ToolACE: Winning the Points of LLM Function Calling
Abstract
Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE/.
1 Introduction
Equipping Large Language Models (LLMs) with external tools has significantly enhanced the capability of AI Agents to solve complex real-world tasks [10, 15, 16]. The integration of function calling enables LLMs to access up-to-date information, perform delicate computations, and utilize third-party services, thereby unlocking a wide range of potential applications across various fields, e.g., workflow automation [26], financial reporting [20], and travel planning [6].
Driven by practical applications, function calls can be quite complicated due to the diversity, complexity, and interactions of real-world APIs [15].111In this report, APIs, tools, functions, and plugins are interchangeable. For instance, real-world API parameters often extend beyond simple strings or numbers to include complex types like lists, dictionaries, nested parameters, and even combinations of these. The number of these API parameters can range from zero to dozens, and the application domains of these APIs span a wide range of businesses and industries [24]. Moreover, a single API is often insufficient to complete a task; instead, multiple tools need to be used together to perform real-world tasks [10]. The input of one API may even depend on the output of another [15], making function calls even more complicated and challenging.
Considering this diversity and complexity, function calls for specific tasks or user queries can generally be grouped into three categories: single function calls, parallel function calls, and dependent function calls. In a single function call, the LLM selects and executes one function to accomplish the user’s task. For parallel function calls, the LLM performs multiple independent function calls simultaneously within one turn. Whereas dependent function calls involve the LLM making a series of sequential calls, with each subsequent call relying on the output of the previous ones.
However, current tool-augmented LLMs primarily focus on simple function-calling scenarios with limited diversity and complexity [16]. Table 1 provides an overview of the data statistics utilized in these representative tool-augmented LLMs. Although satisfying performance has been achieved on the single function calling that executes one API in one turn, the capabilities of parallel and dependent function calls are largely overlooked. Furthermore, the constrained API domains, simplistic parameter types, and uniform data formats may hinder the applicability of the function calling to more complex, real-world tasks. Executing real-world function calls requires precise API selection and accurate parameter configuration, both of which are closely tied to the accuracy of the underlying data. Yet ensuring data accuracy for tooling remains a challenging problem, particularly when dealing with diverse and complex tasks.
| Model | #API | #Domain | Nested | Parallel | Dependent | Multi-type |
| Gorilla [14] | 1645 | 3 | ✗ | ✗ | ✗ | ✗ |
| ToolAlpaca [19] | 3938 | 50 | ✗ | ✗ | ✗ | ✗ |
| ToolLLM [15] | 16464 | 49 | ✗ | ✗ | ✓ | ✗ |
| Functionary [12] | n/a | n/a | ✗ | ✓ | ✗ | ✗ |
| xLAM [11] | 3673 | 21 | ✗ | ✓ | ✗ | ✗ |
| Granite [1] | n/a | n/a | ✗ | ✓ | ✗ | ✓ |
| ToolACE | 26507 | 390 | ✓ | ✓ | ✓ | ✓ |
Therefore, in this report, we present ToolACE, a systematic tool-learning pipeline that encompasses both synthetic data generation and data verification, demonstrating robust performance with enhanced accuracy, diversity, and complexity.
Diversity. Exposing LLMs to diverse function-calling scenarios facilitates a more well-rounded cognitive skill set of tool usage [25]. In ToolACE, we propose to emphasize three dimensions of diversity for function calling: tool diversity, format diversity, and dialog diversity. Tool diversity is achieved through our tool self-evolution synthesis method (TSS), which synthesizes tools from various domains with diverse data types and constraints. For format diversity, we propose a tool format generalization method to support any mainstream tool description and tool calling format (e.g., Json, YAML, XML, markdown) in ToolACE. Dialog diversity includes simple, parallel, dependent function calls, and non-tool-use dialogs, encompassing a wide range of function-calling use cases.
Complexity. In ToolACE, we emphasize the complexity of the data, where the instruction-following data should possess sufficient complexity to develop the necessary skills for function calling. We also find that the LLMs learn more effectively when the data complexity is slightly above their current capability level. Data that is either too simple or too complex proves unproductive for LLMs. This aligns with the Zone of Proximal Development (ZPD) theory in educational psychology, which states that learning is most effective when the tasks are just beyond the learner’s current level of independent capability but achievable with suitable support [17].
Accuracy. Data accuracy is fundamental to the effectiveness of tool-augmented LLMs. To achieve high-quality data, we first implement a formalized thinking and self-consistency strategy to enhance reliability during data generation. Then we deploy a dual-layer verification (DLV) system, integrating rule-based and model-based checks, to further improve accuracy.
2 Data Generation Pipeline
Effective use of synthetic data significantly enhances the capabilities of large language models (LLMs) [13]. Hence, in ToolACE, we propose an automated agentic framework for tool learning to generate high-quality, diverse, and complex data using advanced LLMs, as illustrated in Figure 1. The proposed framework deploys various agents to recursively synthesize diverse APIs, collaboratively construct formalized dialogs, and rigorously reflect on data quality. The following sections present our Tool Self-evolution Synthesis (TSS) module, Multi-Agent Interactive Dialog Generation (MAI) module, and Dual-Layer Validation Process (DLV).
2.1 Tool Self-evolution Synthesis
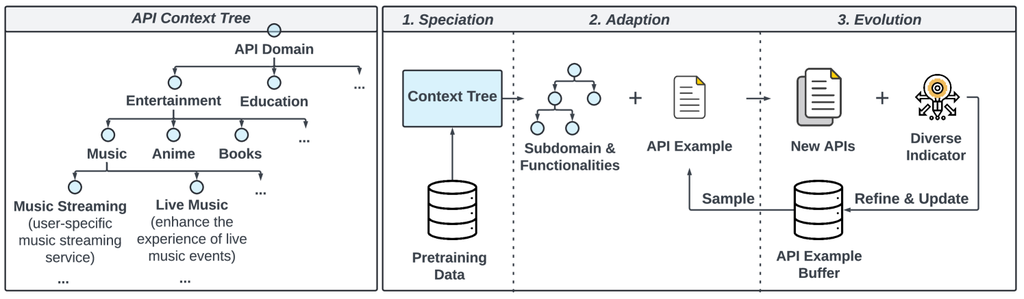
The variety of APIs significantly underpins the diversity and complexity of function-calling data. As shown in Table 1, ToolACE has established a comprehensive API pool that surpasses other representative tool-augmented LLMs in both quantity and domain coverage, incorporating both real and synthesized APIs. Beyond collecting real API data, we developed a Tool Self-Evolution Synthesis (TSS) module that synthesizes API definitions with various data types and constraints. Specifically, we utilize pretraining data to extract an API context tree, where each node represents a potential application domain and functionalities for function calls, e.g., finance, health, and transport. Combining the sampled functionalities and an API example, an agent powered by a frontier LLM synthesizes new APIs. The diversity and complexity of the APIs are gradually increased through recursive self-evolution and updates. This process is achieved through three major steps: 1) Speciation, 2) Adaption, and 3) Evolution. The detailed process is illustrated in Figure 2.
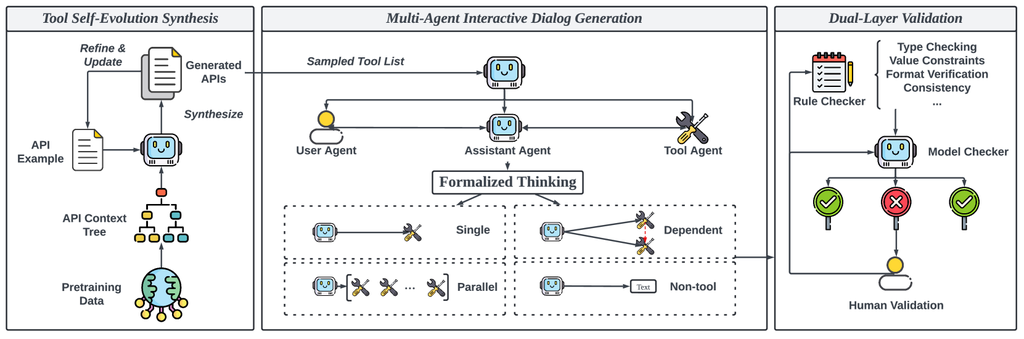
Speciation.
APIs with extensive domain coverage enable tool-augmented LLMs to learn a wider array of use cases from various applications and industries, thereby significantly enhancing their generalization ability. In the speciation step, we propose to create a hierarchical API context tree to guide the synthesis process with possible API domains and functionalities.
We observe that the pretraining data for LLMs encompasses one of the most diverse sources of human corpus, providing a solid foundation for extracting various API domains and use cases. Starting with API-related raw documents from the pretraining data (e.g., technical manuals, API documentation, product specifications, user guides, and tutorials), we prompt an LLM to extract an API domain along with all possible API functionalities or use cases from each document. Children nodes of the context tree are recursively generated at each step. Our final context tree encompasses a comprehensive structure that covers 30 primary domains (e.g., Entertainment, Education), divided into 390 coarse-grained sub-domains (e.g., Music, Anime, Books), and further refined into 3,398 distinct fine-grained domains (e.g., Music Streaming, Live Music). This extensive context tree includes an estimated hundred thousand specific functionalities. The left part of Figure 2 showcases the subtree under the entertainment domain as an example.
Adaption.
In the adaption step, we specify the domain and complexity level of each API. To determine the complexity level of individual APIs, we sample a subtree from the child nodes at the fine-grained domain level of the API context tree and obtain unique functionalities, ensuring that APIs within the same domain possess distinct functionalities. Specifically, a more complex API should cover more context tree nodes, thereby acquiring more domain-specific and detailed capabilities. Conversely, a simpler API may include only a single sub-node from the context tree, focusing on an easy, straightforward purpose.
Evolution.
The evolution step involves the continuous improvement and adaptation of the API based on outcomes and new requirements in terms of diversity and complexity. An LLM is instructed to synthesize new APIs according to a sampled subtree of the API context tree and an API example. The generated definitions of new APIs are required to be clear and thorough. We then apply a set of diversity indicators, e.g., adding new functionalities or parameters, including additional constraints, mutating parameter type, and updating returned results, to diversify the generated APIs. We maintain an API example buffer containing various API examples. Iteratively, we sample an example from the buffer, adapt it to the current subtree of functionalities, and generate the next generation of the APIs.
The proposed TSS module facilitates the efficient generation of a diverse and complex set of API documentation, with nested types including lists of lists or lists of dictionaries. Through this process, we have curated a collection of 26,507 distinct APIs.
2.2 Multi-Agent Interactive Dialog Generation
Real-world tasks involving function calls often encompass complex intents and varied requirements. To solve these real-world tasks, tool-augmented LLMs are expected to accurately identify when, what, and how many function calls are needed. To better represent real-world scenarios, we propose a multi-agent interactive (MAI) dialog generation module to synthesize function-calling dialogs. These dialogs cover a wide range of types, including simple function calls, parallel function calls, dependent functions, and non-tool-use dialogs. The MAI module is designed to ensure accuracy, complexity, and diversity throughout the generation process.
2.2.1 Dialog Generation Overview
The middle part of Figure 1 illustrates our dialog generation process. Initially, we sample one or more API candidates from our curated API pool, ensuring that the selected APIs share the same domain. This helps maintain topic consistency within a single dialog. Additionally, APIs within the same domain are more likely to have similar functions. Dialogs based on similar APIs can enhance the model’s ability to make nuanced distinctions between different APIs.
We then generate dialogs through the interplay among three different agents (user, assistant, and tool), each simulated by an LLM. The user agent mainly makes requests or provides additional information, powered by multi-mode prompting and similarity-guided complication to enhance diversity and complexity. The assistant agent addresses the user’s queries equipped with the given APIs. The action space of the assistant agent includes: calling the APIs, requesting further information, summarizing the tool feedback, and providing non-tool-use answers. Each action is determined through a formalized thinking process and validated by self-consistency to ensure accuracy. The tool agent acts as the API executor, processing tool descriptions and input parameters provided by the assistant, and outputs the potential execution results. Finally, after the dialogs are generated, they can be converted to diverse formats with our designed tool format generalization. Algorithm 1 outlines the overall dialog generation process.
In the following sections, we will elaborate on the MAI module and explain how accuracy, diversity, and complexity are ensured during the generation process.
2.2.2 Generation Ensuring Accuracy, Diversity and Complexity
The MAI module generates function-calling dialogs using multiple strategies to ensure accuracy, diversity, and complexity. We introduce these strategies in sequence below.
Multi-Mode Prompting.
MAI generation begins by determining the target dialog mode for each sample. Our multi-mode prompting allows us to create a wide range of dialog types by varying the instructions given to the user agent. We generate both single-turn and multi-turn dialogs, guided by the specified turn length in the instructions.
To further diversify the dialog types, we adjust the number of tool calls required and the relationships among these calls during prompting, resulting in single, parallel, and dependent function calls. Additionally, we produce non-tool-use dialogs, categorized into two scenarios: when no suitable tools are available and when there is insufficient information to call the tools.
This variety of dialogs is essential for developing a comprehensive skill set in tool usage for LLMs.
Similarity-Guided Complication.
Given guidance from the instructions, the user agent is able to generate an appropriate query requiring demanded function types. Apart from that, we also consider complexity in terms of linguistic level, which can be identified based on a similarity metric (please refer to Section 4.2 for details). To capture queries of varying complexity, we employ a range of templates to prompt the user agent with different linguistic styles. The query’s complexity can be calculated after the dialog concludes, and then used as a criterion for data selection.
Formalized Thinking.
After the user agent generates the query, the assistant agent must determine the appropriate response action. Research has shown that encouraging LLMs to think before acting – such as through chain-of-thought prompting [21] – enhances their reasoning abilities. We employ a similar strategy to improve the accuracy of tool-calling decision-making for our assistant agent. Unlike traditional chain-of-thought prompts, which typically encourage general reflective thinking (e.g., by merely adding "Let’s think step by step"), we implement a specialized and structured thinking process tailored specifically for function calls. This process involves: 1) evaluating the user query, 2) assessing the tool requirements, and 3) ensuring all required parameters are provided.
Formalized Thinking is utilized only during data generation and is excluded from training data formation to maintain conciseness.
Self-Consistency.
To further ensure accuracy, we implement a self-consistency mechanism when deciding actions. Each response from the assistant agent is generated multiple times. A response is adopted only if the action decisions (including whether to make tool calls and the parameter values to be filled) are consistent across at least two instances. If consistency is achieved, we apply majority voting to select the final response. If consistency is not met, the current turn of the dialog is either discarded or a loss mask is applied to prevent the model from learning potentially erroneous content.
If the action determined by the assistant agent involves tool calls, the tool agent will provide simulated results, which the assistant agent then summarizes and presents to the user (for queries requiring dependent function calls, additional interactions between the assistant and tool agents are necessary). The generation process will continue with the user agent querying again or responding to the assistant’s question until the target turn length is reached.
Tool Format Generalization.
Format generalization can be applied to the generated dialogs at the end to increase format diversity. All generated dialogs are initially stored in JSON format, which is easy to process and validate (details will be shown in next section). To support a flexible and user-specific format for tool definitions and function calls, we further convert our generated dialogs and API lists into various formats (e.g., JSON, YAML, XML, Markdown). We observe that the models’ instruction-following capabilities improve as the format diversity increases.
3 Data Verification
A critical factor influencing the function-calling capability of LLMs is the accuracy and reliability of the training data. Data that is inconsistent or inaccurate can hinder the model’s ability to interpret and execute functions [11]. Unlike general question-answering data, where verifying correctness can be challenging, function-calling data is more straightforward to validate. This is because a successful function call must strictly match the format specified in the API definition. Building on this insight, we propose an automatic dual-layer verification system (DLV) to verify our synthesized data, as shown in the right part of Figure 1, which consists of a rule verification layer, and a model verification layer, where these results are all overseen by human experts.

Data Structure.
Each data sample contains three components: system prompt, tool list, and dialogs, all of which are stored in JSON format with the necessary pattern requirements for ToolACE. JSON format is naturally easy to parse and maintains a clear hierarchical structure. Figure 3 shows our data examples of API definition and function call. Each function call is also formatted in JSON under the field tool_usage of the assistant role, with the API name and parameters explicitly listed.
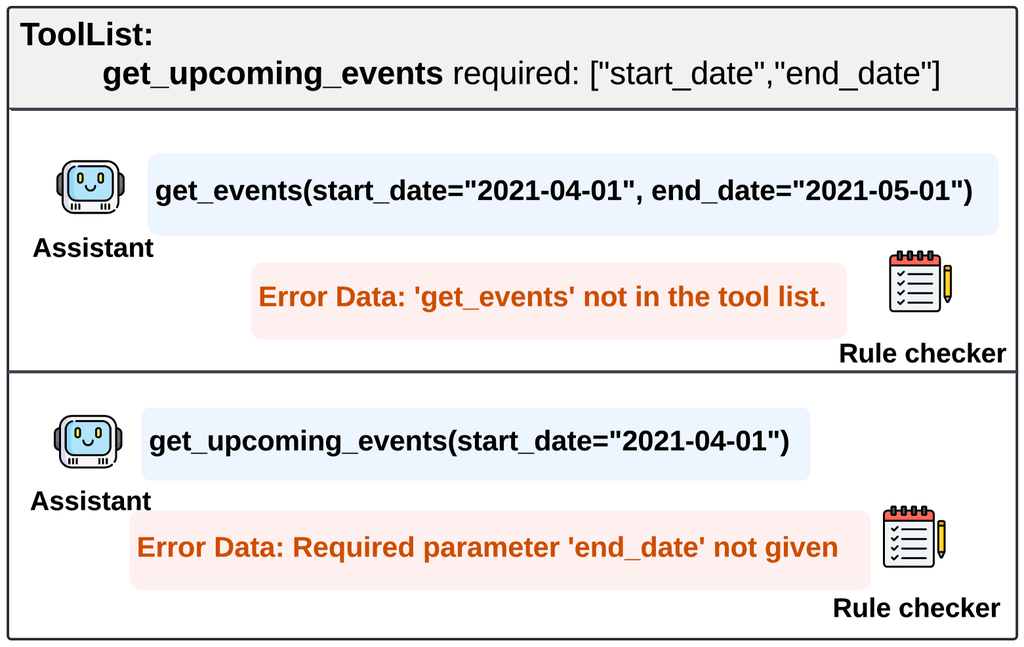
Rule Verification Layer.
The rule verification layer deploys a rule checker to ensure that the data strictly adheres to the predefined syntactic and structural requirements of the API. The quality of the data is evaluated from four key aspects: API definition clarity, function calling executability, dialog correctness, and data sample consistency, guided by a meticulously curated set of rules, as listed in Appendix A.
For instance, to verify function calling executability, we implement the following procedures: First, we confirm that the API name matches one from the given tool list. Next, we verify that all required parameters are accurately provided. Finally, we use regular expressions to ensure that the parameter formats and patterns adhere to those specified in the API documentation. These procedures allow us to validate the correctness and executability of function calls without the need for actual execution, which enhances efficiency and reduces deployment overhead. Examples of possible errors detected by the rule verification layer are displayed in Figure 5.
Model Verification Layer.
The model verification layer further incorporates LLMs to filter out erroneous data that cannot be detected by the rule checker, with a primary focus on content quality. However, we find that presenting a data sample directly to the LLM for correctness evaluation is too complex, often resulting in unsatisfactory outcomes. To address this, we decompose the model verification task into several sub-queries that mainly cover three key aspects:
-
•
Hallucination Detection: Identifies whether the values of input parameters in function calls are fabricated—not mentioned in either the user query or the system prompt.
-
•
Consistency Validation: Verifies that the responses can effectively complete the user’s task and ensures the dialogue content adheres to the constraints and instructions in the user query and system prompt.
-
•
Tool Response Check: Ensures that the simulated tool responses align with the API definition.
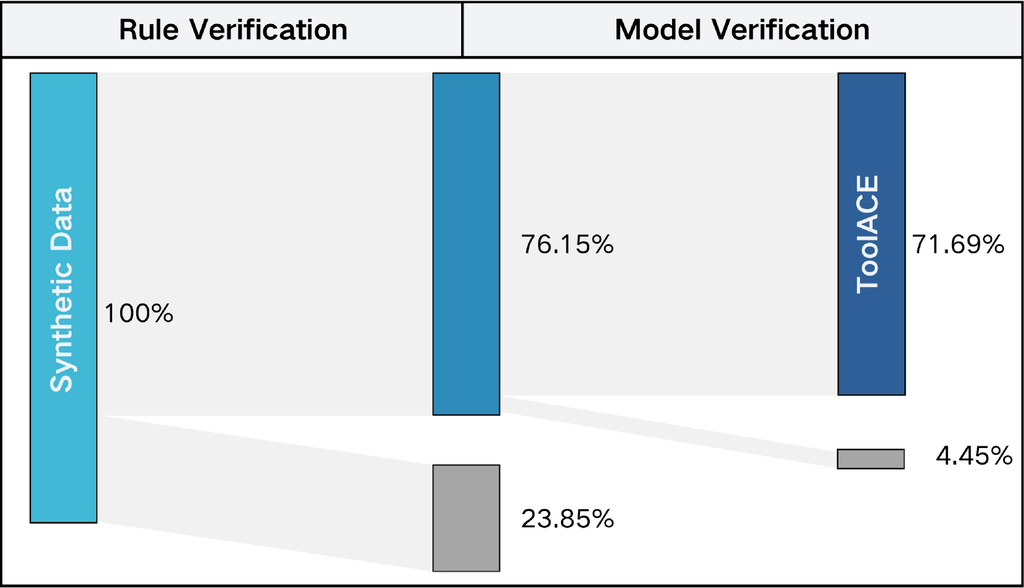
Each aspect is evaluated by an individual expert agent, powered by an LLM. We also incorporate several other data quality verification queries to eliminate repetitive responses and meaningless tokens within the data. The pass rate of our data for the rule verification and the model verification respectively are presented in Figure 5. Additionally, we apply the self-consistency strategy mentioned in Section 2.2 with a majority voting to enhance decision accuracy.
4 Data Analysis
This section provides an in-depth analysis of our final data after verification, focusing on the distribution across multiple dimensions with respect to both diversity and complexity.
4.1 Diversity
In this section, we quantify and present the diversity of our data across three dimensions: tool diversity, format diversity, and dialog diversity. These dimensions are critical for assessing the richness of the dataset and its capacity to support robust tool learning.
4.1.1 Tool Diversity
Large API Pool.
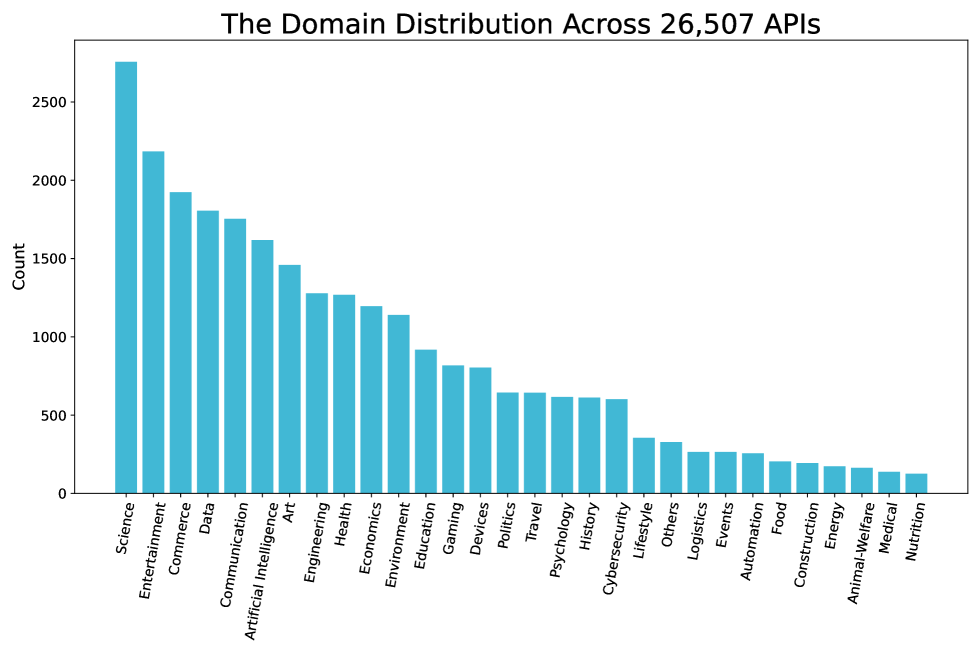
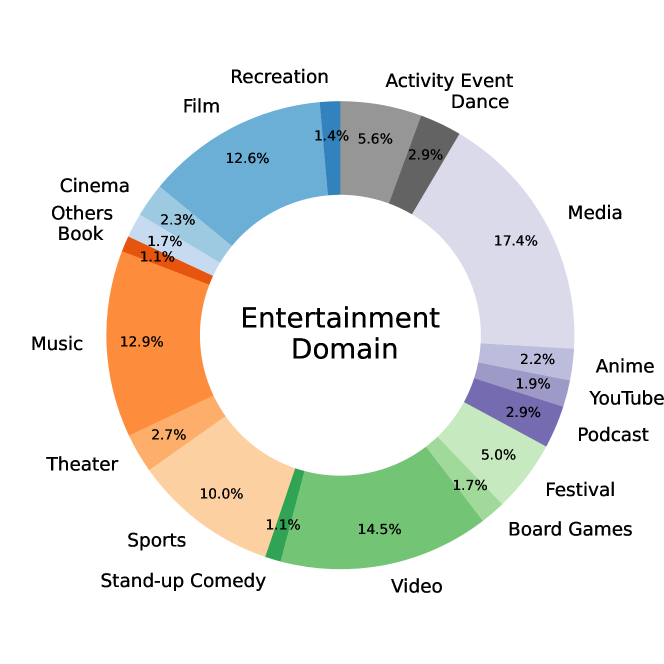
Through our TSS module in Section 2.1, we curate a comprehensive collection of 26,507 distinct APIs, encompassing both real-world and synthesized API definitions. Our APIs span 30 first-level coarse-grained domains, 390 second-level domains and 3,398 third-level domains, significantly enriching the diversity of our tool-learning data. The left figure in Figure 6 illustrates the distribution of the 26,507 APIs across the 30 first-level domains, including science, data, and travel, among others. The right figure details the distribution of the second-level domains within the ’Entertainment’ domain. The diversity of APIs lays a robust foundation for the diversity of the overall dataset, enabling the model to generalize effectively to new APIs and tasks.
Parameter Types.
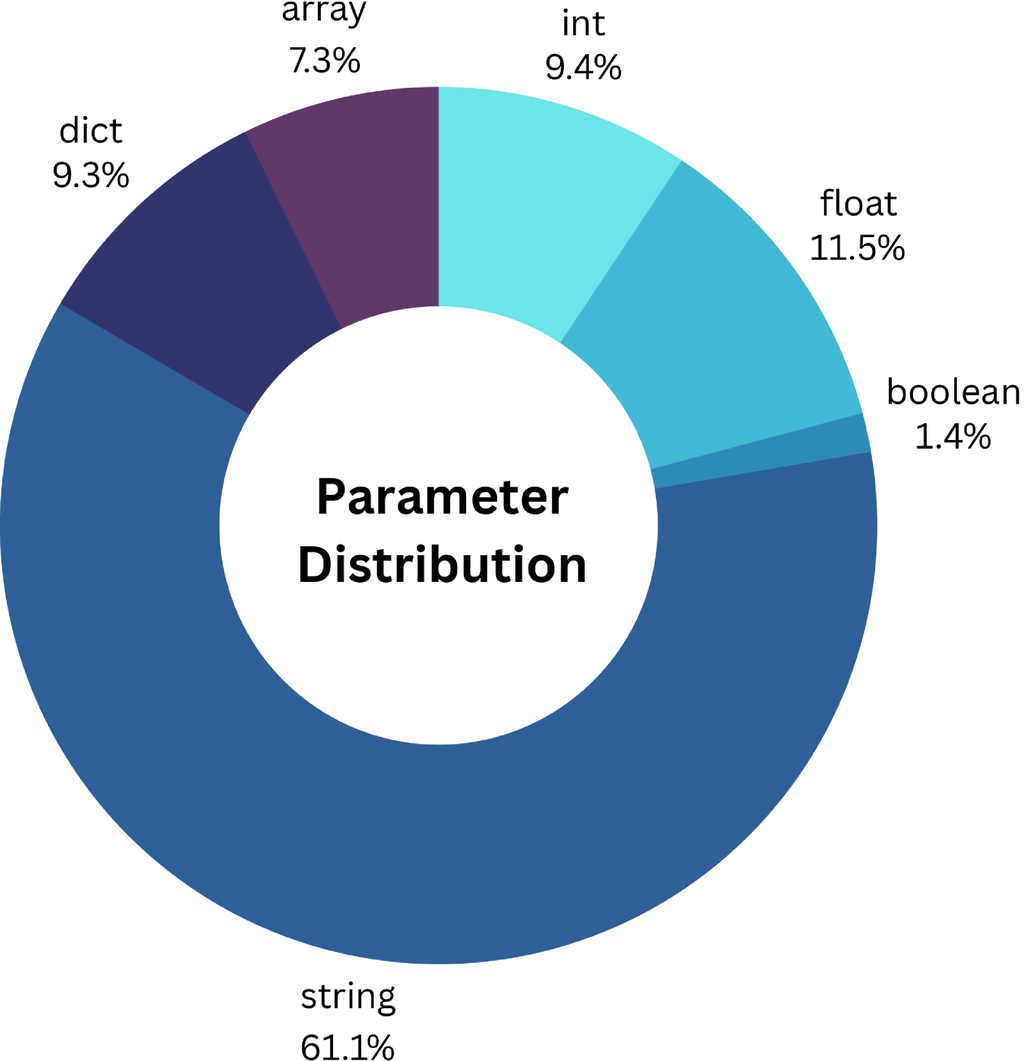
We aim to maintain a balanced distribution of parameter types within the APIs. To prevent the overrepresentation of string parameters, we intentionally increase the proportion of non-string types (e.g., integer, boolean, float, array, dictionary) during the API synthesis process. The resulting distribution is depicted in Figure 8.
Tool diversity in our dataset enhances both the breadth of API coverage and the richness of parameter variety. Such diversity is crucial for the development of models that can adapt to a wide range of scenarios and inputs for real-world tasks.
4.1.2 Format Diversity
Tool Description.
As mentioned in Section 2.2.2, we store API definitions in a standard JSON format for subsequent verification. After the verification process, we convert the API definitions to multiple formats, including JSON, YAML, XML, and Markdown, to accommodate different API specification needs. Figure 17 in Appendix B illustrates examples of the diverse formats.
Function Calls.
We have created hundreds of unique function call formats through various combinations. These format requirements are explicitly declared in the system prompt, ensuring that the dialog data adheres to the specified function call formats, thereby effectively enhancing the format compliance capability of function calling. Examples of such formats are provided in Figure 9.
Format diversity strengthens the model’s ability to understand various requirements across different scenarios, thereby improving its capability to effectively follow any specific format instructions and to avoid the short cutting.
4.1.3 Dialog Diversity
Dialog Mode.
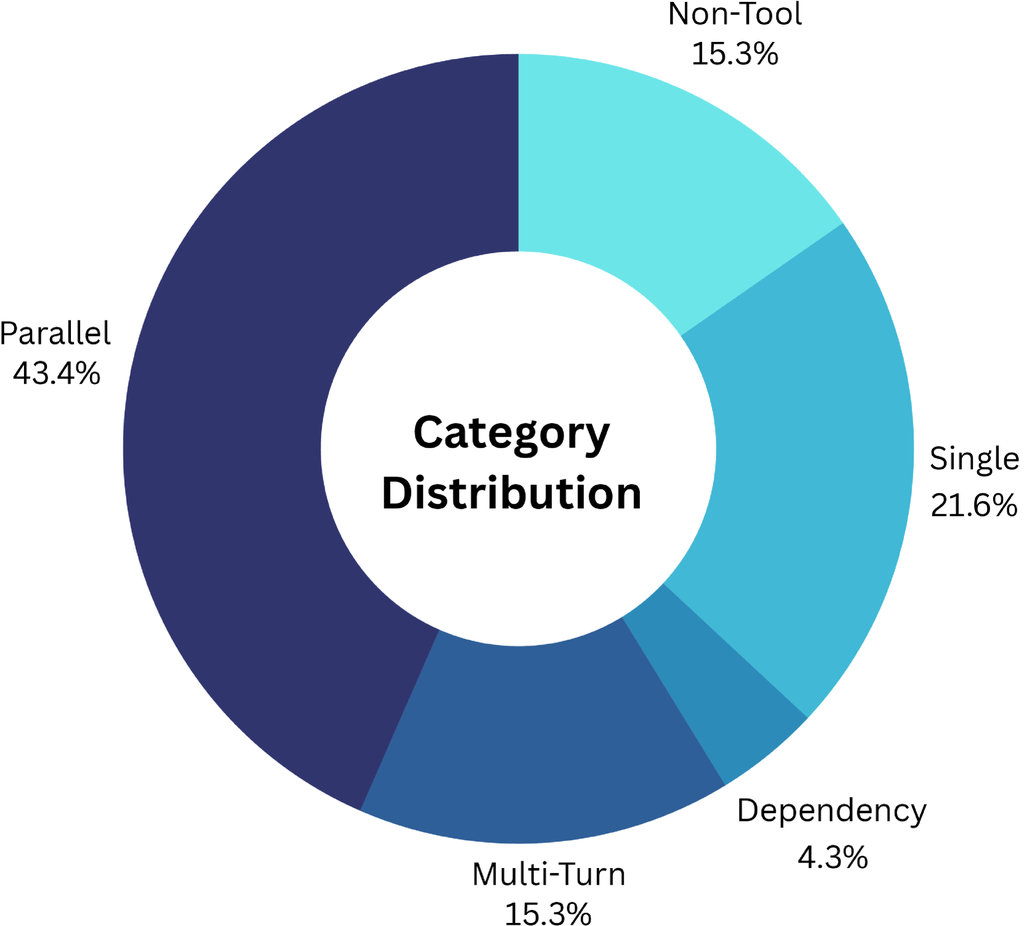
ToolACE supports a range of function call modes, including single, parallel, dependent function calls, and non-tool-use dialogs. It also covers different interaction types, such as single-turn and multi-turn dialogs. Figure 8 illustrates the distribution of these dialog modes, highlighting the extensive coverage of function call use cases in ToolACE.

4.2 Complexity
An appropriate level of complexity is essential for improving the adaptability of models to more challenging function-calling scenarios. We investigate the factors influencing complexity from two perspectives: query-level complexity and dataset-level complexity.
4.2.1 Query-level Complexity
We propose to measure the complexity of individual queries by evaluating the relevance between the user query and the description of the used tools. Generally, a higher affinity between these two elements increases the likelihood that the model will select the correct tool. Conversely, a larger discrepancy suggests that more advanced reasoning is needed to identify the appropriate function, thereby indicating a more challenging and complex query.
To quantify this relevance, we employ BGE [22] to extract embeddings and utilize cosine similarity to assess the degree of similarity. Let and be the embeddings of the query and the API description, respectively. The complexity is then defined as follows:
| (1) |
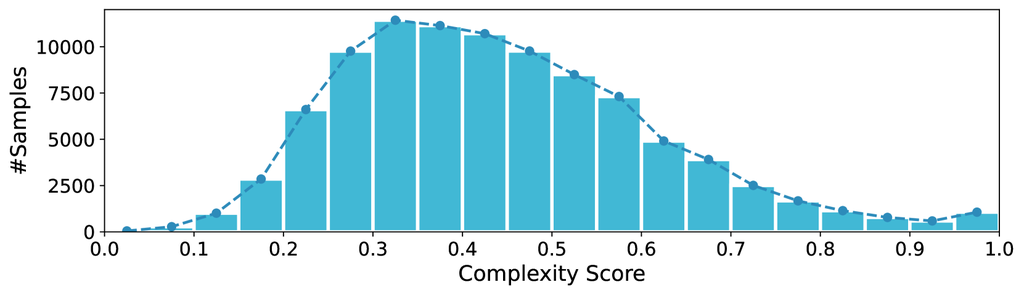
The distribution of the resulting complexity scores is depicted in Figure 10, with an average score of 0.439.
4.2.2 Dataset-level Complexity
We found that basic tool capabilities, such as single function calls, require minimal data for effective model learning. In contrast, more advanced and complex capabilities, such as parallel function calls and multi-turn dialogs, usually require more training data. Therefore, we increase the proportion of complex data (i.e., parallel function calls and multi-turn dialogs) in our dataset. The distribution of these dialog modes is illustrated in Figure 8.
The distribution of dialog modes is crucial in determining the dataset’s complexity. By carefully balancing the composition of dialog modes, we can tailor the dataset’s complexity to the needs of our models, ensuring that they are sufficiently challenged to learn effectively.
5 Experiment
5.1 Experiment Setup
To validate the effectiveness of our approach, we have conducted extensive experiments by training LLMs with the generated data. We train the open-source LLM, LLaMA3.1-8B-Instruct [2], in the supervised fine-tuning (SFT) manner. We refer to the model trained with our data as ToolACE-8B. Due to the limited resources, we adopt the parameter-efficient training strategy LoRA [9] to fine-tune the model. As for the hyper-parameters setting, we adopt one of the most common settings, which sets the rank as 16 and alpha as 32 for all modules in the model. More detailed training settings are shown in Table 2. We compare the overall performance with the state-of-the-art open-source and API-based models, including GPT-4 series 222https://chatgpt.com, Gemini-series 333https://gemini.google.com/ and Claude-3 series 444https://www.anthropic.com/, as well as fine-tuned function calling models including Gorilla-OpenFunctions-v2 [14], xLAM-series [11], and Functionary series [12]. We then conduct in-depth ablation study to reveal the effectiveness of accuracy, diversity, and complexity.
| Learning Rate | WarmUp Ratio | LR Scheduler | Batch Size | Epochs | LoRA rank | LoRA alpha |
| cosine | 48 | 3 | 16 | 32 |
5.2 Overall Performance Analysis
To assess the effectiveness of the proposed ToolACE-series models regarding their functional calling capabilities, we conducted evaluations using the BFCL benchmark [23], including BFCL-v1 and BFCL-v2 555The overall performances are evaluated on both and subsequent studies are evaluated on BFCL-v1 only.. This benchmark is a comprehensive and executable function call evaluation specifically designed to assess the ability of LLMs to invoke functions. The results for our ToolACE-8B model on BFCL-v1 and BFCL-v2, along with various representative models, are summarized in Table 3 and Table 4, respectively.
The findings indicate that API-based models demonstrate significant advantages over open-source models, such as the Claude series and the GPT-4 series. This advantage is likely due to their larger model sizes. Open-source models fine-tuned for function calling, such as Functionary and xLAM, exhibit competitive performance, but still fall short of the leading models, especially in BFCL-v2. Our ToolACE-8B model outperforms all other API-based and open-source models in both the AST and Exec categories of BFCL-v1, and continues to exhibit substantial advantages over most models in the context of BFCL-v2, demonstrating the effectiveness of our training data for functional calling. Additionally, ToolACE excels in detecting tool relevance (or irrelevance in v2), achieving a score of 89.17%, surpassing all other models. ToolACE-8B also consistently and significantly outperforms Functionary-Small-v3.2, which is also fine-tuned from LLaMA3.1-8B-Instruct, in all categories, providing compelling evidence of its superiority.
| Rank | Model | Overall Accuracy | AST Category | Exec Category | Relevance | ||||||
| Simple | Multiple | Parallel |
|
Simple | Multiple | Parallel |
|
||||
| 1 | ToolACE-8B (FC) | 91.41 | 89.09 | 95.50 | 92.50 | 90.50 | 98.24 | 94.00 | 90.00 | 85.00 | 89.17 |
| 2 | Claude-3.5-Sonnet-0620 (Prompt) | 90.53 | 88.55 | 95.00 | 91.50 | 92.50 | 100 | 96 | 84 | 80 | 84.17 |
| 3 | Functionary-Medium-v3.1 (FC) | 88.88 | 86.18 | 95.00 | 93.00 | 89.5 | 95.88 | 94.00 | 90.00 | 80.00 | 81.25 |
| 4 | xLAM-7b-fc-r (FC) | 88.76 | 86.36 | 93.50 | 92.00 | 87.50 | 96.47 | 88.00 | 88.00 | 80.00 | 85.00 |
| 5 | GPT-4-1106-Preview (Prompt) | 88.53 | 88.91 | 95.50 | 89.00 | 91.50 | 99.41 | 94.00 | 82.00 | 82.50 | 72.50 |
| 6 | GPT-4-0613 (Prompt) | 88.53 | 87.27 | 92.50 | 91.00 | 89.00 | 97.06 | 88.00 | 88.00 | 77.5 | 81.67 |
| 7 | GPT-4-0125-Preview (Prompt) | 88.12 | 88.55 | 95.00 | 90.00 | 93.00 | 99.41 | 96.00 | 84.00 | 80.00 | 68.33 |
| 8 | Claude-3-Opus-20240229 (Prompt) | 88.00 | 86.36 | 94.5 | 87.50 | 86.50 | 96.47 | 94.00 | 80.00 | 75.00 | 84.58 |
| 9 | GPT-4o-mini-2024-07-18 (Prompt) | 87.35 | 86.91 | 93.00 | 86.00 | 88.50 | 99.41 | 96.00 | 82.00 | 82.50 | 75.42 |
| 10 | Nemotron-4-340b-instruct (Prompt) | 87.18 | 84.36 | 93.50 | 88.50 | 86.50 | 97.65 | 96.00 | 84.00 | 80.00 | 80.42 |
| 11 | GPT-4-turbo-2024-04-09 (Prompt) | 87.12 | 87.45 | 96.50 | 91.00 | 90.50 | 99.41 | 96.00 | 82.00 | 77.50 | 64.58 |
| 12 | GPT-4-1106-Preview (FC) | 86.65 | 83.09 | 92.50 | 90.00 | 86.50 | 91.76 | 94.00 | 86.00 | 77.50 | 83.75 |
| 13 | GPT-4o-2024-08-06 (FC) | 85.59 | 82.18 | 90.50 | 93.00 | 84.50 | 80.59 | 90.00 | 86.00 | 77.50 | 87.92 |
| 14 | GPT-4-0125-Preview (FC) | 85.47 | 82.73 | 92.50 | 91.00 | 86.50 | 78.24 | 92.00 | 88.00 | 80.00 | 84.58 |
| 15 | Gorilla-OpenFunctions-v2 (FC) | 85.41 | 87.82 | 95.50 | 87.00 | 87.00 | 97.06 | 96.00 | 80.00 | 77.50 | 60.83 |
| 16 | Granite-20b-FunctionCalling (FC) | 85.24 | 82.73 | 90.5 | 85.00 | 81.00 | 87.65 | 90.00 | 86.00 | 80.00 | 88.33 |
| 17 | yi-large (FC) | 85.24 | 83.09 | 93.50 | 90.00 | 86.50 | 92.94 | 96.00 | 82.00 | 82.50 | 71.67 |
| 18 | Meta-Llama-3-70B-Instruct (Prompt) | 84.94 | 84.36 | 92.50 | 91.00 | 87.00 | 91.76 | 90.00 | 88.00 | 77.50 | 67.92 |
| 19 | GPT-4-turbo-2024-04-09 (FC) | 84.41 | 78.73 | 92.00 | 90.50 | 85.50 | 85.29 | 86.00 | 84.00 | 77.50 | 85.42 |
| 20 | GPT-4o-2024-05-13 (FC) | 84.12 | 80.55 | 91.00 | 90.00 | 83.00 | 90.59 | 88.00 | 90.00 | 77.50 | 77.08 |
| 21 | Functionary-Small-v3.2 (FC) | 82.82 | 82.73 | 91.00 | 90.00 | 78.50 | 84.12 | 92.00 | 80.00 | 75.00 | 72.92 |
| Rank | Model | Overall Accuracy | AST Category | Exec Category | Irrelevance | Relevance | ||||||
| Simple | Multiple | Parallel |
|
Simple | Multiple | Parallel |
|
|||||
| 1 | ToolACE-8B (FC) | 85.77 | 71.03 | 85.78 | 87.13 | 80.17 | 96.86 | 94.00 | 86.00 | 87.50 | 81.44 | 87.80 |
| 2 | GPT-4-1106-Preview (Prompt) | 85.65 | 79.01 | 89.90 | 82.25 | 83.00 | 99.29 | 94.00 | 88.00 | 82.50 | 61.04 | 97.56 |
| 3 | GPT-4o-mini-2024-07-18 (Prompt) | 84.35 | 79.32 | 84.24 | 87.50 | 86.67 | 98.29 | 94.00 | 80.00 | 80.00 | 68.09 | 85.37 |
| 4 | GPT-4-0613 (Prompt) | 84.23 | 76.90 | 82.32 | 90.50 | 80.42 | 97.50 | 88.00 | 88.00 | 75.00 | 70.95 | 92.68 |
| 5 | GPT-4-turbo-2024-04-09 (Prompt) | 84.11 | 79.34 | 90.63 | 82.75 | 83.25 | 98.50 | 92.00 | 82.00 | 80.00 | 55.05 | 97.56 |
| 6 | GPT-4-0125-Preview (Prompt) | 84.09 | 78.61 | 89.30 | 85.62 | 81.42 | 98.50 | 94.00 | 86.00 | 75.00 | 54.93 | 97.56 |
| 7 | Functionary-Medium-v3.1 (FC) | 81.73 | 74.03 | 87.37 | 81.38 | 78.83 | 97.29 | 90.00 | 88.00 | 75.00 | 72.24 | 73.17 |
| 8 | Claude-3-Sonnet-20240229 (Prompt) | 80.52 | 71.59 | 79.77 | 79.62 | 82.00 | 93.00 | 92.00 | 88.00 | 80.00 | 48.96 | 90.24 |
| 9 | Claude-3.5-Sonnet-20240620 (Prompt) | 80.34 | 76.07 | 85.07 | 77.25 | 71.00 | 98.00 | 92.00 | 82.00 | 72.50 | 78.77 | 70.73 |
| 10 | Claude-3-Opus-20240229 (Prompt) | 79.75 | 72.25 | 83.07 | 74.50 | 73.42 | 98.79 | 92.00 | 82.00 | 80.00 | 78.03 | 63.41 |
| 11 | GPT-4-1106-Preview (FC) | 79.65 | 68.89 | 83.58 | 80.62 | 70.83 | 89.86 | 90 | 84 | 70 | 73.36 | 85.37 |
| 12 | yi-large (FC) | 79.53 | 67.84 | 82.68 | 82.5 | 77.33 | 91.86 | 94 | 82 | 85 | 68.68 | 63.41 |
| 13 | Functionary-Small-v3.2 (FC) | 79.45 | 68.29 | 81.54 | 77 | 71.42 | 88.29 | 92 | 86 | 77.5 | 72.02 | 80.49 |
| 14 | GPT-4-0125-Preview (FC) | 79.41 | 67.97 | 84.3 | 80.12 | 76.83 | 73.29 | 90 | 86 | 75 | 75.26 | 85.37 |
| 15 | xLAM-7b-fc-r (FC) | 79.36 | 68.43 | 79.3 | 73.88 | 68.5 | 94.21 | 88 | 88 | 75 | 80.24 | 78.05 |
| 16 | Functionary-Small-v3.1 (FC) | 78.86 | 70.07 | 83.21 | 83 | 72.92 | 83.93 | 88 | 84 | 70 | 68.09 | 85.37 |
| 17 | mistral-large-2407 (FC Any) | 78.82 | 80.59 | 87.42 | 84.25 | 83.25 | 96.86 | 92 | 86 | 77.5 | 0.29 | 100 |
| 18 | Gorilla-OpenFunctions-v2 (FC) | 78.64 | 72.89 | 79.8 | 78.38 | 66.42 | 94.36 | 92 | 78 | 72.5 | 64.25 | 87.8 |
| 19 | GPT-4-turbo-2024-04-09 (FC) | 78.57 | 63.29 | 83.23 | 83 | 75 | 81.57 | 88 | 84 | 75 | 79.47 | 73.17 |
| 20 | Command-R-Plus (Prompt) | 78.49 | 71.28 | 79.69 | 81.38 | 75.33 | 91.36 | 92 | 82 | 77.5 | 51.47 | 82.93 |
| 21 | GPT-4o-2024-08-06 (FC) | 78.29 | 69.95 | 80.37 | 84 | 75 | 77.5 | 90 | 86 | 72.5 | 81.71 | 65.85 |
5.3 Ablation Study
To further validate the effect of various mechanisms introduced in data generation and validation, we conduct a series of in-depth ablation studies from the perspective of accuracy, complexity, and diversity, respectively.
5.3.1 Ablation on Accuracy
Effects of Formalized Thinking. This part explores the impact of formalized thinking on the dialogue generation process. We randomly selected user queries generated by our user agent and continued the generation process under two different conditions: one with formalized thinking and the other without. We then evaluated the generated outputs using our DLV data verification module. Table 5 presents the pass rates for the two generated datasets. The results indicate that data generated with formalized thinking consistently achieves higher pass rates across both verification layers, with a significant absolute improvement in the final pass rate. A detailed analysis of specific errors reveals clear gaps between the two datasets in areas such as whether calling tools, tool selection, and the handling of optional parameters. These discrepancies highlight the advantages of formalized thinking in decision-making, which therefore results in the effectiveness of incorporating formalized thinking into the dialogue generation process.
| Method | Rule-based Pass Rate | Model-based Pass Rate | Final Pass Rate |
| With FT | |||
| W/O FT |
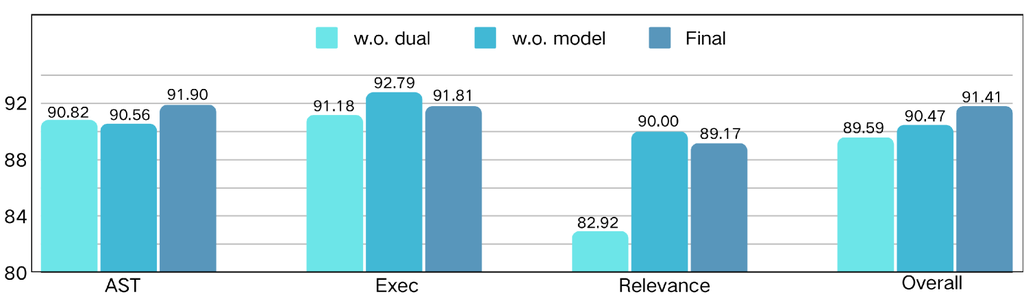
Effects of the verification system. As detailed in previous sections, our verification system comprises two layers: a rule checker and a model checker. To evaluate the efficacy of each layer, we train LLaMA3.1-8B-Instruct with LoRA using three distinct datasets: (1) data without any verification (denoted as w.o. dual), (2) data without model checking (denoted as w.o. model), and (3) data subjected to dual-layer verification (denoted as Final). The resulting fine-tuned models are assessed using the BFCL benchmark, with outcomes summarized in Figure 11. Comparative analysis reveals that the model trained on data without model checking surpasses that trained on unverified data in terms of both executable and overall accuracy, thereby validating the rule checker’s effectiveness. Moreover, the model trained on dually verified data significantly outperforms both ablation models in terms of AST and overall accuracy, underscoring the indispensable role of the model checker.
5.3.2 Ablation on Complexity
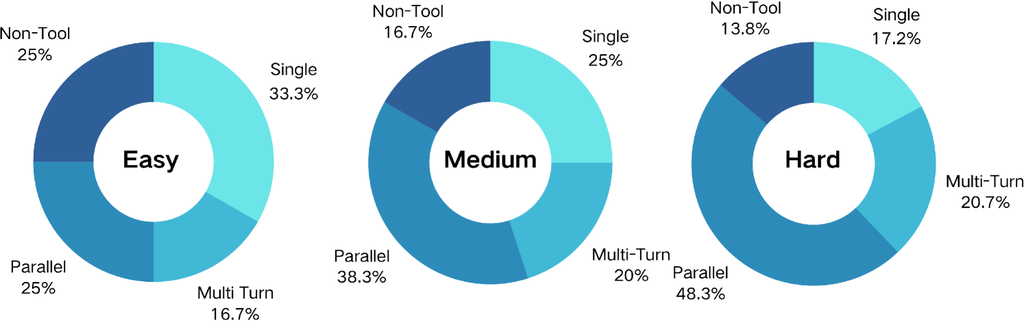
Data Sampling for Various Complexity. To effectively assess the impact of dataset complexity on the model’s performance, we have conducted a sampling of the entire dataset based on the aforementioned complexity assessment metrics. This process has yielded three distinct subsets of varying complexity levels: , , and , each containing about 60,000 instances. Figure 18 and Figure 19 in Appendix C illustrate the different distributions of these subsets in terms of Dataset-level Complexity and Query-level Complexity. The rationale behind this stratified sampling approach is to create a controlled environment where the influence of complexity can be systematically analyzed. By maintaining equal sample sizes across subsets, we ensure a fair comparison while varying the complexity, which allows for a more nuanced understanding of how complexity affects model performance.
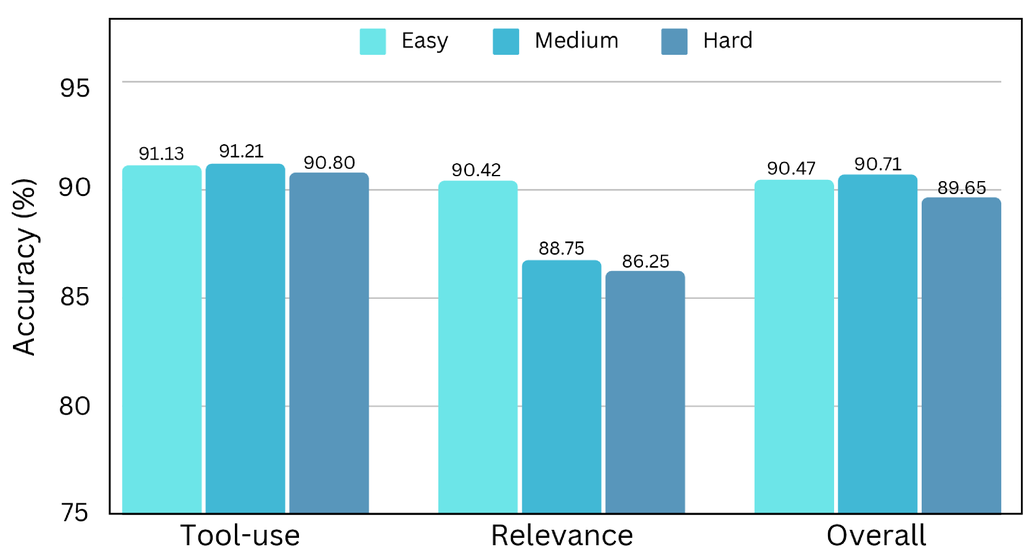
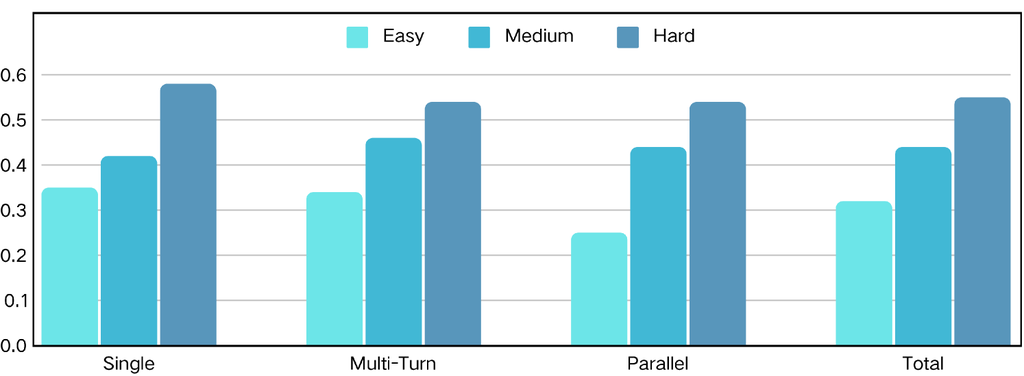
Effects of Complexity. We conduct experiments on those three subsets with varying complexity and evaluate the fine-tuned models on the BFCL benchmark. The results are illustrated in Figure 13. The model trained on shows slight superiority compared with another two subsets, for both overall and tool-use accuracy. This finding aligns with our hypothesis that optimal data complexity is essential for LLM training; excessively simple or complex data can hinder performance.
5.3.3 Ablation on Diversity
Data Sampling for Various Diversity. To assess the impacts of the diversity, we employed a sampling strategy to generate three subsets with varying degrees of diversity, namely , , and . Initially, all APIs are clustered into 30 groups using K-means based on their names and descriptions. Subsequently, API sets are constructed by selecting APIs from 6, 14, and 30 clusters, respectively. Instances are then categorized into three subsets according to their associated APIs. Approximately 30,000 instances are randomly selected from each subset, resulting in three training sets with distinct levels of diversity.
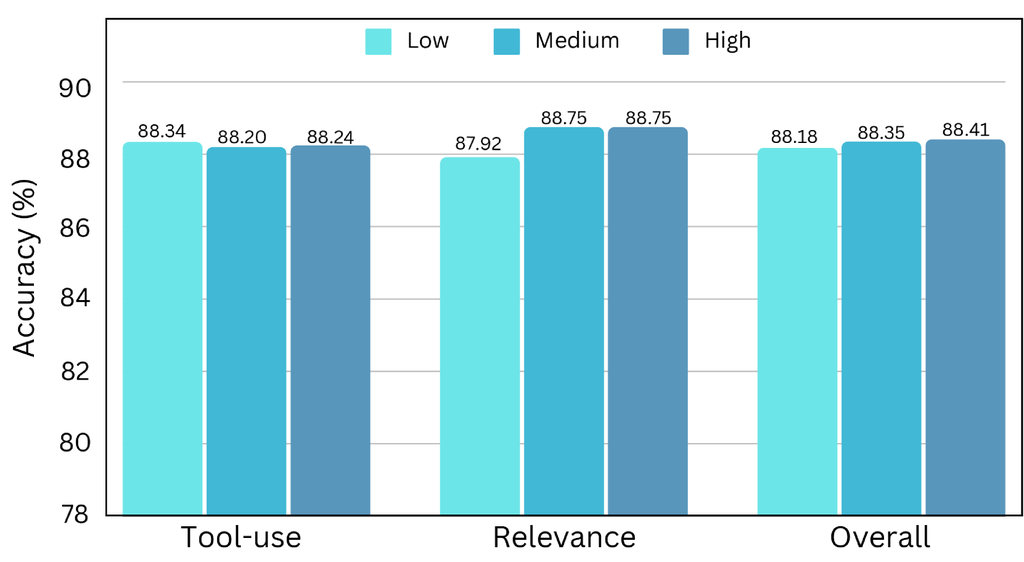
Effects of Diversity. Experiments are conducted to train LLaMA-3.1-8B-Instruct on three subsets described above. The results on BFCL are reported in Figure 13. A clear correlation between training data diversity and overall model accuracy is observed, emphasizing the critical role of API diversity in model performance. Notably, improvements in relevance detection are particularly pronounced, suggesting that exposure to a wider range of APIs enhances the model’s ability to discriminate between subtle API differences, thereby enhancing the ability of irrelevance detection.
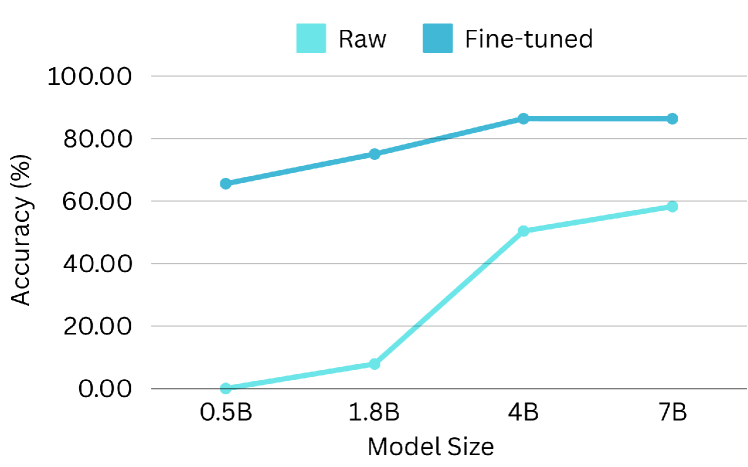
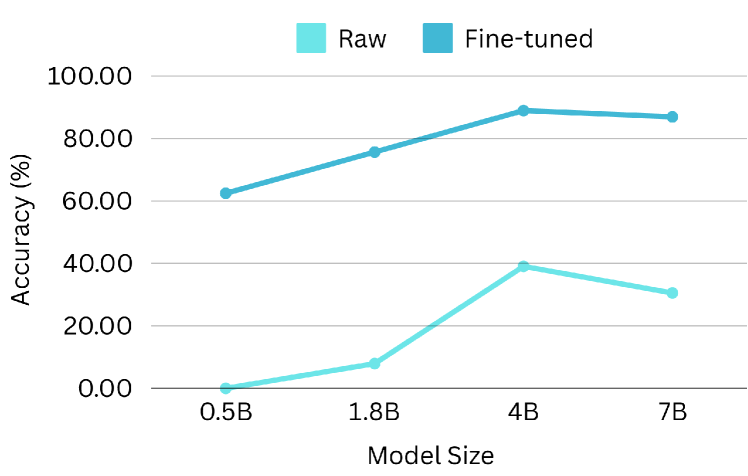
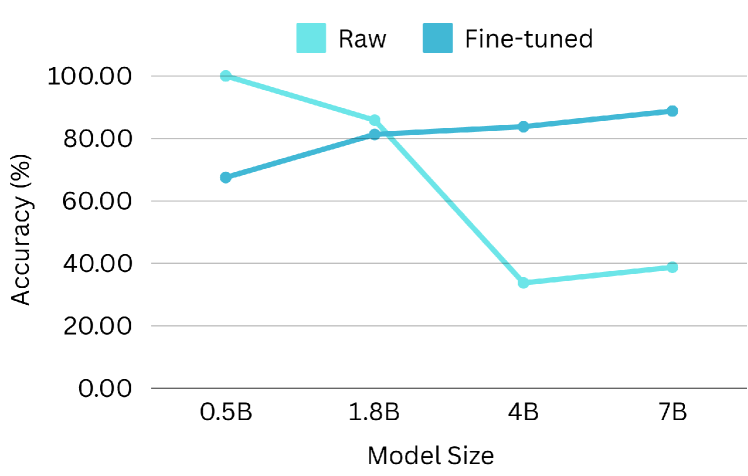
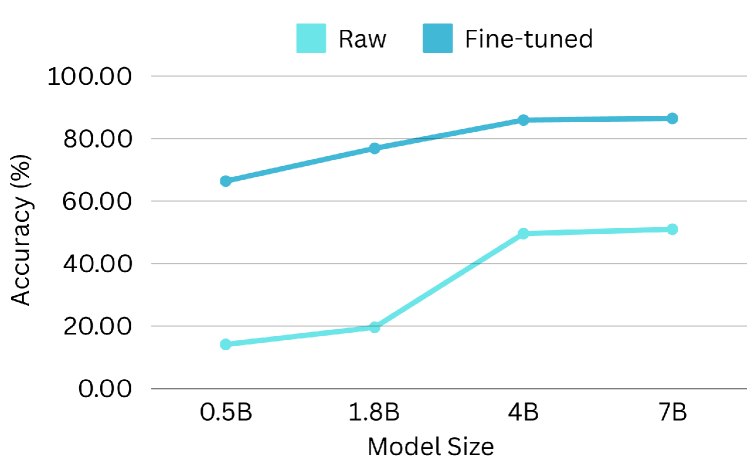
5.4 Scaling Performance of Model Size
Scaling laws posit a correlation between model size and performance. To investigate the scalability of functional calling performance, we conduct experiments using the Qwen-1.5-xB-Chat series, which offers a range of model sizes (0.5B, 1.8B, 4B, 7B, etc.). Both raw and fine-tuned (using our dataset) models are evaluated on the BFCL benchmark, with results presented in Figure 14. As expected, larger models exhibit superior performance in functional calling tasks, as evidenced by improvements in AST accuracy and executable accuracy. Smaller raw models demonstrate unexpectedly high relevance detection scores, likely attributable to the generation of unparsable outputs due to limited instruction-following capabilities. Conversely, fine-tuned models display consistent scaling behavior across all evaluation metrics, highlighting the potential of the ToolACE to enhance the performance of larger LLMs.
5.5 Study on Various Backbone LLMs
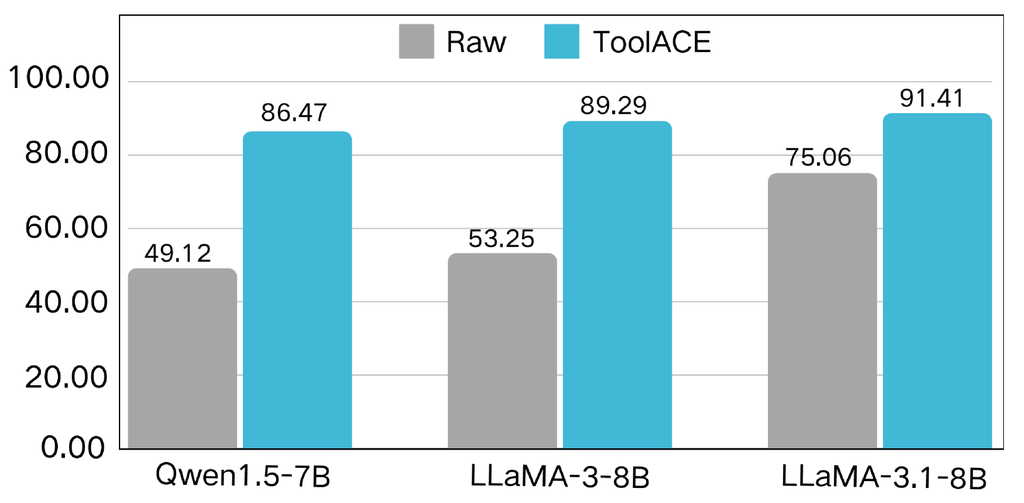
To investigate the influence of the LLM backbone, we experiment with several (approximately) 8B-scale models: Qwen1.5-7B-Chat [3], LLaMA-3-8B-Instruct, and LLaMA-3.1-8B-Instruct. Fine-tuned models are evaluated on the BFCL benchmark, with results presented in Figure 16. Across all models, fine-tuning yields substantial performance gains, highlighting the effectiveness of our ToolACE. Due to differences in pre-training corpora, such as Qwen is trained with more Chinese conversational samples, raw models exhibit varying functional calling capabilities, with LLaMA-3.1-8B-Instruct demonstrating superior performance. While this hierarchy persisted after fine-tuning, the performance gaps narrowed, suggesting that our dataset can potentially enhance the functional-calling abilities of those LLMs tailored for other skills, such as conversational skills.
5.6 Study on General Capabilities
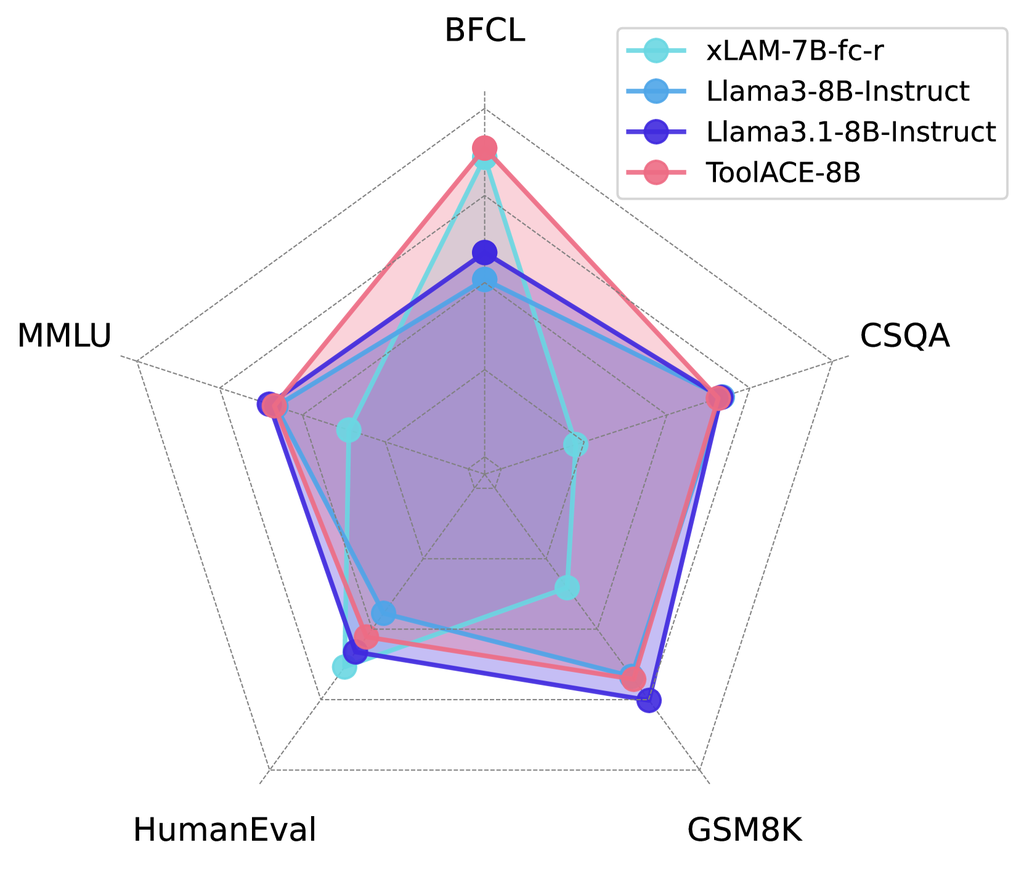
To assess the impact of ToolACE training on broader capabilities of LLMs, we conduct experiments across multiple benchmarks evaluating general ability (MMLU [7, 8]), coding (HumanEval [4]), mathematics (GSM8K [5]), reasoning (CommonSenseQA [18]), and functional calling (BFCL [23]). Raw LLaMA-3-8B-Instruct, LLaMA-3.1-8B-Instruct, and the functionally specialized xLAM-7B-fc-r serve as baselines. Results are presented in Figure 16. ToolACE-8B exhibits substantial improvements over xLAM-7B-fc-r across most benchmarks, with particularly pronounced gains in MMLU, GSM8K, and CommonSenseQA. Compared to the raw LLaMA-3.1-8B-Instruct, ToolACE-8B demonstrates negligible performance degradation on some benchmarks while achieving significant enhancements in functional calling. These findings suggest that the ToolACE dataset effectively enhances functional calling capabilities without compromising the underlying LLM’s general abilities.
6 Conclusion
This paper presents ToolACE, an automated data generation pipeline designed to enhance the function-calling capabilities of large language models. ToolACE utilizes a novel self-evolution synthesis process and a multi-agent interactive system to curate accurate, complex, and diverse APIs and dialogs. Our results demonstrate that even smaller models trained with ToolACE can achieve state-of-the-art performance, thereby advancing the field and setting new benchmarks for tool-augmented AI agents.
7 Acknowledgements
We thank the contribution of Mei Li, Wei Tang, Xi Wang, Meide Zhang, Ke Xiong, and Rencong Shi to this work.
References
- [1] Ibrahim Abdelaziz, Kinjal Basu, Mayank Agarwal, Sadhana Kumaravel, Matthew Stallone, Rameswar Panda, Yara Rizk, GP Bhargav, Maxwell Crouse, Chulaka Gunasekara, et al. Granite-function calling model: Introducing function calling abilities via multi-task learning of granular tasks. arXiv preprint arXiv:2407.00121, 2024.
- [2] AI@Meta. Llama 3 model card. 2024.
- [3] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [4] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. 2021.
- [5] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [6] Yilun Hao, Yongchao Chen, Yang Zhang, and Chuchu Fan. Large language models can plan your travels rigorously with formal verification tools. arXiv preprint arXiv:2404.11891, 2024.
- [7] Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [8] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [9] Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- [10] Shijue Huang, Wanjun Zhong, Jianqiao Lu, Qi Zhu, Jiahui Gao, Weiwen Liu, Yutai Hou, Xingshan Zeng, Yasheng Wang, Lifeng Shang, et al. Planning, creation, usage: Benchmarking llms for comprehensive tool utilization in real-world complex scenarios. arXiv preprint arXiv:2401.17167, 2024.
- [11] Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, et al. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets. arXiv preprint arXiv:2406.18518, 2024.
- [12] Meetkai. Functionary.meetkai. 2024.
- [13] Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei-ge Chen, Olga Vrousgos, Corby Rosset, et al. Agentinstruct: Toward generative teaching with agentic flows. arXiv preprint arXiv:2407.03502, 2024.
- [14] Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334, 2023.
- [15] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
- [16] Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji-Rong Wen. Tool learning with large language models: A survey. arXiv preprint arXiv:2405.17935, 2024.
- [17] Karim Shabani, Mohamad Khatib, and Saman Ebadi. Vygotsky’s zone of proximal development: Instructional implications and teachers’ professional development. English language teaching, 3(4):237–248, 2010.
- [18] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [19] Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301, 2023.
- [20] Adrian Theuma and Ehsan Shareghi. Equipping language models with tool use capability for tabular data analysis in finance. arXiv preprint arXiv:2401.15328, 2024.
- [21] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [22] Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-pack: Packed resources for general chinese embeddings. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 641–649, 2024.
- [23] Fanjia Yan, Huanzhi Mao, Charlie Cheng-Jie Ji, Tianjun Zhang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Berkeley function calling leaderboard. https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html, 2024.
- [24] Junjie Ye, Guanyu Li, Songyang Gao, Caishuang Huang, Yilong Wu, Sixian Li, Xiaoran Fan, Shihan Dou, Qi Zhang, Tao Gui, et al. Tooleyes: Fine-grained evaluation for tool learning capabilities of large language models in real-world scenarios. arXiv preprint arXiv:2401.00741, 2024.
- [25] Dylan Zhang, Justin Wang, and Francois Charton. Instruction diversity drives generalization to unseen tasks. arXiv preprint arXiv:2402.10891, 2024.
- [26] Ruizhe Zhong, Xingbo Du, Shixiong Kai, Zhentao Tang, Siyuan Xu, Hui-Ling Zhen, Jianye Hao, Qiang Xu, Mingxuan Yuan, and Junchi Yan. Llm4eda: Emerging progress in large language models for electronic design automation. arXiv preprint arXiv:2401.12224, 2023.
Appendix A Rule Examples in Rule Verification Layer
Table 6 lists the check rules we have applied. For instance, to verify function calling executability, we implement the following procedures: First, we confirm that the API name matches one from the given tool list. Next, we verify that all required parameters are accurately provided. Finally, we use regular expressions to ensure that the parameter formats and patterns adhere to those specified in the API documentation. These procedures allow us to validate the correctness and executability of function calls without actual execution, which enhances efficiency and reduces deployment overhead.
| Aspect | Rules |
| API Definition Clarity | Check if the API definition complies with JSON Schema specifications. |
| Check if the API definition contains all necessary fields. | |
| Function Calling Executability | Check if the API name is in the tool list. |
| Check if all required parameters are provided. | |
| Check if all the parameter formats and patterns match the API definition. | |
| Dialog Correctness | Check if the dialog contain all necessary fields. |
| Check if the assistant’s response is too long. | |
| Check for invalid characters in the responses. | |
| Check for mixed-language responses. | |
| Check if the response is complete. | |
| Data Sample Consistency | Check if the API names in the function call and the tool response are consistent. |
| Check for format conflicts with the requirements defined in the system prompt. | |
| Check if the order of the dialogue roles is correct. | |
| Check if the tool response follows the function call. |
Appendix B An example of Different API formats
Figure 17 displays an example of API definitions with different formats, including original Json, XML, Markdown and natural language.

Appendix C Data Distribution on Complexity Ablation Study
Appendix D Case Study
Here we present a selection of cases from our generated data, showcasing various examples of tool utilization and function calls.
Figure 20 presents a data sample of parallel function calling. This type of data focuses on building the model’s ability to understanding and extract key parameters from the user query, which makes models learn to call the correct function repeatly for accomplishing a task. In this example, the query indicates that the user needs to get the event information of Theatre, Dance, and Music during 2021-04-01 and 2021-05-01 respectively. The assistant correctly recognizes that it needs to call performanceArt.get_upcoming_events for three times with different assignments of the parameter "category".
Figure 21 shows a data sample of multiple function calling. This kind of data focuses on giving the model the ability to distinguish between different functions, which makes models learn to choose the correct function(s) for finishing a task. There are five functions in the tool list in the case. The user needs the information of the live event count for soccer, NBA stats for the 2025 season, and the latest media for the Lakers. The assistant chooses the corresponding Get Live Events Count by Sport, Get All NBA Stats, and Get Latest Team Media from the toolList and calls them to finish the task.
Figure 22 presents cases that focus on enhancing the model’s ability to determine the relevance of a function to a user’s query. In the first scenario, the user requests movie showtimes at specific cinemas. However, the available functions are designed only for retrieving event details or specific book characters, rendering them irrelevant to the user’s request. The assistant appropriately declines to provide an answer, citing the lack of relevant functionality. In the second scenario, the user asks to start an Android emulator, but the essential parameters—device name, system image, and API level—are missing. The assistant correctly identifies this gap and requests the necessary information rather than attempting an incomplete operation. This type of data is vital for training the model to recognize when a function is not relevant or when it lacks the required inputs, ensuring that the system responds accurately and avoids executing unsupported tasks.
| Case 1: parallel function calling: | |
| ToolList |
performanceArt.get_upcoming_events required: ["start_date", "end_date"] optional: ["category"]
|
| User |
I would like to know about upcoming Theatre, Dance, and Music performance art events happening between 2021-04-01 and 2021-05-01.
|
| Assistant |
performanceArt.get_upcoming_events(start_date="2021-04-01", end_date="2021-05-01", category="Theatre"),
performanceArt.get_upcoming_events(start_date="2021-04-01", end_date="2021-05-01", category="Dance"), performanceArt.get_upcoming_events(start_date="2021-04-01", end_date="2021-05-01", category="Music") |
| Case 2: multiple function calling: | |
| ToolList |
Bet365 Inplay Filter required: optional: ["sport_id"] ["skip_esports"]
Get Live Events Count by Sport required: ["sport", "locale", "timezone"] National Team Statistics required: ["player_id"] Get All NBA Stats required: ["seasons"] optional: ["page", "per_page", "player_ids", "game_ids"] Get Latest Team Media required: ["team_id"] |
| User |
I plan to watch some sports events and want to catch up on the latest NBA stats. Could you find the live event count for soccer, get NBA stats for the 2025 season, and the latest media for the Lakers?
|
| Assistant |
Get Live Events Count by Sport(sport="soccer", locale="en_US", timezone=-4.0),
Get All NBA Stats(seasons=["2025"], page=1, per_page=10), Get Latest Team Media(team_id=13.0) |
| Case 3: relevance | |
| ToolList |
Event optional: ["name", "club", "club_name", "start_time", "end_time", "time_modified", "string_filter"]
Get Character by ID required: ["id"] |
| User |
Can you check the showtimes for the film "Avengers: Endgame" at Cinema 21 and Cinema 45?
|
| Assistant | The provided functions do not support searching for showtimes at specific cinemas. The functions available are limited to retrieving events based on filters or retrieving a specific character from the Throne of Glass series. Therefore, the question lacks the parameters required by the given functions. |
| ToolList |
runAndroidEmulator required: [device_name, system_image, api_level]
|
| User |
Can you start the Android emulator for me?
|
| Assistant | The function runAndroidEmulator can start the Android emulator, but it lacks the required parameters: device_name, system_image, and api_level. Please provide these details to proceed. |