redacted tcb@breakable ∗ Work done during an internship at Google DeepMind. A preliminary draft without the results of Gemma-2 had been circulated internally in early July. Correspondence to: wx13@illinois.edu, tongzhang@tongzhang-ml.org, tianqiliu@google.com.
Building Math Agents with Multi-Turn Iterative Preference Learning
Abstract
Recent studies have shown that large language models’ (LLMs) mathematical problem-solving capabilities can be enhanced by integrating external tools, such as code interpreters, and employing multi-turn Chain-of-Thought (CoT) reasoning. While current methods focus on synthetic data generation and Supervised Fine-Tuning (SFT), this paper studies the complementary direct preference learning approach to further improve model performance. However, existing direct preference learning algorithms are originally designed for the single-turn chat task, and do not fully address the complexities of multi-turn reasoning and external tool integration required for tool-integrated mathematical reasoning tasks. To fill in this gap, we introduce a multi-turn direct preference learning framework, tailored for this context, that leverages feedback from code interpreters and optimizes trajectory-level preferences. This framework includes multi-turn DPO and multi-turn KTO as specific implementations. The effectiveness of our framework is validated through training of various language models using an augmented prompt set from the GSM8K and MATH datasets. Our results demonstrate substantial improvements: a supervised fine-tuned Gemma-1.1-it-7B model’s performance increased from 77.5% to 83.9% on GSM8K and from 46.1% to 51.2% on MATH. Similarly, a Gemma-2-it-9B model improved from 84.1% to 86.3% on GSM8K and from 51.0% to 54.5% on MATH.
keywords:
RLHF, Agent learning, Mathematical reasoning1 Introduction
Large language models (LLMs) have demonstrated remarkable capacities across a variety of language tasks, showcasing their broad-ranging capabilities in natural language processing. Notable models include ChatGPT (OpenAI, 2023), Claude (Anthropic, 2023), and Gemini (Team et al., 2023). However, despite these advances, even the most advanced closed-source LLMs still struggle with complex reasoning tasks that require multi-rounds of decision making. In particular, for the representative task of mathematical problem solving, LLMs often fail with basic arithmetic and symbolic computations (Hendrycks et al., 2021; Cobbe et al., 2021b; Zheng et al., 2021). To address this issue, recent studies recommend the integration of external tools (e.g., calculators, computational Python libraries and symbolic solvers) to augment the LLMs’ mathematical problem-solving capabilities (Cobbe et al., 2021b; Shao et al., 2022; Mishra et al., 2022; Zhang et al., 2024a). Specifically, by integrating natural language reasoning with the use of these external tools, these enhanced LLMs can receive external messages from tool interactions and reason based on both previously generated tokens and external messages, which significantly improves their performance in mathematical tasks (Gou et al., 2023b; Toshniwal et al., 2024; Shao et al., 2024).
These successes of tool-integrated LLMs lead to a natural research question: how can we better train LLMs to combine tool usage with intrinsic reasoning to tackle complex reasoning tasks? For the mathematical problem solving task, existing works primarily focus on synthetic data generation (by a strong teacher model) and supervised fine-tuning (SFT), as seen in ToRA (Gou et al., 2023b), MetaMathQA (Yu et al., 2023), MAmmoTH (Yue et al., 2023, 2024), and Open-MathInstruct (Toshniwal et al., 2024). These methods and synthetic datasets have yielded significant improvements in test accuracy on standard benchmarks like MATH (Hendrycks et al., 2021) and GSM8K (Cobbe et al., 2021a).
Built on strong SFT models, Reinforcement Learning from Human Feedback (RLHF) has proven to be a key technique to elicit LLMs’ knowledge during the post-training stage and has become a standard practice in the LLM training pipeline (Bai et al., 2022; Ouyang et al., 2022; Touvron et al., 2023; Team et al., 2023). Broadly speaking, the RLHF learning paradigm, which was originally designed for aligning large language models (LLMs) with human values and preferences (Bai et al., 2022; Ouyang et al., 2022), is distinct from SFT as it learns from relative feedback (Christiano et al., 2017; Ziegler et al., 2019). It has notably enhanced the capabilities of models like ChatGPT, Claude, and Gemini, enabling them to generate responses that are more helpful, harmless, and honest (Bai et al., 2022). Inspired by RLHF’s success in general chat applications, in this paper, we explore RLHF for improving LLMs’ mathematical problem-solving abilities when equipped with external tools. In particular, since deep RL methods (e.g., the proximal policy optimization, PPO algorithm (Schulman et al., 2017)) are often sample inefficient and unstable (Choshen et al., 2019), our goal is to derive direct preference learning algorithms that directly learn from the preference dataset (Zhao et al., 2023; Rafailov et al., 2023; Azar et al., 2023).
Contribution.
We begin by formulating the learning process as a Markov decision process (MDP), distinct from the contextual bandit approach typically used in RLHF for making general chatbots without external environment interactions (Xiong et al., ; Rafailov et al., 2023). Then, we derive the optimality condition of the optimization problem and develop multi-turn direct alignment algorithms (M-DPO and M-KTO) that incorporate external messages, where the primary modification is to mask out irrelevant tokens during training. Furthermore, we extend our approach to its online iterative variants, which recent works demonstrated to be promising (Xiong et al., ; Guo et al., 2024b). Finally, we evaluate our approach through case studies using augmented training sets from MATH and GSM8K benchmarks, employing various base models such as Gemma (Team et al., 2024), CodeGemma (Team, 2024), and Mistral (Jiang et al., 2023). For instance, the performance of a supervised fine-tuned Gemma-1.1-it-7B model increased from 77.5% to 83.9% on GSM8K and from 46.1% to 51.2% on MATH. Similarly, a Gemma-2-it-9B model improved from 84.1% to 86.3% on GSM8K and from 51.0% to 54.5% on MATH. These empirical results indicate a significant improvement in performance over standard SFT models, demonstrating the potential of RLHF in complex reasoning task. We also provide a comprehensive recipe for the practical implementation of our online iterative multi-turn methods, and make our models, datasets, and code publicly available for further research and development.
1.1 Problem Formulation
We denote prompt as and assume that the interactions run for up to rounds. At the first step, a prompt is sampled from some distribution as the initial state (We use the terminology “state” instead of “context” because we are concerning about an MDP instead of a contextual bandit here). Then, at each step ,
-
•
Action: the agent observes the current state , which is the history of the first interactions with the external environment, and takes an action according to some policy . Typically, the action is in the ReAct manner, which consist of a reasoning step and an execution step (e.g., writing python code) (Yao et al., 2022).
-
•
Observation: in response to the agent’s action, the environment then returns an observation based on the history and current action .
Then, we transit to a new state, which is the history up to the step :
and a new step begins. This process repeats for rounds in total and eventually, we collect a trajectory:
See Figure 1 for an example. The framework presented here is a Markov decision process (MDP), which offers a distinct approach from the contextual bandit model discussed in Xiong et al. . Formally, we define the following MDP.
Definition 1.
An MDP is specified by a tuple , where is the action space, is the episode length111In practice, the episode length can vary across the trajectories. We may additionally define that the shorter trajectories that output the final answer are in an absorbing state. We consider the fixed episode length to simplify the subsequent mathematical analysis. , are the state transition kernels, and denotes the distribution of prompt . For each , is the distribution of the next state given the state-action pair at step . In our setup, a trajectory is generated by: and for all where . When there is no ambiguity, the abbreviation is also adopted.

The MDP formulation of preference learning was recently studied in Zhong et al. (2024); Rafailov et al. (2024); Xie et al. (2024a) but with a focus on the single-turn chat task and without explicitly considering the external messages. A unique feature of RLHF, as opposed to traditional RL studies, is the relative feedback obtained through comparisons between two trajectories that share the same initial state (prompt). We follow Ziegler et al. (2019); Ouyang et al. (2022); Bai et al. (2022) to assume that the preference signal is generated by the so-called Bradley-Terry model.
Definition 2 (Bradley-Terry model).
We denote , where the prompt is excluded from the trajectory. We assume that there exists a utility function of the trajectory such that given , one response is preferred over another response , denoted as , with probability
| (1) |
where is the sigmoid function . Also, given we denote the sampled preference signal as with indicating while indicating .
Under this definition, we only assume access to the trajectory-level preference, but not an action-level one. This should distinguish our approach from a straightforward extension of the single-turn RLHF (Christiano et al., 2017; Ziegler et al., 2019), which fixes a prompt that may include mid-trajectory steps such as and look into the next single step . However, we remark that the utility function itself, can be defined in a step-wise manner. To further illustrate the notion of the BT model in trajectory-level comparisons, we provide some examples of the utility function here.
Example 1 (Result Checking in Math).
Since the math reasoning datasets GSM8K (Cobbe et al., 2021a) and MATH (Hendrycks et al., 2021) have the gold answer, we can check the final answer to determine the reward. In this case, .
Example 2 (Outcome-supervised Reward Models (ORMs)).
Final result checking is not perfectly reliable because we can encounter false positive solutions that have the correct answer but incorrect reasoning trajectory. Instead, as shown in Cobbe et al. (2021b); Lightman et al. (2023), we can uniformly sample trajectories per prompt and train an ORM to predict whether each solution is correct or not. Then, we can take the ORM prediction at the final token as the utility function.
Example 3 (Process-supervised Reward Model (PRM) and PRM without Human Annotation.).
Lightman et al. (2023) argues that if we can provide step-by-step supervision signal, the utility function is more effective. However, this requires more fine-grained human labels to give rating for each step of the trajectory. Wang et al. (2023a) studies how to automatically construct the process-labeled data for math problems with gold answers. Specifically, for , we generate trajectories with final answers . We can define the proxy reward value:
| (2) |
We may also use a hard version
| (3) |
Then, we can train the PRM by
| (4) |
In this case, we can use (Lightman et al., 2023), where is the constructed step-wise reward function.
Notations. To improve the readability of this work, we provide a notable table in Table 6.
1.2 Related Work
LLMs for Mathematical Problem Solving.
A line of works proposes to prompt LLMs to solve the complex reasoning task in a step-by-step manner, known as the Chain-of-Thought (CoT) prompting (Wei et al., 2022; Zhou et al., 2022; Zhu et al., 2022; Tong et al., 2024), which has been a standard practice in reasoning task. However, LLMs often struggle with basic arithmetic and symbolic manipulations when relying solely on internal knowledge and natural language reasoning, as measured by standard benchmarks (Cobbe et al., 2021a; Hendrycks et al., 2021). To overcome these limitations, several studies have explored the use of external tools to enhance the LLMs’ problem-solving abilities. This includes calculators (Cobbe et al., 2021b; Shao et al., 2022), symbolic solvers (Zhang, 2023), and code interpreters (Mishra et al., 2022; OpenAI, 2023). A particularly effective approach is the Program-based method (PoT), which performs CoT reasoning by writing code and using the output of the written code as the final answer (Gao et al., 2023a; Chen et al., 2022). This method significantly outperforms traditional CoT-based techniques in mathematical problem solving. However, PoT also faces challenges in planning and error handling, where natural language reasoning is more suitable (Gou et al., 2023a). In view of this, tool-integrated reasoning is proposed to combine the natural-language-based intrinsic reasoning with the external tools (Gou et al., 2023b) and has achieved great progresses in recent studies (Gou et al., 2023b; Yue et al., 2023; Yu et al., 2023; Shao et al., 2024; Toshniwal et al., 2024). While these efforts have primarily focused on synthetic data generation for tool-integrated reasoning, our work aims to further boost the performance of tool-integrated LLMs by RLHF.
RLHF and RLHF Algorithms.
The predominant approach in RLHF is the deep RL method, Proximal Policy Optimization Algorithms (PPO) (Schulman et al., 2017), which leads to the great successes in Chat-GPT (OpenAI, 2023), Gemini (Team et al., 2023), and Claude (Anthropic, 2023). However, applying PPO requires extensive efforts and resources (Choshen et al., 2019; Engstrom et al., 2020), often beyond the scope of open-source capabilities. In view of this, alternative approaches have been developed. The rejection sampling fine-tuning was first proposed with the name RAFT (reward ranked fine-tuning) in RLHF (Dong et al., 2023) and was later extended to machine translation (Gulcehre et al., 2023) and mathematical problem solving (Yuan et al., 2023a). Its theoretical advantage was explored in Gui et al. (2024). Subsequently, another long line of works proposes direct preference learning algorithms, including SLiC (Zhao et al., 2023), DPO (Rafailov et al., 2023), IPO (Azar et al., 2023), KTO (Ethayarajh et al., 2024), and GPO (Tang et al., 2024). These algorithms bypass the reward modeling step and optimize carefully designed loss objectives directly on the preference dataset, hence the name direct preference learning. There are also some works focusing on more general preference structure Munos et al. (2023); Swamy et al. (2024); Ye et al. (2024); Rosset et al. (2024) beyond the reward-based framework or post-processing of the model (Lin et al., 2023; Zheng et al., 2024).
The newly proposed direct preference learning algorithms have largely advanced the RLHF area, particularly the post-training of open-source models, with the Zephyr project as a notable example (Tunstall et al., 2023). After this, a long line of work (e.g., Liu et al., 2023b; Xiong et al., ; Guo et al., 2024b; Xu et al., 2023; Tajwar et al., 2024; Xie et al., 2024a; Zhang et al., 2024b; Liu et al., 2024a, b; Meng et al., 2024) demonstrates the effectiveness of on-policy sampling (the samples are generated by the policy to be trained) and online exploration in enhancing direct preference learning. In particular, the online iterative DPO (Xiong et al., ; Xu et al., 2023; Hoang Tran, 2024) and its variants (e.g., Chen et al., 2024b; Rosset et al., 2024; Cen et al., 2024; Zhang et al., 2024c) have made state-of-the-art open-source models (Dong et al., 2024), or even the industry models (qwe, 2024; Meta, 2024). Despite these advancements, most algorithms are proposed and designed for single-turn interactions and chat. The scenarios beyond single-turn chat remain largely unexplored in the existing literature. One exception is the very recent work by Shani et al. (2024), which studies multi-turn chat task under general preferences. In contrast, in this paper, we aim to explore the use of RLHF in multi-turn tasks that incorporate interactions with external tools. Meanwhile, they derive a mirror-descent-based policy optimization algorithm, which is also different from ours.
RLHF for Math Problem Solving.
Algorithms traditionally used in general chatbot applications have been adapted to enhance the reasoning capabilities of LLMs in mathematical contexts. For instance, RAFT (Reward-rAnked Fine-Tuning) (Dong et al., 2023; Yuan et al., 2023b; Touvron et al., 2023) is extensively employed for synthetic data generation, whether through on-policy (self-improving) (Yuan et al., 2023a) or off-policy (knowledge distillation) methods (Gou et al., 2023b; Yu et al., 2023; Toshniwal et al., 2024; Singh et al., 2023; Tong et al., 2024). The reward signal in these scenarios is typically derived from either final result checking or Outcome-supervised Reward Models (ORMs) (Uesato et al., 2022; Zelikman et al., 2022). A novel approach by Lightman et al. (2023) introduces Process-supervised Reward Models (PRMs), which provide feedback at each step of the Chain-of-Thought, demonstrating significant improvements over ORMs when combined with rejection sampling (Lightman et al., 2023; Wang et al., 2023a).
In addition to the RAFT, the GRPO algorithm proposed in Shao et al. (2024) studies multi-turn math problem solving but focuses on the CoT format without external inputs and the resulting model achieves the state-of-the-art performance in its class. The GRPO is a variant of Reinforce (Williams, 1992) thus falling into the scope of deep RL methods.
Further advancements include adapting direct preference learning algorithms to mathematical problem solving. For instance, Jiao et al. (2024); Yuan et al. (2024) have applied the original DPO or KTO by taking the trajectory completion as a “meta” action. Xie et al. (2024b); Pang et al. (2024) further adapt the online iterative DPO originally designed for chat (Xiong et al., ; Xu et al., 2023; Hoang Tran, 2024) and achieve better performance for CoT reasoning. Inspired by the success of PRMs, recent studies have explored generating proxy step-wise labels for the intermediate steps of the reasoning trajectories. For instance, Xie et al. (2024b); Chen et al. (2024a); Lai et al. (2024) leverage Monte Carlo Tree Search (MCTS) and use the estimated Q value to generate the proxy labels for the intermediate steps. Lai et al. (2024) proposes to use AI feedback like GPT-4 (Lai et al., 2024) to find the first error step in the trajectory. Meanwhile, Lu et al. (2024) identifies a trajectory with the correct final answer and no errors as preferable, and prompts the SFT model with a high temperature, starting from some intermediate step to collect a rejected trajectory with errors (Pi et al., 2024). Finally, a very recent study by Chen et al. (2024a) proposes to use MCTS with a backward iteration from the final leaf node to compute the proxy unregularized value of each node. Preference pairs are then extracted from the tree by fixing the prefix and comparing the next single reasoning step. Then, they run the original DPO on these intermediate actions with the proxy labels from MCTS. To summarize, these works present different ways of preference data collection and apply the original DPO algorithm (with some additional marginal loss and regularization adapted from the literature), thereby differing from our work in both algorithmic concepts and application scope. In contrast, we study preference learning in the context of trajectory-level comparison, where we derive the optimality condition and introduce a multi-turn DPO within an online iterative framework, specifically for tool-integrated mathematical problem solving. However, we remark that while we focus on the trajectory-level comparison, the preference signal itself can be generated in a step-by-step supervision (see Section 1.1 for the detailed examples). When preference signals for partial trajectories with shared prefixes are available, our method can also adapt to learn these step-level signals (see the optimality condition in (11)). In particular, the algorithmic design presented in this paper can be readily combined with the MCTS-based data collection strategy outlined in recent literature, which we leave for future work.
2 Algorithms Development
We develop the main algorithms of this paper in this section. We proceed to handle the general MDP formulation presented in Section 1.1, which subsumes the tool-integrated mathematical reasoning problem as a special example. Therefore, the algorithms may also be applied to more general scenarios with external messages..
2.1 Planning with a Fixed Model: Optimality Condition
Following Rafailov et al. (2023), we first establish the connection between any model and its associated optimal policy. In particular, we are interested in the following KL-regularized planning problem with respect to a reference policy :
| (5) |
In the single-turn case (i.e., and without transitions ), Rafailov et al. (2023); Azar et al. (2023) show that the optimal solution with respect to a utility function admits a closed-form solution, which is the Gibbs distribution (see Lemma 3):
Moving from the single-step to multi-turn scenario, we first show that we are still concerning about the Gibbs distribution, but in a dynamic programming manner. The results are essentially from the study of entropy-regularized MDPs (Williams and Peng, 1991; Ziebart, 2010).
To illustrate the idea, we first consider the simplest case of , where the model is allowed to call the tool only once. Then, our goal is to maximize the following target:
The idea is to take a backward iteration from to . Specifically, when we fix and consider the inner loop, we can leverage Lemma 3 to solve
Then, we can define the value of the inner loop associated with as
Then, for step , we are concerning the following KL-regularized optimization problem:
By construction, it can be observed that is optimal as it maximizes the KL-regularized target.
For general -step MDP, we can repeat the above process for times starting with where we recursively define
| (6) |
Here the optimal policy and the -values are given by
| (7) | ||||
where is the normalization constant. The second equality in the definition of the -value is from Lemma 3. Then, by definition, is the optimal policy. Essentially, we solve Gibbs distributions in terms of the -values222The definitions of -values are different from that of Ziebart (2010) so that the optimal policy can be interpreted as the Gibbs distribution of -values..
2.2 Planning with a Fixed Model: Practical Algorithm
While (7) can be approximately solved with standard deep RL methods, here we are interested in the implementation in a direct preference learning manner like SLiC (Zhao et al., 2023), DPO (Rafailov et al., 2023) or IPO (Azar et al., 2023). The existing attempts (e.g., Yuan et al., 2024) take the completion as a “meta action” and plug it into the single-step DPO loss. In other words, they treat the external messages as the regular texts generated by the model itself. Another natural idea is to plug the probability of the trajectory into the single-step DPO loss. To be specific, for a pair , where refers to the preferred (i.e., winning) trajectory, we have
| (8) | ||||
Unfortunately, the resulting algorithm does not always lead to the optimal policy as we explain next. In particular, we can solve the -values as
| (9) | ||||
where two equalities uses the definition of the optimal policy and -value in (7), respectively. Furthermore, by the definition of -values in (6), we have
| (10) | ||||
Summing over , we have
| (11) | ||||
Here, term is the counterpart of in the single-step DPO derivation and term will be cancelled if we consider the reward difference of two trajectories with the same prompt . Unfortunately, in practice, term is typically not feasible to directly compute. Especially, some simple math with the Chebyshev’s Inequality leads to that with probability at least ,
where is the conditional variance of . Therefore, the bias term is related to the randomness of the external environment.
For most cases of tool-integrated LLMs for mathematical reasoning, i.e., the focus of this work, luckily the code execution result is determined by the history (the codes written by the LLMs). In other words, given the history , the external observation is deterministic, which leads to . Thus, with a dataset consisting of , the following multi-turn DPO (M-DPO) loss can be adopted:
| (12) |
We emphasize again that although the loss presented in (12) is identical to the one in (8), a rigorous derivation procedure (rather than a direct plug-in) is provided. To the best of our knowledge, (12) is new in the context of multi-turn reasoning task with external messages. In particular, it is noted that such a M-DPO loss is only valid upon deterministic transitions, i.e., term .
Moreover, with (11) implying that with term , the implicit reward is given by , a multi-turn version of KTO (Ethayarajh et al., 2024), denoted as M-KTO, can also be naturally derived:
| (13) |
where
and
Here and are two hyper-parameters. We notice that Mitra et al. (2024) developed an online iterative version of KTO for the CoT format reasoning task. Here we extend it to build the tool-integrated reasoning agent.
The above discussions, in particular, M-DPO and M-KTO losses provided in (12) and (13), are focused on deterministic observations due to the deterministic nature of tool-integrated LLMs for mathematical reasoning. In contrast, some other applications may encounter stochastic observations, e.g., multi-turn chats with the external message provided by a human or another LLM (Shani et al., 2024). In these scenarios, (12) is biased and cannot lead to the optimal policy since . Instead, one should first construct a value network based on the Bellman equations provided in (6) and (7), similar to the approach in Richemond et al. (2024). Subsequently, can be estimated using Monte-Carlo methods and serve as an adaptive margin in the preference training. Particularly, the distinctions between direct preference learning algorithms and classical deep RL methods become less clear. The exploration of this more complex algorithm and its application to general multi-turn learning scenarios is left for future research.
We note that the MDP formulation above and related discussions have been previously derived by Zhong et al. (2024); Rafailov et al. (2024); Xie et al. (2024a) in the context of either token-wise MDP or more general MDP with deterministic transition but their focuses are all on the single-turn chat tasks. Although the mathematical formulations appear similar, our primary focus lies on tool-integrated reasoning tasks that incorporate additional external messages .
2.3 Learning with Online Iterative Training
In the literature of direct preference learning, a long line of work shows that the online single-turn RLHF significantly outperforms their offline counterpart, both in the literature of direct preference learning (Xiong et al., ; Ye et al., 2024; Guo et al., 2024b; Rosset et al., 2024; Dong et al., 2024; Tajwar et al., 2024) and DRL-based approach or rejection sampling fine-tuning (Bai et al., 2022; Ouyang et al., 2022; Touvron et al., 2023). Motivated by these successes, we propose to further incorporate online interactive learning to the multi-turn RLHF studied in this work. In the following, we illustrate the proposed ideas from mainly two aspects: two learning objectives and one unified algorithmic framework.
Learning objective.
We consider two different learning objectives. The first one is the KL-regularized target:
| (14) |
i.e., where is the groundtruth environment and is the initial policy (e.g., from SFT) that RLHF starts from. This target is widely adopted in practice (Christiano et al., 2017; Ouyang et al., 2022; Bai et al., 2022; Rafailov et al., 2023; Dong et al., 2024) and requires us to search for the optimal policy only at a fixed KL ball centered at the SFT policy (Xiong et al., ; Ye et al., 2024; Xie et al., 2024a).
In contrast, the second one is the non-regularized target, i.e., directly optimizing the reward:
| (15) |
This target is the standard one in canonical RL studies (Sutton and Barto, 2018). One motivation for this target is that in the reasoning task, the reward function is more interpretable (e.g. final result checking) compared to the chat task.
Additionally, we note that a stronger KL regularization in the target (14) is known to be beneficial for mitigating over-fitting issue and forgetting on the out-of-domain tasks (Gao et al., 2023b; Lin et al., 2023; Coste et al., 2023). On the other hand, (15) allows the model to move more far away, thus achieving a better in-domain performance. Thus, from one perspective, the choice between the above two targets can be viewed as a tradeoff between out-of-domain and in-domain performances. This intuition is also verified by later experiments, where optimizing the second target in (15) leads to better performance on in-domain test sets. In the rest of this section, we discuss two learning objectives to fully develop the multi-turn preference learning framework. We also conduct an ablation study on these objectives in the experimental section.
Algorithmic framework.
We present a general online iterative algorithmic framework in Algorithm 1. This framework is termed as Online Iterative Multi-turn Gibbs Sampling from Human Feedback (M-GSHF) to highlight the online iterative training process and the optimal condition derived in (7) that the optimal policy is a layer-wise Gibbs distribution, which generalizes the bandit formulation in Xiong et al. . Specifically, starting from , at each iteration, we first collect a pair of trajectories by the current policy pair, where the preference signal is also revealed according to Definition 1. Then, we update our policy pair given the data collected so far and the next iteration begins. We now discuss some features of the framework as follows.
Policy choice for exploration-exploitation trade-off. We update our behavior policies in a non-symmetric way. The first agent, which aims to extract the historical information we have gathered so far, planning with respect to the empirically best model on the historical dataset to get , where the planning algorithms have been discussed in Section 2.2, e.g., optimizing the M-DPO or M-KTO loss in (12) or (13). However, it is widely recognized in RL studies (Sutton and Barto, 2018; Auer et al., 2002) that simply exploiting the historical data via following the empirically best model is not sufficient to obtain a good final policy, while it is also required to explore the environment so that new information can be collected to facilitate subsequent learning, i.e., the exploration-exploitation tradeoff. While the main agent targeting exploitation, we design the second agent, in contrast, to strategically incorporate the uncertainty of the future relative to given the historical information we collect so far into its policy choice. We call the policy of the second agent as an exploration policy because it serves to explore the underlying environment and facilitate the first agent’s learning. In practice, this principle of exploration is generally interpreted as maximizing the difference between the two behavior policies or increasing the diversity of the collected data. We summarize some popular heuristic exploration policy adopted in the online iterative RLHF practice:
-
•
Mixture sampling: in the Claude project (Anthropic, 2023), the authors choose to use the checkpoints from different training steps to collect data;
-
•
Inference parameters tuning: in the LLaMA project (Touvron et al., 2023), the authors carefully tune the sampling temperature to balance data diversity and data quality;
-
•
West-of-n sampling: Xu et al. (2023); Hoang Tran (2024); Pace et al. (2024); Dong et al. (2024) samples n responses per prompt and extract the best one and the worst one (based on some ranking criteria) to construct a preference pair.
We will explore the mixture sampling in the experimental section and also provide a theoretical justification in the next subsection.
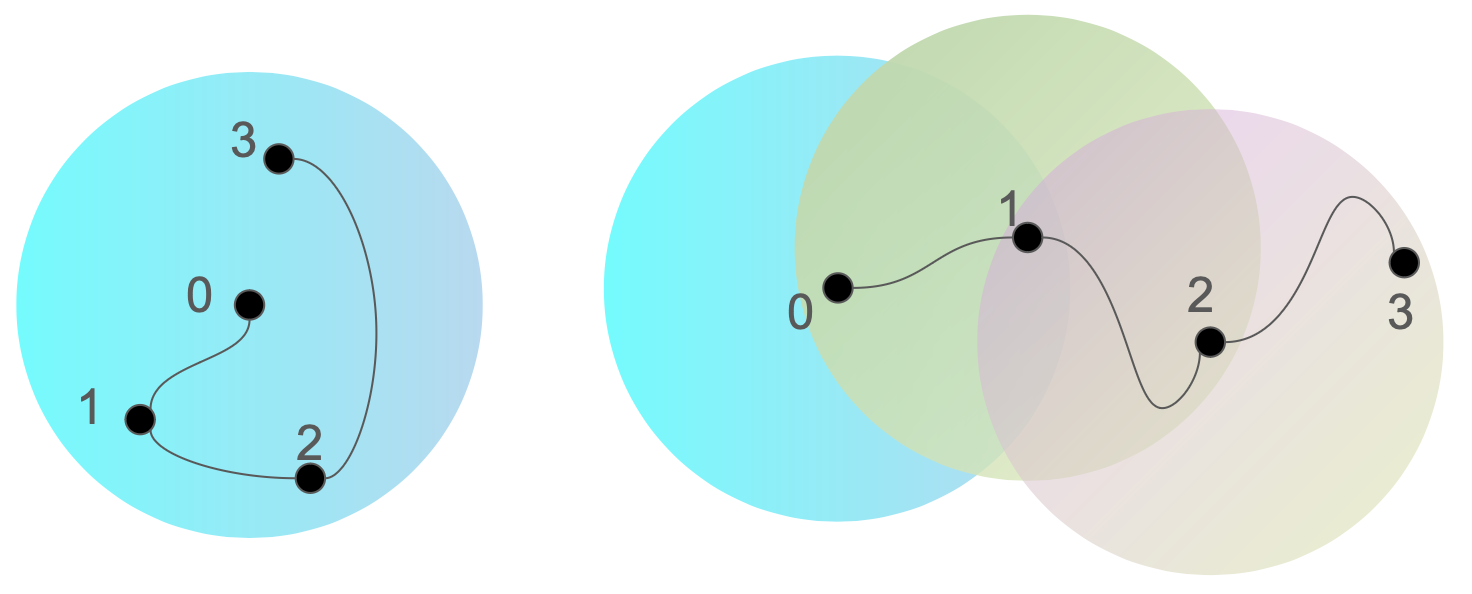
Reference model choice for controlling regularization level. Despite two different learning targets are discussed in (14) and (15) seperately, we note that one general algorithmic framework can be adopted with the reference model choice taking as a hyper-parameter to control the regularization level and account for the two targets:
-
•
KL-regularized target in (14): if we fix the reference model as the initial policy, i.e., , we always search the optimal policy within the KL ball centered at , and thus optimize the KL-regularized target.
-
•
Non-regularized target in (15): in contrast, inspired by the mirror descent (Nemirovskij and Yudin, 1983), if we update the reference policy every iteration to be the policy learned in the last iteration, i.e., , the cumulative update can make the model to move away from the original (while a constraint is made on the per-iteration update magnitude) and we thus optimize the non-regularized target.
A graphical illustration is provided in Figure 2 to facilitate the understanding.
2.4 Theoretical Results
In this section, we show that the multi-turn RLHF problem can be solved in a statistically efficient manner under standard assumptions in learning theory literature. In particular, for generality, we target the most challenging scenario with stochastic and unknown transitions, while as aforementioned, multi-turn mathematical reasoning with external tools falls into an relatively easier regime with deterministic transitions. Here we mostly studies the KL-regularized target due to the lack of theoretical research on it. The other target of optimizing the rewards has been theoretically studied in Wang et al. (2023b) while the techniques of analyzing mirror-descent-style algorithm and corresponding guarantees have also be developed in Cai et al. (2020), which can be migrated to considering preference feedbacks. Also, to ease the presentation, we consider the scenario with batch size , while the results can be easily generalized to large batches.
First, to measure the online learning process, we define the optimal policy as
| (16) |
and introduce the standard notion of regret as
| (17) |
which represents the cumulative performance loss over steps comparing the learned policies against the optimal policy . In addition, we consider that a bounded for all to maintain a reasonable utillity regime. Also, it is assumed that we have accesses to the following policy improvement oracle, that is analogue to the one considered in Xiong et al. .
Definition 3 (Policy Improvement Oracle).
For any model and a reference function , we can compute the optimal policy associated with the model iteratively as in (7).
The overall algorithm, i.e., the theoretical version of online iterative M-GSHF, is also summarized in Algorithm 1. At each round , with as the aggregated dataset, it starts with performing a maximum likelihood estimation (MLE) of the reward function over a set , whose elements are bounded in , as
| (18) |
and also an MLE of the transition kernel over a set as
| (19) |
where denotes the probability of trajectory under policy and transition kernel . With the obtained model , the Oracle defined in Definition 3 is called with the reference policy set as the initial policy , whose output is adopted as the main policy .
Then, we specify how to choose a theoretically sound exploration policy . The previous work of Xiong et al. on single-turn RLHF has demonstrated the intuition that the exploration policy should be in charge of collecting information of the uncertain parts of the environment , which is thus often selected to maximize one uncertainty measurement. In the multi-turn RLHF setup considered in this work, the following proposition serves as the cornerstone to find a suitable uncertainty measurement to decide the exploration policy. In particular, we can observe that the optimal policy is parameterized by the optimal -function. If a different set of -function is adopted for policy parameterization, we can bound its performance as follows.
Proposition 1 (Value Decomposition Lemma for KL-regularized MDP).
If considering a set of -functions and a reference policy with the induced policy as
and the corresponding set of -functions as
for any comparator policy , it holds that
where the expectation is with respect to the prompt and response (i.e., the trajectory) generated following and .
Based on Proposition 1, the exploration policy is selected as
| (20) |
where and are two confidence sets defined as
| (21) | ||||
with denoting an absolute constant here. Note that for the theoretical convenience, we have assumed and are finite here, which can be extended to the infinite case using standard discretization techniques. It can be observed that is selected to maximize a combination of uncertainty from estimations of both rewards and transitions. If considering known transitions (i.e., without the need to estimate ), the uncertainty from the estimation of transitions dimimishes, which leads to a similar uncertainty measurement adopted in Xiong et al. .
The following theorem establishes a rigorous guarantee for the regret incurred.
Theorem 1.
We note that the Eluder coefficient and the generalized Eluder-type condition are standard and well-adopted conditions in the theoretical studies on RL (Zhang, 2023; Zhong et al., 2022; Liu et al., 2023a; Xie et al., 2022; Agarwal et al., 2023) and also RLHF (Zhan et al., 2023; Wang et al., 2023b; Ye et al., 2024). Moreover, for a board class of RL problems (see Zhang (2023); Liu et al. (2023a) for more details), the Eluder coefficient is small and the condition is satisfied with , which implies that the regret of theoretical version of Algorithm 1 is sublinear in , further evidencing its statistical efficiency.
3 Experiments
3.1 Experiment Setup
Task, and datasets.
We use the test sets of MATH (Hendrycks et al., 2021) and GSM8K (Cobbe et al., 2021a) to measure the model’s ability to solve the mathematical problems. The MATH dataset includes 5K problems across diverse mathematical fields such as algebra, geometry, probability, number theory, and calculus. The GSM8K test set consists of 1319 grade-school math word problems, which are generally simpler than those in the MATH dataset. Examples from each dataset are as follows:
-
•
GSM8K: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
-
•
MATH: Find the center of the circle with equation .
To effectively solve these problems, the model needs to perform multi-turn reasoning and arithmetic operations before getting the final answer. To construct the training prompt set, we follow Gou et al. (2023b); Yu et al. (2023); Yue et al. (2023); Liu and Yao (2024); Toshniwal et al. (2024) to use an augmented prompt set from the 7.5K training problems of MATH and 7.47K training problems of GSM8K. In particular, we use the prompts from MetaMathQA (Yu et al., 2023) and MMIQC (Liu and Yao, 2024). The new questions include rephrasing question, backward question (starting with the final answer and thinking backward to determine an unknown variable in the original question), and bootstrapping questions by in-context learning and iterative question composing (Liu and Yao, 2024). We delete the duplicate questions and also ensure that none from the test sets of MATH and GSM8K were used. Eventually, we have 60K training prompts in total for training and randomly split them into three disjoint sets for iterative training. We also reserve a set of 1K prompts for model selection during the training.
Base models.
We train with a range of base models, including Gemma-1.1-it-7B (Team et al., 2024), CodeGemma-1.1-it-7B (Team, 2024), Mistral-7B-v0.3 (Jiang et al., 2023), and Gemma2-it-9B. We use the pre-trained version of Mistral instead of the instruction version because the chat template of its huggingface checkpoint and that of their own code base are not consistent so we start from the pre-trained model and fine-tune it by ourselves.
Data format and generation.
We format the data into a multi-turn chat where the user initially ask the LLMs a question, and provide the messages returned by the Python interpreter in the subsequent user rounds of chat. In each model turn, the model reasons based the history gathered so far and can output a final answer enclosed in boxed, or call the Python interpreter by writing a code wrapped in ```python and ```. After receiving the response of the model, we return the execution result of the code if the model calls the tool, and stop if the model outputs the final answer or reaches the maximal number of rounds H (6 in our setting). See Figure 1 for an illustration. We generated N=30 samples per prompt for each iteration using a temperature setting of 1.0, without employing top-K or top-p sampling. We employ a mixture sampling strategy, where the up-to-date model generates only 20 trajectories, and the remainder (10 trajectories) are collected using the model from the last iteration. For the initial iteration, we employed models fine-tuned for 3 epochs and 1 epoch, respectively, to conduct mixture sampling. Intuitively, the mixture sampling helps to improve the diversity of the collected samples, and have been employed in previous RLHF practices (Bai et al., 2022; Dong et al., 2024). For all the data generation process, we adopt the following constraints: (1) for each turn, the model can generate up to 512 tokens; (2) the maximal number of steps is H=6; (3) the maximal number of token for each trajectory is 2048.
Supervised fine-tuning (SFT).
We first fine-tune the model for the tool-integrated reasoning task (Gou et al., 2023b), using a subset of the Open-MathInstruct dataset, which was generated by the permissively licensed Mixtral-8x7B model through in-context learning. The problems are from the training sets of MATH and GSM8K datasets. We restrict the number of samples for each question to be and remove the nearly duplicate responses. Eventually we get 510K samples in the SFT dataset. We train the models for 4 epochs at most with a learning rate of 5e-6 for Gemma instruct models (Team et al., 2024) and a learning rate of 1e-5 for Mistral-v0.3 model (Jiang et al., 2023). The learning rates are determined by searching {2e-6, 5e-6, 1e-5}. We use the pretrained model of Mistral because the chat template of Mistral instruct models are not consistent in different code bases (huggingface and the official one) at the time of our experiments. We use a cosine learning rate scheduler and set the warm-up steps as 100. The samples are packed into blocks with length 4096 to accelerate training and a global batch size of 64 is used. We also mask all the user messages (i.e., the prompt and the messages returned by the Python interpreter) in the training. It takes roughly 10-15 hours when training with 8xA100 80G GPUs. The checkpoint at the end of the third epoch is used for Gemma and the checkpoint of the end of the second epoch is used for Mistral as the starting point for RLHF. This is because these models outperform the last-iteration one with considerable margin and is very close to the next one. An ablation study on the SFT epochs is also included.
Data Annotation.
For each prompt, we first divide the responses into the winning set and the losing set by checking the final answer. In practice, we observe that the model can memorize the final answer and output it even though the reasoning path itself is incorrect. To mitigate this issue, we include some heuristic filtering process. First, we delete all the trajectories in the winning set where the returned messages in the second last round indicate the code is with some bugs, but the models just ignore it and predict the ground-truth answer. Then, we delete the responses in both the winning set and losing set if they are longer than 2048 tokens. Finally, we randomly sample a trajectory from the and a trajectory from to construct a pair or to add them into the training set of KTO algorithm. For each iteration, we typically get 15K-20K samples because some of the prompts may not have any correct answer. We notice that it is possible to leverage AI feedback like Gemini (Team et al., 2023) or GPT4 (OpenAI, 2023) to further verify the correctness of the trajectory step by step or construct a PRM (Lightman et al., 2023; Wang et al., 2023a) to rank the trajectories, which we leave for future work.
Implementation of M-DPO and M-KTO.
To implement the M-DPO, we simply set the labels of all the user-turn tokens to be -100 and mask the log-probability in the subsequent loss computation. We train the model for 1 epoch at most and tune the learning rate in {2e-7, 4e-7, 7e-7, 1e-6} with the first iteration of iterative training. Eventually, the learning rate of 4e-7 is used for Gemma-1.1 models and 2e-7 is used for Gemma-2 model and Mistral model. The global batch size is 32 with a warm-up step of 40. We evaluate the model every 50 training steps by the split prompt set and the best model is typically obtained between 150 steps to 600 steps, which is expected because the prompts for SFT and prompts for RLHF are overlapped. This has also been observed in previous work of RLHF for making general chatbot (Lin et al., 2023). Further exploration of prompt scaling is also left for future work. The hyper-parameters are of M-KTO are mostly the same as the M-DPO. We also set the following the original KTO paper (Ethayarajh et al., 2024). The RLHF experiments of this paper are run with 8xA100 80G GPUs, where an additional machine with 8xA100 40G GPUs is also used for data collection and model evaluation. The main experiment of this paper can be reproduced by 24 - 48 hours with this setup. We defer some other implementation details to Appendix B due to space constraint.
3.2 Main Results
We evaluate the models in the zero-shot setting and report the main results in Table 1.
Baselines.
The existing literature mainly focuses on the synthetic data generation and teach the models to use the external tool by supervised fine-tuning on the collected data. We use the results from Toshniwal et al. (2024) as baselines because we use the same SFT dataset so the results are generally comparable. For the CoT baselines, we use the Wizardmath models from Luo et al. (2023). We also include the reward ranked fine-tuning (RAFT) as a baseline (Dong et al., 2023), which is also known as rejection sampling fine-tuning in the literature (Touvron et al., 2023). RAFT first collects N trajectories per prompt, filters the low-quality data (by reward function), and fine-tune on the selected trajectories. Another baseline is the single-turn online iterative DPO and KTO (Rafailov et al., 2023; Ethayarajh et al., 2024), which ignores the problem structure (i.e., the external messages) and treats the trajectory as a whole. In implementation, it means that we do not mask the user turn and the tokens of external messages also contribute to the loss.
| Base Model | Method | with Tool | GSM8K | MATH | AVG |
|---|---|---|---|---|---|
| WizardMath-7B | SFT for CoT | ✗ | 54.9 | 10.7 | 32.8 |
| WizardMath-13B | SFT for CoT | ✗ | 63.9 | 14.0 | 39.0 |
| WizardMath-70B | SFT for CoT | ✗ | 81.6 | 22.7 | 52.2 |
| CodeLLaMA-2-7B | SFT | ✓ | 75.9 | 43.6 | 59.8 |
| CodeLLaMA-2-13B | SFT | ✓ | 78.8 | 45.5 | 62.2 |
| CodeLLaMA-2-34B | SFT | ✓ | 80.7 | 48.3 | 64.5 |
| LLaMA-2-70B | SFT | ✓ | 84.7 | 46.3 | 65.5 |
| CodeLLaMA-2-70B | SFT | ✓ | 84.6 | 50.7 | 67.7 |
| Gemma-1.1-it-7B | SFT† | ✓ | 77.5 | 46.1 | 61.8 |
| Gemma-1.1-it-7B | RAFT | ✓ | 79.2 | 47.3 | 63.3 |
| Gemma-1.1-it-7B | Iterative Single-turn DPO | ✓ | 81.7 | 48.9 | 65.3 |
| Gemma-1.1-it-7B | Iterative Single-turn KTO | ✓ | 80.6 | 49.0 | 64.8 |
| Gemma-1.1-it-7B | Iterative M-DPO + fixed reference | ✓ | 79.9 | 48.0 | 64.0 |
| Gemma-1.1-it-7B | M-DPO Iteration 1 | ✓ | 81.5 | 49.1 | 65.3 |
| Gemma-1.1-it-7B | M-DPO Iteration 2 | ✓ | 82.5 | 49.7 | 66.1 |
| Gemma-1.1-it-7B | M-DPO Iteration 3 | ✓ | 83.9 6.4 | 51.2 5.1 | 67.6 5.8 |
| Gemma-1.1-it-7B | Iterative M-KTO | ✓ | 82.1 4.6 | 49.5 3.4 | 65.8 4.0 |
| CodeGemma-1.1-it-7B | SFT† | ✓ | 77.3 | 46.4 | 61.9 |
| CodeGemma-1.1-it-7B | RAFT | ✓ | 78.8 | 48.4 | 63.6 |
| CodeGemma-1.1-it-7B | Iterative Single-turn DPO | ✓ | 79.1 | 48.9 | 64.0 |
| CodeGemma-1.1-it-7B | Iterative Single-turn KTO | ✓ | 80.2 | 48.6 | 64.4 |
| CodeGemma-1.1-it-7B | Iterative M-DPO | ✓ | 81.5 4.2 | 50.1 3.7 | 65.8 4.0 |
| CodeGemma-1.1-it-7B | Iterative M-KTO | ✓ | 81.6 4.3 | 49.6 3.2 | 65.6 3.8 |
| Mistral-7B-v0.3 | SFT† | ✓ | 77.8 | 42.7 | 60.3 |
| Mistral-7B-v0.3 | RAFT | ✓ | 79.8 | 43.7 | 61.8 |
| Mistral-7B-v0.3 | Iterative Single-turn DPO | ✓ | 79.8 | 45.1 | 62.5 |
| Mistral-7B-v0.3 | Iterative Single-turn KTO | ✓ | 81.3 | 46.3 | 63.8 |
| Mistral-7B-v0.3 | Iterative M-DPO | ✓ | 82.3 4.5 | 47.5 4.8 | 64.9 4.7 |
| Mistral-7B-v0.3 | Iterative M-KTO | ✓ | 81.7 3.9 | 46.7 4.0 | 64.2 4.0 |
| Gemma-2-it-9B | SFT† | ✓ | 84.1 | 51.0 | 67.6 |
| Gemma-2-it-9B | RAFT | ✓ | 84.2 | 52.6 | 68.4 |
| Gemma-2-it-9B | Iterative Single-turn DPO | ✓ | 85.2 | 53.1 | 69.2 |
| Gemma-2-it-9B | Iterative Single-turn KTO | ✓ | 85.4 | 52.9 | 69.2 |
| Gemma-2-it-9B | Iterative M-DPO | ✓ | 86.3 2.2 | 54.5 3.5 | 70.4 2.9 |
| Gemma-2-it-9B | Iterative M-KTO | ✓ | 86.1 2.0 | 54.5 3.5 | 70.3 2.8 |
From the first two sections in Table 1, we first observe that the tool-integrated LLMs significantly outperform their CoT counterparts with only SFT, demonstrating the benefits of leveraging external tools. In the subsequent discussions, we focus on the comparison within the scope of tool-integrated LLMs.
Iterative M-DPO and M-KTO considerably improve the SFT models.
We observe that for all the four base models, after the iterative training with M-DPO or M-KTO, the resulting model outperforms their starting SFT checkpoint with considerable margins on both GSM8K and MATH. In particular, with M-DPO, the aligned Gemma-1.1-it-7B model attains accuracies of 83.9% and 51.2% on GSM8K and MATH, respectively, and is comparable to the open-source Open-MathInstruct-finetuned CodeLLaMA-2-70B (slightly worse on GSM8K but also slightly better on MATH). Moreover, the aligned Gemma-2-it-9B model achieves accuracies of 86.3% and 54.5% on GSM8K and MATH, surpassing all of the open-source models trained with Open-MathInstruct in the 7B to 70B range. Overall, our framework can robustly further boost the tool-integrated models’ ability on the top of supervised fine-tuning.
Iterative M-DPO and M-KTO surpass existing RLHF baselines.
We also observe that the iterative M-DPO and M-KTO surpass other existing RLHF baselines. First, they consistently and significantly outperform the RAFT algorithm across all four base models, which is known to be a robust and competitive baseline in the literature (Dong et al., 2023; Yuan et al., 2023a). This is because the RAFT algorithm only utilizes the positive signal by imitating the correct trajectories, while the DPO-based and KTO-based algorithms further leverage the negative signal from those incorrect trajectories. We note that the SFT stage in our pipeline can also be viewed as an application of RAFT, an idea that further dates back to expert iteration (Anthony et al., 2017). Consequently, our results should be interpreted to be that on the top of the first stage of SFT, algorithms with negative signal are more sample efficient. Moreover, while the online iterative single-turn DPO (KTO) (Xiong et al., ; Xu et al., 2023) also gives a boost performance, it is generally worse than the multi-turn version. This suggests that learning to predict the off-policy external messages returned by the code interpreter usually has a negative impact on the reasoning ability improvement. Essentially, this corresponds to the fact that when deriving the optimality condition of the KL-regularized optimization problem, we are not allowed to optimize the external messages. Meanwhile, we present a representative example we encounter in Figure 3, where LLMs generate poorly constructed code resulting in anomalous and lengthy external messages. Forcing LLMs to learn to predict these messages can significantly hurt the model’s reasoning abilities.

Iterative training and reference update lead to better performance.
We use the Gemma-1.1-it-7B and M-DPO as a representative example and observe that the model benefits from online iterative training, where the test accuracy of GSM8K improves from 77.5% (SFT) to 81.5% (iter 1) to 82.5% (iter2) to 83.9% (iter3), and the test accuracy of MATH improves from 46.1% (SFT) to 49.1% (iter 1) to 49.7% (iter2) to 51.2% (iter3). This is consistent with our theoretical insight that iterative training allows the models to explore the underlying space and learn the optimal policy progressively. Moreover, we observe that if we fix the reference model as the SFT policy, the final model performance is much worse compared to the case where we update the reference model as the current model at every iteration. We suspect that this is because this version of algorithm essentially optimizes the non-regularized reward and the reward in the mathematical reasoning task is more accurate than those in the general chat task, leading to the superior in-domain performance. We defer a more detailed ablation study on the impact of KL regularization to next subsection.

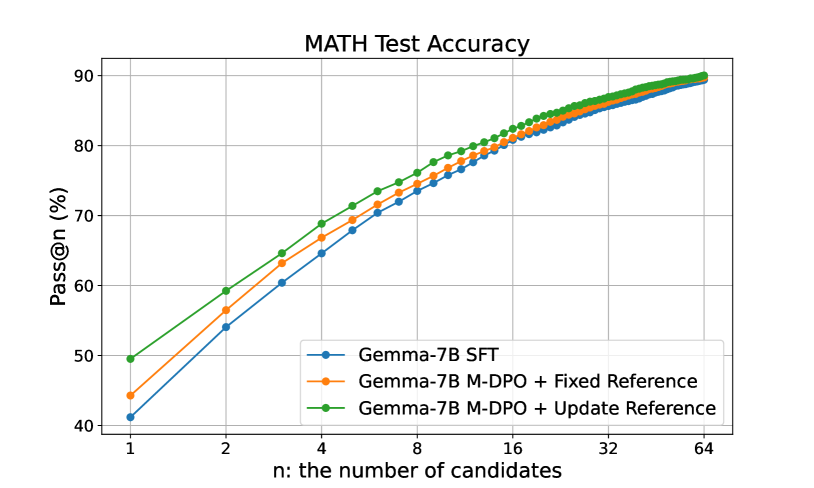
Preference learning improves pass@n only when n is relatively small.
We plot the pass@n accuracy in terms of the number of candidate trajectories n in Figure 4. To evaluate the pass@n, for each question, we independently sample n trajectories, and the question is considered to be solved if there exists at least one trajectory with the correct final answer. We observe that the preference learning only improves the pass@n when n is relatively small. In particular, when , all the models perform similarly on both GSM8K and MATH. In other words, the iterative M-DPO does not inject new knowledge but elicits the models’ knowledge acquired in pre-training and SFT stages by boosting the quality of Top n responses. The observation is consistent with that of Shao et al. (2024), which studies the DRL-based GRPO method for the CoT mathematical reasoning task. Therefore, the success of preference learning is on top of a well-trained SFT model. We expect that the final model performance can be further improved with more high-quality SFT data.
3.3 Ablation Study and Discussion
We conduct ablation studies in this subsection for a more comprehensive understanding of the proposed algorithm.
A moderate level of KL regularization balances the per-iteration improvement and exploration efficiency.
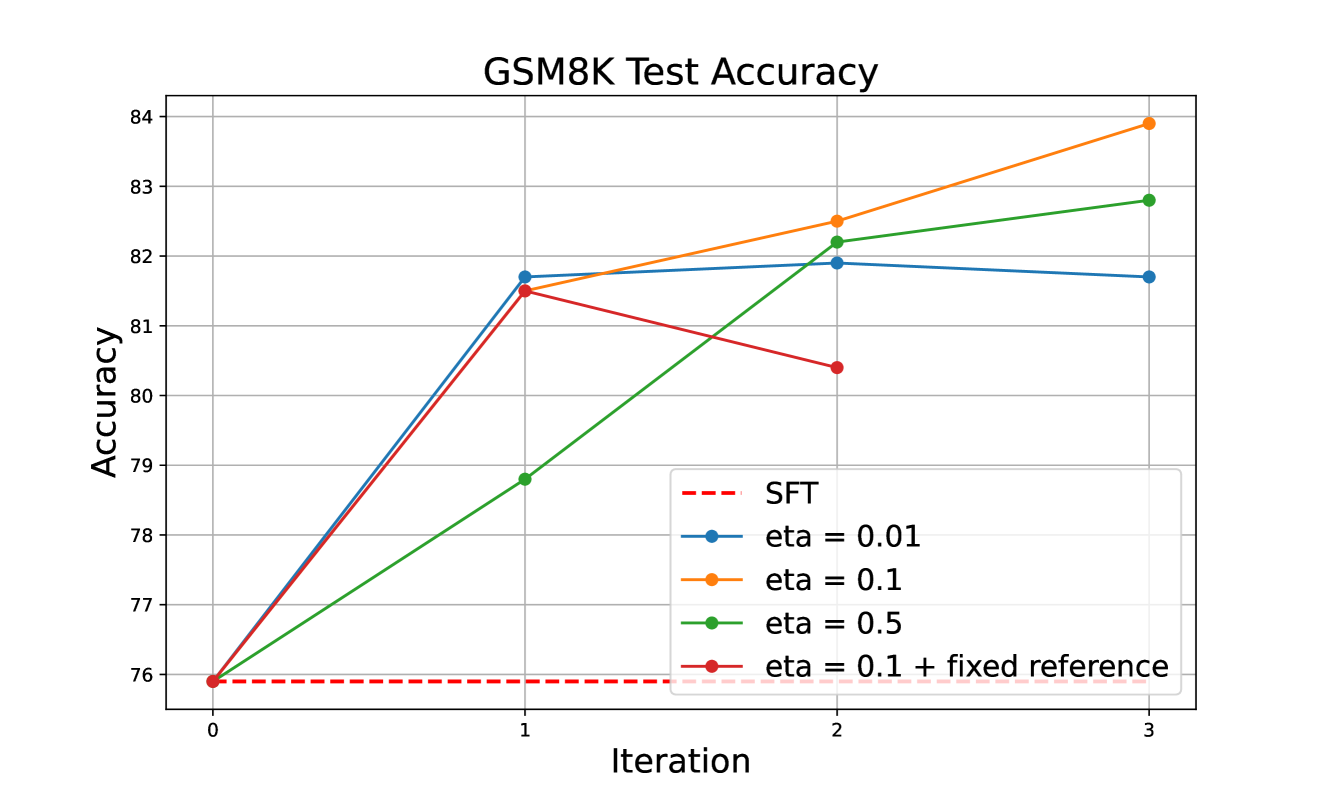
The effectiveness of (iterative) DPO is significantly influenced by the choice of reference model and the KL coefficient. Previous research by Tunstall et al. (2023) on offline DPO for general chatbot applications suggests that a lower KL coefficient, specifically 0.01, yields superior performance by allowing the resulting model to move more far away from the SFT model . Meanwhile, for online iterative training, Xiong et al. ; Dong et al. (2024) adopt a fixed reference model of , and achieves continuous improvements as the training iterates. In our ablation study, we consider two different choices: (1) using the fixed reference model ; (2) updating the reference model to the last iteration’s model at each round. Moreover, we search the KL coefficient . The results are summarized in Table 2. First, we notice that if we update the reference model at each iteration, the final model outperforms the one with a fixed reference model with a large margin. Essentially, this dynamic approach optimizes the non-regularized reward, while the one with a fixed reference model aims to maximize the KL-regularized reward. This can be viewed as a trade-off between the generation diversity and reward optimization. We suspect this performance difference is because for reasoning task, the correct reasoning paths are highly concentrated on a small subset of the generation space, and the diversity is less important in this case.
We also find that the strongest model is obtained by a moderate KL coefficient of , outperforming both 0.01 and 0.5. To understand this phenomena, we plot the test accuracy of GSM8K in Figure 5 along the way of iterative training. As we can see, for the first iteration, the results align with Tunstall et al. (2023)’s findings, where a smaller KL coefficient leads to a larger model improvement. However, the resulting intermediate model is further used to collect trajectories for subsequent iterative training. The models trained with very low KL coefficients tend to lose diversity rapidly, potentially reducing their capacity to collect diverse trajectories for subsequent training, leading to diminishing gains in the second and third iterations. In contrast, a higher KL coefficient of 0.5 imposes strong regularization between the resulting model and the reference model, and the model improvement is less compared to that of for each iteration. To summarize, for online iterative training, we need to strike a balance between the per-iteration improvement and exploration efficiency to optimize the overall performance. We will see that such an intuition also extends to the choices of sampling strategy choice and other experimental tricks.
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | Iterative M-DPO + | 81.7 | 50.1 |
| Gemma-1.1-it-7B | Iterative M-DPO + | 83.9 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO + | 82.8 | 49.7 |
| Gemma-1.1-it-7B | Iterative M-DPO + fixed reference + | 79.9 | 48.0 |
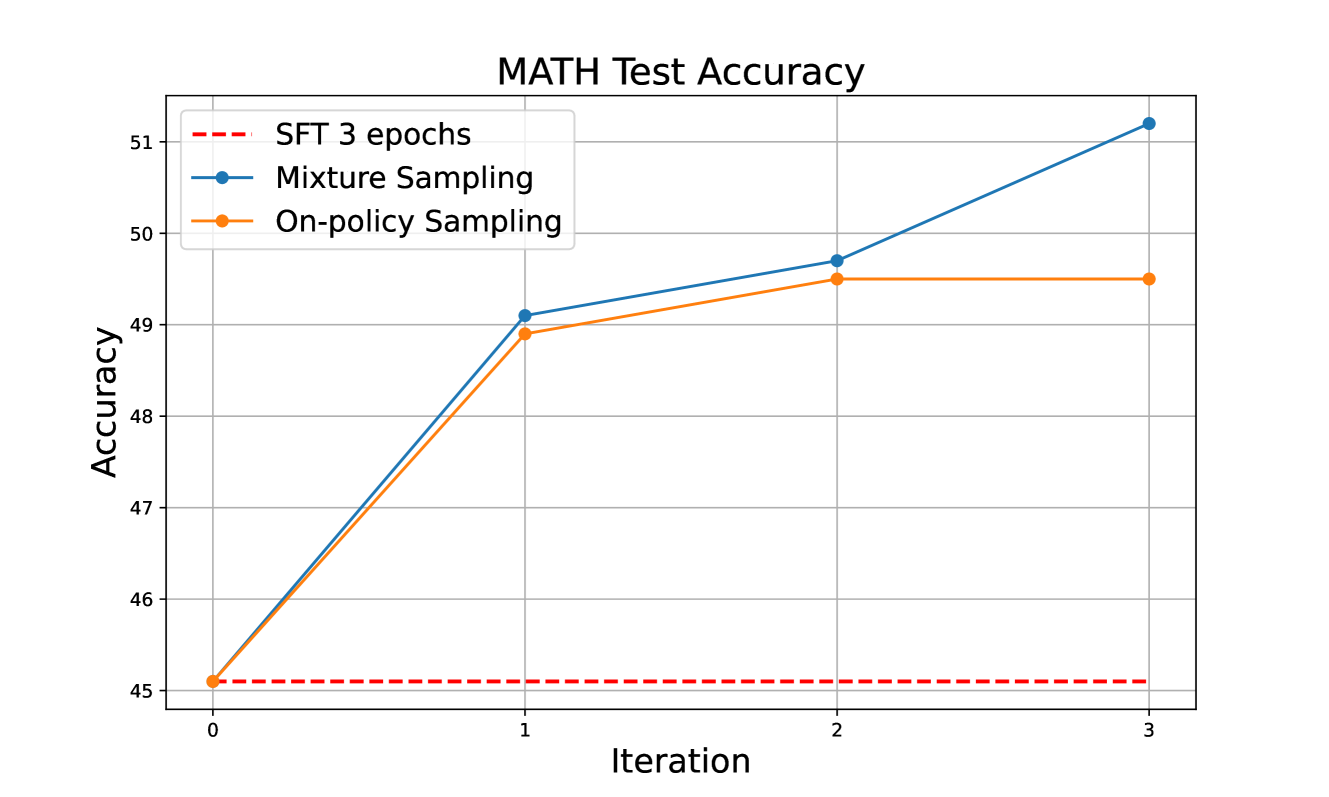
The impact of sampling strategy: data diversity and coverage are crucial.
Throughout our iterative training process of the Gemma-1.1-it-7B, we observed a steady increase in the percentage of correct trajectories—from 47% in the first iteration to 76% in last iteration. Moreover, since we update the reference model at each iteration, the diversity of the generated trajectories also decrease rapidly. However, the diversity of the collected data is critical for DPO/KTO training due to their contrastive nature. Prior studies in online iterative DPO for general chatbots (Dong et al., 2024) recommend employing model variants with different sampling temperatures or training steps to enhance trajectory diversity. Motivated by this, we explored two data collection strategies: (1) on-policy sampling, where all trajectories are sampled using the current policy, and (2) mixture sampling, where 20 trajectories are collected using the current model and 10 from the last iteration’s model. We report the results in Table 5, where with mixture sampling, the final model performance considerably outperform the one with only on-policy sampling. To understand this phenomena, we plot the MATH test accuracy in terms of the iteration in Figure 6. We observe that on-policy sampling fails to improve MATH test accuracy in the third iteration, while we achieve considerable gain with the mixture sampling. This again demonstrates the importance of the diversity of the collected responses in the iterative training and also aligns with previous findings that advanced exploration strategies, which prevent diversity collapse, provide more meaningful signals for iterative preference learning (Bai et al., 2022; Touvron et al., 2023; Xiong et al., ; Pace et al., 2024; Dong et al., 2024). It would be interested to explore more advanced exploration strategy like Monte Carlo tree search (MCTS) in the future study.
In our experiments, we collected N trajectories per prompt to ensure the presence of both correct and incorrect reasoning paths for constructing the comparison pair. A larger N generally leads to a better coverage of the prompt set because for some difficult problem, we need to sample more responses to find a correct reasoning path. For instance, in iteration 1, with N=30, 92.5% of the prompts are covered, compared to 83.0% for N=12 and 60% for N=6. See Figure 4 for an illustration of the relationship between pass@1 and N. However, increasing N also incurs higher computational costs. To understand the impact of the parameter N, we conduct an ablation study with and summarize the results in Table 3. We observe a substantial performance boost when increasing N from 6 to 12, reflecting a better coverage of the complex problems that require more attempts to find a correct path. In contrast, from N=12 to N=30, we only get very minor improvement in the test accuracy, suggesting that the incremental benefits of increasing N in best-of-N sampling diminish rapidly.
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=30 | 83.9 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=12 | 83.5 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=6 | 82.0 | 49.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with N=30 + On-policy sampling | 83.1 | 49.5 |
The best model is obtained with starting checkpoint fine-tuned with more than 1 epochs.
Tunstall et al. (2023) finds that if the SFT model is trained for more than one epoch, the subsequent DPO training will lead to performance regression with longer training in terms of instruction-following ability and benchmark for a general chatbot. In other words, there exists a trade-off between the SFT training epochs and the DPO training steps. Moreover, the best model is obtained by SFT for one epoch in their practice. We also conduct an ablation study on the impact of the SFT epoch and summarize the results in Table 4. Consistently across all tested scenarios, the subsequent iterative M-DPO training leads to considerable model improvement compared to the SFT model. Meanwhile, we also observe a similar trade-off between SFT and RLHF training because with more SFT epochs, the gains from the RLHF stage decrease. However, in our case, the strongest model is obtained with three epochs of SFT, followed by fine-tuning through iterative M-DPO, which is different from the offline DPO training (Tunstall et al., 2023) or the iterative DPO for general chatbot (Dong et al., 2024) with only one epoch of SFT.
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 1 epoch | 75.1 | 41.1 |
| Gemma-1.1-it-7B | SFT 1 epoch + Iterative M-DPO | 80.6 5.5 | 46.7 5.6 |
| Gemma-1.1-it-7B | SFT 2 epoch | 75.3 | 44.0 |
| Gemma-1.1-it-7B | SFT 2 epoch + Iterative M-DPO | 82.4 7.1 | 49.8 5.8 |
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | SFT 3 epoch + Iterative M-DPO | 83.9 6.4 | 51.2 5.1 |
NLL loss helps when the SFT model is substantially underfitting.
The recent work Pang et al. (2024) has introduced iterative RPO, specifically aimed at enhancing Chain of Thought (CoT) capabilities for solving mathematical problems. A key feature of this approach is the inclusion of an additional negative log-likelihood (NLL) loss for the preferred response. The main intuition for adding the NLL loss is that the original DPO algorithm (Rafailov et al., 2023) tends to reduce the likelihood of the preferred responses, and this is believed to hurt the reasoning ability (Wang et al., 2024). Motivated by their results, we explored the applicability of this idea to our setup. We conduct an ablation study by adding the NLL loss into the iterative M-DPO training and observe performance regression as reported in Table 5. We observe that the best model is obtained in the second iteration if we add the additional NLL loss even though we use the mixture sampling to increase the diversity of the collected data. With time-weighted exponential moving average for smoothing training record, we observe that the log probability of the chosen responses and rejected responses are (-126, -222) at the 200th step of the third iteration training when we add the NLL loss, as compared to (-166, -350) in the case without the NLL loss. This is consistent with the result of Pang et al. (2024) where with the additional NLL loss, both the log probability of chosen responses and that of rejected responses increase. These evidences indicate that the NLL loss further contributes to the model distribution collapse and eventually hurt the overall performance of online iterative learning. Finally, we notice that the additional NLL loss can be viewed as an implementation of the pessimistic principle (Liu et al., 2024b). This also explains its inferior in-domain performance though it may be helpful to stable the training, which requires more in-depth studies.
However, one distinct feature between our setup and Pang et al. (2024) is whether we first fine-tune the initialized SFT model with in-domain data. To further understand the phenomena, we fine-tune the Gemma-1.1-it-7B with only 100 steps (so that the model knows to leverage Python code to solve the problem) as the starting checkpoint of preference learning and conduct an ablation study with the NLL loss using this model. We observe when the SFT model is substantially underfitting, the addition of NLL loss actually enhances performance. This scenario mirrors the findings of Pang et al. (2024), who utilized a general LLaMA2-70B-chat model (Touvron et al., 2023) without firstly fine-tuning on the in-domain data. Our observations align with prior research in the context of developing general chatbots (Lin et al., 2023), which suggests that RLHF is less effective without preliminary SFT.
| Model | Method | GSM8K | MATH |
|---|---|---|---|
| Gemma-1.1-it-7B | SFT 3 epoch | 77.5 | 46.1 |
| Gemma-1.1-it-7B | SFT 3 epoch + Iterative M-DPO | 83.9 | 51.2 |
| Gemma-1.1-it-7B | Iterative M-DPO with NLL loss | 81.7 2.2 | 49.5 1.7 |
| Gemma-1.1-it-7B | SFT 100 steps | 50.8 | 23.7 |
| Gemma-1.1-it-7B | + M-DPO Iteration 1 | 57.8 | 27.9 |
| Gemma-1.1-it-7B | + M-DPO and NLL loss Iteration 1 | 61.0 3.2 | 30.1 2.2 |
On-policy sampling and small learning rate mitigate the probability drops in preferred responses.
In the literature, the Direct Preference Optimization (DPO) algorithm is often reported to diminish reasoning capabilities by reducing the likelihood of preferred responses (Yuan et al., 2024; Hong et al., 2024; Meng et al., 2024). In our preliminary experiments, we also observe similar phenomena with a large learning rate (1e-6), where the model’s reasoning ability collapses after only a few training steps, preventing convergence to good reasoning performance. In contrast, we find that using on-policy sampling within our online iterative training framework, coupled with a smaller learning rate (2e-7 or 4e-7), the DPO algorithm enhances the model’s reasoning abilities. To interpret our observation, we can first write down the gradient of the DPO as follows:
where is the implicit reward and we use the single-turn one for simplicity. In practice, the probability of the rejected responses typically decrease, and their gradient quickly dominates when and the optimization becomes unlearning of the rejected responses. In this case, the probability of the chosen responses cannot increase. This phenomenon was also discussed in the blog Guo et al. (2024a). When we adopt on-policy sampling, it leads to a relatively large probability for both rejected and chosen responses at the initial stage, ensuring that both gradients remain valid and effective. Moreover, a small learning rate prevents the model from deviating too significantly, maintaining the effectiveness of both gradients. We also notice that for the KTO algorithm, the preferred responses and the rejected responses do not appear in pairs. We suspect that the probability of the preferred response increases because the gradients of the rejected response do not dominate in every mini-batch of data. A more comprehensive understanding of the training dynamic of the direct preference learning algorithms remains largely open and we leave a more detailed study of this phenomena to future study.
4 Conclusion, Limitation, and Future Research Direction
We demonstrate that preference learning, as an alternative learning paradigm to supervised fine-tuning, can further boost the performance of the tool-integrated reasoning LLMs on top of iterative best-of-n fine-tuning. We introduce an online iterative multi-turn direct preference optimization algorithm and validate its effectiveness through extensive experimentation across various base models. Our results indicate substantial improvements in the pass@1 metric over the SFT policy, as evidenced by performance gains on standard benchmarks such as GSM8K (Cobbe et al., 2021a) and MATH (Hendrycks et al., 2021). Additionally, we also conduct various ablation studies to show that achieving optimal performance requires a careful balance between per-iteration improvement and exploration, facilitated by moderate levels of KL regularization and strategic exploration choices.
There are also several potential directions to further improve the model performance that we have not explored in this paper. Currently, our experiments only use final result check as the preference signal, so we cannot effectively compare trajectories that both end with correct or incorrect answers. Although our algorithm is designed for trajectory-level preference learning, the reward signal in the Bradley-Terry model could be adapted to a step-wise level. In particular, we may leverage AI feedback to verify trajectories step by step or train a process-supervised reward model (Lightman et al., 2023) to provide learning signals. Additionally, with more fine-grained reward signals, it is also possible to adopt more advanced heuristic exploration policy like west-of-n sampling, which prove to be effective in the practice of making general chatbot (Pace et al., 2024; Dong et al., 2024; Xu et al., 2023; Hoang Tran, 2024) and Monte Carlo tree search (MCTS) (Xie et al., 2024b). Furthermore, it is also possible to leverage some well-established tricks like adaptive margin and length regularization for DPO training (Hong et al., 2024; Meng et al., 2024). These techniques have proven to be effective for achieving a better in-domain performance for the chat task. We expect that these more fine-grained preference signals and algorithmic designs can largely improve the models’ performance.
Finally, while the direct preference learning algorithms show promising gains for the mathematical reasoning tasks with code interpreter, it is not directly applicable to the general agent learning with more complex and stochastic external environments or against dynamic opponents. In particular, it requires to construct a value network for involving an adaptive margin in the optimization target and take the randomness of the external environment into consideration. We leave the study of this more involved algorithm to the future work. Moving beyond the framework presented this paper, it is also possible to explore more general preference structures beyond the BT model (Munos et al., 2023; Ye et al., 2024). We hope that the insights from this paper will inspire further research in this direction, extending the utility of preference learning beyond the general structured chat tasks.
*
References
- qwe (2024) Qwen2 technical report. 2024.
- Agarwal et al. (2023) A. Agarwal, Y. Jin, and T. Zhang. VOL: Towards optimal regret in model-free rl with nonlinear function approximation. In The Thirty Sixth Annual Conference on Learning Theory, pages 987–1063. PMLR, 2023.
- Anthony et al. (2017) T. Anthony, Z. Tian, and D. Barber. Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems, 30, 2017.
- Anthropic (2023) Anthropic. Introducing claude. 2023. URL https://www.anthropic.com/index/introducing-claude.
- Auer et al. (2002) P. Auer, N. Cesa-Bianchi, and P. Fischer. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47:235–256, 2002.
- Azar et al. (2023) M. G. Azar, M. Rowland, B. Piot, D. Guo, D. Calandriello, M. Valko, and R. Munos. A general theoretical paradigm to understand learning from human preferences. arXiv preprint arXiv:2310.12036, 2023.
- Bai et al. (2022) Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Cai et al. (2020) Q. Cai, Z. Yang, C. Jin, and Z. Wang. Provably efficient exploration in policy optimization. In International Conference on Machine Learning, pages 1283–1294. PMLR, 2020.
- Cen et al. (2024) S. Cen, J. Mei, K. Goshvadi, H. Dai, T. Yang, S. Yang, D. Schuurmans, Y. Chi, and B. Dai. Value-incentivized preference optimization: A unified approach to online and offline rlhf. arXiv preprint arXiv:2405.19320, 2024.
- Chen et al. (2024a) G. Chen, M. Liao, C. Li, and K. Fan. Step-level value preference optimization for mathematical reasoning. arXiv preprint arXiv:2406.10858, 2024a.
- Chen et al. (2022) W. Chen, X. Ma, X. Wang, and W. W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022.
- Chen et al. (2024b) Z. Chen, Y. Deng, H. Yuan, K. Ji, and Q. Gu. Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335, 2024b.
- Choshen et al. (2019) L. Choshen, L. Fox, Z. Aizenbud, and O. Abend. On the weaknesses of reinforcement learning for neural machine translation. arXiv preprint arXiv:1907.01752, 2019.
- Christiano et al. (2017) P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Cobbe et al. (2021a) K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021a.
- Cobbe et al. (2021b) K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021b.
- Coste et al. (2023) T. Coste, U. Anwar, R. Kirk, and D. Krueger. Reward model ensembles help mitigate overoptimization. arXiv preprint arXiv:2310.02743, 2023.
- Dong et al. (2023) H. Dong, W. Xiong, D. Goyal, Y. Zhang, W. Chow, R. Pan, S. Diao, J. Zhang, K. SHUM, and T. Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=m7p5O7zblY.
- Dong et al. (2024) H. Dong, W. Xiong, B. Pang, H. Wang, H. Zhao, Y. Zhou, N. Jiang, D. Sahoo, C. Xiong, and T. Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024.
- Engstrom et al. (2020) L. Engstrom, A. Ilyas, S. Santurkar, D. Tsipras, F. Janoos, L. Rudolph, and A. Madry. Implementation matters in deep policy gradients: A case study on ppo and trpo. arXiv preprint arXiv:2005.12729, 2020.
- Ethayarajh et al. (2024) K. Ethayarajh, W. Xu, N. Muennighoff, D. Jurafsky, and D. Kiela. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024.
- Gao et al. (2023a) L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig. Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR, 2023a.
- Gao et al. (2023b) L. Gao, J. Schulman, and J. Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023b.
- Gou et al. (2023a) Z. Gou, Z. Shao, Y. Gong, Y. Shen, Y. Yang, N. Duan, and W. Chen. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023a.
- Gou et al. (2023b) Z. Gou, Z. Shao, Y. Gong, Y. Yang, M. Huang, N. Duan, W. Chen, et al. Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv preprint arXiv:2309.17452, 2023b.
- Gui et al. (2024) L. Gui, C. Gârbacea, and V. Veitch. Bonbon alignment for large language models and the sweetness of best-of-n sampling. arXiv preprint arXiv:2406.00832, 2024.
- Gulcehre et al. (2023) C. Gulcehre, T. L. Paine, S. Srinivasan, K. Konyushkova, L. Weerts, A. Sharma, A. Siddhant, A. Ahern, M. Wang, C. Gu, et al. Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- Guo et al. (2024a) S. Guo, W. Xiong, and C. Wang. "alignment guidebook. Notion Blog, 2024a.
- Guo et al. (2024b) S. Guo, B. Zhang, T. Liu, T. Liu, M. Khalman, F. Llinares, A. Rame, T. Mesnard, Y. Zhao, B. Piot, et al. Direct language model alignment from online ai feedback. arXiv preprint arXiv:2402.04792, 2024b.
- Hendrycks et al. (2021) D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Hoang Tran (2024) B. H. Hoang Tran, Chris Glaze. Snorkel-mistral-pairrm-dpo. https://huggingface.co/snorkelai/Snorkel-Mistral-PairRM-DPO, 2024. URL https://huggingface.co/snorkelai/Snorkel-Mistral-PairRM-DPO.
- Hong et al. (2024) J. Hong, N. Lee, and J. Thorne. Orpo: Monolithic preference optimization without reference model. arXiv preprint arXiv:2403.07691, 2(4):5, 2024.
- Jiang et al. (2023) A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Jiao et al. (2024) F. Jiao, C. Qin, Z. Liu, N. F. Chen, and S. Joty. Learning planning-based reasoning by trajectories collection and process reward synthesizing. arXiv preprint arXiv:2402.00658, 2024.
- Lai et al. (2024) X. Lai, Z. Tian, Y. Chen, S. Yang, X. Peng, and J. Jia. Step-dpo: Step-wise preference optimization for long-chain reasoning of llms. arXiv preprint arXiv:2406.18629, 2024.
- Lightman et al. (2023) H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- Lin et al. (2023) Y. Lin, L. Tan, H. Lin, Z. Zheng, R. Pi, J. Zhang, S. Diao, H. Wang, H. Zhao, Y. Yao, et al. Speciality vs generality: An empirical study on catastrophic forgetting in fine-tuning foundation models. arXiv preprint arXiv:2309.06256, 2023.
- Liu and Yao (2024) H. Liu and A. C.-C. Yao. Augmenting math word problems via iterative question composing. arXiv preprint arXiv:2401.09003, 2024.
- Liu et al. (2023a) Q. Liu, P. Netrapalli, C. Szepesvari, and C. Jin. Optimistic mle: A generic model-based algorithm for partially observable sequential decision making. In Proceedings of the 55th Annual ACM Symposium on Theory of Computing, pages 363–376, 2023a.
- Liu et al. (2023b) T. Liu, Y. Zhao, R. Joshi, M. Khalman, M. Saleh, P. J. Liu, and J. Liu. Statistical rejection sampling improves preference optimization. arXiv preprint arXiv:2309.06657, 2023b.
- Liu et al. (2024a) T. Liu, Z. Qin, J. Wu, J. Shen, M. Khalman, R. Joshi, Y. Zhao, M. Saleh, S. Baumgartner, J. Liu, et al. Lipo: Listwise preference optimization through learning-to-rank. arXiv preprint arXiv:2402.01878, 2024a.
- Liu et al. (2024b) Z. Liu, M. Lu, S. Zhang, B. Liu, H. Guo, Y. Yang, J. Blanchet, and Z. Wang. Provably mitigating overoptimization in rlhf: Your sft loss is implicitly an adversarial regularizer. arXiv preprint arXiv:2405.16436, 2024b.
- Lu et al. (2024) Z. Lu, A. Zhou, K. Wang, H. Ren, W. Shi, J. Pan, and M. Zhan. Step-controlled dpo: Leveraging stepwise error for enhanced mathematical reasoning. arXiv preprint arXiv:2407.00782, 2024.
- Luo et al. (2023) H. Luo, Q. Sun, C. Xu, P. Zhao, J. Lou, C. Tao, X. Geng, Q. Lin, S. Chen, and D. Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Meng et al. (2024) Y. Meng, M. Xia, and D. Chen. Simpo: Simple preference optimization with a reference-free reward. arXiv preprint arXiv:2405.14734, 2024.
- Meta (2024) Meta. Introducing meta llama 3: The most capable openly available llm to date. Meta AI Blog, 2024. https://ai.meta.com/blog/meta-llama-3/.
- Mishra et al. (2022) S. Mishra, M. Finlayson, P. Lu, L. Tang, S. Welleck, C. Baral, T. Rajpurohit, O. Tafjord, A. Sabharwal, P. Clark, et al. Lila: A unified benchmark for mathematical reasoning. arXiv preprint arXiv:2210.17517, 2022.
- Mitra et al. (2024) A. Mitra, H. Khanpour, C. Rosset, and A. Awadallah. Orca-math: Unlocking the potential of slms in grade school math. arXiv preprint arXiv:2402.14830, 2024.
- Munos et al. (2023) R. Munos, M. Valko, D. Calandriello, M. G. Azar, M. Rowland, Z. D. Guo, Y. Tang, M. Geist, T. Mesnard, A. Michi, et al. Nash learning from human feedback. arXiv preprint arXiv:2312.00886, 2023.
- Nemirovskij and Yudin (1983) A. S. Nemirovskij and D. B. Yudin. Problem complexity and method efficiency in optimization. 1983.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Pace et al. (2024) A. Pace, J. Mallinson, E. Malmi, S. Krause, and A. Severyn. West-of-n: Synthetic preference generation for improved reward modeling. arXiv preprint arXiv:2401.12086, 2024.
- Pang et al. (2024) R. Y. Pang, W. Yuan, K. Cho, H. He, S. Sukhbaatar, and J. Weston. Iterative reasoning preference optimization. arXiv preprint arXiv:2404.19733, 2024.
- Pi et al. (2024) R. Pi, T. Han, W. Xiong, J. Zhang, R. Liu, R. Pan, and T. Zhang. Strengthening multimodal large language model with bootstrapped preference optimization. arXiv preprint arXiv:2403.08730, 2024.
- Rafailov et al. (2023) R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Rafailov et al. (2024) R. Rafailov, J. Hejna, R. Park, and C. Finn. From r to q*: Your language model is secretly a q-function. arXiv preprint arXiv:2404.12358, 2024.
- Richemond et al. (2024) P. H. Richemond, Y. Tang, D. Guo, D. Calandriello, M. G. Azar, R. Rafailov, B. A. Pires, E. Tarassov, L. Spangher, W. Ellsworth, et al. Offline regularised reinforcement learning for large language models alignment. arXiv preprint arXiv:2405.19107, 2024.
- Rosset et al. (2024) C. Rosset, C.-A. Cheng, A. Mitra, M. Santacroce, A. Awadallah, and T. Xie. Direct nash optimization: Teaching language models to self-improve with general preferences. arXiv preprint arXiv:2404.03715, 2024.
- Schulman et al. (2017) J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shani et al. (2024) L. Shani, A. Rosenberg, A. Cassel, O. Lang, D. Calandriello, A. Zipori, H. Noga, O. Keller, B. Piot, I. Szpektor, et al. Multi-turn reinforcement learning from preference human feedback. arXiv preprint arXiv:2405.14655, 2024.
- Shao et al. (2022) Z. Shao, F. Huang, and M. Huang. Chaining simultaneous thoughts for numerical reasoning. arXiv preprint arXiv:2211.16482, 2022.
- Shao et al. (2024) Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. Li, Y. Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- Singh et al. (2023) A. Singh, J. D. Co-Reyes, R. Agarwal, A. Anand, P. Patil, P. J. Liu, J. Harrison, J. Lee, K. Xu, A. Parisi, et al. Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585, 2023.
- Sutton and Barto (2018) R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Swamy et al. (2024) G. Swamy, C. Dann, R. Kidambi, Z. S. Wu, and A. Agarwal. A minimaximalist approach to reinforcement learning from human feedback. arXiv preprint arXiv:2401.04056, 2024.
- Tajwar et al. (2024) F. Tajwar, A. Singh, A. Sharma, R. Rafailov, J. Schneider, T. Xie, S. Ermon, C. Finn, and A. Kumar. Preference fine-tuning of llms should leverage suboptimal, on-policy data. arXiv preprint arXiv:2404.14367, 2024.
- Tang et al. (2024) Y. Tang, Z. D. Guo, Z. Zheng, D. Calandriello, R. Munos, M. Rowland, P. H. Richemond, M. Valko, B. Á. Pires, and B. Piot. Generalized preference optimization: A unified approach to offline alignment. arXiv preprint arXiv:2402.05749, 2024.
- Team (2024) C. Team. Codegemma: Open code models based on gemma. arXiv preprint arXiv:2406.11409, 2024.
- Team et al. (2023) G. Team, R. Anil, S. Borgeaud, Y. Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Team et al. (2024) G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivière, M. S. Kale, J. Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Tong et al. (2024) Y. Tong, X. Zhang, R. Wang, R. Wu, and J. He. Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving. 2024.
- Toshniwal et al. (2024) S. Toshniwal, I. Moshkov, S. Narenthiran, D. Gitman, F. Jia, and I. Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. arXiv preprint arXiv:2402.10176, 2024.
- Touvron et al. (2023) H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Tunstall et al. (2023) L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y. Belkada, S. Huang, L. von Werra, C. Fourrier, N. Habib, et al. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944, 2023.
- Uesato et al. (2022) J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Wang et al. (2023a) P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935, 2023a.
- Wang et al. (2024) X. Wang, Z. Wang, J. Liu, Y. Chen, L. Yuan, H. Peng, and H. Ji. Mint: Multi-turn interactive evaluation for tool-augmented llms with language feedback. In Proc. The Twelfth International Conference on Learning Representations (ICLR2024), 2024.
- Wang et al. (2023b) Y. Wang, Q. Liu, and C. Jin. Is rlhf more difficult than standard rl? arXiv preprint arXiv:2306.14111, 2023b.
- Wei et al. (2022) J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Williams (1992) R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8:229–256, 1992.
- Williams and Peng (1991) R. J. Williams and J. Peng. Function optimization using connectionist reinforcement learning algorithms. Connection Science, 3(3):241–268, 1991.
- Xie et al. (2022) T. Xie, D. J. Foster, Y. Bai, N. Jiang, and S. M. Kakade. The role of coverage in online reinforcement learning. arXiv preprint arXiv:2210.04157, 2022.
- Xie et al. (2024a) T. Xie, D. J. Foster, A. Krishnamurthy, C. Rosset, A. Awadallah, and A. Rakhlin. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf. arXiv preprint arXiv:2405.21046, 2024a.
- Xie et al. (2024b) Y. Xie, A. Goyal, W. Zheng, M.-Y. Kan, T. P. Lillicrap, K. Kawaguchi, and M. Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451, 2024b.
- (86) W. Xiong, H. Dong, C. Ye, Z. Wang, H. Zhong, H. Ji, N. Jiang, and T. Zhang. Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint. In Forty-first International Conference on Machine Learning.
- Xu et al. (2023) J. Xu, A. Lee, S. Sukhbaatar, and J. Weston. Some things are more cringe than others: Preference optimization with the pairwise cringe loss. arXiv preprint arXiv:2312.16682, 2023.
- Yao et al. (2022) S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Ye et al. (2024) C. Ye, W. Xiong, Y. Zhang, N. Jiang, and T. Zhang. A theoretical analysis of nash learning from human feedback under general kl-regularized preference. arXiv preprint arXiv:2402.07314, 2024.
- Yu et al. (2023) L. Yu, W. Jiang, H. Shi, J. Yu, Z. Liu, Y. Zhang, J. T. Kwok, Z. Li, A. Weller, and W. Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Yuan et al. (2024) L. Yuan, G. Cui, H. Wang, N. Ding, X. Wang, J. Deng, B. Shan, H. Chen, R. Xie, Y. Lin, et al. Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078, 2024.
- Yuan et al. (2023a) Z. Yuan, H. Yuan, C. Li, G. Dong, C. Tan, and C. Zhou. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023a.
- Yuan et al. (2023b) Z. Yuan, H. Yuan, C. Tan, W. Wang, S. Huang, and F. Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023b.
- Yue et al. (2023) X. Yue, G. Z. Xingwei Qu, Y. Fu, W. Huang, H. Sun, Y. Su, and W. Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023.
- Yue et al. (2024) X. Yue, T. Zheng, G. Zhang, and W. Chen. Mammoth2: Scaling instructions from the web. arXiv preprint arXiv:2405.03548, 2024.
- Zelikman et al. (2022) E. Zelikman, Y. Wu, J. Mu, and N. Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- Zhan et al. (2023) W. Zhan, M. Uehara, N. Kallus, J. D. Lee, and W. Sun. Provable offline reinforcement learning with human feedback. arXiv preprint arXiv:2305.14816, 2023.
- Zhang et al. (2024a) B. Zhang, K. Zhou, X. Wei, X. Zhao, J. Sha, S. Wang, and J.-R. Wen. Evaluating and improving tool-augmented computation-intensive math reasoning. Advances in Neural Information Processing Systems, 36, 2024a.
- Zhang et al. (2024b) S. Zhang, D. Yu, H. Sharma, Z. Yang, S. Wang, H. Hassan, and Z. Wang. Self-exploring language models: Active preference elicitation for online alignment. arXiv preprint arXiv:2405.19332, 2024b.
- Zhang (2023) T. Zhang. Mathematical analysis of machine learning algorithms. Cambridge University Press, 2023.
- Zhang et al. (2024c) Y. Zhang, D. Yu, B. Peng, L. Song, Y. Tian, M. Huo, N. Jiang, H. Mi, and D. Yu. Iterative nash policy optimization: Aligning llms with general preferences via no-regret learning. arXiv preprint arXiv:2407.00617, 2024c.
- Zhao et al. (2023) Y. Zhao, R. Joshi, T. Liu, M. Khalman, M. Saleh, and P. J. Liu. Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425, 2023.
- Zheng et al. (2024) C. Zheng, Z. Wang, H. Ji, M. Huang, and N. Peng. Weak-to-strong extrapolation expedites alignment. arXiv preprint arXiv:2404.16792, 2024.
- Zheng et al. (2021) K. Zheng, J. M. Han, and S. Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics. arXiv preprint arXiv:2109.00110, 2021.
- Zhong et al. (2022) H. Zhong, W. Xiong, S. Zheng, L. Wang, Z. Wang, Z. Yang, and T. Zhang. Gec: A unified framework for interactive decision making in mdp, pomdp, and beyond. arXiv preprint arXiv:2211.01962, 2022.
- Zhong et al. (2024) H. Zhong, G. Feng, W. Xiong, L. Zhao, D. He, J. Bian, and L. Wang. Dpo meets ppo: Reinforced token optimization for rlhf. arXiv preprint arXiv:2404.18922, 2024.
- Zhou et al. (2022) D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- Zhu et al. (2022) X. Zhu, J. Wang, L. Zhang, Y. Zhang, Y. Huang, R. Gan, J. Zhang, and Y. Yang. Solving math word problems via cooperative reasoning induced language models. arXiv preprint arXiv:2210.16257, 2022.
- Ziebart (2010) B. D. Ziebart. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010.
- Ziegler et al. (2019) D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
Appendix A Notation Table
| Notation | Description |
|---|---|
| The prompt and the prompt space. | |
| The distribution of initial state (prompt). | |
| The state, action, and observation. | |
| Episode length, e.g., the maximal number of tool calls. | |
| The true observation kernel. | |
| is a trajectory and is the completion part, i.e., we exclude from . | |
| The true utility function associated with the BT model defined in Definition 1. | |
| The true model with observation kernel and utility function | |
| is the sigmoid function. | |
| Preference signal. | |
| The policy, which is parameterized by the LLM. | |
| One arbitrary environment with observation kernel and utility function . | |
| One arbitrary reference policy. | |
| The KL-regularized target ((5)) with environment and reference . | |
| The coefficient of KL penalty, defined in (5). | |
| The optimal -values associated with , defined in (6). | |
| The optimal -values associated with , defined in (7). | |
| The optimal policy associated with , defined in (7). | |
| M-DPO loss, defined in (12). | |
| M-KTO loss, defined in (13). | |
| The abbreviation of , defined in (16). | |
| The optimal policy associated with . | |
| The main and exploration policy at round | |
| Regret over horizon , defined in (17). | |
| Known sets such that and | |
| Assuming . | |
| MLE of and at round , defined in (18) and (19). | |
| Confidences sets of and at round , defined in (21). | |
| Absolute constants. | |
| . | |
| Eluder coefficient from Definition 4. | |
| Generalized Eluder-type condition from Definition 5. | |
| Total variation distance between two distributions. |
Appendix B Implementation Detail
Tools in Math Problem Solving.
Following Gou et al. (2023b); Toshniwal et al. (2024), the LLM agent is allowed to call the python interpreter when it decodes a python code starting with ```python and ending with ```. For each step , to generate the observation , we leverage the python package IPython, and run all the codes in the history one by one and treat each code snippet as a Jupyter cell. We only return the standard output or the error message from the last snippet. When there exists some bug in the code, we only return the error message which is typically less than 20 tokens as in Toshniwal et al. (2024). We notice that some works (e.g. Shao et al. (2024)) also returns the first and the last 50 tokens of the trackback information.
Data Generation.
All the models are evaluated in the zero-shot setting. For all the data generation process, we adopt the following constraints: (1) for each turn, the model can generate up to 512 tokens; (2) the maximal number of steps is H=6; (3) the maximal number of generated token for each trajectory is 2048. When collecting new data for online iterative M-DPO, we set temperature to be 1.0 and decode without top-K or top-p sampling. For evaluation, greedy decoding is employed so that the results are generally comparable with previous works Gou et al. (2023b); Toshniwal et al. (2024). For evaluating the models with pass@n rate, we follow Toshniwal et al. (2024) to adopt a temperature of .
Python Experiment Environment.
We find that the evaluation can be influenced by the python environment, the precision (especially for the Gemma-1.1 models), and even the virtual machine we use. This does not affect the overall trend and conclusion because the magnitude of oscillation is relatively small compared to the overall improvement. For completeness, however, we specify some of the key package versions here. We use transformers 4.42.4, torch 2.3.0, sympy 1.2, antlr4-python3-runtime 4.11.0, IPython 8.26.0 for all models. We evaluate the models using torch.float and use vllm 0.5.0.post1 for most the experiments except for Gemma-2 where vllm 0.5.1 is required. The inconsistency of vllm version is because Gemma-2 model was not released when we performed the main experiments of this project. We fix the python environment and machine for our evaluation throughout the experiment. For SFT, we use the open-source axolotl project with version 0.4.1 and for online iterative preference learning and RAFT, we use the code base from RLHF Workflow (Dong et al., 2024).
RAFT implementation.
The data generation step is similar to the online iterative M-DPO training, except that we only keep the trajectories with correct final answer. For each prompt, we sample at most trajectories where we search and use eventually because we do not see improvement by leveraging more data. We run the algorithm for three iterations in total. The training parameters are similar to the SFT stage, but we use a smaller batch size of 32 so that there are enough optimization steps. For Gemma models, we use a learning rate of 5e-6. For each training stage, we train the models for two epochs in total according to our parameter search. For Mistral model, we find that a smaller learning rate of 1e-6 and training for 1 epoch give us much better performance.
Prompt template.
We do not tune the prompt though we do observe that the prompt engineering can further improve the performance. For all the experiments, we simply adopt the chat template of the models as in Figure 1.
Appendix C Omitted Theoretical Proofs
C.1 Proof of Proposition 1
Proof of Proposition 1.
For one policy , starting with , we recursively define its -value and -value functions on one model and the reference policy as
It is noted that with the optimal policy , and . In the following discussions, we exclusively focus on the model with abbreviations and .
For any comparator policy , it holds that
For any , we can obtain that
In the above derivation, equation (a) is from the definitions of and , and the relationship between and . The equation (b) is because
| (term I) | |||
where the second equation is from the relationship that
Furthermore, if , we can obtain that
where the second equality leverages that ; otherwise, for all , it holds that
The proposition can be obtained by iteratively using the above relationship for . ∎
C.2 Proof of Theorem 1
First, with the assumption and , the following lemma demonstrates that and are valid confidence sets.
Lemma 1 (Proposition B.1 from Liu et al. (2023a)).
There exists an absolute constant such that for any , with probability at least , for all , , and , it holds that
which implies that and .
Then, we provide an additional lemma demonstrating the in-sample error of the MLE and optimistic estimators.
Lemma 2.
There exists an absolute constant such that for any , with probability at least , for all , we have
and for all , , we have
where denotes the TV distance between the probability distributions over the trajectories induced by and .
Proof of Lemma 2.
First, for , we can obtain that with probability at least , there exists an absolute constant such that for all ,
where the first inequality is from Proposition B.2 from Liu et al. (2023a) and the second inequality uses Lemma 1. The result for can be similarly established.
Then, following similar steps, for , we can obtain that with probability at least , there exists an absolute constant such that for all ,
The result for can also be similarly established. ∎
Proof of Theorem 1.
In the following proofs, we omit the KL term in the decomposition to ease the presentation. Then, with probability at least , for all , we can obtain that
where the inequality is from the definition of and the fact that from Lemma 1.
We define the following terms:
For , we have that
For , we have that
In the above derivations, we have repeatedly used similar relationships as follows:
which can be derived as
Then, we can obtain that
Then, we control the sum of each individual term in the following. First, for , with probability at least , we have that
where the first inequality is from the Hoeffding inequality, the second inequality uses the Eluder coefficient from Definition 4, the third inequality leverages the mean value theorem with representing the minimum derivative of in the regime of , and the last inequality incorporates Lemma 2. A similar result can be obtained for .
For , we have that
where the last step is from the generalized Eluder-type condition in Definition 5 and Lemma 2. A similar result can be obtained for .
Finally, we obtain that
which concludes the proof. ∎
Appendix D Technical Lemmas
Lemma 3 (Solution of KL-regularized Optimization (Proposition 7.16 and Theorem 15.3 of Zhang (2023))).
Given a loss functional with respect to , written as
where the minimizer of the loss functional is , also known as Gibbs distribution.
Definition 4 (Eluder Coefficient, Definition 17.17 in Zhang (2023)).
Given a function class , its Eluder coefficient is defined as the smallest number so that for any sequence and ,
Definition 5 (Generalized Eluder-type Condition, Condition 3.1 in Liu et al. (2023a)).
There exists a real number and a function such that for any , transitions and policies , we have