An Empirical Study of Retrieval Augmented Generation with Chain-of-Thought
Abstract
Since the launch of ChatGPT at the end of 2022, generative dialogue models represented by ChatGPT have quickly become essential tools in daily life. As user expectations increase, enhancing the capability of generative dialogue models to solve complex problems has become a focal point of current research. This paper delves into the effectiveness of the RAFT (Retrieval Augmented Fine-Tuning) method in improving the performance of Generative dialogue models. RAFT combines chain-of-thought with model supervised fine-tuning (SFT) and retrieval augmented generation (RAG), which significantly enhanced the model’s information extraction and logical reasoning abilities. We evaluated the RAFT method across multiple datasets and analysed its performance in various reasoning tasks, including long-form QA and short-form QA tasks, tasks in both Chinese and English, and supportive and comparison reasoning tasks. Notably, it addresses the gaps in previous research regarding long-form QA tasks and Chinese datasets. Moreover, we also evaluate the benefit of the chain-of-thought (CoT) in the RAFT method. This work offers valuable insights for studies focused on enhancing the performance of generative dialogue models.
Index Terms: generative dialogue model, large language model, chain-of-thought, retrieval augmented generation
1 Introduction
In recent years, with the rapid development of human-computer dialogue, a key technology in this field, generative dialogue models [1, 2], has shown great potential and wide application prospects. From the early sequence-to-sequence (Seq2Seq) [3] architecture to recent innovations based on the Transformer [4] model with attention mechanisms, more advanced models are constantly emerging. However, generative dialogue models still confront significant challenges in accuracy, consistency, coherence, security, and resource efficiency. Enhancing their performance is a critical issue that demands attention.
To tackle more complex and diverse NLP tasks, the chain-of-thought (CoT) method [5, 6, 7, 8] has been proposed. Chain-of thought breaks down complex reasoning tasks into multiple intermediate steps that are computed sequentially to obtain the final result. It not only improves the logical consistency of the model’s responses but also enhances user interaction experiences. However, recent studies have shown that chain-of-thought prompting method requires models of ~100 billion parameters to fully release their reasoning ability [5], and thus will have a significant demands on computational resources.
Retrieval Augmented Generation (RAG) [9] is also a promising method to improve the performance of generative dialogue models [10, 11, 12, 13]. Retrieval augmented generation method enhances the performance and reliability of generative dialogue models by integrating knowledge from external databases. This method not only increases the accuracy and relevance of the generated text but also enables continuous updates of domain-specific knowledge, especially excelling in knowledge-intensive tasks. However, RAG still faces several challenges. Since the performance of retrieval augmented generation depends on the accuracy and efficiency of the retriever, poor-quality or irrelevant retrieval results may negatively impact the generated content. Additionally, how to effectively integrate the retrieved information with the prior knowledge of the model remains a significant challenge.
This paper studies a method that combines the chain-of-thought with retrieval augmented generation for Supervised Fine-Tuning (SFT) small-scale models to optimize their performance in reasoning tasks, which is called RAFT (Retrieval Augmented Fine-Tuning) [14]. This method not only avoids the reliance of the chain-of-thought prompting on large-scale models, but also alleviates the hallucination [15] and maintenance challenges of the knowledge retrieval process in RAG, enhancing the model’s ability to extract information and perform logical reasoning. In this work, we provide comprehensive optimization and evaluation of RAFT method across different types of reasoning tasks, including short-form QA and long-form QA, English tasks and Chinese tasks, bridge type and comparison tasks, particularly focusing on long-form QA and Chinese datasets. In addition, we evaluated the benefits of the chain-of-thought in the RAFT method and conducted a detailed analysis of the performance across various type of tasks above.
2 Method
2.1 RAFT Finetuning
RAFT [14] is derived from RAG+SFT, which combines retrieval augmented generation (RAG) and Supervised Fine-Tuning (SFT). For better understanding, let us make an analogy between these modeling techniques in generative dialogue models and various kinds of examinations faced by human.
For supervised fine-tuning, the pre-trained language model is fine-tuned for a specific task by introducing a labeled dataset tailored for the task. Supervised fine-tuning is similar to a closed-book exam taken after class, where students answer questions using only the problem-solving methods learned in class without any reference materials.
For the retrieval augmented generation method, the RAG model uses input prompts as query keywords to retrieve relevant documents. These retrieved contents are added to the model’s input, and the model generates responses based on the augmented input. In the examination analogy, this method can be regarded as finding relevant passages from the open-book knowledge according to the question and reasoning the answer.
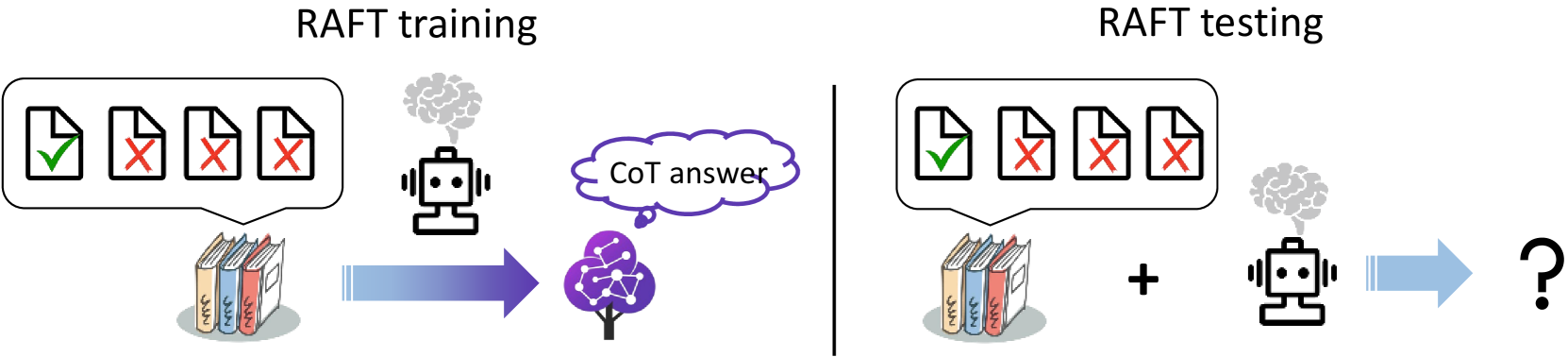
The RAFT method combines retrieval augmented generation and supervised fine-tuning, as well as incorporating the idea of chain-of-thought. This is akin to training the model to compute results from relevant information before taking an exam. Consequently, during an open-book exam, the model can deduce correct answers more quickly and accurately using the reference materials. In summary, the RAFT method has two key features. First, in addition to the oracle documents, irrelevant distractor documents are also included in the reference documents to improve model’s robustness against irrelevant information retrieved during the retrieval process. Second, chain-of-thought style responses are used as the target text in the fine-tuning dataset rather than plain short answers to improve model’s reasoning capability. To be specific, each data in RAFT dataset contains a question (), several distractor documents (), a oracle document containing the effective information to answer the question (), and a chain-of-thought style response () generated from the oracle document (). Figure 1 shows overview of RAFT.
| (1) |

2.2 Dataset Construction
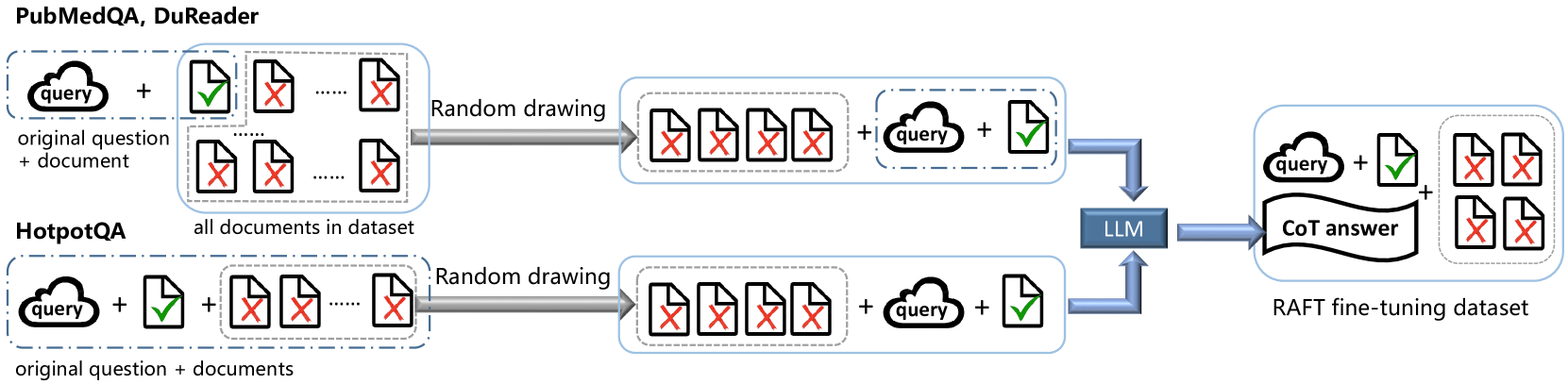
Figure 2 shows our RAFT fine-tuning dataset construction process. In order to make the datasets tailored to RAFT fine-tuning, we use two methods to process open-source datasets. When dealing with a dataset where a question corresponds to several reference documents (include oracle documents and distractor documents), we use the first method: For each question, we extract all the oracle documents from the question’s corresponding documents, then randomly select a specified number of documents from the remaining corresponding documents as the distractor documents. When dealing with a dataset where a question corresponds to only one oracle document, we use the second method: For each question, we take its corresponding document as oracle document and randomly select a specified number of documents from other questions’ reference documents as the question’s distractor documents. In this study, the dataset HotpotQA [16] was processed using the first method, while the datasets like PubMedQA [17] and DuReader_robust [18] were processed using the second method. In our RAFT experiments, we use four distractor documents for each question.
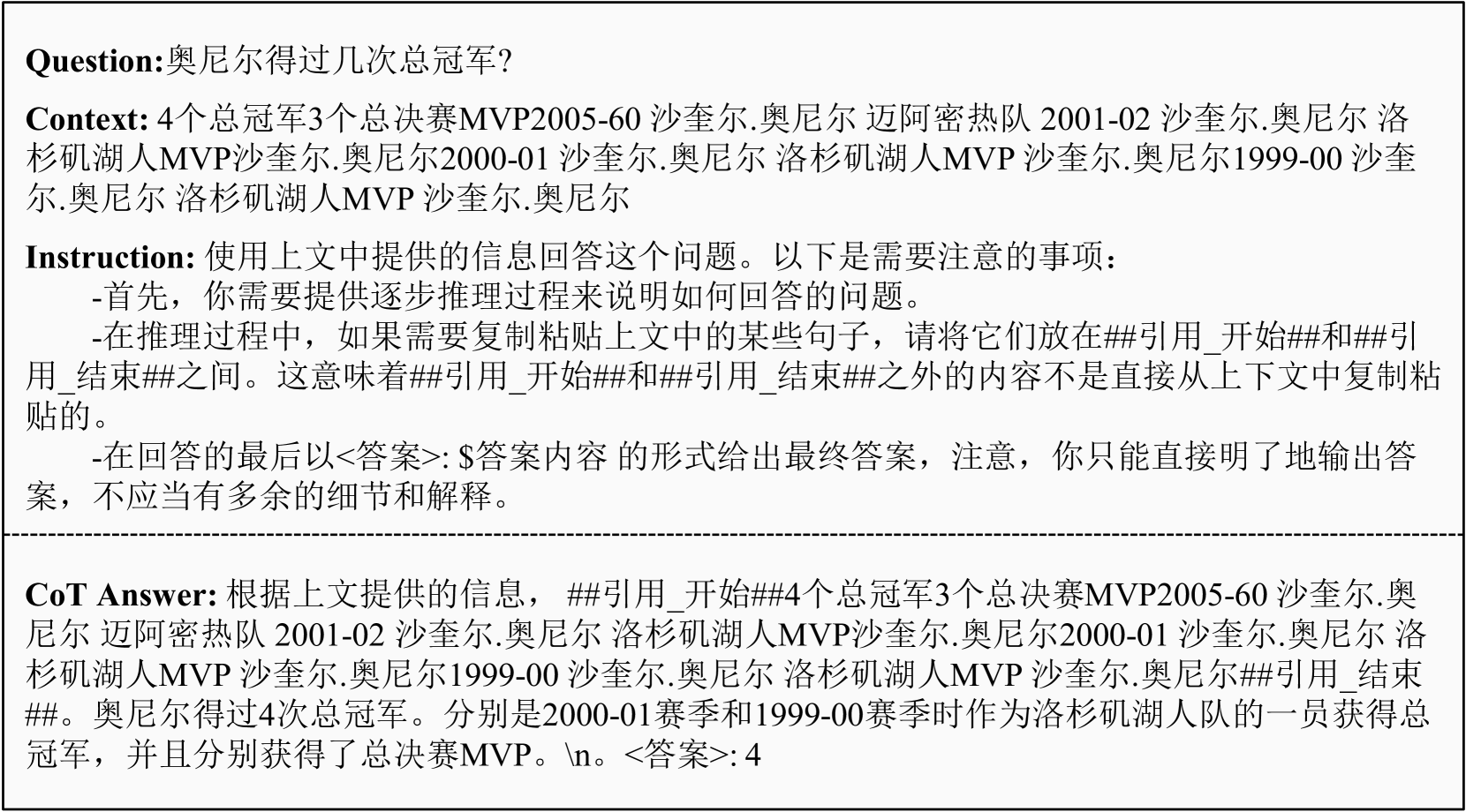
After selecting the oracle and distractor documents, we used GPT-3.5 with to generate chain-of-thought style response. We require the model to generate a chain-of-thought reasoning process based on the input question as well as its corresponding oracle documents. During this reasoning process, the model are prompted to cite the referenced content from the oracle documents and provide a final answer separately at the end. Figure 3 and figure 4 show our CoT answer generation process via GPT-3.5 in Chinese and English respectively.
3 Experiment Setup
3.1 Datasets
-
•
HotpotQA [16]: HotpotQA dataset contains 113,000 multi-hop reasoning question-answer pairs from Wikipedia. It includes two types of QA tasks: bridge and comparison. Bridge QA tasks require the model to find relevant information from multiple reference documents to provide an answer, while comparison QA tasks require the model to compare multiple entities or events. Each data item includes a question, several reference documents, and a short answer.
-
•
PubMedQA [17]: A biomedical question-answering dataset. It extracts data from PubMed abstracts and answers research questions based on these abstracts. Answers are presented in the form of ”yes/no/maybe.” Each data item consists of a question, a reference document, a long answer, and a short answer.
-
•
DuReader_robust [18]: DuReader_robust is a Chinese dataset used to evaluate the robustness and generalization ability of model’s reading comprehension function. Each data item includes a question, a reference document, and a short answer. All datas items are sourced from Baidu users’ search queries and responses.
3.2 Baselines
In this study, we evaluated the Chinese dataset DuReader_robust using Qwen-1.5-7B-chat [19] and the English datasets, HotpotQA and PubMedQA, using LLaMA2-7B-chat [20, 21].
-
•
LLaMA2-7B-chat / Qwen-1.5-7B-chat + zero-shot prompting: Provide the model with clear instructions and the question it needs to answer, without providing any external reference documents, and require the model to generate an answer.
-
•
LLaMA2-7B-chat / Qwen-1.5-7B-chat + RAG: Provide the model with instructions and the question, supplemented with external reference documents, and require the model to derive an answer using the content in these reference documents.
-
•
DSF (Domain Specific Finetuning) + zero-shot prompting: For each dataset standard supervised fine-tuning is performed without reference documents, using the question as the input text and the answer as the target text for fine-tuning. The fine-tuned model is then given the question and instructions and required to respond without referencing external documents.
-
•
DSF + RAG: Standard supervised fine-tuning is performed without reference documents for each dataset, but during testing, the fine-tuned model is supplemented with reference documents for the question. The model is required to derive the answer using external knowledge.
3.3 Evaluation Method
In our experiments, we primarily use F1 score and EM score (Exact Match) to evaluate the performance of the models. We standardize the answers by normalizing the answer text through several steps, including converting all text to lowercase, removing punctuation, removing articles (a, an, the), and standardizing spaces, which ensure that the answers are more uniform in format [22, 23]. Subsequently, the standardized answers are used to calculate their EM scores and F1 scores.
4 Experiment Result
| PubMedQA | HotpotQA[Oracle] | HotpotQA | |
|---|---|---|---|
| zero-shot | 50.50 | 15.06 | 15.06 |
| RAG | 56.42 | 12.07 | 8.72 |
| DSF + zero-shot | 53.91 | 20.04 | 20.04 |
| DSF + RAG | 71.71 | 45.26 | 27.40 |
| RAFT w.o. CoT | 54.80 | 52.38 | 28.74 |
| RAFT | 74.36 | 54.20 | 39.48 |
| PubMedQA[long] | HotpotQA[Oracle] | HotpotQA | DuReader | |
|---|---|---|---|---|
| zero-shot | 1.09 | 22.63 | 22.63 | 13.47 |
| RAG | 3.05 | 25.05 | 18.39 | 26.06 |
| DSF + zero-shot | 7.95 | 27.63 | 27.63 | 20.90 |
| DSF + RAG | 10.68 | 58.67 | 34.52 | 39.91 |
| RAFT w.o. CoT | —— | 64.47 | 37.48 | 42.25 |
| RAFT | 14.09 | 67.83 | 51.33 | 57.81 |
We compared the performance of the models using the RAFT method and the baselines. Table 1 and Table 2 show the results for the EM score and F1 score respectively. In the HotpotQA[Oracle] experiment group, only oracle documents were provided as references for the model in the RAG experiments. For all other groups, distractor documents were included alongside the reference documents in the RAG experiments.
From the experimental results, we can see that the RAFT method consistently outperforms four baseline methods across all datasets, demonstrating superior information extraction and complex problem reasoning capabilities in the models fine-tuned with RAFT method. On the HotpotQA dataset, the RAFT method (with CoT) achieved a performance gain of 42.13% in EM score and 42.78% in F1 score over the plain RAG baseline (without using DSF model) experiments. Even with the inclusion of distractor documents, it still achieved gains of 30.76% in EM score and 32.94% in F1 score. Furthermore, we observed that although the scores for RAFT degrade with the addition of distractor documents in the experiments (comparing the table columns corresponding to HotpotQA[Oracle] and HotpotQA), it achieved a higher performance gain over the DSF+RAG baseline. This indicates that the RAFT method can significantly enhance the model’s robustness in the retrieval process in RAG.
Before fine-tuning, the model’s performance was poor, regardless of whether RAG was included or not. Fine-tuning the model for specific domains, i.e., DSF, can significantly improve its performance by aligning model outputs with the answering patterns of those domains. Through the RAFT method (with CoT), the model not only learned specific domain answering patterns but also significantly improved its ability to extract effective information from complex data.
4.1 Long-form QA Evaluation
Since the ”yes/no” QA of PubMedQA and QA of HotpotQA are both short-form, we also assessed the long-form QA in dataset PubMedQA. The experiment results are shown in Table 2 under the PubMedQA[long] group. The results in F1 score of long-form QA indicate that RAFT method brought about a 13% performance improvement for long-answer questions over zero-shot prompting baseline. However, compared to the DSF+RAG baseline, the performance gain was less prominent than for the short-form QA. This is because the content of long answers tends to be more inclined towards the form of induction and summarization, rather than the certain result which can be obtained through reasoning like the short answers. The study of long-form QA with chain-of-thought needs further exploration.
4.2 Chinese Dataset Evaluation
We also conducted evaluation on DuReader_robust to assess the effectiveness of the RAFT method on the Chinese datasets. Since the questions in this dataset heavily rely on information from reference documents, the gain brought by the use of DSF is only 7.43% over the zero-shot prompting baseline (in Table 2 comparing the ’zero-shot’ and ’DSF+zero-shot’ rows in the DuReader group). In this case, the use of RAG to supplement reference documents with the question is more effective, which obtains a 12.59% performance gain over the zero-shot baseline. After RAFT fine-tuning, the model’s ability to extract and process information, as well as its reasoning capability can be significantly improved. It achieves 44.34% and 19.9% performance gain in F1 score over zero-shot prompting baseline and DSF+RAG baseline respectively. These results demonstrate that the RAFT method performs exceptionally well on both English and Chinese datasets.
4.3 Performance Across Different Types of Reasoning Tasks by RAFT
We evaluated the RAFT method separately on bridge-type QA and comparison-type QA in HotpotQA dataset, as shown in Table 3. The results indicate that RAFT performs better on comparison-type questions. This is likely because comparison-type questions typically involve comparing features between two or more entities, which can rely on direct information retrieval and simple comparison operations. In contrast, bridge-type questions often require the model to extract relevant information from multiple documents, involving longer reasoning chains and multiple intermediate steps so it demands a higher level of understanding and reasoning ability from the model.
| bridge | comparison | |
|---|---|---|
| RAFT-EM score | 36.25 | 50.72 |
| RAFT-F1 score | 48.80 | 60.11 |
4.4 Effect of CoT
To evaluate the benefit of the chain-of-thought (CoT) in the RAFT method, we conducted an ablation experiment (RAFT w.o. CoT). In this experiment, we removed the chain-of-thought style response from the RAFT training dataset and only included the final answer for each question as target text in the fine-tuning process. Comparing the HotpotQA dataset tested with only oracle documents for RAG and the one tested with distractor documents, the CoT method achieved more significant performance gains in the latter setting. This demonstrates that CoT can obtain more considerable benefit in the face of more complex knowledge and more serious information noise. Moreover, the performance of RAFT was consistently superior to the performance of RAFT without CoT across various datasets. Therefore, adding CoT effectively guides the model the correct information from complex input and enhances the model’s logical rigor and accuracy.
5 Conclusion
In this study, we evaluated the RAFT method across multiple datasets, addressing the gaps in previous research regarding long-form QA and Chinese datasets. The results indicate that the RAFT method combined with CoT not only improves the models’ ability to robustly extract and process information in the face of noise, but also enhances their logical reasoning ability in reasoning tasks. Significant performance gains were observed in evaluations on both English and Chinese datasets, as well as on long-form QA and short-form QA. Additionally, we conducted an ablation experiment where we removed the chain-of-thought style response from the RAFT training dataset to fine-tune the model. This experiment verifies the critical role of the chain-of-thought in enhancing the performance of generative dialogue models.
References
- [1] Y. Zhang, Z. Ou, and Z. Yu, “Task-oriented dialog systems that consider multiple appropriate responses under the same context,” in Proc. AAAI, 2020.
- [2] H. Liu, Y. Cai, Z. Ou, Y. Huang, and J. Feng, “Building markovian generative architectures over pretrained lm backbones for efficient task-oriented dialog systems,” in Proc. SLT, 2023.
- [3] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. NeurIPS, 2014.
- [4] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. NeurIPS, 2017.
- [5] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. H. Chi, Q. V. Le, D. Zhou et al., “Chain-of-Thought prompting elicits reasoning in large language models,” in Proc. NeurIPS, 2022.
- [6] M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. Le, E. Chi, D. Zhou et al., “Challenging BIG-Bench tasks and whether chain-of-Thought can solve them,” in Proc. ACL, 2023.
- [7] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano et al., “Training verifiers to solve math word problems,” arXiv preprint arXiv:2110.14168, 2021.
- [8] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “ReAct: Synergizing reasoning and acting in language models,” in Proc. ICLR, 2022.
- [9] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Proc. NeurIPS, 2020.
- [10] G. Izacard, P. Lewis, M. Lomeli, L. Hosseini, F. Petroni, T. Schick, J. Dwivedi-Yu, A. Joulin, S. Riedel, and E. Grave, “Atlas: Few-shot learning with retrieval augmented language models,” Journal of Machine Learning Research, vol. 24, no. 251, pp. 1–43, 2023.
- [11] S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. B. Van Den Driessche, J.-B. Lespiau, B. Damoc, A. Clark et al., “Improving language models by retrieving from trillions of tokens,” in Proc. ICML, 2022.
- [12] K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. Chang, “Retrieval augmented language model pre-training,” in Proc. ICML, 2020.
- [13] U. Khandelwal, O. Levy, D. Jurafsky, L. Zettlemoyer, and M. Lewis, “Generalization through memorization: Nearest neighbor language models,” in Proc. ICLR, 2019.
- [14] T. Zhang, S. G. Patil, N. Jain, S. Shen, M. Zaharia, I. Stoica, and J. E. Gonzalez, “RAFT: Adapting language model to domain specific rag,” arXiv preprint arXiv:2403.10131, 2024.
- [15] L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023.
- [16] Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning, “HotpotQA: A dataset for diverse, explainable multi-hop question answering,” in Proc. EMNLP, 2018.
- [17] Q. Jin, B. Dhingra, Z. Liu, W. Cohen, and X. Lu, “PubMedQA: A dataset for biomedical research question answering,” in Proc. EMNLP, 2019.
- [18] H. Tang, H. Li, J. Liu, Y. Hong, H. Wu, and H. Wang, “DuReader_robust: A chinese dataset towards evaluating robustness and generalization of machine reading comprehension in real-world applications,” in Proc. ACL, 2021.
- [19] J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023.
- [20] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [21] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
- [22] Baidu, “Dureader robust,” https://github.com/baidu/DuReader.
- [23] HotpotQA, “Hotpotqa,” https://github.com/hotpotqa/hotpot.