I2AM: Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps
Abstract
Large-scale diffusion models have made significant advancements in the field of image generation, especially through the use of cross-attention mechanisms that guide image formation based on textual descriptions. While the analysis of text-guided cross-attention in diffusion models has been extensively studied in recent years, its application in image-to-image diffusion models remains underexplored. This paper introduces the Image-to-Image Attribution Maps () method, which aggregates patch-level cross-attention scores to enhance the interpretability of latent diffusion models across time steps, heads, and attention layers. facilitates detailed image-to-image attribution analysis, enabling observation of how diffusion models prioritize key features over time and head during the image generation process from reference images. Through extensive experiments, we first visualize the attribution maps of both generated and reference images, verifying that critical information from the reference image is effectively incorporated into the generated image, and vice versa. To further assess our understanding, we introduce a new evaluation metric tailored for reference-based image inpainting tasks. This metric, measuring the consistency between the attribution maps of generated and reference images, shows a strong correlation with established performance metrics for inpainting tasks, validating the potential use of in future research endeavors.
1 Introduction
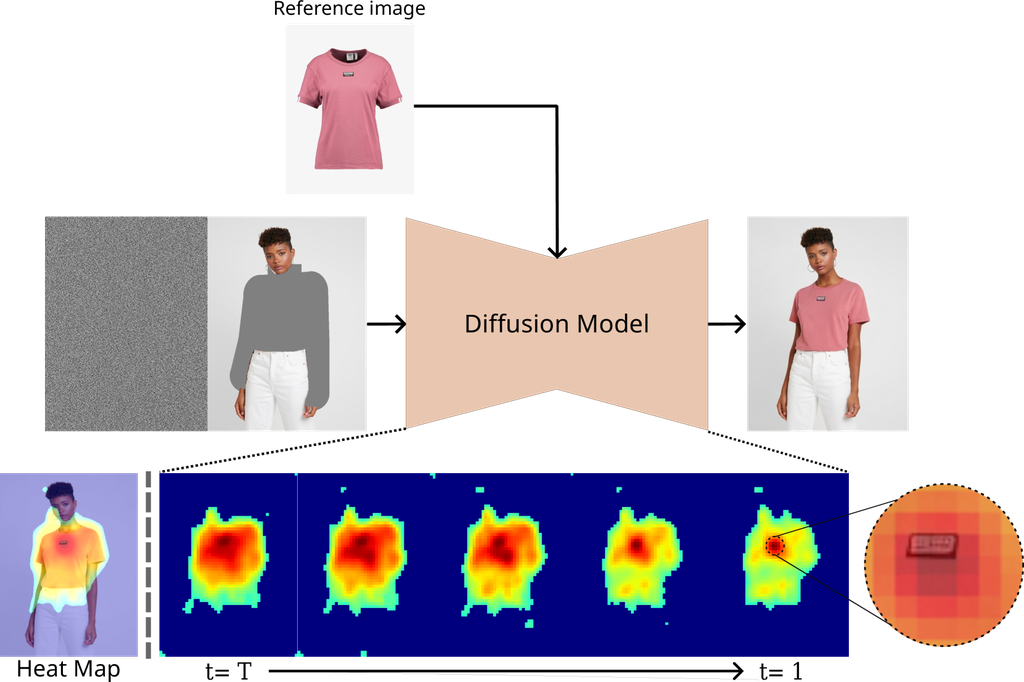
Recent advances in latent diffusion models (LDM) have revolutionized the field of image generation and editing. Noteworthy developments like Google’s Imagen Saharia et al. (2022b), OpenAI’s DALL-E 2 Ramesh et al. (2022), and Stability AI’s Stable Diffusion Rombach et al. (2022) have opened new horizons for realistic image generation. While these models show promise in various applications by generating complex visuals based on different inputs, understanding their decision-making processes remains difficult. This challenge underscores the importance of explainable artificial intelligence (XAI), which offers tools to interpret these models’ actions, enhancing their reliability and user insight.
Analysis of text-to-image LDMs and comprehension of the generating process using cross-attention modules have advanced more recently Hertz et al. (2022); Tang et al. (2022). It enables more precise handling of the model’s output, such as focusing on desirable features or managing particular steps in the generating process. Even the generating process can be examined to determine how a certain text affects the final image. By debugging the model, these technologies produce outcomes that reflect more specific criteria, significantly increasing the model’s usage across a range of industries.
While plentiful solutions have been presented for text-to-image LDM analysis and application, there is currently a shortage of studies on image-to-image LDM. Image-to-image models employ input images, which we call reference images, as conditions to produce images, referred to as generated images. Text-conditioned models generate images that visually interpret provided text descriptions, whereas image-conditioned models transform a reference image into a different visual form of the image, yet contextually related to the reference image. Applying text-to-image interpretation methods Tang et al. (2022) to image-to-image generation holds potential, as reference images are divided into patches similar to text tokens. However, token-wise interpretation, as carried out in text, is less practical due to the spatial and contextual continuity between reference and generated images, which presents difficulties. Besides, the lack of spatial information limits interpretation to one orientation in text-to-image generation.
We aimed to understand image-to-image LDMs and analyze three models performing an inpainting task. Unlike text-to-image models, image-to-image processing seems more intuitive as it operates within the same domain. Still, the latent diffusion model we studied doesn’t work in pixel space but in latent space, making intuitive mapping difficult. Our first research question is, ”Which parts of the generated image are influenced by the reference image?” Addressing this helps determine if the model utilizes information from the reference image in the right areas. Nonetheless, it doesn’t conclusively determine if the model extracts useful information from the reference image. Thus, our second research question is, ”Which parts of the reference image does the generated image refer to?” To answer these, we propose merging cross-attention maps to create attribution maps. Over time, we observed the model gradually forming the object’s shape and focusing on key features (e.g., printed patterns and logos), as shown in Figure 1. This process resembles outlining the overall structure and filling in details, similar to how humans draw. Additionally, the model consistently prioritizes key features that enhance image quality across all attribution maps. We also propose visualizing the crucial areas of the reference image to verify the content is appropriately extracted.
Lastly, we suggest an evaluation metric for image-to-image LDMs in inpainting tasks using attribution maps as an XAI model. While this metric does not determine the performance on downstream tasks, it assesses the interpretability performance of the model and demonstrates consistency with the performance on downstream tasks. We present results for two existing diffusion-based models and one we trained. Our contributions are summarized as follows:
-
1.
We propose analysis and visualization methods for image-to-image latent diffusion models, which have not been actively attempted before.
-
2.
We provide insights into the generation process of diffusion models by analyzing attribution maps at each time step and attention head.
-
3.
We present attribution maps for the generated and reference image using characteristics of image-to-image latent diffusion models. These maps can be explicitly utilized in the model’s training process.
-
4.
We propose an evaluation metric for image-to-image latent diffusion models performing inpainting tasks as an XAI model.
2 Related Work
Interpreting models using attribution map. Traditionally, the internal operations of neural networks have been opaque, often described as black boxes. Earlier efforts Zhou et al. (2016); Wang et al. (2020); Selvaraju et al. (2016); Chattopadhay et al. (2018); Jiang et al. (2021), such as class activation maps and their variants, leveraged CNN-based image classifiers to highlight areas of interest within objects on images, identifying features associated with particular classes. Recently, the emergence of transformers has shifted focus towards using attention, or attribution, maps to discern the relative importance of tokens, thereby enhancing our understanding of model decisions, particularly in text-to-image applications. Some novel approaches, like Prompt-to-prompt Hertz et al. (2022) and DAAM Tang et al. (2022), have adapted techniques to visualize cross-attention maps in U-Net to observe more complex visual interactions, such as text-guided image editing. Specifically, DAAM evaluated how syntax relations are translated into visual interactions, revealing confusion in cohyponyms and excessive attention to adjectives. However, direct applications in image-to-image models have been limited, and no works have yet focused on visualizing or analyzing where the model directs its attention in image-to-image generation.
Image-to-image diffusion-based image inpainting. The image-to-image diffusion models performing image inpainting are less commonly used than the text-to-image diffusion model. Notable examples include Palette Saharia et al. (2022a) and Paint-by-Example (PBE) Yang et al. (2023), which handle inpainting tasks. Palette is a general framework for image-to-image translation that produces faithful results for image inpainting and various other tasks. However, since it receives images as concatenated forms, it cannot be visualized using the method proposed in this study. To alleviate self-referencing in generating images by copying reference images, PBE provides strong augmentation and only the CLS token of the CLIP image encoder Radford et al. (2021) to understand objects in the reference image and ignore noise in the background. As PBE provides image embeddings with cross-attention, the method proposed in this study can be applied. Additionally, StableVITON Kim et al. (2023) and DCI-VTON Gou et al. (2023), which handle a specialized inpainting task of virtually dressing clothes, achieved strong performance as PBE-based models by combining additional ControlNet Zhang et al. (2023) structures and warping networks Ge et al. (2021). These models can also apply our method. Consequently, this study introduces our methodology for these three models.
3 Preliminaries
Diffusion models. Diffusion models Ho et al. (2020); Sohl-Dickstein et al. (2015); Song et al. (2022) are probabilistic generative models that learn a data distribution by gradual denoising an initial Gaussian noise. Given a sample from an unknown distribution , the goal of diffusion models is to learn a parametric model to approximate . These models can be interpreted as an equally weighted sequence of denoising autoencoders , trained to predict a denoised variant of their input at each time , where is a noisy version of the input . The corresponding objective can be simplified to
| (1) |
where is the time step and is a Gaussian noise.
The diffusion model we implemented is the Latent Diffusion Model (LDM), which performs denoising operations in the feature space rather than the image space. Specifically, an encoder of LDM transforms the input image into a latent code , which is trained to denoise a variably-noised latent code with the training objective given as follows:
| (2) |
where is a conditioning vector for an image obtained by a image encoder . While training, and are jointly optimized to minimize the LDM loss (2).
Classifier-free guidance. Classifier-free guidance Ho and Salimans (2022) (CFG) is a method for trading off the quality and diversity of samples generated by diffusion models. It is commonly used in text, class, and image-conditioned image generation to enhance the visual quality of generated images and create sampled images that better match the conditions. CFG effectively shifts probability towards data achieving high likelihood for the condition . Training for unconditional denoising involves setting the condition to a null value at regular intervals. At inference time, the guide scale is set to , extrapolating the modified score estimate towards the conditional output while moving away from the unconditional output direction.
| (3) |
Image inpainting. This task involves controlling image editing using semantic masks. While traditional image inpainting Lugmayr et al. (2022) focused solely on filling masked areas, recent approaches, like multi-modal image inpainting Xie et al. (2023); Nichol et al. (2021); Avrahami et al. (2022); Couairon et al. (2022); Yu et al. (2023), use guidance such as text or segmentation maps to fill masked regions. The main focus of this paper, VITON, is a type of image inpainting where clothes are virtually worn on a person. The unique aspect is that while maintaining the pose, body shape, and identity of the person, the clothing product must seamlessly deform to the desired clothing area. Additionally, preserving the details of the clothing product is a requirement.
4 Methodology:
We utilize cross-attention maps to illustrate the spatial relationships between different parts of the images to analyze image-to-image latent diffusion models. Attribution mapping is a powerful way to analyze a model’s predictions by measuring the importance of different parts of an image or text, e.g., patches or tokens. To this end, we first obtain patch embeddings of reference and generated images, which serve as queries, keys, and values for cross-attention. We note that in image-to-image generation, unlike text-to-image, this cross-attention approach allows for bi-directional analysis, facilitating the visualization of two distinct attribution maps. This dual perspective not only identifies (i) which areas of the generated image are influenced by the reference image but also highlights (ii) which areas of the reference image are most influential in shaping the generated image. This image-to-image attribution maps method, which we call , also allows us to pinpoint the specific parts of the reference image corresponding to particular patches in the generated image, thereby enhancing our understanding of the model’s functionality and accuracy. In this section, we elaborate on the process of visualizing bi-directional attribution maps by segmenting the images into smaller patches and analyzing their interactions across various diffusion time steps, attention heads, and layers.
| Symbol | Description | Dimensions |
| Input image | ||
| Reference image | ||
| Latent code | ||
| Embeddings of reference image | ||
| Number of cross-attention layers | – | |
| Index of cross-attention layer | – | |
| Number of attention heads | – | |
| Index of attention heads | – | |
| g | Generated image | – |
| r | Reference image | – |
| Time step | – | |
| Coordinate of | – | |
| Coordinate of | – | |
| Attention score for of the head and layer at time | ||
| Attention map for generated image g | ||
| Attention map for reference image r | ||
| Inpainting/Reference mask |
4.1 Time-and-Head integrated attribution maps
First, we calculate the attribution map over all diffusion time steps and attention heads, reflecting the characteristics of the diffusion model as proposed in DAAM Tang et al. (2022). From now on, the attribution map for generated images will be denoted with subscript g, and for reference images as r, respectively. Sections up to 4.2 are based on the visualization of attribution maps for the generated image. We examine whether the correlation between the generated and reference images is correctly assigned from the aspect of the generated image. If proper allocation is not achieved, it indicates that information from the reference image is being lost during the generation process. Specifically, given an input image , latent code , and image embeddings , the pre-attention output vectors of the blocks within the U-Net at time step is obtained, where we denote by the number of cross-attention layers. We employ a multi-head cross-attention mechanism with a total of heads to condition these representations on image embeddings. Thus, the attention score of the generated image at each time step and layer is computed by using Softmax as follows:
| (4) |
where and are projection matrices with latent projection dimension of the keys and queries, respectively. With this, per-head score can be obtained by selecting the corresponding row in the first axis, and moreover, aggregation over time steps leads to values to reinforce information at specific locations:
| (5) |
For each per-head and layer attention score , averaging is performed to combine information, allowing for a comprehensive understanding by integrating various insights. We resize the dimensions of for each layer to the dimensions of latent code , as they may vary across layers.
| (6) |
where . Finally, since we will obtain the generated image’s attention map, we need to average over and as follows:
| (7) |
where is normalized to . and are and coordinates, respectively. For pixel-level visualization, simply resize to input image size and overlay at the end. Additionally, remove small values with a threshold for more discernible and crisp visualizations. We set the threshold to , and the overall computation is written as follows:
| (8) | ||||
| (9) |
where is an indicator function.
4.2 Head/Time integrated attribution maps
While time step and attention head were combined in the previous section, we now explore their separation in this section. The diffusion model generates images through an iterative denoising process at each time step. Naturally, to analyze the generation process, we need to consider time steps separately and consider the attention heads due to the attention module.
Head integrated attribution maps. First, we update the method for visualizing the generation process over time. The formula in (5) has been revised, and the remaining formulas can be applied directly to the grouped attention scores as before. Given the total time steps , the number of time groups , and group size , the attention score for each group is calculated as (10). By observing the model’s generation process over time, we grasp how the model gradually synthesizes the image.
| (10) |
Time integrated attribution maps. Visualize the generation process for each attention head to observe their contributions to different parts of the generated image. If there is diversity in the distribution of heads, it signifies that multiple features are well detected and emphasized by each attention head. The core element of an object achieves consistently high scores in the time-integrated attribution maps. To compute attention maps for each attention head , we need to modify equation (6). Specifically, it’s as follows:
| (11) |
4.3 Reference attribution maps
In this section, we introduce a visualization method for reference images. Text-to-image latent diffusion models struggle to visualize how text influences images (text is abstract). In contrast, reference images maintain spatial information, facilitating clear visualization of the utilized information and its extent within the condition.
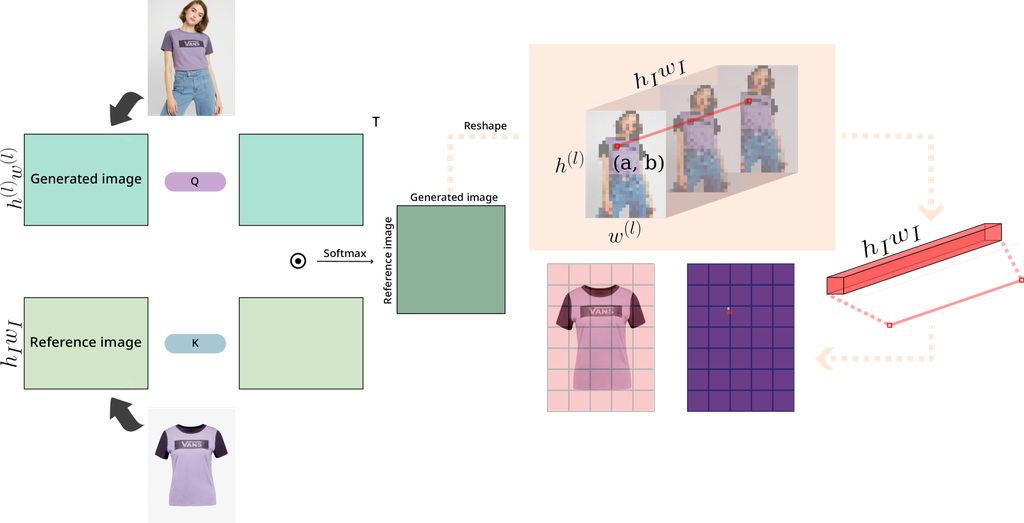
This method requires embeddings for all reference image patches. To visualize time-and-head integrated attribution maps for reference images and confirm which patches in the reference image significantly influence the generated image, Equations (4) to (7) are modified as follows:
| (12) | ||||
| (13) | ||||
| (14) | ||||
| (15) |
where and . Pixel-level and sharp visualizations are obtained by applying to equations (8) and (9), respectively. Time/Head integrated attribution maps are calculated by modifying equations (13) and (14) to equations (10) and (11), respectively.
We even identify which areas of the reference image a specific patch of the generated image has examined. We refer to this attribution map as the specific-reference attribution map . Specifically, it shows whether the model pays attention to specific reference image regions when generating particular image patches while preserving spatial information. We revise equation (15) differently than before. See details in Figure 2.
| (16) |
where is are user-specified values and is a specific-reference attribution map. This map provides concrete positional mapping information between the generated and reference images, enabling its utilization as a feedback signal for model training: for object inpainting, it offers guidance as there’s no need to reference the background of the reference image. For reference-based super-resolution, it enhances the generated image’s detail, sharpness, and structural consistency using matching positional information.
4.4 Inpainting mask attention consistency score
In this section, we introduce the Inpainting Mask Attention Consistency Score (IMACS), a new evaluation metric for image inpainting. Our proposed bidirectional attention visualization is applicable to all image-to-image latent diffusion models. It is particularly useful for mask-based tasks, such as reference-based image inpainting, where bidirectional attention is heavily utilized. Therefore, we focus on tasks with inpainting and reference mask data ( and ). IMACS utilizes a cross-attention module to assess the alignment between the attention maps ( and ) of the generated and reference images with their respective masks (inpainting and reference masks). This consistency measurement indicates how well the model extracts salient information from the reference image and applies it to the appropriate regions of the generated image, serving as a crucial indicator for evaluating XAI model performance.
When calculating the reference attribution map score, the reference image attribution map corresponding to the inpainting mask region is used. If the size of the inpainting mask is small, the background will have a larger proportion, and the reference attribution map score may be inaccurately measured. Therefore, to consider only the score of the reference attribution map corresponding to the inpainting mask region, element-wise multiplication is performed additionally between obtained from (14) and the resized inpainting mask .
| (17) | ||||
| (18) |
Where denotes the inpainting/reference mask (agnostic map/cloth mask in the VITON dataset). The score for the attention map of the generated image is denoted as , while for the reference image, it is denoted as . We represent the combination of the attention maps for both images as IMACS. The penalty factor, denoted by , defaults to . In this context, the ranges , with higher values indicating superior performance as an eXplainable Artificial Intelligence (XAI) metric. Increasing the value imposes stronger penalties for attention that deviates from the purpose of inpainting.
5 Experiments
Datasets. Paint-by-Example (PBE) was trained on the OpenImages Kuznetsova et al. (2020). It consists of million bounding boxes for object classes across million images. StableVITON and DCI-VTON were trained on VITON-HD Choi et al. (2021). It is a dataset for high-resolution (i.e., ) virtual try-on of clothing items. Specifically, it consists of frontal-view woman and top clothing image pairs are further split into training/testing pairs
Evaluation. We evaluated DCI-VTON, StableVITON, and a custom model using IMACS. To demonstrate the consistency of IMACS with downstream tasks, we additionally employ evaluation metrics from the VITON task: FID, KID, SSIM, and LPIPS. Specifically, we use paired settings, where person images wearing reference clothing are available, and unpaired settings, where person images wearing reference clothing are not available. In paired settings, we apply SSIM and LPIPS to measure the similarity between the two images, while in unpaired settings, we use FID and KID to measure the statistical similarity between real and generated images. Lower scores for FID, KID, and LPIPS, and higher scores for SSIM and IMACS, indicate better performance. We conduct all evaluations on images of size and all figures are visualized using introduced in Section 4.
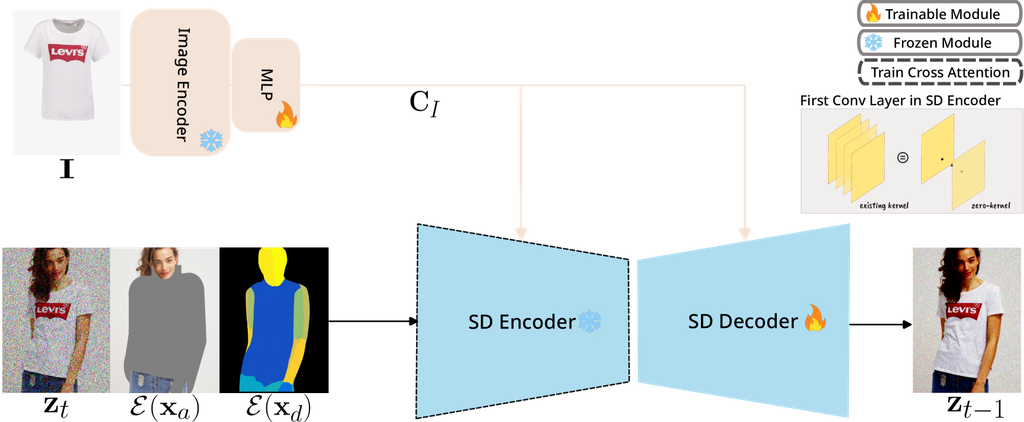
5.1 Models
We visualized attribution maps for three existing models performing inpainting tasks (PBE, StableVITON, DCI-VTON) Yang et al. (2023); Kim et al. (2023); Gou et al. (2023). As Section 4.3 mentions, all patch embeddings must be provided to the cross-attention module to visualize the reference attribution map. However, unlike StableVITON, which receives all patch embeddings from the reference image, PBE, and DCI-VTON only utilize the CLS token. As a result, the limited samples for measuring with the model make it difficult to demonstrate the consistency of with downstream task performance. Therefore, we constructed a custom model that utilizes all patch embeddings of all reference images. Another reason for building the custom model is to showcase the possibility of utilizing other image-to-image latent diffusion models that offer all patch embeddings of reference images, not just StableVITON.
The custom model based on Stable Diffusion v1.5 was fine-tuned on the VITON-HD dataset using a large image encoder (employing all patch embeddings) instead of the CLIP text encoder. Given person image , the clothing-agnostic person representation , dense pose , and clothing image , the model fills the agnostic map with the clothing image (reference image) . As the input of the U-Net, we expand the initial convolution layer of U-Net to (i.e., ) channels with a convolution layer initialized with zero weights. All components except and pass through the encoder . The custom model overview is shown in Figure 3.
Implementation details. We train the custom model for epochs, employing a batch size of . Other models utilized pre-trained models provided on their GitHub repositories, with DDIM Song et al. (2022) as the sampler, set to steps, and set to . The CFG scale is for PBE, StableVITON, and the custom model, while it is for DCI-VTON.
5.2 Time-and-Head integrated attribution maps
The diffusion model relies on Classifier-free Guidance (CFG) technology, as shown in Figure 4, depicting the time-and-head integrated attribution map based on the presence of CFG. CFG assigns a higher likelihood to the reference image, shifting the output accordingly. This shifted output is repeatedly utilized as input for the model, resulting in a shift in the distribution of the attribution map. With the application of CFG, the model better reflects the reference image, facilitating the synthesis of images in appropriate regions.

5.3 Head/Time integrated attribution maps
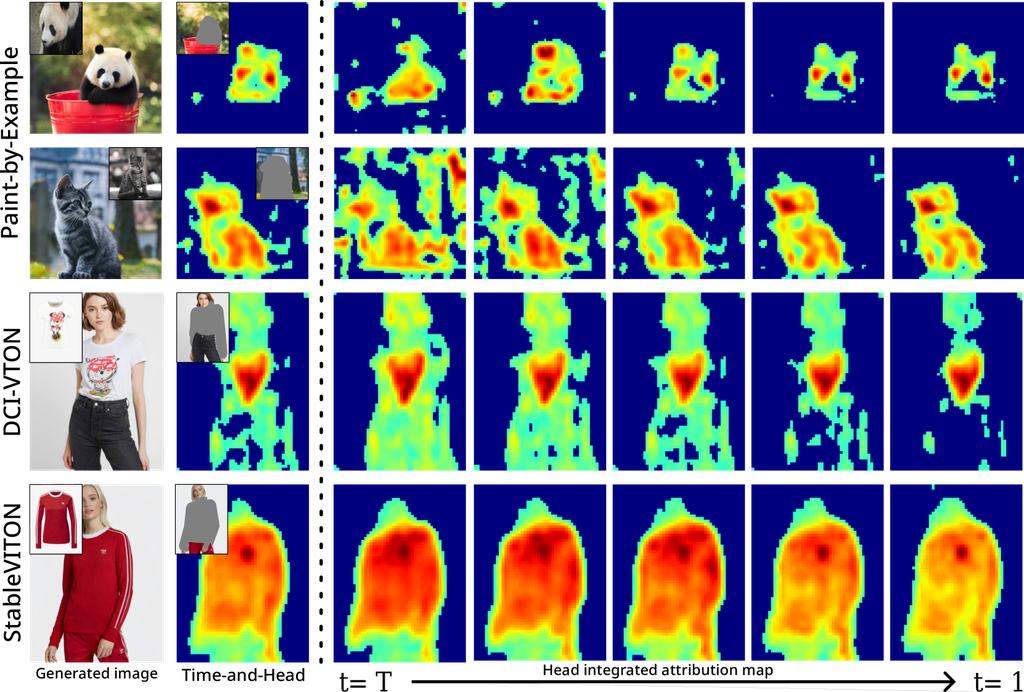

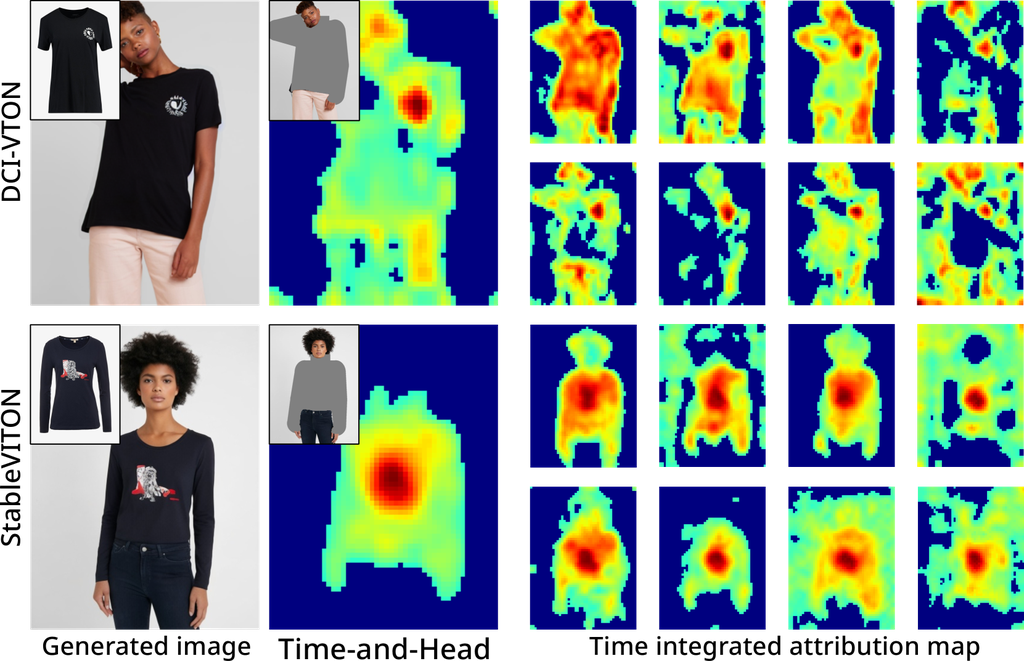
Observing Figure 5 over time steps reveals that the model gradually forms the object’s structure, consistently assigning high attention scores to important features such as facial details or clothing logos. This pattern implies that the model learns to recognize and comprehend objects accurately by emphasizing and comprehending their features as it processes and analyzes input data. Furthermore, the model starts off producing low-frequency characteristics before moving on to high-frequency features.
In Figures 6 and 7, observing attention heads reveals differences in visual areas. Additionally, not all attention scores are within the inpainting mask area, indicating that the model considers other parts of the image regardless of the restoration area’s characteristics, signifying a loss of information from the reference image. However, since the information from the reference image can be either unimportant (e.g., background) or crucial (e.g., clothing), verifying whether this affects negatively requires examination through specific-reference attribution maps. Interestingly, the model’s consistent focus on important features is a common trend across time steps and attention heads. This suggests that the model classifies significant patterns or features throughout the generation process by understanding attributes and producing appropriate outputs considering the overall context.
5.4 Reference attribution maps


To confirm whether meaningful information is extracted from the reference image for image synthesis, one needs to examine the reference attribution map. In Figure 8, different patches of the reference image are extracted based on attention heads, yet there is little variation over time: consistently high scores on important features. Unlike generated images, reference images lack noise and thus provide consistent information. This absence of noise allows important features to be clearly discerned, leading the model to primarily focus on and maintain high attention on these key features. Remarkably, similar to the attribution map of the generated image, the model consistently highlights important features regardless of the stage. Additionally, we verify through specific-reference attribution maps whether the position mapping between each patch is aligned. This allows us to specifically assess whether useful features are extracted from the reference image. In Figure 9, high scores corresponding to the positions of generated patches are accurately achieved, preserving information such as clothing color and pattern location.
5.5 Inpainting mask attention consistency score
It is crucial to consider both the dispersion and alignment levels when evaluating the performance of each model. The analysis so far reveals variations in the dispersion of time-and-head integrated attribution maps among different models. During inpainting tasks, the alignment with each mask differs across models, with DCI-VTON particularly exhibiting scattered scores. When alignment is not properly achieved, issues arise such as color discrepancies, loss of information from the reference image, and unnecessary patterns. These factors degrade the quality of generated images and reduce consistency with the original image. Models with higher alignment are more likely to produce accurate and consistent results.
In Table 2, we evaluated the custom model and existing models using IMACS and several metrics. StableVITON shows the best performance for downstream tasks, followed by the custom model and DCI-VTON. StableVITON also outperformed others in measuring the alignment between attention maps and inpainting/reference masks, as quantified by , followed by the custom model (threshold and are set to and ). These results indicate that IMACS exhibits trends similar to actual performance.
| Method | FID | KID | LPIPS | SSIM | ||
|---|---|---|---|---|---|---|
| DCI-VTON | – | |||||
| StableVITON | 10.6755 | 0.0817 | 0.8634 | 0.3083 | 0.3388 | |
| Custom model | 0.0037 |
6 Conclusion
We propose as a visualization method to analyze the generation process of image-to-image latent diffusion models. By partitioning attribution maps by time and head, We show that the model identifies important factors and consistently gives high attention scores. Especially, we introduce the specific reference attribution map to identify which information from the reference image a specific patch of the generated image is referencing. Bidirectional attribution map visualization goes beyond understanding the model’s operation; it also aids in detecting model errors and can be utilized in training and evaluation. IMACS introduced in this paper and StableVITON’s Kim et al. (2023) ATV loss serve as examples.
Acknowledgements
This work was supported by the MSIT, Korea, under the ITRC (Information Technology Research Center)(IITP-2023-2020-0-01789) and the Artificial Intelligence Convergence Innovation Human Resources Development (IITP-2023-RS-2023-00254592) supervised by the IITP (Institute for Information & Communications Technology Planning & Evaluation).
References
- Avrahami et al. [2022] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- Chattopadhay et al. [2018] Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE winter conference on applications of computer vision (WACV), pages 839–847. IEEE, 2018.
- Choi et al. [2021] Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14131–14140, 2021.
- Couairon et al. [2022] Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance. arXiv preprint arXiv:2210.11427, 2022.
- Ge et al. [2021] Yuying Ge, Yibing Song, Ruimao Zhang, Chongjian Ge, Wei Liu, and Ping Luo. Parser-free virtual try-on via distilling appearance flows. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8485–8493, 2021.
- Gou et al. [2023] Junhong Gou, Siyu Sun, Jianfu Zhang, Jianlou Si, Chen Qian, and Liqing Zhang. Taming the power of diffusion models for high-quality virtual try-on with appearance flow. In Proceedings of the 31st ACM International Conference on Multimedia, pages 7599–7607, 2023.
- Hertz et al. [2022] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Ho and Salimans [2022] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Jiang et al. [2021] Peng-Tao Jiang, Chang-Bin Zhang, Qibin Hou, Ming-Ming Cheng, and Yunchao Wei. Layercam: Exploring hierarchical class activation maps for localization. IEEE Transactions on Image Processing, 30:5875–5888, 2021.
- Kim et al. [2023] Jeongho Kim, Gyojung Gu, Minho Park, Sunghyun Park, and Jaegul Choo. Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. arXiv preprint arXiv:2312.01725, 2023.
- Kuznetsova et al. [2020] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision, 128(7):1956–1981, 2020.
- Lugmayr et al. [2022] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022.
- Nichol et al. [2021] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arxiv 2022. arXiv preprint arXiv:2204.06125, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Saharia et al. [2022a] Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022.
- Saharia et al. [2022b] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- Selvaraju et al. [2016] Ramprasaath R Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. Grad-cam: Why did you say that? arXiv preprint arXiv:1611.07450, 2016.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics, 2015.
- Song et al. [2022] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022.
- Tang et al. [2022] Raphael Tang, Linqing Liu, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Pontus Stenetorp, Jimmy Lin, and Ferhan Ture. What the daam: Interpreting stable diffusion using cross attention. arXiv preprint arXiv:2210.04885, 2022.
- Wang et al. [2020] Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 24–25, 2020.
- Xie et al. [2023] Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. Smartbrush: Text and shape guided object inpainting with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22428–22437, 2023.
- Yang et al. [2023] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18381–18391, 2023.
- Yu et al. [2023] Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting. arXiv preprint arXiv:2304.06790, 2023.
- Zhang et al. [2023] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
- Zhou et al. [2016] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2921–2929, 2016.