Scaling Laws with Vocabulary:
Larger Models Deserve Larger Vocabularies
Abstract
Research on scaling large language models (LLMs) has primarily focused on model parameters and training data size, overlooking the role of vocabulary size. We investigate how vocabulary size impacts LLM scaling laws by training models ranging from 33M to 3B parameters on up to 500B characters with various vocabulary configurations. We propose three complementary approaches for predicting the compute-optimal vocabulary size: IsoFLOPs analysis, derivative estimation, and parametric fit of the loss function. Our approaches converge on the same result that the optimal vocabulary size depends on the available compute budget and that larger models deserve larger vocabularies. However, most LLMs use too small vocabulary sizes. For example, we predict that the optimal vocabulary size of Llama2-70B should have been at least 216K, 7 times larger than its vocabulary of 32K. We validate our predictions empirically by training models with 3B parameters across different FLOPs budgets. Adopting our predicted optimal vocabulary size consistently improves downstream performance over commonly used vocabulary sizes. By increasing the vocabulary size from the conventional 32K to 43K, we improve performance on ARC-Challenge from 29.1 to 32.0 with the same 2.3e21 FLOPs. Our work emphasizes the necessity of jointly considering model parameters and vocabulary size for efficient scaling.
1 Introduction
Large language models (LLMs) achieve remarkable performance by pre-training on vast text corpora using massive computational resources [43]. Extensive prior work on LLMs has focused on deriving so-called scaling laws: a set of empirical formulas to predict how model performance scales, mainly as computing floating-point operations (FLOPs), model parameters, and quantity of training data change [28, 24, 60, 2, 40, 54]. These works show that power-law fits can effectively predict language modeling loss and by extension downstream performance [21, 51]. However, these scaling laws usually disregard the impact of the vocabulary size. For example, in Kaplan et al. [28] only non-vocabulary parameters are considered in their predictive formula. This negligence has resulted in substantial variability in the vocabulary size of current LLMs. For instance, Llama2-7B employs a vocabulary size of 32K [64], while Gemma-7B [61] adopts a much larger vocabulary size of 256K despite both having a similar number of total parameters. This variability in vocabulary sizes across LLMs raises the research question: What is the compute-optimal vocabulary size for an LLM?
The vocabulary size affects performance non-trivially. Intuitively, the optimal vocabulary size should neither be excessively large nor small. A larger vocabulary size improves tokenization fertility, i.e., splitting sentences into fewer tokens, thereby improving the tokenization efficiency. Additionally, a larger vocabulary enhances the representational capacity of the model, enabling it to capture a wider range of concepts and nuances in the corpus. However, the risk of under-fitting representations for rare tokens increases with larger vocabulary sizes, especially in the data-constrained regime [40, 66]. Thus, the optimal vocabulary size needs to be determined by taking the training data and the amount of non-vocabulary parameters into account.
In this paper, we show that the effect of vocabulary on scaling laws has been underestimated, and we quantify the effect to derive a prediction for the optimal vocabulary size. We first introduce a normalized loss formulation to ensure a fair comparison across models with varying vocabulary sizes. Utilizing the normalized loss function, we analyze and discuss the underlying rationale behind the existence of an optimal vocabulary size, which depends on the available computational budget.
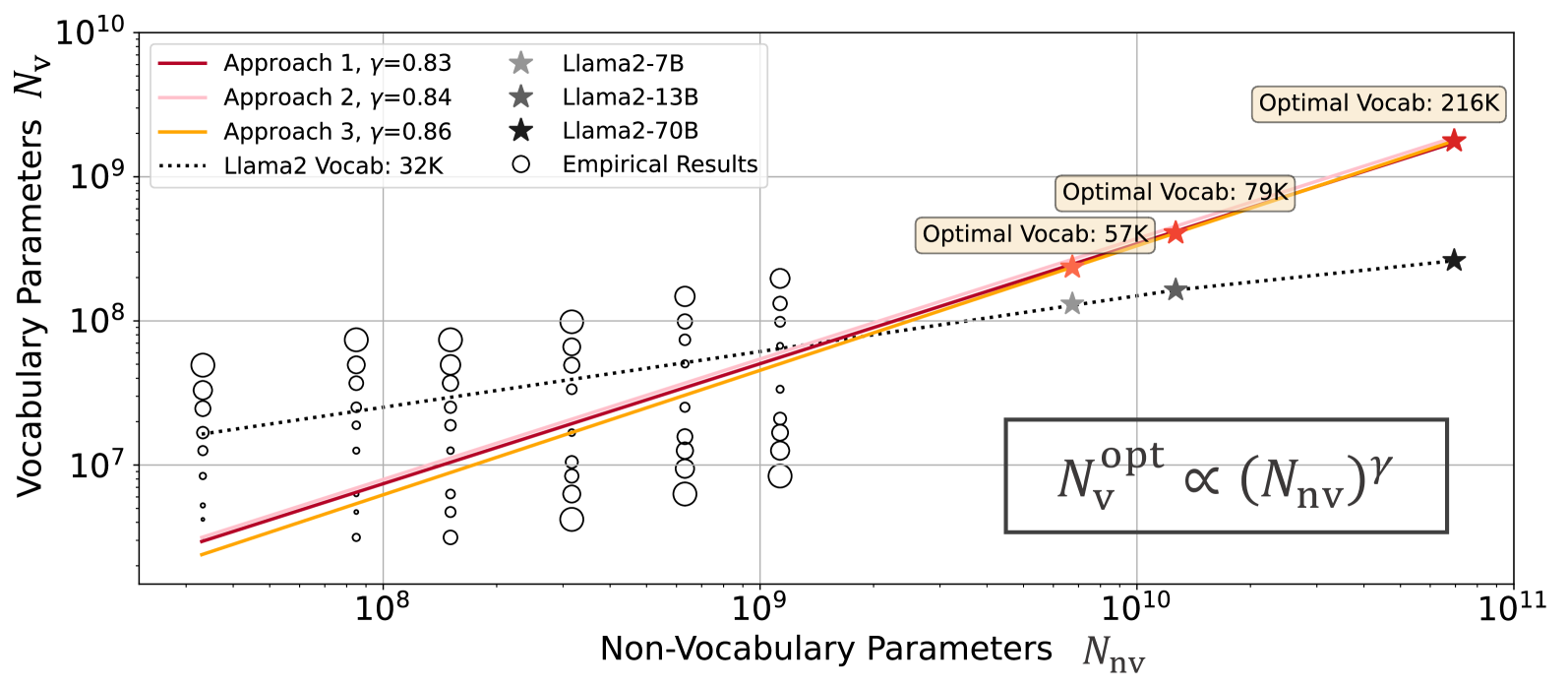
To predict the optimal vocabulary size given a compute budget, we propose three approaches. Approach 1 (Estimating power laws via IsoFLOPs): We pre-train models with non-vocabulary parameters ranging from 33M to 1.13B, with groups of models that share the same FLOPs (“IsoFLOPs”) but varying vocabulary configurations. Then, we fit power laws relating FLOPs to non-vocabulary parameters, vocabulary parameters, and training data, respectively. Our analysis reveals that the optimal vocabulary parameters exhibit a power-law growth with respect to the computational budget, however, at a slower rate than non-vocabulary parameters, as shown in Figure 1. Approach 2 (Derivative-based Estimation): We introduce a derivative-based method that estimates the optimal vocabulary size by using the derivative of FLOPs w.r.t. the vocabulary size and finding the corresponding zero solution. Approach 3 (Parametric Fit of Loss Formula): We modify Chinchilla scaling laws [24] to incorporate vocabulary and fit the resulting formula on our models to predict the normalized loss function based on non-vocabulary parameters, vocabulary parameters, and the amount of training characters jointly. While the prior two approaches are limited to compute-optimal settings, this approach also allows us to determine the optimal vocabulary when the allocation is suboptimal i.e. the model parameters are either trained for too many tokens (“overtrained”) or for too few tokens (“undertrained”). Overtraining is very common [21], such as Llama 2 7B [64] which was trained for 2 trillion tokens, significantly more than the compute-optimal allocation of a 7 billion parameter model of around 150B tokens.
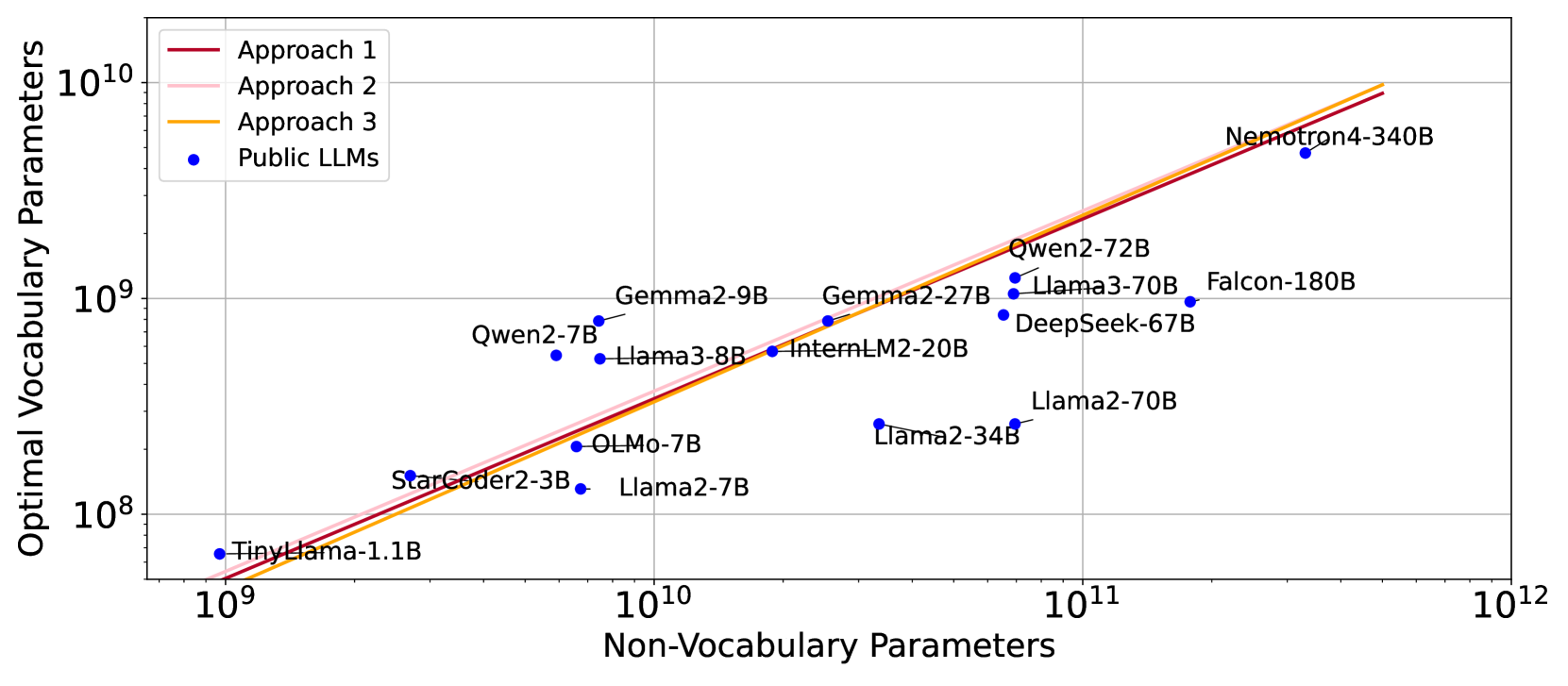
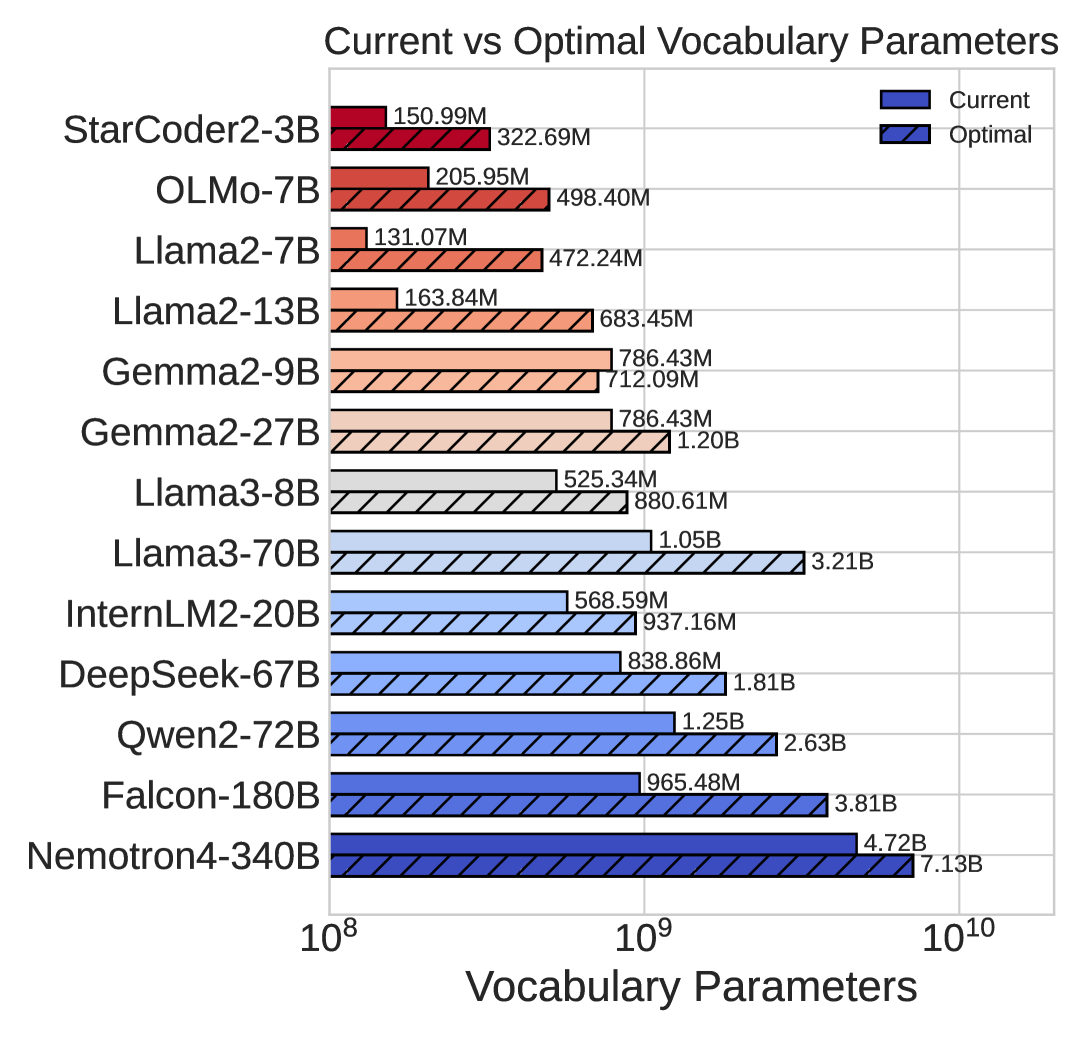
As shown in Figure 1, we observe that the relationship between non-vocabulary parameters and their correspondng optimal vocabulary parameters follows a power law, according to all of our approaches. Our prediction also suggests that vocabulary parameters should be scaled slower than non-vocabulary parameters, i.e., where . Nevertheless, most of existing LLMs [31, 73, 61, 37, 4, 23, 13, 7, 42, 76] neglect the importance of vocabulary and allocate less vocabulary parameters than the suggestions, shown in Figure 2. Note that we assume that the amount of training data for these models is optimally distributed according to Hoffmann et al. [24]. Considering that several LLMs are trained on substantially more data than optimal ones (e.g., Llama2), the optimal vocabulary sizes would likely be larger than currently estimated.
Finally, we empirically verify our predictions on models with 3B parameter models. By using our approach to predict the expected vocabulary size in various practical cases when (1) the training data is insufficient (“undertraining”); (2) the training data is equally scaled with the model parameters, following the Chinchilla laws (“compute-optimal training”) [24]; (3) the training data is overly sufficient like in Llama [64] (“overtraining”). The results show that models with our suggested vocabulary sizes steadily outperform baselines adopting commonly used vocabulary configurations under the same FLOPs budget. Our research underscores the overlooked importance of vocabulary and the need to jointly consider the vocabulary size, model parameters, and training data for effective scaling.
2 Preliminary
In this section, we first present a general formulation of a commonly used scaling law, and then demonstrate how to modify it to incorporate the vocabulary.
2.1 Scaling law
Scaling laws consider a computational budget, , which is measured in FLOPs. The goal is to optimally allocate the compute budget to model parameters and the number of training tokens [28, 6, 24, 40]. It can be formulated as:
| (1) |
Following Radford et al. [47], the loss function is typically the language modeling loss, which can be written as:
| (2) |
where is the output probability of word given the context and the tokenizer with vocabulary size . Generally, the lower indicates better performance of the language model. However, due to its dependency on , cannot be used to compare language models with different vocabulary sizes. Thus, we propose an adaptation later in §2.2. Fitting scaling laws generally requires various models trained for different configurations [21]. A common approach is to select several compute budgets and train models with varying and for each budget to find the best one, i.e. the one with the lowest loss (“IsoFLOPs”) [24]. Using fitting techniques we can then estimate a function that maps from the compute budget to the optimal allocation to and .
2.2 Scaling law with vocabulary
As prior work generally assumes the vocabulary size to be fixed, we cannot adopt the attributes in their scaling laws and their evaluation metric directly. Thus, we detail several considerations that allow us to investigate vocabulary scaling laws.
Attributes
Scaling laws commonly deal with the attributes, model parameters () and number of training tokens () [24, 40]. We adapt them for our analysis in the context of vocabulary size. (1) We break down the total model parameters () into non-vocabulary () and vocabulary parameters (). To understand the importance of vocabulary parameters, we isolate them from other model parameters, where . We use to represent both the vocabulary parameters in the output layer 111Vocabulary parameters typically encompass both the word embedding layer and the output layer. In this paper, for clarity and analytical simplicity, we employ rather than to represent the vocabulary parameters. This methodological choice is predicated on empirical observations: the predominant computational burden, as measured in FLOPs, is associated with the output layer, while the computational cost of the word embedding layer is comparatively insignificant. Consequently, references to vocabulary parameters or their associated FLOPs primarily pertain to those in the output layer, denoted by .. Notably, to change we only vary the vocabulary size and take the embedding dimension as given based on empirically, see §A.5.2 for details. This is based on the observation by Kaplan et al. [28] that the performance of models with varying depth-to-width ratios converges to a single trend. (2) We measure data not in tokens () but in training characters (). The number of tokens depends on the vocabulary of the tokenizer, thus we need a vocabulary-independent measurement of data. By studying training characters, we can better see how the data volume affects the performance regardless of different vocabulary sizes.
Mapping from training characters () to tokens ()
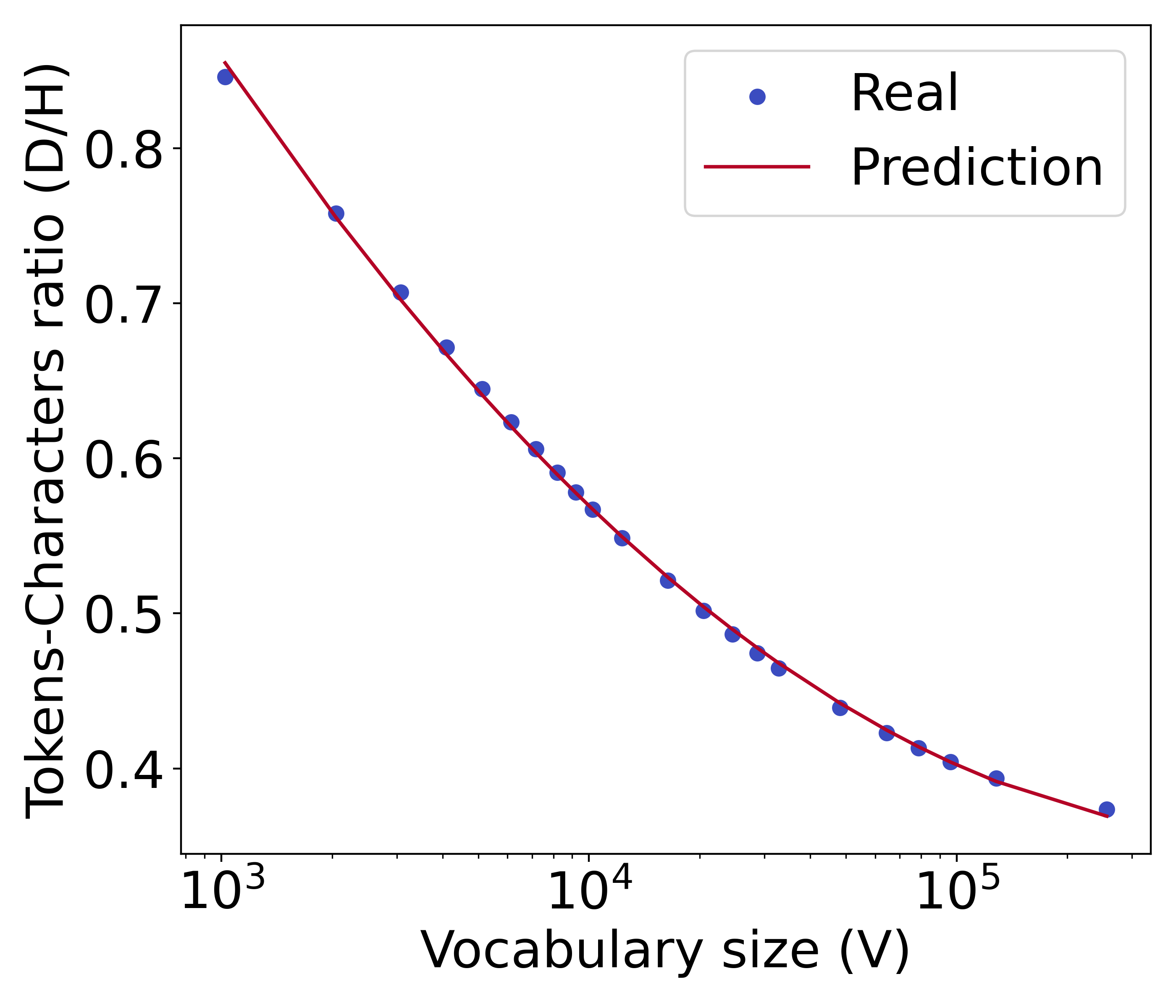
As detailed above we measure training data in training characters (). Nonetheless, to connect our findings with existing studies on scaling laws [24, 40], we need to be able to map from to . This mapping is the tokenizer’s compression ratio which can be computed via . The more tokens the tokenizer needs to represent , the larger , and thus it compresses less. We develop a simple function to estimate this ratio solely from the chosen vocabulary size, . Specifically, we find that a quadratic function on the logarithmic value of achieves accurate predictions:
| (3) |
By fitting several tokenizers with ranging from to , we obtain , and . We find that our function accurately predicts the compression ratio with a low relative mean square error (RMSE) and a high coefficient of determination (). In §A.7, we visualize fitting results and show that our approximation works with different tokenizers and is robust to different . For all our main experiments, we use the BPE algorithm for tokenization [55].
Vocabulary-insensitive loss
To fairly assess models that vary in , the commonly used language model loss in Equation 2 is inappropriate. Models trained with larger naturally have a higher loss, as there are more possibilities in the vocabulary to predict. However, this does not mean that the model is worse. Thus, we need to normalize the loss with respect to the vocabulary size. We reformulate the unigram-normalized metric [50] as a loss function. Suppose we have a -length sequence , we design the unigram-normalized language model loss as:
| (4) |
where is the frequency of word in the tokenized corpus, given the tokenizer with vocabulary size . The loss indicates the improvement in probability that a context-aware language model offers over a unigram model without context, allowing us to assess the language model’s efficacy. Based on theory from prior work [50], the normalized loss remains consistent for a given model with a fixed non-vocabulary component across different vocabulary sizes. The difference of comes from the ability of the language model itself. Compared with , the value of is much smaller and can be negative as adds a negative term . One may also employ the average bits per character (BPC), a common metric for text compression [25], as the vocabulary-insensitive loss. The only difference lies in the normalization. BPC represents the raw per-character language model loss over the corpus, while our is equivalent to the per-character language model loss normalized by the frequency of each character. Since we employ the same corpus for each model we train, there is not much difference between the two metrics in our case.
3 Analysis: Why the optimal vocabulary size is bounded by compute
In this section, we present analyses to explain why the optimal vocabulary size is constrained by the computational budget.
3.1 Analysis 1: The perspective of fixed normalized loss
According to Kaplan et al. [28], the FLOPs () of a Transformer-based language model can be estimated as , which can be re-written as:
| (5) |
where and based on §2.2. The reasons why model performance first increases and then decreases as the vocabulary size grows are: (1) At small , increasing the vocabulary size easily improves tokenization fertility from . Subsequently, more characters can be learned from the model with a fixed number of tokens, thereby improving model performance. (2) At very large , the gain from tokenization fertility decreases, while the parameters from expanding the vocabulary cannot be adequately trained with limited data, which leads to a decline in model performance. We present an expanded derivation in §A.1, and show how the corresponding FLOPs change with the vocabulary size in Figure 3 (left).
3.2 Analysis 2: The perspective of fixed FLOP budget
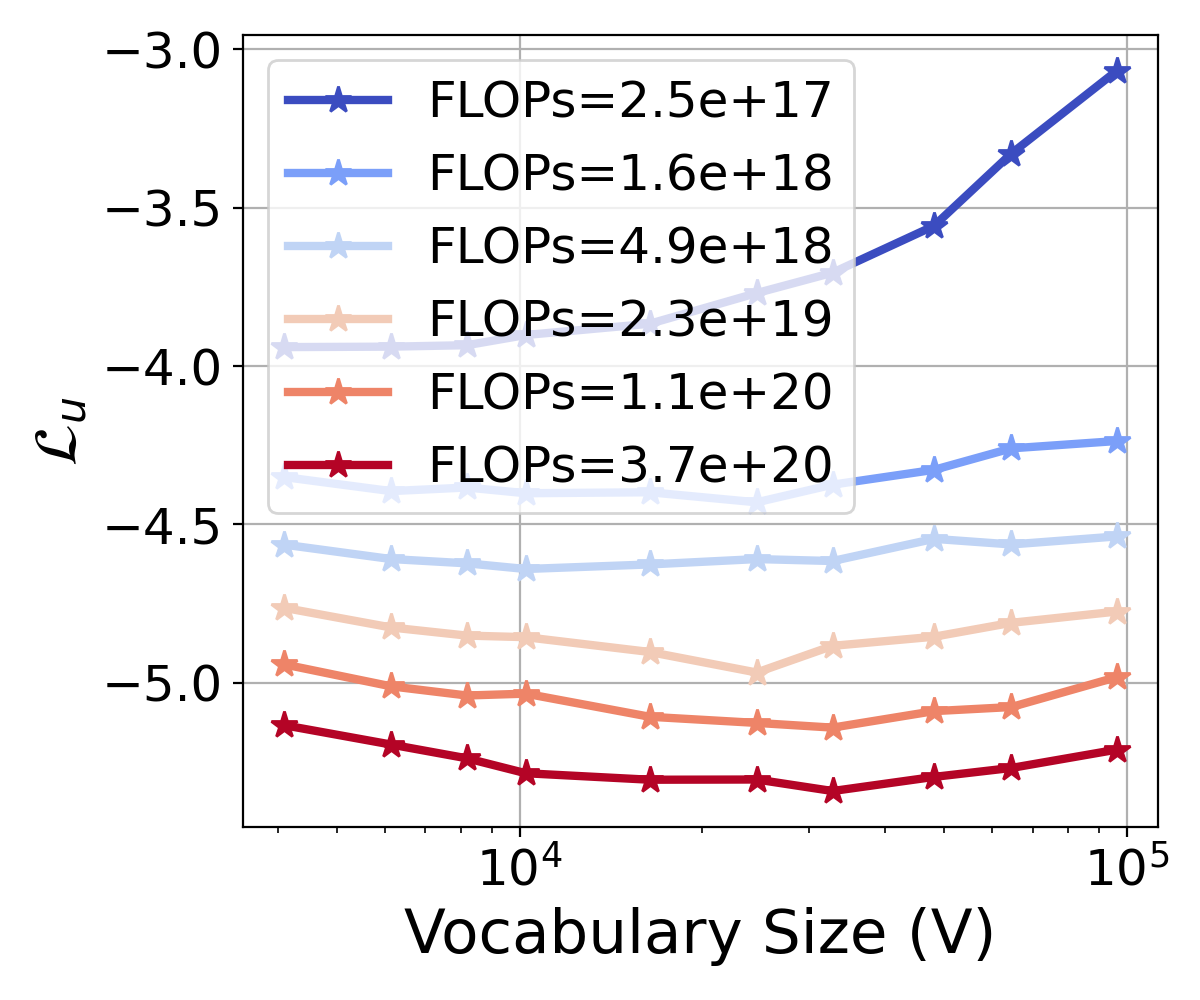
Given a fixed FLOPs budget, we isolate the FLOPs and investigate how the vocabulary influences the loss. In practice, we set several fixed FLOP budgets. For each budget, we adopt a group of models with similar total parameters and vary vocabulary sizes from 4K to 96K. In Figure 3 (right) we plot the relationship between the loss w.r.t. the vocabulary size. It reveals that the vocabulary corresponding to the lowest point on the loss curve increases as the FLOPs budget increases. This suggests that with more computational resources, LLMs can effectively harness larger vocabularies to reduce loss. However, merely expanding the vocabulary does not always lower the loss. For a fixed FLOP budget, the loss initially decreases with the increase in vocabulary and then starts to rise, indicating that an optimal point exists for the vocabulary. This suggests a trade-off between model complexity and computational constraints, where an overly large vocabulary cannot be utilized efficiently, leading to sub-optimal model performance.
3.3 Analysis 3: The perspective of parameter growing
Traditionally, scaling up model parameters in language models has been approached in two ways: increasing depth (i.e., the number of layers) or width (i.e., the hidden size). While extensive research has been conducted on these methods, current empirical practices often involve expanding both simultaneously [60]. This approach, however, may overlook crucial distinctions in how different parameters benefit from these expansions.
Non-vocabulary parameters can benefit from increases in both depth and width, allowing for more complex hierarchical representations and broader feature capture. In contrast, vocabulary parameters, associated with word embeddings and language model heads, are generally confined to a single layer, limiting their ability to benefit from increases in the model depth. Their primary avenue for expansion is through increasing the width. This disparity in growth potential between non-vocabulary and vocabulary parameters suggests that to maintain a balanced growth rate, it may be necessary to expand the vocabulary size along with the depth. This would allow the vocabulary parameter part to keep pace with the growth of non-vocabulary parameters.
4 Estimating the optimal vocabulary size
In this section, we describe three complementary approaches to estimate the optimal vocabulary size.
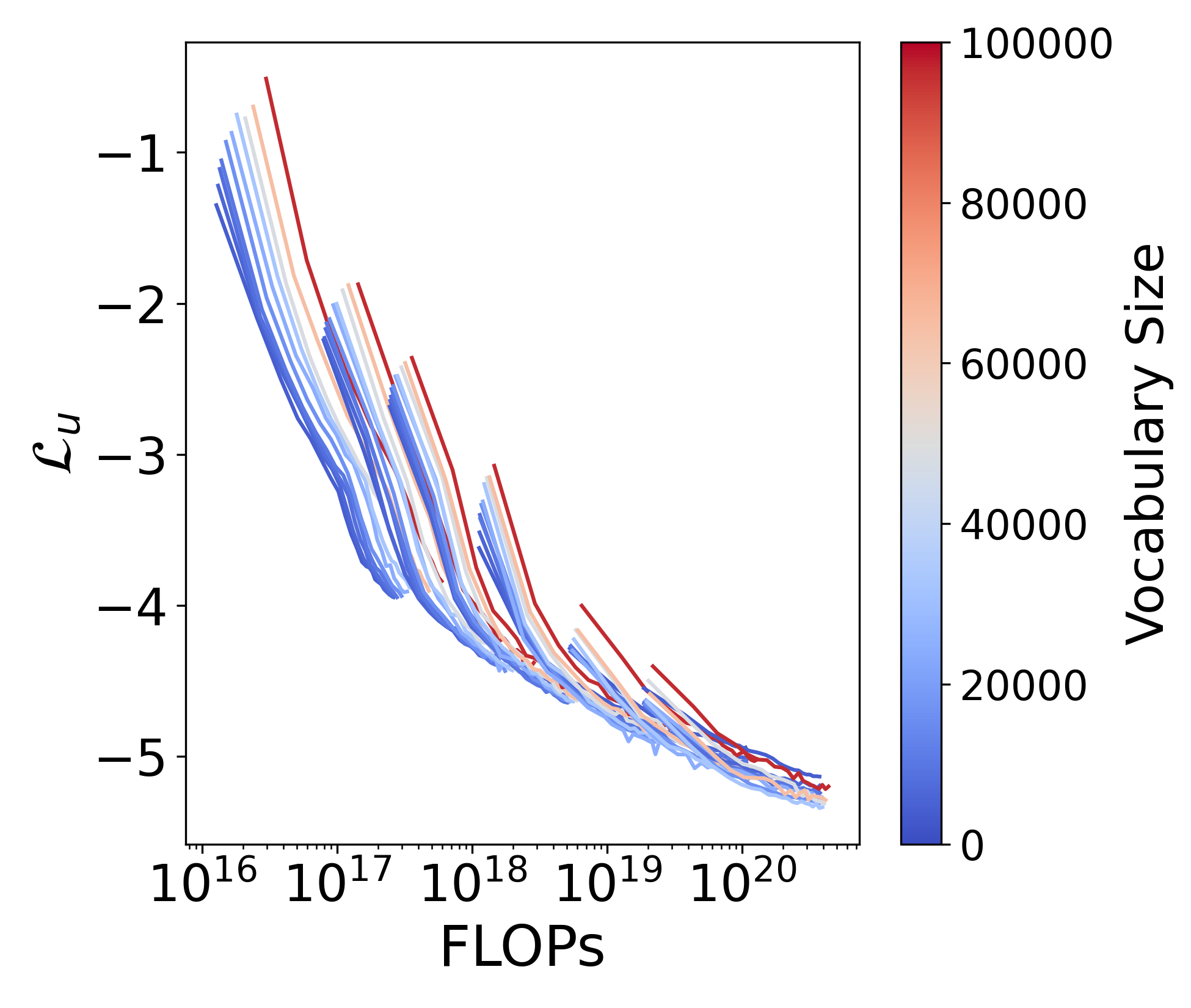
4.1 Approach 1: Estimating power laws via IsoFLOPs
We define 6 groups of models with ranging from 33M to 1.13B. Within each group, we solely vary the vocabulary size from to , and evaluate different models under the same FLOPs budget. We evaluate the normalized loss on a held-out validation dataset. This approach allows us to directly answer the question: For a given FLOPs budget, what is the optimal allocation to non-vocabulary parameters, vocabulary parameters, and training data?
Setup
Given a certain , the embedding dimension is fixed, thus increases as increases. For all experiments, we uniformly sample the training data from different domains in the SlimPajama dataset [57]. All other hyperparameters are fixed with more details in §A.5.
Fitting
We select data points with the minimum for each FLOP budget, with all runs visualized in Figure 4. These points are the compute-optimal allocation to (, , ). Following Kaplan et al. [28] and Hoffmann et al. [24], we hypothesize that the optimal vocabulary parameters meet a power law w.r.t. the FLOPs , just like the non-vocabulary parameters and the amount of training data. Specifically, , and . As model size and training data should be scaled equally for compute-optimal training [24], we set . As our new attribute significantly increases the number of possible experimental configurations, we employ interpolation across data points to obtain more configurations at a low cost. The implementation details of the fitting are in §A.5.4.
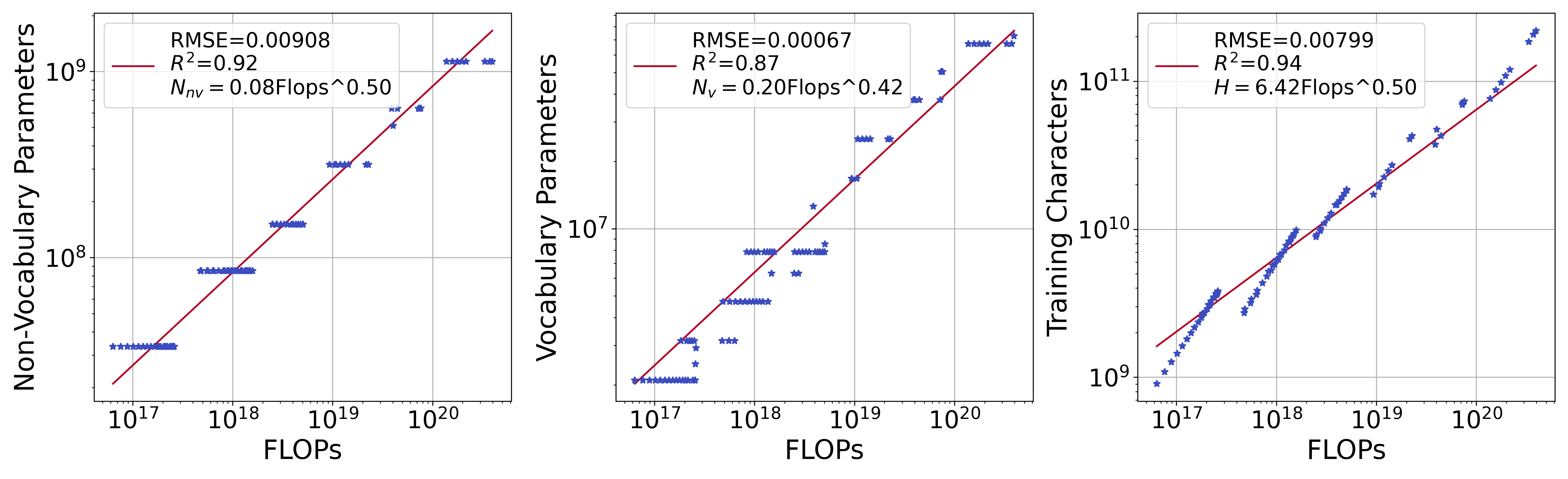
Results
In Figure 5, we display the fitted power laws: , and , where is the FLOPs budget.The low and high values indicate the strength of our fit. Given a certain FLOPs budget, we can utilize the aforementioned relationships to obtain the optimal allocation (, , ). We also draw the following conclusions: (1) LLMs are data-hungry. Compared to the non-vocabulary parameters , practitioners should allocate more compute to the training data [72, 40]. (2) Vocabulary parameters scale in a power-law relation with FLOPs (). As models become more computationally intensive, a larger vocabulary enhances the model’s ability to understand a more diverse array of text, and thus the vocabulary size is critical to scaling. (3) Vocabulary parameters should be scaled slower than non-vocabulary parameters . This difference can be seen in their power law exponents, i.e. . We hypothesize the reason is that: once a sufficiently rich embedding space is present via a large vocabulary, it is more critical to scale non-vocabulary parameters to learn the intricate syntactic and semantic structures of language via Transformer blocks.
4.2 Approach 2: Derivative-based fast estimation
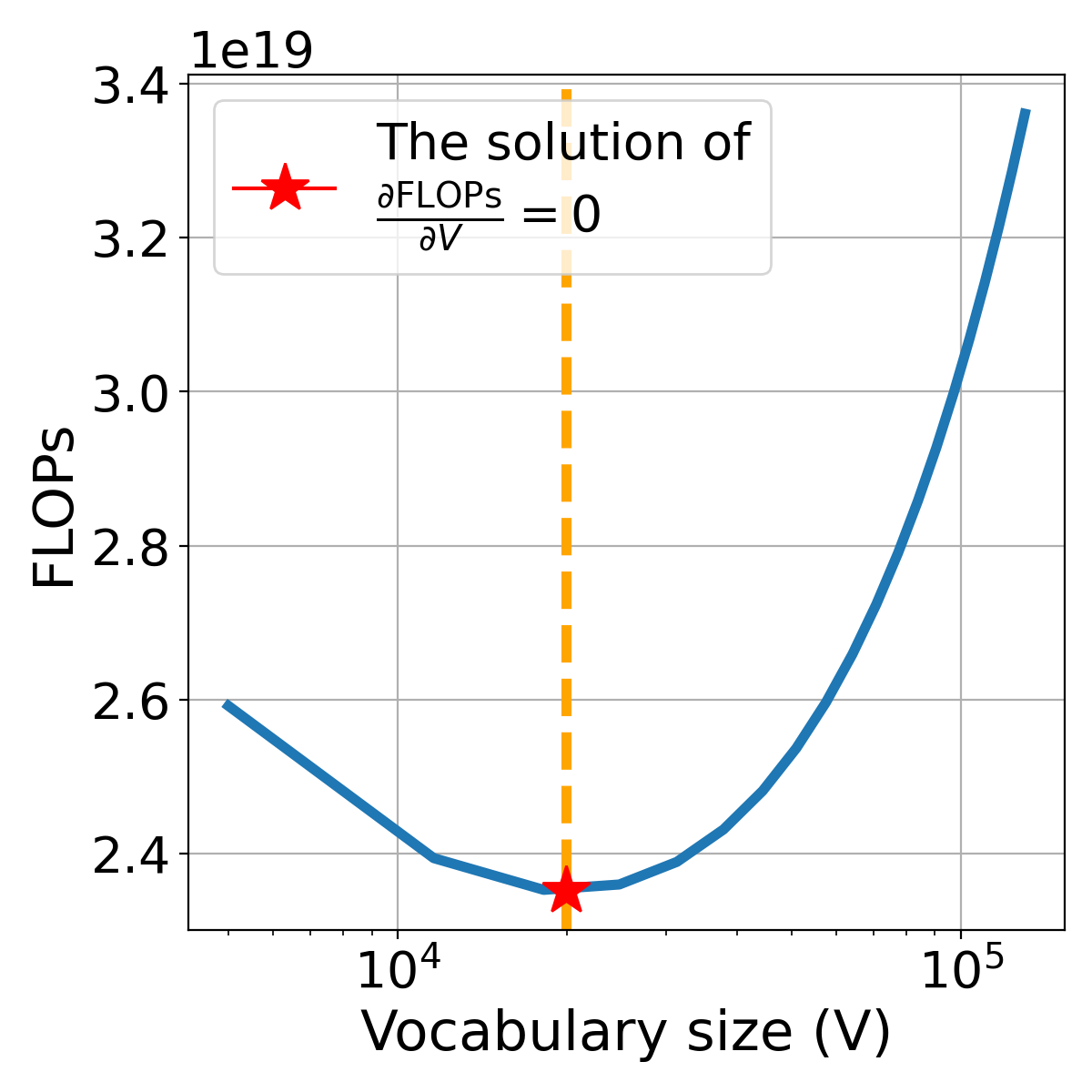
We propose an alternative approach leveraging insights from the estimation of the FLOPs itself. Prior work [24, 28] usually considers a fixed compute budget in FLOPs and then aims to minimize loss by finding the optimal allocation to model parameters and training tokens . Here we flip this recipe on its head following recent work [53]. We aim to find the minimum FLOPs to achieve a certain loss through optimal allocation of the vocabulary size :
| (6) |
By computing the minimum point of FLOPs with respect to via derivative:
| (7) |
we can estimate the optimal under the assumption that it can achieve a certain loss . The parameters , and can be easily obtained from building (§2.2). In theory, as long as the non-vocabulary parameters are provided, can be numerically searched via the solution of . More details are in §A.1.
Usage
Note that the optimal vocabulary size should be determined primarily by the normalized loss , rather than by the compute budget FLOPs. However, when the compute allocation is near optimal, the loss exhibits a power-law relationship with respect to the FLOPs budget, as described by the scaling law [28]. This relationship allows us to use FLOPs with compute-optimal allocation as a reliable proxy for observing the scaling behavior of the optimal vocabulary parameters. In practise, we can first determine an empirically optimal vocabulary size in a low-cost setting (e.g., finding the compute-optimal vocabulary parameters on a small model with equivalent FLOPs). Then, we can scale the optimal vocabulary parameters proportionally as we increase the non-vocabulary parameters. Specifically, we obtain a set of derivative-optimal vocabulary parameters for different non-vocabulary parameters , represented as . We then fit the relationship between and using the power-law function . This results in the scaling equation: where is a relatively small model (e.g., 33M), and is the searched optimal vocabulary parameter with sufficient training characters with the same FLOPs budget. By combining the value obtained from the derivative and the empirical solution on a small model, we can estimate the optimal vocabulary size for any large model without the need for extensive parameter searches following:
where the scaling proportion after our fitting. Consistent with the observation in Approach 1, we find that non-vocabulary parameters should be scaled faster than vocabulary parameters to achieve an optimal allocation.
4.3 Approach 3: Parametric fit of loss formula
Finally, we directly predict the loss given the non-vocabulary parameter, vocabulary parameter and the amount of training characters. Then, the optimal vocabulary configuration can be predicted by finding the minimum point of loss with respect to the vocabulary. Following a classical risk decomposition used in Hoffmann et al. [24], we design the vocabulary-dependent loss formula as:
| (8) |
where . The first term captures the normalized loss for an ideal generative process on the data distribution. The subsequent terms reflect the effect of the non-vocabulary parameters, vocabulary parameters, and the number of training data on the loss, respectively. are learned parameters.
Fitting
We use the points (, , ) collected for experiments in §4.1. Note that we do not only consider the points with the lowest loss for each FLOP budget as we want to predict loss for any combination of (, , ). We add the constraint following Muennighoff et al. [40]. We also filter out points with very small FLOPs following Hoffmann et al. [24]. Fitting yields , , , , , . The detailed fitting process is written in §A.5.4.
Usage
After fitting the parameters in Equation 8, the optimal vocabulary size can be obtained by finding the lowest loss w.r.t the vocabulary size, with a constraint of FLOPs budget. For example, given and FLOPs budget , by replacing with and finding the solution of via numerical search, we can get the prediction. The details of is written in §A.2. Note that all of the proposed approaches can be used in optimally allocating () altogether, while Approach 3 is more flexible in predicting the locally optimal when (, ) are not following the Chinchilla’s law [24], i.e. equally-scaled law. The reason is that the loss formula in Approach 3 does not only considers the combinations () which reach the optimal given a certain training budget. By fixing and varying in Approach 3, we can predict the locally optimal vocabulary size with different amount of training characters. This property makes Approach 3 more valuable, since modern LLMs [64, 61, 3, 4, 8] usually leverage overly sufficient training data to build powerful models with relatively low inference costs.
In Figure 6, we remove the assumption [24] for the practical reason that the parameters and training data are not equally scaled. Then, we predict the locally optimal vocabulary parameters. It can be observed that the allocation of vocabulary parameters are typically under-estimated.
5 Discussion
| -App1 | -App2 | -App3 | Dim. | -App1 | -App2 | -App3 | FLOPs Budget | |
| 3B | 0.1B | 0.1B | 0.1B | 3200 | 39K | 43K | 37K | |
| 7B | 0.3B | 0.3B | 0.2B | 4096 | 62K | 67K | 60K | |
| 13B | 0.4B | 0.5B | 0.4B | 5120 | 83K | 91K | 81K | |
| 30B | 0.9B | 0.9B | 0.9B | 6048 | 142K | 154K | 142K | |
| 70B | 1.7B | 1.9B | 1.8B | 8192 | 212K | 231K | 218K | |
| 130B | 2.9B | 3.2B | 3.0B | 12888 | 237K | 258K | 248K | |
| 300B | 5.8B | 6.4B | 6.3B | 16384 | 356K | 389K | 383K |
Predicting allocations for larger models
Table 1 reports the predicted optimal vocabulary parameters and sizes based on the proposed three approaches, where the amount of training data is optimally allocated, i.e. equally scaled with the non-vocabulary parameters [24]. As shown in Figure 1, the predictions from all proposed approaches align closely. should be scaled faster than . Notably, mainstream LLMs typically assign fewer parameters to vocabulary than what is optimal. However, the community is starting to shift to larger vocabularies, such as with Llama3 [37] having a 128K vocabulary size up from 32K of Llama2 [64]. However, scaling data is still the most critical part, and solving data scarcity issues should be a focus of future work [66].
| ARC-C | ARC-E | Hellaswag | OBQA | WG | PIQA | BoolQ | Average | ||||
| FLOPs Budget 1.2e21 (Optimally-Allocated Training Data) | |||||||||||
| =32K | 0.10B | 67.3B | 266.6B | 28.51.3 | 49.21.0 | 47.50.5 | 31.62.1 | 50.41.4 | 71.41.1 | 56.40.9 | 47.9 |
| =35K | 0.11B | 67.1B | 268.2B | 29.11.3 | 50.61.0 | 48.10.5 | 31.62.1 | 51.91.4 | 71.41.1 | 57.10.9 | 48.5 |
To empirically verify our prediction, we train models with under a compute-optimal training FLOPs budget and evaluate them using lighteval 222https://github.com/huggingface/lighteval. For the baseline model we use the common vocabulary size of . The other model uses as predicted by Approach 3. In Table 2, we show that the model allocated according to our vocabulary predictions yields better performance across multiple downstream tasks. This verifies that our predictions hold at scale.
Experiments with scarce and excessive training data
Our prior experiments focus on the setting where training compute budget is the main constraint and we seek to allocate it optimally to parameters and training data. This is the typical setting in scaling law studies [28, 24, 48]. However, in the real world, we often deal with scarce data (“data-constrained [40]”) forcing us to train sub-optimally or would like to make use of excessive data to train a smaller model that is cheaper to use [76]. To verify that our Approach 3 can handle these practical scenarios, we compare the model with and the model with the vocabulary size predicted by Approach 3. As shown in Table 3, our prediction enables a better model by only adjusting the vocabulary size in different FLOPs budgets.
| ARC-C | ARC-E | Hellaswag | OBQA | WG | PIQA | BoolQ | Average | ||||
| FLOPs Budget 2.8e20 (Insufficient Training Data, “Undertraining”) | |||||||||||
| =32K | 0.10B | 15.7B | 62.2B | 23.61.2 | 40.81.0 | 34.40.5 | 29.02.0 | 49.71.4 | 64.91.1 | 59.80.9 | 43.2 |
| =24K | 0.08B | 15.8B | 60.8B | 24.21.3 | 42.21.0 | 36.00.5 | 28.62.0 | 50.01.4 | 64.91.1 | 61.50.9 | 43.9 |
| FLOPs Budget 2.3e21 (Overly Sufficient Training Data, “Overtraining”) | |||||||||||
| =32K | 0.10B | 128.5B | 509.1B | 29.11.3 | 53.51.0 | 53.00.5 | 33.02.1 | 52.01.4 | 72.01.1 | 59.50.9 | 50.3 |
| =43K | 0.14B | 127.0B | 517.5B | 32.01.4 | 54.71.0 | 54.10.5 | 33.02.1 | 52.81.4 | 72.61.0 | 61.90.9 | 51.6 |
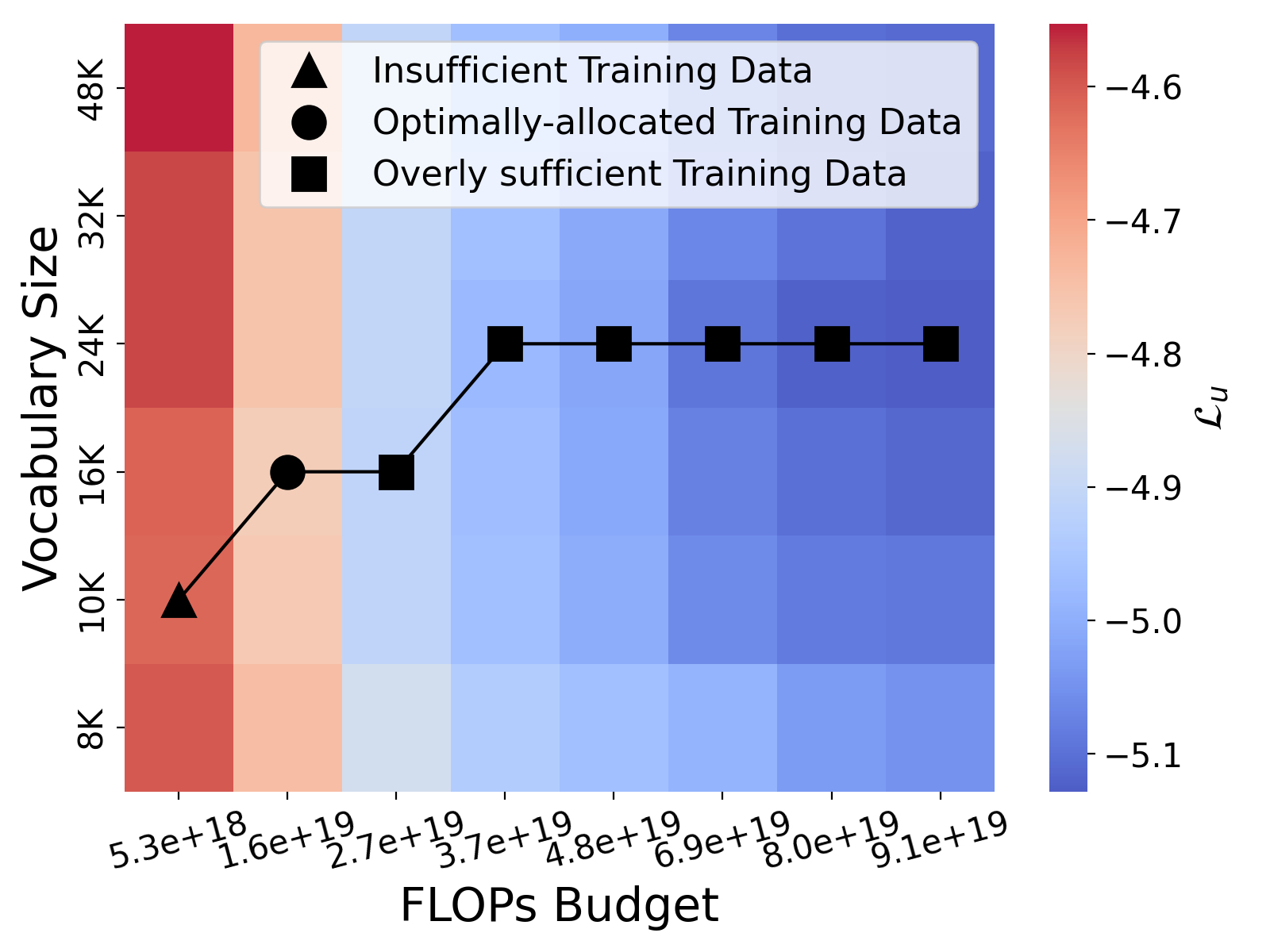
In Figure 7, we further study the trend about how does the optimal vocabulary size shift with different number of training data. We only vary the amount of data but keep the non-vocabulary parameters fixed. The choices of vocabulary size are , , , , and . Taking as an example, when available data is the bottleneck, the optimal vocabulary size decreases empirically, i.e. . This is a mechanism to prevent over-fitting. Conversely, when training on excessive amounts of data, e.g., Llama3-8B uses much more training tokens than what would be compute-optimal for its budget, the optimal vocabulary size increases, i.e. . Note that here we focus solely on training compute-optimal. It is also important to note that expanding the vocabulary size also increases the computational demands during inference. Therefore, we recommend using the optimal vocabulary size corresponding to a given , assuming optimal allocation of training data, even in scenarios where overtraining may occur.
6 Related work
Large language models
The Transformer [65] has proven to be a very scalable architecture with consistent performance gains which has led to a series of large language models (LLMs) [12, 15, 48, 43, 18, 27, 49, 64, 67, 37, 9, 4, 34, 23, 58, 61, 8, 35, 30, 79]. Through their training to predict subsequent tokens in a sequence, these models acquire a deep understanding of language enabling them to perform a variety of language tasks directly after pre-training. Their capabilities include code generation [31, 3, 39, 78, 77], mathematical reasoning [69, 5], question answering [44, 41] among others. In our work, we pre-train large language models from scratch on English corpora and focus on their loss during training and downstream performance on common tasks after training.
Scaling laws
Scaling laws aim to develop a predictive framework to find the best allocation of compute resources to maximize model performance. Besides language models, they have been studied for diffusion models [36], visual auto-regressive modeling [62] and contrastive language-image learning [14]. For language models, Kaplan et al. [28] show that model performance improves as a power law with more compute allocated to both parameters or data. Hoffmann et al. [24] show that the allocation of compute should be such that parameters and data are scaled equally. Other work investigates predicting other attributes such as downstream performance [21, 26, 51] or considering inference time [53]. Some research also predicts the expected benefit and optimal allocation under data constraints [40, 72]. Across all these works, the vocabulary size has generally been ignored. Kaplan et al. [28] even explicitly only consider non-embedding parameters. Our work highlights the critical role of vocabulary in scaling LLMs. Through our predictive frameworks for determining the optimal vocabulary size, we hope that future research will pay more attention to the vocabulary.
Vocabulary in language models
The vocabulary of a language model influences its performance significantly [59, 68, 71]. A larger vocabulary size helps cover more words thus reducing the likelihood of out-of-vocabulary (OOV) cases [19]. Takahashi and Tanaka-Ishii [59] find that larger vocabularies are better at capturing the true statistical distribution of language. Similarly, expanding vocabulary in multilingual models [68] improves performance, especially for low-resource languages. However, large vocabularies [29] increase the computational overhead during both training and generation phases. Liao et al. [32] show that low-frequency words have few instances in the training data, leading to insufficient information to train robust representations if the vocabulary is too large. To this end, our work fills an under-explored gap: How to optimally allocate the vocabulary size?
Byte-level language models
Recent work has explored byte-level language models [74, 70], which offer advantages in decoding efficiency and noise robustness compared to token-level models. However, typically limited to parameters under 1B, these models have not been effectively scaled up. Our scaling laws suggest that the limited vocabulary (i.e., 256 in byte-level language models) may constrain their performance, especially for larger models. The insight provides a potential explanation for the challenges in scaling byte-level models and implies that successful scaling of language models may require proportional increases in vocabulary size.
7 Conclusion
We investigate the impact of the vocabulary size when scaling language models. We analyze and verify that there exists an optimal vocabulary size for a given FLOPs budget. Subsequently, we develop 3 approaches to predict the optimal vocabulary size. Our first approach uses a set of empirical training runs across different IsoFLOPs regimes to fit a scaling law. The second approach investigates the FLOPs w.r.t. the vocabulary size and estimates the vocabulary size with derivatives. The third approach consists of a parametric function to directly predict the impact of different attributes on loss. Across all approaches, we find that while vocabulary parameters should be scaled slower than other parameters, they are still critical for performance and we can accurately predict their optimal allocation. We make predictions for larger models and empirically verify our approaches on up to 3B parameters and on varying amounts of training data. Our results show that models trained with an optimal vocabulary size as predicted by our approaches outperform models with a conventional vocabulary size under the same FLOPs budget.
References
- Aghajanyan et al. [2022] Armen Aghajanyan, Bernie Huang, Candace Ross, Vladimir Karpukhin, Hu Xu, Naman Goyal, Dmytro Okhonko, Mandar Joshi, Gargi Ghosh, Mike Lewis, et al. 2022. Cm3: A causal masked multimodal model of the internet. arXiv preprint arXiv:2201.07520.
- Aghajanyan et al. [2023] Armen Aghajanyan, Lili Yu, Alexis Conneau, Wei-Ning Hsu, Karen Hambardzumyan, Susan Zhang, Stephen Roller, Naman Goyal, Omer Levy, and Luke Zettlemoyer. 2023. Scaling laws for generative mixed-modal language models. In International Conference on Machine Learning, pages 265–279. PMLR.
- Allal et al. [2023] Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, et al. 2023. SantaCoder: don’t reach for the stars! arXiv preprint arXiv:2301.03988.
- Almazrouei et al. [2023] Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. 2023. The falcon series of open language models. arXiv preprint arXiv:2311.16867.
- Azerbayev et al. [2023] Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q Jiang, Jia Deng, Stella Biderman, and Sean Welleck. 2023. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631.
- Bahri et al. [2021] Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. 2021. Explaining neural scaling laws. arXiv preprint arXiv:2102.06701.
- Bi et al. [2024a] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, Huazuo Gao, Kaige Gao, Wenjun Gao, Ruiqi Ge, Kang Guan, Daya Guo, Jianzhong Guo, Guangbo Hao, Zhewen Hao, Ying He, Wenjie Hu, Panpan Huang, Erhang Li, Guowei Li, Jiashi Li, Yao Li, Y. K. Li, Wenfeng Liang, Fangyun Lin, Alex X. Liu, Bo Liu, Wen Liu, Xiaodong Liu, Xin Liu, Yiyuan Liu, Haoyu Lu, Shanghao Lu, Fuli Luo, Shirong Ma, Xiaotao Nie, Tian Pei, Yishi Piao, Junjie Qiu, Hui Qu, Tongzheng Ren, Zehui Ren, Chong Ruan, Zhangli Sha, Zhihong Shao, Junxiao Song, Xuecheng Su, Jingxiang Sun, Yaofeng Sun, Minghui Tang, Bingxuan Wang, Peiyi Wang, Shiyu Wang, Yaohui Wang, Yongji Wang, Tong Wu, Y. Wu, Xin Xie, Zhenda Xie, Ziwei Xie, Yiliang Xiong, Hanwei Xu, R. X. Xu, Yanhong Xu, Dejian Yang, Yuxiang You, Shuiping Yu, Xingkai Yu, B. Zhang, Haowei Zhang, Lecong Zhang, Liyue Zhang, Mingchuan Zhang, Minghua Zhang, Wentao Zhang, Yichao Zhang, Chenggang Zhao, Yao Zhao, Shangyan Zhou, Shunfeng Zhou, Qihao Zhu, and Yuheng Zou. 2024a. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. CoRR, abs/2401.02954.
- Bi et al. [2024b] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. 2024b. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954.
- Biderman et al. [2023] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 2023. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR.
- Bisk et al. [2020] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439.
- Blevins et al. [2024] Terra Blevins, Tomasz Limisiewicz, Suchin Gururangan, Margaret Li, Hila Gonen, Noah A Smith, and Luke Zettlemoyer. 2024. Breaking the Curse of Multilinguality with Cross-lingual Expert Language Models. arXiv preprint arXiv:2401.10440.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Cai et al. [2024] Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, Xiaoyi Dong, Haodong Duan, Qi Fan, Zhaoye Fei, Yang Gao, Jiaye Ge, Chenya Gu, Yuzhe Gu, Tao Gui, Aijia Guo, Qipeng Guo, Conghui He, Yingfan Hu, Ting Huang, Tao Jiang, Penglong Jiao, Zhenjiang Jin, Zhikai Lei, Jiaxing Li, Jingwen Li, Linyang Li, Shuaibin Li, Wei Li, Yining Li, Hongwei Liu, Jiangning Liu, Jiawei Hong, Kaiwen Liu, Kuikun Liu, Xiaoran Liu, Chengqi Lv, Haijun Lv, Kai Lv, Li Ma, Runyuan Ma, Zerun Ma, Wenchang Ning, Linke Ouyang, Jiantao Qiu, Yuan Qu, Fukai Shang, Yunfan Shao, Demin Song, Zifan Song, Zhihao Sui, Peng Sun, Yu Sun, Huanze Tang, Bin Wang, Guoteng Wang, Jiaqi Wang, Jiayu Wang, Rui Wang, Yudong Wang, Ziyi Wang, Xingjian Wei, Qizhen Weng, Fan Wu, Yingtong Xiong, Chao Xu, Ruiliang Xu, Hang Yan, Yirong Yan, Xiaogui Yang, Haochen Ye, Huaiyuan Ying, Jia Yu, Jing Yu, Yuhang Zang, Chuyu Zhang, Li Zhang, Pan Zhang, Peng Zhang, Ruijie Zhang, Shuo Zhang, Songyang Zhang, Wenjian Zhang, Wenwei Zhang, Xingcheng Zhang, Xinyue Zhang, Hui Zhao, Qian Zhao, Xiaomeng Zhao, Fengzhe Zhou, Zaida Zhou, Jingming Zhuo, Yicheng Zou, Xipeng Qiu, Yu Qiao, and Dahua Lin. 2024. InternLM2 Technical Report. arxiv.
- Cherti et al. [2023] Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. 2023. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829.
- Chowdhery et al. [2023] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Clark et al. [2019] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Du et al. [2021] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2021. Glm: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv:2103.10360.
- Enarvi et al. [2017] Seppo Enarvi, Peter Smit, Sami Virpioja, and Mikko Kurimo. 2017. Automatic speech recognition with very large conversational finnish and estonian vocabularies. IEEE/ACM Transactions on audio, speech, and language processing, 25(11):2085–2097.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883.
- Gadre et al. [2024] Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, et al. 2024. Language models scale reliably with over-training and on downstream tasks. arXiv preprint arXiv:2403.08540.
- Gao et al. [2019] Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. 2019. Representation degeneration problem in training natural language generation models. arXiv preprint arXiv:1907.12009.
- Groeneveld et al. [2024] Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. 2024. Olmo: Accelerating the science of language models. arXiv preprint arXiv:2402.00838.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
- Huang et al. [2024] Yuzhen Huang, Jinghan Zhang, Zifei Shan, and Junxian He. 2024. Compression Represents Intelligence Linearly. CoRR, abs/2404.09937.
- Isik et al. [2024] Berivan Isik, Natalia Ponomareva, Hussein Hazimeh, Dimitris Paparas, Sergei Vassilvitskii, and Sanmi Koyejo. 2024. Scaling Laws for Downstream Task Performance of Large Language Models. arXiv preprint arXiv:2402.04177.
- Jiang et al. [2023] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7B. arXiv preprint arXiv:2310.06825.
- Kaplan et al. [2020] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Le Scao et al. [2023] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2023. Bloom: A 176b-parameter open-access multilingual language model.
- Li et al. [2024] Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G. Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, and Vaishaal Shankar. 2024. DataComp-LM: In search of the next generation of training sets for language models.
- Li et al. [2023] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161.
- Liao et al. [2021] Xianwen Liao, Yongzhong Huang, Changfu Wei, Chenhao Zhang, Yongqing Deng, and Ke Yi. 2021. Efficient estimate of low-frequency words’ embeddings based on the dictionary: a case study on Chinese. Applied Sciences, 11(22):11018.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Lozhkov et al. [2024] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. StarCoder 2 and The Stack v2: The Next Generation. arXiv preprint arXiv:2402.19173.
- Luukkonen et al. [2023] Risto Luukkonen, Ville Komulainen, Jouni Luoma, Anni Eskelinen, Jenna Kanerva, Hanna-Mari Kupari, Filip Ginter, Veronika Laippala, Niklas Muennighoff, Aleksandra Piktus, et al. 2023. Fingpt: Large generative models for a small language. arXiv preprint arXiv:2311.05640.
- Mei et al. [2024] Kangfu Mei, Zhengzhong Tu, Mauricio Delbracio, Hossein Talebi, Vishal M Patel, and Peyman Milanfar. 2024. Bigger is not Always Better: Scaling Properties of Latent Diffusion Models. arXiv preprint arXiv:2404.01367.
- Meta AI [2024] Meta AI. 2024. Meta LLaMA-3: The most capable openly available LLM to date. https://ai.meta.com/blog/meta-llama-3/.
- Mihaylov et al. [2018] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789.
- Muennighoff et al. [2023a] Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro Von Werra, and Shayne Longpre. 2023a. Octopack: Instruction tuning code large language models. arXiv preprint arXiv:2308.07124.
- Muennighoff et al. [2024] Niklas Muennighoff, Alexander Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Aleksandra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin A Raffel. 2024. Scaling data-constrained language models. Advances in Neural Information Processing Systems, 36.
- Muennighoff et al. [2023b] Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Khalid Almubarak, Samuel Albanie, Zaid Alyafeai, Albert Webson, Edward Raff, and Colin Raffel. 2023b. Crosslingual Generalization through Multitask Finetuning.
- Nvidia et al. [2024] Nvidia, :, Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H. Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, Sirshak Das, Ayush Dattagupta, Olivier Delalleau, Leon Derczynski, Yi Dong, Daniel Egert, Ellie Evans, Aleksander Ficek, Denys Fridman, Shaona Ghosh, Boris Ginsburg, Igor Gitman, Tomasz Grzegorzek, Robert Hero, Jining Huang, Vibhu Jawa, Joseph Jennings, Aastha Jhunjhunwala, John Kamalu, Sadaf Khan, Oleksii Kuchaiev, Patrick LeGresley, Hui Li, Jiwei Liu, Zihan Liu, Eileen Long, Ameya Sunil Mahabaleshwarkar, Somshubra Majumdar, James Maki, Miguel Martinez, Maer Rodrigues de Melo, Ivan Moshkov, Deepak Narayanan, Sean Narenthiran, Jesus Navarro, Phong Nguyen, Osvald Nitski, Vahid Noroozi, Guruprasad Nutheti, Christopher Parisien, Jupinder Parmar, Mostofa Patwary, Krzysztof Pawelec, Wei Ping, Shrimai Prabhumoye, Rajarshi Roy, Trisha Saar, Vasanth Rao Naik Sabavat, Sanjeev Satheesh, Jane Polak Scowcroft, Jason Sewall, Pavel Shamis, Gerald Shen, Mohammad Shoeybi, Dave Sizer, Misha Smelyanskiy, Felipe Soares, Makesh Narsimhan Sreedhar, Dan Su, Sandeep Subramanian, Shengyang Sun, Shubham Toshniwal, Hao Wang, Zhilin Wang, Jiaxuan You, Jiaqi Zeng, Jimmy Zhang, Jing Zhang, Vivienne Zhang, Yian Zhang, and Chen Zhu. 2024. Nemotron-4 340B Technical Report. arxiv.
- OpenAI et al. [2023] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Peng et al. [2023] Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, et al. 2023. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048.
- Peng et al. [2024] Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Teddy Ferdinan, Haowen Hou, Przemysław Kazienko, et al. 2024. Eagle and Finch: RWKV with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.05892.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. 2018. Improving language understanding by generative pre-training.
- Rae et al. [2021] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. 2021. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446.
- Ren et al. [2023] Xiaozhe Ren, Pingyi Zhou, Xinfan Meng, Xinjing Huang, Yadao Wang, Weichao Wang, Pengfei Li, Xiaoda Zhang, Alexander Podolskiy, Grigory Arshinov, et al. 2023. Pangu-Sigma: Towards trillion parameter language model with sparse heterogeneous computing. arXiv preprint arXiv:2303.10845.
- Roh et al. [2020] Jihyeon Roh, Sang-Hoon Oh, and Soo-Young Lee. 2020. Unigram-normalized perplexity as a language model performance measure with different vocabulary sizes. arXiv preprint arXiv:2011.13220.
- Ruan et al. [2024] Yangjun Ruan, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Observational Scaling Laws and the Predictability of Language Model Performance.
- Sakaguchi et al. [2021] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Sardana and Frankle [2023] Nikhil Sardana and Jonathan Frankle. 2023. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws. arXiv preprint arXiv:2401.00448.
- Scao et al. [2022] Teven Le Scao, Thomas Wang, Daniel Hesslow, Lucile Saulnier, Stas Bekman, M Saiful Bari, Stella Biderman, Hady Elsahar, Niklas Muennighoff, Jason Phang, et al. 2022. What language model to train if you have one million gpu hours? arXiv preprint arXiv:2210.15424.
- Sennrich et al. [2016] Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, Volume 1: Long Papers. The Association for Computer Linguistics.
- Shoeybi et al. [2019] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053.
- Soboleva et al. [2023] Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R Steeves, Joel Hestness, and Nolan Dey. 2023. SlimPajama: A 627B token cleaned and deduplicated version of RedPajama.
- Soldaini et al. [2024] Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, et al. 2024. Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. arXiv preprint arXiv:2402.00159.
- Takahashi and Tanaka-Ishii [2017] Shuntaro Takahashi and Kumiko Tanaka-Ishii. 2017. Do neural nets learn statistical laws behind natural language? PloS one, 12(12):e0189326.
- Tay et al. [2023] Yi Tay, Mostafa Dehghani, Samira Abnar, Hyung Chung, William Fedus, Jinfeng Rao, Sharan Narang, Vinh Tran, Dani Yogatama, and Donald Metzler. 2023. Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling? In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 12342–12364, Singapore. Association for Computational Linguistics.
- Team et al. [2024] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295.
- Tian et al. [2024] Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. 2024. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. arXiv preprint arXiv:2404.02905.
- Touvron et al. [2023a] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. [2023b] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Villalobos et al. [2022] Pablo Villalobos, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, and Anson Ho. 2022. Will we run out of data? an analysis of the limits of scaling datasets in machine learning. arXiv preprint arXiv:2211.04325.
- Wan et al. [2023] Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, et al. 2023. Efficient large language models: A survey. arXiv preprint arXiv:2312.03863, 1.
- Wang et al. [2019] Hai Wang, Dian Yu, Kai Sun, Janshu Chen, and Dong Yu. 2019. Improving pre-trained multilingual models with vocabulary expansion. arXiv preprint arXiv:1909.12440.
- Wang et al. [2023] Haiming Wang, Ye Yuan, Zhengying Liu, Jianhao Shen, Yichun Yin, Jing Xiong, Enze Xie, Han Shi, Yujun Li, Lin Li, et al. 2023. Dt-solver: Automated theorem proving with dynamic-tree sampling guided by proof-level value function. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12632–12646.
- Wang et al. [2024] Junxiong Wang, Tushaar Gangavarapu, Jing Nathan Yan, and Alexander M Rush. 2024. Mambabyte: Token-free selective state space model. arXiv preprint arXiv:2401.13660.
- Xu et al. [2020] Jingjing Xu, Hao Zhou, Chun Gan, Zaixiang Zheng, and Lei Li. 2020. Vocabulary learning via optimal transport for neural machine translation. arXiv preprint arXiv:2012.15671.
- Xue et al. [2024] Fuzhao Xue, Yao Fu, Wangchunshu Zhou, Zangwei Zheng, and Yang You. 2024. To repeat or not to repeat: Insights from scaling llm under token-crisis. Advances in Neural Information Processing Systems, 36.
- Yang et al. [2024] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, Peng Wang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie Wang, Shuai Bai, Sinan Tan, Tianhang Zhu, Tianhao Li, Tianyu Liu, Wenbin Ge, Xiaodong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin Wei, Xuancheng Ren, Yang Fan, Yang Yao, Yichang Zhang, Yu Wan, Yunfei Chu, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, and Zhihao Fan. 2024. Qwen2 Technical Report. arxiv.
- Yu et al. [2024] Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. 2024. Megabyte: Predicting million-byte sequences with multiscale transformers. Advances in Neural Information Processing Systems, 36.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830.
- Zhang et al. [2024] Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. 2024. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385.
- Zhuo et al. [2024a] Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, David Lo, Binyuan Hui, Niklas Muennighoff, Daniel Fried, Xiaoning Du, Harm de Vries, and Leandro Von Werra. 2024a. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions.
- Zhuo et al. [2024b] Terry Yue Zhuo, Armel Zebaze, Nitchakarn Suppattarachai, Leandro von Werra, Harm de Vries, Qian Liu, and Niklas Muennighoff. 2024b. Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models.
- Üstün et al. [2024] Ahmet Üstün, Viraat Aryabumi, Zheng-Xin Yong, Wei-Yin Ko, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, Freddie Vargus, Phil Blunsom, Shayne Longpre, Niklas Muennighoff, Marzieh Fadaee, Julia Kreutzer, and Sara Hooker. 2024. Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model.
Appendix A Appendix
A.1 The derivation of FLOPs w.r.t the vocabulary size for the Approach 2
Here we provide the detailed process of how we compute the extreme point of FLOPs with respect to . From Kaplan et al. [28], we know that:
| (9) |
We then compute the derivative as follows:
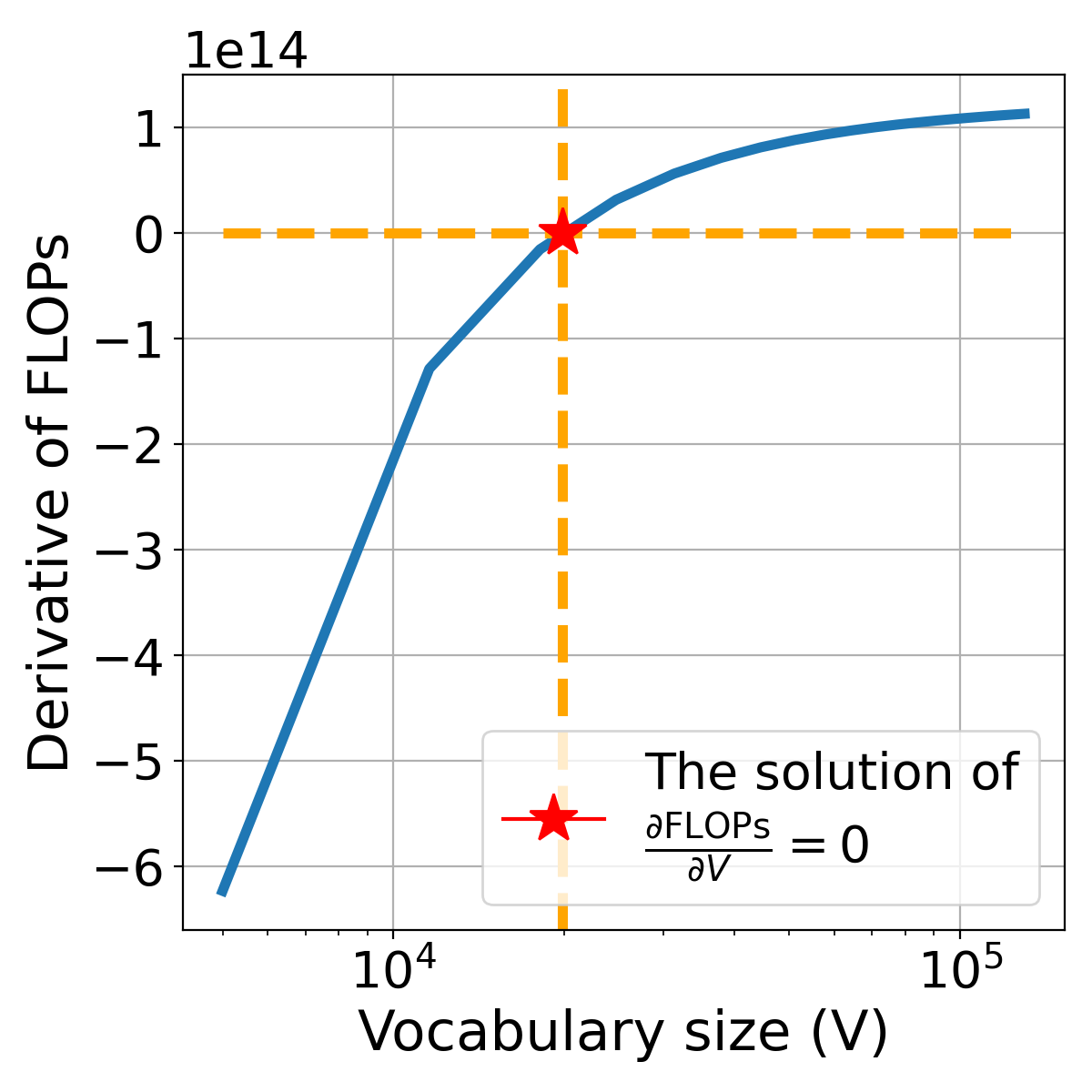
The solution of corresponds to the minimum point of the FLOPs. Since the variable in this equation is not separated conveniently, we use a numerical search method, specifically scipy.optimize.fsolve, to find the solution.
Example demonstration
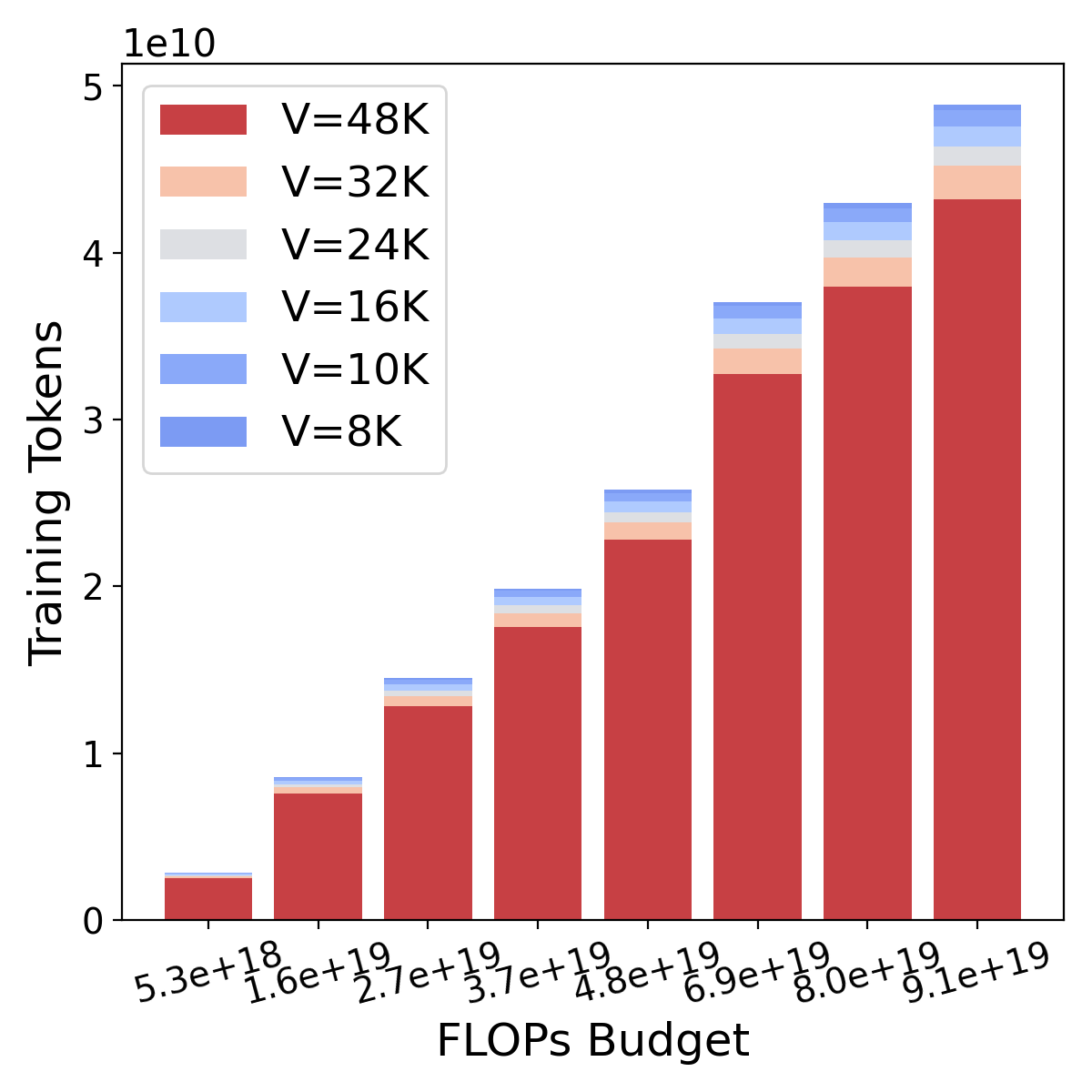
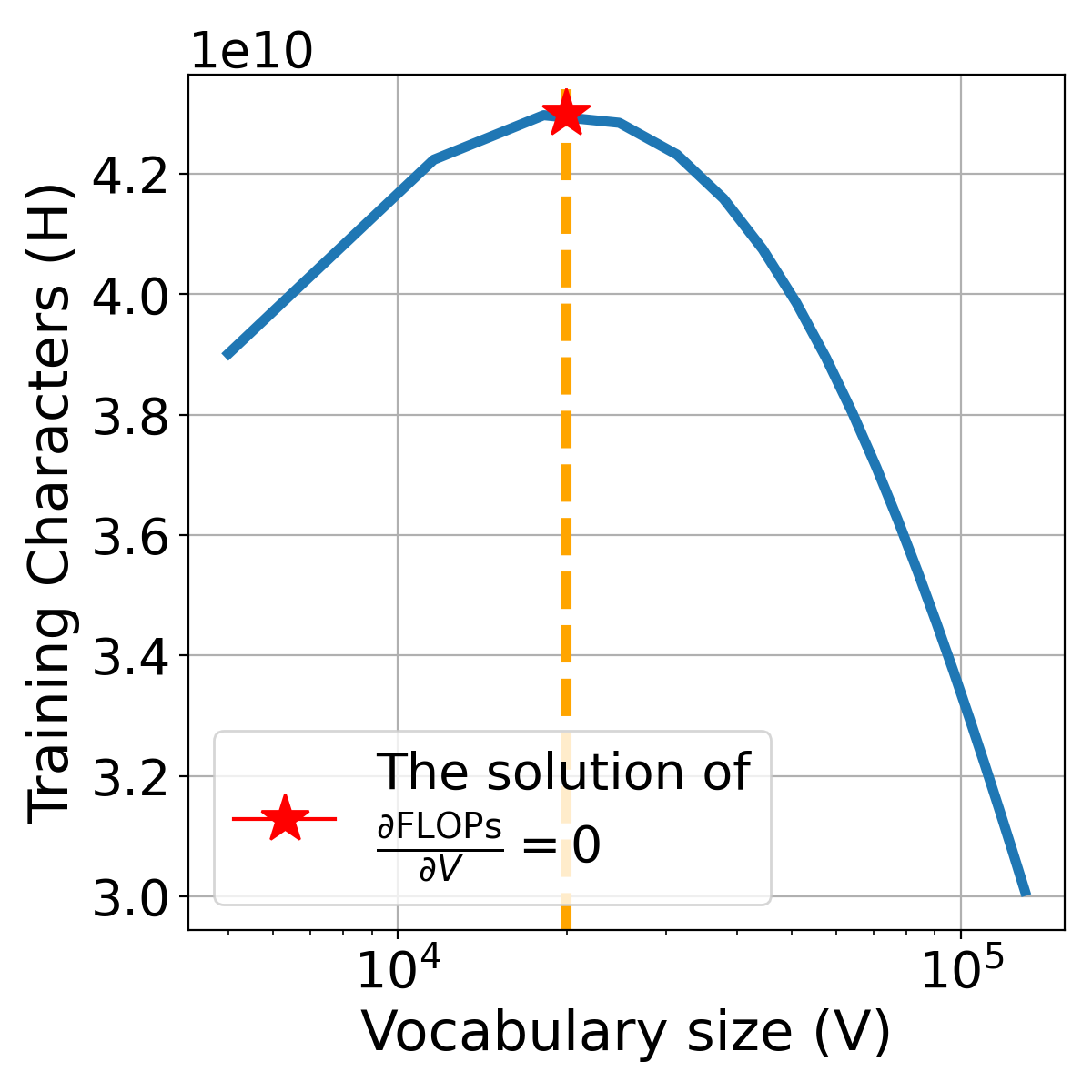
Figure 8 illustrates the relationship between the derivative of FLOPs with respect to the vocabulary size and itself. Setting as the solution to , we find the point at which FLOPs are minimized. As depicted in Figure 8 (right), the FLOPs budget is fixed, and we observe how the training character varies with . Notably, at the optimal vocabulary size , the model expends the maximum number of training characters for a given budget. This observation provides insight into why an optimal vocabulary size exists for a given FLOPs budget.
A.2 The derivation of loss w.r.t the vocabulary size in Approach 3
Here we provide how we derive the loss w.r.t the vocabulary size given a FLOPs budget in Approach 3. After substituting the with the based on Equation 9:
| (10) |
The loss is solely dependent on the , given a . The derivative w.r.t. is:
The solution of corresponds to the optimal . Similar with Approach 2, we use scipy.optimize.fsolve to find the solution.
A.3 More visualizations for the analyses: Why the optimal vocabulary size is bounded by the compute
Word embeddings in a large vocabulary are hard to learn when FLOPs are constrained

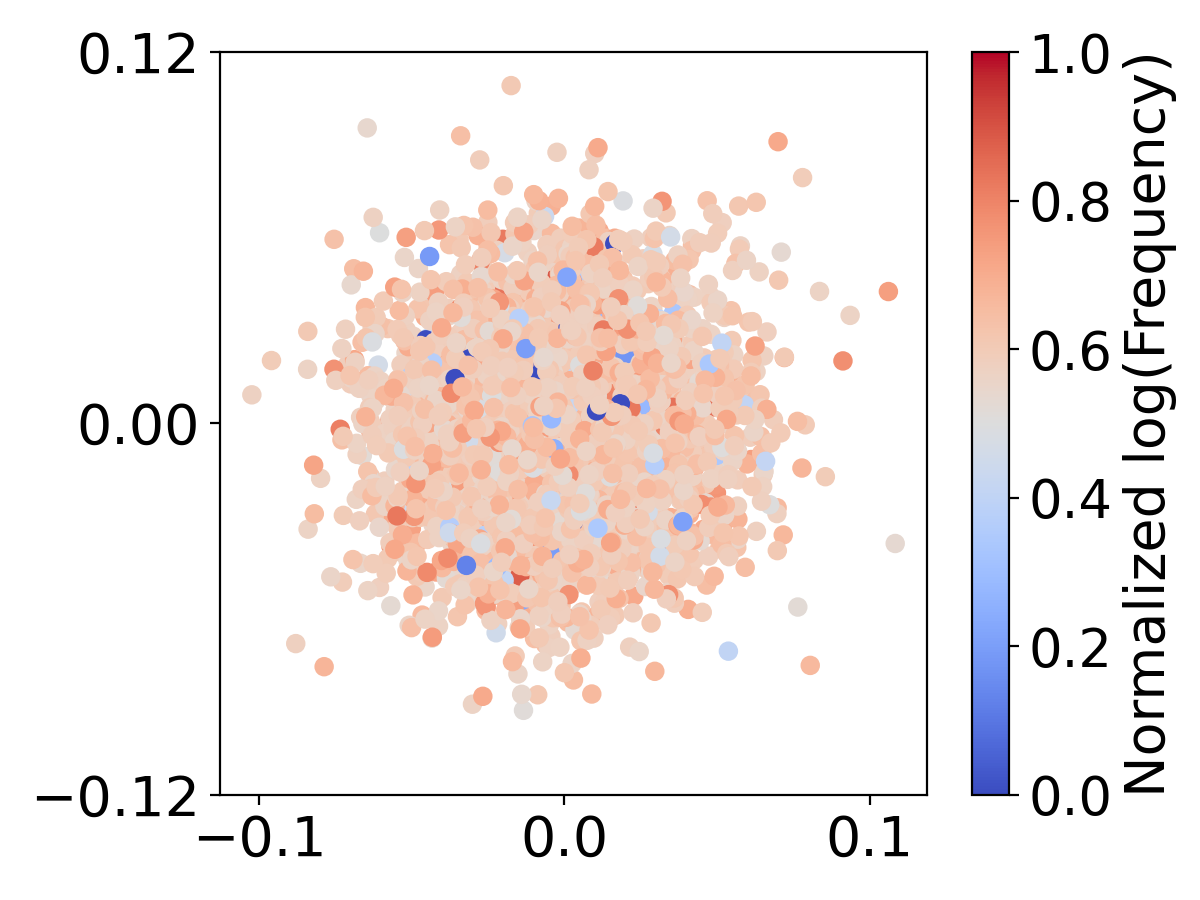
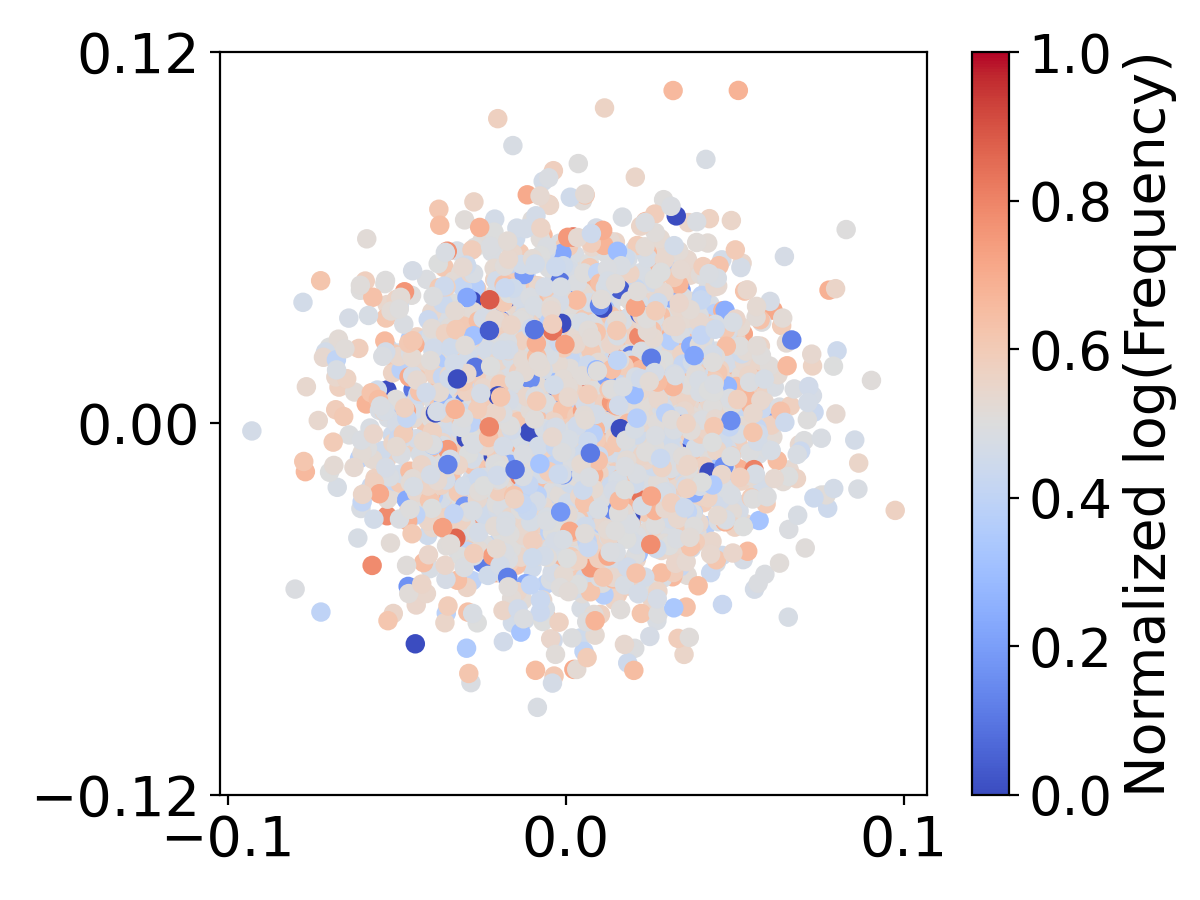
Previous studies have shown embeddings suffer from representation degradation, where low-frequency word embeddings cluster together due to limited parameter updating [22]. In Figure 9, we visualize how the word embeddings distribute using different vocabulary sizes. We use the average Euclidean distance among all the embeddings, , to quantify the degree of clustering, which is 1.067, 1.011, and 0.952 for , and , respectively. Larger vocabularies () lead to more clustering of embeddings, especially for infrequent words. This clustering suggests that they have been insufficiently trained. Conversely, a small-sized vocabulary () and middle-sized vocabulary () display a more dispersed distribution of embeddings. These observations suggest that there exists an optimal vocabulary size that balances lexicon coverage and sufficient updating of word embedding. Language models with large vocabulary sizes may have better lexicon coverage, but on the other hand, hinder the model’s ability to sufficiently update the word embeddings, especially for low-frequency words.
A.4 Exploration of Larger Range of Vocabulary Sizes
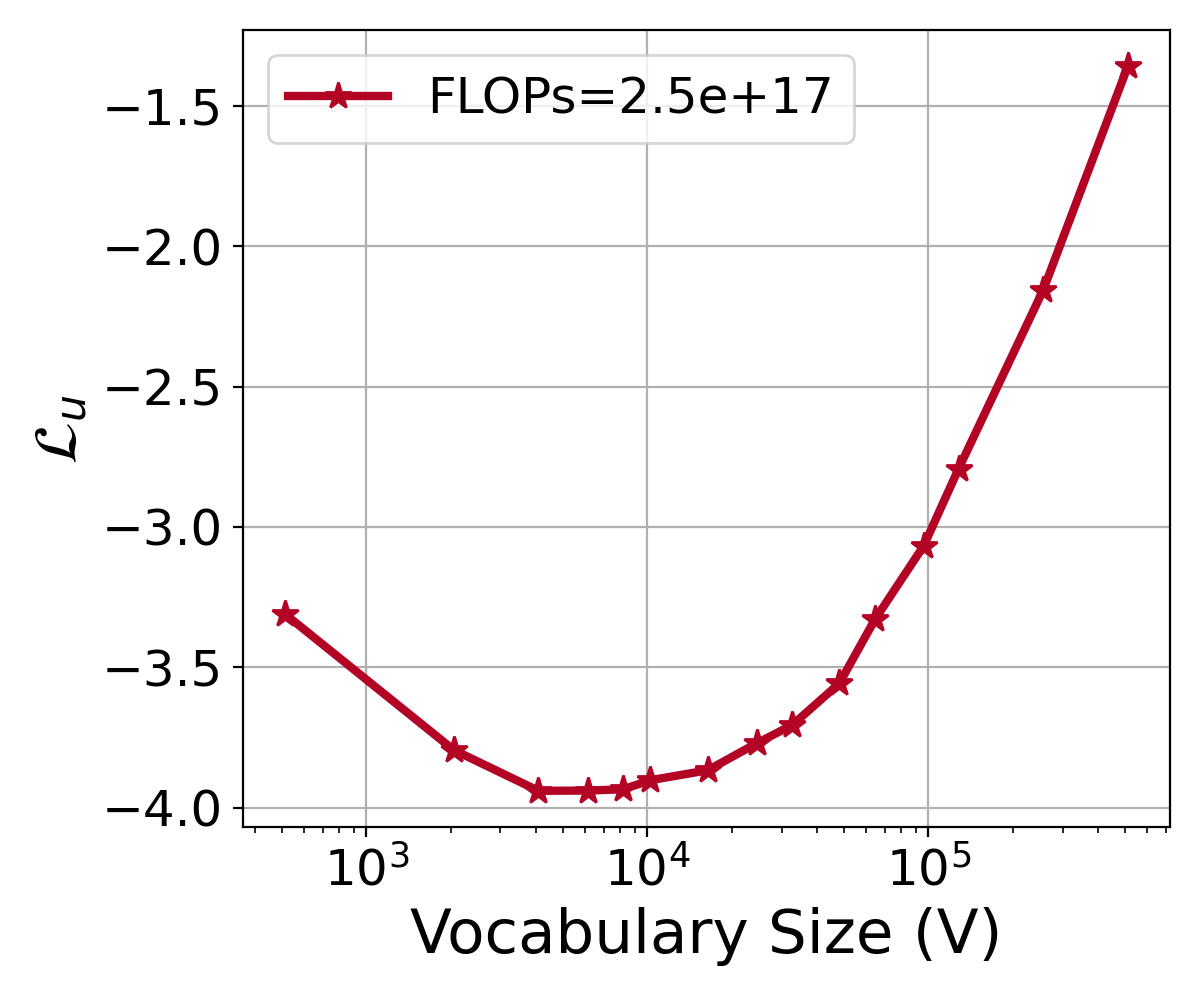
Because of computational resource constraints, the vocabulary sizes we used to fit the scaling laws are in the range of 4K to 96K. This range is sufficient to fit, because the optimal vocabulary sizes for all the training configurations we used fall in this range.
To further verify that there is always an optimal vocabulary size holds for a larger range of vocabulary lists, we increase the range of vocabulary sizes from 1K to 512K, with the fixed as 33M. As depicted in the Figure 10, the model’s performance declines consistently as the vocabulary size increases beyond the optimal configuration. This figure shows loss curves for vocabulary sizes up to 512K, given a specific FLOPs budget. The data indicates a consistent degradation in model performance with the vocabulary size away from the optimal one. It suggests that there is a critical point beyond which the model’s efficiency in handling the vocabulary diminishes. This exploration underscores the importance of carefully selecting the vocabulary size to maintain optimal model performance within the constraints of a given computational budget.
A.5 Implementation details
A.5.1 Setting of model architecture, vocabulary size and training characters
We list the architectures of the models and the corresponding number of training characters in Table 4. For each model family, we fix the non-vocabulary parameters and vary the vocabulary size. We adopt the Llama architecture [63], except for the vocabulary size. For the vocabulary size, we use numbers divisible by 128 for compatibility with NVIDIA’s tensor core to accelerate matrix multiplication 333https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html. Specifically, the vocabulary sizes we adopt for each model family are 4096, 6144, 8192, 10240, 16384, 24576, 32768, 48128, 64512 and 96256. The expected number of training tokens and characters vary slightly given a fixed number of non-vocabulary parameters and a FLOP budget. We use the middle-sized of 16384 to determine the number of training characters and the corresponding FLOPs budget, except for we use .
| (M) | #Sequence Length | #Layers | #Heads | #Embedding Dim. | #Intermediate Size | Training Characters (B) |
| 33 | 2048 | 8 | 8 | 512 | 2048 | 4.3 |
| 85 | 2048 | 12 | 12 | 768 | 2048 | 11.1 |
| 151 | 2048 | 16 | 12 | 768 | 3072 | 19.6 |
| 302 | 2048 | 18 | 16 | 1024 | 4096 | 43.0 |
| 631 | 2048 | 20 | 24 | 1536 | 4800 | 101.6 |
| 1130 | 2048 | 22 | 32 | 2048 | 5632 | 201.3 |
| 2870 | 2048 | 24 | 32 | 3200 | 8192 | 509.3 |
A.5.2 The relationship between non-vocabulary parameters and embedding dimension
According to the observation in Kaplan et al. [28], the depth-width ratio has a relatively small effect on performance given the total non-vocabulary parameters. Thus, to ease the modeling of our scaling laws taking vocabulary size into account, we take the width (i.e. embedding dimension) as given following prior work [28, 24, 40, 64, 76]. The relationship between the non-vocabulary parameters and embedding dimension used in our experiments are in Table 5.
| Non-vocabulary Parameters | #Embedding Dim. |
| 512 | |
| 768 | |
| 1024 | |
| 1536 | |
| 2048 | |
| 3200 | |
| 4096 | |
| 5120 | |
| 6048 | |
| 8192 | |
| 12288 | |
| 16384 | |
| 20480 |
A.5.3 Training details
The maximum learning rate is set to 4e-4 and decays to 10% i.e. 4e-5 similar to prior scaling work [24, 40]. We use AdamW [33] as our optimizer and accelerate training with bfloat16 mixed precision training. For models with , we use a single node with 8 GPUs for training. Otherwise, we adopt the Megatron-LM framework [56] for multi-node training with 8 GPUs on each node. For our experiments with , it takes about 120 hours to train on over training characters with 64 total GPUs. We use a global batch size of 512 for all runs and run all experiments on 40GB Nvidia-A100 GPUs.
A.5.4 Fitting techniques
Approach 1
To avoid numerical underflow and overflow of the fitting parameters, we fit the data in a logarithmic form inspired by Hoffmann et al. [24]. Taking as an example, we learn the parameters , by minimizing:
| (11) |
where and denotes the Huber loss with delta value ( is 0.001 in our paper). We use the LBFGS algorithm to find the local minima of the function. The later Approach 2 and 3 use the same optimization algorithm. We initialize all attributes from the same uniform grid where and with 20 initial guesses respectively. The fitting takes less than half of one minute.
To cheaply obtain more experimental data points, we perform interpolation of (, , ) triplets in the logarithmic scale and predict the validation loss based on real data points. Then, we compute the required FLOPs for each data point using Equation 5.
Approach 2
By using different and obtaining the corresponding optimal based on Equation 7, we have a set of . Denoting and , we learn the scaling proportion by minimizing:
| (12) |
The initial guess of is uniformly sampled from .
Approach 3
We recast the designed vocabulary-dependent loss formula here:
| (13) |
where . In practice, we try to minimize:
where . We initialize all attributes from the same uniform grid where , , , , and with 3 initial guesses respectively. Given the prior that the scaling factor is typically ranged between 0 and 1 [24], we add a constraint during fitting. The fitting also takes less than half of one minute.
A.6 Details of fitting tokens-character relationship function
We train 25 tokenizers with the following vocabulary sizes: 1024, 2048, 3072, 4096, 5120, 6144, 7168, 8192, 9216, 10240, 12288, 16384, 20480, 24576, 28672, 32768, 48128, 64512, 78848, 96256, 128000, 256000, 512000, 1024000. Then, we train the tokenizers on a uniformly sampled version of the Slimpajama dataset.
Later, we apply the trained tokenizers on the validation set of the Slimpajama dataset and collect the number of tokens for each tokenizer with vocabulary size . We use scipy.optimize.curve_fit to fit the parameters in (§2.2).
A.7 Robustness of the tokens-characters relationship function
Robustness to the type of tokenizers
Besides the widely adopted BPE tokenizer used in our experiment, we also consider the unigram tokenizer and the word-based tokenizer. We visualize their tokens-characters ratio and corresponding predictive function in Figure 11. We find that our proposed formula of is a good predictor for the tokens-character ratio, regardless of which tokenizer is used. This verifies the effectiveness of our proposed formula. The tokenization fertility of the unigram tokenizer is close to that of the BPE tokenizer as seen in their similar y-axis values, since they both employ subword-based tokenization. Meanwhile, the tokenization fertility of word-based tokenization is poor, thus requiring more tokens on average to compress characters.
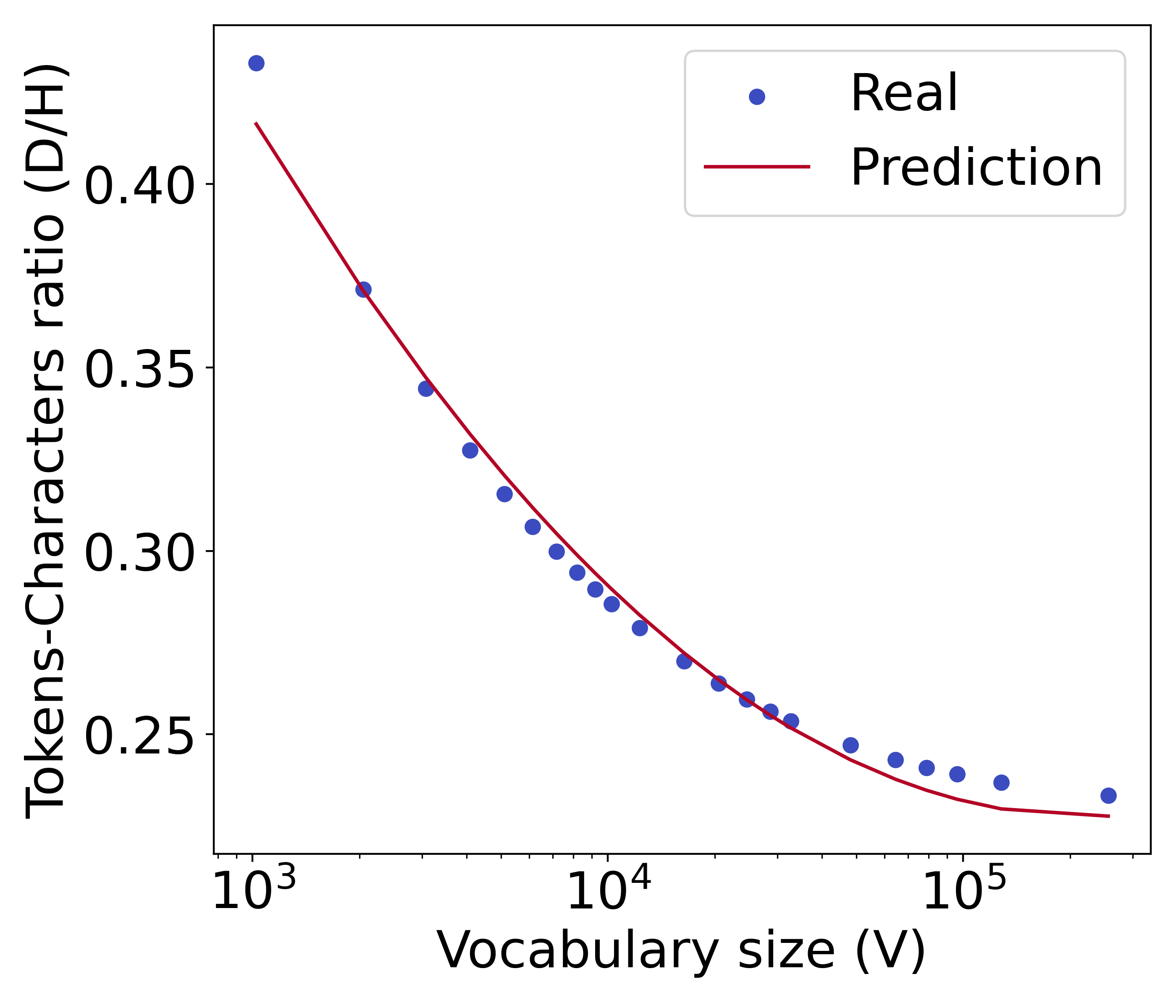
=3.8e-4, =0.99
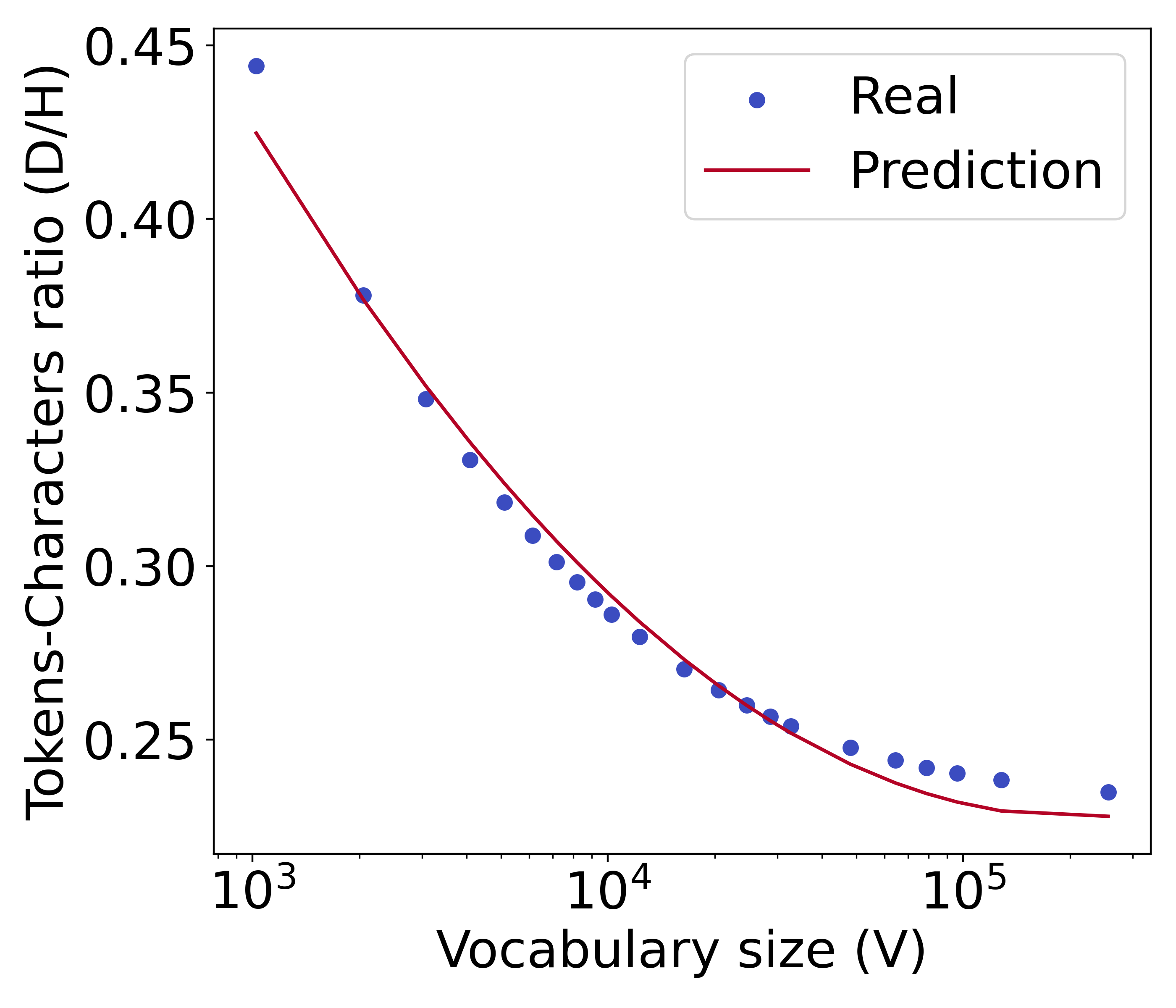
=5.2e-4, =0.98
=3.6e-5, =0.99
Robustness to the range of the vocabulary size
The quadratic function on the logarithmic value of vocabulary size that we propose can precisely predict the tokens-characters ratio with an RMSE of 1.5e-6 and of 0.99. However, as a quadratic function is single-peaked, increasing will increase the output value of when is very large, e.g. in our case.
Fortunately, when is sufficiently large, the tokenization fertility improvement of the tokenizer decays sharply, which results in almost no change to the value of . This is because the words in the training corpus can already be effectively covered by the vocabulary list when the vocabulary size is sufficiently large. In this extreme, the tokenization fertility of the corresponding tokenizer is approaching saturation, thus further increasing the vocabulary size will hardly improve the tokenization fertility.
As an example, there are about 2300M characters in the validation set of the Slimpajama corpus. A tokenizer using a vocabulary size of 2 would yield 140 fewer tokens than a 1 counterpart, but the number of tokens only decreases by 0.7 when going from a vocabulary size of 256 to 257. Therefore, we add before calculating to ensure its decreasing nature. According to our prediction, a model with 300 parameters has an optimal vocabulary size of no more than 400 with a sufficient amount of training data. If we need to consider extremely large in the future, we can train tokenizers with larger in the process of fitting to arrive at more precise predictions.
A.8 Experimental verification on the fairness of the unigram-normalized language modeling loss
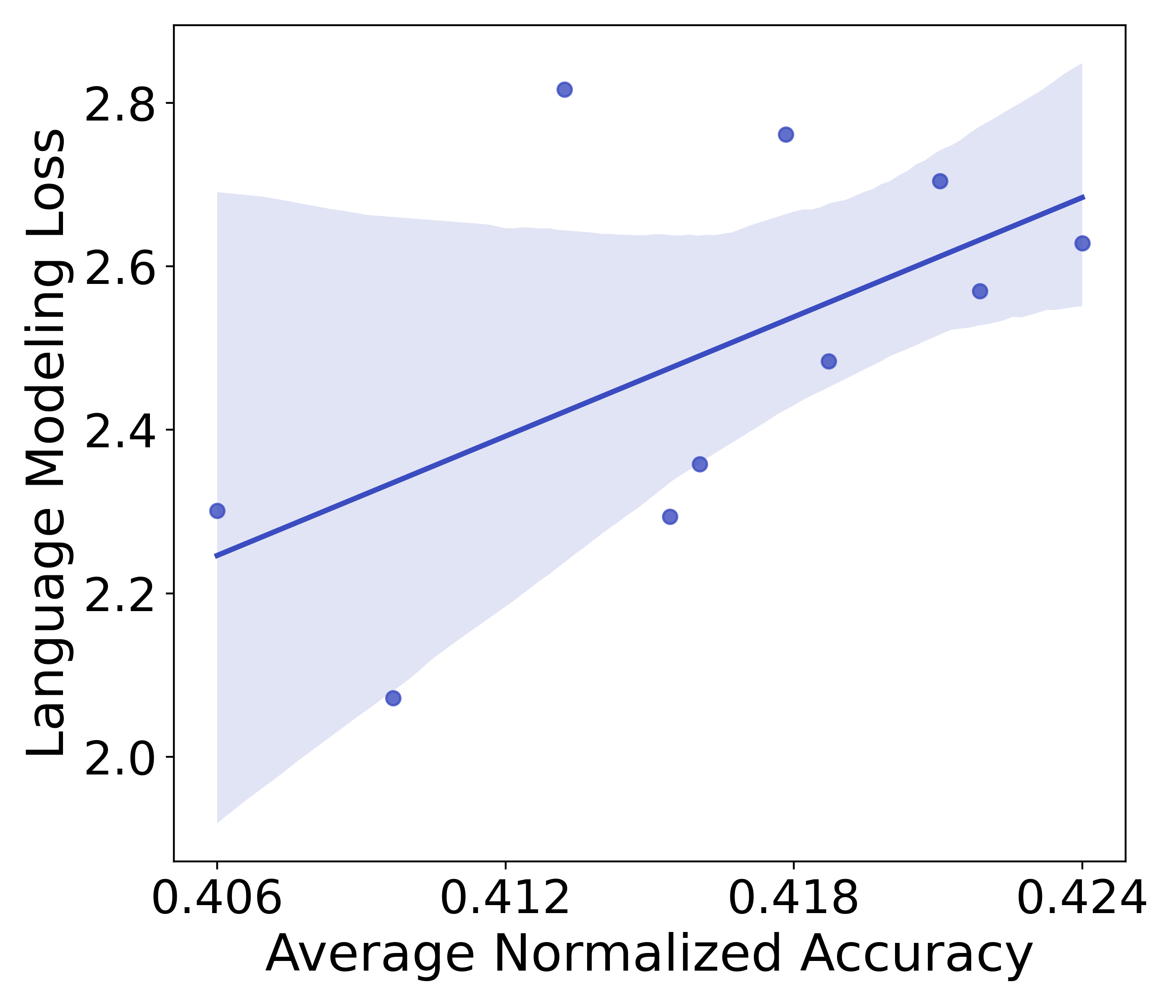
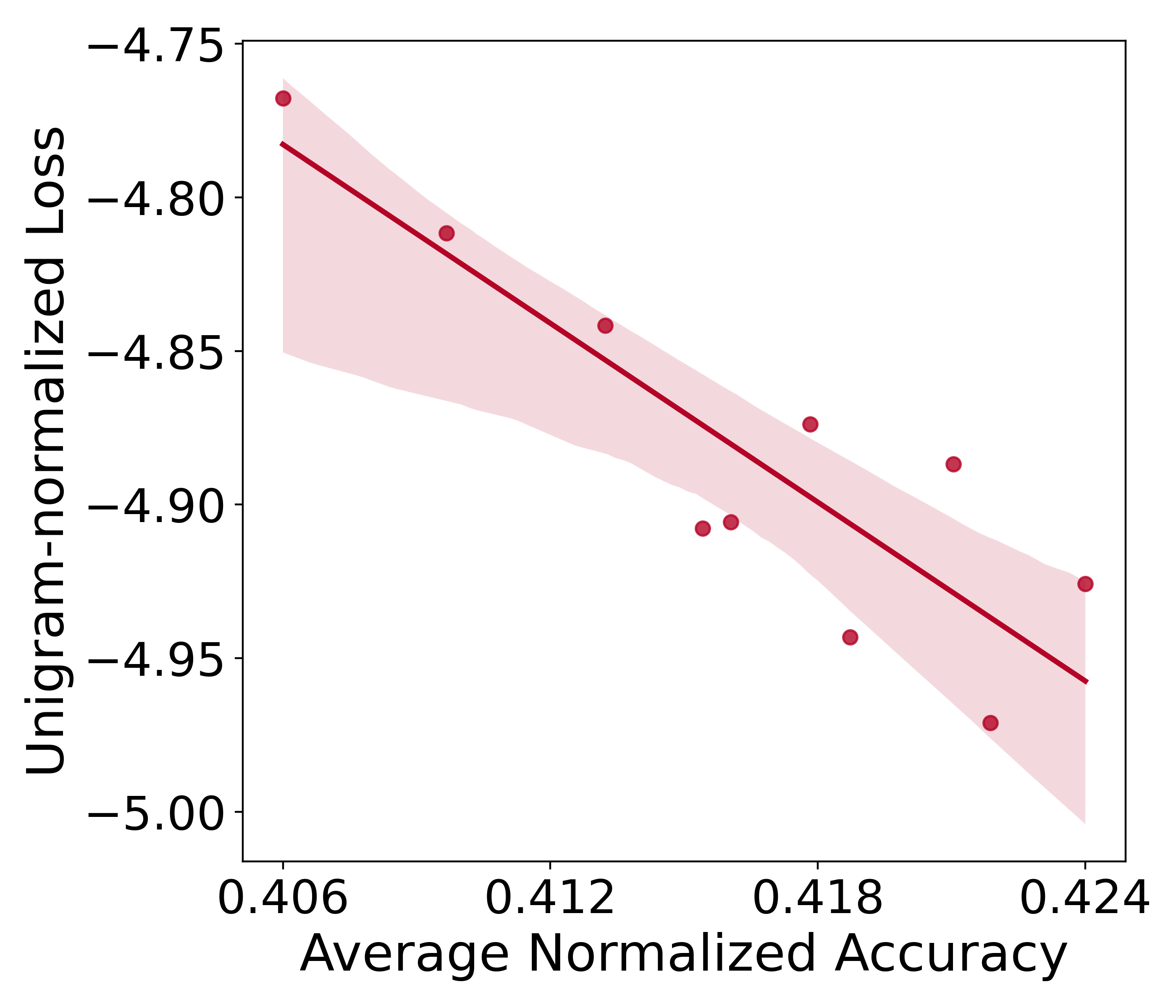
In §2.2, we have explained that we use a unigram-normalized loss, , to fairly evaluate models that vary in vocabulary size. Here we empirically verify this choice. We train models with a fixed number of non-vocabulary parameters and embedding dimension but varying vocabulary sizes . Thus, their vocabulary parameters also vary. We plot the final language model loss and unigram-normalized loss of these models compared to downstream performance in Figure 12. The language modeling loss exhibits a positive correlation with downstream performance: Models with a higher language modeling loss have better downstream performance. This is because our models with larger vocabularies naturally have a higher loss due to the objective function, yet they can be actually better models with better downstream performance. Our unigram-normalized loss solves this problem and exhibits the expected negative correlation between loss and downstream performance: a lower loss comes with better downstream performance. This empirically justifies our use of throughout this work.
Appendix B Limitation and future work
B.1 Limitations of our proposed approaches
Approach 1
The Approach 1 provides a broader solution by predicting the allocation of computational resources across non-vocabulary parameters, vocabulary parameters, and training data based on experimental data points. This method’s strength lies in its holistic view, allowing for a balanced resource distribution that potentially enhances model efficiency and performance. However, this approach is constrained by the granularity and range of the experimental data points available, which can introduce errors in the fitting process. The requirement for substantial computational resources to perform these fittings may also limit its accessibility and scalability. Despite these challenges, when experimental data is ample and computational resources are sufficient, the Approach 1 can significantly refine the precision of resource allocation decisions in the development of large-scale language models.
Approach 2
By calculating the derivative of FLOPs with respect to the vocabulary size and solving for zero, this approach fundamentally relies on the precision of the FLOPs equation and our tokens-characters relationship function. Further, this method does not allow us to independently determine the optimal allocation of non-vocabulary parameters and training data size. Therefore, it necessitates information about the relationships between these attributes and the FLOPs budget from the experimentally fitted scaling laws, making this approach less useful in practice. Despite these limitations, the derivative-based approach offers notable advantages, including closely matched predictions with the scaling laws derived from actual experimental data in the Approach 2. Furthermore, its reliance on numerical solutions rather than exhaustive deep learning experiments makes it rapid and broadly applicable across various tokenizers, highlighting its utility in preliminary model configuration stages where quick estimates are key.
Approach 3
Similar with the Approach 1, the proposed Approach 3 requires multiple experimental runs across different non-vocabulary parameters, vocabulary sizes and number of training data. Therefore, the approach is constrained by the granularity and range of the experimental data points available to some extent. However, the proposed Approach 3 is flexible that it considers the fact that the non-vocabulary parameters and the number of training data are not always following the compute-optimal scaling laws [24], i.e., equal scaling, in real-world applications.
B.2 Larger models and different architectures
We have shown that our predictions hold for models with up to three billion parameters (§5). However, LLMs are often orders of magnitude larger, such as the 400-billion parameter Llama-3 model [37]. Further, we have decided to focus on dense transformer language models, as they are most commonly used for LLMs. However, many non-transformer models have been proposed and scaled up to billions of parameters [45, 46]. Exploring to what extent our findings hold in even larger models and with different architectures is a promising direction for future work.
B.3 Parametric function for the loss when considering the vocabulary
Researchers [24, 40] consider modeling the language modeling loss with parametric functions in the form of , where are learnable variables. The first term of loss represents the minimum achievable loss, and the second and third terms represent the contribution to the loss from the model size and number of training tokens . The parametric function allows predicting the loss given and even if (,) are not optimally allocated. In prior work, this loss formula accounts for changes in model size and training data but does not explicitly address the complexities introduced by varying vocabulary sizes. Incorporating vocabulary size into the loss predictor is challenging: Vocabulary size affects the model directly as well as the number of training tokens and the quality of tokenization by the tokenizer. A tokenizer with a large vocabulary size makes it easier to capture semantic information in raw text and reduces the frequency of out-of-vocabulary words. For instance, a large vocabulary size may cover common phrases, common subwords, and specialized terminology. Therefore, even if the same number of tokens are trained, the performance of the model trained on tokens with different qualities will be different.
Future work in this area could explore various parametric non-linear loss functions to predict the interactions between vocabulary size, model size, and training data with different compute allocations, not just the case of optimal compute allocation. Additionally, empirical studies on different datasets could help in understanding how vocabulary size impacts loss under varied data conditions, guiding the development of more adaptive loss prediction models.
B.4 Extensions to multilingual and multimodal scenarios
Future work could extend the proposed approaches to encompass multilingual and multimodal scenarios. Multilingual models require a nuanced understanding of vocabulary due to linguistic diversity, which may affect the optimal vocabulary size and the computation of FLOPs differently across languages. Adapting these methods to consider linguistic features and tokenization variations could lead to more tailored and efficient resource allocations for multilingual models. Different languages compete with each other for the model’s ability to allocate to that language [11], which makes it necessary to take into account the relationship between different languages when setting the size of word lists for different languages in a multilingual scenario.
For multimodal models that integrate text with other data types such as images or video, the optimal vocabulary size might interact uniquely with non-linguistic parameters. Recent work [1, 62] models visual concepts in an autoregressive manner with tokenization like the processing of text data. It is interesting to explore the size of visual vocabulary size, i.e., the codebook size [20], in the visual tasks and vision-language tasks. How to set the vocabulary size and the compute resource efficiently for different modalities remains an open issue.
Appendix C Potential social impact
The positive potential social impact of this research on vocabulary size in language model scaling is substantial. By optimizing large language models with the consideration of the vocabulary size and other attributes jointly, the paper provides a foundational understanding that can lead to more lightweight and cost-effective pre-trained large language models. This efficiency can democratize access to advanced language processing technologies, making it feasible for smaller organizations and the general public to benefit from powerful AI tools. Such advancements can benefit various domains, for example, improve accessibility features for individuals with disabilities, where efficient language models can be used to analyze medical records and assist in diagnostics. Furthermore, the reduction in computational requirements for training these models can lead to a decrease in energy usage, contributing positively to environmental sustainability efforts.
On the other hand, the misuse of pretrained language models may pose risks, including the creation of highly realistic deepfakes that can spread disinformation and undermine trust in media and institutions. These models can generate misleading content, automate cyberattacks through convincing phishing schemes, and produce large-scale spam, degrading online communication. Additionally, they can be used to generate harmful or abusive content, such as hate speech, which perpetuates discrimination and harms vulnerable populations. To mitigate these risks, it is crucial to develop trustworthy language models, implement robust monitoring systems, and foster collaboration among researchers, policymakers, and users.