tcb@breakable
Aligning Large Language Models with Representation Editing: A Control Perspective
Abstract
Aligning large language models (LLMs) with human objectives is crucial for real-world applications. However, fine-tuning LLMs for alignment often suffers from unstable training and requires substantial computing resources. Test-time alignment techniques, such as prompting and guided decoding, do not modify the underlying model, and their performance remains dependent on the original model’s capabilities. To address these challenges, we propose aligning LLMs through representation editing. The core of our method is to view a pre-trained autoregressive LLM as a discrete-time stochastic dynamical system. To achieve alignment for specific objectives, we introduce external control signals into the state space of this language dynamical system. We train a value function directly on the hidden states according to the Bellman equation, enabling gradient-based optimization to obtain the optimal control signals at test time. Our experiments demonstrate that our method outperforms existing test-time alignment techniques while requiring significantly fewer resources compared to fine-tuning methods.
1 Introduction
Autoregressive large language models (LLMs) such as ChatGPT achiam2023gpt , PaLM chowdhery2022palm , and LLama touvron2023llama , which are trained on extensive datasets, have demonstrated impressive abilities across a diverse array of tasks. However, the heterogeneous nature of their training data may lead these models to inadvertently generate misinformation and harmful content gehman2020realtoxicityprompts ; deshpande2023toxicity ; weidinger2021ethical . This issue highlights the critical challenge of aligning language models with human objectives and safety considerations, a concern extensively discussed in recent research ngo2024the ; casper2023open .
Existing approaches to aligning LLMs generally fall into two categories: fine-tuning and test-time alignment. Among fine-tuning methods, Reinforcement Learning from Human Feedback (RLHF; stiennon2020learning ; zhu2023principled ; touvron2023llama ) is particularly powerful. RLHF involves training a Reward Model (RM) based on human preferences and then using this model to fine-tune LLMs through reinforcement learning techniques schulman2017proximal . However, RL training can be difficult and unstable. Recent works rafailov2023direct ; xu2023some ; dai2024safe propose simpler alternatives to RLHF, but these methods still demand substantial computational resources. Additionally, the necessity of fine-tuning to adapt alignment objectives complicates the ability to swiftly customize models in response to evolving datasets and emerging needs.
On the other front, several test-time alignment techniques have been developed to tailor LLMs to specific objectives without altering their weights, such as prompt engineering and guided decoding mudgal2023controlled ; khanov2024alignment ; huang2024deal . However, since these methods do not modify the underlying LLM, their alignment capability remains questionable, and performance may heavily depend on the original LLM.
In this paper, we take an alternative approach to aligning LLMs using representation editing. Instead of updating model weights, representation engineering perturbs a small fraction of model representations to steer behaviors, demonstrating great potential in improving LLMs’ truthfulness li2024inference and reducing hallucinations zou2023representation . However, previous works typically rely on adding a fixed perturbation to the representation space during the generation process and do not take into account the autoregressive generation nature of LLMs. To address this, we propose a dynamic representation editing method from a control perspective.
The foundation of our model design is the connection between discrete-time stochastic dynamical systems and autoregressive language models. Inspired by techniques from control theory, we introduce control signals to the state space of the language dynamical system to achieve specific alignment objectives. According to Bellman equation, we directly train a value function in the representation space of LLMs. At test time, we perform gradient-based optimization to determine the control signals. Since the value function is simply a two- or three-layer neural network, the intervention is very fast and efficient. To align with the objective while preserving the generation quality of the original LLMs, we regularize the control signal to be as small as possible. This regularization is equivalent to control the step size or the number of steps during interventions at test time.
The main contributions of our work are: (1) We propose a new representation editing method to align LLMs from a control perspective. Our model, named Re-Control, does not require extensive computing resources compared to fine-tuning methods. Unlike existing test-time alignment methods such as prompt engineering and guided decoding, our approach perturbs the representation space of LLMs, offering greater flexibility. (2) We propose training a value function and computing the control signal at test time using gradient-based optimization. (3) We empirically show that Re-Control outperforms various existing test-time alignment methods and exhibits strong generalization ability.
2 Related Works
2.1 Large Language Model Alignment
Alignment through Fine-tuning:
RLHF has been a popular method in LLM alignment stiennon2020learning ; zhu2023principled ; touvron2023llama . While effective, RLHF entails a complex process that involves training multiple models and continuously sampling from the LM policy during the learning loop. DPO rafailov2023direct simplifies the RLHF framework by using a direct optimization objective derived from Proximal Policy Optimization (PPO; schulman2017proximal ), reducing the process to supervised training of the policy model alone. However, DPO is memory-intensive and resource-demanded as it requires managing two policies simultaneously. Contrastive Preference Optimization (CPO; xu2024contrastive ) mitigates these challenges by utilizing a uniform reference model, which not only reduces memory requirements but also enhances training efficiency. Alternative methods such as yuan2023rrhf ; song2023preference simplify model management and parameters tuning in the RLHF framework by adopting a supervised fine-tuning (SFT) approach. Additionally, RSO liu2023statistical and RAFT dong2023raft employ rejection sampling to refine the alignment process. RSO focuses on estimating the optimal policy more accurately, while RAFT uses high-quality samples for iterative fine-tuning of the policy model.
Despite these advancements, a notable limitation of aligning LLMs through fine-tuning methods is their inflexibility in adapting quickly to emerging data and standards without extensive retraining, which poses challenges in dynamic environments where rapid adaptability is crucial.
Test time alignment:
The other branch of methods to align LLMs involves adjustments at inference time. The simplest way is through prompt engineering. Existing works askell2021general ; zhang2023defending ; lin2023unlocking have proposed the use of prompts that blend instructions with in-context examples to enhance the honesty and harmlessness of responses from LLMs. For instruction-tuned models, it has been shown that simply employing prompt engineering—without the addition of in-context examples—can enhance the safety of the models, as reported in touvron2023llama .
In addition to prompting methods, guided decoding techniques have also been explored. ARGS khanov2024alignment , incorporate the score of a pre-trained reward model into the token probabilities. Other works mudgal2023controlled ; han2024value learn a prefix scorer for the reward that is used to steer the generation from a partially decoded path. Moreover, DeAL huang2024deal approaches the decoding process as an A* search agent, optimizing the selection of tokens
2.2 Representation Engineering
Representation engineering zou2023representation introduces steering vectors to the representation space of LLMs to enable controlled generation without resource-intensive fine-tuning. This concept of activation perturbation has its origins in plug-and-play controllable text generation methods Dathathri2020Plug , which utilizes a separate classifier for each attribute to perturb the model’s activations, thereby producing text that aligns more closely with the classifier’s target attributes. Prior research have demonstrated that both trained and manually selected steering vectors can facilitate style transfer in language models subramani2022extracting ; turner2023activation . Li et al. li2024inference have shown that steering the outputs of attention heads can enhance the truthfulness of LLMs. Liu et al. liu2023context suggest that standard in-context learning can be seen as a process of "shifting" the latent states of a transformer. More recently, representation fine-tuning wu2024reft ; wu2024advancing has been introduced as a direct substitute for existing parameter-efficient fine-tuning methods. Remarkably, Wu et al.wu2024reft show that the representation editing can even surpass fine-tuning based methods by intervening on hidden representations within the linear subspace defined by a low-rank projection matrix. The effectiveness of these approaches confirms that the representations of pretrained LMs are semantically rich. Liu et al. liu2023aligning also explore representation engineering for aligning LLMs. However, their approach is notably more complex, necessitating an initial fine-tuning phase to capture the representation pattern, followed by a subsequent fine-tuning of the final model based on these patterns.
2.3 Control Theory and Large Language Models
Understanding LLMs from a dynamical system perspective is a burgeoning field. Current research leverages control theory to enhance prompt design, demonstrating that LLMs can be effectively directed by carefully chosen inputs ("prompts") given sufficient time and memory resources. The seminal work by Soatto et al. soatto2023taming investigates the controllability of LLMs, focusing on ’meaningful sentences’ defined as the sigma-algebra generated by text fragments on the Internet. Subsequent research bhargava2023s broadens this analysis to encompass arbitrary sentences. Additionally, Luo et al. luo2023prompt expand the scope to include multi-round interactions with LLMs and multi-agent collaboration, offering new insights into the dynamical capabilities of these models. To the best of our knowledge, our study is the first to investigate optimal control for representation editing in LLMs.
3 Background: Stochastic Dynamical System and Optimal Control
Optimal control theory todorov2006 ; berkovitz2013optimal , when applied to discrete-time dynamical systems robinson2012introduction , seeks to determine a control strategy that maximizes a cumulative reward over a sequence of time steps. This framework is particularly relevant to fields such as robotics togai1985analysis ; tolani2021visual ; kormushev2013reinforcement ; ibarz2021train , automated trading systems liu2021finrl ; wei2017adaptive ; dempster2006automated ; liu2021finrl , autonomous vehicle navigation josef2020deep ; wang2019autonomous ; isele2018navigating ; koh2020real , where decisions must be made sequentially to achieve a long-term goal.
Formally, a discrete-time stochastic dynamical system can be defined as follows:
where denotes the system’s state at time , and represents the control input at the same time step. The stochastic term is typically modeled as a random noise drawn from a known probability distribution (e.g. Brownian motion), which introduces uncertainty into the state transition process. The function specifies the state transition dynamics influenced by the current state, control input, and the stochastic nature of the environment.
The process begins from an initial state , which serves as the starting point for all subsequent decisions and state transitions. The aim of optimal control is to determine a control policy , mapping states to optimal control actions, that maximizes the expected cumulative reward:
where is the cumulative reward and is the intermediate reward received at each time step.
Methods such as policy iteration bertsekas2011approximate ; liu2013policy can be used to determine the optimal control policy. Each iteration involves two steps. First, we evaluate the current policy by solving the Bellman equation:
where represents the expected return over when the system starts in state and follows policy .
Next, we improve the policy:
These evaluation and improvement steps are repeated until convergence.
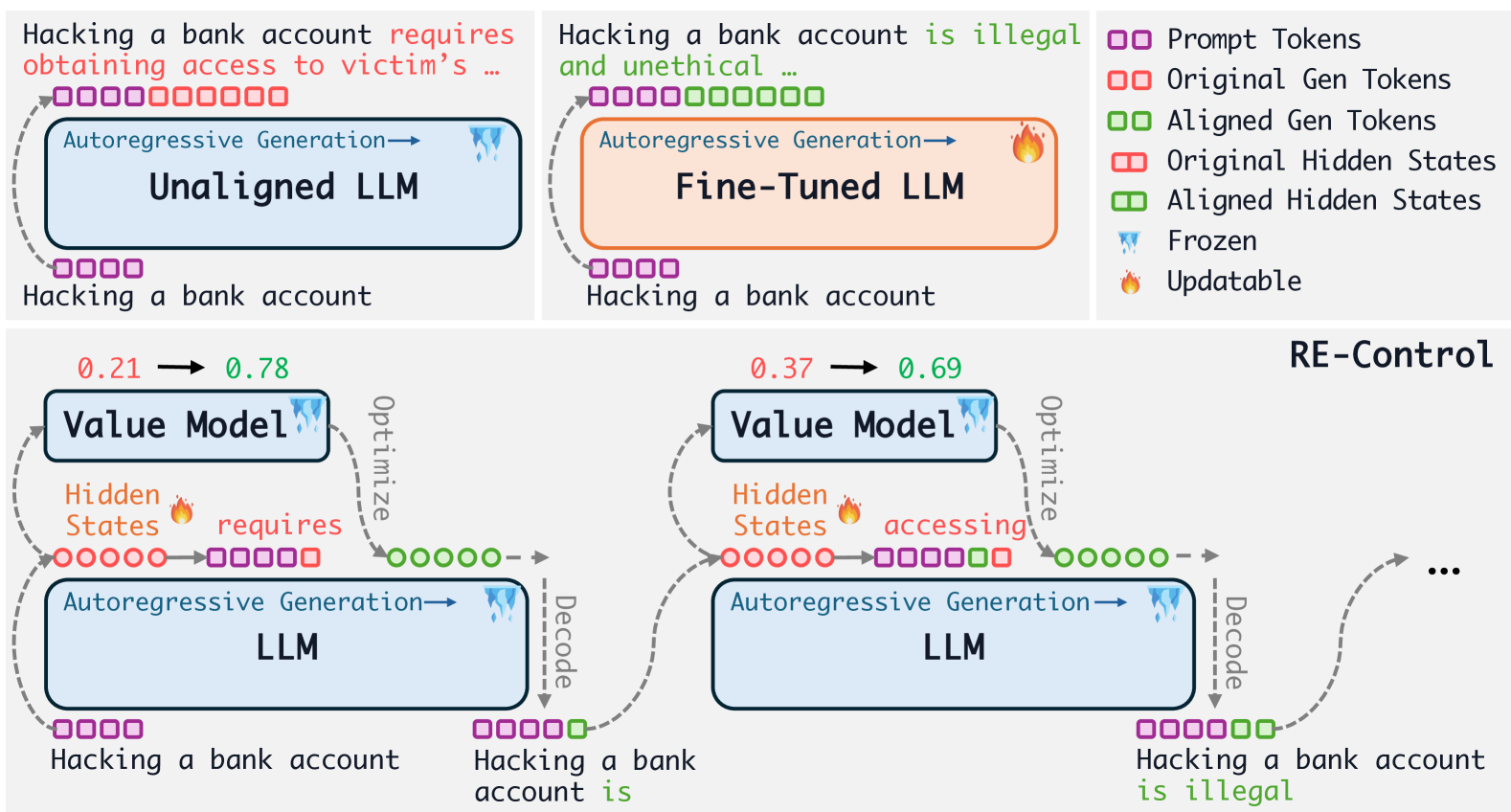
4 Aligning Large Language Models from a Control Perspective
In this section, we present our method, Re-Control. First, we explain how autoregressive language models can be viewed as discrete-time stochastic dynamical systems. Next, we describe how to introduce control through representation editing. Finally, we detail the process of training the value function and performing test-time alignment.
4.1 Autoregressive LLMs are Discrete-Time Stochastic Dynamical Systems
A pre-trained autoregressive language model processes a sequence of input tokens and predicts subsequent tokens by recursively processing the sequence. we focus on the transformer-based architecture vaswani2017attention prevalent in modern language models brown2020language ; team2023gemini ; achiam2023gpt .
Definition 4.1 (Language dynamical system)
The behavior of a language dynamical system is governed by a function , which acts as the state transition function, defined as:
Here, is the newly generated token at each time step. comprises key-value pairs accumulated from previous time steps, represented as . Each pair corresponds to the key-value pairs generated from the -th layer at time . is a linear transformation that maps the logits to a probability distribution over the vocabulary space . The system’s evolution continues until , where represents a special stopping token that signifies the end of the system.
In this system, the hidden state along with the logits corresponds to the state in a traditional stochastic dynamical system. The newly sampled token at each time step plays a role similar to the random variable , introducing stochasticity into the system. The initial state, , is set by a given prompt , marking the starting point of the dynamical process.
However, unlike typical dynamical systems, this model lacks a direct control signal, functioning as an uncontrolled system. Next, we will explore how optimal control techniques can be applied to align the behavior of pre-trained language models with specific objectives.
4.2 Adding Control Signals to Large Language Models with Representation Editing
We introduce control signals into the state of the language dynamical system at each time step to achieve specific alignment objectives. Thus, the controlled language dynamical system is described as follows:
As we can see, adding control to such a language dynamical system is similar to representation editing. However, unlike existing representation editing methods li2024inference , which add a fixed vector during the generation process, we dynamically perturb the representation space from a control perspective, offering greater flexibility. In practice, it is not necessary to add controls to the entire state space; perturbing only a subset is sufficient. For example, we can perturb only the state of the last layer.
For an alignment task, the reward function is defined as:
where denotes the concatenation of the prompt and the model’s response generated up to time . A reward is given only upon completion of decoding, with no reward assigned to a partial decoding path. The reward on the final response can come from a pre-trained reward model stiennon2020learning based on human preference data or specified by heuristics, such as a concise summary in fewer than 10 words, with a reward of 1 if achieved and 0 if it fails.
Our objective is to determine the control signals at each time step that maximize the expected reward while not deviating too much from the original state:
| (1) |
where is a hyper-parameter for regularization. The regularization term is designed to prevent reward overoptimization and maintain the generation quality of the perturbed LLMs.
4.3 Training of Value Function
Traditional policy iteration involves multiple iterations of policy evaluation and policy improvement. However, in our case, to avoid significant deviation from the pre-trained model’s original state, we perform only one-step policy iteration. The initial policy is to not add any control signal to LLMs, i.e., . Therefore, we only need to estimate the value function of the original language model.
The value function of the initial zero policy satisfies the Bellman equation sutton2018reinforcement :
To construct the training dataset for the value function, for a prompt in the given training dataset, we sample responses . We score each response using the reward function and extract the states along the trajectories . Our training objective is:
Here, and represent the state and the generated token of the LLM at generation time step . indicates that the gradient is not propagated through . The target value is computed as follows:
Parameterization of the Value Function
The simplest approach is to add control signals only to the logit . In this case, we can directly use a simple neural network as the value function. If we want to incorporate the attention key-value pairs , we need to handle the varying size of the input. To achieve this, we can initialize a vector and compute an attention weight by taking the dot product with the keys to aggregate all value embeddings. Then, we concatenate the aggregated value embedding with and input it into a neural network. In practice, we find that parameterizing the value function as a two- or three-layer neural network is sufficient for achieving good empirical performance.
4.4 Test-time Intervention
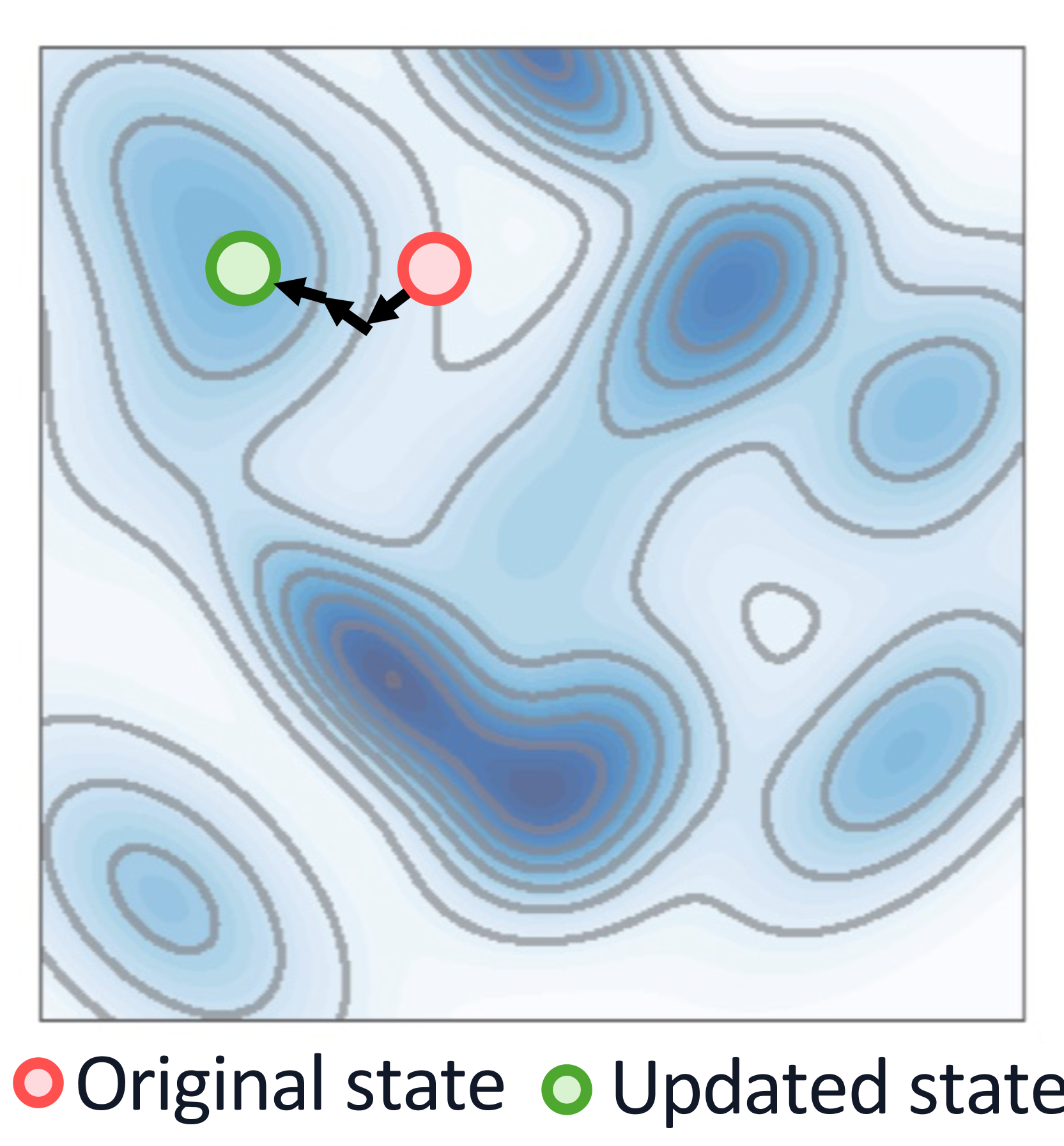
At inference time, we can directly perform gradient ascent on the model states to maximize the expected value score, as we train the value function on the state space. Our goal is not to find the global optimum in the state space but to improve the current state while staying close to the original state. Specifically, we initialize and update through gradient ascent as:
where is the step size. This update step can be repeated times.
Implicit Regularization. Note that this update already incorporates the regularization effect. The regularization is achieved by using a small step size and a limited number of updates , ensuring that the control signal remains small. After adding the final control signals to the hidden states, we perform a forward pass in the language model to generate a new token.
5 Experiment
In this section, we conduct experiments to examine the effectiveness of our method. Our focus is on aligning large language models (LLMs) for helpfulness and minimizing harmfulness, which are essential qualities for an AI assistant.
5.1 Experimental Setup
We evaluate our method on the HH-RLHF bai2022training dataset, which is the most widely used dataset for LLM alignment. This dataset is used to improve the AI assistant’s helpfulness and harmlessness, comprising 161,000 training samples and 8,550 test samples. Each sample contains a prompt and two responses with one preferred over another. For the base model, we adopt Vicuna-7B chiang2023vicuna and Falcon-7B-Instruct almazrouei2023falcon as the instructed fine-tuned AI assistant. We evaluate these models by generating text responses based on test prompts from of HH-RLHF. For the reward model, we use a publicly available one that employs LLaMA-7B111https://huggingface.co/argsearch/llama-7b-rm-float32 as the backbone, trained on HH-RLHF using the pairwise reward loss ouyang2022training . We train the value network on the last layer of the hidden states , and at test time, we add control signals only to this layer. For future studies, we can also explore adding controls to the attention key-value pairs which should further improve the performance.
Following khanov2024args , we leverage Diversity, Coherence, Average Reward, and Win Rate as our evaluation metrics. Diversity measures the frequency of repeated n-grams in generated text. The diversity score for a given response is represented as . A higher diversity score suggests a broader vocabulary range in text generation. Coherence calculates the cosine similarity between the embeddings of the prompt and its continuation. We use the pre-trained SimCSE sentence embedding model, following the approach outlined in yixuansu2022 , to obtain these embeddings. Average Reward is the mean of the rewards evaluated by the reward model across all responses corresponding to the test prompts. Win Rate is the rate at which the model’s response is rated better than the preferred response in the dataset. Following khanov2024args ; chiang2023vicuna , we use GPT-4 as the judge, having it review and score two responses to the same prompt on a scale from 1 to 10. We provide explicit instructions to assess the responses based on criteria such as helpfulness, harmlessness, relevance, accuracy, and insightfulness. The detailed prompt is provided in Appendix D. We randomly sample 300 prompts from the test set of HH-RLHF for the GPT-4 evaluation. To mitigate position bias, we randomize the order in which we present the generated responses to GPT-4, as in zheng2023judging .
We randomly sample 1000 data points from the training set as a separate validation set to select the hyperparameters—the step size and the number of updates —based on the sum of coherence, diversity, and average reward. Additional experimental details are provided in Appendix C.
5.2 Baselines
We compare our method with several existing test-time alignment methods.
Prompt Engineering: In this method, we instruct the model within the prompt to provide responses that are more helpful and harmless touvron2023llama . Controlled Decoding (CD): During the decoding process of LLMs, this method combines token probabilities with reward scores. We consider two versions. The first version khanov2024args directly uses a reward model trained on human preference data, requiring the tokenization strategies of both the reward model and the base model to be the same. The second version mudgal2023controlled trains a prefix scorer to predict the expected reward from partially generated responses. We refer to it as CD prefix. Static Representation Editing (RE): Following li2024inference , we first train a linear regression layer on the hidden state of an LLM, after feeding it the prompt, to predict the expected reward. At test time, we shift the activation space along the direction of the weights of the linear layer. Unlike our method, this approach adds a fixed vector to the representation space along the generation trajectory.
We provide more implementation details of the baselines in Appendix C.
| Backbone | Model | Diversity | Coherence | Average Reward | Win Rate (%) | Inference time (hour) |
|---|---|---|---|---|---|---|
| Vicuna 7B | Base | 0.816 | 0.568 | 5.894 | 57.6 | 0.60 |
| Prompting | 0.817 | 0.570 | 5.913 | 66.0 | 0.69 | |
| Static RE | 0.818 | 0.568 | 5.907 | 64.3 | 0.65 | |
| CD | 0.806 | 0.608 | 5.458 | 72.3 | 47.43 | |
| CD Prefix | 0.805 | 0.576 | 6.105 | 74.6 | 32.13 | |
| Ours | 0.824 | 0.579 | 6.214 | 75.6 | 0.85 | |
| CD Prefix + Prompting | 0.812 | 0.593 | 6.120 | 74.3 | 47.16 | |
| Ours + Prompting | 0.830 | 0.577 | 6.267 | 80.3 | 0.93 | |
| Falcon 7B | Base | 0.705 | 0.613 | 3.439 | 42.3 | 0.67 |
| Prompting | 0.746 | 0.620 | 4.010 | 52.3 | 0.59 | |
| Static RE | 0.698 | 0.610 | 3.449 | 52.6 | 0.56 | |
| CD | N/A | N/A | N/A | N/A | N/A | |
| CD Prefix | 0.648 | 0.575 | 4.397 | 49.6 | 48.13 | |
| Ours | 0.699 | 0.615 | 3.512 | 58.0 | 1.93 | |
| CD Prefix + Prompting | 0.571 | 0.638 | 3.619 | 51.6 | 47.87 | |
| Ours + Prompting | 0.741 | 0.619 | 4.083 | 62.6 | 2.00 |
5.3 Experimental Results
Table 1 shows the performance of all the methods. Our findings can summarized as follows: (1) Re-Control achieves the highest alignment score in terms of the win rate evaluated by GPT-4. Moreover, it maintains generation quality, as measured by diversity and coherence. While controlled decoding achieves the best average reward on Falcon-7B, Re-Control outperforms it in terms of the other three metrics. This suggests that controlled decoding may encounter reward overoptimization. (2) The strongest baseline is controlled decoding. However, controlled decoding is 20 times slower than Re-Control. This is because controlled decoding needs to evaluate multiple candidate tokens and perform forward passes through the entire reward model repeatedly, while Re-Control only requires optimization through a value function that is a two- or three-layer neural network, making it much faster. (3) Combining prompt engineering with Re-Control can further improve alignment performance in terms of both average reward and GPT-4 evaluation. Specifically, it outperforms the strongest baseline by 5.5% and 9.7% in terms of the GPT-4 win rate. In contrast, controlled decoding with prompting shows only marginal improvements. This might be because Re-Control perturbs the activation space of the LLM, which is more flexible than merely changing the final token probability. (4) Re-Control significantly outperforms static representation editing by 11.7% on Vicuna-7B and 9.7% on Falcon-7B. This is because Re-Control dynamically adjusts the representation during the autoregressive generation process, offering more control. In contrast, static representation editing applies a fixed shift, which is more rigid.
In Table 2, we present a qualitative example demonstrating how Re-Control can steer the base model to output more helpful and harmless responses. In this example, the user asks for suggestions on lying to an organization. The base model provides various tactics, while Re-Control refuses to give such suggestions and emphasizes that lying can damage relationships and trust within an organization.
6 Further Analysis
6.1 Comparison with Training-time Alignment

In the previous section, we compared Re-Control with test-time alignment methods that do not require extensive computing resources. This feature is crucial when we need the model to quickly adapt to different requirements, as it only involves training a simple value network with just two or three layers. In this subsection, we further compare Re-Control with fine-tuning based approaches. Figure 3 shows the comparison between Re-Control, Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO) rafailov2023direct . All the models use Vicuna-7B as the base model. The training details for PPO and DPO are provided in C. We observe that Re-Control achieves a higher GPT-4 win rate and average reward compared to both PPO and DPO. Furthermore, Re-Control also outperforms these methods in terms of diversity and coherence. Overall, the results indicate that our approach is a competitive alternative to fine-tuning methods.
6.2 Generalization to a new input distribution
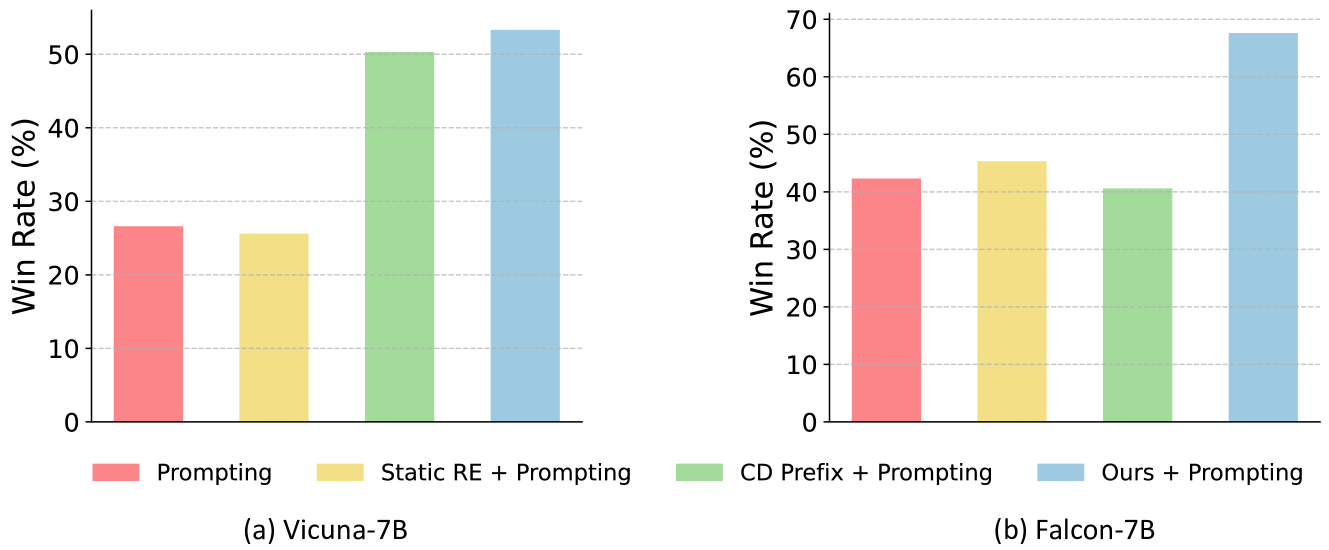
An important question is how our method can generalize to a new input distribution different from the value function is trained on. To investigate this question, we further test on a out-of-distribution (OOD) dataset HarmfulQA bhardwaj2023red . The test split of HarmfulQA contains harmful questions to evaluate language model performance against red-teaming attempts. We focus on the GPT-4 evaluation since the reward model will not be accurate for the OOD data. We compare Re-Control + promoting with other test-time alignment methods + prompting. Figure 4 presents the results. As illustrated, Re-Control + Prompting achieves the highest performance in terms of the GPT-4 win rate on both Vicuna-7B and Falcon-7B. This is an important ability especially when we want to deploy the LLM in the open world.
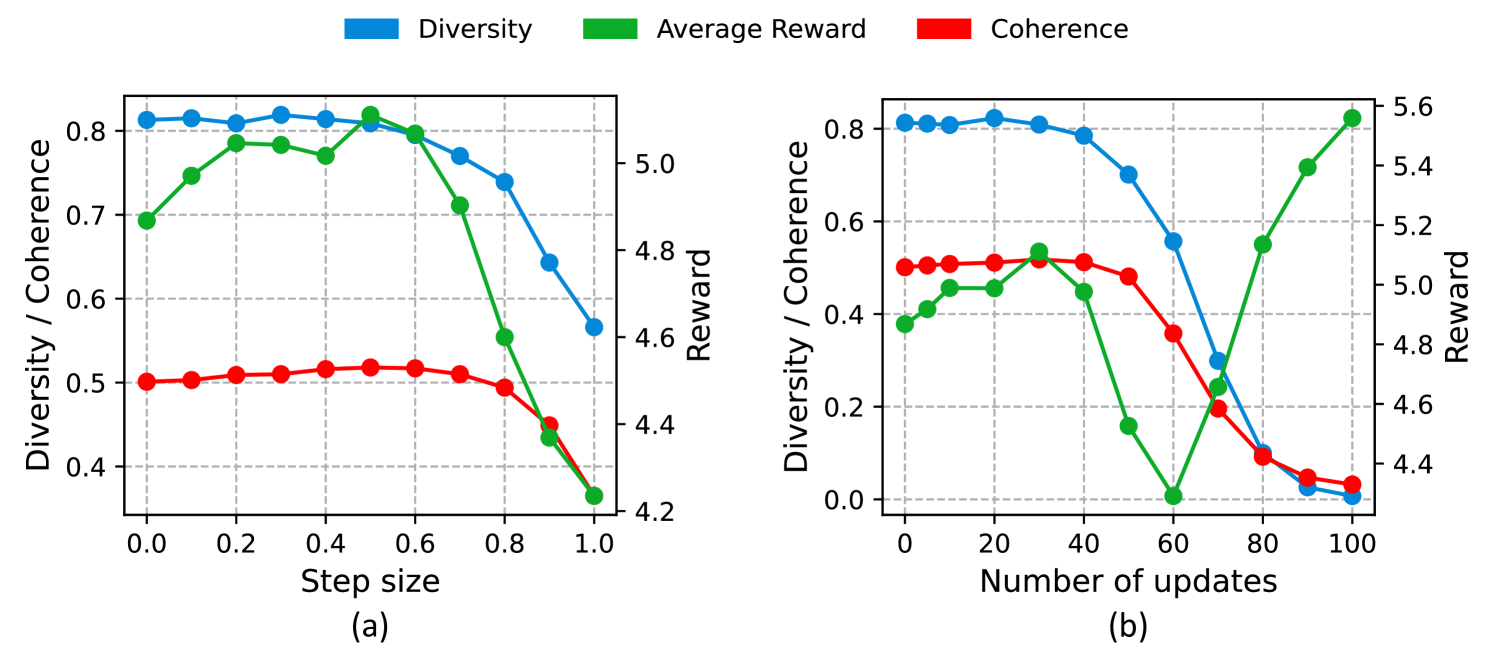
6.3 Hyperparameter Study
To better understand the characteristics of Re-Control, we vary two hyperparameters—the step size and the number of updates for the test-time intervention—and measure key performance statistics. Figure 5 shows the diversity, coherence, and average reward of the generated responses in relation to these two parameters on 1000 randomly sampled prompts from HH-RLHF.
As we can see, increasing the step size initially improves the reward, but beyond a certain point, larger step sizes fail to compute the control signal accurately, causing the reward to decrease. The influence of the number of updates shows a more complex pattern: the reward first improves, then decreases, and improves again, indicating a transition from escaping a local minimum to moving towards another minimum. The coherence and diversity metrics drop to nearly zero, which is evidence of reward overoptimization. Thus, regularization to prevent significant deviation from the original states is essential. In practice, we select these two hyperparameters based on the sum of all three metrics on the validation set.
7 Conclusion, Limitations and Future Work
In this paper, we propose Re-Control to align large language models (LLMs) at test-time using representation editing. We view autoregressive language models as discrete-time stochastic dynamical systems and introduce control signals to their representation space. Throughout the generation process, the representation space is dynamically perturbed to achieve higher value scores. Our method does not require fine-tuning the LLMs and offers more flexibility than existing test-time alignment methods such as prompting and guided decoding. We empirically show that Re-Control outperforms existing test-time alignment methods and exhibits strong generalization ability. Due to the space limit, we discuss limitations and future work in Appendix A.
References
- (1) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- (2) Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. The falcon series of open language models. arXiv preprint arXiv:2311.16867, 2023.
- (3) Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861, 2021.
- (4) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Ben Mann, and Jared Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- (5) Leonard David Berkovitz. Optimal control theory, volume 12. Springer Science & Business Media, 2013.
- (6) Dimitri P Bertsekas. Approximate policy iteration: A survey and some new methods. Journal of Control Theory and Applications, 9(3):310–335, 2011.
- (7) Rishabh Bhardwaj and Soujanya Poria. Red-teaming large language models using chain of utterances for safety-alignment. arXiv preprint arXiv:2308.09662, 2023.
- (8) Aman Bhargava, Cameron Witkowski, Manav Shah, and Matt Thomson. What’s the magic word? a control theory of llm prompting. arXiv preprint arXiv:2310.04444, 2023.
- (9) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- (10) Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback. Transactions on Machine Learning Research, 2023.
- (11) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023.
- (12) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arxiv 2022. arXiv preprint arXiv:2204.02311, 10, 2022.
- (13) Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback. In The Twelfth International Conference on Learning Representations, 2024.
- (14) Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations, 2020.
- (15) Michael AH Dempster and Vasco Leemans. An automated fx trading system using adaptive reinforcement learning. Expert systems with applications, 30(3):543–552, 2006.
- (16) Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. Toxicity in chatgpt: Analyzing persona-assigned language models. arXiv preprint arXiv:2304.05335, 2023.
- (17) Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767, 2023.
- (18) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, 2020.
- (19) Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. Finding alignments between interpretable causal variables and distributed neural representations. In Causal Learning and Reasoning, pages 160–187. PMLR, 2024.
- (20) Nyoman Gunantara. A review of multi-objective optimization: Methods and its applications. Cogent Engineering, 5(1):1502242, 2018.
- (21) Seungwook Han, Idan Shenfeld, Akash Srivastava, Yoon Kim, and Pulkit Agrawal. Value augmented sampling for language model alignment and personalization. arXiv preprint arXiv:2405.06639, 2024.
- (22) James Y Huang, Sailik Sengupta, Daniele Bonadiman, Yi-an Lai, Arshit Gupta, Nikolaos Pappas, Saab Mansour, Katrin Kirchoff, and Dan Roth. Deal: Decoding-time alignment for large language models. arXiv preprint arXiv:2402.06147, 2024.
- (23) Julian Ibarz, Jie Tan, Chelsea Finn, Mrinal Kalakrishnan, Peter Pastor, and Sergey Levine. How to train your robot with deep reinforcement learning: lessons we have learned. The International Journal of Robotics Research, 40(4-5):698–721, 2021.
- (24) David Isele, Reza Rahimi, Akansel Cosgun, Kaushik Subramanian, and Kikuo Fujimura. Navigating occluded intersections with autonomous vehicles using deep reinforcement learning. In 2018 IEEE international conference on robotics and automation (ICRA), pages 2034–2039. IEEE, 2018.
- (25) Shirel Josef and Amir Degani. Deep reinforcement learning for safe local planning of a ground vehicle in unknown rough terrain. IEEE Robotics and Automation Letters, 5(4):6748–6755, 2020.
- (26) Maxim Khanov, Jirayu Burapacheep, and Yixuan Li. Alignment as reward-guided search. In The Twelfth International Conference on Learning Representations, 2024.
- (27) Maxim Khanov, Jirayu Burapacheep, and Yixuan Li. Args: Alignment as reward-guided search. arXiv preprint arXiv:2402.01694, 2024.
- (28) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- (29) Songsang Koh, Bo Zhou, Hui Fang, Po Yang, Zaili Yang, Qiang Yang, Lin Guan, and Zhigang Ji. Real-time deep reinforcement learning based vehicle navigation. Applied Soft Computing, 96:106694, 2020.
- (30) Petar Kormushev, Sylvain Calinon, and Darwin G Caldwell. Reinforcement learning in robotics: Applications and real-world challenges. Robotics, 2(3):122–148, 2013.
- (31) Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36, 2023.
- (32) Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. The unlocking spell on base llms: Rethinking alignment via in-context learning. arXiv preprint arXiv:2312.01552, 2023.
- (33) Derong Liu and Qinglai Wei. Policy iteration adaptive dynamic programming algorithm for discrete-time nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 25(3):621–634, 2013.
- (34) Sheng Liu, Lei Xing, and James Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering. arXiv preprint arXiv:2311.06668, 2023.
- (35) Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J Liu, and Jialu Liu. Statistical rejection sampling improves preference optimization. arXiv preprint arXiv:2309.06657, 2023.
- (36) Wenhao Liu, Xiaohua Wang, Muling Wu, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Aligning large language models with human preferences through representation engineering. arXiv preprint arXiv:2312.15997, 2023.
- (37) Xiao-Yang Liu, Hongyang Yang, Jiechao Gao, and Christina Dan Wang. Finrl: Deep reinforcement learning framework to automate trading in quantitative finance. In Proceedings of the second ACM international conference on AI in finance, pages 1–9, 2021.
- (38) Yifan Luo, Yiming Tang, Chengfeng Shen, Zhennan Zhou, and Bin Dong. Prompt engineering through the lens of optimal control. arXiv preprint arXiv:2310.14201, 2023.
- (39) Sidharth Mudgal, Jong Lee, Harish Ganapathy, YaGuang Li, Tao Wang, Yanping Huang, Zhifeng Chen, Heng-Tze Cheng, Michael Collins, Trevor Strohman, et al. Controlled decoding from language models. arXiv preprint arXiv:2310.17022, 2023.
- (40) Richard Ngo, Lawrence Chan, and Sören Mindermann. The alignment problem from a deep learning perspective. In The Twelfth International Conference on Learning Representations, 2024.
- (41) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- (42) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- (43) Rex Clark Robinson. An introduction to dynamical systems: continuous and discrete, volume 19. American Mathematical Soc., 2012.
- (44) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- (45) Stefano Soatto, Paulo Tabuada, Pratik Chaudhari, and Tian Yu Liu. Taming ai bots: Controllability of neural states in large language models. arXiv preprint arXiv:2305.18449, 2023.
- (46) Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference ranking optimization for human alignment. arXiv preprint arXiv:2306.17492, 2023.
- (47) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- (48) Yixuan Su, Tian Lan, Yan Wang, Dani Yogatama, Lingpeng Kong, and Nigel Collier. A contrastive framework for neural text generation. Advances in Neural Information Processing Systems, 2022.
- (49) Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting latent steering vectors from pretrained language models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 566–581, 2022.
- (50) Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
- (51) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- (52) Emanuel Todorov. Optimal control theory. Bayesian Brain, 2006.
- (53) Masaki Togai and Osamu Yamano. Analysis and design of an optimal learning control scheme for industrial robots: A discrete system approach. In 1985 24th IEEE Conference on Decision and Control, pages 1399–1404. IEEE, 1985.
- (54) Varun Tolani, Somil Bansal, Aleksandra Faust, and Claire Tomlin. Visual navigation among humans with optimal control as a supervisor. IEEE Robotics and Automation Letters, 6(2):2288–2295, 2021.
- (55) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- (56) Alex Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248, 2023.
- (57) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- (58) Chao Wang, Jian Wang, Yuan Shen, and Xudong Zhang. Autonomous navigation of uavs in large-scale complex environments: A deep reinforcement learning approach. IEEE Transactions on Vehicular Technology, 68(3):2124–2136, 2019.
- (59) Zhikang T. Wang and Masahito Ueda. Convergent and efficient deep q learning algorithm. In International Conference on Learning Representations, 2022.
- (60) Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. Assessing the brittleness of safety alignment via pruning and low-rank modifications. arXiv preprint arXiv:2402.05162, 2024.
- (61) Qinglai Wei, Guang Shi, Ruizhuo Song, and Yu Liu. Adaptive dynamic programming-based optimal control scheme for energy storage systems with solar renewable energy. IEEE Transactions on Industrial Electronics, 64(7):5468–5478, 2017.
- (62) Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359, 2021.
- (63) Muling Wu, Wenhao Liu, Xiaohua Wang, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Advancing parameter efficiency in fine-tuning via representation editing. arXiv preprint arXiv:2402.15179, 2024.
- (64) Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D Manning, and Christopher Potts. Reft: Representation finetuning for language models. arXiv preprint arXiv:2404.03592, 2024.
- (65) Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. arXiv preprint arXiv:2401.08417, 2024.
- (66) Jing Xu, Andrew Lee, Sainbayar Sukhbaatar, and Jason Weston. Some things are more cringe than others: Preference optimization with the pairwise cringe loss. arXiv preprint arXiv:2312.16682, 2023.
- (67) Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023.
- (68) Zhexin Zhang, Junxiao Yang, Pei Ke, and Minlie Huang. Defending large language models against jailbreaking attacks through goal prioritization. arXiv preprint arXiv:2311.09096, 2023.
- (69) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- (70) Banghua Zhu, Michael Jordan, and Jiantao Jiao. Principled reinforcement learning with human feedback from pairwise or k-wise comparisons. In International Conference on Machine Learning, pages 43037–43067. PMLR, 2023.
- (71) Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023.
Appendix for Re-Control
[sections] [sections]l1
Appendix A Limitations and Future Work
We discuss limitations and possible extensions of Re-Control. (1) Injecting inductive bias into the control policy. In our current work, we only train a value function on the last layer of the model’s hidden space. However, we can follow the approach in li2024inference , first training multiple value functions on all intermediate hidden layers and then selecting the layer that achieves the best accuracy on the validation set. Additionally, we can draw from the methods in geiger2024finding ; wu2024reft ; wei2024assessing to perturb only a low-rank subspace of the representation space. (2) Multi-objective aligment. In the current paper, we consider the objective from a single reward model. However, in practice, alignment may involve multiple, potentially conflicting objectives. It would be interesting to leverage multi-objective optimization techniques gunantara2018review at test time to obtain a Pareto frontier in the representation space for such settings. (3) More advanced training algorithm. Currently, we train the value function using a simple one-iteration policy iteration method. It would be interesting to explore whether increasing the number of iterations could further improve the training of the value function. Additionally, we can consider using algorithms for training the value function that provide provable convergence wang2022convergent .
Appendix B Broader Impacts
Aligning large language models (LLMs) with human preferences is crucial. We expect that the test-time alignment method introduced in this paper will positively impact society by helping to prevent LLMs from generating harmful content. However, it is essential to ensure that the training of the value function does not involve negative goals. Care must be taken to prevent this misuse.
Appendix C Experimental Details
C.1 Computing Infrastructure
We conduct our experiments on a server equipped with NVIDIA A100 (80GB VRAM) GPUs. We utilize the NVIDIA CUDA toolkit version 12.4. All experiments are implemented using Python 3.12.2 and the PyTorch framework version 2.2.2.
C.2 HH-RLHF
We evaluate our method on the HH-RLHF bai2022training dataset, which is the most widely used dataset for LLM alignment. This dataset is used to improve the AI assistant’s helpfulness and harmlessness, comprising 161,000 training samples and 8,550 test samples. Each sample contains a prompt and two responses with one preferred over another. For the base model, we adopt Vicuna-7B222https://huggingface.co/lmsys/vicuna-7b-v1.5 chiang2023vicuna and Falcon-7B-Instruct333https://huggingface.co/tiiuae/falcon-7b almazrouei2023falcon as the instructed fine-tuned AI assistant. We evaluate these models by generating text responses based on test prompts from of HH-RLHF. Following the standard practice, we limit the maximum lengths of the prompt and generated continuation to and tokens, respectively.
For the reward model, we use a publicly available one that employs LLaMA-7B444https://huggingface.co/argsearch/llama-7b-rm-float32 as the backbone, trained on HH-RLHF using the pairwise reward loss ouyang2022training .
Re-Control.
When constructing the training dataset for the value function, we sample only one response for each training prompt of HH-RLHF, i.e., . For both Vicuna-7B and Falcon-7B, we train the value network on the last layer of the hidden states , and at test time, we add control signals only to this layer. For future studies, we can also explore adding controls to the attention key-value pairs which should further improve the performance.
For Vicuna-7B, the value function is a three-layer network with a hidden dimension of 4096. For Falcon-7B, the value function is a two-layer network with a hidden dimension of 4096.
To train the value function of Re-Control, we adopt the Adam optimizer kingma2014adam . The training hyperparameters of the value networks are summarized in Table 3.
| Backbone | Parameters | Value |
|---|---|---|
| Vicuna | Number of epochs | 100 |
| Learning rate | ||
| batch size | 512 | |
| Floating point format | fp16 (Half-precision) | |
| Number of Layers | 3 | |
| Hidden Dimension | 4096 | |
| Falcon | Number of epochs | 100 |
| Learning rate | ||
| batch size | 512 | |
| Floating point format | fp16 (Half-precision) | |
| Number of Layers | 2 | |
| Hidden Dimension | 4096 |
We randomly sample 1000 data points from the training set of HH-RLHF as a separate validation set. The step size and number of updates are selected on the validation set to maximize the sum of coherence, diversity, and average reward. The inference parameters are summarized in Table 4.
| Backbone | Parameters | Value |
| Vicuna | Step size | 0.5 |
| Number of updates | 30 | |
| batch size | 30 | |
| Floating point format | fp16 (Half-precision) | |
| Maximum lengths of the prompt | 2048 | |
| Maximum lengths of genearted continuation | 128 | |
| Falcon | Step size | 0.2 |
| Number of updates | 200 | |
| batch size | 60 | |
| Floating point format | fp16 (Half-precision) | |
| Maximum lengths of the prompt | 2048 | |
| Maximum lengths of genearted continuation | 128 |
Prompting engineering.
We instruct the model to provide responses that are more helpful and harmless. The prompt template is as follows:
Static representation editing.
We first train a linear regression layer on the hidden state of a large language model (LLM) after feeding the prompt, to predict the expected reward as in li2024inference . For a fair comparison, we use the same hidden state layer as Re-Control. At test time, we shift the activation space along the direction of the weights using an intervention strength parameter , which is selected based on the validation set. The hyperparameters used during the training and testing stages are summarized in Table 5.
Controlled Decoding.
We use the codebase555https://github.com/deeplearning-wisc/args from khanov2024args . We employ the default hyperparameters suggested in the paper and repository. The number of candidates to rank with the reward model is set to 10, and the weight controlling the tradeoff between the LLM text objective and the reward is 1. For controlled decoding with the value function, we stack the value function of Re-Control on top of the hidden state of the LLM as the prefix scorer, ensuring a fair comparison with our method.
| Backbone | Parameters | Value |
|---|---|---|
| Vicuna | Number of epochs | 100 |
| Learning rate | ||
| Training batch size | 512 | |
| Testing batch size | 30 | |
| Intervention strength | 2.5 | |
| Falcon | Number of epochs | 100 |
| Learning rate | ||
| Training batch size | 512 | |
| Testing batch size | 60 | |
| Intervention strength | 2.0 |
Training configurations for PPO
For experiments involving Proximal Policy Optimization (PPO), we use the Transformer Reinforcement Learning (TRL) repository from Huggingface, along with the PPO Trainer module. The configuration values are detailed in Table 6.
| Parameters | Value | |
|---|---|---|
| Vicuna | Max number of PPO update steps | 10000 |
| Generation batch | 1 | |
| PPO batch size | 16 | |
| PPO minibatch size | 8 | |
| Lora rank | 8 | |
| Learning rate | ||
| Batch size | 4 | |
| Gradient accumulation steps | 2 | |
| Input maximum length | 512 | |
| Output maximum length | 256 | |
| Weight decay | 0.001 |
Training configurations for DPO
For experiments involving Direct Policy Optimization (DPO), we use the Transformer Reinforcement Learning (TRL) repository from Huggingface, along with the DPO Trainer module. The configuration values are detailed in Table 7.
| Parameters | Value | |
|---|---|---|
| Vicuna | Max number of training steps | 10000 |
| Learning rate | ||
| Lora rank | 8 | |
| Warmup steps | 100 | |
| Batch size | 4 | |
| Gradient accumulation steps | 4 | |
| Maximum sequence length | 1024 | |
| Weight decay | 0.05 | |
| Regularization parameter | 0.1 |
C.3 HarmfulQA
This dataset666https://huggingface.co/datasets/declare-lab/HarmfulQA contains 1,960 harmful questions specifically designed to evaluate the performance of language models. Additionally, it includes a conversation set comprising 9,536 harmless conversations and 7,356 harmful conversations for model alignment purposes. For our experiments, we focused solely on the evaluation portion of the HarmfulQA dataset to test the performance of our method.
Appendix D GPT-4 Evaluation
Following chiang2023vicuna ; khanov2024args , we use GPT-4 as the judge, having it review and score two responses to the same prompt on a scale from 1 to 10. We provide explicit instructions to assess the responses based on criteria such as helpfulness, harmlessness, relevance, accuracy, depth, creativity, and level of detail. The detailed prompt is provided in 8. Existing works zheng2023judging have shown that GPT-4’s judgments align with human evaluations over 80% of the time. We randomly sample 300 prompts from the test set of RLHF. To mitigate position bias, we randomize the order in which we present the generated responses to GPT-4, as in zheng2023judging .
Appendix E Additional Qualitative Examples
In Table 9 and Table 10, we present several qualitative examples that clearly illustrate how Re-Control can effectively steer the generated outputs to better helpfulness and harmlessness.