Constructing the CORD-19 Vaccine Dataset
Abstract
We introduce new dataset ‘CORD-19-Vaccination’111Our dataset is available at https://github.com/manisha-Singh-UW/CORD-19-Vaccination to cater to scientists specifically looking into COVID-19 vaccine-related research. This dataset is extracted from CORD-19 dataset (Wang et al., 2020) and augmented with new columns for language detail, author demography, keywords, and topic per paper. Facebook’s fastText model is used to identify languages (Joulin et al., 2016). To establish author demography (author affiliation, lab/institution location, and lab/institution country columns) we processed the JSON file for each paper and then further enhanced using Google’s search API to determine country values. ‘Yake’ was used to extract keywords from the title, abstract, and body of each paper and the LDA (Latent Dirichlet Allocation) algorithm was used to add topic information (Campos et al., 2020, 2018a, 2018b). To evaluate the dataset, we demonstrate a question-answering task like the one used in the CORD-19 Kaggle challenge (Goldbloom et al., 2022). For further evaluation, sequential sentence classification was performed on each paper’s abstract using the model from Dernoncourt et al. (2016). We partially hand-annotated the training dataset and used a pre-trained BERT-PubMed layer. ‘CORD-19-Vaccination’ contains 30k research papers and can be immensely valuable for NLP research such as text mining, information extraction, and question answering, specific to the domain of COVID-19 vaccine research.
1 Introduction
A report released in early 2021 declared, “World to spend $157 billion on COVID-19 vaccines through 2025” (Mishra, 2021). Despite this, there are no datasets that are specific to COVID-19 vaccine research. The COVID-19 Open Research Dataset (CORD-19) (Wang et al., 2020) is a corpus of academic papers on coronavirus research. However, the metadata file for the CORD-19 dataset (release version 109) consists of over one million journals, resulting in big data issues and information overload. The overall goal is to create a dataset that was based out of CORD-19 but only includes the papers that are relevant to vaccine research. In this work, we introduce a dataset curated from the CORD-19 dataset and tailored to aid research on COVID-19 vaccines.
Our approach utilizes a pipeline of information extraction, data augmentation, and task implementation:
Extraction phase: In this phase, we created a SQLite data pipeline to manage the large volume of the CORD-19 dataset. The language of each paper’s abstract was determined using Facebook’s fastText library (Joulin et al., 2016). Subsequently, using SQLite query we created a subset of the CORD-19 dataset, taking only those papers where the starting ‘publish time’ was ‘2020’ and either the ‘Abstract’ or ‘Title’ contained the word ‘vaccine’ or ‘vaccination’ in all the languages present in CORD-19.
Data augmentation phase: In this phase we added new columns to the dataset. The language ID determined from the previous phase was retained. Data on author affiliation was collected from the ‘json parse’ files of the research papers web search of each research paper. Keywords were added using ‘Yake’ (Campos et al., 2020). Finally, we implemented ‘Topic modeling’ where we classified the dataset into topics based on the ‘Abstract’ using the LDA model (Dernoncourt et al., 2016).
Task implementation phase: We implemented ‘Question and Answering’ and ‘Sequence sentence classification’ task using the CORD-19-Vaccination dataset.
The implementation of each of these steps is detailed in the sections below. Figure 1 shows a visual overview of the creation of the dataset.

In what follows, we motivate and describe each phase, highlighting discoveries at each step. We then demonstrate the utility of the dataset on the tasks of Question and Answering and Sequential Sentence Classification.
2 Extraction phase: user and context information extraction from CORD-19
The CORD-19-Vaccination dataset is extracted from the CORD-19 dataset based on the following filtering criteria:
Publish time:
The CORD-19 metadata.csv has a column publish_time. The extraction filter extracts all data where publish_time is greater than or equal to ’2020’.
Pattern search:
’vaccine’/’vaccination’ in either title or abstract: CORD-19 metadata.csv does not indicate the language of a paper. Figure 2 shows the language distribution of CORD-19 using the fastText model. CORD-19-Vaccination dataset is extracted from the CORD-19 dataset. In order to extract papers with the word ’vaccine/vaccination’ in every language a query for information extraction was customized to search the pattern of ’vaccine/vaccination’ in every language. This query was applied on columns title and abstract. The language ID abbreviations are taken from ISTD .


Pdf_json_files / pmc_json_files:
CORD-19 metdata.csv has the columns pdf_json_files and pmc_json_files. These columns give the path of the json files in the CORD-19 dataset. All papers selected had the pdf_json_file or pmc_json_files present.
Abstract is not null:
All papers selected had the abstract column present. Our exploratory data analysis revealed that almost all standard published papers must follow a particular template where the abstract must be present. The papers which did not have an abstract were mostly articles that were not published papers. This improved the quality of our dataset as it only includes research papers.
Since several of the ‘CORD-19-Vaccination’ columns are based on CORD-19, the preprocessing for CORD-19 is detailed in Wang et al. (2020).
3 Data augmentation phase: language detail, author demography, keyword and topic
Table 1 includes a list of fields added to the CORD-19-Vaccination dataset. The code to generate these augmented fields is available in the GitHub repo222The code for the data augmentation is available at https://github.com/manisha-Singh-UW/CORD-19-Vaccination.
| Language Detail | Author Demography | Keywords | Topic |
| lang_id, lang_id_confidence, lang_id_predictions | aff_lab_inst, aff_location, aff_country | keywords | topic, topic_index, topic_prob |
3.1 Language id
Language ID is included in the dataset in order to support text demography. The input to the fastText model is the text of the ‘abstract’ from each paper and the output are the three fields as shown in Table 2.
| lang_id | lang_id_confidence | lang_id_predictions |
| en | 0.9167 | en=0.9167, id=0.0055, fr=0.0043 |
The fastText model predicts the language as ’English’ with a confidence level of ’0.9167’. However, the fastText model also gives a small confidence level to ’Indonesian’ at ’0.0055’ and ’French’ at ’0.0043’. This is likely due to the medical domain including many loan words. In the example in Table 2, the confidence level of ‘English’ compared to the other languages is much higher, so Language ID field is set to ‘English’. The graph in Figure 3 shows the language distribution of the CORD-19-Vaccination dataset.
3.2 Author’s demography (lab/institution location and country)
The CORD-19 dataset contains authors and a journal name for each paper. However, in order to get more details regarding the authors’ demography, we augmented the data with authors’ ‘lab/institution affiliation’, ‘lab/institution location’ and ‘lab/institution country’. Details on the authors’ demography can be used to construct a collaboration network to illustrate collaborations or coauthor-ship relations among institutions as in the article Haihua Chen (2022).
| aff_lab_inst | aff_location | aff_country | ||||
|---|---|---|---|---|---|---|
|
|
USA |
The author’s ’lab/institution affiliation’, ’lab/institution location’ and ’lab/institution country’ was not mentioned in the CORD-19 metadata file. However, in order to do descriptive analysis such as number of the papers contributed by each institution, geographical distribution of institutions and collaboration among institutions from different countries/regions we need the institution details related to each author of the paper.
Additionally, as the country of affiliation metadata was only available for approximately 63% of the JSON files, further data augmentation was carried out to extract the country of the first author via web scraping. For this process, titles of papers with missing country data were searched through Python’s Google search API and the HTML source code of the webpage corresponding to the first query result was parsed using Selenium and Beautiful Soup. Scraped titles from the search query and their linked countries of affiliation were stored and subsequently validated by comparing similarity between the original CORD-19 paper title and the scraped title. Entries with a similarity below 0.4 (calculated using the Sequence Matcher module from Python’s diff lib library) were excluded.
Author demographic:
Speaker/Author demographic was mainly assessed via examination of the distribution of first author’s countries of affiliation. We initially extracted the country data from the full text JSON files, achieving coverage of 63% over the total of papers. Through web scraping, we identified the country of affiliation for an additional group of papers, increasing coverage to 93%.

50% of the total papers were concentrated over 7 countries: United States of America, China, India, Italy, United Kingdom, Germany, and Canada, with the USA representing 20% of the dataset. A complete map depicting the distribution of number of papers by country of affiliation of the first author can be observed in Figure 4. Most notably, apart from the concentration of research in the previously mentioned countries, a stark lack of representation from the Global South (with the exception of Brazil) was also evident.
The authors’ detail is present in the associated JSON file of each paper, from which institution of affiliation, location and country were extracted. The input is the JSON file and output are the columns corresponding to each author and paper id.
3.3 Keywords from ’abstract’, ’title’ and ’text body’
Top 20 keywords have been extracted using the Yake library. Keywords from every paper can be used further in topic modeling and for keyword search, which gives an idea about the main content of the paper.
Yake was used because it uses an unsupervised approach, which is corpus-independent, and domain and language independent. Yake follows an unsupervised approach that builds upon features extracted from the text, making it applicable to documents written in different languages without the need for domain-specific knowledge.
The input to the Yake object is the text string, generated from the ’title’, ’abstract’ and ’body text’ of the paper. The output is the list of the keywords. One can customize the number of the top key words and n-grams. For our current implementation we have chosen the top-20 keywords and n-grams size as ’3’. The rest of the parameters for Yake are default values. A sample result of the keyword extraction is shown in Table 4.
| Keywords | ||||||
|
3.4 Topic modeling
We further augmented the dataset by implementing a topic modelling algorithm (Latent Dirichlet Allocation). Generation of topic labels has a twofold intention: first, given the variety of possible themes within the papers (even when filtered to only include vaccine-related documents), it provides a comprehensive overview of recurrent subjects and allows for easy inspection of the distribution amongst them. Second, it facilitates quick sub-setting of the data to allow potential users to fit more scoped tasks.
Training of the LDA was performed over the complete set of paper abstracts, which were pre-processed into lower case; and had stop words, punctuations, and small words (e.g. character length below 3) removed. We tested a range of “number of topics (n)” parameters (from n=5 to n=14) and evaluated each model via the Coherence score described by Röder et al. (2015), ultimately selecting n=5 as the final parameter due to its higher score and parsimony.
To assign a label to each trained topic, we selected the top 20 words per topic and cross-referenced this list against the paper titles of the documents with the highest probability of pertaining to a particular theme. Additional evaluation was performed visually to assess possible topic overlaps by applying dimensionality reduction (through t-SNE) over the topic distribution vectors of each document and plotting them, colored by label. The resulting topic labels and their distribution over the dataset are shown in Table 5.
| Topic | % of dataset |
|---|---|
| T1: Vaccine development | 20% |
| T2: Vaccination side-effects | 14% |
| T3: Vaccination efficacy | 16% |
| T4: Methodologies for COVID studies (e.g. simulations) | 25% |
| T5: Vaccine uptake (by factors of age, sex, race, etc.) | 25% |
4 Task implementation phase
CORD-19-Vaccination dataset contains the metadata of approximately 30k research papers. As the next step, we evaluated the dataset by performing ‘Question and Answering’ and ‘Sequential Sentence Classification’ tasks.
4.1 Question and answering task
We designed a task similar to the Goldbloom et al. (2022)’s Kaggle competition challenge on CORD-19. ’Covid-19 vaccine’ Question and Answering system is a domain specific task. In an ideal situation we need a medical expert to design the questions and evaluate the answers. However, in absence of a medical expert we designed a simple vaccine specific question. We tried to follow the "user-based approach" as per Diekema et al. (2004) to evaluate the answer.
The Question and Answering task consists of three parts: ’question’, ’context’, and ’answer’. The input to the model is a covid-19 vaccine specific question and the context. In this implementation we are assuming that the question is contained in the context. We needed to keep the context small to implement this model on 30k papers. This is done by selecting the papers similar to the answers, using ’Okapi BM25’ (Wikipedia, 2022). Okapi BM25 is a ranking function used by search engines to estimate the relevance of the document for a given search query. For each question and context, we are using “Huggingface transformer library” to predict the answer (Wolf et al., 2020). We have used the pretrained QA model ’bert-large-uncased-whole-word-masking finetuned-squad’. The solution for this task was customized for ‘CORD-19-vaccination’ dataset which is inspired by Besomi (2020)’s Kaggle notebook.
Figure 5 is output of the ‘Question and Answering’ task for the question ‘is covid-19 vaccine safe?’.

| Question | Papers | Citation | Viewed | Downloads |
|---|---|---|---|---|
| Is Covid-19 vaccine safe? | 10.1038/s41577-021-00525-y | 111 | ||
| 10.1016/j.puhe.2020.05.007 | 9 | |||
| 10.1093/jlb/lsaa024 | 3 | 1146 | 435 | |
| 10.3390/vaccines10020298 | 627 | |||
| 10.1111/jdv.17499 | 3 | |||
| 10.1111/dth.15146 | 6 |
Table 6 gives the list of the papers as answers for the question ’Is Covid-19 vaccine safe? ’. According to the "user-based approach" of evaluation we can say that the papers in the result seem relevant, as most of the papers were recently published.
’CORD-19-Vaccination’ dataset is better than ’CORD-19’ for vaccination related ’Question and Answering’ task due to following reasons: ’CORD-19-Vaccination’ was augmented with fields in Table 5. These fields are not present in ’CORD-19’. Researchers using ’CORD-19-Vaccination’ can make use of these augmented fields for better answers.
The column keyword in ’CORD-19-Vaccination’ dataset is the list of keywords extracted from the body of the text papers using ’Yake’, so if we extract the context search using ’Title’/’Abstract’/’Keyword’, the answer should be more accurate.
4.2 Sequential sentence classification task
Text classification is a very important task in Natural Language Processing (NLP) where a label or class is assigned to a text. In the current task, the focus is on the classification of sentences in medical abstracts. The sentences in the abstracts appear in a sequence therefore this task is called "Sequential Sentence Classification Task". This task converts unstructured block-of-text abstracts into structured abstracts (text organized into semantic headings such as Background, Methods, Results, and Conclusions), making it easy to quickly locate relevant information. This task is based on the paper Dernoncourt et al. (2016). The output of this task has been provided as a new column named labeled_abstract in the dataset.
The data for training the model for this task is obtained from the PubMed 200k RCT dataset Dernoncourt and Lee (2017) and the CORD-19 dataset itself. 11.58% of the abstracts from the CORD-19 dataset (approximately 117k samples) were found to have abstracts structured with semantic headings. Similarly, 14.66% of the records in the CORD-19-Vaccine dataset (4294 samples) were found to have abstracts structured with semantic headings. These records were split into test and validation datasets for model training. A single data sample contains information on target labels, sentence from abstract, and order of sentences, compatible with Dernoncourt et al. (2016). The pubmed_id and cord_uid fields are available as comments and are not inputs to the training model. As per the guidance of the PubMed 200k RCT paper, numbers from the dataset have been replaced with the @ sign.
The distribution of various target labels is shown across datasets in Figure 6. It is important to note that the percentage of OBJECTIVE labels is quite high (at 16.13%) in the CORD-19-Vaccination dataset, while the percentage of CONCLUSION labels is quite low (at 6.21%) compared to PubMed RCT200k and CORD-19 datasets.

Task Workflow:
The workflow in figure 7 shows the sequence of tasks performed during the training and subsequent fine-tuning of the model. This particular workflow was chosen to allow coarse-grained to fine-grained model training.

The model architecture used for training is based on the Dernoncourt et al. (2016) paper. A pre-trained and frozen BERT-PubMed layer has been used to improve performance. The original training/validation data split of PubMed 200k RCT dataset was used fir the initial round of training. For fine tuning, a random split of 70-30 was used for stage 1 and split of 50-50 was used for stage 2. The model training was performed initially with a learning rate of 1e-4, which was reduced to 1e-4 for fine tuning. A system based on Nvidia Tesla P100 GPU was used for training.
Output:
Table 7 shows performance metrics of this model on the CORD-19-Vaccine dataset.
| Accuracy | F1-score | Precision | Recall |
| 0.7618 | 0.7569 | 0.7569 | 0.7618 |
Evaluation:
Figures 9 and 9 are the Confusion Matrix plotted using scikit learn. The matrix in Figure 9 shows the raw numbers of label distribution, while the matrix in Figure 9 is normalized on the “true” labels.
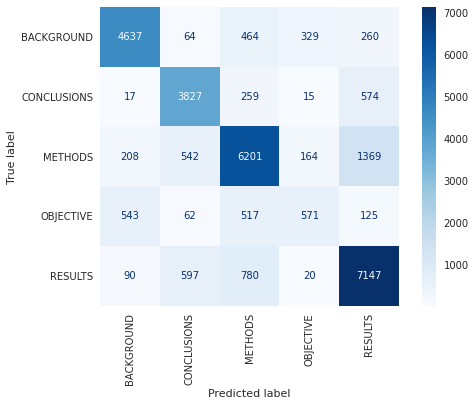
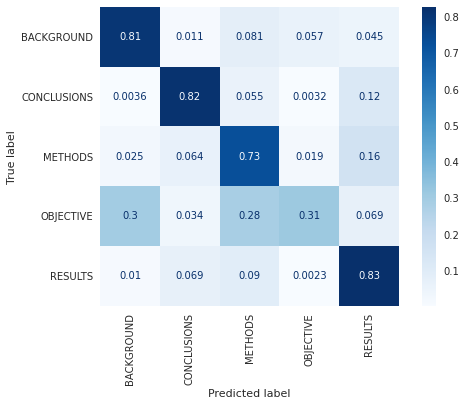
We can observe from the confusion matrix that the OBJECTIVE label was often confused with BACKGROUND and METHODS. Similarly, METHODS label was often confused with RESULTS.
Additional evaluation was performed by manually reviewing the most wrong predictions. Some patterns that we found in these predictions are short sentences consisting of just a few words were incorrectly predicted, and ungrammatical or ambiguous sentences were misclassified.
5 License
‘CORD-19-Vaccination’ dataset is extracted from ‘CORD-19’ dataset, so ‘CORD-19-Vaccination’ dataset also follows all the licenses333CORD-19 Dataset License: https://ai2-semanticscholar-cord-19.s3-us-west-2.amazonaws.com/2020-03-13/COVID.DATA.LIC.AGMT.pdf that are followed by ‘CORD-19’.
6 Conclusion
In this paper, we are introducing our new dataset ‘CORD-19-Vaccination’. This dataset consists of approximately 30k rows of metadata of scientific research papers, specific to the domain of COVID-19 vaccine research, making it the largest known curated resource in this domain. This dataset has been augmented with valuable details that extends the information present in the CORD-19 dataset. The ‘Question and Answering’ and ‘Sequential Sentence Classification’ evaluation results further highlights the value of this dataset for various NLP tasks. We hope that the release of this dataset can be immensely valuable to the COVID-19 vaccine-research community and used for NLP research such as text mining, information extraction, and question answering, specific to the domain of COVID-19 vaccine research.
References
- Besomi [2020] Jonathan Besomi. A qa model to answer them all, 2020. URL https://www.kaggle.com/code/jonathanbesomi/a-qa-model-to-answer-them-all/comments.
- Campos et al. [2018a] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Mário Jorge, Célia Nunes, and Adam Jatowt. A text feature based automatic keyword extraction method for single documents. In Gabriella Pasi, Benjamin Piwowarski, Leif Azzopardi, and Allan Hanbury, editors, Advances in Information Retrieval, pages 684–691, Cham, 2018a. Springer International Publishing. ISBN 978-3-319-76941-7.
- Campos et al. [2018b] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Mário Jorge, Célia Nunes, and Adam Jatowt. Yake! collection-independent automatic keyword extractor. In Gabriella Pasi, Benjamin Piwowarski, Leif Azzopardi, and Allan Hanbury, editors, Advances in Information Retrieval, pages 806–810, Cham, 2018b. Springer International Publishing. ISBN 978-3-319-76941-7.
- Campos et al. [2020] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Jorge, Célia Nunes, and Adam Jatowt. Yake! keyword extraction from single documents using multiple local features. Information Sciences, 509:257–289, 2020. ISSN 0020-0255. doi: https://doi.org/10.1016/j.ins.2019.09.013. URL https://www.sciencedirect.com/science/article/pii/S0020025519308588.
- Dernoncourt and Lee [2017] Franck Dernoncourt and Ji Young Lee. Pubmed 200k RCT: a dataset for sequential sentence classification in medical abstracts. CoRR, abs/1710.06071, 2017. URL http://arxiv.org/abs/1710.06071.
- Dernoncourt et al. [2016] Franck Dernoncourt, Ji Young Lee, and Peter Szolovits. Neural networks for joint sentence classification in medical paper abstracts, 2016. URL https://arxiv.org/abs/1612.05251.
- Diekema et al. [2004] Anne Diekema, Ozgur Yilmazel, and Elizabeth Liddy. Evaluation of restricted domain question-answering systems. Center for Natural Language Processing, 01 2004.
- Goldbloom et al. [2022] Anthony Goldbloom, Allen Institute for AI, Peijen Lin, Paul Mooney, Carissa Schoenick, Sebastian Kolmeier, Debrishi, Timo Bozsolik, and Ben Hammer. Covid-19 open research dataset challenge (cord-19), 2022. URL https://www.kaggle.com/datasets/allen-institute-for-ai/CORD-19-research-challenge?datasetId=551982&sortBy=dateCreated.
- Haihua Chen [2022] Huyen Nguyen Haihua Chen, Jiangping Chen. Demystifying covid-19 publications: institutions, journals, concepts, and topics, 2022. URL https://jmla.pitt.edu/ojs/jmla/article/view/1141/1342.
- [10] ISTD. Language studies. URL https://www.science.co.il/language/Codes.php.
- Joulin et al. [2016] Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov. Fasttext.zip: Compressing text classification models, 2016. URL https://arxiv.org/abs/1612.03651.
- Mishra [2021] Manas Mishra. World to spend $157 billion on covid-19 vaccines through 2025 -report, 2021. URL https://www.reuters.com/business/healthcare-pharmaceuticals/world-spend-157-billion-covid-19-vaccines-through-2025-report-2021-04-29/.
- Röder et al. [2015] Michael Röder, Andreas Both, and Alexander Hinneburg. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, WSDM ’15, page 399–408, New York, NY, USA, 2015. Association for Computing Machinery. ISBN 9781450333177. doi: 10.1145/2684822.2685324. URL https://doi.org/10.1145/2684822.2685324.
- Wang et al. [2020] Lucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar, Russell Reas, Jiangjiang Yang, Doug Burdick, Darrin Eide, Kathryn Funk, Yannis Katsis, Rodney Michael Kinney, Yunyao Li, Ziyang Liu, William Merrill, Paul Mooney, Dewey A. Murdick, Devvret Rishi, Jerry Sheehan, Zhihong Shen, Brandon Stilson, Alex D. Wade, Kuansan Wang, Nancy Xin Ru Wang, Christopher Wilhelm, Boya Xie, Douglas M. Raymond, Daniel S. Weld, Oren Etzioni, and Sebastian Kohlmeier. CORD-19: The COVID-19 open research dataset. In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, Online, July 2020. Association for Computational Linguistics. URL https://aclanthology.org/2020.nlpcovid19-acl.1.
- Wikipedia [2022] Wikipedia. Okapi bm25, 2022. URL https://en.wikipedia.org/wiki/Okapi_BM25.
- Wolf et al. [2020] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.