StreamPrompt: Learnable Prompt-guided Data Selection for Efficient Stream Learning
Abstract
Stream Learning (SL) requires models to rapidly adapt to continuous data streams, setting it apart from traditional Continual Learning (CL). Recent SL methods emphasize efficiency by selecting data subsets for training, but they often struggle due to their reliance on static, rule-based selection algorithms that cannot effectively adapt to the changing importance of data. In this work, we introduce StreamPrompt, a method that enhances data selection through dynamic, learnable prompts. These dynamic prompts serve two purposes beyond guiding model inference: 1) optimizing data selection, and 2) guiding updates to the rehearsal buffer. This approach addresses the challenges of adaptability and computational efficiency in processing continuous data streams. Moreover, StreamPrompt introduces “Prompt Attunement,” a mechanism that enhances the efficiency of prompt learning. By leveraging attention layers from vision transformers and softly combining their outputs with a gate unit, “Prompt Attunement” refines prompts with minimal computational resources. Comprehensive evaluations demonstrate StreamPrompt’s superior performance over state-of-the-art, with significant improvements in accuracy and reductions in training time. These results underscore the efficacy and efficiency of StreamPrompt, establishing its potential as a scalable and effective solution for the evolving demands of SL. Our code is available at https://github.com/intellistream/Efficient-Stream-Learning.
1 Introduction
Stream Learning (SL) marks a significant advancement in machine learning, facilitating rapid model adaptation to continuous data streams without revisiting earlier data [8, 34, 15]. In contrast, Continual Learning (CL) processes tasks sequentially, allowing revisits to past information to counteract what is known as catastrophic forgetting [24, 20, 22]. Recently, Online Continual Learning (OCL) has sought to address some unrealistic assumptions inherent in offline CL by limiting methods to a single pass over a shuffled split of existing benchmarks. However, OCL does not meet the demands of high-throughput streams with rapidly changing distributions, a core challenge that SL aims to tackle. In SL, the ability to integrate new information while retaining old is crucial, particularly when the pace of incoming data exceeds processing capabilities. This scenario often results in missing potential data segments during training [8], underscoring the importance of maintaining training efficiency and effectively managing the retention of learned information to enhance model adaptability and effectiveness.
Data selection plays a crucial role in accelerating training in SL. Previous research has approached data selection through frameworks like submodular maximization or k-Center problems, employing rule-based methods [29, 23, 15, 35]. For instance, Li et al. [15] propose a rule-based approach designed to enhance training efficiency in SL. However, these methods often fail to cope with the ever-changing nature of online data streams. In parallel, other studies [36, 13] have leveraged evolving model-based states—such as gradients or losses—to dynamically assess data importance for selection. While these approaches utilize real-time model feedback, they require extensive model involvement, which does not align well with the real-time processing demands of data streams. Collectively, these methodologies highlight a persistent challenge in SL: achieving efficient learning that can continuously adapt to rapidly changing data environments.
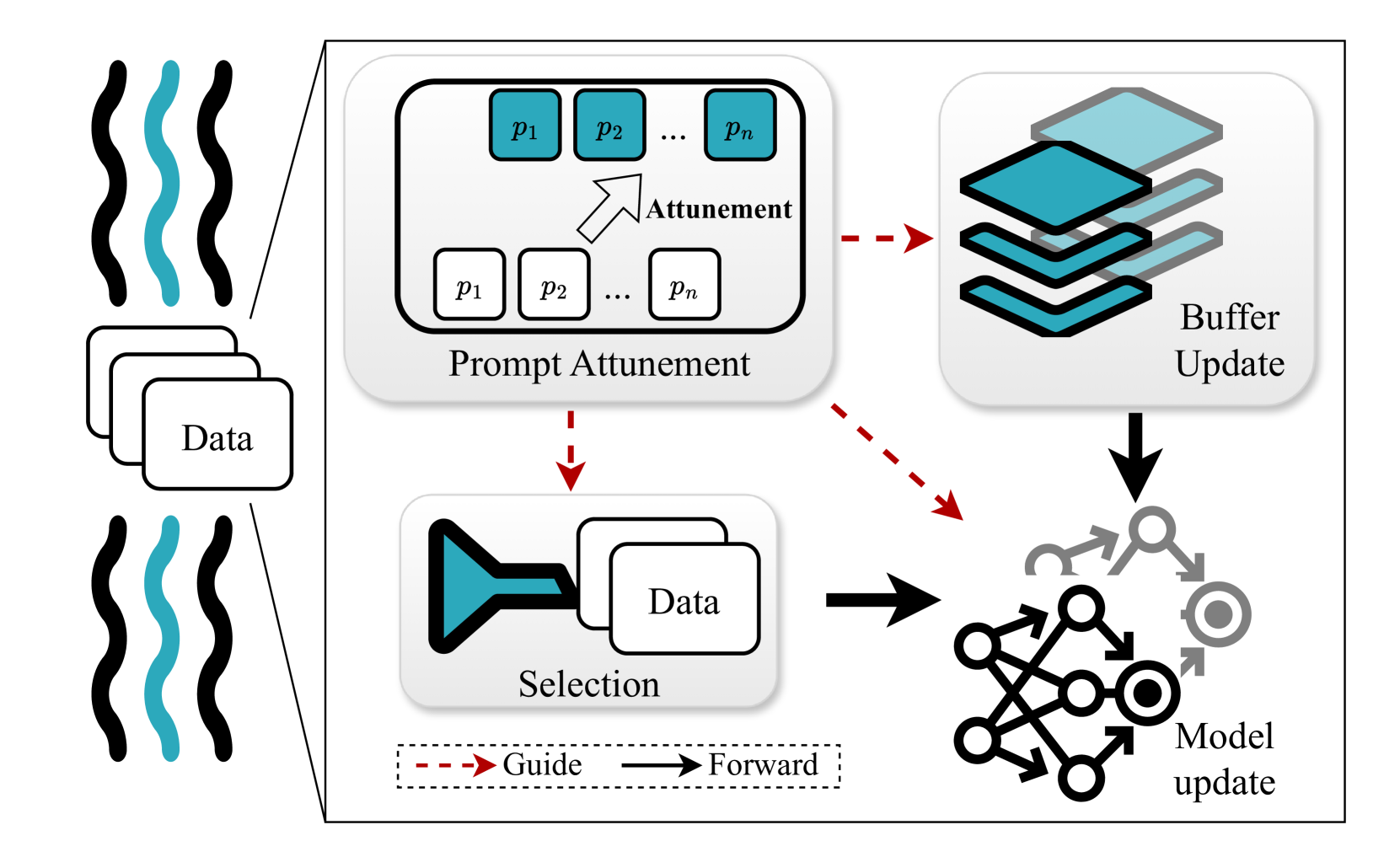
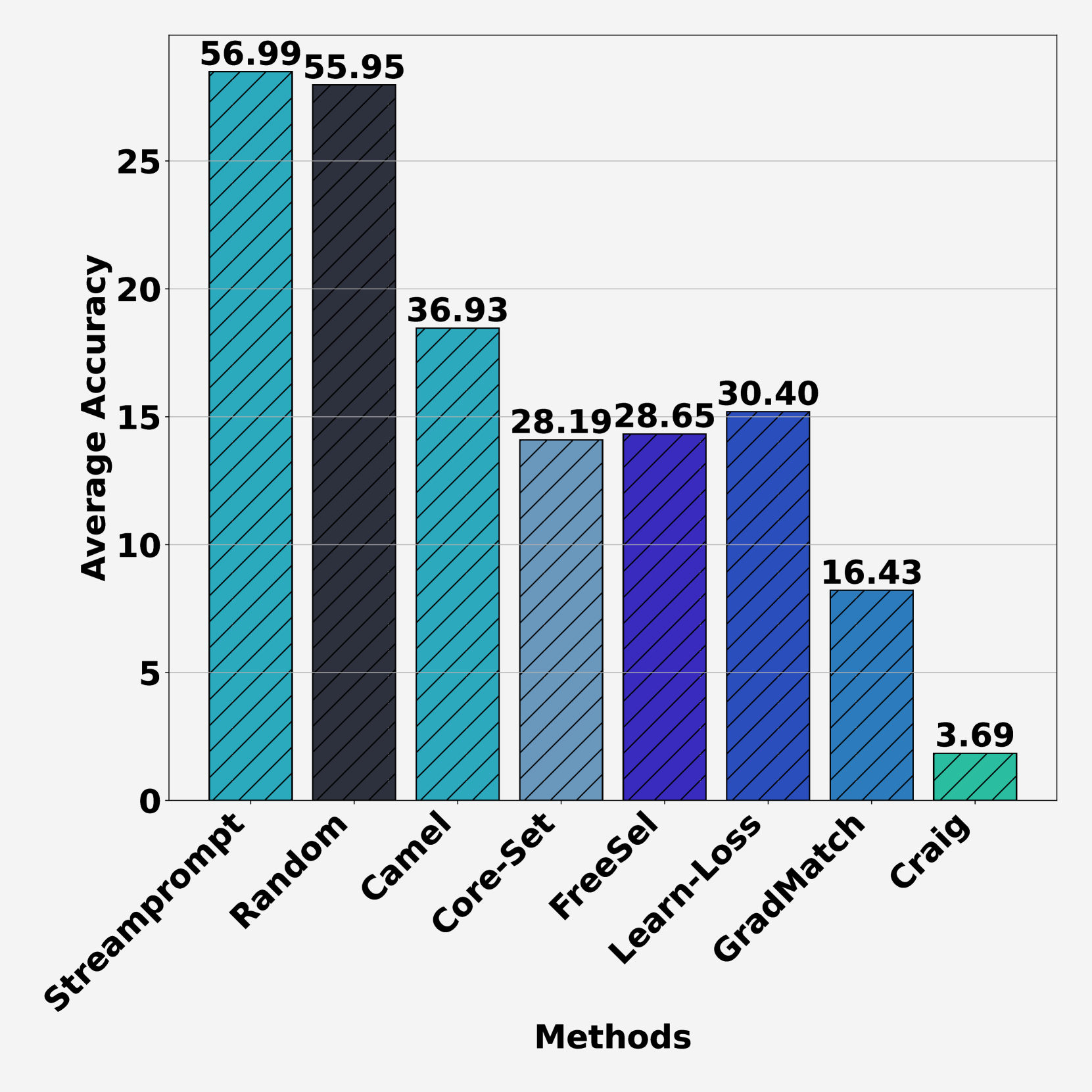
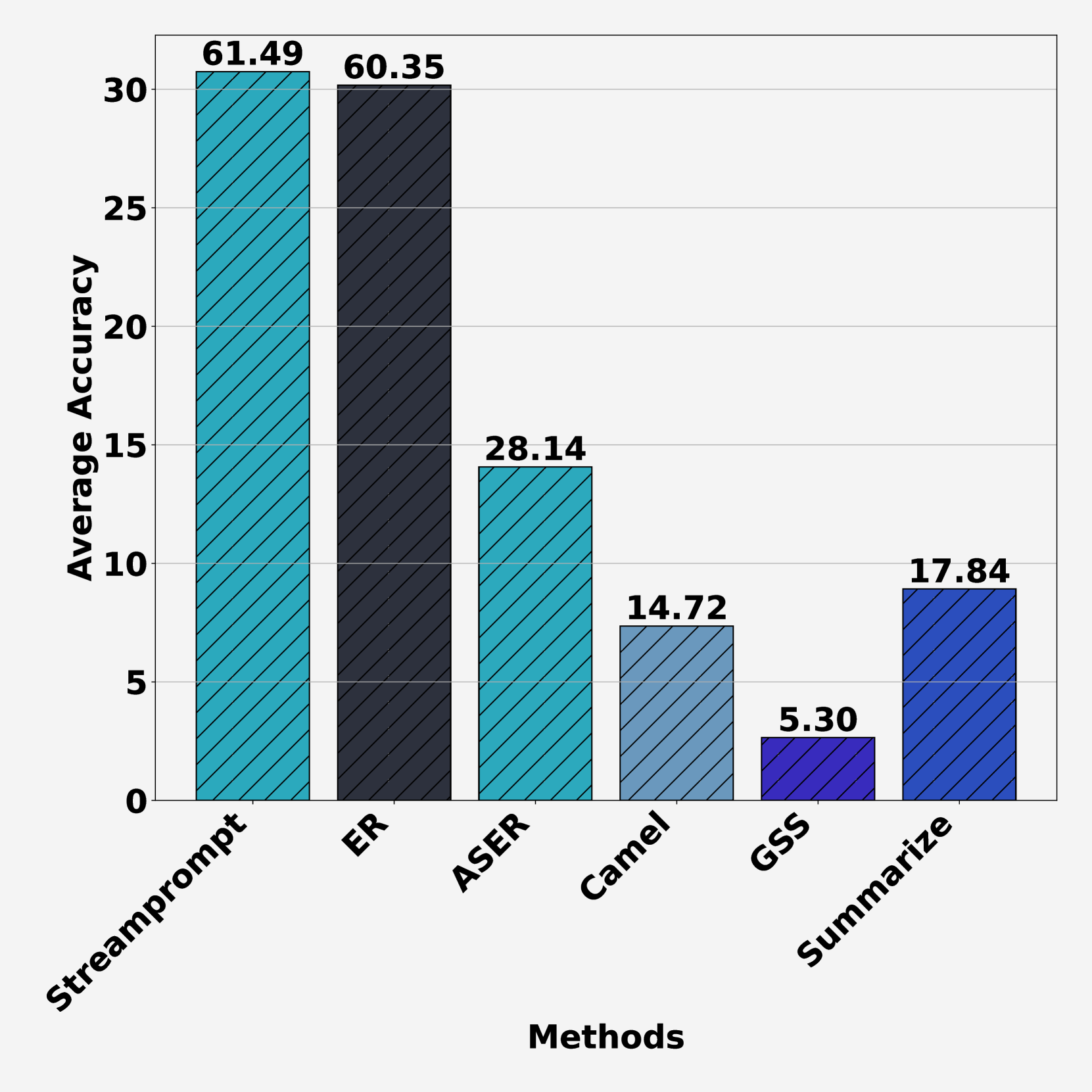
In response to the challenges of SL, we introduce StreamPrompt, an innovative methodology inspired by Prompt-based Continual Learning (PCL)[31]. StreamPrompt employs dynamic, learnable prompts to enhance adaptability to rapidly changing data scenarios and address catastrophic forgetting. By treating data relevance as an evolving attribute, StreamPrompt optimizes data selection and rehearsal buffer updates, ensuring the model remains responsive to the most pertinent data. This approach maintains training efficiency and fosters a self-reinforcing cycle of data management and prompt refinement, achieving a balance of adaptability, computational efficiency, and learning effectiveness within the SL framework. As depicted in Figure 1 (middle), StreamPrompt outperforms both rule-based methods (Camel [15], Core-Set [29], FreeSel [35]) and model-based methods (GradMatch [13], Learn-Loss [36], Craig [23]) in stream settings by efficiently leveraging dynamic prompts to adapt in real-time. Furthermore, Figure 1 (right) demonstrates StreamPrompt’s superiority in buffer update strategies, outperforming ER [4], ASER [30], Camel [15], GSS [2], and Summarize [9].
To further address the computational challenges of continuously updating prompts, we introduce “Prompt Attunement,” a novel mechanism leveraging the robust architecture and general knowledge of Vision Transformers. This mechanism refines prompts using pre-trained attention layers with minimal computational overhead, merging their outputs through an optimized gating unit. This strategy ensures that StreamPrompt remains scalable and efficient, enhancing its learning process without incurring the high computational costs typically associated with managing continuous data streams. Comprehensive evaluations demonstrate that StreamPrompt significantly improves accuracy, adaptability, and computational efficiency over existing methods, highlighting its potential to advance the field of SL. For robust comparative analysis, we establish competitive baselines by integrating representative data selection methods with advanced continual learning techniques. StreamPrompt consistently outperforms these baselines in both efficiency and accuracy. Furthermore, evaluations on multiple real-world datasets illustrate the practical applicability of the StreamPrompt framework.
In summary, our work makes the following contributions:
-
•
Propose a novel dynamic data selection strategy leveraging learnable prompts to enhance learning efficacy in SL.
-
•
Introduce “Prompt Attunement,” a mechanism utilizing Vision Transformers for efficient prompt refinement.
-
•
Demonstrate StreamPrompt’s superior performance through comprehensive evaluations, establishing it as a new standard in SL.
2 Related Work
Continual Learning and Online Continual Learning. Continual Learning (CL) aims to mitigate catastrophic forgetting, where new learning may overwrite previous knowledge. Strategies include rehearsal methods, which either retain or synthesize data from past tasks, and regularization techniques that safeguard essential parameters [19, 14]. Dynamic architectures further address this by adapting structurally, such as through network expansion or modularization [28, 21]. Online Continual Learning (OCL) adapts these strategies to sequential, single-pass learning scenarios over shuffled datasets. While OCL reduces dependency on data re-exposure, it does not address the broader challenges posed by Stream Learning (SL). SL involves managing dynamic and unbounded data streams, which increase the risks of catastrophic forgetting and computational demands [2, 1, 12]. The transition from OCL to SL highlights the need for methods that can handle high-throughput streams with rapidly changing distributions, a core challenge that SL aims to tackle.
Advancements in Stream Learning. SL requires strategies beyond those developed for CL and OCL due to its dynamic data flows and higher computational needs. Recent advancements include enhanced buffer mechanisms for data integration and sophisticated real-time benchmarks to assess and refine training efficiency [4, 1, 10, 8]. Innovations such as Camel’s approach to coreset selection through submodular maximization exemplify efforts to improve learning efficacy by adapting to data dynamism [15]. Yet, both rule-base and model-base data selection methods face challenges: rule-base methods do not adjust quickly to changes, and model-base methods, though responsive, are computationally intensive and difficult to scale [29, 23, 36, 13].
Prompt-based Continual Learning. Prompt-based methods have proven effective for both NLP and CV tasks [17, 11], enabling pre-trained models to adapt to new challenges with minimal changes. These methods preserve the essential knowledge of the core model while adding flexibility for specific tasks. Integrating prompt-based learning into continual learning represents a significant advancement. For instance, L2P [33] initializes a set of learnable prompts, each with components for keying and querying. Building on this, DualPrompt [32] categorizes prompts into “expert” and “general” to distinguish task-invariant knowledge from task-specific knowledge. Additionally, CODA-Prompt [31] introduces a new attention-based, end-to-end key-query mechanism. Our method, StreamPrompt, extends these concepts to SL by using dynamic, learnable prompts. These prompts not only adapt to sequential tasks but also respond adeptly to the changing importance of data streams. This approach enhances adaptability and computational efficiency, which are crucial for real-time data processing.
3 Stream Learning Problem Setup
In conventional Continual Learning (CL), it is generally assumed that the model processes all batch data, as the data for each task arrives at a rate compatible with the model’s learning speed, ensuring effective inference performance. In contrast, Stream Learning (SL) introduces unique challenges that often necessitate skipping data. In SL, a model is trained on a sequence of tasks , where each task consists of pairs of inputs and labels that arrive at a high rate. To effectively adapt to the single-pass stream and its rapid rate, the model must employ a robust strategy to manage the fast data streams. This includes selectively skipping parts of the data streams to align with the model’s training speed [7]. Models with faster training speeds will skip less data, and vice versa. By leveraging dynamic data selection strategies, such as those employed by StreamPrompt, the model can reduce its workload and enhance training efficiency, thereby minimizing data skipping. We will further explore the impact of these dynamic data selection strategies under various data arrival rates in our experiments. Moreover, our study addresses the complexities of Class-Incremental Learning (Class-IL), where the task identity is unknown during testing. This scenario poses greater challenges compared to Task-Incremental Learning (Task-IL), where the task identity is known. Class-IL necessitates advanced strategies for handling data and learning efficiently in the face of unknown task identities.
4 System Design
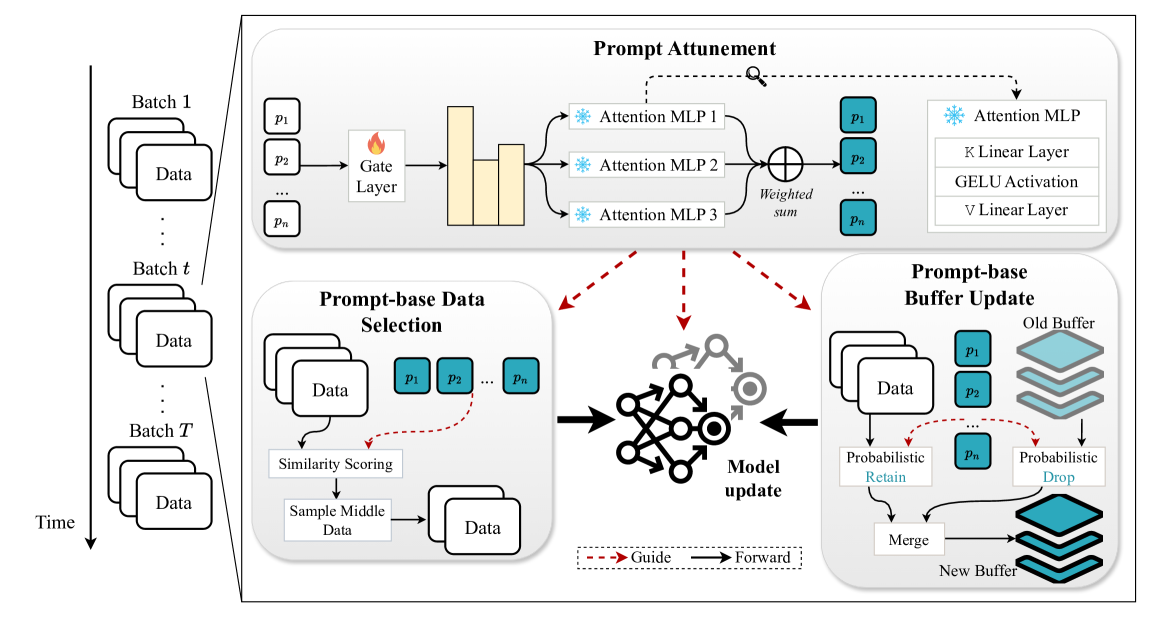
StreamPrompt utilizes dynamic, learnable prompts to enhance both model adaptability and computational efficiency. These prompts enable the model to swiftly respond to changes in the data landscape, sharpening focus and streamlining the learning process. Prompts also guide model training in a similar way as in prior work [31], which we discuss in Appendix A. Figure 2 illustrates the interaction of these components within our framework. The architecture includes three core components: Prompt-based Data Selection, Prompt-based Buffer Updates, and Prompt Attunement. Each component will be detailed in the following sections. More implementation details can be found in Appendix B.
4.1 Data Selection by Prompts
To enhance computational efficiency, StreamPrompt employs a sophisticated data selection strategy leveraging prompts to filter data effectively, ensuring the model focuses on the most relevant and informative data points. This approach improves overall learning efficiency and adaptability. At the start of each training iteration, embeddings of the batch data are extracted using the first embedding layer of the ViT, denoted as , where is the batch size, is the sequence length, and is the dimension of the embeddings. Concurrently, the extracted prompt parameters are aggregated and reshaped to . Here, , and represent the number and length of the prompts respectively, where the prompts’ dimension aligns with the data embeddings for subsequent operations. We compute the cosine similarity between the data embeddings and prompts to select new data using the following formula:
| (1) |
Here, represents the cosine similarity scores, which are averaged and reshaped to derive . The similarity scores are then ranked, and a central segment is selected, with representing the ratio of chosen data among . This process identifies data points that are neither too similar nor too dissimilar, ensuring that the model incorporates new knowledge smoothly and maintains consistency with established knowledge. By conserving computational resources and dynamically adapting to the model’s evolving states, this prompt-based selection enhances the robustness and adaptability of StreamPrompt amid an evolving data stream.
4.2 Prompt-guided Rehearsal Buffer Management
Building on the enhanced efficiency from data selection, rehearsing data from the previous stream can improve model accuracy. Therefore, we equip the rehearsal buffer with StreamPrompt, an effective update strategy that balances learning new information and retaining previously learned knowledge. StreamPrompt employs dynamic prompts to manage the rehearsal buffer, ensuring it remains representative of the model’s knowledge base while minimizing the risk of catastrophic forgetting. As illustrated in Figure 2, StreamPrompt performs buffer updates in a Retain-Drop manner. This process involves selectively retaining new data from the batch using probabilistic sampling, probabilistically dropping old data from the buffer, and then merging the retained new data with the remaining buffer data to form the updated buffer. This approach ensures that the buffer remains current and relevant, effectively maintaining a balance between new information and previously learned knowledge.
We calculate the batch-prompt and buffer-prompt similarities, and , using Eq.1. The softmax function is then applied to these similarities to obtain the probabilities and :
| (2) |
Using these probabilities as distributions, we employ probabilistic sampling to update the buffer. Batch data points with higher probabilities are retained, and buffer data points with lower probabilities are discarded. Formally, this process is represented as:
| (3) |
where represents probabilistic sampling, i.e., sampling data points based on the probability distribution . The retained batch data replace the corresponding positions of the discarded buffer data, completing the buffer update process.
StreamPrompt remains efficient in managing the buffer due to two key factors: 1) the minimal cost of data embedding extraction, achieved by using only the model’s first embedding layer rather than all layers; 2) the efficient computation of embedding similarity between data embeddings and prompts, owing to their relatively small number of parameters. Consequently, StreamPrompt effectively maintains a cohesive and relevant dataset within the buffer by continually updating all buffer data.
4.3 Prompt Attunement Mechanism
Prompts play a crucial role in the data selection and buffer updates of StreamPrompt. However, in a stream learning setting, single-pass data processing hinders prompt learning, posing a significant challenge. Inspired by the robustness and general knowledge of Vision Transformers (ViTs) [6], we propose Prompt Attunement to fully exploit the expertise of attention layers in ViTs and fine-tune the initial prompts, as illustrated in Figure 2. The Prompt Attunement mechanism consists of two main components: a gate layer and three attention MLPs.
Given the prompts , we feed them into the gate layer. In the -th layer of the ViT, the weights of the prompts for the -th attention MLP outputs in Prompt Attunement are computed as follows:
| (4) |
where represents the weights of the gate layer, with being the hidden dimension size of each attention MLP, and being the number of total attention MLPs. Using the gate layer features, we select their top-3 values and corresponding indexes , which then pass through the softmax function to become the final weights of the attention MLP features.
The core of Prompt Attunement is the attention MLP that fully exploits the expertise of ViT’s attention layers. We propose to split the last three pretrained ViT attention layers into the key and value weights and load them into the linear layer of the attention MLP as the K and V linear layers, respectively. To maintain the general knowledge of preloaded attention weights, we freeze the updates of attention MLPs to avoid biasing towards specific task knowledge. Specifically, we reorder the prompts based on the gate index , and the reordered outputs are fed into three distinct attention-based MLPs. Formally, the rest of Prompt Attunement, including the attention MLPs and output linear layer, is calculated as:
| (5) |
where and are the weights of K and V linear layers in the -th attention MLP. Combining all MLP outputs as attention MLP features , we weight and sum the attention features by the feature weights obtained from the gate layer to get the final refined prompts .
5 Experiments
In this section, we present the results of our empirical evaluation, comparing our method against several closely related data selection baselines across different experimental conditions. Some more experimental results can be found at Appendix C.
5.1 Experiment Setting
Datasets. To evaluate the performance of data selection in a streaming environment, we use four datasets: Clear10, Clear100 [16], CORe50 [18], and Stream-51 [26]. These datasets are partitioned for Class-IL as discussed in Section 3, reflecting the natural temporal evolution of visual concepts and emphasizing the importance of data sequence in stream learning. Clear10 contains 330,000 training images and 66,550 test images, derived from the CLEAR benchmark dataset, reflecting a decade of natural temporal evolution of visual concepts (2004-2014). Clear10 is divided into 5 tasks, with the first having 3 classes and the remaining having 2 each. Clear100 includes 1,209,197 training images and 605,000 test images, also from the CLEAR dataset, and is divided into 10 tasks, each with 10 classes. CORe50 comprises 164,866 images across 50 classes, emphasizing stream sequence among intra-class images, and is divided into 9 tasks, with the first having 10 classes and the remaining having 5 each. Stream-51 contains 150,736 images across 51 classes, highlighting temporal significance, and is partitioned into 8 tasks, with the first having 9 classes and the remaining having 6 each.
Comparing methods. We compare StreamPrompt with several frameworks that incorporate both data selection and buffer update strategies for stream learning. First, we use CODA-Prompt [31] as the baseline method, denoted as None, which does not involve data selection or buffer updates. The Random method randomly selects data from the input data stream and uses an ER method [4] for buffer updates. Camel [15] formalizes data selection as a submodular maximization problem and applies this method for buffer updates. To comprehensively evaluate the effectiveness of data selection, we also include several rule-based methods such as Camel, Core-Set [29], and FreeSel [35], as well as model-based approaches like GradMatch [13], Learn-Loss [36], and Craig [23]. For evaluating buffer update strategies, we compare StreamPrompt against state-of-the-art methods including ER [4], ASER [30], Camel [15], GSS [2], and Summarize [9].
Evaluation Metrics. We assess the performance of OCL using Average Accuracy and Average Forgetting metrics [30]. Average Accuracy is calculated across all seen tasks and is defined as , where denotes the accuracy on task after training from task 1 through . Average Forgetting measures the extent of memory loss for each task following training on the final task and is defined as , where .
Experiment Details. As mentioned in Section 3, real-world stream data does not always arrive at a rate that matches the model’s learning speed [7]. Following prior work [7], we simulate diverse arrival rates by skipping batches. Specifically, given an arrival rate and the dataset size, we calculate the overall duration during which all data arrives, referred to as the “total duration.” For each method, we run 500 batches to measure the training time per batch, then multiply this by the total number of batches to determine the expected overall training time. By dividing the expected overall training time by the total duration, we obtain the stream-model relative complexity . When , data has to be skipped as training time exceeds the total duration. We then perform uniform sampling across all batch data, retaining only a fraction of the batches, effectively skipping batches. Unless mentioned otherwise, for data selection methods, we apply a selection ratio of 0.5, selecting half of the data from each non-skipped batch. For buffer-related methods, we maintain a rehearsal buffer with a size of 102. The impact of varying and will be evaluated in our study in Section 5.3. The experiments were conducted on a server with the CPU of i7-13700K, 1 GeForce RTX A6000 GPU, and 64 GB memory.
5.2 Main Results
| Method | =30140 | =15070 | =6028 | |||
|---|---|---|---|---|---|---|
| Acc () | Forgetting () | Acc () | Forgetting () | Acc () | Forgetting () | |
| None | 04.70 | 5.43 | 07.81 | 9.93 | 38.04 | 12.12 |
| Random | 14.18 | 0.77 | 31.40 | 0.00 | 59.99 | 03.70 |
| Camel | 05.87 | 0.33 | 08.59 | 0.77 | 13.20 | 00.85 |
| StreamPrompt | 16.70 | 0.29 | 34.40 | 1.14 | 63.99 | 10.30 |
Comparison with SL Methods. Table 1 presents a comparison of StreamPrompt with other SL methods on the Stream-51 dataset, evaluated at different data arrival rates (). The results demonstrate that StreamPrompt consistently improves accuracy while enhancing training efficiency across varying arrival rates. At the highest arrival rate (=30140), StreamPrompt achieves an accuracy of 16.70%, outperforming the other methods, with the next best being Random at 14.18%. StreamPrompt also maintains a low forgetting value of 0.29%, indicating its ability to retain learned knowledge effectively. At the moderate arrival rate (=15070), StreamPrompt significantly outperforms the baseline and other methods with an accuracy of 34.40%, compared to Random’s 31.40% and Camel’s 8.59%. Although the forgetting for StreamPrompt increases slightly to 1.14%, it remains competitive and demonstrates robust performance in terms of knowledge retention. At the lowest arrival rate (=6028), StreamPrompt achieves the highest accuracy of 63.99%, surpassing Random’s 59.99% and Camel’s 13.20%. However, the forgetting value for StreamPrompt rises to 10.30%, reflecting the challenges associated with lower data arrival rates and the need for improved memory retention strategies. Overall, StreamPrompt demonstrates superior accuracy across all arrival rates, highlighting its effectiveness and efficiency in stream learning environments. The trade-off between accuracy and forgetting is well-managed, showcasing StreamPrompt’s robustness in handling diverse streaming scenarios.
| Method | Class order 1 | Class order 1 | Class order 3 | Class order 4 | Class order 5 | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | |
| None | 07.81 | 9.93 | 12.69 | 8.87 | 08.82 | 10.82 | 08.76 | 10.83 | 06.75 | 14.10 | 08.972.79 | 10.912.43 |
| Random | 31.40 | 0.00 | 39.55 | 2.84 | 34.93 | 02.50 | 31.44 | 00.75 | 33.51 | 01.52 | 34.174.17 | 01.521.47 |
| Camel | 8.99 | 0.86 | 11.70 | 1.26 | 11.15 | 01.78 | 8.72 | 01.13 | 08.10 | 00.68 | 09.731.98 | 01.140.52 |
| StreamPrompt | 34.40 | 1.14 | 42.18 | 3.01 | 36.15 | 03.70 | 32.78 | 02.61 | 36.15 | 05.32 | 36.334.42 | 03.161.90 |
Comparison with Class Orders. In the stream setting, the order of class appearances can significantly influence the performance of stream learning methods. As shown in Table 2, the results vary with different class orders, illustrating how class order affects learning characteristics. This variation occurs because the similarity between consecutive tasks can either facilitate or hinder the transfer of task-related knowledge. When tasks are more similar, models can leverage this similarity to enhance performance. Conversely, when tasks are significantly different, it becomes more challenging to utilize previous knowledge, potentially leading to a decline in performance. Table 2 demonstrates the robustness of StreamPrompt across five different class orders. StreamPrompt consistently outperforms other methods in terms of accuracy, achieving a mean accuracy of 36.33% compared to Random’s 34.17% and Camel’s 9.73%. While StreamPrompt shows some variability in forgetting, it generally maintains a balance between high accuracy and manageable forgetting. For instance, StreamPrompt achieves the highest accuracy of 42.18% with a forgetting value of 3.01% in Class Order 2, indicating its ability to adapt and perform well despite changes in class order. The mean forgetting value for StreamPrompt is 3.16%, which, although higher than Random’s 1.52%, is compensated by the significant gains in accuracy. These results highlight StreamPrompt’s adaptability and effectiveness across varying class orders, showcasing its robustness in stream learning environments.
Comparison with Four Datasets. Table 3 presents the results of comparing StreamPrompt with other SL methods across four datasets when =15070. StreamPrompt consistently achieves the highest accuracy across all datasets, notably 78.09% on Clear10 and 34.40% on Stream-51, significantly outperforming baseline and other methods. Additionally, StreamPrompt maintains low forgetting levels, particularly 0.38% on Clear100 and 1.14% on Stream-51, demonstrating its efficiency in retaining learned knowledge despite the challenges of varying data sequences and scales. These results highlight StreamPrompt ’s robust data selection and buffer update strategies, effectively balancing accuracy and memory retention in diverse stream learning environments.
Comparison with Different Pretrained Models. As PCL is based on the pretrained ViT, we also experiment with varying pretrained models based on the supervised (ImageNet-1K [27] and ImageNet-21K [25]) and the self-supervised (iBOT [37], DINO [3], and MoCo v3 [5]) datasets. Results are shown in Table 4. StreamPrompt consistently outperforms the Random method across different pretrained models in terms of accuracy. For instance, when using the ImageNet-1K pretrained model, StreamPrompt achieves an accuracy of 34.40%, compared to Random’s 31.40%. Similar trends are observed with other pretrained models like ImageNet-21K and DINO-1K, where StreamPrompt also demonstrates superior accuracy. However, StreamPrompt exhibits higher forgetting in some cases, such as 3.83% with DINO-1K, compared to Random’s 1.36%. This suggests that while StreamPrompt enhances accuracy, it may trade off some memory retention. Notably, the performance differences highlight the impact of different pretraining strategies on stream learning outcomes, with StreamPrompt consistently providing significant improvements in accuracy, albeit with varying degrees of forgetting. These results underscore the robustness and versatility of StreamPrompt across different pretraining contexts.
| Method | Clear10 | Clear100 | CORe50 | Stream-51 | ||||
|---|---|---|---|---|---|---|---|---|
| Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | |
| None | 43.73 | 17.67 | 05.04 | 5.70 | 06.85 | 1.14 | 07.81 | 9.93 |
| Random | 76.02 | 05.37 | 18.33 | 0.73 | 12.90 | 2.24 | 31.40 | 0.00 |
| Camel | 52.44 | 02.08 | 05.66 | 0.80 | 06.96 | 3.09 | 08.59 | 0.77 |
| StreamPrompt | 78.09 | 04.33 | 19.87 | 0.38 | 15.88 | 5.18 | 34.40 | 1.14 |
| Method | ImageNet-1K | ImageNet-21K | DINO-1K | |||
|---|---|---|---|---|---|---|
| Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | |
| Random | 31.40 | 0.00 | 32.37 | 1.50 | 28.33 | 1.36 |
| StreamPrompt | 34.40 | 1.14 | 34.63 | 2.71 | 29.45 | 3.83 |
| Method | iBOT-1K | iBOT-21K | MoCo-1K | |||
| Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | |
| Random | 26.44 | 3.70 | 2.18 | 6.25 | 2.72 | 2.94 |
| StreamPrompt | 28.40 | 4.32 | 2.67 | 9.43 | 3.04 | 4.13 |
5.3 Effectiveness of Key Components
Ablation Studies. We present a detailed ablation study in Table 6 using StreamPrompt with a 0.5 data selection ratio and a buffer size of 102 on Stream-51 with . The table demonstrates that each component of StreamPrompt contributes to improved performance. The first row, where no components are applied, serves as the baseline, showing an accuracy of 33.29% and a forgetting of 15.41%. Adding Prompt Attunement (PA) alone, as seen in the second row, increases accuracy to 35.69% and reduces forgetting to 13.82%, indicating that PA enhances model inference by improving the quality of prompts. In the third row, both Prompt Attunement and prompt-based data selection (PDS) are employed, leading to a substantial improvement in accuracy to 56.74% and a reduction in forgetting to 11.35%. This shows that PDS significantly boosts model performance by selecting more informative data and speeding up the training process, allowing the model to make better use of the fast-stream data. The final row illustrates the combined effect of all components, including Prompt Attunement, prompt-based data selection, and prompt-based buffer update (PBU). Here, the accuracy peaks at 62.94%, though the forgetting slightly increases to 12.11%. This suggests that while the prompt-based buffer update further enhances accuracy, it also introduces some challenges related to data drift in the fast stream, leading to a slight increase in forgetting. Overall, the ablation study confirms that each component of StreamPrompt plays a crucial role in enhancing accuracy and managing forgetting, with the full combination providing the best overall performance.
| PA | PDS | PBU | Acc | Forgetting |
|---|---|---|---|---|
| ✗ | ✗ | ✗ | 33.29 | 15.41 |
| ✓ | ✗ | ✗ | 35.69 | 13.82 |
| ✓ | ✓ | ✗ | 56.74 | 11.35 |
| ✓ | ✓ | ✓ | 62.94 | 12.11 |
| Acc | Forgetting | Acc | Forgetting | ||
|---|---|---|---|---|---|
| 0.1 | 61.99 | 20.36 | 0051 | 56.59 | 17.78 |
| 0.2 | 64.33 | 15.85 | 0102 | 61.49 | 13.00 |
| 0.4 | 64.31 | 09.82 | 0204 | 70.26 | 02.91 |
| 0.6 | 57.00 | 12.86 | 0510 | 66.96 | 01.87 |
| 0.8 | 58.07 | 07.67 | 1020 | 60.55 | 00.60 |
Sensitivity Study. To understand the impact of the data selection ratio and the buffer size , we present the corresponding experimental results in Table 6. The table illustrates how varying these parameters affects model accuracy and forgetting. When the selection ratio is low (0.1 and 0.2), the model’s accuracy remains relatively stable but exhibits higher forgetting. As increases to 0.4, the accuracy improves significantly while the forgetting value decreases, indicating that selecting a higher proportion of data batches benefits the model’s retention of knowledge. Increasing the buffer size also has a notable impact. With smaller buffer sizes (51 and 102), the model’s accuracy and forgetting values are less favorable compared to larger buffer sizes (204, 510, and 1020). A buffer size of 204 achieves the best balance, with high accuracy and low forgetting, suggesting that there is an optimal buffer size that maximizes performance. Larger buffer sizes continue to maintain low forgetting but do not significantly improve accuracy beyond a certain point. Overall, the results highlight the importance of both the data selection ratio and buffer size in optimizing model performance in stream learning settings. A balanced approach with moderate values of and appears to provide the best trade-off between accuracy and forgetting.
6 Conclusion
This paper presents a novel framework named StreamPrompt for efficient Stream Learning (SL) that achieves both adaptability and computational efficiency. StreamPrompt comprises three complementary strategies: Prompt Attunement for prompt refinement, prompt-based data selection for data efficiency, and prompt-based buffer updates for training effectiveness. Extensive experiments on various datasets demonstrate that our method significantly improves upon existing SL methods in terms of accuracy and adaptability. StreamPrompt’s dynamic, learnable prompts ensure the model can seamlessly integrate new information while retaining previously learned knowledge, addressing the core challenges of SL. Furthermore, StreamPrompt’s Prompt Attunement mechanism leverages the robustness of attention layers in vision transformers, enhancing the efficiency of prompt learning with minimal computational overhead. These innovations collectively establish StreamPrompt as a scalable and effective solution for the evolving demands of SL. We discuss the limitations and future research directions of our method in Section 7.
7 Limitations
One limitation of StreamPrompt is its reliance on pre-trained components, such as vision transformers, which may not always be available or suitable for all scenarios. Although this reliance is common in current SL methods, there are situations where appropriate pre-trained models are lacking. However, as a framework designed for efficiency, StreamPrompt has the potential to adapt to various SL methods. For example, integrating alternative architectures or reducing dependency on pre-trained models could make StreamPrompt more versatile. Another limitation is the computational overhead introduced by the dynamic nature of the prompts, which can be particularly challenging in high-velocity or large-volume data streams. Despite the “Prompt Attunement” mechanism’s design to minimize these demands, further optimization is needed to enhance scalability and performance in industrial-scale applications. Moreover, the current evaluations are limited to specific SL tasks, predominantly in the vision domain. While this is a common practice, evaluating StreamPrompt, as well as other SL methods, on datasets from other domains, such as text and audio, would provide a more comprehensive and reliable assessment. Additionally, the data selection process may inadvertently introduce bias, potentially overlooking novel and critical information. We aim to address these limitations by reducing computational overhead, broadening the evaluation across diverse domains, and refining the data selection process to avoid bias. Future work will focus on enhancing StreamPrompt’s efficiency, adaptability, and generalization capabilities, thereby extending its utility in SL and beyond.
References
- [1] R. Aljundi, E. Belilovsky, T. Tuytelaars, L. Charlin, M. Caccia, M. Lin, and L. Page-Caccia. Online continual learning with maximally interfered retrieval. In Advances in Neural Information Processing Systems, volume 32, pages 11849–11860, 2019.
- [2] R. Aljundi, M. Lin, B. Goujaud, and Y. Bengio. Gradient based sample selection for online continual learning. Advances in Neural Information Processing Systems, 32, 2019.
- [3] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- [4] A. Chaudhry, M. Rohrbach, M. Elhoseiny, T. Ajanthan, P. K. Dokania, P. H. Torr, and M. Ranzato. Tiny episodic memories supports continual learning in neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12470–12479, 2019.
- [5] X. Chen, S. Xie, and K. He. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9640–9649, 2021.
- [6] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [7] Y. Ghunaim, A. Bibi, K. Alhamoud, M. Alfarra, H. A. Al Kader Hammoud, A. Prabhu, P. H. Torr, and B. Ghanem. Real-time evaluation in online continual learning: A new hope. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11888–11897, 2023.
- [8] Y. Ghunaim, A. Bibi, K. Alhamoud, M. Alfarra, H. Hammoud, A. Prabhu, P. S. Torr, and B. Ghanem. Real-time evaluation in online continual learning: A new hope. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11888–11897, Los Alamitos, CA, USA, jun 2023. IEEE Computer Society.
- [9] J. Gu, K. Wang, W. Jiang, and Y. You. Summarizing stream data for memory-restricted online continual learning. arXiv preprint arXiv:2305.16645, 2023.
- [10] J. He and F. Zhu. Online continual learning for visual food classification. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2337–2346, 2021.
- [11] M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim. Visual prompt tuning. In European Conference on Computer Vision, pages 709–727. Springer, 2022.
- [12] X. Jin, A. Sadhu, J. Du, and X. Ren. Gradient-based editing of memory examples for online task-free continual learning. Advances in Neural Information Processing Systems, 34:29193–29205, 2021.
- [13] K. Killamsetty, S. Durga, G. Ramakrishnan, A. De, and R. Iyer. Grad-match: Gradient matching based data subset selection for efficient deep model training. In International Conference on Machine Learning, pages 5464–5474. PMLR, 2021.
- [14] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- [15] Y. Li, Y. Shen, and L. Chen. Camel: Managing data for efficient stream learning. In Proceedings of the 2022 International Conference on Management of Data, pages 1271–1285, 2022.
- [16] Z. Lin, J. Shi, D. Pathak, and D. Ramanan. The clear benchmark: Continual learning on real-world imagery. In Thirty-fifth conference on neural information processing systems datasets and benchmarks track (round 2), 2021.
- [17] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv., 55(9), jan 2023.
- [18] V. Lomonaco and D. Maltoni. Core50: a new dataset and benchmark for continuous object recognition. In Conference on robot learning, pages 17–26. PMLR, 2017.
- [19] D. Lopez-Paz and M. Ranzato. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30, 2017.
- [20] Z. Mai, R. Li, J. Jeong, D. Quispe, H. Kim, and S. Sanner. Online continual learning in image classification: An empirical survey. Neurocomputing, 469:28–51, 2022.
- [21] A. Mallya and S. Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018.
- [22] M. Masana, X. Liu, B. Twardowski, M. Menta, A. D. Bagdanov, and J. Van De Weijer. Class-incremental learning: survey and performance evaluation on image classification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):5513–5533, 2022.
- [23] B. Mirzasoleiman, J. Bilmes, and J. Leskovec. Coresets for data-efficient training of machine learning models. In International Conference on Machine Learning, pages 6950–6960. PMLR, 2020.
- [24] G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter. Continual lifelong learning with neural networks: A review. Neural networks, 113:54–71, 2019.
- [25] T. Ridnik, E. Ben-Baruch, A. Noy, and L. Zelnik-Manor. Imagenet-21k pretraining for the masses. arXiv preprint arXiv:2104.10972, 2021.
- [26] R. Roady, T. L. Hayes, H. Vaidya, and C. Kanan. Stream-51: Streaming classification and novelty detection from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 228–229, 2020.
- [27] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211–252, 2015.
- [28] A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell. Progressive neural networks. In arXiv preprint arXiv:1606.04671, 2016.
- [29] O. Sener and S. Savarese. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489, 2017.
- [30] D. Shim, Z. Mai, J. Jeong, S. Sanner, H. Kim, and J. Jang. Online class-incremental continual learning with adversarial shapley value. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 9630–9638, 2021.
- [31] J. S. Smith, L. Karlinsky, V. Gutta, P. Cascante-Bonilla, D. Kim, A. Arbelle, R. Panda, R. Feris, and Z. Kira. Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11909–11919, 2023.
- [32] Z. Wang, Z. Zhang, S. Ebrahimi, R. Sun, H. Zhang, C.-Y. Lee, X. Ren, G. Su, V. Perot, J. Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. In European Conference on Computer Vision, pages 631–648. Springer, 2022.
- [33] Z. Wang, Z. Zhang, C.-Y. Lee, H. Zhang, R. Sun, X. Ren, G. Su, V. Perot, J. Dy, and T. Pfister. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 139–149, 2022.
- [34] S. M. Xie, S. Santurkar, T. Ma, and P. Liang. Data selection for language models via importance resampling. NeurIPS, 2023.
- [35] Y. Xie, M. Ding, M. Tomizuka, and W. Zhan. Towards free data selection with general-purpose models. Advances in Neural Information Processing Systems, 36, 2024.
- [36] D. Yoo and I. S. Kweon. Learning loss for active learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 93–102, 2019.
- [37] J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong. ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832, 2021.
Appendix A Model Training
For model training, we apply prefix tuning for continual learning: the refined prompts are equally split into and concatenated with and , where and are the hidden states of the -th multi-head self-attention (MSA) layers. Thus, the -th MSA layer is calculated as:
| (6) |
where , , , and are the projection matrices and is the number of heads. In Eq.6, only are learnable, thus progressively storing task-related knowledge during learning.
Appendix B Implementation Details
We apply CODA-Prompt as the primary component, inserting prompts in layers 1-5 with a prompt length of 8 and a pool of 100 prompt components. Our architecture is based on the ViT-B/16 backbone [6], which is pre-trained on ImageNet1K [27]. We employ the Adam optimizer with a learning rate of 0.001 and manage our data in batches of 20 with resizing and normalization data transformation. To evaluate different data selection methods, we also utilize the same pretrained ViT-B/16 backbone to extract features, losses, or gradients. For the lossnet of Leanloss, the input dimension is set at 768 with an intermediate dimension of 128.
Appendix C More Experimental Results
| Setting | Class order 1 | Class order 2 | Class order 3 | Class order 4 | Class order 5 | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | Acc | Forgetting | |
| w/o skipping | 68.60 | 26.76 | 64.06 | 38.16 | 63.15 | 37.56 | 56.00 | 46.53 | 65.59 | 33.75 | 63.485.80 | 36.558.93 |
| w/ skipping | 65.33 | 36.84 | 70.12 | 33.43 | 72.00 | 32.70 | 66.72 | 38.26 | 68.30 | 24.27 | 68.503.29 | 33.106.77 |
Following the approach outlined in a prior work [7], we conducted most of our experiments in a setting where data had to be skipped because the model could not train at the same speed as the incoming data, even with data selection to choose a subset of data from non-skipped batches using a relatively high selection ratio. In this additional experiment, we studied the scenario where no data is skipped, but less data is selected from each batch by adjusting the selection ratio to be relatively low. This approach ensures that while each batch is not skipped, the total amount of data fed to the model for training remains roughly the same. From Table 7, we observe that the configuration with batch skipping generally outperforms the no-skipping configuration in terms of overall accuracy and forgetting metrics. Specifically, the average accuracy across the five class orders improves from 63.48% to 68.50%, while the forgetting metric decreases from 36.55% to 33.10%. These results suggest that although skipping batches is not ideal, it allows the model to focus on more relevant data points, thereby enhancing training efficiency and performance. While the results indicate that skipping is better, it is possible that the selection ratio should not be fixed but varied among batches of data. We consider this dynamic selection ratio approach as a potential future work to explore.
Checklist
-
1.
For all authors…
-
(a)
Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes] The claims match the experimental results and it is expected to generalize according to the diverse experiments stated in our paper. We include all of our code, data, and models in the supplementary materials, which can reproduce our experimental results.
-
(b)
Did you describe the limitations of your work? [Yes] See Section 7.
-
(c)
Did you discuss any potential negative societal impacts of your work? [N/A]
-
(d)
Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes] We have read the ethics review guidelines and ensured that our paper conforms to them.
-
(a)
-
2.
If you are including theoretical results…
-
(a)
Did you state the full set of assumptions of all theoretical results? [N/A] Our paper is based on the experimental results and we do not have any theoretical results.
-
(b)
Did you include complete proofs of all theoretical results? [N/A] Our paper is based on the experimental results and we do not have any theoretical results.
-
(a)
-
3.
If you ran experiments…
-
(a)
Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [Yes] We provide code to reproduce the main experimental results at https://github.com/intellistream/Efficient-Stream-Learning.
- (b)
- (c)
-
(d)
Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [Yes] See Section 5.1.
-
(a)
-
4.
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
-
(a)
If your work uses existing assets, did you cite the creators? [Yes] We mentioned and cited the datasets (Clear10, Clear100, CORe50 and Stream-51), and all comparing methods with their paper.
-
(b)
Did you mention the license of the assets? [Yes] The licenses of used datasets/models are provided in the cited references.
-
(c)
Did you include any new assets either in the supplemental material or as a URL? [Yes] We provide code for our proposed method in the supplement.
-
(d)
Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [N/A]
-
(e)
Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [N/A]
-
(a)
-
5.
If you used crowdsourcing or conducted research with human subjects…
-
(a)
Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
-
(b)
Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
-
(c)
Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
-
(a)