(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
https://jiahao620.github.io/gaussreg
GaussReg: Fast 3D Registration with Gaussian Splatting
Abstract
Point cloud registration is a fundamental problem for large-scale 3D scene scanning and reconstruction. With the help of deep learning, registration methods have evolved significantly, reaching a nearly-mature stage. As the introduction of Neural Radiance Fields (NeRF), it has become the most popular 3D scene representation as its powerful view synthesis capabilities. Regarding NeRF representation, its registration is also required for large-scale scene reconstruction. However, this topic extremly lacks exploration. This is due to the inherent challenge to model the geometric relationship among two scenes with implicit representations. The existing methods usually convert the implicit representation to explicit representation for further registration. Most recently, Gaussian Splatting (GS) is introduced, employing explicit 3D Gaussian. This method significantly enhances rendering speed while maintaining high rendering quality. Given two scenes with explicit GS representations, in this work, we explore the 3D registration task between them. To this end, we propose GaussReg, a novel coarse-to-fine framework, both fast and accurate. The coarse stage follows existing point cloud registration methods and estimates a rough alignment for point clouds from GS. We further newly present an image-guided fine registration approach, which renders images from GS to provide more detailed geometric information for precise alignment. To support comprehensive evaluation, we carefully build a scene-level dataset called ScanNet-GSReg with scenes obtained from the ScanNet dataset and collect an in-the-wild dataset called GSReg. Experimental results demonstrate our method achieves state-of-the-art performance on multiple datasets. Our GaussReg is faster than HLoc (SuperPoint as the feature extractor and SuperGlue as the matcher) with comparable accuracy.
Keywords:
Gaussian Splatting Registration Coarse-to-fine1 Introduction
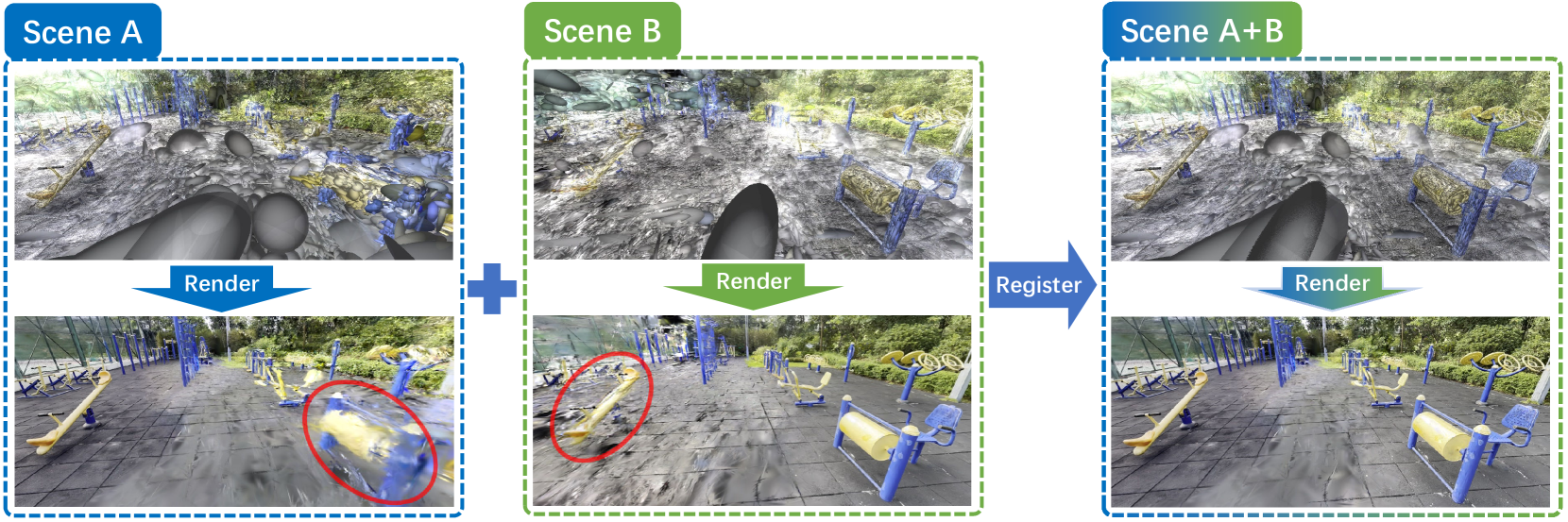
In traditional 3D scene scanning and reconstruction, a large-scale scene is usually divided into different blocks, resulting in many independent sub-scenes that may not in the same coordinate system. Therefore, the registration between them plays a crucial role. Currently, point cloud registration has been widely studied and reached a relative mature stage, with several representative works such as ICP [4], D3Feat [1], Geotransformer [26], etc. The mainstream methods typically involve extracting features from point clouds and locating matching points to calculate the transformation between the two input scenes.
Recently, a new 3D representation - Neural Radiance Fields (NeRF) has been introduced and quickly gained attention due to its powerful capability in view synthesis, and it has been widely used in representing 3D scenes. When considering large-scale scene reconstruction based on NeRF, there are two main challenges: 1) Due to the complex occlusions present in real-world scenes, lots of images or videos are often required to capture for large-scale reconstruction, leading to a time-consuming data collection process. 2) Optimizing NeRF with numerous images is computationally intensive. Therefore, a direct approach is to divide a large-scale scene into some smaller scenes, reconstruct them separately, and then use registration to combine all these small scenes together.
Consider two overlapping scenes, each with its own NeRF model. Currently, the methods for registering two reconstructed NeRF scenes can be generally categorized into two types: 1) As the method proposed in NeRFuser [10], we can render a large number of images for each scene, then recover poses of all these images together from structure-from-motion (SfM). However, this method is very time-consuming; 2) As in the method DReg-NeRF [6], we can convert the implicit radiance field to explicit voxel by querying voxel grids from NeRF of two scenes, and extract features to establish their matching relationship for registration. But this method faces two issues: a) it is difficult to turn NeRF of unbounded scene to bounded voxel; b) the resolution limitation of the voxel grid makes this method unsuitable for larger scenes.
Most recently, Gaussian Splatting (GS) [16] has been proposed, which introduces an explicit representation of 3D Gaussians, ensuring high-quality rendering while speeding up the rendering process. Then, an interesting question comes up: “As GS provides a point-like representation, can we conduct GS registration resorting to point-cloud registration methods? ”
In this work, we explore fast and accurate 3D registration with GS to answer the question. Taking GS models of the two scenes as input, we first extract their point clouds from GS. Thus, the straightforward approach is to adapt point cloud registration methods to the registration between these GS point clouds. To this end, a coarse registration method is designed which follows standard point cloud registration pipeline, such as GeoTransformer [26], but with special consideration of extra attributes (e.g., opacity) in 3D gaussians.
Compared with traditionally collected point cloud data, point clouds from GS only capture rough geometric structure and are usually noisy. Thus, a coarse registration can not achieve precise results with sufficient accuracy. We further propose a novel image-guided fine registration pipeline built upon the coarse registration result. Our main idea is from the observation that GS not only contains geometry information but also inherently detailed image information, which can support more accurate alignment. Therefore, we first locate the overlapping regions with the help of coarse registration, where a few images are rendered with the help of GS. Then, the fine registration pipeline projects images into 3D volumetric features for final matching and transformation estimation.
Ultimately, we propose a novel coarse-to-fine GS registration framework: GaussReg. However, it still lacks evaluation benchmarks of scene-level registration with GS. To support this, we construct a dataset called ScanNet-GSReg, comprising 1379 scenes from the ScanNet [7] dataset. In addition, we collect a dataset named GSReg, comprising 6 indoor and 4 outdoor scenarios, to assess the generalization capability of our method. We conduct extensive experiments on the ScanNet-GSReg dataset, the Objaverse [8] dataset used in DReg-NeRF [6], and the GSReg dataset, demonstrating the effectiveness of our method.
The main contributions can be summarized as:
-
To the best of our knowledge, we are the first to explore the registration of 3D scenes considering Gaussian Splatting representations.
-
We carefully designed a novel coarse-to-fine pipeline that fully considers the characteristics of 3D gaussians, which performs both fast and accurate.
-
An image-guided fine registration is newly presented that takes rendered images of GS into account for fine-level alignment. We also believe this strategy opens minds fro GS-related researches.
-
A benchmark is also newly built for the proposed new task, which includes scenes from ScanNet and several self-collected in-the-wild scenes.
2 Related Work
3D point cloud registration
3D point cloud registration has been developed for decades. Given two overlapping point clouds with different coordinate systems, the target of this task is to find the transformation between them. Traditional methods [4, 18, 17, 40, 21, 23, 42] divide this process into two parts: correspondence searching and transformation estimation. Correspondence searching involves finding sparse matched feature points between the source and target point clouds. Transformation estimation is to calculate the transformation matrix using these correspondences. These two stages will be conducted iteratively to find the optimal transformation. However, these methods require many complex strategies [18, 17, 23, 42] to overcome noise, outliers, or density variations. To overcome these problems, deep feature extractors [35, 13, 41] are proposed to find more robust correspondences between two point clouds. 3DRegNet [22] goes one step further to learn transformation between point clouds end-to-end. Recently, REGTR [38] incorporate self-attention and cross-attention mechanisms and MAC [43] utilizes graph networks to further improve the robustness of end-to-end point cloud registration. GeoTransformer [26] proposes a geometric transformer to match superpoint [9] features and utilizes an overlap-aware circle loss for better convergence. New approaches are constantly being proposed, proving the importance of this task in scene reconstructions.
3D scene representation
Furukawa and Ponce [11] provide a comprehensive classification of 3D reconstruction methods, categorizing them into four primary scene representations: volumetric fields [30, 24], point clouds [29], 3D meshes [15, 39], and depth maps [37, 31, 12]. Except for these representations, NeRF [19] introduces an innovative approach by leveraging a neural implicit field to model the scene. NeRF utilizes an MLP network to optimize a 5D function (3d position plus 2d viewing direction) from a set of training images which can be used to implicitly model the scene. It has shown impressive results in image reconstruction and novel view synthesis and is widely recognized as the first photorealistic 3D scene reconstruction method. Various types of NeRFs have been proposed for acceleration [20, 5, 32] and better rendering quality [3, 2, 34]. Another recent advancement, 3D Gaussian splatting [16] utilizes explicit 3D Gaussians to represent the scene. Each Gaussian is characterized by a covariance matrix, a center point, and opacity for a flexible optimization regime. The model’s efficient differentiable rasterization implementation and well-designed architecture enable rapid training and real-time rendering. Moreover, The optimization strategy is cleverly designed to adaptively control the Gaussians for ensuring very high rendering quality. Despite the fast innovation of scene representations, 3D registration remains to be an important issue for stable large-scale reconstructions, thus developing new registration methods for different representations is crucial.
NeRF Registration
Neural Implicit Field [19] has been widely accepted as a new scene representation, several methods have been proposed to do NeRF registration. NeRF2NeRF [14] utilizes human-annotated key points to obtain an initial transformation and refines it using a surface field distilled from a pre-trained NeRF. DReg-NeRF [6] extracts features from the occupancy grid of NeRF and applies a decoupling model [38] for NeRF registration, eliminating the need for human interaction in the registration process. However, it’s hard to generalize to larger scenes due to its global feature-extracting strategy. NeRFuser [10] directly uses the structure from motion method to estimate the transformation using rendered images from NeRF which is very time-consuming. CL-NeRF [36] concentrates on the continual learning of NeRF models and proposes an expert adaptor for learning newly changed scenes without finetuning the whole network. Most recently, 3D Gaussian splatting has been proposed as a promising scene representation, to the best of our knowledge, we are the first to propose registration methods for 3D Gaussian Splatting and achieve SOTA performance with faster registration speed and better rendering quality. Moreover, continual learning and modifying scenes can be naturally done using our pipeline.
3 Method
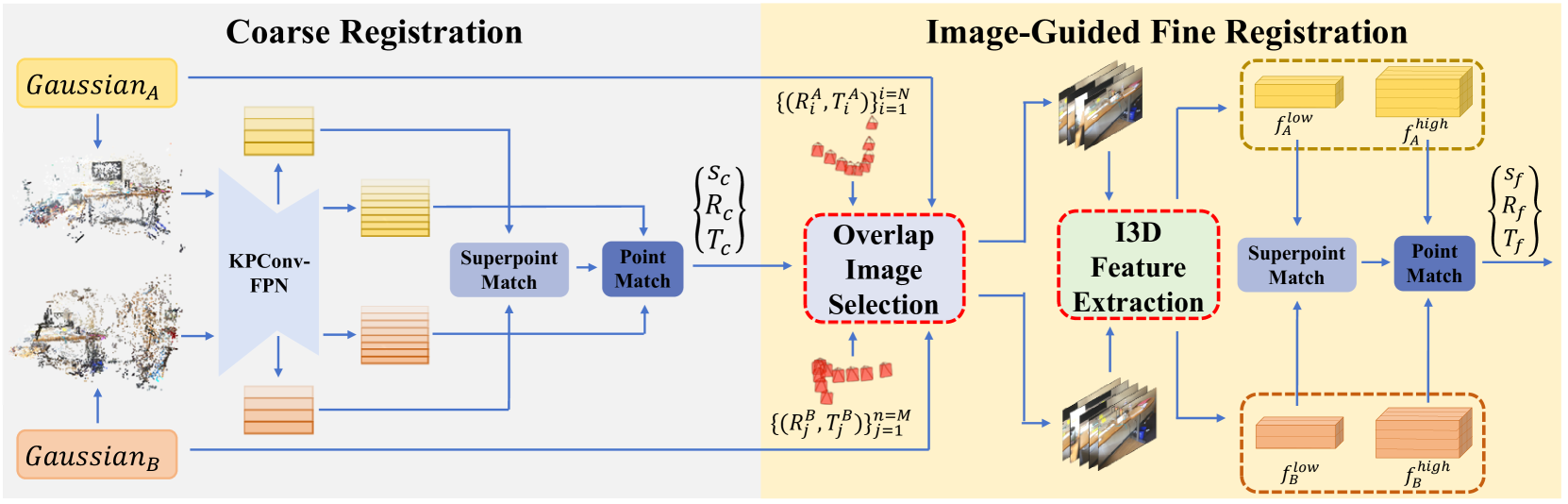
In this section, we present our proposed GaussReg for 3D Registration with Gaussian Splatting (GS). The overall architecture is illustrated in Figure 2.
3.1 Overview
As shown in Figure 2, the proposed GaussReg mainly consists of two stages, including the Coarse Registration, and the Image-Guided Fine Registration. Here we give a brief introduction to the entire process. Assuming two overlapping scenes A and B, each with its own GS model, only the camera poses of all training images are saved and accessible. We denote the camera poses of all training images as and for A and B respectively. The GS models are denoted as and and the derived point clouds from GS models are termed as and . Our goal is to discover the rigid transformation that makes scene B align with A, where means scale factor, means rotation matrix, and represents translation vector. The coarse registration directly accepts and as input, and output a coarse transformation . Since the extracted point cloud from a GS model tends to be noisy and distorted, the coarse alignment often needs to be more accurate. Then, in the image-guided fine registration, we first locate a highly overlapping region based on the coarse alignment result. Around the highly overlapping region, two subsets of cameras are then selected from and respectively, from which we render several images. After that, an Image-Guided 3D (I3D) Feature Extraction is adopted to obtain volumetric features from images, which are used for subsequent local matching, ultimately achieving the accurate transformation output .
3.2 Coarse Registration
As we all know, the GS model is stored in the form of 3D gaussians. Each 3D gaussian stores the position , opacity , rotation, scale, and the coefficients of the spherical harmonics. First, we select those confident points with the opacity greater than a threshold (0.7 is chosen empirically). For each sampled point, the color is determined via spherical harmonic functions. Finally, for every point in or , we use as the input channel to feed into the coarse registration pipeline.
As shown in Figure 2, the Coarse Registration follows the workflow as GeoTransformer [26], we extract multi-scale features of each point cloud through a shared KPConv-FPN [33]. The coarsest level point features and are used for Superpoint Match and the finest level point features and are used for Point Match. The process of Superpoint Match refers to Geotransformer [26]. Noted that in Point Match, we directly utilize the ICP [4] algorithm to obtain the coarse registration results between GS, instead of the Local-to-Global Registration in Geotransformer [26].
Training Strategy and Loss Function
Due to the scale uncertainty in monocular video reconstruction, we performed data augmentation not only on rotation and translation but also on scaling for the input Gaussian point cloud. Even though we normalized the scale of input point clouds within a certain range, such data augmentation still preserves the diversity of relative scale differences between the point clouds to be matched.
We apply two loss functions (overlap-aware circle loss and point matching loss) from the GeoTransformer [26] to constrain our coarse registration network.
3.3 Image-Guided Fine Registration
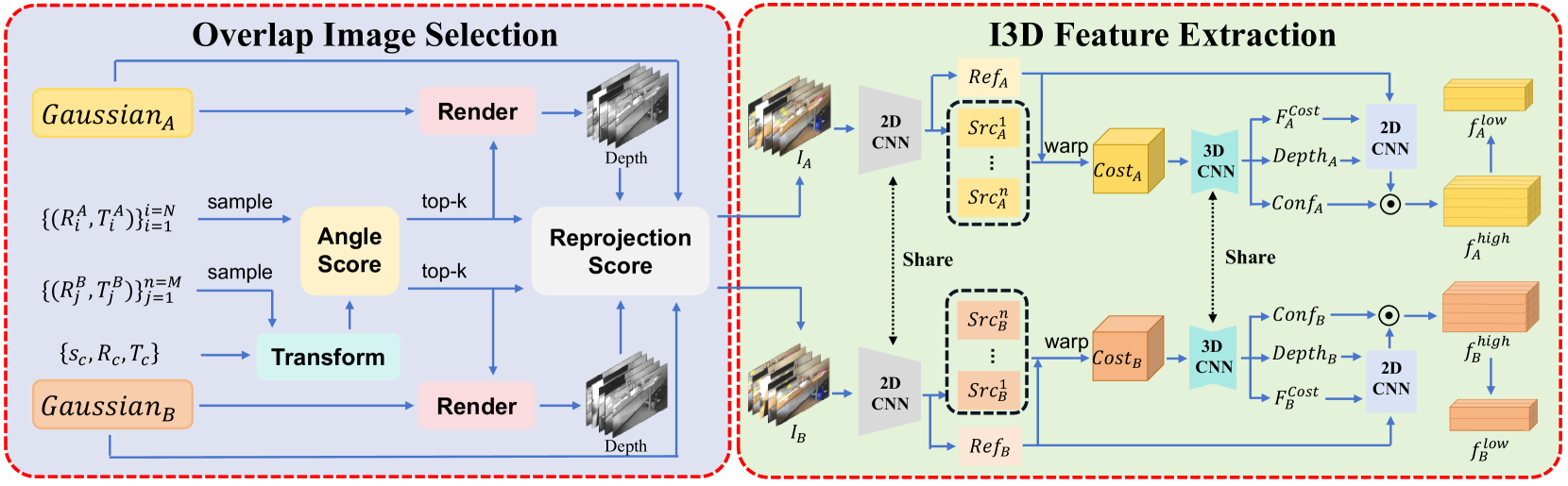
Since the GS model doesn’t impose specific geometric constraints during training, resulting point clouds may exhibit some degree of distortion. Relying solely on GS models might not guarantee accurate registration results. Considering that GS inherently contain detailed image information, an image-guided fine registration is proposed. Our key idea is to first locate overlapping regions between scene and scene and render some training images covering the region to support more precise geometric features for fine alignment. Specifically, as shown in Figure 2, our Image-Guided Fine Registration primarily involves two steps: 1) Efficiently and accurately selecting highly overlapping cameras and rendering images accordingly; 2) Utilizing these images to construct volumetric features for further fine registration.
Overlap Image Selection
As shown in Figure 3, the main goal of this part is to find two small subsets of cameras, from and respectively, which share as large common perspective area as possible. Before selection, we first uniformly sampled two subsets and to reduce computational cost, and then apply on for a coarse alignment, causing . Each subset contains images in our experiments. Our selection follows 3 steps: 1) For every pair , we calculate the cosine value of the angle between their camera orientations. Finally, top-k closest pairs will be kept, where in our experiments. Thanks to the coarse alignment, this step can accurately and quickly removes many useless pairs; 2) To achieve more accurate selection, for each pair remained after step 1, we further calculate the area of their perspective sharing. To do so, two low-resolution depth maps and are rendered from and respectively. Then, we calculate how portion of points derived from can be seen from and how portion of points derived from can be seen from . With the evaluation of the averaged portion, we find the closest pair . Thanks to the fast rendering speed of GS, the depth map rendering is done efficiently; 3) We finally pick two subsets of training cameras respectively in the neighborhood of and . Under the selected cameras, the image sets and are obtained by rendering from and to be fed into the next feature extraction stage.
Image-Guided 3D Feature Extraction
As shown in Figure 3, we adopt the principle of multi-view stereo (MVS) by utilizing images to assist in estimating the depth and extracting volumetric features of the reference image. Without loss of generality, we use scene as an example in the following description. First of all, we input into a 2D convolutional neural network to get features , which turn into the cost volume according to the depth hypotheses by differentiable homography. Building the cost volume requires the minimum and maximum distances, which can be automatically computed from the rendered depth map of the reference image. Followed by the 3DCNN regularization, the probability volume and feature volume are obtained from the cost volumes, where is the number of feature channels, and is the resolution of . For any pixel on , our network predicts a probability distribution . We pick out satisfying:
| (1) |
where represents the probability of the pixel being at depth . The feature from cost volume , predicted depth and confidence map are calculated by:
| (2) | ||||
Then we concatenate , , and , and pass them through convolutional layers. After confidence-based filtering, we obtain high-resolution feature and low-resolution feature . This process can be described as
| (3) | ||||
and are obtained in the same manner. Next, we project the features into the coordinate system of according to the corresponding depth maps. Finally, following the same procedure as in coarse registration, we obtain the fine registration result .
Training Strategy and Loss Function
Overlap Image Selection is not involved in the training of the fine registration network. We randomly sample pairs of multi-view images with overlap from ScanNet dataset for training. During training, we also apply data augmentation to the camera extrinsic.
Our loss function mainly consists of two parts, depth loss and registration loss. Depth loss is a cross-entropy loss to supervise the probability volume:
| (4) |
where and are the sets of valid points. and denote the one-hot labels from the ground-truth depth of . and denote the predicted probability distribution of . Registration loss is the same as loss function used in coarse registration. Therefore, our total loss in the fine registration network is:
| (5) |
where in our experiments.

3.4 Gaussian Splatting Fusion and Filtering
After obtaining the final registration result, it is time to merge the two GS models. To transform into the coordinate system of , denoted as , we start by transforming the position of the 3D gaussian:
| (6) |
The opacity is invariant to the transformation . The rotation and scale of the 3D gaussian can be computed as:
| (7) | ||||
From the properties of spherical harmonics (SH) coefficients, we know that the rotation of SH coefficients is a linear transformation of the SH coefficients, and the rotation of each order of SH coefficients can be performed separately. Hence, for the -th order of SH coefficients, we can obtain the transformation of SH coefficients through the following approach: 1) Select any 2i+1 unit vectors , let , where is the function that projects the direction vector to the corresponding SH values; 2) Apply transformation to vectors to yield ; 3) is the transformation matrix of SH coefficients. Note that, it is difficult to choose vectors to ensure that is invertible, so in our experiments, we use the pseudo inverse as an approximation to inverse while calculating . Finally, we merge the 3D gaussians in closer to the center of with the 3D gaussians in closer to the center of to get .
4 Experiment
4.1 Experiment Setup
| Methods | RRE | RTE | RSE | Succss Ratio | Time(s) |
|---|---|---|---|---|---|
| HLoc [27]* | 2.725 | 0.099 | 0.098 | 0.756 | 212.3 |
| FGR [44] | 157.126 | 3.328 | 0.268 | 1.000 | 3.4 |
| REGTR [38] | 80.095 | 2.768 | 0.408 | 1.000 | 3.5 |
| Ours | 2.827 | 0.042 | 0.032 | 1.000 | 4.8 |
Dataset
As there is currently no scene-level dataset available for our task, it is necessary for us to create a dataset in order to evaluate GS registration. ScanNet [7] is a frequently used 3D dataset for indoor scenes, consisting of training scenes and test scenes. Each scene in ScanNet includes camera intrinsics, a sequence of images, along with the corresponding camera extrinsics and depth maps. Therefore, we decide to build a dataset based on ScanNet, called ScanNet-GSReg dataset. First, we randomly sample two continue image sequences from each scene. Each sequence contains to images, and the sampling interval ranges from to . The overlap ratio, calculated as the proportion of repeated images between two sequences, ranges from to . Then, we apply random transformations to each set of camera extrinsics independently to simulate the inconsistency between the world coordinates of the two sequences and record these two transformations as the ground-truth transformation between their world coordinates. Using these image sequences and corresponding camera parameters, we reconstruct the GS models separately. Each model undergoes iterations of training. Eventually, after excluding cases of failed initial point cloud generation or unsuccessful GS reconstruction, we obtain training samples and test samples. Furthermore, to validate the generalization of our method, we collected 10 real-world scenes for testing, called GSReg dataset, which includes indoor and outdoor scenes. For each scene, we record two videos. First, we use HLoc [27] (SuperPoint [9] as the feature extractor and SuperGlue [28] as the matcher) to obtain the camera poses individually for each video, and then combine the two videos for a joint camera pose estimation to obtain the ground-truth transformation between the two GS models. To evaluate the performance of GaussReg on objects, we also conduct tests on the Objaverse dataset [8] used in DReg-NeRF [6], whose test set contains 44 objects.
Metric
We refer to metrics of point cloud registration as in [26] and modify them to account for scale factors. Finally, we evaluate GaussReg on the ScanNet-GSReg and GSReg datasets with three metrics: 1) Relative Rotational Error (RRE), the geodesic distance between the estimated and ground-truth rotation matrix; 2) Relative Translation Error (RTE), the ratio of the Euclidean distance between the estimated and ground-truth translation vectors to the norm of the ground-truth translation vector; 3) Relative Scale Error (RSE), the ratio of the Euclidean distance between the estimated and ground-truth scale factors to the ground-truth scale factor. For a fair comparison, we follow DReg-NeRF [6] to evaluate GaussReg on the Objaverse dataset with two metrics: 1) Relative Rotational Error (RRE); 2) Absolute Translational Error (ATE), the Euclidean distance between the estimated and ground-truth translation vectors.
Implementation Details
Our GaussReg is merely trained on the ScanNet-GSReg training set and evaluated on the ScanNet-GSReg test set, Objaverse test set, and GSReg dataset. Our method was implemented with PyTorch [25]. In the coarse registration network, we limit the number of input points to during training. In the image-guided fine registration network, we render images per GS model as input and set the number of depth hypotheses to . Both networks are trained separately for epochs with a batch size of . The learning rate starts from and decays exponentially by every epoch.
| Methods | RRE | ATE |
|---|---|---|
| FGR [44] | 61.59 | 13.50 |
| REGTR [38] | 113.78 | 43.31 |
| Dreg-NeRF [6] | 9.67 | 3.85 |
| Ours w/o. fine | 2.47 | 3.46 |
| Methods | RRE | RTE | RSE |
|---|---|---|---|
| Ours w/o. fine | 6.904 | 0.074 | 0.051 |
| Ours | 2.989 | 0.065 | 0.047 |
4.2 Comparison with Other Methods
Evaluation on the ScanNet-GSReg Dataset
Due to the maturity of Structure from Motion (SFM) technology, a natural approach for 3D registration with GS is to render a large number of images and utilize SFM for joint registration. Therefore, we select the current SOTA method, HLoc [27] (SuperPoint [9] + SuperGlue [28]), as the baseline for comparison on ScanNet. In the subsequent discussion, we refer to HLoc [27] (SuperPoint [9] + SuperGlue [28]) as HLoc for brevity. For the two GS models to be registered, we uniformly sample training poses each to render images, and use images in total for HLoc to estimate pose. We can obtain the registration result of the two GS models following the procedure described in NeRFuser [10]. We also evaluate traditional point cloud registration method Fast Global Registration (FGR) [44] and deep point cloud registration method REGTR [38] (retrained on 3DMatch) by inputting the point cloud from GS. FGR and REGTR are also followed by the ICP solver with scaling to output the transformation results, and we also limit the number of input points to . The quantitative results are shown in Table 1, where the Success Ratio indicates the portion of successful registrations. As shown in Table 1, for scenes in ScanNet-GSReg, HLoc only registers of them successfully, while our method achieves a success ratio. For indoor scenes in ScanNet-GSReg, SuperPoint [9] sometimes fails to extract effective keypoints, leading to registration failures. Our method outperforms HLoc in RTE and RSE metrics and is comparable in RRE. Notably, our method was significantly faster than HLoc ( vs. ). FGR and REGTR are slightly faster than our GaussReg, however, they perform much worse than ours. We think the reason is that the point cloud from GS is much noisier than scanning data. Visualizations of our method on the ScanNet-GSReg test set are presented in the first two rows of Figure 4. More visual results can be found in Supplementary Material. These experiments fully demonstrate the efficiency and accuracy of our method.
Evaluation on the Objaverse Dataset
For a fair comparison on the Objaverse dataset [8] used in DReg-NeRF, we assume there is no scale difference between the two GS models as in DReg-NeRF [6]. In addition, we do not adopt training poses, and only use our proposed coarse registration for comparison. As shown in Table 3, our coarse registration method (ours w/o. fine) significantly outperforms other methods without fine-tuning, demonstrating its strong generalization capability to objects.
Evaluation on the GSReg Dataset
The ground-truth registration results of our GSReg dataset are obtained when HLoc was successful. As shown in Table 3, our method achieves registration results close to HLoc without fine-tuning, proving the strong generalizability of our approach. Moreover, our method (ours) significantly outperforms our coarse registration (ours w./o. fine), proving the effectiveness of our fine registration. Visualizations of our method on the GSReg dataset are presented in the last two rows of Figure 4.
| Index | Methods | RRE | RTE | RSE | Succss Ratio | Time(s) |
|---|---|---|---|---|---|---|
| 1 | Hloc [27] | 2.725 | 0.099 | 0.098 | 0.756 | 212.3 |
| 2 | Ours w./o. fine | 3.403 | 0.061 | 0.034 | 1.000 | 3.7 |
| 3 | Ours w./o. fine + HLoc | 1.104 | 0.186 | 0.278 | 0.512 | 206.8 |
| 4 | Ours | 2.827 | 0.042 | 0.032 | 1.000 | 4.8 |
4.3 Ablation Study
To deeply analyze GaussReg, we conduct detailed ablation studies on the ScanNet-GSReg dataset to evaluate the effectiveness of the proposed components.
Effectiveness of Image-Guided Fine Registration
HLoc can also utilize image information to refine the coarse registration. Therefore, to validate the effectiveness of image-guided fine registration, we directly combine coarse registration with HLoc. After obtaining the coarse registration result, we use overlap image selection to select two sets of multi-view images, and , and jointly use and for pose estimation with HLoc. As shown in Table 4, by comparing Index-2 with Index-4, we can see that the performance is improved, which demonstrates the effectiveness of our image-guided fine registration. Comparing Index-2 and Index-3, we find that although HLoc shows lower RRE, its success ratio is very low (), whereas our fine registration not only outperforms HLoc in RTE and RSE metrics but also has a higher success ratio (). Meanwhile, our fine registration is faster than HLoc ( vs. ). In addition, we explore the effect of the top-k pairs of cameras we kept in overlap image selection. Hence, we vary k from 5 to 30. In Table 6, there is almost no change in performance when k is larger than 10 and the performance drops when k is smaller than 10. For the sake of accuracy and efficiency, we believe that 10 is enough for k.
| Top-k | RRE | RTE | RSE |
|---|---|---|---|
| 5 | 3.677 | 0.115 | 0.079 |
| 10 | 2.827 | 0.042 | 0.032 |
| 20 | 2.604 | 0.063 | 0.044 |
| 30 | 2.311 | 0.091 | 0.028 |
| Index | Method | RRE | RTE | RSE | RDE |
|---|---|---|---|---|---|
| 5 | Ours w/o. I3D | 3.169 | 0.036 | 0.061 | 0.066 |
| 6 | Ours | 2.827 | 0.042 | 0.032 | 0.080 |
Effectiveness of Image-Guided 3D Feature Extraction
Here, we also report the Relative Depth Error (RDE), which is the ratio of the Euclidean distance between the estimated and ground-truth depth to the ground-truth depth. As shown in Table 6, in Index-5, we remove the image-guided 3D (I3D) feature extraction. Instead, we use MVSNet [12] to calculate depth and project depth maps to obtain two point clouds, which serve as input to KPConv-FPN [33] to extract features for registration refinement. Comparing Index-5 and Index-6, we observe that although Index-5 has better depth estimation accuracy, the registration results are poor, proving that extracting geometric information from images complements feature descriptors extraction.
4.4 Results of Gaussian Splatting Fusion and Filtering
In Figure 5, we present some quantitative results on GSReg dataset to demonstrate the effectiveness of our GS fusion and filtering. Please refer to the video attachment in Supplementary Material for the dynamic presentation. Our GS fusion and filtering strategy successfully merges the two GS models.
5 Discussion

Limitations and Future Work
We only adopt a simple strategy to fuse and filter two GS models. For some more complex situations, the fusion in our way is imperfect. For instance, when two scenes are captured at different times, changes in lighting can result in differing appearances for two scenes. Consequently, the fused GS model obtained through our strategy may exhibit inconsistencies at the fusion boundary. Future work can further explore to address this issue.
Conclusion
The advent of Neural Radiance Fields (NeRF) has transformed the landscape of 3D scene representation, necessitating advancements in registration methodologies. However, the registration of NeRF representations for large-scale scenes remains underexplored due to the inherent complexities of implicitly modeled geometric relationships. The recent introduction of Gaussian Splatting (GS) has significantly enhanced NeRF by introducing explicit 3D gaussians, facilitating rapid rendering while maintaining high quality. In this study, we introduce GaussReg, a pioneering coarse-to-fine framework that utilizes GS for 3D registration with GS. The coarse phase leverages existing point cloud registration methods to establish a preliminary alignment for input GS point clouds. We innovatively devise an image-guided fine registration strategy that incorporates rendered images from these Gaussian points, enriching geometric details for accurate alignment. To comprehensively evaluate our approach, we construct a benchmark consisting of scenes from ScanNet and several in-the-wild scenes. Our experimental results show GaussReg’s state-of-the-art performance across multiple datasets.
References
- [1] Bai, X., Luo, Z., Zhou, L., Fu, H., Quan, L., Tai, C.L.: D3feat: Joint learning of dense detection and description of 3d local features. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
- [2] Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srinivasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 5835–5844 (2021). https://doi.org/10.1109/ICCV48922.2021.00580
- [3] Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5460–5469 (2022). https://doi.org/10.1109/CVPR52688.2022.00539
- [4] Besl, P., McKay, N.D.: A method for registration of 3-d shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence 14(2), 239–256 (1992). https://doi.org/10.1109/34.121791
- [5] Chen, A., Xu, Z., Geiger, A., Yu, J., Su, H.: Tensorf: Tensorial radiance fields. In: European Conference on Computer Vision (ECCV) (2022)
- [6] Chen, Y., Lee, G.H.: Dreg-nerf: Deep registration for neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22703–22713 (October 2023)
- [7] Dai, A., Nießner, M., Zollöfer, M., Izadi, S., Theobalt, C.: Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface re-integration. ACM Transactions on Graphics 2017 (TOG) (2017)
- [8] Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., VanderBilt, E., Kembhavi, A., Vondrick, C., Gkioxari, G., Ehsani, K., Schmidt, L., Farhadi, A.: Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663 (2023)
- [9] DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (June 2018)
- [10] Fang, J., Lin, S., Vasiljevic, I., Guizilini, V., Ambrus, R., Gaidon, A., Shakhnarovich, G., Walter, M.R.: Nerfuser: Large-scale scene representation by nerf fusion (2023)
- [11] Furukawa, Y., Ponce, J.: Accurate, dense, and robust multiview stereopsis. IEEE Transactions on Pattern Analysis and Machine Intelligence 32(8), 1362–1376 (2010). https://doi.org/10.1109/TPAMI.2009.161
- [12] Goesele, M., Curless, B., Seitz, S.: Multi-view stereo revisited. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06). vol. 2, pp. 2402–2409 (2006). https://doi.org/10.1109/CVPR.2006.199
- [13] Gojcic, Z., Zhou, C., Wegner, J.D., Andreas, W.: The perfect match: 3d point cloud matching with smoothed densities. In: International conference on computer vision and pattern recognition (CVPR) (2019)
- [14] Goli, L., Rebain, D., Sabour, S., Garg, A., Tagliasacchi, A.: nerf2nerf: Pairwise registration of neural radiance fields. In: International Conference on Robotics and Automation (ICRA). IEEE (2023)
- [15] Hernández Esteban, C., Schmitt, F.: Silhouette and stereo fusion for 3d object modeling. Computer Vision and Image Understanding 96(3), 367–392 (Dec 2004). https://doi.org/10.1016/j.cviu.2004.03.016, http://dx.doi.org/10.1016/j.cviu.2004.03.016
- [16] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42(4) (July 2023), https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
- [17] Li, J., Hu, Q., Ai, M.: Point cloud registration based on one-point ransac and scale-annealing biweight estimation. IEEE Transactions on Geoscience and Remote Sensing 59(11), 9716–9729 (2021). https://doi.org/10.1109/TGRS.2020.3045456
- [18] Mellado, N., Dellepiane, M., Scopigno, R.: Relative scale estimation and 3d registration of multi-modal geometry using growing least squares. IEEE Transactions on Visualization and Computer Graphics 22(9), 2160–2173 (2016). https://doi.org/10.1109/TVCG.2015.2505287
- [19] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
- [20] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 41(4), 102:1–102:15 (Jul 2022). https://doi.org/10.1145/3528223.3530127, https://doi.org/10.1145/3528223.3530127
- [21] Myronenko, A., Song, X.: Point set registration: Coherent point drift. IEEE Transactions on Pattern Analysis and Machine Intelligence 32(12), 2262–2275 (2010). https://doi.org/10.1109/TPAMI.2010.46
- [22] Pais, G.D., Ramalingam, S., Govindu, V.M., Nascimento, J.C., Chellappa, R., Miraldo, P.: 3dregnet: A deep neural network for 3d point registration. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7191–7201 (2020). https://doi.org/10.1109/CVPR42600.2020.00722
- [23] Pan, Y., Yang, B., Liang, F., Dong, Z.: Iterative global similarity points: A robust coarse-to-fine integration solution for pairwise 3d point cloud registration. In: 2018 International Conference on 3D Vision (3DV). pp. 180–189 (2018). https://doi.org/10.1109/3DV.2018.00030
- [24] Paris, S., Sillion, F.X., Quan, L.: A surface reconstruction method using global graph cut optimization. International Journal of Computer Vision 66(2), 141–161 (Feb 2006). https://doi.org/10.1007/s11263-005-3953-x, https://doi.org/10.1007/s11263-005-3953-x
- [25] Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., Lerer, A.: Automatic differentiation in pytorch (2017)
- [26] Qin, Z., Yu, H., Wang, C., Guo, Y., Peng, Y., Xu, K.: Geometric transformer for fast and robust point cloud registration. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11133–11142 (2022). https://doi.org/10.1109/CVPR52688.2022.01086
- [27] Sarlin, P.E., Cadena, C., Siegwart, R., Dymczyk, M.: From coarse to fine: Robust hierarchical localization at large scale. In: CVPR (2019)
- [28] Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: SuperGlue: Learning feature matching with graph neural networks. In: CVPR (2020), https://arxiv.org/abs/1911.11763
- [29] Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4104–4113 (2016). https://doi.org/10.1109/CVPR.2016.445
- [30] Slabaugh, G., Schafer, R., Malzbender, T., Culbertson, B.: A survey of methods for volumetric scene reconstruction from photographs. In: Mueller, K., Kaufman, A.E. (eds.) Volume Graphics 2001. pp. 81–100. Springer Vienna, Vienna (2001)
- [31] Strecha, C., Fransens, R., Van Gool, L.: Combined depth and outlier estimation in multi-view stereo. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06). vol. 2, pp. 2394–2401 (2006). https://doi.org/10.1109/CVPR.2006.78
- [32] Sun, C., Sun, M., Chen, H.T.: Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5459–5469 (June 2022)
- [33] Thomas, H., Qi, C.R., Deschaud, J.E., Marcotegui, B., Goulette, F., Guibas, L.J.: Kpconv: Flexible and deformable convolution for point clouds. Proceedings of the IEEE International Conference on Computer Vision (2019)
- [34] Wang, P., Liu, Y., Chen, Z., Liu, L., Liu, Z., Komura, T., Theobalt, C., Wang, W.: F2-nerf: Fast neural radiance field training with free camera trajectories. CVPR (2023)
- [35] Wang, Y., Solomon, J.M.: Deep closest point: Learning representations for point cloud registration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
- [36] Wu, X., Dai, P., DENG, W., Chen, H., Wu, Y., Cao, Y.P., Shan, Y., QI, X.: CL-neRF: Continual learning of neural radiance fields for evolving scene representation. In: Thirty-seventh Conference on Neural Information Processing Systems (2023), https://openreview.net/forum?id=uZjpSBTPik
- [37] Yao, Y., Luo, Z., Li, S., Fang, T., Quan, L.: Mvsnet: Depth inference for unstructured multi-view stereo. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. pp. 785–801. Springer International Publishing, Cham (2018)
- [38] Yew, Z.J., Lee, G.H.: Regtr: End-to-end point cloud correspondences with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6677–6686 (June 2022)
- [39] Zaharescu, A., Boyer, E., Horaud, R.: Transformesh : A topology-adaptive mesh-based approach to surface evolution. In: Yagi, Y., Kang, S.B., Kweon, I.S., Zha, H. (eds.) Computer Vision – ACCV 2007. pp. 166–175. Springer Berlin Heidelberg, Berlin, Heidelberg (2007)
- [40] Zang, Y., Lindenbergh, R., Yang, B., Guan, H.: Density-adaptive and geometry-aware registration of tls point clouds based on coherent point drift. IEEE Geoscience and Remote Sensing Letters 17(9), 1628–1632 (2020). https://doi.org/10.1109/LGRS.2019.2950128
- [41] Zeng, A., Song, S., Nießner, M., Fisher, M., Xiao, J., Funkhouser, T.: 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In: CVPR (2017)
- [42] Zhang, J., Yao, Y., Deng, B.: Fast and robust iterative closest point. IEEE Transactions on Pattern Analysis and Machine Intelligence 44(7), 3450–3466 (2022). https://doi.org/10.1109/TPAMI.2021.3054619
- [43] Zhang, X., Yang, J., Zhang, S., Zhang, Y.: 3d registration with maximal cliques. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17745–17754 (2023)
- [44] Zhou, Q.Y., Park, J., Koltun, V.: Fast global registration. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision – ECCV 2016. pp. 766–782. Springer International Publishing, Cham (2016)