Meta Knowledge for Retrieval Augmented Large Language Models
Abstract.
Retrieval Augmented Generation (RAG) is a technique used to augment Large Language Models (LLMs) with contextually relevant, time-critical, or domain-specific information without altering the underlying model parameters. However, constructing RAG systems that can effectively synthesize information from large and diverse set of documents remains a significant challenge. We introduce a novel data-centric RAG workflow for LLMs, transforming the traditional retrieve-then-read system into a more advanced prepare-then-rewrite-then-retrieve-then-read framework, to achieve higher domain expert-level understanding of the knowledge base. Our methodology relies on generating metadata and synthetic Questions and Answers (QA) for each document, as well as introducing the new concept of Meta Knowledge Summary (MK Summary) for metadata-based clusters of documents. The proposed innovations enable personalized user-query augmentation and in-depth information retrieval across the knowledge base. Our research makes two significant contributions: using LLMs as evaluators and employing new comparative performance metrics, we demonstrate that (1) using augmented queries with synthetic question matching significantly outperforms traditional RAG pipelines that rely on document chunking (), and (2) meta knowledge-augmented queries additionally significantly improve retrieval precision and recall, as well as the final answer’s breadth, depth, relevancy, and specificity. Our methodology is cost-effective, costing less than $20 per 2000 research papers using Claude 3 Haiku, and can be adapted with any fine-tuning of either the language or embedding models to further enhance the performance of end-to-end RAG pipelines.
Test
1. Introduction
Retrieval Augmented Generation (RAG) is a standard technique used to augment Large Language Models (LLMs) with the capability to integrate contextually relevant, time-critical, or domain-specific information without altering the underlying model weights. This approach is particularly effective for knowledge-intensive tasks where proprietary or timely data is required to guide the language model’s response, and has become an attractive solution for reducing model hallucinations and ensuring alignment with the latest and most relevant information for the task at hand. In practice, RAG pipelines consist of several modules structured around the traditional retrieve-then-read framework (lewis2020retrieval, ). Given a user question, a retriever is tasked with dynamically searching for related document chunks and providing them as context for the LLM to predict the answer, rather than relying solely on pre-trained model knowledge (also known as in-context learning). A simple, yet powerful and cost-effective retriever framework involves using a dual-encoder dense retrieval model to encode both the query and the documents individually into a high-dimensional vector space, and computing their inner product as a measure of similarity (karpukhin2020dense, ).
However, several challenges specifically hinder the quality of the knowledge augmented context. First, knowledge base documents may contain substantial noise, either intrinsic for the task at hand or as a result of the lack of standardization across the documents of interest (from various documents layouts or formats such as .pdf, .ppt, .wordx, etc.). Second, little to no human-labelled information or relevance labels are typically available to support the document chunking, embedding, and retrieval processes, making the overall retrieval problem a largely unsupervised approach and challenging to personalize for a given user. Third, chunking and separately encoding long documents pose a challenge in extracting relevant information for the retrieval models (gao2023retrieval, ). Indeed, document chunks do not conserve the semantic context of the entire document, and the larger the chunk, the less precise the context of the chunk is maintained for further retrieval. This makes the choice of document chunking strategy non-trivial for a given use-case, although critical for the quality of the subsequent steps due to potentially significant information loss. Fourth, user queries are typically short, ambiguous, may contain vocabulary mismatches, or are complex enough to require multiple documents to address, making it generally difficult to precisely capture the user’s intents and subsequently identify the most appropriate documents to retrieve (zhu2023large, ). Finally, there is no guarantee that the relevant information is localized in the knowledge base, but rather spread across multiple documents. As a result, domain expert-level usage of the knowledge base is made dramatically more challenging with automated information retrieval systems. Such high level reasoning across the knowledge base is a yet unsolved problem and constitutes the basis for recent LLM-based retrieval agent frameworks research.
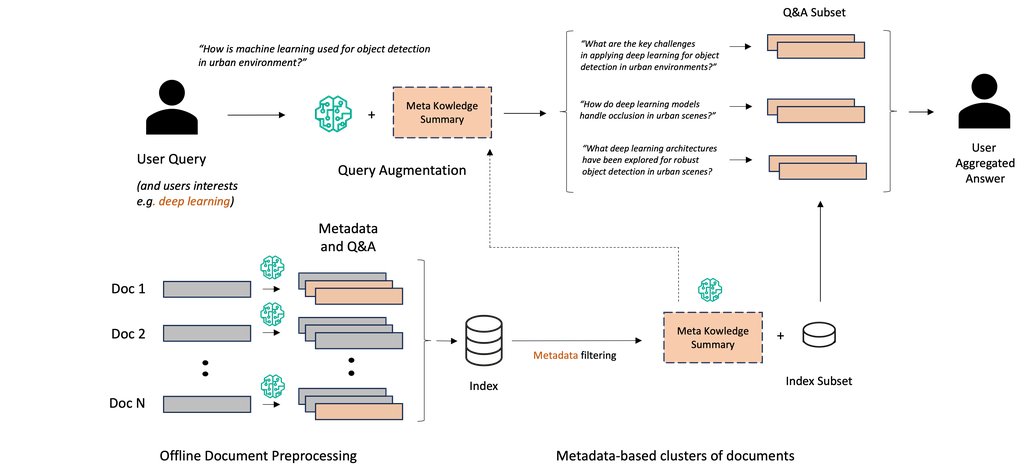
In this work, we are interested in cases where user queries require the information search to be specific to users interests or profile, are ambiguous, and require high level reasoning across documents (for example: “What challenges are associated with applying machine learning for marketing?”), making recall, specificity, and depth our metrics of interest. To improve the search results performance across those metrics, query augmentation has been a widely used technique in both traditional Information Retrieval (IR) use cases such as e-commerce search (peng2024large, ), as well as in the more recent RAG frameworks leveraging LLMs (gao2022precise, ). Query augmentation consists in explicitly rewriting or extending the original user query into one or more tailored queries that better match search results, alleviating issues related to query underspecification. This adjustment adds a module to the RAG framework and transforms it into the more sophisticated rewrite-then-retrieve-then-read workflow. Leveraging their vast underlying parametric world knowledge, LLMs constitute a fitting choice to understand and enhance users queries, subsequently boosting the relevance of the retrieve step (gao2022precise, ; ma2023query, ; mackie2023generative, ; mackie2023grm, ; shen2023large, ; jagerman2023query, ; srinivasan2022quill, ). Our approach introduces a new data-centric RAG workflow, prepare-then-rewrite-then-retrieve-then-read (PR3), where each document is processed by LLMs to create both custom metadata tailored to users characteristics and QA pairs to unlock new knowledge base reasoning capabilities through query augmentation. Our data preparation and retrieval pipeline mitigates the information loss inherent to large document chunking and embedding, as only QA are being encoded instead of documents chunks, while acting as a noise filtering approach for both noisy and irrelevant documents for the task at hand. By introducing metadata-based clusters of QAs and Meta Knowledge Summary, our framework conditionally augment the initial user query into multiple dedicated queries, therefore increasing the specificity, breadth, and depth of the knowledge base search (see Figure 1). The proposed out-of-the-shelve methodology is easily applicable to new datasets, does not rely on manual data labelling or model fine-tuning, and constitutes a step towards autonomous, agent-based documents database reasoning with LLMs, for which the literature remains limited to date (zhu2023large, ).
2. Related Work
Our work integrates concepts from methodologies that generate QA from document collections for downstream fine-tuning of either LLMs or encoder models, with techniques leveraging query augmentation to boost the performance of retrievers in RAG pipelines. Below, we outline related work relevant to these two areas of RAG enhancement.
2.1. RAG Enhancement with Fine-tuning
Methodologies that aim at improving RAG pipelines based on fine-tuning generally constitute a higher barrier to entry for performing both the initial parameters update, and the maintenance of the accuracy of the model over time to new documents. They require careful data cleaning and (often manual) curation, and manual iterations across training hyperparameters sets to successfully adapt the model to the task at hand without causing catastrophic forgetting of the pre-trained model knowledge (luo2023empirical, ). In addition, model tuning may not be sustainable for frequent knowledge-base updates, and represents a generally higher cost due the underlying requirements of compute resources, despite the recent development of parameter-efficient fine-tuning (PEFT) techniques (hu2021lora, ; dettmers2024qlora, ).
In e-commerce retrieval frameworks, TaoBao created a query rewriting framework based on company logs and rejection sampling to fine-tune a LLM in a supervised fashion, without QA generation. They further introduced a new contrastive learning methods to calibrate query generation probability to be aligned with desired search results, leading to a significant boost of merchandise volume, number of transactions and unique visitors (peng2024large, ). As an alternative, reinforcement learning methods based on black-box LLM evaluation has also been leveraged to train a smaller query-rewriter LLM, which showed a consistent performance improvement in open-domain and multiple-choice questions and answers (QA) in web search (ma2023query, ). Reinforcement learning-based approaches, however, are subject to more instability during the training phase, and require a careful investigations of the trade-offs between generalization and specialization among downstream tasks (ma2023query, ). Other approaches have focused on specifically improving the embedding space between the user query and the documents at hand, rather than augmenting the query itself. Authors of InPars (bonifacio2022inpars, ) augmented their documents knowledge base by generating synthetic questions and answers pairs in a unsupervised fashion, and subsequently used them to fine-tune a T5 base embedding model. They showed that using the fine-tuned embedding model followed by a neural reranker such as ColBERT (khattab2020colbert, ) outperformed strong baselines such as BM25 (robertson2009probabilistic, ).
Most recently, other types of approaches have been developed to improve the end-to-end pipeline performance, such as RAFT (zhang2024raft, ), which consists in specifically training a reader to differentiate between relevant and irrelevant documents, or QUILL (srinivasan2022quill, ) that aims at entirely replacing the RAG pipeline using RAG-augmented distillation training of another LLM.
2.2. RAG Enhancement without Fine-tuning
As an alternative to fine-tuning LLMs or encoder models, query augmentation methodologies have been developed to increase the performance of the retrievers by transforming the user query pre-encoding. These approaches can further be classified into two categories: either leveraging a retrieval pass through the documents, or zero-shot (without any example document).
Among the zero-shot approaches, HyDE (gao2022precise, ) introduced a data augmentation methodology that consists in generating an hypothetical response document to the user query by leveraging LLMs. The underlying idea is to bring closer the user query and the documents of interest in the embedding space, therefore increasing the performance of the retrieval process. Their experiments showed performance comparable to fine-tuned retrievers across various tasks. The generated document, however, is a naïve data augmentation in the sense that it does not change given the underlying embedded data for the task at hand, such that it can lead to performance decrease in multiple situations, for there is inevitably a gap between the generated content and the knowledge base. Alternatively, methodologies have been proposed to perform an initial pass through the embedding space of the documents first, and subsequently augment the initial query to perform a more informed search. These Pseudo Relevance Feedback (PRF) (mackie2023generative, ) and Generative Relevance Feedback (GRF) modeling approaches (mackie2023grm, ) are typically dependent on the quality of the most highly-ranked documents used to first condition their query augmentation to, and are therefore prone to significant performance variation across queries, or may even forget the essence of the original query.
3. Methodology
In both RAG pipeline enhancements approaches cited above, the retrievers are generally unaware of the distribution of the target collection of documents despite an initial pass through the retrieval pipeline. In our proposed framework, for each document and prior to inference, we create a set of dedicated metadata, and subsequently generate guided QA spanning across the documents using Chain of Thoughts (CoT) prompting with Claude 3 Haiku (anthropic2024claude, ; wei2022chain, ). The synthetic questions are then encoded, and the metadata used for filtering purposes. For any user-relevant combination of metadata, we create a Meta Knowledge Summary (MK Summary), leveraging Claude 3 Sonnet, which consists in a summarization of the key concepts available in the database for a given filter. At inference time, the user query is dynamically augmented by relying on the personalized MK Summary given the metadata of interest, therefore providing tailored response for this user. By doing so, we provide the retriever with the capability to reason across multiple documents which may have required multiple retrieval and reasoning rounds otherwise. Our goal is to ultimately increase the quality of the end-to-end retrieval pipeline across multiple metrics, such as depth, coverage, and relevancy, by enabling complex reasoning across the database through tailored searches and the leverage of meta knowledge information. Importantly, our approach does not rely on any model weights update, and may very well be combined with any fine-tuning of either the language or the encoding models to any domain to further improve the performance of the end-to-end RAG pipeline (gupta2024rag, ). We represent our methodology pipeline in Figure 1, and describe the synthetic QA generation process and the concept of MK Summary below.
3.1. Datasets
Our public benchmark use case comprises a dataset of 2,000 research papers from 2024, collated using the arXiv API. This dataset represents a diverse spectrum of research in statistics, machine learning, artificial intelligence, and econometrics111The dataset was filtered using the following categories on the Arxiv API: ”stat.ML”, ”stat.TH”, ”stat.AP”, ”stat.ME”, ”math.ST”, ”cs.AI”, ”cs.LG”, ”econ.EM”. Thank you to arXiv for use of its open access interoperability., for a total of approximately 35M tokens.
3.2. Synthetic QA Generation
First, for each document, we generate a set of metadata and subsequent QA using CoT prompting (see Appendix A). The prompt aims at creating a list of metadata by classifying the documents into a predefined set of categories (such as research field, or applications types for our research papers benchmark). Relying on these metadata, we generate a set of synthetic questions and answers, using teacher-student prompting and assess the knowledge of the student on the document. We specifically leverage Claude 3 Haiku for its long-context reasoning abilities and potential to create synthetic QA pairs with context spanning across documents. The generated metadata serve both as filtering parameters for the augmented search, and to select the synthetic QA used for the users queries augmentation in the form of meta knowledge information (MK Summary). In addition, the synthetic QA are used for the retrieval, but only questions are vectorized for downstream retrieval. For our public scientific research papers use case, a total of 8657 QA were generated from the 2000 research documents, accounting for 5 to 6 questions for 70% of cases, and 2 questions in 21% of cases. Examples of synthetic questions and answers are provided in Appendix B. The total number of token generated as parts of the processing step amount to approximately 8M output tokens, corresponding to a total of $20.17 for the entire processing pipeline of all 2000 documents (including input tokens) using Amazon Bedrock (pricingbedrock, ). We investigated the redundancy of the generated QA across the document using hierarchical clustering on the embedding space of the questions using e5-mistral-7b-instruct (wang2023improving, ), but did not de-duplicated the generated QA for our use cases due to the low QAs overlap. QA Filtering can be application and metadata specific, and other high-dimensional approaches such as Determinantal Point Processes (DPP) (kulesza2012determinantal, ) are left for future work, together with the automated discovery of metadata topics and self-correcting QA-generation (pan2023automatically, ).
3.3. Generation of Meta Knowledge Summary
For a given combination of metadata, we create a Meta Knowledge Summary (MK Summary) aiming at supporting the data augmentation phase for a given user query. For our research papers use case, we limited our metadata to the specific field of research (such as reinforcement learning, supervised vs unsupervised learning, bayesian methods, econometrics, etc.) identified during the document processing phase by Claude 3 Haiku. For this research, we create the MK Summary by summarizing the concepts across a set of questions tagged with the metadata of interest using Claude 3 Sonnet. An alternative left for future work is that of prompt tuning to optimize for the content of the summary prompt (tam2022parameter, ).
3.4. Augmented Generation of Queries and Retrieval
Given a user query and a set of pre-selected metadata of interests, we retrieve the corresponding pre-computed MK Summary and use it to condition the user query augmentation into the database subset. For our research paper benchmark, we created a set of 20 MK Summary corresponding to research fields (e.g. deep learning for computer vision, statistical methods, bayesian analysis, etc.), relying on the metadata created in the processing phase. We leverage the ”plan-and-execute” prompting methodology to address complex queries, reason across documents, and ultimately improve the recall, precision, and diversity of the provided answers (sun2023pearl, ). For example, for a user query related to the Reinforcement Learning research topic, the pipeline will first retrieve the meta knowledge (MK Summary) about Reinforcement Learning of the database, augment the user query into multiple sub queries based on the content of the MK Summary, and perform a parallel search in the filtered database relevant for manufacturing questions. For this purpose, the synthetic Questions are embedded, and replace the original documents chunk-based similarity matching, therefore mitigating the information loss due to document chunking discontinuity. Once the best match of a synthetic question is found, the corresponding QA are retrieved, together with the original document title. Only the document title, the synthetic question, and the answer are returned as a result of the retrieval. We use JSON formatting for downstream summarization performance. The final response of the RAG pipeline is obtained by providing the original query, the augmented queries, the retrieved context and few shot examples (see Figure 1).
4. Evaluation
4.1. Generating Evaluation Queries
To evaluate our data-centric augmented retrieval pipeline, we generated 200 questions for the arXiv dataset using Claude 3 Sonnet (see Appendix C). In addition, we compared our methodology against traditional document chunking, query augmentation with document chunking, and naïve (not using MK Summary) augmentation with the QA processing of the documents. As a comparison, we created documents chunks consisting of 256 tokens with 10% overlap. For our use case, traditional chunking generated 69,334 documents chunks.
4.2. Evaluation Metrics and Prompts
Without relevance labels, we use Claude 3 Sonnet as a trusted evaluator (anthropic2024claude, ) to compare the performance of all four benchmark methodologies considered: traditional chunking without any query augmentation, traditional document chunking with naive query augmentation, augmented search using our PR3 pipeline without MK Summary, and augmented search using our PR3 pipeline with MK Summary. The query augmentation prompt is provided in Appendix D. We use the custom performance metrics defined below directly in the prompt to compare the results of both the retrieval model and the final response on a scale from 0 to 100. An example of Claude 3 Sonnet comparison answer is provided in Appendix E.
- Recall: evaluates the coverage of key, highly relevant information contained in the retrieved documents
- Precision: evaluates the ratio of relevant documents against irrelevant ones
- Specificity: evaluates how precisely focused the final answer is on the query at hand, with clear and direct information that addresses the question
- Breadth: evaluates the coverage of all relevant aspects or areas related to the question, providing a complete overview
- Depth: evaluates the extent to which the final answer provides a thorough understanding through detailed analysis and insights into the subject
- Relevancy: evaluates how well-tailored the final answer is to the needs and interests of the audience or context, focusing on providing directly applicable and essential information while omitting extraneous details that do not contribute to addressing the specific question
5. Results
We considered 4 cases for the evaluation of our retrieval pipeline: (1) traditional document chunking, without any augmentation, (2) traditional document chunking and augmentation, (3) QA-based search and retrieval, with naïve augmentation (our first proposal), and (4) QA-based search and retrieval, with the use of MK summary (our second proposal). For a single query, the computational latency of the end-to-end-pipeline amounts to 20-25 seconds.
5.1. Retrieval and End-to-end Evaluation Metrics
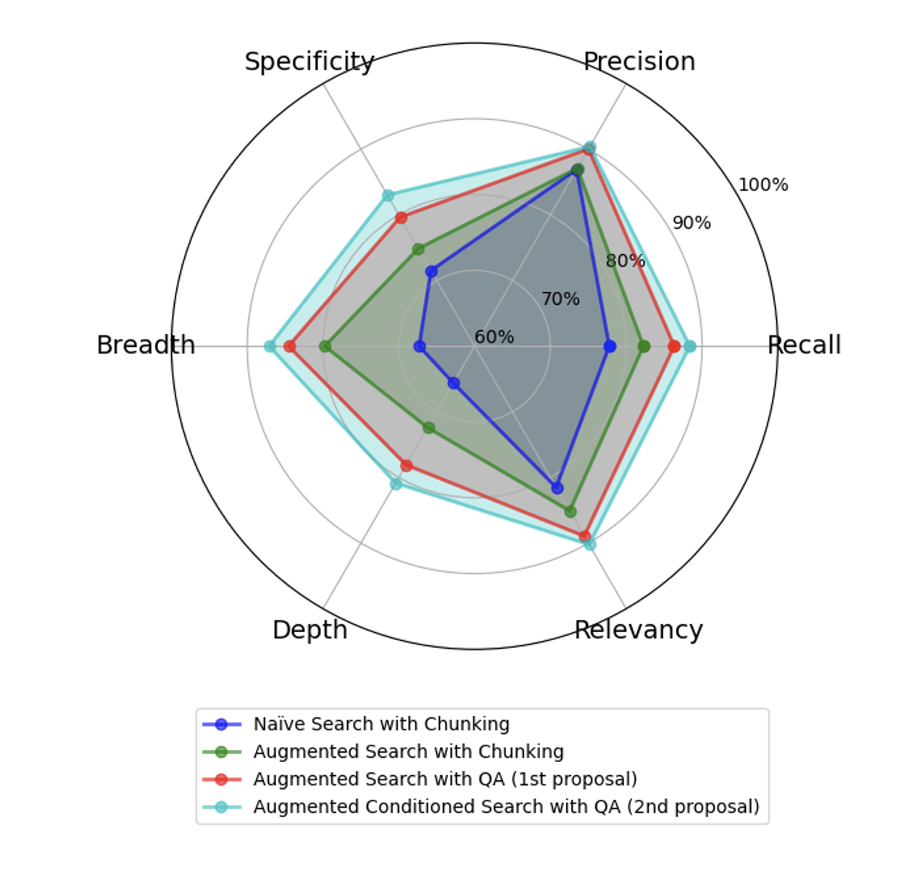
For each of the synthetic user queries generated, we ran a comparison prompt that includes the context retrieved as part of each approach, together with their final answers. We prompted Claude 3 Sonnet to rate each of the metrics on a scale from 0 to 100, together with a justification text. An example of the evaluation response is provided in Appendix E. The obtained metrics are then averaged across all queries and displayed below in Figure 2. We observe a clear benefit across all metrics but the precision of the retrieved documents by our two proposed QA-based methodologies. The lack of strong improvement over the precision metric is consistent with the usage of a single encoding model and show that few documents are considered completely irrelevant. Specifically, we note a significant performance boost in both the breadth and the depth of the final LLM response. This result shows that the MK Summary is providing additional information that is leveraged by the query augmentation step. Finally, the contribution of the MK summary to the conditioning of the search itself appears statistically significant across all metrics but the precision of the retriever ( between the augmented QA search and the MK-Augmented QA search)(see Table 1). We observe that the the proposed methodology significantly improves the breadth of the search (by more than 20%, compared to traditional naïve search with chunking approaches), which aligns to the intuition that our proposal allows for effectively synthetizing more information from the content of the database, and leveraging its content more extensively.
| Public Research Benchmark | Recall (%) | Precision (%) | Specificity (%) |
|---|---|---|---|
| Naïve Search with Chunking | 77.76 | 86.91 | 71.51 |
| Augmented Search with Chunking | 82.27 | 87.09 | 74.86 |
| Augmented QA Search | 86.33 | 90.04 | 79.64 |
| MK-Augmented QA Search | 88.39 | 90.40 | 83.03 |
| Public Research Benchmark | Breadth (%) | Depth (%) | Relevancy (%) |
|---|---|---|---|
| Naïve Search with Chunking | 67.32 | 65.62 | 81.51 |
| Augmented Search with Chunking | 79.77 | 72.41 | 85.08 |
| Augmented QA Search | 84.55 | 78.08 | 88.92 |
| MK-Augmented QA Search | 87.09 | 80.84 | 90.22 |
6. Conclusion and Discussion
We proposed a new data-centric RAG workflow which leverages synthetic QA generation instead of the traditional document chunking framework, and a query augmentation-based approach based on high level summary of the content metadata-based clusters of documents to improve the accuracy and quality of the end-to-end LLM augmentation pipeline. Our methodology significantly outperforms traditional RAG pipelines relying on document chunking and naïve user query augmentation. We introduced the concept of MK Summary to further boost the zero-shot search augmentation in the knowledge base, which subsequently increased the performance of the end-to-end RAG pipeline in our test case. In essence, our methodology improves on simple semantic matching information retrieval in the encoding vector space of the documents, where we allow for more diverse but highly relevant documents search, therefore providing more well-rounded, domain expert-level, and comprehensive answers to the user query. On all metrics considered, recall, precision, specificity, breadth, depth, and relevancy, the proposed approach improved on state-of-the-art work. Finally, the approach is cost-effective, costing $20 for 2000 research papers. As a limitation, while we recognize the difficulty in crafting a set of metadata prior to document processing, the metadata generation can become an iterative approach to generate the metadata upon discovery. In addition, we left multi-hop iterative searches and improvement of the summary of the clustered knowledge base for future work.
References
- [1] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [2] Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020.
- [3] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- [4] Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Zhicheng Dou, and Ji-Rong Wen. Large language models for information retrieval: A survey. arXiv preprint arXiv:2308.07107, 2023.
- [5] Wenjun Peng, Guiyang Li, Yue Jiang, Zilong Wang, Dan Ou, Xiaoyi Zeng, Derong Xu, Tong Xu, and Enhong Chen. Large language model based long-tail query rewriting in taobao search. In Companion Proceedings of the ACM on Web Conference 2024, pages 20–28, 2024.
- [6] Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496, 2022.
- [7] Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283, 2023.
- [8] Iain Mackie, Shubham Chatterjee, and Jeffrey Dalton. Generative and pseudo-relevant feedback for sparse, dense and learned sparse retrieval. arXiv preprint arXiv:2305.07477, 2023.
- [9] Iain Mackie, Ivan Sekulic, Shubham Chatterjee, Jeffrey Dalton, and Fabio Crestani. Grm: generative relevance modeling using relevance-aware sample estimation for document retrieval. arXiv preprint arXiv:2306.09938, 2023.
- [10] Tao Shen, Guodong Long, Xiubo Geng, Chongyang Tao, Tianyi Zhou, and Daxin Jiang. Large language models are strong zero-shot retriever. arXiv preprint arXiv:2304.14233, 2023.
- [11] Rolf Jagerman, Honglei Zhuang, Zhen Qin, Xuanhui Wang, and Michael Bendersky. Query expansion by prompting large language models. arXiv preprint arXiv:2305.03653, 2023.
- [12] Krishna Srinivasan, Karthik Raman, Anupam Samanta, Lingrui Liao, Luca Bertelli, and Mike Bendersky. Quill: Query intent with large language models using retrieval augmentation and multi-stage distillation. arXiv preprint arXiv:2210.15718, 2022.
- [13] Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747, 2023.
- [14] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [15] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- [16] Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. Inpars: Data augmentation for information retrieval using large language models. arXiv preprint arXiv:2202.05144, 2022.
- [17] Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020.
- [18] Stephen Robertson, Hugo Zaragoza, et al. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- [19] Tianjun Zhang, Shishir G Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E Gonzalez. Raft: Adapting language model to domain specific rag. arXiv preprint arXiv:2403.10131, 2024.
- [20] AI Anthropic. The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card, 1, 2024.
- [21] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [22] Aman Gupta, Anup Shirgaonkar, Angels de Luis Balaguer, Bruno Silva, Daniel Holstein, Dawei Li, Jennifer Marsman, Leonardo O Nunes, Mahsa Rouzbahman, Morris Sharp, et al. Rag vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture. arXiv preprint arXiv:2401.08406, 2024.
- [23] https://aws.amazon.com/bedrock/pricing/. 2024.
- [24] Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Improving text embeddings with large language models. arXiv preprint arXiv:2401.00368, 2023.
- [25] Alex Kulesza, Ben Taskar, et al. Determinantal point processes for machine learning. Foundations and Trends® in Machine Learning, 5(2–3):123–286, 2012.
- [26] Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies. arXiv preprint arXiv:2308.03188, 2023.
- [27] Weng Lam Tam, Xiao Liu, Kaixuan Ji, Lilong Xue, Xingjian Zhang, Yuxiao Dong, Jiahua Liu, Maodi Hu, and Jie Tang. Parameter-efficient prompt tuning makes generalized and calibrated neural text retrievers. arXiv preprint arXiv:2207.07087, 2022.
- [28] Simeng Sun, Yang Liu, Shuohang Wang, Chenguang Zhu, and Mohit Iyyer. Pearl: Prompting large language models to plan and execute actions over long documents. arXiv preprint arXiv:2305.14564, 2023.
- [29] Van Pham and Scott Cunningham. Chatgpt can predict the future when it tells stories set in the future about the past. arXiv preprint arXiv:2404.07396, 2024.
- [30] Shawn Im and Yixuan Li. Understanding the learning dynamics of alignment with human feedback. arXiv preprint arXiv:2403.18742, 2024.
Appendix A Appendix
A.1. Prompts
Appendix B Example of Synthetic QA
We present below samples of synthetic QA generated from the 2,000 research papers. The questions and answers were generated using the metadata and QA generation prompt (Appendix A).
- Question #1: ”What are the researchers’ conjectures about why the future narrative prompting approach seemed to unlock improved predictive capabilities in ChatGPT-4 compared to direct prompting?” (from [29])
- Answer #1: ”The researchers conjecture that the narrative prompting approach may leverage ChatGPT-4’s capacity for ”hallucinatory” narrative construction, allowing it to more effectively synthesize and extrapolate from its training data to make more accurate predictions, compared to the direct prompting approach. This suggests the models’ creative abilities can be strategically utilized for predictive tasks.”
- Question #2: ”How does the distribution of preference datasets influence the rate of model updates and the training accuracy when using the Direct Preference Optimization (DPO) objective? What are the implications for practical alignment approaches?” (from [30])
- Answer #2: ”The paper provides theoretical analysis showing that the distribution of preference datasets, characterized by ”preference distinguishability”, has a strong influence on the rate of model updates and training accuracy under the DPO objective. Behaviors with higher distinguishability exhibit faster loss reduction and parameter updates. This can lead to an intricate prioritization effect, where DPO tends to prioritize learning behaviors with higher distinguishability, potentially deprioritizing less distinguishable but crucial behaviors.”
Appendix C Benchmark User Queries
We present below a sample of 200 benchmark research queries generated with Claude 3 Sonnet.
- Field of Research (metadata) #1 : Reinforcement Learning
- Synthetic Benchmark query #1: How is reinforcement learning used in adaptive traffic management systems?
- Field of Research (metadata) #2 : Econometrics
- Synthetic Benchmark query #2: How is econometrics applied in understanding consumer demand elasticity?
- Field of Research (metadata) #3 : Statistical Anomaly Detection
- Synthetic Benchmark query #3: How are anomalies identified in unstructured data like images and videos?
- Field of Research (metadata) #4 : Supervised vs Unsupervised Learning
- Synthetic Benchmark query #4: How are supervised learning techniques adapted for complex, high-dimensional data?
- Field of Research (metadata) #5 : AI in Autonomous Vehicles
- Synthetic Benchmark query #5: What advancements have been made in integrating sensor data using AI in autonomous vehicles?