Rectifier: Code Translation with Corrector via LLMs
Abstract.
Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
1. Introduction
Code translation is an important problem in software engineering. Translating code from one programming language to another enables reusing and porting software artifacts across languages and platforms. Early studies mainly relied on handcrafted translation rules to translate between two languages (2to, 2024; C2G, 2024; C2R, 2024). The translation is poor in readability and correctness, and needs extra manual corrections. Therefore, the translation process is error-prone and time-consuming (Zhong et al., 2010).
With the development of deep learning technologies, in recent years, techniques based on Neural Machine Translation (NMT) have been extensively studied in recent years (Chen et al., 2018; Gu et al., 2017; Roziere et al., 2020). These approaches treat translating code as an NMT problem, where the goal is to translate source code into target code and rely heavily on parallel training datasets obtained from open-source repositories. However, parallel resources are much more scarce in the programming language domain than in natural language. It is costly to collect bilingual program data manually. Therefore, applying the NMT technology to code translation still faces many challenges.
To overcome the limitations of NMT-based approaches, researchers are exploring the use of pre-trained large language models (LLMs) for code translation, such as Codex (Chen et al., 2021), StarCoder (Li et al., 2023), CodeGen (Nijkamp et al., 2022), CodeLlama (Rozière et al., 2023) and ChatGPT (OpenAI, 2022), which generate correct code directly based on context by pre-training on large amounts of open-source code snippets. Although prior works (Pan et al., 2024, 2023b) have shown promise in using LLMs for code translation, there is a dearth of research on understanding their limitations for this task. This is an important undertaking because code translation is a complex task that requires LLMs to understand code syntax (to generate syntactically correct code) and semantics (to preserve functionality during translation) simultaneously. However, LLMs would produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more).
In this study, our objective is to enhance code translation through the introduction of a micro model exhibiting proficient error correction capabilities. This model can be applied universally to rectify errors arising from any LLM. To achieve this goal, we present Rectifier with the following principal contributions. Initially, we present a micro-level automated model tailored for rectifying translation errors. In contrast to LLMs, which demand substantial computational resources and associated costs, our micro model, fine-tuned on CodeT5+ 220M, necessitates significantly fewer resources than larger-scale LLMs such as Llama-2 13B. Subsequently, we devise a universal model for rectifying errors produced by any LLM. Our model possesses a universal character, as it is not tailored to rectify errors specific to a particular LLM, but rather targets errors commonly encountered across different LLMs. This design is LLM agnostic and operates independently of any specific LLM architecture.
We conducted experiments on two extensively researched datasets, namely CodeNet (Puri et al., 2021) and AVATAR (Liu et al., 2019), covering three highly prevalent programming languages: C++, Java, and Python. These experiments involved a comparative assessment of four cutting-edge LLMs: ChatGPT (OpenAI, 2022), StarCoder (Li et al., 2023), CodeGen (Nijkamp et al., 2022), and CodeLlama (Rozière et al., 2023).
Initially, we executed code translation tasks across all LLMs, with the outcomes strongly favoring ChatGPT. Specifically, on the CodeNet dataset, ChatGPT achieved an impressive success rate ranging from 59.5% to 85.5%. Likewise, on the AVATAR dataset, ChatGPT demonstrated the highest success rate, registering between 38.0% and 73.1%, which was notably 11.6% to 61.8% superior to its LLM counterparts. Furthermore, the examined LLMs exhibited consistent patterns of translation errors, primarily manifesting as invalid code. These errors were manually rectified, resulting in valid code instances. These paired sets of valid and invalid codes were subsequently employed to fine-tune the CodeT5+ model. The results demonstrated the effectiveness of the CodeT5+ model fine-tuned on errors originating from ChatGPT, StarCoder, and CodeGen, effectively rectifying a total of 6 to 22 errors produced by CodeLlama.
Additionally, we conducted cross-experiments wherein we selected error code translations from ChatGPT, StarCoder, CodeGen, and CodeLlama sequentially, utilizing the error codes from the remaining models for fine-tuning. The experimental findings highlighted CodeT5+’s capacity to ameliorate translation errors across LLMs (i.e., 4.6%43.2% of ChatGPT, 3.8%28.4% of StarCoder, 3.9%21.3% of CodeGen, and 6.4%24.4% of CodeLlama). This underscores the presence of similar error patterns across LLMs and affirms the universal, LLM-agnostic nature of Rectifier, which operates independently of any specific LLM architecture.
In brief, the key contributions of this paper include:
A. Comprehensive Evaluation of LLM-based Code Translation: We perform a large-scale evaluation of the code translation using multiple LLMs. We consider the most recently released LLMs and our evaluation includes two crafted benchmarks spanning across C++, Java, and Python.
B. Rectifier: Micro and Universal Model for Repairing Translation Errors: We found that these LLMs generate similar error patterns during translation, so we manually corrected the errors generated by the LLMs and used a micro model to capture these error patterns. The model fine-tuned on error data can be universally applied to any unknown LLMs.
C. Extensive Empirical Evaluation: We conducted cross experiments on 4 state-of-the-art LLMs on the widely studied CodeNet (Puri et al., 2021) and AVATAR (Ahmad et al., 2021) datasets to explore the effectiveness and robustness of Rectifier. The replication of this paper is publicly available (rep, 2024).
2. Motivation Example
2.1. A Motivation Example

Fig. 1 shows the translation of the Java code “atcoder_ABC169_D” in the AVATAR dataset into Python code. The left part represents the Java code to be translated, while the right part represents the translation results of LLMs (i.e. ChatGPT, StarCoder, CodeGen, and CodeLlama). This code is a solution to a programming problem on the AtCoder website. The problem is given a positive integer N, consider repeatedly applying the operation below on N. First, choose a positive integer z satisfying all of the conditions below: (1) z can be represented as z=, where p is a prime number and e is a positive integer; (2) z divides N; (3) z is different from all integers chosen in previous operations. Then, replace N with N/z. The solution code uses the class to read input from the standard input stream and outputs the answer using the statement. These LLMs successfully translated the functionality of the original Java code, but they mistakenly translated the line to , which would result in different loop counts and incorrect results. The correct translation should start from 1 and increase by 1 at each loop until equals 0.
Observation 1. LLMs would generate similar erroneous patterns during code translation. Over the years, several state-of-the-art LLMs (OpenAI, 2022; Li et al., 2023; Nijkamp et al., 2022; Wang et al., 2023; Touvron et al., 2023; Rozière et al., 2023; Chen et al., 2021; Zheng et al., 2023) have been proposed, and show strong translation capabilities through pre-trained using millions of code snippets from open-source projects. However, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). By identifying common error types that repeatedly appear in the code, we can use unified correction operations to fix these errors, making the process of error correction more automated and reliable.
Observation 2. The existing neural machine translation based (NMT-based) models do not have the ability to generally correct errors, while using LLM to correct mistakes is relatively costly. Several SOTA NMT-based models (Jiang et al., 2023; Meng et al., 2023; Ye et al., 2022b, a; Jiang et al., 2021) show strong error fixing capabilities through training on large amounts of labeled data. However, none of them has possessed powerful analytical reasoning capabilities to auto-fix the error shown in Fig. 1. If there are no similar repair patterns in their limited training data, it becomes difficult to correctly fix the error, as none of them can understand and reason to add new logic into the code for fixing. Unlike current NMT-based models using limited training data, the LLMs are directly pre-trained using millions of code snippets from open-source projects. By utilizing high-quality prompts or fine-tuning, it can comprehend translation errors in the code and execute repairs (Xia et al., 2023; Xia and Zhang, 2023). However, using LLM to correct translation errors requires significant computational resources at a high cost.
2.2. Key Ideas
Based on the above observations, we design our code translation framework with an automated corrector via LLMs, namely Rectifier, with the following key ideas.
(1) Compact Error Correction Model. We present an efficient error correction model capable of assimilating rectification patterns gleaned from translation errors generated by LLMs. This model exhibits the capacity to automatically rectify analogous errors caused by diverse LLMs. In contrast to LLMs, which entail substantial computational resources and associated costs, our compact model, fine-tuned on CodeT5+ 220M, demands significantly fewer resources than its LLM counterparts (e.g., Llama 2 13B).
(2) Universal Model for Translation with Corrector. When a novel LLM undertakes code translation, it tends to manifest comparable patterns of translation errors. Our model assimilates these patterns and can be applied to rectify errors generated by a spectrum of LLMs. In essence, our model boasts a universal applicability, as it is not tailored to rectify errors in any specific LLM but rather addresses common error patterns exhibited across various LLMs. This underscores its LLM-agnostic design paradigm.
3. Rectifier: Code Translation with Corrector via LLMs
3.1. Collection Phase
The purpose of this phase is to gather erroneous translations from the output of LLM. These errors will serve as the foundation for identifying patterns of mistakes for the subsequent phase. To achieve this, we need to address three tasks: (1) Prompt Preparation, (2) Translation Collection, and (3) Mistake Correction.
3.1.1. Task 1: Prompt Preparation
We followed the prompt similar to those we found in the artifacts, papers, or technical reports associated with each model (Nijkamp et al., 2022; Li et al., 2023; Rozière et al., 2023). The prompt used for LLMs involves three important components as illustrated in Fig. 2:
-
•
Source Code (marked as ①). We provide LLMs with code to be translated from different languages (i.e. Java, C++, and Python) in code translation task.
-
•
Task Description (marked as ②). LLMs are provided with the description constructed as ‘‘Translate the above $SOURCE_LANG code to $TARGET_LANG.’’. The task descriptions used in the translation task vary based on the source and target programming languages we employ.
-
•
Indicator (marked as ③). ChatGPT outputs a large amount of descriptive text during inference. Therefore, we need a strict prompt template to keep ChatGPT focused on the translation code rather than the descriptive text. In this paper, we follow the best practice in previous work (Pan et al., 2023a) and adopt the same prompt named ‘‘Print only the $TARGET_LANG code, end with "|End-of-Code|".’’. Other models are instructed to generate ‘‘$TARGET_LANG’’.

3.1.2. Task 2: Translation Collection
Through the interaction of the Language Model (LLM) with the embellished prompt, it adheres to the task description in order to produce a translated code corresponding to the provided source code. It is worth noting that these generated translations might incorporate extraneous dialogue and descriptive text. To isolate the essential code segments, we employ regular expressions. As a result, the execution of Task 2 yields a compilation of translated codes from all LLMs.
3.1.3. Task 3: Mistake Correction
We utilize the test cases in the dataset to verify the accuracy of the code generated by LLM. If the translated code successfully passes all test cases, it is deemed a valid translation; otherwise, it is marked as invalid. There are four categories of translation errors: (1) compilation errors, (2) runtime errors, (3) functional errors, and (4) non-terminating executions.
Subsequently, we apply minor corrections to the invalid code in order to ensure it passes all test cases, resulting in what we refer to as valid code. Many of the errors produced by LLM can be rectified through straightforward adjustments, such as adding packages, modifying operators, or adjusting boundary conditions. The distinguishing factor between valid and invalid code lies in the specific erroneous statement, which aids the model in learning from its mistakes. These pairs of valid and invalid codes are then employed for error pattern learning in the subsequent phase.
3.2. Fine-Tune and Inference Phase
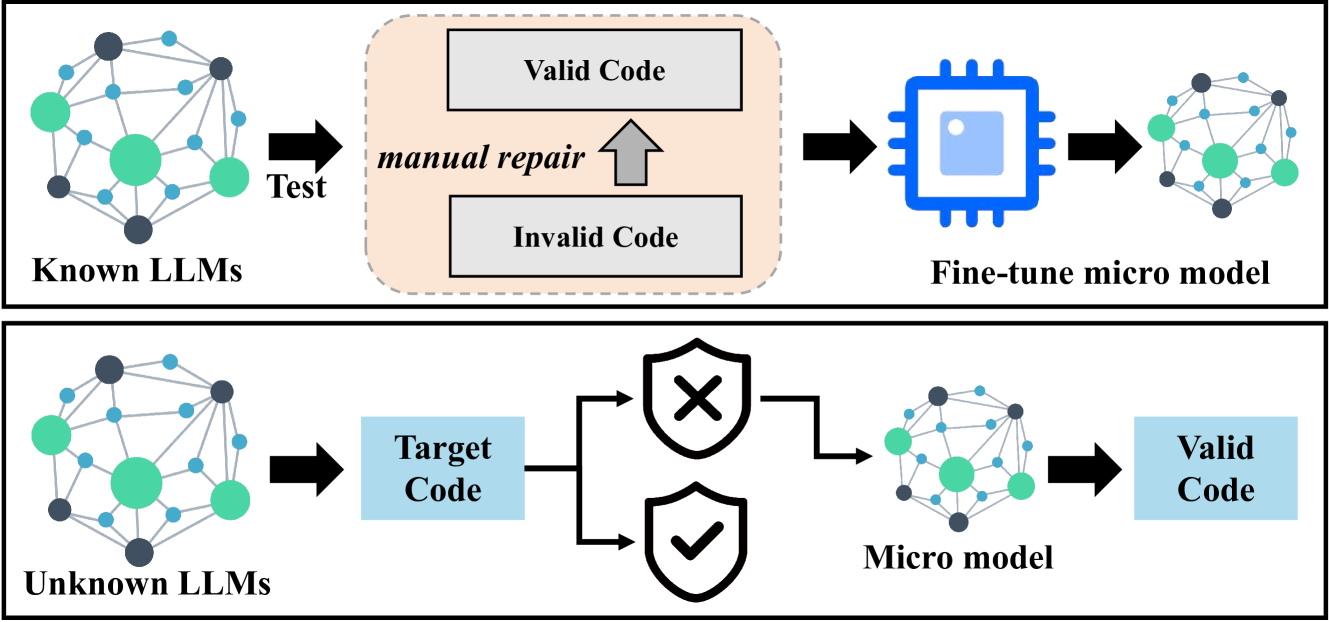
As illustrated in Fig. 3, we employ the pairs of valid and invalid codes obtained during the collection phase to fine-tune a generated model. The purpose of fine-tuning is to assimilate the mistake patterns produced by established LLMs. The input to this generated model comprises the erroneous translation generated by LLMs, with the output being the corrected code.
For our study, we utilize the CodeT5+ model (Wang et al., 2023) as the underlying LLM, although it can be readily substituted with various other generated LLMs, such as Llama 2 (Touvron et al., 2023). Detailed fine-tuning procedures are elucidated in Section 4.3.
Following fine-tuning, CodeT5+ effectively learns the mistake patterns associated with LLMs in code translation, particularly within the training set. Subsequently, we utilize the fine-tuned CodeT5+ to correct the invalid code within the test set, which comprises models that CodeT5+ has not encountered previously (i.e., unknown LLMs, as depicted in Fig. 3). Here, we input the erroneous translation generated by the unknown model into the fine-tuned CodeT5+, which then employs its learned correction pattern to find a solution for the current incorrect translation, ultimately producing the corrected code.
4. Experimental Methodology
4.1. Dataset Collection and Pre-Processing
In order to ensure the thoroughness and validity of our research findings regarding the nature of LLM translation errors, we have leveraged two widely recognized code translation benchmarks: the CodeNet dataset (Puri et al., 2021) and the AVATAR dataset (Ahmad et al., 2021). These datasets have been previously employed in studies (Pan et al., 2023a; Szafraniec et al., 2022) and cover three highly popular programming languages, namely C++, Java, and Python. The detailed characteristics of these selected datasets, along with their respective statistics, are shown in Table 1. Each of these datasets is equipped with test cases designed to validate code translations. Specifically, for CodeNet and AVATAR, the tests comprise input data and corresponding expected outputs.
| Dataset | Source Language | # Number | # Testcase | Target Language | # Translation |
| CodeNet | C++ | 200 | 200 | Java, Python | 400 |
| Java | 200 | 200 | C++, Python | 400 | |
| Python | 200 | 200 | C++, Java | 400 | |
| AVATAR | Java | 249 | 6255 | C++, Python | 498 |
| Python | 250 | 6255 | C++, Java | 500 | |
| # Total | - | 1099 | 13110 | - | 2198 |
4.2. Studied Baseline Models
Baselines. To comprehensively compare the performance of existing work, in this paper, we consider the four state-of-the-art LLMs, namely ChatGPT (OpenAI, 2022), StarCoder (Li et al., 2023), CodeGen (Nijkamp et al., 2022), and CodeLlama (Rozière et al., 2023), and for error pattern corrector, we choose CodeT5+ (Wang et al., 2023) for our Rectifier. Here, we briefly introduce these methods to make our paper self-contained.
ChatGPT proposed by OpenAI (OpenAI, 2022) is a large pre-trained language model and is fine-tuned with the Reinforcement Learning with Human Feedback (RLHF) approach. It conducts multi-turn natural dialogs, comprehending history and generating coherent responses. ChatGPT represents advanced language modeling and conversational AI. It’s key strengths include common sense reasoning and dialog coherence.
StarCoder proposed by Li et al. (Li et al., 2023) is a large pre-trained language model specifically designed for code. It was pre-trained on a large amount of code data to acquire programming knowledge and trained on permissive data from GitHub, including over 80 programming languages, Git commits, GitHub issues, and Jupyter notebooks. StarCoder can perform code editing tasks, understand natural language prompts, and generate code that conforms to APIs. StarCoder represents the advancement of applying large language models in programming.
CodeGen proposed by Nijkamp et al. (Nijkamp et al., 2022) is an AI system for generating code from natural language. It utilizes a large pre-trained language model fine-tuned on programming data. CodeGen can translate natural language descriptions into working code in multiple languages. CodeGen can be used to synthesize code that matches the specified functionality and integrate the generated code into the project.
CodeLlama proposed by Rozière et al. (Rozière et al., 2023) is a set of large pre-trained language models for code built on Llama 2. They achieve state-of-the-art performance among open models on code tasks, provide infilling capabilities, support large input contexts, and demonstrate zero-shot instruction following for programming problems. CodeLlama is created by further training Llama 2 using increased sampling of code data. As with Llama 2, the authors applied extensive safety mitigations to the fine-tuned CodeLlama versions.
CodeT5+ proposed by Wang et al. (Wang et al., 2023) is a family of encoder-decoder models for code. Its component modules can be combined in diverse ways to fit various downstream code tasks. This flexibility comes from the mix of pre-training objectives designed by the authors to reduce the gap between pre-training and fine-tuning. These objectives include single-modal and dual-modal cross-lingual model pre-training tasks for cross-lingual code and text, such as span denoising, contrastive learning, and text-code matching.
4.3. Experimental Procedure
Data Splitting. We divided LLMs into two groups (i.e. LLM used for the error pattern corrector and LLM used for the code translator). For the LLM used for collecting errors, we adopt the data splitting approach: 80%:10%:10%. More precisely, the whole dataset is split into 80% of training data, 10% of validation data, and 10% of testing data. For the LLM used for inference, we take all the errors generated by the LLM as the testing data.
Model Implementation. Regarding StarCoder, CodeGen, and CodeLlama, we utilize their publicly available source code and perform inference with the default parameters provided in their original code. All these models are implemented using the PyTorch (Paszke et al., 2019) framework by fully adopting the pre-trained models hosted on Huggingface (hug, 2024). The fine-tuning process is performed on NVIDIA RTX 3090 graphics card. Considering ChatGPT’s code is not publicly available, we implemented translation in Python by wrapping the ChatGPT ability through its API support (chatgptendpoint, 2023) and adhere to the best-practice guide (Shieh, 2023) for each prompt. We utilize the GPT-3.5-Turbo-0301 model from the ChatGPT family, which is the version used uniformly for our experiments.
5. Empirical Results
To investigate the error patterns of different LLMs in code translation and evaluate our code translation framework with a corrector, our experiment focuses on the following research questions:
-
•
RQ-1 Effectiveness of LLMs in Code Translation. How do state-of-the-art code LLMs perform in code translation across various benchmarks?
-
•
RQ-2 Category of Translation Errors. What are the different types of erroneous patterns for unsuccessful translation?
-
•
RQ-3 Effectiveness of Rectifier in Error Repairing. (1) Can the patterns learned from existing errors be used to fix errors generated by unknown LLM? (2) How do different sources of errors affect the overall performance of the model (i.e., the robustness of model)?
5.1. RQ-1: Effectiveness of LLMs in Code Translation
RQ1-Analysis Procedure. In this research, we delineate four categories of translation errors: (1) compilation errors, (2) runtime errors, (3) functional errors, and (4) instances of non-terminating execution. We deliberately exclude static evaluation metrics such as exact match, syntax match, dataflow match (Ren et al., 2020), CodeBLEU (Ren et al., 2020), and CrystalBLEU (Eghbali and Pradel, 2022), as our primary objective is to verify the viability of the translations through compilation and execution. It is worth noting that static metrics can potentially be misleading in the context of code synthesis (Chen et al., 2021). Specifically, language models may yield seemingly favorable scores on these metrics, yet produce code that proves inexecutable due to compilation or runtime issues (Ahmad et al., 2021; Chen et al., 2021).
RQ1-Results. Performance of LLMs in translating code. Table 2 shows the detailed results of LLMs for code translation. We can observe that: (1) ChatGPT, StarCoder, and CodeLlama perform far better than CodeGen, especially ChatGPT achieving the best performance (except for Java Python translation on the CodeNet dataset), with translation success rates 38.0%85.5%. (2) When LLM performs translation C++ Java or Java C++, it usually achieves better translation effects, such as translation C++ Java on the CodeNet dataset (i.e., 85.0%), translation Java C++ on the CodeNet dataset (i.e., 85.5%), and translation Java C++ on the AVATAR dataset (i.e., 73.1%), which indicates that LLM is better at translating for the languages of the same type (e.g., Java and C++ are both static languages). (3) The translation performance of LLM on the AVATAR dataset is lower than that on the CodeNet dataset, which is due to a strong correlation between the translation success rate and the number of test cases in the dataset (i.e., 200 test cases in CodeNet dataset and 6,255 test cases in AVATAR dataset, shown in Table 1). That is, the more stricter the existing test suite is, the better the evaluation of whether the translation has successfully preserved the functionality.
| Dataset | Source Language | Target Language | # Number | % Successful Translation | |||
| ChatGPT | StarCoder | CodeGen | CodeLlama | ||||
| CodeNet | C++ | Java | 200 | 85.0% | 63.5% | 3.5% | 67.0% |
| C++ | Python | 200 | 62.0% | 33.0% | 6.0% | 36.0% | |
| Java | C++ | 200 | 85.5% | 60.0% | 32.0% | 65.5% | |
| Java | Python | 200 | 57.5% | 25.0% | 6.0% | 43.0% | |
| Python | C++ | 200 | 80.5% | 57.0% | 35.5% | 62.5% | |
| Python | Java | 200 | 59.5% | 61.0% | 0.5% | 55.0% | |
| AVATAR | Java | C++ | 249 | 73.1% | 35.7% | 12.4% | 47.4% |
| Java | Python | 249 | 62.2% | 16.1% | 0.4% | 31.7% | |
| Python | C++ | 250 | 38.8% | 26.8% | 7.2% | 24.8% | |
| Python | Java | 250 | 38.0% | 26.4% | 1.6% | 24.8% | |
Breakdown of Unsuccessful Translations. The prior findings indicate that a majority of Large Language Models (LLMs) demonstrate satisfactory performance in the realm of code translation when assessed on meticulously designed benchmarks. Toward our goal, we subsequently categorize unsuccessful translations based on their respective error outcomes, which encompass: (1) Compilation Error, denoting instances where the translated code cannot be successfully compiled; (2) Runtime Error, signifying scenarios in which the translated code compiles but subsequently encounters a runtime exception; (3) Functional Error, characterizing cases where the translated code compiles and executes without error, yet yields a test failure due to output discrepancies compared to the source program; and (4) Non-terminating Execution, referring to situations in which the translated code successfully compiles and initiates execution, but fails to terminate, often due to an encounter with an infinite loop or a waiting state for user input.
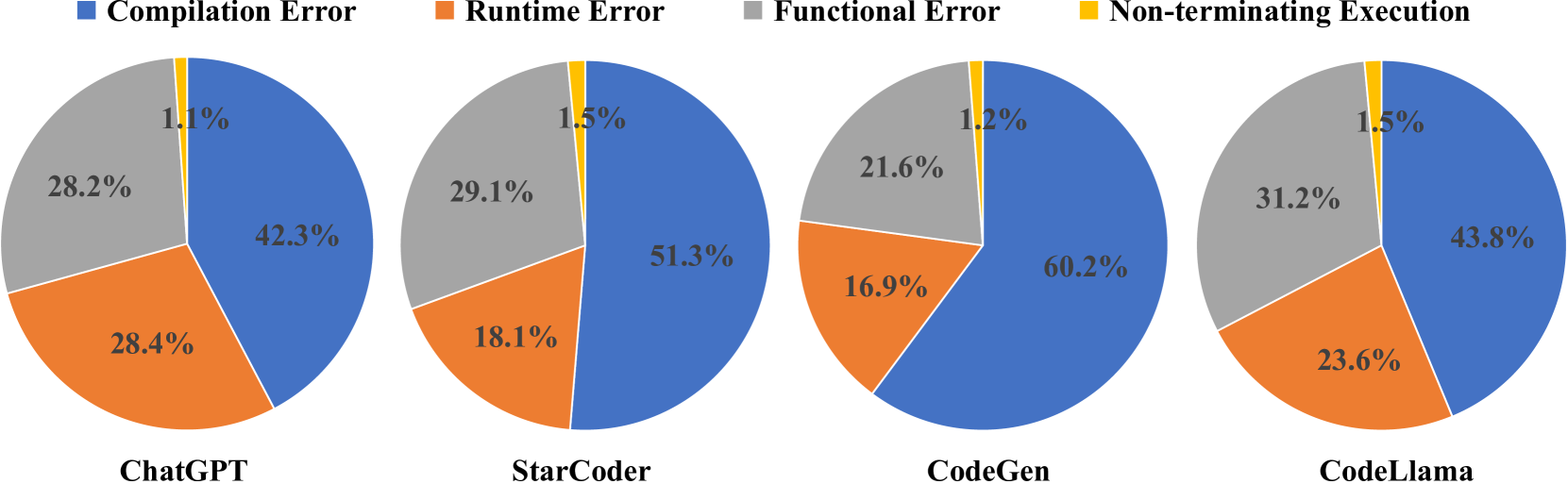
Table 3 and Fig. 4 show the breakdown of the unsuccessful translations produced by LLMs for each dataset and the proportion of translation results for each LLM. We observe that: (1) The proportion of compilation errors generated by translation is the highest (i.e. 36.9%68.2% shown in Table 3 and 42.3%60.2% shown in Fig. 4), which indicated that these LLMs are difficult to understand the target code syntax. (2) Further breakdown of the results per PLs shows that Java and C++ have comparatively stricter syntax, while it is easier for LLMs to generate syntactically correct Python code. (3) The next most common effect of unsuccessful translation is a functional error (i.e., 12.2%46.7% shown in Table 3 and 21.6%31.2% shown in Fig. 4), demonstrating that even when the code is syntactically correct and terminates with no exception or runtime error, it does not maintain the functionality implemented in the source language.
| Dataset | CodeNet | AVATAR | ||||||||
| Source Language | C++ | Java | Python | Java | Python | |||||
| Target Language | Java | Python | C++ | Python | C++ | Java | C++ | Python | C++ | Java |
| Compilation Error | 68.2% | 47.5% | 66.5% | 39.1% | 61.0% | 64.7% | 55.7% | 36.9% | 48.9% | 50.1% |
| Runtime Error | 19.1% | 33.7% | 1.3% | 46.6% | 0.6% | 22.8% | 1.6% | 38.4% | 1.3% | 25.4% |
| Functional Error | 12.2% | 18.4% | 31.0% | 13.8% | 37.2% | 12.1% | 40.1% | 23.7% | 46.7% | 23.4% |
| Non-terminating Execution | 0.6% | 0.4% | 1.3% | 0.6% | 1.2% | 0.4% | 2.6% | 1.0% | 3.0% | 1.2% |
5.2. RQ-2: Category of Translation Errors
RQ2-Analysis Procedure. To gain insights into the nature of translation anomalies, a rigorous investigation was conducted involving a manual scrutiny of the fundamental causes underlying unsuccessful translations. This inquiry is structured around the three above research questions, culminating in the establishment of an inclusive classification system for translation errors. Additionally, the study probes into the prevalence and spatial dispersion of each error category within the domain of unsuccessful translations. To streamline the manual labor involved in error comprehension and categorization, our attention was directed towards 5,342 instances of unsuccessful translations emanating from ChatGPT, StarCoder, CodeGen, and CodeLlama. The construction of the error classification system engaged the collaborative efforts of four human annotators, each with expertise in research or software engineering. The four annotators (not the authors) examine 5,342 errors of generated code. For each error, the four annotators independently study the translation error and classify it. When the labeling is finished, the annotators then compare their results and discuss each disagreement until reaching a consensus. We have a Cohen’s Kappa (Cantor, 1996) value of 0.80 in this process, which indicates a substantial agreement. This endeavor encompassed unsuccessful translations across all ten translation pairs outlined in Table 1.
RQ2-Results. We produced a category organized into six groups of root causes (Table 4): (1) Syntactic difference between languages, (2) Semantic difference between languages, (3) Dependency error, (4) Logic error, (5) Data-related error, (6) Model-specific error, and (7) Others. In the rest of this section, we discuss the category groups with illustrative examples.
| Category of Translation Errors | ChatGPT | StarCoder | CodeGen | CodeLlama |
| Syntactic difference between languages | 24.4% | 29.0% | 30.1% | 26.5% |
| Semantic difference between languages | 1.2% | 1.0% | 1.7% | 1.3% |
| Dependency error | 16.8% | 10.3% | 15.2% | 14.7% |
| Logic error | 8.0% | 9.8% | 8.5% | 11.8% |
| Data-related error | 43.9% | 25.4% | 23.3% | 27.0% |
| Model-specific error | 0.7% | 20.7% | 16.5% | 14.2% |
| Others | 4.9% | 3.8% | 4.7% | 4.5% |
5.2.1. Syntactic difference between languages
In this group, a set of discrepancies is evident, primarily attributed to the inefficacy of Language LLMs in proficiently managing syntactic disparities among Programming Languages (PLs) in code translation. LLMs frequently emulate the syntax of the source PL, even when it is incompatible with the target PL.

For instance, as illustrated in Fig. 5, an instance of an erroneous translation from Python to Java is depicted. In this instance, the LLM erroneously incorporates the for…else loop from the source language, a construct not permissible within Java syntax.
5.2.2. Semantic difference between languages
Specifically, common errors include mismatches in API behaviors and incorrect use of operators. LLMs may incorrectly map source APIs to target PL methods, leading to code that does not properly execute. Similarly, different PLs may have different operator syntax, leading to incorrect translations that can cause unexpected errors. As shown in Fig. 6, in the case where both the divisor and dividend are integers, / in Java represents integer division, while in Python it represents regular division.

5.2.3. Dependency error
Import statements load necessary libraries, classes, and modules utilized in code. We found translation often leads to missing or incorrect imports, resulting in errors. among many errors, LLMs struggle to translate definitions and implementations of data types, methods, etc. when imports are wrong.
5.2.4. Logic error
When LLM performs code translation, it may misunderstand the logic of the source code and generate incorrect translation logic. This category covers: (1) incorrect loop and conditional boundaries, (2) inclusion of logic not in the source code, and (3) removal of logic in the source code. Changes made to the logic of the source code will lead to differences in functionality.
5.2.5. Data-related error
We observed numerous errors stemming from incorrect translation in data handling-including input parsing, data types, and output formatting. Specifically, LLMs failed to correctly parse and extract values from inputs, chose inappropriate data types for variables and return values, and formatted outputs incorrectly.
5.2.6. Model-specific error
Certain errors stem from inherent limitations in LLM design. For example, we have found some issues where the LLM does not output any target language code during code translation, outputs a large amount of duplicate code, or the token size of the LLM exceeds, resulting in compilation errors or no output being generated.
Table 4 provides an exhaustive breakdown of translation errors. Our observations are as follows:
-
•
Predominantly, ChatGPT exhibits errors pertaining to data handling, constituting approximately 43.9% of the total errors. These primarily manifest as input/output discrepancies. Fortunately, these errors are amenable to correction through pattern-based learning.
-
•
Model-specific errors denote discrepancies unique to the Large Language Model (LLM), such as code output in a non-target language. These errors typically pose a greater challenge for resolution. Notably, ChatGPT exhibits a substantially lower incidence of such errors compared to other LLMs, underscoring its heightened resilience in code translation.
5.3. RQ-3: Effectiveness of Universal Model (Rectifier) in Error Correction
RQ3-Analysis Procedure. Our results from RQ1 show that a majority of the translations by LLMs are unsuccessful due to the introduction of different errors, resulting in compilation errors, runtime errors, functional errors, and non-terminating execution. In this section, we investigate whether our model learned from these errors can be used to repair translation errors generated by unknown (new) models. We manually fixed the translation errors generated by the known LLMs (i.e., ChatGPT, StarCoder, and CodeGen), using a series of invalid-valid pairs to fine-tune the CodeT5+ model of Rectifier. Then, we evaluate whether the fine-tuned CodeT5+ learning from similar error patterns can repair the incorrect translation generated by an unknown model (i.e., CodeLlama).
To explore the universality of our proposed framework and its ability to run independently of any specific LLM model. We conducted cross experiment wherein we selected error code translations from ChatGPT, StarCoder, CodeGen, and CodeLlama sequentially, utilizing the error codes from the remaining models for fine-tuning. Essentially, in this experiment, we conducted three additional experiments: (1) learn from StarCoder, CodeGen, and CodeLlama, test in ChatGPT, (2) learn from ChatGPT, CodeGen, and CodeLlama, test in StarCoder, and (3) learn from ChatGPT, StarCoder and CodeLlama, test in CodeGen.
RQ3-Results. Table 5 shows that our correction model of Rectifier can repair translation errors generated by CodeLlama. Our model learns from errors generated by ChatGPT, StarCoder, and CodeGen, and can fix errors generated by CodeLlama models that have not been learned before. Specifically, it can fix 22 out of 90 errors generated in PythonJava translation in the CodeNet dataset. Overall, we provide an effective translation-error-repairing model that can fix errors in the range of 6.4% (12 out of 188) 24.4% (22 out of 90). The above results indicate that LLM generates similar errors in code translation tasks. The patterns learned from existing code translation errors can be used to fix errors generated by new LLM.
| Dataset | Source Language | Target Language | # Number | # Invalid | # Repair |
| CodeNet | C++ | Java | 200 | 66 | 6 (9.1%) |
| C++ | Python | 200 | 128 | 10 (7.8%) | |
| Java | C++ | 200 | 69 | 8 (11.6%) | |
| Java | Python | 200 | 114 | 16 (14.0%) | |
| Python | C++ | 200 | 75 | 7 (9.3%) | |
| Python | Java | 200 | 90 | 22 (24.4%) | |
| AVATAR | Java | C++ | 249 | 131 | 15 (11.5%) |
| Java | Python | 249 | 170 | 13 (7.6%) | |
| Python | C++ | 250 | 188 | 12 (6.4%) | |
| Python | Java | 250 | 188 | 18 (9.6%) |
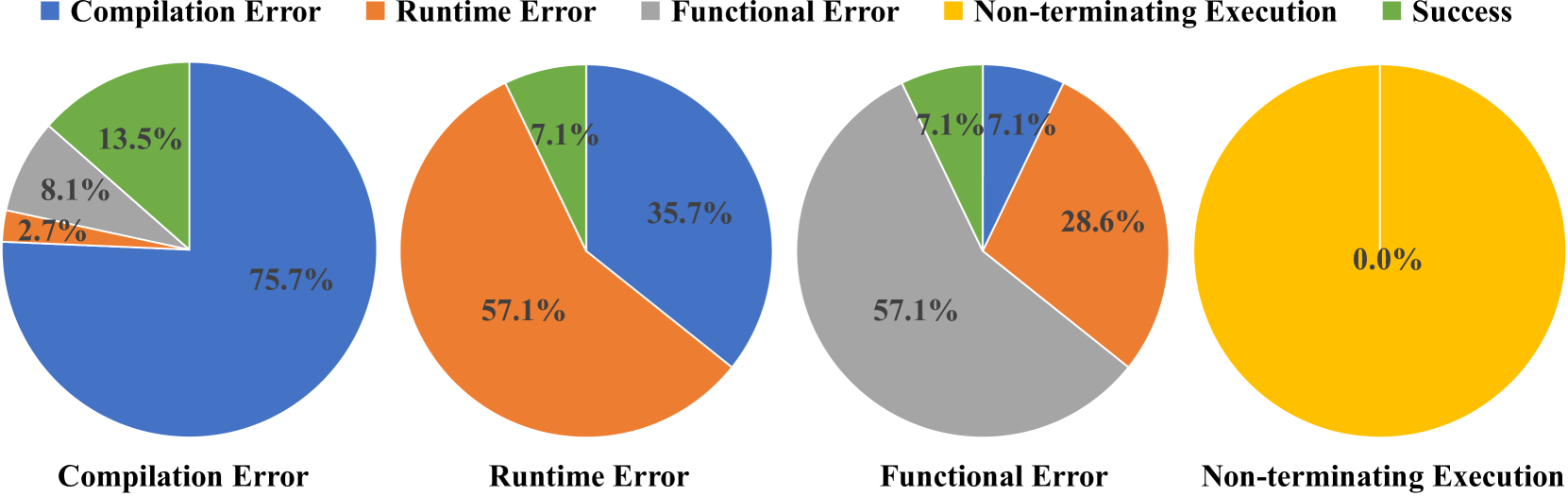
We also wanted to understand how translation errors evolve during this repairing process. To that end, we tracked the error outcomes of unsuccessful translations to further illustrate the effectiveness of error repair. For a better presentation, we used pie charts to represent the distribution of each error type after the repair operation. If an error is repaired and successfully passes all test cases, it is considered as a success.
Fig. 7 illustrates the results of our analysis of CodeLlama and we make the following observations:
-
(1)
The model is more sensitive to compilation errors, and can successfully fix 13.5% of this error. This is because LLM produces a large number of compilation errors during translation (cf. Section 5.1), so the majority of the compilation error samples in the fine-tuning dataset for CodeT5+ are included.
-
(2)
For other errors, the successful percentage is lower (i.e., 7.1% for Runtime Error and 7.1% for Functional Error)-suggesting these errors are harder to mitigate.
-
(3)
We also observe a few cases where the outcome of the translation upgrades (i.e., Compilation Error transforms to Runtime/Functional Error). The model cannot fully restore the functionality of the code, but it still repairs some errors that currently exist in these codes.
Cross experiment. In order to investigate how different error sources affect the overall performance of the model (i.e. the robustness of the model), we conducted a cross experiment. According to the results in Table 6, we can observe that:
-
(1)
Our model is more sensitive to errors generated by ChatGPT. In RQ2 (cf. Section 5.2), we mentioned that 43.9% of errors generated by ChatGPT are due to data-related errors, particularly input/output format errors. These types of errors also frequently appear in other LLMs, therefore, through effective error pattern learning, our model can fix 4.6%43.2% of ChatGPT errors.
-
(2)
Although StarCoder, CodeGen, and ChatGPT generate similar error patterns, StarCoder and CodeGen produce a large number of model-specific errors when translating code, such as outputting code that is irrelevant to the target language. This type of error is difficult to repair, resulting in weaker repair performance of our model on StarCoder and CodeGen (i.e., 3.8%28.4%).
| Dataset | Source Language | Target Language | # Invalid / # Repair | ||
| ChatGPT | StarCoder | CodeGen | |||
| CodeNet | C++ | Java | 30/3 (10.0%) | 73/10 (13.7%) | 193/19 (9.8%) |
| C++ | Python | 76/17 (22.4%) | 134/38 (28.4%) | 188/40 (21.3%) | |
| Java | C++ | 29/4 (13.8%) | 80/6 (7.5%) | 136/10 (7.4%) | |
| Java | Python | 85/28 (32.9%) | 150/38 (25.3%) | 188/10 (5.3%) | |
| Python | C++ | 39/7 (17.9%) | 86/10 (11.6%) | 129/9 (7.0%) | |
| Python | Java | 81/35 (43.2%) | 78/8 (10.3%) | 199/20 (10.1%) | |
| AVATAR | Java | C++ | 67/6 (9.0%) | 160/9 (5.6%) | 218/19 (8.7%) |
| Java | Python | 94/11 (11.7%) | 209/16 (7.7%) | 248/20 (8.1%) | |
| Python | C++ | 153/7 (4.6%) | 183/7 (3.8%) | 232/9 (3.9%) | |
| Python | Java | 155/31 (20.0%) | 184/12 (6.5%) | 246/17 (6.9%) | |
6. Case Studies
To further understand why our Rectifier performs well in correcting translation errors, we further analyzed some examples as case studies, including (1) syntactic differences between languages, (2) semantic differences between languages, (3) dependency error, and (4) data-related error. We also present two examples of translation errors that are difficult to repair. We will elaborate on the causes of each error and demonstrate how our proposed model repairs them in detail.
6.1. Syntactic differences between languages
We analyze the example of the error on syntactic differences between languages (i.e., atcoder_ABC174 _C.py in AVATAR) in Fig. 8. The purpose of this Python code is to find the smallest integer , when represented in base 10 with every digit replaced by 7, results in a number that is divisible by . The loop simulates the replacement and verification process. stores the current test value, and checks if it is divisible by . If it is, then the number of iterations is the answer. If the loop ends and no feasible value of is found, then there is no such , and -1 is printed. Overall, this code intelligently searches for the smallest integer that satisfies a specific condition through simulating base conversion and modulo operations. There are compilation error in the translated C++ code, the StarCoder erroneously incorporates the for…else loop from the source language, a construct not permissible within C++ syntax. Our proposed model successfully identified this error, and the modified C++ code has exactly the same functionality as the Python code, passing all test cases.

6.2. Semantic differences between languages
We analyze the example of semantic differences between languages error (i.e., s369598583.Java in CodeNet) in Fig. 9. The function of this Java code is to calculate the sum of the digits of all positive integers between 1 and N. Specifically, it uses a scanner to obtain an integer N, then uses a loop to calculate the sum of the digits of all numbers between 1 and N, and finally outputs the result. In the calculation process, it uses a counter count and a variable next to update the range of the loop calculation according to a specific pattern. CodeLlama translated this Java code into Python code. Although it did not produce any compilation errors, it did not realize the difference between for loops in Java and Python languages. In Fig. 12, line 8 of the Java code is a loop, while line 6 of the translated Python code is a loop. In Python’s loop, does not act as a counter loop variable, but refers to the elements in the iterable object range. Therefore, when in the Python code, the loop statement is still executed, which is different from the functionality of the Java code. Our proposed model successfully fixed this error by adding statement in the for loop. Therefore, if , the loop is exited.

6.3. Dependency error
We analyzed the example of dependency error (i.e., codeforces_421_A.py in AVATAR) in Fig. 10. This error is a representative example of dependency errors, which occurs because Scanner class is used in Java code but the relevant package is not imported. Our model adds the import statement to successfully repair the error.

6.4. Data-related error
The investigation centered on a data-related anomaly (i.e., s987117545.java in CodeNet) illustrated in Fig. 11. This anomaly stemmed from an input parsing discrepancy within the translated Python code. Specifically, the test case’s input comprised two data elements situated on a single line, delimited by a space. Utilizing the function led to the concurrent retrieval of both data items from the same line. Thus, adopting for the reading operation became imperative to capture both data items accurately. This category of anomaly was found to be prevalent across numerous translations produced by other LLMs. Consequently, a model attuned to identifying and rectifying such error patterns could proficiently address this particular type of anomaly generated by ChatGPT.

7. Un-solved cases
In this section, we present two types of translation errors in which our model did not fix: (1) logic error and (2) model-specific error. We will provide a detailed explanation of the reasons for each error type and demonstrate why our proposed model cannot fix them.
7.1. Logic error
We examine an unresolved logical discrepancy, exemplified by codeforces_203_A.java in AVATAR, as depicted in Fig. 12. This Java implementation employs a straightforward dynamic programming algorithm to ascertain whether, following a series of decreasing steps, two given numbers can be manipulated to yield a target value . In detail, and denote initial values, while and denote the decremental quantities applied at each step. Following t iterations, we scrutinize whether there exists a combination of decremental adjustments to and yielding a sum equal to . If such a combination is present, output “YES”; otherwise, output “NO”.
During the translation of this Java code into Python code by ChatGPT, inadvertent alterations were introduced to the logic. Specifically, the statements on lines 12 and 14 in the Java code, and , were erroneously transcribed as the statements on lines 9 and 11 in the Python code, and . This led to a shift in semantics relative to the original Java code, resulting in the failure of the test cases. Regrettably, our model is unable to rectify this form of discrepancy due to the absence of an established pattern for repairing specific logical errors. The only recourse is to comprehend the underlying semantic logic and the precise implementation of the source code.

7.2. Model-specific error
We examine an unresolved model-specific anomaly, exemplified by atcoder_AGC002_A.py in AVATAR. As depicted in Fig. 13, when CodeGen attempted to translate the Python code into Java, it consistently generated an extensive volume of extraneous and nonsensical code. Regrettably, our model is unable to rectify this code to successfully clear the test cases.
This type of anomaly arises frequently in CodeGen’s execution of code translation, underscoring its current limitations in robustness. This limitation further contributes to our model’s suboptimal performance in addressing CodeGen-related issues, as it lacks the capability to specifically target and resolve this particular challenge.

8. Threats to Validity
The threats of our study come from the following main aspects. The first threat is about the generalizability of our findings. Our approach was evaluated on two datasets: CodeNet and AVATAR, and also in three program languages: Java, Python, and C++. The performance of our approach can vary for other programming languages and datasets. However, the chosen datasets are well-known benchmarks and have been used extensively in the literature (Pan et al., 2023a; Szafraniec et al., 2022). The studied three programming languages (PL) also the major PLs used widely in industry. We encourage future research on more PLs and datasets. The second threat is from the manual classification of translation errors in RQ2 (Section 5.2). To mitigate the threat, we chose 4 human annotators (non-authors) with 2-4 year software development experience and they analyzed the errors independently. They resolved disagreements through multiple discussions. We have a Cohen’s Kappa value of 0.8 in the whole process, indicating a substantial agreement.
9. Related Work
9.1. Large Language Model
Large Language Models (LLMs) (Brown et al., 2020) have been widely adopted since the advances in Natural Language Processing which enable LLMs to be well-trained with both billions of parameters and billions of training samples, which consequently brings a large performance improvement on tasks adopted by LLMs (Yin and Ni, 2024; Yin, 2024; Bang et al., 2023; Ouyang et al., 2022). The open-source LLMs (e.g., CodeLlama (Rozière et al., 2023) and CodeGen (Nijkamp et al., 2022)) have attracted great attention for their excellent generative abilities. These LLMs can be easily used for a downstream task by being fine-tuned (Radford et al., 2018; Zhang et al., 2024; Ni et al., 2023; Yin and Ni, 2024) or being prompted (Xia and Zhang, 2023; Xia et al., 2023; Yin, 2024; Liu et al., 2023b) since they are trained to be general and they can capture different knowledge from various domains data. Fine-tuning is used to update model parameters for a particular downstream task by iterating the model on a specific dataset while prompting can be directly used by providing natural language descriptions or a few examples of the downstream task. Compared to prompting, fine-tuning is expensive since it requires additional model training and has limited usage scenarios, especially in cases where sufficient training datasets are unavailable.
In this paper, we fine-tune a micro model (balancing efficiency and cost) named Rectifier, while prompting LLMs to perform code translation tasks. By providing a natural language prompt that encodes the desired task, the LLMs can generate outputs without modifying its parameters.
9.2. Code Translation
Traditional approaches for code translation rely on rule-based methods like C2Rust (C2R, 2024), C2Go (C2G, 2024), and 2to3 (2to, 2024) which translate C to Rust and Go or convert Python 2 code to Python 3. With the development of deep learning technologies, in recent years, techniques based on Neural Machine Translation (NMT) have been extensively studied in recent years. With recent advances in deep learning, Neural Machine Translation (NMT) techniques have become a major focus for code translation research. Chen et al. (Chen et al., 2018) proposed a pioneering tree-to-tree neural architecture for this task. They parsed programs into ASTs and converted them into binary trees, then fed the trees into a Tree-LSTM based encoder-decoder neural model. Gu et al. (Gu et al., 2017) proposed DeepAM, an RNN sequence-to-sequence model that automatically extracts API mappings programming between language pairs. TransCoder (Roziere et al., 2020) pioneered the application of unsupervised machine translation techniques for program translation, training on massive monolingual codebases for translation between C++, Java and Python. TransCoder-ST (Roziere et al., 2021) then enhanced TransCoder by filtering out invalid translations using automated unit testing during back-translation, reducing noise and further improving translation performance. However, TransCoder and TransCoder-ST still require expensive pre-training on large monolingual code corpora. They also struggle to generalize to languages unseen during pre-training. Fang et al. (Liu et al., 2023a) proposed a novel approach SDA-Trans for unsupervised program translation, which leverages the syntax structure and domain knowledge to enhance the model’s crosslingual transfer ability. SDA-Trans achieves impressive performance on program translation, which is comparable with the large-scale pre-trained models, especially on unseen language translation.
Recently, large language models trained on code, such as Codex (Chen et al., 2021), StarCoder (Li et al., 2023), CodeGeeX (Zheng et al., 2023), CodeGen (Nijkamp et al., 2022), Llama 2 (Touvron et al., 2023), CodeLlama (Rozière et al., 2023) and ChatGPT (OpenAI, 2022) have demonstrated strong unsupervised code translation capabilities, trained on millions of snippets from open source projects. However, these models still produce certain common error types when translating code: (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. Analysis shows these errors stem from similar root causes like missing package imports, loop boundary issues, operator mistakes, etc. By recognizing these recurring error patterns in translated code, we can develop unified correction operations to automatically fix them in a more reliable way. This makes the error correction process more automated and robust.
10. Conclusion and Future Work
In this paper, we present a model-agnostic and efficient compact error corrector, namely Rectifier, for LLM-based code translation models. Through the analysis of error patterns of LLM-based code translation models, our approach assimilates the patterns and can be applied to rectify a wide spectrum of LLMs for code translation. Through empirical analysis, the results show that our approach can rectify the translation errors of different LLM-based translation models, e.g., 4.6%43.2% of ChatGPT translation errors. In the future, we plan to test different smaller models for Rectifier and expand the analysis procedure to other software engineering tasks.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No.62202419 and No. 62172214), the Fundamental Research Funds for the Central Universities (No. 226-2022-00064), Zhejiang Provincial Natural Science Foundation of China (No. LY24F020008), the Ningbo Natural Science Foundation (No. 2022J184), the Key Research and Development Program of Zhejiang Province (No.2021C01105), and the State Street Zhejiang University Technology Center.
References
- (1)
- C2G (2024) 2024. C2Go. https://github.com/gotranspile/cxgo
- C2R (2024) 2024. C2Rust. https://github.com/immunant/c2rus
- hug (2024) 2024. Hugging Face. https://huggingface.co
- 2to (2024) 2024. Python 2 to Python 3. https://docs.python.org/2/library/2to3.html
- rep (2024) 2024. Replication. https://github.com/vinci-grape/Rectifier
- Ahmad et al. (2021) Wasi Uddin Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang. 2021. Avatar: A parallel corpus for java-python program translation. arXiv preprint arXiv:2108.11590 (2021).
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023 (2023).
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Cantor (1996) Alan B Cantor. 1996. Sample-size calculations for Cohen’s kappa. Psychological methods 1, 2 (1996), 150.
- chatgptendpoint (2023) chatgptendpoint. 2023. Introducing ChatGPT and Whisper APIs. https://openai.com/blog/introducing-chatgpt-and-whisper-apis.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- Chen et al. (2018) Xinyun Chen, Chang Liu, and Dawn Song. 2018. Tree-to-tree neural networks for program translation. Advances in neural information processing systems 31 (2018).
- Eghbali and Pradel (2022) Aryaz Eghbali and Michael Pradel. 2022. CrystalBLEU: precisely and efficiently measuring the similarity of code. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12.
- Gu et al. (2017) Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim. 2017. DeepAM: Migrate APIs with multi-modal sequence to sequence learning. arXiv preprint arXiv:1704.07734 (2017).
- Jiang et al. (2023) Nan Jiang, Thibaud Lutellier, Yiling Lou, Lin Tan, Dan Goldwasser, and Xiangyu Zhang. 2023. Knod: Domain knowledge distilled tree decoder for automated program repair. arXiv preprint arXiv:2302.01857 (2023).
- Jiang et al. (2021) Nan Jiang, Thibaud Lutellier, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1161–1173.
- Li et al. (2023) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. StarCoder: may the source be with you! arXiv preprint arXiv:2305.06161 (2023).
- Liu et al. (2023a) Fang Liu, Jia Li, and Li Zhang. 2023a. Syntax and Domain Aware Model for Unsupervised Program Translation. arXiv preprint arXiv:2302.03908 (2023).
- Liu et al. (2019) Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. Avatar: Fixing semantic bugs with fix patterns of static analysis violations. In 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 1–12.
- Liu et al. (2023b) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023b. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. Comput. Surveys 55, 9 (2023), 1–35.
- Meng et al. (2023) Xiangxin Meng, Xu Wang, Hongyu Zhang, Hailong Sun, Xudong Liu, and Chunming Hu. 2023. Template-based Neural Program Repair. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1456–1468.
- Ni et al. (2023) Chao Ni, Xin Yin, Kaiwen Yang, Dehai Zhao, Zhenchang Xing, and Xin Xia. 2023. Distinguishing Look-Alike Innocent and Vulnerable Code by Subtle Semantic Representation Learning and Explanation. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1611–1622.
- Nijkamp et al. (2022) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474 (2022).
- OpenAI (2022) OpenAI. 2022. ChatGPT: Optimizing Language Models for Dialogue. (2022). https://openai.com/blog/chatgpt/.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Pan et al. (2023b) Jialing Pan, Adrien Sadé, Jin Kim, Eric Soriano, Guillem Sole, and Sylvain Flamant. 2023b. SteloCoder: a Decoder-Only LLM for Multi-Language to Python Code Translation. arXiv preprint arXiv:2310.15539 (2023).
- Pan et al. (2023a) Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2023a. Understanding the Effectiveness of Large Language Models in Code Translation. arXiv preprint arXiv:2308.03109 (2023).
- Pan et al. (2024) Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2024. Lost in translation: A study of bugs introduced by large language models while translating code. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). IEEE Computer Society, 866–866.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32. Curran Associates, Inc., 8024–8035. http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
- Puri et al. (2021) Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al. 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655 (2021).
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. 2018. Improving language understanding by generative pre-training. (2018).
- Ren et al. (2020) Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297 (2020).
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023).
- Roziere et al. (2020) Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample. 2020. Unsupervised translation of programming languages. Advances in Neural Information Processing Systems 33 (2020), 20601–20611.
- Roziere et al. (2021) Baptiste Roziere, Jie M Zhang, Francois Charton, Mark Harman, Gabriel Synnaeve, and Guillaume Lample. 2021. Leveraging automated unit tests for unsupervised code translation. arXiv preprint arXiv:2110.06773 (2021).
- Shieh (2023) Jessica Shieh. 2023. Best practices for prompt engineering with OpenAI API. OpenAI, February https://help.openai. com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api (2023).
- Szafraniec et al. (2022) Marc Szafraniec, Baptiste Roziere, Hugh Leather, Francois Charton, Patrick Labatut, and Gabriel Synnaeve. 2022. Code translation with compiler representations. arXiv preprint arXiv:2207.03578 (2022).
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Wang et al. (2023) Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH Hoi. 2023. Codet5+: Open code large language models for code understanding and generation. arXiv preprint arXiv:2305.07922 (2023).
- Xia et al. (2023) Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In Proceedings of the 45th International Conference on Software Engineering (ICSE 2023). Association for Computing Machinery.
- Xia and Zhang (2023) Chunqiu Steven Xia and Lingming Zhang. 2023. Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT. arXiv preprint arXiv:2304.00385 (2023).
- Ye et al. (2022b) He Ye, Matias Martinez, Xiapu Luo, Tao Zhang, and Martin Monperrus. 2022b. Selfapr: Self-supervised program repair with test execution diagnostics. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–13.
- Ye et al. (2022a) He Ye, Matias Martinez, and Martin Monperrus. 2022a. Neural program repair with execution-based backpropagation. In Proceedings of the 44th International Conference on Software Engineering. 1506–1518.
- Yin (2024) Xin Yin. 2024. Pros and Cons! Evaluating ChatGPT on Software Vulnerability. arXiv preprint arXiv:2404.03994 (2024).
- Yin and Ni (2024) Xin Yin and Chao Ni. 2024. Multitask-based Evaluation of Open-Source LLM on Software Vulnerability. arXiv preprint arXiv:2404.02056 (2024).
- Zhang et al. (2024) Jian Zhang, Chong Wang, Anran Li, Weisong Sun, Cen Zhang, Wei Ma, and Yang Liu. 2024. An Empirical Study of Automated Vulnerability Localization with Large Language Models. arXiv preprint arXiv:2404.00287 (2024).
- Zheng et al. (2023) Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, et al. 2023. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x. arXiv preprint arXiv:2303.17568 (2023).
- Zhong et al. (2010) Hao Zhong, Suresh Thummalapenta, Tao Xie, Lu Zhang, and Qing Wang. 2010. Mining API mapping for language migration. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1. 195–204.