Edresson Casanova1∗, Kelly Davis2, Eren Gölge3∗, Görkem Göknar2, Iulian Gulea2, Logan Hart3∗, Aya Aljafari1∗, Joshua Meyer2, Reuben Morais4∗, Samuel Olayemi2, and Julian Weber3∗
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Abstract
Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
keywords:
Speech Synthesis, Text-to-Speech, Multilingual Zero-shot Multi-speaker TTS, Speaker Adaptation, Cross-lingual TTS1 Introduction
Text-to-Speech (TTS) systems have received a lot of attention in recent years due to the great advances in deep learning. Most TTS systems were tailored from a single speaker’s voice, but there is current interest in synthesizing voices for new speakers (not seen during training) employing only a few seconds of speech. This approach is called zero-shot multi-speaker TTS (ZS-TTS) as in (jia2018transfer, ; choi2020attentron, ; casanova2021sc, ; yourtts, ; wang2023neural, ; jiang2023mega, ).
Monolingual ZS-TTS was first proposed by arik2018neural which extended the DeepVoice 3 model deepvoice3 . Meanwhile, Tacotron 2 tacotron2 was adapted using external speaker embeddings, allowing for speech generation that resembles the target speaker jia2018transfer ; cooper2020zero . SC-GlowTTS casanova2021sc explored a flow-based architecture and improved voice similarity for unseen speakers in training with respect to previous studies while maintaining comparable quality. VALL-E wang2023neural was the pioneer in exploring the language modeling approach for ZS-TTS. It is a text-conditioned language model trained on Encodec defossez2022high tokens. Encodec encodes each audio frame with 8 codebooks at a 75Hz frame rate. VALL-E improved voice similarity and naturalness for unseen speakers. Tortoise tortoise also explored the language modeling approach for ZS-TTS. It was trained with 49k hours of English speech and it achieved promising ZS-TTS performance, enhancing naturalness. StyleTTS 2 li2023styletts was built upon the StyleTTS framework and it leverages style diffusion and adversarial training with large speech-language models (e.g. WavLM chen2022wavlm ) to achieve human-level TTS and SOTA ZS-TTS performance. P-Flow kim2023p combines a prompted text encoder with a low-matching generative decoder to sample high-quality mel-spectrograms efficiently. P-Flow matches the speaker similarity performance of the VALL-E model with two orders of magnitude less training data and has more than faster sampling speed. HierSpeech++ lee2023hierspeech++ is an efficient hierarchical speech synthesis framework that consists of a hierarchical speech synthesizer, text-to-vec, and speech super-resolution model. To improve speaker similarity the authors introduced a bidirectional normalizing flow Transformer network using AdaLN-Zero. To improve audio quality, they have proposed a dual-audio acoustic encoder to enhance the acoustic posterior. HierSpeech++ achieved ZS-TTS SOTA results, enhancing especially the generated audio quality.
Most ZS-TTS models support only a single language. However, there is current interest in training models in multiple languages, reducing the number of speech hours and speakers needed to have a ZS-TTS model in a target language. YourTTS yourtts was the first multilingual ZS-TTS model. The authors proposed several changes to VITS model kim2021conditional architecture to support multilingual training and ZS-TTS. The authors trained the model using approximately 1k speakers in the English language, 5 speakers in French, and 1 speaker in Portuguese. The model achieved SOTA results in the English language and promising results in the French and Portuguese languages. It can also do cross-lingual TTS producing a native accent in the target language. YourTTS model has shown the viability of training ZS-TTS models in scenarios where only a few speakers are available, enabling synthetic data generation for low-resource scenarios casanova23_interspeech . VALL-E X zhang2023speak was built upon VALL-E; however, the authors introduced a language ID to support multilingual TTS and speech-to-speech translation. VALL-E X can also do cross-lingual TTS, producing a native accent in the target language. Mega-TTS 2 jiang2023mega is a ZS-TTS model capable of handling arbitrary-length speech prompts. The model was trained on 38k hours of multi-domain language-balanced speech in English and Chinese. Mega-TTS 2 achieved SOTA performance with short speech prompts and also produced better results with longer speech prompts. In parallel with our work, Voicebox le2023voicebox was proposed. Voicebox is a non-autoregressive continuous normalizing flow model. In contrast to auto-regressive models (e.g. VALL-E), Voicebox can consume context not only in the past but also in the future. The Voicebox model was trained in 6 languages and it achieved SOTA results in cross-lingual ZS-TTS.
Although some papers explored multilingual ZS-TTS as in yourtts ; zhang2023speak ; le2023voicebox ; jiang2023mega the number of supported languages is still low. YourTTS model was trained with only three languages, VALL-E X and Mega-TTS 2 explored only two languages, and Voicebox explored six languages. Given that, the current ZS-TTS models are limited to a few medium/high resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to solve this issue by proposing a massive multilingual ZS-TTS model that supports 16 languages, including English (en), Spanish (es), French (fr), German (de), Italian (it), Portuguese (pt), Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh), Hungarian (hu), Korean (ko), and Japanese (ja).
The contributions of this work are as follows:
-
•
We introduced XTTS, a new multilingual ZS-TTS model that achieves SOTA results in 16 languages;
-
•
XTTS is the first massively multilingual ZS-TTS model supporting low/medium resource languages;
-
•
Our model can perform cross-language ZS-TTS without needing a parallel training dataset.
-
•
XTTS model and checkpoints are publicly available at Coqui TTS111https://github.com/coqui-ai/TTS and also on Hugging Face XTTS222https://huggingface.co/coqui/XTTS-v2/tree/v2.0.2 repository.
The audio samples for each of our experiments are available on the demo website333https://edresson.github.io/XTTS/.
2 XTTS model
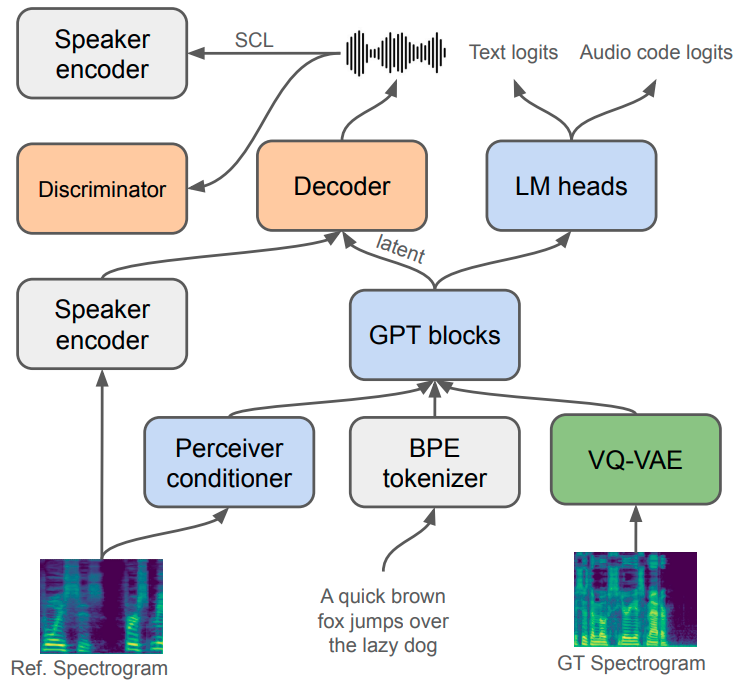
XTTS builds upon Tortoise tortoise , but includes several novel modifications to enable multilingual training, improve ZS-TTS, and enable faster training and inference. Figure 1 shows an overview of the XTTS architecture. XTTS is composed of three components:
VQ-VAE: A Vector Quantised-Variational AutoEncoder (VQ-VAE) with 13M parameters receives a mel-spectrogram as input and encodes each frame with 1 codebook consisting of 8192 codes at a 21.53 Hz frame rate. The architecture and training procedure of VQ-VAE is the same as the one used in tortoise ; however, after VQ-VAE training we have filtered the codebook keeping only the first 1024 most frequent codes. In preliminary experiments, we verified that filtering the less frequent codes improved the model’s expressiveness.
Encoder: The GPT-2 encoder is a decoder-only transformer that is composed of 443M parameters, similar to tortoise . It receives as inputs text tokens obtained via a 6681-token custom Byte-Pair Encoding (BPE) gage1994new tokenizer and as output predicts the VQ-VAE audio codes. The GPT-2 encoder is also conditioned by a Conditioning Encoder, described below, that receives mel-spectrograms as input and produces 32 1024-dim embeddings for each audio sample. The Conditioning Encoder is composed of six 16-head Scaled Dot-Product Attention layers followed by a Perceiver Resampler alayrac2022flamingo to produce a fixed number of embeddings independently of the input audio length. Note that in tortoise the authors didn’t use the Perceiver Resampler, instead, they used only a single 1024-dim embedding to condition the GPT-2 encoder. In our preliminary experiments, we noticed that in massive multilingual training, the use of a single embedding leads to a decrease in the model’s speaker cloning capability. We also have romanized the texts before tokenization for the Korean, Japanese, and Chinese languages using hangul-romanize444https://pypi.org/project/hangul-romanize/, Cutlet555https://github.com/polm/cutlet, and Pypinyin666https://pypi.org/project/pypinyin/ packages respectively.
Decoder: The decoder is based on the HiFi-GAN vocoder kong2020hifi with 26M parameters. It receives the latent vectors out of the GPT-2 encoder. Due to the high compression rate of the VQ-VAE, reconstructing the audio directly from the VQ-VAE codes leads to pronunciation issues and artifacts. To avoid this issue, we follow tortoise and we have used the GPT-2 encoder latent space as input to the decoder instead of VQ-VAE codes. Our proposed decoder is also conditioned with speaker embedding from the H/ASP model heo2020clova . The speaker embedding was added in each upsampling layer via linear projection. Inspired by yourtts , to improve the speaker similarity, we also added the Speaker Consistency Loss (SCL).
To speed up inference we have trained the VQ-VAE and the encoder using 22.5 kHz audio signals. However, we train the decoder by upsampling the input vectors linearly to the correct length to produce 24khz audio.
3 Experiments
3.1 XTTS dataset
The XTTS dataset is composed of public and internal datasets. Most of our internal data is in English and only public data is used for many languages. Table 1 presents the number of hours for each language in the XTTS dataset. For English, we have used 541.7 hours from LibriTTS-R koizumi23_interspeech and 1812.7 hours from LibriLight kahn2020libri . The rest of the English data was from the internal dataset that was composed of mostly audiobook-like data. For other languages, most of the data are from the Common Voice ardila2020common dataset.
| Language | Hours | Language | Hours |
| English | 14,513.1 | Czech | 52.4 |
| German | 3,584.4 | Korean | 539.1 |
| Spanish | 1,514.3 | Hungarian | 62.0 |
| French | 2,215.5 | Japanese | 57.3 |
| Italian | 1,296.6 | Turkish | 165.3 |
| Portuguese | 2,386.8 | Arabic | 240.9 |
| Russian | 147.1 | Chinese | 233.9 |
| Dutch | 74.1 | Polish | 198.8 |
| Total | 27,281.6 | ||
3.2 Experimental setup
Previous works li2023styletts ; wang23c_interspeech ; wang2023neural ; kim2023p that explored monolingual ZS-TTS have compared their models with the YourTTS model using the multilingual checkpoint released by the authors. This comparison is not fair because the number of hours of speech and the number of speakers are really important during ZS-TTS model training. Although the YourTTS multilingual model has been trained with more than 1k speakers in English, the model was trained with only 5 speakers in French and 1 speaker in Portuguese. Considering that the YourTTS authors have used a language batch balancer it means that during the training 66% of the batch will be composed of samples from only 6 speakers. This can lead to overfitting reducing the performance in the English language (For more details see Section 4.1).
In this paper we have trained YourTTS on both LibriTTS zen2019libritts and XTTS datasets to avoid these issues. In this way, we can compare YourTTS trained on only LibriTTS with current English ZS-TTS SOTAs. We can also compare it with the original multilingual YourTTS checkpoint to exhibit the problem with the comparison done in previous works. We can also fairly compare YourTTS trained with the XTTS dataset in 16 languages with our proposal model. For both XTTS and YourTTS trained with the XTTS dataset, we have used a language batch balancer.
We carried out three training experiments:
-
•
Experiment 1: YourTTS model trained only on English using LibriTTS train-clean-460 subset (the same data used in li2023styletts ) with the bug on SCL fixed777https://github.com/Edresson/YourTTS#erratum. We trained the model for 405k steps;
-
•
Experiment 2: YourTTS trained on 16 languages using the XTTS dataset with SCL fixed for 1.96M steps;
-
•
Experiment 3: XTTS model trained with the XTTS dataset for approximately 2.5M steps.
3.3 Training setup
For YourTTS training we have used the Coqui TTS repository888https://github.com/coqui-ai/TTS. XTTS and YourTTS were trained using an NVIDIA A100 with 80 GB GPUs. YourTTS experiments were run on a single GPU. XTTS was trained on 4 GPUs.
For the YourTTS generator training and for the discrimination of vocoder HiFi-GAN we use the AdamW optimizer with betas and , weight decay , and an initial learning rate of decaying exponentially by a gamma of . We have used batch size equal to . To speed up YourTTS experiments we used transfer learning from the checkpoints made publicly available at Cmltts2023 .
For XTTS training, we used the AdamW optimizer with betas and , weight decay , and an initial learning rate of with a batch size equal to with grad accumulation equal to steps for each GPU. Following tortoise , we only applied weight decay for weights and we also decayed the learning rate using MultiStepLR by a gamma of using the milestones , , and .
4 Results and Discussion
We compared our model with the SOTAs ZS-TTS models: StyleTTS 2, Tortoise, YourTTS, HierSpeech++, and Mega-TTS 2. We also compared our model with a YourTTS model trained on our dataset for multilingual ZS-TTS. To make our work more reproducible, the evaluation code and all the audio samples are available at the ZS-TTS-Evaluation999https://github.com/Edresson/ZS-TTS-Evaluation repository.
To compare the models we have used 240 sentences for each supported language from FLORES+ nllb-22 . The sentences were chosen randomly from the subset. We have chosen the FLORES+ dataset because it has parallel translations for all languages supported by our model. In this way, we can compare all the language results using the same vocabulary. To test the ZS-TTS capability we decided to use all 20 speakers (10M and 10F) from the clean subset of the DAPS dataset101010https://zenodo.org/records/4660670. For each speaker, we randomly selected one audio segment between 3 and 8 seconds to use as a reference during the test sentence generation. We have used these samples to evaluate all languages, that way for non-English languages the models are compared in a cross-lingual way.
For YourTTS inference we have used a length scale equal to , a noise scale equal to , and a duration predictor noise scale equal to . For XTTS inference we have used a temperature equal to , length penalty equal to , repetition penalty equal to , top k equal to , and top p equal to . For Tortoise inference, we used the open-source available checkpoint with the parameters equal to , equal to , and for the rest of the parameters we have used the default values. For StyleTTS 2, we have used the open-source checkpoint111111https://github.com/yl4579/StyleTTS2#inference trained on the LibriTTS train-clean-460 subset, and for inference we have used the default parameters. For HierSpeech++, we have used the original model released by the authors on GitHub121212https://github.com/sh-lee-prml/HierSpeechpp, and for inference, we have used the default parameters. For Mega-TTS 2, we have used samples kindly provided by the authors.
For the objective evaluation, following lee2023hierspeech++ we have used the UTMOS model saeki2022utmos to predict the Naturalness Mean Opinion Score (nMOS). In lee2023hierspeech++ , the authors have used the open-source version of UTMOS131313https://github.com/tarepan/SpeechMOS, and the presented results of human nMOS and UTMOS are almost aligned. Although this can not be considered an absolute evaluation metric, it can be used to easily compare models in quality terms. To compare the similarity between the synthesized voice and the original speaker, we compute the Speaker Encoder Cosine Similarity (SECS) casanova2021sc using the SOTA ECAPA2 thienpondt2024ecapa2 speaker encoder. Following previous works wang2023neural ; kim2023p ; lee2023hierspeech++ , we evaluate pronunciation accuracy using an ASR model. For it, we have computed the Character Error Rate (CER) using the Whisper Large v3 radford2022whisper model.
For subjective evaluation, we have measured user preference scores by comparing XTTS with previous models.
4.1 English evaluation
| Model | Hours | CER() | UTMOS() | SECS() | ||||
|---|---|---|---|---|---|---|---|---|
| Ground truth | - | - | 4.2775 0.15 | 0.8952 | ||||
| Tortoise tortoise |
|
1.0934 | 4.0883 0.31 | 0.5492 | ||||
| StyleTTS 2 li2023styletts | 245 | 0.6789 | 4.4260 0.07 | 0.4728 | ||||
| Mega-TTS 2 jiang2023mega |
|
1.4269 | 4.184 0.17 | 0.6428 | ||||
| HierSpeech++ lee2023hierspeech++ | 2.7k | 0.7741 | 4.457 0.06 | 0.6530 | ||||
|
|
2.8736 | 3.6034 0.29 | 0.4621 | ||||
| YourTTS (Exp. 1) | 245 | 1.091 | 4.102 0.25 | 0.7120 | ||||
| YourTTS (Exp. 2) |
|
3.4803 | 3.6821 0.29 | 0.5651 | ||||
| XTTS (Exp. 3) |
|
0.5425 | 4.007 0.25 | 0.6423 |
Table 2 presents CER, UTMOS, and SECS for all our experiments and related works in the English language. YourTTS monolingual (Exp. 1) presents better results in speaker similarity (SECS) it also shows competitive results in CER and UTMOS metrics. However, it achieved the worst CER among the monolingual models. In fact, YourTTS prosody is not great because it sometimes produces unnatural durations. Comparing Monolingual YourTTS (Exp. 1) with the original multilingual YourTTS we can see a huge improvement. In that way, confirming the over-fitting issue, and showing that previous models miss-compared their model with YourTTS. Comparing Monolingual YourTTS (Exp. 1) with the YourTTS trained on the XTTS dataset (Exp. 2) we can see a huge gap, in all the metrics indicating that comparing multilingual models with monolingual models is not fair. It also shows that YourTTS had difficulties to learn all 16 languages well. XTTS model (Exp. 3) achieved the better CER and it achieved competitive results in all the other metrics. It is impressive especially because our model was trained in 16 languages and we are comparing it with related works that were trained only in the English language. Considering the monolingual-related works, HierSpeech++ achieved better results. It achieved better UTMOS, it also achieved the second better SECS and third better CER. Considering the multilingual-related works, Mega-TTS 2 achieved better results than the original YourTTS on English Language.
We also measure user preference scores by comparing XTTS with HierSpeech++ and Mega-TTS 2 models. Following kim2023p , We evaluate the preference for naturalness, acoustic quality, and human likeness using a comparative mean opinion score (CMOS). Preference tests for speaker similarity are reported using comparative speaker similarity mean opinion score (SMOS). SMOS evaluators are provided with the speaker reference used to generate the model outputs. The CMOS and SMOS values range on a gradual scale varying from -2 (meaning that XTTS is worse than the other model) to +2 (meaning the opposite). We obtain evaluation scores with a minimum of 8 samples from each evaluator with at least 15 evaluators per comparison experiment. Table 3 demonstrates that XTTS exhibits significantly better results in terms of naturalness, acoustic quality, and human likeness (CMOS) than previous works. It also shows that XTTS is a little worse than previous models in terms of speaker similarity (SMOS). We think that this is expected due to the complexity of massive multilingual training. These results are also aligned with the objective evaluation presented in Table 2.
| Comparison | CMOS() | SMOS() |
|---|---|---|
| XTTS vs HierSpeech++ | 0.41 0.26 | -0.31 0.36 |
| XTTS vs Mega-TTS2 | 0.92 0.22 | -0.39 0.38 |
4.2 Multilingual evaluation
For Multilingual evaluation, we compared YourTTS and XTTS trained on the XTTS dataset (respectively, Exp. 2 and Exp. 3) with the original Mega-TTS 2 model. Table 4 presents CER and SECS for XTTS, YourTTS, and Mega-TTS 2 models. XTTS model was able to achieve better CER and speaker similarity in almost all languages.
| Lang. | YourTTS | XTTS | Mega-TTS 2 | |||
|---|---|---|---|---|---|---|
| CER() | SECS() | CER() | SECS() | CER() | SECS() | |
| ar | 11.1713 | 0.4400 | 3.3503 | 0.5007 | - | - |
| cs | 4.0174 | 0.4496 | 1.3295 | 0.4655 | - | - |
| de | 2.2411 | 0.4612 | 3.1694 | 0.5175 | - | - |
| en | 2.9727 | 0.5651 | 0.5425 | 0.6423 | 1.4269 | 0.6428 |
| es | 1.0926 | 0.4879 | 1.4606 | 0.5371 | - | - |
| fr | 3.3965 | 0.4376 | 1.4937 | 0.4799 | - | - |
| hu | 4.5098 | 0.4819 | 1.4622 | 0.4570 | - | - |
| it | 1.7010 | 0.4520 | 0.7982 | 0.5008 | - | - |
| ja | 10.2808 | 0.4873 | 5.3748 | 0.5207 | - | - |
| ko | 8.8567 | 0.4836 | 4.0647 | 0.4760 | - | - |
| nl | 3.4228 | 0.4269 | 0.946 | 0.4825 | - | - |
| pl | 1.5925 | 0.4561 | 0.7593 | 0.4833 | - | - |
| pt | 1.5481 | 0.4693 | 1.1068 | 0.5033 | - | - |
| ru | 2.8566 | 0.4606 | 0.932 | 0.5012 | - | - |
| tr | 2.6367 | 0.4855 | 1.042 | 0.5031 | - | - |
| zh-cn | 14.4220 | 0.4825 | 5.2016 | 0.5023 | 6.1031 | 0.4529 |
| Avg. | 4.7949 | 0.4704 | 2.0646 | 0.5046 | - | - |
5 Speaker Adaptation
The different recording conditions are a challenge for the generalization of the ZS-TTS models yourtts . Speakers who have a voice that differs greatly from those seen in training also become a challenge tan2021survey . Nevertheless, to show the potential of the XTTS model for adaptation to new speakers/recording conditions, we selected samples of approximately 10 min of speech from well-known or unique-style voices (e.g. whispering voices) in different languages. We choose 3 speakers of English, 3 speakers of Portuguese, 1 speaker of Chinese, and 1 speaker of Arabic. We fine-tuned using these speakers and we evaluated the model using the cross-lingual approach used in Section 4; however, we replaced the DAPS speakers with the chosen speakers. The fine-tuned model improves the SECS from 0.5852 to 0.7166 when cloning these voices in a cross-lingual way. It indicates that the XTTS fine-tuning improved the speaker similarity a lot in cross-lingual speaker transfer settings. The results are available on the demo page141414https://edresson.github.io/XTTS.
6 Conclusions and future work
In this work, we presented XTTS, which achieved SOTA results in Multilingual zero-shot multi-speaker TTS in 16 languages. Furthermore, we showed that XTTS can be fine-tuned with a small portion of speech and achieves impressive results in prosody and style mimicking, being able to mimic a whispering voice style in all 16 languages even though it was trained with only 10 minutes of a whispering English voice. The XTTS model is also faster than VALL-E because our encoder produces tokens at a 21.53 Hz frame rate as compared with 75Hz from the VALL-E model. In future work, we intend to seek improvements to our VQ-VAE component to be able to generate speech with the VQ-VAE decoder instead of using the current XTTS Decoder component. We also intend to disentangle speaker and prosody information to be able to do cross-speaker prosody transfer.
7 Acknowledgments
We would like to thank all Coqui TTS151515https://github.com/coqui-ai/TTS contributors, this work was only possible thanks to the commitment of all. Also, we want to thank HierSpeech++, Tortoise, and StyleTTS 2 authors for making their work open-source and easily accessible to the community. In addition, we want to thank Ziyue Jiang, for kindly generating Mega-TTS 2 model samples used in this paper.
References
- (1) Y. Jia, Y. Zhang, R. Weiss, Q. Wang, J. Shen, F. Ren, P. Nguyen, R. Pang, I. L. Moreno, Y. Wu et al., “Transfer learning from speaker verification to multispeaker text-to-speech synthesis,” in Advances in neural information processing systems, 2018, pp. 4480–4490.
- (2) S. Choi, S. Han, D. Kim, and S. Ha, “Attentron: Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding,” in Proc. Interspeech 2020, 2020, pp. 2007–2011.
- (3) E. Casanova, C. Shulby, E. Gölge, N. M. Müller, F. S. de Oliveira, A. Candido Jr., A. da Silva Soares, S. M. Aluisio, and M. A. Ponti, “SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-To-Speech Model,” in Proc. Interspeech 2021, 2021, pp. 3645–3649.
- (4) E. Casanova, J. Weber, C. D. Shulby, A. C. Junior, E. Gölge, and M. A. Ponti, “Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,” in International Conference on Machine Learning. PMLR, 2022, pp. 2709–2720.
- (5) C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
- (6) Z. Jiang, J. Liu, Y. Ren, J. He, Z. Ye, S. Ji, Q. Yang, C. Zhang, P. Wei, C. Wang, X. Yin, Z. MA, and Z. Zhao, “Mega-tts 2: Boosting prompting mechanisms for zero-shot speech synthesis,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=mvMI3N4AvD
- (7) S. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou, “Neural voice cloning with a few samples,” in Advances in Neural Information Processing Systems, 2018, pp. 10 019–10 029.
- (8) W. Ping, K. Peng, A. Gibiansky, S. O. Arik, A. Kannan, S. Narang, J. Raiman, and J. Miller, “Deep voice 3: 2000-speaker neural text-to-speech,” in International Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=HJtEm4p6Z
- (9) J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779–4783.
- (10) E. Cooper, C.-I. Lai, Y. Yasuda, F. Fang, X. Wang, N. Chen, and J. Yamagishi, “Zero-shot multi-speaker text-to-speech with state-of-the-art neural speaker embeddings,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6184–6188.
- (11) A. Défossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” Transactions on Machine Learning Research, 2023, featured Certification, Reproducibility Certification. [Online]. Available: https://openreview.net/forum?id=ivCd8z8zR2
- (12) J. Betker, “Better speech synthesis through scaling,” arXiv preprint arXiv:2305.07243, 2023.
- (13) Y. A. Li, C. Han, V. Raghavan, G. Mischler, and N. Mesgarani, “Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- (14) S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- (15) S. Kim, K. J. Shih, R. Badlani, J. F. Santos, E. Bakhturina, M. T. Desta, R. Valle, S. Yoon, and B. Catanzaro, “P-flow: A fast and data-efficient zero-shot tts through speech prompting,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- (16) S.-H. Lee, H.-Y. Choi, S.-B. Kim, and S.-W. Lee, “Hierspeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis,” arXiv preprint arXiv:2311.12454, 2023.
- (17) J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in International Conference on Machine Learning. PMLR, 2021, pp. 5530–5540.
- (18) E. Casanova, C. Shulby, A. Korolev, A. C. Junior, A. da Silva Soares, S. Aluísio, and M. A. Ponti, “ASR data augmentation in low-resource settings using cross-lingual multi-speaker TTS and cross-lingual voice conversion,” in Proc. INTERSPEECH 2023, 2023, pp. 1244–1248.
- (19) Z. Zhang, L. Zhou, C. Wang, S. Chen, Y. Wu, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,” arXiv preprint arXiv:2303.03926, 2023.
- (20) M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V. Manohar, Y. Adi, J. Mahadeokar et al., “Voicebox: Text-guided multilingual universal speech generation at scale,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- (21) P. Gage, “A new algorithm for data compression,” C Users Journal, vol. 12, no. 2, pp. 23–38, 1994.
- (22) J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: a visual language model for few-shot learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 23 716–23 736, 2022.
- (23) J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” arXiv preprint arXiv:2010.05646, 2020.
- (24) H. S. Heo, B.-J. Lee, J. Huh, and J. S. Chung, “Clova baseline system for the voxceleb speaker recognition challenge 2020,” arXiv preprint arXiv:2009.14153, 2020.
- (25) Y. Koizumi, H. Zen, S. Karita, Y. Ding, K. Yatabe, N. Morioka, M. Bacchiani, Y. Zhang, W. Han, and A. Bapna, “LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus,” in Proc. INTERSPEECH 2023, 2023, pp. 5496–5500.
- (26) J. Kahn, M. Rivière, W. Zheng, E. Kharitonov, Q. Xu, P.-E. Mazaré, J. Karadayi, V. Liptchinsky, R. Collobert, C. Fuegen et al., “Libri-light: A benchmark for asr with limited or no supervision,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7669–7673.
- (27) R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” in Proceedings of the 12th Language Resources and Evaluation Conference, 2020, pp. 4218–4222.
- (28) W. Wang, Y. Song, and S. Jha, “Generalizable Zero-Shot Speaker Adaptive Speech Synthesis with Disentangled Representations,” in Proc. INTERSPEECH 2023, 2023, pp. 4454–4458.
- (29) H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” Interspeech 2019, 2019.
- (30) F. S. Oliveira, E. Casanova, A. C. Junior, A. S. Soares, and A. R. Galvão Filho, “Cml-tts: A multilingual dataset for speech synthesis in low-resource languages,” in Text, Speech, and Dialogue, K. Ekštein, F. Pártl, and M. Konopík, Eds. Cham: Springer Nature Switzerland, 2023, pp. 188–199.
- (31) NLLB Team, M. R. Costa-jussà, J. Cross, O. Çelebi, M. Elbayad, K. Heafield, K. Heffernan, H. Kalbassi, …, and J. Wang, “No language left behind: Scaling human-centered machine translation,” 2022.
- (32) T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,” Interspeech 2022, 2022.
- (33) J. Thienpondt and K. Demuynck, “Ecapa2: A hybrid neural network architecture and training strategy for robust speaker embeddings,” arXiv preprint arXiv:2401.08342, 2024.
- (34) A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” 2022.
- (35) X. Tan, T. Qin, F. Soong, and T.-Y. Liu, “A survey on neural speech synthesis,” arXiv preprint arXiv:2106.15561, 2021.