[affiliation=]KoheiMatsuura
[affiliation=]TakanoriAshihara
[affiliation=]TakafumiMoriya
[affiliation=]MasatoMimura
[affiliation=]
TakatomoKano
[affiliation=]AtsunoriOgawa
[affiliation=]MarcDelcroix
Sentence-wise Speech Summarization:
Task, Datasets, and End-to-End Modeling with LM Knowledge Distillation
Abstract
This paper introduces a novel approach called sentence-wise speech summarization (Sen-SSum), which generates text summaries from a spoken document in a sentence-by-sentence manner. Sen-SSum combines the real-time processing of automatic speech recognition (ASR) with the conciseness of speech summarization. To explore this approach, we present two datasets for Sen-SSum: Mega-SSum and CSJ-SSum. Using these datasets, our study evaluates two types of Transformer-based models: 1) cascade models that combine ASR and strong text summarization models, and 2) end-to-end (E2E) models that directly convert speech into a text summary. While E2E models are appealing to develop compute-efficient models, they perform worse than cascade models. Therefore, we propose knowledge distillation for E2E models using pseudo-summaries generated by the cascade models. Our experiments show that this proposed knowledge distillation effectively improves the performance of the E2E model on both datasets.
keywords:
Sentence-wise Speech Summarization, End-to-end Modeling, Knowledge Distillation, Gigaword, CSJ1 Introduction
Automatic speech recognition (ASR) has undergone significant advancements in the past decades [1], primarily aiming to produce word-for-word transcriptions, but such transcriptions can be difficult to read for humans due to spoken-style and redundant expressions. On the other hand, speech summarization (SSum) condenses a spoken document into a concise and written-style summary offering informative and easily digestible summaries, and has gained increasing interest for processing speech from various domains, such as meetings [2] and lectures [3]. However, unlike ASR, SSum is unsuitable for real-time applications because it typically processes an entire spoken document at once, indicating the lack of technology to produce real-time and concise summaries of spoken content.
To address this issue, we propose sentence-wise speech summarization (Sen-SSum) to bridge the gap between ASR and SSum. Figure 1 compares ASR, SSum, and Sen-SSum with examples. Sen-SSum goes beyond related technologies such as disfluency detection and removal [4] and provides more concise and clearer outputs. Furthermore, users can access summaries immediately, without waiting until the end of an entire meeting or lecture, because Sen-SSum incrementally produces summaries after each speech sentence. Therefore, as a substitute for personal notes, Sen-SSum could help users review a meeting flow later or catch up on the discussion when joining a lecture in the middle. Despite its many promising applications, the Sen-SSum task has not been well explored, partially due to the lack of publicly available datasets for Sen-SSum.
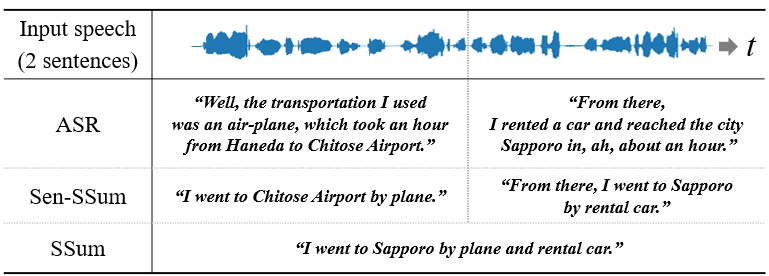
In this paper, we introduce a novel Sen-SSum dataset: Mega-SSum. The Mega-SSum dataset is based on the Gigaword dataset [5, 6] and contains 3.8M English triplets of synthesized speech, transcriptions, and summaries.111https://huggingface.co/datasets/komats/Mega-SSum We utilize a state-of-the-art multi-speaker text-to-speech model [7] to synthesize high-quality natural speech. This dataset enables us to explore the impact of training data availability on a large scale. To increase the validity of our experiments with a more practical dataset, we also use our internal Japanese Sen-SSum corpus, CSJ-SSum, which is based on the Corpus of Spontaneous Japanese [8] and contains 38k triplets with real speech.
We investigate two approaches for Sen-SSum: 1) cascade and 2) end-to-end (E2E) models. The cascade model combines ASR and text summarization (TSum) models [9] and can output high-quality summaries thanks to the TSum model pre-trained on large-scale text data. The E2E model directly generates text summaries from input speech with a single encoder-decoder model [10]. This approach is promising in terms of parameter efficiency and potentially fast decoding, but it requires many expensive speech-summary pairs for training, and the lack of such large training dataset hampers the performance of E2E models.
To tackle this issue, we propose knowledge distillation for the E2E models. We assume a practical scenario where a small subset of the training set (“core set”) contains both summary and transcription labels, while the remaining samples lack either or both labels. We increase the training data by creating pseudo-summaries from unlabeled speech using a cascade model trained on the core set. Subsequently, we train an E2E model using the core set and the pseudo-summaries. We expect that the rich linguistic knowledge of the strong language model (LM), i.e., the TSum model, will be distilled into the E2E model via the pseudo-summaries. The experimental evaluation showed that it significantly improved the performance of E2E models on both datasets. Additionally, we found that the pseudo-summaries led to better summarization accuracies than the manual summaries in certain conditions.
| dataset | lang. | orig. data | split | #samples | #speakers | total dur. (hrs) | ave. dur. (sec) | CR (%) |
|---|---|---|---|---|---|---|---|---|
| Mega-SSum | En | Gigaword | train | 3,800,000 | 2,559 | 11,678.2 | 11.1 | 26.2 |
| core set* | 50,000 | 2,559 | 154.6 | 11.1 | 25.8 | |||
| DUC2003 | eval | 624 | 80 | 2.1 | 12.2 | 27.5 | ||
| CSJ-SSum | Ja | CSJ | train | 38,515 | 726 | 115.8 | 10.8 | 43.1 |
| eval-CSJ | 467 | 9 | 1.4 | 10.8 | 42.8 | |||
| TED | eval-TED | 1329 | 10 | 2.5 | 6.9 | 51.1 |
2 Related Work
Text sentence summarization has been widely studied in the natural language processing (NLP) field [6, 11], but little research has dealt with the audio modality. [12] is most closely related to our work, where they experimented with Sen-SSum using a synthesized Gigaword dataset. However, they investigated only cascade modeling and did not publish Sen-SSum datasets. Furthermore, their dataset is ten times smaller than ours and has high word error rates (WERs), indicating poor speech quality.
The Sen-SSum task is also related to disfluency detection and removal [4] since it excludes less important words and enhances the comprehensibility of ASR transcriptions. However, the primary goal of disfluency removal is not to make the document shorter. In fact, after eliminating disfluencies, the compression rates were 86% for the Switchboard dataset [13] and 92% for the CSJ dataset, according to [14]. Other related studies, such as spoken-to-written style conversion [15, 16], subtitling [17], and other comprehensive post-processing [18, 19], have similar compression rates, though they further involve paraphrasing to generate more user-friendly transcriptions. On the other hand, our Sen-SSum datasets introduced in Section 3 have lower compression rates of only 20% (Mega-SSum) and 40% (CSJ-SSum). Thus, Sen-SSum is a significantly different task and more suitable for quickly grasping spoken content.
3 Datasets for Sen-SSum
The availability of high-quality datasets is crucial for advancing research and development on the Sen-SSum task. We introduce a novel dataset, Mega-SSum, to investigate Sen-SSum. We also validate our experimental results on Mega-SSum using an in-house Japanese dataset, CSJ-SSum. Table 1 presents overviews and statistics of these datasets.
Mega-SSum is a large-scale English dataset for Sen-SSum, containing 3.8M synthesized spoken sentences and corresponding transcriptions and summaries. It is based on the Gigaword dataset [5, 6], composed of the first sentences of news articles and their headlines, and is widely used for text sentence summarization studies [11]. The DUC2003 dataset [20], which is in a similar domain to Gigaword but with four manual summaries, rather than headlines, for each input sentence, is used for the evaluation set. The summaries are fairly condensed, with a compression rate (CR)222The compression rate is defined as (#words in summary) / (#words in input text), following [21]. Shorter summaries have lower rates. of about 20%. To synthesize high-quality and natural-sounding speech from the text sentences, a multi-speaker text-to-speech model VITS [7] was trained from scratch using the LibriTTS-R dataset [22], which is a sound quality improved version of LibriTTS [23]. The synthesized speech retains linguistic information, enabling us reasonable investigations for Sen-SSum. For example, when decoded with the Whisper (small.en) ASR model [24] without fine-tuning, the WER on the evaluation set is only 7.8%, which is as low as typical natural speech. To simulate a realistic setting, the training set is split into a core set with the first 50k samples and a remaining set with 3.75M samples. The core set is used to investigate low-resource and practical situations.
We validate the results obtained on the Mega-SSum dataset using an in-house Sen-SSum dataset named CSJ-SSum, which contains 38k real speech sentences, transcriptions, and summaries in Japanese. It is based on the SPS subset of the CSJ [8], consisting of spontaneous monologues and corresponding transcriptions on daily general topics such as commentary on recent news. In addition, it has an out-of-domain evaluation set based on 10 Japanese TED talks (“eval-TED”). Professional annotators are employed to provide summaries following two instructions: 1) Segment the speech and its transcription into sentences by manually inserting periods. 2) Give a concise and written-style summary for each transcribed sentence, retaining the most essential information. This dataset enables us to confirm the possibility of Sen-SSum on real data and for a different language. Incidentally, since this dataset is much smaller, it justifies the practical need for our proposed knowledge distillation scheme in Section 4.2.
4 Method
4.1 Cascade and end-to-end modeling
We implement Sen-SSum with two distinct approaches: cascade [9] and E2E [10] speech-to-text summarization.
The cascade model combines the ASR and TSum models. The ASR model first transcribes the input speech into its corresponding transcription, and then the TSum model predicts the target summary:
| (1) |
where represents the summary hypothesis. We implement the ASR and TSum models using the Transformer-based encoder-decoder architecture [25], trained with cross-entropy loss. The main advantage of cascade modeling lies in enabling the TSum model to acquire robust NLP capabilities by initializing it with a LM trained on a vast unlabeled text corpus. Cascade modeling is a natural choice for Sen-SSum given that conventional SSum typically employs it [26, 27].
In E2E modeling, an encoder-decoder model directly predicts the target summary from the input speech :
| (2) |
Note that we build the E2E model by fine-tuning the ASR model, following [10]. E2E modeling is attractive with its compact and parameter-efficient structure, along with the potential for lower decoding latency. Additionally, it mitigates the propagation of ASR errors and leverages the acoustic information in the input speech to predict summaries. Despite its advantages, E2E modeling necessitates a substantial number of speech-summary pairs, which are expensive to collect and often limited, resulting in its poor summarization capabilities.
4.2 Sequence-level knowledge distillation for E2E models
To mitigate the training data scarcity for E2E models, we propose leveraging a cascade model to generate additional training data. Specifically, the cascade model, trained on a small available dataset (i.e., the core set), generates pseudo-summaries from unlabeled speech sentences by transcribing them with the ASR model and then summarizing the transcriptions with the TSum model. These pseudo-summaries, along with the human summaries in the core set, are used to train an E2E model. We anticipate that the rich linguistic knowledge embedded in the TSum model will be distilled to the E2E model through the pseudo-summaries. Although this method is motivated by the success in the E2E speech translation field [28, 29] and widely known as sequence-level knowledge distillation [30], this is the first application to E2E SSum.
4.3 Leveraging self-supervised models
We also investigte the impact of integrating WavLM large333https://huggingface.co/microsoft/wavlm-large [31], a state-of-the-art speech self-supervised learning (SSL) model renowned for its effectiveness in low-resource spoken language understanding tasks, on enhancing our E2E model with the Mega-SSum dataset. Specifically, we first use WavLM as a feature extractor, and then fine-tune it alongside the downstream E2E model. Speech SSL models hold promise as potential alternatives to our proposed method, given their inherent linguistic knowledge from pre-training on vast speech-only data [32].
5 Experiment
5.1 Setup
5.1.1 Model architectures
We implemented three encoder-decoder models for ASR, TSum, and E2E Sen-SSum. Both the ASR and E2E models comprised a 2-layer convolutional neural network with a sub-sampling rate of 4 for initial feature extraction, a 12-layer Conformer encoder with a model dimension of 512 and a kernel size of 31, and a 12-layer Transformer decoder. Both the encoder and decoder featured 2048-dimensional feed-forward (FF) layers. Following [33], batch normalization layers in the Conformer blocks were replaced with layer normalization layers, and learnable positional embedding was used for the decoder. For the TSum model, we used T5 models [34], consisting of a 12-layer Transformer encoder and decoder with a model dimension of 768 and 3072-dimensional FF layers. The number of parameters in the cascade and E2E models were 362M (=142M+220M) and 139M, respectively.
5.1.2 Training details: datasets and hyper-parameters
For the experiments on Mega-SSum, we first trained an ASR model on the 960 hours of the Librispeech dataset [35] and fine-tuned it using the 50k speech-transcription pairs in the core set. We further fine-tuned the ASR model with the 50k speech-summary pairs to obtain an E2E model. We denoted this baseline model as “E2E-base”. We prepared a TSum model by fine-tuning an English T5 model444https://huggingface.co/google-t5/t5-base with 50k transcription-summary pairs. The combination of the ASR and TSum models were denoted as “Cascade-base”. To investigate the impact of training data volume, we also prepared ASR, E2E, and TSum models trained with the first 100k, 500k, 1M, or 3.8M samples. We denoted them as “E2E-HS” and “Cascade-HS” because they were trained with human summaries, in contrast to ones trained with pseudo-summaries in Section 4.2. The WERs of the ASR models were 11.7%, 10.7%, 9.2%, 9.4%, and 7.7% for the evaluation set, respectively.
For the proposed knowledge distillation, we assumed that the core set with 50k samples was fully available, and only the speech data of the first 50k, 450k, 950k, or 3.75M samples in the remaining set was additionally available. The transcriptions and summaries were prepared as explained in Section 4.2. The total number of training samples was 100k, 500k, 1M, or 3.8M since the 50k samples in the core set were added. We denote these E2E models with the proposed knowledge distillation as “E2E-KD”. To assess the effect of ASR errors on the proposed method, we also investigate the E2E models trained with pseudo-summaries generated from the reference transcriptions, denoted as “E2E-KD (ref)”.
For CSJ-SSum, we used the entire CSJ datasets [8] and 1M speech-transcription pairs from our in-house ASR datasets to train a ASR model. The character error rates on the eval-CSJ/TED were 3.1% and 16.7%, respectively. We then fine-tuned it with all 38k speech-summary pairs to obtain the baseline E2E model. A Japanese T5 model555https://huggingface.co/sonoisa/t5-base-japanese was fine-tuned with the 38k transcription-summary pairs to obtain the baseline TSum model. For knowledge distillation, we leveraged the same 1M speech-transcription pairs used to train the ASR model. We generated 1M pseudo-summaries from the reference transcriptions using the baseline TSum model, then used these to train the proposed E2E model alongside the 38k human summaries. Note that the 1M pairs were selected from our in-house ASR dataset to ensure that each reference transcription was longer than 10 characters and contained sentence-ending expressions, enabling the TSum model to produce reasonable summaries.
We adopted the same hyper-parameters for both Mega-SSum and CSJ-SSum unless specified otherwise. To obtain an ASR model, we utilized the WarmupLR scheduler and the Adam optimizer, setting the maximum learning rate (LR) to 2x and the number of warmup steps to 40k. The average batch size was set to 168 for LibriSpeech and 350 for CSJ. We also applied the connectionist temporal classification (CTC) auxiliary loss with a weight of 0.3, SpecAugment [36], and speed perturbation. The vocabulary size was set to 5,000 using byte-pair encoding [37] for Mega-SSum and 3,262 with the character unit for CSJ-SSum. For the fine-tuning, we adjusted the LR to 2x and the number of warmup steps to 1k, reduced the batch size by one-fifth, and used the AdamW optimizer. CTC loss was omitted during E2E Sen-SSum model training. To obtain a TSum model, we utilized a linearly decaying LR starting from 5x. We used early stopping based on validation loss with a patience of 5 epochs.
5.1.3 Evaluation details
In the evaluation, we consistently set the beam width to 4 for the ASR, E2E, and TSum models. For objective metrics, we used ROUGE-L (R-L) [38] and BERTScore (BScr) [39], which have been commonly used in previous TSum and SSum studies. The R-L score measures superficial word matching, while BScr leverages BERT embeddings to capture the semantic meanings of words. Additionally, inspired by [40], we conducted A/B tests using the ChatGPT API666https://platform.openai.com/docs/api-reference for a more comprehensive assessment. Specifically, GPT4-turbo (gpt-4-1106-preview) was instructed to select the better summary of the two, considering the reference transcription.
| Model | ROUGE-L | BERTScore | CR (%) |
|---|---|---|---|
| Cascade-base | 36.01.5 | 62.60.8 | 25.00.7 |
| E2E-base | 30.71.5 | 58.00.8 | 21.30.6 |
| + WavLM | 30.41.5 | 58.20.8 | 21.70.6 |
| E2E-KD3.8M | 35.61.6 | 61.90.8 | 23.50.6 |
5.2 Results
5.2.1 Results on Mega-SSum
The first three columns in Table 2 show the 95% confidential intervals of R-L and BScr scores and CRs by the cascade and E2E models trained on the core set. As expected, the cascade model outperformed the E2E model due to the pre-trained TSum model’s strong NLP capability. In fact, the baseline E2E model occasionally generated only one or two words as a summary, likely due to its limited generalization capability, resulted in lower CRs compared with the cascade model. Although WavLM was also pre-trained on a large amount of unlabeled speech, its combination with the E2E model did not improve the scores. Its linguistic knowledge seemed insufficient to help the E2E model solve the summarization task. The final column “E2E-KD3.8M” shows the performance of the E2E model trained with the 50k human summaries from the core set and an additional 3.75M pseudo-summaries. This proposed method significantly enhanced the E2E model to achieve a performance level comparable to that of the cascade model.
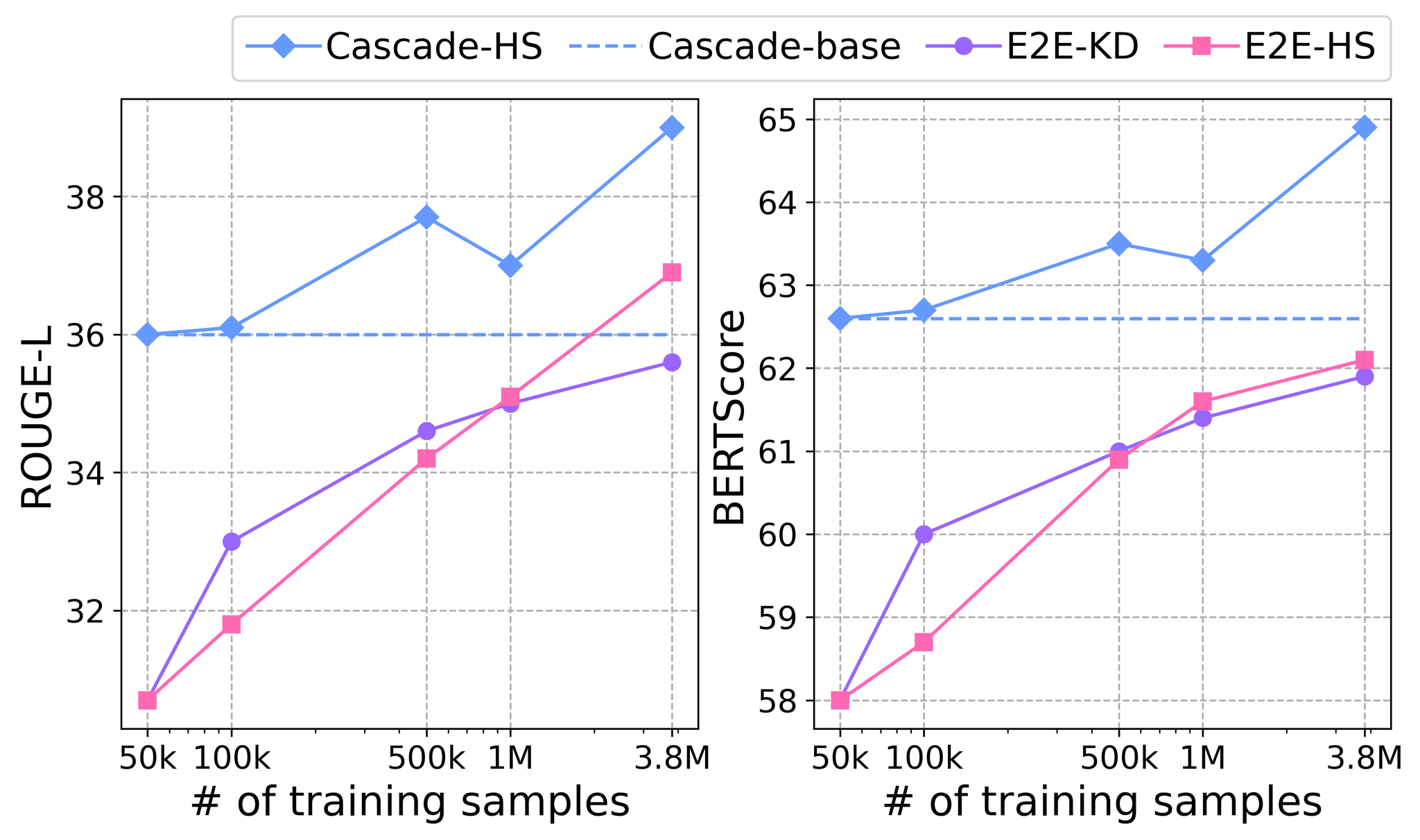
Figure 2 illustrates the R-L and BScr scores when the cascade and E2E models were trained on varying amounts of training data, including the scores of the E2E models trained with pseudo-summaries. As evident from the results of Cascade-HS and E2E-HS, the cascade and E2E models generated better summaries with more training samples. Additionally, the pseudo-summaries effectively improved the E2E model E2E-KD with its scores gradually approaching those of cascade-base, which generated the pseudo-summaries.
Interestingly, training with the pseudo-summaries resulted in better scores for the E2E model up to 500k samples. This was likely because the pseudo-summaries were easier for the E2E model to learn compared with the human summaries. For instance, the R-L score, which considers the longest common sub-sequence of two sequences, between the pseudo-summaries and transcriptions (34.60.94, on the evaluation set) was significantly higher than that between the human summaries and transcriptions (27.21.03). This suggests that the pseudo-summaries made Mega-SSum a more extractive summarization task, which is more similar to the ASR task and easier to reproduce. However, with 1M or more human summaries, E2E-HS showed better scores than E2E-KD because it could reproduce more human-like summaries, which cannot be completely learned with erroneous and simplified pseudo-summaries.
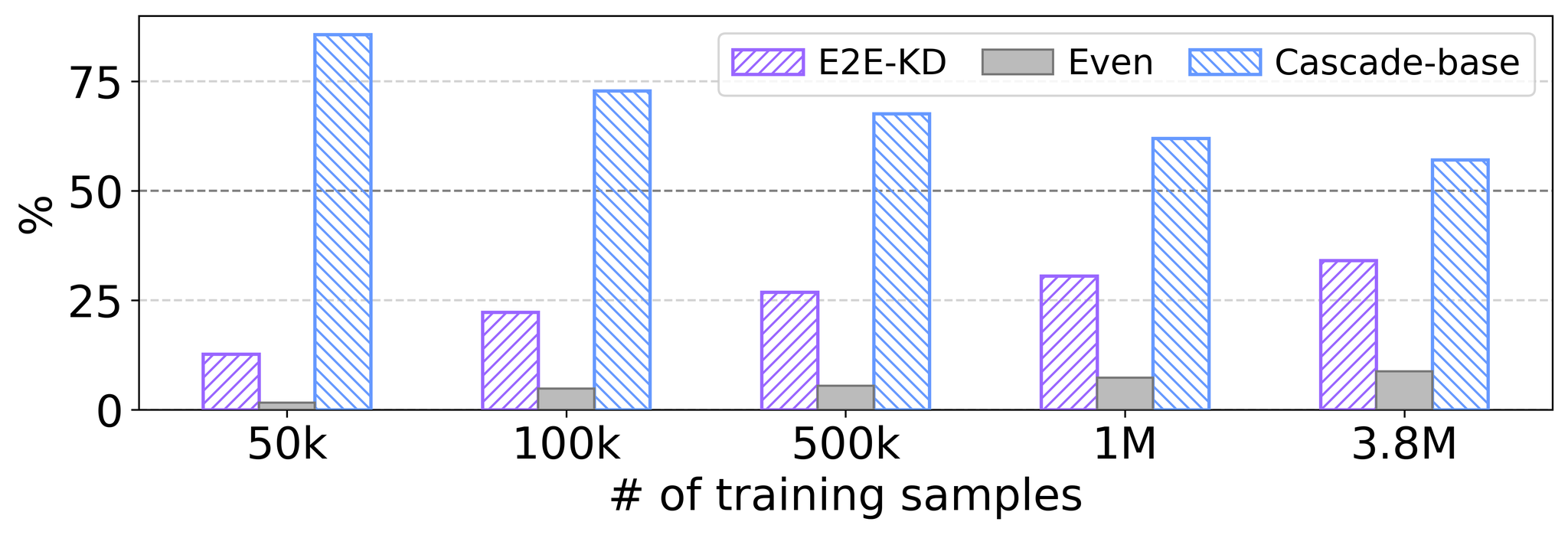
Figure 3 shows the preference percentages of ChatGPT-conducted A/B tests comparing summaries generated by the baseline cascade model with those produced by the E2E models trained with varying amounts of pseudo-summaries. As the dataset expanded, preferences gradually shifted towards the E2E model’s summaries over those of the cascade model. However, even with 3.8M training samples, the E2E model’s summaries were frequently deemed inferior to those of the cascade model. This performance gap was not evident through conventional metrics such as R-L or BScr, indicating that more effective knowledge distillation methods may be required.
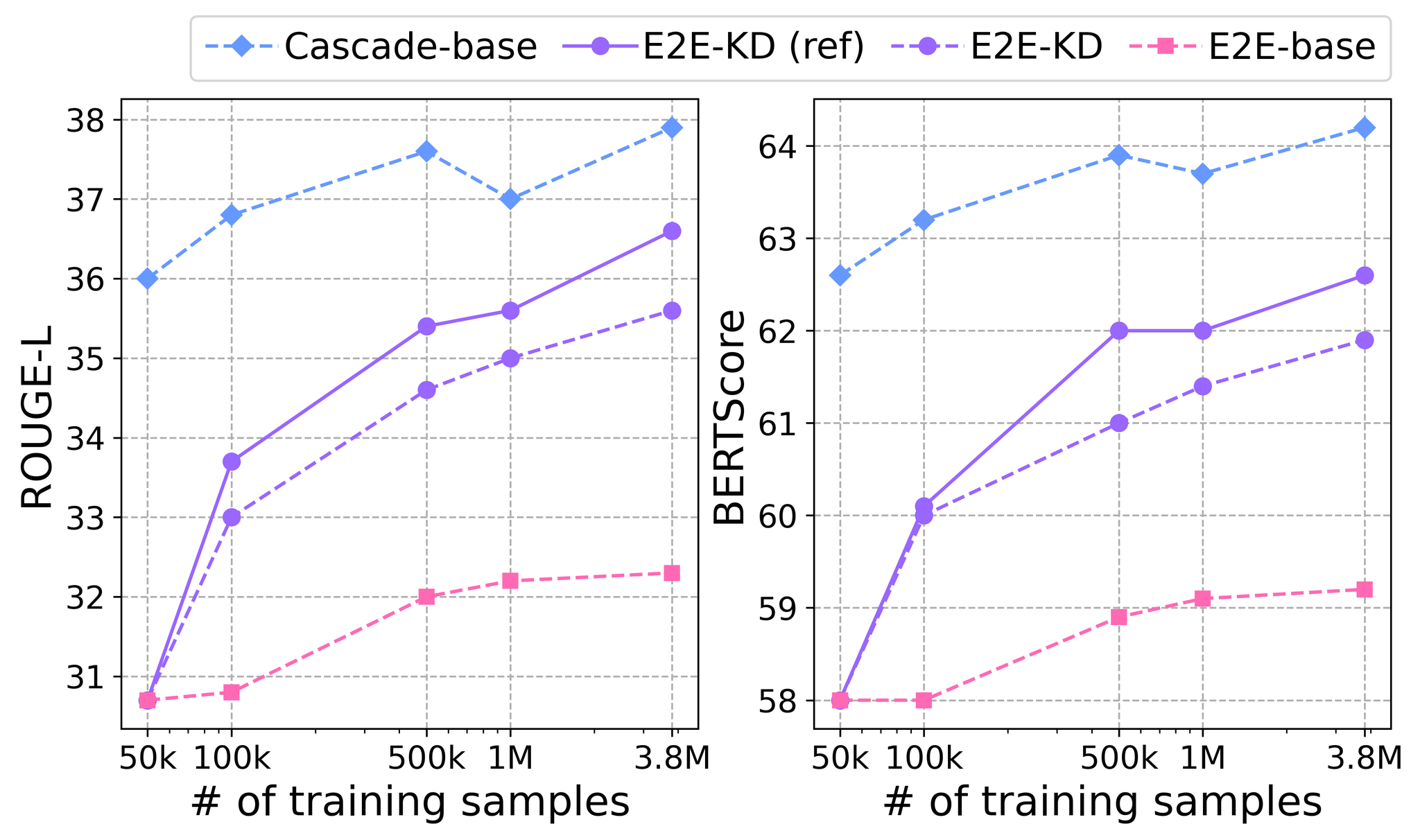
Figure 4 shows the effect of knowledge distillation when the reference transcriptions of the remaining set were also available in addition to the speech. Note that the baseline cascade and E2E models, i.e., Cascade-base and E2E-base, were also improved because the ASR model was trained on larger datasets. While the speech-only data substantially improved, higher-quality pseudo-summaries derived from the reference transcriptions was important and resulted in better scores.
5.2.2 Results on CSJ-SSum
Table 3 shows the R-L and BScr scores on the CSJ-SSum dataset. The scores were significantly higher than those for Mega-SSum because of more extractive nature and simpler structure of the summaries in the CSJ-SSum dataset. Nevertheless, the proposed method significantly improved the scores on both evaluation sets, indicating its effectiveness in real-world scenarios. We gained more improvements on the out-of-domain eval-TED set compared with the in-domain eval-CSJ set. This discrepancy may be attributed to the inherent generalizability of the proposed method, which was better suited to adapt to diverse vocabularies in out-of-domain datasets.
| Model | eval-CSJ | eval-TED | ||
|---|---|---|---|---|
| R-L | BScr | R-L | BScr | |
| Cascade | 66.92.1 | 84.70.9 | 63.31.2 | 82.60.6 |
| E2E | 63.12.3 | 82.81.0 | 60.11.3 | 80.70.6 |
| + KD | 65.72.2 | 84.01.0 | 63.11.3 | 82.10.6 |
6 Conclusion
In this study, we introduced Sen-SSum along with two supporting datasets, Mega-SSum and CSJ-SSum. We demonstrated the potential of both cascade and E2E models in Sen-SSum and the effectiveness of knowledge distillation for E2E models using the cascade model. Future work could explore more efficient methods like [41], which directly integrates LMs into E2E SSum models and does not rely on pseudo-summaries. It is also important to develop context-aware models [42] to consistently handle long speech documents in a sentence-by-sentence manner, which represents a more practical setting.
References
- [1] R. Prabhavalkar, T. Hori, T. N. Sainath, R. Schlüter, and S. Watanabe, “End-to-end speech recognition: A survey,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, pp. 325–351, 2024.
- [2] V. Rennard, G. Shang, J. Hunter, and M. Vazirgiannis, “Abstractive Meeting Summarization: A Survey,” Transactions of the Association for Computational Linguistics, pp. 861–884, 2023.
- [3] T. Kano, A. Ogawa, M. Delcroix, and S. Watanabe, “Attention-based multi-hypothesis fusion for speech summarization,” in ASRU, 2021, pp. 487–494.
- [4] P. Jamshid Lou and M. Johnson, “Disfluency detection using a noisy channel model and a deep neural language model,” in ACL, 2017, pp. 547–553.
- [5] D. Graff, J. Kong, K. Chen, and K. Maeda, “English Gigaword,” vol. 4, 2003, p. 34.
- [6] A. M. Rush, S. Chopra, and J. Weston, “A neural attention model for abstractive sentence summarization,” pp. 379–389, 2015.
- [7] J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in ICML, M. Meila and T. Zhang, Eds., 2021, pp. 5530–5540.
- [8] K. Maekawa, “Corpus of spontaneous Japanese: its design and evaluation,” in ISCA/IEEE Workshop on Spontaneous Speech Processing and Recognition, 2003, pp. 7–12.
- [9] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in ACL, 2020, pp. 7871–7880.
- [10] R. Sharma, S. Palaskar, A. Black, and F. Metze, “End-to-end speech summarization using restricted self-attention,” in ICASSP, 2022, pp. 8072–8076.
- [11] S. Chopra, M. Auli, and A. M. Rush, “Abstractive sentence summarization with attentive recurrent neural networks,” in NAACL, 2016, pp. 93–98.
- [12] Z. Huang, M. Rao, A. Raju, Z. Zhang, B. Bui, and C. Lee, “MTL-SLT: Multi-task learning for spoken language tasks,” in Workshop on NLP for Conversational AI, 2022, pp. 120–130.
- [13] J. Godfrey, E. Holliman, and J. McDaniel, “SWITCHBOARD: Telephone speech corpus for research and development,” in ICASSP, 1992, pp. 517–520.
- [14] H. Futami, E. Tsunoo, K. Shibata, Y. Kashiwagi, T. Okuda, S. Arora, and S. Watanabe, “Streaming joint speech recognition and disfluency detection,” in ICASSP, 2023, pp. 1–5.
- [15] M. Ihori, A. Takashima, and R. Masumura, “Large-context pointer-generator networks for spoken-to-written style conversion,” in ICASSP, 2020, pp. 8189–8193.
- [16] M. Sunkara, C. Shivade, S. Bodapati, and K. Kirchhoff, “Neural inverse text normalization,” in ICASSP, 2021, pp. 7573–7577.
- [17] D. Liu, J. Niehues, and G. Spanakis, “Adapting end-to-end speech recognition for readable subtitles,” in ICSLT, 2020, pp. 247–256.
- [18] G. Neubig, Y. Akita, S. Mori, and T. Kawahara, “A monotonic statistical machine translation approach to speaking style transformation,” Computer Speech & Language, vol. 26, no. 5, pp. 349–370, 2012.
- [19] J. Liao, S. Eskimez, L. Lu, Y. Shi, M. Gong, L. Shou, H. Qu, and M. Zeng, “Improving readability for automatic speech recognition transcription,” ACM Transactions on Asian and Low-Resource Language Information Processing, vol. 22, no. 5, pp. 1–23, 2023.
- [20] P. Over, H. Dang, and D. Harman, “DUC in context,” Special issue of Information Processing and Management on Text Summarization, pp. 1506–1520, 2007.
- [21] J. Goldstein, M. Kantrowitz, V. Mittal, and J. Carbonell, “Summarizing text documents: Sentence selection and evaluation metrics,” in SIGIR, 1999, pp. 121–128.
- [22] Y. Koizumi, H. Zen, S. Karita, Y. Ding, K. Yatabe, N. Morioka, M. Bacchiani, Y. Zhang, W. Han, and A. Bapna, “LibriTTS-R: A restored multi-speaker text-to-speech corpus,” in INTERSPEECH 2023, 2023, pp. 5496–5500.
- [23] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “LibriTTS: A corpus derived from librispeech for text-to-speech,” in INTERSPEECH, 2019, pp. 1526–1530.
- [24] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in ICML, 2023, pp. 28 492–28 518.
- [25] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in NeurIPS, 2017.
- [26] G. Murray, S. Renals, and J. Carletta, “Extractive summarization of meeting recordings,” in EUROSPEECH, 2005, pp. 593–596.
- [27] J. J. Zhang, H. Y. Chan, and P. Fung, “Improving lecture speech summarization using rhetorical information,” in ASRU, 2007, pp. 195–200.
- [28] M. Gaido, M. A. Di Gangi, M. Negri, and M. Turchi, “End-to-end speech-translation with knowledge distillation: FBK@IWSLT2020,” in ICSLT, 2020, pp. 80–88.
- [29] H. Inaguma, T. Kawahara, and S. Watanabe, “Source and target bidirectional knowledge distillation for end-to-end speech translation,” in NAACL-HLT, 2021, pp. 1872–1881.
- [30] Y. Kim and A. M. Rush, “Sequence-level knowledge distillation,” in EMNLP, 2016, pp. 1317–1327.
- [31] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y. Qian, Y. Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, pp. 1505–1518, 2022.
- [32] T. Ashihara, T. Moriya, K. Matsuura, T. Tanaka, Y. Ijima, T. Asami, M. Delcroix, and Y. Honma, “SpeechGLUE: How well can self-supervised speech models capture linguistic knowledge?” in INTERSPEECH, 2023, pp. 2888–2892.
- [33] K. Matsuura, T. Ashihara, T. Moriya, T. Tanaka, A. Ogawa, M. Delcroix, and R. Masumura, “Leveraging large text corpora for end-to-end speech summarization,” in ICASSP, 2023, pp. 1–5.
- [34] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., 2020.
- [35] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: An asr corpus based on public domain audio books,” in ICASSP, 2015, pp. 5206–5210.
- [36] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “SpecAugment: A simple data augmentation method for automatic speech recognition,” in INTERSPEECH, 2019, pp. 2613–2617.
- [37] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in ACL, 2016, pp. 1715–1725.
- [38] C. Lin, ROUGE: A Package for Automatic Evaluation of Summaries, 2004.
- [39] T. Zhang, V. Kishore, F. Wu, K. Weinberger, and Y. Artzi, “BERTScore: Evaluating text generation with bert,” in ICLR, 2020.
- [40] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-bench and chatbot arena,” in NeurIPS Datasets and Benchmarks Track, 2023.
- [41] K. Matsuura, T. Ashihara, T. Moriya, T. Tanaka, T. Kano, A. Ogawa, and M. Delcroix, “Transfer Learning from Pre-trained Language Models Improves End-to-End Speech Summarization,” in INTERSPEECH, 2023, pp. 2943–2947.
- [42] J. Tiedemann and Y. Scherrer, “Neural machine translation with extended context,” in Workshop on Discourse in Machine Translation, pp. 82–92.