Stable-Pose: Leveraging Transformers for Pose-Guided Text-to-Image Generation
Abstract
Controllable text-to-image (T2I) diffusion models have shown impressive performance in generating high-quality visual content through the incorporation of various conditions. Current methods, however, exhibit limited performance when guided by skeleton human poses, especially in complex pose conditions such as side or rear perspectives of human figures. To address this issue, we present Stable-Pose, a novel adapter model that introduces a coarse-to-fine attention masking strategy into a vision Transformer (ViT) to gain accurate pose guidance for T2I models. Stable-Pose is designed to adeptly handle pose conditions within pre-trained Stable Diffusion, providing a refined and efficient way of aligning pose representation during image synthesis. We leverage the query-key self-attention mechanism of ViTs to explore the interconnections among different anatomical parts in human pose skeletons. Masked pose images are used to smoothly refine the attention maps based on target pose-related features in a hierarchical manner, transitioning from coarse to fine levels. Additionally, our loss function is formulated to allocate increased emphasis to the pose region, thereby augmenting the model’s precision in capturing intricate pose details. We assessed the performance of Stable-Pose across five public datasets under a wide range of indoor and outdoor human pose scenarios. Stable-Pose achieved an AP score of 57.1 in the LAION-Human dataset, marking around 13% improvement over the established technique ControlNet. The project link and code is available at https://github.com/ai-med/StablePose.
1 Introduction
Pose-guided text-to-image (T2I) generation holds immense potential for swiftly producing photo-realistic images that exhibit contextual relevance and accurate posing through the integration of text prompts and pose instructions. The kinematic or skeleton pose provides a set of key points (joints) that represent the skeletal framework of the human body (shown in Figure A.1). Despite the sparsity, skeleton-pose data offers sufficient details of human poses with high flexibility and computational efficiency for T2I generation in various applications such as animation, robotics, sports training, and e-commerce, making it user-friendly and ideal for real-time applications Liu et al. [2015]. Juxtaposed with other forms of pose information like volumetric pose with dense content, skeleton pose is capable of conveying heightened articulation information, facilitating intuitive interpretation and flexible manipulation of human poses Qi et al. [2016], Liu et al. [2017].
Traditional pose-guided human image generation methods require a source image during training for dictating the style of the generated images Ma et al. [2017], Men et al. [2020], Tang et al. [2020], Siarohin et al. [2018], Zhu et al. [2019]. Such methods, while offering control over the appearance, limit the flexibility and diversity of the output and depend heavily on the need for paired source-target data during training. In contrast, recent advancements in controllable T2I diffusion models have shown the potential to eliminate the need for source images and allowed for higher creative freedom by relying on text prompts and external conditions Zhang et al. [2023], Zhao et al. [2024], Huang et al. [2023], Mou et al. [2023], Li et al. [2023]. Enabling more versatile visual content creation, these methods often face challenges in precisely aligning conditional images with sparse representations such as skeleton pose data, especially when dealing with complex pose scenarios like those depicting the back or side views of human figures (Figure 1). Moreover, existing methods may also fail to maintain accurate body proportions, resulting in an unnatural appearance of the body.

To address the insufficient binding of sparse pose data in T2I generation models, a potential strategy is to capture long-range patch-wise relationships among various anatomical parts of human poses. In this paper, we introduce Stable-Pose that integrates vision Transformers (ViT) into pre-trained T2I diffusion models like Stable Diffusion (SD) Rombach et al. [2022], with the goal of improving pose control by capturing patch-wise relationships from the specified pose. In Stable-Pose, the learnable attentions adhere to an innovative coarse-to-fine masking approach, ensuring that pose conditioning is directed toward the relevant pose areas while preserving the diversity of the overall image. To further enhance this effect, a pose-mask guided loss is introduced to optimize the fidelity of the generated images in adherence to the given pose instructions. We evaluated Stable-Pose across five distinct datasets, covering indoor and outdoor image/video datasets. Compared to the state-of-the-art methods, Stable-Pose achieved the highest accuracy and robustness in pose adherence and generation fidelity, making it a promising solution for enhancing pose control in T2I generation. We further performed comprehensive ablation studies to demonstrate the effectiveness of our design. In summary, our contributions are:
-
•
Addressing the challenge of generating photo-realistic human images in pose-guided T2I by integrating a novel ViT, achieving highly accurate synthesis in pose adherence and image fidelity, even under challenging conditions.
-
•
Introducing a hierarchical integration of pose masks for coarse-to-fine guidance, with a novel pose-masked self-attention mechanism and pose-mask guided loss function to enhance pose control.
-
•
Stable-Pose effectively learns to preserve intricate human shape structures and accurate body proportions, achieving exceptional performance across five publicly available datasets, encompassing both image and video data.
2 Related Work
Pose-Guided Human Image Generation: Traditional pose-guided human image generation takes a source image and pose as input, aiming to generate photo-realistic human images in specific poses while preserving the appearance from the source image. Prior works Ma et al. [2017], Men et al. [2020], Tang et al. [2020], Siarohin et al. [2018], Esser et al. [2018] primarily utilized generative adversarial network (GAN) or variational autoencoder (VAE), treating the synthesis task as conditional image generation. Zhu et al. Zhu et al. [2019] integrated attention mechanism for appearance optimization in a Pose Attention Transfer Network (PATN). Zhang et al. Zhang et al. [2022] implemented a Dual-task Pose Transformer Network (DPTN), using a Transformer module to incorporate features from two tasks: an auxiliary source image reconstruction task and the main pose-guided target image generation task, thereby capturing the dual-task correlation. With the recent emergence of diffusion models Ho et al. [2020], Bhunia et al. Bhunia et al. [2023] proposed a texture diffusion module to transfer texture patterns from the source image to the denoising process. Moreover, classifier-free guidance Ho and Salimans [2022] is applied to provide disentangled guidance for style and pose. Shen et al. Shen et al. [2023] proposed a three-stage synthesis pipeline which progressively performs global feature extraction, target prediction, and refinement with three diffusion models. While the source image offers control over appearance, a limitation arises from the necessity of paired source-target data during training. Text, however, obviates this need and offers higher flexibility and diversity for the synthesis. Thus, incorporating text conditions for pose-skeleton-guided human image generation shows significant promise Liu et al. [2023], Ju et al. [2023b].
Controllable Diffusion Models: Large-scale T2I diffusion models Rombach et al. [2022], Ramesh et al. [2021, 2022], Saharia et al. [2022], Nichol et al. [2021] excel at creating diverse and high-quality images, yet they often lack precise control with solely text-based prompts. Recent studies aim to enhance the control of T2I models using various conditions such as canny edge, sketch, and human pose Huang et al. [2023], Zhang et al. [2023], Mou et al. [2023], Li et al. [2023], Zhao et al. [2024], Ju et al. [2023b], Ming et al. [2024], Qiu et al. [2023]. These approaches can be broadly classified into two groups: training the entire T2I model or developing plug-in adapters for pre-trained T2I models. As in the first group, Composer Huang et al. [2023] trains a diffusion model from scratch with a decomposition-composition paradigm, enabling multi-control capability. HumanSD Ju et al. [2023b] fine-tunes the entire SD model using a heatmap-guided loss tailored for pose control. In contrast, T2I-Adapter Mou et al. [2023] and GLIGEN Li et al. [2023] train lightweight adapters whose outputs are incorporated into the frozen SD. Similarly, ControlNet Zhang et al. [2023] employs a trainable copy of the SD encoder to encode conditions for the frozen SD. Uni-ControlNet Zhao et al. [2024] introduces a uni-adapter for multiple conditions injection to the trainable branch in a multi-scale manner. ControlNet++ Ming et al. [2024] proposes to improve controllable generation by explicitly optimizing the cycle consistency between generated images and conditional controls. Our method aligns with the latter category, as it is characterized by reduced training time, cost-effectiveness, and generalizability.
3 Proposed Method
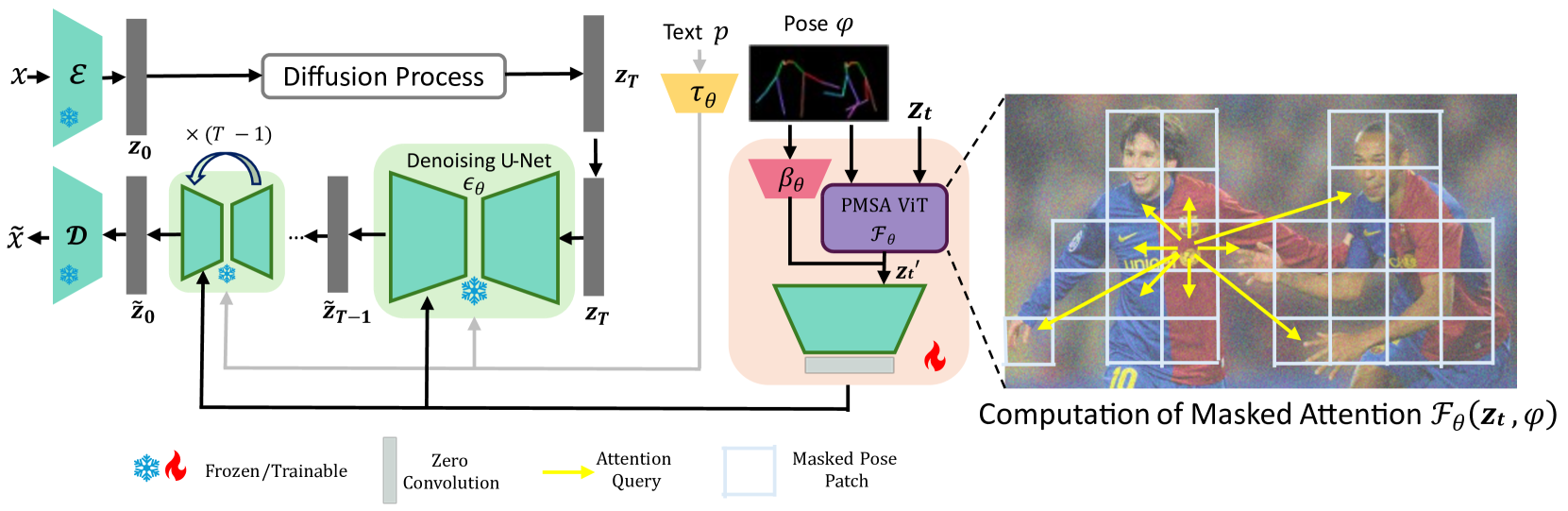
Stable-Pose has a trainable ViT unit that is integrated into the pre-trained T2I diffusion models to direct diffusion models toward the conditioned pose. In latent diffusion models (LDMs) Rombach et al. [2022], a pre-trained encoder and decoder are employed to transform an input RGB image with height and width into a latent space with reduced spatial dimensions and vice versa. The diffusion process is then efficiently conducted in the down-scaled latent space. During the training, the forward process in diffusion models adds noise to the encoded RGB image to generate its noisy sample with height , width , and channel via
| (1) |
where is a pre-determined hyperparameter that controls the noise level at step . The reverse process of diffusion models, so-called denoising, learns the statistics of the Gaussian distribution at each time step. The reverse process is formulated as:
| (2) |
As shown in Figure 2, the denoising network adopts a UNet backbone, which is equipped with Stable-Pose for augmenting the latent encoding given the input conditional pose image. Let , , represent a T-step denoising UNet with gradients over a batch and input text prompt . The conditional LDM is learned through steps by minimizing , where Stable-Pose conditions the latent encoding on the input pose skeleton , and is a text encoder that maps the text prompt to an intermediate sequence. The proposed framework is detailed in Figure 3. Stable-Pose aims at improving the frozen decoder in the UNet of SD to condition the input latent encoding on the conditional pose image :
| (3) |
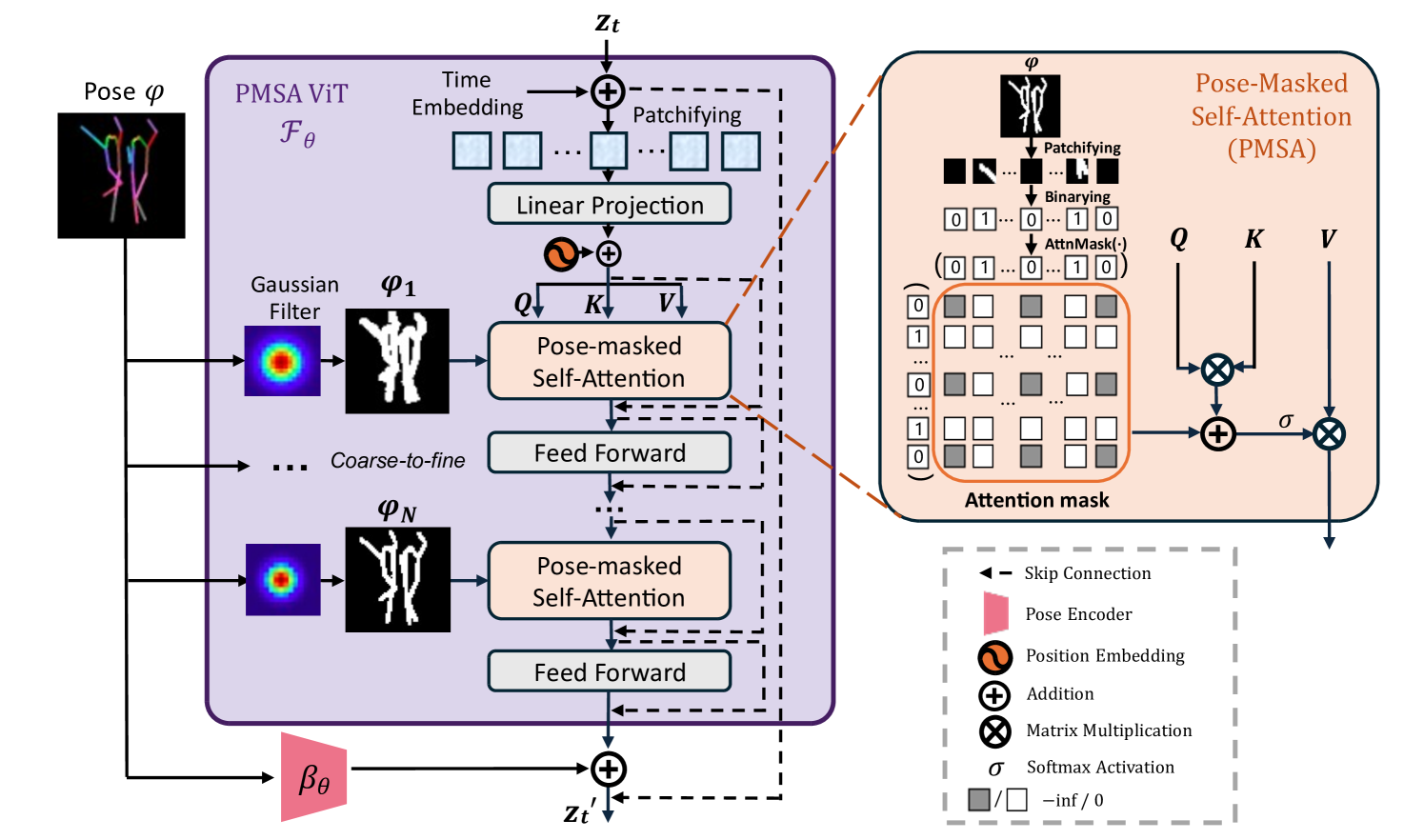
In Stable-Pose, the pose image and the given latent encoding are processed by two main blocks named Pose-Masked Self-Attention (PMSA) and pose encoder in such a way that
| (4) |
where the pose encoder provides high-level features for the input pose while PMSA explores the patch-wise relationship across input using a self-attention mechanism and the binary-masked version of the pose image. PMSA employs a coarse-to-fine framework that provides additional guidance to the latent encoding, directing it towards attending to the conditioned pose. We detail each block in the subsequent sections. The updated latent encoding is subsequently fed through the encoder of SD, followed by a series of zero convolutional blocks, a structural resemblance to the architecture employed in ControlNet Zhang et al. [2023] for ensuring a robust encoding of conditional images.
Pose encoder is a trainable encoder that maps input pose skeleton image into a feature with height , width , and channel . To this end, we employ a combination of six convolutional layers with SiLU activation layers Elfwing et al. [2018], downsampling the input pose image by a factor of 8. A zero-convolutional layer is added in the end. As the input pose image contains sparse information, this straightforward pose encoder is sufficient for accurate encoding of the skeleton pose.
PMSA seeks the potential relationships between patches within the latent encoding . The interconnections of various parts of the human body suggest the presence of cohesive relationships among them. To capture this, we leverage the self-attention mechanism. We divide into non-overlapping patches of size , i.e., . PMSA projects the patch embeddings into Query , Key , and Value via three learnable weight matrices , , and , respectively. Then it computes the attention scores between all patches via
| (5) |
In this equation, denotes a binary mask derived from the input pose image, which is expanded by for being used in the self-attention computation (see Figure 3). is obtained by converting the pose image into a binary mask and downsampling it into the same size of the latent vector . The resultant mask is then dilated by a Gaussian kernel of length . The dilated-binary mask is then partitioned into non-overlapping patches of size . The patches containing pose are labelled as 1 while others are marked as 0. We form a resulting attention mask based on these patches through the function . As illustrated in Algorithm 1, for patch entries that correspond to pose regions, both the respective row and column in the mask are set to 0. For all other regions not associated with pose, we assign an extremely small integer value. The attention mask helps to enhance the focus of PMSA on the pose-specific regions.
We implement a sequence of blocks of ViTs, each associated with a unique pose mask, arranged in a coarse-to-fine progression on the latent encoding. This approach gradually steers the latent encoding towards conforming to the specified pose condition. If denotes a set of Gaussian kernels where , then the coarse-to-fine self-attention is obtained via
| (6) | ||||
Each encoding undergoes further processing by a Feed Forward unit, with the resulting integrated into the feature from the pose encoder , as shown in Figure 3. The Feed Forward block consists of two linear transformations Ba et al. [2016] combined with dropout layers, followed by ReLU non-linear activation functions Agarap [2018].
Pose-mask guided loss criterion: The training of SD models requires high costs in hardware and datasets. Therefore, plug-in adapters for the frozen SD models, such as Stable-Pose, can enhance training efficiency by eliminating the need to compute gradients or maintain optimizer states for SD parameters. Instead, the optimization process focuses on improving Stable-Pose parameters. The loss in Stable-Pose aligns with the coarse-to-fine approach and is defined as follows:
| (7) | ||||
Here, represents a predetermined pose-mask guidance hyperparameter that emphasizes the significance of masked region contents.
4 Experimental Results
| Dataset | Method | Pose Accuracy | Image Quality | T2I Alignment | |||||
|---|---|---|---|---|---|---|---|---|---|
| AP | CAP | PCE | FID | KID | CLIP-score | ||||
| Human-Art | SD* | 0.24 | 55.71 | 2.30 | 11.53 | 3.36 | 33.33 | ||
| T2I-Adapter | 27.22 | 65.65 | 1.75 | 11.92 | 2.73 | 33.27 | |||
| ControlNet | 39.52 | 69.19 | 1.54 | 11.01 | 2.23 | 32.65 | |||
| Uni-ControlNet | 41.94 | 69.32 | 1.48 | 14.63 | 2.30 | 32.51 | |||
| GLIGEN | 18.24 | 69.15 | 1.46 | – | – | 32.52 | |||
| HumanSD | 44.57 | 69.68 | 1.37 | 10.03 | 2.70 | 32.24 | |||
| Stable-Pose (Ours) | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 | |||
| LAION-Human | SD* | 0.73 | 44.47 | 2.45 | 4.53 | 4.80 | 32.32 | ||
| T2I-Adapter* | 36.65 | 63.64 | 1.62 | 6.77 | 5.44 | 32.30 | |||
| ControlNet* | 44.90 | 66.74 | 1.55 | 7.53 | 6.53 | 32.31 | |||
| Uni-ControlNet | 50.83 | 66.16 | 1.41 | 6.82 | 4.52 | 32.39 | |||
| GLIGEN | 19.65 | 66.29 | 1.40 | – | – | 32.04 | |||
| HumanSD | 50.95 | 65.84 | 1.25 | 5.62 | 7.48 | 30.85 | |||
| Stable-Pose (Ours) | 57.11 | 67.78 | 1.37 | 6.25 | 4.50 | 32.38 | |||
Datasets. We assessed the performance of the proposed Stable-Pose as well as competing methods on five large-scale human-centric datasets including Human-Art Ju et al. [2023a], LAION-Human Ju et al. [2023b], UBC Fashion Zablotskaia et al. [2019], Dance Track Sun et al. [2022], and DAVIS Perazzi et al. [2016] dataset. Details of the datasets and processing steps can be found in Sec. A.1.
Implementation Details. Similar to previous work Zhang et al. [2023], Mou et al. [2023], Zhao et al. [2024], we fine-tuned our model on SD with version 1.5. We utilized Adam Kingma and Ba [2014] optimizer with a learning rate of . For our proposed PMSA ViT module, we adopted a depth of 2 and a patch size of 2, where coarse-to-fine pose masks were generated using two Gaussian filters, each with a sigma value of 3 but with differing kernel sizes of 23 and 13, respectively. We will explore the effects of these hyperparameters with more details in Sec. 4.2. In the pose-mask guided loss function, we set an of 5 as the guidance factor. We also followed Zhang et al. [2023] to randomly replace text prompts as empty strings at a probability of 0.5, which aims to strengthen the control of the pose input. During inference, no text prompts were removed and a DDIM sampler Song et al. [2020] with time steps 50 was utilized to generate images. On the Human-Art dataset, we trained all techniques, including ours for 10 epochs to ensure a fair comparison. On the LAION-Human subset, we trained Stable-Pose, HumanSD Ju et al. [2023b], GLIGEN Li et al. [2023] and Uni-ControlNet Zhao et al. [2024] for 10 epochs, while we used released checkpoints from other techniques due to computational limitations. The training was executed using two NVIDIA A100 GPUs, with our method completing in 15 hours for the Human-Art dataset and 70 hours for the LAION-Human subset. This represents a substantial decrease in GPU hours compared to SOTA techniques. For instance, the T2I-Adapter requires approximately 300 GPU hours to train on a large-scale dataset. In contrast, our approach requires less than a quarter of that time and still delivers superior performance.
Evaluation Metrics. We adopt six metrics for evaluation, covering pose accuracy, image quality, and text-image alignment. For pose accuracy, we employ mean Average Precision (AP), Pose Cosine Similarity-based AP (CAP) cap , and People Counting Error (PCE) Cheong et al. [2022], measuring the accuracy between the provided poses and the pose results extracted from the generated images by the pretrained pose estimator HigherHRNet Cheng et al. [2020]. For image quality, we use Fréchet inception distance (FID) Heusel et al. [2017] and Kernel Inception Distance (KID) Bińkowski et al. [2018]. Both metrics measure the diversity and fidelity of generated images and are widely used in image synthesis tasks. For text-image alignment, we include the CLIP score Radford et al. [2021] that indicates how well the CLIP model believes the text describes the image. Details of the evaluation metrics can be found in Sec. A.2.
4.1 Results
Quantitative and Qualitative Results. Table 1 reports the quantitative results on both datasets among different methods. We reported the mean Average Precision (AP), Pose Cosine Similarity-based AP (CAP), People Count Error (PCE), Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and the CLIP Similarity (CLIP-score). KID is multiplied by 100 for Human-Art and 1000 for LAION-Human for readability. Table 1 shows that Stable-Pose achieved the highest AP (48.87 on Human-Art and 57.41 on LAION-Human) and CAP (71.04 on Human-Art and 68.06 on LAION-Human), surpassing the SOTA methods by more than 10%. This highlights Stable-Pose’s superiority in pose alignment. In terms of image quality and text-image alignment, Stable-Pose achieved comparable results against other methods, with only marginal discrepancy in FID/KID scores, yet the difference is negligible and the resulting quality remains high. Overall, these results underscore Stable-Pose’s exceptional accuracy and robustness in both pose control and visual fidelity.
The qualitative results obtained from Human-Art Ju et al. [2023a] and LAION-Human Ju et al. [2023b] are illustrated in Figure 4. Consistent with the quantitative results, Stable-Pose demonstrates superior control compared to the other SOTA methods in both pose accuracy and text alignment, even in scenarios involving complex poses (the first row of Figure 4, which is a back view of the figure), and multiple individuals (the third row of Figure 4), while the other methods fail to consistently maintain the integrity of the original pose instructions. This is particularly evident in dynamic poses (e.g., yoga poses and athletic activities), where Stable-Pose manages to capture the pose dynamism more faithfully than others.

Results on Varying Pose Orientations. Our experiments revealed that the current SOTA methods often faltered when tasked with creating images of humans in less common orientations, such as side or back poses. To investigate the capabilities of these methods in rendering atypical poses, we assembled a collection of around 2,650 images from the UBC Fashion dataset Zablotskaia et al. [2019], which comprises exclusively front, side, and back poses. We evaluated the checkpoints of each technique from the LAION-Human dataset to assess pose alignment. As reported in Table 2, Stable-Pose significantly outperforms other methods in recognizing and generating humans in all pose orientations, especially for rarer poses in side and back views, which surpasses the other methods by around 20% in AP. This further validates the robust controllability of Stable-Pose.
| Orientation | T2I-Adapter | ControlNet | Uni-ControlNet | GLIGEN | HumanSD | Stable-Pose (Ours) |
|---|---|---|---|---|---|---|
| Front | 72.20 | 74.64 | 79.47 | 73.97 | 76.83 | |
| Side | 36.80 | 52.83 | 58.26 | 45.32 | 57.09 | |
| Back | 6.03 | 23.68 | 19.97 | 4.45 | 11.05 |
| Method | DAVIS | Dance Track | ||
|---|---|---|---|---|
| AP | CAP | AP | CAP | |
| T2I-Adapter | 20.28 | 60.76 | 10.36 | 72.38 |
| ControlNet | 30.13 | 60.81 | 16.45 | 73.16 |
| Uni-ControlNet | 37.64 | 60.57 | 25.22 | 73.62 |
| GLIGEN | 12.17 | 59.87 | 5.61 | 72.57 |
| HumanSD | 38.32 | 60.59 | 24.13 | 69.93 |
| Stable-Pose (Ours) | 42.87 | 62.43 | 28.58 | 74.97 |
Results on the Outdoor and Indoor Poses. We extend the evaluation on both outdoor and indoor pose-guided T2I generation. We selected approximately 2,000 frames from the DAVIS dataset Perazzi et al. [2016], which comprises videos of human outdoor activities, as our outdoor pose assessment. In addition, we randomly chose around 2,000 images from the Dance Track dataset Sun et al. [2022], which is characterized by its group dance videos where most videos were shot indoors with multiple individuals and complex poses, as indoor pose-alignment evaluation. As shown in Table 3, the consistently highest AP and CAP scores achieved by Stable-Pose demonstrate its robustness in pose-controlled T2I generation across diverse environments, highlighting its potential as a backbone for pose-guided video generation.
4.2 Ablation Study
We conducted a comprehensive ablation study of Stable-Pose on the Human-Art dataset, including the effectiveness of pose masks, coarse-to-fine design, pose-mask guidance strength, and the effectiveness of PMSA and its ViT backbone.
Effectiveness of Pose Masks. To evaluate the impact of pose masks as input to our proposed PMSA and pose-mask guided loss function, we compared with removing them from the PMSA and/or from the associated loss function. As shown in Table 4, incorporating pose masks in both PMSA and loss function significantly enhanced the performance in both pose alignment and image quality.
| Pose mask | AP | CAP | PCE | FID | KID | CLIP-score | |
|---|---|---|---|---|---|---|---|
| in PMSA | in loss | ||||||
| ✗ | ✗ | 39.40 | 69.18 | 1.55 | 13.94 | 2.56 | 32.63 |
| ✓ | ✗ | 44.50 | 70.51 | 1.51 | 14.24 | 2.61 | 32.58 |
| ✗ | ✓ | 45.39 | 70.18 | 1.56 | 13.17 | 2.62 | 32.65 |
| ✓ | ✓ | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 |
Coarse-to-Fine Masking Guidance. The granularity of pose-masks is specified by the Gaussian kernels in Gaussian Filters, where a larger kernel generates coarser pose-masks. We compared the results of constant granularity, fine-to-coarse as well as coarse-to-fine setting. All experiments are based on a ViT with PMSA and depth of 2 and Gaussian Filters with fixed sigma . As indicated in Table 5, the coarse-to-fine approach consistently offers the best performance across metrics for pose alignment and image quality. This improvement is likely due to its progressive refinement from coarser to finer granularity in pose regions. By methodically narrowing the focus to more precise controllable areas, this strategy smoothly enhances the accuracy of pose adjustments and the overall quality of the generated images.
| Pose mask granularity | AP | CAP | PCE | FID | KID | CLIP-score |
|---|---|---|---|---|---|---|
| Constant (23, 23) | 48.10 | 70.77 | 1.59 | 12.55 | 2.59 | 32.62 |
| Fine-to-coarse (13, 23) | 47.86 | 70.84 | 1.57 | 12.48 | 2.54 | 32.54 |
| Coarse-to-fine (23, 13) | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 |
Effectiveness of PMSA and its ViT backbone. Our PMSA incorporates additional pose masks, derived from pose skeletons that have been expanded using Gaussian filters. To evaluate the effectiveness of PMSA, we instead only integrated these augmented pose masks into ControlNet without our PMSA block. We explored two configurations: one in which the original pose skeleton was concatenated with one coarsely enlarged pose mask, denoted as ControlNet-PM1, and another where it was concatenated with both the coarsely and finely enlarged pose masks, referred to as ControlNet-PM2. Table 6 indicates that the enlarged pose masks yield only marginal improvements in ControlNet, suggesting that the substantial enhancements observed in Stable-Pose are primarily due to the innovative design of PMSA, rather than the additional pose masks input.
| Method | AP | CAP | PCE | FID | KID | CLIP-score |
|---|---|---|---|---|---|---|
| ControlNet | 39.52 | 69.19 | 1.54 | 11.01 | 2.23 | 32.65 |
| ControlNet-PM1 | 39.24 | 68.45 | 1.50 | 11.52 | 2.26 | 32.70 |
| ControlNet-PM2 | 40.73 | 69.27 | 1.49 | 11.63 | 2.24 | 32.67 |
| PMSA w/ ResNet | 45.24 | 70.09 | 1.56 | 13.48 | 2.60 | 32.58 |
| PMSA w/ ViT (Ours) | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 |
Further, to validate the effectiveness of the ViT backbone in PMSA (PMSA w/ ViT), we replaced it with a conventional pose-masked self-attention module operating between residual blocks (PMSA w/ ResNet). We integrated the same pose masks in both configurations to ensure a fair comparison. Table 6 demonstrates that the ViT design in PMSA significantly outperforms the conventional approach. This substantiates the superior capability of ViT to capture long-range, patch-wise interactions among various anatomical parts of human poses to enhance the pose alignment.
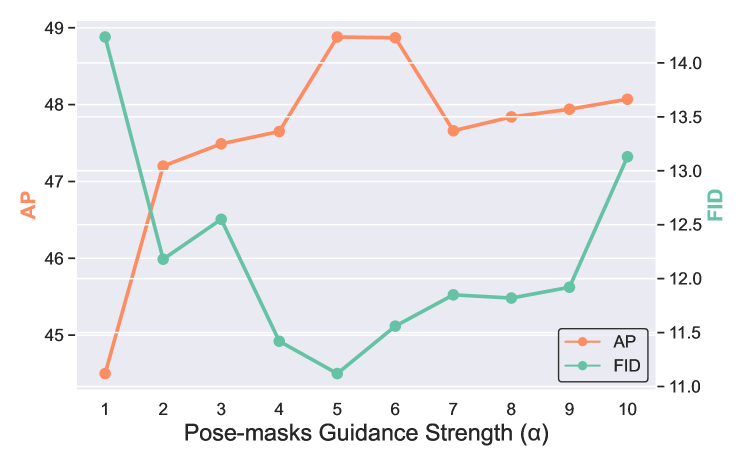
Pose-mask Guidance Strength in Loss. In our proposed loss function in Eq. (7), the parameter , referred to as the pose-mask guidance strength, controls the intensity of penalization applied to the pose regions. We evaluated the impact of varying from 1 to 10 on pose alignment and image quality, with the results presented in Figure 5. These results demonstrate that higher values of typically enhance model performance by increasingly directing the focus toward the pose areas, while also maintaining a high quality of generated images.
5 Discussion and Conclusion
We introduced Stable-Pose, a novel adapter that leverages vision transformers with a coarse-to-fine pose-masked self-attention strategy, specifically designed to efficiently manage precise pose controls during T2I generation. Stable-Pose outperforms current controllable T2I generation methods across five distinct public datasets, demonstrating high generation robustness across diverse environments and various pose scenarios. Notably, in complex scenarios involving rare poses such as side or back views and multiple figures, Stable-Pose exhibits exceptional performance in both pose and visual fidelity. This can be attributed to its advanced capability in capturing long-range patch-wise relationships between different anatomical parts of human pose images through our intricate conditioning design. As a result, Stable-Pose holds significant potential in applications demanding high pose accuracy. One limitation of Stable-Pose is its slightly longer inference time, primarily due to the integration of self-attention mechanisms within the ViT. In addition, despite excelling in pose control, Stable-Pose has yet to be evaluated with other conditions such as edge maps. Nevertheless, its design allows for straightforward adaptation to various external conditions, suggesting high potential for diverse applications.
Broader Impacts: Stable-Pose’s excellent pose control makes it a valuable tool in creating diverse artworks, animations, movies, and sports training programs. Additionally, it can be a reliable tool in healthcare and rehabilitation for correcting posture and preventing patients from musculoskeletal issues. However, there also exist the risks for misuse in generating forged images or videos, which could pose negative social concerns. Addressing these issues requires a combination of technical safeguards, regulatory frameworks, and ethical guidelines.
Acknowledgements
This work was supported by the Munich Center for Machine Learning (MCML) and the German Research Foundation (DFG). The authors gratefully acknowledge the computational and data resources provided by the Leibniz Supercomputing Centre.
References
- [1] Posenet similarity. URL https://github.com/freshsomebody/posenet-similarity.
- Agarap [2018] A. F. Agarap. Deep learning using rectified linear units (relu). arXiv preprint arXiv:1803.08375, 2018.
- Ba et al. [2016] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Bhunia et al. [2023] A. K. Bhunia, S. Khan, H. Cholakkal, R. M. Anwer, J. Laaksonen, M. Shah, and F. S. Khan. Person image synthesis via denoising diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5968–5976, 2023.
- Bińkowski et al. [2018] M. Bińkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying mmd gans. arXiv preprint arXiv:1801.01401, 2018.
- Cheng et al. [2020] B. Cheng, B. Xiao, J. Wang, H. Shi, T. S. Huang, and L. Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5386–5395, 2020.
- Cheong et al. [2022] S. Y. Cheong, A. Mustafa, and A. Gilbert. Kpe: Keypoint pose encoding for transformer-based image generation. arXiv preprint arXiv:2203.04907, 2022.
- Elfwing et al. [2018] S. Elfwing, E. Uchibe, and K. Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural networks, 107:3–11, 2018.
- Esser et al. [2018] P. Esser, E. Sutter, and B. Ommer. A variational u-net for conditional appearance and shape generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8857–8866, 2018.
- Heusel et al. [2017] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho and Salimans [2022] J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Huang et al. [2023] L. Huang, D. Chen, Y. Liu, Y. Shen, D. Zhao, and J. Zhou. Composer: Creative and controllable image synthesis with composable conditions. arXiv preprint arXiv:2302.09778, 2023.
- Ju et al. [2023a] X. Ju, A. Zeng, J. Wang, Q. Xu, and L. Zhang. Human-art: A versatile human-centric dataset bridging natural and artificial scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 618–629, 2023a.
- Ju et al. [2023b] X. Ju, A. Zeng, C. Zhao, J. Wang, L. Zhang, and Q. Xu. Humansd: A native skeleton-guided diffusion model for human image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15988–15998, 2023b.
- Kingma and Ba [2014] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Li et al. [2023] Y. Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y. J. Lee. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22511–22521, 2023.
- Liu et al. [2023] D. Liu, L. Wu, F. Zheng, L. Liu, and M. Wang. Verbal-person nets: Pose-guided multi-granularity language-to-person generation. IEEE Transactions on Neural Networks and Learning Systems, 34(11):8589–8601, 2023.
- Liu et al. [2017] J. Liu, G. Wang, L.-Y. Duan, K. Abdiyeva, and A. C. Kot. Skeleton-based human action recognition with global context-aware attention lstm networks. IEEE Transactions on Image Processing, 27(4):1586–1599, 2017.
- Liu et al. [2015] Z. Liu, J. Zhu, J. Bu, and C. Chen. A survey of human pose estimation: the body parts parsing based methods. Journal of Visual Communication and Image Representation, 32:10–19, 2015.
- Ma et al. [2017] L. Ma, X. Jia, Q. Sun, B. Schiele, T. Tuytelaars, and L. Van Gool. Pose guided person image generation. Advances in neural information processing systems, 30, 2017.
- Men et al. [2020] Y. Men, Y. Mao, Y. Jiang, W.-Y. Ma, and Z. Lian. Controllable person image synthesis with attribute-decomposed gan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5084–5093, 2020.
- Ming et al. [2024] L. Ming, Y. Taojiannan, K. Huafeng, W. Jie, W. Zhaoning, X. Xuefeng, and C. Chen. Controlnet++: Improving conditional controls with efficient consistency feedback. arXiv preprint arXiv:2404.07987, 2024.
- Mou et al. [2023] C. Mou, X. Wang, L. Xie, Y. Wu, J. Zhang, Z. Qi, Y. Shan, and X. Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453, 2023.
- Nichol et al. [2021] A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Perazzi et al. [2016] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. V. Gool, M. Gross, and A. Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Qi et al. [2016] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. J. Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5648–5656, 2016.
- Qiu et al. [2023] Z. Qiu, W. Liu, H. Feng, Y. Xue, Y. Feng, Z. Liu, D. Zhang, A. Weller, and B. Schölkopf. Controlling text-to-image diffusion by orthogonal finetuning. In NeurIPS, 2023.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2021] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. In International conference on machine learning, pages 8821–8831. Pmlr, 2021.
- Ramesh et al. [2022] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Rombach et al. [2022] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Saharia et al. [2022] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- Schuhmann et al. [2022] C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Shen et al. [2023] F. Shen, H. Ye, J. Zhang, C. Wang, X. Han, and W. Yang. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv preprint arXiv:2310.06313, 2023.
- Siarohin et al. [2018] A. Siarohin, E. Sangineto, S. Lathuiliere, and N. Sebe. Deformable gans for pose-based human image generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3408–3416, 2018.
- Song et al. [2020] J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- Sun et al. [2022] P. Sun, J. Cao, Y. Jiang, Z. Yuan, S. Bai, K. Kitani, and P. Luo. Dancetrack: Multi-object tracking in uniform appearance and diverse motion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- Szegedy et al. [2016] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
- Tang et al. [2020] H. Tang, S. Bai, L. Zhang, P. H. Torr, and N. Sebe. Xinggan for person image generation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16, pages 717–734. Springer, 2020.
- Zablotskaia et al. [2019] P. Zablotskaia, A. Siarohin, B. Zhao, and L. Sigal. Dwnet: Dense warp-based network for pose-guided human video generation. arXiv preprint arXiv:1910.09139, 2019.
- Zhang et al. [2023] L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
- Zhang et al. [2022] P. Zhang, L. Yang, J.-H. Lai, and X. Xie. Exploring dual-task correlation for pose guided person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7713–7722, 2022.
- Zhao et al. [2024] S. Zhao, D. Chen, Y.-C. Chen, J. Bao, S. Hao, L. Yuan, and K.-Y. K. Wong. Uni-controlnet: All-in-one control to text-to-image diffusion models. Advances in Neural Information Processing Systems, 36, 2024.
- Zhu et al. [2019] Z. Zhu, T. Huang, B. Shi, M. Yu, B. Wang, and X. Bai. Progressive pose attention transfer for person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2347–2356, 2019.
Appendix A Appendix / supplementary material
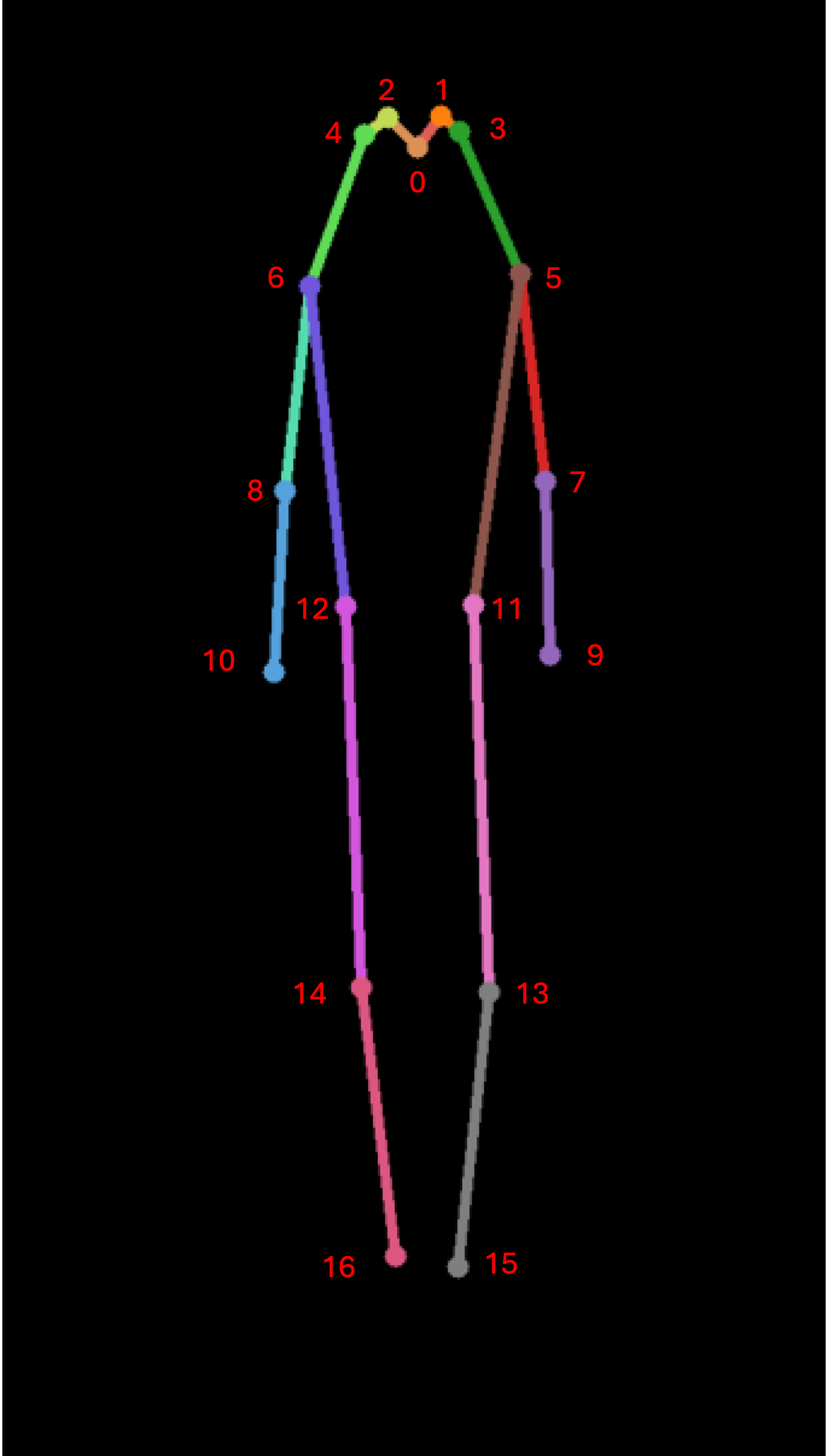

A.1 Datasets and Preprocessing
Our method and the other techniques are trained and evaluated on five distinct datasets as below:
Human-Art Ju et al. [2023a]: The Human-Art dataset comprises 38,000 images distributed across 19 scenarios, encompassing natural scenes, 2D artificial scenarios, and 3D artificial scenarios. We adopt the same train-validation split as the authors suggested. The annotations in Human-Art belong to the International Digital Economy Academy (IDEA) and are licensed under the Attribution-Non Commercial-Share Alike 4.0 International License (CC-BY-NC-SA 4.0).
LAION-Human Ju et al. [2023b]: The LAION-Human is derived from the LAION-5B dataset Schuhmann et al. [2022], consisting of approximately 1 million images filtered by human estimation confidence scores. We randomly selected a subset of 200,000 images for training and 20,000 images for validation. The dataset is licensed under the Creative Common CC-BY 4.0 license, which poses no particular restriction. The images are under their copyright.
UBC Fashion Zablotskaia et al. [2019]: The UBC Fashion dataset comprises sequences showcasing fashion models executing turns. We extracted frames representing various orientations: front, side, and back, to rigorously test our model’s aptitude for handling both complex and infrequently encountered poses. The dataset yields approximately 1100 front, 450 side, and 1100 back frames. The dataset is licensed under the Creative Commons Attribution-Non Commercial 4.0 International Public License.
Dance Track Sun et al. [2022]: The Dance Track dataset presents group dance footage, typified by multiple subjects and intricate postures. We curated 20 videos from the Dance Track validation set and extracted a total of 2000 frames to assess our model. The annotations of DanceTrack are licensed under a Creative Commons Attribution 4.0 License and the dataset of DanceTrack is available for non-commercial research purposes only.
DAVIS Perazzi et al. [2016]: The DAVIS dataset is a widely used dataset for video-related tasks. We randomly chose 26 human-centric scenarios from the DAVIS Test-Dev 2017 set and the DAVIS Test-Challenge 2017 set, which provided around 2000 frames for evaluation. The DAVIS dataset is released under the BSD License.
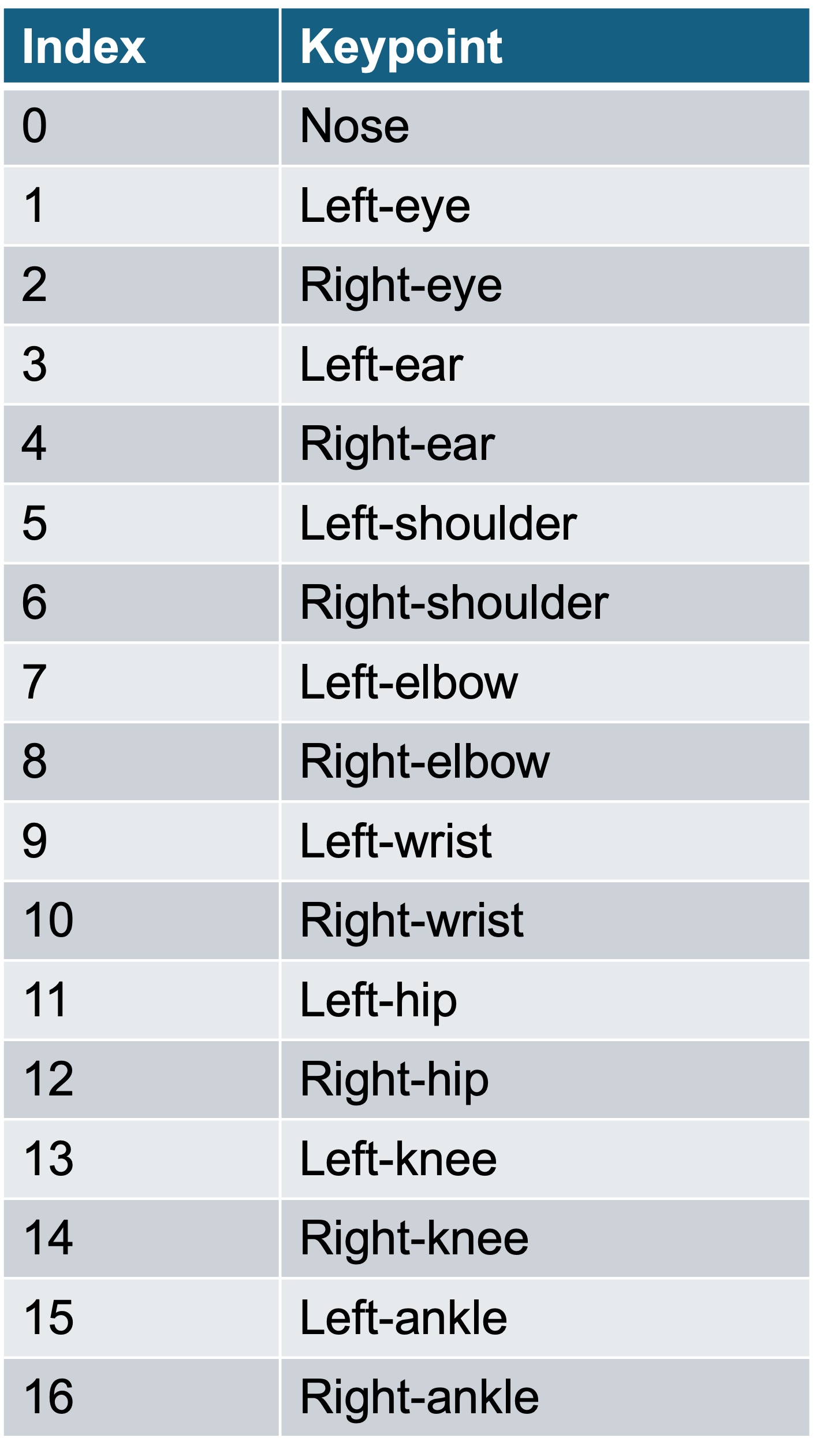
All datasets adhere to a standardized protocol featuring 17 keypoints and a maximum of 10 persons per image, following COCO and Human-Art. Despite the original checkpoints of ControlNet and T2I-Adapter being anchored in the OpenPose keypoint protocol, it is feasible to convert keypoints between different styles without loss of accuracy. In preprocessing the datasets for network input, we applied a score threshold of 0.05 to filter out keypoints and connected corresponding keypoints, following the procedure outlined by the authors of Human-Art. Each connecting line is depicted in distinct colors, as illustrated in Figure A.1, enabling the network to learn associations between each line and specific body parts. Please note that the colors of the pose skeleton presented in this paper are solely for visualization purposes and do not correspond to those used in the experiments. During training, we employed consistent data augmentations, including random cropping at 512 pixels, random rotation, random color shift, and random brightness contrast. These augmentations were applied uniformly across all techniques.
It is worth noting that the scale of the LAION-Human subset and its data distribution closely align with those reported in the SOTA works, such as ControlNet Zhang et al. [2023], which was trained on 200,000 images sourced from the Internet. Thus, ensuring a fair comparison is possible. Since none of the aforementioned video datasets are annotated with poses or textual descriptions, we employed the GPT-4 API for generating prompts and HigherHRNet Cheng et al. [2020] for deducing pose labels.
A.2 Evaluation Metrics
We define the evaluation metrics in detail here. FID assumes that the features extracted from real and generated images by the Inception v3 model Szegedy et al. [2016] follow a Gaussian distribution. It measures the Fréchet distance between these distributions. KID, however, relaxes the assumption of a Gaussian distribution and calculates the squared Maximum Mean Discrepancy (MMD) between the Inception features of real and generated images using a polynomial kernel. Mean Average Precision (AP) computes the alignment between keypoints in real images and generated images. Poses of generated images are detected by the same Considering that images may contain multiple persons, we included People Counting Error (PCE)Cheong et al. [2022] as a metric, measuring the false positive rate when generating images featuring multiple people. The CLIP score measures the similarity between embeddings of generated images and text prompts, both of which are encoded by CLIP.