A Survey on LLM-Based Agentic Workflows and LLM-Profiled Components
Abstract
Recent advancements in Large Language Models (LLMs) have catalyzed the development of sophisticated agentic workflows, offering improvements over traditional single-path, Chain-of-Thought (CoT) prompting techniques. This survey summarize the common workflows, with the particular focus on LLM-Profiled Components (LMPCs) and ignorance of non-LLM components. The reason behind such exploration is to facilitate a clearer understanding of LLM roles and see how reusabile of the LMPCs.
A Survey on LLM-Based Agentic Workflows and LLM-Profiled Components
Xinzhe Li School of IT, Deakin University, Australia lixinzhe@deakin.edu.au
1 Introduction
Generative Large Language Models (GLMs or LLMs) have acquired extensive general knowledge and human-like reasoning capabilities (Santurkar et al., 2023; Wang et al., 2022; Zhong et al., 2022, 2023), positioning them as pivotal in constructing AI agents known as LLM-based agents. In the context of this survey, LLM-based agents are defined by their ability to interact actively with external tools (such as Wikipedia) or environments (such as householding environments) and are designed to function as integral components of agency, including acting, planning, and evaluating.
Purpose of the Survey
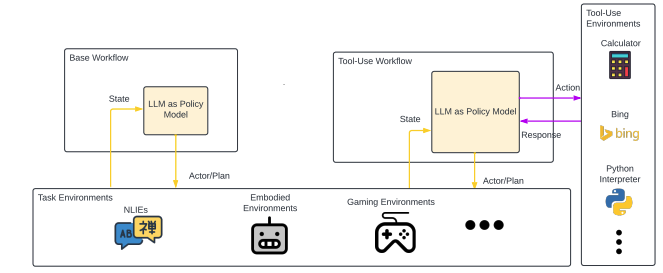
The motivation behind this survey stems from the observation that many LLM-based agents incorporate similar workflows and components, despite the presence of a wide variety of technical and conceptual challenges, e.g., search algorithms (Yao et al., 2023a), tree structures (Hao et al., 2023), and Reinforcement Learning (RL) components (Shinn et al., 2023). (Wu et al., 2023) offer a modular approach but lack integration with prevalent agentic workflows. Wang et al. (2024) provide a comprehensive review of LLM agents, exploring their capabilities across profiling, memory, planning, and action. In contrast, our survey does not attempt to cover all components of LLM-based agents comprehensively. Instead, we concentrate on the involvement of LLMs within agentic workflows and aim to clarify the roles of LLMs in agent implementations. We create common workflows incorporating reusable LLM-Profiled Components (LMPCs), as depicted in Figure 1.
Contributions
We summarize four task-agnostic LMPCs (actors, planners, evaluators, and dynamic models) and other task-dependent LMPCs (e.g., verbalizers). All existing works, like ReAct (Yao et al., 2023b), Reflexion (Shinn et al., 2023) and Tree-of-Thoughts (Yao et al., 2023a), are composed of these workflows and LMPCs, along with some specific non-LLM components. We categorize and detail three types of modular workflows: policy-only workflows, search-based workflows, and feedback-learning workflows. Additionally, §3 describes four task-agnostic LMPCs (actors, planners, evaluators, and dynamic models) and introduces task-specific LMPCs. §4 and Table 2 showcase the integration of these components into prominent models like ReAct, Reflexion, and Tree-of-Thoughts, along with non-GLM elements. The description of these workflows and common LMPCs offers several advantages: 1) It enhances the understanding of existing LLM-based agentic workflows. 2) It enables the reuse and adaptation of workflow-level and component-level implementations for constructing complex agents. 3) It simplifies the modification and extension of existing workflows, as they typically incorporate one or more of these components. §5 also includes common implementations of LMPCs to support further extensions.
| Env Types | Entities Interacted With by Agent | Action Properties | Examples of Action Instances | Examples of Env Instances |
| Task Environments | ||||
|
Gaming
Environments |
Virtual game elements (objects, avatars, other characters), and possibly other players or game narratives |
Discrete,
Executable, Deterministic |
Move(Right) | BlocksWorld, CrossWords |
|
Embodied
Environments |
Physical world (through sensors and actuators) |
Discrete,
Executable, Deterministic |
Pick_Up[Object] |
AlfWorld (Shridhar et al., 2021),
VirtualHome, Minecraft (Fan et al., 2022) |
| NLIEs | Humans (through conversation or text) |
Free-form,
Discrete, Deterministic (Single-step QA) Stochastic (Multi-step) |
The answer is Answer
Finish[Answer] |
GSM8K,
HotpotQA |
| Tool Environments ( Nested with Task Environments) | ||||
| Retrieval | Retrieval |
Discrete,
Executable, Deterministic, Non-State-Altering |
Wiki_Search[Entity] | A Wikipedia API (Goldsmith, 2023) (used by ReAct (Yao et al., 2023b)) |
| Calculator | Calculator |
Executable,
Deterministic, Non-State-Altering |
2 x 62 = << Calculator >> | Python’s eval function (used by MultiTool-CoT (Inaba et al., 2023)) |
2 Task Environments And Tool Environments
This section explores task environments and tool environments, which present different settings compared to traditional AI and reinforcement learning (RL) agent frameworks (Russell and Norvig, 2010; Sutton and Barto, 2018) . After a brief overview of standard logic-based gaming and simulated embodied environments, we focus on two specific areas: Natural Language Interaction Environments (NLIEs) and Tool Environments.
2.1 Typical Task Environments
Typically, there are two common types of task environments: 1) Rule-Based Gaming Environments: These environments, which are deterministic and fully observable, include a variety of abstract strategy games like Chess and Go, and logic puzzles such as the Game of 24 (Yao et al., 2023a) and Blocksworld (Hao et al., 2023). They demand deep logical reasoning and strategic planning to navigate and solve. 2) Simulated Embodied Environments: These settings simulate real-world physical interactions and spatial relationships. They require agents to engage in navigation, object manipulation, and other complex physical tasks, reflecting changes in the physical environment.
2.2 Natural Language Interaction Environments
With the rise of LLM agents, there is a growing trend among NLP researchers to recontextualize typical NLP tasks as agentic environments (Yao et al., 2023b; Hao et al., 2023; Yao et al., 2023a). These settings are referred to as Natural Language Interaction Environments in our survey.
In NLIEs, the environment remains static until the agent acts. Unlike typical task environments where natural language serves as an intermediary, in NLIEs, both the states and actions are defined linguistically, making the states conceptual and the actions often ambiguous and broadly defined.
Single-Step NLIEs for Question Answering
Many works (Yao et al., 2023b; Shinn et al., 2023) formulate the traditional QA setup as a single-step decision-making process, where the agent generates an answer in response to a question. The process starts with the question as the initial state and concludes when the answer is provided as an action.
Deliberate Multi-step NLIEs
For tasks where "intermediate steps are not explicitly defined", several studies have transformed NLP tasks into a Markov Decision Process to facilitate agentic workflows. For example, Hao et al. (2023) reformulate subquestions in QA tasks as actions, enabling responses to user queries through a multi-step process. This approach allows the initial question to serve as the beginning of a series of state transitions. Actions may vary from providing direct, free-form answers in single-step QA to strategically formulating subquestions that navigate the agent through sequential updates toward a comprehensive solution. This method aligns more closely with a sequential decision-making process, making it apt for deployment in planning-based agent systems. Additionally, Wan et al. (2024) suggest that "splitting an output sequence into tokens might be a good choice" for defining multi-step NLIEs methodically. Furthermore, Yao et al. (2023a) formulate two-step NLIEs for creative writing by segmenting the problem-solving process into distinct planning and execution phases.
2.3 Tool Environments
Modern LLM agents are often enhanced with external tools that improve their problem-solving capabilities (Inaba et al., 2023; Yao et al., 2023b). The design and integration of these tools add complexity, requiring careful consideration of how LLMs interact not only with the task environments but also with these auxiliary tools. Typically, actions in tool environments involve interactions with resources that remain unaffected by these interactions. For instance, retrieving data from Wikipedia constitutes a "read-only" action, which does not modify the Wikipedia database. This feature distinguishes such tool-use actions from those in conventional task environments or typical reinforcement learning (RL) settings, where actions generally alter the environmental state. Nevertheless, it is important to recognize that tool environment can be dynamic that can undergo changes externally. This aspect reflects the nature that tools should be considered external environments rather than the agent’s internal processes.
Nested NLIE-QA + Tool Environments
Tool environments are frequently established along with NLIEs to aid in solving QA tasks. Shinn et al. (2023); Yao et al. (2023b) incorporate tools to enhance the factuality of responses. They define command-like actions such as “Search” and “LookUp” to interact with Wikipedia, with “Search” suggesting the top-5 similar entities from the relevant wiki page, and “LookUp” simulating the Ctrl+F functionality in a browser. Beyond simple retrieval, Thoppilan et al. (2022) include a language translator and a calculator for dialog tasks. Similarly, Inaba et al. (2023) employ a calculator, implemented using the Python eval function, to resolve numerical queries within the NumGLUE benchmark.
3 LLM-Profiled Components
This section explores common agentic roles for which LLMs are typically profiled. The components leverage the internal commonsense knowledge and reasoning abilities of LLMs to generate actions, plans, estimate values 111Values refer to the estimated rewards (a quantitative measure of the success or desirability of the outcomes) associated with taking a certain action in a state, widely used in typical RL and MDP settings to learn policy models that perform desirable behaviors., and infer subsequent states.
Universal LLM-Profiled Components
Specifically, the following task-agnostic components are profiled and commonly used across various workflows. 1) LLM-Profiled Policy : Policy models are designed to generate decisions, which could be an action or a series of actions (plans) for execution in external environments or use in search and planning algorithms. 222Note that planning algorithms may be utilized to structure a plan of plans; for example, Tree-of-Thought employs tree search, where each node potentially represents either a single action or an entire plan. In contrast to typical RL policy models, which learn to maximize cumulative rewards through trial and error, LLM-profiled policy models, denoted as , utilize pre-trained knowledge and commonsense derived from extensive textual data. We distinguish between two types of : an actor directly maps a state to an action, whereas a planner generates a sequence of actions from a given state. 2) LLM-Profiled Evaluators : provide feedback crucial for different workflows. They evaluate actions and states in search-based workflows (Hao et al., 2023; Yao et al., 2023a) and revise decisions in feedback-learning workflows (Shinn et al., 2023; Wang et al., 2023b) (refer to §4 for more details). These evaluators are integral to both direct action assessment and broader strategic adjustments. 3) LLM-Profiled Dynamic Models : They predict or describe changes to the environment. Generally, dynamic models form part of a comprehensive world model by predicting the next state from the current state and action . While typical RL uses the probability distribution to model potential next states, LLM-based dynamic models directly predict the next state .
Task-dependent LLM-Profiled Components
In addition to the universal components, certain LLM-profiled components are tailored to specific tasks. For instance, verbalizers are crucial in embodied environments but unnecessary in NLIEs. A verbalizer translates actions and observations into inputs for planners; for example, in the Planner-Actor-Reporter workflow (Wang et al., 2023a), a fine-tuned Visual Language Model (VLM) along with translates pixel states into textual inputs. Similarly, if environmental feedback is perceivable along with states, a verbalizer may be needed to translate this feedback into verbal descriptions for , akin to reward shaping in RL where numerical stimuli are generated for policy learning. LLMs profiled as verbalizers, (Shinn et al., 2023), often guide descriptions according to specified criteria.
| Involved Workflows |
Generative-LLM
Components |
Non-Generative-LLM
Components |
Applied
Environments |
|
|---|---|---|---|---|
| ToT (Yao et al., 2023a) |
Search-based
(Fixed value models) |
, ,
(only for NLIEs-Writing) |
Search Tree | Gaming; NLIEs-Writing |
| Tree-BeamSearch (Xie et al., 2023) |
Search-based
(Fixed value models) |
, | Search Tree | NLIE-QA |
| RAP (Hao et al., 2023) |
Search-based
(Adaptive Value Estimate) |
, , | Search Tree | Gaming; NLIEs-QA |
| LLM Planner (Huang et al., 2022) | Direct | MLM for action translation | Embodied Env | |
| DEPS (Wang et al., 2023b) | Direct | ,, | Immediate actor, VLM+GLM as verbalizer | Embodied Env |
| Planner-Actor-Reporter (Dasgupta et al., 2022) | Direct | RL actor, Trained classifier+Hard code as verbalizer | Embodied Env | |
| Plan-and-solve (Wang et al., 2023a) | Direct | / | NLIEs-QA | |
| MultiTool-CoT (Inaba et al., 2023) | Tool-Use | / | NLIEs | |
| ReAct (Yao et al., 2023b) | Tool-Use | / | NLIEs | |
| Direct | / | Embodied Env | ||
| Guan et al. (2023) |
Feedback Learning
(from Tools & Humans) |
, | Domain Experts, Domain-independent Planner | Embodied Env |
| CRITIC (Gou et al., 2024) |
Feedback Learning
(from Tool & Self) |
/ | NLIEs | |
| Reflexion (Shinn et al., 2023) |
Feedback Learning
(from Self), Tool-Use |
, , | / | NLIEs-QA |
|
Feedback Learning
(from Task Env & Self), |
, , | Embodied Env | ||
| Self-refine (Madaan et al., 2023) |
Feedback Learning
(from Self) |
, , | / | NLIEs |
4 Workflows of LLM-Based Agents
This section illustrates how various LLM-profiled components are employed, as depicted in Figure 1.
4.1 Policy-Only Workflows
Base and tool-use workflows only require LLMs to be profiled as policy models. In the realm of embodied tasks, many projects deploy base workflows with to generate plans using LLM agents, such as the LLM Planner (Huang et al., 2022), Planner-Actor-Reporter (Dasgupta et al., 2022), and DEPS (Wang et al., 2023b). The Plan-and-solve approach (Wang et al., 2023a) applies a base workflow to NLIEs. In contrast, the tool-use workflow with is always applied to NLIEs like ReAct (Yao et al., 2023b), Reflexion (Shinn et al., 2023), and MultiTool-CoT (Inaba et al., 2023).
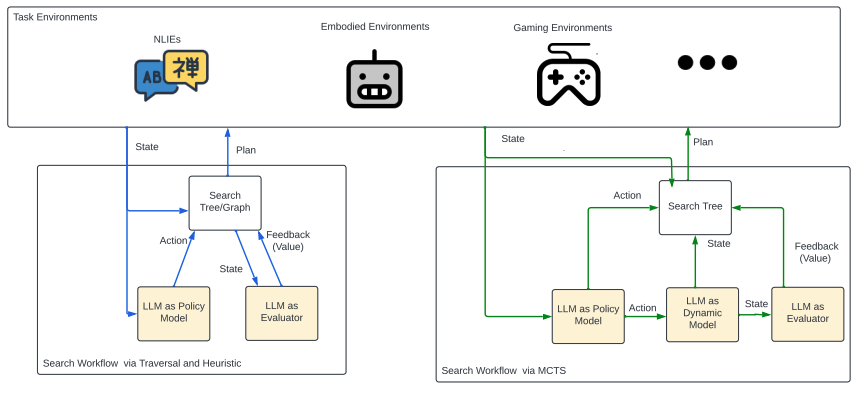
4.2 Search Workflows
Unlike base agents with , which generates a sequence of actions for a plan at one generation, actions can be organized into tree (Yao et al., 2023a; Hao et al., 2023) and graph (Liu et al., 2023) for exploration. Such planning agents with search can explore states in a non-linear manner. The tree (or solution) is constructed by adding nodes, each representing a partial solution with the input and the sequence of thoughts/actions so far. Using these data structures allows strategically search over actions generated from multiple reasoning paths, using algorithms like beam search (Xie et al., 2023), depth-/breadth-first search (DFS and BFS) (Yao et al., 2023a) and Monte-Carlo Tree Search (MCTS) (Hao et al., 2023).
LMPCs are used to explore the path towards the goal. Instead of directly applying actions on external environments, generates multiple action samples to facilitate action selection for a search process, while is used to calculate values for action/state evaluation during exploration (Yao et al., 2023a; Chen et al., 2024).
Search via Traversal and Heuristic
The ToT workflow (Yao et al., 2023a) uses to expand nodes over a tree and graph, and provides a fixed value estimate to select a node for further expansion. To expand a tree, the Tree-BeamSearch workflow (Xie et al., 2023) employs beam search, while ToT apply depth-/breadth-first search (DFS and BFS). However, the BFS is indeed beam search with beams since the values generated by the unitity model to maintain the most promising nodes. Typically, BFS does not use a utility model to decide which nodes to expand because it systematically explores all possible nodes at each depth. A CoT implementation of would reason over the resulting states and result in values to "determine which states to keep exploring and in which order" Yao et al. (2023a).
Search via MCTS
The RAP workflow (Hao et al., 2023) also builds a tree through searching and includes to expand nodes. However, by using MCTS, the nodes chosen to expand is based on dynamic value estimate, which is determined not only by but also a dynamic model and the backpropagation phrase for updating built in MCTS. Specifically, is used to simulate the next state given and (look ahead the next state), and then , working as a reward model, assesses and outputs a feedback , e.g., numerical scores or verbal judgements. After rolling out a trajectory, the values (the expected rewards) of the nodes along the trajectory will be updated.
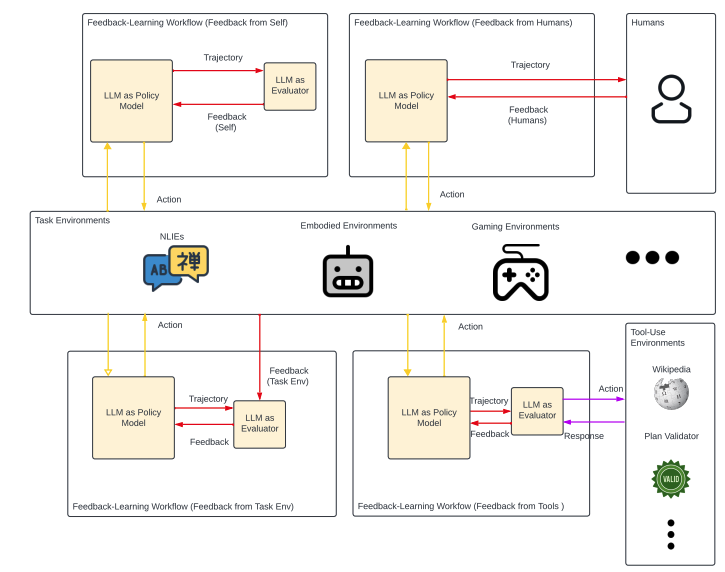
4.3 Feedback-Learning Workflows
Feedback sources in different workflows vary considerably. There are primarily four main sources of feedback: (internal feedback), humans, task environments, and tools.
Reflexion (Shinn et al., 2023) and Self-Refine (Madaan et al., 2023) utilize glmeval to reflect on the prior generations of glmpolicy, enabling glmpolicy to learn from such reflections. Unlike search-based workflows where glmeval evaluates actions or states for action selection in tree expansion, here, the feedback is used to revise decisions, allowing glmpolicy to re-generate actions or plans. In tasks that involve physical interaction, glmeval in Reflexion also integrates external information from the task environments (Shinn et al., 2023). Similarly, glmeval can receive information from tools to generate feedback, as demonstrated in the CRITIC workflow (Gou et al., 2024). In this setup, the necessity of feedback from tool environments is autonomously determined by glmeval, whereas in Reflexion, feedback transmission is hardcoded by the workflow design. Table 15 illustrates how glmeval is configured to activate tools when necessary. Humans could provide direct feedback to glmpolicy without the need of glmeval, as noted by the workflow from Guan et al. (2023).
| Zero-shot CoT | Few-shot CoT | |
|---|---|---|
| MultiTool-CoT (Inaba et al., 2023) |
ReAct (Yao et al., 2023b),
Reflexion (Shinn et al., 2023), RAP (Hao et al., 2023) |
|
|
Plan-and-Solve (Wang et al., 2023a),
LLM Planner (Huang et al., 2022) |
DEPS (Wang et al., 2023b), Planner-Actor-Reporter (Dasgupta et al., 2022) | |
| / |
RAP (Hao et al., 2023),
Tree-BeamSearch (Xie et al., 2023), Reflexion (Shinn et al., 2023), CRITIC (Gou et al., 2024) |
| Task Formulation | Feedback Types | Applicable Workflows | Example Works |
|---|---|---|---|
| Text Generation | Free-form reflection | Feedback-learning workflows | Self-Refine (Madaan et al., 2023), Reflexion (Shinn et al., 2023), CRITIC (Gou et al., 2024) |
|
Binary/Multi-class
Classification |
Discrete values | Search workflows |
RAP (Hao et al., 2023),
Tree-BeamSearch (Xie et al., 2023) ToT (Yao et al., 2023a) |
| Binary Classification | Continuous values (logits) | Search workflows for MCTS | RAP (Hao et al., 2023) |
| Multi-choice QA | Choices of top-N actions | Search workflows via traversal and heuristic | ToT (Yao et al., 2023a) |
5 Implementations of LMPCs
In this section, we explore different implementation approaches for LMPCs, covering strategies that are independent of specific workflows and tasks, implementations specifically designed for certain tasks, and those tailored to particular workflows.
5.1 Universal Implementations
Generally, LLMs can be profiled via the following prompting methods:
-
•
Input-Output (IO) prompting: In this approach, LLMs receive only the current task instance and generate a corresponding action.
-
•
CoT prompting: To facilitate the creation of intermediate reasoning steps, two types of prompts are implemented:
-
–
Zero-shot CoTs: Prompts incorporate a Chain of Thought (CoT) trigger within the task instructions, such as “Let’s think step-by-step” (Kojima et al., 2022).
-
–
Few-shot CoTs: Manually crafted reasoning steps are integrated within a few-shot learning context (Wei et al., 2022).
-
–
Table 3 categorizes LLM-profiled components according to prompting methods. Some studies (Inaba et al., 2023; Wang et al., 2023a) employ zero-shot CoT methods, but most (Yao et al., 2023b; Shinn et al., 2023; Hao et al., 2023) implement LLM policy models via few-shot CoT prompting, as the examples in Table 5 and 7 for . Zero-shot CoT implementation of often fails to produce long-horizon plans, unlike few-shot CoT prompting (Wang et al., 2023b). While effective, few-shot prompting requires manual compilation of demonstrations with reasoning sequences, leading to increased manual work and computational resource use. Methods like Auto CoTs (Zhang et al., 2023) that automatically generate few-shot demonstrations could mitigate this challenge.
5.2 Task-Specific Implementations
Implementations
For tasks that inherently involve sequential decision-making (e.g., “put a cool tomato in the microwave”), post-processing steps are often required for . When CoT methods are used, an LLM is prompted to generate a reasoning path leading to a decision. Subsequently, a call is made to extract executable actions for , as seen in the Reflexion (Shinn et al., 2023). For , the generated plans often contain high-level actions (HLA) that must be further transformed into primitive actions. Subsequently, the primitive actions have to be extracted as executable actions. Another point to consider is that although are not prompted to generate plans, it may autonomously formulate plans during the reasoning phase before deciding on the current action (Shinn et al., 2023; Yao et al., 2023b) (see an example in Table LABEL:tab:alfred_world_actor). These generated plans are maintained as internal states and do not serve as communication signals with other components. For tasks derived from NLIEs, a notable feature is that both plan generation and execution may occur within a single LLM generation, as demonstrated in the examples in Table 5.
Implementations
can be configured to assess different task-specific perspectives, with specific agentic prompts determining the evaluation criteria. For general applications, it evaluates the usefulness of actions (Hao et al., 2023) (see Table 12 and Table 13). In NLIE-QA scenarios, a common metric is the factuality (truthfulness) of responses (Gou et al., 2024), as illustrated in Table 15).
5.3 Workflow-Specific Implementations
Implementations
For tool-use and feedback learning workflows (receiving feedback from tools), two distinct implementations can be employed to enable to trigger tool usage by LLMs:
-
1.
Using In-Generation Triggers: Some approaches, like MultiTool-CoT (Inaba et al., 2023), incorporate tools during the reasoning generation process. The agent program monitors each token produced, pausing text generation when a tool trigger is detected. This pause allows for the invocation of tools, whose outputs are then inserted into the prompt to complete the reasoning. The triggers for these tools are defined either through tool descriptions, few-shot demonstrations (see an example in Table 15), or a combination of both (see an example in Table 6).
-
2.
Reasoning-Acting Strategy: Introduced by ReAct (Yao et al., 2023b), this workflow varies slightly depending on the task. For question answering (QA), the reasoning and acting sequence is predefined, with alternating prompts for thinking and acting as depicted in Table LABEL:tab:glm_actor_reflexion_hotpotqa. In contrast, the decision whether to proceed with thinking or acting in the next step is autonomously determined by , as shown in Table 8.
Implementations
can be tailored for various evaluation tasks, resulting in different types of feedback specific to particular workflows, as detailed in Table 4: 1) Generating free-form reflection: This reflective output is frequently integrated into the prompt of within feedback-learning workflows (Shinn et al., 2023; Gou et al., 2024). LLMs are designed to reflect on previous states and actions as part of the fundamental feedback-learning workflow, often incorporating external inputs from task or tool environments to enrich the reflection process. 2) Binary/Multiclass Classification: Feedback is obtained from discrete output tokens, commonly "no" or "yes." These can be converted into 0/1 values to serve as rewards in a search-based workflow for MCTS (Hao et al., 2023) or used directly to select actions in search-based workflows for DFS and BFS (Yao et al., 2023a). 3) Binary classification with scalar values: This approach differs from the previous one by employing the logit values of tokens to calculate scalar feedback values. For instance, the probability of a “yes” response is computed using the formula:
where and are the logits for the “yes” and “no” tokens, respectively. 333Note that such implementations of are not accessible via black-box LLMs. These scalar values can then be utilized as rewards in search-based workflows for MCTS. 4) Multi-choice QA: Employed in settings where a selection from multiple choices is required, supporting tasks that involve choosing from top-N possible actions, as utilized in search-based workflows for action selection (Yao et al., 2023a).
6 Future Work
As we delve deeper into LMPCs and agentic workflows, several key directions for future research are identified to advance the development of fully autonomous agents across various tasks.
Universal Tool Use
Universal Tool Use: One direction is to move beyond predefined tool use for specific tasks and develop strategies that enable LLMs to autonomously determine tool usage based on the specific requirements of the task at hand. Another direction is to integrate tool use for both policy models and evaluators. In other words, LLMs should reason over the use of the tool across various tasks and could flexibly jump between different roles. The insight for the possibility is demonstrated in Appendix E
A Unified workflow across tasks
As detailed in §5, despite some workflows conceptually integrating various perspectives, all workflows having task-specific implementations. For example, the ReAct (reasoning-and-acting strategies) seeks to harmonize actions between the tool-use environment and base workflows for task environments. However, these workflows still manifest distinct characteristics for different tasks 444For instance, hardcoded reasoning and acting steps in NLIE-QA versus autonomously determined reasoning and acting steps in embodied environments. Similarly, although the feedback-learning loop in Reflexion is theoretically unified, in practice, external feedback is generated only in embodied environments, not in NLIE-QA.
Reducing Bandwidth
There are several potential strategies for reducing the bandwidth required for LLM inference 555Here, bandwidth refers to the volume of information processed during a single LLM generation, including using Stochastic (Details in Appendix F).
7 Conclusion
This survey provides a summary of common workflows and LLM-Profiled Components to encourage the reuse of these components and the expansion of existing workflows through the integration of both task-specific LMPCs and non-LLM components. This approach aims to foster the development and reproducibility of agentic workflows.
Limitations
This survey specifically omits discussions on memory design 666Refer to Appendix G for details on memory in LLM-based agents and the integration of peripheral components into agentic workflows 777These are concisely summarized in Table 2, as our focus is solely on the involvement of LLM-profiled components within these workflows. This distinctly sets our work apart from other surveys.
References
- Chen et al. (2024) Sijia Chen, Baochun Li, and Di Niu. 2024. Boosting of thoughts: Trial-and-error problem solving with large language models. In The Twelfth International Conference on Learning Representations.
- Dasgupta et al. (2022) Ishita Dasgupta, Christine Kaeser-Chen, Kenneth Marino, Arun Ahuja, Sheila Babayan, Felix Hill, and Rob Fergus. 2022. Collaborating with language models for embodied reasoning. In Second Workshop on Language and Reinforcement Learning.
- Fan et al. (2022) Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. 2022. Minedojo: Building open-ended embodied agents with internet-scale knowledge. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Goldsmith (2023) Jonathan Goldsmith. 2023. Wikipedia: A python library that makes it easy to access and parse data from wikipedia. Python Package Index.
- Gou et al. (2024) Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2024. CRITIC: Large language models can self-correct with tool-interactive critiquing. In The Twelfth International Conference on Learning Representations.
- Guan et al. (2023) Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. 2023. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Hao et al. (2023) Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. 2023. Reasoning with language model is planning with world model. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, Singapore. Association for Computational Linguistics.
- Huang et al. (2022) Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR.
- Inaba et al. (2023) Tatsuro Inaba, Hirokazu Kiyomaru, Fei Cheng, and Sadao Kurohashi. 2023. MultiTool-CoT: GPT-3 can use multiple external tools with chain of thought prompting. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1522–1532, Toronto, Canada. Association for Computational Linguistics.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems.
- Liu et al. (2023) Hanmeng Liu, Zhiyang Teng, Leyang Cui, Chaoli Zhang, Qiji Zhou, and Yue Zhang. 2023. Logicot: Logical chain-of-thought instruction-tuning.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2023. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv preprint arXiv:2303.08896.
- Russell and Norvig (2010) Stuart J Russell and Peter Norvig. 2010. Artificial intelligence a modern approach. London.
- Santurkar et al. (2023) Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose opinions do language models reflect? arXiv preprint arXiv:2303.17548.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning.
- Shridhar et al. (2021) Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2021. {ALFW}orld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations.
- Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. 2018. Reinforcement learning: An introduction. MIT press.
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. 2022. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
- Wan et al. (2024) Ziyu Wan, Xidong Feng, Muning Wen, Ying Wen, Weinan Zhang, and Jun Wang. 2024. Alphazero-like tree-search can guide large language model decoding and training.
- Wang et al. (2024) Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):1–26.
- Wang et al. (2023a) Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023a. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2609–2634, Toronto, Canada. Association for Computational Linguistics.
- Wang et al. (2022) Siyuan Wang, Zhongkun Liu, Wanjun Zhong, Ming Zhou, Zhongyu Wei, Zhumin Chen, and Nan Duan. 2022. From lsat: The progress and challenges of complex reasoning. IEEE/ACM Trans. Audio, Speech and Lang. Proc., 30:2201–2216.
- Wang et al. (2023b) Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, and Yitao Liang. 2023b. Describe, explain, plan and select: Interactive planning with LLMs enables open-world multi-task agents. In Thirty-seventh Conference on Neural Information Processing Systems.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
- Willard and Louf (2023) Brandon T Willard and Rémi Louf. 2023. Efficient guided generation for llms. arXiv preprint arXiv:2307.09702.
- Wu et al. (2023) Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. 2023. Self-evaluation guided beam search for reasoning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Yao et al. (2023a) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023a. Tree of thoughts: Deliberate problem solving with large language models.
- Yao et al. (2023b) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023b. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations.
- Zhang et al. (2023) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2023. Automatic chain of thought prompting in large language models. In The Eleventh International Conference on Learning Representations (ICLR 2023).
- Zhong et al. (2023) Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2023. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364.
- Zhong et al. (2022) Wanjun Zhong, Siyuan Wang, Duyu Tang, Zenan Xu, Daya Guo, Yining Chen, Jiahai Wang, Jian Yin, Ming Zhou, and Nan Duan. 2022. Analytical reasoning of text. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 2306–2319, Seattle, United States. Association for Computational Linguistics.
|
Q: In a dance class of 20 students, enrolled in contemporary dance, of the remaining enrolled in jazz dance, and the rest enrolled in hip-hop dance. What percentage of the entire students enrolled in hip-hop dance?
A: Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step. Plan: Therefore, the answer (arabic numerals) is |
| Use the following tools at your disposal and answer some questions: |
| - <<Calculator >> |
| - <<Chemical reaction predictor >> |
| - <<Molar mass list >> |
| Q: Find the amount of formed on combining 2 moles of and 2 moles of . |
| A: First, use the chemical reaction predictor to determine the chemical equation for the reaction. |
| Reactants: |
| Products: ? |
| <<Chemical reaction predictor >> |
| Second, use the molar mass list to determine the molar mass of . Molar mass list |
| Third, use the calculator to calculate the amount of 2 moles of . Calculator |
| Therefore, of is formed. |
| Q: Find the amount of Calcium hydroxide that is required to react with 2 moles of Carbon dioxide to form 2 moles of Calcium carbonate along with 2 moles of Water. |
| A: |
|
Q: Julie is reading a 120-page book. Yesterday, she was able to read 12 pages and today, she read twice as many pages as yesterday. If she wants to read half of the remaining pages tomorrow, how many pages should she read?
A: Julie read twice as many pages as yesterday, so she read 12 * 2 = 24 pages today. Since yesterday, Julie read 12 + 24 = 36 pages. So, there are 120 - 36 = 84 pages left to be read. Since she wants to read half of the remaining pages, she should read 84 / 2 = 42 pages. The answer is 42. Q: Ken created a care package to send to his brother, who was away at boarding school. Ken placed a box on a scale, and then he poured into the box enough jelly beans to bring the weight to 2 pounds. Then, he added enough brownies to cause the weight to triple. Next, he added another 2 pounds of jelly beans. And finally, he added enough gummy worms to double the weight once again. What was the final weight of the box of goodies, in pounds? A: Ken poured jelly beans into the box until the weight was 2 pounds, so the weight of the box was 2 pounds at first. Then Ken added enough brownies to cause the weight to triple, so the weight of the box was 2 * 3 = 6 pounds. After Ken added another 2 pounds of jelly beans, the weight of the box was 6 + 2 = 8 pounds. Finally, he added enough gummy worms to double the weight once again, so the weight of the box was 8 * 2 = 16 pounds. The answer is 16. Q: James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year? A: James writes a 3-page letter to 2 different friends twice a week, so he writes 3 * 2 * 2 = 12 pages every week. There are 52 weeks in a year, so he writes 12 * 52 = 624 pages a year. The answer is 624. Q: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? A: Natalia sold 48 clips in April and half as many clips in May, so she sold 48 / 2 = 24 clips in May. Altogether, she sold 48 + 24 = 72 clips. The answer is 72. Q: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? A:" |
|
Interact with a household to solve a task. Here are two examples.
You are in the middle of a room. Looking quickly around you, you see a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 9, a drawer 8, a drawer 7, a drawer 6, a drawer 5, a drawer 4, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1.
Your task is to: put a cool mug in shelf. > think: To solve the task, I need to find and take a mug, then cool it with fridge, then put it in shelf. OK. > think: First I need to find a mug. A mug is more likely to appear in countertop (1-3), coffeemachine (1), cabinet (1-9), shelf (1-3), drawer (1-9). I can check one by one, starting with countertop 1. OK. > go to countertop 1 On the countertop 1, you see a knife 1, a pan 2, a pan 1, and a plate 1. … > think: Now I cool the mug. Next, I need to put it in/on shelf 1. OK. > go to shelf 1 On the shelf 1, you see a cup 2, a cup 1, a peppershaker 1, and a saltshaker 1. > put mug 3 in/on shelf 1 You put the mug 3 in/on the shelf 1. Here is the task: You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a cool tomato in microwave. > OK. > OK. > On the countertop 1, you see a dishsponge 1, and a mug 2. … |
| Solve a question answering task by having a Thought, then Finish with your answer. Thought can reason about the current situation. Finish[answer] returns the answer and finishes the task. |
| Here are some examples: |
| Question 1: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into? |
| Thought: Let’s think step by step. The eastern sector of Colorado orogeny extends into the High Plains. High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft. |
| Action: Finish[1,800 to 7,000 ft] |
| … |
| Question 6: Were Pavel Urysohn and Leonid Levin known for the same type of work? |
| Thought: Let’s think step by step. Pavel Urysohn is a mathematician. Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work. |
| Action: Finish[Yes] |
| END OF EXAMPLES) |
| Question: VIVA Media AG changed itś name in 2004. What does their new acronym stand for? |
| Thought: |
| Action: |
| Given a question, please decompose it into sub-questions. For each sub-question, please answer it in a complete sentence, ending with "The answer is". When the original question is answerable, please start the subquestion with "Now we can answer the question:" |
| Question 1: James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year? |
| Question 1.1: How many pages does he write every week? |
| Answer 1.1: James writes a 3-page letter to 2 different friends twice a week, so he writes 3 * 2 * 2 = 12 pages every week. The answer is 12. |
| Question 1.2: How many weeks are there in a year? |
| Answer 1.2: There are 52 weeks in a year. The answer is 52. |
| Question 1.3: Now we can answer the question: How many pages does he write a year? |
| Answer 1.3: James writes 12 pages every week, so he writes 12 * 52 = 624 pages a year. The answer is 624. |
| … |
| Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? |
| Question 5.1: |
Appendix A Examples: Prompting Workflows of LLM Actors
A.1 Direct Agents
A.2 Search-Based Agents
An actor is required during the expansion stage of MCTS in the RAP workflow. The prompts and expected generations are shown in Table 10.
Appendix B Prompts for LLM Evaluators
LLMs are profiled as a classification-based evaluator, as shown in Table 11 and LABEL:tab:value24game.
| Given a question and some sub-questions, determine whether the last sub-question is useful to answer the question. Output ’Yes’ or ’No’, and a reason. |
| Question 1: Four years ago, Kody was only half as old as Mohamed. If Mohamed is currently twice as 30 years old, how old is Kody? |
| Question 1.1: How old is Mohamed? |
| Question 1.2: How old was Mohamed four years ago? |
| New question 1.3: How old was Kody four years ago? |
| Is the new question useful? Yes. We need the answer to calculate how old is Kody now. |
| … |
| Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? |
| New question 5.1: Now we can answer the question: How much in dollars does she make every day at the farmers’ market? |
| Is the new question useful? |
|
Evaluate if given numbers can reach 24 (sure/likely/impossible)
10 14 10 + 14 = 24 sure … 1 3 3 1 * 3 * 3 = 9 (1 + 3) * 3 = 12 1 3 3 are all too small impossible {input} |
| Factuality |
Context: …
Sentence: … Is the sentence supported by the context above? Answer Yes or No: |
| Usefulness |
Given a question and some sub-questions, determine whether the last sub-question is useful to answer the question. Output ’Yes’ or ’No’, and a reason.
Question 1: Four years ago, Kody was only half as old as Mohamed. If Mohamed is currently twice as 30 years old, how old is Kody? Question 1.1: How old is Mohamed? Question 1.2: How old was Mohamed four years ago? New question 1.3: How old was Kody four years ago? Is the new question useful? Yes. We need the answer to calculate how old is Kody now. … Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? New question 5.1: How much in dollars does she make every day at the farmers’ market? Is the new question useful? Yes/No [Provide your reasoning here]. |
Appendix C LLMs as Dynamic Models
| Given a question, please decompose it into sub-questions. For each sub-question, please answer it in a complete sentence, ending with "The answer is". When the original question is answerable, please start the subquestion with "Now we can answer the question: ". |
| Question 1: Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn? |
| Question 1.1: How much does Weng earn per minute? |
| Answer 1.1: Since Weng earns $12 an hour for babysitting, she earns $12 / 60 = $0.2 per minute. The answer is 0.2. |
| Question 1.2: Now we can answer the question: How much did she earn? |
| Answer 1.2: Working 50 minutes, she earned $0.2 x 50 = $10. The answer is 10. |
| … |
| Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? |
| Question 5.1: How many eggs does Janet have left after eating three for breakfast and using four for muffins? |
| Answer 5.1: |
Appendix D Actor+Evaluator
| … |
| Question: Serianna is a band of what genre that combines elements of heavy metal and hardcore punk? |
| Proposed Answer: Let’s think step by step. Serianna is a band of metalcore genre. Metalcore is a subgenre of heavy metal and hardcore punk. So Serianna is a band of heavy metal and hardcore punk. So the answer is: heavy metal and hardcore punk. |
| 1. Plausibility: [Metalcore - Wikipedia] Metalcore is a fusion music genre that combines elements of extreme metal and hardcore punk. |
| [Serianna - Wikipedia] Serianna was a metalcore band from Madison, Wisconsin. The band formed in 2006… |
Appendix E Creation of a Task-Agnostic Tool Environment
Previous work always limits tools to specific applications like NLIE-QA, future work should aim to establish a comprehensive tool environment that encompasses a wide array of tools suitable for various tasks. A major challenge here is adapting a single actor to utilize such an environment effectively. While in-generation strategies are constrained as triggers are typically only straightforward for basic tools with simple arguments, a reasoning-acting strategy might offer more promise. Nonetheless, defining tools remains a challenge, especially in terms of efficient in-context learning or fine-tuning for tool utilization.
Appendix F Stochastic
Typically, a single action is sampled from the output of glmactor. Exploring a stochastic glmactor, which provides a distribution over possible actions, can enhance the stochastic nature of the glmpolicy and improve efficiency. This approach could include investigating constrained generation techniques (Willard and Louf, 2023). Additionally, using such a distribution could efficiently serve as rewards for all possible actions, potentially eliminating the need for a separate glmeval to model rewards in certain workflows. This method allows for the simultaneous expansion of multiple potential nodes in one generation step, rather than expanding each node individually in search-based workflows (Hao et al., 2023).
Appendix G Memory
The implementations of memory in the reviewed works are typically straightforward and arbitrary. Commonly, static information (e.g., profiling messages) is manually constructed and stored, whereas dynamic information (e.g., feedback) is handled via runtime data structures during interactions within each workflow. While the management of hybrid memory systems—requiring the explicit processing and management of short-term and long-term memory—is extensively discussed in a previous survey by Wang et al. (2024), such memory management aspects are beyond the focus of this survey, which centers on LLM-based workflows.