1193 Research please specify Xingchen Zeng, Haichuan Lin, Yilin Ye, Wei Zeng are with the Hong Kong University of Science and Technology (Guangzhou), Guangzhou, China. Yilin Ye and Wei Zeng are also with the Hong Kong University of Science and Technology, Hong Kong SAR, China. E-mail: {xzeng159@connect., hlin386@connect., yyebd@connect., weizeng@}hkust-gz.edu.cn Wei Zeng is the corresponding author. Biv et al.: Global Illumination for Fun and Profit
Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
Abstract
Emerging multimodal large language models (MLLMs) exhibit great potential for chart question answering (CQA). Recent efforts primarily focus on scaling up training datasets (i.e., charts, data tables, and question-answer (QA) pairs) through data collection and synthesis. However, our empirical study on existing MLLMs and CQA datasets reveals notable gaps. First, current data collection and synthesis focus on data volume and lack consideration of fine-grained visual encodings and QA tasks, resulting in unbalanced data distribution divergent from practical CQA scenarios. Second, existing work follows the training recipe of the base MLLMs initially designed for natural images, under-exploring the adaptation to unique chart characteristics, such as rich text elements. To fill the gap, we propose a visualization-referenced instruction tuning approach to guide the training dataset enhancement and model development. Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. Experimental results validate the effectiveness of our approach. Even with fewer training examples, our model consistently outperforms state-of-the-art CQA models on established benchmarks. We also contribute a dataset split as a benchmark for future research. Source codes and datasets of this paper are available at https://github.com/zengxingchen/ChartQA-MLLM.
keywords:
Chart-question answering, multimodal large language models, benchmark![[Uncaptioned image]](x1.png)
Comparison of our model with state-of-the-art MLLMs on chart question answering. Existing MLLMs often fail to understand visual mappings, such as inverted Y-axis, truncated axis, bubble sizing, and area stacking. In contrast, our model, trained with the visualization-referenced dataset we constructed, showcases a better understanding of visualization domain knowledge.
1 Introduction
Multimodal large language models (MLLMs), such as GPT4-Vision[3], have made remarkable strides in understanding and interpreting natural images, enabling breakthroughs in various vision-language tasks (e.g., visual question answering[4]). These models excel by aligning the image representation of pre-trained vision encoders with the powerful linguistic understanding of LLMs. Thereby, MLLMs show great potential for visualization tasks that involve interpreting charts using natural language, such as chart question answering (CQA), chart summarization[74], and chart reverse-engineering[64]. CQA poses intricate challenges, requiring both the comprehension of complex natural language, along with the recognition of information from charts and the reasoning ability to derive accurate answers[27].
Building MLLMs tailored for CQA necessitates high-quality training datasets and benchmarks. Recent research[24, 57, 45] in this field primarily focuses on scaling up training datasets that include charts, data tables, and QA pairs, employing manual labeling and data synthesis techniques. These efforts have enhanced the performance of MLLMs in traditional CQA benchmarks[54, 58]. However, bottlenecks have emerged, posing challenges for further improving performance and adapting to real-world scenarios. Simply scaling up the training dataset without implementing quality control measures poses significant challenges in training efficiency and the feasibility of integrating these data into general MLLM training.
Recent research[20] emphasizes the impact of different QA types on model performance, finding that reasoning-oriented[20] and complexity-enhanced[63] instruction sets are particularly useful in improving the performance of MLLMs. In the context of CQA, existing MLLMs for CQA encompass visual instructions in the format of <chart, question, answer>. The quality of the chart and question-answering (QA) pairs is pivotal for the effectiveness and generalizability of MLLMs. However, the utilization of visual instruction data to enhance CQA remains largely under-explored, leaving unanswered questions about what makes good visual instructions and how to improve the dataset from the perspectives of visual instructions.
To address these inquiries, we conduct a comprehensive evaluation (Sect. 4) of MLLMs on CQA, aiming to pinpoint deficiencies and identify visual instructions that enhance MLLMs’ performance. The study utilizes the ChartQA dataset [54], a widely adopted benchmark for CQA. Through empirical analysis (Sect. 4.1.1), we uncover notable distribution bias in both chart and QA pairs within the ChartQA dataset, as compared to practical datasets such as the Beagle image dataset[6] and visual literacy assessment datasets[36, 21, 60]. Thorough experiments (Sect. 4.1.2) uncover significant impacts of the distribution bias on MLLMs’ performance in CQA, highlighting the necessity of incorporating more instructions for compositional and visual-compositional questions. Ablation studies (Sect. 4.2) further confirm that incorporating more reasoning-oriented QAs can significantly enhance model performance compared to including data retrieval QAs.
Drawing inspiration from the results, we introduce a novel data engine (Sect. 5) to generate instruction-enhanced CQA datasets. This engine comprises a data-filtering component (Sect. 5.1), utilizing a classifier with fine-grained chart features to reveal distributions and filter existing chart datasets. To mitigate the bias in the chart distributions and generate unavailable chart tasks, we further design a data generation component (Sect. 5.2) employing a chart space-guided data augmentation strategy to ensure the inclusivity of real-world possible charts. We further enrich reasoning-oriented QAs for the generated charts, contributing to a new CQA dataset and benchmark (Sect. 5.3) that features a wider variety of chart types and more QAs with effective visual instructions.
Existing MLLMs, mostly relying on CLIP encoders trained on natural images, are not optimally suited for visualization charts due to inherent differences. Recognizing the limitations, we develop a new MLLM (Sect. 6) that unfreezes the vision encoders in CLIP to better adapt to chart-specific features. Our MLLM is trained using the newly curated CQA dataset with more effective visual instructions. Additionally, we incorporate a mixture-of-resolution adaptation strategy[52] to enhance the fine-grained recognition capabilities of chart elements. Quantitative experiments (Sect. 7) demonstrate that even trained on a dataset with significantly less CQA data, our model consistently outperforms state-of-the-art CQA models on established benchmarks.
In summary, our contributions are three-fold:
-
•
An empirical study that identifies limitations of current MLLMs and ChartQA dataset and key factors (i.e., recognition and reasoning) that contribute to effective visual instructions for MLLMs’ chart understanding.
-
•
A novel data engine encompassing data filtering and data generation, producing a high-quality dataset and benchmark using visualization-referenced instruction tuning.
-
•
An MLLM that outperforms existing open-source CQA models on existing CQA benchmarks and is comparable to the best commercial models on our proposed benchmark.
2 Background of MLLMs
Recently, LLMs[67, 8] have showcased powerful text generation and comprehension capabilities. However, native LLMs live in the pure-text world and cannot process other common modalities such as images and videos, thereby limiting their application scope[5]. To break this limitation, a group of MLLMs (e.g., LLaVA[48], Qwen-VL[5], and GPT4-Vision[3]) have emerged to endow LLMs with the ability to perceive and understand visual images.
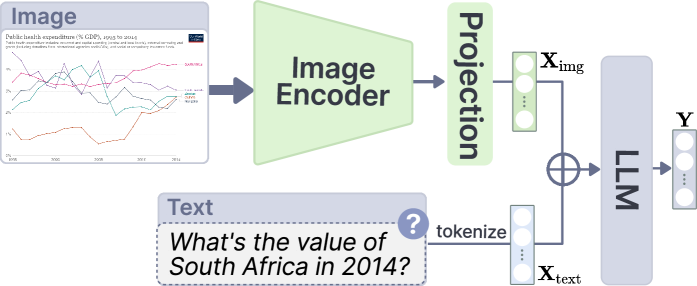
 represents the concatenation process of image and text tokens .
represents the concatenation process of image and text tokens .Inspired by LLaVA[48], current open-source MLLMs adopted a similar architecture to align the visual and textual features. Figure 1 illustrates the typical MLLM architecture that comprises three modules: Vision Encoder, Projection Layer, and Large Language Model. Particularly, the Vision Encoder (e.g., CLIP-Vit[61]) extracts a sequence of visual features from the input image. Then, the Projection Layer (e.g., multiple linear layers[48] and querying transformer [40]) transforms the visual features into the LLM word embedding space, resulting in compatible visual tokens for the subsequent LLM (e.g., Vicuna-1.5[77]). Finally, the LLM processes the concatenated visual and text tokens , i.e., , and then autoregressively generates responses . Formally, the language model predicts the response conditioned on the multimodal input , where means the number of tokens in the response. Therefore, the response is predicted by maximizing
| (1) |
where is the trainable parameters.
Despite the architectural harmonization, the biggest challenge in training generic MLLMs is collecting high-quality visual instruction data, i.e., . Visual instructions facilitate the alignment of the multimodal (i.e., language-image) space, thus preserving and fusing the knowledge and abilities in the pre-trained vision encoder and LLM, empowering the MLLM with image-based conversation capabilities. In a general form, visual instructions are composed of <target image, text task description, text output>, namely <chart, question, answer> in CQA.
3 Related Work
Vision-Language Models for Chart Understanding. Researchers have long been committed to developing vision-language (VL) models with strong capabilities in chart-related tasks (e.g., CQA and chart summarizing). Previous works fall into two categories: 1) two-stage approaches that employ vision models to convert charts into data tables for subsequent processing with language models[54, 43, 19, 15]; and 2) unified VL models that directly process and interpret the fused chart and text features in a single integrated phase[55, 44, 57].
The two-stage pipeline struggles with preserving visual information (e.g., color and spatial location)[43] when performing the chart-to-table transformation, which inherently limits their applicability to specific scenarios. For unified models, Matcha[44] integrates mathematical reasoning and chart data extraction tasks into a pre-trained generic VL model, Pix2Struct[35], thus excelling at CQA and chart summarizing. UniChart[55] follows Matcha while collecting more data to undergo multitask instruction tuning for more chart-related tasks. However, their limited language model performances pose challenges, especially in reasoning problems that necessitate numerical calculations[54].
The advent of MLLMs has shifted the paradigm, achieving breakthroughs in visual question answering[4]. Notably, the open-source generic model Qwen-VL[5] demonstrates superior performance over all specialized chart models in the ChartQA benchmark[54], especially those posed by humans as opposed to machine-generated questions. Despite these advancements, our extensive empirical study has uncovered limitations in the current MLLMs’ ability to handle real-world CQA tasks, especially those that fall outside of the training data distribution. Rectifying these limitations necessitates the consideration of the visualization reference model[9] when constructing training data, which elucidates the practical mapping process from raw data to final graphical representations. Accordingly, this study contributes to enhancing the performance of MLLMs in CQA by integrating knowledge from the visualization reference process into training data generation and augmentation.
Enhancing Capabilities of MLLMs. The enhancement of MLLMs in specific scenarios, such as medicine images and text-dense images, can be categorized into two primary approaches: model-centric works that aim to improve the performance and efficiency of vision encoders or projectors; data-centric works that try to improve the model performance by boosting the number and quality of training data. In data-centric advancements, several studies employ powerful LLMs (e.g., GPT-4[3]) to generate various instruction-format VL tasks, like caption generation[48]. Another line of studies has explored converting classical VL task datasets (e.g., COCO[42]) into an instruction-following format with pre-defined templates. Within this context, to enhance chart comprehension, ChartLLaMA[24] finetunes LLaVA with 160K instruction data generated by GPT-4. Similarly, ChartAst[57] crawls a huge amount of tables from arXiv and then uses tables to generate charts for large-scale chart-to-table pre-training. ChartAst also generates QA pairs based on the tables they collected. Despite these efforts, the factors contributing to efficient instruction data for chart understanding are still unclear.
Our research seeks to investigate this gap with an empirical study that revisits the differences in improving model performance using different types of CQA task data. The results underscore the significance of integrating complex chart reasoning questions, prompting us to develop a data engine enriched with real-world chart tasks. Moreover, we have also made improvements to the model-centric side by tailoring the training methodology of base MLLMs, initially tailored for natural images, to suit visualization contexts.
Visualization Datasets and Benchmarks. Datasets form the foundation of model training, and well-structured benchmarks help researchers evaluate and choose appropriate models for downstream tasks. Specific to visualization scenarios, current benchmarks mainly focus on evaluating chart understanding performance via chart-to-table transformation[54, 58], CQA tasks[54, 58], and chart summarizing[66, 30, 62].
ChartQA[54] and PlotQA[58] are representative of the QA datasets and benchmarks. ChartQA features partially high-quality human-annotated QA pairs, while PlotQA offers a more voluminous collection of lower-quality items crafted using templates. Beyond QA tasks, VisText[66] introduces a comprehensive benchmark, which incorporates multi-level and fine-grained chart labeling, covering aspects such as chart construction, summary statistics, relations, and complex trends. The primary strength of these datasets is their expansive size and the carefully crafted templates used for data generation. However, they have limitations, including a restricted range of chart types, the challenge of maintaining high-quality questions and answers, and a tendency to focus excessively on basic data retrieval from the charts.
In the visualization field, real-world image datasets like Beagle[6], VisImage[18], Vis30K[12], multi-view [14] and composite visualizations [16, 22], and dashboards [17, 65], together with practical QA benchmarks for visual literacy test[36, 60, 21], have been introduced. The challenge lies in converting them into high-quality instruction data due to sparse label annotations. Our research draws upon methodologies that utilize GPT to generate code-format charts and associated instruction data. Specifically, we aim to guide the data generation process with the well-defined chart-task space[36] to contribute a dataset encompassing the real-world spectrum of chart features and QA tasks, thereby improving current MLLMs’ chart understanding capability.
4 Empirical Study: Revisiting MLLMs for CQA
We conduct an empirical study to revisit the effectiveness of existing MLLMs for CQA, aiming to identify limitations and glean insights for further improvements. The study is informed by the CQA leaderboard111https://paperswithcode.com/task/chart-question-answering and recent research[47, 5, 3], where highlights that ChartQA[54] serves as the primary training and testing dataset for MLLM in chart understanding. ChartQA encompasses large-scale real-world charts sourced from online platforms, accompanied by data tables and both human-authored and machine-generated QA pairs. Nevertheless, in-depth analyses are imperative to ensure that MLLMs exhibiting good benchmark performance on ChartQA can reliably transition to real-world scenarios. In particular, this empirical study aims to address the following research questions:
-
•
RQ1: How can ChartQA be enhanced to reflect real-world scenarios better? We aim to refine ChartQA to align more closely with real-world contexts. While the charts in ChartQA are sourced from online platforms, they do not encompass the entire spectrum of chart designs, as a recent study[75] identifies a biased distribution of online charts. Specifically, we will explore the diversity of chart design and QA pairs, both essential aspects for enhancing the effectiveness of CQA models.
-
•
RQ2: What makes effective visual instructions for CQA? While QA pairs inherently serve as instruction data, they include various question types (e.g., data retrieval and visual). Exploring which specific QA features can better improve the effectiveness of visual instructions is notably under-explored. Furthermore, previous studies[43, 54] suggest that incorporating the chart-to-table translation task improves VL models’ general chart understanding performance, while its effect within the context of MLLMs merits deeper investigation.
4.1 Computational Analysis of ChartQA Dataset
To address RQ1, we conduct computational analyses of ChartQA’s distribution in terms of chart and QA pairs. We identify distribution bias by comparing them with practical charts and visual literacy data. Subsequently, we assess the performance of various MLLMs on ChartQA and contrast these results with performances in real-world scenarios, emphasizing the impacts of distribution bias on model performance.
4.1.1 Distribution Biases in Chart and QA Pairs

| Model | ChartQA-M | ChartQA-H | Literacy | |||
|---|---|---|---|---|---|---|
| Data Retrieval | Compositional | Visual | Visual-Compositional | |||
| LLaVA-1.6-13b | ||||||
| LLaVA-1.6-34b | ||||||
| Qwen-VL-Chat | ||||||
| Qwen-VL-Plus | ||||||
| GPT-4-vision-preview | ||||||
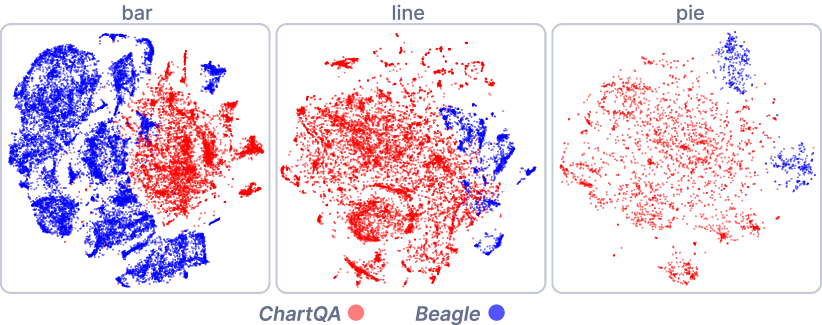
Chart distribution. ChartQA primarily consists of bar, line, and pie charts sourced from online platforms. These charts have similar visual styles (e.g., color themes) and lack the coverage of the diverse range of chart types such as area charts and scatterplots. Moreover, even within their included chart types, there can be significant differences in fine-grained chart features compared to practical charts. To investigate these differences, we utilize Beagle[6] as the control group to compare their distributions of chart features. Beagle crawls visualizations from the web using keyword searches and is considered to be comparatively diverse among available visualization datasets[75], encompassing charts from various visualization tools and libraries (e.g., D3[7] and Chartblocks[11]). Specifically, we use the pre-trained CLIP-Vit[61], a commonly used vision encoder of MLLMs, to extract high-dimensional features from the images. We then project the features into two dimensions with t-SNE[68]. Figure 2 presents the projection results, which show the distribution bias within specific chart types.
Importantly, chart type serves as a broad categorization, limiting the utilization of fine-grained chart features in constructing visual instructions. For instance, number annotations allow MLLMs to recognize and retrieve data directly. In contrast, when numerical annotations are absent, MLLMs must approximate data values based on the axes and positions of visual elements, posing a significantly more complex task. This highlights the need for considering fine-grained chart features when formulating CQA datasets, as elaborated in Sect. 5.1.
QA pair distribution. ChartQA comprises two testing QA datasets: ChartQA-H for human-authored QAs and ChartQA-M for machine-generated QAs. These QAs are categorized into data retrieval, visual, compositional, and visual-and-compositional types, as defined in [31].
-
•
Data retrieval: finding the value of the corresponding elements through the entity name in the chart.
-
•
Visual: leveraging visual channels, such as color identification, comparison between entities using visual attributes (e.g., which is rightmost, highest, or largest)
-
•
Compositional: requiring mathematical operations like sum, difference, and average.
-
•
Visual-and-compositional: blending of visual and compositional.
However, ChartQA does not annotate the question type for each QA pair, hindering the fine-grained accuracy analysis based on question types. To address the issue, we manually labeled the questions in the ChartQA-H and ChartQA-M test sets, each containing 1250 QAs. Statistics reveal that data retrieval task (1035/1250) dominates the ChartQA-M set. This distribution likely stems from the limited performance of the language model used for generation, which restricts ChartQA-M to specific question templates. In contrast, the human-authored ChartQA-H set features a more diverse distribution, containing (251) data retrieval, (476) visual, (251) compositional, and (272) visual-and-compositional types. The diversified distribution motivates us to conduct a more comprehensive evaluation of the model’s chart understanding ability across different question types, as detailed in the subsequent section.
4.1.2 Impacts of Distribution Bias
We further study how the distribution bias identified in the above section affect the model performance.
Models. Our selected MLLMs include open-source models explicitly trained on ChartQA: LLaVA-1.6-13b[47], LLaVA-1.6-34b[47] and Qwen-VL-Chat[5]; and mainstream commercial models: Qwen-VL-Plus[5], and GPT-4-vision-preview[59]. The commercial models are accessed through their official APIs.
Evaluation metric. Following existing research[55, 54, 24], we adopt the widely-used relaxed correctness [54], which requires exact matches for text responses but allows 5% error for numerical responses.
Prompt settings. The CQA evaluation requires the model to answer with a single word or short phrase. Following the LLaVA setup for short answers[46], we prompt the model with "Please answer with a single word or phrase" for metric evaluation and "Please think step by step" for zero-shot chain-of-thought (CoT)[70] to investigate the key and error steps in the model’s reasoning process.
Datasets. Besides ChartQA-H and ChartQA-M test sets, we have mixed QA pairs from studies on visual literacy[36, 21, 60], resulting in the creation of a new dataset comprising 131 QA pairs. Visual literacy QAs are designed to assess an individual’s ability to read, comprehend, and interpret data visualizations. These are representative examples of real-world QAs covering most of the chart-task space[36].
| Model | Data Retrieval | Compositional | Visual | Visual-Compositional |
|---|---|---|---|---|
| Baseline LLaVA-1.5 | 24.50% | 9.27% | 28.60% | 13.51% |
| LLaVA-1.5 + ChartQA-H | 32.93% | 15.73% | 47.25% | 8.11% |
| LLaVA-1.5 + ChartQA-M | 31.33% | 10.08% | 38.77% | 8.11% |
| LLaVA-1.5 + Chart2Table | 36.55% | 9.68% | 47.46% | 13.51% |
| LLaVA-1.5 + ChartQA-H & ChartQA-M | 43.37% | 15.73% | 51.91% | 5.41% |
| LLaVA-1.5 + ChartQA-H & Chart2Table | 42.17% | 16.94% | 51.91% | 13.51% |
| LLaVA-1.5 + ChartQA-H & ChartQA-M & Chart2Table | 48.59% | 18.55% | 54.66% | 13.51% |
Result analysis. Table 1 presents the experimental results, showing that all MLLMs exhibit a performance disparity between ChartQA-M and visual literacy. A plausible hypothesis is the uneven distribution of question types in ChartQA-M. To validate this hypothesis, we disaggregate the performances on different question types in ChartQA-H. The results unveil significant discrepancies among various question types. Specifically, all models demonstrate high performances on data retrieval and visual questions, while their performances notably decline on compositional and visual-compositional questions. Typically, data retrieval and visual questions mainly require the ability for chart recognition. In contrast, the compositional questions need chart recognition followed by calculation and reasoning, heavily relying on MLLM’s reasoning ability. This confirms the validity of the hypothesis.
To gain deeper insights into the underlying reasons for the issue, we examine the responses generated by MLLMs equipped with CoT. Figure 3 illustrates three typical cases, highlighting deficiencies in three categories: recognition errors, inference errors for numerical calculations, and inference errors regarding chart knowledge. Multiple factors contribute to these errors. First, errors often occur for chart types common in visual literacy but rare in ChartQA, such as stacked bar charts. Additionally, uncommon questions in ChartQA, such as accurately determining a range of data values, may lead MLLMs to struggle to identify the correct range.
Summary. These insights highlight a crucial issue with ChartQA: while it includes a wide range of real-world images and QAs, biases in chart and QA distributions constrain its generalizability. This emphasizes the need for a dataset incorporating a broader variety of chart types and QAs. Such a dataset can potentially enhance MLLM’s ability to tackle the complex challenges inherent in real-world scenarios.
4.2 Instruction Tuning Ablations
To address RQ2, we design a series of ablation studies to examine the effect of different question types and chart-related tasks on CQA, aiming to identify effective visual instructions.
4.2.1 Experiment settings
Backbone MLLM: We select LLaVA-1.5[46] as the baseline because its training data does not contain a specific chart dataset, making it easier to study the effect of different training data composition. We follow the official fine-tuning settings of LLaVA-1.5, where we freeze the vision encoder and only update the parameters of the projector and the LLM. Specifically, we employ the Low-Rank Adaptation (LoRA)[28] strategy to train LLM to reduce the training workload.
Dataset Control: Despite the biased chart distribution with ChartQA, we utilize it for instruction tuning ablation tests due to its suitability for examining how MLLMs learn from and react to specific data distributions. In addition to ChartQA-H and ChartQA-M, each chart in ChartQA is associated with its data table, constituting a chart-to-table translation task, denoted as Chart2Table. Studies[54, 43] reveal that Chart2Table has the potential to enhance chart recognition capabilities, which justifies its inclusion in our ablation study. Specifically, the instruction data for Chart2Table are structured as <chart, "Please extract the underlying data table from the given chart", data table>.
Ablation Models: We use the backbone MLLM without fine-tuning as the baseline. Furthermore, we fine-tune the backbone model with individual and different combinations of ChartQA-H, ChartQA-M, and Chart2Table, resulting in a total of six fine-tuned MLLMs.
4.2.2 Results and Analysis
Table 2 shows the results of the ablation experiment of baseline and the fine-tuned MLLMs on different question types in ChartQA-H test set. Overall, models fine-tuned with more training data (individual vs. combinations datasets) achieve higher accuracy. Specifically, the inclusion of the human-generated ChartQA-H dataset substantially enhances model performance across all question types. In contrast, ChartQA-M dataset is less effective and mainly improves data retrieval and visual questions. This difference further underscores the limited impact of data retrieval questions for tackling CQA challenges and the critical role of diverse, reasoning-intensive questions over simple recognition questions. Moreover, Chart2Table serves as an accompanying effective instruction task if the data tables are available.
In summary, enhancing MLLM’s chart understanding necessitates focusing on diversity, especially in question types demanding reasoning, over expanding the volume of data retrieval-focused training examples.
5 Data Engine
Collecting all available CQA data for training an MLLM is inefficient and cannot address inherent distribution flaws. First, research has revealed the importance of data balance in training a generic MLLM[10]. Without precise labeling, aggregating all data produces a massive dataset, causing learning inefficiency and training expensiveness of MLLMs[26]. For instance, LLaVA[48] as a leading generic MLLM only requires 1223K instruction data, whilst UniChart[55] and ChartAssistant[57] use about 6900K and 39.4M chart-related instruction data. This disparity highlights the impracticality of incorporating all available chart data into generic MLLMs’ training data. Furthermore, our empirical study has demonstrated the distribution flaws in existing CQA data, underscoring the necessity of generating new data.
To this end, we opt to design a data engine for a dataset of appropriate size while encompassing the real-world spectrum of chart features and QA tasks. The data engine consists of two modules: data filtering (Sect. 5.1) for efficiently utilizing the existing data and also ensuring appropriate training cost; and data generation (Sect. 5.2) for optimizing the data distribution. Finally, we present the obtained visualization-referenced dataset and benchmark (Sect. 4).
| Dataset |
|
|
||
|---|---|---|---|---|
| Statista, OECD, OWID | 144,147 | 679,420 | ||
| PlotQA | 155,082 | 2,414,359 | ||
| Unichart | 189,792 | 2,218,468 | ||
| Beagle | 3,972 | 51 | ||
| ChartInfo | 1,796 | 21,949 | ||
| VisText | 9,969 | 0 | ||
| ExcelChart | 106,897 | 0 | ||
| Total existing | 611,655 | 5,334,247 | ||
| Filtered dataset | 69,418 | 68,223 |
5.1 Data filtering
This module is designed to filter representative data from existing CQA datasets. We first establish principles for what constitutes an appropriate chart distribution. Specifically, drawing on the taxonomy of the chart and corresponding task types outlined by [36] (see Table 4), our methodology involves analyzing the distribution across the following:
-
•
chart types summarized in visualization literacy papers[36, 21] (see Table 4 for details);
-
•
fine-grained chart attributes identified in visualization retrieval tasks[72], e.g., color, trends and layouts; and
-
•
chart attributes that significantly affect MLLMs’ chart understanding, i.e., number annotations (existent or absent) and data grouping (single or multiple).
Given that studies have shown common pre-trained visual feature extractors (e.g., CLIP-Vit[61]) are not sensitive to fine-grained chart attributes[72], conventional filtering approaches that sample data in the pre-trained feature space lead to inhomogeneity in these attributes. Additionally, most existing datasets lack detailed annotations beyond coarse-grained chart types (e.g., bar, line, and pie), posing challenges for stratified sampling. To mitigate this issue, we construct classifiers to learn those attributes in a supervised manner and then perform stratified sampling based on the labels predicted by the classifiers.
5.1.1 Image Classifier
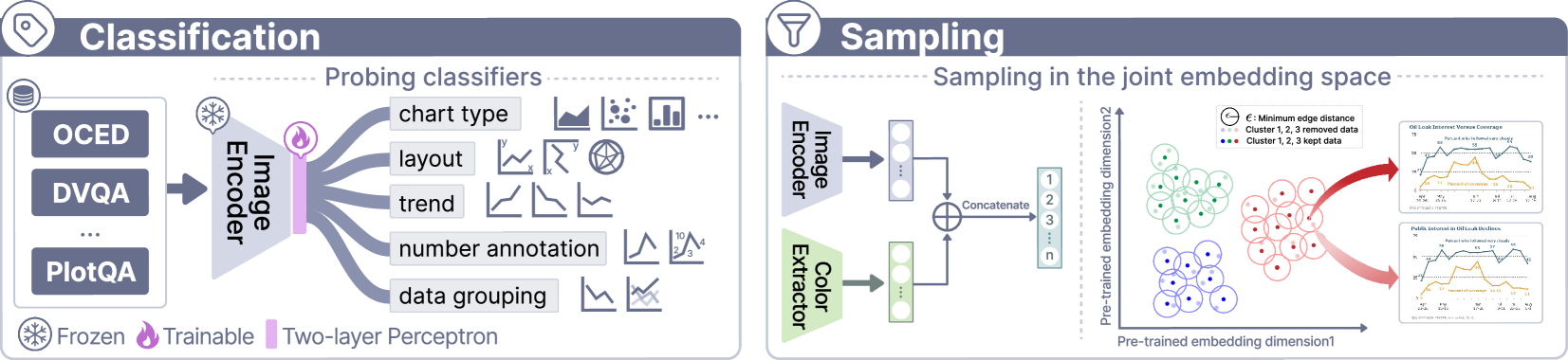
As shown in Figure 4 ![]() , we build probing classifiers (i.e., two-layer perceptron) based on the frozen ConvNeXt[71] backbone to accurately assess the distribution of these fine-grained chart types and attributes.
We collect training data sourced from [72] alongside a manually collected subset.
To mitigate the issue of lacking some attribute annotations, we manually labeled each image for missing attributes.
Due to the unbalanced nature of chart type and attribute distribution (e.g., number annotations), we choose to use focal loss[41] as the loss function, designed to focus on unbalanced image type.
Focal loss is defined as:
, we build probing classifiers (i.e., two-layer perceptron) based on the frozen ConvNeXt[71] backbone to accurately assess the distribution of these fine-grained chart types and attributes.
We collect training data sourced from [72] alongside a manually collected subset.
To mitigate the issue of lacking some attribute annotations, we manually labeled each image for missing attributes.
Due to the unbalanced nature of chart type and attribute distribution (e.g., number annotations), we choose to use focal loss[41] as the loss function, designed to focus on unbalanced image type.
Focal loss is defined as:
where represents the estimated probability of class represents the scaling factor, and represents the modulating factor. Among them, is set by inverse class frequency. Thus, learning parameters tend to contribute to classes with fewer samples, and assists in up-weighting the loss assigned to poorly-classified examples, avoiding the possibility that the amount of well-classified samples dominates the training process. We empirically compare several design alternatives of backbone models (e.g., CLIP-Vit[61] and ResNet50[25]) and trainable modules (e.g., linear probe[61]) in Table 5.
Note that not all chart types possess the same set of fine-grained attributes. For instance, pie charts do not exhibit a trend attribute, so the trend classifier training will not consider pie charts. We leverage the trained classifiers to label our collected existing data, providing clear inspections of the chart attributes and laying the foundation for data balancing in the subsequent sampling.
5.1.2 Image Sampling and Instruction Data Sampling
Figure 4 ![]() illustrates the image sampling process.
We employ the CLIP-Vit[61] and a color extractor [1] to extract the overall feature and color feature of each image and then concatenate the two feature vectors to formulate a joint embedding space.
Inspired by Bunny[26] and SemDeDup[2],
we cluster images into clusters via -means within the joint embedding space, aiming to group charts with similar features.
To ensure chart attribute balancing, we incorporate stratified sampling within each cluster.
Specifically, we create strata within each cluster according to predicted chart attributes and further perform sampling in each stratum.
We identify duplicates by constructing an undirected graph, where edges connect image pairs with cosine similarity above a specified threshold , indicating high feature similarity.
We streamline the process by directly retaining only the image with the lowest cosine similarity to the stratum’s centroid from each set of semantic duplicates,
thereby effectively reducing dataset size while preserving diversity.
Finally, we manually adjust to obtain approximately 69K charts, ensuring an appropriate training cost.
illustrates the image sampling process.
We employ the CLIP-Vit[61] and a color extractor [1] to extract the overall feature and color feature of each image and then concatenate the two feature vectors to formulate a joint embedding space.
Inspired by Bunny[26] and SemDeDup[2],
we cluster images into clusters via -means within the joint embedding space, aiming to group charts with similar features.
To ensure chart attribute balancing, we incorporate stratified sampling within each cluster.
Specifically, we create strata within each cluster according to predicted chart attributes and further perform sampling in each stratum.
We identify duplicates by constructing an undirected graph, where edges connect image pairs with cosine similarity above a specified threshold , indicating high feature similarity.
We streamline the process by directly retaining only the image with the lowest cosine similarity to the stratum’s centroid from each set of semantic duplicates,
thereby effectively reducing dataset size while preserving diversity.
Finally, we manually adjust to obtain approximately 69K charts, ensuring an appropriate training cost.
For instruction data, Sect. 4.2 summarizes the effects of different components of existing datasets. Drawing on the insights from the empirical study, we keep the table data of all sampled images for Chart2Table task and further sample numerical and visual reasoning questions in their attached QA pairs.
5.2 Data Generation
This module is designed to generate a dataset encompassing real-world chart types and QA tasks, thus alleviating the distribution bias issue of existing datasets. Specifically, we refer to the chart-task space types summarized in visualization literacy research[36] (see Table 4).
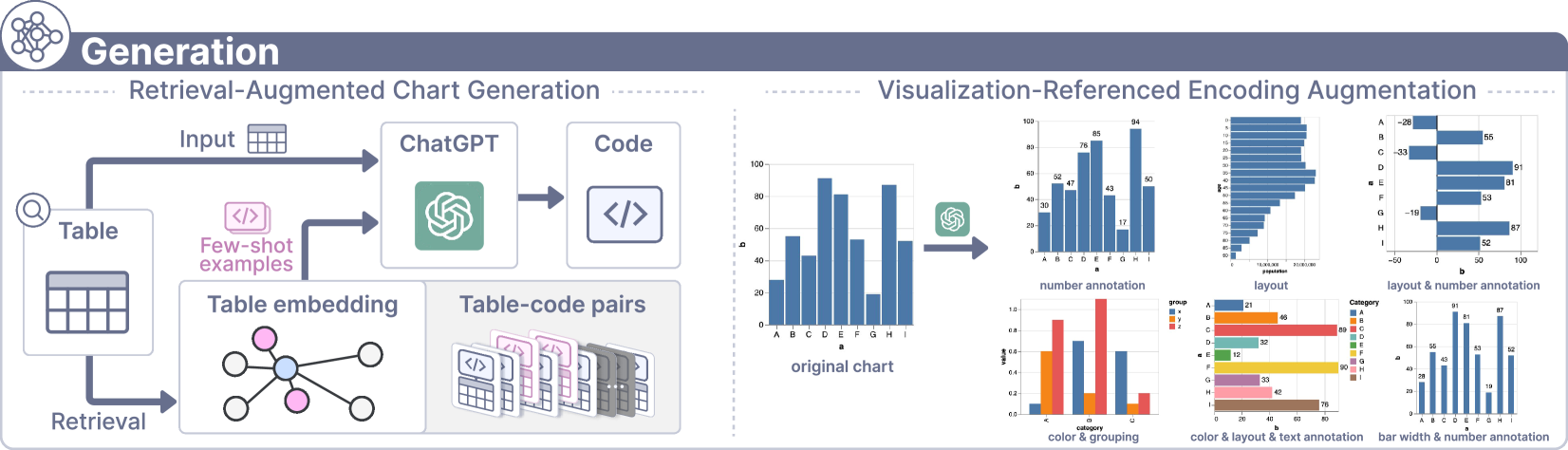
With collected tables, former works have explored generating charts and QA pairs using LLMs [24, 57]. However, they overlook potential quality distortions arising from the instability inherent in language model outputs, nor has it considered guiding the generative process through an informed understanding of the chart space. We harness LLMs’ in-context learning ability to follow the visualization reference process[9], ensuring the variety of the resulting charts and thus covering the chart space. Figure 5 outlines our chart generation pipeline, which encompasses two phases: Retrieval-Augmented Chart Generation and Visualization-Referenced Encoding Augmentation. Templates of prompts constructed for LLM input in this section can be found in Supplementary Section S1.
5.2.1 Collection and Expansion of Seed Charts
Generating charts begins with aggregating a diverse and high-quality set of seed examples that cover a wide representation of styles and chart types. These examples are table-code pairs collected from a variety of authoritative chart libraries, such as Vega-Lite222https://vega.github.io/vega-lite/examples, Matplotlib333https://matplotlib.org/stable/gallery, Seaborn444https://seaborn.pydata.org/examples, and ECharts555https://echarts.apache.org/examples. Moreover, we collect high-quality table-code pairs from previous studies[34] and handpick select examples from the web. To further expand our seed examples, we also gather high-quality table data from various sources[53, 75]. Notably, charts filtered from existing datasets are not used here, as most of them are not in code format.
As depicted in Figure 5 (left), the expansion process employs the retrieval-augmented generation (RAG) method[37], which enhances the accuracy and quality of the generated charts by providing LLMs with contextually relevant examples during the generation process. To implement this, we first extract table features to identify and match each collected table with the most similar tables among existing table-code pairs. Specifically, following visualization recommendation research[29, 39, 69], we extract 30 cross-column data features that capture the relationships between columns and 81 single-column data features that quantify the properties of each column. These features allow us to represent the table features of the seed examples in a vector space, enabling the retrieval of nearest neighbors based on cosine similarity. When constructing prompts for seed chart expansion, the corresponding codes of these matched seed examples serve as few-shot examples alongside the new tables.
5.2.2 Enhancement Through Visual Mapping Variations
To broaden the collection of seed examples, we leverage the LLM to introduce variations in the visual mappings or encodings of charts. This phase follows the visualization reference process[9] and is crucial to encompass a broader array of possible chart presentations and to align with the diverse distributions of real-world data. We guide the LLM by specifying which visual mappings each chart type can adopt and incorporating instances featuring diverse visual encodings in the input context for reference. For instance, as illustrated in Figure 5 (right), the LLM is instructed to modify chart elements like number annotations, groupings, and bar widths and to truncate or invert axes in bar charts. This approach facilitates generating a richer collection of table-code pairs by varying data-related encodings, such as the height of bars. The modified data tables are correspondingly recorded.
5.2.3 Generation of Question and Answer Pairs
We further generate QA pairs based on the enriched set of table-code pairs, which are expected to be accurate and cover the chart-task space. Specifically, for each type of chart, we employ the LLM to generate Q&A pairs by prompting it with tables for numerical information, code for encoded visual information, and the corresponding chart-task space as context. We also require the LLM to classify generated Q&A pairs with category labels following the chart-task taxonomy (e.g., data retrieval and find extremum), balancing the distribution of different tasks. During the generation process, we randomly select some QA pairs for manual checking and ensure they are as accurate as expected.
Reasoning process. Recent studies show that unnecessary step-by-step training annotation leads to downgraded generalizability and instruction-following ability. For simple questions (e.g., data retrieval of bar charts), the reasoning process does not provide useful information compared to single-word answers. We only attach reasoning processes to questions that need numerical calculations and visual references. For visual references, we mainly consider visual channels that are less used in former work, such as the point area of the bubble chart and the truncated or inverted axis of line charts.
5.3 Visualization-referenced Dataset and Benchmark
| Visualization | Visualization Task | Note of | |||||||||||||||||||||||||
|
|
|
|
|
|
|
|
ETC | |||||||||||||||||||
| Line Chart | X | X | X | X | X | ||||||||||||||||||||||
| Bar Chart | X | X | |||||||||||||||||||||||||
| Stacked Bar Chart | X | X |
|
||||||||||||||||||||||||
| 100% Stacked Bar Chart | Only Relative Value | ||||||||||||||||||||||||||
| Pie Chart | Only Relative Value | ||||||||||||||||||||||||||
| Histogram | X |
|
Only Derived Value | ||||||||||||||||||||||||
| Scatterplot | X | X | X | X | X | X | X | X | |||||||||||||||||||
| Area Chart | X | X | X | X | X | ||||||||||||||||||||||
| Stacked Area Chart | X | X | X |
|
|||||||||||||||||||||||
| Bubble Chart | X | X | X | X | X | X | X | X | |||||||||||||||||||
| Treemap |
|
Only Relative Value |
Overview of Dataset. Our generated dataset comprises 11 chart types and 8 task categories, as outlined in visual literacy research [36, 21, 60]. Table 4 illustrates the chart-task space. The generated dataset includes 10,385 table-chart pairs and 51,245 chart-QA pairs. By integrating the generated dataset with the filtered dataset (shown in Table LABEL:tab:existing-datasets), we ultimately produce a dataset of 199K, which includes 80K table-chart pairs and 119K chart-QA pairs. In contrast to earlier datasets that relied on single sources or template-driven designs, our approach effectively combines our generated dataset with existing datasets derived from a wide range of real-world and synthetic sources. This integration features a diverse array of visual encodings, referencing real-world charts from multiple sources. We have made deliberate efforts to ensure an equitable distribution of chart types and QA pairs, with a particular emphasis on underrepresented chart types and question types in current datasets, such as range determination and distribution characterization, to provide a more comprehensive and balanced resource. Detailed chart and QA examples can be found in Supplementary Section S2.
Benchmark. To establish a benchmark covering the chart-task space, we meticulously curated an additional 368 table-chart pairs and 736 chart-QA pairs highly representative of our dataset. We focus on achieving diversity within each chart category, selecting charts with various visual encodings, and maintaining coverage into chart sub-types. Additionally, we consider the complexity of the question, aiming for a wide representation in both the number of entities and the range of quantities presented.
Metrics. Our dataset is designed to reflect authentic scenarios encountered in chart-based question answering, and for that purpose, we have chosen to utilize the GPT for evaluation[49]. This manner is suitable for our benchmark as it can accommodate a wide range of answer formats, including ambiguous or long texts. The GPT accuracy metric compares textual responses to a standard expected answer, ensuring a match based on semantic equivalence. For numerical responses, we allow a tolerance level of 5%, which is consistent with former works[54]. However, this error margin is subject to adjustment in specific scenarios where it is inappropriate. For instance, in cases involving years or countable quantities, precision is crucial, and as such, absolute accuracy is demanded, with no error margin permitted.
6 Model
To enhance MLLMs’ chart comprehension in real-world contexts, we consider two design improvements in both the model architecture and its training. Particularly, we adopt a mixture-of-resolution adaptation strategy[52] for enhanced fine-grained recognition (Sect. 6.1). Moreover, for a better representation of the chart’s visual feature, we unfreeze the vision encoder during training and utilize the visualization-referenced dataset described in Sect. 5 for training (Sect. 6.2).
6.1 Model Architecture
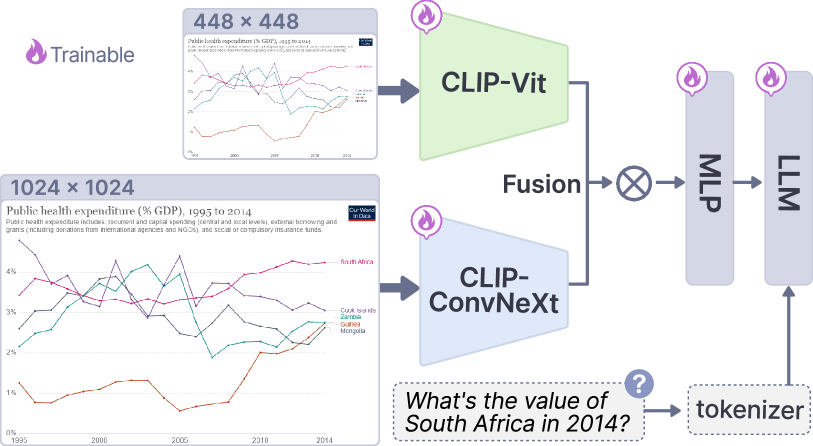
Base model. We use LLaVA-1.5[48] as the base model architecture, which employs CLIP-Vit-334px as the vision encoder, two-layer MLP as the projector, and the Vicuna-13B[77] as the LLM.
High-resolution input by mixing vision encoders with tokens compression. The employed two-layer MLP effectively connects the feature space of vision encoders and LLMs but results in visual tokens that positively correlate with the image resolution. For instance, CLIP-Vit-L-14 results in 5,329 tokens for a 1,022×1,022 resolution image, as each token corresponds to a 14×14 image patch[52], which is computationally expensive for MLLMs. The popular query-based strategy for implementing high-resolution input, QFormer[40], requires large-scale pre-training to achieve vision-language alignments, which is impractical for visualization scenarios as high-quality data is scarce. Therefore, we adopt a resolution-adaptation strategy[52] to improve the resolution while supporting training on normal scale data. The strategy embeds high-resolution features into the low-resolution features via adapters, thus reducing visual feature tokens. Specifically, following the settings of LLaVA-HR[52], we integrate CLIP-ViT-L[61] and CLIP-ConvNeXt[50] as a mixture of vision encoders and then mix their features with an adaptation strategy, thus maintaining control over the length of the visual token sequence. The resolutions of ViT and CNN are set to 448×448 and 1,024×1,024, respectively.
6.2 Training Settings
Unfreezing the vision encoders. Former works[48, 24, 45] choose to freeze the vision encoder in the whole training process as the pre-trained CLIP is already good at capturing features of natural images. Their MLLM training target is aligning the features extracted by CLIP to the LLM embedding space by tuning the projector and LLM. However, former research[72] has found that CLIP performs much worse in visualization images, as its pre-training corpus has a relatively small amount of charts with coarse annotation, leading to limited chart recognition ability without further tuning. Unfreezing CLIP’s parameters enables better adaptation to chart features and improves the overall performance of MLLM’s chart understanding for improved chart recognition ability.
Training data. We skip the pre-training process and directly leverage the initial projector weight of LLaVA-HR[52] to conduct instruction tuning. Our study aims to improve general MLLM’s chart comprehension ability. Therefore, our training data consists of two parts: the 665K original instruction tuning data of LLaVA-1.5 and the 199K chart-related data described in Sect. 4.
Hyperparameters settings. AdamW[33] is used as the optimizer, and the learning rate (LR) and the global batch size are set to 2e-5 and 128, respectively. The training epoch is set to 1. The LR scheduler is cosine decay, with a warmup ratio of 0.03. The training is running on 16×NVIDIA A800 for approximately 19 hours.
7 Evaluation
We first present the accuracy of our classifier to show its effectiveness in measuring the chart distribution. Then, we compare our model with previous works in traditional benchmarks and our benchmark. Also, we provide a group of ablation studies to show the effectiveness of our data engine.
7.1 Chart Attributes Classification
We compare the performance of classifiers with different backbones (i.e., ResNet50[25], ConvNeXt[50], and CLIP-Vit[61]) and trainable modules (linear probe[61] and two-layer MLP with focal loss[41]). Table 5 lists each attribute’s macro F1 score, showing that ConvNeXt consistently outperforms other backbones. Therefore, we adopt the ConvNeXt designated focal loss, which consistently performs well.
| Models |
|
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50+Linear Probe | 90.4 | 86.8 | 85.8 | 75.2 | 95.1 | ||||||||
| ResNet50+Focal Loss | 90.6 | 84.3 | 87.0 | 72.9 | 94.1 | ||||||||
| CLIP-Vit+Linear Probe | 93.0 | 87.6 | 92.7 | 70.8 | 94.4 | ||||||||
| CLIP-Vit+Focal Loss | 92.7 | 89.7 | 93.8 | 72.2 | 95.3 | ||||||||
| ConvNeXt+Linear Probe | 93.7 | 90.6 | 89.2 | 75.9 | 96.2 | ||||||||
| ConvNeXt+Focal Loss | 94.3 | 92.4 | 91.3 | 75.8 | 97.7 |
| Models |
|
|
|
|
|
|
|
|
||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA1.6-34b | 37.69 | 35.83 | 3.85 | 20.00 | 21.43 | 27.27 | 51.95 | 48.84 | ||||||||||||||||||
| GPT-4-vision-preview | 56.92 | 60.96 | 30.77 | 36.67 | 42.86 | 36.36 | 68.83 | 56.40 | ||||||||||||||||||
| Qwen-VL-Plus | 43.08 | 21.39 | 11.54 | 10.00 | 7.14 | 13.64 | 41.56 | 34.30 | ||||||||||||||||||
| Our model | 46.15 | 53.48 | 35.57 | 30.00 | 42.86 | 36.36 | 64.94 | 58.14 |
| ChartQA | ||||
| Model | Aug. | Human | Average | Chart-to-table |
| Chart-T5 | 74.4 | 31.8 | 52.95 | 37.5 |
| Donut | 78.1 | 29.8 | 53.95 | 38.2 |
| Matcha | 88.9 | 38.8 | 63.85 | 39.4 |
| Unichart | 87.8 | 43.9 | 65.85 | 91.1 |
| ChartLLaMa | 90.4 | 48.9 | 69.7 | 90.0 |
| ChartAst-D (39.4M CQA data) | 91.3 | 45.3 | 68.3 | 92.0 |
| ChartAst-S (39.4M CQA data) | 92.0 | 58.2 | 75.1 | 91.6 |
| No Unfreezing vision encoder | 77.4 | 47.1 | 62.3 | 44.6 |
| No High Resolution | 88.6 | 55.8 | 72.2 | 87.9 |
| No Filtered Data | 91.5 | 60.9 | 76.2 | 90.9 |
| No Generation Data | 92.6 | 62.7 | 77.65 | 91.2 |
| Our model (199K CQA data) | 93.6 | 63.6 | 78.6 | 91.8 |
7.2 Comparison to the State of the Art
7.2.1 Benchmarks
ChartQA. The dataset information, the relaxed accuracy metric, and the prompt for short answers have been illustrated in Sect. 4.1.2. ChartQA’s training set is included in our training data.
Chart-to-table. For evaluating MLLM’s recognition ability towards chart, we follow the evaluation framework of DePlot[43] and report the F1 scores of chart-to-table data extraction, which measures the similarity of tables by comparing their structure and values but is invariant to column/row permutations.
Our benchmark. For evaluating MLLM’s performance across real-world charts and task distribution, we adopt the benchmark and its corresponding metric established in Sect. 4.
7.2.2 Baselines
We choose and organize MLLMs into two groups for our comparison experiments. For traditional benchmarks, we benchmark our models against traditional chart-specialized models, including Chart-T5[54], Donut[32], Matcha[44], Unichart[55], ChartLlama[24], and ChartAssistant[57]. For our benchmark, which tests for tasks not typically included in previous chart-specific model training, we compare with SOTA generic models, including LLaVA1.6-34b[46], GPT-4-vision-preview[59], and Qwen-VL-Plus[5].
7.2.3 Results
Table 7 presents the results of our model’s performance against other models. It demonstrates that our model consistently outperforms the baseline across all tasks. Particularly, we surpass the current leading models while utilizing significantly less data, showcasing our data filtering and generation effectiveness. Moreover, the ablation studies present the effectiveness of unfreezing vision encoders and mixing vision encoders for high-resolution.
Table 6 showcases comparative results on our benchmark, illustrating that our model outperforms baseline models in most tasks. These results highlight our model’s strong performances, which are evident in frequently encountered tasks like data retrieval and less common tasks such as determine range and characterize distributions. Nevertheless, current MLLMs, including our model, still exhibit subpar performance in specific tasks. For instance, find anomalies and find clusters, associated with scatterplots and bubble charts, remain challenging. Both chart types encode data using points, which necessitates extremely powerful recognition capabilities to discern and correlate data-visual mappings at a fine-grained level due to the small size of the visual "point." This underscores the difficulty of certain CQA tasks that demand precise recognition of small graphical elements, particularly when addressing the challenge of just-noticeable-difference problems[23, 51]. In contrast, for tasks like find correlations/trends of scatterplots or line charts, the answer space is limited (e.g., positive correlation and negative correlation), and they can be inferred based on the overall feature of images rather than specific small areas of images.
7.2.4 Cases
Figure Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning shows the comparison of state-of-the-art MLLMs (Qwen-VL-Max[5] and GPT-4-vision-preview[59]) with our model on common difficult chart questions requiring a fine-grained understanding of visual encodings. In the first example, the line chart has an inverted y-axis, which confuses the other models. The second bar chart example contains a truncated y-axis that introduces recognition difficulty. In the third bubble chart example, other MLLMs cannot understand the mapping between the bubble size and the number of employees. In the last example, GPT-4-vision-preview and Qwen-VL-Max also misunderstand the meaning of the stacked area. In comparison, our model can successfully cope with these questions because of its enhanced understanding of visual encodings.
8 Discussion
Visual encoder enhancement. Our research finds that unfreezing the vision encoders substantially enhances the chart recognition capabilities of MLLMs, showing the original CLIP-Vit’s under-performance in chart images[72]. An intuitive alternative design is replacing CLIP-Vit with an encoder pre-trained specifically on chart images. For example, ChartInstruct-LLaMA [56] substitute the CLIP-Vit in LLaVA with the UniChart vision encoder[55]. However, the researchers did not observe model performance improvements compared to Unichart. This highlights the superiority of generic vision encoders, which learn robust image interpreting capabilities (e.g., localization) from millions of natural images. Moreover, understanding some real-world charts requires broad vision knowledge. For instance, infographics may incorporate natural images to depict certain chart elements[73] vividly. Borrowing LLaVA-Med’s lesson[38] in initializing CLIP-Vit, developing a visualization-domain CLIP with enhanced basic chart interpretation performance is a promising future work.
Better textual representation for chart understanding. Aligning the language model with the vision encoder is crucial, and dense image representations, such as high-quality captions, play an essential role in this process. Typically, data tables are used for charts due to their abundant information. However, the intrinsic limitation of the data table is the loss of all visual information. While captions for charts keep certain visual information, the numerical information is hard to keep completely. Vistext[66] has explored the use of scene graphs as a potential alternative to data tables. Despite this, the choice of data format for a language model is a significant consideration, and it remains to be thoroughly investigated whether the scene graph format can effectively integrate within the context of MLLMs.
Insights on applying MLLMs to complex reasoning visualization tasks. Our research finds that current MLLMs still face challenges in analytical tasks (e.g., find anomalies and determine range). Recently, referential question-answering [76, 13] has been shown to benefit the comprehension of complex spatial relationships. It requires annotating bounding boxes and arrows in images and referring to these elements in questions. This task was not considered in our training data because of the lack of chart data with referential annotations. However, referential QAs are common in real-world visual analytics and potentially beneficial for tasks like find anomalies. For example, we can use bounding boxes to label anomaly points or highlight a range of data elements, boosting MLLMs’ understanding of relevant tasks. We place the exploration of referential and other possible complex QA formats tailored for charts in future work. Furthermore, end-to-end MLLM outputs inherently pose uncertainty. Incorporating golden tables and code of charts with MLLM for interaction applications may be robust in complex visual analytics scenarios.
9 Conclusion
This study addresses significant challenges in advancing MLLMs’ performances in CQA. An empirical study is conducted to investigate the limitations of existing MLLMs and CQA datasets. We identify a critical need for fine-grained consideration of visual encodings and QA tasks, which current data collection and synthesis methods overlook, leading to unbalanced data distribution and inconsistent data quality. With a two-stage data engine of filtering-then-generation, we filter existing datasets and enlarge them through LLM-based generation techniques, ensuring a broader range of high-quality data that captures the characteristics of charts. By incorporating a mixture-of-resolution adaptation strategy and unfreezing the vision encoder during model training, we significantly improve the performance of our MLLM on CQA tasks. Experiments demonstrate that, even with a more compact dataset, our model surpasses SOTA CQA models, highlighting the efficacy of our methodology. We also contribute a benchmark for future advancements in MLLMs for CQA tasks.
Acknowledgements.
This work is supported partially by National Natural Science Foundation of China (62172398), and the Guangzhou Basic and Applied Basic Research Foundation (2024A04J6462, 2023A03J0142).References
- [1] Color histograms in image retrieval, 2024. https://www.pinecone.io/learn/series/image-search/color-histograms/, last accessed on 29/06/2024.
- [2] A. Abbas, K. Tirumala, D. Simig, S. Ganguli, and A. S. Morcos. Semdedup: Data-efficient learning at web-scale through semantic deduplication. arXiv, 2023. doi: 10 . 48550/arXiv . 2303 . 09540
- [3] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv, 2023. doi: 10 . 48550/arXiv . 2303 . 08774
- [4] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh. Vqa: Visual question answering. In Proc. ICCV, pp. 2425–2433, 2015. doi: 10 . 1109/ICCV . 2015 . 279
- [5] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv, 2023. doi: 10 . 48550/arXiv . 2308 . 12966
- [6] L. Battle, P. Duan, Z. Miranda, D. Mukusheva, R. Chang, and M. Stonebraker. Beagle: Automated extraction and interpretation of visualizations from the web. In Proc. ACM CHI, pp. 594:1–594:8, 2018. doi: 10 . 1145/3173574 . 3174168
- [7] M. Bostock, V. Ogievetsky, and J. Heer. D3 data-driven documents. IEEE Trans. Vis. Comput. Graph., 17(12):2301–2309, 2011.
- [8] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. In Proc. NeurIPS, vol. 33, pp. 1877–1901, 2020.
- [9] S. K. Card, J. D. Mackinlay, and B. Shneiderman. Readings in information visualization: using vision to think. Morgan Kaufmann, San Francisco, 1999.
- [10] J. Cha, W. Kang, J. Mun, and B. Roh. Honeybee: Locality-enhanced projector for multimodal llm. In Proc. CVPR, 2024 To appear.
- [11] Chartblocks. Online chart builder, 2017. https://www.chartblocks.io/, last accessed on 29/06/2024.
- [12] J. Chen, M. Ling, R. Li, P. Isenberg, T. Isenberg, M. Sedlmair, T. Möller, R. S. Laramee, H.-W. Shen, K. Wünsche, et al. Vis30k: A collection of figures and tables from ieee visualization conference publications. IEEE Trans. Vis. Comput. Graph., 27(9):3826–3833, 2021. doi: 10 . 1109/TVCG . 2021 . 3054916
- [13] K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv, 2023. doi: arXiv:2306 . 15195
- [14] X. Chen, W. Zeng, Y. Lin, H. M. Al-maneea, J. Roberts, and R. Chang. Composition and configuration patterns in multiple-view visualizations. IEEE Trans. Vis. Comput. Graph., 27(2):1514–1524, 2021. doi: 10 . 1109/TVCG . 2020 . 3030338
- [15] Z.-Q. Cheng, Q. Dai, and A. G. Hauptmann. ChartReader: A unified framework for chart derendering and comprehension without heuristic rules. In Proc. ICCV, pp. 22202–22213, 2023. doi: 10 . 1109/ICCV51070 . 2023 . 02029
- [16] D. Deng, W. Cui, X. Meng, M. Xu, Y. Liao, H. Zhang, and Y. Wu. Revisiting the design patterns of composite visualizations. IEEE Trans. Vis. Comput. Graph., 29(12):5406–5421, 2023. doi: 10 . 1109/TVCG . 2022 . 3213565
- [17] D. Deng, A. Wu, H. Qu, and Y. Wu. DashBot: Insight-driven dashboard generation based on deep reinforcement learning. IEEE Trans. Vis. Comput. Graph., 29(1):690–700, 2023. doi: 10 . 1109/TVCG . 2022 . 3209468
- [18] D. Deng, Y. Wu, X. Shu, J. Wu, S. Fu, W. Cui, and Y. Wu. VisImages: A fine-grained expert-annotated visualization dataset. IEEE Trans. Vis. Comput. Graph., 29(7):3298–3311, 2023. doi: 10 . 1109/TVCG . 2022 . 3155440
- [19] X. L. Do, M. Hassanpour, A. Masry, P. Kavehzadeh, E. Hoque, and S. Joty. Do LLMs work on charts? designing few-shot prompts for chart question answering and summarization. arXiv, 2023. doi: 10 . 48550/arXiv . 2312 . 10610
- [20] Y. Du, H. Guo, K. Zhou, W. X. Zhao, J. Wang, C. Wang, M. Cai, R. Song, and J.-R. Wen. What makes for good visual instructions? synthesizing complex visual reasoning instructions for visual instruction tuning. arXiv, 2023. doi: 10 . 48550/arXiv . 2311 . 01487
- [21] L. W. Ge, Y. Cui, and M. Kay. CALVI: Critical thinking assessment for literacy in visualizations. In Proc. ACM CHI, pp. 815:1–815:18, 2023. doi: 10 . 1145/3544548 . 3581406
- [22] E. D. Giacomo, W. Didimo, G. Liotta, F. Montecchiani, and A. Tappini. Comparative study and evaluation of hybrid visualizations of graphs. IEEE Trans. Vis. Comput. Graph., 30(7):3503–3515, 2024. doi: 10 . 1109/TVCG . 2022 . 3233389
- [23] D. Haehn, J. Tompkin, and H. Pfister. Evaluating ‘graphical perception’with cnns. IEEE Trans. Vis. Comput. Graph., 25(1):641–650, 2018. doi: 10 . 1109/TVCG . 2018 . 2865138
- [24] Y. Han, C. Zhang, X. Chen, X. Yang, Z. Wang, G. Yu, B. Fu, and H. Zhang. Chartllama: A multimodal llm for chart understanding and generation. arXiv, 2023. doi: 10 . 48550/arXiv . 2311 . 16483
- [25] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proc. CVPR, pp. 770–778, 2016. doi: 10 . 1109/CVPR . 2016 . 90
- [26] M. He, Y. Liu, B. Wu, J. Yuan, Y. Wang, T. Huang, and B. Zhao. Efficient multimodal learning from data-centric perspective. arXiv, 2024. doi: 10 . 48550/arXiv . 2402 . 11530
- [27] E. Hoque, P. Kavehzadeh, and A. Masry. Chart question answering: State of the art and future directions. Comput. Graph. Forum, 41(3):555–572, 2022. doi: 10 . 1111/cgf . 14573
- [28] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. In Proc. ICLR, 2022.
- [29] K. Hu, M. A. Bakker, S. Li, T. Kraska, and C. Hidalgo. VizML: A machine learning approach to visualization recommendation. In Proc. ACM CHI, pp. 128:1–128:12, 2019. doi: 10 . 1145/3290605 . 3300358
- [30] S. Kantharaj, R. T. Leong, X. Lin, A. Masry, M. Thakkar, E. Hoque, and S. Joty. Chart-to-text: A large-scale benchmark for chart summarization. In Proc. ACL, pp. 4005–4023, 2022. doi: 10 . 18653/v1/2022 . acl-long . 277
- [31] D. H. Kim, E. Hoque, and M. Agrawala. Answering questions about charts and generating visual explanations. In Proc. ACM CHI, pp. 340:1–340:13, 2020. doi: 10 . 1145/3313831 . 3376467
- [32] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, and S. Park. Ocr-free document understanding transformer. In Proc. ECCV, pp. 498–517, 2022. doi: 10 . 1007/978-3-031-19815-1_29
- [33] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv, 2014. doi: 10 . 48550/arXiv . 1412 . 6980
- [34] H.-K. Ko, H. Jeon, G. Park, D. H. Kim, N. W. Kim, J. Kim, and J. Seo. Natural language dataset generation framework for visualizations powered by large language models. In Proc. ACM CHI, pp. 843:1–843:22, 2024. doi: 10 . 1145/3613904 . 3642943
- [35] K. Lee, M. Joshi, I. R. Turc, H. Hu, F. Liu, J. M. Eisenschlos, U. Khandelwal, P. Shaw, M.-W. Chang, and K. Toutanova. Pix2Struct: Screenshot parsing as pretraining for visual language understanding. In Proc. ICML, pp. 18893–18912, 2023.
- [36] S. Lee, S.-H. Kim, and B. C. Kwon. VLAT: Development of a visualization literacy assessment test. IEEE Trans. Vis. Comput. Graph., 23(1):551–560, 2016. doi: 10 . 1109/TVCG . 2016 . 2598920
- [37] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proc. NeurIPS, vol. 33, pp. 9459–9474, 2020.
- [38] C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In Proc. NeurIPS, vol. 36, 2024.
- [39] H. Li, Y. Wang, S. Zhang, Y. Song, and H. Qu. KG4Vis: A knowledge graph-based approach for visualization recommendation. IEEE Trans. Vis. Comput. Graph., 28(1):195–205, 2021. doi: 10 . 1109/TVCG . 2021 . 3114863
- [40] J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proc. ICML, pp. 19730–19742, 2023.
- [41] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár. Focal loss for dense object detection. In Proc. ICCV, pp. 2980–2988, 2017. doi: 10 . 1109/ICCV . 2017 . 324
- [42] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In Proc. ECCV, pp. 740–755, 2014. doi: 10 . 1007/978-3-319-10602-1_48
- [43] F. Liu, J. Eisenschlos, F. Piccinno, S. Krichene, C. Pang, K. Lee, M. Joshi, W. Chen, N. Collier, and Y. Altun. DePlot: One-shot visual language reasoning by plot-to-table translation. In Proc. ACL Findings, pp. 10381–10399, 2023. doi: 10 . 18653/v1/2023 . findings-acl . 660
- [44] F. Liu, F. Piccinno, S. Krichene, C. Pang, K. Lee, M. Joshi, Y. Altun, N. Collier, and J. Eisenschlos. MatCha: Enhancing visual language pretraining with math reasoning and chart derendering. In Proc. ACL, pp. 12756–12770, 2023. doi: 10 . 18653/v1/2023 . acl-long . 714
- [45] F. Liu, X. Wang, W. Yao, J. Chen, K. Song, S. Cho, Y. Yacoob, and D. Yu. Mmc: Advancing multimodal chart understanding with large-scale instruction tuning. In Proc. NAACL, 2024 To appear.
- [46] H. Liu, C. Li, Y. Li, and Y. J. Lee. Improved baselines with visual instruction tuning. In Proc. CVPR, 2024 To appear.
- [47] H. Liu, C. Li, Y. Li, B. Li, Y. Zhang, S. Shen, and Y. J. Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024. https://llava-vl.github.io/blog/2024-01-30-llava-next/, last accessed on 29/06/2024.
- [48] H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning. In Proc. NeurIPS, vol. 36, pp. 34892–34916, 2023.
- [49] Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, and C. Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. In Proc. EMNLP, pp. 2511–2522, 2023. doi: 10 . 18653/v1/2023 . emnlp-main . 153
- [50] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie. A convnet for the 2020s. In Proc. CVPR, pp. 11976–11986, 2022. doi: 10 . 1109/CVPR52688 . 2022 . 01167
- [51] M. Lu, J. Lanir, C. Wang, Y. Yao, W. Zhang, O. Deussen, and H. Huang. Modeling just noticeable differences in charts. IEEE Trans. Vis. Comput. Graph., 28(1):718–726, 2021. doi: 10 . 1109/TVCG . 2021 . 3114874
- [52] G. Luo, Y. Zhou, Y. Zhang, X. Zheng, X. Sun, and R. Ji. Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models. arXiv, 2024. doi: 10 . 48550/arXiv . 2403 . 03003
- [53] Y. Luo, N. Tang, G. Li, C. Chai, W. Li, and X. Qin. Synthesizing natural language to visualization (nl2vis) benchmarks from nl2sql benchmarks. In Proc. ACM SIGMOD, pp. 1235–1247, 2021.
- [54] A. Masry, X. L. Do, J. Q. Tan, S. Joty, and E. Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Proc. ACL Findings, pp. 2263–2279, 2022. doi: 10 . 18653/v1/2022 . findings-acl . 177
- [55] A. Masry, P. Kavehzadeh, X. L. Do, E. Hoque, and S. Joty. UniChart: A universal vision-language pretrained model for chart comprehension and reasoning. In Proc. EMNLP, pp. 14662–14684, 2023. doi: 10 . 18653/v1/2023 . emnlp-main . 906
- [56] A. Masry, M. Shahmohammadi, M. R. Parvez, E. Hoque, and S. Joty. ChartInstruct: Instruction tuning for chart comprehension and reasoning. arXiv, 2024. doi: 10 . 48550/arXiv . 2403 . 09028
- [57] F. Meng, W. Shao, Q. Lu, P. Gao, K. Zhang, Y. Qiao, and P. Luo. Chartassisstant: A universal chart multimodal language model via chart-to-table pre-training and multitask instruction tuning. arXiv, 2024. doi: 10 . 48550/arXiv . 2401 . 02384
- [58] N. Methani, P. Ganguly, M. M. Khapra, and P. Kumar. PlotQA: Reasoning over scientific plots. In Proc. WACV, pp. 1516–1525, 2020. doi: 10 . 1109/WACV45572 . 2020 . 9093523
- [59] OpenAI. gpt-4-vision-preview, 2024. https://api.openai.com/v1/chat/completions, last accessed on 29/06/2024.
- [60] S. Pandey and A. Ottley. Mini-VLAT: A short and effective measure of visualization literacy. Comput. Graph. Forum, 42(3):1–11, 2023. doi: 10 . 1111/cgf . 14809
- [61] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In Proc. ICML, pp. 8748–8763. PMLR, 2021.
- [62] R. Rahman, R. Hasan, A. A. Farhad, M. T. R. Laskar, M. H. Ashmafee, and A. R. M. Kamal. ChartSumm: A comprehensive benchmark for automatic chart summarization of long and short summaries. In Proc. CCAI, 2023. doi: 10 . 21428/594757db . 0b1f96f6
- [63] D. Schwenk, A. Khandelwal, C. Clark, K. Marino, and R. Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In Proc. ECCV, pp. 146–162, 2022. doi: 10 . 1007/978-3-031-20074-8_9
- [64] C. Shi, C. Yang, Y. Liu, B. Shui, J. Wang, M. Jing, L. Xu, X. Zhu, S. Li, Y. Zhang, et al. Chartmimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation. arXiv, 2024. doi: 10 . 48550/arXiv . 2406 . 09961
- [65] P. Soni, C. de Runz, F. Bouali, and G. Venturini. A survey on automatic dashboard recommendation systems. Visual Informatics, 8(1):67–79, 2024. doi: 10 . 1016/j . visinf . 2024 . 01 . 002
- [66] B. J. Tang, A. Boggust, and A. Satyanarayan. VisText: A Benchmark for Semantically Rich Chart Captioning. In Proc. ACL, p. 7268–7298, 2023. doi: 10 . 18653/v1/2023 . acl-long . 401
- [67] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv, 2023. doi: 10 . 48550/arXiv . 2307 . 09288
- [68] L. Van der Maaten and G. Hinton. Visualizing data using t-sne. J. Mach. Learn. Res., 9(11):2579–2605, 2008.
- [69] L. Wang, S. Zhang, Y. Wang, E.-P. Lim, and Y. Wang. Llm4vis: Explainable visualization recommendation using chatgpt. In Proc. EMNLP, p. 675–692, 2023. doi: 10 . 18653/v1/2023 . emnlp-industry . 64
- [70] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Proc. NeurIPS, vol. 35, pp. 24824–24837, 2022.
- [71] S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie. ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders. In Proc. CVPR, pp. 16133–16142, 2023. doi: 10 . 1109/CVPR52729 . 2023 . 01548
- [72] S. Xiao, Y. Hou, C. Jin, and W. Zeng. WYTIWYR: A user intent-aware framework with multi-modal inputs for visualization retrieval. Comput. Graph. Forum, 42(3):311–322, 2023. doi: 10 . 1111/cgf . 14832
- [73] S. Xiao, S. Huang, Y. Lin, Y. Ye, and W. Zeng. Let the chart spark: Embedding semantic context into chart with text-to-image generative model. IEEE Trans. Vis. Comput. Graph., 2023. doi: 10 . 1109/TVCG . 2023 . 3326913
- [74] Y. Ye, J. Hao, Y. Hou, Z. Wang, S. Xiao, Y. Luo, and W. Zeng. Generative AI for visualization: State of the art and future directions. Visual Informatics, 8(2):43–66, 2024. doi: 10 . 1016/j . visinf . 2024 . 04 . 003
- [75] Y. Ye, R. Huang, and W. Zeng. VISAtlas: An image-based exploration and query system for large visualization collections via neural image embedding. IEEE Trans. Vis. Comput. Graph., 30:3224 – 3240, 2024. doi: 10 . 1109/TVCG . 2022 . 3229023
- [76] S. Zhang, P. Sun, S. Chen, M. Xiao, W. Shao, W. Zhang, K. Chen, and P. Luo. Gpt4roi: Instruction tuning large language model on region-of-interest. arXiv, 2023. doi: arXiv:2307 . 03601
- [77] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. In Proc. NeurIPS, vol. 36, pp. 46595–46623, 2023.