https://en.navinfo.com/
†miao.fan@ieee.org
Neural HD Map Generation from Multiple Vectorized Tiles Locally Produced by Autonomous Vehicles††thanks: This work is supported by the National Natural Science Foundation of China under Grant No. U22A20104. For more details about our recent studies, please visit corresponding author’s website: https://godfanmiao.github.io/homepage-en/.
Abstract
High-definition (HD) map is a fundamental component of autonomous driving systems, as it can provide precise environmental information about driving scenes. Recent work on vectorized map generation could produce merely local map elements around the ego-vehicle at runtime by one tour with onboard sensors, leaving a puzzle of how to construct a global HD map projected in the world coordinate system under high-quality standards. To address the issue, we present GNMap as an end-to-end generative neural network to automatically construct HD maps with multiple vectorized tiles which are locally produced by autonomous vehicles through several tours. It leverages a multi-layer and attention-based autoencoder as the shared network, of which parameters are learned from two different tasks (i.e., pretraining and finetuning, respectively) to ensure both the completeness of generated maps and the correctness of element categories. Abundant qualitative evaluations are conducted on a real-world dataset and experimental results show that GNMap can surpass the SOTA method by more than F1 score, reaching the level of industrial usage with a small amount of manual modification. We have already deployed it at Navinfo Co., Ltd., serving as an indispensable software to automatically build HD maps for autonomous driving systems.
Keywords:
HD map Autonomous driving Vectorized tile Multiple tours1 Introduction
High-definition (HD) map [7] plays a pivotal role in autonomous driving [4, 11]. Illustrated by Fig. 1, it provides high-precision vectorized elements (including pedestrian crossings, lane dividers, road boundaries, etc.) about road topologies and traffic rules, which are quite essential for the navigation of self-driving vehicles. Vectorized map elements are geometrically discretized into polylines or polygons, and conventionally produced offline by SLAM-based methods [20, 17] with heavy reliance on human labor of annotation, facing both scalability and up-to-date issues.
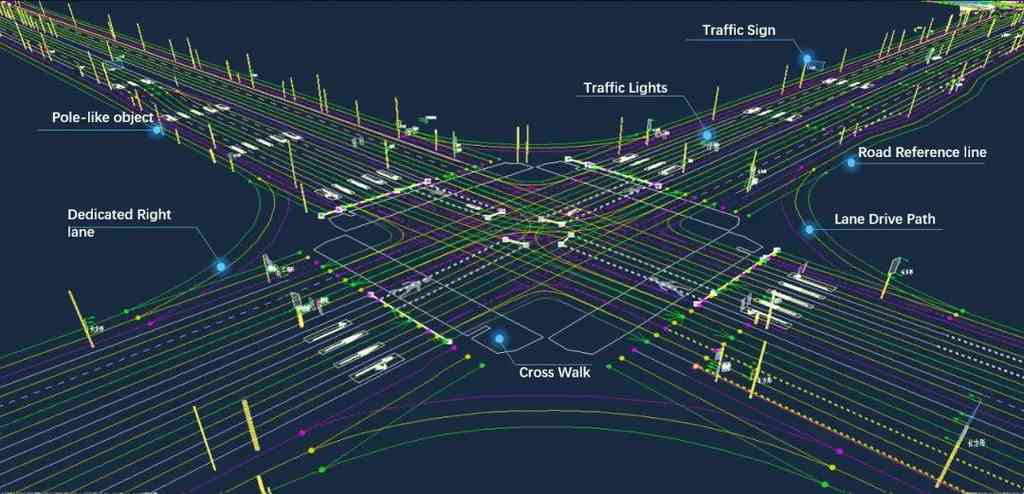
To address the issues, recent studies [9, 10, 14, 18, 6, 12] focus on developing online approaches for vectorized map construction. These methods aim at devising vehicle-mounted models that learn to generate local elements around the ego-vehicle at runtime with onboard sensors such as LiDARs [16] and cameras. Learning-based approaches have drawn ever-increasing attention as they can alleviate human efforts to some extent. However, even the SOTA methods [10, 6] among them could merely produce vehicle-around map elements by one tour, leaving a puzzle of how to construct a global HD map projected in the world coordinate system under high-quality standards.
As the first attempt to solve the puzzle, we present GNMap in this paper. It is an end-to-end generative neural network which takes vehicle-produced vectorized tiles through multiple tours as inputs and automatically generates a globalized HD map under the world coordinates as the output. Specifically, GNMap adopts a multi-layer and attention-based autoencoder as the shared network, of which parameters are learned from two different tasks (i.e., pretraining and finetuning, respectively). At pretraining phase, the shared autoencoder is responsible for completing the masked vectorized tiles. The pretrained parameters are further leveraged as the initial weights for finetuning, which aims at assigning each pixel of map elements to the correct category. In this way, we ensure both the completeness of generated maps and the correctness of element categories.
Additionally, we build a real-world dataset to conduct qualitative assessments offline. Each instance of the data belongs to a vectorized tile mainly composed of three kinds of map elements, i.e., pedestrian crossings, lane dividers, and road boundaries. Besides that, a tile is passed through multiple tours by autonomous vehicles with a street view for each tour. Ablation studies demonstrate that it is vital to conduct pretraining on GNMap for the sake of achieving the best performance. Experimental results of abundant evaluations also show that it can surpass the SOTA method by more than 5% F1 score. So far, GNMap has already been deployed at Navinfo Co., Ltd. for industrial usage, serving as an indispensable software to automatically build HD maps of Mainland China for autonomous driving.
2 Related Work
2.1 SLAM-based Methods (Offline)
HD maps are conventionally annotated manually on LiDAR point clouds of the environment. These point clouds are collected from LiDAR scans of survey vehicles with GPS [8] and IMU [3]. In order to fuse LiDAR scans into an accurate and consistent point cloud, SLAM methods [20, 17] are mostly used, and they generally adopt a decoupled pipeline as follows. Pairwise alignment algorithms like ICP [1] and NDT [2] are firstly employed to match LiDAR data between two nearby timestamps. And for the purpose of constructing a globally consistent map, it is critical to estimate the accurate pose of ego-vehicle by GTSAM [5]. Although several machine learning methods [13] are further devised to extract static map elements such as pedestrian crossings, lane dividers and road boundaries from fused LiDAR point clouds, it is still laborious and costly to maintain a scalable HD map since it requires timely update for autonomous driving.
2.2 Learning-based Approaches (Online)
To get rid of offline human efforts, learning-based HD map construction has attracted ever-increasing interests. These approaches [9, 10, 14, 18, 6, 12] propose to build local maps at runtime based on surround-view images captured by vehicle-mounted cameras. Specifically, HDMapNet [9] first produces semantic map and then groups pixel-wise semantic segmentation results in the post-processing. VectorMapNet [12] adopts a two-stage coarse-to-fine framework and utilizes auto-regressive decoder to predict points sequentially, leading to long inference time and the ambiguity about permutation. To alleviate the problem, BeMapNet [14] adopts a unified piece-wise Bezier curve to describe the geometrical shape of map elements. InstaGraM [18] proposes a novel graph modeling for vectorized polylines of map elements that models geometric, semantic and instance-level information as graph representations. MapTR [10] uses a fixed number of points to represent a map element, regardless of its shape complexity. PivotNet [6] models map elements through pivot-based representation in a set prediction framework. However, even the SOTA methods among them could merely produce vehicle-around map elements by one tour, leaving a puzzle of how to build a global HD map projected under the world coordinates.
3 Model
3.1 Problem Formulation
The objective of GNMap is to generate a globalized HD map under the world coordinates from several vehicle-produced tiles. The vehicle-produced tiles are represented by RGB images, and we use to denote the set of the images as inputs. As shown by Eq. 1, GNMap is formulated as which learns to fuse the images and to generate a globalized HD map as the output denoted by :
| (1) |
where represents the set of best parameters that GNMap needs to explore.
3.2 Shared Autoencoder
To realize , we devise an autoencoder that is structured into two parts: a neural encoder and a neural decoder . The relationship between the encoder and the decoder is shown by Eq. 2 and Eq. 3:
| (2) |
and
| (3) |
where takes as inputs to produce the intermediate feature representation by means of the parameters of encoder, and takes intermediate feature as the input to generate the output by means of the parameters of decoder. Both and belong to :
| (4) |
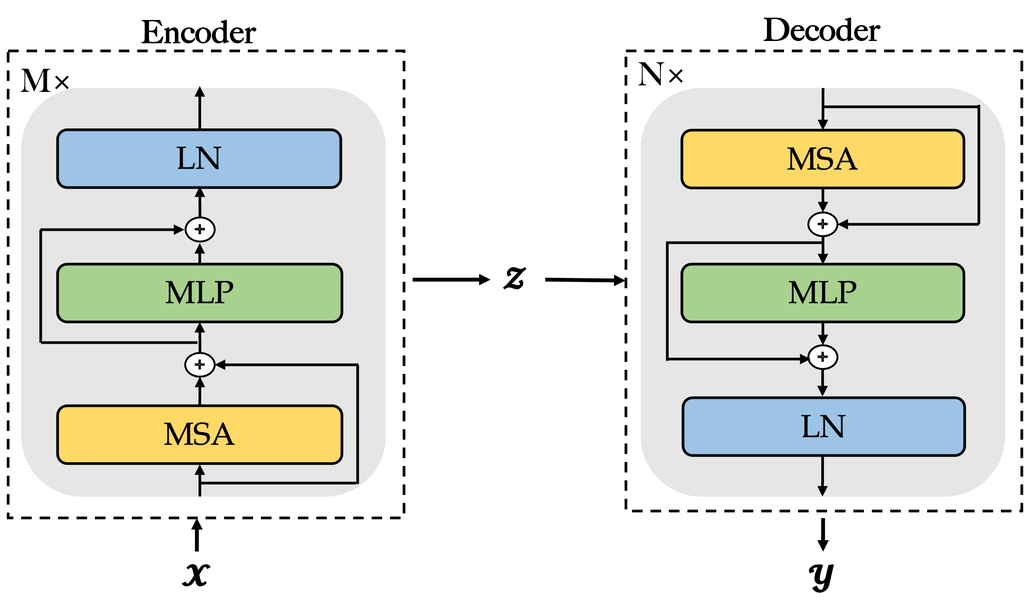
Illustrated by Fig. 2, both the encoder and the decoder are multi-layer networks mainly composed of multi-head self-attention functions. We will elaborate on them in the following paragraphs.
Encoder:
is composed of layer neural blocks with the same structure. Each block includes a multi-head self-attention (MSA [19]), a multi-layer perceptron (MLP), and a layer normalization (LN) module. Here we use to denote the intermediate output of the block at the -th layer of encoder, and is calculated by Eq. 5 and Eq. 6:
| (5) |
and
| (6) |
where and .
Decoder:
has stacked blocks with the same structure. Each block is composed of includes a multi-head self-attention (MSA [19]), a multi-layer perceptron (MLP), and a layer normalization (LN) function as well. If we use to denote the intermediate output of the block at the -th layer of decoder, is calculated by Eq. 7 and Eq. 8:
| (7) |
and
| (8) |
where and .
In order to obtain the best parameters of both and , we propose to adopt the ”pretraining & finetuning” manner which divides the training procedure into two phases, corresponding to different tasks and learning objectives. Details about the two phases will be elaborated by Section 3.3 and Section 3.4.
3.3 Pretraining Phase
At the pretraining phase, the learning objective of the shared autoencoder is to complete masked vectorized tiles, and the pretrained parameters are further leveraged as the initial weights for finetuning. Illustrated by Fig. 3, we will elaborate pretraining phase from the perspectives of input, output, ground truth, and loss function in the following paragraphs.
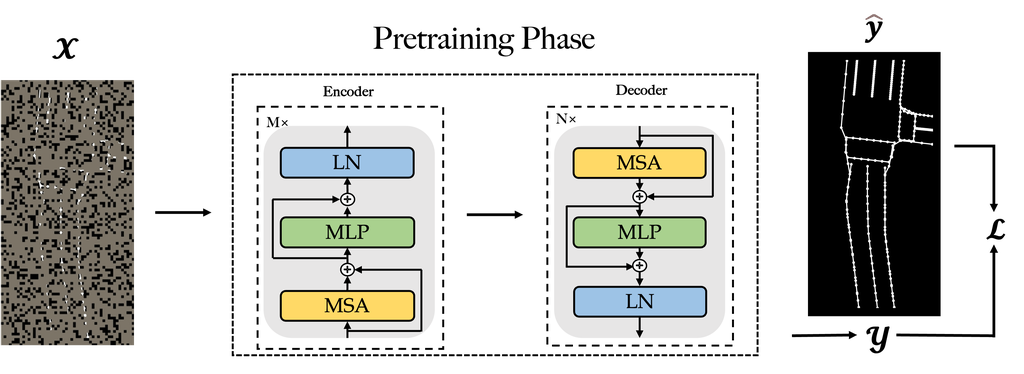
Input:
We split the manually annotated HD maps into multiple vectorized tiles. Each of the vectorized tiles can be transferred into a gray-scaled image denoted by , where and represent the height and the width of the image respectively. In , each pixel of any may elements is set to 255 and the background’s pixel is set to 0. Then the image is divided into non-overlapping patches with the shape of . As a result, patches (each ) can be obtained. We sample a subset of patches and mask (i.e., remove) the remaining ones. Our strategy is straightforward: sampling random patches without replacement, following a uniform distribution with a high masking ratio (i.e., the ratio of removed patches). In this way, we have created a task that cannot be easily solved by extrapolation from visible neighboring patches.
Output:
We expect to obtain a completed gray-scale tile as the output through the shared autoencoder which takes the masked patches as inputs. The completed image is denoted by , where and represent the height and the width of the completed image, respectively. The value of each predicted pixel where ranges from to since it is scaled by the softmax function.
Ground Truth:
Correspondingly, the ground-truth image is the unsliced one (i.e., ) used as the input. We denoted it by since each pixel of is set by either 0 or 1 to indicate whether it belongs to the background or vectorized map elements.
Loss Function:
We employ the mean squared error (MSE) as the loss function (denoted by ) for pretraining.
| (9) |
As shown by Eq. 9, it measures the overall difference between and , by calculating the squared errors between the predicted pixels and the ground-truth pixels at the same coordinates.
3.4 Finetuning Phase
At finetuning phase, the learning objective of the shared autoencoder changes to assigning each pixel of the elements of the generated map to the correct category, leveraging the pretrained parameters as initial weights. Illustrated by Fig. 4, we will elaborate finetuning phase from the perspectives of input, output, ground truth, and loss function in the following paragraphs.
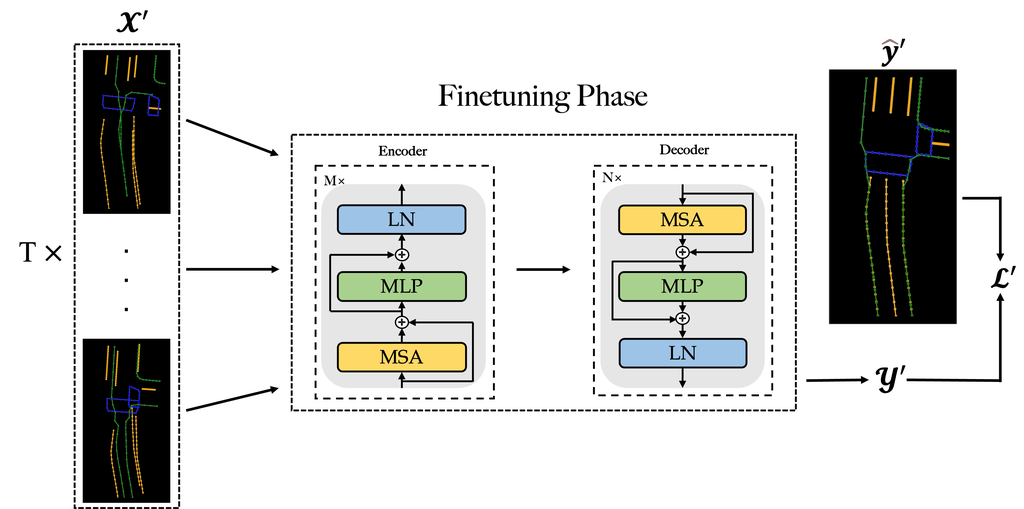
Input:
In this work, a tile is passed through times of tours by autonomous vehicles with a street view for each tour. The original street views collected by the cameras mounted on survey vehicles are usually RGB images and learning-based approaches [9, 10, 14, 18, 6, 12] generally transfer them into vectorized images where each pixel belongs to a certain category such as the background or land divider, etc.. As a matter of fact, we can obtain images at the beginning of the finetuning phase. We use a shared CNN network to fetch the features from the images and concatenate them together as the input of the shared autoencoder.
Output:
We expect to achieve a fused tile from GNMap as the output at the finetuning phase. The generated image is denoted by , where and represent the height and the width of the image, respectively, and stands for the kinds of map elements. Each predicted pixel is represented by a -dimensional vector where the value at each dimension ranges from 0.0 to 1.0 to indicate the probability of the predicted category and the sum of all these values is 1.0.
Ground Truth:
Correspondingly, the ground-truth image is denoted by . In addition, each pixel of is denoted by a -dimensional vector where only one of the values is set by 1.0 exclusively indicating that the pixel belongs to a certain category such as the background, pedestrian crossing, or etc.
Loss Function:
We employ the cross-entropy (CE) function as the loss (denoted by ) of the finetuning phase.
| (10) |
As shown by Eq. 10, it measures the divergence between and , by summing up the log-likelihood at ground-truth pixels.
4 Experiments
4.1 Dataset and Metrics
| Subset | #(Tiles) | #(Map Elements) | Avg. #(Tours)/Tile | #(Street Views) |
| Train | 40,000 | 162,493 | 5.2 | 208,207 |
| Valid | 5,000 | 19,928 | 5.0 | 24,982 |
| Test | 5,000 | 20,061 | 5.1 | 25,564 |
In order to conduct an offline assessment on methods of HD map generation, we build a real-world dataset that contains street views and vectorized tiles produced by autonomous vehicles through multiple tours. We randomly split the dataset into three subsets. As shown by Table 1, they are separately leveraged for the purpose of model training (abbr. Train), hyper-parameter tuning (abbr. Valid), and performance testing (abbr. Test). Each subset is composed of many exclusive tiles, each of which is passed through multiple tours by autonomous vehicles. For each tour, a street view is collected and a vectorized tile is produced simultaneously online by vehicle-mounted models. Following up previous work, we mainly focus on three kinds of map elements, including pedestrian crossings (abbr. as ped.), lane dividers (abbr. as div.), and road boundaries (abbr. as bou.).
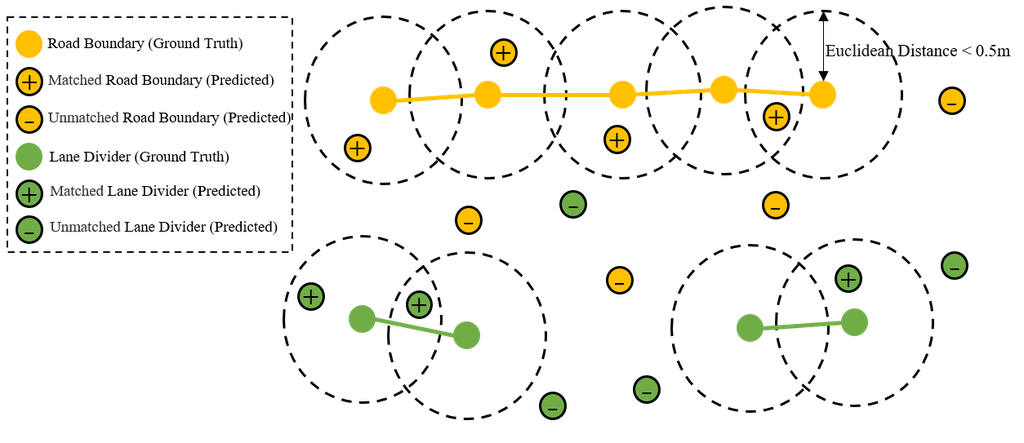
For each generated tile, we use precision (P) and recall (R) to evaluate the quality of HD map reconstruction at the pixel level in one instance. Illustrated by Fig. 5, a predicted point is accepted as the positive pixel when it is located near a ground-truth (GT) point within the Euclidean distance of 0.5 meters and they must belong to the same category as well. More importantly, a GT point can only accept one nearest predicted point for evaluation. Assuming that the test set contains instances, average precision (AP) and average recall (AR) are formulated by Eq. 11 and Eq. 12 as follows,
| (11) |
and
| (12) |
Then mAP and mAR represent the mean average precision and recall over all categories (i.e., pedestrian crossing, lane divider, and road boundary), which are shown by Eq. 13 and Eq. 14.
| (13) |
| (14) |
To measure the overall performance of approaches on HD map generation, we adopt F1 score, as shown by Eq. 15, which calculates the harmonic mean of mAP and mAR.
| (15) |
4.2 Comparison Details
| Method | mAP APped. APdiv. APbou. | mAR ARped. ARdiv. ARbou. | F1 |
| HDMapNet [9] | 45.3 42.8 47.9 45.1 | 44.1 41.3 47.5 43.6 | 44.7 |
| VectorMapNet [12] | 62.9 60.4 65.3 63.1 | 61.5 59.2 61.8 63.4 | 62.2 |
| InstaGraM [18] | 53.6 51.9 54.2 54.8 | 62.4 59.8 62.3 65.1 | 57.7 |
| BeMapNet [14] | 62.3 60.5 61.6 64.9 | 66.1 62.8 70.3 65.1 | 64.1 |
| MapTR [10] | 64.5 62.8 65.2 65.5 | 73.2 71.3 73.4 74.9 | 68.6 |
| PivotNet [6] | 64.8 63.1 66.5 64.8 | 72.4 70.3 72.8 74.1 | 68.4 |
| GMM [15] | 63.4 61.4 64.7 64.0 | 63.2 59.8 67.6 62.3 | 63.3 |
| GNMap (Ours) | 72.5 70.5 74.8 72.3 | 75.6 75.4 78.1 73.3 | 74.0 |
We mainly compare GNMap with two groups of approaches. One group contains vehicle-mounted models (including HDMapNet [9], VectorMapNet [12], InstaGraM [18], BeMapNet [14], MapTR [10], and PivotNet [6]) which infer vectorized tiles online from real-time street views captured by onsite cameras. The other group represents approaches (i.e., GMM [15] and our GNMap) on fusing the vehicle-produced tiles to construct a global HD map. Table 2 reports the experimental results of these two groups of methods for HD map construction. All the approaches are tested by the real-world dataset shown in Table 1 and measured by the metrics mentioned in Section 4.1. Based on our results, MapTR and PivotNet achieve comparable performance of online map learning through only one tour. Our GNMap outperforms GMM over F1 score. Even compared with the existing SOTA method of online map learning, GNMap achieves over higher F1, demonstrating advanced performance on HD map construction.
4.3 Ablation Study
We report ablation experiments in Table 3, to validate the effectiveness of employing the pretraining phase, and the robustness of using different vehicle-mounted models. We select MapTR [10] and PivotNet [6], as the SOTA one-tour vehicle-mounted models, to produce vectorized tiles for GMM [15] and our GNMap. Experimental results demonstrate that GNMap achieves consistent improvements over GMM regardless of the vehicle-mounted models. Moreover, the pretrained GNMap can provide at least higher F1 score than those without pretraining.
| Method | mAP APped. APdiv. APbou. | mAR ARped. ARdiv. ARbou. | F1 |
| GMM (MapTR) | 62.5 61.8 63.2 62.5 | 66.5 65.4 67.3 66.9 | 64.5 |
| GNMap (MapTR) w/o Pre. | 64.2 64.3 63.6 64.8 | 67.3 66.3 67.4 68.3 | 65.7 |
| GNMap (MapTR) w/ Pre. | 72.7 70.8 74.8 72.5 | 75.6 73.3 78.1 75.4 | 74.1 |
| GMM (PivotNet) | 61.7 60.9 61.5 62.7 | 65.6 64.7 66.6 65.4 | 63.6 |
| GNMap (PivotNet) w/o Pre. | 63.8 62.8 63.7 64.9 | 66.5 65.2 66.3 67.9 | 65.1 |
| GNMap (PivotNet) w/ Pre. | 72.6 72.8 73.1 71.9 | 75.5 74.2 77.3 75.1 | 74.0 |
5 Conclusion
In this paper, we present GNMap as an end-to-end generative framework for HD map construction, which is distinguished from recent studies on producing vectorized tiles locally by autonomous vehicles with onboard sensors such as LiDARs and cameras. GNMap is an essential research to follow up those studies, as it first attempts to fuse multiple vehicle-produced tiles to automatically build a globalized HD map under the world coordinates. To be specific, it adopts a multi-layer autoencoder purely composed of multi-head self-attentions as the shared network, where the parameters are learned from two different tasks (i.e., pretraining and finetuning, respectively) to ensure both the completeness of map generation and the correctness of element categories. Ablation studies demonstrate that it is vital to conduct pretraining on GNMap for the sake of achieving the best performance for industrial usage. And experimental results of abundant evaluations on a real-world dataset show that GNMap can surpass the SOTA method by more than F1 score. So far, it has already been deployed at Navinfo Co., Ltd., serving as an indispensable software to automatically build HD maps of Mainland China for autonomous driving.
References
- [1] Besl, P., McKay, N.D.: A method for registration of 3d shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence 14(2), 239–256 (1992)
- [2] Biber, P., Straßer, W.: The normal distributions transform: A new approach to laser scan matching. Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems 3, 2743–2748 vol.3 (2003)
- [3] Borodacz, K., Szczepański, C., Popowski, S.: Review and selection of commercially available imu for a short time inertial navigation. Aircraft Engineering and Aerospace Technology (2021)
- [4] Boubakri, A., Gammar, S.M., Brahim, M.B., Filali, F.: High definition map update for autonomous and connected vehicles: A survey. 2022 International Wireless Communications and Mobile Computing (IWCMC) pp. 1148–1153 (2022)
- [5] Dellaert, F., Kaess, M.: Factor Graphs for Robot Perception. Foundations and Trends in Robotics, Vol. 6 (2017)
- [6] Ding, W., Qiao, L., Qiu, X., Zhang, C.: Pivotnet: Vectorized pivot learning for end-to-end hd map construction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3672–3682 (2023)
- [7] Elghazaly, G., Frank, R., Harvey, S., Safko, S.: High-definition maps: Comprehensive survey, challenges, and future perspectives. IEEE Open Journal of Intelligent Transportation Systems 4, 527–550 (2023)
- [8] Kaplan, E.D.: Understanding gps : principles and applications (1996)
- [9] Li, Q., Wang, Y., Wang, Y., Zhao, H.: Hdmapnet: An online hd map construction and evaluation framework. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 4628–4634. IEEE (2022)
- [10] Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: Maptr: Structured modeling and learning for online vectorized hd map construction. In: The Eleventh International Conference on Learning Representations (2023)
- [11] Liu, R., Wang, J., Zhang, B.: High definition map for automated driving: Overview and analysis. Journal of Navigation (2020)
- [12] Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: Vectormapnet: End-to-end vectorized hd map learning. In: International Conference on Machine Learning. pp. 22352–22369. PMLR (2023)
- [13] Mi, L., Zhao, H., Nash, C., Jin, X., Gao, J., Sun, C., Schmid, C., Shavit, N., Chai, Y., Anguelov, D.: Hdmapgen: A hierarchical graph generative model of high definition maps. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 4225–4234 (2021)
- [14] Qiao, L., Ding, W., Qiu, X., Zhang, C.: End-to-end vectorized hd-map construction with piecewise bezier curve. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13218–13228 (2023)
- [15] Reynolds, D.A., et al.: Gaussian mixture models. Encyclopedia of biometrics 741(659-663) (2009)
- [16] Roriz, R., Cabral, J., Gomes, T.: Automotive lidar technology: A survey. IEEE Transactions on Intelligent Transportation Systems 23, 6282–6297 (2021)
- [17] Shan, T., Englot, B., Meyers, D., Wang, W., Ratti, C., Rus, D.: Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp. 5135–5142 (2020)
- [18] Shin, J., Rameau, F., Jeong, H., Kum, D.: Instagram: Instance-level graph modeling for vectorized hd map learning. arXiv preprint arXiv:2301.04470 (2023)
- [19] Voita, E., Talbot, D., Moiseev, F., Sennrich, R., Titov, I.: Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: Korhonen, A., Traum, D., Màrquez, L. (eds.) Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 5797–5808. Association for Computational Linguistics, Florence, Italy (Jul 2019)
- [20] Zhang, J., Singh, S.: Loam: Lidar odometry and mapping in real-time. In: Robotics: Science and Systems (2014)