “Anomaly detection in 3d point clouds using deep geometric descriptors,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 2613–2623.
- [48] Z. Gu, J. Zhang, L. Liu, X. Chen, J. Peng, Z. Gan, G. Jiang, A. Shu, Y. Wang, and L. Ma, “Rethinking reverse distillation for multi-modal anomaly detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 8, 2024, pp. 8445–8453.
- [49] Z. Hu, Z. Yang, X. Hu, and R. Nevatia, “Simple: Similar pseudo label exploitation for semi-supervised classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 099–15 108.
- [50] K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li, “Fixmatch: Simplifying semi-supervised learning with consistency and confidence,” Advances in neural information processing systems, vol. 33, pp. 596–608, 2020.
- [51] J. Li, R. Socher, and S. C. Hoi, “Dividemix: Learning with noisy labels as semi-supervised learning,” arXiv preprint arXiv:2002.07394, 2020.
- [52] M. Xu, Z. Zhang, H. Hu, J. Wang, L. Wang, F. Wei, X. Bai, and Z. Liu, “End-to-end semi-supervised object detection with soft teacher,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3060–3069.
- [53] Y.-C. Liu, C.-Y. Ma, Z. He, C.-W. Kuo, K. Chen, P. Zhang, B. Wu, Z. Kira, and P. Vajda, “Unbiased teacher for semi-supervised object detection,” arXiv preprint arXiv:2102.09480, 2021.
- [54] F. Yang, K. Wu, S. Zhang, G. Jiang, Y. Liu, F. Zheng, W. Zhang, C. Wang, and L. Zeng, “Class-aware contrastive semi-supervised learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 421–14 430.
- [55] S. Han, X. Hu, H. Huang, M. Jiang, and Y. Zhao, “Adbench: Anomaly detection benchmark,” Advances in Neural Information Processing Systems, vol. 35, pp. 32 142–32 159, 2022.
- [56] G. Pang, C. Yan, C. Shen, A. v. d. Hengel, and X. Bai, “Self-trained deep ordinal regression for end-to-end video anomaly detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 12 173–12 182.
- [57] B. Liu, D. Wang, K. Lin, P.-N. Tan, and J. Zhou, “Rca: A deep collaborative autoencoder approach for anomaly detection,” in IJCAI: proceedings of the conference, vol. 2021. NIH Public Access, 2021, p. 1505.
- [58] C. Zhou and R. C. Paffenroth, “Anomaly detection with robust deep autoencoders,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 2017, pp. 665–674.
- [59] S. Wu, J. Zhao, and G. Tian, “Understanding and mitigating data contamination in deep anomaly detection: A kernel-based approach.” in IJCAI, 2022, pp. 2319–2325.
- [60] J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: a visual language model for few-shot learning,” Advances in neural information processing systems, vol. 35, pp. 23 716–23 736, 2022.
- [61] C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. Le, Y.-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” in International conference on machine learning. PMLR, 2021, pp. 4904–4916.
- [62] R. Taori, A. Dave, V. Shankar, N. Carlini, B. Recht, and L. Schmidt, “Measuring robustness to natural distribution shifts in image classification,” Advances in Neural Information Processing Systems, vol. 33, pp. 18 583–18 599, 2020.
- [63] G. Goh, N. Cammarata, C. Voss, S. Carter, M. Petrov, L. Schubert, A. Radford, and C. Olah, “Multimodal neurons in artificial neural networks,” Distill, vol. 6, no. 3, p. e30, 2021.
- [64] Y. Rao, W. Zhao, G. Chen, Y. Tang, Z. Zhu, G. Huang, J. Zhou, and J. Lu, “Denseclip: Language-guided dense prediction with context-aware prompting,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 082–18 091.
- [65] Y. Zhong, J. Yang, P. Zhang, C. Li, N. Codella, L. H. Li, L. Zhou, X. Dai, L. Yuan, Y. Li et al., “Regionclip: Region-based language-image pretraining,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 793–16 803.
- [66] C. Zhou, C. C. Loy, and B. Dai, “Extract free dense labels from clip,” in European Conference on Computer Vision. Springer, 2022, pp. 696–712.
- [67] J. Jeong, Y. Zou, T. Kim, D. Zhang, A. Ravichandran, and O. Dabeer, “Winclip: Zero-/few-shot anomaly classification and segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 606–19 616.
- [68] X. Chen, Y. Han, and J. Zhang, “A zero-/few-shot anomaly classification and segmentation method for cvpr 2023 vand workshop challenge tracks 1&2: 1st place on zero-shot ad and 4th place on few-shot ad,” arXiv preprint arXiv:2305.17382, 2023.
- [69] Y. Cao, X. Xu, C. Sun, Y. Cheng, Z. Du, L. Gao, and W. Shen, “Segment any anomaly without training via hybrid prompt regularization,” arXiv preprint arXiv:2305.10724, 2023.
- [70] X. Chen, J. Zhang, G. Tian, H. He, W. Zhang, Y. Wang, C. Wang, Y. Wu, and Y. Liu, “Clip-ad: A language-guided staged dual-path model for zero-shot anomaly detection,” arXiv preprint arXiv:2311.00453, 2023.
- [71] J. Zhang, X. Chen, Z. Xue, Y. Wang, C. Wang, and Y. Liu, “Exploring grounding potential of vqa-oriented gpt-4v for zero-shot anomaly detection,” arXiv preprint arXiv:2311.02612, 2023.
- [72] R. Zhang, Z. Guo, W. Zhang, K. Li, X. Miao, B. Cui, Y. Qiao, P. Gao, and H. Li, “Pointclip: Point cloud understanding by clip,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8552–8562.
- [73] X. Zhu, R. Zhang, B. He, Z. Guo, Z. Zeng, Z. Qin, S. Zhang, and P. Gao, “Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2639–2650.
- [74] L. Xue, M. Gao, C. Xing, R. Martín-Martín, J. Wu, C. Xiong, R. Xu, J. C. Niebles, and S. Savarese, “Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1179–1189.
- [75] Y. Zheng, X. Wang, Y. Qi, W. Li, and L. Wu, “Benchmarking unsupervised anomaly detection and localization,” 2022.
- [76] G. Wang, S. Han, E. Ding, and D. Huang, “Student-teacher feature pyramid matching for anomaly detection,” in 32nd British Machine Vision Conference 2021, BMVC 2021, Online, November 22-25, 2021. BMVA Press, 2021, p. 306. [Online]. Available: https://www.bmvc2021-virtualconference.com/assets/papers/1273.pdf
- [77] M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,” Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981.
- [78] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [79] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9650–9660.
- [80] H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V. Koltun, “Point transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 259–16 268.
- [81] Y. Pang, W. Wang, F. E. H. Tay, W. Liu, Y. Tian, and L. Yuan, “Masked autoencoders for point cloud self-supervised learning,” 2022.
- [82] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su et al., “Shapenet: An information-rich 3d model repository,” arXiv preprint arXiv:1512.03012, 2015.
- [83] B. Schölkopf, J. C. Platt, J. Shawe-Taylor, A. J. Smola, and R. C. Williamson, “Estimating the support of a high-dimensional distribution,” Neural computation, vol. 13, no. 7, pp. 1443–1471, 2001.
- [84] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019.
Overview
The appendix provides additional sections below to enhance the main manuscript:
P-AUROC for regular anomaly segmentation on MVTec 3D-AD
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | FPFH [20] | 99.4 | 96.6 | 99.9 | 94.6 | 96.6 | 92.7 | 99.6 | 99.9 | 99.6 | 99.0 | 97.8 | ||
| M3DM [9] | 98.1 | 94.9 | 99.7 | 93.2 | 95.9 | 92.5 | 98.9 | 99.5 | 99.4 | 98.1 | 97.0 | |||
| Ours | 98.1 | 95.0 | 99.6 | 93.2 | 95.9 | 92.4 | 98.9 | 99.6 | 99.4 | 98.1 | 97.0 | |||
| RGB | PatchCore[5] | 98.3 | 98.4 | 98.0 | 97.4 | 97.2 | 84.9 | 97.6 | 98.3 | 98.7 | 97.7 | 96.7 | ||
| M3DM [9] | 99.2 | 99.0 | 99.4 | 97.7 | 98.3 | 95.5 | 99.4 | 99.0 | 99.5 | 99.4 | 98.7 | |||
| Ours | 99.1 | 99.0 | 99.4 | 97.7 | 98.4 | 95.5 | 99.3 | 99.0 | 99.5 | 99.5 | 98.7 | |||
| RGB+3D | AST[18] | - | - | - | - | - | - | - | - | - | - | 97.6 | ||
| PatchCore + FPFH[20] | 99.6 | 99.2 | 99.7 | 99.4 | 98.1 | 97.4 | 99.6 | 99.8 | 99.4 | 99.5 | 99.2 | |||
| M3DM [9] | 99.5 | 99.3 | 99.7 | 98.5 | 98.5 | 98.4 | 99.6 | 99.4 | 99.7 | 99.6 | 99.2 | |||
| Ours | 99.6 | 99.3 | 99.7 | 97.9 | 98.5 | 98.9 | 99.6 | 99.5 | 99.7 | 99.6 | 99.2 |
In the regular anomaly segmentation setting, we compare our method with several 3D-based, RGB-based, and hybrid multi-modal 3D/RGB methods on MVTec-3D. Tab. A1 shows the segmentation results record with P-AUROC and we can conclude that our M3DM-NR also maintains the regular anomaly segmentation ability.
P-AUROC for noisy anomaly segmentation on MVTec 3D-AD
In the main paper, we report the AUPRO score for anomaly segmentation. In this section, we report the P-AUROC score under Overlap and Non-Overlap settings to further verify the segmentation performance of our method, as shown in Tab. A2 and Tab. A3.
3D. On pure 3D anomaly segmentation, we get the highest P-AUROC and outperform Shape-Guided [44] 0.8% in Overlap and M3DM [9] 0.1% in Non-Overlap. This shows our method has better segmentation performance than the previous method and is more resistant to noise in the training dataset, and with our PFA, the Point Transformer is the better 3D feature extractor for this task.
RGB. Our P-AUROC in RGB domain is the same as SoftPatch [8] in Overlap and the same as M3DM in Non-Overlap. But our method has a lower standard deviation, which means our method is more robust.
3D+RGB. On 3D + RGB multi-modal anomaly segmentation, we get the best result with AUPRO and outperform Shape-Guided 0.6% in Overlap and PatchCore+FPFH [20] 0.1% in Non-Overlap. These results are contributed by our novel 3-stage multi-modal noise-resistant framework.
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | SIFT | 69.84.6 | 80.61.4 | 95.40.5 | 78.20.9 | 70.62.0 | 77.11.6 | 66.61.5 | 76.410.0 | 91.10.3 | 75.91.7 | 78.21.6 | ||
| FPFH | 84.52.7 | 92.60.2 | 96.50.4 | 85.80.6 | 86.32.2 | 84.51.4 | 87.81.2 | 87.42.0 | 83.30.7 | 91.80.7 | 88.00.3 | |||
| AST | 89.50.6 | 90.20.0 | 96.90.0 | 85.70.6 | 86.80.0 | 86.40.0 | 93.50.0 | 97.00.6 | 89.60.6 | 89.90.6 | 90.60.2 | |||
| Shape-Guided | 93.51.7 | 94.21.5 | 99.40.6 | 92.41.2 | 88.16.5 | 91.03.1 | 94.60.8 | 92.53.8 | 97.11.9 | 91.21.2 | 93.40.6 | |||
| M3DM | 94.31.1 | 94.20.9 | 98.90.2 | 90.60.9 | 89.86.7 | 87.32.8 | 95.11.0 | 91.95.1 | 98.00.5 | 92.63.8 | 93.30.9 | |||
| Ours | 96.61.7 | 94.30.3 | 99.30.3 | 91.80.4 | 90.24.9 | 88.81.8 | 95.71.2 | 92.63.2 | 98.70.7 | 94.32.6 | 94.20.7 | |||
| RGB | PaDim | 93.40.9 | 93.90.9 | 97.30.4 | 90.61.3 | 93.56.1 | 88.40.5 | 91.84.5 | 89.31.2 | 98.50.2 | 93.83.8 | 93.10.1 | ||
| PatchCore | 75.23.2 | 73.66.2 | 80.04.0 | 80.23.4 | 71.15.5 | 75.49.5 | 68.97.8 | 72.39.3 | 64.917.3 | 75.36.8 | 73.71.4 | |||
| AST | 67.80.0 | 74.20.0 | 54.20.0 | 65.80.6 | 68.90.0 | 63.40.6 | 57.50.6 | 61.10.6 | 57.20.0 | 69.30.6 | 63.90.1 | |||
| Shape-Guided | 78.03.5 | 91.21.4 | 93.11.1 | 84.70.3 | 90.10.4 | 73.81.6 | 82.81.1 | 89.30.8 | 88.60.2 | 88.80.3 | 86.00.6 | |||
| SoftPatch | 90.41.7 | 91.94.1 | 96.91.1 | 87.72.2 | 94.84.6 | 96.54.9 | 94.40.5 | 90.90.7 | 96.71.6 | 97.30.8 | 93.80.5 | |||
| M3DM | 68.85.0 | 77.01.8 | 77.22.6 | 77.10.4 | 71.82.0 | 68.92.3 | 65.81.7 | 65.83.8 | 60.52.3 | 75.21.4 | 70.81.1 | |||
| Ours | 98.50.5 | 95.81.6 | 98.70.4 | 95.01.1 | 88.55.9 | 85.91.7 | 93.42.6 | 89.51.0 | 98.60.3 | 94.60.4 | 93.80.7 | |||
| 3D+RGB | PatchCore+FPFH | 69.14.8 | 77.01.8 | 77.42.6 | 78.40.4 | 71.52.1 | 69.31.5 | 66.01.7 | 65.83.8 | 60.52.3 | 75.21.4 | 71.00.9 | ||
| AST | 90.70.6 | 94.30.6 | 97.50.0 | 89.40.0 | 90.60.6 | 89.40.0 | 93.30.6 | 96.90.6 | 90.60.6 | 93.60.0 | 92.60.2 | |||
| Shape-Guided | 91.01.7 | 94.70.4 | 98.10.2 | 90.90.1 | 91.65.3 | 90.81.6 | 95.30.3 | 95.84.6 | 96.00.3 | 95.52.7 | 94.01.0 | |||
| M3DM | 69.84.7 | 77.02.0 | 77.42.6 | 79.20.5 | 71.93.1 | 74.02.4 | 66.21.8 | 66.23.8 | 61.82.5 | 75.61.3 | 71.91.2 | |||
| Ours | 99.10.5 | 95.81.7 | 99.00.5 | 95.81.0 | 90.72.8 | 88.12.5 | 93.82.8 | 89.81.1 | 98.80.2 | 94.90.5 | 94.60.3 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D | SIFT | 94.03.1 | 94.23.0 | 93.94.9 | 93.01.9 | 95.71.3 | 92.32.9 | 96.02.8 | 98.12.9 | 99.20.7 | 98.60.7 | 95.50.6 | ||
| FPFH | 97.70.5 | 93.82.4 | 95.24.5 | 94.40.4 | 96.50.5 | 92.61.4 | 96.11.1 | 99.11.2 | 98.91.2 | 99.10.1 | 96.30.5 | |||
| AST | 96.40.6 | 91.30.6 | 98.30.6 | 91.90.6 | 86.40.6 | 94.00.6 | 98.90.6 | 99.30.6 | 92.90.0 | 93.80.0 | 94.30.3 | |||
| Shape-Guided | 98.40.5 | 94.41.5 | 98.81.0 | 93.01.7 | 95.50.6 | 90.94.0 | 98.71.2 | 97.92.0 | 98.00.6 | 97.70.1 | 96.30.6 | |||
| M3DM | 97.90.3 | 94.80.3 | 99.60.1 | 91.90.9 | 94.82.0 | 91.53.1 | 97.52.2 | 99.10.1 | 99.30.1 | 97.51.0 | 96.40.7 | |||
| Ours | 98.60.2 | 94.60.2 | 99.60.1 | 92.40.6 | 95.40.9 | 90.82.9 | 98.11.1 | 98.21.6 | 99.20.3 | 97.70.6 | 96.50.7 | |||
| RGB | PaDim | 97.51.2 | 96.10.9 | 97.90.2 | 95.10.2 | 97.80.4 | 99.60.3 | 99.10.2 | 98.60.3 | 98.80.4 | 99.20.2 | 98.00.2 | ||
| PatchCore | 96.00.2 | 98.90.0 | 98.11.9 | 96.70.4 | 98.90.1 | 99.90.0 | 98.10.1 | 96.32.3 | 98.80.8 | 99.20.6 | 98.10.5 | |||
| AST | 88.50.6 | 92.70.6 | 65.80.6 | 79.41.0 | 96.00.6 | 80.61.0 | 84.40.6 | 80.00.0 | 89.10.6 | 85.60.6 | 84.20.2 | |||
| Shape-Guided | 94.50.4 | 97.20.4 | 98.30.2 | 95.00.6 | 98.10.1 | 87.80.8 | 95.10.2 | 96.10.3 | 97.31.0 | 97.50.5 | 95.70.1 | |||
| SoftPatch | 96.30.5 | 98.50.3 | 99.20.1 | 96.80.4 | 98.90.1 | 98.91.0 | 98.30.3 | 97.11.3 | 98.20.4 | 98.51.0 | 98.10.1 | |||
| M3DM | 98.80.3 | 98.90.6 | 99.00.6 | 96.60.3 | 98.40.4 | 93.90.8 | 99.10.1 | 98.70.3 | 99.50.1 | 99.40.1 | 98.20.2 | |||
| Ours | 99.00.2 | 98.90.2 | 99.20.1 | 96.40.3 | 97.70.8 | 94.60.4 | 98.90.1 | 98.40.5 | 99.40.2 | 98.90.1 | 98.20.0 | |||
| 3D+RGB | PatchCore+FPFH | 99.40.1 | 98.80.5 | 99.30.6 | 98.11.6 | 98.10.5 | 97.50.2 | 99.30.1 | 98.60.1 | 99.50.1 | 99.10.6 | 98.80.1 | ||
| AST | 97.40.6 | 97.10.6 | 99.50.6 | 94.00.0 | 91.30.6 | 97.10.6 | 98.70.0 | 98.70.6 | 93.20.6 | 96.90.0 | 96.40.1 | |||
| Shape-Guided | 97.60.1 | 98.20.3 | 99.50.1 | 97.00.3 | 98.90.1 | 97.20.2 | 98.60.1 | 99.11.0 | 98.90.5 | 99.60.2 | 98.50.2 | |||
| M3DM | 98.90.2 | 99.10.1 | 99.30.6 | 96.80.3 | 97.50.9 | 96.00.3 | 99.20.1 | 99.00.3 | 99.70.1 | 99.30.1 | 98.50.1 | |||
| Ours | 99.40.1 | 99.00.1 | 99.50.1 | 97.20.2 | 98.20.4 | 98.10.4 | 99.30.1 | 99.20.0 | 99.60.1 | 99.20.1 | 98.90.0 |
Visualization results of Non-Overlap setiing
In this section, we visualize anomaly segmentation results for all categories of MVTec-3D AD datasets under Non-Overlap setting. As shown in Fig. A1, we visualize the heatmap results of our method and PatchCore + FPFH [20], M3DM [9] and Shape-Guided [44] with multi-modal inputs. Compared with previous methods, our method gets better segmentation maps.

Eyecandies
We have noticed that recently a new dataset Eyecandies [23] provides multimodel information of 10 categories of candies, and each category contains 1000 samples for training, 50 labeled samples for public testing and 400 unlabeled samples for private testing. The source dataset provides 6 RGB images, which are in different light conditions, a depth map, and a normal map of each sample. In this section, we convert the Eyecandies dataset to the format supported by M3DM-NR. In detail, we use the environment light image as our input RGB data, and for 3D data, we first convert the depth image to point clouds with internal parameters, then we remove the background points with point coordinates. For computation efficiency, we use only less than 400 samples from each category for training. Because the public test dataset only contains 25 normal and 25 anomalous samples, which doesn’t meet 10% of the size of training dataset, we implement the Overlap and Non-Overlap setting differently. For Overlap setting, we only conduct experiments of 5% noise by selecting 400 images from training dataset and 20 images from public test dataset as the whole noisy training dataset. For Non-Overlap setting, as the private test dataset contains 200 normal samples and 200 anomalous samples mixed together, we random select 80 samples from the private test dataset and regard it as 40 normal samples and 40 anomalous samples. These 80 samples, along with 320 normal samples selected from the training dataset, make up of the whole noisy training dataset. We report the mean and standard deviation over 3 random seeds for each measurement.
As illustrated in Tabs. A4, A5, A6, A7, A8 and A9, we report the best I-AUCROC, AUPRO and P-AUCROC scores. under both Overlap and Non-Overlap settings.
| Method |
|
|
|
Confetto |
|
|
|
Lollipop |
|
|
Mean | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D+RGB | PatchCore+FPFH | 11.42.8 | 19.23.6 | 20.91.6 | 19.70.9 | 25.15.9 | 20.84.7 | 17.61.2 | 24.53.6 | 24.81.4 | 19.11.3 | 20.30.3 | ||||||||||||||||
| AST | 8.00.6 | 13.80.6 | 6.70.6 | 10.90.6 | 16.70.6 | 10.90.6 | 18.40.6 | 24.01.0 | 9.40.0 | 13.70.0 | 13.40.2 | |||||||||||||||||
| Shape-Guided | 9.14.5 | 18.51.0 | 15.32.5 | 24.72.2 | 15.53.0 | 11.82.4 | 15.80.6 | 25.71.2 | 25.91.3 | 23.63.1 | 18.60.8 | |||||||||||||||||
| M3DM | 17.03.6 | 30.54.2 | 39.62.7 | 41.91.6 | 39.43.4 | 20.73.8 | 28.22.3 | 33.13.4 | 54.60.4 | 50.90.9 | 35.60.9 | |||||||||||||||||
| Ours | 33.53.4 | 74.94.5 | 76.95.5 | 89.33.0 | 55.86.1 | 48.05.7 | 79.45.2 | 65.04.9 | 98.91.0 | 70.52.4 | 69.21.9 |
| Method |
|
|
|
Confetto |
|
|
|
Lollipop |
|
|
Mean | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D+RGB | PatchCore+FPFH | 55.40.8 | 86.42.3 | 72.22.1 | 94.31.9 | 71.53.5 | 49.25.3 | 80.91.0 | 82.01.2 | 99.10.8 | 85.84.7 | 77.70.6 | ||||||||||||||||
| AST | 47.70.6 | 93.41.0 | 78.30.6 | 93.90.0 | 74.70.6 | 66.21.0 | 83.10.6 | 87.30.0 | 99.40.6 | 92.90.6 | 81.70.2 | |||||||||||||||||
| Shape-Guided | 49.40.5 | 94.81.3 | 77.52.2 | 93.91.1 | 74.80.9 | 64.92.0 | 83.30.4 | 86.01.6 | 99.60.1 | 92.61.3 | 81.70.7 | |||||||||||||||||
| M3DM | 53.95.0 | 90.10.6 | 89.40.8 | 98.40.4 | 81.51.0 | 52.31.8 | 78.41.1 | 83.31.7 | 99.50.2 | 99.40.2 | 82.60.5 | |||||||||||||||||
| Ours | 54.57.7 | 85.60.5 | 88.92.1 | 97.20.7 | 82.26.1 | 54.32.5 | 86.80.2 | 85.61.2 | 99.80.1 | 98.60.7 | 83.30.6 |
| Method |
|
|
|
Confetto |
|
|
|
Lollipop |
|
|
Mean | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D+RGB | PatchCore+FPFH | 16.71.9 | 20.52.1 | 15.61.4 | 18.73.2 | 22.24.8 | 18.32.6 | 17.31.9 | 25.86.2 | 19.01.1 | 19.60.5 | 19.40.6 | ||||||||||||||||
| Shape-Guided | 65.60.6 | 44.10.9 | 21.10.9 | 57.84.2 | 52.82.2 | 20.71.7 | 34.32.0 | 84.03.2 | 59.13.0 | 57.62.2 | 49.71.1 | |||||||||||||||||
| M3DM | 21.73.2 | 21.02.3 | 18.30.2 | 18.83.2 | 23.35.1 | 21.52.1 | 17.62.3 | 26.74.7 | 19.11.2 | 20.20.0 | 20.80.7 | |||||||||||||||||
| Ours | 50.52.5 | 82.12.9 | 66.82.2 | 89.72.7 | 60.74.0 | 59.32.2 | 80.81.6 | 70.32.9 | 94.12.6 | 55.93.4 | 71.00.8 |
| Method |
|
|
|
Confetto |
|
|
|
Lollipop |
|
|
Mean | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D+RGB | PatchCore+FPFH | 83.51.5 | 89.90.7 | 67.00.8 | 96.40.0 | 81.90.8 | 51.61.2 | 86.70.6 | 89.90.3 | 94.60.6 | 88.60.7 | 83.00.3 | ||||||||||||||||
| Shape-Guided | 84.90.5 | 91.00.1 | 69.80.4 | 95.50.3 | 84.60.7 | 61.10.9 | 90.50.8 | 95.10.2 | 96.40.2 | 93.80.3 | 86.30.2 | |||||||||||||||||
| M3DM | 88.01.1 | 90.41.2 | 80.60.2 | 96.13.6 | 87.41.2 | 65.71.3 | 86.41.4 | 91.20.2 | 96.20.6 | 96.20.8 | 87.80.3 | |||||||||||||||||
| Ours | 89.80.6 | 91.60.3 | 77.61.8 | 98.10.1 | 86.62.0 | 65.21.1 | 85.81.4 | 90.80.6 | 96.90.3 | 96.10.8 | 87.80.2 |
| Method |
|
|
|
Confetto |
|
|
|
Lollipop |
|
|
Mean | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D+RGB | PatchCore+FPFH | 21.72.3 | 21.42.5 | 28.93.0 | 25.02.0 | 34.65.5 | 35.53.7 | 20.62.0 | 25.621.0 | 22.33.3 | 26.87.9 | 26.21.1 | ||||||||||||||||
| AST | 48.30.6 | 49.30.6 | 48.30.6 | 48.60.6 | 78.11.0 | 49.01.0 | 76.11.0 | 48.71.0 | 77.00.6 | 49.00.0 | 57.20.5 | |||||||||||||||||
| Shape-Guided | 89.70.4 | 82.40.8 | 71.61.2 | 86.01.5 | 78.11.5 | 67.62.4 | 78.40.7 | 94.12.0 | 81.00.6 | 65.53.1 | 79.51.0 | |||||||||||||||||
| M3DM | 37.52.6 | 24.21.8 | 30.23.9 | 22.72.1 | 34.84.9 | 39.73.0 | 21.62.6 | 26.521.1 | 19.63.6 | 19.01.3 | 27.61.2 | |||||||||||||||||
| Ours | 57.02.5 | 87.46.0 | 78.02.4 | 91.63.9 | 70.73.3 | 82.04.0 | 90.22.3 | 81.86.4 | 98.51.2 | 60.38.3 | 79.80.7 |
| Method |
|
|
|
Confetto |
|
|
|
Lollipop |
|
|
Mean | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3D+RGB | PatchCore+FPFH | 95.70.2 | 97.40.1 | 91.70.3 | 99.40.0 | 92.90.2 | 87.40.5 | 96.90.2 | 98.10.2 | 99.20.1 | 97.30.2 | 95.60.1 | ||||||||||||||||
| AST | 95.10.6 | 98.31.0 | 91.40.6 | 99.30.6 | 92.00.6 | 88.20.6 | 96.00.6 | 95.90.6 | 98.80.6 | 97.00.6 | 95.20.2 | |||||||||||||||||
| Shape-Guided | 95.80.1 | 98.30.0 | 92.70.0 | 99.00.1 | 91.90.3 | 89.00.2 | 97.90.2 | 98.50.1 | 99.50.1 | 98.40.1 | 96.10.1 | |||||||||||||||||
| M3DM | 96.40.3 | 98.30.3 | 95.21.9 | 99.80.0 | 97.50.3 | 93.30.2 | 95.53.1 | 98.90.0 | 99.60.1 | 99.40.1 | 97.40.5 | |||||||||||||||||
| Ours | 96.90.3 | 98.40.0 | 95.50.7 | 99.80.1 | 96.70.5 | 92.80.7 | 97.10.2 | 98.70.1 | 99.70.0 | 99.30.3 | 97.50.0 |
Experiments on different noise level
To further validate the robustness of our method against noise in the training dataset, we conducted experiments by injecting different percentages of noise into the training set. Specifically, we performed experiments with 20% and 30% noise data injected into the training dataset. The results of these experiments are presented in the Tabs. A11, A10, A12, A13, A14 and A15 below. Comparing the results of injecting 10% noise, 20% noise and 30% noise, we can conclude that our method is much more robust to noise in the training dataset than previous methods.
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise 20% | PatchCore+FPFH | 42.01.6 | 40.82.8 | 49.50.3 | 53.00.6 | 44.11.3 | 28.22.1 | 27.31.2 | 25.91.5 | 13.21.3 | 45.12.0 | 36.90.3 | ||
| AST | 37.31.0 | 44.80.6 | 50.30.6 | 59.50.0 | 43.20.6 | 33.20.6 | 29.41.0 | 31.51.0 | 12.40.6 | 38.10.6 | 38.00.1 | |||
| Shape-Guided | 42.31.1 | 45.11.6 | 53.20.3 | 50.60.5 | 44.61.3 | 32.80.7 | 29.40.1 | 30.10.5 | 14.00.7 | 45.91.3 | 38.80.3 | |||
| M3DM | 45.01.1 | 47.31.0 | 47.61.0 | 56.81.9 | 51.41.0 | 41.30.5 | 32.70.7 | 27.91.5 | 25.51.4 | 53.81.2 | 42.90.5 | |||
| Ours | 92.81.5 | 76.41.8 | 93.00.5 | 85.70.9 | 82.40.7 | 71.45.2 | 67.75.0 | 60.22.9 | 90.21.5 | 73.32.3 | 79.31.0 | |||
| Noise 30% | PatchCore+FPFH | 18.61.5 | 22.21.8 | 30.80.8 | 39.73.4 | 18.21.2 | 13.42.0 | 4.20.4 | 4.10.4 | 7.00.3 | 24.91.3 | 18.30.7 | ||
| AST | 14.60.6 | 21.41.0 | 28.70.6 | 38.40.0 | 16.40.0 | 9.31.0 | 4.30.6 | 5.60.6 | 6.80.0 | 20.21.0 | 16.60.1 | |||
| Shape-Guided | 15.70.6 | 22.31.2 | 32.81.0 | 31.30.2 | 18.30.3 | 9.70.9 | 4.20.1 | 4.70.8 | 7.20.1 | 24.71.5 | 17.10.3 | |||
| M3DM | 30.41.6 | 27.41.9 | 32.50.8 | 40.71.4 | 36.72.4 | 25.53.1 | 16.01.4 | 12.21.2 | 19.92.0 | 37.91.3 | 27.90.8 | |||
| Ours | 89.71.3 | 69.11.8 | 93.70.7 | 83.72.0 | 78.82.1 | 69.94.9 | 67.13.4 | 55.32.0 | 90.50.9 | 70.02.1 | 76.80.6 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise 20% | PatchCore+FPFH | 84.01.4 | 84.00.8 | 87.50.1 | 79.52.5 | 93.00.5 | 56.93.6 | 82.63.7 | 73.04.8 | 90.38.1 | 84.83.3 | 81.60.1 | ||
| AST | 82.11.0 | 91.60.6 | 87.60.6 | 92.81.0 | 93.40.6 | 79.71.0 | 91.10.6 | 90.10.6 | 88.10.6 | 72.30.6 | 86.90.3 | |||
| Shape-Guided | 82.82.3 | 81.82.9 | 86.60.5 | 79.00.9 | 86.21.3 | 69.11.5 | 74.10.3 | 72.81.2 | 60.33.0 | 79.82.3 | 77.30.7 | |||
| M3DM | 92.63.4 | 76.82.1 | 82.61.2 | 82.43.1 | 95.20.8 | 75.30.6 | 83.04.1 | 74.14.2 | 98.02.4 | 84.32.1 | 84.41.0 | |||
| Ours | 97.40.3 | 85.04.2 | 95.10.3 | 90.60.9 | 94.01.9 | 88.11.9 | 87.41.4 | 79.82.4 | 98.11.0 | 85.50.9 | 90.10.7 | |||
| Noise 30% | PatchCore+FPFH | 78.22.3 | 81.52.9 | 86.52.4 | 80.73.6 | 95.42.7 | 62.05.8 | 74.13.6 | 74.66.8 | 96.73.2 | 88.54.5 | 81.81.5 | ||
| AST | 73.40.6 | 88.80.6 | 81.80.6 | 96.60.6 | 94.41.0 | 74.00.0 | 96.60.6 | 94.41.0 | 73.70.6 | 85.30.6 | 85.70.8 | |||
| Shape-Guided | 60.22.2 | 69.23.7 | 77.32.3 | 68.50.5 | 65.91.1 | 45.54.1 | 28.00.4 | 31.05.1 | 41.40.5 | 69.24.0 | 55.60.9 | |||
| M3DM | 90.63.5 | 85.77.6 | 78.52.1 | 82.40.9 | 93.20.9 | 84.83.8 | 87.22.3 | 71.521.3 | 95.84.1 | 85.15.3 | 85.53.1 | |||
| Ours | 97.90.9 | 80.76.2 | 95.61.0 | 89.71.4 | 94.12.0 | 83.81.5 | 90.23.5 | 78.54.7 | 98.61.0 | 83.86.8 | 89.30.9 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise 20% | PatchCore+FPFH | 46.31.6 | 48.91.1 | 56.00.3 | 58.51.3 | 43.31.0 | 35.31.4 | 31.90.5 | 35.32.8 | 13.70.7 | 48.20.6 | 41.70.2 | ||
| Shape-Guided | 68.50.6 | 69.21.3 | 90.01.2 | 64.41.3 | 85.10.9 | 60.51.6 | 82.71.1 | 92.40.5 | 82.40.4 | 90.41.0 | 78.60.1 | |||
| M3DM | 45.71.1 | 48.81.4 | 55.90.4 | 56.12.3 | 43.00.7 | 36.31.3 | 32.30.2 | 35.72.9 | 13.70.8 | 48.20.6 | 41.60.3 | |||
| Ours | 93.00.8 | 85.51.6 | 95.20.6 | 86.30.5 | 78.32.1 | 76.82.7 | 76.05.0 | 74.63.1 | 90.30.6 | 81.32.9 | 83.70.5 | |||
| Noise 30% | PatchCore+FPFH | 18.11.0 | 23.61.3 | 35.20.6 | 38.30.9 | 17.20.1 | 11.72.7 | 5.31.3 | 6.21.0 | 7.00.8 | 25.00.1 | 18.80.3 | ||
| Shape-Guided | 70.90.3 | 64.91.9 | 89.10.3 | 55.31.4 | 83.20.1 | 56.62.2 | 85.60.5 | 93.70.3 | 82.60.4 | 89.71.3 | 77.20.1 | |||
| M3DM | 18.71.0 | 24.01.0 | 35.30.6 | 39.20.6 | 17.70.2 | 18.21.7 | 5.71.4 | 7.10.7 | 7.60.6 | 25.10.2 | 19.90.2 | |||
| Ours | 90.71.2 | 81.51.4 | 94.80.3 | 84.51.5 | 75.42.0 | 76.53.4 | 75.21.8 | 71.41.8 | 90.40.6 | 80.62.8 | 82.10.4 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise 20% | PatchCore+FPFH | 97.00.2 | 96.80.6 | 96.80.0 | 94.81.6 | 91.60.9 | 89.70.4 | 96.60.5 | 95.60.2 | 96.61.6 | 95.51.1 | 95.10.3 | ||
| Shape-Guided | 91.61.2 | 89.40.7 | 96.00.5 | 88.20.8 | 93.10.8 | 84.96.0 | 90.11.5 | 95.11.0 | 84.44.7 | 96.01.2 | 90.91.2 | |||
| M3DM | 93.81.3 | 95.60.8 | 96.50.1 | 88.11.3 | 92.62.1 | 80.00.9 | 97.10.2 | 95.30.7 | 97.90.5 | 97.00.5 | 93.40.3 | |||
| Ours | 96.50.6 | 95.60.2 | 97.70.1 | 92.20.5 | 92.61.7 | 90.10.7 | 97.30.1 | 96.00.2 | 97.61.0 | 96.60.7 | 95.20.3 | |||
| Noise 30% | PatchCore+FPFH | 96.60.9 | 96.31.9 | 96.81.0 | 94.60.9 | 93.11.2 | 87.94.0 | 97.00.6 | 92.37.5 | 97.51.4 | 97.60.3 | 95.00.3 | ||
| Shape-Guided | 73.73.3 | 79.41.9 | 93.60.3 | 82.42.1 | 88.42.6 | 69.30.2 | 72.63.4 | 88.73.3 | 81.05.7 | 93.71.9 | 82.30.7 | |||
| M3DM | 94.32.7 | 97.20.7 | 96.40.9 | 87.50.4 | 92.51.6 | 83.66.5 | 97.40.1 | 93.35.5 | 97.61.2 | 96.91.1 | 93.70.6 | |||
| Ours | 96.60.7 | 95.00.4 | 97.70.1 | 92.30.8 | 93.90.5 | 89.52.6 | 97.70.4 | 95.40.4 | 97.51.3 | 96.11.2 | 95.20.2 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise 20% | PatchCore+FPFH | 50.22.1 | 52.42.6 | 55.83.0 | 62.32.0 | 46.30.6 | 39.81.0 | 32.92.1 | 36.32.1 | 18.36.3 | 49.40.8 | 44.40.8 | ||
| AST | 83.10.0 | 91.90.6 | 95.81.0 | 83.61.0 | 89.10.6 | 84.60.6 | 88.80.6 | 88.00.6 | 89.00.6 | 88.91.0 | 88.80.2 | |||
| Shape-Guided | 89.90.3 | 91.00.5 | 97.00.1 | 86.50.2 | 85.10.5 | 86.40.6 | 84.90.3 | 81.35.8 | 94.70.4 | 91.15.6 | 88.80.5 | |||
| M3DM | 52.42.3 | 53.03.1 | 56.12.7 | 65.81.9 | 47.31.3 | 51.30.7 | 34.42.3 | 37.02.1 | 18.76.0 | 50.70.4 | 46.70.8 | |||
| Ours | 97.80.4 | 91.42.1 | 96.40.6 | 94.30.1 | 85.52.4 | 80.82.8 | 81.42.1 | 78.43.0 | 97.80.4 | 86.71.9 | 89.00.4 | |||
| Noise 30% | PatchCore+FPFH | 24.04.5 | 26.81.3 | 34.52.8 | 40.63.4 | 21.32.6 | 17.40.9 | 8.81.6 | 8.02.1 | 8.23.2 | 25.82.7 | 21.61.4 | ||
| AST | 15.30.0 | 21.40.0 | 29.30.6 | 37.80.6 | 16.41.0 | 8.90.6 | 3.61.0 | 5.30.0 | 6.80.0 | 19.90.6 | 16.50.1 | |||
| Shape-Guided | 90.70.7 | 89.40.5 | 96.60.3 | 83.01.0 | 80.95.8 | 80.84.8 | 90.05.1 | 81.65.7 | 94.50.2 | 87.80.5 | 87.50.9 | |||
| M3DM | 26.34.5 | 27.31.7 | 35.02.3 | 48.35.0 | 22.63.1 | 35.41.6 | 9.91.4 | 9.01.9 | 7.93.5 | 28.42.4 | 25.01.4 | |||
| Ours | 96.60.5 | 89.31.5 | 96.50.3 | 92.71.5 | 81.92.8 | 79.92.7 | 81.90.7 | 74.81.3 | 97.80.4 | 86.81.9 | 87.80.4 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
| Noise 20% | PatchCore+FPFH | 99.50.0 | 99.10.3 | 98.20.1 | 98.70.1 | 98.00.8 | 97.60.1 | 99.30.1 | 98.00.3 | 99.70.2 | 99.50.1 | 98.80.0 | ||
| AST | 97.90.6 | 97.80.0 | 99.41.0 | 92.20.6 | 93.10.0 | 99.20.6 | 99.51.0 | 99.80.6 | 97.50.0 | 98.61.0 | 97.50.1 | |||
| Shape-Guided | 97.51.7 | 97.50.5 | 98.90.3 | 95.20.3 | 97.80.4 | 93.33.3 | 97.10.3 | 98.90.2 | 95.61.4 | 99.20.7 | 97.10.4 | |||
| M3DM | 99.00.2 | 98.80.3 | 98.10.1 | 96.80.1 | 97.81.0 | 95.40.1 | 99.40.1 | 99.00.2 | 99.80.1 | 99.50.2 | 98.40.0 | |||
| Ours | 99.50.1 | 99.00.1 | 99.60.1 | 97.30.3 | 97.90.6 | 97.70.2 | 99.50.1 | 99.10.1 | 99.80.2 | 99.30.2 | 98.90.1 | |||
| Noise 30% | PatchCore+FPFH | 99.60.1 | 99.30.1 | 98.21.3 | 98.50.2 | 98.11.3 | 98.30.5 | 99.50.2 | 95.37.8 | 99.60.6 | 99.60.1 | 98.60.7 | ||
| AST | 91.01.0 | 96.30.6 | 99.11.0 | 92.40.6 | 95.60.0 | 97.40.6 | 99.70.6 | 100.20.6 | 97.70.6 | 98.61.0 | 96.80.2 | |||
| Shape-Guided | 93.31.3 | 93.81.0 | 98.20.3 | 90.51.2 | 97.01.1 | 85.62.8 | 92.70.0 | 96.70.5 | 92.81.9 | 98.60.7 | 93.90.2 | |||
| M3DM | 99.10.2 | 99.30.4 | 98.01.4 | 96.00.8 | 97.61.1 | 96.61.9 | 99.60.1 | 98.22.0 | 99.70.5 | 99.50.3 | 98.40.2 | |||
| Ours | 99.50.2 | 98.70.3 | 99.60.1 | 97.10.6 | 98.50.3 | 97.41.3 | 99.60.1 | 98.80.3 | 99.60.6 | 99.20.4 | 98.80.0 |