NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks
Abstract
Self-supervised learning has been proved to benefit a wide range of speech processing tasks, such as speech recognition/translation, speaker verification and diarization, etc. However, most of current approaches are computationally expensive due to lacking in sub-sampling or using clustering based speech quantization. In this paper, we propose a simplified and more efficient self-supervised learning framework termed as NeMo Encoder for Speech Tasks (NEST). Specifically, we adopt the FastConformer architecture, which has an 8x sub-sampling rate and is faster than Transformer or Conformer architectures. Instead of clustering-based token generation, we resort to fixed random projection for its simplicity and effectiveness. We also propose a generalized noisy speech augmentation that teaches the model to disentangle the main speaker from noise or other speakers. Experiments show that NEST improves over existing self-supervised models on a variety of speech processing tasks. Code and checkpoints will be available via NVIDIA NeMo toolkit111https://github.com/NVIDIA/NeMo.
Index Terms:
self-supervised learning, speech recognition, speaker diarization, spoken language understandingI Introduction
Most recent speech self-supervised models are inspired by the BERT [1] model, which learn text token embedding by predicting the target of the masked positions given the context of the unmasked ones. Among them, are two main streams of contrastive and predictive models. The contrastive approach [2, 3, 4, 5] quantizes the speech features into a set of target feature vectors and trains with a contrastive loss using the positive and negative target features. Meanwhile, the predictive approach [6, 7, 8, 9] quantizes the speech features into tokens and train with masked token prediction loss as in BERT [1]. In addition to the two approaches, some works also learn from the masked auto-encoding [10] approach and train speech self-supervised models with a reconstruction objective [11, 5].
One representative work of contrastive models is Wav2vec-2.0 [2], which demonstrates initializing ASR models from SSL checkpoints can outperform previous semi-supervised and train-from-scratch ASR models. Later, Wav2vec-C [3] improves over Wav2vec-2.0 by adding a consistency loss to reconstruct the quantized embedding, similar to VQ-VAE [12]. XLS-R [13] extends Wav2vec-2.0 to multilingual setting and shows impressive performance on multilingual speech recognition and translation.
HuBERT [6], as a pioneer work of the predictive approach, generates the target tokens by running k-means clustering on the middle layer features extracted from anohter SSL model that is pretrained for a small number of steps. Then, W2v-BERT [14] proposes to combine the training objectives of both Wav2vec-2.0 [2] and HuBERT [6] by applying contrastive loss on the middle layer output while predictive loss at the final output layer. Later, BEST-RQ [7] shows that the clustering based token generation can be replaced by simple fixed random-projection quantization, and this simple modification is able to match or outperform HuBERT on ASR.
In order to improve performance on speaker tasks, WavLM [8] proposes a noisy speech augmentation technique and a denoising masked token prediction objective, by adding a speech segment of a different speaker to the current speech and training the model to predict the target tokens generated using original clean speech. XEUS [9] further extends WavLM [8] by adding a de-reverberation task and extending to multilingual data of 1M hours.
However, previous SSL models also have their different limitations. First, some models [2, 6, 8] use CNN+transformer architecture which has a short frame length of 20ms, which slows down the model’s inference speed. Second, the HuBERT-style quantization is very computationally expensive, which could take 20% of total training time according to XEUS [9]. Third, although BEST-RQ [7] uses Conformer [15] encoder with 40ms frame length and simple random quantization, it lacks the ability to explicitly tell one speaker from another, which limits its performance on speaker tasks (e.g., speaker diarization).
In this paper, we tackle all these challenges and bring the best practices from previous works, which constitute the proposed NeMo Encoder for Speech Tasks (NEST) framework. Our contributions are summarized as follows:
-
•
A new speech SSL model that achieves SOTA performance with a simplified and more efficient framework.
-
•
Experiments show that NEST can help achieve SOTA performance on a variety of downstream tasks (ASR, AST, SLU, SD, etc).
-
•
Different from previous SSL works that focus mostly on downstream tasks with limited data, we also show that NEST can benefit speech recognition and translation even when data is relatively larger.
-
•
To the best of our knowledge, we are the first to show that SSL model trained on English data can also help improve speech recognition on other languages.
II Approach
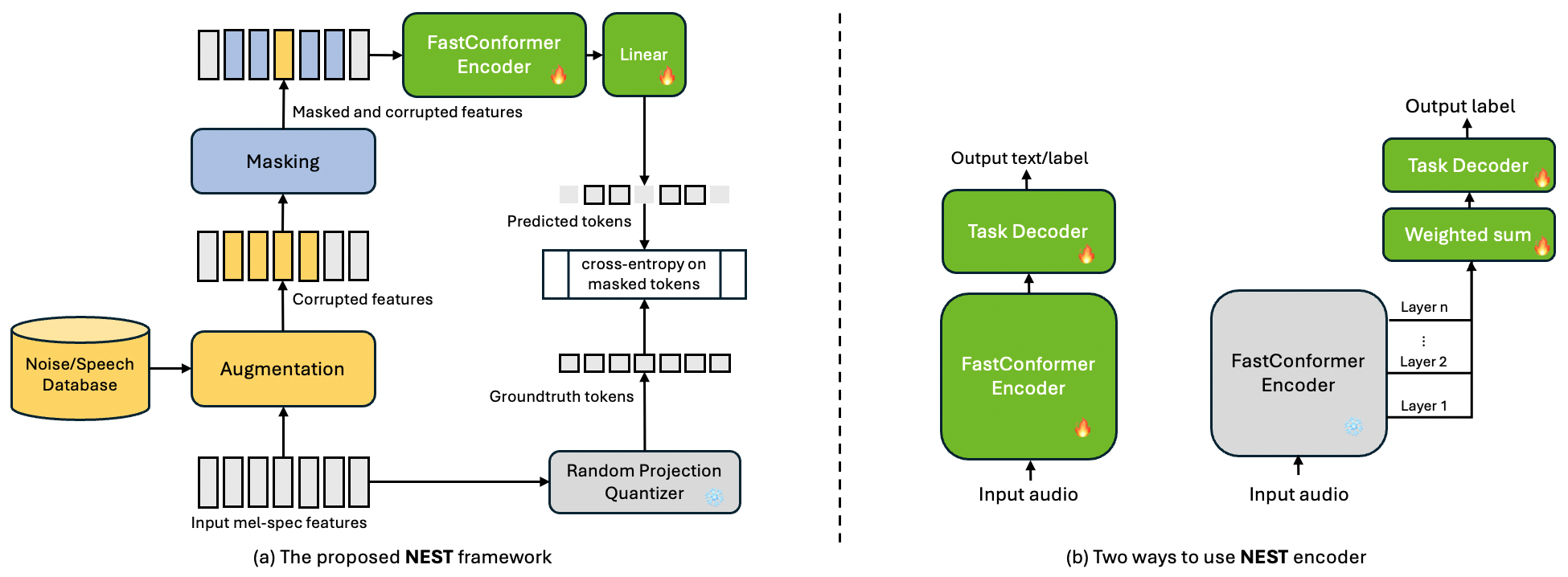
The proposed NEST framework is illustrated in Figure 1(a).
II-A Speech Encoder
Current SOTA speech SSL models [8, 6] mostly use transformer encoder [16] or Conformer [15] as speech encoder, which have either 20ms or 40ms frame length. Here we choose the more efficient FastConformer [17] which applies 8x convolutional sub-sampling on the input Mel-spectrogram before the following FastConformer layers, resulting in an 80ms frame length that can significantly reduce the sequence length to be processed by self-attention layers.
II-B Speech Augmentation
We augment the input speech with random noise or speech of another speaker, similar to the techniques proposed in WavLM [8]. However, we generalize the augmentation in three ways: (1) the length of augmentation audio is sampled between 0.4 and 0.6 of the primary audio length, instead of a fixed 0.5 ratio; (2) the length of augmentation audio is randomly split into 1, 2 or 3 segments with uniform probability, such that the augmentation is scattered to different positions of the primary audio; (3) instead of using single negative speaker, for each segment with speaker augmentation, we randomly select a different speaker from other speakers in the same batch, such that there can be more speakers in the resulted audios.
| Model | Params | SSL Data (hrs) | Speaker | Content | ParaLinguistics | ||||
|---|---|---|---|---|---|---|---|---|---|
| SID (Acc ) | SV (EER ) | SD (DER ) | PR (PER ) | ASR (WER ) | KS (Acc ) | ER (Acc ) | |||
| WavLM-base++ [8] | 95M | En-96K | 86.84 | 4.26 | 4.07 | 4.07 | 5.59 | 96.69 | 67.98 |
| WavLM-large [8] | 316M | En-96K | 95.25 | 4.04 | 3.47 | 3.09 | 3.44 | 97.40 | 70.03 |
| XEUS [9] | 577M | MulLing-1M | 91.70 | 4.16 | 3.11 | 3.21 | 3.34 | 98.32 | 71.08 |
| NEST-L | 108M | En-100K | 94.94 | 3.85 | 2.28 | 1.95 | 3.49 | 96.85 | 68.12 |
| NEST-XL | 600M | En-100K | 95.76 | 2.49 | 1.89 | 1.80 | 3.19 | 97.11 | 69.94 |
| Model | Params | Data (hrs) | En | De | Es | Fr | Avg | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MCV16.1 | Voxpopuli | MCV16.1 | Voxpopuli | MCV16.1 | Voxpopuli | MCV16.1 | Voxpopuli | ||||
| SeamlessM4T-medium-v1 [19] | 1.2B | 4M | 14.20 | 10.02 | 11.25 | 16.20 | 11.43 | 12.01 | 17.34 | 12.49 | 13.11 |
| SeamlessM4T-large-v2 [19] | 2.3B | 4M | 11.13 | 7.77 | 7.53 | 13.39 | 8.671 | 10.53 | 14.37 | 10.13 | 10.44 |
| Whisper-large-v3 [20] | 1.5B | 5M | 15.73 | 13.42 | 9.24 | 21.41 | 10.95 | 14.31 | 17.35 | 13.58 | 14.49 |
| Canary-1b [21] | 1B | 86k | 12.46 | 7.52 | 8.71 | 15.32 | 8.28 | 9.56 | 15.46 | 8.78 | 10.76 |
| FastConformer-XL-hybrid (ASR init) | 600M | 14K | 16.78 | 8.21 | 9.17 | 12.69 | 9.75 | 10.19 | 17.42 | 9.89 | 11.76 |
| NEST-XL-hybrid | 600M | 14K | 14.43 | 7.58 | 8.07 | 11.83 | 8.70 | 9.27 | 16.18 | 9.74 | 10.72 |
II-C Speech Quantization
We resort to BEST-RQ [7] as our speech quantization method. Specifically, we use a single randomly initialized and frozen codebook of 8192 vocabulary and 16 dimension features. A randomly initialized and frozen linear layer is applied to the input Mel-spectrogram features to project them into the same dimension as the codebook, then a nearest neighbor search is applied to obtain the target tokens. Since there is a 8x subsampling, we channel-concatenate the features for each 8 consecutive frames before feeding into the linear layer, such that the lengths for the target tokens and input features are equal.
II-D Feature Masking
We employ a random block-wise masking mechanism on the input Mel-spectrogram features, where each frame in the input has a probability as being selected as the start of a masking block. After randomly selecting a set of starting frames, we mask consecutive frames for each of the starting frames. Note that there could be overlapping between two masked blocks, which allows for arbitrary lengths in the resulting masked segments that do not overlap with each other. We use and in all our experiments.
II-E Training
Since masking is performed before the convolutional sub-sampling, there is a mismatch in the lengths between the predictions and masks. To match the sequence lengths, masks are averaged for every 8 frames, then apply threshold of 0.9 to select frames to be taken into loss calculation. Cross-entropy loss is applied on selected positions determined by the averaged input masks.
III Experiments
III-A Dataset and Settings
We train the NEST-L (108M) and NEST-XL (600M) models using 100K hours of both English speech data, including 60K hours from LibriLight [22], 24K hours from English subset of Voxpopuli [23], and about 20K hours sampled data from the combination of Fisher [24], Switchboard [25], WSJ [26], NSC [27], People’s Speech [28]. The audios for speech augmentation is randomly selected within each batch, while we use noise audios from MUSAN [29] and Freesound [30]. We train the models with global batch size of 2048 for 80K steps on 128 NVIDIA A100 GPUs, with Noam annealing [16] and peak learning rate of 0.004, weight decay of 1e-3, gradient clipping 1.0 and warm-up of 25K steps. We set the speech augmentation probability as 0.2, among which we set noise and speech augmentation probabilities as 0.1 and 0.9.
III-B Results on SUPERB Multi-task Speech Processing
We evaluate our model’s performance on the SUPERB [18] benchmark for multi-task evaluation on self-supervised speech models. For speech recognition (ASR), phoneme recognition (PR) and speaker diarization (SD) tasks, we use the architecture in the left part of Figure 1(b) and a simple linear layer as the task decoder. We train ASR and PR with CTC [31] loss, while the SD task is trained with permutation invariant loss (PIL) [32]. For speaker identification/verification (SID/SV), keyword spotting (KS) and emotion recognition (ER) tasks, we resort to the architecture presented in the right part of Figure 1(b), and use the ECAPA-TDNN-small [33] as the task decoder. We following the same train/val/test splits as in the SUPERB [18] and train the models for 100 epochs.
As presented in Table I, our NEST-L model is able to outperform WavLM-base++ [8] with similar size of parameters on all tasks, and also outperforms WavLM-large [8] that is 3x as large on speaker verification (SV), speaker diarization (SD) and phoneme recognition (PR). When compared with the XEUS [9] model that is trained on 10x data, we can see that our NEST-XL model is still able to achieve better performance on all speaker and content tasks, with especially large improvements on speaker verification, speaker diarization and phoneme recognition. Overall, we are able to achieve new state-of-the-art results on SID, SV, SD, PR and ASR tasks compared with WavLM [8] that has data size as well as XEUS [9] that is trained on much large data, demonstrating the effectiveness of NEST when applied on various downstream speech processing tasks.
| Model | Params | Data (hrs) | Europarl | mExpresso | Fleurs | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EnDe | EnEs | EnFr | EnDe | EnEs | EnFr | EnDe | EnEs | EnFr | EnDe | EnEs | EnFr | |||
| SeamlessM4T-medium | 1.2B | 4M | 28.03 | 38.44 | 30.50* | 9.65 | 16.23 | 8.64 | 28.30 | 21.05 | 37.36 | 21.99 | 25.24 | 25.50 |
| SeamlessM4T-v2-large | 2.3B | 4M | 19.96 | 32.32 | 23.33 | 21.48 | 34.89 | 26.04 | 33.17 | 23.72 | 43.05 | 24.87 | 30.31 | 30.80 |
| Canary-1B [21] | 1B | 86K | 32.53 | 40.84 | 30.65 | 23.83 | 35.73 | 28.28 | 32.15* | 22.66* | 40.76* | 29.50 | 33.07 | 33.23 |
| NEST-XL-Transformer | 1B | 42K | 30.87* | 39.95* | 30.01 | 22.82* | 34.92* | 27.99* | 29.50 | 22.61 | 39.27 | 27.73* | 32.51* | 32.42* |
| Model | DIHARD3 eval | CALLHOME-part2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
||||||||
| EEND-EDA [34, 35] | 15.55 | 7.83* | 12.29 | 17.59 | |||||||
| NeMo MSDD [36] | 29.40 | 11.41 | 16.45 | 19.49* | |||||||
| RandFC-L-MLP | 21.71 | 11.60 | 15.89 | 24.34 | |||||||
| NEST-L-MLP | 16.83 | 7.88 | 11.71* | 23.46 | |||||||
| RandFC-L-Sortformer | 18.93 | 9.39 | 13.56 | 23.30 | |||||||
| NEST-L-Sortformer [sortformer] | 16.06* | 6.40 | 11.02 | 20.10 | |||||||
III-C Results on Multi-lingual Speech Recognition
Besides multi-task evaluation, we also study if an SSL model trained on single language can help other languages. To this end, we train an ASR model on four different languages: English (En), German (De), French (Fr), Spanish (Es). Specifically, we train an ASR model using NEST-XL as weight initialization and the hybrid-CTC-RNNT loss [37]. The training data comprises of 2.5K hours of German speech (MCV, MLS, Voxpopuli), 8.5K hours of English speech (MCV [38], MLS [39], Voxpopuli [23], SPGI [40], Europarl [41], LibriSpeech [42], NSC1 [27]), 1.4K hours of Spanish speech (MCV, MLS, Voxpopuli, Fisher [24]) and 1.9K hours of French speech (MCV, MLS, Voxpopuli). For baselines, we train another model using an English ASR model [43] as weight initialization, and also include some of the best ASR models like Whisper [20], SeamlessM4T [19] and Canary [21]. We run all models with the same beam size 5 with no language models on test sets of MCV-16.1 [38] and Voxpopuli [23].
From the last two rows of Table II, we can see that NEST can help achieve better WER on all datasets than the model with ASR pretrained initialization, which shows that NEST can help improve ASR performance on languages that is not seen during SSL pretraining. In addition, when compared with other SOTA ASR models (Whisper [20], SeamlessM4T [19], Canary [21]) trained with much more parameters and data, we are still able to match the performance of Canary [21] on averaged WER across all languages. On some of the datasets, although there is still a gap between our model’s performance and that of the SOTA models trained with much more data, we can still see that NEST can be used as an efficient way to obtain superior ASR performance comparable to models trained on massive datasets.
III-D Results on Speech Translation
We further study how NEST can help speech-to-text translation (AST) and present the results in Table III. We use the same model architecture and training procedure as proposed in Canary [21], while the training data contains 42K hours of English ASR data with machine generated translation [44] from English (En) to German (De), French (Fr) and Spanish (Es) text. We compare our model with other SOTA AST models SeamlessM4T [19] and Canary [21] on Europarl [41], mExpresso [45] and FLEURS [46] test sets. Given the same number of parameters, due to much less training data, there is still a gap between Canary [21] and our model on all evaluated datasets. Also, given that Canary [21] is initialized with a multi-lingual ASR encoder that is pretrained on all of the evaluated languages, it is expected that Canary performs better than the NEST initialization. Nonetheless, our model is able to outperform SeamlessM4T [19] and achieves the second best average BLEU scores on EnDe, EnEs and EnFr translations, showing that the proposed NEST model is able to help achieve impressive AST performance with less data.
III-E Results on Speaker Diarization
To evaluate our model’s performance on speaker diarization, we train two variants of end-to-end diarization models: (1) simple two-layer multi-layer-perceptron (MLP) on top of FastConformer encoder and train with PIL; (2) more sophisticated Sortformer [sortformer] model with 18 layers of transformer on top of the encoder and train with a hybrid PIL and sorting loss. We also apply both NEST and random initialization to both methods for comparison. For training data, we use a combination of real data (Fisher [24], AMI Mix-Headset [47], ICSI [48], DIHARD3 dev [49], VoxConverse v0.3 [50], AISHELL [51]) and simulated data (composed from LibriSpeech [42], SRE [52, 53]) generated by the NeMo speech data simulator [54], with a total of 6.4K hours. We evaluate models’ performance on DIHARD3-eval [49] and CALLHOME-part2222We used splits from the Kaldi x-vector recipe [55]: Part 1 for training and Part 2 for evaluation [56].
As in Table IV, by comparing RandFC-L-MLP with NEST-L-MLP, and RandFC-L-Sortformer with NEST-L-Sortformer, we can see that NEST is able to significantly reduce the DER of models using randomly initialized encoder, showing the importance of using NEST in speaker diarization. We can also notice that Sortformer [sortformer] with NEST initialization is able to achieve second best results on DIHARD3 eval set, and outperforms EEND-EDA [34] on 2 and 3 speaker settings of the CALLHOME-part2.
| Model |
|
|
|
|
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SpeechBrain-Hubert-large [58] | LL-60K | 89.37 | 80.54 | 77.44 | 78.96 | ||||||||||
| ESPnet-Conformer [59] | N/A | 86.30 | N/A | N/A | 71.40 | ||||||||||
| Open-BEST-RQ [60] | LS-960 | 74.80 | N/A | N/A | N/A | ||||||||||
| Wav2vec-CTI-RoBERTa [61] | LS-960 | 86.92 | N/A | N/A | 74.66 | ||||||||||
| NeMo-SSL-FC-Trans-L [62] | LL-60K | 89.40 | 77.90 | 76.65 | 77.22 | ||||||||||
| NEST-L-Transformer | En-100K | 89.79 | 80.55 | 78.70 | 79.61 | ||||||||||
| NEST-XL-Transformer | En-100K | 89.04 | 82.35 | 78.36 | 80.31 |
III-F Results on Spoken Language Understanding
For spoken language understanding, we focus on the joint intent detection and slot filling task and evaluate our model’s performance using the SLURP [57] dataset. Specifically, we attach a transformer decoder to the NEST encoder, and use the same hyper-parameter setting as in NeMo-SLU [62]. We compare with other SSL-based end-to-end SLU models and show the results in Table V. For fair comparison, we do not include the ASR pretrained baseline [62] as we focus on SSL.
As we can see, among all SSL-based SLU models, the proposed NEST model achieves the best performance on both intent detection accuracy and slot filling F1 scores. We also notice that scaling up from NEST-L to NEST-XL does bring some improvement on precision score on slot filling, but do not have significant effects on other metrics. In addition, compared with the NeMo-SSL-FC-Trans-L [62] baseline, we can see a more than 2% absolute improvement on F1 score by merely replacing the SSL speech encoder with NEST while keeping other hyper-parameters the same, which demonstrate the instant benefits that NEST can bring to existing speech processing models.
IV Conclusion
In this paper, we propose a speech self-supervised framework termed NEST, and extensive experiments on multiple speech processing tasks show that the NEST model can help achieve state-of-the-art performance. Code, configurations and checkpoints are available through NVIDIA NeMo toolkit.
References
- [1] J. Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [2] A. Baevski et al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020.
- [3] S. Sadhu et al., “Wav2vec-c: A self-supervised model for speech representation learning,” arXiv preprint arXiv:2103.08393, 2021.
- [4] A. Baevski et al., “vq-wav2vec: Self-supervised learning of discrete speech representations,” arXiv preprint arXiv:1910.05453, 2019.
- [5] D. Jiang et al., “Speech simclr: Combining contrastive and reconstruction objective for self-supervised speech representation learning,” arXiv preprint arXiv:2010.13991, 2020.
- [6] W.-N. Hsu et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021.
- [7] C.-C. Chiu et al., “Self-supervised learning with random-projection quantizer for speech recognition,” in ICML, 2022.
- [8] S. Chen et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- [9] W. Chen et al., “Towards robust speech representation learning for thousands of languages,” arXiv preprint arXiv:2407.00837, 2024.
- [10] K. He et al., “Masked autoencoders are scalable vision learners,” in CVPR, 2022.
- [11] A. Baevski et al., “Data2vec: A general framework for self-supervised learning in speech, vision and language,” in ICML, 2022.
- [12] A. Van Den Oord et al., “Neural discrete representation learning,” Advances in neural information processing systems, vol. 30, 2017.
- [13] A. Babu et al., “Xls-r: Self-supervised cross-lingual speech representation learning at scale,” arXiv preprint arXiv:2111.09296, 2021.
- [14] Y.-A. Chung et al., “W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” in ASRU. IEEE, 2021, pp. 244–250.
- [15] A. Gulati et al., “Conformer: Convolution-augmented transformer for speech recognition,” arXiv preprint arXiv:2005.08100, 2020.
- [16] A. Vaswani, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017.
- [17] D. Rekesh et al., “Fast conformer with linearly scalable attention for efficient speech recognition,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8.
- [18] S.-w. Yang et al., “Superb: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021.
- [19] L. Barrault et al., “Seamless: Multilingual expressive and streaming speech translation,” arXiv preprint arXiv:2312.05187, 2023.
- [20] A. Radford et al., “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning. PMLR, 2023, pp. 28 492–28 518.
- [21] K. C. Puvvada et al., “Less is more: Accurate speech recognition & translation without web-scale data,” Interspeech, 2024.
- [22] J. Kahn et al., “Libri-light: A benchmark for asr with limited or no supervision,” in ICASSP. IEEE, 2020, pp. 7669–7673.
- [23] C. Wang et al., “Voxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,” arXiv preprint arXiv:2101.00390, 2021.
- [24] C. Cieri et al., “The fisher corpus: A resource for the next generations of speech-to-text.” in LREC, vol. 4, 2004, pp. 69–71.
- [25] E. H. John J. Godfrey, “Switchboard-1 release 2,” https://catalog.ldc.upenn.edu/LDC97S62.
- [26] J. S. Garofolo et al., “Csr-i (wsj0) complete,” https://catalog.ldc.upenn.edu/LDC93S6A.
- [27] J. X. Koh et al., “Building the singapore english national speech corpus,” Malay, vol. 20, no. 25.0, pp. 19–3, 2019.
- [28] D. Galvez et al., “The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,” arXiv preprint arXiv:2111.09344, 2021.
- [29] D. Snyder et al., “Musan: A music, speech, and noise corpus,” arXiv preprint arXiv:1510.08484, 2015.
- [30] E. Fonseca et al., “Freesound datasets: a platform for the creation of open audio datasets.” ISMIR, 2017.
- [31] A. Graves et al., “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in ICML, 2006.
- [32] Y. Fujita et al., “End-to-end neural speaker diarization with self-attention,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 296–303.
- [33] B. Desplanques et al., “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” arXiv preprint arXiv:2005.07143, 2020.
- [34] S. H. et al., “Encoder-decoder based attractors for end-to-end neural diarization,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1493–1507, 2022.
- [35] S. Horiguchi et al., “Online neural diarization of unlimited numbers of speakers using global and local attractors,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 706–720, 2022.
- [36] T. J. Park et al., “Multi-scale speaker diarization with dynamic scale weighting,” arXiv preprint arXiv:2203.15974, 2022.
- [37] V. Noroozi et al., “Stateful conformer with cache-based inference for streaming automatic speech recognition,” in ICASSP, 2024.
- [38] R. Ardila et al., “Common voice: A massively-multilingual speech corpus,” in LREC, 2020, pp. 4211–4215.
- [39] V. Pratap et al., “Mls: A large-scale multilingual dataset for speech research,” arXiv preprint arXiv:2012.03411, 2020.
- [40] P. K. O’Neill et al., “Spgispeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition,” arXiv preprint arXiv:2104.02014, 2021.
- [41] J. Iranzo-Sánchez et al., “Europarl-st: A multilingual corpus for speech translation of parliamentary debates,” in ICASSP, 2020.
- [42] V. Panayotov et al., “Librispeech: an asr corpus based on public domain audio books,” in 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210.
- [43] NVIDIA, “Nemo english fastconformer-rnnt asr model,” https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/megatronnmt_any_en_500m.
- [44] NVIDIA, “Megatron multilingual translation model,” https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/megatronnmt_any_en_500m.
- [45] META, “mexpresso (multilingual expresso),” https://huggingface.co/facebook/seamless-expressive#mexpresso-multilingual-expresso.
- [46] A. Conneau et al., “Fleurs: Few-shot learning evaluation of universal representations of speech,” in SLT, 2023.
- [47] U. of Edinburgh, “The ami corpus,” https://www.openslr.org/16/.
- [48] ——, “The icsi meeting corpus,” https://groups.inf.ed.ac.uk/ami/icsi/.
- [49] N. Ryant et al., “Third dihard challenge evaluation plan,” arXiv preprint arXiv:2006.05815, 2020.
- [50] J. S. Chung et al., “Spot the conversation: speaker diarisation in the wild,” arXiv preprint arXiv:2007.01216, 2020.
- [51] Y. Fu et al., “Aishell-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,” arXiv preprint arXiv:2104.03603, 2021.
- [52] G. R. Doddington et al., “The nist speaker recognition evaluation–overview, methodology, systems, results, perspective,” Speech communication, vol. 31, no. 2-3, pp. 225–254, 2000.
- [53] NIST, “Nist speaker recognition evaluation (sre),” https://www.nist.gov/itl/iad/mig/speaker-recognition.
- [54] T. J. Park et al., “Property-aware multi-speaker data simulation: A probabilistic modelling technique for synthetic data generation,” arXiv preprint arXiv:2310.12371, 2023.
- [55] Kaldi, “Kaldi x-vector recipe v2,” https://github.com/kaldi-asr/kaldi/tree/master/egs/callhome_diarization/v2.
- [56] M. Przybocki et al., “2000 nist speaker recognition evaluation,” https://catalog.ldc.upenn.edu/LDC2001S97.
- [57] E. Bastianelli et al., “Slurp: A spoken language understanding resource package,” arXiv preprint arXiv:2011.13205, 2020.
- [58] Y. Wang et al., “A fine-tuned wav2vec 2.0/hubert benchmark for speech emotion recognition, speaker verification and spoken language understanding,” arXiv preprint arXiv:2111.02735, 2021.
- [59] S. Arora et al., “Espnet-slu: Advancing spoken language understanding through espnet,” in ICASSP, 2022.
- [60] R. Whetten et al., “Open implementation and study of best-rq for speech processing,” arXiv preprint arXiv:2405.04296, 2024.
- [61] S. Seo et al., “Integration of pre-trained networks with continuous token interface for end-to-end spoken language understanding,” in ICASSP, 2022.
- [62] H. Huang et al., “Leveraging pretrained asr encoders for effective and efficient end-to-end speech intent classification and slot filling,” Interspeech, 2023.