Downstream-Pretext Domain Knowledge Traceback for Active Learning
Abstract
Active learning (AL) is designed to construct a high-quality labeled dataset by iteratively selecting the most informative samples. Such sampling heavily relies on data representation, while recently pre-training is popular for robust feature learning. However, as pre-training utilizes low-level pretext tasks that lack annotation, directly using pre-trained representation in AL is inadequate for determining the sampling score. To address this problem, we propose a downstream-pretext domain knowledge traceback (DOKT) method that traces the data interactions of downstream knowledge and pre-training guidance for selecting diverse and instructive samples near the decision boundary. DOKT consists of a traceback diversity indicator and a domain-based uncertainty estimator. The diversity indicator constructs two feature spaces based on the pre-training pretext model and the downstream knowledge from annotation, by which it locates the neighbors of unlabeled data from the downstream space in the pretext space to explore the interaction of samples. With this mechanism, DOKT unifies the data relations of low-level and high-level representations to estimate traceback diversity. Next, in the uncertainty estimator, domain mixing is designed to enforce perceptual perturbing to unlabeled samples with similar visual patches in the pretext space. Then the divergence of perturbed samples is measured to estimate the domain uncertainty. As a result, DOKT selects the most diverse and important samples based on these two modules. The experiments conducted on ten datasets show that our model outperforms other state-of-the-art methods and generalizes well to various application scenarios such as semantic segmentation and image captioning.
Index Terms:
Active learning, pretext training, domain knowledge, self-supervised learning.I Introduction
The success of deep neural networks relies heavily on the use of large-scale labeled data to train the associated models to achieve good performance. In view of this paradigm, active learning (AL) [1] was proposed for constructing high-quality labeled datasets by labeling only the most representative samples while maximizing the training performance. Since AL methods commonly estimate the importance of samples by analyzing their underlying data distribution, the performance of AL-based sampling heavily depends on the quality of the given data representation. The previous AL methods learn representations based on labeled/unlabeled data, which is an inefficient approach due to the presence of inadequate annotations in the early sampling stages and the limited scale of the input data. Recently, self-supervised pre-trained models [2, 3, 4, 5] learn high-quality representations via large-scale pretext tasks. However, the representations in pretext tasks do not involve domain knowledge with manual annotations; therefore, the AL method cannot select instructive samples near the decision boundary. Therefore, this paper explores how to embed downstream domain knowledge into a pre-training feature space for efficiently implementing AL sampling.
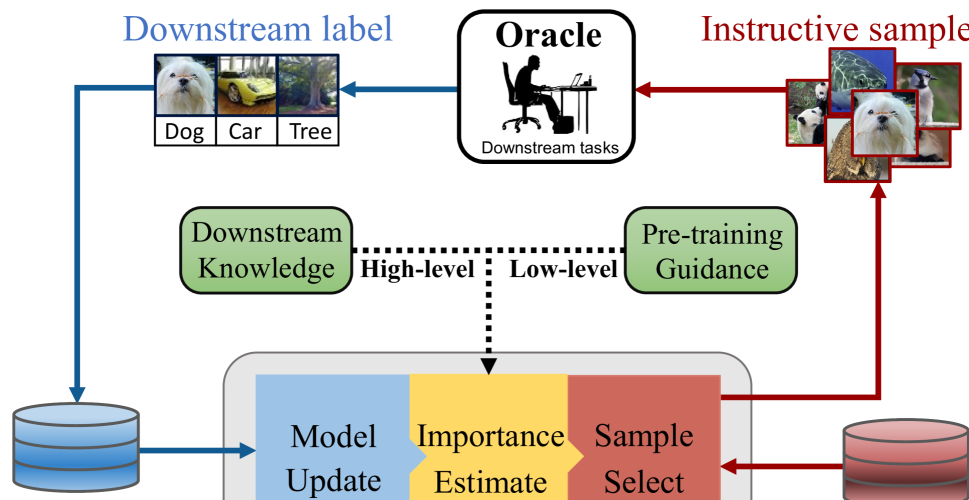
As shown in Fig. 1, an AL algorithm is typically an iterative schedule in which a set of samples are selected from an unlabeled pool to be labeled in each iteration. Its goal is to maximize the training performance with a limited annotation budget. Currently, the popular AL methods can be categorized as distribution-based or uncertainty-based methods. Distribution-based methods choose samples that are diverse for covering the distribution of the whole dataset. Uncertainty-based AL methods label the most uncertain samples to improve the target model. In both strategies, data representations embedded with key information serve to estimate the data distribution or quantify data uncertainty, and this step plays an essential role. However, since AL iteratively trains a model from scratch, the available labeled samples are insufficient for supporting robust representation learning, particularly in early AL iterations. Without reliable data representations, distribution-based methods cannot capture data relationships to estimate data diversity, and uncertainty-based methods cannot locate the decision boundary to select the most uncertain samples. This results in unreliable data diversity and uncertainty estimates. Furthermore, the limited data scale and long-tailed label distribution also introduce serious bias to the AL.
Recently, self-supervised pre-trained models are proposed to learn effective representation from large-scale datasets. With the help of pretext tasks, the pre-trained model is perceptive to visual information and provides high-quality data representation, which can help to reduce the above shortcoming for AL. However, as pre-training only learns from low-level pretext tasks without annotation, these model has good visual perception but lacks domain knowledge for manual annotation. Directly using pre-trained representations can only help to select samples with diverse visual patterns rather than key information of high-level semantics. Thus, directly using pre-training representations of pretext tasks is incomplete to model the relationship between labeled and unlabeled data, and cannot determine the most important samples for constructing a high-quality dataset and maximizing model training.
In this paper, we propose a downstream pretext-domain knowledge traceback (DOKT) method for AL that traces data interactions between pretext pre-training and downstream domain knowledge to select the most instructive samples. DOKT consists of a traceback diversity indicator for exploring the data distributions in high- and low-level feature spaces and a domain-based uncertainty estimator for enforcing perceptual perturbations to measure the degree of data uncertainty.
With respect to the traceback diversity indicator, we pre-train a pretext encoder, which learns the pretext space of the low-level vision task. Then, we employ intra-class mixing to embed the domain knowledge of annotations into the downstream encoder to alleviate the annotation inadequacy problem encountered when constructing the downstream high-level data representation space. With the high-quality encoders, we build a traceback module to transfer the adaptive neighbors of unlabeled data from the low-level pretext space to the high-level downstream space, thereby obtaining the neighbor relations of the high- and low-level distributions. Traceback diversity overcomes the lack of domain knowledge in the pre-training task for comprehensive diversity estimation purposes. For the domain-based uncertainty estimator, we design a perceptual perturbation method to introduce the pretext neighbors as perturbations and force them to construct domain-mixing augmentations. With this, we build an attached uncertainty model to determine the uncertainty level using a ranking loss, and the domain uncertainty can be used to jointly estimate the domain divergence of perturbed probabilities. Benefiting from the traceback diversity and domain uncertainty, DOKT selects the most diverse unlabeled samples and instructive samples of both pretext and downstream domain knowledge.
To demonstrate the effectiveness of DOKT, we conduct comprehensive experiments on ten public datasets. DOKT outperforms state-of-the-art AL methods, showing it is a good fit to facilitate AL for downstream tasks. Further, the ablation study also verifies the contribution of the traceback diversity indicator and domain-based uncertainty estimator. Besides, since DOKT leverages domain knowledge of annotation for selection, it is adaptive to various downstream applications, such as semantic segmentation and multi-modal tasks. Thus, we extend DOKT to semantic segmentation and image captioning, in which DOKT still achieves superior performance.
The main contributions of this paper are summarized as:
-
(i)
We propose a downstream-pretext domain knowledge traceback (DOKT) AL method. It unifies pre-training guidance and domain knowledge to explore data distribution for selecting the most instructive samples.
-
(ii)
We design a traceback diversity indicator to trace the data relationships in both the low-level and high-level spaces to evaluate the diversity of unlabeled data with comprehensive knowledge.
-
(iii)
We design a domain-based uncertainty estimator that introduces domain disturbance by uncertainty mixing to jointly estimate the divergence for selecting the most uncertain samples near the decision boundary.
-
(iv)
Extensive experiments demonstrate that DOKT outperforms the SOTA methods and generalizes on multi-modal tasks. The visualization also verifies the effectiveness of DOKT to deeply analyze the AL mechanism.
II Related work
Due to the growing demand for large-scale datasets and abundant data sources, most contemporary AL works focus on pool-based AL, which can be categorized as distribution-based and uncertainty-based approaches.
Distribution-based approaches choose data points that can increase the diversity of labeled data. These methods usually measure diversity based on extracted representations. Some methods [6, 7, 8, 9] select diverse samples by mapping the distribution distance to the informativeness of a data point. Moreover, some approaches estimate the diversity of a distribution based on the gradients [10, 11], errors [12, 13], and output changes [14] of trained models or visual information [15, 16]. CCAL [17] determines the selected data by evaluating class distribution mismatches, and BADGE [18] selects samples in a gradient space. However, these methods heavily depend on the supervision of labeled data, while inadequate labeled data in the early sampling stages affect the representation quality.
Uncertainty-based approaches estimate data uncertainty and select the most uncertain samples. The traditional methods estimate uncertainty by calculating the confidence of classifier errors [19], Gaussian processes [20, 21] or discrepancies [22, 23]. Several studies [24, 25] have analyzed the experimental design criteria and biases in statistics. These traditional methods perform well in some specific tasks but are not effective in cases with deep networks or large-scale datasets. Some recent works have designed ensemble models [13] or introduced Monte Carlo dropout [26], but these methods are computationally inefficient and unstable for uncertainty estimation tasks. Yoo et al. [27] designed a prediction loss learning model and inspired some related works [28, 29]. Their method consists of a target module and a loss prediction module for predicting the target loss. However, the above methods utilize only limited annotation information, and their loss prediction accuracy heavily depends on the generalizability of the target model. Core-GCN [30] utilizes graph embeddings to calculate confidence scores and adapts other AL techniques; however, this approach is easily affected by a disorganized unlabeled pool.
Recently, some AL methods [31, 32, 16, 33, 28] train the encoder in an unsupervised manner and distinguish informative samples in an adversarial manner. They map the unlabeled samples to a labeled/unlabeled state label while the binary label is not equivalent to informativeness and cannot reflect the relative importance. Moreover, the representation by VAE trained on unlabeled pool is also unreliable for AL sampling. Some AL methods [34, 35, 36] utilize the Vision Transformer (ViT) [37] or supervised pretext tasks. ALFA [35] trains the ViT by labeled samples and mixes the representation of unlabeled samples to estimate the inconsistency. However, the labeled samples in AL iterations are usually insufficient to support the training of the Transformer network. Besides, the random mixing of two different images may also result in heavy inconsistency and lead to inefficient sampling. PAL [34] and PT4AL [36] train an encoder with self-supervised pretext tasks and select samples based on the pretext loss, while the pretext tasks do not involve domain knowledge of manual annotation. Thus the pretext loss is not a reliable uncertainty criterion.
III Method
III-A Overview
In this section, we formally define the active learning (AL) scenario and provide the notations. The key task of an AL algorithm is to select the most informative samples for efficient annotation. We assume that AL serves to annotate samples for training a target model for a shared target task. In the initial stage, a large unlabeled data pool is given, and we annotate a few samples to form an initialized labeled pool. Let us denote the initial unlabeled pool by and the initial labeled pool by . denotes a data point in the unlabeled pool, and denotes a data point and its annotation in the labeled pool. In each iteration, the AL method selects samples and obtains their annotations via an oracle. This iterative process repeats until the model performance satisfies user’s requirements or the label budget runs out.
Fig. 2 shows the downstream-pretext domain knowledge traceback (DOKT) model. In order to select most diverse and instructive samples, it traces data interaction from the low-level feature of pre-training guidance to the high-level feature of downstream domain knowledge. The DOKT consists of a traceback diversity indicator (Section III-B) and a domain-based uncertainty estimator (Section III-C). The former explores data relationships in two feature spaces to select the most diverse samples, and the latter estimates domain uncertainty based on probability divergence and uncertainty acquisition to select samples near the decision boundary. A sampling strategy based on the indicator and estimator is introduced in Section III-D.
As DOKT learns the data relations with pretext and downstream domain knowledge, DOKT generalizes on different downstream tasks with more data modalities [38, 39]. To verify this, we extend DOKT to the semantic segmentation and multi-modal image captioning AL scenarios, which are more challenging and require labeled datasets with higher quality to learn a competitive target model.

III-B Traceback diversity indicator
To comprehensively estimate the diversity of unlabeled samples, we introduce a pre-trained model as a traceback diversity indicator for better learning representations. For the indicator, we set a pretext encoder , which is a vision transformer (ViT) [37] network parameterized by the weight of the MAE of the pre-training model [4]. Following the transformer, the input of the pretext encoder is a sequence of image patches . Since the pre-training model learns from self-supervised pretext tasks without annotations, it involves only low-level visual perception and lacks domain knowledge concerning the manual annotations. Thus, directly using the pre-training representations in the AL sampling process would result in the selection of samples that are diverse only in the pretext space and not instructive for learning downstream annotations. Thus, since the rudimentary process of using the pre-trained model is inefficient, we train a downstream encoder based on and embed domain knowledge in it.
Intuitively, to embed the encoder with domain knowledge of downstream annotation, the model should be trained by the labeled samples in downstream tasks. However, AL sampling is an iterative process and at its early stages the labeled samples are inadequate to train a robust encoder. Inspired by the mixup [40], we design the intra-class mixing to mix up the patches of different labeled samples. Due to annotation inadequacy, random mixing is hard to learn and sometimes there is no valid object in the mixed image in the result of the random process. In view of this, the intra-class mixing method only mixes samples that are in the same category and locate closely in the pretext feature space. With its help, we augment the labeled samples and make the encoder easier to fit. The training loss of is formulated as follows,
| (1) | ||||
where is a predictor with encoder , is labeled data, and is the median cosine of sample pairs in a same category.
With the pretext encoder and downstream encoder , we obtain the low-level representation and high-level representation of the labeled and unlabeled samples:
| (2) | ||||
As the pretext encoder is pre-trained by low-level vision tasks and the downstream encoder is fine-tuned by labeled data, learns low-level perceptual information, and learns high-level information from downstream domain knowledge.
Then, the indicator constructs the pretext space with the low-level representation and the downstream space with the high-level representation . In the two spaces, we can analyze the relationship of unlabeled samples and calculate the diversity. Intuitively, we can separately calculate the scores of data diversity in two spaces and sum them up as a synthetic diversity for unlabeled samples. However, this synthetic manner is not available for AL sampling. On one hand, the data distance in the high-level space cannot precisely denote the label similarity because it is not the predicted probability. On the other hand, diversity is a non-additive quantity, so selection based on the sum of two diversity scores is not effective.
Hence, we design the traceback method to naturally quantify the diversity scores of the two spaces. For an unlabeled sample , we select the closest labeled samples in the pretext space as its neighbors. Then, we trace the labeled neighbors to the downstream space to query their annotations and obtain , where is a one-hot label vector whose label is denoted as 1 and whose other elements are 0. denotes the number of closest samples selected as neighbors. It is an adaptive parameter, and we design a dynamic approach to optimize its value; through this parameter the neighbors can reflect the diversity of in two spaces. To optimize , the indicator scales the cosine similarity range to [0,1] and averages the cosine similarities of and as
| (3) |
Then, a traceback domain vector is calculated as
| (4) |
where the one-hot label vector of is weighted by the cosine similarity ; then, the indicator sums the results to obtain the domain distribution of .
represents the domain distribution of the neighbors scaled by the low-level similarity. With this, the objective function for optimizing is formulated as follows:
| (5) |
where is optimized to minimize the product of the variance and mean similarity, and its maximum value is , which is 1% of the labeled pool. Eq. 5 is not differentiable or monotonic, so we cannot optimize by directly constraining Eq. 5 or using a binary search. Thus, we apply enumeration over in .
Intuitively, this variance quantifies the annotation concentration of the neighbors, and the mean similarity quantifies the diversity in the low-level space. Thus, the indicator adaptively optimizes to find the set of pretext neighbors that maximizes the diversity of the unlabeled samples . In this way, the indicator calculates the traceback diversity score of as
| (6) |
III-C Domain-based uncertainty estimator
With the help of its traceback diversity indicator, DOKT traces the data interactions in two spaces and calculates a comprehensive diversity score based on the low- and high-level features. To improve the AL sampling process, DOKT combines both diversity and uncertainty for selection purposes. Therefore, we propose a domain-based uncertainty estimator. Inspired by the learning loss method [27], we design a multiperception uncertainty learning model to predict the uncertainty of data based on hidden features derived from transformer blocks. As the CE loss focuses only on the ground-truth element and ignores other probabilities, we design an uncertainty score for to learn. The uncertainty score is formulated as follows:
| (7) |
where is the predicted probability vector and is the maximum probability vector. is defined as follows:
| (8) | ||||
where is the number of classes.
is the variance for a probability vector whose maximum is the same as that of , and the other probabilities are equal to . It quantifies the highest concentration of a probability vector. By combining and , the result is negatively correlated with the maximum probability and concentration of the probability vector, providing a better uncertainty acquisition. Based on , we formulate a ranking loss to update :
| (9) |
where and are the scores calculated using Eq. 7; and are the scores predicted by using the hidden features in ; and is a margin. As is limited to [0,1), updating with the ranking loss is easy to converge. Assume that , minimizing enlarges unless their difference is larger than the margin. Compared with MSE, this loss using ranking relation is easy to converge. Meanwhile, the ranking loss also constrains the concrete difference to ensure that the range of output in is similar to the uncertainty score. In this way, utilizes the ranking information and the ground-truth difference to optimize uncertainty prediction. By training the uncertainty model via Eq. 9, the estimator can extract hidden features through and precisely quantify uncertainty with :
| (10) |
Further, we enforce domain mixing on unlabeled samples to apply perceptual perturbation. In ALFA-Mix [35], it mixed transformer patches by randomly mixing representations via interpolation to calculate the inconsistency as the uncertainty. However, the mixing process for representation confuses the embedded information and makes it difficult to learn, and the random mixing strategy may mix two highly different images so that the mixing results exhibit strong inconsistency while remaining uncertain for the target model.
In view of this, we design a perturbation augmentation process to mix unlabeled samples with similar labeled data to form an applicable mixing strategy. For an unlabeled sample , the estimator mixes its patches with its neighbors in the pretext space to form domain mixing samples. Then, the estimator duplicates the domain mixing samples and replaces the mixed patches with masked patches. In this way, the model obtains the domain mixing samples and the corresponding masking samples . The downstream encoder is fine-tuned with a labeled pool, as shown in Eq. 1, to predict the probability vectors and for the two samples. Based on these vectors, the estimator calculates the divergence for these two probabilities as follows:
| (11) |
where KL divergence [41] and are used to quantify the data uncertainty when the data are mixed with similar labeled samples. A smaller value denotes a more certain prediction, and a larger value means that the perceptual perturbation process implemented via similar samples makes the prediction unsteady and more uncertain.
By summing up the uncertainty acquisition as Eq. 10 and domain divergence as Eq. 11, the estimator can estimate the domain uncertainty of unlabeled samples to maximize the performance gain in each sampling iteration:
| (12) |
Using Eq. 12, DOKT analyzes the data uncertainty with perceptual perturbing and domain divergence. By combining the domain uncertainty and traceback diversity in two spaces, DOKT can select instructive samples near the decision boundary to boost modal training and avoid overlapping of selected samples.
III-D Sampling strategy in active learning
DOKT consists of two steps in each sampling iteration: model training and sample selection. In the training stage, the indicator trains the downstream encoder using intraclass mixing and augmentation to embed domain knowledge. Along with this training process, the estimator trains the attached uncertainty model using Eq. 7 by mixing labeled samples, and the model learns to predict an uncertainty score based on the hidden features in transformer blocks.
In the selection stage, the indicator quantifies the traceback diversity in the pretext and downstream spaces. The estimator learns to predict uncertainty scores using the ranking loss and performs perceptual perturbation to produce augmentations. Then, the divergence of probabilities is calculated to estimate the prediction stability. By combining the uncertainty score and domain divergence, the domain uncertainty can be estimated. With these two modules, DOKT first filters out the most diverse samples as candidates based on the traceback diversity and subsequently selects the most uncertain samples among the candidates based on the domain uncertainty.
IV Experiment
IV-A Experiment Settings
In this section, we compare the performance of our method with those of the latest AL methods on ten datasets. Following other AL works [27, 31], we conduct our experiments on two common tasks: image classification and semantic segmentation. For classification purposes, we also test on fine-grained data to evaluate the performance achieved for images with subtle downstream categorization differences. As DOKT is also effective in cross-modal AL tasks, we explore the AL sampling for image captioning. Moreover, we conduct experiments on long-tailed datasets to verify the generalizability of the proposed method to problems with categorical imbalances.
For rigorous comparison, all the AL methods begin with the same random initial labeled pool and they are evaluated by the same target model. Since the performance achieved with the initial labeled data is fixed for all the AL methods, we only provide the performance starting from the first iteration.
IV-B Experimental Results on Image Classification
Dataset. We test on CIFAR-10, CIFAR-100 [42], SVHN [43] and the fine-grained Aircraft dataset [44]. CIFAR-10 and CIFAR-100 have 60,000 images with sizes of 32323, including 50,000 training images and 10,000 testing images. The CIFAR-10 has 10 categories and 6,000 images per class, while the CIFAR-100 has 100 classes containing 600 images each. SVHN is a real-world image dataset with 73,257 digits for training and 26,032 digits for testing. For SVHN, we test on the original images with multiple digits. Aircraft is a fine-grained classification dataset that contains 100 images for each of the included 100 aircraft variants. We split Aircraft into 6,667 training samples and 3,333 test samples.
Compared methods. We compare DOKT with several recently developed state-of-the-art approaches, including LL [27], PT4AL [36], ALFA [35], and BAL [45]. We introduce the random sampling method as a baseline.
Performance measurement. Following the settings of other AL methods, in the beginning, we randomly select 2% of the data as the initial labeled pool. We rigorously report the mean performance achieved across 5 trials with different random initializations. In each iteration, 2% of the samples are selected to be labeled, and the label budget is 20% of the dataset. The target model is an 18-layer residual network (ResNet-18)[46].
IV-B1 Performance on CIFAR-10
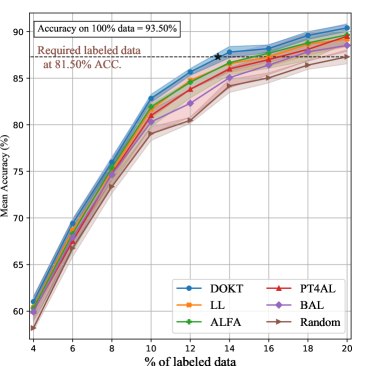
Fig. 3 (a) shows the AL performances achieved on CIFAR-10. First, DOKT outperforms the other state-of-the-art methods under all ratios. The consistent margin indicates that DOKT with the traceback module can efficiently leverage its pre-trained model and select more informative samples than can the other AL methods. Second, the accuracy of DOKT reaches 90.35% when using 20% of the data, while the highest accuracy achieved on fully labeled data is 93.5%, which is only 3.15% better than that of DOKT with an 80% annotation cutoff. This competitive performance demonstrates that DOKT can significantly improve the quality of labeled datasets for robustly training models.
IV-B2 Performance on CIFAR-100
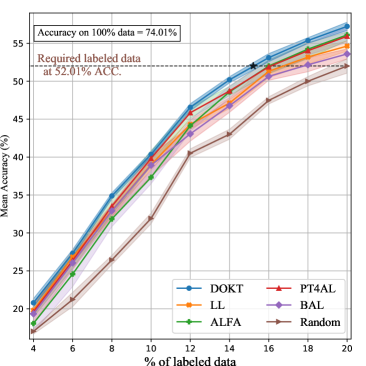
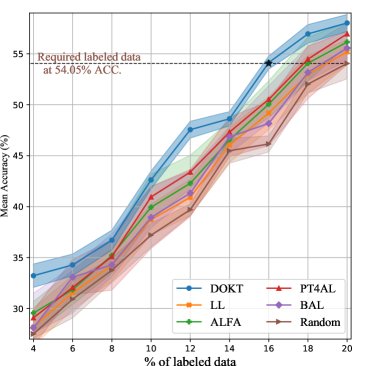
As CIFAR-100 has more categories and fewer images per category, it is more challenging than CIFAR-10 is. Fig. 3 (b) shows the performances achieved on CIFAR-100. As observed with CIFAR-10, DOKT still performs better than the other AL methods. In addition, several different conclusions can be drawn. First, we observe that the uncertainty-based LL method [27] does not perform as competitively on CIFAR-100 as it does on CIFAR-10. This indicates that insufficient domain knowledge restrains the backbone model and leads to an inefficient sampling process. Moreover, larger margins are produced between DOKT and the other AL methods because domain mixing augments the limited samples for general model training. Second, PT4AL [36] surpasses ALFA [35] in the early iterations since ALFA trains a ViT with labeled samples and because the inadequacy of the annotations in the early stages invalidate its estimation results. This observation demonstrates that DOKT learns correct data interactions with limited annotations by tracing back two steps and generalizing to datasets with more categories.
| Dataset | CIFAR-10 | CIFAR-100 | SVHN | Aircraft | CIFAR-10-LT | CIFAR-100-LT | ImageNet | iNaturalist |
| (Target ACC) | (81.50%) | (52.01%) | (80.02%) | (64.87%) | (54.05%) | (22.04%) | (46.71%) | (55.76%) |
| Random | 10,000 | 10,000 | 17,305 | 1,333 | 2,482 | 2,179 | 384,350 | 131,253 |
| LL [27] | 8,049 | 9,039 | 15,632 | 1,197 | 2,353 | 1,998 | 366,413 | 120,316 |
| BAL [45] | 8,571 | 8,477 | 14,891 | 1,121 | 2,337 | 2,012 | 358,726 | 120,705 |
| PT4AL [36] | 8,428 | 8,047 | 13,930 | 1,112 | 2,221 | 1,945 | 345,914 | 118,129 |
| ALFA [35] | 7,650 | 8,033 | 13,945 | 1,228 | 2,237 | 1,892 | 326,313 | 126,441 |
| DOKT | 6,552 | 7,414 | 11,853 | 904 | 1,977 | 1,681 | 288,390 | 105,003 |
IV-B3 Performance on SVHN
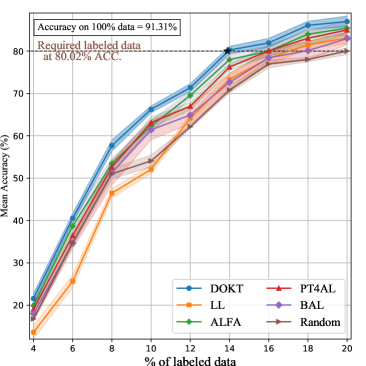
On the SVHN dataset, the target model recognizes multiple digits in an image, and the number of digits per image is unknown, which makes it much more difficult. Fig. 3 (c) compares different AL methods on a multidigit dataset. First, we find that DOKT outperforms the state-of-the-art AL methods on SVHN by a significant margin. This benefits from the use of the traceback module, which quantifies low- and high-level diversity to satisfy complex scenarios. Second, LL [27] and BAL [45] perform worse than does the random method in the early sampling stages. Since it is difficult to learn the uncertainty of multiple digits based on the predicted probability, the above uncertainty-based methods are unreliable. Especially in early stages, the limited number of available labeled samples intensifies this problem. In contrast, DOKT utilizes the traceback to bridge two feature spaces, so that it can comprehensively estimate the data distribution and select diverse samples with a complex data format.
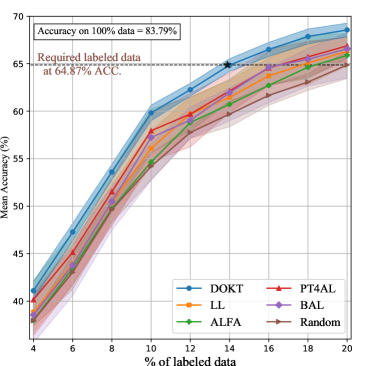
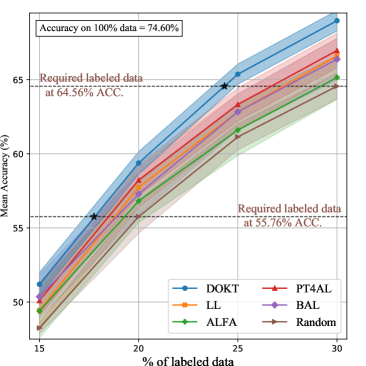
Further, we analyze the required number of labeled samples to achieve competitive performance. As shown in Table I, DOKT requires only 13.1% (6,552), 14.8% (7,414), and 13.7% (11,853) of the labeled samples to achieve the same performance when using 20.0% of the randomly selected samples from CIFAR-10, CIFAR-100, and SVHN, respectively. Compared with state-of-the-art methods, DOKT reduces the numbers of required annotations by 18.6% (1,497) on CIFAR-10, 12.5% (1,063) on CIFAR-100, and 20.4% (3,038) on SVHN. These results verify that DOKT can improve the annotation efficiency and quality of datasets to boost the model training.
IV-B4 Performance on Aircraft
For the Aircraft dataset, the fine-grained samples in each class differ only in terms of subtle optical details, which is more challenging. Fig. 3 (d) shows the performances. We find that DOKT outperforms the state-of-the-art methods and that the gap between DOKT and the other methods becomes larger than those observed on CIFAR datasets. This improvement stems from the use of the traceback module, which locates important samples near the decision boundary to boost the AL process for fine-grained classification.
In addition, we test on Caltech-101, Caltech-256 [47], CINIC-10 [48], Tiny-ImageNet and Mini-ImageNet [49] in the supplementary material. The results also demonstrate that DOKT achieves the best AL performance and can be generalized to various datasets with the help of the traceback.
IV-C Experimental Results on Long-tailed Datasets
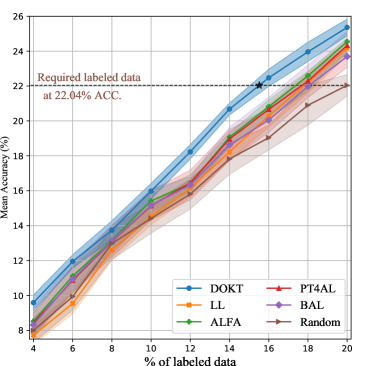
The popular datasets are usually artificially balanced with respect to the instances belonging to each class in the training set. However, real-world datasets usually have highly imbalanced class distributions with long tails [50]. To evaluate the performance achieved in this practical scenario, we conduct experiments on long-tailed versions of the CIFAR datasets, CIFAR-10-LT and CIFAR-100-LT. To simulate long tails, we reduce the number of training samples per class according to an exponential function , where is the class index, is the number of classes, is the original number of training images and is the imbalance factor. The experimental settings are the same as those used in Section IV-B.
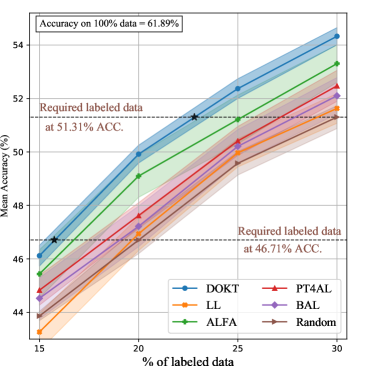
Figs. 4 (a) and (b) show the results on CIFAR-10-LT and CIFAR-100-LT. Due to the label imbalance issue, it is more difficult to learn the target model, especially for categories in the tail. First, DOKT outperforms the other AL methods at all sampling ratios by large margins. This demonstrates that DOKT can better select the most informative samples from imbalanced datasets with the help of trackback diversity. Second, ALFA [35] and LL [27] perform less competitively in this scenario. Since the label imbalance makes model training more difficult, the backbones in ALFA and LL become unreliable, affecting their ability to estimate data inconsistency and the learning loss. In DOKT, domain mixing can augment the inadequate samples of long-tailed categories, and trackback diversity leverages pre-training for robust distribution learning. These modules can overcome label imbalances and construct high-quality datasets. Third, as shown in Table I, DOKT requires only 15.9% (1,977) and 15.4% (1,681) of total samples to achieve competitive performance on CIFAR-10-LT and CIFAR-100-LT, respectively. Compared with other methods, the proposed method requires 15.4% fewer labeled samples on CIFAR-10-LT and 16.5% fewer samples on CIFAR-100-LT. These reductions further verify that DOKT can overcome the bottleneck of AL in cases with imbalanced data. This approach benefits from the domain knowledge of the downstream and pretext spaces to balance a long-tailed distribution.
IV-D Experimental Results on Large-scaled Datasets
Dataset. In addition, we demonstrate the scalability of DOKT on two large-scale datasets: ImageNet [49] and iNaturalist 2018 [51]. ImageNet consists of more than 1.2 M images belonging to 1000 classes. iNaturalist is a large-scale real-world dataset for species classification that contains 437,513 images from 8,142 categories. Furthermore, iNaturalist is an extremely long-tailed dataset with an imbalanced label distribution.
Compared methods. The compared AL methods are the same as those in Section IV-B.
Performance measurement. Following the settings of previously AL methods, we randomly select 10% of the available data as the initial labeled pool. We rigorously report the mean performance achieved across 5 trials with different random initializations. In each iteration, 5% of the samples are selected to be labeled, and the label budget is 30%.
IV-D1 Performance on ImageNet
The experimental results are shown in Fig. 4 (c). First, DOKT consistently outperforms all the baselines, with average margins of 3.42% over random sampling and 1.17% over the most competitive AL method (PT4AL) [36]. These margins are larger than above observation. This finding verifies the generalizability of DOKT to different data scales, which benefits from the domain uncertainty measurement process that locates instructive samples near the decision boundary. Second, as shown in Table I, we find that DOKT achieves the same performance attained when using 30% of the random data with 22.5% (288,390) of the samples, which are 25.0% (95,960) and 16.6% (57,524) less than the number of data used by random sampling and the second-best method, respectively. This illustrates that DOKT can improve the quality of large-scale datasets, benefitting from the traceback to select more diverse samples.
IV-D2 Performance on iNaturalist
iNaturalist is a large-scale dataset with an imbalanced label distribution. The experimental results are shown in Fig. 4 (d). First, DOKT outperforms the other AL methods by margins of 4.25% over random sampling and 1.89% over the second-best method. This finding verifies the scalability and robustness of DOKT for cases with different data scales and label imbalances. Second, as shown in Table I, DOKT achieves competitive performance with only 22.5% (105,003) of the total samples, which are 20.0% (26,250) and 12.8% (15,452) less than those of random sampling and the second-best method, respectively. This indicates that DOKT can overcome the label imbalance problem to efficiently implement AL annotation. This advantage derives from the ability of the downstream and pretext spaces to trace data interactions in the downstream domain knowledge to balance labeled datasets.
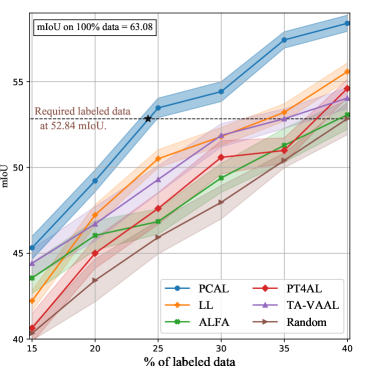
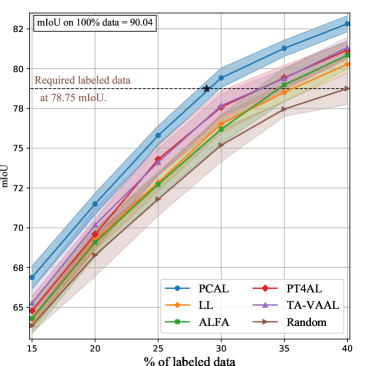
IV-E Experimental Results on Semantic Segmentation
We also evaluate the performance of AL methods on semantic segmentation, which is more challenging and practical. Datasets. For the segmentation task, we test on Cityscapes [52] and BraTS [53]. Cityscapes consists of 5,000 images of urban street scenes, and we convert it into 19 classes. The BraTS 2018 dataset is a medical dataset that contains preoperative 3D MRI scans of 285 patients with brain tumors. Following [54], we use 242 subjects for training and 43 for testing.
Compared methods. We compare DOKT with several state-of-the-art AL approaches that are available for this task, including LL [27], TA-VAAL [28], PT4AL [36], and ALFA [35]. We also introduce the random sampling method as a baseline.
Performance measurement. Following the settings of previous AL methods, we select 10% of the available random data as the initial labeled pool. We rigorously report the mean performance achieved across 5 trials with different random initializations. In each iteration, 5% of the samples are selected to be labeled, and the label budget is 40% of the dataset. The target model used for the performance evaluation is PSPNet [55].
Figs. 5 (a) and (b) show the results obtained on Cityscapes and BraTS, which involve traffic and medical data from real-world applications, respectively. First, DOKT outperforms the other state-of-the-art methods in all iterations on both datasets. Specifically, ALFA [35] and PT4AL [36] perform worse because their pixelwise outputs have difficulty estimating uncertainty via random mixing and the pretext loss. In contrast, DOKT utilizes perceptual perturbation to enable domain mixing for complex data formats and traces downstream domain knowledge to embed high-level features for selection purposes. With their help, DOKT can efficiently extract more informative samples than other AL methods in semantic segmentation. Second, the gaps between DOKT and the other AL methods on segmentation are larger than those observed on classification datasets, benefitting from the ability of traceback diversity and domain uncertainty to optimize the distributions of both traffic and medical data. This demonstrates that DOKT performs better than other methods in complex real-world applications.
| Method | Sampling ratio(%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | |
| Coreset | 5.95 | 20.14 | 38.99 | 54.62 | 59.40 | 64.19 | 73.62 | 79.63 | 82.47 | 83.05 |
| MAE-Coreset | 5.95 | 19.84 | 39.41 | 56.62 | 63.00 | 69.19 | 76.02 | 80.13 | 83.07 | 83.95 |
| DOKT-T&M | 5.95 | 18.13 | 35.04 | 52.63 | 59.08 | 65.21 | 72.64 | 77.43 | 80.59 | 81.31 |
| DOKT-M | 5.95 | 18.33 | 38.64 | 55.25 | 63.41 | 68.91 | 77.13 | 80.47 | 82.47 | 84.65 |
| DOKT-T | 5.95 | 18.47 | 36.01 | 53.25 | 61.41 | 67.15 | 74.01 | 78.86 | 81.23 | 82.00 |
| DOKT-LL | 5.95 | 17.95 | 38.27 | 55.03 | 63.14 | 68.54 | 76.87 | 80.22 | 82.11 | 84.23 |
| DOKT-MSE | 5.95 | 17.52 | 37.91 | 54.18 | 62.51 | 68.34 | 76.31 | 79.80 | 81.49 | 83.54 |
| DOKT | 5.95 | 21.57 | 40.53 | 57.69 | 66.26 | 71.38 | 78.85 | 83.34 | 86.09 | 86.99 |
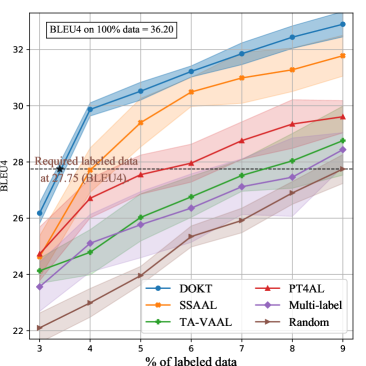
IV-F Experimental Results on Image Captioning
We evaluate DOKT on image captioning datasets to verify its effectiveness in multimodal tasks.
Dataset. MS-COCO [56] is the most popular image captioning dataset. As annotated captions of the official testing images are not provided, we utilize the Karpathy split [57] for this experiment. The Karpathy split has 113287/5000/5000 training/validation/testing images, respectively.
Compared methods. In this experiment, we compare our method with Multi-label [58], SSAAL [59], TA-VAAL [28], PT4AL [36], and random sampling.
Performance measurement. Following the settings of the previously developed AL methods, we initialize the labeled pool with 2% of the samples and label 1% of the samples in each iteration until the labeled ratio reaches 9%. To objectively evaluate the performance of the tested methods, we use four standard automatic evaluation metrics: BLEU4 [60], METEOR [61], ROUGE-L [62], and CIDEr [63]. The obtained METEOR and ROUGE-L results are shown in the supplementary material.
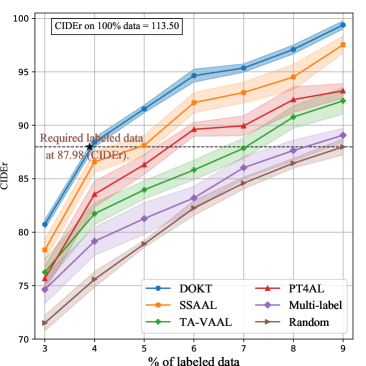
Figs. 5 (c) and (d) show the results using the BLEU4 and CIDEr metrics, respectively. First, DOKT evidently achieves the highest metric scores in each iteration. This indicates that DOKT can select more informative cross-modal samples. Furthermore, DOKT outperforms the second-best method (SSAAL) [59], with average margins of 1.31 and 2.71 in terms of BLEU4 and CIDEr, respectively, verifying the superiority of DOKT. Second, with 9% of the labeled data, DOKT achieves scores of 32.68 (BLEU4) and 99.18 (CIDEr), which are close to those of the image captioning model with 100% of the labeled data. This competitive performance benefits from the use of a traceback module that integrates low- and high-level features to improve the sampling quality of the proposed method. Third, PT4AL [36] and DOKT both utilize pretext guidance, while DOKT integrates downstream annotations to trace the data relationships between the low- and high-level spaces. As a result, DOKT can select the most instructive samples with diverse descriptions from the unlabeled pool.
IV-G Ablation Study
To deeply analyze the effectiveness of key modules in DOKT, we perform the ablation study. First, we conduct the ablation to directly use the pre-trained model as follows: (1) Coreset: Coreset method. (2) MAE-Coreset: Coreset [9] method with data representations of the pre-trained model(MAE [4]). Further, we conduct the ablation on the traceback diversity, domain uncertainty and the ranking loss as follows: (3) DOKT-T&M: DOKT without both of the above. (4) DOKT-M: DOKT without domain mixing. (5) DOKT-T: DOKT without traceback module. (6) DOKT-LL: DOKT using LL loss. (7) DOKT-MSE: DOKT using MSE loss. (8) DOKT: the proposed method.
The ablation is shown in Table II. First, we can observe that DOKT consistently outperforms DOKT-D and DOKT-U by a significant improvement, which verifies the superiority of DOKT. Second, DOKT-D and DOKT-U both perform better than DOKT-T&M. The above phenomenon illustrates that both the traceback diversity and the domain mixing augmentation help to improve the AL performance, where the traceback module covers the whole data distribution and the domain mixing alleviates the annotation insufficiency for uncertainty estimation. Third, MAE-Coreset performs better than Coreset, and this verifies that the high-quality representation of pre-training can boost AL selection. However, MAE-Coreset still obviously underperforms DOKT. This indicates that the rudimentary manner of using pre-training in AL methods only brings limited improvement due to the lack of domain knowledge. The comparison of DOKT and MAE-Coreset demonstrates that DOKT effectively leverages the pre-trained guidance by bridging it with domain knowledge. Fourth, both DOKT-LL and DOKT-MSE perform not well, and they even perform worse than DOKT-M. Since the MSE prediction is unstable and the LL loss cannot constrain the value range, it not suitable to combine them with prediction divergence. The large margins between DOKT and the two ablation groups demonstrate that the ranking loss can provide a robust uncertainty estimation to improve the quality of labeled datasets.
IV-H Visualization of AL Sampling
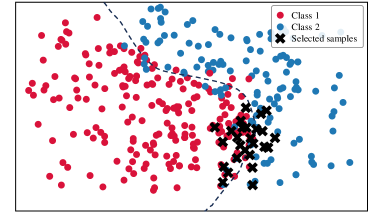
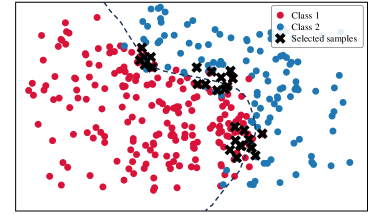
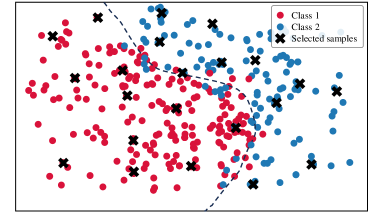
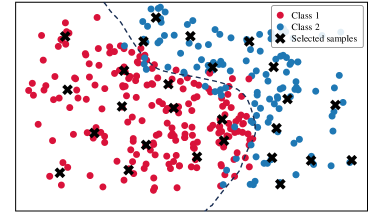
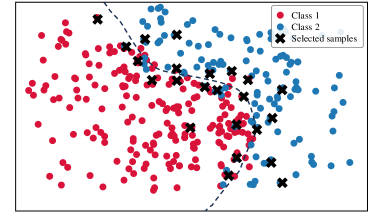
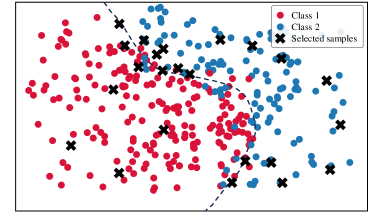
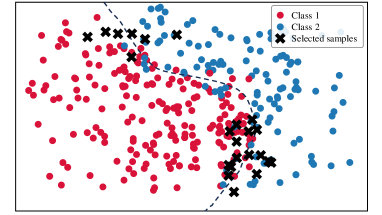
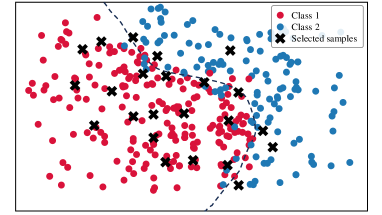
To analyze the data distribution of AL sampling results, we show the t-SNE [64] visualization in Fig. 6. In the plots, we visualize samples from two categories in CIFAR-10 and display the decision boundary for better analysis. (a)-(e) show the results of different AL methods; (f) shows the result of DOKT with fixed . (g)-(h) show the results of DOKT with different loss functions. For LL [27] in Fig. 6(a), the learning loss method tends to select difficult samples but lacks information about global distribution. Thus, we can find that its selected samples are located close to the decision boundary but are clustered in a narrow region, which leads to sampling overlapping and inefficiency. Besides, ALFA [35] in Fig. 6(b) estimates the data uncertainty and inconsistency. Although random mixing in ALFA helps to find samples that spread spatially, the random process is uncontrollable and results in the local cluster. For PT4AL [36] in Fig. 6(c), since it estimates sampling value with pretext loss that only involves low-level perception, the selection is diverse but ignores the uncertain samples near the boundary. The same problem occurs for BAL [45] in Fig. 6(d). BAL only focuses on balancing label distribution, so that it allocates the annotation equally to classes 1 and 2 while the selection is far from the boundary and not instructive. For DOKT in Fig. 6(e), we can observe that the selected samples are all near the decision boundary and there is no sampling cluster, which is much more efficient. This demonstrates that DOKT can select instructive and diverse samples near the decision boundary, where the traceback module traces data interaction of pre-training guidance and domain knowledge to improve the quality of labeled datasets. For fixed in Fig. 6(f), we can observe that the fixed cannot select suitable neighbors to explore the data relationships, which verifies that the adaptive helps to estimate the data diversity in two spaces for better AL sampling. For Fig. 6(g), since LL loss cannot constrain the value range, it is impossible to balance the diversity and uncertainty score so that there is obvious sampling overlapping. For Fig. 6(h), selected samples are not near the boundary due to the difficult convergence of MSE. The results demonstrate that the ranking loss can help DOKT to select instructive samples.
V Conclusion and Future work
In this paper, we analyze the active learning (AL) mechanism and propose a downstream-pretext domain knowledge traceback model (DOKT) that traces two spaces of pre-training guidance and domain knowledge to explore data interaction for constructing high-quality labeled datasets. The model consists of a traceback diversity indicator that explores data diversity in low-level and high-level spaces, and a domain-based uncertainty estimator that learns to predict uncertainty scores by perceptual perturbing for domain mixing samples. The experiments demonstrate that DOKT boosts model training with significant label reduction and generalizes for various application scenarios. We hope DOKT will spawn ideas for AL by using pretext training and downstream knowledge.
Although DOKT can utilize a pre-trained model, it can only handle features and cannot analyze the large parameters in the pre-trained model for uncertainty estimation. This makes DOKT inefficient for constructing high-quality labeled data for transferring large models to specific downstream tasks. In the future, we will extend the proposed DOKT algorithm to label important samples for transferring large pre-trained models. Since large pre-trained models still require downstream labeled data for generalizing to a specific task, the use of AL in pre-trained models is desirable for related research. The main challenges are (1) the complexity of model structures and (2) the wide range of domain knowledge, which make it difficult for traditional AL methods to estimate model uncertainty and adapt to downstream tasks. In view of these limitations, we will attempt to optimize the AL process and design new strategies to improve our method for use with large pre-trained models.
References
- [1] B. Settles, “Active learning literature survey,” University of Wisconsin-Madison Department of Computer Sciences, Tech. Rep., 2009.
- [2] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597–1607.
- [3] H. Bao, L. Dong, and F. Wei, “Beit: Bert pre-training of image transformers,” arXiv preprint arXiv:2106.08254, 2021.
- [4] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009.
- [5] H. Ben, Y. Pan, Y. Li, T. Yao, R. Hong, M. Wang, and T. Mei, “Unpaired image captioning with semantic-constrained self-learning,” IEEE Transactions on Multimedia, vol. 24, pp. 904–916, 2022.
- [6] Y. Yang, Z. Ma, F. Nie, X. Chang, and A. G. Hauptmann, “Multi-class active learning by uncertainty sampling with diversity maximization,” International Journal of Computer Vision, 2015.
- [7] M. Hasan and A. K. Roy-Chowdhury, “Context aware active learning of activity recognition models,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 4543–4551.
- [8] H.-S. Chang, C.-F. Hsu, T. Hoßfeld, and K.-T. Chen, “Active learning for crowdsourced qoe modeling,” IEEE Transactions on Multimedia, vol. 20, pp. 3337–3352, 2018.
- [9] O. Sener and S. Savarese, “Active learning for convolutional neural networks: A core-set approach,” in International Conference on Learning Representations, 2018.
- [10] B. Settles, M. Craven, and S. Ray, “Multiple-instance active learning,” in Advances in neural information processing systems, 2008, pp. 1289–1296.
- [11] S. Agarwal, H. Arora, S. Anand, and C. Arora, “Contextual diversity for active learning,” in European Conference on Computer Vision, 2020.
- [12] N. Roy and A. McCallum, “Toward optimal active learning through monte carlo estimation of error reduction,” ICML, Williamstown, pp. 441–448, 2001.
- [13] W. H. Beluch, T. Genewein, A. Nürnberger, and J. M. Köhler, “The power of ensembles for active learning in image classification,” in the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
- [14] C. Käding, E. Rodner, A. Freytag, and J. Denzler, “Active and continuous exploration with deep neural networks and expected model output changes,” arXiv preprint arXiv:1612.06129, 2016.
- [15] Y. Yan, F. Nie, W. Li, C. Gao, Y. Yang, and D. Xu, “Image classification by cross-media active learning with privileged information,” IEEE Transactions on Multimedia, vol. 18, pp. 2494–2502, 2016.
- [16] S. Wang, Y. Li, K. Ma, R. Ma, H. Guan, and Y. Zheng, “Dual adversarial network for deep active learning,” in Proceedings of the European Conference on Computer Vision, 2020, pp. 680–696.
- [17] P. Du, S. Zhao, H. Chen, S. Chai, H. Chen, and C. Li, “Contrastive coding for active learning under class distribution mismatch,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 8927–8936.
- [18] J. T. Ash, C. Zhang, A. Krishnamurthy, J. Langford, and A. Agarwal, “Deep batch active learning by diverse, uncertain gradient lower bounds,” in International Conference on Learning Representations, 2020.
- [19] E. Chatzilari, S. Nikolopoulos, Y. Kompatsiaris, and J. Kittler, “Salic: Social active learning for image classification,” IEEE Transactions on Multimedia, vol. 18, pp. 1488–1503, 2016.
- [20] A. Kapoor, K. Grauman, R. Urtasun, and T. Darrell, “Active learning with gaussian processes for object categorization,” in 2007 IEEE 11th International Conference on Computer Vision. IEEE, 2007, pp. 1–8.
- [21] G. Zhao, E. Dougherty, B.-J. Yoon, F. Alexander, and X. Qian, “Uncertainty-aware active learning for optimal bayesian classifier,” in International Conference on Learning Representations, 2021.
- [22] S. Huang, T. Wang, H. Xiong, J. Huan, and D. Dou, “Semi-supervised active learning with temporal output discrepancy,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
- [23] X. Ben, C. Gong, T. Huang, C. Li, R. Yan, and Y. Li, “Tackling micro-expression data shortage via dataset alignment and active learning,” IEEE Transactions on Multimedia, 2022.
- [24] J. Wu, S. Zhao, V. S. Sheng, J. Zhang, C. Ye, P. Zhao, and Z. Cui, “Weak-labeled active learning with conditional label dependence for multilabel image classification,” IEEE Transactions on Multimedia, vol. 19, pp. 1156–1169, 2017.
- [25] S. Farquhar, Y. Gal, and T. Rainforth, “On statistical bias in active learning: How and when to fix it,” arXiv preprint arXiv:2101.11665.
- [26] L. Yang, Y. Zhang, J. Chen, S. Zhang, and D. Z. Chen, “Suggestive annotation: A deep active learning framework for biomedical image segmentation,” in International conference on medical image computing and computer-assisted intervention. Springer, 2017, pp. 399–407.
- [27] I. S. K. Donggeun Yoo, “Learning loss for active learning,” in the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
- [28] K. Kim, D. Park, K. I. Kim, and S. Y. Chun, “Task-aware variational adversarial active learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8166–8175.
- [29] B. Xie, L. Yuan, S. Li, C. H. Liu, and X. Cheng, “Towards fewer annotations: Active learning via region impurity and prediction uncertainty for domain adaptive semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8068–8078.
- [30] R. Caramalau, B. Bhattarai, and T.-K. Kim, “Sequential graph convolutional network for active learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021.
- [31] S. Sinha, S. Ebrahimi, and T. Darrell, “Variational adversarial active learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5972–5981.
- [32] B. Zhang, L. Li, S. Yang, S. Wang, Z.-J. Zha, and Q. Huang, “State-relabeling adversarial active learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- [33] J. Choi, K. M. Yi, J. Kim, J. Choo, B. Kim, J. Chang, Y. Gwon, and H. J. Chang, “Vab-al: Incorporating class imbalance and difficulty with variational bayes for active learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6749–6758.
- [34] S. Bhatnagar, S. Goyal, D. Tank, and A. Sethi, “Pal: Pretext-based active learning,” arXiv preprint arXiv:2010.15947, 2020.
- [35] A. Parvaneh, E. Abbasnejad, D. Teney, G. R. Haffari, A. van den Hengel, and J. Q. Shi, “Active learning by feature mixing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 237–12 246.
- [36] J. S. K. Yi, M. Seo, J. Park, and D.-G. Choi, “Pt4al: Using self-supervised pretext tasks for active learning,” in European Conference on Computer Vision. Springer, 2022, pp. 596–612.
- [37] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [38] X. Liu, L. Li, S. Wang, Z.-J. Zha, Z. Li, Q. Tian, and Q. Huang, “Entity-enhanced adaptive reconstruction network for weakly supervised referring expression grounding,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, pp. 3003–3018, 2022.
- [39] J. Deng, L. Li, B. Zhang, S. Wang, Z. Zha, and Q. Huang, “Syntax-guided hierarchical attention network for video captioning,” IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [40] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017.
- [41] C. Rao and T. Nayak, “Cross entropy, dissimilarity measures, and characterizations of quadratic entropy,” IEEE Transactions on Information Theory, vol. 31, no. 5, pp. 589–593, 1985.
- [42] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” 2009.
- [43] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural images with unsupervised feature learning,” in NIPS workshop on unsupervised feature learning, 2011.
- [44] S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine-grained visual classification of aircraft,” arXiv preprint arXiv:1306.5151.
- [45] R. Zhang, A. A. Khan, R. L. Grossman, and Y. Chen, “Scalable batch-mode deep bayesian active learning via equivalence class annealing,” in The International Conference on Learning Representations, 2023.
- [46] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
- [47] F. Li, R. Fergus, and P. Perona, “Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2004, p. 178.
- [48] L. N. Darlow, E. J. Crowley, A. Antoniou, and A. J. Storkey, “Cinic-10 is not imagenet or cifar-10,” arXiv preprint arXiv:1810.03505, 2018.
- [49] J. Deng, W. Dong, R. Socher, L. Li, Kai Li, and Li Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2009.
- [50] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: synthetic minority over-sampling technique,” J. Artif. Intell. Res., vol. 16, pp. 321–357, 2002.
- [51] G. Van Horn, O. Mac Aodha, Y. Song, Y. Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie, “The inaturalist species classification and detection dataset,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8769–8778.
- [52] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223.
- [53] B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, Y. Burren, N. Porz, J. Slotboom, R. Wiest et al., “The multimodal brain tumor image segmentation benchmark (brats),” IEEE transactions on medical imaging, vol. 34, pp. 1993–2024, 2014.
- [54] X. Gong, A. Sharma, S. Karanam, Z. Wu, T. Chen, D. Doermann, and A. Innanje, “Ensemble attention distillation for privacy-preserving federated learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 076–15 086.
- [55] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890.
- [56] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: common objects in context,” in Proceedings of the European Conference on Computer Vision, 2014.
- [57] A. Karpathy and F. Li, “Deep visual-semantic alignments for generating image descriptions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015.
- [58] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in international conference on machine learning, 2016, pp. 1050–1059.
- [59] B. Zhang, L. Li, L. Su, S. Wang, J. Deng, Z.-J. Zha, and Q. Huang, “Structural semantic adversarial active learning for image captioning,” in Proceedings of the ACM International Conference on Multimedia, 2020.
- [60] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002.
- [61] M. Denkowski and A. Lavie, “Meteor universal: Language specific translation evaluation for any target language,” in Proceedings of the ninth workshop on statistical machine translation, 2014.
- [62] C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out, 2004, pp. 74–81.
- [63] R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015.
- [64] L. van der Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008.