Learning with Instance-Dependent Noisy Labels by Anchor Hallucination and Hard Sample Label Correction
Abstract
Learning from noisy-labeled data is crucial for real-world applications. Traditional Noisy-Label Learning (NLL) methods categorize training data into clean and noisy sets based on the loss distribution of training samples. However, they often neglect that clean samples, especially those with intricate visual patterns, may also yield substantial losses. This oversight is particularly significant in datasets with Instance-Dependent Noise (IDN), where mislabeling probabilities correlate with visual appearance. Our approach explicitly distinguishes between clean vs. noisy and easy vs. hard samples. We identify training samples with small losses, assuming they have simple patterns and correct labels. Utilizing these easy samples, we hallucinate multiple anchors to select hard samples for label correction. Corrected hard samples, along with the easy samples, are used as labeled data in subsequent semi-supervised training. Experiments on synthetic and real-world IDN datasets demonstrate the superior performance of our method over other state-of-the-art NLL methods.
Index Terms— Noisy-label learning, instance-dependent noise, anchor hallucination, semi-supervised learning
1 Introduction
The success of Deep Neural Networks (DNNs) heavily relies on extensively annotated datasets. However, data annotation is often costly and inevitably comes with label noise [1, 2]. The correction of label errors and the exploration of robust representations have become focal points in recent research [3]. In this paper, we consider practical real-world scenarios of training an image classification model from a dataset with noisy labels [2], where the probability of mislabeling each image is contingent on its visual appearance, characterized as Instance-Dependent Noise (IDN).
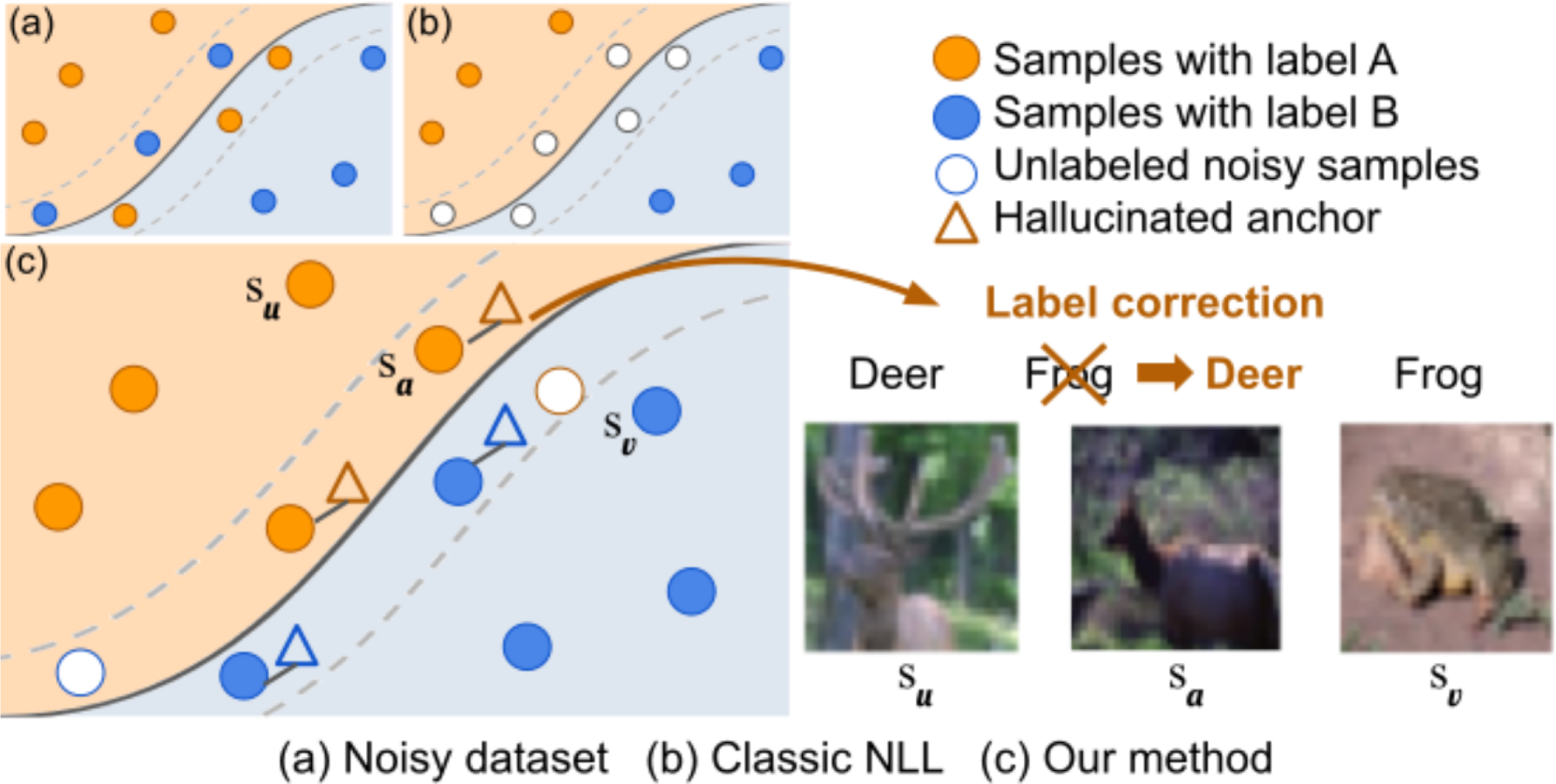
Traditional Noisy-Label Learning (NLL) methods primarily rely on sample selection [4, 5]. These methods identify correctly-labeled (i.e., clean) samples in the training set by employing the small-loss criterion during an initial training. Samples with small classification loss are assumed to have correct labels, and samples with large loss have potentially incorrect labels. However, there is a major drawback to this approach. DNNs are known to prioritize learning simple patterns over complex ones [6]. Consequently, the initially identified small-loss samples may only represent a subset of clean samples with simple visual patterns. Conversely, labels of samples with large classification losses are not necessarily always noisy; they may have clean labels that are hard to learn due to their complex visual patterns. For example, in CIFAR-10 [7], airplanes are typically in the sky, and ships are usually on the water; but a few airplane samples also appear on the water that are harder to classify. We argue that these hard samples with clean labels are important to characterize the decision boundary for effective model learning. Simply discarding their potentially noisy labels, as common in typical NLL methods, results in performance degradation [8].
To address this challenge, our approach distinguishes easy from hard samples, in addition to differentiating between samples with clean vs. noisy labels. Fig. 1 illustrates our method, starting with easy samples to identify and correct labels of hard samples. Initially, we use the standard small-loss criterion to partition the training set into class-balanced easy and hard samples. To identify hard samples for label correction, we introduce a novel anchor hallucination technique that synthesizes feature vectors in the feature space. These hallucinated features, called anchors, are generated from easy samples to simulate hard samples that are with complex visual compositions. Anchors are then used to select hard samples from the original training set in the nearby feature space, see Fig. 1(c). Since anchors are synthesized with pre-known labels, they are used to correct the labels of the selected hard samples via majority voting. Lastly, the label-corrected hard samples together with the initial easy samples constitute the labeled data, while the remaining samples are used as unlabeled data in a semi-supervised model training. This effectively enhances the data and label utilization.
Contributions of this paper are summarized as follows:
-
•
We focus on the Noisy-Label Learning (NLL) problem, in particular data with Instance-Dependent Noise (IDN). We advocate for differentiating easy and hard training samples, while also distinguishing their clean vs. noisy labels. This design address the sample selection dilemma in NLL.
-
•
We introduce an anchor hallucination technique by synthesizing feature vectors for selecting hard samples and performing label correction for them. Followed by a semi-supervised model training to maximize data and label utilization.
-
•
Extensive experiments are conducted on synthetic IDN datasets derived from CIFAR-10 [7], as well as real-world CIFAR-10N/100N [2] and Clothing1M [1] datasets. The results demonstrate the superiority of our method over the State-of-The-Art (SoTA) NLL methods, including DivideMix [4] and TSCSI [9].
2 Related works
Noisy-Label Learning (NLL). In NLL literature, Instance-Independent Noise (IIN) stands out as the most prevalent type of label noise. IIN is characterized by the probability of an image being mislabeled, which depends solely on the involved class pair, regardless of its visual content. Notable examples of IIN include symmetric and asymmetric noise patterns proposed in [10], which have gained widespread adoption in related fields. Various NLL approaches are developed based on this noise assumption, encompassing the design of noise-robust loss functions [11], loss correction [12], label correction [13], and sample selection [4].
Recent prominent studies regarding IIN combine sample selection with Semi-Supervised Learning (SSL), yielding notable progress [4, 5]. The majority of methods resort to the small-loss criterion and consider samples with small training loss as clean. Subsequently, an off-the-shelf SSL algorithm, such as [14], is applied, treating the selected samples as labeled data and the remainder as unlabeled. However, these approaches often overfit to a small training subset of easy samples chosen based on the small-loss criterion [8]. This limitation hampers their ability to fully exploit critical labeling information contained in hard samples near the decision boundary. Despite their success on various IIN benchmarks, performance under the IDN assumption remains unclear.
Learning from Instance-Dependent Noise (IDN) Data. In contrast to the naive assumption of IIN, recent works [8, 15, 16, 2, 17, 18, 9] contend that real-world noise patterns are more likely to depend on visual content, prompting a shift towards addressing IDN. Some methods combat IDN by estimating the noise transition matrix [18, 19], requiring additional information and achieving mediocre performance on real-world data. Others adopt a selection-based method combined with SSL, similar to previous works for IIN [9], and have reached SoTA results on several IDN benchmarks. However, the effective utilization of valuable hard samples with potentially noisy labels remain an unsolved challenge. Our work aligns with this research line, focusing on leveraging robust information from the easy samples to: (1) identify hard samples with noisy labels, and (2) perform label correction.
3 The proposed method
This paper addresses the noisy label learning of image classification for data with Instance-Dependent Noise (IDN). We work with a noisy training set , where denotes the -th image, and is the corresponding label for classes. The given label may differ from the real ground truth label , which remains unobservable during training. The goal is to train an image classification model on that performs well on a clean test set.
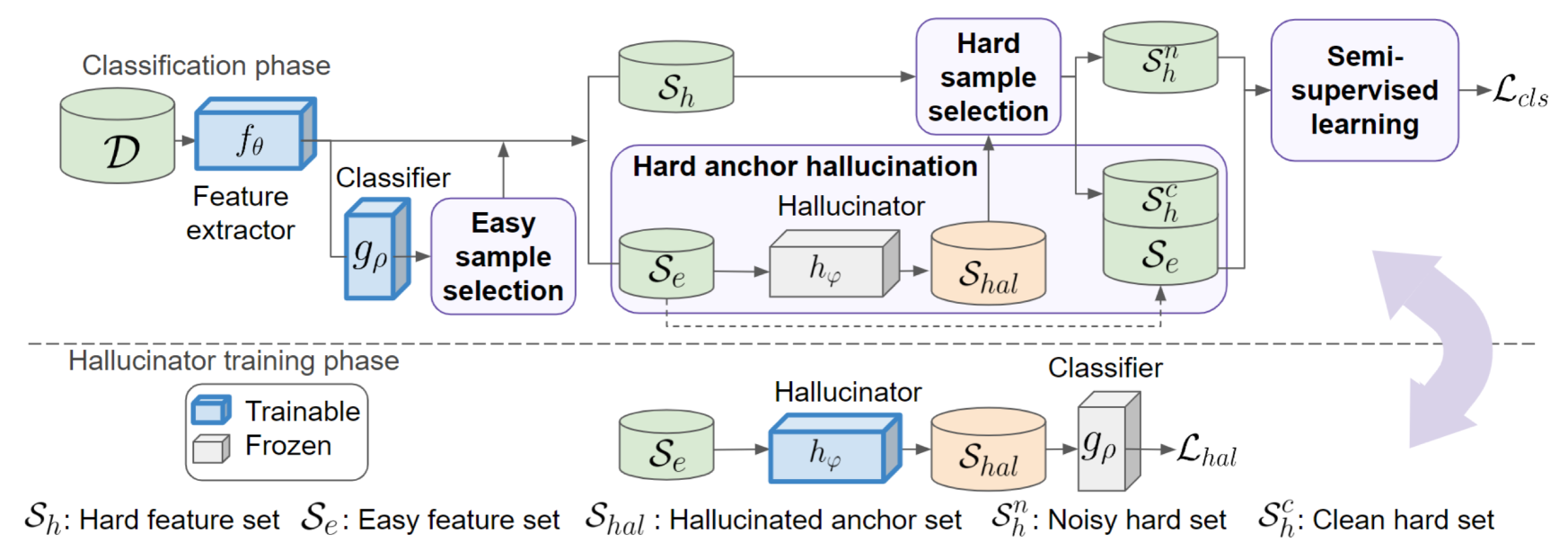
Our approach operates by distinguishing between easy and hard training samples, using the cleanly-labeled easy samples to identify hard samples for label correction. This process is achieved through anchor hallucination, where features are synthesized from the easy samples to create anchors. These anchors are then employed to select hard samples via majority voting for label correction. Overall, our model is structured with a classification module, comprising a feature extractor and a linear classifier , along with an anchor hallucinator .
Our training framework comprises two iterative phases, as in Fig. 2. First, in the classification phase, we keep fixed and optimize and via semi-supervised training ( 3.4) using clean-labeled easy sample and label-corrected hard samples. The pipeline comprises three steps: easy sample selection ( 3.1), hard anchor hallucination ( 3.2), and hard sample selection ( 3.3). Secondly, in the hallucinator training phase, and remain fixed, and only undergoes updates based on a hallucination loss outlined in 3.2. Further details regarding the steps and losses are elaborated in the subsequent sections.
3.1 Easy sample selection
Our method starts with selecting easy samples using small-loss criterion [4]. Drawing on the insight that DNNs tend to learn simple patterns faster than complex ones [6], we identify easy samples by analyzing the distribution of classification losses during initial training. Specifically, we compute the cross-entropy loss for each sample and fit the loss distribution across all training samples using a two-component Gaussian Mixture Model (GMM), which provides greater flexibility in capturing sharpness of the fitted distribution [4]. The Gaussian component with the smaller mean represents the distribution of smaller losses. The probability of each sample belonging to this Gaussian component is then calculated as the easiness score for that sample.
Subsequently, we select a fixed fraction of samples with the top- easiness scores to form the set of easy training samples. The hyperparameter defaults to 60 and is fine-tuned using a small clean validation set. To maintain balance across all classes, we ensure a sufficient number of easy samples for each class. Let denote the total number of samples of the -th class in the training set . We control the number of easy samples for the -th class to be:
| (1) |
We thus obtain class-balanced easy training samples with assumed clean labels. The remaining samples with potentially noisy labels are regarded as hard samples. We next utilize the feature extractor to embed both easy and hard samples into a -dimensional feature space, resulting in the easy feature set and hard feature set , which will be used for anchor hallucination, hard sample selection and label correction.
3.2 Hard anchor hallucination
The easy feature set comprises feature vectors of training samples with simple visual patterns and clean labels. By combining features from , we can form complex visual patterns, which form the basis for hard anchor hallucination. Through feature concatenation and generating a substantial number of feature anchors spanning the feature space, we can employ majority voting of nearby anchors to search for the most matching feature vectors in the hard feature set .
Anchors are hallucinated by aggregating features of easy samples in an automatic, data-driven process. Specifically, for each from class , we randomly select another feature from a different class (where ) for mixing. Subsequently, we concatenate and , and feed it to the hallucinator to produce a hallucinated anchor, . To ensure that is transformed into a hard anchor of the desired class, we formulate the hallucination loss according to the following two designs.
First, to encourage the hallucinated anchor represents a hard instance, we optimize the hallucinator by regularizing the similarities between and both and . Specifically, we define a similarity loss based on the cosine distances between features as , where is a hyperparameter controlling the difficulty level of , and computes the cosine similarity between its arguments. By minimizing , the hallucinated anchor will be encouraged to reside in the area between and in the feature space, and thus share visual patterns from both classes and .
Second, to ensure hallucinated anchor belongs to a known, desired class, we follow the work of [20] and define a classification loss using its target label . The overall hallucination loss is calculated as:
| (2) |
where computes the cross-entropy loss. Minimizing Eq. (2) prompts the hallucinator to generate an anchor with complex visual patterns positioned near the decision boundary between classes and , while remaining on the side closer to . Multiple hallucinated anchors can be produced from a single feature by sampling different . The set of hallucinated anchors is denoted as .
3.3 Hard sample selection
The hallucinated anchors extend throughout the feature space, with varying degrees of representative qualities. Computationally, a hallucinated anchor is considered representative of a real hard feature sample , if they are sufficiently close in the feature space. We measure this proximity between and using cosine similarity . To filter out the representative , we identify the nearest hard feature sample of a hallucinated anchor , denoted as . The anchor is considered a valid representative of , if exceeds a threshold . The hyperparameter can be tuned based on a small validation set with clean labels. These valid representatives disperse near the hard feature samples and can be used to match them. For each , we collect up to of its surrounding valid representatives. These valid representatives are leveraged to determine the correct label of by majority voting.
By identifying hard samples with corrected labels in this manner, the classification module ( and ) is trained on more valuable labeling information contained in the hard samples, leading to improved performance.
3.4 Semi-supervised learning
The set of hard samples with corrected labels, denoted , is combined with the easy feature set to form the labeled dataset for model training, while the remaining noisy hard features, denoted as , constitute the unlabeled dataset for semi-supervised learning (SSL).
We adopt the classic SSL method MixMatch [14] to augment samples from and . We obtain pseudo labels for samples in from the average of model predictions across its two augmented copies. Similarly, we refine the labels of samples in by using a linear combination of their given labels in and the average of model predictions across the two augmented images. The weight assigned to the given label is determined by the easiness score from 3.1.
After obtaining the refined pseudo labels, we then perform SSL using the combined classification loss:
| (3) |
where is the cross-entropy loss for the labeled data, is the mean squared error for the unlabeled data, and is a hyperparameter set through validation. By minimizing Eq. (3), the resulting image classifier comprising feature extractor and linear classifier would become more robust, as it incorporates information from critical hard samples with clean labels during training.
3.5 Iterative model training
To prevent the hallucinator from degeneration, i.e., always producing identical hallucinated anchors regardless of the input pair , we adopt an iterative training procedure, as illustrated in Fig. 2. After a few epochs of warm-up training, we start the iterative training stage, which consists of two training phases. In the classification phase, we freeze the hallucinator and train the feature extractor and the linear classifier jointly using the corrected labeled and unlabeled training sets ( and ) in 3.4 by minimizing Eq. (3). In the hallucinator training phase, we freeze and and train by minimizing Eq. (2). The two phases are performed iteratively until sufficient epochs are reached.
4 Experiments
4.1 Datasets and IDN noise generation
We follow previous NLL works on learning from datasets with IDN labels [15, 8, 17, 9] to conduct the experiments on both synthetic and real-world IDN datasets.
Synthetic IDN datasets. We conduct experiments on synthetic IDN datasets created from the CIFAR-10 dataset [7], which contains 50,000 training images and 10,000 test images from 10 cleanly annotated classes. We considered two approaches in generating IDN noises: 1) part-dependent label noise (PTD) [15], which is generated according to a combination of multiple noise transition matrices of different parts of an image; 2) classification-based label noise [8], which is generated by averaging the collected softmax outputs during training using a standard CNN trained on all the training data for multiple epochs.
Real-world IDN datasets. To evaluate the effectiveness of our method on real-world IDN datasets, we conducted experiments using the CIFAR-10N/100N [2] and the real-world Clothing1M [1] datasets. CIFAR-10N/100N were generated from CIFAR-10/100 by collecting labels from three human annotations for each training image through Amazon Mechanical Turk. The three noisy labels for each image are denoted as Random 1/2/3, and are further aggregated by majority vote (denoted as Aggregate) and by random selection of one wrong label if there is any (denoted as Worst). The Clothing1M dataset contains over 1 million training images of 14 different types of clothing collected online, with labels extracted from the surrounding text of images. We use the 14K clean validation set for hyperparameter tuning and the 10K clean test set to evaluate the model performance. These IDN datasets present real-world scenarios with various noise sources and thus provide a suitable testbed for comparing our method with the SoTA methods.
4.2 Baselines and implementation details
We compare our framework with recent SoTA NLL works, including those focusing on IIN datasets such as DivideMix [4], and those focusing on IDN datasets such as TSCSI [9]. It is worth noting that both DivideMix and TSCSI employ two networks in a co-training fashion for model ensemble thus incurring higher computational costs, whereas our framework only trains a single network in most of our experiment settings except on Clothing1M. For CIFAR-10 with IDN and the CIFAR-10N/100N datasets, we follow previous works [2, 9] and adopt ResNet-34 network as our classification module, and a two-layer Multi-Layer Perceptron (MLP) as our hallucinator . We evaluate our method on a clean testing set and report the best testing accuracy on average over three runs. As for Clothing1M, we adopt an ImageNet-pretrained ResNet-50 network as per the prior works [4, 9] while also implementing as a two-layer MLP. We also adopt the same procedures as those used in DivideMix to select easy samples(GMM-based selection without class balancing) for better comparison. During training, we use the 14K clean validation set to choose the best model, which is applied to the 10K clean test to get the test accuracy. More implementation details are available in the supplementary materials.
4.3 Quantitative results
Results on PTD label noise. Table 1 shows experimental results on the CIFAR-10 datasets with PTD noise [15]. Our proposed method achieves significant performance improvement compared to prior state-of-the-art methods under both 20% and 40% noise ratios. Our model also shows robustness against the increasing noise rate under PTD.
Method PTD 20% PTD 40% Forward T [10] 87.221.60 79.372.72 Co-teaching [21] 88.870.24 73.001.24 Co-teaching+ [22] 89.800.28 73.781.39 JoCoR [23] 88.780.15 71.643.09 DivideMix [4] 93.330.14 95.070.11 CAL [17] 92.010.75 84.961.25 TSCSI [9] 93.680.12 94.970.09 Ours 94.260.19 95.280.10
Method 10% 20% 40% CE (Standard) 91.250.27 86.340.11 75.680.29 Forward [10] 91.060.02 86.350.11 71.120.47 Co-teaching [21] 91.220.25 87.280.20 78.820.47 DAC [24] 90.940.09 86.160.13 74.800.32 SEAL [8] 91.320.14 87.790.09 82.980.05 TSCSI [9] 91.390.08 88.360.11 84.180.40 Ours 93.680.47 92.980.11 92.470.41
CIFAR-10N CIFAR-100N Method Random1 Random2 Random3 Worst Noisy CE (Standard) 85.020.65 86.461.79 85.160.61 77.691.55 55.500.66 Forward T [10] 86.880.50 86.140.24 87.040.35 79.790.46 57.011.03 Co-teaching+ [22] 89.700.27 89.470.18 89.540.22 83.260.17 57.880.24 DivideMix [4] 95.160.19 95.230.07 95.210.14 92.560.42 71.130.48 Negative-LS [25] 90.290.32 90.370.12 90.130.19 82.990.36 58.590.98 VolMinNet [26] 88.300.12 88.270.09 88.190.41 80.530.20 57.800.31 CAL [17] 90.930.31 90.750.30 90.740.24 85.360.16 61.730.42 PES [27] 95.060.15 95.190.23 95.220.13 92.680.22 70.360.33 Ours 95.210.05 95.310.10 95.250.17 93.520.49 70.790.06
Results on classification-based label noise. Table 2 provides performance comparisons on CIFAR-10 with classification-based label noise [8] under different noise levels. The classification-based label noise is considered challenging due to its originating from a classification model [9]. Our method consistently demonstrates significantly superior performance compared to previous methods across all noise levels. Our method exhibits remarkable resistance to higher levels of label noise (40%) on classification-based label noise, while other methods suffer substantial performance degradation.
Method Co-teaching JoCoR DivideMix CAL TSCSI Ours [21] [23] [4] [17] [9] Accuracy 69.21 70.30 74.400.08 74.17 75.40 74.620.14
Easy sample sel. Hard sample corr. Test accuracy - - 86.240.90 - 89.771.45 92.470.41
Results on CIFAR-N. Table 3 shows performance comparisons on the CIFAR-10N/CIFAR-100N datasets [2]. Our method consistently outperforms other methods on CIFAR-10N with all the noise settings of Random 1, Random 2, Random 3, and Worst. Notably, our method achieves comparable performance against DivideMix [4] on CIFAR-100N while only trained a single network. This demonstrates the efficacy of our method in learning from real-world IDN datasets.
Results on Clothing1M. Table 4 shows performance comparisons on the Clothing1M dataset. Our method achieves competitive results compared with TSCSI and is superior to DivideMix and other methods. Since our method adopts similar strategies with DivideMix in easy sample selection ( 3.1), the superior performance compared to DivideMix indicates the effectiveness of our hallucination-based hard sample selection ( 3.2 and 3.3) in learning from such a large-scale IDN dataset.
Ablation study. To evaluate the effectiveness of each design component, we conducted an ablation analysis of our proposed framework on the CIFAR-10 dataset with 40% classification-based IDN. We compared the performance of three different settings: (1) vanilla GMM selection-based method, which is essentially DivideMix [4] without co-training and model ensemble, (2) our method with only the easy sample selection stage as described in 3.1, and (3) our method with both stages of easy sample selection and hard sample correction in 3.3. Table 5 presents the comparison results. As can be seen from the table, the design of each of the two stages contributes to the performance improvement of our framework. Notably, the easy sample selection stage contributed the most to the performance boost, indicating the importance of obtaining a class-balanced easy subset for effective model training. The second stage of hard sample selection further improved the performance to the SoTA level of . This validates and confirms our proposal that information contained in hard samples is valuable for the model to learn a robust representation.
4.4 Visualization of Hard Anchor Hallucination
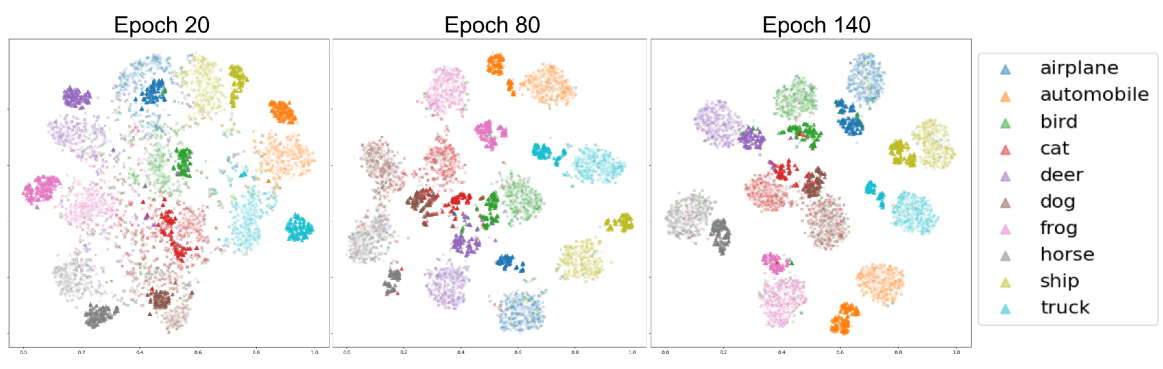
To demonstrate the effectiveness of our method, Fig. 3 presents the t-SNE visualization of our hallucination on the CIFAR-10 dataset with 40% classification-based label noise in various training epochs. For simplicity, we limit the display to 25 hallucinated and 500 real samples for each class randomly sampled from . The colors of darker hues indicate the hallucinated anchors with pseudo-labels that match the corresponding lighter shades. Observe that the features of hallucinated anchors for each class align with the corresponding cluster of real features. This demonstrates that our hallucinated anchors can effectively mimic the desired hard samples with appropriate pseudo-labels, which can facilitate the subsequent hard sample selection for improved decision boundary training. We provide additional visualization on the hard anchors in the supplementary materials.
5 Conclusions
In this paper, we present a novel framework to tackle the underestimation of hard samples in classic selection-based Noisy-Label Learning (NLL) methods. By leveraging easy samples to hallucinate the hard anchors, our approach captures crucial information from hard samples in the presence of instance-dependent noise. While we could not cover all the possible works, we compared with the most similar ones and demonstrated the effectiveness of our model on several benchmark datasets, achieving superior performance compared to state-of-the-art methods. We believe that our work offers a fresh perspective on the significance of hard samples in training models under label noise, a factor frequently overlooked by conventional NLL methods. We show that leveraging the critical labeling information in clean hard samples can enhance the robustness of the decision boundary. Other domains may also benefit from our proposal, such as active learning, which also focuses on leveraging the information of the data effectively.
Limitations. Our framework identifies hard samples and corrects their labels through hard anchor hallucination, with the assumption that the selected easy feature set (and hence the hallucinated anchor set ) span the class of interest. As a result, the proposed hallucination process might not work well for highly imbalanced datasets.
Future work. A thorough investigation and evaluation of the proposed framework on larger real-world datasets will preferably generate new insights to improve the current solution. We also plan to integrate the proposed framework into other domains beyond image classification to enhance the generalizability of our work.
References
- [1] T. Xiao, T. Xia, Y. Yang, C. Huang, and X. Wang, “Learning from massive noisy labeled data for image classification,” in CVPR, 2015.
- [2] J. Wei, Z. Zhu, H. Cheng, T. Liu, G. Niu, and Y. Liu, “Learning with noisy labels revisited: A study using real-world human annotations,” in ICLR, 2022.
- [3] H. Song, M. Kim, D. Park, Y. Shin, and J.-G. Lee, “Learning from noisy labels with deep neural networks: A survey,” in TNNLS, 2022.
- [4] J. Li, R. Socher, and S.C.H. Hoi, “DivideMix: Learning with noisy labels as semi-supervised learning,” in ICLR, 2020.
- [5] N. Karim, M.N. Rizve, N. Rahnavard, A. Mian, and M. Shah, “UNICON: Combating label noise through uniform selection and contrastive learning,” in CVPR, 2022.
- [6] D. Arpit, S. Jastrzebski, N. Ballas, D. Krueger, E. Bengio, M.S. Kanwal, T. Maharaj, A. Fischer, A. Courville, Y. Bengio, and S. Lacoste-Julien, “A closer look at memorization in deep networks,” in ICML, 2017.
- [7] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” in Master’s thesis, University of Toronto, 2009.
- [8] P. Chen, J. Ye, G. Chen, J. Zhao, and P.-A. Heng, “Beyond class-conditional assumption: A primary attempt to combat instance-dependent label noise.,” in AAAI, 2021.
- [9] G. Zhao, G. Li, Y. Qin, F. Liu, and Y. Yu, “Centrality and consistency: Two-stage clean samples identification for learning with instance-dependent noisy labels,” in ECCV, 2022.
- [10] G. Patrini, A. Rozza, A. Menon, R. Nock, and L. Qu, “Making deep neural networks robust to label noise: a loss correction approach,” in CVPR, 2017.
- [11] X. Ma, H. Huang, Y. Wang, S. Romano, S. Erfani, and J. Bailey, “Normalized loss functions for deep learning with noisy labels,” in ICML, 2020.
- [12] Z. Wang, G. Hu, and Q. Hu, “Training noise-robust deep neural networks via meta-learning,” in CVPR, 2020.
- [13] X. Wang, Y. Hua, E. Kodirov, D.A. Clifton, and N.M. Robertson, “ProSelfLC: Progressive self label correction for training robust deep neural networks,” in CVPR, 2021.
- [14] D. Berthelot, N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C.A. Raffel, “MixMatch: A holistic approach to semi-supervised learning,” in NeurIPS, 2019.
- [15] X. Xia, T. Liu, B. Han, N. Wang, M. Gong, H. Liu, G. Niu, D. Tao, and M. Sugiyama, “Part-dependent label noise: Towards instance-dependent label noise,” in NeurIPS, 2020.
- [16] Y. Zhang, S. Zheng, P. Wu, M. Goswami, and C. Chen, “Learning with feature-dependent label noise: A progressive approach,” in ICLR, 2021.
- [17] Z. Zhu, T. Liu, and Y. Liu, “A second-order approach to learning with instance-dependent label noise,” in CVPR, 2021.
- [18] D. Cheng, T. Liu, Y. Ning, N. Wang, B. Han, G. Niu, X. Gao, and M. Sugiyama, “Instance-dependent label-noise learning with manifold-regularized transition matrix estimation,” in CVPR, 2022.
- [19] A. Berthon, B. Han, G. Niu, T. Liu, and M. Sugiyama, “Confidence scores make instance-dependent label-noise learning possible,” in ICML, 2021.
- [20] W. Zhang and Y.-X. Wang, “Hallucination improves few-shot object detection,” in CVPR, 2021.
- [21] B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I.W. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural networks with extremely noisy labels,” in NeurIPS, 2018.
- [22] X. Yu, B. Han, J. Yao, G. Niu, I.W. Tsang, and M. Sugiyama, “How does disagreement help generalization against label corruption?,” in ICML, 2019.
- [23] H. Wei, L. Feng, X. Chen, and B. An, “Combating noisy labels by agreement: A joint training method with co-regularization,” in CVPR, 2020.
- [24] S. Thulasidasan, T. Bhattacharya, J. Bilmes, G. Chennupati, and J. Mohd-Yusof, “Combating label noise in deep learning using abstention,” in ICML, 2019.
- [25] J. Wei, H. Liu, T. Liu, G. Niu, and Y. Liu, “To smooth or not? when label smoothing meets noisy labels,” in ICML, 2022.
- [26] X. Li, T. Liu, B. Han, G. Niu, and M. Sugiyama, “Provably end-to-end label-noise learning without anchor points,” in ICML. PMLR, 2021, pp. 6403–6413.
- [27] Y. Bai, E. Yang, B. Han, Y. Yang, J. Li, Y. Mao, G. Niu, and T. Liu, “Understanding and improving early stopping for learning with noisy labels,” in NeurIPS, 2021.