*![[Uncaptioned image]](lego_block_small.png) Block Transformer:
Global-to-Local
Block Transformer:
Global-to-Local
Language Modeling for Fast Inference
Abstract
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10–20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling.
1 Introduction
Generating tokens with transformer-based autoregressive language models (LMs) is costly due to the self-attention mechanism that attends to all previous tokens [6, 66]. To alleviate the cost of the self-attention, it is common to cache the key-value (KV) states of all tokens across all layers during the autoregressive decoding. However, while each decoding step only computes the KV state of a single token, it still has to load the KV states of all previous tokens for computing self-attention scores. Subsequently, this KV cache IO mostly dominates the inference cost spent on serving LMs. While several techniques have been proposed for reducing the inference cost of the attention component [20, 35, 69], developing effective transformer-based LM architectures that inherently avoid the attention overhead is still an ongoing challenge.
Hierarchical global-to-local architectures [49, 31] have shown significant potential to effectively model large-scale data by addressing global dependencies in coarse detail and capturing fine details within local regions. Inspired by these frameworks, we identify a unique opportunity to mitigate key bottlenecks in autoregressive transformer inference: (1) coarse global modeling can reduce overall costs by its granularity; but more importantly, (2) localized self-attention can nearly eliminate the costs of attention as there is no need to compute, store, and retrieve KV-cache of past tokens beyond the small local context.
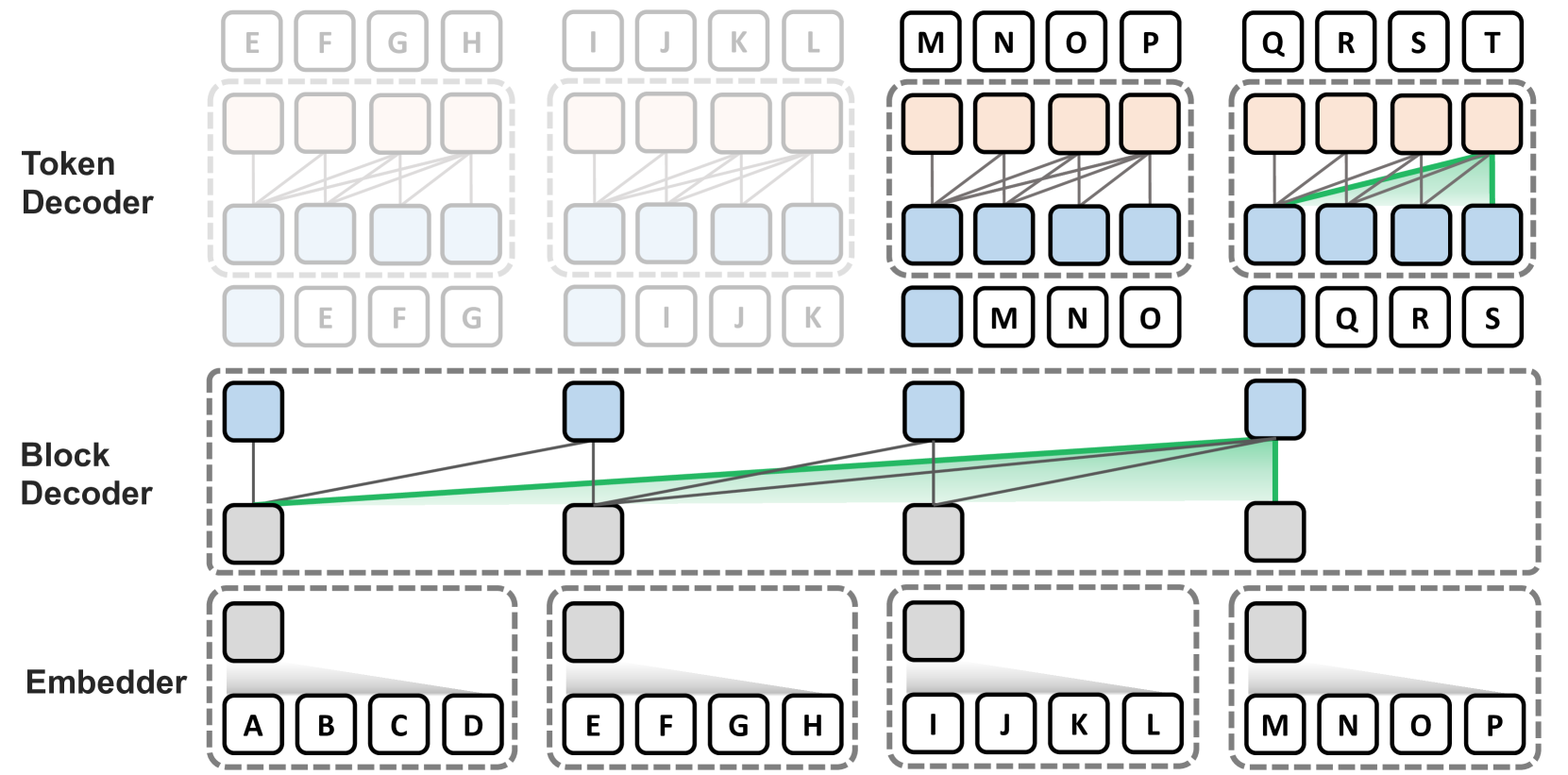
This paper presents the Block Transformer architecture which models global dependencies through self-attention between coarse blocks (each representing multiple tokens) at lower layers, and decodes fine-grained tokens within each local block at upper layers, as shown in Figure 1. Specifically, a lightweight module called (1) the embedder first embeds each block of input tokens into an input block embedding. These become the input units of (2) the block decoder, an autoregressive transformer that applies self-attention between blocks to decode a context block embedding which contains information for predicting the next block. Finally, (3) the token decoder autoregressively decodes the token contents of the next block, applying local self-attention between only the tokens within the block. While this leaves the token decoder to solely rely on the output block embedding for global context information, it drastically reduces self-attention costs to be linear to total context length, and eliminates the need to prefill prompt tokens during inference.
While analogous transformer architectures have been proposed to handle long sequences comprised of raw bytes [74], prior work consider the global module to be the primary model, benefiting from coarse processing, while the embedder and local module simply map between coarse and fine representations to reduce context length. Our approach to global-to-local modeling in LMs challenges these prior beliefs, and uncovers substantial inference-time benefits that have been overlooked in previous work. In detail, we propose that both the global block decoder and local token decoder can play vital roles in language modeling, hence the term global-to-local language modeling. Our ablations reveal that a more balanced parameter allocation across the global and local modules enhances performance, and also results in higher throughput due to significantly shortened context lengths in the local module.
Extensive experiments on models up to 1.4 billion parameters show that Block Transformers notably improve inference throughput for both prefill- and decode-intensive scenarios, achieving 10–20 gains in throughput compared to vanilla transformers with equivalent perplexity or zero-shot task performance. Despite the architectural restriction of global attention in Block Transformers, our models show similar ability to utilize global context compared to their vanilla transformer counterparts. In addition, we show that it is possible to uptrain pretrained vanilla model into Block Transformers, closely approaching the performance of those pretrained from scratch, using just 10% of the training budget for adaptation.
Our main contributions are summarized below:
-
•
We are the first to recognize the central role and inference-time benefits of both global and local modeling in autoregressive transformers–particularly the significance of local modules.
-
•
We leverage these insights to optimize inference throughput in our architecture to significantly extend the Pareto frontier of performance to throughput compared to vanilla transformers.
2 Block Transformer
The Block Transformer employs global and local attention mechanisms with hierarchical paradigm by separating the comprehension of the full context and detailed interactions into two distinct stages. Precisely, global context is captured at lower layers as coarse block-level granularity, where each block consists of a fixed number of tokens aggregated into a single embedding. The local dependencies are resolved at upper layers, where multiple subword tokens are decoded in an autoregressive manner by solely attending context block embedding from the block decoder. The Block Transformer consists of three components:
-
1.
Embedder: The embedder aggregates each block of tokens into an input block embedding.
-
2.
Block decoder: The block decoder applies self-attention across the full sequence of blocks to model global dependencies.
-
3.
Token decoder: The token decoder applies self-attention within each block to handle fine-grained local dependencies and decode individual tokens.
2.1 Why is Block Transformer efficient?
The main goal of our architecture design is to minimize the wall-clock bottlenecks during inference. In vanilla transformers, the global treatment of self-attention to all previous tokens significantly hinders batch decoding throughput, mainly due to memory overhead of retrieving previous KV cache [20, 25]. This also necessitates all prompt tokens, which are typically quite lengthy, to be fully prefilled prior to decoding the first token, contributing to increased latency [1, 25].
A global-to-local approach can mitigate these costs by isolating the expensive bottlenecks of global modeling to the lower layers and perform local modeling within independent blocks at the upper layers. Coarse-grained global modeling (block-level decoding) alleviates KV cache bottlenecks by a factor of block length, while maintaining the ability to account for the full context Local decoding comes free of the cost of prefill, and nearly removes KV cache overhead, thus benefits from significantly higher utilization of the compute units on inference hardware. This allows the token decoder to use more FLOPs for fine-grained language modeling with minimal impact on inference throughput. Table 1 outlines the principal wall-time bottlenecks at the prefill and decode stages, and summarizes the efficiency gains of our block and token decoders.
Although our models require more parameters than vanilla transformers to maintain comparable performance, the actual bottleneck in throughput is the KV cache overhead, allowing our model to still achieve higher speed improvements. Thereby, we focus on production systems like cloud platforms, which can accommodate the higher parameter demands. Edge devices are constrained by memory [3] and typically use small batches [61]. Since parameter IO is a critical bottleneck [51], we leave the optimization of the Block Transformer for on-device scenarios to future work.
| Inference bottleneck | Relative complexity | |||||
| Metric | Name | Prefill | Decode | Vanilla | Block | |
| Memory | Parameter | - | - | | ||
| KV cache | - | - | ||||
| IO | Parameter | ✗ | ✗ | | ||
| KV cache | ✗ | ✓ | ||||
| FLOPs | Attention score | ✗ | ✓ | |||
| Linear projections | ✓ | ✗ | ||||
2.2 Embedder
Our embedder design prioritizes simplicity given the small block length (2–8) in our study. We primarily use a lookup table to retrieve and concatenate trainable token embeddings, where the token embedding dimension is set to , with being the dimension of block representations used throughout the network). While we explored variants such as small encoder transformers (Appendix F), these did not yield performance improvements (subsection 3.4).
2.3 Block decoder
The block decoder aims to contextualize block representations by attending to preceding blocks, utilizing the embedder’s output as input. This autoregressive transformer operates at the block level, producing output block embeddings (also called context embeddings) that enable the token decoder to autoregressively decode the subsequent block’s token contents. Given input block embeddings from the embedder, derived from input tokens , the block decoder outputs a context embedding which contains the information to predict .
This approach mitigates the quadratic costs of self-attention by using coarse-grained block inputs instead of individual tokens, while preserving global modeling capabilities and ease of hardware acceleration of dense attention [75]. This reduces the context length of a given sequence by compared to a vanilla transformer. In terms of FLOPs (the main bottleneck during prefill), all positionwise computations are reduced by a factor of , and attention score computation is reduced by [74]. During decoding, KV cache usage and KV cache IO (the main bottleneck during batch decoding) are reduced by and , respectively, allowing for larger batch sizes and higher compute utilization.
2.4 Token decoder
The token decoder locally decodes the individual tokens of the next block using the context block embedding as the sole source of global context information. The token decoder is also a standard autoregressive transformer, featuring it’s own embedding table and classifier. The key to designing the token decoder lies in how to incorporate the context embedding into the decoding process, in a way that effectively leverages the high compute density of the token decoder.
The token decoder eliminates prefill (necessary only in the block decoder), as context information is provided by the output block embedding–hence the term context embedding. Additionally, KV cache IO, a major bottleneck during batch decoding, is nearly removed. While vanilla attention’s KV cache IO is quadratic to the full context length (), the token decoder’s local attention costs per block over blocks, resulting in a linear cost to the full context length and a reduction factor of (e.g., in our main models). This allows for significantly higher compute unit utilization compared to vanilla transformers, which have ~1% model FLOPs utilization (MFU) [51], making the inference wall-time cost of extra FLOPs relatively cheap.
To incorporate the context embedding and leverage this low-cost compute, we project the context block embedding into prefix tokens, enabling further refinement of the global context. Expanding the number of prefix tokens (prefix length) broadens the token decoder’s computation width and allows for finer attention to context information, similar to pause tokens [29]. Owing to parallel processing and small local context, these extra prefix tokens do not incur significant wall-time overhead. While we also considered summation and cross-attention based variants (Appendix F), these proved less effective than our main method (subsection 3.4).
3 Experiments
3.1 Experimental setup
We use the transformer architecture of Pythia [8], and train both vanilla and Block Transformer models on the Pile [26, 7] with a context length of 2048. The models are pretrained on 300B tokens, which corresponds to about 1.5 epochs. We employ the HuggingFace training framework [70]. Eight A100 GPUs with 40 GiB of VRAM are used for training, while an H100 GPU is used for inference wall-time measurements. Experimental details of each subsection are summarized in Appendix G.
3.2 Main results
| # Parameter | Zero-shot Eval | Memory | Throughput | |||||||||
| Models | Total | N-Emb | Loss | LD | WK | HS | PQ | ARC | ||||
| Vanilla | 31M | 5M | 3.002 | 282.7 | 78.4 | 26.47 | 57.97 | 37.10 | 355.0 | 38.5 | 10.8 | 41.6 |
| 70M | 19M | 2.820 | 67.2 | 46.9 | 27.20 | 59.73 | 40.24 | 390.0 | 76.8 | 6.9 | 19.1 | |
| 160M | 85M | 2.476 | 20.2 | 28.5 | 29.80 | 64.22 | 46.85 | 675.0 | 229.6 | 2.3 | 6.2 | |
| 410M | 302M | 2.224 | 10.0 | 20.1 | 35.05 | 68.10 | 51.68 | 1140.0 | 608.2 | 0.8 | 2.1 | |
| Block | 33M* | 5M | 3.578 | 2359.9 | 134.2 | 26.25 | 55.90 | 35.17 | 25.0 | 5.0 | 272.3 | 809.5 |
| 77M* | 19M | 3.181 | 390.5 | 80.1 | 27.21 | 57.69 | 38.31 | 48.9 | 9.9 | 175.3 | 421.4 | |
| 170M* | 85M | 2.753 | 67.9 | 43.7 | 28.28 | 62.22 | 43.43 | 56.3 | 29.1 | 59.0 | 134.7 | |
| 420M | 302M | 2.445 | 29.5 | 27.7 | 31.13 | 64.35 | 48.48 | 105.0 | 77.2 | 21.0 | 44.1 | |
| 1.0B | 805M | 2.268 | 16.5 | 21.4 | 34.68 | 68.18 | 52.26 | 130.2 | 102.8 | 19.8 | 42.5 | |
| 1.4B | 1.2B | 2.188 | 12.2 | 19.1 | 36.66 | 68.63 | 54.63 | 194.2 | 153.9 | 12.4 | 25.7 | |
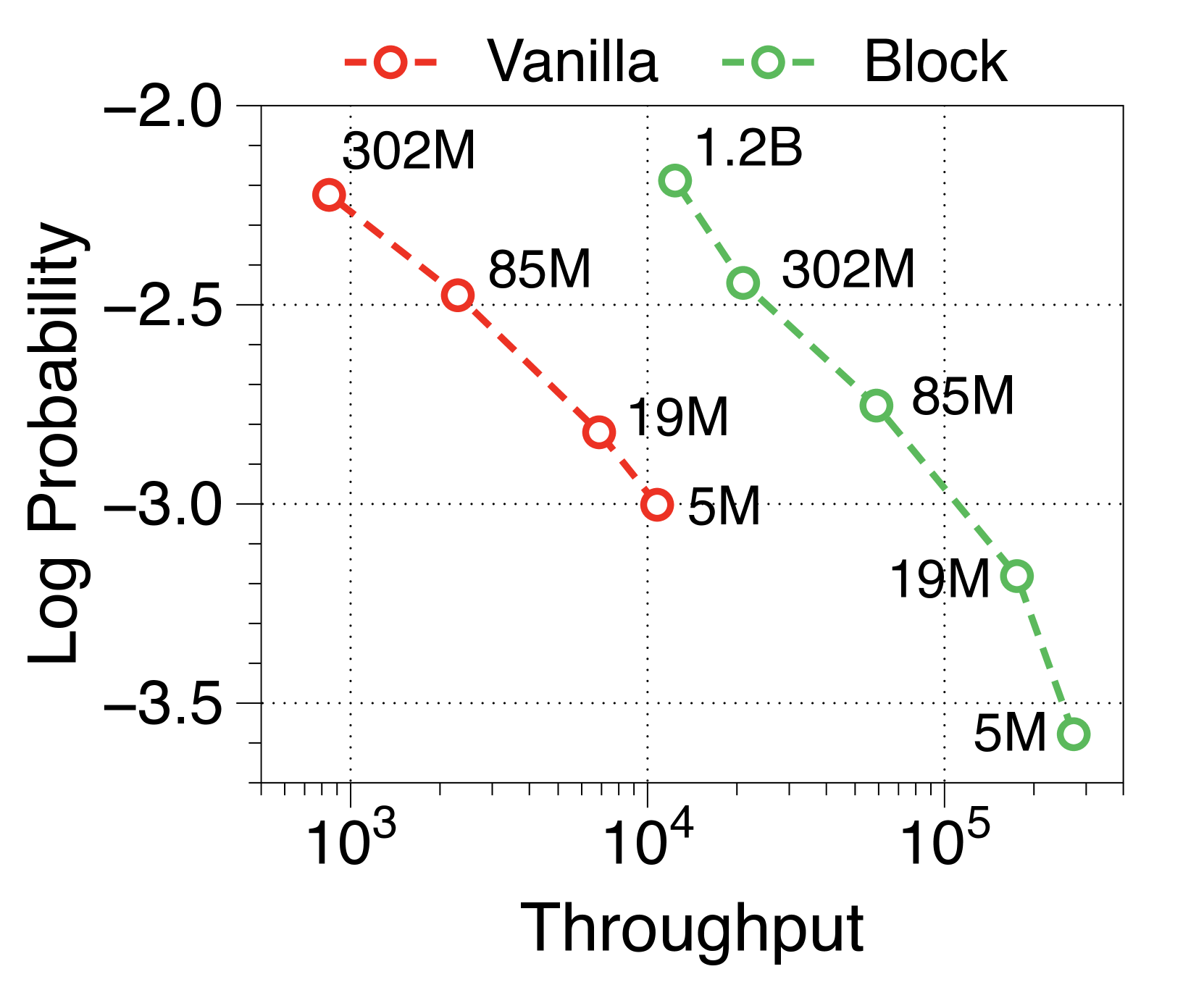
In Table 2, we measure the language modeling performance of the Block Transformer. Block models are scaled to have the same number of non-embedding parameters as the vanilla model variants. Our models, when having two or three times more parameters, achieve comparable perplexity and accuracy on five zero-shot evaluation tasks as the vanilla models. This is an expected result because two separate decoders spend fewer FLOPs per forward pass, reducing the attention complexity by a factor of at the block-level and by roughly at the token-level.
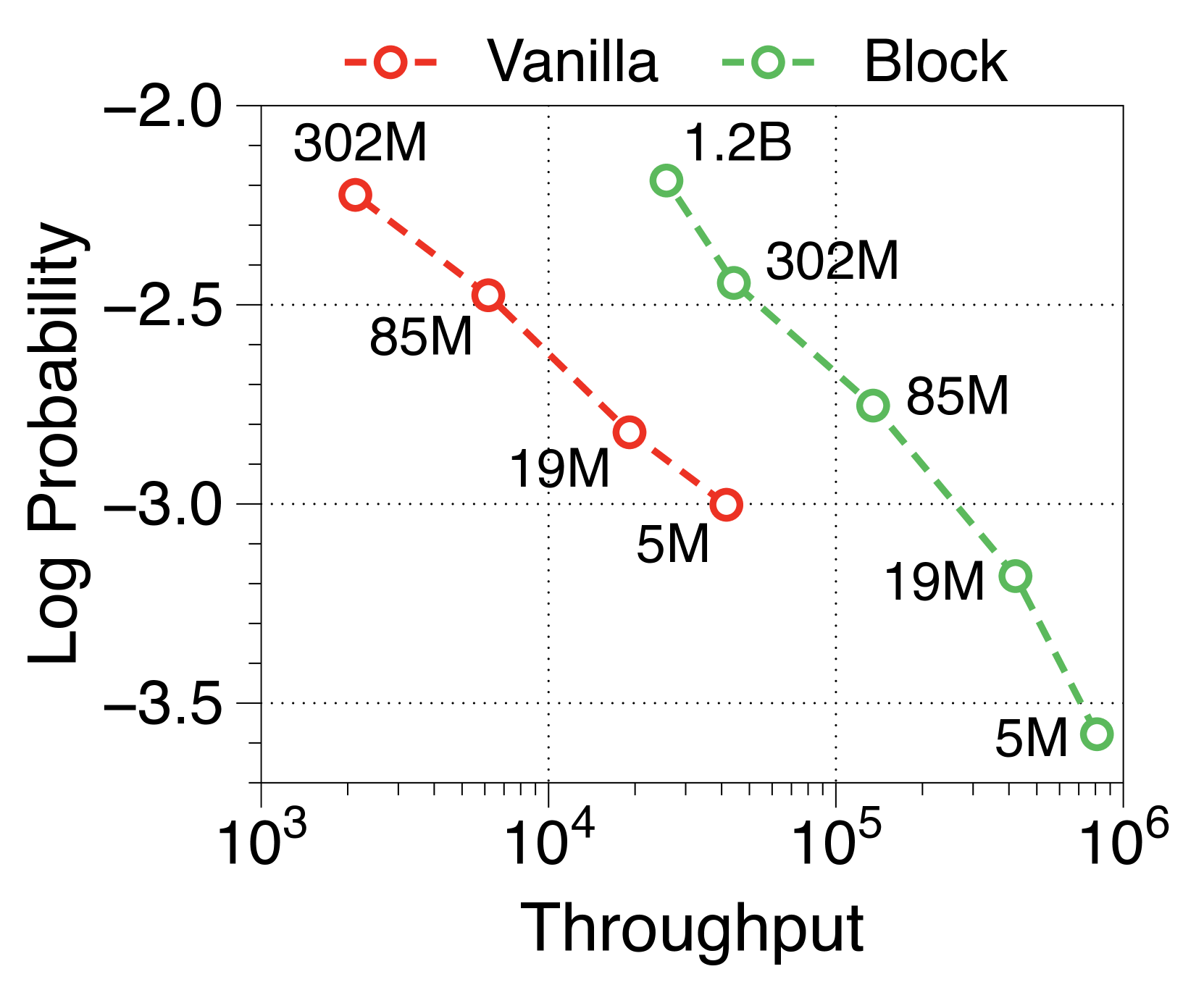
The actual inference throughput and memory efficiency of the Block Transformer are significantly higher compared to vanilla models. We measure the maximum throughput [60], which use maximum batch sizes of each model variant allowed by memory. As shown in 2(a) and 2(b), our models achieve Pareto-optimality, especially demonstrating up to 25 times increase, under two scenarios: prefill-heavy and decode-heavy, where the input and output sequence lengths are 2048, 128 and vice-versa. This efficiency improvement is due to effective reductions in KV cache memory, which allows batch sizes to be about six times larger, as summarized in memory per sample in Table 2. The Block Transformer further reduces latency in a prefill-heavy setting, as past KV states of prompts need to be cached only in the block decoder, without forwarding them to the token decoder.
The Pareto frontiers for variable fixed batch sizes, i.e., 1, 32, and 256, are illustrated in Appendix I. We discover that as both the model size and batch size increase, the throughput rate of the Block Transformer scales exponentially. Considering that the LLMs typically utilized in real-world applications have billions of parameters, and taking into account the strategy of aggregating multiple user requests to optimize batch inference [35, 50, 60], the results suggest that our proposed architecture will demonstrate even more benefits in practical multi-tenant deployment scenarios.
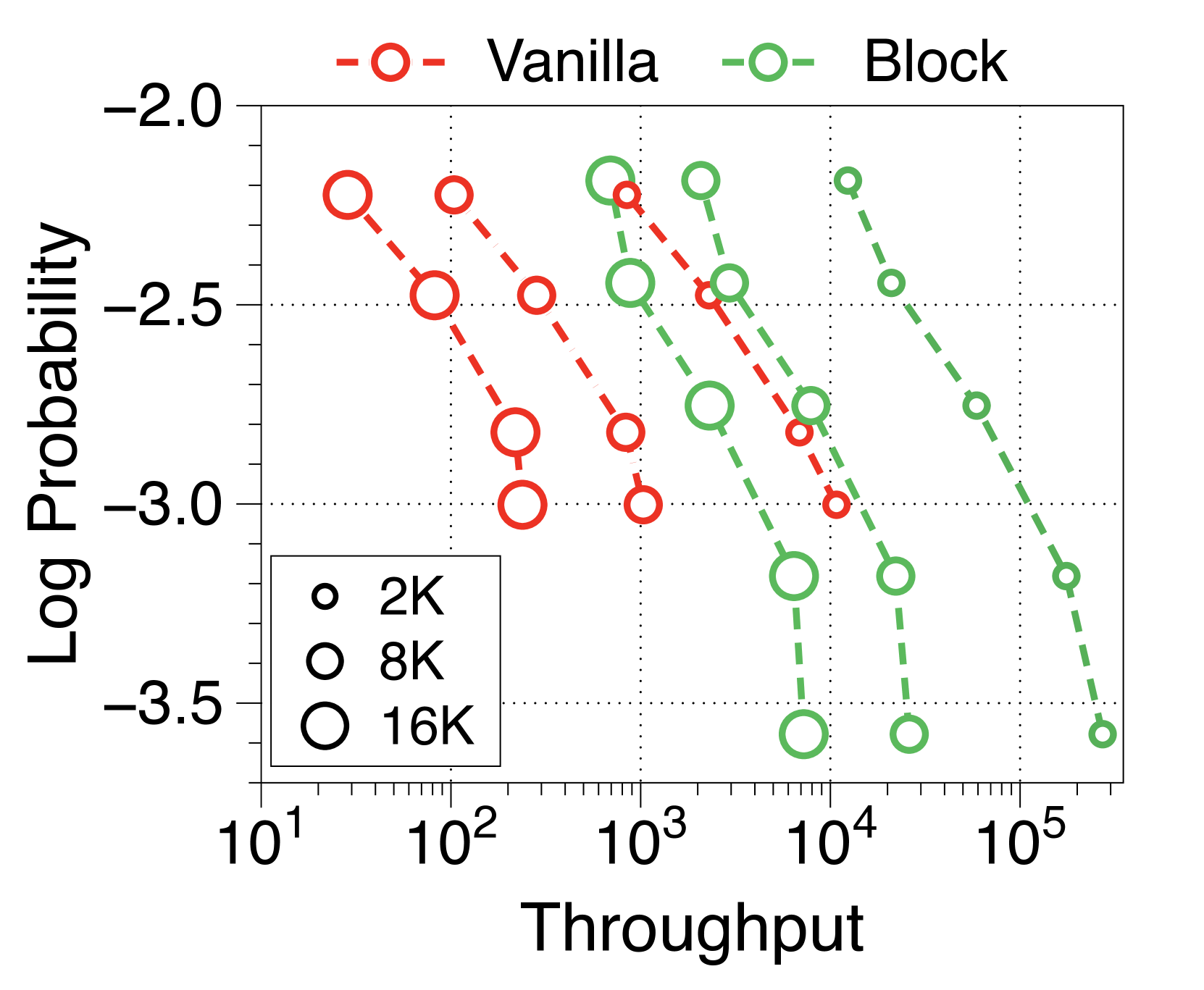
In 2(c), we observe that the throughput of the Block Transformer with an 8K prompt length surpasses that of the vanilla model with a 2K prompt length. This is reasonable because the context length of the block decoder is reduced by a factor of 4, and the token decoder is nearly free of KV-cache overheads. Given the rising interest in enabling longer context lengths, even over one million tokens [13, 57, 46], the Block Transformer has potential to enhance throughput even further.
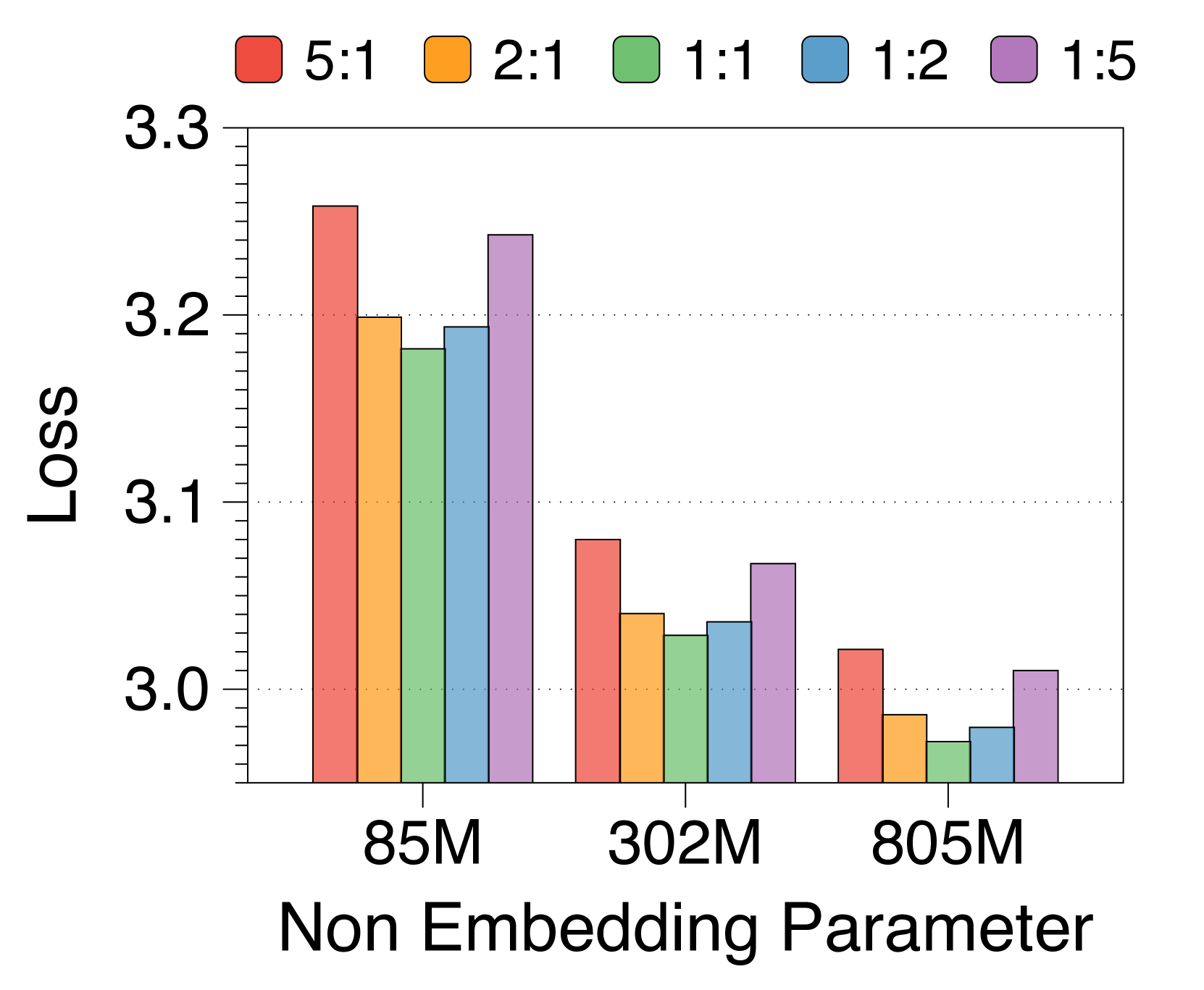
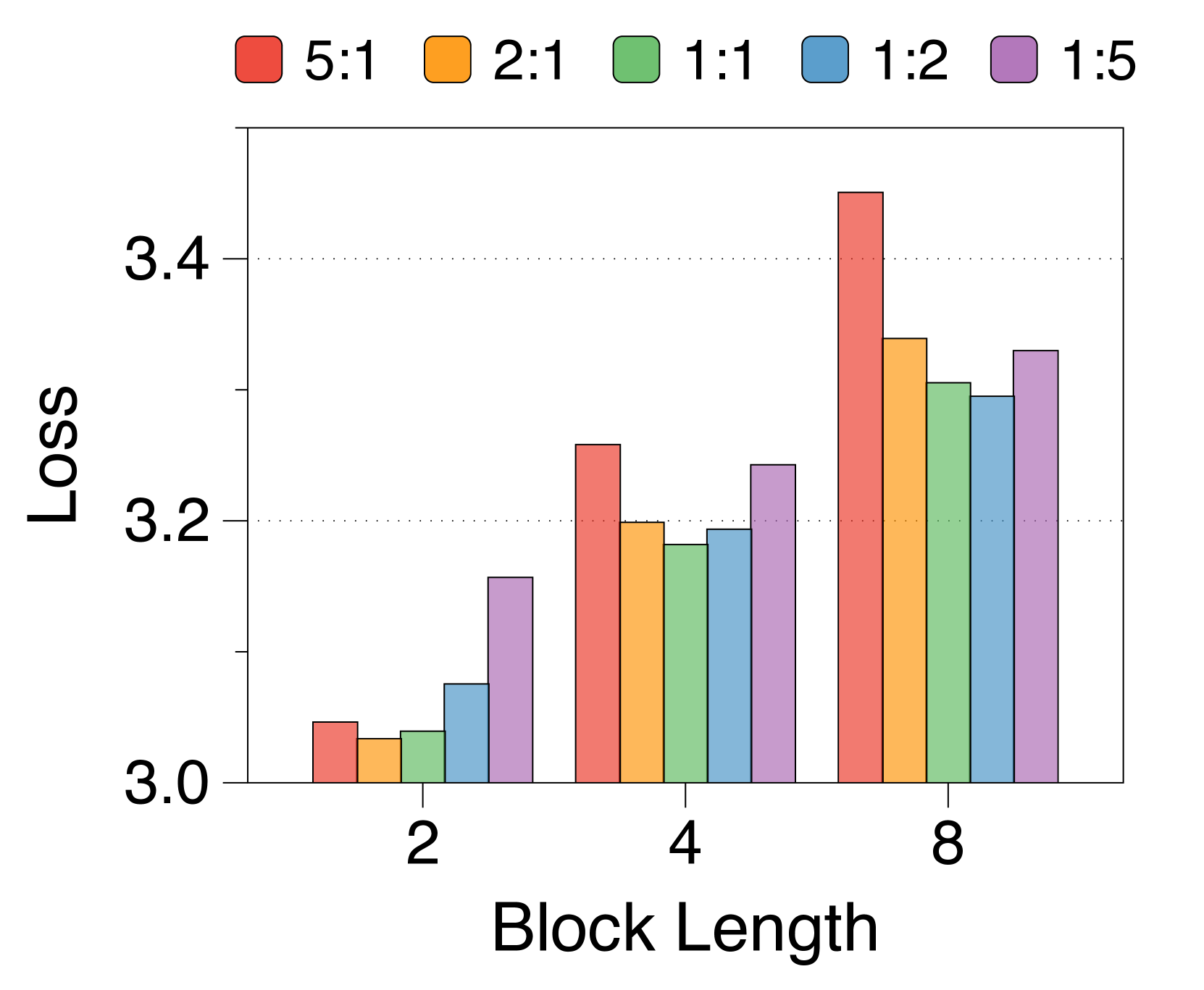


3.3 Analysis on parameter allocation ratio and block length
Perplexity shows a U-shaped pattern across different allocation ratios
We explore the impact of different allocation ratios between the block and token decoders on language modeling performance, while keeping the total number of non-embedding parameters constant. 3(a) illustrates the training loss across five distinct ratios for three model sizes. Interestingly, there is a clear U-shaped trade-off at all three model sizes. We find that a one-to-one ratio is optimal for models with consistently across all model sizes. If either side is too small, there is a noticeable decline in performance. This demonstrates the synergistic effect and the equal importance of the block and token decoders in language modeling.
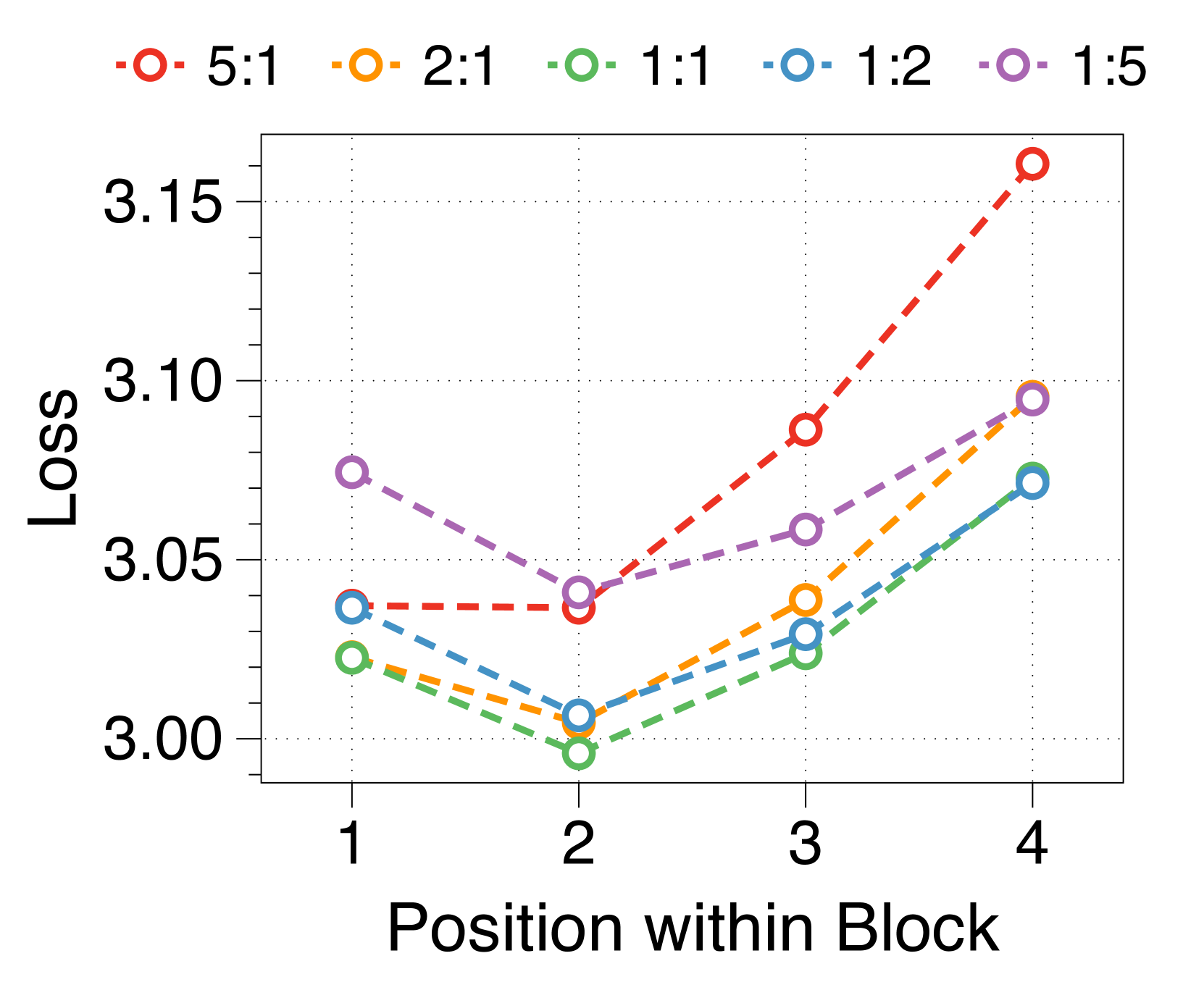
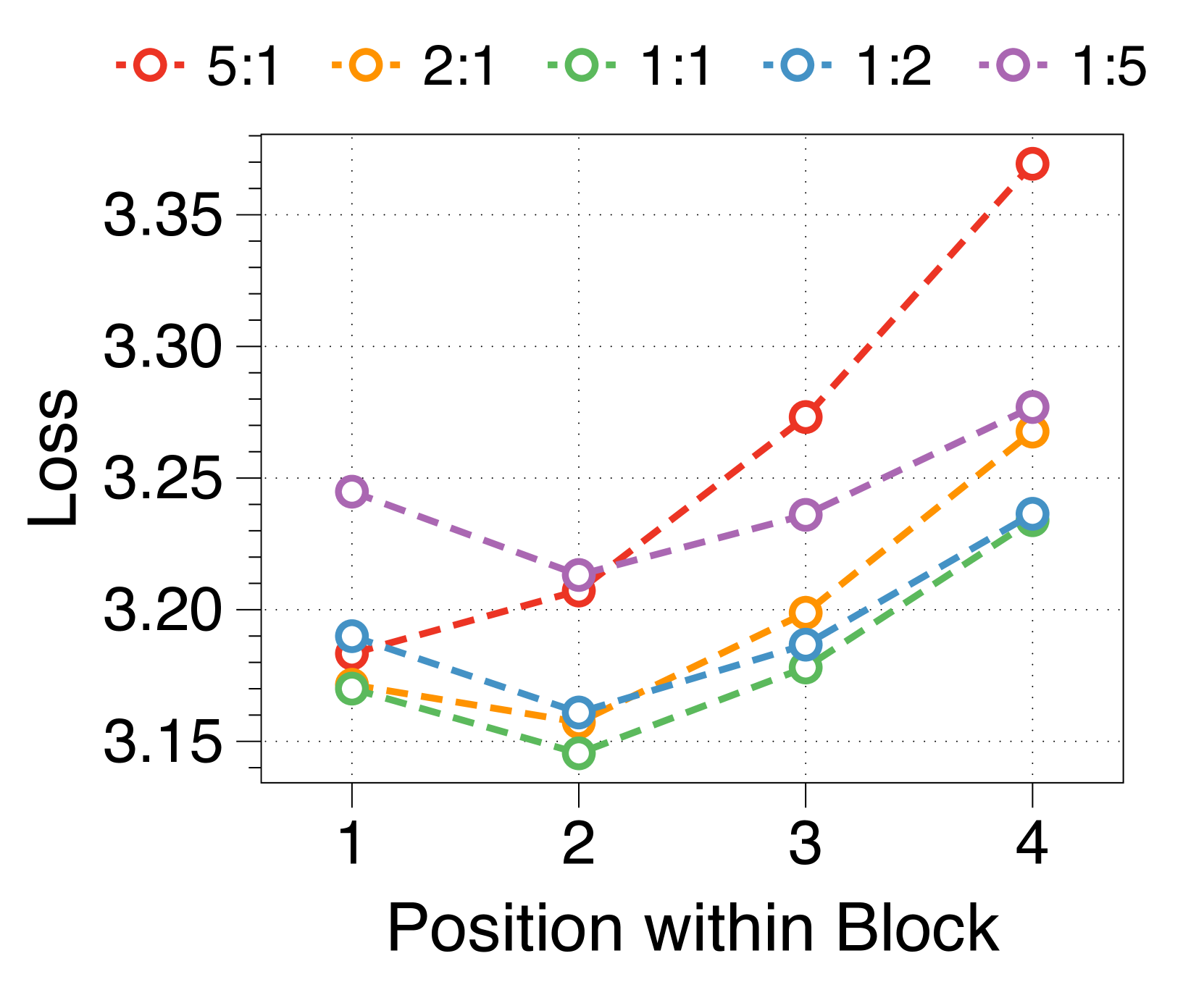
Larger block and token decoders reduce perplexity at initial and later positions respectively
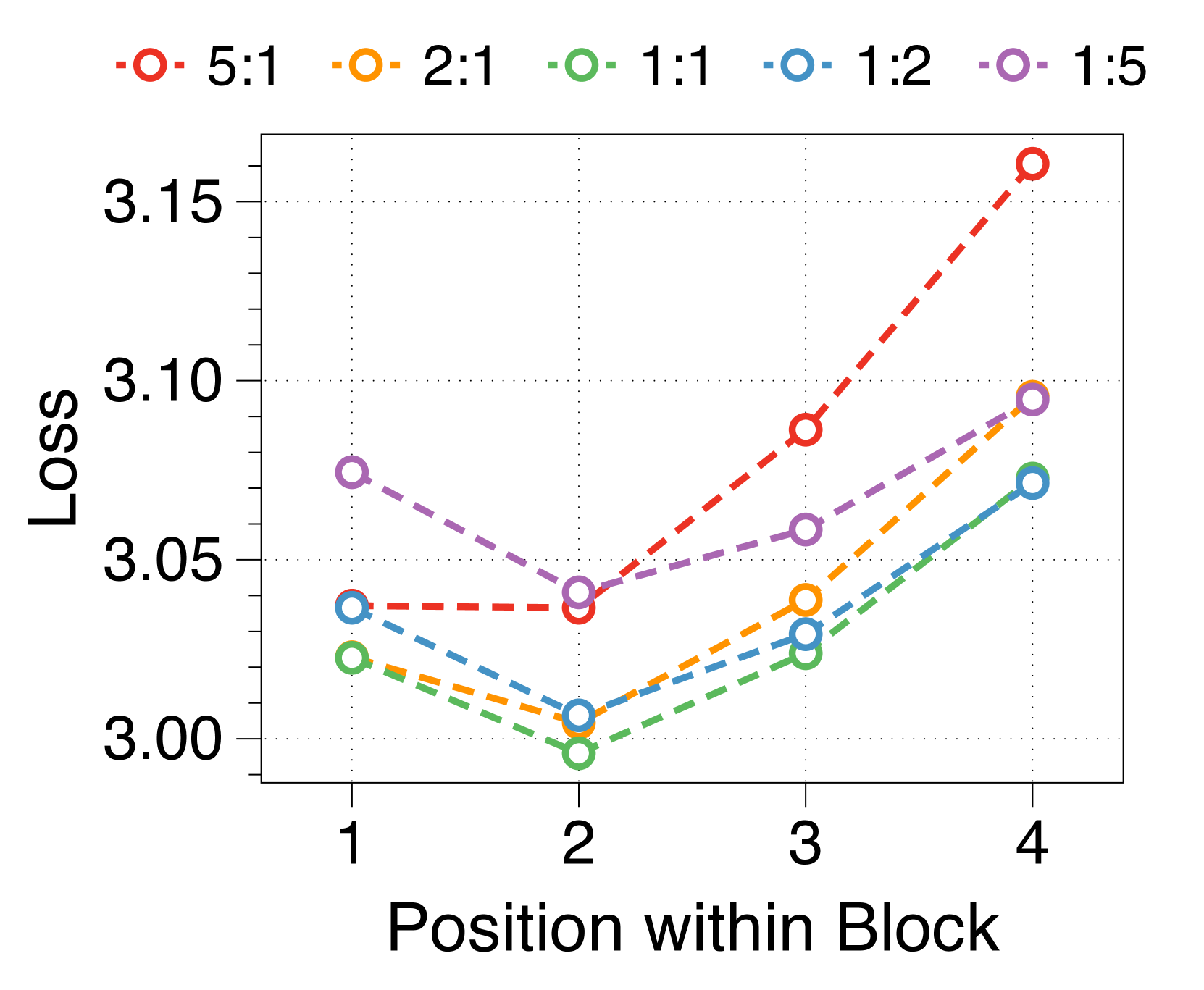
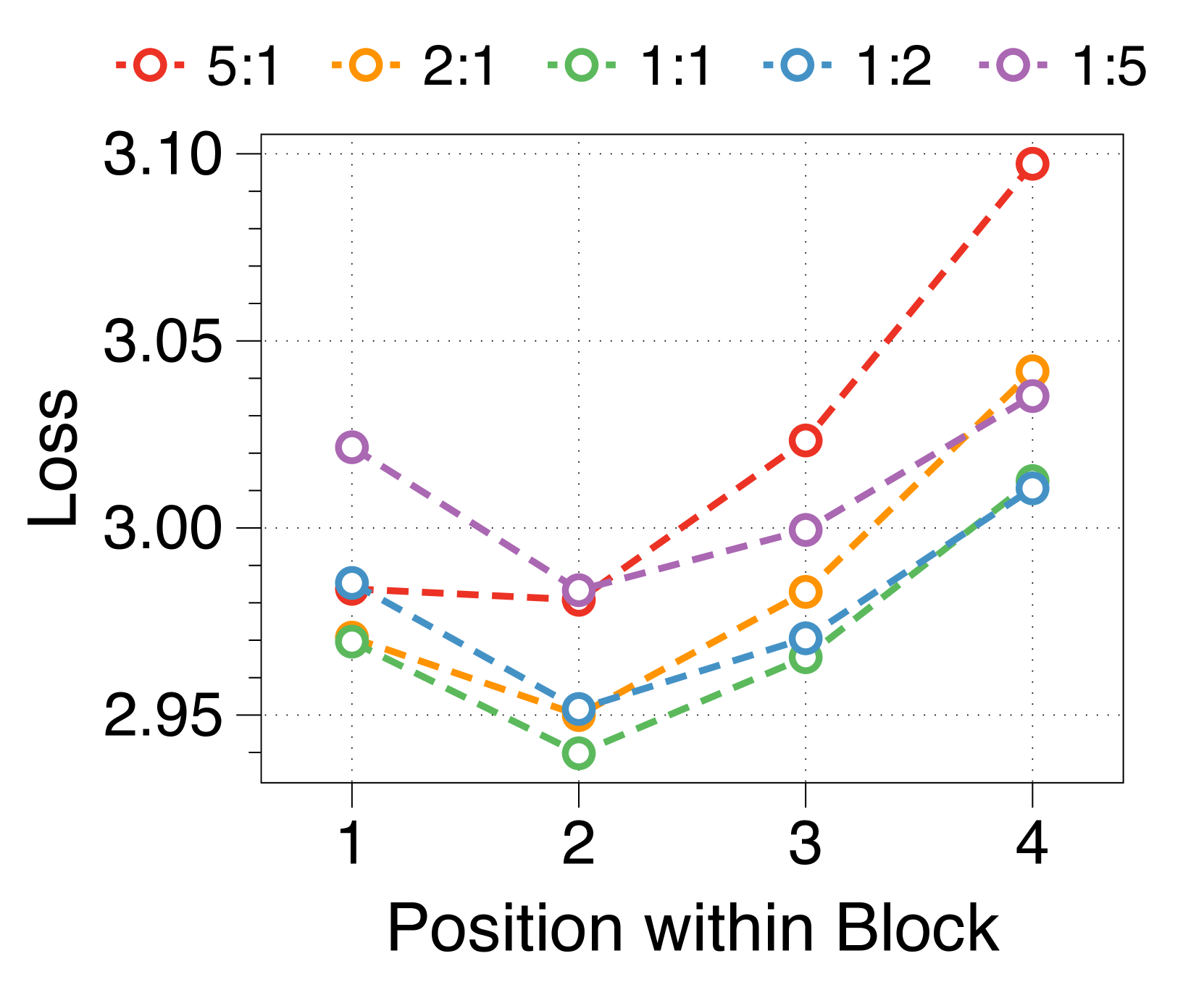
We measure average loss at each position within a block, depicted in 3(d). The position-wise loss typically exhibits a U-shaped pattern, aligning with findings from a previous multiscale language model [74] and blockwise parallel decoding methods [62, 14, 34]. This trend stems from the lack of global context in context embeddings, which escalates uncertainty at later positions. Moreover, perplexity at specific positions correlates with the parameter sizes of two decoders. A larger block decoder significantly lowers initial position loss due to predictions solely based on the context embedding. In contrast, a larger token decoder improves prediction accuracy for later tokens by better leveraging local context. These interdependent effects dictate the optimal parameter ratio, with similar patterns evident in models of various sizes, detailed in Appendix J.
Shorter block length favors larger block decoder whereas longer length prefers token decoder
3(b) demonstrates that training loss still follows a U-shaped pattern across different allocation ratios, regardless of block length. Optimal ratios shift with block length: shorter blocks benefit from a larger block decoder, while longer blocks perform better with more parameters in the token decoder. This is due to the inverse relationship between block length and FLOPs of the block decoder, which influences model capacity [22, 23, 29]. As 3(e) shows, first position loss significantly decreases with shorter blocks, reflecting increased capacity in the block decoder. While the token decoder shows minimal differences in FLOPs across block lengths, it has more chance to improve the likelihood of later tokens as block length increases, favoring a larger token decoder. These trends are consistent across different model sizes and allocation ratios, detailed in Appendix K.
Larger token decoder and longer block length are beneficial for achieving high-throughput
We evaluate the allocation ratio and block length from a throughput perspective, summarizing the Pareto frontier in Appendix L. Models with larger token decoders reach Pareto-optimality by achieving higher throughput at a minor performance compromise. Since KV cache IO significantly influences inference time, allocating more parameters to the token decoder is advantageous because the local context length is bounded by the block length. Additionally, increasing the block length improves throughput as KV cache length in the block decoder reduces proportionally. Therefore, although our main configuration uses a one-to-one ratio and a block length of four, opting for a longer block length and a larger token decoder could result in a higher-throughput model.
3.4 Ablation on components of the Block Transformer
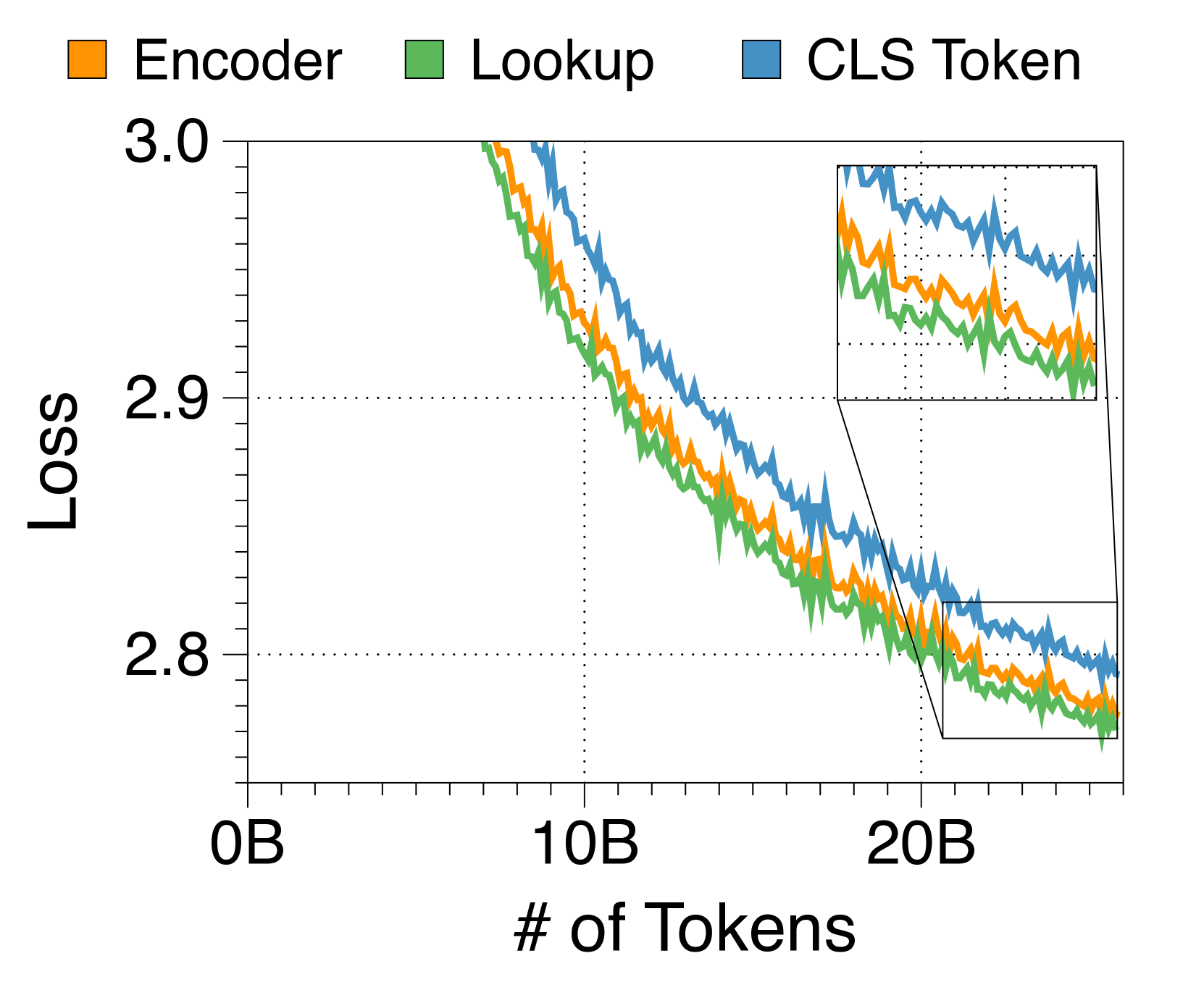
Lookup strategy is the most effective approach for the embedder
In 3(c), we experiment with three embedder strategies to bundle block tokens into a single embedding. Surprisingly, a complex transformer encoder like RoBERTa [40] does not outperform a simpler lookup table strategy. Moreover, the encoder-based embedder lowers generation throughput due to additional computational overhead. As a result, we opt for the lookup strategy to steamline the Block Transformer architecture. Although the CLS token approach allows flexibility in block length, we leave it for future work as it compromises language modeling performance.
Prefix token decoder with longer prefixes enhances performance with minimal overhead
3(f) shows the training loss curve for three token decoder strategies. Using a cross-attention module with key and value sequences equal to the block length considerably diminishes performance. In contrast, forwarding context embeddings through self-attention operations enhances performance, with prefix decoding surpassing other methods. Furthermore, extending the prefix beyond four tokens markedly improves perplexity, effectively broadening the computation width of token decoder. Since longer prefixes add minimal inference overhead, we select a prefix length of two by balancing performance with FLOPs. This approach offers new insights into global-to-local modeling, diverging from previous studies [74] which overlook the potential of local computational capacity in the token decoder. Detailed results across various model sizes are summarized in Appendix M.
3.5 Analysis on global-to-local language modeling
Global-to-local language modeling efficiently optimizes throughput relative to performance
In 4(a), we transition from vanilla to Block Transformers by adjusting block lengths. As block length increases, training loss changes log-linearly and throughput increases exponentially, clearly demonstrating the efficiency of global-to-local modeling. Using a lookup embedder and token decoder with one prefix token, our model with differs from the vanilla model only by removing global attention in the upper layers. Notably, this model achieves loss equivalent to that of the vanilla model after training on 70% of the tokens, while doubling throughput. Despite pruning all past sequences, this robust performance shows that the context embedding can retain relevant information, enabling the effective of use local computations in global-to-local language modeling.
Block transformer can effectively leverage full context
Since the token decoder depends solely on the context embedding, there could be a concern about whether the Block Transformer fully utilize context information. To address this, we evaluate the loss of token positions within a 2K context window using the test set of PG19 dataset [52]. 4(b) indicates that later tokens are consistently predicted with higher likelihood, suggesting that our architecture, which distinguishes between block-level and token-level decoders, effectively leverages at least 2K tokens of context.
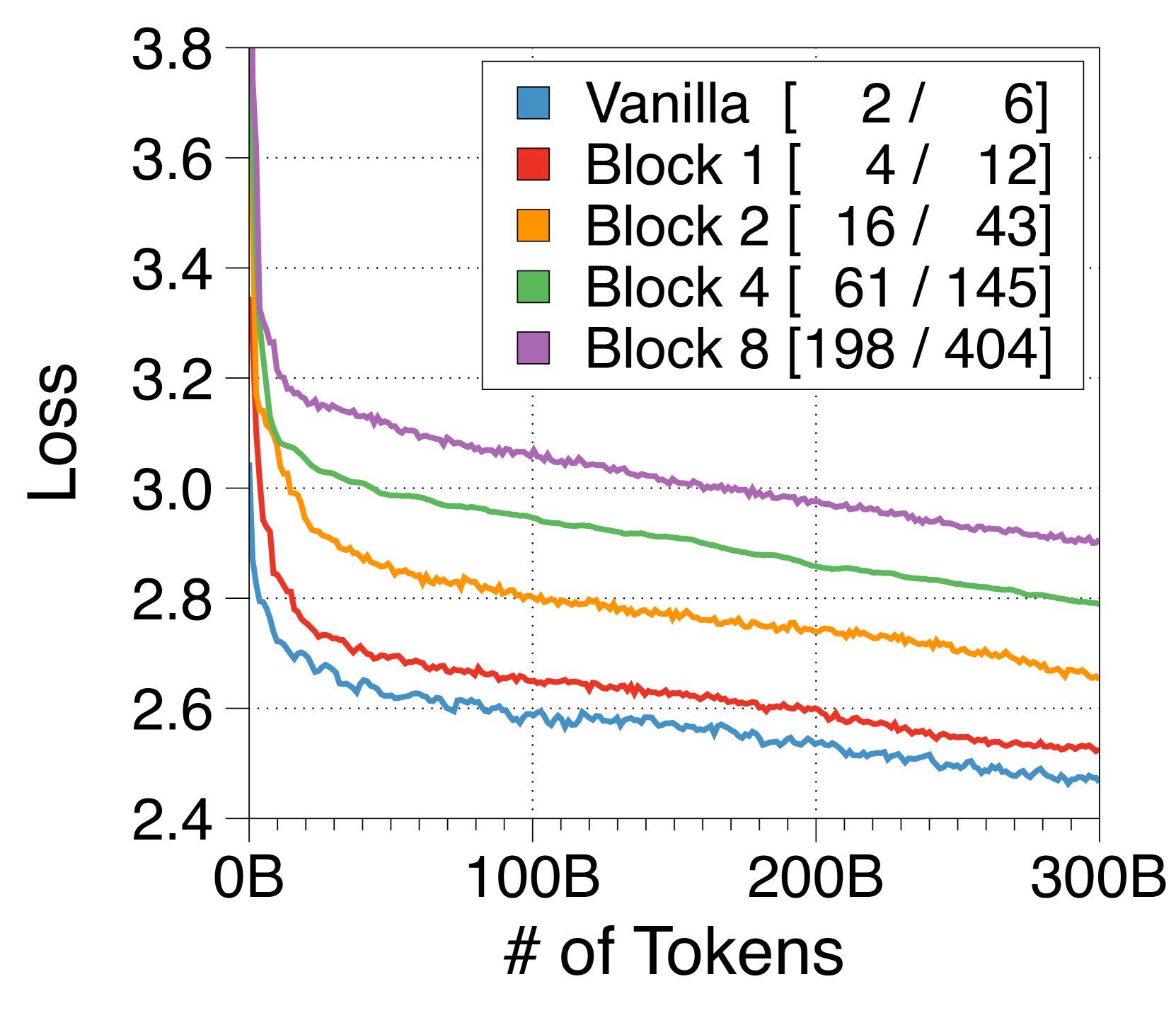
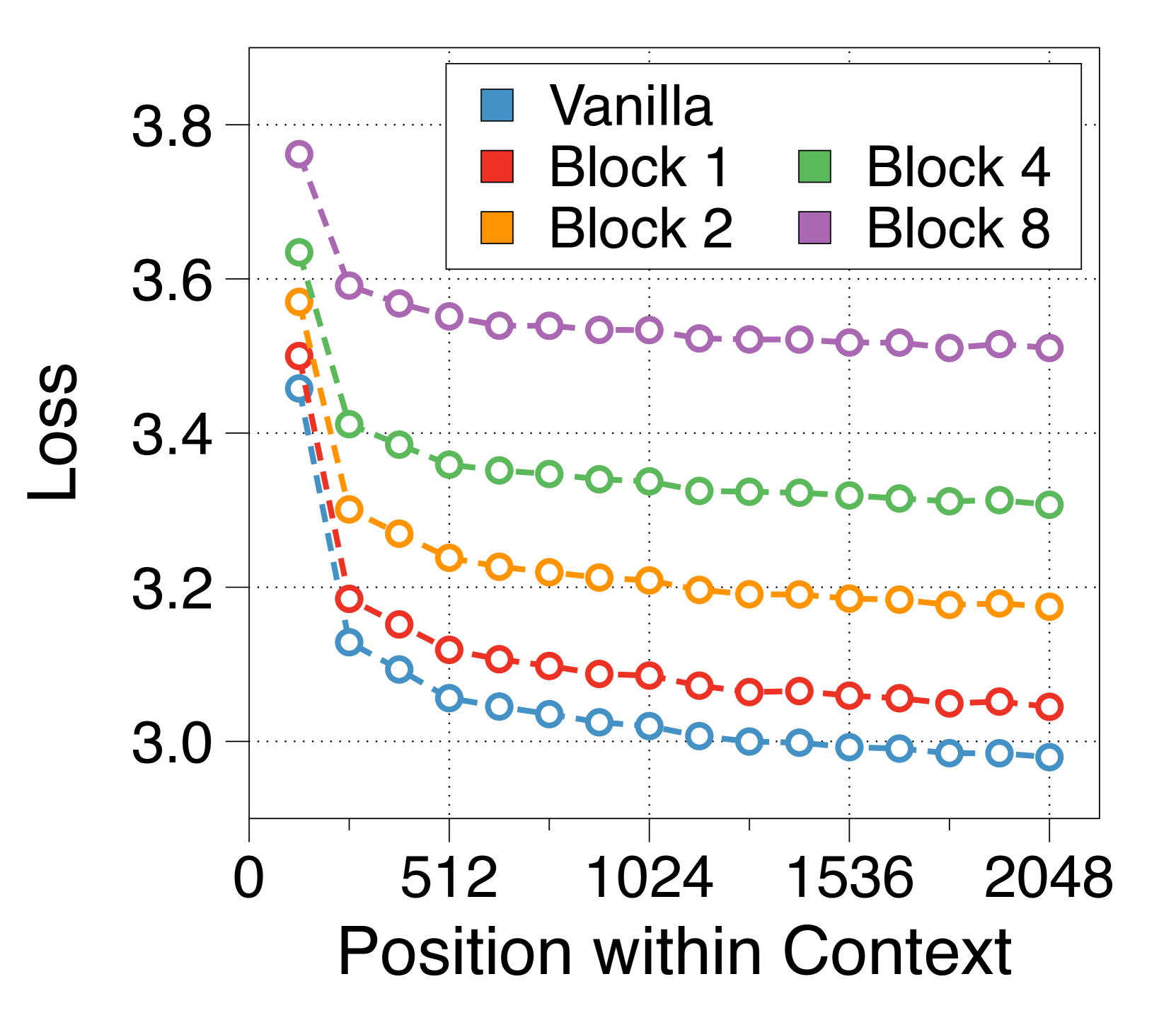
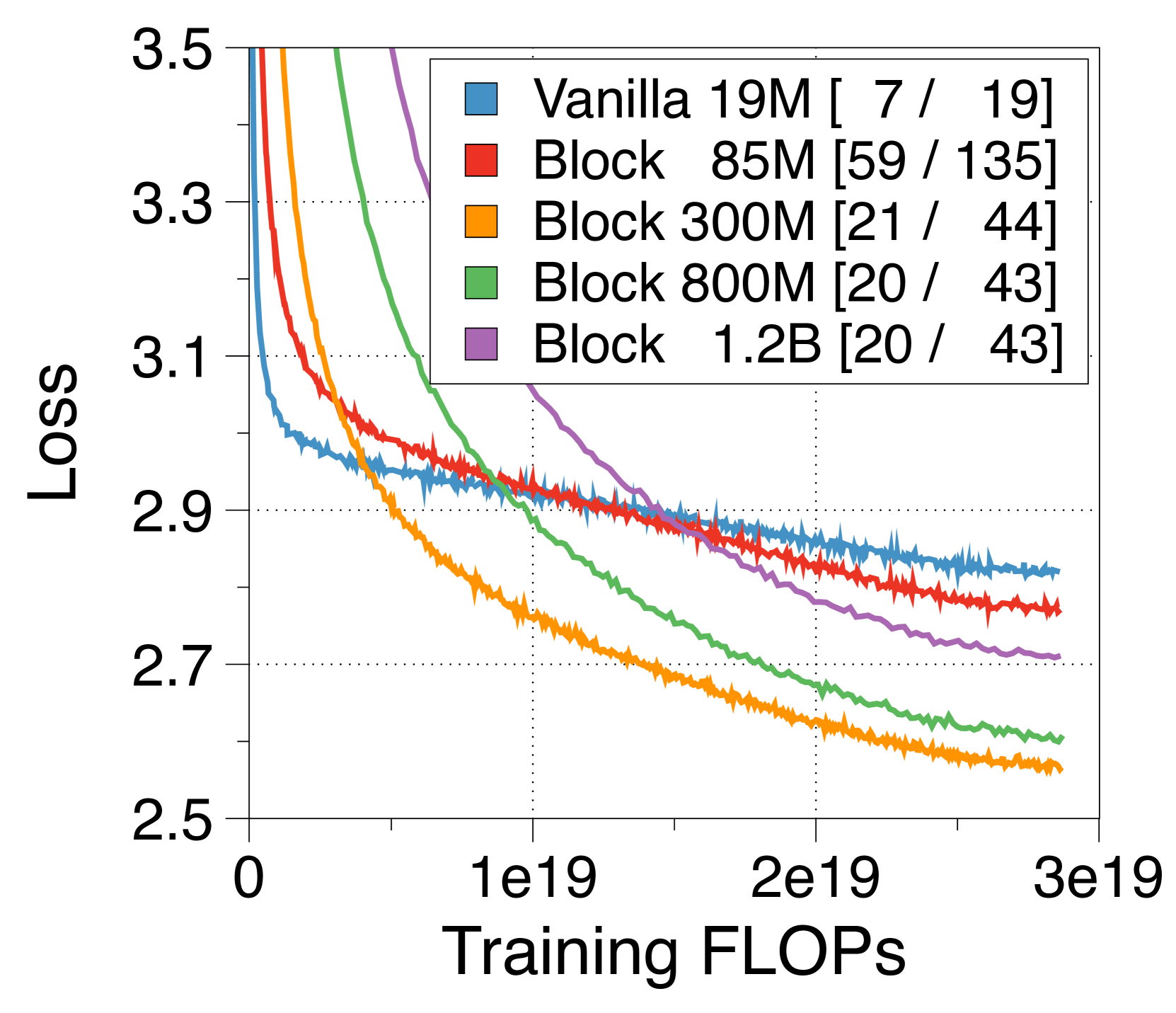
3.6 IsoFLOP analysis under inference throughput constraints
Previous studies have focused on compute-optimal models to maximize performance within training FLOPs budgets [33, 32], while typically overlooking inference throughput. Recent trends, however, emphasize models that also consider inference throughput constraints, either by overtraining smaller models [65, 64] or by reducing FLOPs of the model itself [55]. In 4(c), an optimal Block Transformer model achieves superior perplexity and triples the throughput when using the training FLOPs and throughput of the vanilla model as budget constraints. This illustrates that our models can effectively balance training efficiency and inference throughput.
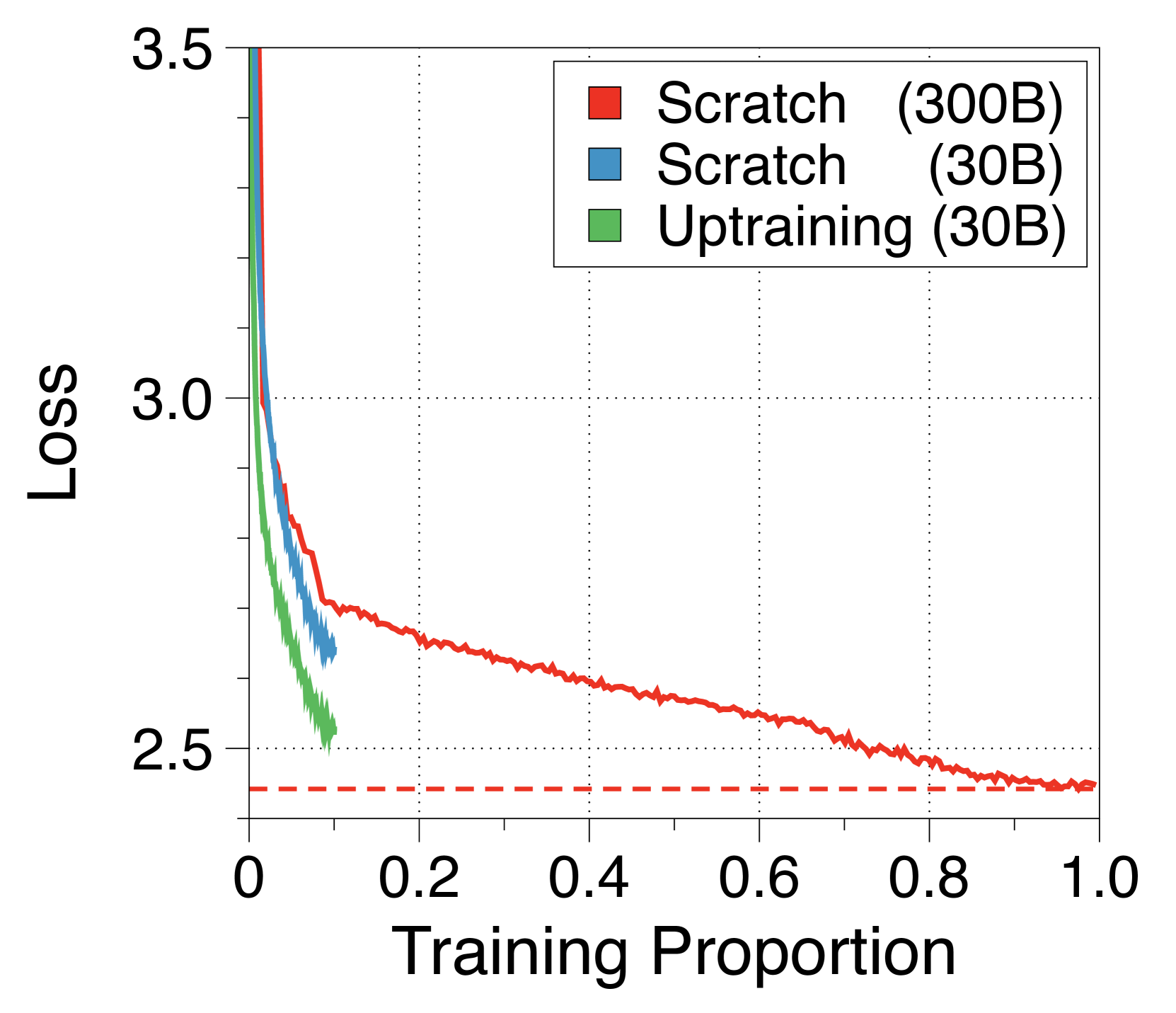
3.7 Uptraining from vanilla transformers
Unlike previous studies [74], our subword-level global-to-local architecture can leverage the initialization from a pretrained vanilla transformer. This enables efficient training, requiring only a small number of data. As shown in 5(a), this uptraining strategy can lead to near-full performance recovery with just 10% of the original training steps, outperforming random initialization strategy. Consistent with previous studies [2], investigating deliberate weight initialization techniques can further enhance the performance convergence. We summarize details in Appendix N.
4 Discussion
4.1 Comparison to related works
Performance comparison to MEGABYTE
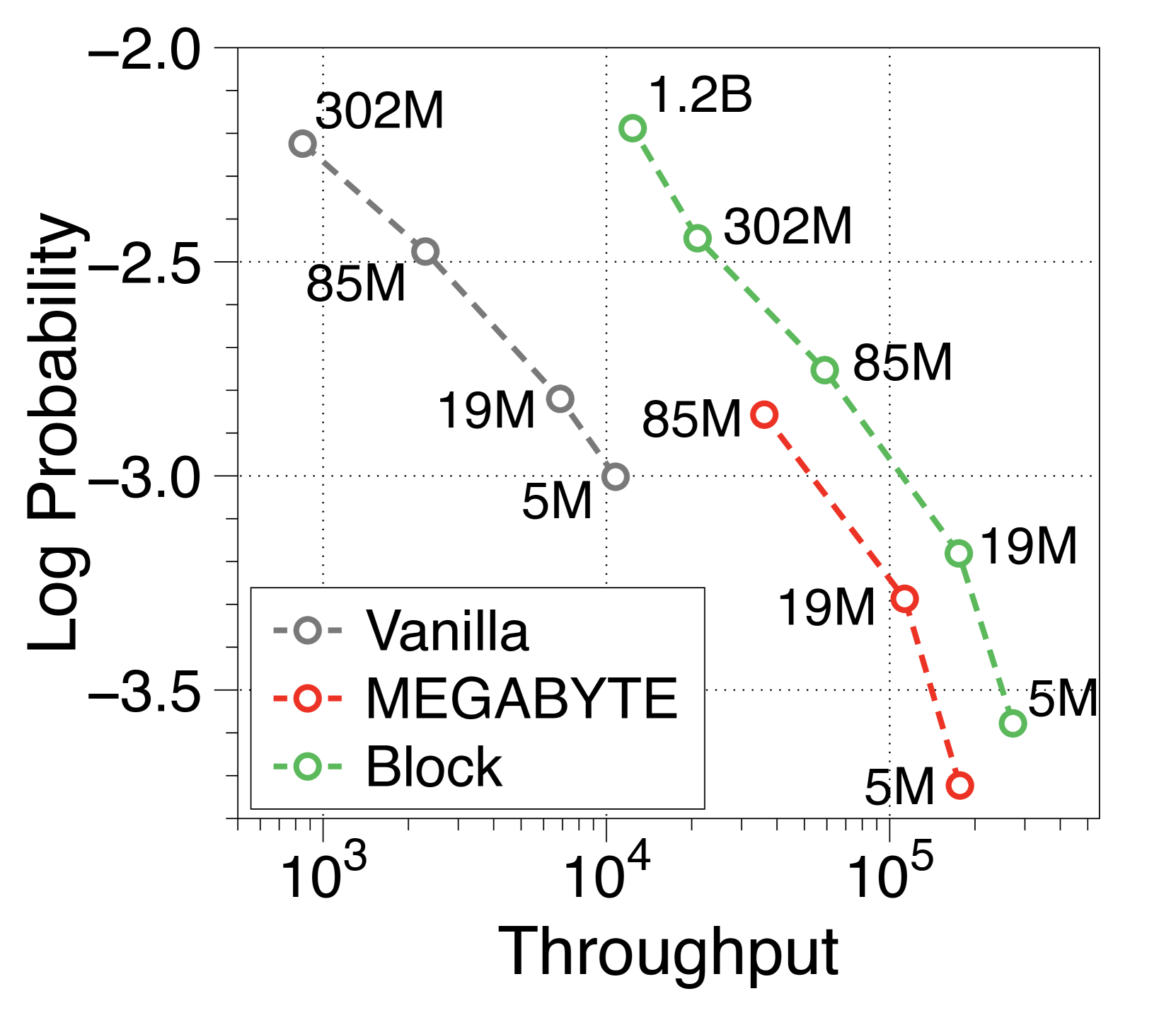
The MEGABYTE model [74] adopts a global-to-local structure but focuses on efficient pretraining over inference. Thus, within the training FLOPs budget, they argue for a larger block decoder based on a 6:1 ratio deemed optimal. As shown in 5(b), we reimplement the token-level MEGABYTE models, and they also achieve significantly higher throughput compared to vanilla models through global-to-local modeling. Nevertheless, consistent with our insights in subsection 3.3, our models with enhanced local computational capacity demonstrate a significant throughput increase of over 1.5 times on top of MEGABYTE. See Appendix O for more details.
Relation to KV cache compression
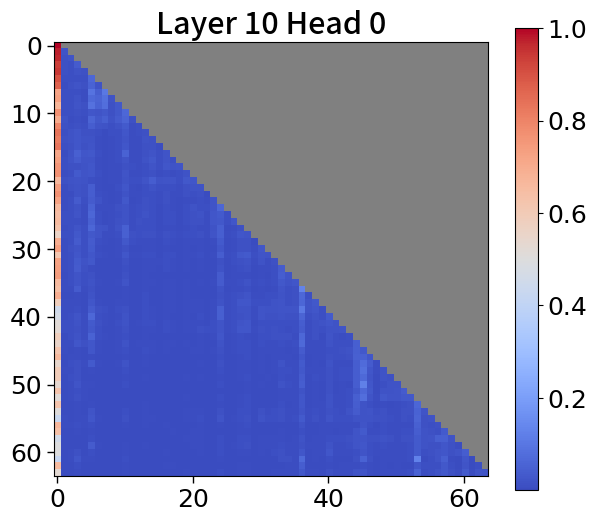
Global-to-local modeling can be viewed through the lens of KV cache compression, where past sequences are entirely pruned in the upper layers. Recent studies have introduced algorithms that preserve only meaningful tokens, determined by accumulated attention scores [67, 77], with observing that most attention tends to sink into the first token [72, 28]. In 5(c), our models exhibit a similar pattern. This observation suggests that performance could be enhanced by leveraging not just the current context embedding but also by incorporating global embeddings or context embeddings from the previous window. See Appendix P for more details.
4.2 Contextual information encapsulated in context block embedding
Since the input tokens and context embeddings share the same latent space in the token decoder, we analyze the nearest tokens to these block embeddings. Interestingly, Table 5 in Appendix Q reveals that context embeddings compress global context rather than outlining the next block. The second prefix often contains information about the last token of current block to aid predicting the first token of the next block. Meanwhile, the first prefix typically matches non-intuitive or the EOS token, suggesting that they carry more general information. In light of this, the block decoder effectively compresses past global contexts, which the token decoder leverages for its local language modeling.
4.3 Techniques for further throughput improvement
Block autoregressive model with parallel token decoding
When we pretrain the block decoder to predict next input block embeddings, the token decoder can decode all blocks in parallel if the predictions from block decoder are precise. While Mujika [44] enhance pretraining efficiency by directly predicting the embedding matrix, we find that MSE or contrastive losses [16] at the block decoder actually degrades performance. Moreover, error accumulation at the block level needs to be addressed, as discretization is not possible with block embeddings. Nevertheless, using pretrained text embeddings [68, 36] as ground truth, instead of jointly training embedder, could be beneficial.
Predicting multiple blocks at once with longer output length
If the model is trained to predict two or three blocks simultaneously, throughput will increase proportionally. For example, if the input block length is four, the token decoder can be pretrained to predict eight tokens, equivalent to two blocks. One efficient training method could be uptraining the original Block Transformer models. To guarantee performance, we can adaptively adjust the prediction length based on the confidence of subsequent blocks or verify those drafts, similar to speculative decoding [37, 15, 39].
5 Conclusion
We introduced the Block Transformer architecture which highlights the inference-time advantages of global-to-local modeling in autoregressive transformers. Our empirical findings demonstrate that both global and local components play vital roles, and we recognize the inference benefits of token decoder, which was overlooked in previous work. By strategically designing our architecture, we significantly improve throughput compared to vanilla transformers of equal performance. Refer to Appendix A for limitation, Appendix B for future works, and Appendix C for broader impacts.
Acknowledgments and Disclosure of Funding
We would like to thank Honglak Lee for his critical feedback on the outline of the paper. We also extend our gratitude to Yujin Kim for extensive discussions on efficient inference and related work. Additionally, we appreciate the continuous feedback from Kyungmin Lee, Junwon Hwang, Park Sangha, and Hyojin Jeon, throughout the development of our work.
References
- Agrawal et al. [2024] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. arXiv preprint arXiv:2403.02310, 2024.
- Ainslie et al. [2023] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.
- Alizadeh et al. [2023] Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. Llm in a flash: Efficient large language model inference with limited memory. arXiv preprint arXiv:2312.11514, 2023.
- Andonian et al. [2023] Alex Andonian, Quentin Anthony, Stella Biderman, Sid Black, Preetham Gali, Leo Gao, Eric Hallahan, Josh Levy-Kramer, Connor Leahy, Lucas Nestler, Kip Parker, Michael Pieler, Jason Phang, Shivanshu Purohit, Hailey Schoelkopf, Dashiell Stander, Tri Songz, Curt Tigges, Benjamin Thérien, Phil Wang, and Samuel Weinbach. GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch, 9 2023. URL https://www.github.com/eleutherai/gpt-neox.
- Bae et al. [2023] Sangmin Bae, Jongwoo Ko, Hwanjun Song, and Se-Young Yun. Fast and robust early-exiting framework for autoregressive language models with synchronized parallel decoding. arXiv preprint arXiv:2310.05424, 2023.
- Bahdanau et al. [2014] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- Biderman et al. [2022] Stella Biderman, Kieran Bicheno, and Leo Gao. Datasheet for the pile. arXiv preprint arXiv:2201.07311, 2022.
- Biderman et al. [2023] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023.
- Bisk et al. [2020] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- Black et al. [2022] Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, et al. Gpt-neox-20b: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745, 2022.
- Brandon et al. [2024] William Brandon, Mayank Mishra, Aniruddha Nrusimha, Rameswar Panda, and Jonathan Ragan Kelly. Reducing transformer key-value cache size with cross-layer attention, 2024.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Bulatov et al. [2023] Aydar Bulatov, Yuri Kuratov, Yermek Kapushev, and Mikhail S Burtsev. Scaling transformer to 1m tokens and beyond with rmt. arXiv preprint arXiv:2304.11062, 2023.
- Cai et al. [2024] Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024.
- Chen et al. [2023] Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318, 2023.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Chowdhery et al. [2023] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Dai et al. [2020] Zihang Dai, Guokun Lai, Yiming Yang, and Quoc V. Le. Funnel-transformer: Filtering out sequential redundancy for efficient language processing, 2020.
- Dao et al. [2022] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- DeepSeek-AI et al. [2024] DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian Liang, Jianzhong Guo, Jiaqi Ni, Jiashi Li, Jin Chen, Jingyang Yuan, Junjie Qiu, Junxiao Song, Kai Dong, Kaige Gao, Kang Guan, Lean Wang, Lecong Zhang, Lei Xu, Leyi Xia, Liang Zhao, Liyue Zhang, Meng Li, Miaojun Wang, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Mingming Li, Ning Tian, Panpan Huang, Peiyi Wang, Peng Zhang, Qihao Zhu, Qinyu Chen, Qiushi Du, R. J. Chen, R. L. Jin, Ruiqi Ge, Ruizhe Pan, Runxin Xu, Ruyi Chen, S. S. Li, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shaoqing Wu, Shengfeng Ye, Shirong Ma, Shiyu Wang, Shuang Zhou, Shuiping Yu, Shunfeng Zhou, Size Zheng, T. Wang, Tian Pei, Tian Yuan, Tianyu Sun, W. L. Xiao, Wangding Zeng, Wei An, Wen Liu, Wenfeng Liang, Wenjun Gao, Wentao Zhang, X. Q. Li, Xiangyue Jin, Xianzu Wang, Xiao Bi, Xiaodong Liu, Xiaohan Wang, Xiaojin Shen, Xiaokang Chen, Xiaosha Chen, Xiaotao Nie, Xiaowen Sun, Xiaoxiang Wang, Xin Liu, Xin Xie, Xingkai Yu, Xinnan Song, Xinyi Zhou, Xinyu Yang, Xuan Lu, Xuecheng Su, Y. Wu, Y. K. Li, Y. X. Wei, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Li, Yaohui Wang, Yi Zheng, Yichao Zhang, Yiliang Xiong, Yilong Zhao, Ying He, Ying Tang, Yishi Piao, Yixin Dong, Yixuan Tan, Yiyuan Liu, Yongji Wang, Yongqiang Guo, Yuchen Zhu, Yuduan Wang, Yuheng Zou, Yukun Zha, Yunxian Ma, Yuting Yan, Yuxiang You, Yuxuan Liu, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhen Huang, Zhen Zhang, Zhenda Xie, Zhewen Hao, Zhihong Shao, Zhiniu Wen, Zhipeng Xu, Zhongyu Zhang, Zhuoshu Li, Zihan Wang, Zihui Gu, Zilin Li, and Ziwei Xie. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model, 2024.
- Dehghani et al. [2018] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2018.
- Dehghani et al. [2021] Mostafa Dehghani, Anurag Arnab, Lucas Beyer, Ashish Vaswani, and Yi Tay. The efficiency misnomer. arXiv preprint arXiv:2110.12894, 2021.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Fu [2024] Yao Fu. Challenges in deploying long-context transformers: A theoretical peak performance analysis. arXiv preprint arXiv:2405.08944, 2024.
- Gao et al. [2020] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
- Gao et al. [2023] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 12 2023. URL https://zenodo.org/records/10256836.
- Ge et al. [2023] Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801, 2023.
- Goyal et al. [2023] Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023.
- Graves [2016] Alex Graves. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983, 2016.
- Han et al. [2021] Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang. Transformer in transformer. Advances in neural information processing systems, 34:15908–15919, 2021.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Kaplan et al. [2020] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Kim et al. [2024] Taehyeon Kim, Ananda Theertha Suresh, Kishore Papineni, Michael Riley, Sanjiv Kumar, and Adrian Benton. Towards fast inference: Exploring and improving blockwise parallel drafts. arXiv preprint arXiv:2404.09221, 2024.
- Kwon et al. [2023] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023.
- Lee et al. [2024] Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, et al. Gecko: Versatile text embeddings distilled from large language models. arXiv preprint arXiv:2403.20327, 2024.
- Leviathan et al. [2023] Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023.
- Li et al. [2024a] Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. arXiv preprint arXiv:2404.14469, 2024a.
- Li et al. [2024b] Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty. arXiv preprint arXiv:2401.15077, 2024b.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Liu et al. [2024] Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024.
- Merity et al. [2016] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- Milbauer et al. [2023] Jeremiah Milbauer, Annie Louis, Mohammad Javad Hosseini, Alex Fabrikant, Donald Metzler, and Tal Schuster. LAIT: Efficient multi-segment encoding in transformers with layer-adjustable interaction. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10251–10269, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.571. URL https://aclanthology.org/2023.acl-long.571.
- Mujika [2023] Asier Mujika. Hierarchical attention encoder decoder. arXiv preprint arXiv:2306.01070, 2023.
- Mukherjee et al. [2023] Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707, 2023.
- Munkhdalai et al. [2024] Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv:2404.07143, 2024.
- Nair et al. [2024] Pranav Ajit Nair, Yashas Samaga, Toby Boyd, Sanjiv Kumar, Prateek Jain, Praneeth Netrapalli, et al. Tandem transformers for inference efficient llms. arXiv preprint arXiv:2402.08644, 2024.
- Paperno et al. [2016] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. arXiv preprint arXiv:1606.06031, 2016.
- Pappagari et al. [2019] Raghavendra Pappagari, Piotr Zelasko, Jesús Villalba, Yishay Carmiel, and Najim Dehak. Hierarchical transformers for long document classification. In 2019 IEEE automatic speech recognition and understanding workshop (ASRU), pages 838–844. IEEE, 2019.
- Pham et al. [2023] Aaron Pham, Chaoyu Yang, Sean Sheng, Shenyang Zhao, Sauyon Lee, Bo Jiang, Fog Dong, Xipeng Guan, and Frost Ming. OpenLLM: Operating LLMs in production, June 2023. URL https://github.com/bentoml/OpenLLM.
- Pope et al. [2023] Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 5, 2023.
- Rae et al. [2019] Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- Rajbhandari et al. [2020] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
- Raposo et al. [2024] David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam Santoro. Mixture-of-depths: Dynamically allocating compute in transformer-based language models. arXiv preprint arXiv:2404.02258, 2024.
- Rasley et al. [2020] Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506, 2020.
- Reid et al. [2024] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Schuster et al. [2022] Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling. Advances in Neural Information Processing Systems, 35:17456–17472, 2022.
- Shazeer [2019] Noam Shazeer. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150, 2019.
- Sheng et al. [2023] Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: High-throughput generative inference of large language models with a single gpu. In International Conference on Machine Learning, pages 31094–31116. PMLR, 2023.
- Spector and Re [2023] Benjamin Spector and Chris Re. Accelerating llm inference with staged speculative decoding. arXiv preprint arXiv:2308.04623, 2023.
- Stern et al. [2018] Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. Advances in Neural Information Processing Systems, 31, 2018.
- Sun et al. [2024] Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, and Furu Wei. You only cache once: Decoder-decoder architectures for language models, 2024.
- Team et al. [2024] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. [2021] Hanrui Wang, Zhekai Zhang, and Song Han. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 97–110. IEEE, 2021.
- Wang et al. [2022] Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
- Wang et al. [2020] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Wolf et al. [2020] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020.
- Wu and Tu [2024] Haoyi Wu and Kewei Tu. Layer-condensed kv cache for efficient inference of large language models, 2024.
- Xiao et al. [2023] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
- Yang et al. [2024] Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, and Hai Zhao. Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference, 2024.
- Yu et al. [2024] Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. Megabyte: Predicting million-byte sequences with multiscale transformers. Advances in Neural Information Processing Systems, 36, 2024.
- Zaheer et al. [2020] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283–17297, 2020.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Zhang et al. [2024] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36, 2024.
Appendix A Limitation
The Block Transformer variants considered in our study require more parameters and FLOPs compared to their perplexity-equivalent vanilla models. Despite higher parameter and FLOP requirements, our Block Transformers achieve higher inference throughput, owing to low memory overhead and omission of prefill in the token decoder. However, this advantage is diminished during training–resulting in higher wall-time training costs compared to vanilla Transformers. The large parameter requirements also hinder the applicability of Block Transformers in situations with hard memory constraints such as on-device usage. We note that these are partially a result of our focus on inference throughput, rather than architectural limitations. There are many promising avenues to minimize parameter and FLOP (training cost) requirements, with minor adjustments to the architecture or hyperparameters. In the following section, we discuss several of these for future work.
Appendix B Future works
B.1 Optimizing hyperparameters for parameters or FLOPs
We can optimize the hyperparameters of the Block Transformer architecture to minimize parameter or FLOP requirements, as opposed to inference throughput as in our main experiments. Frist, we can reduce the block length to enhance performance while maintaining the same parameter count. Our ablations on block length demonstrate that a shorter block length can significantly improve perplexity, while compromising inference throughput with increased FLOPs in the block decoder. Thus, to achieve comparable perplexity, we can utilize less parameters, which offsets the decreased throughput resulting from the shortened block length.
Secondly, we find that increasing the proportion of the block decoder can significantly reduce FLOP requirements with minor degradation in performance, due to the FLOP-intensive nature of the token decoder. However, this comes at the cost of increased inference wall-time due to the KV cache bottlenecks of the block decoder. Further experimentation is needed to precisely identify the tradeoffs associated with these hyperparameter choices with respect to various cost metrics.
B.2 Densification of the block decoder with longer block embedding
Another approach to improving the performance of Block Transformers without extra parameters would be through better utilization of those already in the block decoder, i.e., by passing more tokens through them. We could do this by representing a single block with a longer input block embedding, say , instead of one. Let’s call these subblock tokens. During a single decoding step, input tokens would be projected into subblock tokens. Then, these would be passed to the block decoder and forwarded in parallel.
This would effectively preserve the computational width [29] of the block decoder, i.e., the total embedding dimension of the inputs, to be equivalent to a vanilla Transformer of the same width and depth. The minor difference in perplexity between the vanilla Transformer and Block Transformer with in 4(a) suggests that Block Transformers could approach the performance of same-sized vanilla transformers when the computational width of the block decoder is the same.
While this would require the same FLOPs as a vanilla Transformer, we can expect roughly times reduction in decoding wall-time due to parallel execution—since parameters and previous KV cache would only need to be fetched once per block, instead of once per input token. Note that total KV cache storage would be the same as vanilla Transformers since the number of input tokens and subblock tokens would be the same (this is why we expect reduction in KV cache IO rather than as in our original block decoder).
B.3 Relieving the locality of the token decoder for performance gains
In our experiments, we bottleneck the global information passed to the token decoder into a single context embedding. This is done for simplicity and to highlight the viability of global-to-local modeling, where the local module has limited access to global context. However, we posit that the token decoder can benefit from performance gains with minimal extra costs by relieving this rather extreme limitation.
It is possible use additional context embeddings in the token decoder to facilitate the propagation of context information, as discussed in subsection 4.1. Instead of projecting only the last output block embedding to the token decoder, we could utilize a small window of previous output block embeddings. This could resolve the rise in perplexity in later positions in the token decoder due to insufficient context information, with only slight increase in FLOPs and KV cache overhead in the token decoder.
B.4 Further scaling and advanced uptraining schemes
The scale of experiments in our paper is relatively small compared to even previous-generation frontier models [12, 17]. While our experiments show that the inference throughput benefits of Block Transformers scale positively across two orders of magnitude, further experiments are required to verify this beyond 1 billion parameters.
We can consider uptraining as a cost-effective training approach for this analysis, which effectively utilizes existing pretrained vanilla transformers to minimize the training costs of Block Transformers. For example, we can consider a progressive adaptation approach where a vanilla transformer is first adapted to a Block Transformer with block length 1, to maximize compatability, and then progressively trained with larger block lengths. Moreover, instead of simply splitting the layers of a pretrained vanilla transformer to initialize the block and token decoders, exploring weight initialization methods like averaging the layers or identifying weights that produces similar activations could significantly enhance performance.
B.5 Adaptive block lengths for dynamic compute allocation
What if we can dynamically allocate computation to generate ‘easy’ tokens faster but ponder longer on ‘hard’ tokens? This has been the central question of several previous works on dynamic compute allocation [30, 58, 5, 55]. The multiscale nature of the Block Transformer architecture offers a novel avenue to achieving this in autoregressive language models–by dynamically setting the input and output length of blocks based on the ‘difficulty’ of its contents. For the embedder and token decoders, we can use our CLS-token and prefix token based designs respectively, and padding can be used to maintain static computation during training. A challenge remains in training the model to dynamically determine optimal input and output block lengths.
Appendix C Broader impact
Recent language models have been scaled up significantly to achieve human-like capabilities, resulting in substantial training costs. Deploying these extensively large models in real-world services incurs significant computational overhead. Moreover, the escalating computational costs associated with large language models are raising environmental concerns. Our model enhances memory utilization and inference throughput, potentially mitigating these issues. The efficiency gains from the Block Transformer architecture can reduce the cost of deploying language models. Additionally, the global-to-local modeling at the subword level facilitates efficient uptraining from existing pretrained models to Block Transformers, providing a training-efficient pathway for enhancement. We encourage further research to fully explore these impacts, ensuring responsible development and deployment of Block Transformers.
Appendix D Related work
D.1 Global-to-local modeling
While prior research has explored global-to-local modeling in various modalities, it has not been utilized in autoregressive language models to optimize inference efficiency. Local modules have been incorporated in vision transformers to enhance the encoding of fine-grained local features with minimal computational overhead [31]. A similar approach has been used in BERT-based encoder LMs to effectively classify long documents by first encoding each fixed-size segments independently [49, 19, 43]. This is similar to how we put emphasis on the local token decoder, but we apply locality to decoder LMs at the upper layers rather than encoder LMs at lower layers.
Byte-level hierarchical models
Several works on byte-level modeling apply a similar architecture to our Block Transformer [74, 44]. However, while we attempt to mitigate the bottlenecks of global attention by isolating the task of language modeling into global and local components, prior work mainly utilize the hierarchical structure to mitigate the long contexts lengths of byte-level data from various modalities in the absence of tokenization. In contrast to the central role of the local module in our Block Transformer, prior work consider the role of the local model as ‘mapping a hidden state to a distribution over possible patches’, and suggest that ‘much smaller model can be used for inter-patch modelling’ [74] and may ‘cease to contribute to overall performance’ [44]. Similarly, while Yu et al. [74] finds that it is optimal to assign more parameters to the global module under same training-time constraint, we find that a more balanced allocation, e.g., 1:1 for , is optimal under fixed parameter constraints, and that even larger token decoders are beneficial for inference throughput, further highlighting the benefits of the local module. We believe these differences in interpretation and findings stem from a difference in the granularity of input units, i.e., bytes vs subwords, as well as the cost metrics considered, i.e., training-time vs inference cost.
D.2 KV cache compression
Recent advancements in KV cache compression aim to optimize memory usage by selectively retaining essential key-value pairs [72, 77, 28, 73, 38]. Scissorhands [28] and H2O [77] enhances compression by leveraging attention scores to preserve only the crucial components of the KV cache. FastGen [41] refines this approach by employing distinct policies per attention head. StreamingLLM [72] maintains only the recent context window and a few initial tokens as an ‘attention sink’, thereby discarding other past context. SnapKV [38] focuses on pruning tokens in the input prompt, in response to increasing input lengths. PyramidInfer [73] prunes KV heads during prefill, as each layer is computed, to tackle memory usage in this stage. While various methods have been proposed to intelligently prune tokens that are relatively less important, these approaches essentially permanently discard information which may become relevant again in future contexts. In contrast, Block Transformer retains access to all previous context in the block decoder. KV cache compression methods can also be applied to the block decoder to improve efficiency.
D.3 Architectures for optimizing KV cache
Recent works modify the design of the attention block such that multiple query heads can attend to the same shared KV heads, significantly reducing the number of unique KV heads while minimal degradation in performance. Multi-query attention (MQA) [59] allows multiple query heads to attend to shared key/value pairs, reducing storage overhead. Grouped-query attention (GQA) [2] generalizes this by organizing query heads into groups sharing a single KV head to achieve the same goal. Several concurrent works take this idea even further, by sharing KV heads between adjacent layers [11] or share the KV head of the top layer across the majority of layers [71]. A recent architecture [21] introduces multi-head latent attention (MLA) to jointly quantize KV states. By adopting standard transformer architectures, our Block Transformer can also benefit from these techniques to mitigate the remaining KV cache bottlenecks in the block decoder.
Several works take novel approaches to the overall architectural formulation. Tandem Transformers [47] alternate between a large block-level encoder and small token-level decoder. YOCO [63] is a decoder-decoder architecture that employs a cross-attention based decoder at upper layers which all refer to KV cache from a single middle layer which mitigates KV cache storage. In contrast, we take a different approach where the context information is compressed into a single context embedding to enable local modeling, nearly free of KV cache storage and access costs, mitigating critical bottlenecks in inference throughput.
Appendix E Analysis on the inference efficiency of Block Transformer
E.1 Background: inference stages and principal bottlenecks
To generate a response to an input prompt, it is necessary to prefill and cache the KV values of all input tokens, as they are attended by subsequent tokens under global self-attention. (1) The prefill phase is computation-bound because all input tokens can be processed in parallel during one forward pass. In contrast, when generating new tokens, only a single token can be processed per forward pass, as the output of the previous token is needed as the input for the next. While linear projection FLOPs are dominant with short context lengths, self-attention FLOPs surpass linear projection FLOPs with very large context lengths, due to quadratic scaling. (2) The decode phase is memory access-bound because all model parameters and previous KV cache must be loaded from memory at each forward pass. To achieve high compute utilization and throughput, production serving systems typically leverage batching to amortize the cost of parameter IO [1, 45]. Thus, under large batch sizes (and sufficiently long contexts), KV cache IO becomes the main bottleneck in decoding [51].
E.2 Inference-time advantages of block and token decoders
Block decoder reduces prefill computation by and decode IO by
The block decoder maintains global attention similar to vanilla transformers but operates at a much coarser block level, reducing context length by compared to the original token-level sequence. This reduction decreases position-wise computation during prefill by compared to vanilla transformers of the same size. The main bottleneck during batch decoding, i.e., KV cache IO, is reduced by as it is quadratic to context length. The same savings apply to attention computation, which can become a bottleneck during prefill as context lengths grow. KV cache storage in GPU memory during decoding is also reduced linearly by , enabling larger batch sizes and higher parallelism.
Token decoder skips prefill entirely and nearly eliminates decode IO
The token decoder does not use global attention but relies on a single context embedding for global context information, applying attention within each independent block for local context. Thus, the token decoder does not need to preserve or retrieve KV cache values from previous blocks, eliminating the need to prefill input tokens. This also nearly eliminates KV cache IO overhead during decoding, as quadratic scaling applies to the small local context of rather than the global context . Compared to the KV cache IO complexity of in vanilla transformers, token decoders have complexity per block, across blocks, achieving an overall reduction of . For our main models with and , this results in a 256-fold reduction in KV cache IO overhead. Asymptotically, this reduces KV cache IO overhead from quadratic to linear with respect to context length, solving a key challenge in scaling to very long contexts [25]. KV cache storage is also reduced by the same factor, enabling larger batch sizes. This significantly improves the utilization of inference hardware, which is typically as low as 1% model FLOPs utilization (MFU) in vanilla transformers [51]. Thus, we can apply more FLOPs in the token decoder to improve performance, with minimal effect on inference throughput.
Appendix F Architectural details
F.1 Embedder methods
Lookup
For our main embedder design, we simply retrieve token-level embeddings from a lookup table and concatenate them to obtain the input block embeddings. The token-level embedding dimension is set to be of the main model dimension.
Encoder
To ablate the effect of adding encoding capability to the embedder, we encode the input tokens of a block with a small RoBERTa-based encoder. We use a fixed sized encoder with dimension size of 256 and 3 hidden layers. We concatenate the output hidden states and apply linear projection to obtain the input block embedding.
CLS token
To investigate the feasibility of an embedder that can accept various input block lengths, we use CLS tokens previously used to extract sentence embeddings [24]. We use the same model size as the RoBERTa model and encode information in 3 CLS tokens, to increase the embedding dimension while minimizing the model dimension of the embedder. Similar to the RoBERTa embedder, we concatenate the output hidden states of the CLS tokens and apply linear projection to obtain the input block embedding.
F.2 Token decoder methods
Prefix
For the main token decoder design, we incorporate the context embeddings from the block decoder by projecting them as prefix token embeddings. The token decoder can retrieve the context information from the prefix tokens via attention, and also further encode the context information. We can use multiple prefix tokens, i.e., increase the prefix length, to increase the computational width [29] of the token decoder to increase performance with addtional FLOPs, are relatively cheap in terms of inference time in the token decoder.
Summation
We also consider the summation method used in previous work [74]. Here, the context embeddings are projected to embeddings of dimension and added to the token embeddings at each input position of the token decoder. This does not benefit from additional computation of the context information in the token decoder.
Cross-attention
Finally, we consider an approach that uses cross-attention, treating the output context embedding as the output hidden states of an encoder in an encoder-decoder transformer [53]. Specifically, we project the the context embedding into hidden states each with dimension and apply cross-attention between self-attention and feedforward operations at each transformer layer in the token decoder. This also does not benefit from additional computation of the context information in the token decoder.
Appendix G Experimental settings
G.1 Overall settings
We use the same transformer architecture as Pythia [8], utilizing the open-source GPT-NeoX library [4]. We train both vanilla and Block Transformer models on the Pile [26, 7], which is a curated collection of English datasets specifically developed for training large language models. We utilize a BPE tokenizer tailored for the Pile dataset [10], including a vocabulary size of 50,304. The models are pretrained on approximately 300 billion tokens, which corresponds to about 1.5 epochs of training, given that the deduplicated Pile comprises 207 billion tokens. To evaluate the models on various zero-shot tasks, we use the Language Model Evaluation Harness framework [27]. We employ the HuggingFace training framework [70] and enhance memory efficiency through mixed precision training and the Zero Redundancy Optimizer (ZeRO) [54] from the DeepSpeed library [56]. We use eight A100s with 40 GiB of VRAM for training, while we measure the inference latency using an H100 GPU.
G.2 Model sizes and hyperparameters
Our models are trained across six different sizes, varying from 33 million (M) to 1.4 billion (B) parameters, to explore how performance scales with model size. We train four vanilla models corresponding to our Block Transformer models. We summarize detailed model configurations and training hyperparameters in Table 3.
| Token Decoder | Block Decoder | ||||||||||||
| Models | Size | Method | Dim | Head | Dim | Head | LR | Batch | |||||
| Vanilla | 5M | - | 2048 | 6 | 256 | 8 | - | - | - | - | - | 1e-3 | 256 |
| 19M | - | 2048 | 6 | 512 | 8 | - | - | - | - | - | 1e-3 | 256 | |
| 85M | - | 2048 | 12 | 768 | 12 | - | - | - | - | - | 6e-4 | 256 | |
| 302M | - | 2048 | 24 | 1024 | 16 | - | - | - | - | - | 3e-4 | 256 | |
| Block | 5M | Prefix | 2 + 4 | 3 | 256 | 8 | 4 | 512 | 3 | 256 | 8 | 1e-3 | 256 |
| 19M | Prefix | 2 + 4 | 3 | 512 | 8 | 4 | 512 | 3 | 512 | 8 | 1e-3 | 256 | |
| 85M | Prefix | 2 + 4 | 6 | 768 | 12 | 4 | 512 | 6 | 768 | 12 | 6e-4 | 256 | |
| 302M | Prefix | 2 + 4 | 12 | 1024 | 16 | 4 | 512 | 12 | 1024 | 16 | 3e-4 | 256 | |
| 805M | Prefix | 2 + 4 | 8 | 2048 | 16 | 4 | 512 | 8 | 2048 | 16 | 3e-4 | 512 | |
| 1.2B | Prefix | 2 + 4 | 12 | 2048 | 16 | 4 | 512 | 12 | 2048 | 16 | 2e-4 | 512 | |
G.3 Settings for subsection 3.2
Each model is trained for 300 billion tokens with a context length of 2048. For the Block Transformer models, we set the block length to four, and leverage prefix decoding with a length of two and lookup methods as the token decoder and embedder components, respectively. To measure the allocated memory and throughput, we use synthetic samples where all prompts are padded to the target length.
G.4 Settings for subsection 3.3
Unless otherwise specified, we use a default setting of a model with 302M non-embedding parameters, allocating the same size of parameters to both the block and token decoders. For the default strategies of embedder and token decoder components, we use three CLS tokens from a RoBERTa model, composed of three layers with a dimension of 256, and a prefix with a length of one, respectively. Extensive experiments reveal that finding the optimum requires minimal overhead because the ranking trend between ablations remains consistent from the early training stages, across various model sizes. Therefore, we train the models with just 8 billion tokens.
G.5 Settings for subsection 3.4
Each model is trained with a block length of four on 26 billion tokens, with the parameters of the block and token decoder being distributed equally. We have experimented with two model sizes of 85M and 302M non-embedding parameters. We set the default strategy for the embedder as utilizing three CLS tokens from the RoBERTa model, composed of three layers with a dimension of 256, and for the token decoder as prefix decoding with a length of one.
G.6 Settings for subsection 3.5
We use both vanilla and Block Transformers with the non-embedding parameters of 85M. All models are fully pretrained on 300 billion tokens with a context length of 2K. For Block Transformer models, we use a lookup strategy and prefix decoding with a length of one to facilitate a smooth transition from vanilla models to Block Transformers.
G.7 Settings for subsection 3.6
We train Block Transformer variants using the training FLOPs and inference throughput of a vanilla 70M model as constraints. All models are pretrained from scratch, with their training steps adjusted to match their respective FLOPs. The learning rate has fully decayed at the end of training steps.
G.8 Settings for subsection 3.7
To leverage the pretrained layer weights of the vanilla transformer model, we allocate parameters equally to the block and token decoders, preserving the overall non-embedding parameter size. Additionally, after concatenating four token embeddings from a lookup table of the vanilla models, we introduce a fully-connected layer to map it into the hidden dimension of the block decoder. We evaluate two models with 85 million and 302 million non-embedding parameters, training them on 30 billion tokens (10% of the original training data).
G.9 Settings for subsection 4.1
Performance comparison to MEGABYTE
We have reimplemented several variations of the MEGABYTE model, with their configurations detailed in Table 4. MEGABYTE bases its model dimensions on the GPT-3 model configuration [12] and argues that a block and token decoder parameter ratio of approximately 6:1 is optimal when considering training FLOPs budgets. We pretrained these models from scratch on 300 billion tokens.
| Token Decoder | Block Decoder | ||||||||||||
| Models | Size | Method | Dim | Head | Dim | Head | LR | Batch | |||||
| MEGABTYE | 5M | Sum | 4 | 4 | 128 | 4 | 4 | 512 | 5 | 256 | 8 | 1e-3 | 256 |
| 19M | Sum | 4 | 4 | 256 | 8 | 4 | 512 | 5 | 512 | 8 | 1e-3 | 256 | |
| 85M | Sum | 4 | 4 | 512 | 8 | 4 | 512 | 11 | 768 | 12 | 6e-4 | 256 | |
Relation to KV cache compression
To explore attention scores, we utilize a pretrained Block Transformer model with 1.2B non-embedding parameters. The attention scores are extracted from randomly selected samples. Furthermore, we focus on the first attention head of each of the 12 layers in both the block and token decoders.
Appendix H Random length padding during pre-training
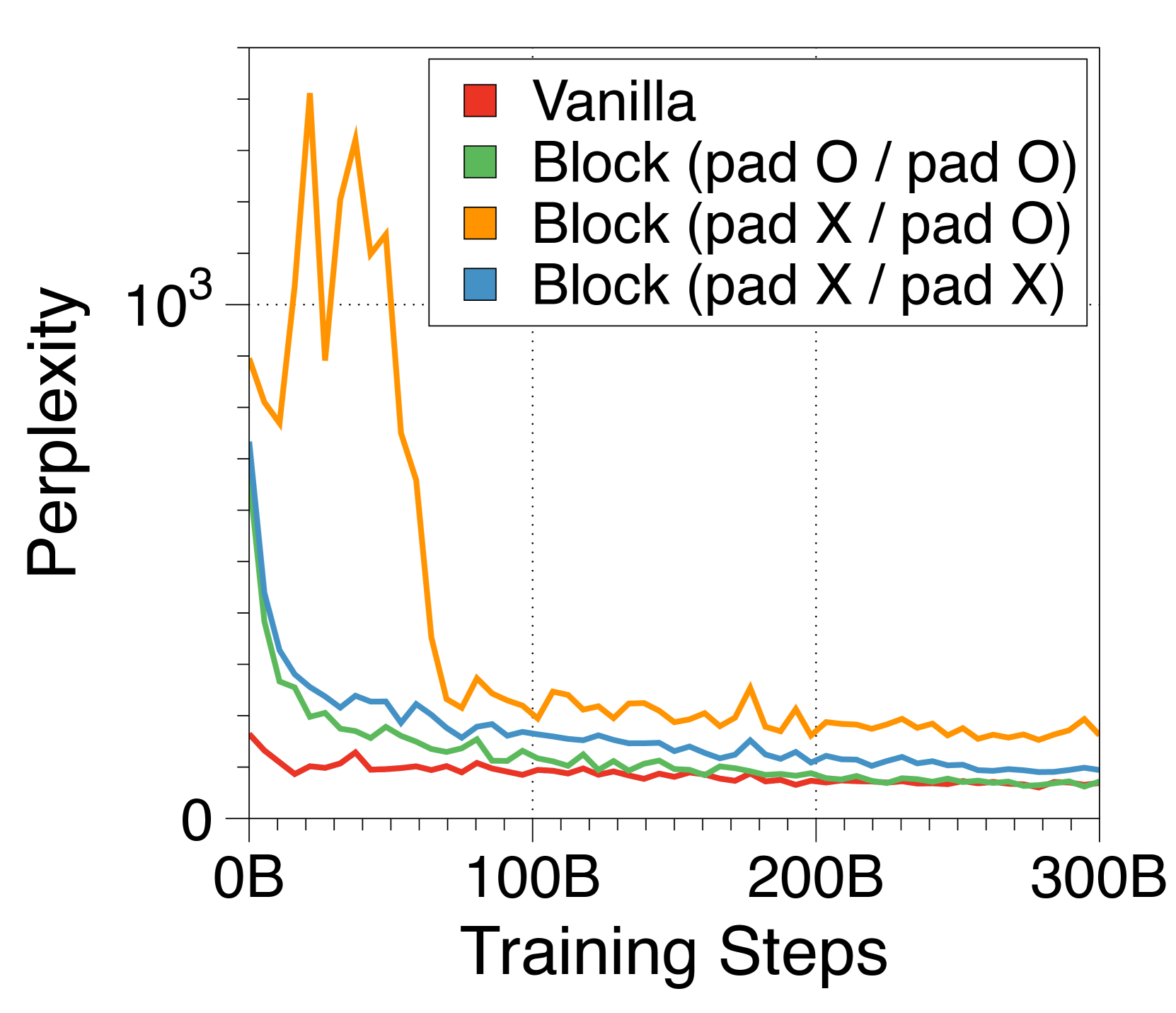
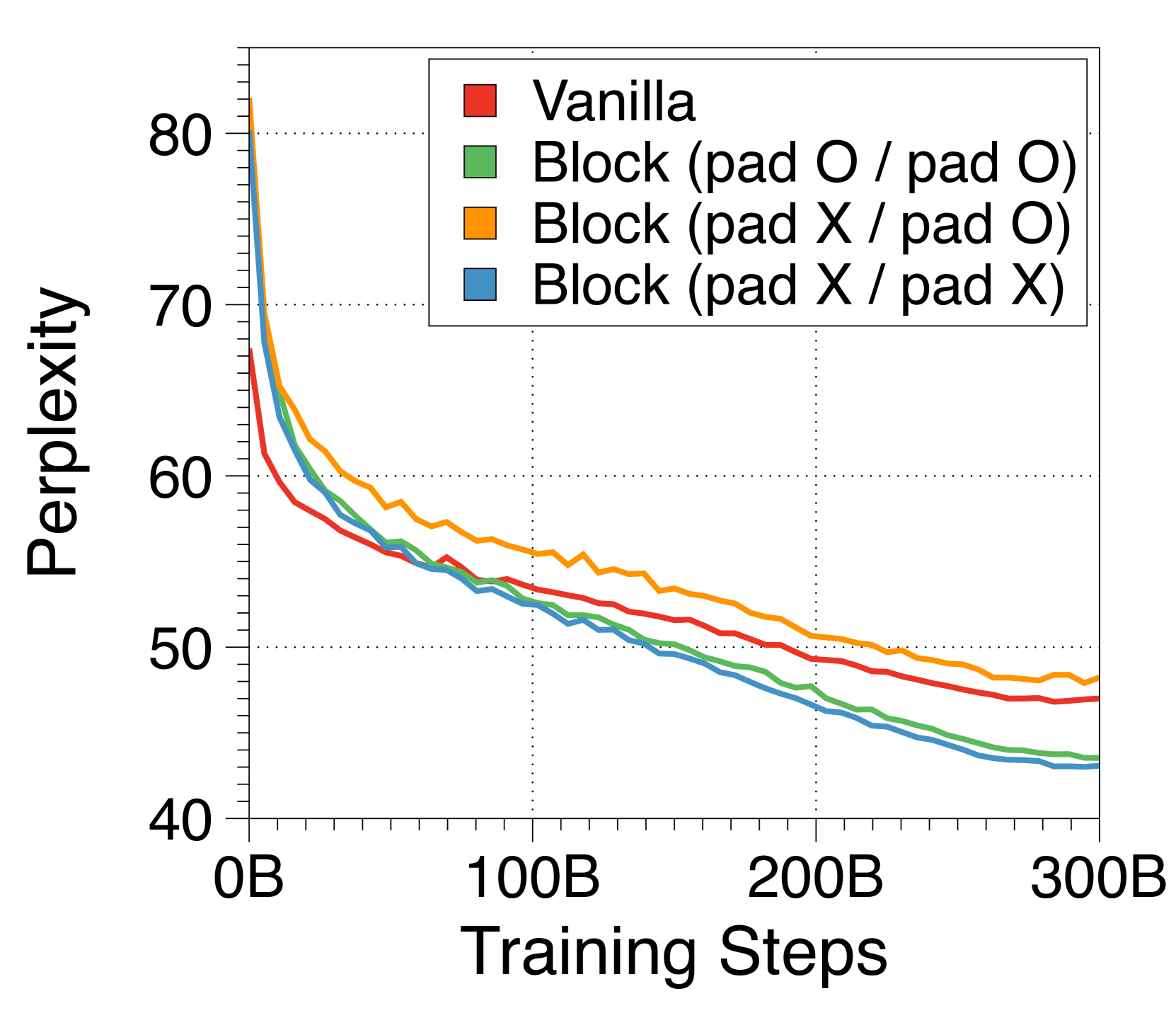
To apply inference on prompts whose lengths are not multiples of , we need to add padding tokens to the prompt to fill the input blocks. Unlike padding tokens in vanilla transformers, these padding tokens are actually considered in the computation of the input block embedding, due to the fixed-size nature of our embedding methods, except for the CLS token variant. Therefore, we add random padding tokens with uniform length between 0 and at the beginning of each document when applying input packing during pre-training. We also pad the unfilled tokens in the last block of each document, to prevent multiple documents being included in a single block. Note that this was applied after our main experiments, thus were not applied to our largest models in Table 2. We posit that this has adversely affected some downstream task performance evaluations.
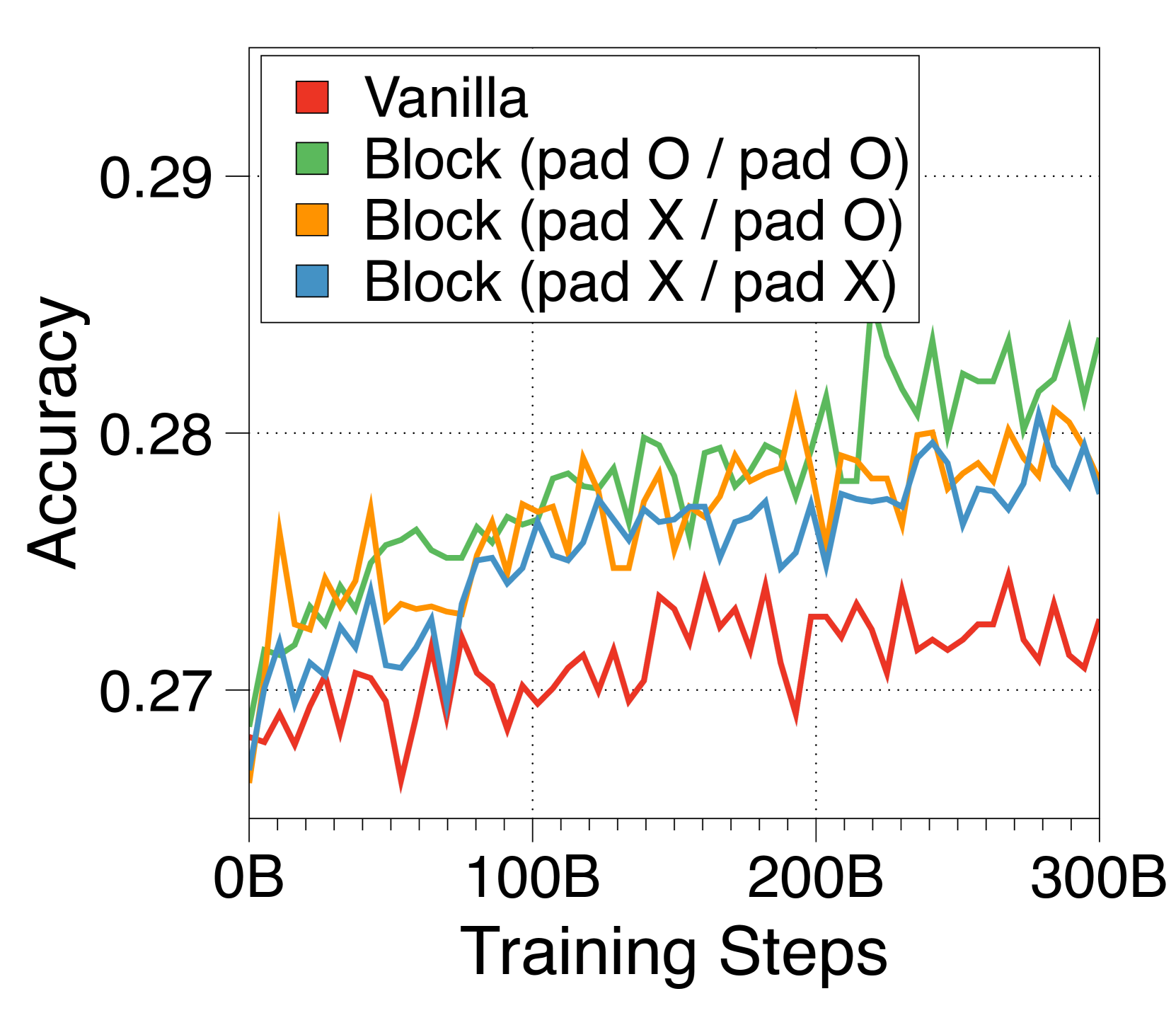
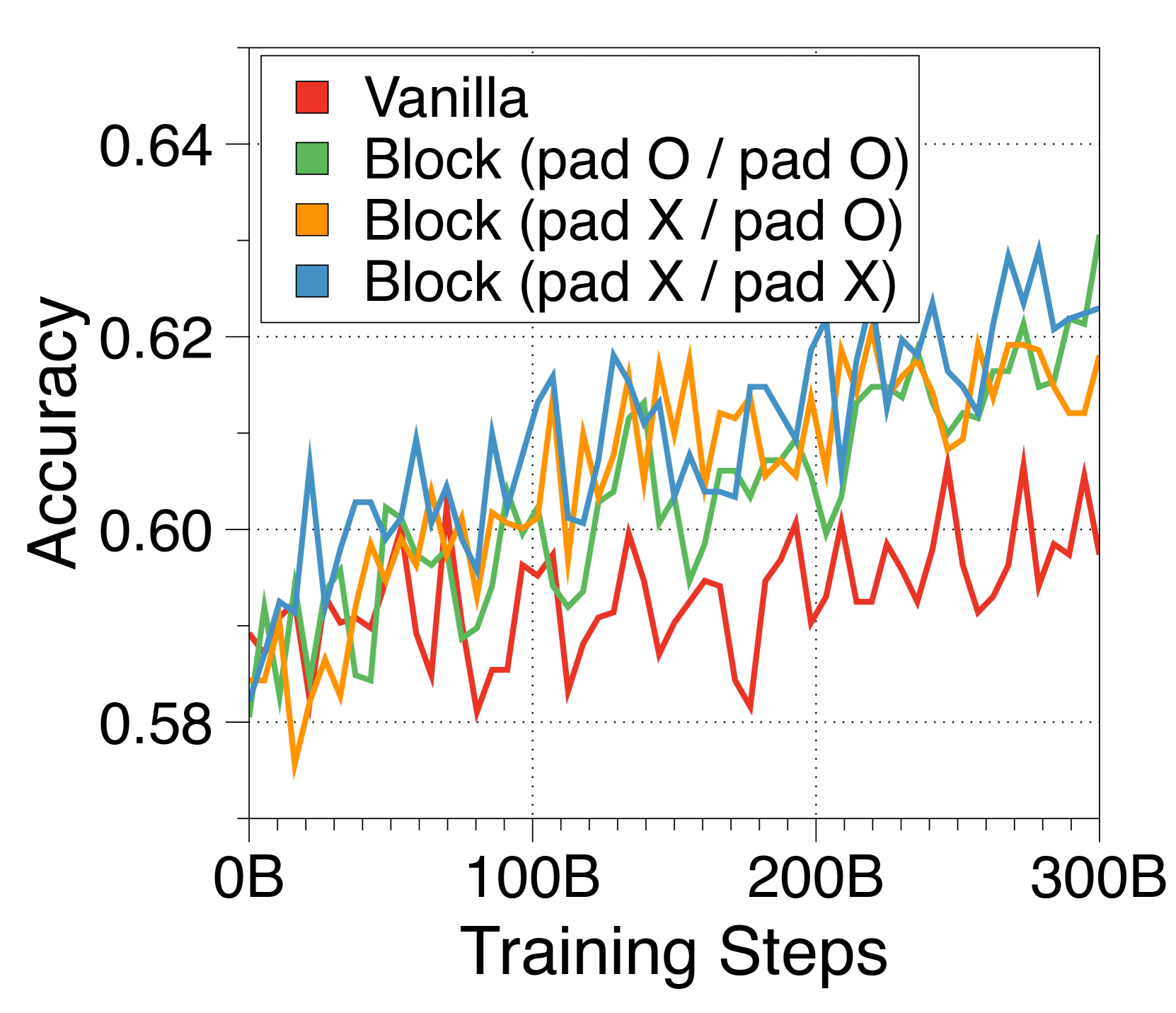
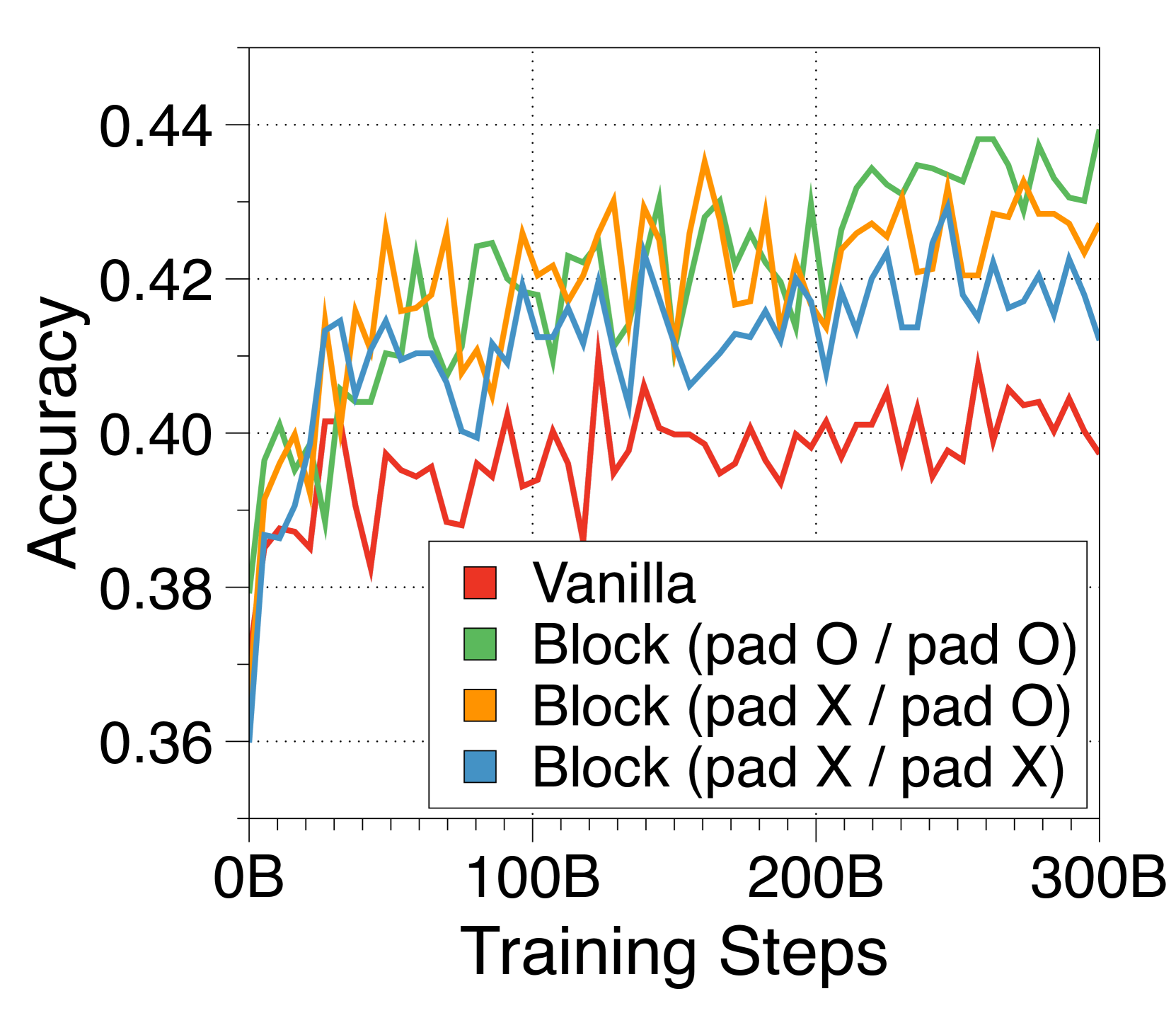
Appendix I Pareto frontiers at variable batch sizes and context lengths
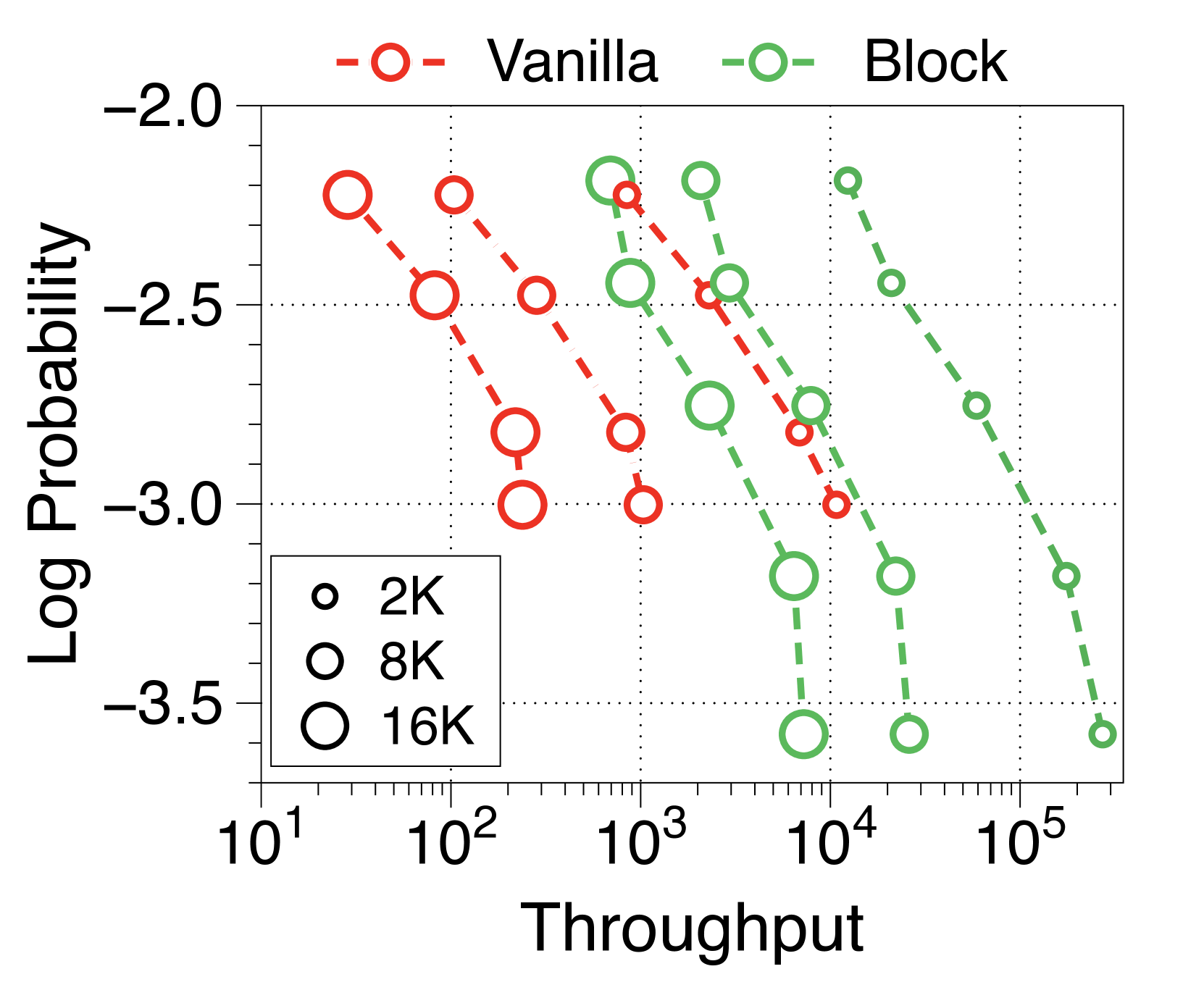
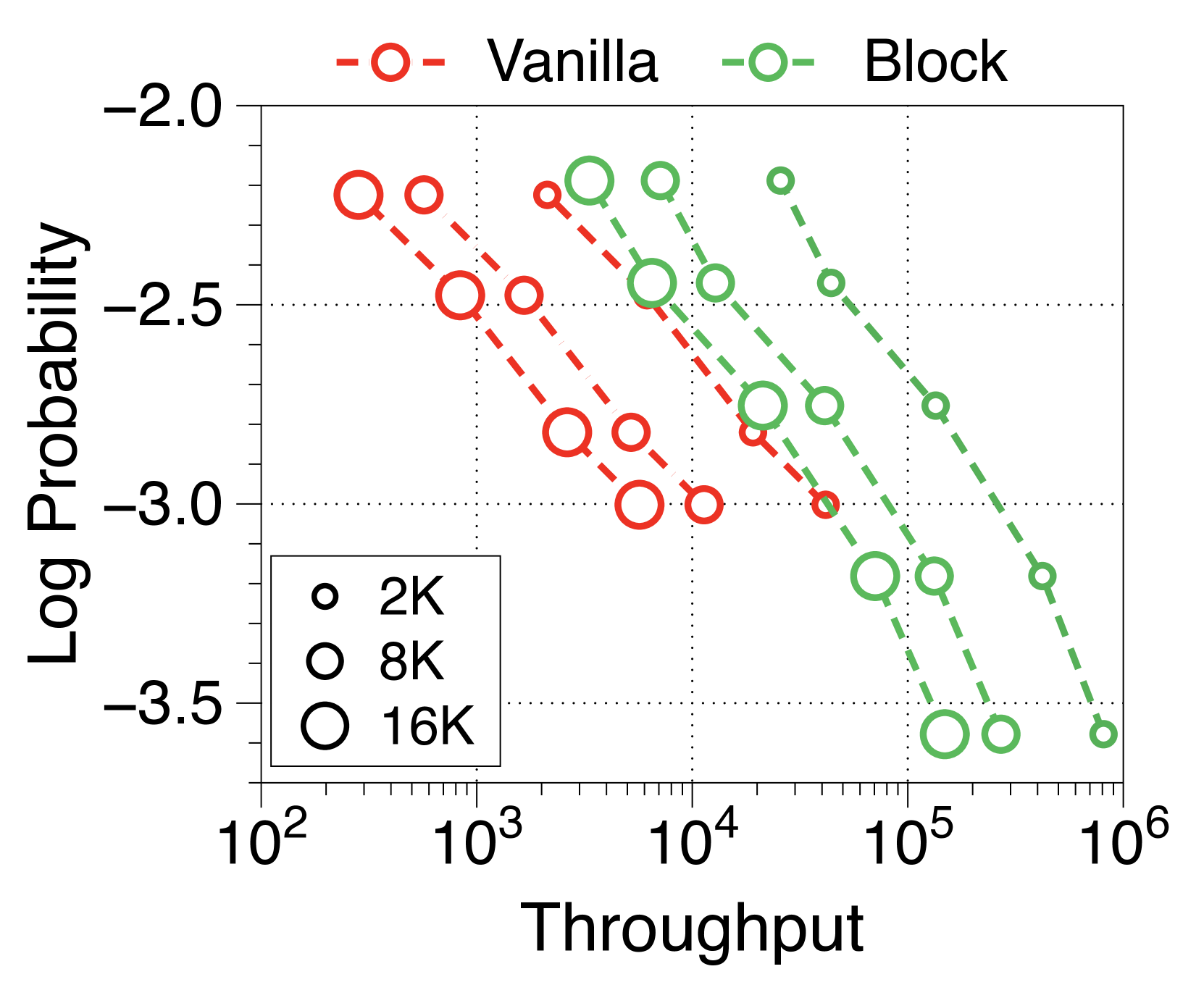
In Figure 7 and Figure 8, we measure throughput in both prefill-heavy and decode-heavy settings across three different batch sizes. At a batch size of 1, parameter IO has a much greater impact on throughput compared to KV cache IO, resulting in slightly lower throughput for Block Transformer. However, as the model sizes increase beyond a certain point, the increased KV cache memory causes this trend to reverse. With a batch size of 32, our models achieve significantly higher throughput. To ensure that the improvements in decode-heavy settings are not solely due to gains in the prefill phase from not needing to forward the token decoder, we also experiment with a setting without a prompt. The results, summarized in Figure 9, show consistent performance improvements.
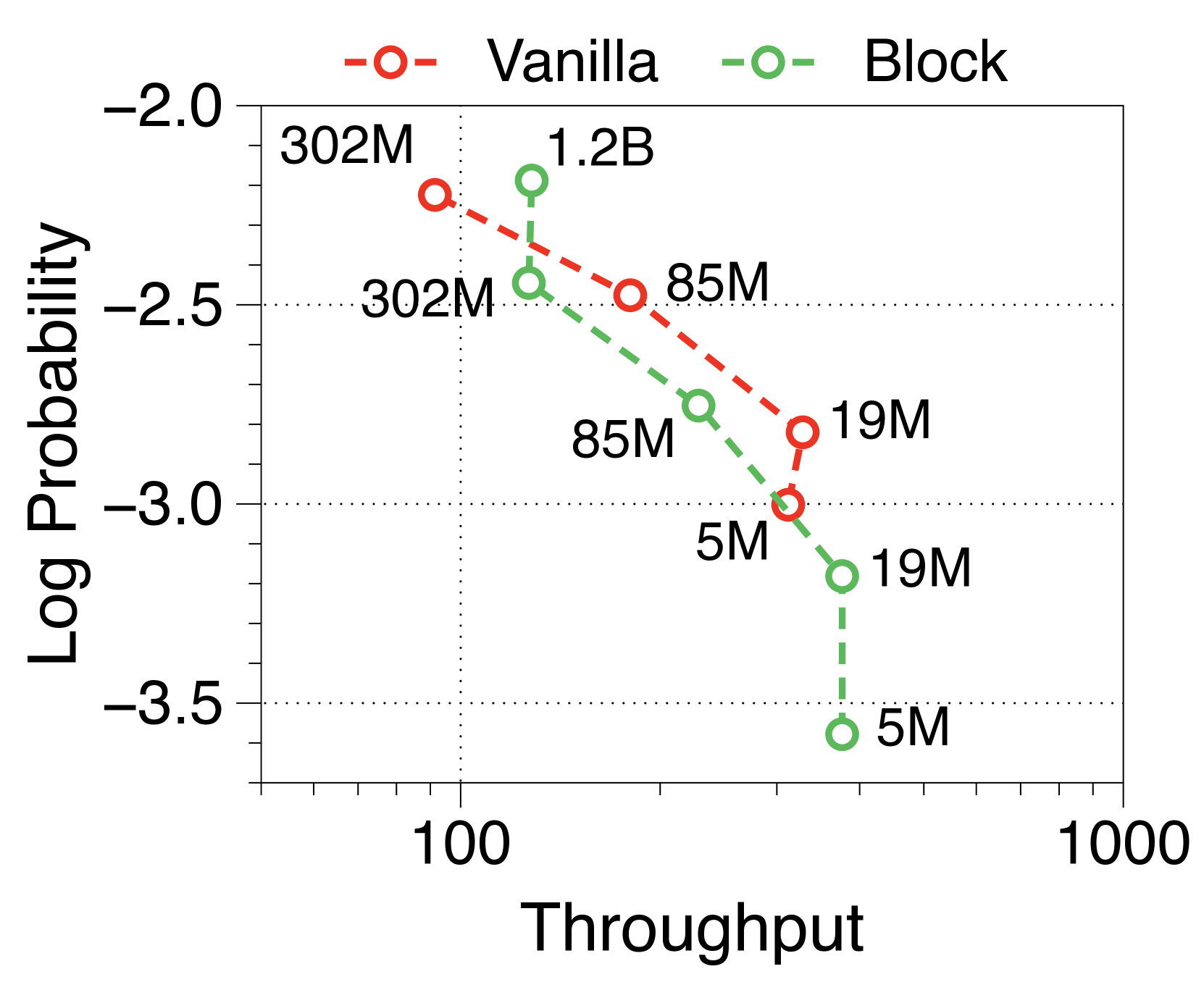
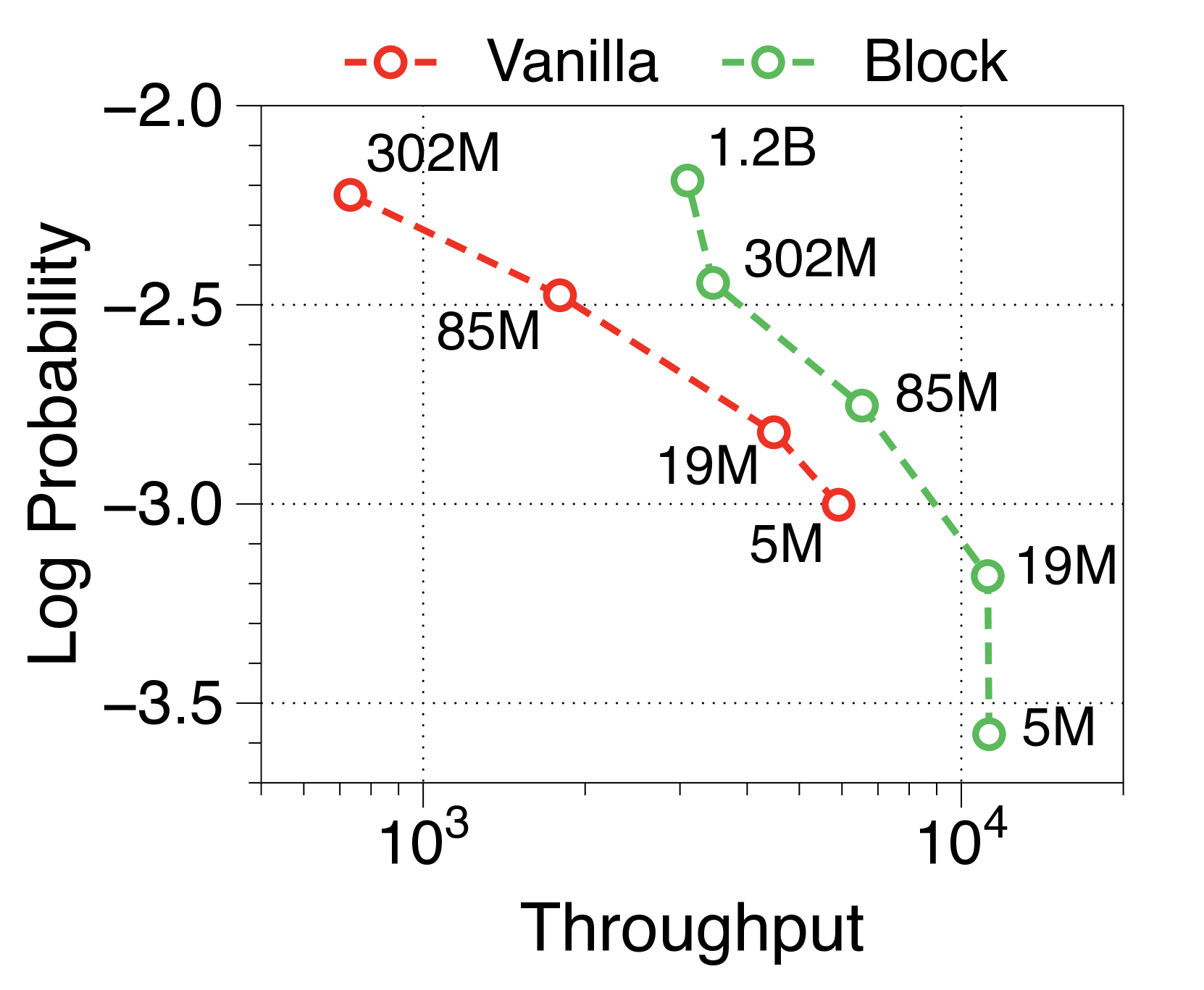
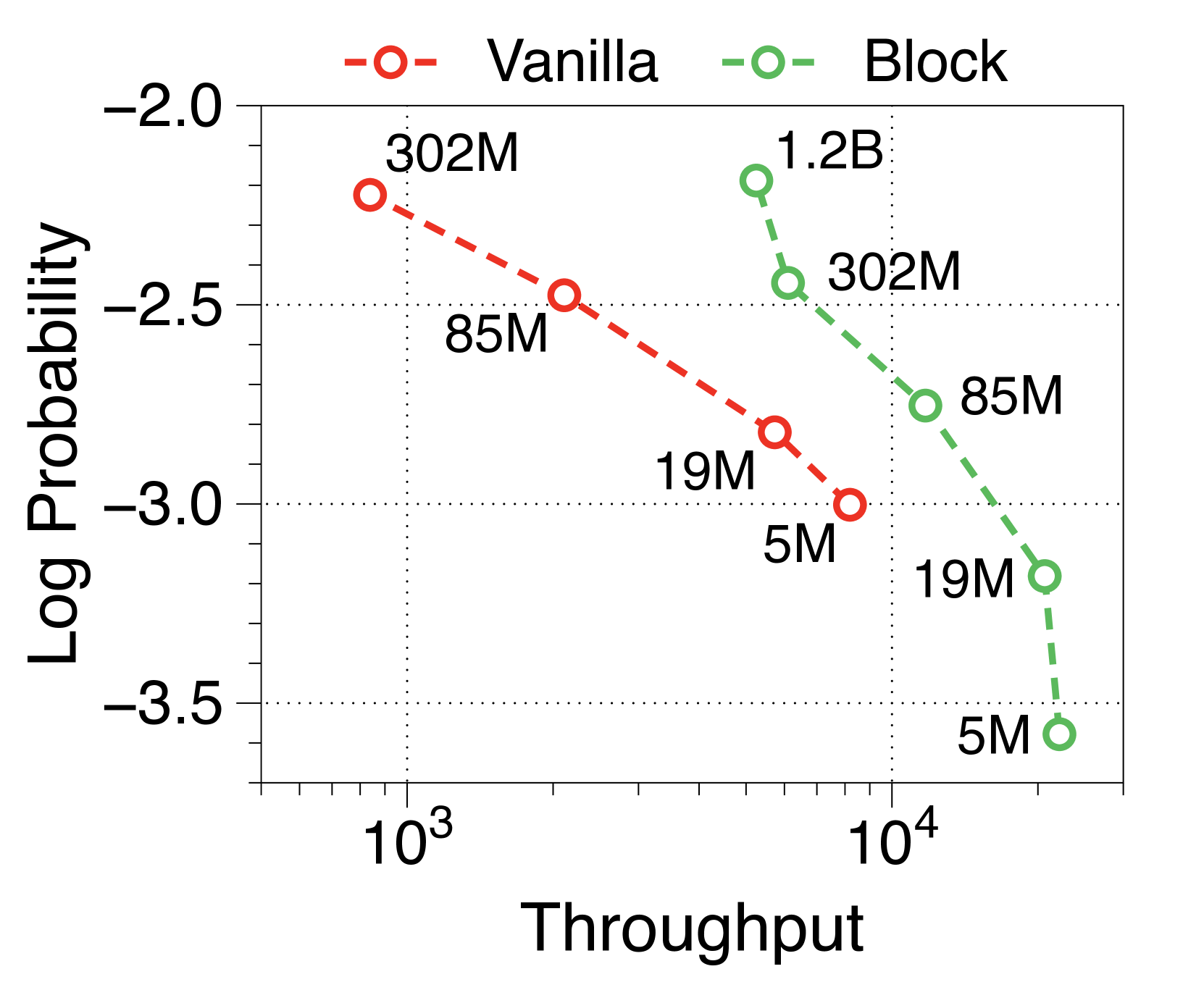
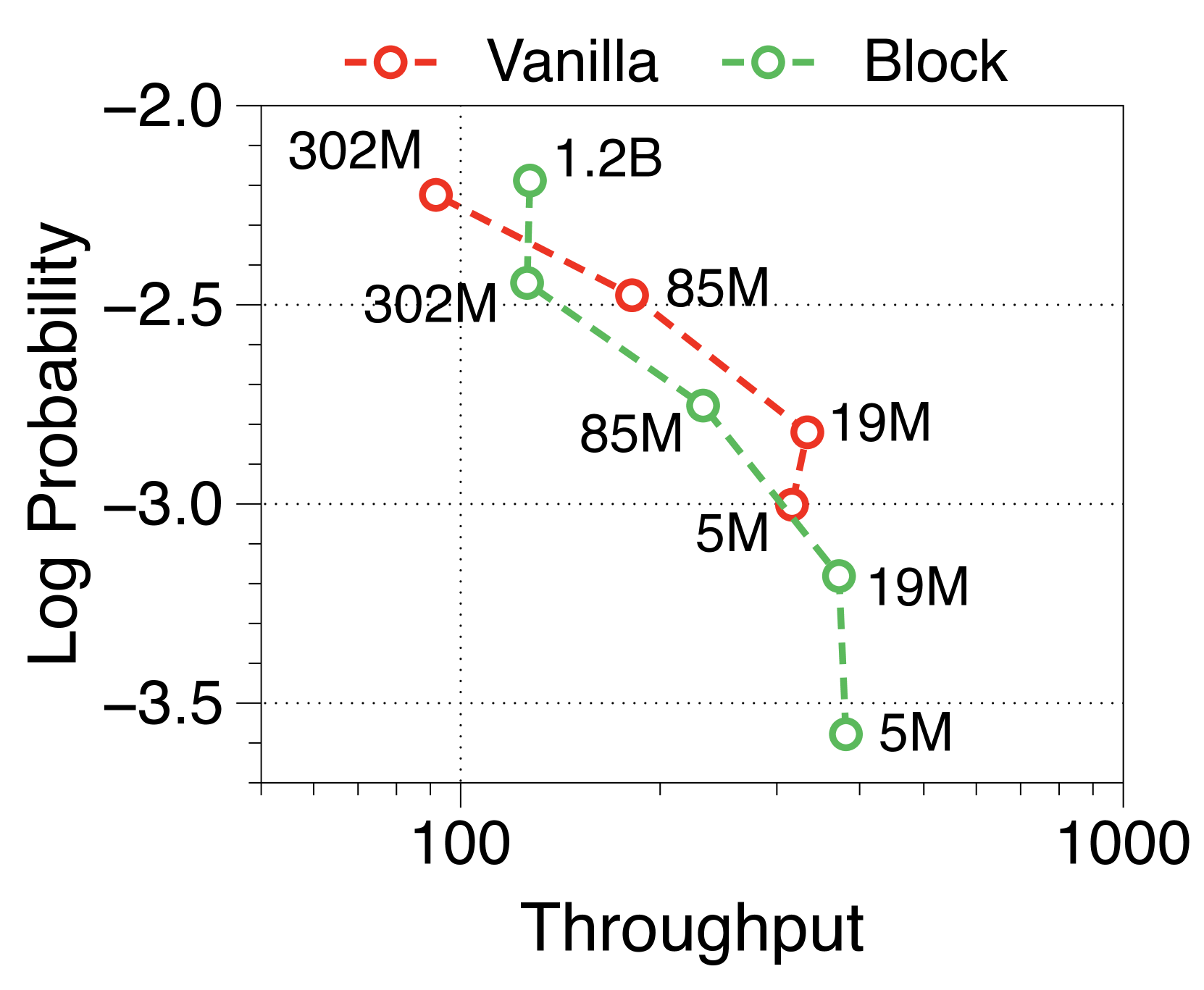
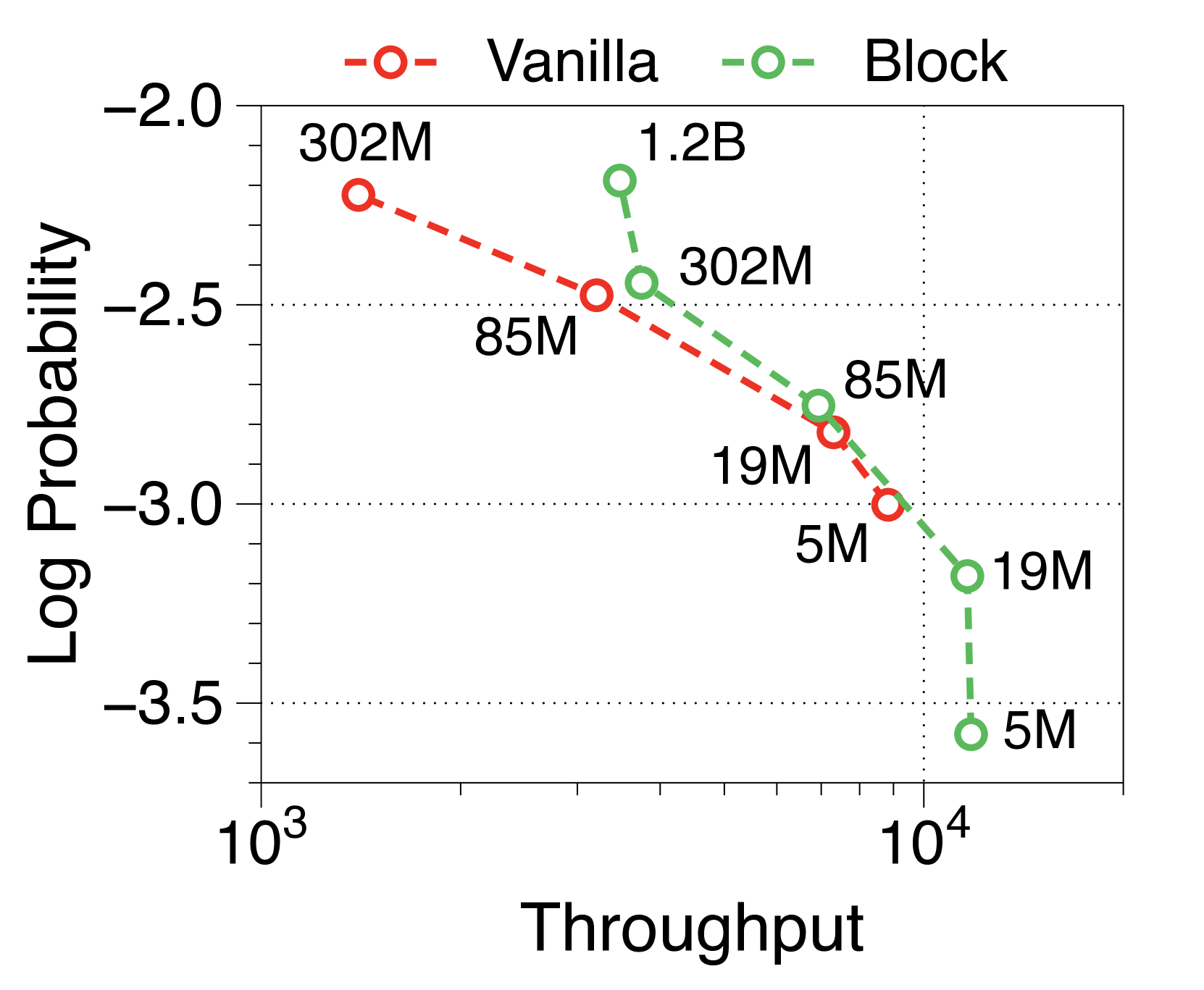
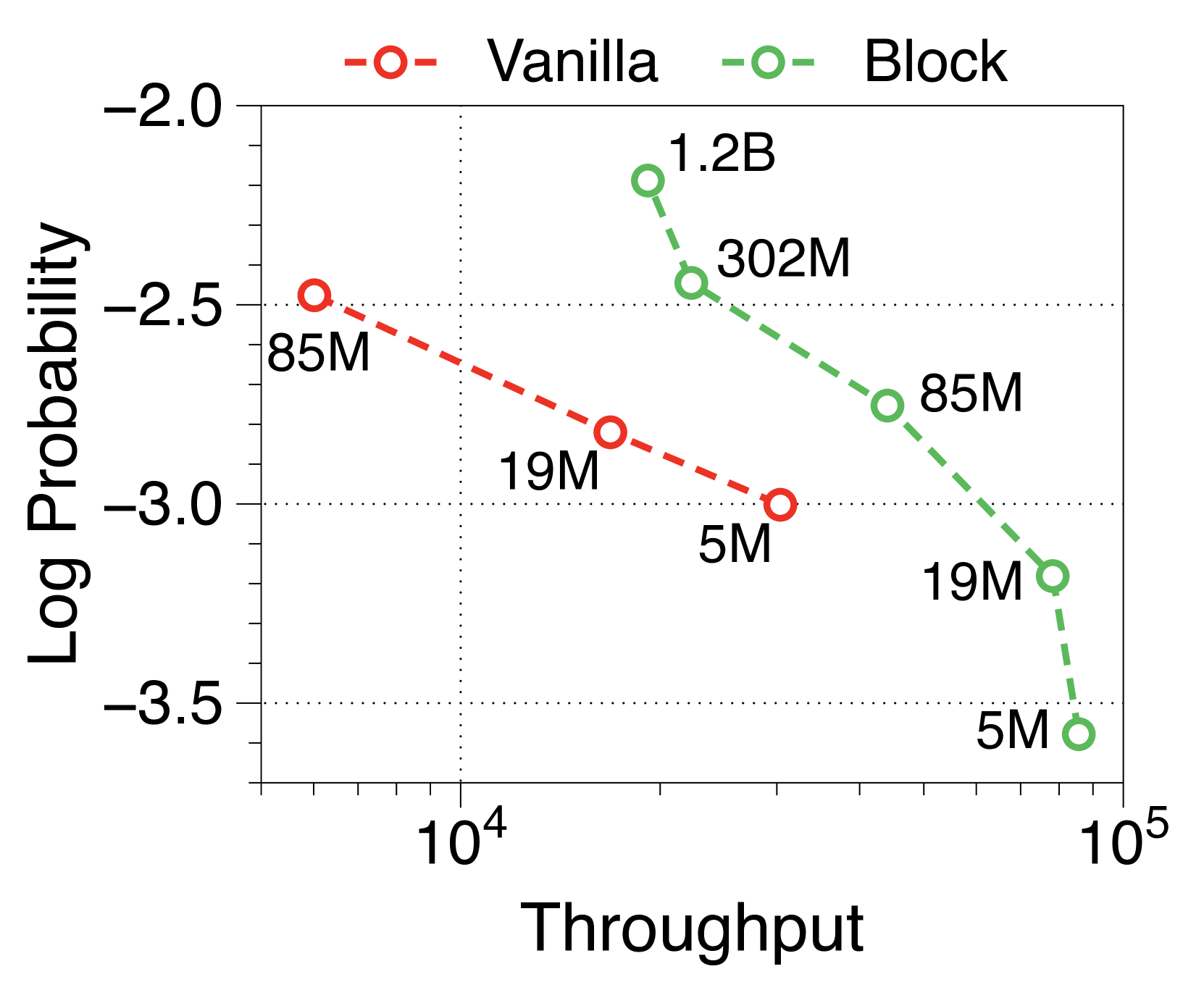
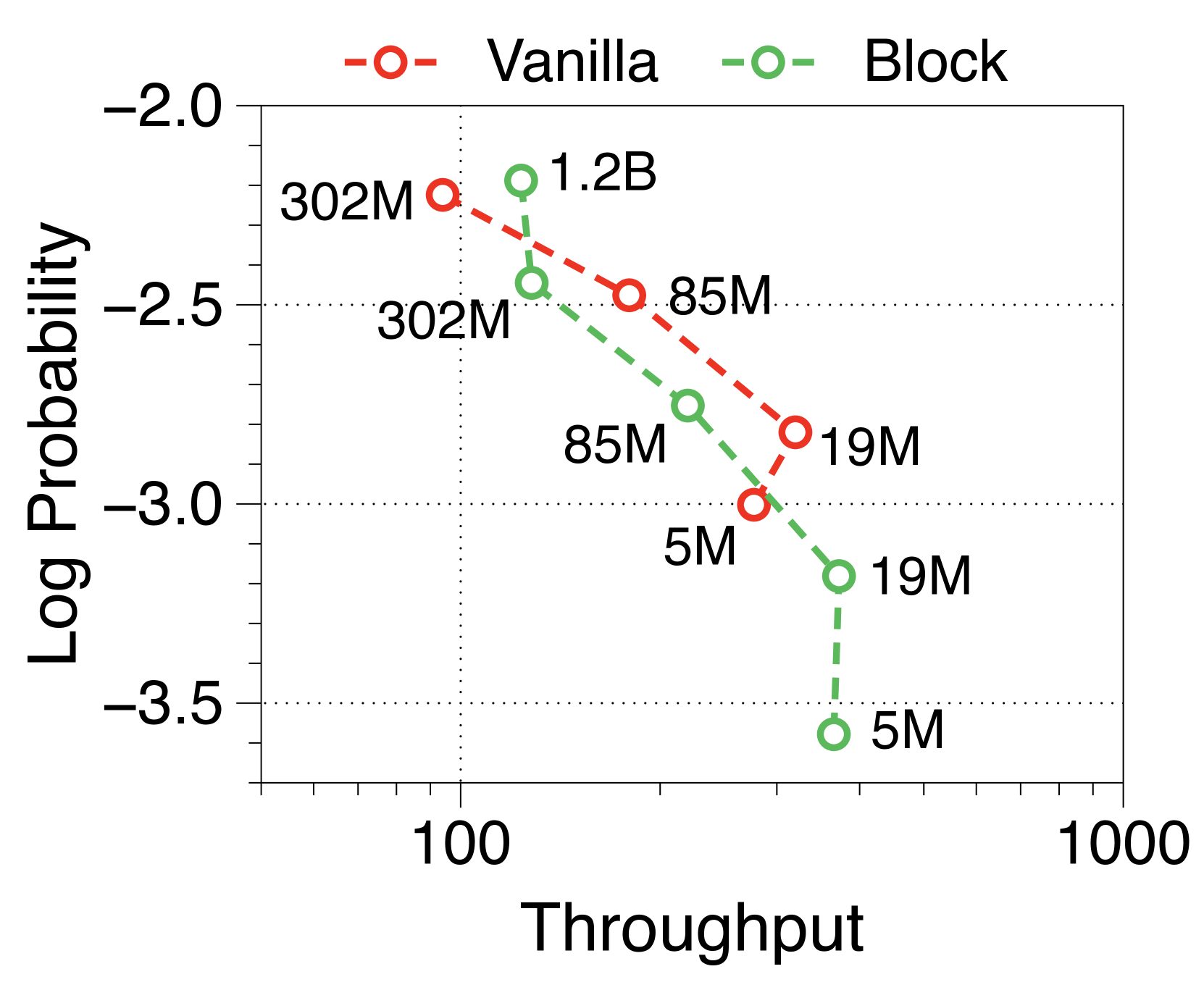
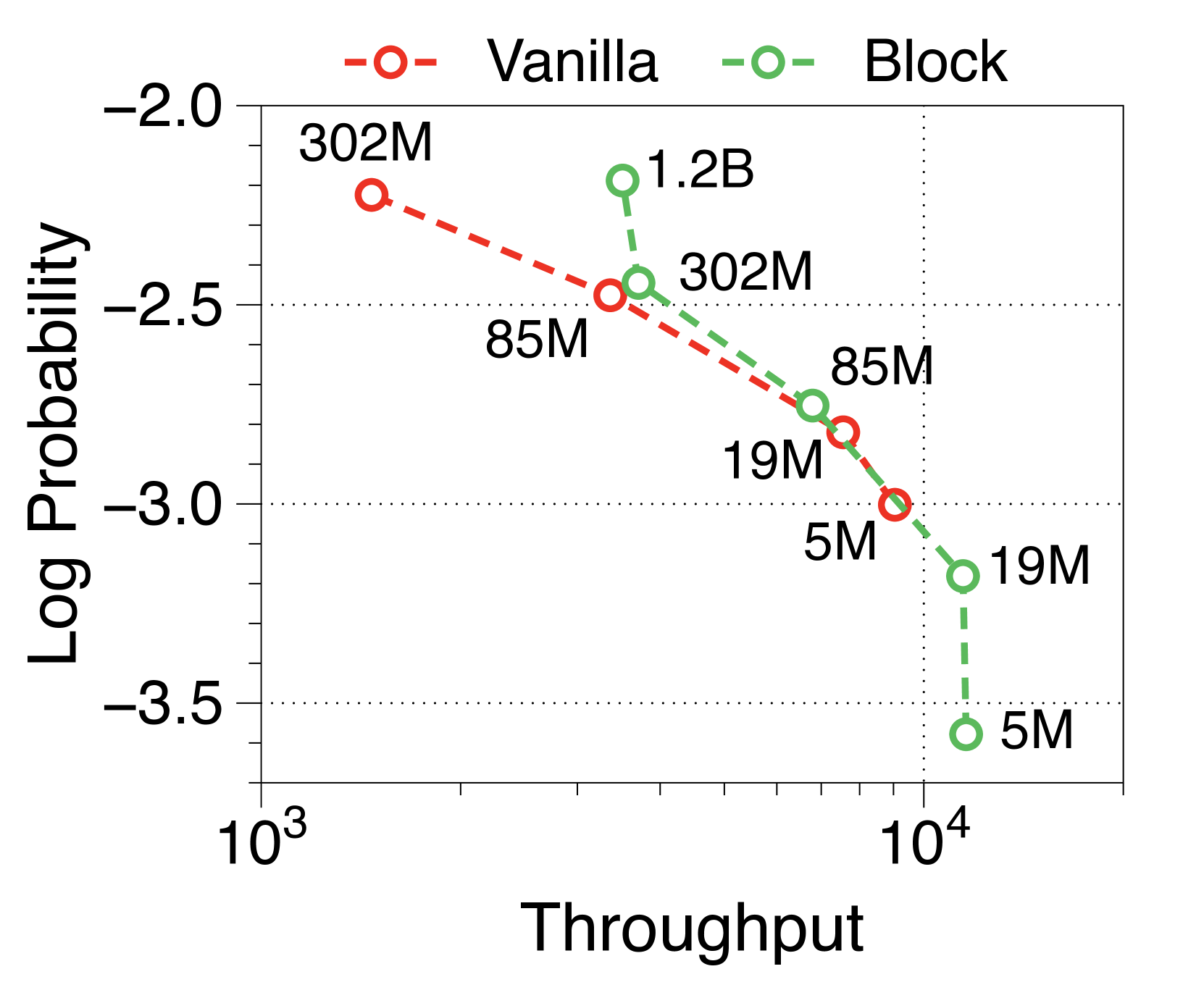
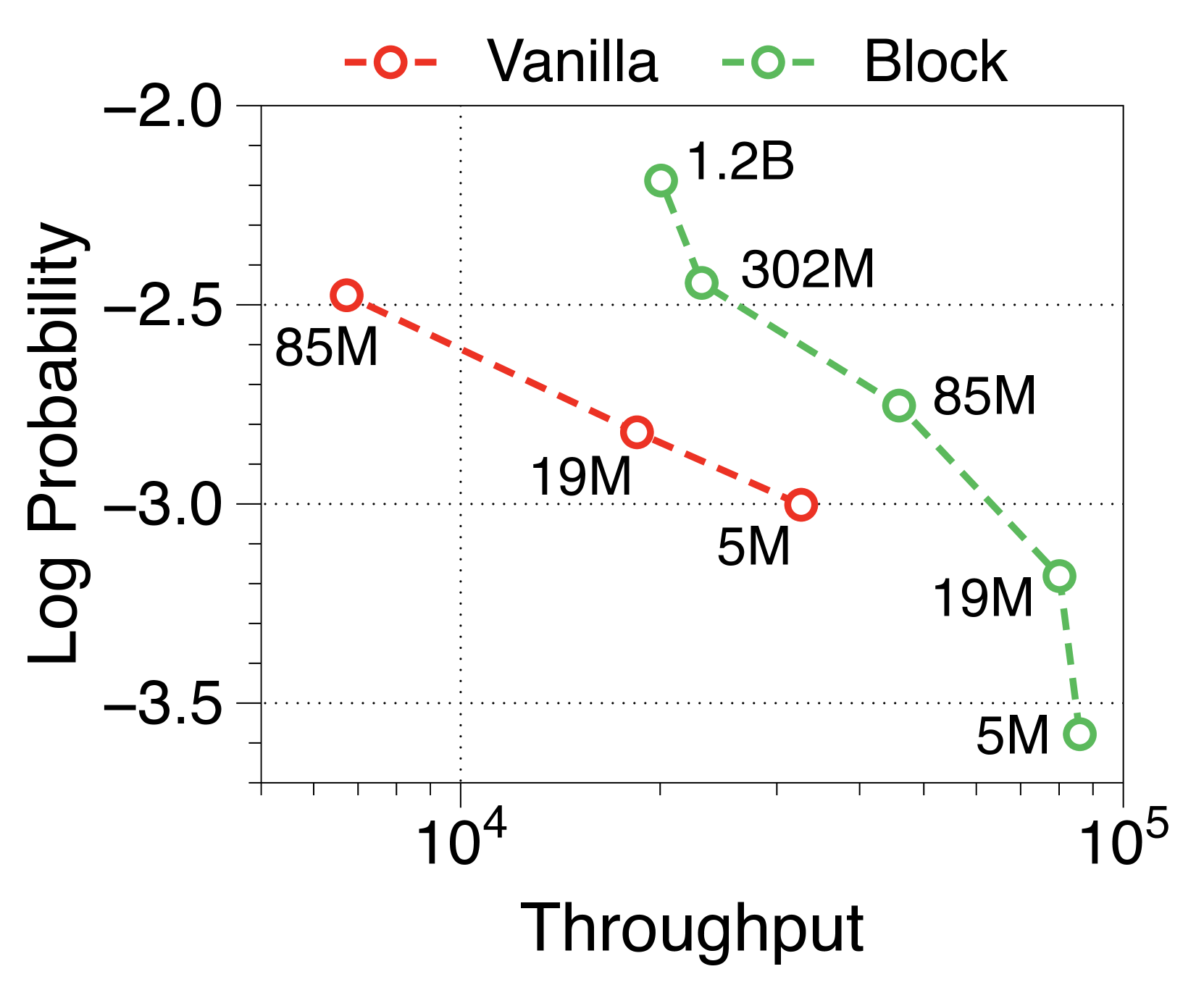
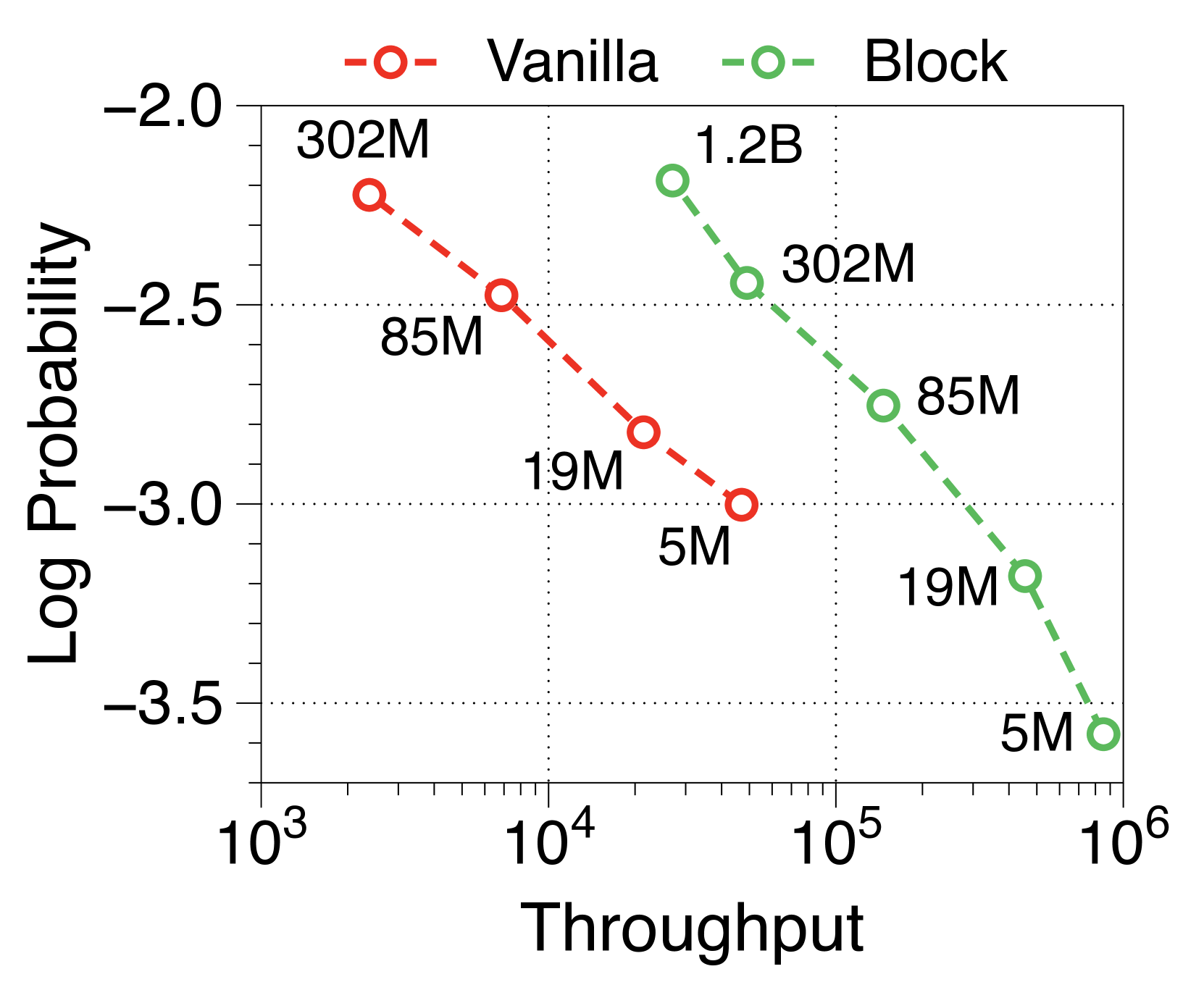
Moreover, we compare the throughput of vanilla and Block Transformer models across various context lengths under two scenarios. In Figure 10, each point corresponds to the same order of model sizes. Our models demonstrate remarkable speed improvements, and even when the context length is increased by four or eight times, they outperform the vanilla models with a context length of 2K. By reducing the context length at the block decoder by a factor of block length, our models achieve faster generation speeds even with much longer context length.
Appendix J Position-wise loss by parameter allocation ratio
We summarize the position-wise loss for three different model sizes in Figure 11. We confirm that changing the model size does not alter the overall trend, which exhibits a U-shape pattern depending on the token position. Additionally, we observe that a larger block decoder consistently improves the likelihood of earlier tokens, while a larger token decoder improves the likelihood of later tokens.
Appendix K Loss trend by allocation ratio and block length
We analyze average loss in Figure 12 and position-wise loss in Figure 13 and Figure 14, adjusting for three block lengths and five allocation ratios across two model sizes. Surprisingly, all experimental results demonstrate the same trend. Notably, shorter block lengths favor larger block decoders, while longer block lengths benefit from larger token decoders. The rationale behind this trend becomes apparent through an examination of position-wise perplexity, particularly by observing the changes in loss for the first token and the variations in loss for later tokens. We believe that our extensive ablation studies will facilitate the determination of parameter ratios tailored to the specific scenarios for which the Block Transformer is designed.
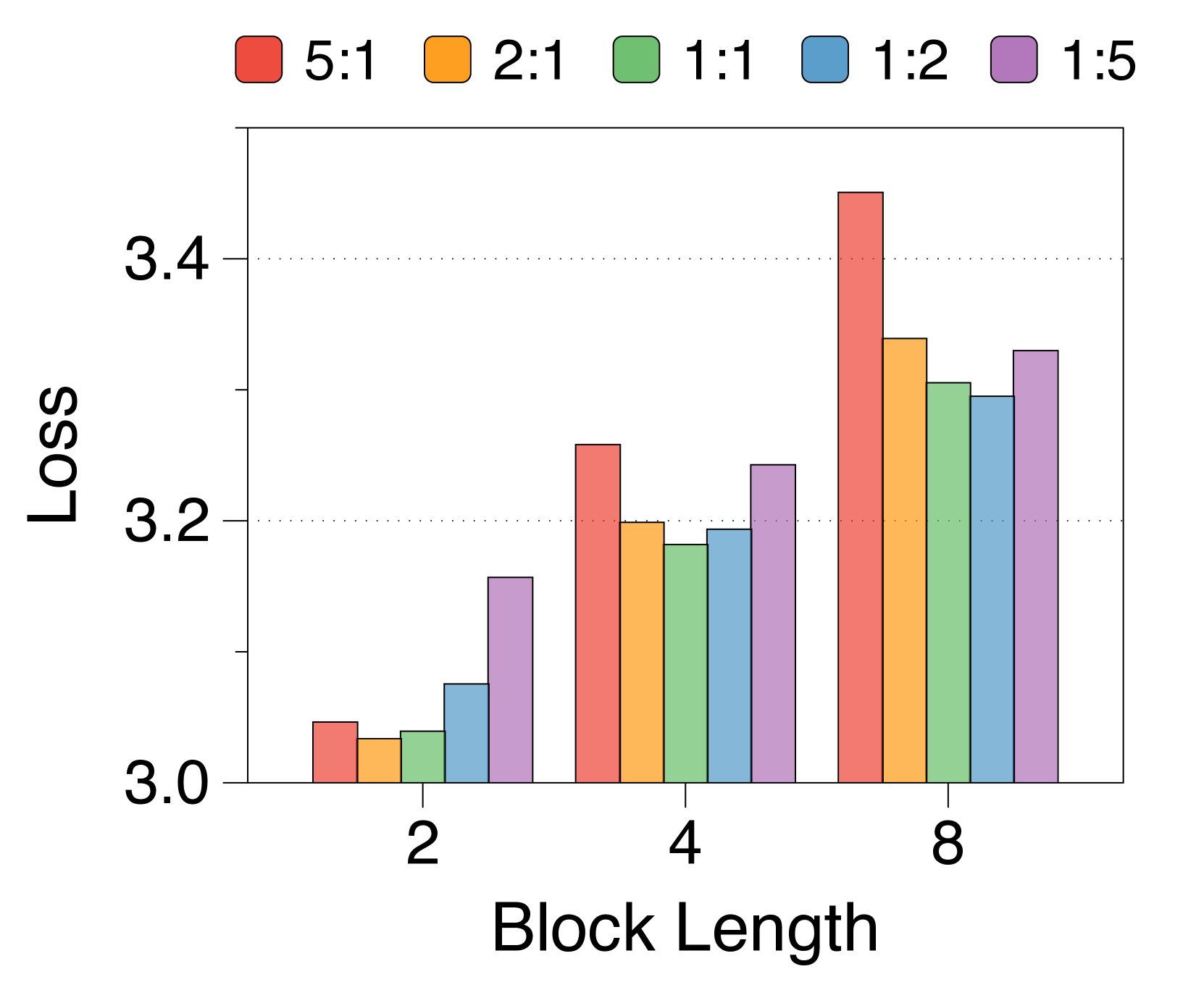
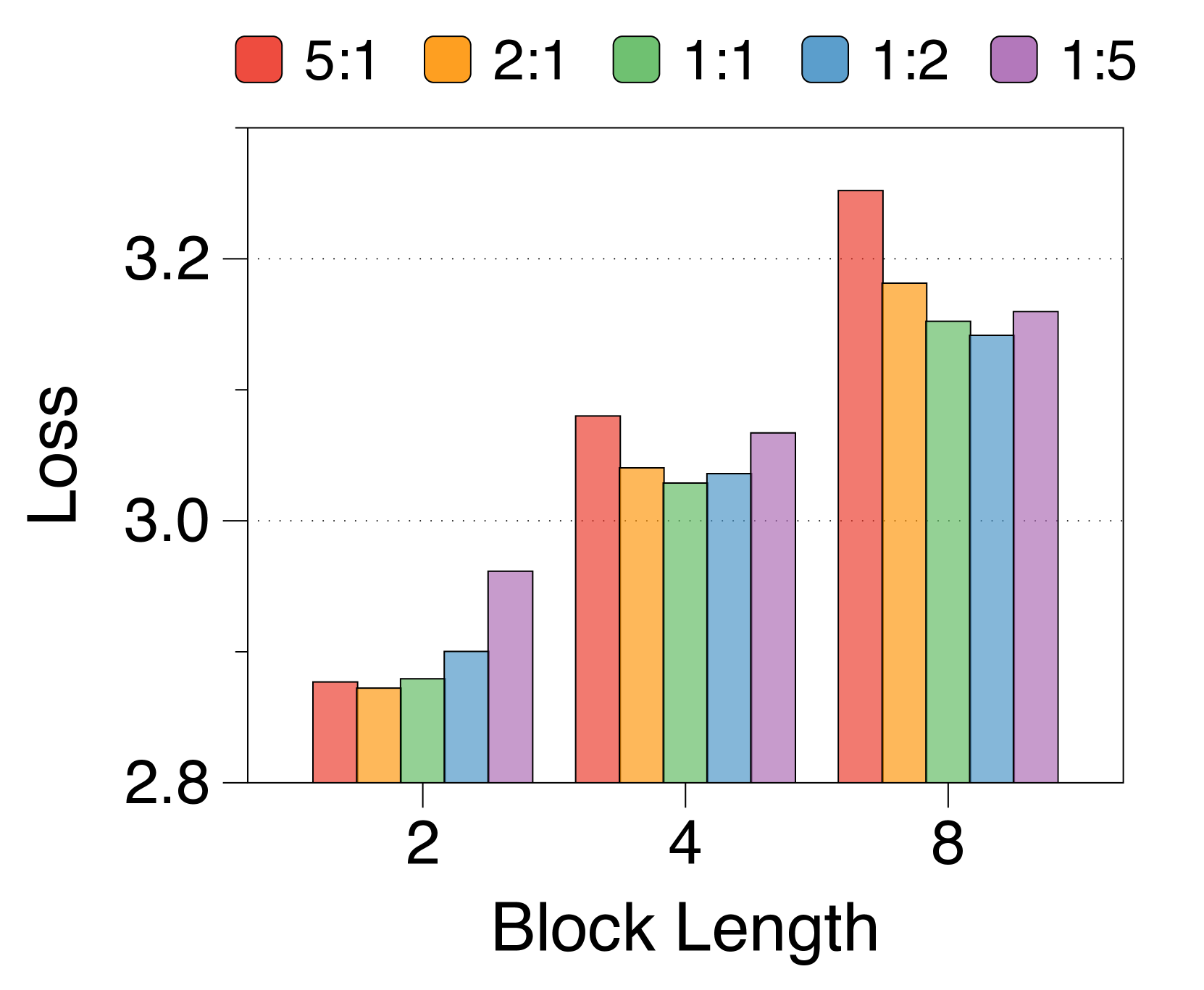
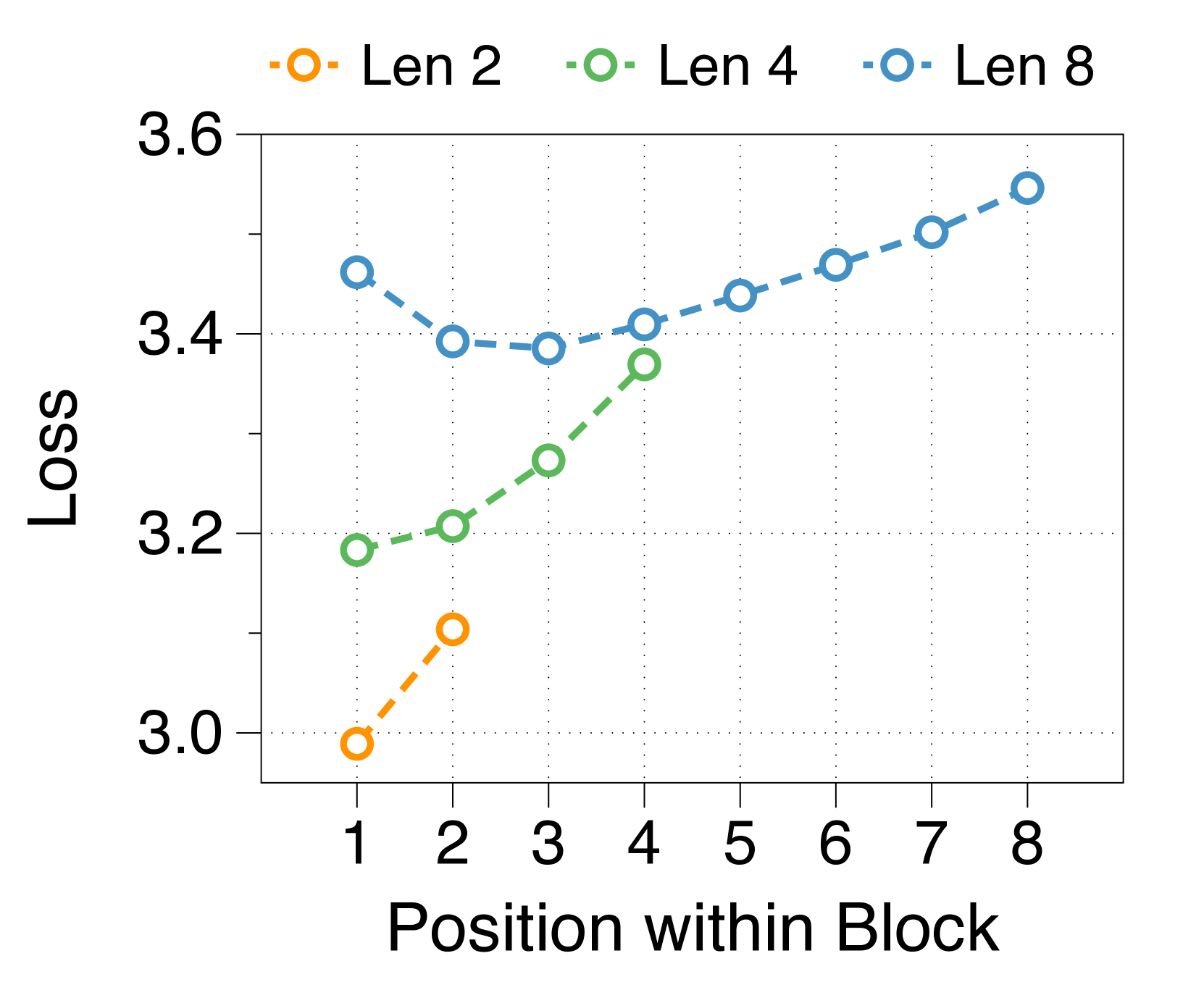
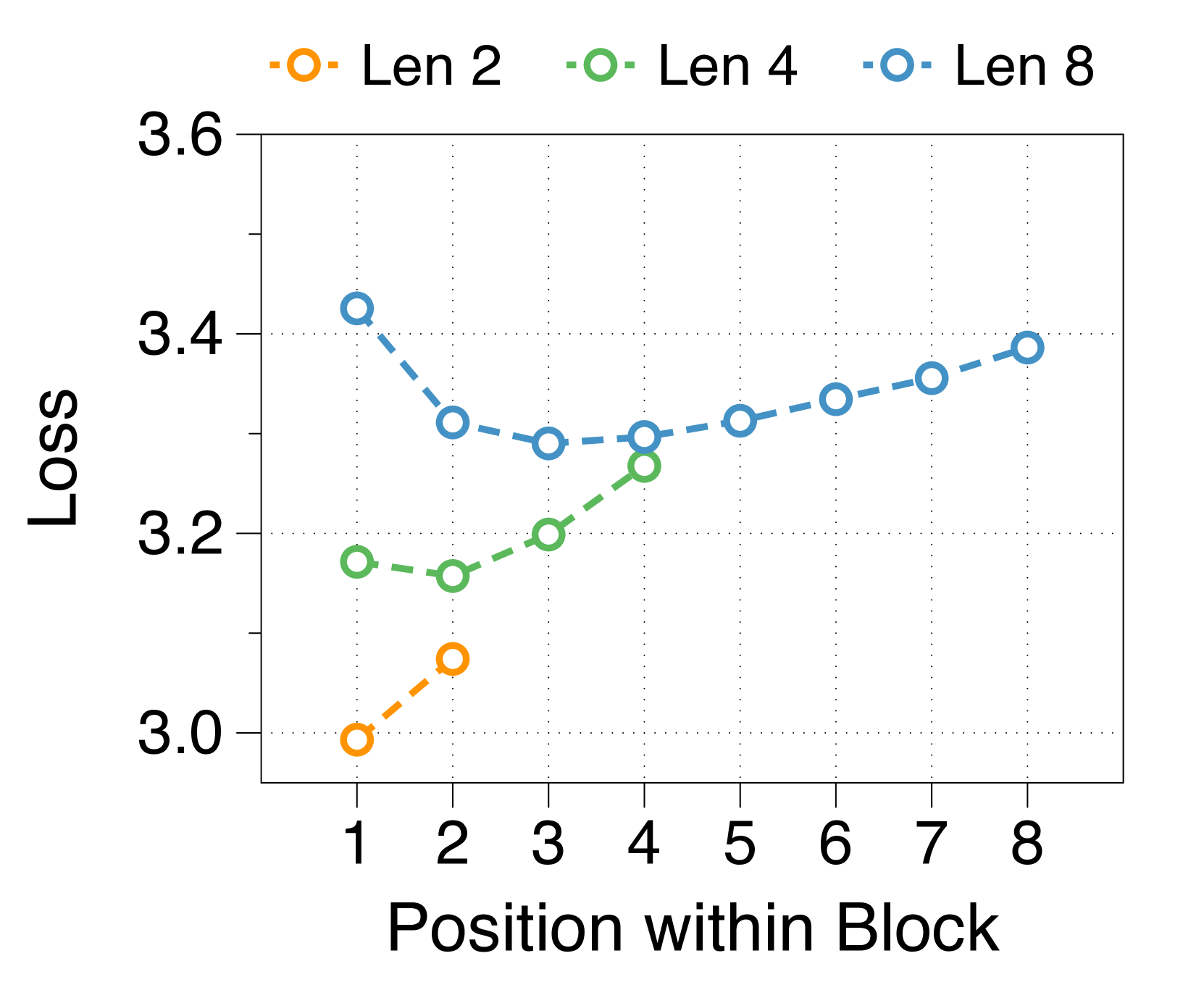
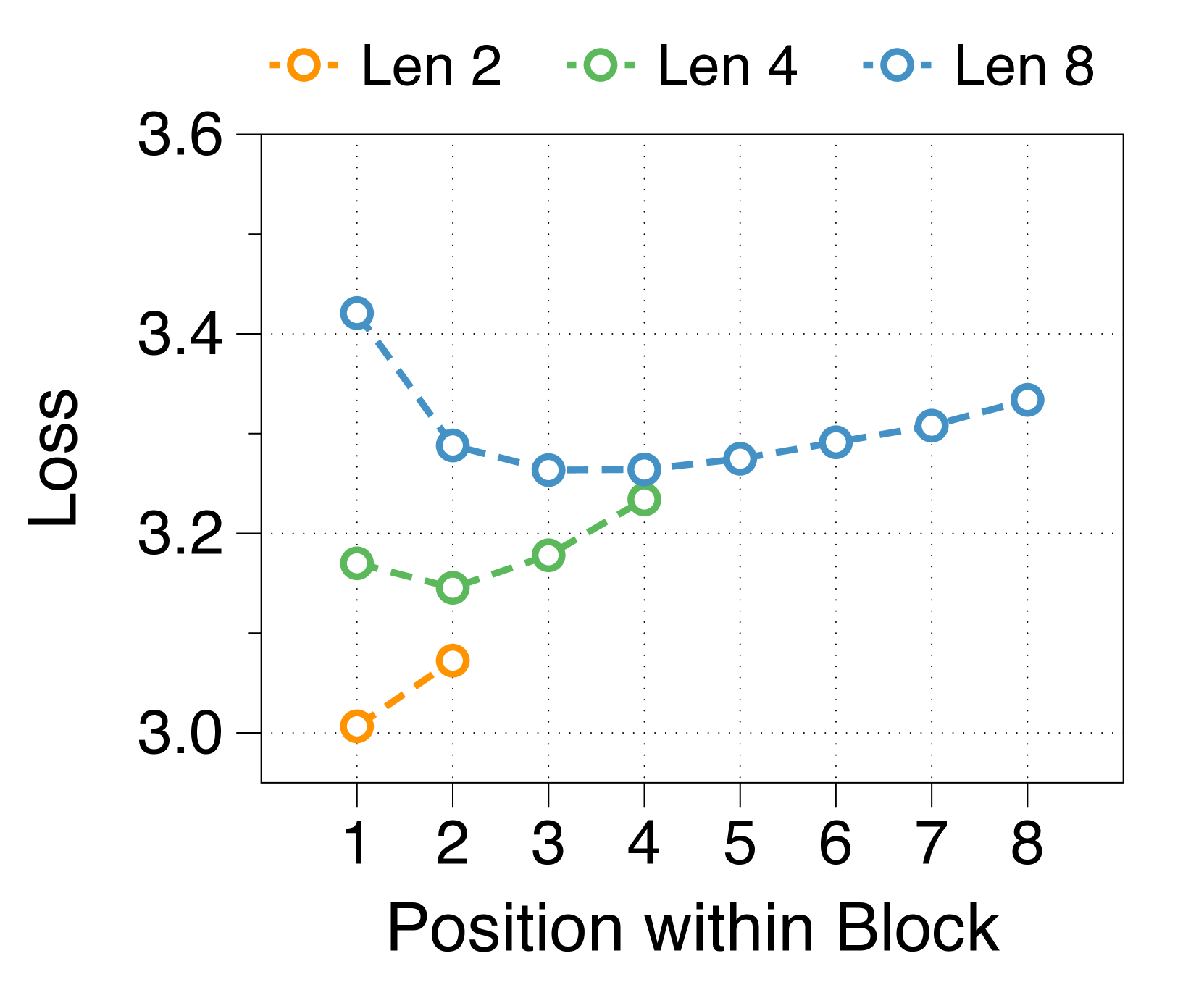

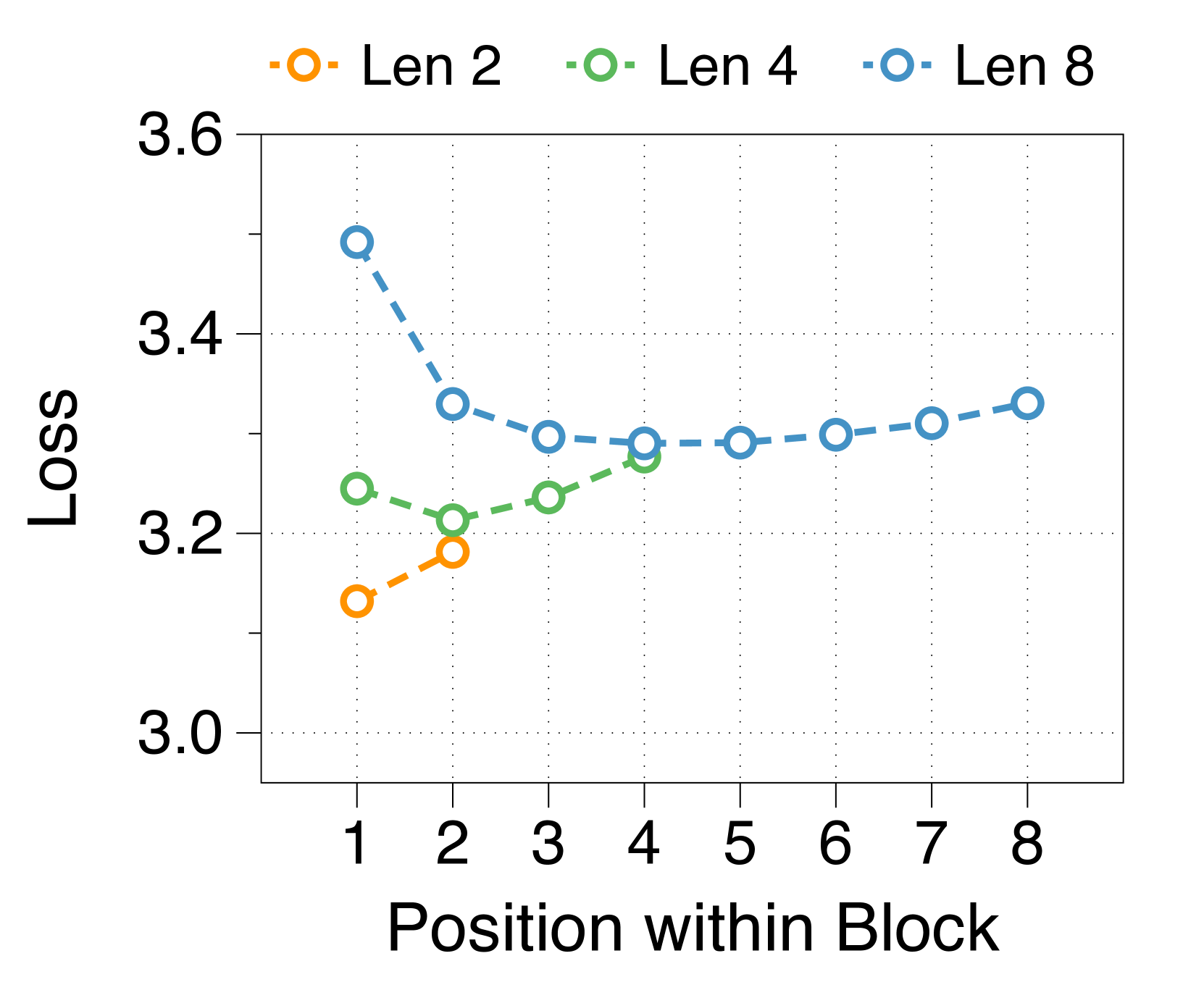

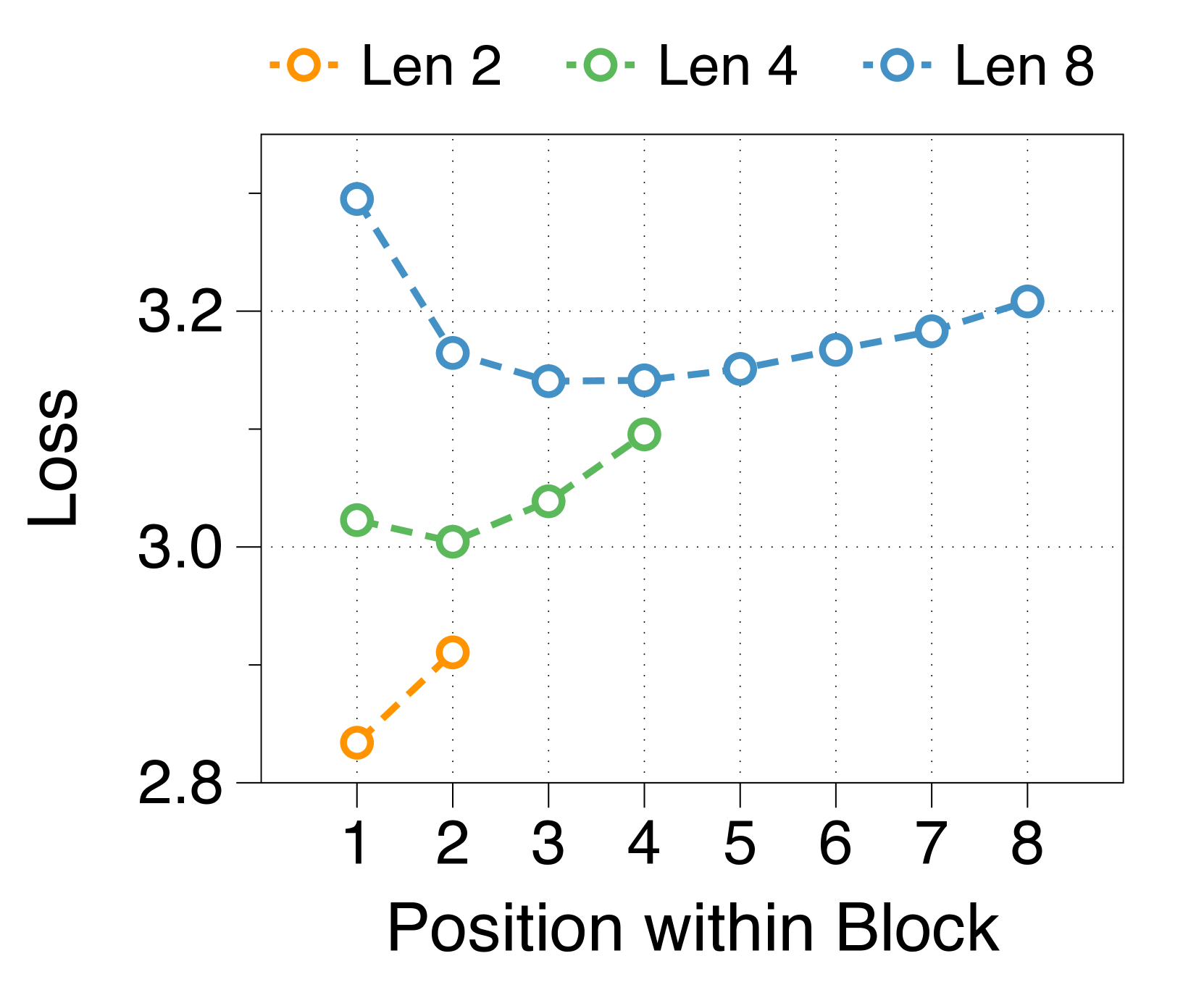

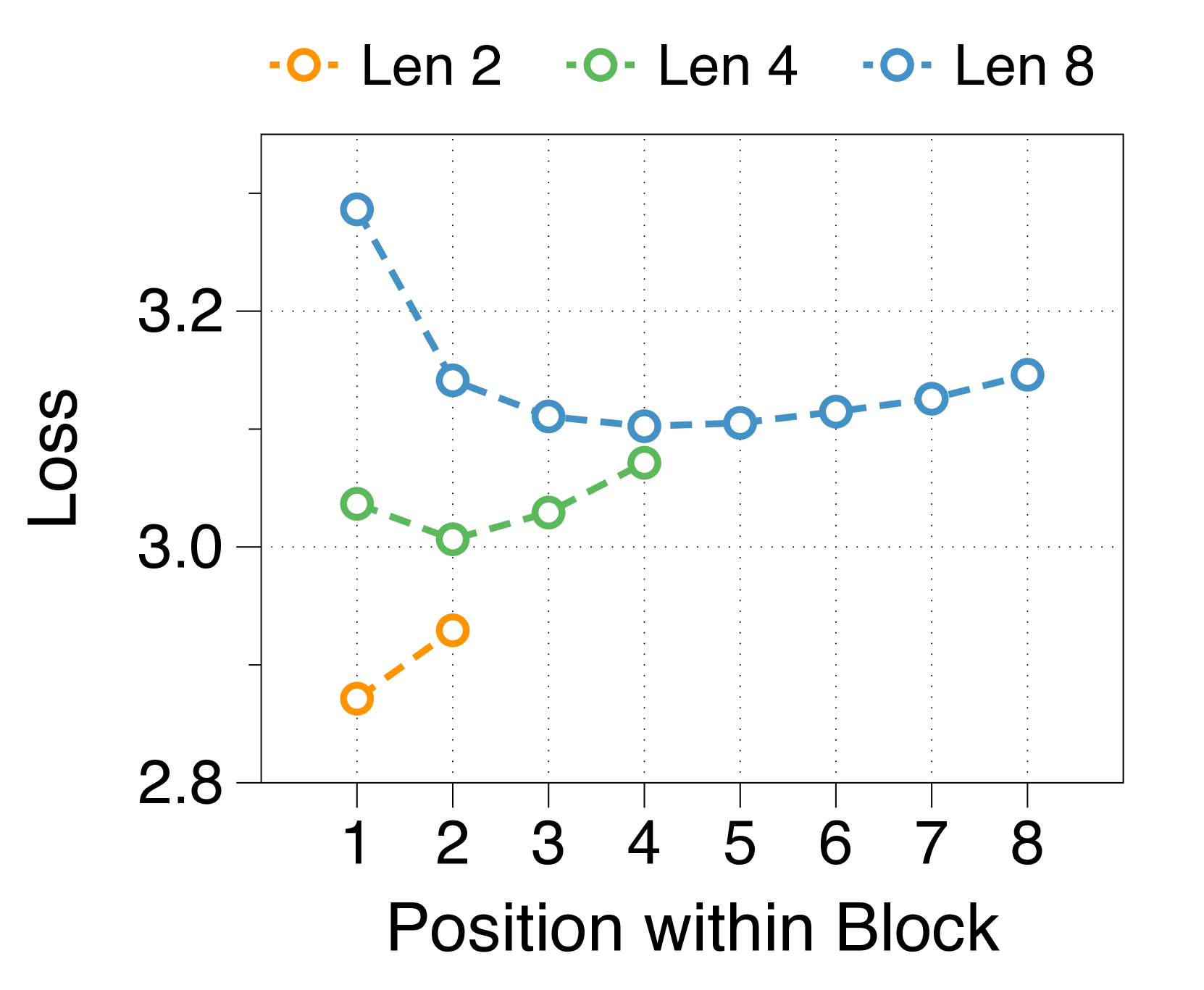
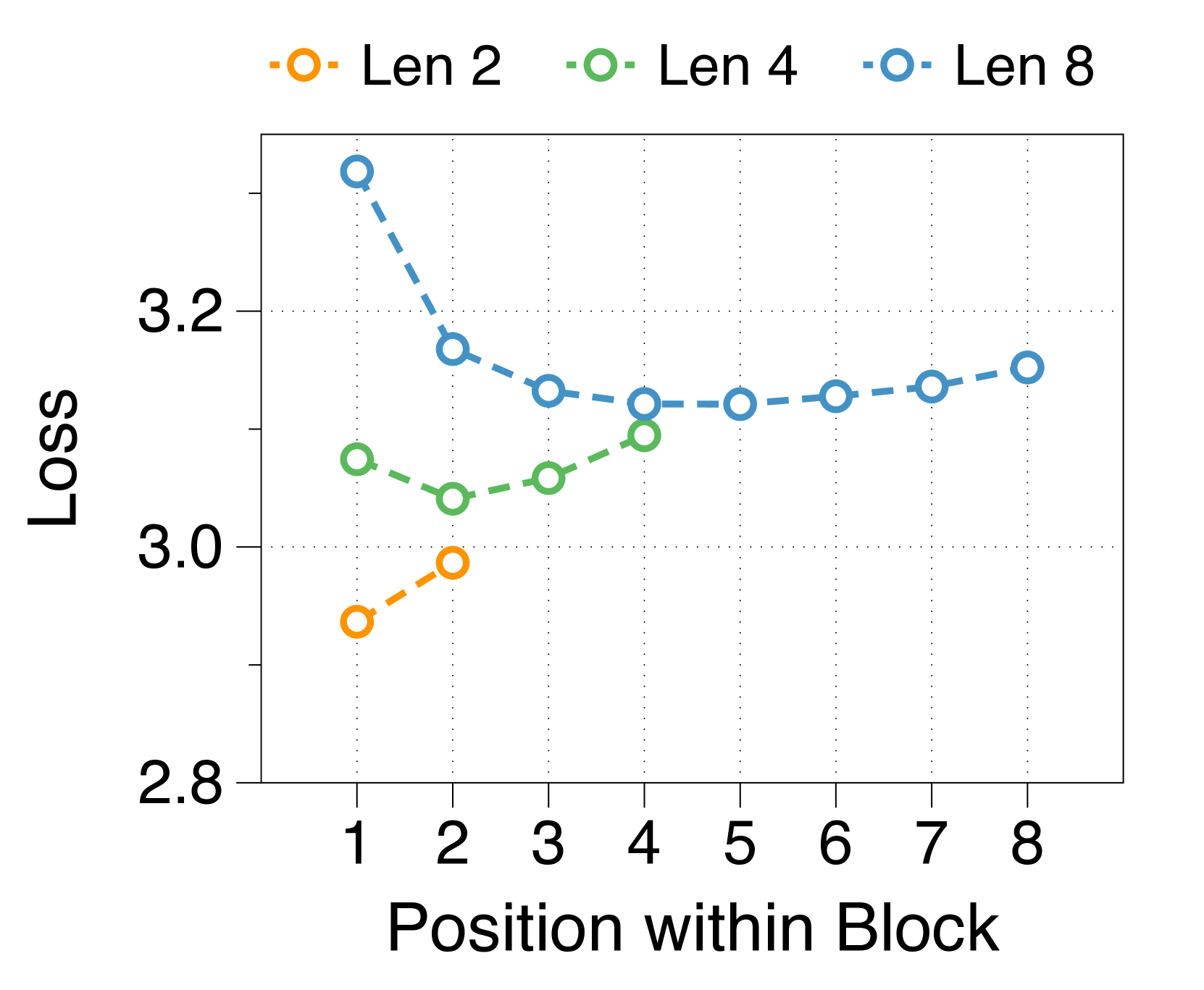
Appendix L Pareto frontier of throughput by allocation ratio and block length
While we have analyzed the optimal parameter ratio and block length from a perplexity perspective, we also evaluate which settings perform best from a throughput standpoint. The Pareto frontier for all model variants is depicted in Figure 15. Although there is a trade-off between throughput and performance, two clear findings emerge from the extensive combinations. First, the larger the token decoder, the higher the throughput improvement. Despite the token decoder consumes more FLOPs, the significantly shorter context length does not add overhead to the actual generation speed. Conversely, the block decoder, with its longer context length compared to the token decoder, hinders throughput as its size increases. The second observation is that longer block lengths significantly benefit throughput because they effectively reduce the context length. In conclusion, to optimize inference throughput, the token decoder should be enlarged, and the block length increased. However, to also consider perplexity, it is necessary to finely adjust the total model size, the allocation ratio, and the block length.
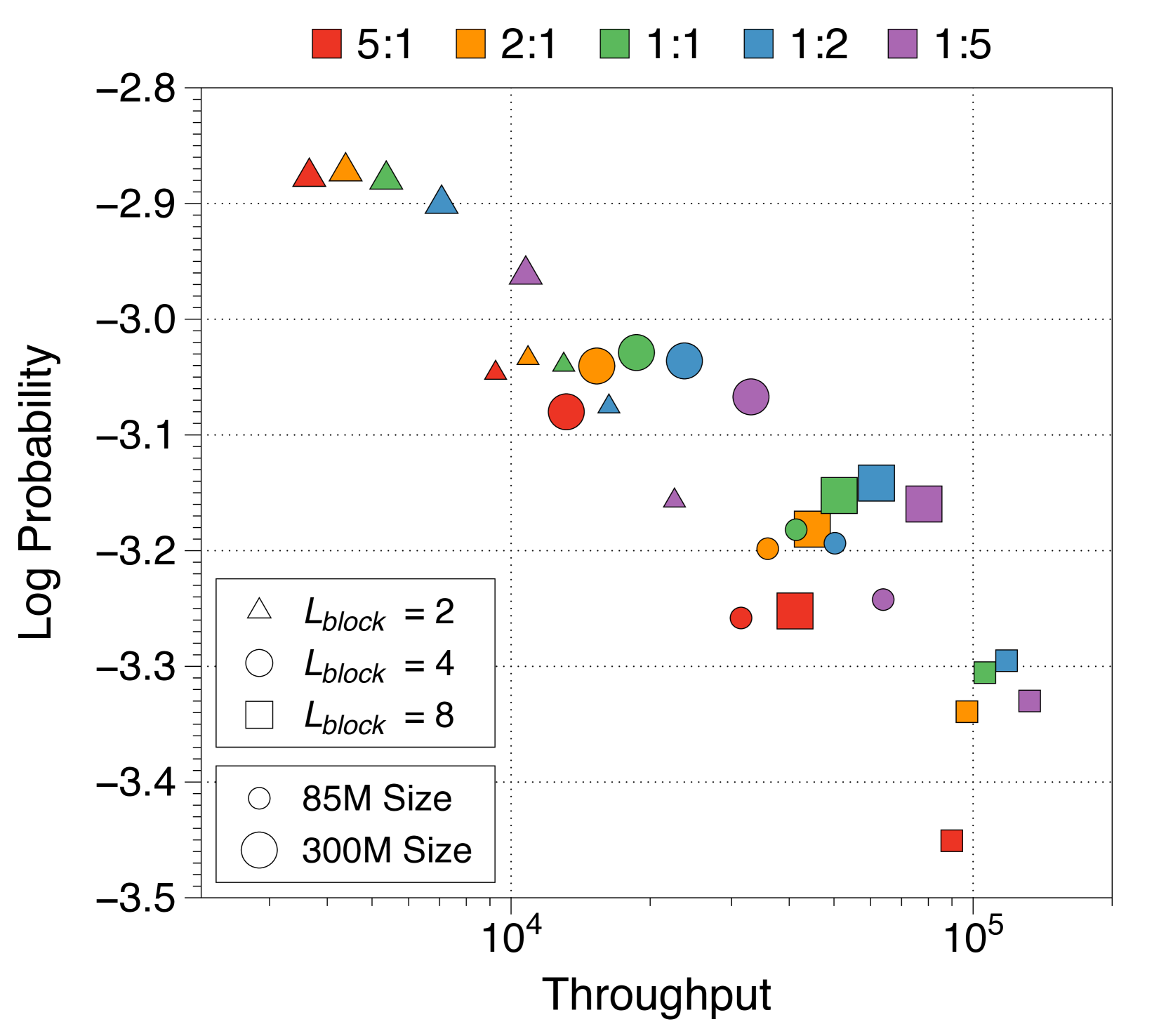
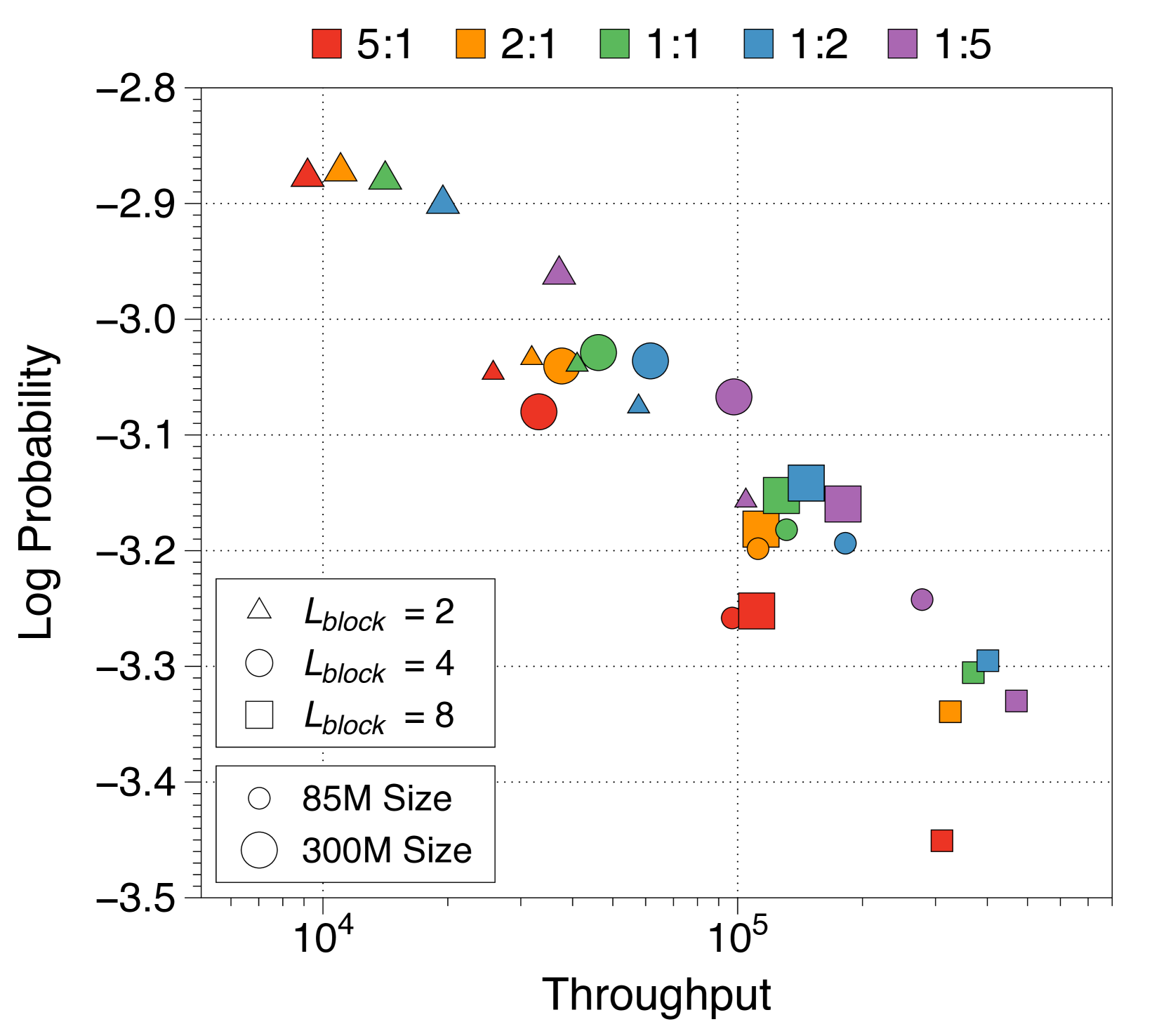
Appendix M Ablation studies on components of Block Transformer
M.1 Embedder design
We compare three methodologies as embedder components in Figure 16. Surprisingly, the lookup strategy using an embedding table shows faster convergence than the transformer-based encoder, despite eventually reaching the same level of performance with prolonged training. Although increasing the number of layers of encoders could potentially improve performance, we choose not to pursue this due to its detrimental impact on inference throughput. Using a fixed number of CLS tokens allows for flexibility in adjusting the length of each block. Drawing inspiration from studies that adaptively allocate computational costs based on the difficulty of predictions [58, 5], this strategy could be effectively utilized when designing a Block Transformer capable of handling adaptive output lengths.
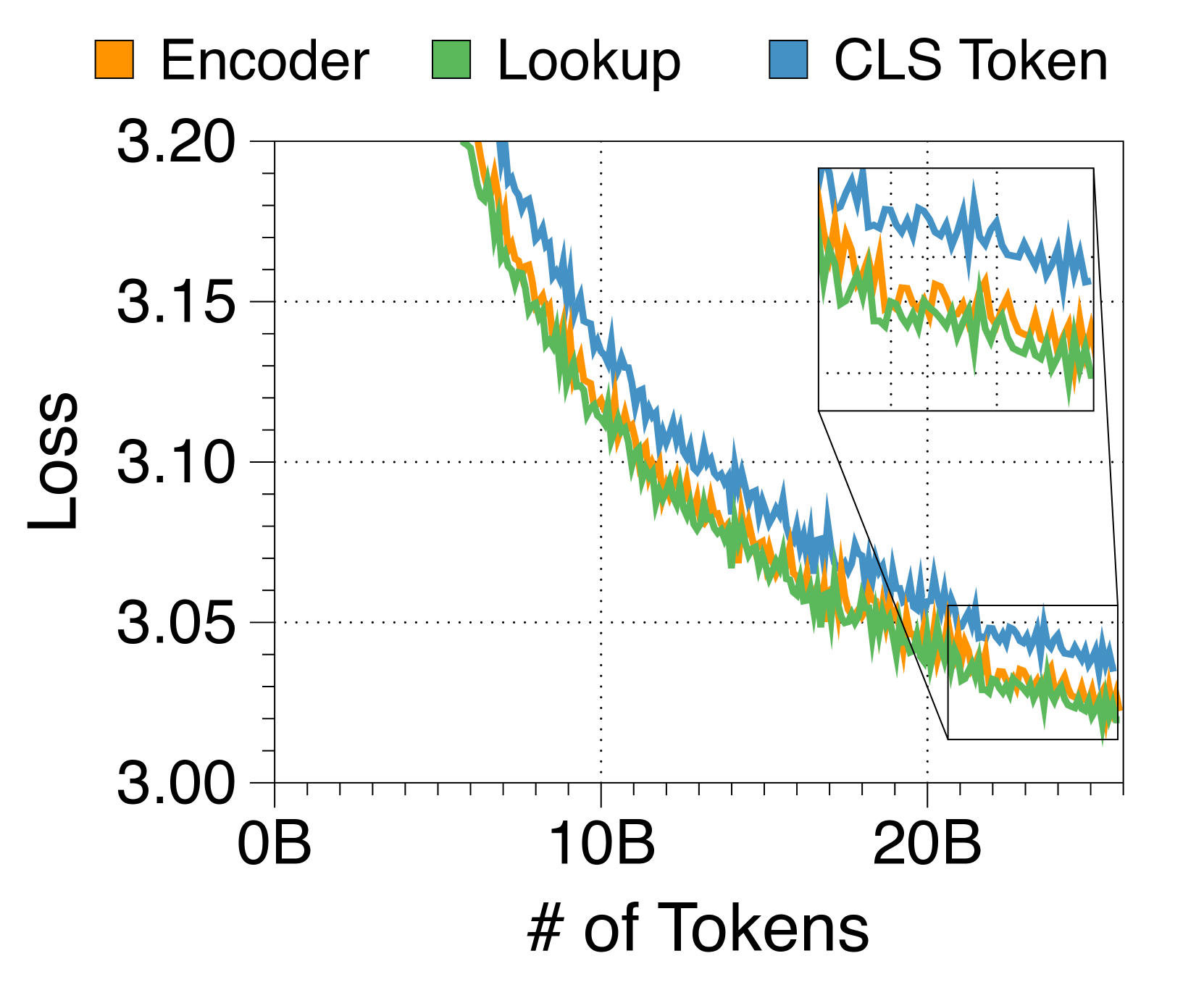
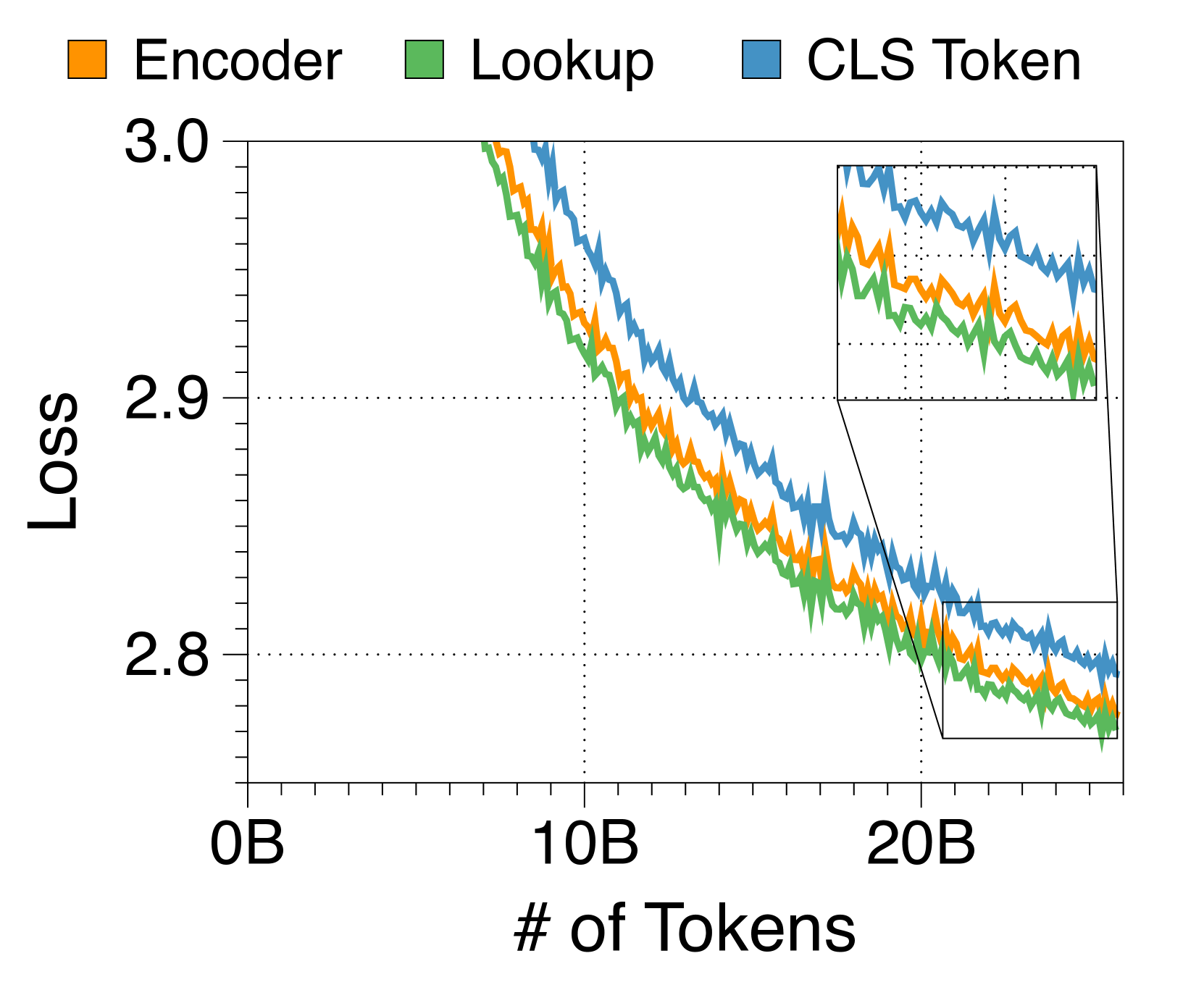
M.2 Token decoder design
In Figure 17, we compare three components for the optimal design of the token decoder. Prefix decoding outperform other strategies, particularly when the prefix length is increased, leading to a significant boost in performance. Given that the token decoder has a short context length, extending the prefix length does not substantially slow down the actual generation speed. However, since FLOPs increase proportionally, we set the prefix length to two as the main configuration to maintain a balance between performance and computational efficiency.
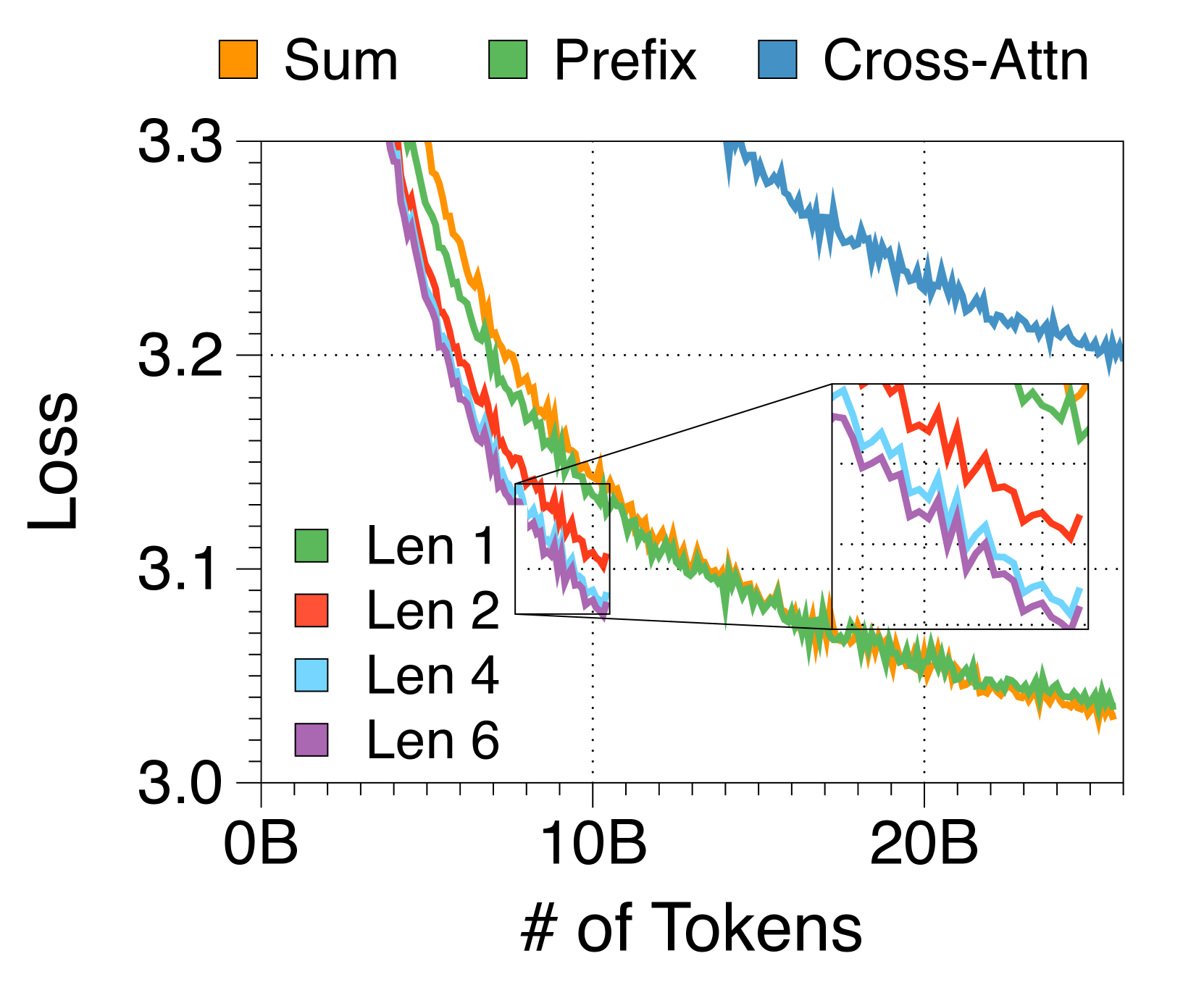

Appendix N Uptraining strategy for training efficiency
Ainslie et al. [2] have demonstrated the significance of weight initialization for effectively uptraining models. Our extensive ablation studies reveal the optimal strategies for the Block Tramsformers: (1) Dividing a vanilla transformer layer in half and assigning each half to the block and token decoders, respectively, outperforms assigning the same weights of selected layers to both. (2) Initializing the input block embedding as the average of token embeddings within the block improves performance. (3) Initilizing token decoder prefixes by replicating the context embedding enhances convergence. As depicted in Figure 18, these initialization technqiues allow uptrained models to nearly match fully pretrained models. While larger models generally require longer uptraining, this approach still converges faster and recovers performance better than random intialization.
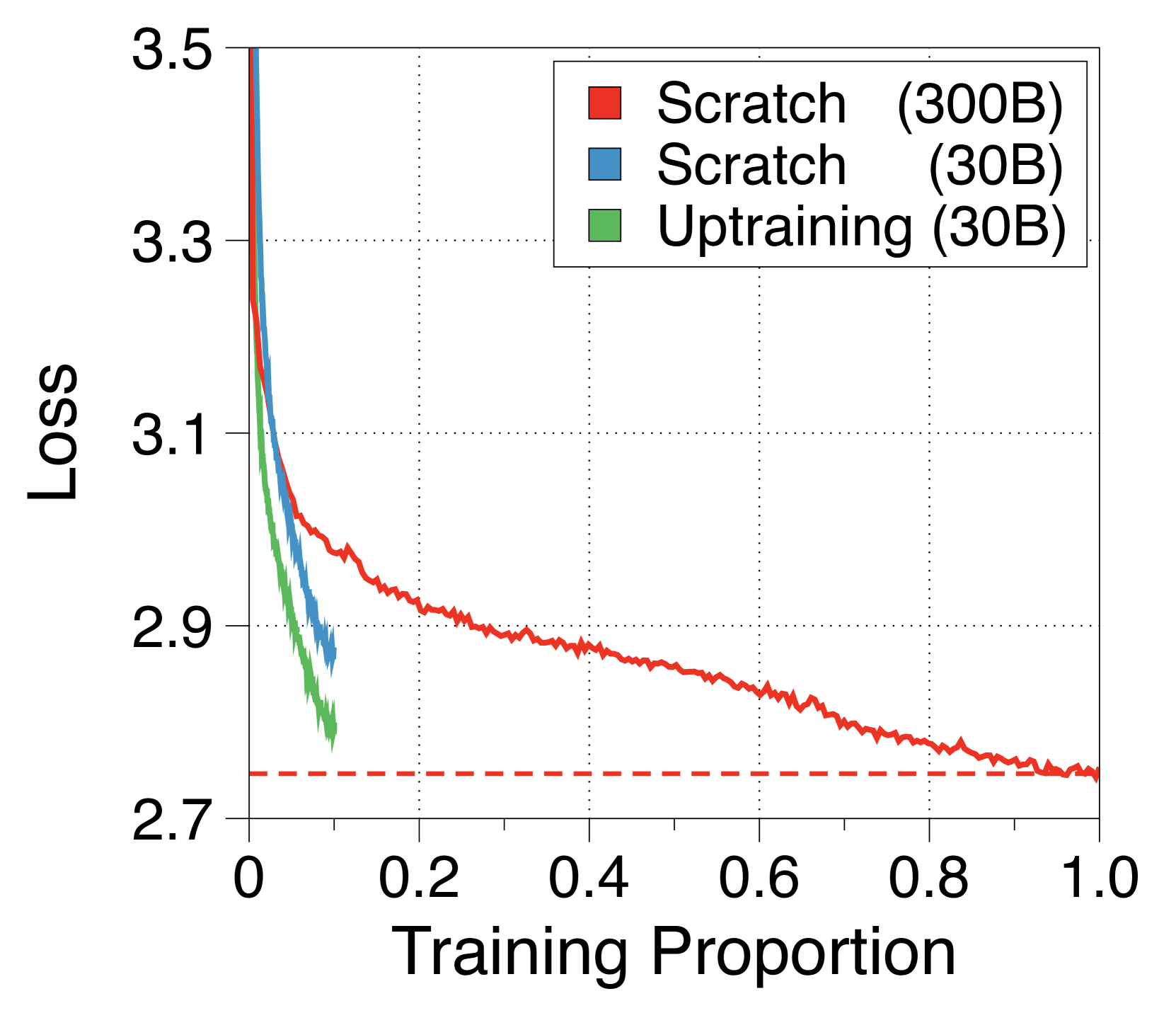
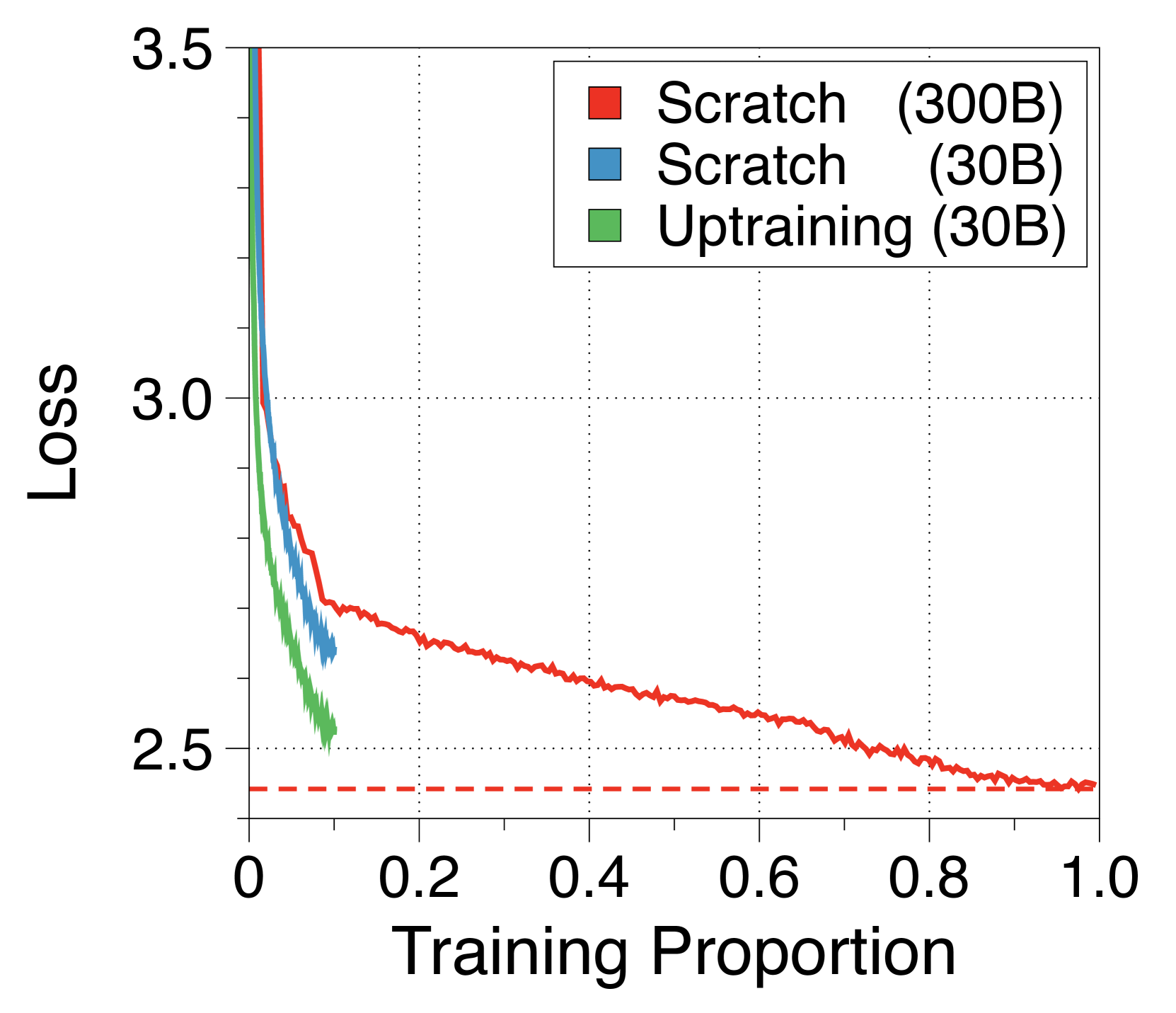
Appendix O Performance comparison to MEGABYTE
MEGABYTE propose a global-to-local architecture similar to ours, but their emphasis on efficient training leads to different conclusions. For instance, they claim that a model structure with a block decoder six times larger than the token decoder is optimal, while overlooking the significance of local computation within the token decoder. However, our observations indicate that increasing the block decoder size is detrimental to throughput, and significantly reducing token decoder severely impacts language modeling performance. This is evident in Figure 19, where our reimplementation of MEGABYTE, based on their reported results, demonstrates considerably lower generation speed and performance than our baseline model in both prefill-heavy and decode-heavy settings. In light of this, we believe that our findings, focused on efficient inference, will open up new directions for global-to-local language models.
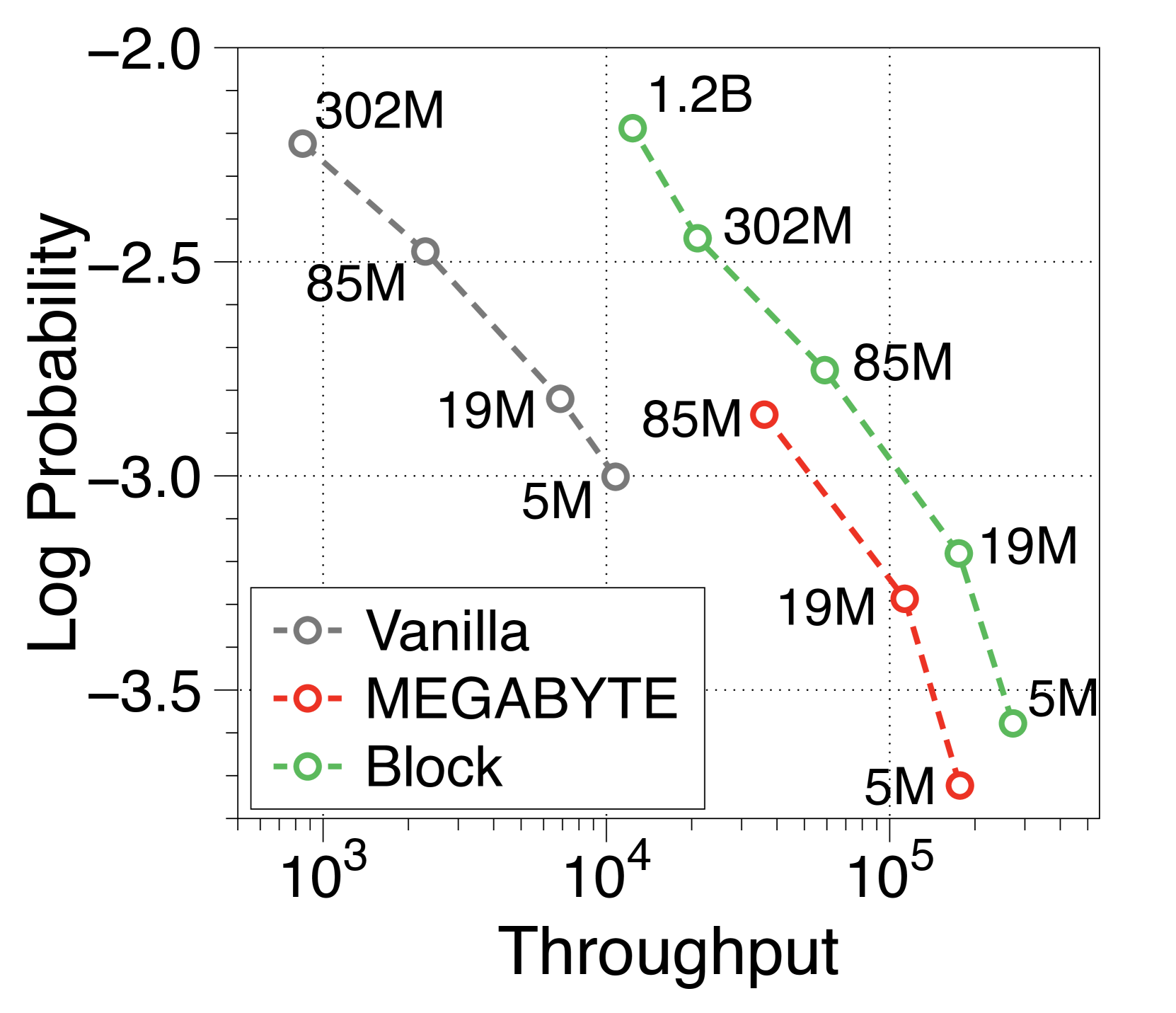
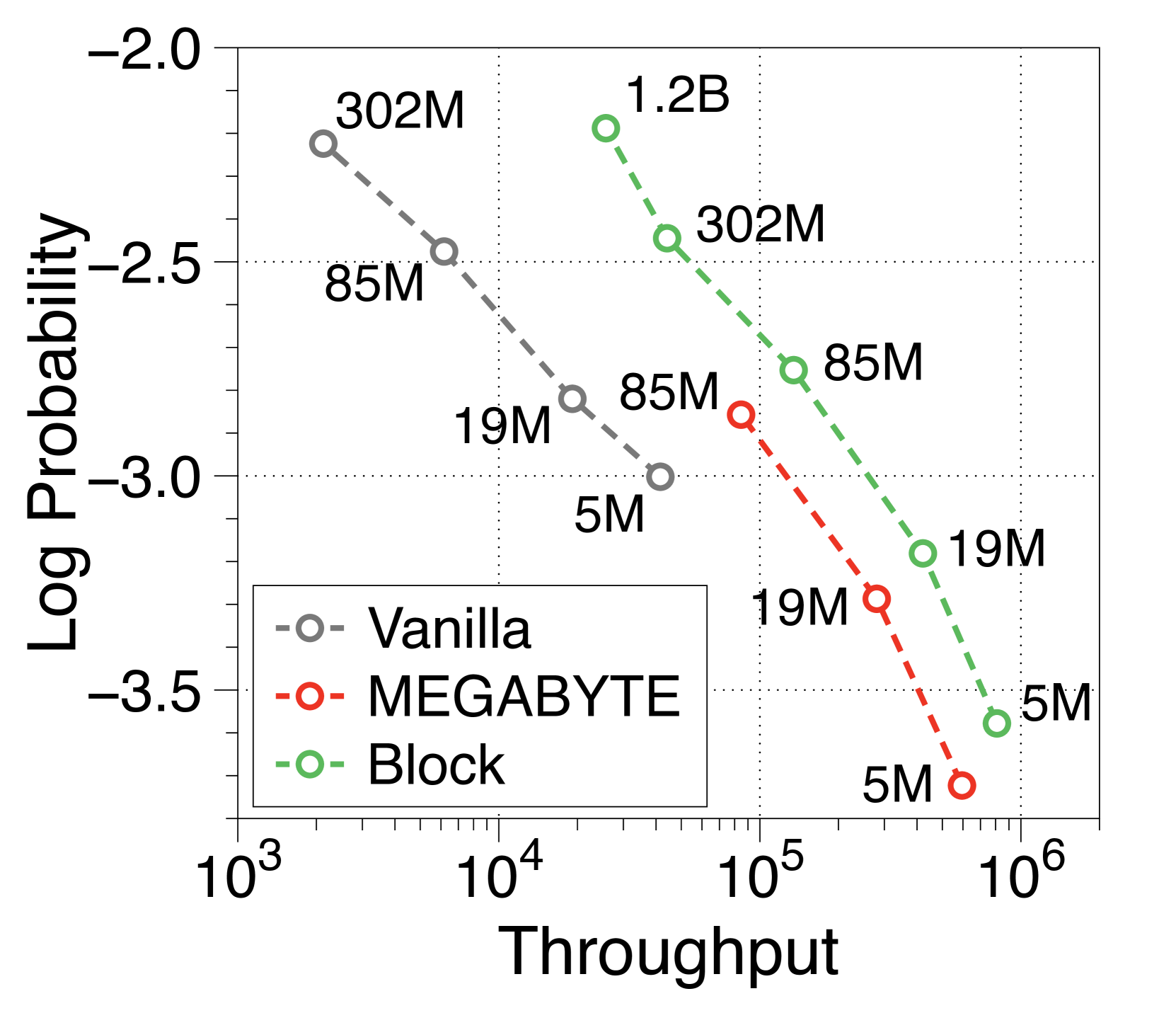
Appendix P Visualization of attention scores in Block Transformer
We visualize the attention scores from both block and token decoder in Figure 20 and Figure 21. In block decoders, we observe a similar pattern of attention sinking to the first token. Previous research has taken advantage of this by keeping the first token as a global token to prevent performance drop when compressing long sequences of past tokens. We believe this approach could also benefit Block Transformers. Furthermore, the attention map in token decoders shows that later tokens strongly attend to the context embedding. This suggests that the global context is effectively compressed within them, which aligns with the insights in subsection 4.2.
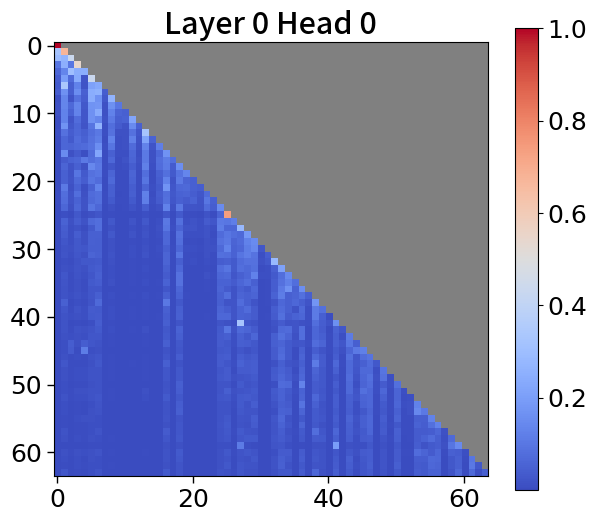
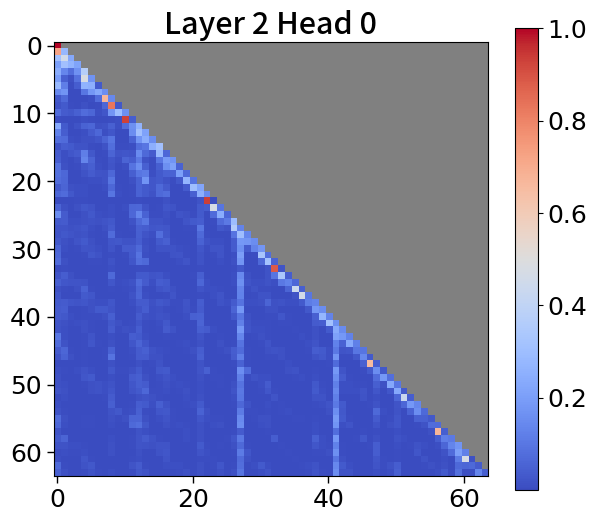
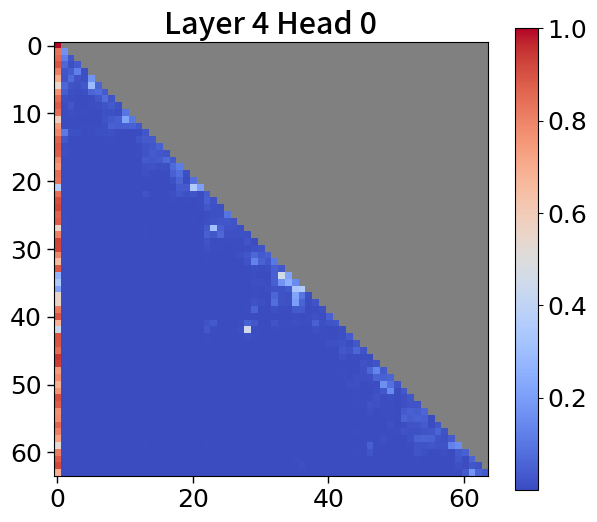
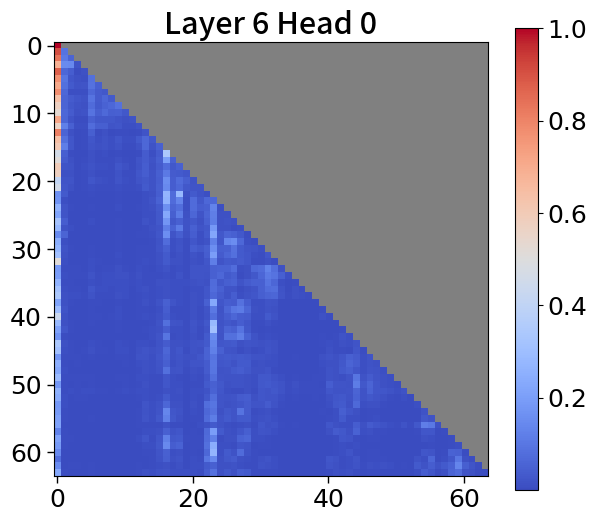
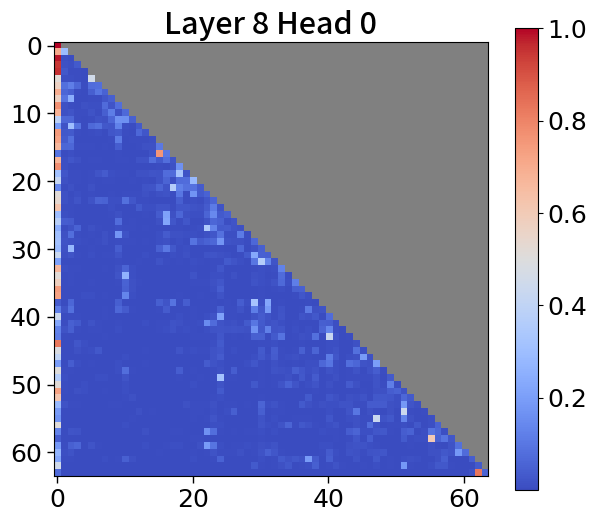

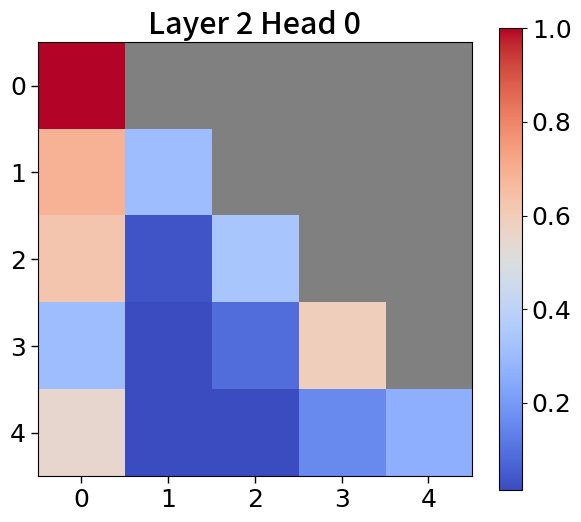
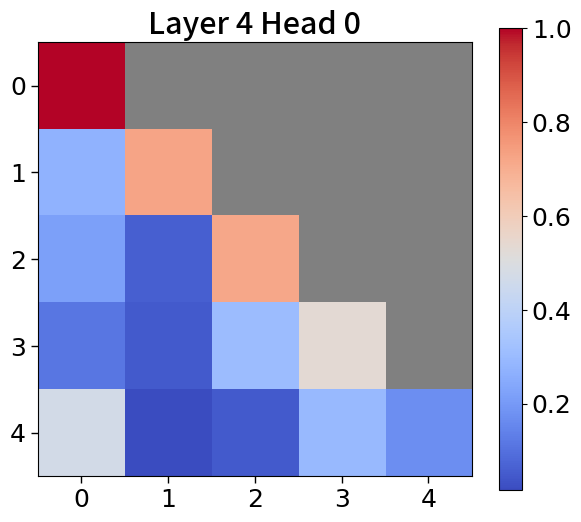
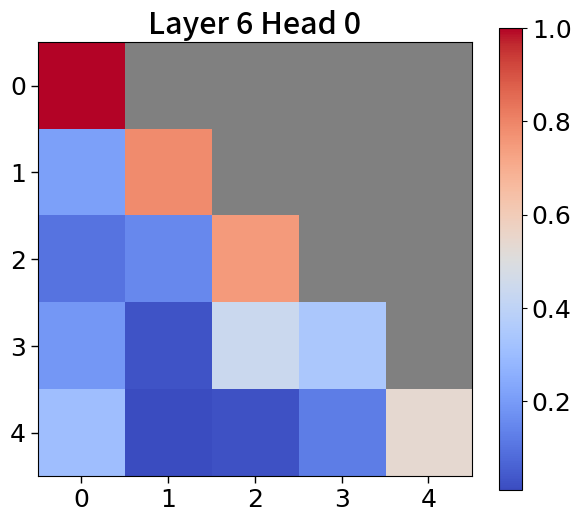
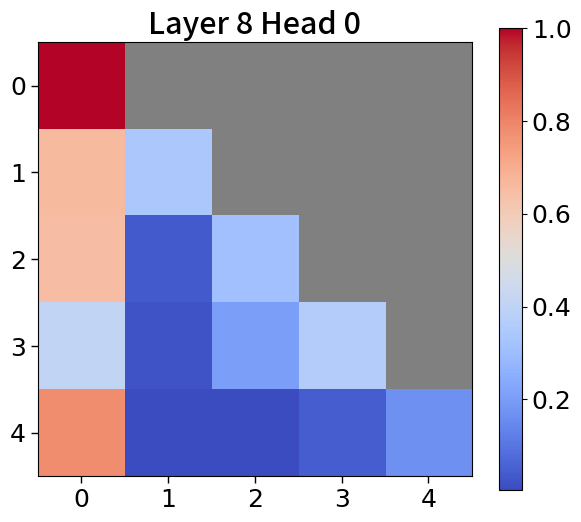
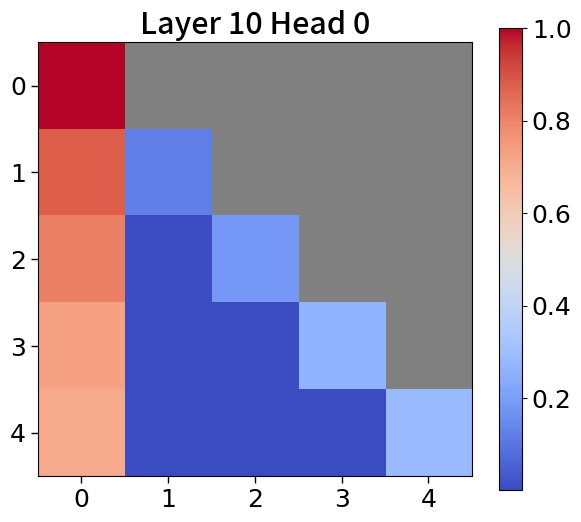
Appendix Q Analysis on the context block embedding
To investigate whether global-to-local language modeling utilizes full context, we examine the information stored in context block embeddings. Specifically, given that the input token and context embedding share the same latent space in the token decoder, we analyze the three closest vocabulary terms to prefixes, which are projected from the context embedding, as shown in Table 5. We use a Block Transformer with 1.2 billion non-embedding parameters and prefix decoding with a prefix length of two. There are several interesting findings. The second prefix typically contains information about the last token of the current block. This suggests that the block decoder incorporates information about that specific token, rather than the previous sequences, to better predict the first token of the next block. Conversely, the first prefix of the context embedding contains uninterpretable tokens, indicating that it serves primarily to capture the global context as much as possible. This is further supported by Figure 21, which shows that later tokens in the token decoder tend to attend more to this prefix.
| Sample | Tokens | Top-k | Block # 0 | Block # 1 | Block # 2 | Block # 3 | Block # 4 |
| #0 | Input | - | iff The | exuberant capital | of Wales, compact | Cardiff has recently | |
| Nearest | =1 | (‘<|endoftext|>’, ‘ Card’) | (‘ the’, ‘The’) | (‘ guarantee’, ‘ captial’) | (‘ guranteee’, ‘ compact’) | (‘ the’, ‘ has’) | |
| =2 | (‘the’, ‘Card’) | (‘<|endoftext|>’, ‘ the’) | (‘ocardial’, ‘captial’) | (‘ the’, ‘,’) | (‘,’, ‘ recently’) | ||
| =3 | (‘.’, ‘card’) | (‘219’, ‘ The’) | (‘28’, ‘ Capital’) | (‘ unfamiliar’, ‘compact’) | (‘.’, ‘ve’) | ||
| #1 | Input | - | the medieval Jewish community | , who were not | allowed to bury their | dead within the city | , would take bodies |
| Nearest | =1 | (‘ and’, ‘ community’) | (‘ the’, ‘ not’) | (‘maybe’, ‘ their’) | (‘ LOSS’, ‘City’) | (‘ deteriorated’, ‘ body’) | |
| =2 | (‘,’, ‘ Community’) | (‘ and’, ‘ were’) | (‘ LOSS’, ‘Their’) | (‘ removed’, ‘ City’) | (‘iding’, ‘ bodies’) | ||
| =3 | (‘ the’, ‘community’) | (‘.’, ‘ are’) | (‘ and’, ‘ Their’) | (‘otten’, ‘ city’) | (‘pped’, ‘Body’) | ||
| #2 | Input | - | to six daily | Fort William (£28 | .20, 3 | ¾ hours, four | to five daily), |
| Nearest | =1 | (‘<|endoftext|>’, ‘,’) | (‘ fiercely’, ‘ 28’) | (‘ijing’, ‘ 3’) | (‘ulsions’, ‘ four’) | (‘illes’, ‘,’) | |
| =2 | (‘ the’, ‘),’) | (‘ foe’, ‘28’) | (‘n ’, ‘3’) | (‘ fierecely’, ‘ 4’) | (‘yscall’, ‘),’) | ||
| =3 | (‘ and’, ‘]]’) | (‘illes’, ‘ 30’) | (‘ῦ’, ‘ 4’) | (‘n ’, ‘ three’) | (‘boats’, ‘!),’) | ||
| #3 | Input | - | can get almost anywhere | in Britain without having | to drive.n | nThe main public | transport options are train |
| Nearest | =1 | (‘<|endoftext|>’, ‘ anywhere’) | (‘uin’, ‘ having’) | (‘ the’, ‘.’) | (‘ the’, ‘ public’) | (‘onet’, ‘ train’) | |
| =2 | (‘ the’, ‘ anything’) | (‘ […]’, ‘ without’) | (‘ and’, ‘Ċ’) | (‘.’, ‘ Public’) | (‘stuff’, ‘train’) | ||
| =3 | (‘.’, ‘anything’) | (‘ the’, ‘ have’) | (‘,’, ‘?).’) | (‘ in’, ‘Public’) | (‘atisfaction’, ‘ Train’) | ||
| #4 | Input | - | nn**Length | ** : 2 miles | ; two to four | hoursnnIt | ’s fitting to start |
| Nearest | =1 | (‘ the’, ‘length’) | (‘ the’, ‘ miles’) | (‘ the’, ‘ four’) | (‘ the’, ‘It’) | (‘ the’, ‘ start’) | |
| =2 | (‘<|endoftext|>’, ‘ length’) | (‘ and’, ‘km’) | (‘079’, ‘ two’) | (‘ in’, ‘ It’) | (‘305’, ‘ started’) | ||
| =3 | (‘ and’, ‘Length’) | (‘ in’, ‘ mile’) | (‘ and’, ‘ 4’) | (‘ and’, ‘ it’) | (‘,’, ‘ starts’) | ||
| #5 | Input | - | the English church. | If this is the | only cathedral you visit | in England, you | ’ll still walk away |
| Nearest | =1 | (‘<|endoftext|>’, ‘.’) | (‘ the’, ‘ the’) | (‘zione’, ‘ visit’) | (‘zione’, ‘ you’) | (‘aciones’, ‘ away’) | |
| =2 | (‘ and’, ‘ ).’) | (‘cción’, ‘The’) | (‘icions’, ‘ visiting’) | (‘ Heather’, ‘ You’) | (‘ 326’, ‘ walk’) | ||
| =3 | (‘ the’, ‘)$.’) | (‘ and’, ‘ this’) | (‘opsis’, ‘ visits’) | (‘icions’, ‘You’) | (‘ the’, ‘ walked’) | ||
| #6 | Input | - | nnStart at | the 1 **Store | y Arms car park | ** off the A | 470. A clear |
| Nearest | =1 | (‘<|endoftext|>’, ‘ at’) | (‘ the’, ‘ Store’) | (‘ãĤĬ’, ‘ Park’) | (‘ and’, ‘ A’) | (‘etus’, ‘ clear’) | |
| =2 | (‘ the’, ‘At’) | (‘ãĤĬ’, ‘Store’) | (‘ and’, ‘Park’) | (‘ the’, ‘A’) | (‘ the’, ‘ Clear’) | ||
| =3 | (‘,’, ‘ At’) | (‘ and’, ‘ store’) | (‘ishops’, ‘park’) | (‘.’, ‘ a’) | (‘ção’, ‘Clear’) |