STAB: Speech Tokenizer Assessment Benchmark
Abstract
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
Index Terms:
speech tokenization, evaluation benchmark, multimodal representation learningI Introduction
Speech representation learning, the task of developing models that extract succinct feature representations of speech for downstream tasks, has been area of active interest in the recent years. Motivated by zero-resource speech processing to develop methods that can learn sub-word or word units directly from unlabeled raw speech [1], several unsupervised methods have been proposed for learning continuous representations [2, 3] and discrete acoustic units [4]. Techniques based on predictive coding [5] and self-supervision learning such as the class of wav2vec models [6], have been developed to derive quantized representations of audio. More recently, iterative learning of discrete units and acoustic representations such as HuBERT [7] and joint learning of denoising and self-supervision in wavLM [8] have shown promising results.
Discrete representations are a natural fit for speech and language given their ability to be represented as a sequence of symbolic, phonetic, graphemic or sub-word/word units. The approach of representing speech in the form of discrete tokens offers a significant advantage by converting speech into a format that mirrors text, thereby leveraging the application of speech as an input for various large language models (LLMs) [9, 10]. Furthermore, speech tokens have the ability to capture non-verbal cues such as emotion and rhythm, which contain additional information compared to their textual counterparts [11, 12]. Utilizing discrete speech tokens has proven advantageous in tasks such as automatic speech translation and speech-to-speech translation, while demonstrating comparable performance on automatic speech recognition [13, 14]. This also contributes to the advancement of multimodal LMs [15].
Speech tokenizers optimized for specific downstream task(s) exist [16], however, measuring their generalization ability remains a challenging problem. Assessing the performance of all tokenizers across various downstream tasks is a computationally expensive endeavor that presents challenges for scalability. Additionally, speech tokenizers are often utilized as a black box, with limited examination [17] of the nature of the tokens they generate or their adherence to specific properties. Therefore, it is timely to create a low-compute evaluation benchmark for assessing tokenizers across multiple dimensions. Our contributions can be summarized as follows:
-
•
We propose STAB, a speech tokenizer assessment benchmark which evaluates capabilities of a given speech tokenizer.
-
•
STAB presents a cost-effective evaluation approach and holds potential for expediting research on speech tokenization.
-
•
Through extensive experiments, we demonstrate that STAB provides a reliable indication of the speech tokenizer’s performance on a range of downstream tasks.
II Related Work
Speech Tokenization: Self-supervised learning for speech historically relied on contrastive loss on audio embeddings, as exemplified by wav2vec [18]. Vq-wav2vec [19] and DiscreteBERT [20] introduced tokenization based objectives for learning better speech representations. Following this, HuBERT [7] introduced iterative refinement of speech tokens within a masked language modeling (MLM) framework. W2v-BERT [21] combined the benefits of the contrastive approaches and MLM with speech tokens in a single model. Interestingly, BEST-RQ [22] utilizes random projection to generate target tokens. Hence, speech tokens have become central to self-supervised pre-training models and are typically obtained through methods such as K-means or vector quantization [23]. AudioLM [13] and AudioPaLM [14] auto-regressively model the speech token sequences derived from clustering representations generated by an audio encoding model. In this study, we assess various speech tokenizers employed in existing methods.
Speech Benchmarks With the development of various representation learning frameworks, there have also been efforts to evaluate and benchmark speech representations. In the latest edition of the Zero Resource Speech Challenge, evaluations focused on exploring text-less speech language modeling tasks [24]. The speech processing universal performance benchmark (SUPERB) considers a multitude of downstream evaluation tasks that included semantic and para-linguistic tasks [25]. An extension to multi-lingual tasks is benchmarked in ML-SUPERB [26]. For multitask evaluation in a zero-shot setting, Dynamic-SUPERB [27] has been introduced recently. A non-semantic evaluation benchmark, NOSS has also been proposed for audio representations [28].
III STAB Details
III-A Invariance
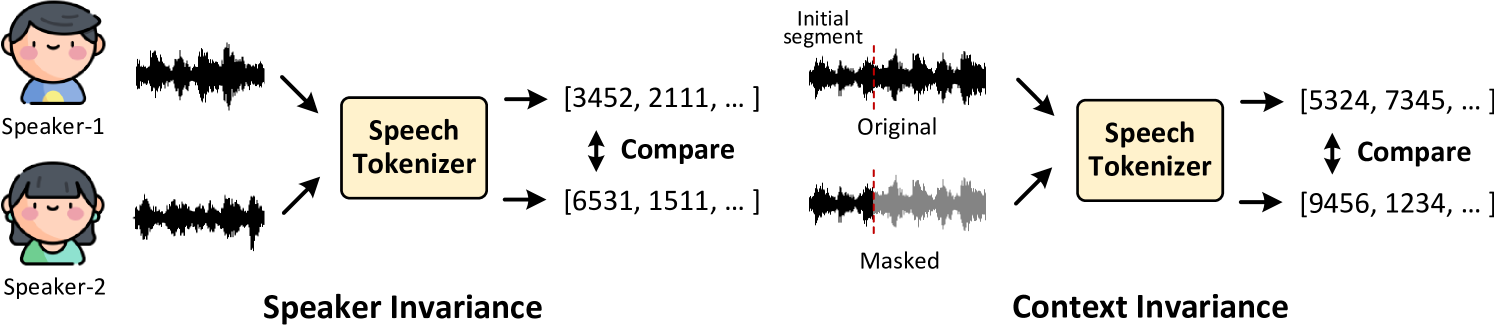
For tasks such as ASR, extracting semantic meaning from speech is crucial. Previous studies have introduced the concept of semantic and acoustic speech tokenization [13, 14]. Semantic tokens focus solely on extracting semantic information from the speech signal, while acoustic tokens capture other properties such as speaker information, language, and emotion. Here, we assess the ability of a speech tokenizer to accurately capture semantics by evaluating it along the following dimensions.
-
•
Speaker invariance: Examines variance in tokenization of identical sentences uttered by two different speakers such as comparing a sentence spoken by a female/male speaker.
-
•
Context invariance: Analyses how tokens are altered when a part of the speech context is masked. This measurement reflects the influence neighborhood of a token. We compare the tokens extracted from a segment (initial 4 seconds) of the utterance against the same segment with its original context.
-
•
Language invariance: Measures the variation in tokenization of the same concept spoken in two different languages. For example, comparing the tokens of ”Cat is drinking the milk” in English and ”Eine Katze trinkt Milch” in German.
III-B Robustness
We evaluate the resilience of a speech tokenizer to different types of noise and acoustic variations in speech signals. This is crucial for effectively handling real-world data, which may include recordings from a variety of microphones and speakers.
-
•
Pitch Change: Pitch change is a common phenomenon in speech, often resulting from factors such as equipment imperfections or signal processing [29]. We investigate how tokenization varies when the pitch of a speech signal is modified, while ensuring that the audio remains intelligible.
-
•
Playback speed: Modifying the playback speed of audio involves adjusting the rate at which the audio is played. We examine how tokenization changes when we alter this.
-
•
Background Noise: Here, we introduce background noise where is s.t. SNR = 10dB into the original speech signal and assess the behavior of a speech tokenizer in response to the added noise.
| 8k-Tokenizers | 32k-Tokenizers | |||||||
| Dimensions | Metrics | w2v2 | w2v-BERT | BEST-RQ | USM-v1 | USM-v2 | USM-v3 | |
| Invariance | Speaker Invariance | chrF | 7.5 | 13.0 | 4.7 | 15.8 | 36.6 | 13.9 |
| Context Invariance | chrF | 27.8 | 45.6 | 48.4 | 73.2 | 45.8 | 50.9 | |
| Language Invariance | chrF | 5.2 | 7.5 | 4.6 | 6.9 | 4.3 | 4.6 | |
| Robustness | Pitch Change | chrF | 10.2 | 21.4 | 8.1 | 25.1 | 33.3 | 19.7 |
| Gaussian Noise (10 dB) | chrF | 42.5 | 48.3 | 39.7 | 67.2 | 72.5 | 57.0 | |
| Speed Change (0.8) | chrF | 26.0 | 23.8 | 24.9 | 30.3 | 30.9 | 27.0 | |
| Compressibility | Huffman Efficiency | % | 13.9 | 16.9 | 11.4 | 13.5 | 16.8 | 16.0 |
| Byte-pair Efficiency | % | 2.6 | 9.8 | 6.1 | 6.3 | 8.8 | 4.2 | |
| De-duplication Efficiency | % | 1.4 | 9.1 | 10.9 | 4.3 | 6.0 | 4.8 | |
| Vocabulary | Per-language Utilization | % | 75.3 | 56.8 | 87.2 | 21.7 | 42.4 | 44.5 |
| Overall Utilization | % | 99.7 | 95.4 | 99.8 | 47.5 | 99.3 | 96.4 | |
| Vocabulary Entropy | Score | 95.0 | 91.0 | 97.3 | 82.8 | 94.4 | 90.6 | |
III-C Compressibility
In natural language processing (NLP), models based on words or subwords have been shown to outperform character-based models [30, 31]. However, most speech tokenizers tokenize at a level lower than phonemes. Previous studies [32] have shown that training a sentence piece tokenizer on speech sequences yields subword-level tokens, resulting in improvements in downstream tasks. Nevertheless, the degree of compressibility varies among different tokenizers. Hence, we propose the following dimensions to measure this property.
-
•
Huffman Encoding Efficiency: Huffman coding algorithm [33] is widely used for lossless data compression. We use the Huffman coding algorithm to compress a corpus of speech sequences of a particular language, following which we calculate the compression efficiency.
-
•
Byte-pair Encoding Efficiency: Byte-pair encoding (BPE) [34, 35] is a tokenization technique that involves iteratively merging the most frequent pair of consecutive tokens to create new tokens. This merging process is repeated until a predefined vocabulary size is reached. Using BPE, it is possible to learn subword-level tokens by merging repeated patterns found in speech token sequences.
-
•
De-duplication Efficiency: We assess the compressibility of speech sequences by merging adjacent repeating tokens.
III-D Vocabulary
Here, we evaluate how a speech tokenizer utilizes its vocabulary and how this utilization varies across languages. A larger vocabulary size in a speech tokenizer increases the number of parameters in the Speech Language Models (SLMs). Therefore, it is crucial to analyze how the vocabulary is being used and to ensure that there are no mode collapse issues. To achieve this, we analyze tokenizers along the following axes,
-
•
Per-language Utilization: We examine the proportion of the total vocabulary utilized for each language, considering a fixed number (500k) of observed tokens.
-
•
Overall Utilization and Entropy: We explore the vocabulary utilization across all languages and compute entropy of the vocabulary distribution to evaluate any bias towards a subset of tokens.
-
•
Vocabulary Distribution Comparison Across Language: We investigate whether the tokenizer captures relationships among languages, with the hypothesis that a tokenizer designed to consider language similarity should exhibit similar vocabulary distributions for related languages.
IV Experimental Setup
IV-A Datasets
STAB Datasets: In our proposed benchmark, we employ the FLEURS dataset [36], which is the speech counterpart of the FLoRes-101 machine translation dataset [37]. FLEURS comprises 2,000 n-way parallel sentences spoken in 102 languages, enabling evaluation on metrics such as language awareness. Additionally, we employ the TIMIT dataset [38], which includes recordings of 630 speakers reciting 10 sentences each, accompanied by transcripts for each spoken sentence. This enables us to assess speaker-awareness.
Pre-training Datasets: In our experiments, we employ the AudioPaLM model [14] which involves initializing with a pre-trained text decoder (PaLM-2 [10]) and subsequently making it multimodal by expanding its vocabulary and training it on a speech-text data mixture. Our data mixture consists of a blend of 75% original text data [10] and 25% automatic speech recognition (ASR) data sourced from the Babel [39], VoxPopuli ASR, Multilingual Librispeech [40], FLEURS, and YouTube ASR datasets [41]. In total, the speech dataset comprises 221k hours of ASR data spanning across 100 languages.
Evaluation Datasets: Along with STAB benchmark, we evaluate our models on several downstream tasks as well such as ASR, emotion recognition, speaker identification, and intent classification. For ASR, we utilize transcribed VoxPopuli dataset which spans across 14 languages and CoVoST-2 [42] dataset for AST. We use IEMOCAP dataset [43] for emotion recognition and VoxCeleb [44] for speaker identification. Since AudioPaLM is a decoder-only model we approach the classification task as a seq2seq task. For all these datasets, we fine-tune our model on their training split followed by evaluation on the corresponding dev/test split.
IV-B Baseline systems
In our experimental analysis, we compare several speech tokenizers commonly utilized within the research community.
-
•
w2v2: Similiar to Rubenstein et al. [14], we employ wav2vec 2.0 [6], which is trained on multilingual data, for encoding speech. Subsequently, a k-means (with k = 8k) is trained on the embeddings generated by the model, and the centroid indices are extracted as semantic tokens.
-
•
w2v-BERT: Same as w2v2 with speech encoder replaced by a pre-trained w2v-BERT encoder [21] trained using Masked Language Modeling (MLM) objective.
-
•
BEST-RQ: Here, we employ MLM-based BEST-RQ model [22] as the speech encoder.
-
•
USM-v1: Following Rubenstein et al. [14], we employ Google Universal Speech model (USM) [41], which is trained using MLM objective for encoding speech. For USM-v1 and subsequent tokenizers, the vocabulary size is 32k.
-
•
USM-v2 [14]: Similar to USM-v1, this involves USM but with the inclusion of an auxiliary ASR loss during training. Moreover, instead of K-means, vector quantization [23] is used for discretizing representations.
-
•
USM-v3: This is identical to USM-v2 tokenizer. However, it utilizes USM trained with spectrogram reconstruction [45] loss in addition to ASR.
Implementation details: Most of the hyper-parameters are directly adopted from AudioPaLM [14]. We report results with models of size 1B, initialized with PaLM-2 checkpoint and pre-trained for 30k steps on our speech-text mixture. For each downstream evaluation task, we fine-tune the pre-trained model on its corresponding training split before evaluation. Please note that no fine-tuning is necessary for STAB, as metrics can be directly computed over the raw tokens.
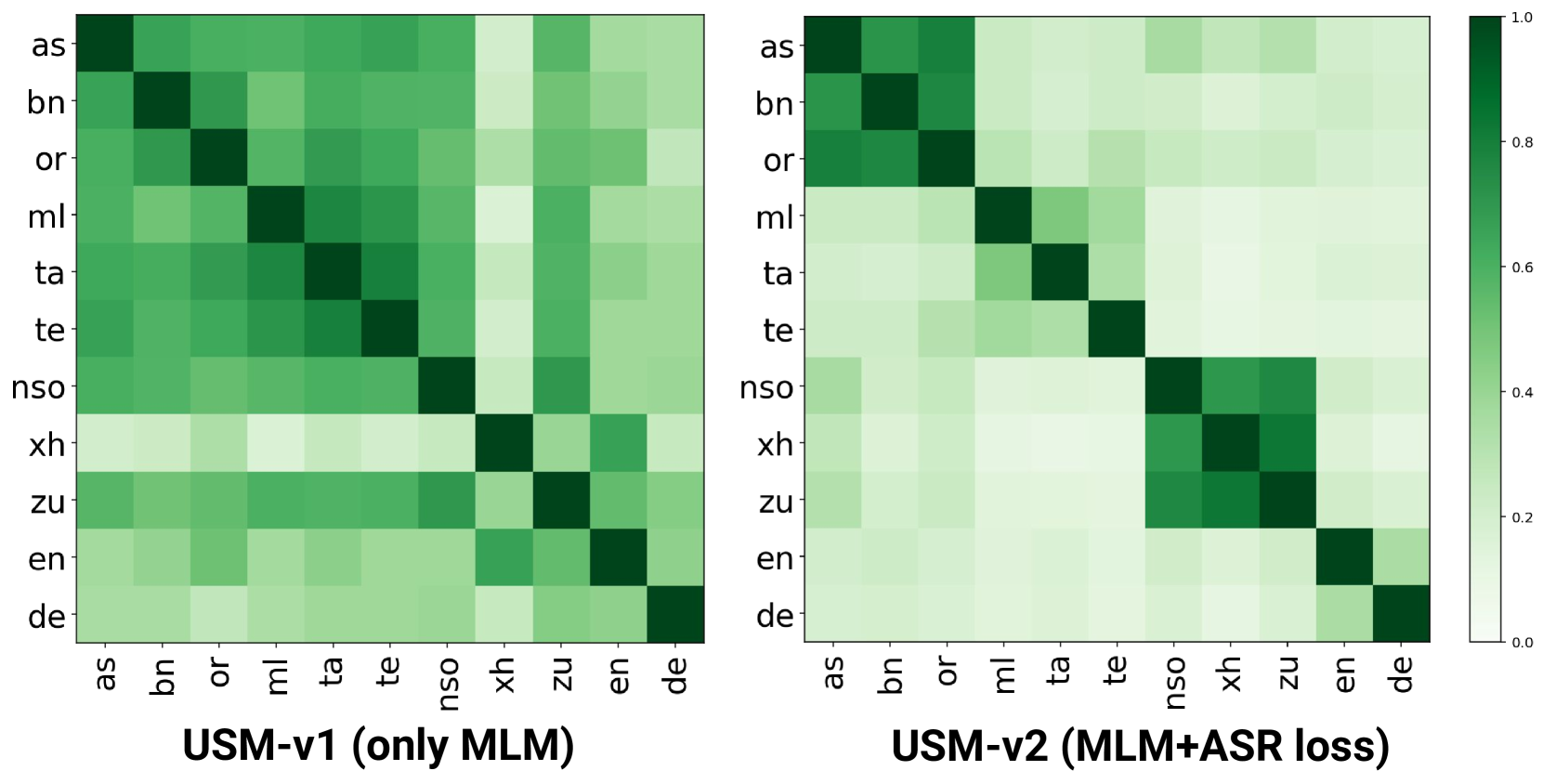
V Results
V-A STAB Performance Comparison
In this section, we evaluate different tokenizers, as outlined in Section IV-B, on various STAB dimensions. The summary of the results is presented in Table I. As previously described, w2v2 is trained using contrastive loss whereas w2v-BERT, BEST-RQ and USM-v1 are trained using Masked Language Modeling (MLM) loss. Further, USM-v2 incorporates both MLM and Automatic Speech Recognition (ASR) losses and USM-v3 additionally includes reconstruction loss. Please note that the vocabulary size of w2v2, w2v-BERT, and BEST-RQ tokenizers is 8k, whereas USM-based tokenizers utilize a vocabulary of 32k. Thus, the majority of our conclusions are drawn from comparisons within the group of tokenizers having the same vocabulary size.
Invariance: The results demonstrate that the inclusion of ASR loss (such as in USM-v2) makes tokenizers more invariant to speaker information. Moreover, it boosts contextual dependence, as it necessitates a semantic understanding of all frames collectively. This is evident through fall in context invariance metric on USM-v2 among 32k-tokenizers. Further, contrastive loss of w2v2 drastically increases the dependence on context compared to MLM-based losses in w2v-BERT and BEST-RQ. Regarding language invariance, most tokenizers generate distinct token sequences for different languages. However, ASR loss appears to reduce language invariance, as it necessitates generating text in the correct script based on the specific language used in the speech.
Robustness: We observe that USM-based tokenizers exhibit greater robustness to noise compared to other tokenizers, likely due to the more extensive data used during pre-training. Additionally, incorporating ASR loss during training enhances the tokenizers’ resilience to noisy speech signals. In contrast, training with a spectrogram reconstruction loss appears to increase the model’s susceptibility to noise. Among the 8k-tokenizers, the w2v-BERT tokenizer demonstrates superior noise robustness relative to its counterparts.
Compressibility: The results indicate that 8k-tokenizers demonstrate higher compressibility compared to 32k-tokenizers, which can be attributed to their smaller vocabulary size. Among 8k-tokenizers, w2v-BERT exhibits higher overall compressibility. Additionally, similar to previous findings, incorporating ASR loss enhances tokenizer compressibility.
Vocabulary: Among all 32k-tokenizers, USM-v1 exhibits the lowest per-language and overall vocabulary utilization. This is attributed to its use of K-means quantization, in contrast to the vector quantization employed by USM-v2 and USM-v3. This indicates that simple K-means representation is ineffective in fully utilizing the entire vocabulary, potentially resulting in the wastage of model parameters. The vocabulary utilization among 8k-tokenizers is higher given their smaller vocabulary.
Language Relationships: The ASR loss enhances tokenizer’s awareness of language relationships. As shown in Figure 2, USM-v2 exhibits a higher similarity in vocabulary distribution across closely related languages, a characteristic not elicited by tokens from the USM-v1 tokenizer. This demonstrates the potential of ASR-trained tokenizers to exhibit higher levels of cross-lingual knowledge transfer.
V-B Correlation with Downstream tasks
We evaluate various tokenizers on multiple downstream tasks: Automatic Speech Recognition (ASR), Automatic Speech Translation (AST), Emotion Classification (EC), Speaker Identification (SID), and Language Identification (LID). For each task, we fine-tune our already pre-trained models on the training split of corresponding dataset before evaluation.
The results on downstream tasks are summarized in Table II. Overall, we find that STAB metrics correlates well with the performance on downstream tasks. On ASR and AST tasks, w2vBERT and USM-v2, which are more speaker invariant and robust to noise, perform best in their categories. On the contrary, the tokenizers which have lower speaker invariance performs better on speaker identification tasks as expected. Previous studies [46] on emotion classification using IEMOCAP dataset have shown that utilizing the output of an ASR system yields better results compared to models that directly use the speech modality. Our findings support this observation, as w2v-BERT and USM-v2 outperform other tokenizers in our experiments. USM-v2 also captures language similarity better, as shown in Figure 2, which reflects in its improved language identification performance.
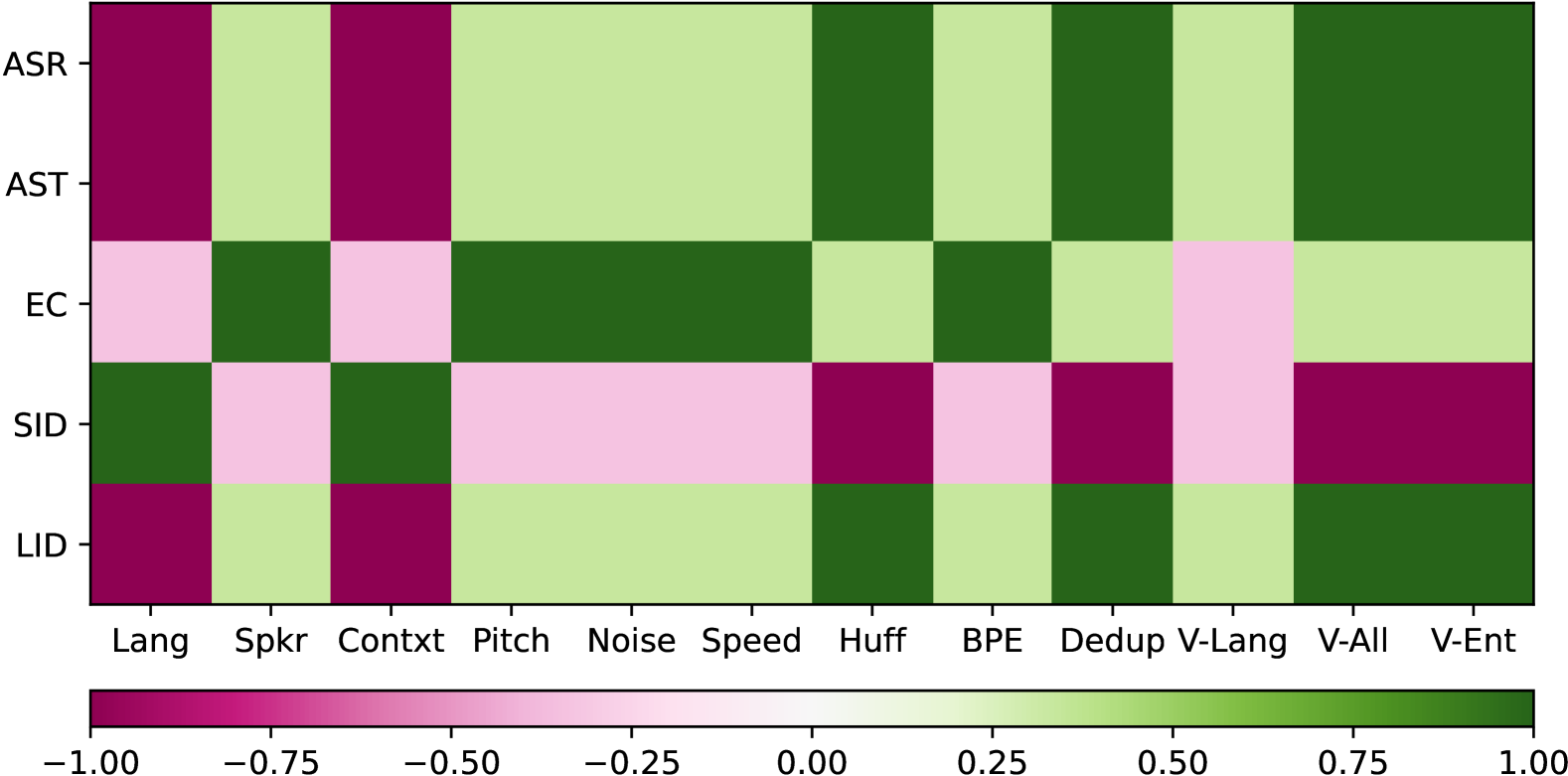
For identifying the coupled relationship between the STAB metrics (Table I) and the downstream tasks (Table II), we consider pairs of tokenizers (eg. USM-v1, USM-v2). For this pair, we compute correlation between the binarized relative improvements in a STAB metric and the relative improvements in a downstream task performance. In this manner, the correlation plot is generated (Figure 3) using average correlation over all 32k-tokenizer pairs for different choices of STAB metrics and downstream tasks. As seen here, the ASR and AST tasks follow an identical trend with vocabulary utilization metrics showing the maximal correlation while language/context invariance is seen to have the maximal negative correlation. The LID task also shows a similar trend. The EC task shows the highest correlation for speaker and noise invariance, which essentially allows the model to focus on emotion related cues in the tokenized audio signal. The SID task shows somewhat of an opposite trend to most of the other tasks considered, where the language and context invariance are positively correlated while the overall vocabulary utilization is negatively correlated with the SID performance. These findings illustrate that STAB metrics correlate with downstream tasks and offers insights into a tokenizer’s performance on downstream applications.
| Tokenizers | ASR | AST | EC | SID | LID |
| WER | BLEU | Accuracy | |||
| w2v2 | 73.8 | 2.4 | 50.8 | 65.0 | 16.0 |
| w2v-BERT | 53.4 | 7.4 | 55.0 | 38.2 | 28.8 |
| BEST-RQ | 66.6 | 4.1 | 54.0 | 49.8 | 17.2 |
| USM-v1 | 49.3 | 3.6 | 55.9 | 53.0 | 79.4 |
| USM-v2 | 11.8 | 16.8 | 60.0 | 16.3 | 97.1 |
| USM-v3 | 16.5 | 10.2 | 50.9 | 24.6 | 91.8 |
Cost-Effectiveness of STAB: For any tokenizer, each STAB metric requires less than 15 minutes of CPU compute on our Apache Beam based implementation. In contrast, evaluating each tokenizer for a downstream task involves approximately 16 hours of pre-training on 256 accelerated hardware chips across multiple datasets, followed by 22 hours of fine-tuning on 128 accelerated hardware chips. Hence, STAB is at least 100x more efficient in terms of compute and data resources compared to downstream evaluation. Consequently, the proposed benchmark has the potential to be a valuable tool in advancing the design of speech tokenizers.
VI Conclusion
In this paper, we introduced STAB (Speech Tokenizer Assessment Benchmark), a comprehensive benchmark for evaluating speech tokenizers and illuminating their inherent characteristics. The benchmark offers a deeper understanding of the inner workings of a speech tokenizer, and STAB metrics correlate with the performance on several downstream tasks. STAB is 100x more efficient in terms of compute and data than using downstream tasks to compare speech tokenizers, making it a potential catalyst for the development of speech tokenizers.
References
- [1] M. Versteegh, X. Anguera, A. Jansen, and E. Dupoux, “The zero resource speech challenge 2015: Proposed approaches and results,” Procedia Computer Science, vol. 81, pp. 67–72, 2016.
- [2] D. Renshaw, H. Kamper, A. Jansen, and S. Goldwater, “A comparison of neural network methods for unsupervised representation learning on the zero resource speech challenge,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
- [3] W.-N. Hsu, Y. Zhang, and J. Glass, “Unsupervised learning of disentangled and interpretable representations from sequential data,” Advances in neural information processing systems, vol. 30, 2017.
- [4] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164.
- [5] Y.-A. Chung and J. Glass, “Generative pre-training for speech with autoregressive predictive coding,” in ICASSP 2020. IEEE, 2020, pp. 3497–3501.
- [6] A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “Wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proceedings of the 34th NeurIPS Conference, 2020.
- [7] W.-N. Hsu and et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing.
- [8] S. Chen and et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, 2022.
- [9] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” ArXiv, vol. abs/2302.13971, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257219404
- [10] R. A. et al., “Palm 2 technical report,” ArXiv, vol. abs/2305.10403, 2023.
- [11] F. Kreuk, A. Polyak, J. Copet, E. Kharitonov, T. Nguyen, M. Rivière, and et al., “Textless speech emotion conversion using decomposed and discrete representations,” ArXiv, vol. abs/2111.07402, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:244117178
- [12] E. Kharitonov, A. Lee, A. Polyak, Y. Adi, J. Copet, K. Lakhotia, T. Nguyen, M. Rivière, A. rahman Mohamed, E. Dupoux, and W.-N. Hsu, “Text-free prosody-aware generative spoken language modeling,” ArXiv, vol. abs/2109.03264, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:237439400
- [13] Z. Borsos and et al., “Audiolm: A language modeling approach to audio generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2523–2533, 2022.
- [14] P. K. Rubenstein and et al., “Audiopalm: A large language model that can speak and listen,” ArXiv, vol. abs/2306.12925, 2023.
- [15] R. A. et al., “Gemini: A family of highly capable multimodal models,” ArXiv, vol. abs/2312.11805, 2023.
- [16] R. Eloff and et al., “Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks,” arXiv preprint arXiv:1904.07556, 2019.
- [17] M. Ravanelli and et al., “Neurips workshop on interpretability and robustness in audio, speech, and language.”
- [18] S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised Pre-Training for Speech Recognition,” in Proc. Interspeech 2019, 2019, pp. 3465–3469.
- [19] A. Baevski, S. Schneider, and M. Auli, “vq-wav2vec: Self-supervised learning of discrete speech representations,” ArXiv, vol. abs/1910.05453, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:204512445
- [20] A. Baevski, M. Auli, and A. rahman Mohamed, “Effectiveness of self-supervised pre-training for speech recognition,” ArXiv, vol. abs/1911.03912, 2019.
- [21] Y.-A. Chung and et al., “w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” 2021 IEEE ASRU Workshop, pp. 244–250, 2021.
- [22] C.-C. Chiu and et al., “Self-supervised learning with random-projection quantizer for speech recognition,” in Proc. 39th ICML, ser. Proc. Mach. Learn. Res. PMLR, 2022, pp. 3915–3924.
- [23] R. Gray, “Vector quantization,” IEEE ASSP Magazine, vol. 1, no. 2, pp. 4–29, 1984.
- [24] E. Dunbar and et al., “Self-supervised language learning from raw audio: Lessons from the zero resource speech challenge,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6.
- [25] S.-w. Yang and et al., “Superb: Speech processing universal performance benchmark,” arXiv preprint arXiv:2105.01051, 2021.
- [26] J. Shi and et al., “Ml-superb: Multilingual speech universal performance benchmark,” arXiv preprint arXiv:2305.10615, 2023.
- [27] C.-y. Huang and et al., “Dynamic-superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,” arXiv preprint arXiv:2309.09510, 2023.
- [28] J. Shor, A. Jansen, R. Maor, O. Lang, O. Tuval, F. d. C. Quitry, M. Tagliasacchi, I. Shavitt, D. Emanuel, and Y. Haviv, “Towards learning a universal non-semantic representation of speech,” arXiv preprint arXiv:2002.12764, 2020.
- [29] F. P. Mechel, “Acoustics of moving sources moving source,” 2008.
- [30] P. Bojanowski, A. Joulin, and T. Mikolov, “Alternative structures for character-level rnns,” ArXiv, vol. abs/1511.06303, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:2415419
- [31] T. Nguyen, M. de Seyssel, R. Algayres, P. Roze, E. Dunbar, and E. Dupoux, “Are word boundaries useful for unsupervised language learning?” ArXiv, vol. abs/2210.02956, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:252735287
- [32] R. Algayres and et al., “Generative spoken language model based on continuous word-sized audio tokens,” in EMNLP, 2023.
- [33] D. A. Huffman, “A method for the construction of minimum-redundancy codes,” Proceedings of the IRE, vol. 40, no. 9, pp. 1098–1101, 1952.
- [34] P. Gage, “A new algorithm for data compression,” C Users J., vol. 12, no. 2, p. 23–38, feb 1994.
- [35] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), K. Erk and N. A. Smith, Eds. Berlin, Germany: Association for Computational Linguistics, Aug. 2016, pp. 1715–1725. [Online]. Available: https://aclanthology.org/P16-1162
- [36] A. Conneau and et al., “Fleurs: Few-shot learning evaluation of universal representations of speech,” 2022 IEEE Spoken Language Technology Workshop, pp. 798–805, 2022.
- [37] N. Goyal and et al., “The flores-101 evaluation benchmark for low-resource and multilingual machine translation,” TACL, vol. 10, pp. 522–538, 2021.
- [38] J. S. Garofolo and et al., “Darpa timit acoustic-phonetic continous speech corpus cd-rom. nist speech disc 1-1.1,” NASA STI/Recon technical report n, vol. 93, p. 27403, 1993.
- [39] M. J. F. Gales and et al., “Speech recognition and keyword spotting for low-resource languages: Babel project research at cued,” in SLTU, 2014.
- [40] V. Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A Large-Scale Multilingual Dataset for Speech Research,” in Proc. Interspeech 2020, 2020, pp. 2757–2761.
- [41] Y. Zhang, W. Han, J. Qin, Y. Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V. Axelrod, G. Wang, Z. Meng, K. Hu, A. Rosenberg, R. Prabhavalkar, D. S. Park, P. Haghani, J. Riesa, G. Perng, H. Soltau, T. Strohman, B. Ramabhadran, T. N. Sainath, P. J. Moreno, C.-C. Chiu, J. Schalkwyk, F. Beaufays, and Y. Wu, “Google usm: Scaling automatic speech recognition beyond 100 languages,” ArXiv, vol. abs/2303.01037, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257280021
- [42] C. Wang, A. Wu, and J. Pino, “Covost 2 and massively multilingual speech-to-text translation,” arXiv preprint arXiv:2007.10310, 2020.
- [43] C. Busso, M. Bulut, C.-C. Lee, E. A. Kazemzadeh, E. M. Provost, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: interactive emotional dyadic motion capture database,” Language Resources and Evaluation, vol. 42, pp. 335–359, 2008. [Online]. Available: https://api.semanticscholar.org/CorpusID:11820063
- [44] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: A large-scale speaker identification dataset,” in Interspeech, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:10475843
- [45] K. W. Cheuk, Y.-J. Luo, E. Benetos, and D. Herremans, “The effect of spectrogram reconstruction on automatic music transcription: An alternative approach to improve transcription accuracy,” 2020 25th International Conference on Pattern Recognition (ICPR), pp. 9091–9098, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:224803213
- [46] S. Dutta and S. Ganapathy, “Multimodal transformer with learnable frontend and self attention for emotion recognition,” ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6917–6921, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:249437569