LoRA-GA: Low-Rank Adaptation with Gradient Approximation
Abstract
Fine-tuning large-scale pretrained models is prohibitively expensive in terms of computational and memory costs. LoRA, as one of the most popular Parameter-Efficient Fine-Tuning (PEFT) methods, offers a cost-effective alternative by fine-tuning an auxiliary low-rank model that has significantly fewer parameters. Although LoRA reduces the computational and memory requirements significantly at each iteration, extensive empirical evidence indicates that it converges at a considerably slower rate compared to full fine-tuning, ultimately leading to increased overall compute and often worse test performance. In our paper, we perform an in-depth investigation of the initialization method of LoRA and show that careful initialization (without any change of the architecture and the training algorithm) can significantly enhance both efficiency and performance. In particular, we introduce a novel initialization method, LoRA-GA (Low Rank Adaptation with Gradient Approximation), which aligns the gradients of low-rank matrix product with those of full fine-tuning at the first step. Our extensive experiments demonstrate that LoRA-GA achieves a convergence rate comparable to that of full fine-tuning (hence being significantly faster than vanilla LoRA as well as various recent improvements) while simultaneously attaining comparable or even better performance. For example, on the subset of the GLUE dataset with T5-Base, LoRA-GA outperforms LoRA by 5.69% on average. On larger models such as Llama 2-7B, LoRA-GA shows performance improvements of 0.34, 11.52%, and 5.05% on MT-bench, GSM8K, and Human-eval, respectively. Additionally, we observe up to 2-4 times convergence speed improvement compared to vanilla LoRA, validating its effectiveness in accelerating convergence and enhancing model performance. Code is available at github.
1 Introduction
Fine-tuning large language models (LLMs) is essential for enabling advanced techniques such as instruction fine-tuning [1], reinforcement learning from human feedback (RLHF) [2], and adapting models to specific downstream applications. However, the computational and storage costs associated with full fine-tuning are prohibitively high, particularly as model sizes continue to grow. To address these challenges, methods of Parameter-Efficient Fine-Tuning (PEFT) (see e.g., [3]), such as Low-Rank Adaptation (LoRA) [4], have emerged and gained significant attention.
Instead of updating the parameters of the model directly, LoRA incorporates auxilary low-rank matrices and into the linear layers of models (such as the , and matrices in a self-attention block [5]), while keeping the original layer weights fixed. The modified layer is represented as , where is the input of that layer, is the output, and is the scaling factor. This approach significantly reduces the number of parameters that need to be fine-tuned, thereby lowering the computational and memory costs at each step.
Despite these benefits, extensive empirical evidence (see e.g., [6, 7, 8, 9]) shows that LoRA converges significantly slower compared to full finetune. This slower convergence often increases overall computational costs (measured in Floating Point Operations) and can sometimes lead to worse test performance. In our experiments, we typically observe that LoRA requires 5-6x more iterations and FLOPs to reach the same performance as full fine-tuning under the same learning rate, as shown in Figure 1.
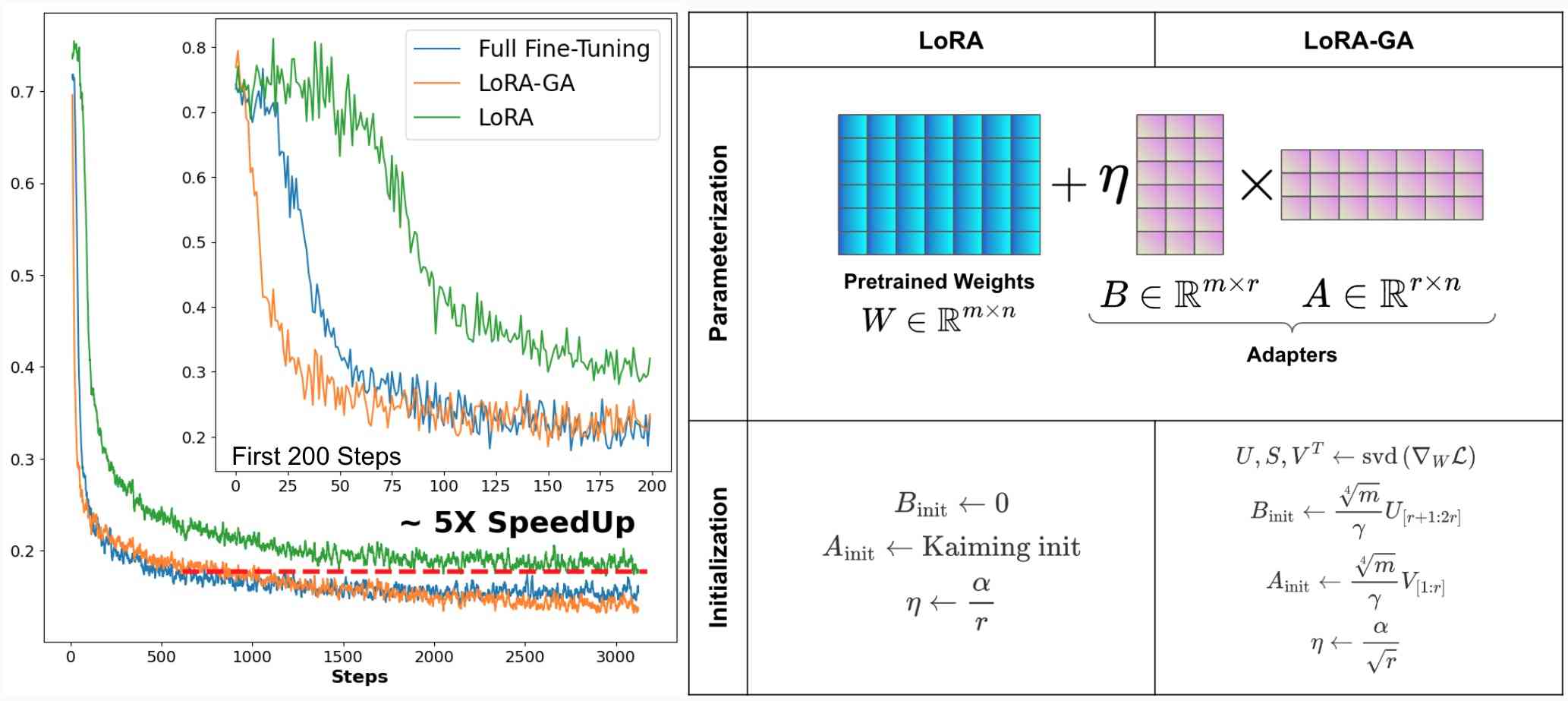
To study the cause of slow convergence, we perform an in-depth investigation of the initialization strategy of LoRA’s adapter weights. It is known that fine-tuning pretrained models using the same objective (e.g., language modeling) often converges faster than re-initializing new parameters (e.g., a classification head) [10]. This observation leads us to question whether the slow convergence of vanilla LoRA might be attributed to the default random initialization of adapter weights (LoRA initializes using Kaiming initialization [11] and sets to zero [4]). In our experiments, we find that different initialization strategies for LoRA can significantly impact the results, and its default initialization is suboptimal.
In pursuit of a convergence rate comparable to full fine-tuning, we aim for initialization so that the update of matches the update of closely. Previous work suggests that gradient descent operates in a low-dimensional subspace [12, 13]. If we can closely approximate the gradients of the full model at the initial step, subsequent steps can also be approximated, potentially accelerating the convergence of LoRA.
To this end, we introduce a novel initialization method, LoRA-GA (Low Rank Gradient Approximation). By initializing and with the eigenvectors of the full gradient matrix, the gradient of the low-rank product aligns with the direction of the gradient of the full weight matrix . Mathematically, we aim to ensure that:
Our contributions can be summarized as follows:
1. We propose LoRA-GA , a novel initialization method for LoRA that accelerates convergence by approximating the gradients of the low-rank matrices with ones of the full weight matrix.
2. We identify the scaling factor under non-zero initialization, which ensures the variance of adapter outputs is invariant to the rank of the adapter and the dimension of the input.
3. We validate LoRA-GA through extensive experiments, demonstrating significant performance improvements and faster convergence compared to vanilla LoRA. Specifically, LoRA-GA outperforms LoRA by 5.69% on the GLUE[14] subset with T5-Base [15], and by 0.34, 11.52%, and 5.05% on MT-bench [16], GSM8K [17], and HumanEval [18] with Llama 2-7B [19], respectively, while achieving up to 2-4 times faster convergence.
2 Related Work
2.1 Initialization
The significance of maintaining variance stability during initialization has been widely acknowledged to prevent the occurrence of diminishing or exploding phenomena. Xavier initialization [20] ensures stability in both the forward and backward passes of a network under a linear activation function. He initialization [11] extends this solution to networks using ReLU activation. Distinct from these, LSUV initialization [21] selects a mini-batch of data, performing a forward pass to determine the output variance, and subsequently normalizing it to ensure stability. Tensor program (see e.g., [22]) has emerged as a powerful technique for tuning various hyperparameters, including the initialization, for large models.
2.2 Parameter-Efficient Fine-Tuning (PEFT)
To fine-tune increasingly large language models within the constraints of limited hardware resources, researchers have developed various Parameter-Efficient Fine-Tuning (PEFT) methods. One approach is Adapter-based methods [23, 24, 25, 26], which incorporate new layers into existing layers of a model. By fine-tuning only these inserted layers (typically with much few parameters), resource consumption is significantly reduced. However, this approach introduces additional latency during both the forward and backward passes, as the computation must traverse the newly added layers. Another approach is Soft Prompt-based methods [10, 27, 28, 29, 30], which prepend learnable soft tokens (prompts) to the model’s input to adapt the model to specific tasks. This approach leverages the pre-trained model’s inherent capabilities, needing only appropriate prompts to adapt to downstream tasks. Despite its effectiveness, this method also incurs additional computational overhead and hence latency during inference.
2.3 LoRA’s Variants
LoRA is one of the most popular PEFT methods that introduces the product of low-rank matrices alongside existing layers to approximate weight changes during fine-tuning. Several methods have been proposed to improve the structure of LoRA. AdaLoRA [31] dynamically prunes insignificant weights during fine-tuning using SVD, allowing more rank allocation to important areas within a fixed parameter budget. DoRA [8] enhances the model’s expressiveness by adding learnable magnitudes to the direction adjustments made by low-rank matrix products. Additionally, LoHA [32] and LoKr [33] employ Hamiltonian and Kronecker products, respectively.
Despite these advancements, vanilla LoRA remains the most popular method due to its robust library and hardware support. Therefore, improving LoRA without altering its structure and at a low cost is crucial. Several recent methods focus on this aspect. ReLoRA [34] suggests periodically merging learned adapters into the weight matrices to enhance LoRA’s expressibility. LoRA+ [35] proposes using different learning rates for the two matrices in LoRA to improve convergence. rsLoRA [36] introduces a new scaling factor to make the scale of the output invariant to rank. Although our stable scale approach appears similar to rsLoRA, rsLoRA assumes initialization, making invariant to the update . In contrast, our stable scale ensures that non-zero initialized remains invariant to both rank and input dimension from the start.
Recently, PiSSA [37] proposes to initializing and to approximate the original matrix , by performing SVD on . Our method, however, is based on a very different idea, that is to approximate the gradient of , which involves performing SVD on sampled gradients and properly scaling the initialized matrices, as detailed in Section E.
3 Methods
In this section, we analyze the initialization of LoRA and introduce our method, LoRA-GA. LoRA-GA consists of two key components: (i) approximating the direction of the gradient of full finetune and (ii) ensuring rank and scale stability in the initialization process. We examine each component and subsequently present their integration within LoRA-GA.
3.1 Review of Vanilla LoRA
Structure of LoRA
Based on the hypothesis that the updates of fine-tuning are low-rank [13], LoRA [4] proposes to use the product of two low-rank matrices to represent the incremental part of the original matrix . Here, is the weight matrix of a linear layer in the model. For example, in transformers, it could be the , or matrices of the self-attention layer or the weight matrix in the MLP layer. Specifically, LoRA has the following mathematical form:
where , , and , with . is the pre-trained weight matrix, remains frozen during the fine-tuning process, while and are trainable.
Initialization of LoRA
Under LoRA’s default initialization scheme [4, 38], matrix is initialized using Kaiming uniform [11], while matrix is initialized with all zeros. Consequently, and , ensuring that the initial parameters are unchanged.
If the additional term is initially non-zero (e.g., [37]), the frozen parameter can be adjusted to ensure the initial parameters unchanged. This can be expressed as:
where is frozen, and and are trainable in this case.
3.2 Gradient Approximation
Our goal is to ensure that the first-step update approximate the direction of the weight update , i.e., for some non-zero positive constant . We will discuss how to choose in Section 3.3 and one can treat as a fixed constant for now.
Consider a gradient descent step with learning rate , the updates for and are and , respectively. Assuming learning rate is small, the update of at the first step can be expressed as:
To measure its approximation quality of scaled the update of the weights in full finetune , we use the Frobenius norm of the difference between these two updates as a criterion:
| (1) |
Lemma 3.1.
Suppose the loss function is and , where is the output of a layer and is the input, the gradients of and are linear mappings of the gradient of :
Remarkably, in LoRA and in full fine-tuning are equal at the beginning of the training.
By substituting the gradients in Lemma 3.1 into Equation 1, we can rewrite the criterion as follows:
| (2) |
This criterion evaluates how well the adapter’s gradient approximates the direction of the gradient of full fine-tuning, and minimizing it brings the gradient of LoRA closer to that of full fine-tuning with a scaling factor :
| (3) |
Theorem 3.1.
For the optimization problem in Equation 3 with given , if the Singular Value Decomposition (SVD) of is , the solution is:
where and are index sets.
Theorem 3.1 provides an appropriate initialization scheme for and given a specific . The selection of , which influences the scaling of the update , will be discussed in the following section.
3.3 Scale Stability
Inspired by rsLoRA [36] and the Kaiming initialization[11], we define stabilities:
Definition 3.1.
When , an adapter exhibits two distinct types of scale stabilities:
1. Forward stability: If the inputs to the adapter are independently and identically distributed (i.i.d.) with 2nd moment , then the 2nd moment of the outputs remains .
2. Backward stability: If the gradient of the loss with respect to the adapter outputs is , then the gradient with respect to the inputs remains .
Theorem 3.2.
Given the initialization proposed in Theorem 3.1, assume that the orthogonal vectors in and are randomly selected from the unit spheres in and with the constraint that the vectors are orthogonal to each other, and as suggested by rsLoRA [36]. Under these conditions, the adapters are forward scale-stable if and backward scale-stable if .
Similar to the results obtained from Kaiming Initialization [11], we observe that either or work well independently. For all models presented in this paper, either form ensures convergence. Consequently, for all subsequent experiments, we adopt .
3.4 LoRA-GA Initialization
Combining the gradient approximation and stable scale components, we propose the LoRA-GA initialization method. First, we initialize and using the solution from Theorem 3.1. Then, we determine the scaling factor according to Theorem 3.2 to ensure rank and scale stability. Thus, based on Theorems 3.1 and 3.2, we propose a novel initialization method, LoRA-GA.
LoRA-GA :
We adopt and , where is a hyperparameter. We define the index sets and . Denote the singular value decomposition (SVD) of as . The initializations are as follows:
To save GPU memory during LoRA-GA initialization, we utilized a technique similar to [39]. By hooking into PyTorch’s backward process, we compute the gradient for one layer at a time and discard the computed gradients immediately. This ensures that our memory usage remains at instead of , where is the number of layers. This approach allows the memory consumption during the initialization phase to be less than that during the subsequent LoRA finetuning phase. Our algorithm is shown in Algorithm 1. If the sampled batch size is large, we can also use gradient accumulation to save memory further, as shown in Algorithm 2.
4 Experiments
In this section, we evaluate the performance of LoRA-GA on various benchmark datasets. Initially, we assess Natural Language Understanding (NLU) capabilities using a subset of the GLUE dataset [14] with the T5-Base model [15]. Subsequently, we evaluate dialogue [16, 40], mathematical reasoning [17, 41], and coding abilities [18, 42] using the Llama 2-7B model [19]. Finally, we do the ablation study to prove the effectiveness of our method.
Baselines
We compare LoRA-GA with several baselines to demonstrate its effectiveness:
1. Full-Finetune: Fine-tuning the model with all parameters, which requires the most resources.
2. Vanilla LoRA [4]: Fine-tuning the model by inserting a low-rank matrix product into linear layers. is initialized using Kaiming initialization, while is initialized to zero.
3. LoRA Variants with Original Structure: This includes several methods that retain the original LoRA structure:
- rsLoRA [36] introduces a new scaling factor to stabilize the scale of LoRA.
- LoRA+ [35] updates the two matrices in LoRA with different learning rates.
- PiSSA [37] proposes performing SVD on the weight matrix at the beginning of training and initializing and based on the components with larger singular values.
4. LoRA Variants with Modified Structure: This includes methods that modify the original LoRA structure:
- DoRA [8] enhances the model’s expressiveness by adding learnable magnitudes.
- AdaLoRA [31] dynamically prunes insignificant weights during fine-tuning using SVD, allowing more rank allocation to important areas within a fixed parameter budget.
4.1 Experiments on Natural Language Understanding
Models and Datasets
We fine-tune the T5-Base model on several datasets from the GLUE benchmark, including MNLI, SST-2, CoLA, QNLI, and MRPC. Performance is evaluated on the development set using accuracy as the primary metric.
Implementation Details
We utilize prompt tuning to fine-tune the T5-Base model on the GLUE benchmark. This involves converting labels into tokens (e.g., "positive" or "negative") and using the normalized probability of these tokens as the predicted label probability for classification. We provide the hyperparameters in Appendix D.1. Each experiment is conducted with 3 different random seeds, and the average performance is reported.
Results
As shown in Table 1, LoRA-GA consistently outperforms the original LoRA and other baseline methods, achieving performance comparable to full fine-tuning. Notably, LoRA-GA excels on smaller datasets such as CoLA and MRPC, demonstrating its ability to converge faster and effectively utilize limited training data.
| MNLI | SST-2 | CoLA | QNLI | MRPC | Average | |
| Size | 393k | 67k | 8.5k | 105k | 3.7k | |
| Full | ||||||
| LoRA | ||||||
| PiSSA | ||||||
| rsLoRA | ||||||
| LoRA+ | ||||||
| DoRA | ||||||
| AdaLoRA | ||||||
| LoRA-GA |
4.2 Experiment on Large Language Model
Models and Datasets
To evaluate the scalability of LoRA-GA , we train Llama 2-7B on three tasks: chat, math, and code.
1. Chat: We train our model on a 52k subset of WizardLM [40], filtering out responses that begin with "As an AI" or "Sorry". We test our model on the MT-Bench dataset [16], which consists of 80 multi-turn questions designed to assess LLMs on multiple aspects. The quality of the responses is judged by GPT-4, and we report the first turn score.
2. Math: We train our model on a 100k subset of MetaMathQA [41], a dataset bootstrapped from other math instruction tuning datasets like GSM8K[17] and MATH [43], with higher complexity and diversity. We select data bootstrapped from the GSM8K training set and apply filtering. Accuracy is reported on the GSM8K evaluation set.
3. Code: We train our model on a 100k subset of Code-Feedback [42], a high-quality code instruction dataset, removing explanations after code blocks. The model is tested on HumanEval [18], which consists of 180 Python tasks, and we report the PASS@1 metric.
Implementation Details
Our model is trained using standard supervised learning for language modelling. The loss for the input prompt is set to zero. Detailed hyperparameters can be found in Appendix D.2. Each experiment uses 3 different random seeds, and the average performance across these runs is reported.
Result
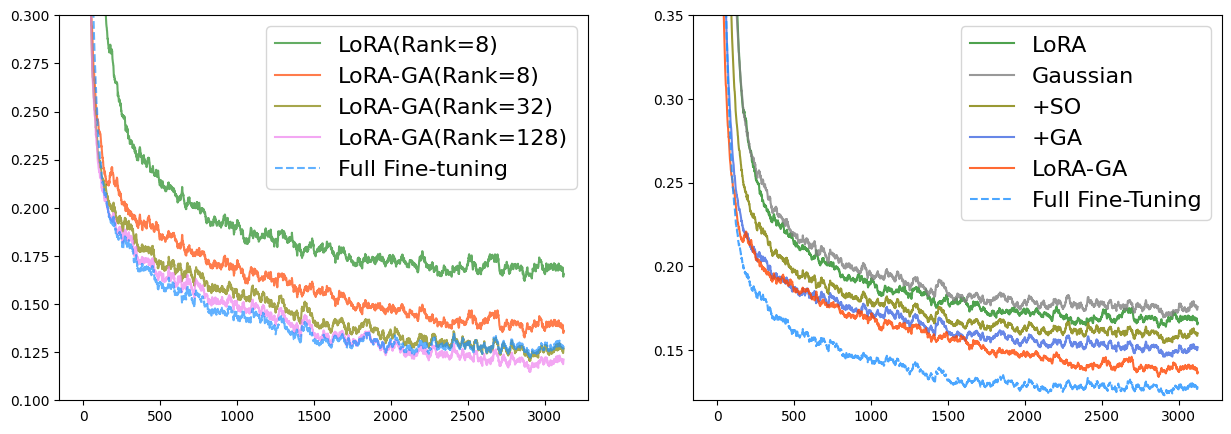
Our results, as summarized in Table 2, indicate that LoRA-GA outperforms or is comparable to other methods, including full-finetuning. Specifically, LoRA-GA achieves superior performance on both the GSM8K and Human-eval datasets, underscoring its effectiveness in handling tasks with higher complexity and diversity. On MT-Bench, LoRA-GA also demonstrates competitive performance, although it slightly trails behind DoRA. Nevertheless, LoRA-GA achieves this with fewer parameters and approximately 70% of the training time required by DoRA. Additionally, as illustrated in Figure 2 (Left), our method exhibits a significantly faster convergence rate compared to Vanilla LoRA, with convergence rates comparable to those of full-finetuning.
Effect of Rank
We attribute the performance discrepancies on the GSM8K and Human-eval datasets, when compared to full-finetuning, primarily to the representational limitations imposed by the low-rank approximation. To address this, we experimented with higher ranks, specifically rank=32 and rank=128. Our findings reveal that LoRA-GA maintains stability across different rank settings and, in some cases, even surpasses full-finetuning performance. As shown in Figure 2 (Left), higher ranks with our initialization also result in loss curves that closely resemble those of full-finetuning.
| MT-Bench | GSM8K | Human-eval | |
|---|---|---|---|
| Full | |||
| LoRA | |||
| PiSSA | |||
| rsLoRA | |||
| LoRA+ | |||
| DoRA | |||
| AdaLoRA | |||
| LoRA-GA | |||
| LoRA-GA (Rank=32) | |||
| LoRA-GA (Rank=128) |
4.3 Ablation Study
We conducted ablation studies to evaluate the contributions of non-zero initialization, stable output, and gradient approximation in LoRA-GA using five distinct experimental settings. Details of each setting are provided in Table 3.
| Method | Initialization | Initialization | |
|---|---|---|---|
| LoRA | 0 | ||
| Gaussian | |||
| +SO | |||
| +GA | |||
| LoRA-GA |
| MT-Bench | GSM8K | Human-eval | Average of GLUE | |
|---|---|---|---|---|
| Full | ||||
| LoRA | ||||
| Gaussian | ||||
| + SO | ||||
| + GA | ||||
| LoRA-GA |
Ablation Result
The results are presented in Tables 4 and 6. For both small and large models, we observe that simply changing LoRA’s initialization to Gaussian does not yield any performance gains and may result in a slight performance decline. However, when combined with either "+SO" (Stable Output) or "+GA" (Gradient Approximation), performance improves upon that of LoRA. LoRA-GA, which integrates both techniques, outperforms other methods. As shown in Figure 2 (Left) and Figure 4, +SO and +GA also enhance convergence speed, and when both are combined, the training loss curve is even closer to that of full-finetuning. This indicates that both output stability and gradient approximation contribute to the improvement of LoRA, each addressing different aspects of the model’s performance.
4.4 Memory Costs and Running Time
We benchmark LoRA-GA on a single RTX 3090 24GB GPU, a 128-core CPU, and 256GB of RAM. As shown in Table 5, the memory consumption of our new method does not exceed that used for training with LoRA, indicating no extra memory is needed. Additionally, the time cost of this operation is relatively negligible compared to the subsequent fine-tuning process. For instance, in the Code-Feedback task, the training process took approximately 10 hours, while the initialization required only about 1 minute, which is insignificant.
| Parameters | Time(LoRA-GA) | Memory(LoRA-GA) | LoRA | Full-FT | |
|---|---|---|---|---|---|
| T5-Base | 220M | 2.8s | 1.69G | 2.71G | 3.87G |
| Llama 2-7B | 6738M | 74.7s | 18.77G | 23.18G | 63.92G |
5 Conclusions
In this paper, we present a novel initialization scheme for low-rank adaptation (LoRA), with the goal of acelerating its convergence. By examining the initialization methods and update processes of LoRA, we develop a new initialization method, LoRA-GA , which approximates the gradients of the low-rank matrix product with those of full fine-tuning from the very first step.
Through extensive experiments, we have demonstrated that LoRA-GA achieves a convergence rate comparable to that of full fine-tuning while delivering similar or even superior performance. Since LoRA-GA solely modifies the initialization of LoRA without altering the architecture or training algorithms, it offers an efficient and effective approach that is easy to implement. Furthermore, it can also be incorporated with other LoRA variants. For example, ReLoRA [34] periodically merges the adapters into frozen weights , which may allow LoRA-GA to demonstrate its advantages over more steps. We leave it as an interesting future direction.
References
- [1] Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792, 2023.
- [2] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- [3] Zeyu Han, Chao Gao, Jinyang Liu, Sai Qian Zhang, et al. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv:2403.14608, 2024.
- [4] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021.
- [5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [6] Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3):220–235, 2023.
- [7] Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, and Tong Zhang. Lisa: Layerwise importance sampling for memory-efficient large language model fine-tuning, 2024.
- [8] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation, 2024.
- [9] Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. Lora learns less and forgets less. arXiv preprint arXiv:2405.09673, 2024.
- [10] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, 2015.
- [12] Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. arXiv preprint arXiv:1812.04754, 2018.
- [13] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255, 2020.
- [14] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- [15] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- [16] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- [17] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [18] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [19] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [20] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010.
- [21] Dmytro Mishkin and Jiri Matas. All you need is a good init. arXiv preprint arXiv:1511.06422, 2015.
- [22] Greg Yang, Edward J Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer. arXiv preprint arXiv:2203.03466, 2022.
- [23] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790–2799. PMLR, 2019.
- [24] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning, 2022.
- [25] Yaqing Wang, Sahaj Agarwal, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, and Jianfeng Gao. Adamix: Mixture-of-adaptations for parameter-efficient model tuning. arXiv preprint arXiv:2205.12410, 2022.
- [26] Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247, 2020.
- [27] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning, 2021.
- [28] Anastasia Razdaibiedina, Yuning Mao, Rui Hou, Madian Khabsa, Mike Lewis, Jimmy Ba, and Amjad Almahairi. Residual prompt tuning: Improving prompt tuning with residual reparameterization, 2023.
- [29] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. AI Open, 2023.
- [30] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- [31] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning, 2023.
- [32] Nam Hyeon-Woo, Moon Ye-Bin, and Tae-Hyun Oh. Fedpara: Low-rank hadamard product for communication-efficient federated learning. arXiv preprint arXiv:2108.06098, 2021.
- [33] Ali Edalati, Marzieh Tahaei, Ivan Kobyzev, Vahid Partovi Nia, James J Clark, and Mehdi Rezagholizadeh. Krona: Parameter efficient tuning with kronecker adapter. arXiv preprint arXiv:2212.10650, 2022.
- [34] Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, and Anna Rumshisky. Relora: High-rank training through low-rank updates, 2023.
- [35] Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models, 2024.
- [36] Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora, 2023.
- [37] Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models, 2024.
- [38] Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- [39] Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, and Xipeng Qiu. Full parameter fine-tuning for large language models with limited resources. arXiv preprint arXiv:2306.09782, 2023.
- [40] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions, 2023.
- [41] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models, 2024.
- [42] Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement, 2024.
- [43] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021.
- [44] Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1(3):211–218, 1936.
- [45] Leon Mirsky. Symmetric gauge functions and unitarily invariant norms. The quarterly journal of mathematics, 11(1):50–59, 1960.
- [46] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019.
Appendix A Proofs of Theorems
A.1 Proof of Theorem 3.1
Lemma 3.1.
Suppose the loss function is and , where is the output of a layer and is the input, the gradients of adapters and are linear mappings of the gradient of :
Remarkably, the gradient of in LoRA and the gradient of in full fine-tuning are equal at the beginning of the training.
Proof.
For the gradients in LoRA,
At the beginning of training, both LoRA and full fine-tuning have and identical , therefore,
∎
Theorem 3.1.
Consider the following optimization problem:
If the Singular Value Decomposition (SVD) of is , the solution to this optimization problem is:
where are index sets.
Proof.
Since that and , we can assert that the matrix has .
Under this given solution,
By Eckart-Young Theorem[44, 45], the optimal low-rank approximation with respect to Frobenius norm is:
This is identical to what we have got. Therefore, this is the optimal solution. ∎
A.2 Proof of Theorem 3.2
Lemma A.1.
In , if we randomly pick a vector that , we have:
-
1.
, and ;
-
2.
;
-
3.
;
-
4.
;
Proof.
It is equivalent to sampling a random point uniformly from a unit sphere in .
For property 1, holds obvious by symmetry. Since and uniformly distributed, each entry has identical expectation, , . .
For property 2, it can also be proved by symmetry: we can always find vector that contains also lies on the sphere. Therefore, .
For property 3, .
For property 4, again it can be proved by symmetry: we can always find vector that contains also lies on the sphere. Therefore, . ∎
Lemma A.2.
For a randomly selected orthogonal matrix , and we randomly pick two different column vectors and from it. For these two vectors, we have the following:
-
1.
;
-
2.
;
Proof.
It is equivalent to first selecting a random vector from a unit sphere in uniformly, and then selecting the other one that is orthogonal to .
For property 1, .
For property 2, consider that , and given , we can always find is also an orthogonal vector. Therefore, . ∎
Theorem 3.2.
Given the initialization proposed in Theorem 3.1, assume that the orthogonal vectors in and are randomly selected from and , and set as suggested by rsLoRA [36]. Under these conditions, the adapters are forward scale-stable if and backward scale-stable if .
Proof.
In LoRA, , since that is not considered here, therefore, denote . When backward propagation, it’s like . Represente as and as . Therefore,
| (4) |
Since that the output of each layer in model always passes a softmax function, so that the vector is . Further, since that input ’s are i.i.d., without loss of generality, assume that and .
For the adapter, as Equation 4 shows, and by the expectations we have proved in Lemma A.1 and A.2, we can calculate the scale of forward and backward process.
The scale of forward process is:
| (5) |
The scale of the backward process is:
| (6) |
Appendix B Additional Experimental Results
B.1 Convergence Speed
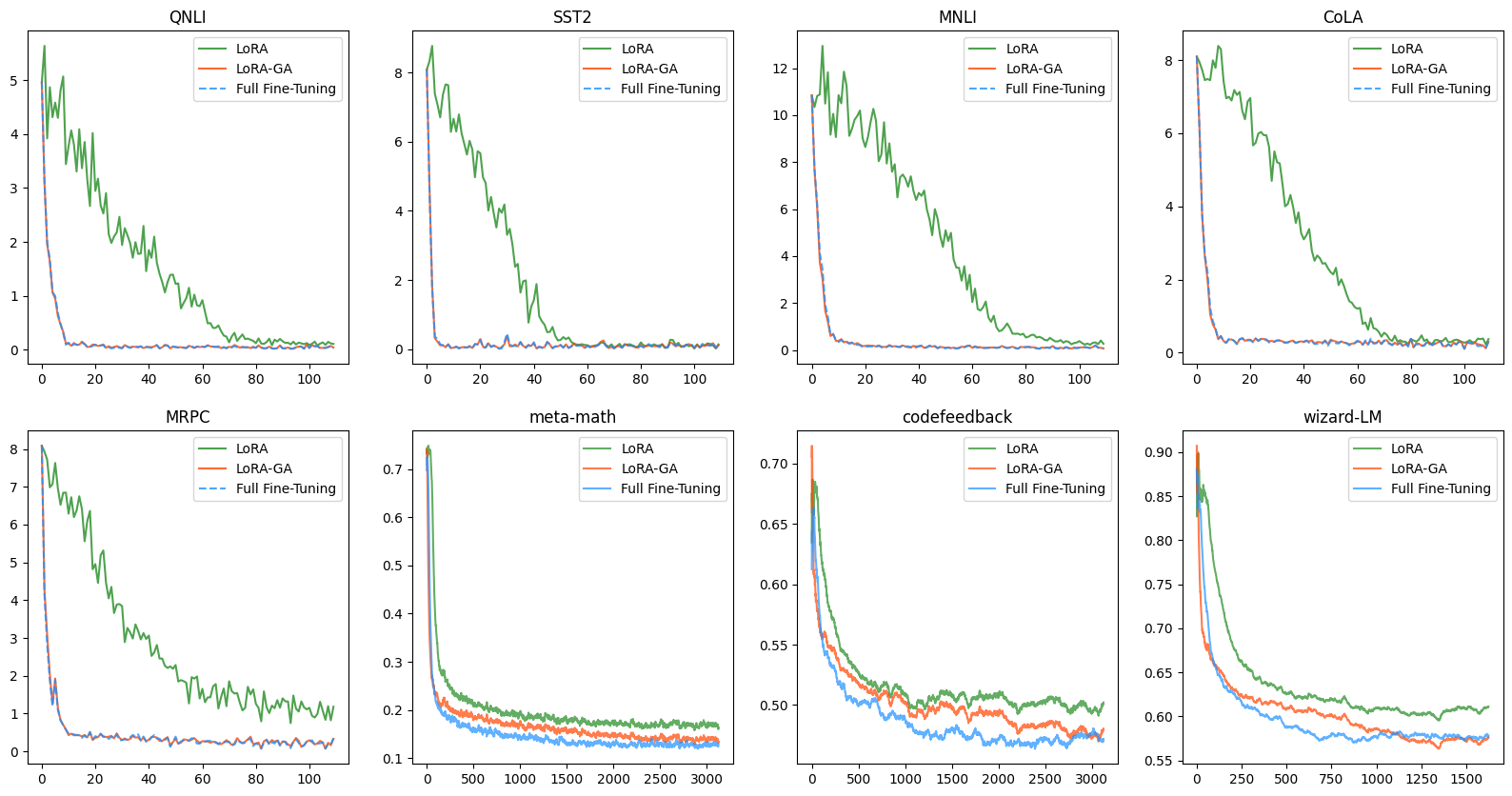
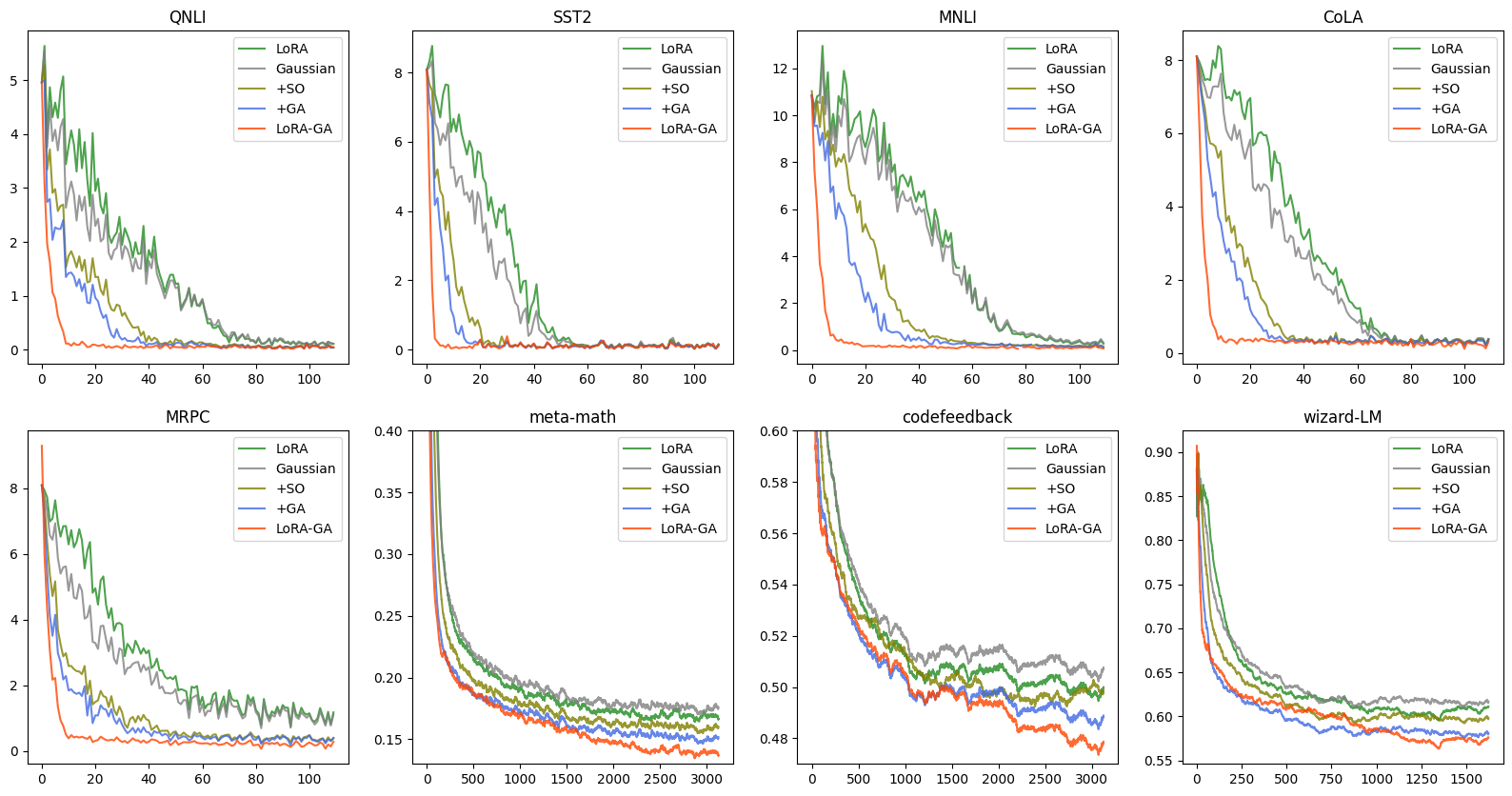
As Figure 3 and 4 shown, the convergence of LoRA-GA is significantly faster than vanilla LoRA and other ablation models, almost close to that of full fine-tuning, which support our claim about the speed of convergence.
B.2 Evaluating the Rank of the Gradient Matrix
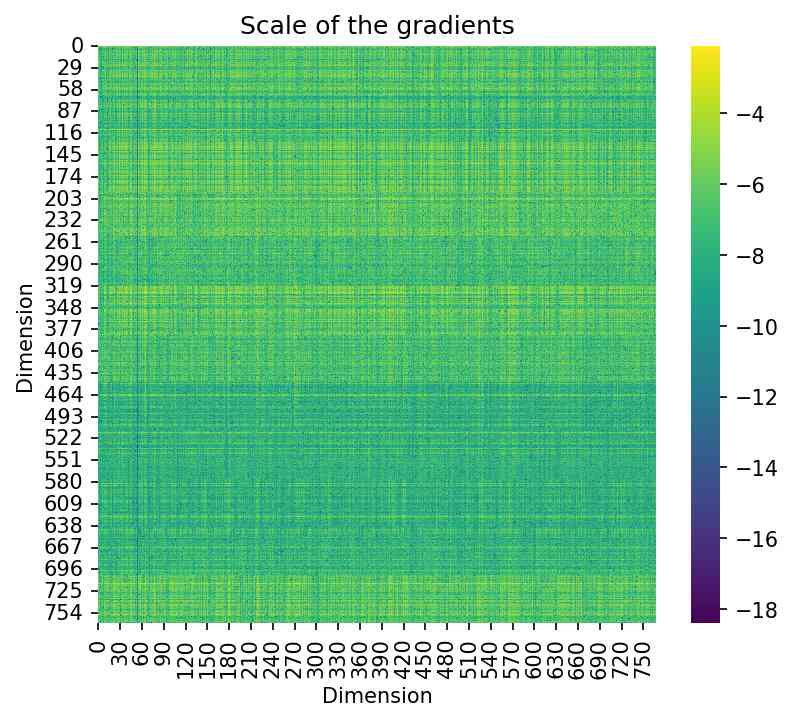
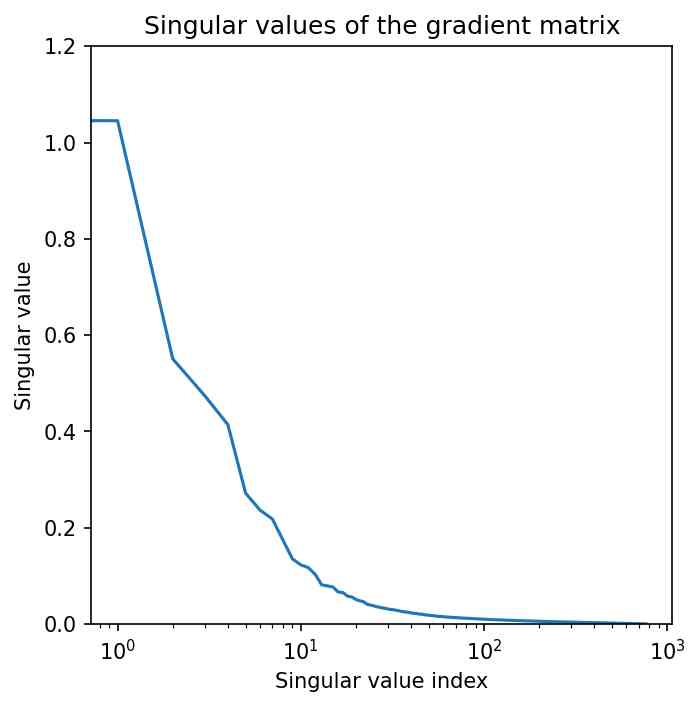
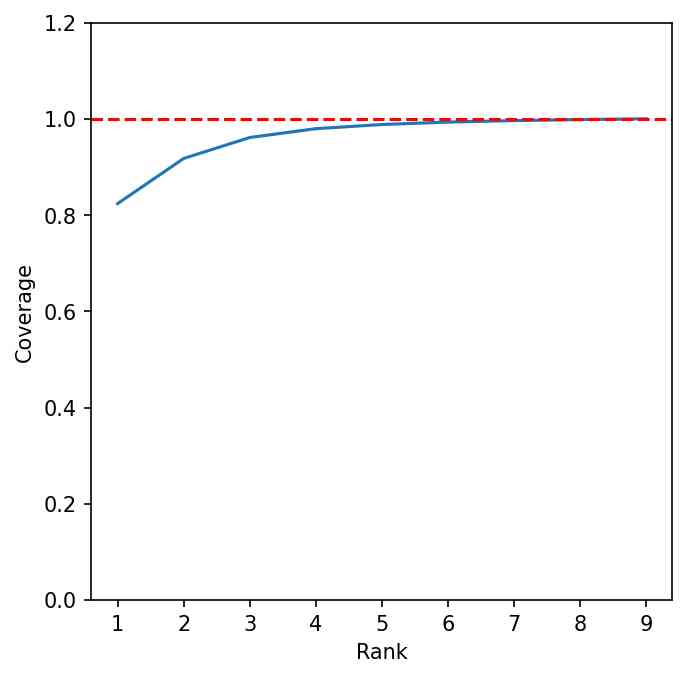
Theorem 3.1 suggests that the closer the rank of the gradient matrix is to , the better the gradient approximated, thereby enhancing the theoretical effectiveness of our initialization. Figure 5 illustrates the low-rank nature of gradient matrices. The left panel depicts a grid-like pattern in the gradients of a weight matrix, indicating a low-rank structure. The middle panel shows a steeply declining curve of singular values, reflecting the highly low-rank nature of the gradient matrix. The right panel presents the cumulative curve of squared singular values, demonstrating that a few ranks account for nearly all the singular values of the gradient matrix. Specifically, the coverage in the right panel is defined as
where is the LoRA rank used in LoRA-GA , indicating how much of the low-rank matrix can be approximated by this rank.
B.3 Detailed Ablation Study Result of GLUE
Table 6 shows the full results of ablation study on the subset of GLUE, where the average scores are briefly reported in Table 4. As Table 6 demonstrated, LoRA-GA outperforms all other ablation models, while both "+SO" and "+GA" methods gain some improvement from vanilla LoRA and simple non-zero initialization "Gaussian". This illustrates that both components in LoRA-GA have positive contribution to the improvement of performance.
| MNLI | SST-2 | CoLA | QNLI | MRPC | Average | |
|---|---|---|---|---|---|---|
| Trainset | 393k | 67k | 8.5k | 105k | 3.7k | |
| Full | ||||||
| LoRA | ||||||
| Gaussian | ||||||
| + SO | ||||||
| + GA | ||||||
| LoRA-GA |
B.4 Experimental result with different learning rate
Furthermore, we also conduct experiments under learning rates 1e-5 and 5e-5. As Table 7 and 8 shown, LoRA-GA maintains strong performance across different learning rates, which illustrating its robustness to the variation of learning rate.
| MT-Bench | GSM8K | Human-eval | |
|---|---|---|---|
| Full | |||
| LoRA | |||
| PiSSA | |||
| rsLoRA | |||
| LoRA+ | |||
| LoRA-GA |
| MT-Bench | GSM8K | Human-eval | |
|---|---|---|---|
| Full | |||
| LoRA | |||
| PiSSA | |||
| rsLoRA | |||
| LoRA+ | |||
| LoRA-GA |
Appendix C LoRA-GA Initialization With Gradient Accumulation
Appendix D Hyperparameter
D.1 Experiments on Natural Language Understanding
We use the following hyperparameters with T5-Base.
-
•
Training Algorithm: AdamW [46] with , , and weight decay of 0. For full finetuning, LoRA, and its variants, a learning rate of , a warmup ratio of 0.03, and cosine decay are employed. For DoRA [8], a learning rate of is used, while for Adalora, a learning rate of is applied, both with the same warmup ratio and cosine decay adhering to their respective papers.
-
•
LoRA Hyperparameters: LoRA rank , . LoRA target is all linear modules except embedding layer, layer norm and language model head.
-
•
LoRA-GA Hyperparameter: , sampled batch size
-
•
Other Hyperparameters: Sequence Length , train batch size , number of train epochs . Precision FP32
D.2 Experiment on Large Language Model
We use the following hyperparameters with Llama 2-7B.
-
•
Training Algorithm: AdamW [46] with with , , and weight decay of 0. For full finetuning, LoRA, and its variants, a learning rate of [37], a warmup ratio of 0.03, and cosine decay are employed. For DoRA [8], a learning rate of is used, while for Adalora, a learning rate of is applied, both with the same warmup ratio and cosine decay adhering to their respective papers.
-
•
Precision: The backbone model uses bf16 precision, while during training, LoRA’s and matrices use fp32 precision, following the implementation of PEFT [38].
-
•
LoRA-GA Hyperparameter: , micro sampled batch size with gradient accumulation of 32.
-
•
LoRA Hyperparameters: LoRA rank and for all experiments.
-
•
Generation Hyperparameters: All generation is performed with and temperature .
-
•
Other Hyperparameters: Number of train epochs , train micro batch size with gradient accumulation of 32. Sequence Length
Appendix E Comparison between LoRA-GA and PiSSA
Both LoRA-GA and PiSSA [37] concentrate on the initialization of LoRA, and utilizing SVD on pre-trained models. While they may appear similar superficially, significant differences exist between them.
Firstly, the motivations behind LoRA-GA and PiSSA are fundamentally different. As discussed in Section 3.2, LoRA-GA is motivated by the approximation of the LoRA update and full fine-tuning. We employ SVD on gradients solely because the optimal solution to the gradient approximation problem is precisely obtained (as stated in Theorem 3.1). Conversely, PiSSA adopts SVD under the assumption that pre-trained weights possess a low intrinsic rank, and thus, the SVD of weights can provide an accurate representation of original weights. In essence, LoRA-GA emphasizes on gradients and decomposes them, whereas PiSSA concentrates on weights and decomposes them.
Secondly, LoRA-GA and PiSSA employ different scales of initialization. In Section 3.3, LoRA-GA derives an appropriate scaling factor by considering the forward and backward stability of our initialization scheme. On the other hand, PiSSA uses the largest singular values as the magnitude of orthogonal matrices directly.
Appendix F Limitations
In this paper, we have demonstrated that LoRA-GA can achieve performance comparable to full fine-tuning on the T5-Base (220M) and Llama 2-7B models, while significantly reducing the number of parameters and associated costs. However, due to computational resource constraints, we have not validated LoRA-GA on larger pre-trained models (e.g., Llama 2-70B).
Another limitation pertains to our evaluation scope. While we provide evaluations on MTBench, GSM8K, and Human-eval, we did not assess our method on other datasets. Consequently, we cannot fully guarantee that our findings are universally consistent across all benchmarks.
Additionally, we did not implement our method on other LoRA variants that are orthogonal to our improvements (e.g., ReLoRA [34]). Therefore, we cannot ascertain whether LoRA-GA would perform equally well with other LoRA architectures/improvements.
Finally, compared to the original LoRA, LoRA-GA requires double the checkpoint storage, as it necessitates storing both the initial adapter checkpoints ( and ) and the final adapter checkpoints ( and ).
Appendix G Compute Resources
In this paper, we utilized two types of GPUs: the RTX 3090 24GB GPU, supported by a 128-core CPU and 256GB of RAM (hereinafter referred to as "the RTX 3090"), and the A100 80GB GPU (hereinafter referred to as "the A100").
For the experiments on T5-Base using the GLUE dataset, reported in Section 4.1, all computations were performed on a single RTX 3090. For the Llama 2-7B experiments, reported in Section 4.2, full fine-tuning and DoRA scenarios were conducted on a single A100, while all other LoRA variants and LoRA-GA were executed on a single RTX 3090. Additionally, all ablation studies presented in Section 4.3 were carried out on a single RTX 3090.
Appendix H Broader Impacts
In this paper, we identify some limitations of vanilla LoRA and propose a more efficient and effective method for LoRA initialization, LoRA-GA. LoRA-GA converges faster than vanilla LoRA and consistently achieves better evaluation results.
We believe that this work will have a positive social impact. The primary reasons are as follows: The high cost of training and fine-tuning large models is a significant challenge today. LoRA-GA offers a way to fine-tune with fewer parameters and lower computational costs while still achieving comparable performance. This will reduce the cost of fine-tuning models and, in turn, decrease energy consumption, such as electricity, contributing to the goal of a low-carbon environment. Furthermore, as the size of large language models (LLM) continues to grow, it becomes increasingly difficult for individuals or small organizations to develop their own LLMs. However, with the help of LoRA-GA and open-source large models, the hardware barrier to entry in this area is greatly reduced. This will promote democratization in the field of large models, preventing monopolies and dictatorships by a few companies.
On the other hand, our method could potentially make it easier to train language models that generate fake news or misleading information. This underscores the necessity for designing effective detectors to identify content generated by large language models (LLMs). Ensuring the responsible use of this technology is crucial to mitigating the risks associated with the misuse of advanced language models.