colorlinks=true, linkcolor=mydarkblue, citecolor=mydarkblue, filecolor=mydarkblue, urlcolor=mydarkblue, pdfview=FitH, *latexMarginpar on page 0 moved *captionThe option ‘hypcap=true’ will be ignored
Step-by-Step Diffusion: An Elementary Tutorial
Abstract
We present an accessible first course on diffusion models and flow matching for machine learning, aimed at a technical audience with no diffusion experience. We try to simplify the mathematical details as much as possible (sometimes heuristically), while retaining enough precision to derive correct algorithms.
Preface
There are many existing resources for learning diffusion models. Why did we write another? Our goal was to teach diffusion as simply as possible, with minimal mathematical and machine learning prerequisites, but in enough detail to reason about its correctness. Unlike most tutorials on this subject, we take neither a Variational Auto Encoder (VAE) nor an Stochastic Differential Equations (SDE) approach. In fact, for the core ideas we will not need any SDEs, Evidence-Based-Lower-Bounds (ELBOs), Langevin dynamics, or even the notion of a score. The reader need only be familiar with basic probability, calculus, linear algebra, and multivariate Gaussians. The intended audience for this tutorial is technical readers at the level of at least advanced undergraduate or graduate students, who are learning diffusion for the first time and want a mathematical understanding of the subject.
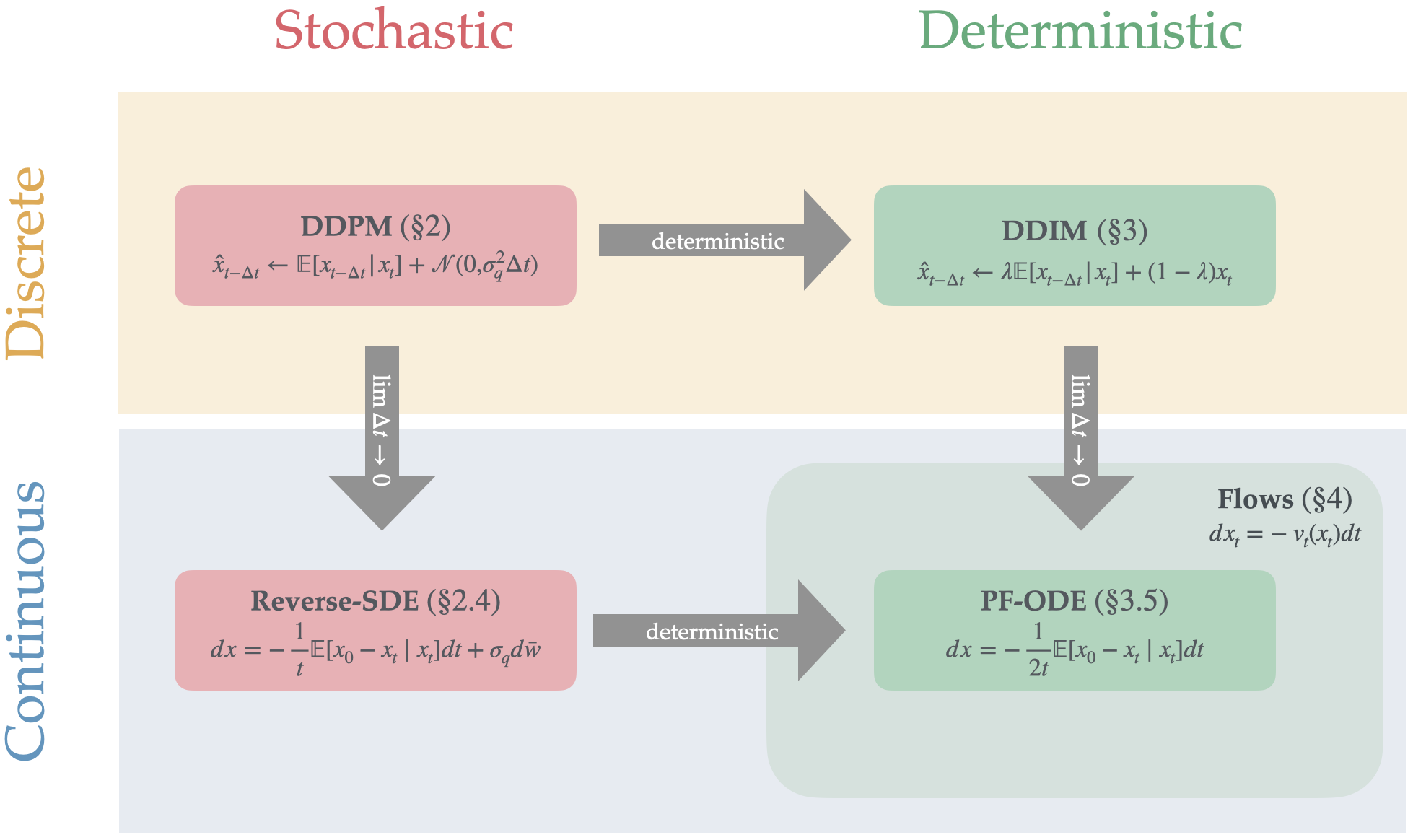
This tutorial has five parts, each relatively self-contained, but covering closely related topics. Section 1 presents the fundamentals of diffusion: the problem we are trying to solve and an overview of the basic approach. Sections 2 and 3 show how to construct a stochastic and deterministic diffusion sampler, respectively, and give intuitive derivations for why these samplers correctly reverse the forward diffusion process. Section 4 covers the closely-related topic of Flow Matching, which can be thought of as a generalization of diffusion that offers additional flexibility (including what are called rectified flows or linear flows). Finally, in Section 5 we return to diffusion and connect this tutorial to the broader literature while highlighting some of the design choices that matter most in practice, including samplers, noise schedules, and parametrizations.
Acknowledgements
We are grateful for helpful feedback and suggestions from many people, in particular: Josh Susskind, Eugene Ndiaye, Dan Busbridge, Sam Power, De Wang, Russ Webb, Sitan Chen, Vimal Thilak, Etai Littwin, Chenyang Yuan, Alex Schwing, and Miguel Angel Bautista Martin.
1 Fundamentals of Diffusion
The goal of generative modeling is: given i.i.d. samples from some unknown distribution , construct a sampler for (approximately) the same distribution. For example, given a training set of dog images from some underlying distribution , we want a method of producing new images of dogs from this distribution.
One way to solve this problem, at a high level, is to learn a transformation from some easy-to-sample distribution (such as Gaussian noise) to our target distribution . Diffusion models offer a general framework for learning such transformations. The clever trick of diffusion is to reduce the problem of sampling from distribution into to a sequence of easier sampling problems.
This idea is best explained via the following Gaussian diffusion example. We’ll sketch the main ideas now, and in later sections we will use this setup to derive what are commonly known as the DDPM and DDIM samplers111These stand for Denoising Diffusion Probabilistic Models (DDPM) and Denoising Diffusion Implicit Models (DDIM), following Ho et al. (2020) and Song et al. (2021)., and reason about their correctness.
1.1 Gaussian Diffusion
For Gaussian diffusion, let be a random variable in distributed according to the target distribution (e.g., images of dogs). Then construct a sequence of random variables , by successively adding independent Gaussian noise with some small scale :
| (1) |
This is called the forward process222 One benefit of using this particular forward process is computational: we can directly sample given in constant time., which transforms the data distribution into a noise distribution. Equation (1) defines a joint distribution over all , and we let denote the marginal distributions of each . Notice that at large step count , the distribution is nearly Gaussian333Formally, is close in KL divergence to , assuming has bounded moments., so we can approximately sample from by just sampling a Gaussian.
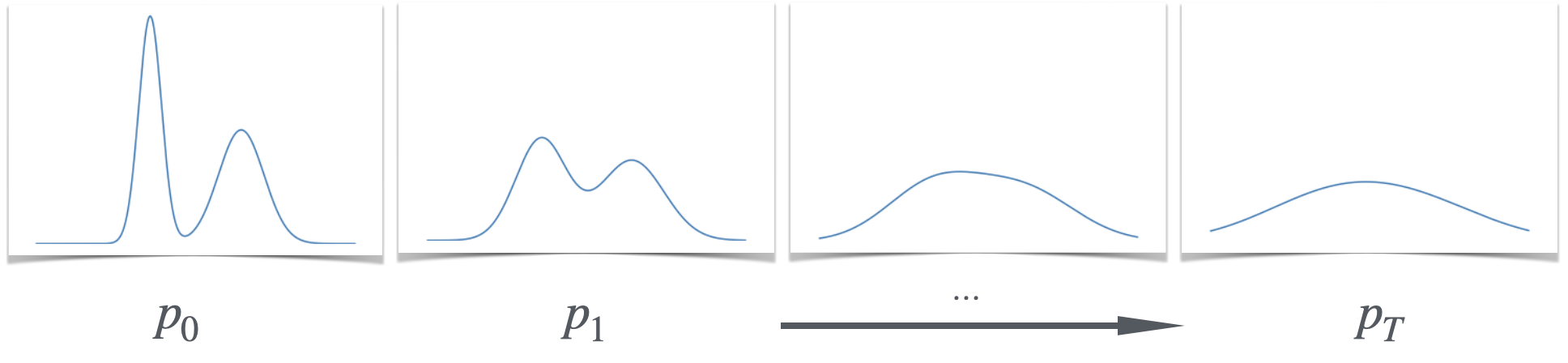
Now, suppose we can solve the following subproblem:
“Given a sample marginally distributed as , produce a sample marginally distributed as ”.
We will call a method that does this a reverse sampler444Reverse samplers will be formally defined in Section 1.2 below., since it tells us how to sample from assuming we can already sample from . If we had a reverse sampler, we could sample from our target by simply starting with a Gaussian sample from , and iteratively applying the reverse sampling procedure to get samples from and finally .
The key insight of diffusion is, learning to reverse each intermediate step can be easier than learning to sample from the target distribution in one step555 Intuitively this is because the distributions are already quite close, so the reverse sampler does not need to do much.. There are many ways to construct reverse samplers, but for concreteness let us first see the standard diffusion sampler which we will call the DDPM sampler666This is the sampling strategy originally proposed in Sohl-Dickstein et al. (2015)..k
The Ideal DDPM sampler uses the obvious strategy: At time , given input (which is promised to be a sample from ), we output a sample from the conditional distribution
| (2) |
This is clearly a correct reverse sampler. The problem is, it requires learning a generative model for the conditional distribution for every , which could be complicated. But if the per-step noise is sufficiently small, then it turns out this conditional distribution becomes simple:
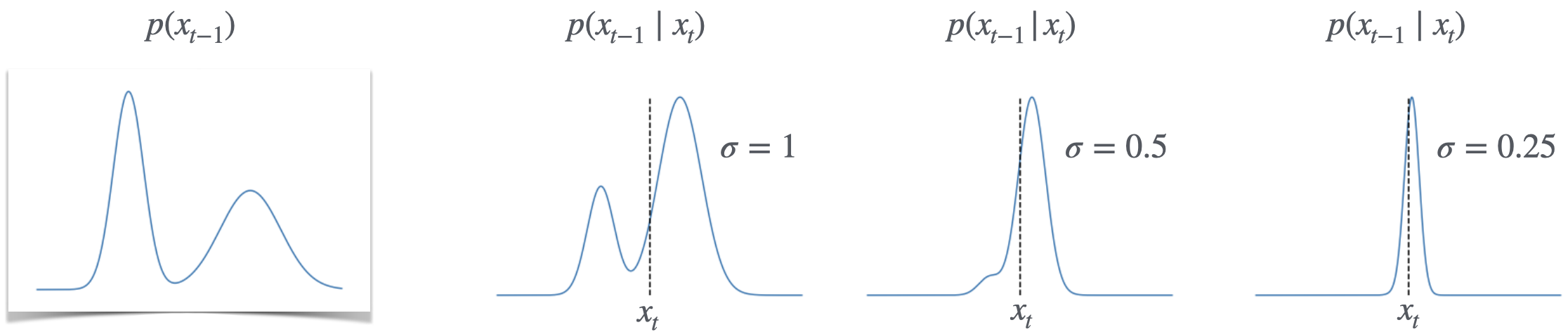
Fact 1 (Diffusion Reverse Process).
For small , and the Gaussian diffusion process defined in (1), the conditional distribution is itself close to Gaussian. That is, for all times and conditionings , there exists some mean parameter such that
| (3) |
This is not an obvious fact; we will derive it in Section 2.1. This fact enables a drastic simplification: instead of having to learn an arbitrary distribution from scratch, we now know everything about this distribution except its mean, which we denote777 We denote the mean as a function because the mean of depends on the time as well as the conditioning , as described in Fact 1. . The fact that we can approximate the posterior distribution as Gaussian when is sufficiently small is illustrated in Fig 2. This is an important point, so to re-iterate: for a given time and conditioning value , learning the mean of is sufficient to learn the full conditional distribution .
Learning the mean of is a much simpler problem than learning the full conditional distribution, because we can solve it by regression. To elaborate, we have a joint distribution from which we can easily sample, and we would like to estimate . This can be done by optimizing a standard regression loss888 Recall the generic fact that for any distribution over , we have: :
| (4) | ||||
| (5) | ||||
| (6) |
where the expectation is taken over samples from our target distribution .999Notice that we simulate samples of by adding noise to the samples of , as defined in Equation 1. This particular regression problem is well-studied in certain settings. For example, when the target is a distribution on images, then the corresponding regression problem (Equation 6) is exactly an image denoising objective, which can be approached with familiar methods (e.g. convolutional neural networks).
Stepping back, we have seen something remarkable: we have reduced the problem of learning to sample from an arbitrary distribution to the standard problem of regression.
1.2 Diffusions in the Abstract
Let us now abstract away the Gaussian setting, to define diffusion-like models in a way that will capture their many instantiations (including deterministic samplers, discrete domains, and flow-matching).
Abstractly, here is how to construct a diffusion-like generative model: We start with our target distribution , and we pick some base distribution which is easy to sample from, e.g. a standard Gaussian or i.i.d bits. We then try to construct a sequence of distributions which interpolate between our target and the base distribution . That is, we construct distributions
| (7) |
such that is our target, the base distribution, and adjacent distributions are marginally “close” in some appropriate sense. Then, we learn a reverse sampler which transforms distributions to . This is the key learning step, which presumably is made easier by the fact that adjacent distributions are “close.” Formally, reverse samplers are defined below.
Definition 1 (Reverse Sampler).
Given a sequence of marginal distributions , a reverse sampler for step is a potentially stochastic function such that if , then the marginal distribution of is exactly :
| (8) |
There are many possible reverse samplers101010Notice that none of this abstraction is specific to the case of Gaussian noise— in fact, it does not even require the concept of “adding noise”. It is even possible to instantiate in discrete settings, where we consider distributions over a finite set, and define corresponding “interpolating distributions” and reverse samplers., and it is even possible to construct reverse samplers which are deterministic. In the remainder of this tutorial we will see three popular reverse samplers more formally: the DDPM sampler discussed above (Section 2.1), the DDIM sampler (Section 3), which is deterministic, and the family of flow-matching models (Section 4), which can be thought of as a generalization of DDIM.111111 Given a set of marginal distributions , there are many possible joint distributions consistent with these marginals (such joint distributions are called couplings). There is therefore no canonical reverse sampler for a given set of marginals — we are free to chose whichever coupling is most convenient.
1.3 Discretization
Before we proceed further, we need to be more precise about what we mean by adjacent distributions being “close”. We want to think of the sequence as the discretization of some (well-behaved) time-evolving function , that starts from the target distribution at time and ends at the noisy distribution at time :
| (9) |
The number of steps controls the fineness of the discretization (hence the closeness of adjacent distributions).121212This naturally suggests taking the continuous-time limit, which we discuss in Section 2.4, though it is not needed for most of our arguments.
In order to ensure that the variance of the final distribution, , is independent of the number of discretization steps, we also need to be more specific about the variance of each increment. Note that if , then . Therefore, we need to scale the variance of each increment by , that is, choose
| (10) |
where is the desired terminal variance. This choice ensures that the variance of is always , regardless of . (The scaling will turn out to be important in our arguments for the correctness of our reverse solvers in the next chapter, and also connects to the SDE formulation in Section 2.4.)
At this point, it is convenient to adjust our notation. From here on, will represent a continuous-value in the interval (specifically, taking one of the values ). Subscripts will indicate time rather than index, so for example will now denote at a discretized time . That is, Equation 1 becomes:
| (11) |
which also implies that
| (12) |
since the total noise added up to time (i.e. ) is also Gaussian with mean zero and variance .
2 Stochastic Sampling: DDPM
In this section we review the DDPM-like reverse sampler discussed in Section 1, and heuristically prove its correctness. This sampler is conceptually the same as the sampler popularized in Denoising Diffusion Probabilistic Models (DDPM) by Ho et al. (2020) and originally introduced by Sohl-Dickstein et al. (2015), when adapted to our simplified setting. However, a word of warning for the reader familiar with Ho et al. (2020): Although the overall strategy of our sampler is identical to Ho et al. (2020), certain technical details (like constants, etc) are slightly different131313 For the experts, the main difference is we use the “Variance Exploding” diffusion forward process. We also use a constant noise schedule, and we do not discuss how to parameterize the predictor (“predicting vs. vs. noise ”). We elaborate on the latter point in Section 2.3. .
We consider the setup from Section 1.3, with some target distribution and the joint distribution of noisy samples defined by Equation (11). The DDPM sampler will require estimates of the following conditional expectations:
| (13) |
This is a set of functions , one for every time step . In the training phase, we estimate these functions from i.i.d. samples of , by optimizing the denoising regression objective
| (14) |
typically with a neural-network141414 In practice, it is common to share parameters when learning the different regression functions , instead of learning a separate function for each timestep independently. This is usually implemented by training a model that accepts the time as an additional argument, such that . parameterizing . Then, in the inference phase, we use the estimated functions in the following reverse sampler.
[nobreak=true]
Algorithm 1: Stochastic Reverse Sampler (DDPM-like)
For input sample , and timestep , output:
| (15) |
To actually generate a sample, we first sample as an isotropic Gaussian , and then run the iteration of Algorithm 1 down to , to produce a generated sample . (Recall that in our discretized notation (12), is the fully-noised terminal distribution, and the iteration takes steps of size .) Explicit pseudocode for these algorithms are given in Section 2.2.
We want to reason about correctness of this entire procedure: why does iterating Algorithm 1 produce a sample from [approximately] our target distribution ? The key missing piece is, we need to prove some version of Fact 1: that the true conditional can be well-approximated by a Gaussian, and this approximation gets better as we scale .
2.1 Correctness of DDPM
Here is a more precise version of Fact 1, along with a heuristic derivation. This will complete the argument that Algorithm 1 is correct— i.e. that it approximates a valid reverse sampler in the sense of Definition 1.
Claim 1 (Informal).
Let be an arbitrary, sufficiently-smooth density over . Consider the joint distribution of , where and . Then, for sufficiently small , the following holds. For all conditionings , there exists such that:
| (16) |
for some constant depending only on . Moreover, it suffices to take151515Experts will recognize this mean as related to the score. In fact, Tweedie’s formula implies that this mean is exactly correct even for large , with no approximation required. That is, . The distribution may deviate from Gaussian, however, for larger .
| (17) | ||||
| (18) |
where is the marginal distribution of .
Before we see the derivation, a few remarks: Claim 1 implies that to sample from , it suffices to first sample from , then sample from a Gaussian distribution centered around . This is exactly what DDPM does, in Equation (15). Finally, in these notes we will not actually need the expression for in Equation (18); it is enough for us know that such a exists, so we can learn it from samples.
Proof of Claim 1 (Informal).
Here is a heuristic argument for why the score appears in the reverse process. We will essentially just apply Bayes rule and then Taylor expand appropriately. We start with Bayes rule:
| (19) |
Then take logs of both sizes. Throughout, we will drop any additive constants in the log (which translate to normalizing factors), and drop all terms of order ††[-1cm]Note that . Dropping terms means dropping in the expansion of , but keeping in .. Note that we should think of as a constant in this derivation, since we want to understand the conditional probability as a function of . Now:
| Drop constants involving only . | |||
| Since . | |||
| Definition of . | |||
| Taylor expand around and drop constants. | |||
| Complete the square in , and drop constant involving only . | |||
| For . |
This is identical, up to additive factors, to the log-density of a Normal distribution with mean and variance . Therefore,
| (20) |
∎
Reflecting on this derivation, the main idea was that for small enough , the Bayes-rule expansion of the reverse process is dominated by the term , from the forward process. This is intuitively why the reverse process and the forward process have the same functional form (both are Gaussian here)161616This general relationship between forward and reverse processes holds somewhat more generally than just Gaussian diffusion; see e.g. the discussion in Sohl-Dickstein et al. (2015)..
Technical Details [Optional].
The meticulous reader may notice that Claim 1 is not obviously sufficient to imply correctness of the entire DDPM algorithm. The issue is: as we scale down , the error in our per-step approximation (Equation 16) decreases, but the number of total steps required increases. So if the per-step error does not decrease fast enough (as a function of ), then these errors could accumulate to a non-negligible error by the final step. Thus, we need to quantify how fast the per-step error decays. Lemma 1 below is one way of quantifying this: it states that if the step-size (i.e. variance of the per-step noise) is , then the KL error of the per-step Gaussian approximation is . This decay rate is fast enough, because the number of steps only grows as171717 The chain rule for KL implies that we can add up these per-step errors: the approximation error for the final sample is bounded by the sum of all the per-step errors. .
Lemma 1.
Let be an arbitrary density over , with bounded 1st to 4th order derivatives. Consider the joint distribution , where and . Then, for any conditioning , we have
| (21) |
where
| (22) |
2.2 Algorithms
Pseudocode listings 1 and 2 give the explicit DDPM train loss and sampling code. To train181818Note that the training procedure optimizes for all timesteps simultaneously, by sampling uniformly in Line 2. the network , we must minimize the expected loss output by Pseudocode 1, typically by backpropagation.
Pseudocode 3 describes the closely-related DDIM sampler, which will be discussed later in Section 3.
2.3 Variance Reduction: Predicting
Thus far, our diffusion models have been trained to predict : this is what Algorithm 1 requires, and what the training procedure of Pseudocode 1 produces. However, many practical diffusion implementations actually train to predict , i.e. to predict the expectation of the initial point instead of the previous point . This difference turns out to be just a variance reduction trick, which estimates the same quantity in expectation. Formally, the two quantities can be related as follows:
Claim 2.
This claim implies that if we want to estimate , we can instead estimate and then then essentially divide by , which is the number of steps taken thus far. The variance-reduced versions of the DDPM training and sampling algorithms do exactly this; we include them in Appendix B.9.
![[Uncaptioned image]](predict_eps_dt.png)
The intuition behind Claim 2. Given , the final noise step is distributed identically as all other noise steps, intuitively because we only know the sum . The intuition behind Claim 2 is illustrated in Figure 2: first, observe that predicting given is equivalent to predicting the last noise step, which is in the forward process of Equation (11). But, if we are only given the final , then all of the previous noise steps intuitively “look the same”— we cannot distinguish between noise that was added at the last step from noise that was added at the 5th step, for example. By this symmetry, we can conclude that all of the individual noise steps are distributed identically (though not independently) given . Thus, instead of estimating a single noise step, we can equivalently estimate the average of all prior noise steps, which has much lower variance. There are elapsed noise steps by time , so we divide the total noise by this quantity in Equation 23 to compute the average. See Appendix B.8 for a formal proof.
Word of warning: Diffusion models should always be trained to estimate expectations. In particular, when we train a model to predict , we should not think of this as trying to learn “how to sample from the distribution ”. For example, if we are training an image diffusion model, then the optimal model will output which will look like a blurry mix of images (e.g. Figure 1b in Karras et al. (2022))— it will not look like an actual image sample. It is good to keep in mind that when diffusion papers colloquially discuss models “predicting ”, they do not mean producing something that looks like an actual sample of .
2.4 Diffusions as SDEs [Optional]
In this section, we connect the discrete-time processes we have discussed so far to stochastic differential equations (SDEs). In the continuous limit, as , our discrete diffusion process turns into a stochastic differential equation. SDEs can also represent many other diffusion variants (corresponding to different drift and diffusion terms), offering flexibility in design choices, like scaling and noise-scheduling. The SDE perspective is powerful because existing theory provides a general closed-form solution for the time-reversed SDE. Discretization of the reverse-time SDE for our particular diffusion immediately yields the sampler we derived in this section, but reverse-time SDEs for other diffusion variants are also available automatically (and can then be solved with any off-the-shelf or custom SDE solver), enabling better training and sampling strategies as we will discuss further in Section 5. Though we mention these connections only briefly here, the SDE perspective has had significant impact on the field. For a more detailed discussion, we recommend Yang Song’s blog post (Song, 2021).
The Limiting SDE
Recall our discrete update rule:
In this limit as , this corresponds to a zero-drift SDE:
| (25) |
where is a Brownian motion. A Brownian motion is a stochastic process with i.i.d. Gaussian increments whose variance scales with .191919See Eldan (2024) for a high-level overview of Brownian motions and Itô’s formula. See also Evans (2012) for a gentle introductory textbook, and Kloeden and Platen (2011) for numerical methods. Very heuristically, we can think of and thus “derive” (25) by
More generally, different variants of diffusion are equivalent to SDEs with different choices of drift and diffusion terms:
| (26) |
The SDE (25) simply has and . This formulation encompasses many other possibilities, though, corresponding to different choices of , in the SDE. As we will revisit in Section 5, this flexibility is important for developing effective algorithms. Two important choices made in practice are tuning the noise schedule and scaling ; together these can help to control the variance of , and control how much we focus on different noise levels. Adopting a flexible noise schedule in place of the fixed schedule corresponds to the SDE (Song et al., 2020)
If we also wish to scale each by a factor , Karras et al. (2022) show that this corresponds to the SDE 202020As a sketch of how arises, let’s ignore the noise and note that:
These are only a few examples of the rich and useful design space enabled by the flexible SDE (26).
Reverse-Time SDE
The time-reversal of an SDE runs the process backward in time. Reverse-time SDEs are the continuous-time analog of samplers like DDPM. A deep result due to Anderson (1982) (and nicely re-derived in Winkler (2021)) states that the time-reversal of SDE (26) is given by:
| (27) |
That is, SDE (27) tells us how to run any SDE of the form (26) backward in time! This means that we don’t have to re-derive the reversal in each case, and we can choose any SDE solver to yield a practical sampler. But nothing is free: we sill cannot use (27) directly to sample backward, since the term – which is in fact the score that previously appeared in equation 18 – is unknown in general, since it depends on . However, if we can learn the score, then we can solve the reverse SDE. This is analogous to discrete diffusion, where the forward process is easy to model (it just adds noise), while the reverse process must be learned.
Let us take a moment to discuss the score, , which plays a central role. Intuitively, since the score “points toward higher probability”, it helps to reverse the diffusion process, which “flattens out” the probability as it runs forward. The score is also related to the conditional expectation of given . Recall that in the discrete case
Similarly, in the continuous case we have 212121We can see this directly by applying Tweedie’s formula, which states: Since Tweedie with gives:
| (28) |
3 Deterministic Sampling: DDIM
We will now show a deterministic reverse sampler for Gaussian diffusion— which appears similar to the stochastic sampler of the previous section, but is conceptually quite different. This sampler is equivalent to the DDIM222222DDIM stands for Denoising Diffusion Implicit Models, which reflects a perspective used in the original derivation of Song et al. (2021). Our derivation follows a different perspective, and the “implicit” aspect will not be important to us. update of Song et al. (2021), adapted to in our simplified setting.
We consider the same Gaussian diffusion setup as the previous section, with the joint distribution and conditional expectation function The reverse sampler is defined below, and listed explicitly in Pseudocode 3.
[nobreak=true]
Algorithm 2: Deterministic Reverse Sampler (DDIM-like)
For input sample , and step index , output:
| (31) |
where and from Equation (12).
How do we show that this defines a valid reverse sampler? Since Algorithm 2 is deterministic, it does not make sense to argue that it samples from , as we argued for the DDPM-like stochastic sampler. Instead, we will directly show that Equation (31) implements a valid transport map between the marginal distributions and . That is, if we let be the update of Equation (31):
| (32) | ||||
| (33) |
then we want to show that232323 The notation means the distribution of . This is called the pushforward of by the function .
| (34) |
Proof overview: The usual way to prove this is to use tools from stochastic calculus, but we’ll present an elementary derivation. Our strategy will be to first show that Algorithm 2 is correct in the simplest case of a point-mass distribution, and then lift this result to full distributions by marginalizing appropriately. For the experts, this is similar to “flow-matching” proofs.
3.1 Case 1: Single Point
Let’s first understand the simple case where the target distribution is a single point mass in . Without loss of generality242424Because we can just “shift” our coordinates to make it so. Formally, our entire setup including Equation 33 is translation-symmetric., we can assume the point is at . Is Algorithm 2 correct in this case? To reason about correctness, we want to consider the distributions of and for arbitrary step . According to the diffusion forward process (Equation 11), at time the relevant random variables are252525We omit the Identity matrix in these covariances for notational simplicity. The reader may assume dimension without loss of generality.
The marginal distribution of is , and the marginal distribution of is .
Let us first find some deterministic function , such that . There are many possible functions which will work262626For example, we can always add a rotation around the origin to any valid map., but this is the obvious one:
| (35) |
The function above simply re-scales the Gaussian distribution of , to match variance of the Gaussian distribution . It turns out this is exactly equivalent to the step taken by Algorithm 2, which we will now show.
Claim 3.
Proof.
To apply , we need to compute for our simple distribution. Since are jointly Gaussian, this is††[-2cm]Recall the conditional expectation of two jointly Gaussian random variables is , where are the respective means, and the cross-covariance of and covariance of . Since and are centered at , we have . For the covariance term, since we have . Similarly, .
| (37) |
The rest is algebra:
| by definition of | ||||
| by definition of | ||||
| by Equation (37) | ||||
We therefore conclude that Algorithm 2 is a correct reverse sampler, since it is equivalent to , and is valid. ∎
3.2 Velocity Fields and Gases
Before we move on, it will be helpful to think of the DDIM update as equivalent to a velocity field, which moves points at time to their positions at time . Specifically, define the vector field
| (38) |
Then the DDIM update algorithm of Equation (31) can be written as:
| from Equation (31) | ||||
| (39) |
The physical intuition for is: imagine a gas of non-interacting particles, with density field given by . Then, suppose a particle at position moves in the direction . The resulting gas will have density field . We write this process as
| (40) |
In the limit of small stepsize , speaking informally, we can think of as a velocity field — which specifies the instantaneous velocity of particles moving according to the DDIM algorithm.
![[Uncaptioned image]](x1.png)
3.3 Case 2: Two Points
Now let us show Algorithm 2 is correct when the target distribution is a mixture of two points:
| (41) |
for some . According to the diffusion forward process, the distribution at time will be a mixture of Gaussians282828Linearity of the forward process (with respect to ) was important here. That is, roughly speaking, diffusing a distribution is equivalent to diffusing each individual point in that distribution independently; the points don’t interact. :
| (42) |
We want to show that with these distributions , the DDIM velocity field (of Equation 38) transports .
Let us first try to construct some velocity field such that . From our result in Section 3.1 — the fact that DDIM update works for single points — we already know velocity fields which transport each mixture component individually. That is, we know the velocity field defined as
| (43) |
transports292929Pay careful attention to which distributions we take expectations over! The expectation in Equation (43) is w.r.t. the single-point distribution , but our definition of the DDIM algorithm, and its vector field in Equation (38), are always w.r.t. the target distribution. In our case, the target distribution is of Equation (41).
| (44) |
and similarly for .
We now want some way of combining these two velocity fields into a single velocity , which transports the mixture:
| (45) |
We may be tempted to just take the average velocity field , but this is incorrect. The correct combined velocity is a weighted-average of the individual velocity fields, weighted by their corresponding density fields303030Note that we can write the density as ..
| (46) | ||||
| (47) |
Explicitly, the weight for at a point is the probability that was generated from initial point , rather than .
To be intuitively convinced of this313131The time step must be small enough for this analogy to hold, so the DDIM updates are essentially infinitesimal steps. Otherwise, if the step size is large, it may not be possible to combine the two transport maps with “local” (i.e. pointwise) operations alone., consider the corresponding question about gasses illustrated in Figure 3. Suppose we have two overlapping gases, a red gas with density and velocity , and a blue gas with density and velocity . We want to know, what is the effective velocity of the combined gas (as if we saw only in grayscale)? We should clearly take a weighted-average of the individual gas velocities, weighted by their respective densities — just as in Equation (47).

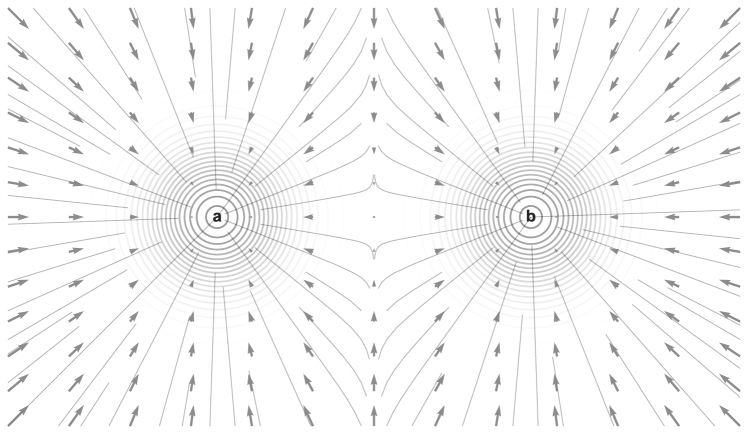
We have now solved the main subproblem of this section: we have found one particular vector field which transports to , for our two-point distribution . It remains to show that this is equivalent to the velocity field of Algorithm 2 ( from Equation 38).
To show this, first notice that the individual vector field can be written as a conditional expectation. Using the definition in Equation (43)323232We add conditioning , because we want to take expectations w.r.t the two-point mixture distribution, not the single-point distribution.,
| (48) | ||||
| (49) |
Now the entire vector field can be written as a conditional expectation:
| (50) | ||||
| (51) | ||||
| (52) | ||||
| (53) | ||||
| (from Equation 38) |
where all expectations are w.r.t. the distribution . Thus, the combined velocity field is exactly the velocity field given by the updates of Algorithm 2 — so Algorithm 2 is a correct reverse sampler for our two-point mixture distribution.
3.4 Case 3: Arbitrary Distributions
Now that we know how to handle two points, we can generalize this idea to arbitrary distributions of . We will not go into details here, because the general proof will be subsumed by the subsequent section.
It turns out that our overall proof strategy for Algorithm 2 can be generalized significantly to other types of diffusions, without much work. This yields the idea of flow matching, which we will see in the following section. Once we develop the machinery of flows, it is actually straightforward to derive DDIM directly from the simple single-point scaling algorithm of Equation (35): see Appendix B.5.
3.4.1 The Probability Flow ODE [Optional]
Finally, we generalize our discrete-time deterministic sampler to an ordinary differential equation (ODE) called the probability flow ODE (Song et al., 2020). The following section builds on our discussion of SDEs as the continuous limit of diffusion in section 2.4. Just as the reverse-time SDEs of section 2.4 offered a flexible continuous-time generalization of discrete stochastic samplers, so we will see that discrete deterministic samplers generalize to ODEs. The ODE formulation offers both a useful theoretical lens through which to view diffusion, as well as practical advantages, like the opportunity to choose from a variety of off-the-shelf and custom ODE solvers to improve sampling (like the popular DPM++ method, as discussed in chapter 5).
Recall the general SDE (26) from section 2.4:
Song et al. (2020) showed that is possible to convert this SDE into a deterministic equivalent called the probability flow ODE (PF-ODE): 333333A proof sketch is in appendix B.2. It involves rewriting the SDE noise term as the deterministic score (recall the connection between noise and score in equation (18)). Although it is deterministic, the score is unknown since it depends on .
| (54) |
SDE (26) and ODE (54) are equivalent in the sense that trajectories obtained by solving the PF-ODE have the same marginal distributions as the SDE trajectories at every point in time343434To use a gas analogy: the SDE describes the (Brownian) motion of individual particles in a gas, while the PF-ODE describes the streamlines of the gas’s velocity field. That is, the PF-ODE describes the motion of a “test particle” being transported by the gas— like a feather in the wind.. However, note that the score appears here again, as it did in the reverse SDE (27); just as for the reverse SDE, we must learn the score to make the ODE (54) practically useful.
Just as DDPM was a (discretized) special-case of the reverse-time SDE (27), so DDIM can be seen as a (discretized) special case of the PF-ODE (54). Recall from section 2.4 that the simple diffusion we have been studying corresponds to the SDE (25) with and . The corresponding ODE is
| (55) | ||||
| (56) |
Reversing and discretizing yields
Noting that , we recover the deterministic (DDIM) sampler (31).
3.5 Discussion: DDPM vs DDIM
The two reverse samplers defined above (DDPM and DDIM) are conceptually significantly different: one is deterministic, and the other stochastic. To review, these samplers use the following strategies:
-
1.
DDPM ideally implements a stochastic map , such that the output is, pointwise, a sample from the conditional distribution .
-
2.
DDIM ideally implements a deterministic map , such that the output is marginally distributed as . That is, .
Although they both happen to take steps in the same direction353535Steps proportional to . (given the same input ), the two algorithms end up evolving very differently. To see this, let’s consider how each sampler ideally behaves, when started from the same initial point and iterated to completion.
DDPM will ideally produce a sample from . If the forward process mixes sufficiently (i.e. for large in our setup), then the final point will be nearly independent from the initial point. Thus , so the distribution output by the ideal DDPM will not depend at all363636 Actual DDPMs may have a small dependency on the initial point , because they do not mix perfectly (i.e. the final distribution is not perfectly Gaussian). Randomizing the initial point may thus help with sample diversity in practice. on the starting point . In contrast, DDIM is deterministic, so it will always produce a fixed value for a given , and thus will depend very strongly on .
The picture to have in mind is, DDIM defines a deterministic map , taking samples from a Gaussian distribution to our target distribution. At this level, the DDIM map may sound similar to other generative models — after all, GANs and Normalizing Flows also define maps from Gaussian noise to the true distribution. What is special about the DDIM map is, it is not allowed to be arbitrary: the target distribution exactly determines the ideal DDIM map (which we train models to emulate). This map is “nice”; for example we expect it to be smooth if our target distribution is smooth. GANs, in contrast, are free to learn any arbitrary mapping between noise and images. This feature of diffusion models may make the learning problem easier in some cases (since it is supervised), or harder in other cases (since there may be easier-to-learn maps which other methods could find).
3.6 Remarks on Generalization
In this tutorial, we have not discussed the learning-theoretic aspects of diffusion models: How do we learn properties of the underlying distribution, given only finite samples and bounded compute? These are fundamental aspects of learning, but are not yet fully understood for diffusion models; it is an active area of research373737 We recommend the introductions of Chen et al. (2022) and Chen et al. (2024b) for an overview of recent learning-theoretic results. This line of work includes e.g. De Bortoli et al. (2021); De Bortoli (2022); Lee et al. (2023); Chen et al. (2023, 2024a). .
To appreciate the subtlety here, suppose we learn a diffusion model using the classic strategy of Empirical Risk Minimization (ERM): we sample a finite train set from the underlying distribution, and optimize all regression functions w.r.t. this empirical distribution. The problem is, we should not perfectly minimize the empirical risk, because this would yield a diffusion model which only reproduces the train samples383838 This is not specific to diffusion models: any perfect generative model of the empirical distribution will always output a uniformly random train point, which is far-from-optimal w.r.t. the true underlying distribution..
In general learning the diffusion model must be regularized, implicitly or explicitly, to prevent overfitting and memorization of the training data. When we train deep neural networks for use in diffusion models, this regularization often occurs implicitly: factors such as finite model size and optimization randomness prevent the trained model from perfectly memorizing its train set. We will revisit these factors (as sources of error) in Section 5.
This issue of memorizing training data has been seen “in the wild” in diffusion models trained on small image datasets, and it has been observed that memorization reduces as the training set size increases (Somepalli et al., 2023; Gu et al., 2023). Additionally, memorization as been noted as a potential security and copyright issue for neural networks as in Carlini et al. (2023) where the authors found they can recover training data from stable diffusion with the right prompts.
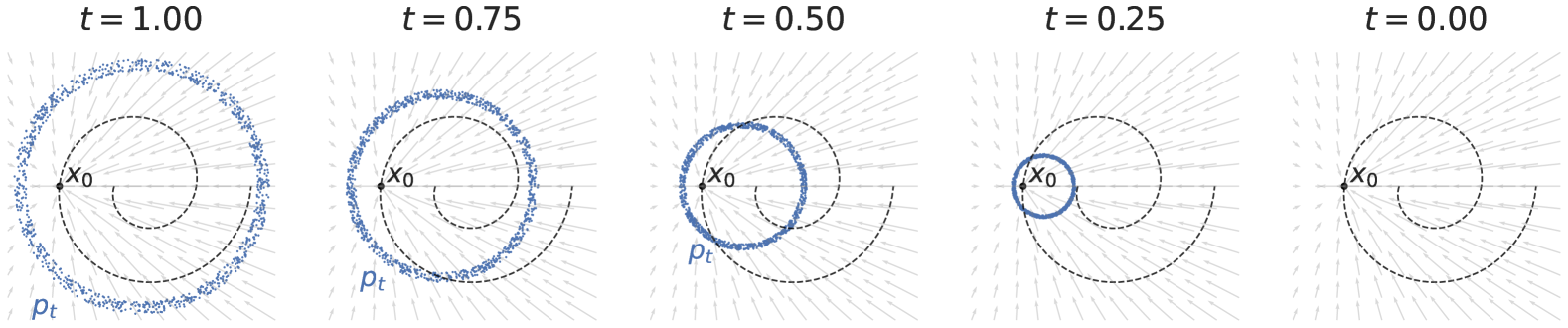
Figure 4 demonstrates the effect of training set size, and shows the DDIM trajectories for a diffusion model trained using a 3 layer ReLU network. We see that the diffusion model on samples “memorizes” its train set: its trajectories all collapse to one of the train points, instead of producing the underlying spiral distribution. As we add more samples, the model starts to generalize: the trajectories converge to the underlying spiral manifold. The trajectories also start to become more perpendicular the underlying manifold, suggesting that the low dimensional structure is being learned. We also note that in the case where the diffusion model fails, it is not at all obvious a human would be able to identify the “correct” pattern from these samples, so generalization may be too much to expect.
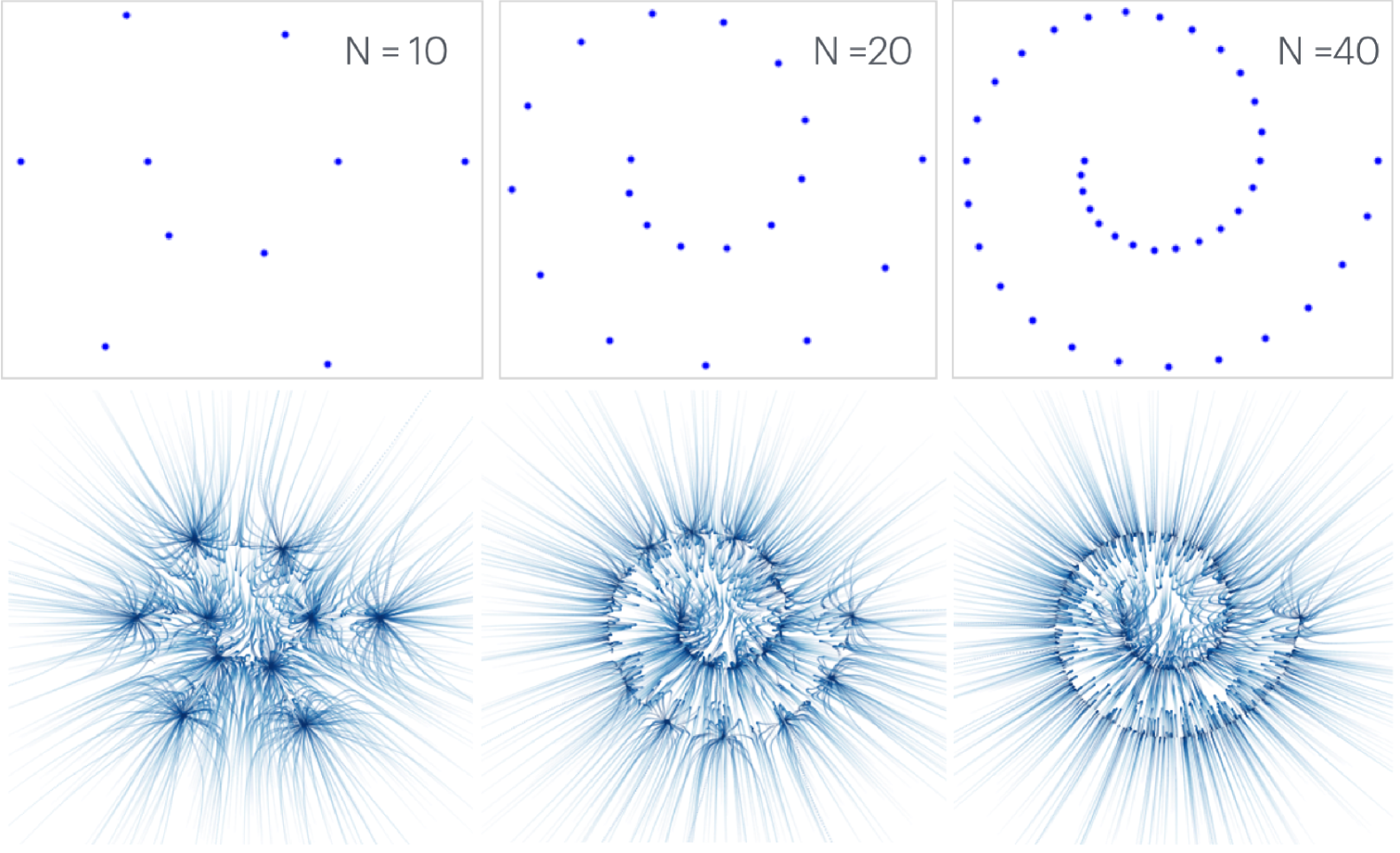
4 Flow Matching
![[Uncaptioned image]](x5.png)
Running a flow which generates a spiral distribution (bottom) from an annular distribution (top).
We now introduce the framework of flow matching (Lipman et al., 2023; Albergo et al., 2023; Liu et al., 2022). Flow matching can be thought of as a generalization of DDIM, which allows for more flexibility in designing generative models— including for example the rectified flows (sometimes called linear flows) used by Stable Diffusion 3 (Liu et al., 2022; Esser et al., 2024).
We have actually already seen the main ideas behind flow matching, in our analysis of DDIM in Section 3. At a high level, here is how we constructed a generative model in Section 3:
-
1.
First, we defined how to generate a single point. Specifically, we constructed vector fields which, when applied for all time steps, transported a standard Gaussian distribution to an arbitrary delta distribution .
-
2.
Second, we determined how to combine two vector fields into a single effective vector field. This lets us construct a transport from the standard Gaussian to two points (or, more generally, to a distribution over points — our target distribution).
Neither of these steps particularly require the Gaussian base distribution, or the Gaussian forward process (Equation 1). The second step of combining vector fields remains identical for any two arbitrary vector fields, for example.
So let’s drop all the Gaussian assumptions. Instead, we will begin by thinking at a basic level about how to map between any two points and . Then, we see what happens when the two points are sampled from arbitrary distributions (data) and (base), respectively. We will see that this point of view encompasses DDIM as a special case, but that it is significantly more general.
4.1 Flows
Let us first define the central notion of a flow. A flow is simply a collection of time-indexed vector fields . We should think of this as the velocity-field of a gas at each time , as we did earlier in Section 3.2. Any flow defines a trajectory taking initial points to final points , by transporting the initial point along the velocity fields .
Formally, for flow and initial point , consider the ODE††[] The corresponding discrete-time analog is the iteration: , starting at with initial point .
| (57) |
with initial condition at time . We write
| (58) |
to denote the solution to the flow ODE (Equation 57) at time , terminating at final point . That is, RunFlow is the result of transporting point along the flow up to time .
Just as flows define maps between initial and final points, they also define transports between entire distributions, by “pushing forward” points from the source distribution along their trajectories. If is a distribution on initial points393939Notational warning: Most of the flow matching literature uses a reversed time convention, so is the target distribution. We let be the target distribution to be consistent with the DDPM convention., then applying the flow yields the distribution on final points404040 We could equivalently write this as the pushforward .
| (59) |
We denote this process as meaning the flow transports initial distribution to final distribution414141 In our gas analogy, this means if we start with a gas of particles distributed according to , and each particle follows the trajectory defined by , then the final distribution of particles will be . .
The ultimate goal of flow matching is to somehow learn a flow which transports , where is the target distribution and is some easy-to-sample base distribution (such as a Gaussian). If we had this , we could generate samples from our target by first sampling , then running our flow with initial point and outputting the resulting final point . The DDIM algorithm of Section 3 was actually a special case424242To connect to diffusion: The continuous-time limit of DDIM (56) is a flow with . The base distribution is Gaussian. DDIM Sampling (algorithm 3) is a discretized method for evaluating RunFlow. DDPM Training (algorithm 2) is a method for learning – but it relies on the Gaussian structure and differs somewhat from the flow-matching algorithm we will present in this chapter. of this, for a very particular choice of flow . Now, how do we construct such flows in general?
4.2 Pointwise Flows
Our basic building-block will be a pointwise flow which just transports a single point to a point . Intuitively, given an arbitrary path that connects to , a pointwise flow describes this trajectory by giving its velocity at each point along it (see Figure 4.2). Formally, a pointwise flow between and is any flow that satisfies Equation 57 with boundary conditions and at times respectively. We denote such flows as . Pointwise flows are not unique: there are many different choices of path between and .
![[Uncaptioned image]](x6.png)
A pointwise flow transporting to .
4.3 Marginal Flows
Suppose that for all pairs of points , we can construct an explicit pointwise flow that transports a source point to target point . For example, we could let travel along a straight line from to , or along any other explicit path. Recall in our gas analogy, this corresponds to an individual particle that moves between and . Now, let us try to set up a collection of individual particles, such that at the particles are distributed according to , and at they are distributed according to . This is actually easy to do: We can pick any coupling434343A coupling between and , specifies how to jointly sample pairs of source and target points, such that is marginally distributed as , and as . The most basic coupling is the independent coupling, with corresponds to sampling independently. between and , and consider particles corresponding to the pointwise flows . This gives us a distribution over pointwise flows (i.e. a collection of particle trajectories) with the desired behavior in aggregate.
We would like to combine all of these pointwise flows somehow, to get a single flow that implements the same transport between distributions444444 Why would we like this? As we will see later, it simplifies our learning problem: instead of having to learn the distribution of all the individual trajectories, we can instead just learn one velocity field representing their bulk evolution.. Our previous discussion454545Compare to Equation (47) in Section 3. A formal statement of how to combine flows is given in Appendix B.4. in Section 3 tells us how to do this: to determine the effective velocity , we should take a weighted-average of all individual particle velocities , weighted by the probability that a particle at was generated by the pointwise flow . The final result is464646 An alternate way of viewing this result at a high level is: we start with pointwise flows which transport delta distributions: (60) And then Equation (62) gives us a fancy way of “averaging these flows over and ”, to get a flow transporting (61)
| (62) |
where the expectation is w.r.t. the joint distribution of induced by sampling and letting .
At this point, we have a “solution” to our generative modeling problem in principle, but some important questions remain to make it useful in practice:
-
•
Which pointwise flow and coupling should we chose?
-
•
How do we compute the marginal flow ? We cannot compute it from Equation (62) directly, because this would require sampling from for a given point , which may be complicated in general.
We answer these in the next sections.
4.4 A Simple Choice of Pointwise Flow
We need an explicit choices of: pointwise flow, base distribution , and coupling . There are many simple choices which would work474747 Diffusion provides one possible construction, as we will see later in Section 4.6..
The base distribution can be essentially any easy-to-sample distribution. Gaussians are a popular choice but certainly not the only one— Figure 4 uses an annular base distribution, for example. As for the coupling between the base and target distribution, the simplest choice is the independent coupling, i.e. sampling from and independently.
For a pointwise flow, arguably the simplest construction is a linear pointwise flow:
| (63) | ||||
| (64) |
which simply linearly interpolates between and (and corresponds to the choice made in Liu et al. (2022)). In Figure 5 we visualize a marginal flow composed of linear pointwise flows, the same annular base distribution of Figure 4, and target distribution equal to a point-mass ()484848A marginal distribution with a point-mass target distribution – or equivalently the average of pointwise flows over the the base distribution only – is sometimes called a (one-sided) conditional flow (Lipman et al., 2023). .
4.5 Flow Matching
Now, the only remaining problem is that naively evaluating using Equation (62) requires sampling from for a given . If we knew how do this for , we would have already solved the generative modeling problem!
Fortunately, we can take advantage of the same trick from DDPM: it is enough for us to be able to sample from the joint distribution , and then solve a regression problem. Similar to DDPM, the conditional expectation function in Equation (62) can be written as a regressor494949This result is analogous to Theorem 2 in Lipman et al. (2023), but ours is for a two-sided flow.:
| (65) | ||||
| (66) |
(by using the generic fact that ).
In words, Equation (66) says that to compute the loss of a model for a fixed time , we should:
-
1.
Sample source and target points from their joint distribution.
-
2.
Compute the point deterministically, by running505050 If we chose linear pointwise flows, for example, this would mean , via Equation (64). the pointwise flow starting from point up to time .
-
3.
Evaluate the model’s prediction at , as . Evaluate the deterministic vector . Then compute L2 loss between these two quantities.
To sample from the trained model (our estimate of ), we first sample a source point , then transport it along the learnt flow to a target sample . Pseudocode listings 4 and 5 give the explicit procedures for training and sampling from flow-based models (including the special case of linear flows for concreteness; matching Algorithm 1 in Liu et al. (2022).).
Summary
To summarize, here is how to learn a flow-matching generative model for target distribution .
The Ingredients.
We first choose:
-
1.
A source distribution , from which we can efficiently sample (e.g. a standard Gaussian).
-
2.
A coupling between and , which specifies a way to jointly sample a pair of source and target points with marginals and respectively. A standard choice is the independent coupling, i.e. sample and independently.
-
3.
For all pairs of points , an explicit pointwise flow which transports to . We must be able to efficiently compute the vector field at all points.
These ingredients determine, in theory, a marginal vector field which transports to :
| (67) |
where the expectation is w.r.t. the joint distribution:
Training.
Train a neural network by backpropogating the stochastic loss function computed by Pseudocode 4. The optimal function for this expected loss is: .
Sampling.
Run Pseudocode 5 to generate a sample from (approimately) the target distribution .
4.6 DDIM as Flow Matching [Optional]
The DDIM algorithm of Section 3 can be seen as a special case of flow matching, for a particular choice of pointwise flows and coupling. We describe the exact correspondence here, which will allow us to notice an interesting relation between DDIM and linear flows.
We claim DDIM is equivalent to flow-matching with the following parameters:
- 1.
-
2.
Coupling: The “diffusion coupling” – that is, the joint distribution on generated by
(71)
This claim is straightforward to prove (see Appendix B.5), but the implication is somewhat surprising: we can recover the DDIM trajectories (which are not straight in general) as a combination of the straight pointwise trajectories in Equation (70). In fact, the DDIM trajectories are exactly equivalent to flow-matching trajectories for the above linear flows, with a different scaling of time ( vs. )525252 DDIM at time corresponds to the linear flow at time ; thus linear flows are “slower” than DDIM when is small. This may be beneficial for linear flows in practice (speculatively).. [nobreak]
Claim 4 (DDIM as Linear Flow; Informal).
A formal statement of this claim535353 In practice, linear flows are most often instantiated with the independent coupling, not the above “diffusion coupling.” However, for large enough terminal variance , the diffusion coupling is close to independent. Therefore, Claim 4 tells us that the common practice in flow matching (linear flows with a Gaussian terminal distribution and independent coupling) is nearly equivalent to standard DDIM, with a different time schedule. Finally, for the experts: this is a claim about the “variance exploding” version of DDIM, which is what we use throughout. Claim 4 is false for variance-preserving DDIM. is provided in Appendix B.7.
4.7 Additional Remarks and References [Optional]
[1cm]
![[Uncaptioned image]](x8.png) The trajectories of individual samples for the flow in Figure 4.
The trajectories of individual samples for the flow in Figure 4.
-
•
See Figure 6 for a diagram of the different methods described in this tutorial, and their relations.
-
•
We highly recommend the flow-matching tutorial of Fjelde et al. (2024), which includes helpful visualizations of flows, and uses notation more consistent with the current literature.
-
•
As a curiosity, note that we never had to define an explicit “forward process” for flow-matching, as we did for Gaussian diffusion. Rather, it was enough to define the appropriate “reverse processes” (via flows).
-
•
What we called pointwise flows are also called two-sided conditional flows in the literature, and was developed in Albergo and Vanden-Eijnden (2022); Pooladian et al. (2023); Liu et al. (2022); Tong et al. (2023).
-
•
Albergo et al. (2023) define the framework of stochastic interpolants, which can be thought of as considering stochastic pointwise flows, instead of only deterministic ones. Their framework strictly generalizes both DDPM and DDIM.
-
•
See Stark et al. (2024) for an interesting example of non-standard flows. They derive a generative model for discrete spaces by embedding into a continuous space (the probability simplex), then constructing a special flow on these simplices.
5 Diffusion in Practice
To conclude, we mention some aspects of diffusion which are important in practice, but were not covered in this tutorial.
Samplers in Practice.
Our DDPM and DDIM samplers (algorithms 2 and 3) correspond to the samplers presented in Ho et al. (2020) and Song et al. (2021), respectively, but with different choice of schedule and parametrization (see footnote 13). DDPM and DDIM were some of the earliest samplers to be used in practice, but since then there has been significant progress in samplers for fewer-step generation (which is crucial since each step requires a typically-expensive model forward-pass).545454Even the best samplers still require around sampling steps, which may be impractical. A variety of time distillation methods seek to train one-step-generator student models to match the output of diffusion teacher models, with the goal of high-quality sampling in one (or few) steps. Some examples include consistency models (Song et al., 2023b) and adversarial distillation methods (Lin et al., 2024; Xu et al., 2023; Sauer et al., 2024). Note, however, that the distilled models are no longer diffusion models, nor are their samplers (even if multi-step) diffusion samplers. In sections 2.4 and 3.4.1, we showed that DDPM and DDIM can be seen as discretizations of the reverse SDE and Probability Flow ODE, respectively. The SDE and ODE perspectives automatically lead to many samplers corresponding to different black-box SDE and ODE numerical solvers (such as Euler, Heun, and Runge-Kutta). It is also possible to take advantage of the specific structure of the diffusion ODE, to improve upon black-box solvers (Lu et al., 2022a, b; Zhang and Chen, 2023).
Noise Schedules.
The noise schedule typically refers to , which determines the amount of noise added at time of the diffusion process. The simple diffusion (1) has with . Notice that the variance of increases at every timestep.555555Song et al. (2020) made the distinction between “variance-exploding” (VE) and “variance-preserving” (VP) schedules while comparing SMLD (Song and Ermon, 2019) and DDPM (Ho et al., 2020). The terms VE and VP often refer specifically to SMLD and DDPM, respectively. Our diffusion (1) could also be called a variance-exploding schedule, though our noise schedule differs from the one originally proposed in Song and Ermon (2019).
In practice, schedules with controlled variance are often preferred. One of the most popular schedules, introduced in Ho et al. (2020), uses a time-dependent variance and scaling such that the variance of remains bounded. Their discrete update is
| (72) |
where is chosen so that is (very close to) clean data at and pure noise at .
The general SDE (26) introduced in 2.4 offers additional flexibility. Our simple diffusion (1) has , , while the diffusion (72) of Ho et al. (2020) has , . Karras et al. (2022) reparametrize the SDE in terms of an overall scaling and variance of , as a more interpretable way to think about diffusion designs, and suggest a schedule with , (which corresponds to , ). Generally, the choice of , or equivalently , offers a convenient way to explore the design-space of possible schedules.
Likelihood Interpretations and VAEs.
One popular and useful interpretation of diffusion models is the Variational Auto Encoder (VAE) perspective565656This was actually the original approach to derive the diffusion objective function, in Sohl-Dickstein et al. (2015) and also Ho et al. (2020).. Briefly, diffusion models can be viewed as a special case of a deep hierarchical VAE, where each diffusion timestep corresponds to one “layer” of the VAE decoder. The corresponding VAE encoder is given by the forward diffusion process, which produces the sequence of noisy as the “latents” for input . Notably, the VAE encoder here is not learnt, unlike usual VAEs. Because of the Markovian structure of the latents, each layer of the VAE decoder can be trained in isolation, without forward/backward passing through all previous layers; this helps with the notorious training instability of deep VAEs. We recommend the tutorials of Turner (2021) and Luo (2022) for more details on the VAE perspective.
One advantage of the VAE interpretation is, it gives us an estimate of the data likelihood under our generative model, by using the standard Evidence-Based-Lower-Bound (ELBO) for VAEs. This allows us to train diffusion models directly using a maximum-likelihood objective. It turns out that the ELBO for the diffusion VAE reduces to exactly the L2 regression loss that we presented, but with a particular time-weighting that weights the regression loss differently at different time-steps . For example, regression errors at large times (i.e. at high noise levels) may need to be weighted differently from errors at small times, in order for the overall loss to properly reflect a likelihood.575757 See also Equation (5) in Kadkhodaie et al. (2024) for a simple bound on KL divergence between the true distribution and generated distribution, in terms of regression excess risks. The best choice of time-weighting in practice, however, is still up for debate: the “principled” choice informed by the VAE interpretation does not always produce the best generated samples585858 For example, Ho et al. (2020) drops the time-weighting terms, and just uniformly weights all timesteps.. See Kingma and Gao (2023) for a good discussion of different weightings and their effect.
Parametrization: / / v -prediction.
Another important practical choice is which of several closely-related quantities – partially-denoised data, fully-denoised data, or the noise itself – we ask the network to predict.595959More accurately, the network always predicts conditional expectations of these quantities. Recall that in DDPM Training (Algorithm 1), we asked the network to learn to predict by minimizing . However, other parametrizations are possible. For example, recalling that , we see that that
is a (nearly) equivalent problem, which is often called -prediction.606060This corresponds to the variance-reduced algorithm (6). The objectives differ only by a time-weighting factor of . Similarly, defining the noise , we see that we could alternatively ask the the network to predict : this is usually called -prediction. Another parametrization, v-prediction, asks the model to predict (Salimans and Ho, 2022) – mostly predicting data for high noise-levels and mostly noise for low noise-levels. All the parametrizations differ only by time-weightings (see Appendix B.10 for more details).
Although the different time-weightings do not affect the optimal solution, they do impact training as discussed above. Furthermore, even if the time-weightings are adjusted to yield equivalent problems in principle, the different parametrizations may behave differently in practice, since learning is not perfect and certain objectives may be more robust to error. For example, -prediction combined with a schedule that places a lot of weight on low noise levels may not work well in practice, since for low noise the identity function can achieve a relatively low objective value, but clearly is not what we want.
Sources of Error.
Finally, when using diffusion and flow models in practice, there are a number of sources of error which prevent the learnt generative model from exactly producing the target distribution. These can be roughly segregated into training-time and sampling-time errors.
-
1.
Train-time error: Regression errors in learning the population-optimal regression function. The regression objective is the marginal flow in flow-matching, or the scores in diffusion models. For each fixed time , this a standard kind of statistical error. It depends on the neural network architecture and size as well as the number of samples, and can be decomposed further into approximation and estimation errors in the usual way (e.g. see Advani et al. (2020, Sec. 4) decomposing a 2-layer network into approximation error and over-fitting error).
-
2.
Sampling-time error: Discretization errors from using finite step-sizes . This error is exactly the discretization error of the ODE or SDE solver used in sampling. These errors manifest in different ways: for DDPM, this reflects the error in using a Gaussian approximation of the reverse process (i.e. Fact 1 breaks for large ). For DDIM and flow matching, it reflects the error in simulating continuous-time flows in discrete time.
These errors interact and compound in nontrivial ways, which are not yet fully understood. For example, it is not clear exactly how train-time error in the regression estimates translates into distributional error of the entire generative model. (And this question itself is complicated, since it is not always clear what type of distributional divergence we care about in practice). Interestingly, these “errors” can also have a beneficial effect on small train sets, because they act as a kind of regularization which prevents the diffusion model from just memorizing the train samples (as discussed in Section 3.6).
Conclusion
We have now covered the basics of diffusion models and flow matching. This is an active area of research, and there are many interesting aspects and open questions which we did not cover (see Page A for recommended reading). We hope the foundations here equip the reader to understand more advanced topics in diffusion modeling, and perhaps contribute to the research themselves.
Appendix A Additional Resources
Several other helpful resources for learning diffusion (tutorials, blogs, papers), roughly in order of mathematical background required.
-
1.
Perspectives on diffusion.
Dieleman (2023). (Webpage.)Overview of many interpretations of diffusion, and techniques.
-
2.
Tutorial on Diffusion Models for Imaging and Vision.
Chan (2024). (49 pgs.)More focus on intuitions and applications.
-
3.
Interpreting and improving diffusion models using the euclidean distance function.
Permenter and Yuan (2023). (Webpage.)Distance-field interpretation. See accompanying blog with simple code (Yuan, 2024).
-
4.
On the Mathematics of Diffusion Models.
McAllester (2023). (4 pgs.)Short and accessible.
-
5.
Building Diffusion Model’s theory from ground up
Das (2024). (Webpage.)ICLR 2024 Blogposts Track. Focus on SDE and score-matching perspective.
-
6.
Denoising Diffusion Models: A Generative Learning Big Bang.
Song, Meng, and Vahdat (2023a). (Video, 3 hrs.)CVPR 2023 tutorial, with recording.
-
7.
Diffusion Models From Scratch.
Duan (2023). (Webpage, 10 parts.)Fairly complete on topics, includes: DDPM, DDIM, Karras et al. (2022), SDE/ODE solvers. Includes practical remarks and code.
-
8.
Understanding Diffusion Models: A Unified Perspective.
Luo (2022). (22 pgs.)Focus on VAE interpretation, with explicit math details.
-
9.
Demystifying Variational Diffusion Models.
Ribeiro and Glocker (2024). (44 pgs.)Focus on VAE interpretation, with explicit math details.
-
10.
Diffusion and Score-Based Generative Models.
Song (2023). (Video, 1.5 hrs.)Discusses several interpretations, applications, and comparisons to other generative modeling methods.
-
11.
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Sohl-Dickstein, Weiss, Maheswaranathan, and Ganguli (2015). (9 pgs + Appendix)Original paper introducing diffusion models for ML. Includes unified description of discrete diffusion (i.e. diffusion on discrete state spaces).
-
12.
An Introduction to Flow Matching.
Fjelde, Mathieu, and Dutordoir (2024). (Webpage.)Insightful figures and animations, with rigorous mathematical exposition.
-
13.
Elucidating the Design Space of Diffusion-Based Generative Models.
Karras, Aittala, Aila, and Laine (2022). (10 pgs + Appendix.)Discusses the effect of various design choices such as noise schhedule, parameterization, ODE solver, etc. Presents a generalized framework that captures many choices.
-
14.
Denoising Diffusion Models
Peyré (2023). (4 pgs.)Fast-track through the mathematics, for readers already comfortable with Langevin dynamics and SDEs.
-
15.
Generative Modeling by Estimating Gradients of the Data Distribution.
Song, Sohl-Dickstein, Kingma, Kumar, Ermon, and Poole (2020). (9 pgs + Appendix.)Presents the connections between SDEs, ODEs, DDIM, and DDPM.
-
16.
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions.
Albergo, Boffi, and Vanden-Eijnden (2023). (46 pgs + Appendix.)Presents a general framework that captures many diffusion variants, and learning objectives. For readers comfortable with SDEs
-
17.
Sampling, Diffusions, and Stochastic Localization.
Montanari (2023). (22 pgs + Appendix.)Presents diffusion as a special case of “stochastic localization,” a technique used in high-dimensional statistics to establish mixing of Markov chains.
Appendix B Omitted Derivations
B.1 KL Error in Gaussian Approximation of Reverse Process
Here we prove Lemma 1, restated below.
Lemma 2.
Let be an arbitrary density over , with bounded 1st to 4th order derivatives. Consider the joint distribution , where and . Then, for any conditioning we have
| (73) |
where
| (74) |
Proof.
WLOG, we can take . We want to estimate the KL:
| (75) |
where we will let be arbitrary for now.
Let , and . We have . This implies:
| (76) |
Let us first expand the logs of the two distributions we are comparing:
| (77) | |||
| (78) | |||
| (79) | |||
| (80) |
And also:
| (82) |
Now we can expand the KL:
| (83) | |||
| (84) | |||
| (85) | |||
| (86) | |||
| (work) | |||
| (87) | |||
| (88) | |||
| (89) | |||
| (90) | |||
| (91) |
We will now estimate the first term, :
| (92) | ||||
| (93) | ||||
| (94) | ||||
| (95) | ||||
| (Taylor expand around ) | ||||
| (96) |
To compute the derivatives of , observe that:
| (97) | ||||
| (98) | ||||
| (99) | ||||
| (100) | ||||
| (101) |
We can now plug this estimate of into Line (91). We omit the argument from for simplicity:
| (103) | |||
| (104) | |||
| (105) | |||
| (106) | |||
| (107) |
Up to this point, was arbitrary. We now set
| (108) |
And continue:
| (109) | |||
| (110) | |||
| (111) | |||
| (112) |
as desired.
∎
Notice that our choice of in the above proof was crucial; for example if we had set , the terms in Line (111) would not have cancelled out.
B.2 SDE proof sketches
Here is sketch of the proof of the equivalence of the SDE and Probability Flow ODE, which relies on the equivalence of the SDE to a Fokker-Planck equation. (See Song et al. (2020) for full proof.)
Proof.
∎
The equivalence of the SDE and Fokker-Planck equations follows from Itô’s formula and integration-by-parts. Here is an outline for a simplified case in 1d, where is constant (see Winkler (2023) for full proof):
Proof.
| Itô’s formula | ||||
| integration-by-parts | ||||
| Fokker-Planck |
∎
B.3 DDIM Point-mass Claim
Here is a version of Claim 3 where is a delta at an arbitrary point .
Claim 5.
Suppose the target distribution is a point mass at , i.e. . Define the function
| (113) |
Then we clearly have , and moreover
| (114) |
Thus Algorithm 2 defines a valid reverse sampler for target distribution
B.4 Flow Combining Lemma
Here we provide a more formal statement of the marginal flow result stated in Equation (62).
Equation (62) follows from a more general lemma (Lemma 3) which formalizes the “gas combination” analogy of Section 3. The motivation for this lemma is, we need a way of combining flows: of taking several different flows and producing a single “effective flow.” As a warm-up for the lemma, suppose we have different flows, each with their own initial and final distributions :
We can imagine these as the flow of different gases, where gas has initial density and final density . Now we want to construct an overall flow which takes the average initial-density to the average final-density:
| (115) |
To construct , we must take an average of the individual vector fields , weighted by the probability mass the -th flow places on , at time . (This is exactly analogous to Figure 3).
This construction is formalized in Lemma 3. There, instead of averaging over just a finite set of flows, we are allowed to average over any distribution over flows. To recover Equation (62), we can apply Lemma 3 to a distribution over , that is, pointwise flows and their associated initial delta distributions.
[nobreak]
Lemma 3 (Flow Combining Lemma).
Let be an arbitrary joint distribution over pairs of flows and their associated initial distributions . Let denote the final distribution when initial distribution is transported by flow , so
For fixed , consider the joint distribution over generated by:
Then, taking all expectations w.r.t. this joint distribution, the flow defined as
| (116) | ||||
| (117) |
is known as the marginal flow for , and transports:
| (118) |
B.5 Derivation of DDIM using Flows
Now that we have the machinery of flows in hand, it is fairly easy to derive the DDIM algorithm “from scratch”, by extending our simple scaling algorithm from the single point-mass case.
First, we need to find the pointwise flow. Recall from Claim 5 that for the simple case where the target distribution is a Dirac-delta at , the following scaling maps to :
implies the pointwise flow:
which agrees with (68).
Now let us compute the marginal flow generated by the pointwise flow of Equation (68) and the coupling implied by the diffusion forward process. By Equation (67), the marginal flow is:
| By gas-lemma. | ||||
| For our choices of coupling and flow. | ||||
| Expanding the flow trajectory. | ||||
| Plugging in |
This is exactly the differential equation describing the trajectory of DDIM (see Equation 56, which is the continuous-time limit of Equation 31).
B.6 Two Pointwise Flows for DDIM give the same Trajectory
B.7 DDIM vs Time-reparameterized linear flows
Lemma 4 (DDIM vs Linear Flows).
Let be an arbitrary target distribution. Let be the joint distribution defined by the DDPM forward process applied to , so the marginal distribution of is .
Let be an arbitrary initial point. Consider the following two deterministic trajectories:
-
1.
The trajectory of the continuous-time DDIM flow, with respect to target distribution , when started at initial point .
That is, is the solution to the following ODE (Equation 56):
(122) (123) with boundary condition at .
-
2.
The trajectory produced when initial point is transported by the marginal flow constructed from:
-
•
Linear pointwise flows
-
•
The DDPM-coupling of Line (71).
That is, the marginal flow
since under the DDPM coupling. -
•
Then, we claim these two trajectories are identical with the following time-reparameterization:
| (124) |
B.8 Proof Sketch of Claim 2
We will show that, in the forward diffusion setup of Section 1:
| (125) |
Proof sketch.
Recall . So by linearity of expectation:
| (126) | ||||
| (127) |
Now, we claim that for given , the conditional distributions are identical for all . To see this, notice that the joint distribution function is symmetric in the s, by definition of the forward process, and therefore the conditional distribution function is also symmetric in the s. Therefore, all have identical conditional expectations:
| (128) |
And since there are of them,
| (129) |
Now continuing from Line 127,
| (130) | ||||
| (131) | ||||
| (132) |
as desired. ∎
B.9 Variance-Reduced Algorithms
Here we give the “varianced-reduced” versions of the DDPM training and sampling algorithms, where we train a network to approximate
| (133) |
instead of a network to approximate
| (134) |
Via Claim 2, these two functions are equivalent via the transform:
| (135) |
Plugging this relation into Pseudocode 2 yields the variance-reduced DDPM sampler of Pseudocode 7.
B.10 Equivalence of and - and -prediction
We will discuss this in our usual simplified setup:
the scaling factors are more complex in the general case (see Luo (2022) for VP diffusion, for example) but the idea is the same. The DDPM training algorithm 1 has objective and optimal value
That is, the network to learn to predict . However, we could instead require the network to predict other related quantities, as follows. Noting that
we get the following equivalent problems:
References
- Advani et al. [2020] Madhu S Advani, Andrew M Saxe, and Haim Sompolinsky. High-dimensional dynamics of generalization error in neural networks. Neural Networks, 132:428–446, 2020.
- Albergo et al. [2023] Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions, 2023.
- Albergo and Vanden-Eijnden [2022] Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. In The Eleventh International Conference on Learning Representations, 2022.
- Anderson [1982] Brian DO Anderson. Reverse-time diffusion equation models. Stochastic Processes and their Applications, 12(3):313–326, 1982.
- Carlini et al. [2023] Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pages 5253–5270, 2023.
- Chan [2024] Stanley H. Chan. Tutorial on diffusion models for imaging and vision, 2024.
- Chen et al. [2023] Hongrui Chen, Holden Lee, and Jianfeng Lu. Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions. In International Conference on Machine Learning, pages 4735–4763. PMLR, 2023.
- Chen et al. [2022] Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. In The Eleventh International Conference on Learning Representations, 2022.
- Chen et al. [2024a] Sitan Chen, Sinho Chewi, Holden Lee, Yuanzhi Li, Jianfeng Lu, and Adil Salim. The probability flow ode is provably fast. Advances in Neural Information Processing Systems, 36, 2024a.
- Chen et al. [2024b] Sitan Chen, Vasilis Kontonis, and Kulin Shah. Learning general gaussian mixtures with efficient score matching. arXiv preprint arXiv:2404.18893, 2024b.
- Das [2024] Ayan Das. Building diffusion model’s theory from ground up. In ICLR Blogposts 2024, 2024. URL https://iclr-blogposts.github.io/2024/blog/diffusion-theory-from-scratch/. https://iclr-blogposts.github.io/2024/blog/diffusion-theory-from-scratch/.
- De Bortoli [2022] Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hypothesis. arXiv preprint arXiv:2208.05314, 2022.
- De Bortoli et al. [2021] Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion schrödinger bridge with applications to score-based generative modeling. Advances in Neural Information Processing Systems, 34:17695–17709, 2021.
- Dieleman [2023] Sander Dieleman. Perspectives on diffusion, 2023. URL https://sander.ai/2023/07/20/perspectives.html.
- Duan [2023] Tony Duan. Diffusion models from scratch, 2023. URL https://www.tonyduan.com/diffusion/index.html.
- Eldan [2024] Ronen Eldan. Lecture notes - from stochastic calculus to geometric inequalities, 2024. URL https://www.wisdom.weizmann.ac.il/ ronene/GFANotes.pdf.
- Esser et al. [2024] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. arXiv preprint arXiv:2403.03206, 2024.
- Evans [2012] Lawrence C Evans. An introduction to stochastic differential equations, volume 82. American Mathematical Soc., 2012.
- Fjelde et al. [2024] Tor Fjelde, Emile Mathieu, and Vincent Dutordoir. An introduction to flow matching, January 2024. URL https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html.
- Gu et al. [2023] Xiangming Gu, Chao Du, Tianyu Pang, Chongxuan Li, Min Lin, and Ye Wang. On memorization in diffusion models. arXiv preprint arXiv:2310.02664, 2023.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Kadkhodaie et al. [2024] Zahra Kadkhodaie, Florentin Guth, Eero P Simoncelli, and Stéphane Mallat. Generalization in diffusion models arises from geometry-adaptive harmonic representations. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ANvmVS2Yr0.
- Karras et al. [2022] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models, 2022.
- Kingma and Gao [2023] Diederik P Kingma and Ruiqi Gao. Understanding diffusion objectives as the ELBO with simple data augmentation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=NnMEadcdyD.
- Kloeden and Platen [2011] P.E. Kloeden and E. Platen. Numerical Solution of Stochastic Differential Equations. Stochastic Modelling and Applied Probability. Springer Berlin Heidelberg, 2011. ISBN 9783540540625. URL https://books.google.com/books?id=BCvtssom1CMC.
- Lee et al. [2023] Holden Lee, Jianfeng Lu, and Yixin Tan. Convergence of score-based generative modeling for general data distributions. In International Conference on Algorithmic Learning Theory, pages 946–985. PMLR, 2023.
- Lin et al. [2024] Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation. arXiv preprint arXiv:2402.13929, 2024.
- Lipman et al. [2023] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t.
- Liu et al. [2022] Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. In The Eleventh International Conference on Learning Representations, 2022.
- Lu et al. [2022a] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Systems, 35:5775–5787, 2022a.
- Lu et al. [2022b] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095, 2022b.
- Luo [2022] Calvin Luo. Understanding diffusion models: A unified perspective, 2022.
- McAllester [2023] David McAllester. On the mathematics of diffusion models, 2023.
- Montanari [2023] Andrea Montanari. Sampling, diffusions, and stochastic localization, 2023.
- Permenter and Yuan [2023] Frank Permenter and Chenyang Yuan. Interpreting and improving diffusion models using the euclidean distance function. arXiv preprint arXiv:2306.04848, 2023.
- Peyré [2023] Gabriel Peyré. Denoising diffusion models, 2023. URL https://mathematical-tours.github.io/book-sources/optim-ml/OptimML-DiffusionModels.pdf.
- Pooladian et al. [2023] Aram-Alexandre Pooladian, Heli Ben-Hamu, Carles Domingo-Enrich, Brandon Amos, Yaron Lipman, and Ricky TQ Chen. Multisample flow matching: Straightening flows with minibatch couplings. In International Conference on Machine Learning, pages 28100–28127. PMLR, 2023.
- Ribeiro and Glocker [2024] Fabio De Sousa Ribeiro and Ben Glocker. Demystifying variational diffusion models, 2024.
- Salimans and Ho [2022] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022.
- Sauer et al. [2024] Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. arXiv preprint arXiv:2403.12015, 2024.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585, 2015. URL http://arxiv.org/abs/1503.03585.
- Somepalli et al. [2023] Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6048–6058, 2023.
- Song et al. [2021] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=St1giarCHLP.
- Song et al. [2023a] Jiaming Song, Chenlin Meng, and Arash Vahdat. Cvpr 2023 tutorial: Denoising diffusion models: A generative learning big bang, 2023a. URL https://cvpr2023-tutorial-diffusion-models.github.io.
- Song [2021] Yang Song. Generative modeling by estimating gradients of the data distribution, 2021. URL https://yang-song.net/blog/2021/score/.
- Song [2023] Yang Song. Diffusion and score-based generative models, 2023. URL https://www.youtube.com/watch?v=wMmqCMwuM2Q.
- Song and Ermon [2019] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
- Song et al. [2020] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020. URL https://arxiv.org/pdf/2011.13456.pdf.
- Song et al. [2023b] Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. arXiv preprint arXiv:2303.01469, 2023b.
- Stark et al. [2024] Hannes Stark, Bowen Jing, Chenyu Wang, Gabriele Corso, Bonnie Berger, Regina Barzilay, and Tommi Jaakkola. Dirichlet flow matching with applications to dna sequence design, 2024.
- Tong et al. [2023] Alexander Tong, Nikolay Malkin, Kilian Fatras, Lazar Atanackovic, Yanlei Zhang, Guillaume Huguet, Guy Wolf, and Yoshua Bengio. Simulation-free schr” odinger bridges via score and flow matching. arXiv preprint arXiv:2307.03672, 2023.
- Turner [2021] Angus Turner. Diffusion models as a kind of vae, June 2021. URL https://angusturner.github.io/generative_models/2021/06/29/diffusion-probabilistic-models-I.html.
- Winkler [2021] Ludwig Winkler. Reverse time stochastic differential equations [for generative modeling], 2021. URL https://ludwigwinkler.github.io/blog/ReverseTimeAnderson/.
- Winkler [2023] Ludwig Winkler. Fokker, planck, and ito, 2023. URL https://ludwigwinkler.github.io/blog/FokkerPlanck/.
- Xu et al. [2023] Yanwu Xu, Yang Zhao, Zhisheng Xiao, and Tingbo Hou. Ufogen: You forward once large scale text-to-image generation via diffusion gans. arXiv preprint arXiv:2311.09257, 2023.
- Yuan [2024] Chenyang Yuan. Diffusion models from scratch, from a new theoretical perspective, 2024. URL https://www.chenyang.co/diffusion.html.
- Zhang and Chen [2023] Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Loek7hfb46P.