Tele-LLMs: A Series of Specialized Large Language Models for Telecommunications
Abstract.
The emergence of large language models (LLMs) has significantly impacted various fields, from natural language processing to sectors like medicine and finance. However, despite their rapid proliferation, the applications of LLMs in telecommunications remain limited, often relying on general-purpose models that lack domain-specific specialization. This lack of specialization results in underperformance, particularly when dealing with telecommunications-specific technical terminology and their associated mathematical representations. This paper addresses this gap by first creating and disseminating Tele-Data, a comprehensive dataset of telecommunications material curated from relevant sources, and Tele-Eval, a large-scale question-and-answer dataset tailored to the domain. Through extensive experiments, we explore the most effective training techniques for adapting LLMs to the telecommunications domain, ranging from examining the division of expertise across various telecommunications aspects to employing parameter-efficient techniques. We also investigate how models of different sizes behave during adaptation and analyze the impact of their training data on this behavior. Leveraging these findings, we develop and open-source Tele-LLMs111The Hugging Face links to both the datasets and Tele-LLMs can be found at https://github.com/Ali-maatouk/Tele-LLMs, the first series of language models ranging from 1B to 8B parameters, specifically tailored for telecommunications. Our evaluations demonstrate that these models outperform their general-purpose counterparts on Tele-Eval while retaining their previously acquired capabilities, thus avoiding the catastrophic forgetting phenomenon.
1. Introduction

Large language models (LLMs) have recently marked a major breakthrough in natural language processing. Since 2022, these deep learning systems have proliferated rapidly, with numerous models released by tech giants, research institutions, and open-source communities (OpenAI, 2024; et al., 2023, 2024). Trained on vast text corpora, LLMs have demonstrated unprecedented capabilities in understanding context, generating human-like text, and performing reasoning tasks across diverse domains (Radford et al., 2019). These abilities have sparked interest from researchers and industry professionals to adopt and explore their potential applications across a wide variety of fields.
Researchers in the telecommunications and networking domain are no exception, aiming to leverage LLMs’ potential across various tasks within the field. These applications include chatbots for engineers (Kotaru, 2023), network document analysis (Bariah et al., 2023b), network modeling and development (Maatouk et al., 2024), and wireless systems design (Du et al., 2023; Xu et al., 2024). The list of tasks being explored for potential LLM support continues to grow (Bariah et al., 2023a), with new research emerging rapidly to assess the limits and utility of these models in the telecommunications context.
Thus far, applications of LLMs in the telecommunications domain have primarily involved prompting (Du et al., 2023; Maatouk et al., 2024), in-context learning (Kotaru, 2023), and task-specific fine-tuning (Zhou et al., 2024; Bariah et al., 2023b), utilizing either proprietary LLMs like OpenAI’s GPT (OpenAI, 2024) or local open-source generic LLMs like Meta’s LLaMA series (et al., 2024). However, proprietary LLMs raise privacy concerns, as they require sharing prompts and related data with the LLM owners. Additionally, they offer limited maneuverability and adaptability, as users do not have access to the model weights. Furthermore, despite their adaptability, general-purpose open-source LLMs lack specialization in telecommunications, as they encompass knowledge from diverse domains such as medicine, history, and law. This lack of specialization hinders their performance; in fact, it is well established that LLM applications in specific domains, from prompting to task-specific fine-tuning, perform better when using domain-specific LLMs rather than general ones (Gururangan et al., 2020).
Given the above, in a multitude of domains, efforts have been made to create specialized open-source LLMs to push the performance limits of LLMs applications in those fields, such as medicine (Labrak et al., 2024), law (Colombo et al., 2024), and finance (Xie et al., 2023). However, to date, there are no domain-specific open-source models in the telecommunications literature. This stems from the particularities of the telecommunications domain, which includes heterogeneous material such as standards and scholarly work, a heavy reliance on complex equations, varying formatting in datasets, and the generally closed-source nature of work done by companies thus far with LLMs (Kotaru, 2023; Holm, 2021). Given the anticipated role of LLMs in telecommunications, this represents a significant gap in the field.
Proposed Work. This work aims to address the aforementioned gap by introducing the first series of LLMs specialized for the telecommunications field. Our contribution extends beyond open-sourcing the models; we open-source every step of the framework required for this specialization. We also provide, through extensive experiments, key insights into the process of adapting LLMs to the telecommunications domain. This includes the techniques to be used and the different behaviors exhibited by various LLMs during adaptation, based on their sizes and overall tendencies.
First, we curate a comprehensive set of telecommunications material, referred to as Tele-Data, by leveraging an LLM-based filtering of arXiv papers, standards, Wikipedia articles, and web content to identify relevant sources. We report the precision and recall of our filtering method based on human-labeled data and highlight its high recall rate. The collected material is then subjected to extensive cleaning using regular expressions and LLM-based filtering techniques tailored to the particularities of the telecommunications domain. Specifically, our process addresses formatting differences in standards documents and unifies the equation materials across all types of documents into LaTeX formatting. To quantify the cleanliness of the resulting material, we propose a cross-entropy-based approach and demonstrate that the material is significantly cleaner after this process.
Second, leveraging Tele-Data, we use an LLM-based framework to create an evaluation dataset consisting of 750k question-and-answer (QnA) pairs, referred to as Tele-Eval. This dataset represents the first large-scale open-ended QnA dataset in the telecommunications field. It also includes references to the specific material from which each question was generated, allowing users to select questions from the material they are interested in and facilitating retrieval-augmented generation frameworks (Lewis et al., 2021). To ensure the relevance and quality of the questions generated by the LLM, we apply strict regular expressions and LLM-based filtering to exclude questions of local interest, such as simulation results or locally-defined content.
Third, we examine the viability of using parameter-efficient fine-tuning (PEFT) techniques to inject telecommunications knowledge into these models, demonstrating how this injection instead requires the full fine-tuning (FFT) paradigm. Based on this, we conduct experiments to determine the number of training epochs needed to maximize model performance and identify the point at which overfitting occurs during this adaptation. Throughout this exploration, we also examine how models of different sizes behave during the adaptation process and investigate how the training dynamics of this adaptation vary based on the original model’s training data. Furthermore, we assess the effectiveness of dividing this adaptation by training multiple specialized models focused on different aspects of telecommunications rather than one overall combined model. Our findings demonstrate that the latter approach is superior due to the transfer learning that occurs across these aspects.
Finally, our experiments culminate in the adaptation to telecommunications and open-sourcing of a series of LLMs, ranging from 1B to 8B parameters. Our series is based on Tinyllama-1.1B, Phi-1.5, Gemma-2B, and LLama-3-8B, and includes both the base models and their instruct-fine-tuned versions for chatbot applications. We evaluate these models by comparing them with their original versions through both quantitative analyses, using a set of proposed metrics, and qualitative assessments. The results highlight their superiority in the telecom domain, achieving an average of 25% relative improvement on Tele-Eval. Additionally, our findings demonstrate how smaller adapted models can rival larger general-purpose models on Tele-Eval. The evaluation also indicates that these models retain their original capabilities, effectively avoiding the catastrophic forgetting phenomenon. The overall adaptation pipeline is provided in Fig. 1.
2. Domain Adaptation
2.1. Background
LLMs are trained using a next-token prediction objective on corpora that encompass a wide variety of domains, such as medicine, history, and more. In this context, a token refers to a subword that represents the most basic unit in the text. This training process allows the LLM to become accustomed to the distribution of tokens in these datasets and develop an understanding of the statistical relationships between them. Consequently, the LLM develops a well-rounded understanding of the multiple domains it has been trained on.
As demonstrated in (Çağatay Yıldız et al., 2024), if one intends to use an LLM solely for a specific domain, specializing the LLM in that domain is advantageous for any subsequent in-context learning or task-specific fine-tuning. This is because the probability distribution of tokens in the domain of interest can differ significantly from those in other domains internalized by the LLM. By adapting to this distribution, the LLM’s knowledge becomes more targeted to the domain, leading to transfer learning for subsequent usage stages.
The primary approach for domain adaptation is continual pretraining. This method involves further training the LLM on domain-specific corpora, allowing it to adapt its parameters to the field of interest (Gururangan et al., 2020). Continual pretraining has become the standard for LLM domain adaptation, as evidenced by its application in various fields such as medicine (Labrak et al., 2024), law (Colombo et al., 2024), and finance (Xie et al., 2023). In the following, we will explore the details of continual pretraining, with a particular emphasis on its application in the telecommunications domain.
Remark 1.
Adapting a pretrained LLM to a specific domain is typically preferred over training an LLM from scratch on domain-specific data. This approach leverages capabilities learned from other domains (e.g., English language proficiency, coding) and transfers them to the new domain, reducing the need for extensive data and time to learn basic skills.
2.2. Continual Pretraining
Given the scale of the training datasets of current LLMs (e.g., 15T tokens for LLama-3 (et al., 2024)), it is fair to assume that the language models available in the literature have been trained on all available public-source data. Therefore, these models have likely already encountered most of the publicly available telecommunications-related data. Nevertheless, the goal of continual pretraining is to adapt the LLM’s knowledge to this specific domain by re-exposing the model to these data. Specifically, consider an LLM trained on a corpus of tokens drawn from a distribution . This LLM is trained over the entire corpus to minimize the cross-entropy loss function for tokens drawn from this corpus:
| (1) |
where is the context length, is equal to , is the LLM’s parameters, and is the total number of parameters. On the other hand, let us consider a set of telecom-related data . The samples of tokens drawn from originate from a different distribution, denoted by . Continual pretraining involves initializing the LLM to its existing parameters, denoted by , and further reducing the cross-entropy loss, this time using samples of tokens drawn from :
| (2) |
By doing so, the model parameters shift closer to the new distribution, allowing the LLM to be better calibrated to telecommunications-specific data.
2.3. Catastrophic Forgetting
Ideally, one would hope that such domain adaptation comes at no penalty. However, generally, a penalty is incurred. By shifting the focus from the general token distribution of the training dataset to a new distribution , the model risks forgetting previously acquired knowledge. This risk depends on the size of the model, the size of the domain-specific dataset, and how different is from (Luo et al., 2024). Addressing this issue is crucial; otherwise, one may end up with a telecom-knowledge proficient LLM but lose reasoning capabilities, coding abilities, and general English language understanding in the process. Later in this paper, specifically in Section 7, we will detail how we addressed this issue in our continual pretraining framework. With this in mind, the next step in our framework involves curating a comprehensive telecommunications corpus, which we will refer to as Tele-Data.
3. Tele-Data
| Items | Size | Tokens | |
|---|---|---|---|
| Arxiv | 90k | 4 GBs | 1.08B |
| Standards | 2.8k | 334 MBs | 86.45M |
| Wikipedia | 19.5k | 123 MBs | 26.44M |
| Web | 740k | 6.8 GBs | 1.55B |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Arxiv | 0.666 | 0.956 | 0.785 |
| Wikipedia | 0.632 | 0.897 | 0.741 |
| Webpages | 0.455 | 1 | 0.625 |
Our collection of telecommunications material comprises four main sources: (1) scientific papers from arXiv, (2) 3GPP standards, (3) Wikipedia articles related to telecommunications, and (4) telecommunications-related websites extracted from Common Crawl dumps. This diverse range of sources ensures broad coverage of telecommunications knowledge and is essential for enabling the transfer of expertise from one aspect of telecommunications covered in one source to another, as will be shown later in Section 8.1. The detailed composition of our dataset is reported in Table 1, with LLama-3 tokenizer used to provide token counts as an example.
3.1. Arxiv
Curation. One of the largest sources of open-access research on telecommunications consists of preprints submitted by authors to the arXiv repository. As of March 2024, the combined arXiv snapshot for both computer science and electrical engineering categories contains approximately 610k papers. However, given the overlap between these categories and the inclusion of topics beyond telecommunications , targeted filtering is necessary to identify the relevant material. To achieve this, we use a language model-based filtering approach. Specifically, we leverage the Mixtral 8x-7B-Instruct222https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 model, providing it with the abstract of each paper to determine if it is related to the telecommunications and networking domain. The model is prompted333All the prompts utilized in our framework are reported in Appendix C to provide a Yes or No answer regarding whether the paper is relevant. We then utilize the logits of the ‘Yes’ and ‘No’ tokens to classify whether or not a paper is related to telecommunications.
To assess the quality of our filtering process, we randomly sampled 500 arXiv papers and manually annotated them to determine their relevance to the telecommunications and networking domain. To ensure a balance between relevant and irrelevant examples, we drew an equal number of samples from both the computer science and electrical engineering categories given that the latter is more likely to contain telecommunications material, while the former is more likely to include unrelated papers. We then evaluated both the precision and recall of the filtering process. As shown in Table 2, the process demonstrates high recall and moderate precision. High recall is particularly important, as it indicates that our filtering process captures virtually all relevant telecommunications material. The moderate precision can be attributed to the inclusion of papers from related domains. For instance, some papers investigating cloud computing topics were included. Since these additional domains are not orthogonal to telecommunications, they can provide transferable knowledge that may enhance the language model’s adaptation to the telecommunications domain. All in all, this demonstrates the effectiveness of our filtering process.
Cleaning. Following curation, we implement a comprehensive cleaning process for the papers, which includes: (1) removing comments, (2) flattening LaTeX sources, (3) substituting user-defined macros with standard LaTeX commands, (4) eliminating LaTeX native commands, and (5) standardizing citation formats and removing markup changes. We also remove figures and tables to focus on inline text and equations. Details on this procedure are provided in Appendix A. To assess the effectiveness of our cleaning process, we randomly selected 500 arXiv papers and derived a cross-entropy-based approach to evaluate cleanliness as detailed below. Let and denote the non-overlapping chunks of tokens from the raw and cleaned datasets, respectively, where and are the total number of chunks. Next, let us define the cross-entropy loss for any token index in any chunk of either the raw or cleaned data using GPT-2 (Radford et al., 2019) as follows
| (3) |
GPT-2 was chosen because it was primarily trained on web content, excluding arXiv scientific papers. Therefore, the cross-entropy here serves as a proxy for how closely the text resembles generic online content rather than the more complex arXiv papers, thus providing an indication of the dataset’s cleanliness. With this in mind, we set to 1024, in line with GPT-2’s training data (Radford et al., 2019), and define the total set of cross-entropy losses for the raw and cleaned datasets as
| (4) |
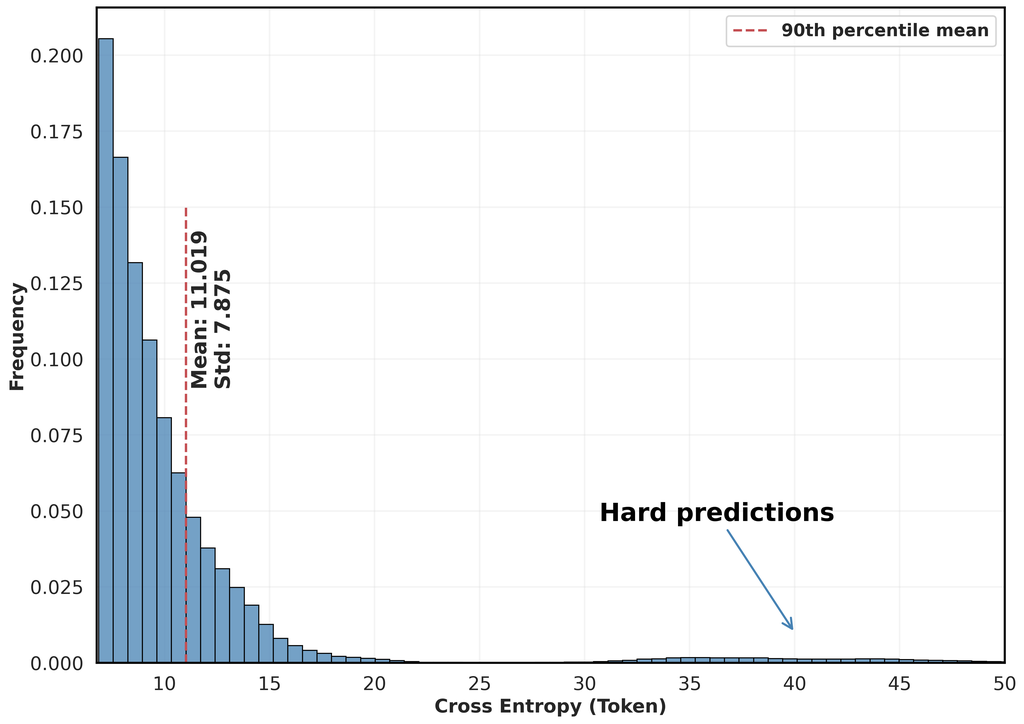
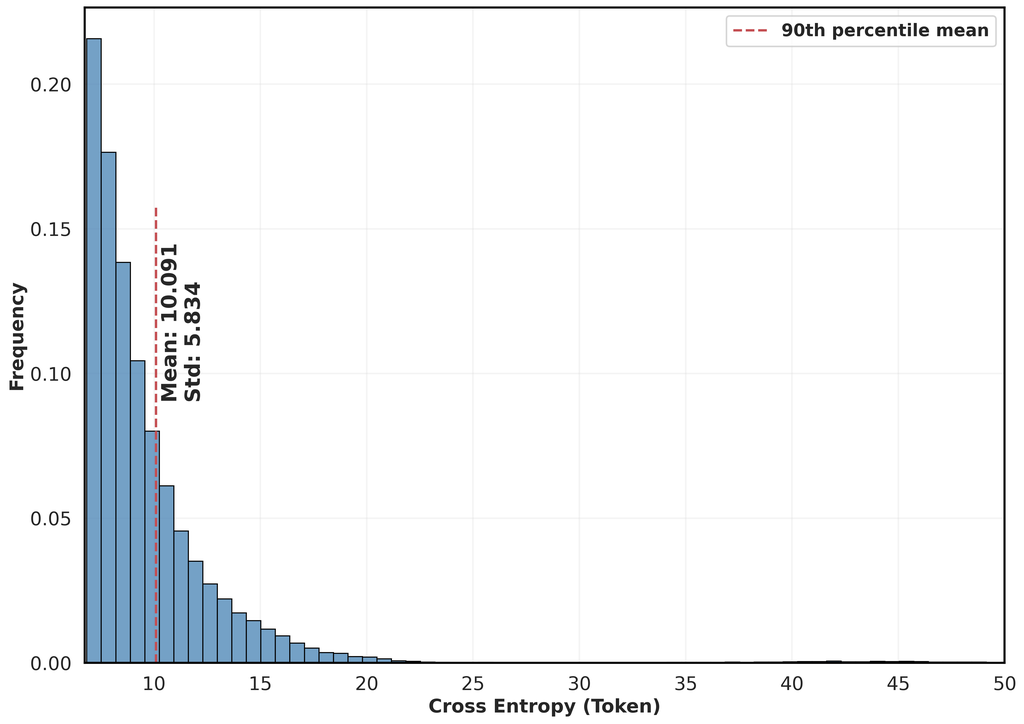
respectively. We then focus on the hardest 10% of the tokens to evaluate the differences between the two sets and . To that end, let and represent their 90th percentiles. By comparing the distributions of and in Figures 2 and 3, we observe that both the mean cross-entropy loss and its standard deviation within this percentile are lower in the cleaned dataset compared to the raw, uncleaned papers. This demonstrates the improved cleanliness of our dataset.
3.2. Standards
Curation. Standards play a pivotal role in telecommunications as they ensure interoperability among technologies from various vendors. These standards are established and maintained by recognized bodies such as 3GPP, IEEE, and ITU. Due to their open-source nature, we focus on incorporating 3GPP documents into our dataset. To do so, using the 3GPP FTP portal444https://www.3gpp.org/ftp/, we downloaded the latest specifications for each standard of each series, resulting in a dataset of approximately 2.8k documents.
Cleaning. Following the curation process, we clean and process the standards files through several steps. We begin by removing non-essential sections such as related works and appendices, and eliminating figures and tables to focus on inline text and equations, similar to our approach with arXiv papers. A key caveat is that equations in .doc files are formatted in XML, unlike the LaTeX format used in arXiv papers. To address this, we first convert all .doc files to .docx format and then utilize docx2tex555https://github.com/transpect/docx2tex to transform the standards into LaTeX format. This standardization improves the training process by ensuring consistency of equations across all document types. Finally, we apply the same cleaning pipeline used for arXiv papers to the converted standards LaTex files to ensure a uniform level of cleanliness and coherence across our entire dataset.
3.3. Wikipedia
Another source of telecommunications material is the Wikipedia corpus, specifically articles related to the telecommunications domain and its associated technical content. To curate this dataset, we utilize the English subset of the Wikipedia dataset666https://huggingface.co/datasets/wikimedia/wikipedia, which contains 6.4 million samples. Given the size of this dataset, applying a pure LLM-based classification would be computationally expensive. Instead, we employ a two-step process:
-
(1)
Keyword Filtering: We define a set of 100 telecom-related keywords, including terms such as telecommunications, base station, Wi-Fi, and 5G. Articles containing any of these keywords are flagged for the next step. This process significantly reduces the number of articles from 6.4M to approximately 70k.
-
(2)
LLM-based Content Evaluation: In this second step, we apply an LLM-based filtering process to the flagged articles. Particularly, the first 10,000 characters of each article are provided to the Mixtral 8x-7B-Instruct model, and the LLM is prompted to provide a Yes or No answer regarding the article’s relevance and the presence of technical content related to telecommunications. The reason behind this is to exclude articles that discuss non-technical aspects, such as a telecom operator’s history.
Through this two-step process, we curate a dataset of 19.5k technically relevant telecommunications articles from Wikipedia. Similarly, we evaluated our LLM-based filtering by sampling 500 flagged articles and manually annotating them. We then assessed the precision and recall of our filtering process. The results in Table 2 showcase the high recall of the process, showcasing its ability to identify relevant technical content in telecommunications. The moderate precision, on the other hand, stems from the challenge of determining the appropriate level of technicality required for an article, resulting in false positives within the dataset.
3.4. Websites
The last source of telecommunications material we consider is the Common Crawl dataset, which comprises web archives from across the internet. To avoid issues with duplicates, non-English content, and potential profanity found in raw dumps, we utilized the refined web dataset (Penedo et al., 2023). This curated version of Common Crawl contains approximately 1 billion rows across 2.8 terabytes of data. To further eliminate duplicates, we filtered out Wikipedia articles from the dataset. Next, to extract telecommunications-related content from this refined dataset, we employed the same two-step process used for Wikipedia articles. Additionally, we incorporated content from well-known telecommunications blogs, such as ShareTechNote, to enhance the dataset’s relevance. The resulting collection consists of content from 740k website links, providing a comprehensive representation of telecommunications information available on the web.
To evaluate the quality of the LLM-based filtering process, we sampled and manually annotated 500 websites containing telecommunications keywords. We then assessed the precision and recall of our filtering process. We observed perfect recall, as the incorporated websites included patents, technical blogs, and forum discussions about telecommunications. However, precision was lower due to the difficulty in discerning the technical content. As a result, websites with product technical specifications, marketing sites for VPN services containing technical details, and product reviews were also included, leading to false positives in the dataset.
3.5. Dataset Format
Tele-Data is structured as a JSONL (JSON Lines) file, where each line represents a JSON object with five distinct fields:
-
•
ID: A unique identifier for each data entry, combining the data category and a number. For example, ‘wiki_132’ refers to the 132th item of the Wikipedia data points.
-
•
Category: A string indicating the source of the data: wiki, standard, arxiv, or web.
-
•
Content: A string containing the main text of the material.
-
•
Metadata: A JSON object containing various information relevant to each specific element, with the structure varying depending on the category. For example, for standards, the JSON object includes the 3GPP series number, release, and standard file name, while for arXiv papers, it contains the arXiv ID, title, and abstract.
Examples of the dataset can be found in Appendix B.
4. Evaluation Dataset
After preparing Tele-Data, the next step involves creating an evaluation dataset to test the resulting domain-adapted models’ telecommunications knowledge. Currently, only one such dataset exists: TeleQnA (Maatouk et al., 2023). TeleQnA is a multiple-choice question (MCQ) dataset drawn from standards and research papers, generated with human involvement. Although an MCQ dataset simplifies evaluation in terms of accuracy, it remains limiting because LLMs are not robust MCQ selectors due to their inherent ‘selection bias,’ a bias prevalent in virtually all LLMs (Zheng et al., 2024; Griot et al., 2024).
Given the above, to examine the telecommunications proficiency of LLMs, we take another approach by creating a dataset of open-ended telecommunications questions. Open-ended questions assess a model’s ability to elaborate on its own to answer questions about specific telecommunications concepts. Given the large number of concepts to be covered and the specialized nature of telecommunications knowledge, large-scale open-ended questions are needed, making a purely human-based approach infeasible.
To overcome this challenge, we adopt an LLM-based approach to create our evaluation dataset, which we refer to as Tele-Eval. Specifically, we gather material from papers, standards, and wiki articles within the collected Tele-Data. We focus on these categories due to their relative cleanliness compared to the Common Crawl data. We then segment the material into 20,000-character chunks. Using Mixtral 8x7B-Instruct, we prompt the LLM to generate five questions for each segment in a three-shot manner, providing examples similar to those in Trivia QA (Joshi et al., 2017), but tailored to the telecommunications domain. The generated questions then undergo extensive regular expression-based filtering. Particularly, we implement filters to remove questions containing expressions such as ‘in this context,’ ‘in this paper,’ ‘as highlighted in,’ and references to equations, figures, tables, and other local elements, along with 100 other similar filters. Our aim is to achieve the lowest possible retention rate to ensure the highest quality in the automatically generated dataset.
The next step in our process involves feeding the QnA pairs to another instance of the Mixtral LLM. This instance is prompted to determine if the provided QnA pair can be answered without access to the source material (i.e., eliminate local context dependency). We retain only those QnA pairs that pass both the regex-based filtering and this LLM-based filtering. As a result, a retention rate of 1% was achieved, and the dataset consists of 750k QnA pairs. It is important to note that given this scale, even if some questions are not perfectly answerable by an LLM, the dataset still serves its purpose as an effective evaluator of telecommunications knowledge.
Remark 2.
One important aspect of our dataset is that each generated QnA pair includes the ID of the specific telecommunications material upon which it was based. This allows users to select questions from the material they are interested in and facilitating retrieval-augmented generation frameworks (Lewis et al., 2021). For example, if someone is interested in a specific topic (e.g., source and channel coding), they can identify the relevant content in the telecommunications dataset, obtain their IDs, and then use the portion of Tele-Eval linked to those IDs.
We provide below a couple of examples of the dataset to illustrate the style and format of the data:
Statement: Under what circumstances should the UE insert a public GRUU value in the Contact header field?
Answer: The UE should insert the public GRUU value in the Contact header field if a public GRUU value has been saved associated with the public user identity from the P-Called-Party-ID header field, and the UE does not indicate privacy of the P-Asserted-Identity.
ID: standard_1309
Statement: What is the difference between unassisted capacity and entanglement assisted capacity in the context of quantum channels?
Answer: Unassisted capacity refers to the maximum rate of transmitting classical or quantum information through a quantum channel without the use of entanglement, while entanglement assisted capacity refers to the maximum rate with the assistance of entanglement.
ID: arxiv_36721
5. Evaluation Metrics
One of the key challenges after continual pretraining is effectively evaluating the resulting domain-adapted model. As seen in the previous section, Tele-Eval consists of open-ended question-answer pairs. Evaluating open-ended responses is more complex compared to MCQ datasets. For example, traditional evaluation metrics such as ROUGE (Lin, 2004) and BLEU (Papineni et al., 2002), commonly used for summarization and translation tasks, measure lexical overlap between the model’s output and the reference answers. However, they fail to capture the semantic similarity and correctness of responses when the model uses alternative wording or lexicon to convey the same meaning as the reference answers. This challenge is especially pronounced when evaluating equations generated by the models, as is often required in the telecommunications domain, since these metrics struggle to capture such nuances. To address this, we adopted three evaluation metrics: Answer perplexity, SemScore (Aynetdinov and Akbik, 2024), and LLM-Eval (Zheng et al., 2023). In Section 7, we will showcase the pros and cons of each evaluation metric and conclude that LLM-Eval is the most robust comparative tool for the telecommunications domain. Below, we provide details on each of these metrics.
5.1. Answer Perplexity
We define answer perplexity as the perplexity of the model with respect to the ground truth answer, conditioned on the question. Specifically, let us consider samples of Tele-Eval, where represents a concatenation of both the question and the ground truth answer of the i-th pair. Assume that at index , the ground truth answer begins. With that in mind, we define the answer perplexity as:
| (5) |
where is the number of tokens in the i-th pair, and represents the model weights. This metric can be seen as how surprised the model is by the answer, given the question. Intuitively, a model that is well-versed in telecommunications should be less surprised by the answer (hence, have a lower perplexity) compared to a non-specialized model.
5.2. SemScore
Another metric we use to evaluate the correctness of a model’s output relative to the ground truth answer is semantic similarity. This is achieved by leveraging sentence transformer models (Reimers and Gurevych, 2020), such as the all-mpnet-base model777https://sbert.net/docs/sentence_transformer/pretrained_models.html from the Sentence Transformers family. These encoder-only BERT models are trained using contrastive loss to encode pairs of sequences into a high-dimensional space, such that the cosine similarity between embeddings of similar pairs is high (closer to 1), while it is lower for dissimilar ones (closer to -1). With this in mind, we define the SemScore (Aynetdinov and Akbik, 2024) as
| (6) |
where refers to the BERT embedding model, and and refer to the ground-truth answer and the model’s output, respectively. Thus, this metric allows us to judge how closely the model’s output aligns with the correct answer.
5.3. LLM-Eval
The last metric in our framework involves using an LLM as a judge to assess the correctness of a model’s output compared to the ground truth answer (Zheng et al., 2023). Given the extensive knowledge LLMs have acquired through their training, we can leverage them as assistants to evaluate the quality and accuracy of model outputs. Previous studies have demonstrated that LLM-based judges can effectively match both controlled and crowdsourced human preferences in various evaluation tasks (Zheng et al., 2023). With this approach, when evaluating any model outputs for questions in Tele-Eval, we prompt Mixtral 8x-7B-Instruct to compare the model’s output to the ground truth and provide a Yes or No answer regarding its correctness. We define the LLM-Eval metric as the average score of these boolean responses, such that
| (7) |
where is the model’s answer to question of Tele-Eval, is the total number of evaluated outputs, and is the indicator function.
6. Initial Experiments
With both the training and evaluation datasets prepared, the next step is to train our models. However, before proceeding, several key questions regarding training techniques and parameters need to be addressed to lay the foundation for the training procedure. While general guidelines on training parameters, such as learning rate and batch size, can be drawn from previous research (Labrak et al., 2024; Colombo et al., 2024; Xie et al., 2023), the characteristics of telecommunications knowledge—such as the prevalence of equations—introduce specific challenges. Key questions that need to be answered include whether full parameter fine-tuning is necessary or if parameter-efficient tuning methods are sufficient, as well as determining the number of training epochs needed to effectively adapt the LLM to the telecommunications domain. We address these questions in this section, while noting that our results can serve as a guide for adapting other models to the telecommunications domain beyond those discussed in our paper.
6.1. Training Settings
For these experiments, we consider two models: Gemma-2B and LLaMA-3-8B. Throughout these studies, we use 20% of the Tele-Data dataset as the training data, with 10% of this subset serving as the validation set. To solve eq. (2), we set the batch size to 4M tokens (with a sequence length of 8192 tokens) and use the AdamW optimizer with a weight decay of 0.1, keeping the default Hugging Face parameters unchanged. The maximum gradient norm is set to . The learning rate is decreased according to a cosine learning rate schedule, down to 10% of the maximum learning rate, and a linear warmup of 10% of an epoch is applied (Gupta et al., 2023). The maximum learning rate is set to 1e-5 for LLaMA and 2e-5 for Gemma. These values are aligned with the pretraining stages of these LLMs (et al., 2024; Team, 2024). To improve efficiency, we employ mixed-precision training alongside sample packing and block attention techniques to avoid cross-contamination (Krell et al., 2022).
6.2. PEFT vs. FFT
PEFT techniques aim to reduce computational costs and memory requirements during domain adaptation by training only a minimal number of parameters, in contrast to FFT methods that update all the model’s parameters. Among these techniques, LoRa (Hu et al., 2022) stands out as a prominent PEFT method. It adds small, trainable low-rank matrices to the existing weights of the pretrained model. To investigate whether PEFT methods like LoRa are sufficient for adapting language models to the telecommunications domain, we conducted a comparative study between LoRa and FFT using both Gemma-2B and LLaMA-3-8B models. For our LoRa implementations, we fixed the LoRa rank to r=64, set the Lora alpha to 32, and used a LoRa dropout rate of 0.1.
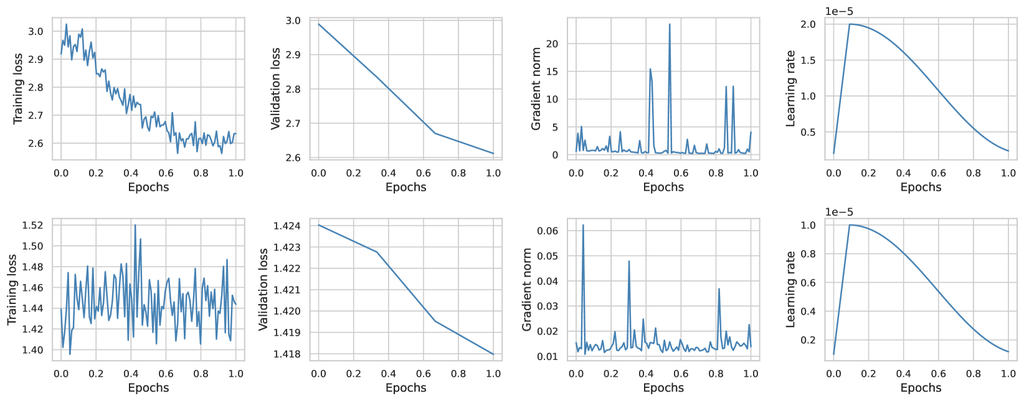
The results, reported in Fig. 4, demonstrate that for smaller models, LoRa can initially inject telecom knowledge but quickly saturates due to its limited capacity. In contrast, for the LLaMA-3-8B model, which is more knowledgeable about telecommunications, the gradient norm of the LoRa method remained extremely low. This hindered parameter updates, causing the training loss to barely change and limiting LoRa’s ability to inject additional knowledge. These findings indicate that, despite its computational efficiency, LoRa may not be sufficient to adapt the model to the telecommunications field. Consequently, in the next sections, we will rely on full parameter fine-tuning for all our training.
6.3. One or Multiple Epochs?
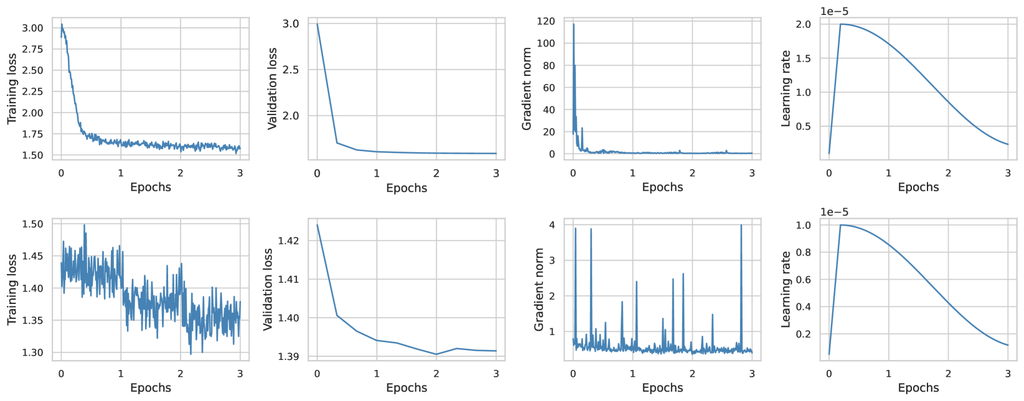
A crucial question when adapting an LLM to a target domain, in our case being telecommunications, is determining the most effective duration for model training. Is a single epoch enough to adapt the model, or do multiple exposures to the data with shuffling at each epoch yield better results? To address this, we conducted experiments using two different model scales: Gemma-2B and LLama-3-8B. As we will demonstrate, this distinction arises from the distinct behaviors of these models due to their different sizes. The results are reported in Fig. 5 and discussed below.
Gemma-2B. As shown in Fig. 5, the training loss of Gemma-2B demonstrates consistent behavior, decreasing and then plateauing after approximately two epochs. A similar pattern is observed in the validation loss, which also stabilizes after two epochs. Additionally, the gradient norm approaches 0, indicating that the training is reaching convergence. It is worth noting that for smaller models, after three epochs of training, there are no signs of overfitting, as both validation and training losses plateau at similar levels. This suggests that the model has developed a comprehensive understanding of the telecom data, and further training results in only minor adjustments to this understanding without significantly adding to or diminishing the existing telecom knowledge.
LLama-3-8B. The first observation one can make by investigating the bottom plots of Fig. 5 is that the training loss starts with a cross-entropy of around 1.42. This indicates that the model is already quite knowledgeable when it comes to telecommunications. This is not surprising for two reasons: first, this model was trained on 15T tokens, hence it has likely encountered a wide variety of telecom-related data; second, the large number of parameters in the model allows it to retain such information. Regardless, continual pretraining is helpful to further solidify this knowledge.
By further examining the training loss, an interesting phenomenon can be witnessed: at the end of each epoch, the training loss experiences a noticeable drop. This suggests that the model is memorizing patterns in the training dataset and becoming more confident in its next token prediction as it encounters these patterns after each epoch. These patterns have some generalizable components, as evidenced by the drop in validation loss up to the second epoch. However, beyond two epochs, this memorization becomes problematic as the learned patterns become more specific to the training data and less transferable to the validation data, thus leading to overfitting. We hypothesize that two epochs represent a sweet spot: the first epoch serves to warm up the model and absorb telecom knowledge, while the second epoch, aided by the cosine decay, shapes this knowledge with a very low learning rate, allowing the model to make final adjustments in the loss landscape. Based on the above, we use two epochs to create the Tele-LLMs series in the next section.
Remark 3.
We have observed similar training loss behavior across other models (e.g., Mistral-7B). As the number of parameters increases, the model becomes more expressive and better able to capture intricate relationships in the training data, leading to this behavior. We have not reported these results due to their similarity to those shown in the bottom plots of Fig. 5.
7. Tele-LLMs
| Tele-Eval | General Knowledge | |||||
|---|---|---|---|---|---|---|
| Ans-PPL | SemScore | LLM-Eval | MMLU | HellaSWAG | GSM8K | |
| Tinyllama-1.1B | 230.44 | 0.5952 | 8.26 | 0.2501 | 0.4670 | 0.0258 |
| Tinyllama-1.1B-Tele | 9.06 | 0.6093 | 11.37 | 0.2519 | 0.4663 | 0.0212 |
| Gemma-2B | 13.31 | 0.5998 | 13.59 | 0.3289 | 0.5275 | 0.0576 |
| Gemma-2B-Tele | 11.73 | 0.6302 | 17.07 | 0.3497 | 0.5304 | 0.0622 |
| LLama-3-8B | 9.17 | 0.6358 | 24.60 | 0.6209 | 0.6009 | 0.144 |
| LLama-3-8B-Tele | 8.49 | 0.6482 | 29.60 | 0.6157 | 0.6068 | 0.2441 |
Having completed the initial experiments, we proceed with the full-scale training of the LLMs to create the telecom-adapted series of models, starting with the following three models: Tinyllama-1.1B-Tele, Gemma-2B-Tele, and LLaMA-3-8B-Tele. Our selection of these base models was guided by a combination of factors, including their performance on the Hugging Face Open LLM leaderboard and a consideration of their licenses. We also accounted for the diversity of the releasing companies to mitigate potential risks associated with changes in these licenses.
Training Settings. We maintain the settings described in Section 6.1, with Tinyllama-1.1B following the same approach as Gemma-2B. One caveat is the use of a sequence length of 2048 for Tinyllama-1.1B, aligning with its initial pretraining specifications (et al., 2023). For the training dataset across the entire series, we utilize the entire Tele-Data dataset for two epochs, augmented with 5% of regular general-purpose data taken from SlimPajama888https://huggingface.co/datasets/cerebras/SlimPajama-627B. This augmentation is designed to mitigate the catastrophic forgetting phenomenon by reintroducing general-purpose data to the model, helping it retain key skills acquired during the initial pretraining stage. The training of these models was conducted on a cluster of 8 NVIDIA A6000 GPUs, consuming a total of 2,500 GPU hours.
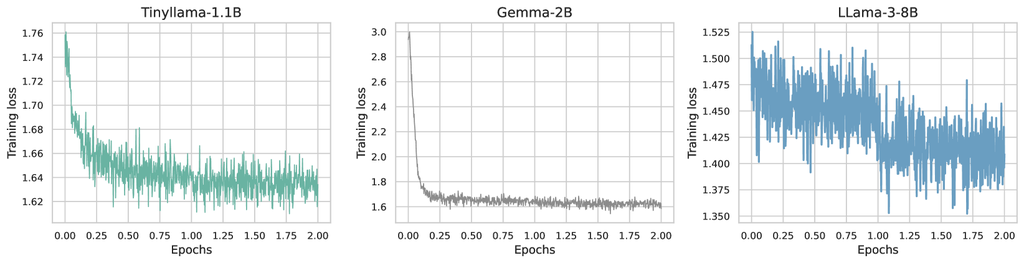
Loss Trends. As shown in Fig. 6, the three models exhibit results consistent with those reported in our previous section’s training experiments. Specifically, Tinyllama-1.1B and Gemma-2B demonstrate the steady training loss behavior typical of smaller models, while LLaMA-3-8B displays the sharp loss reduction characteristic of larger models at each epoch. On another note, due to its shorter context length, Tinyllama-1.1B starts with a lower training loss than Gemma-2B, highlighting the challenge in capturing long-range dependencies within 8k token sequences.
Evaluation Settings. We evaluate the LLMs on Tele-Eval using the three metrics discussed in Section 5, generating model answers through greedy decoding of 100 new tokens with the prompt provided in Appendix C. To assess the impact of our training on other LLM capabilities, we evaluate our models on three additional benchmarks: MMLU (Hendrycks et al., 2021) for general world knowledge, HellaSWAG (Zellers et al., 2019) for commonsense understanding, and GSM-8K (Cobbe et al., 2021) for mathematical reasoning abilities. All evaluations, including Tele-Eval and the additional benchmarks, are conducted in a zero-shot setting.
Quantitative Evaluation. As shown in Table 3, the adapted telecom LLMs outperform their counterparts across all metrics on Tele-Eval. For general knowledge tasks, these models exhibit stable performance compared to the original models, with slight variations—either improvements or degradations—across most tasks. Notably, there are improvements on GSM-8K, with LLama-3-8B-Tele achieving a 10% higher accuracy. This enhancement is attributed to the equations found in Tele-Data, which enable the adapted model to become stronger in mathematical reasoning.
Comparing the LLMs’ performance on Tele-Eval across the three metrics reveals several insights: First, Ans-PPL shows minimal relative differences for larger models. This occurs because larger models, with their higher proficiency, are less surprised by the terms used in the ground truth answers. Consequently, improvements in telecommunications knowledge become less apparent and more diluted in this metric. Another observation is the lack of comparability across different models using the Ans-PPL metric, as evidenced by the performance comparison between Tinyllama-1.1B-Tele and Gemma-2B-Tele. The tendency of a model to follow certain formats when answering questions biases this metric, resulting in either better or worse performance. This makes Ans-PPL more useful for comparing models within the same family rather than across different families, due to the heterogeneous nature of their tendencies.
SemScore exhibits patterns similar to Ans-PPL; an LLM producing coherent responses with appropriate technical terminology may achieve good scores even when providing incorrect answers. With this in mind, and given the heterogeneous response styles across LLM families, both SemScore and Ans-PPL are more effective at highlighting significant differences within the same LLM family. For detecting subtle disparities and comparing across different LLM families, LLM-Eval proves more robust. It disregards linguistic variations and instead focuses on the underlying concepts being assessed. Using this metric, we observe an average relative improvement of 25% for the telecom-adapted LLMs.
Although LLM-Eval provides the most accurate evaluation, its drawback is the runtime. Given the scaling of the attention mechanism, where is the input prompt length for the evaluation, our evaluation with Mixtral-8x-7B took approximately 50 milliseconds per question on a single Nvidia A6000 GPU. Note that given the size of Tele-Eval, the standard deviation of our results is negligible.
Remark 4.
It is worth noting that Tele-Eval, with its focus on highly granular telecommunications concepts, presents a significant challenge for LLMs, as evidenced by their performance on the LLM-Eval metric. This inherent difficulty is one of Tele-Eval’s advantages; if the questions were easily answerable, the dataset would fail to effectively distinguish the advantages gained through adapting models to the telecom domain.
Qualitative Evaluations. Going beyond the quantitative comparison provided in Table 3, we offer a set of examples in Appendix D that illustrate how the behavior of these models change, using Gemma-2B and Gemma-2B-Tele as a case study. These examples highlight the model’s enhanced ability to provide detailed explanations, confidently answer telecommunications-related questions, and even delve into telecommunications concepts when they are mentioned in the prompt. These qualitative observations further emphasize the successful adaptation of these models to the telecommunications domain.
8. Further Exploration
In the final phase of our work, we investigate various adaptation strategies and specific dynamics that emerge when tailoring LLMs to the telecommunications domain. We particularly focus on two key aspects: the potential for expertise division in the adaptation process, and the unique adaptation dynamics that arise based on each model’s characteristics and training data. We also adapt our models to follow instructions, creating chatbot-like models that users can interact with. We show that these adapted models demonstrate greater proficiency in telecommunications compared to their general-purpose instruct counterparts.
8.1. Division of Expertise
| Tele-Eval | General Knowledge | ||||
|---|---|---|---|---|---|
| Standards | Overall | MMLU | HellaSWAG | GSM8K | |
| Gemma-2B | 8.12 | 13.59 | 0.3289 | 0.5275 | 0.0576 |
| Gemma-2B-Tele | 10.15 | 17.07 | 0.3497 | 0.5304 | 0.0622 |
| Gemma-2B-Standards | 9.58 | 11.18 | 0.3314 | 0.5250 | 0.0432 |
When adapting an LLM to the telecommunications domain, a key question arises: should we adapt a single LLM to cover the entire domain, or should we adapt multiple LLMs, each specialized in a specific aspect of telecommunications? For example, one LLM could focus on scholarly material while another concentrates on standards. To explore this, we compare two versions of the Gemma-2B model: one trained exclusively on the standards portion of Tele-Data, referred to as Gemma-2B-Standards, and Gemma-2B-Tele. The training parameters align with those previously reported for Gemma-2B-Tele. Evaluation is based on both the entirety of Tele-Eval and questions related to standards using the LLM-eval metric, along with general knowledge evaluation datasets to assess the retention of the model’s capabilities. The results are reported in Table 4.
As shown, Gemma-2B-Tele outperforms Gemma-2B-Standards on the standards-related questions while also demonstrating stronger general knowledge capabilities. Additionally, Gemma-2B-Standards performs worse than the base model Gemma-2B on the overall Tele-Eval dataset. The reason behind this is that the Gemma-2B-Standards model, having been trained solely on standards, becomes more attuned to that specific type of content. Standards tend to be highly technical with a unique token distribution that differs from the broader telecommunications knowledge found in scholarly and Wikipedia articles. This narrow focus makes the model less capable of handling scholarly material compared to the base model, leading to underperformance on Tele-Eval. At the same time, this narrow focus also negatively impacts the LLM’s general abilities. All in all, this highlights that the most effective strategy is to adapt the LLM to the entire telecommunications dataset, thereby benefiting from the transfer learning that occurs across these diverse materials rather than narrowly focusing on a single aspect.
8.2. Pretraining Data Impact
Perhaps the most impactful element that shapes an LLM’s behavior is its pretraining data. This data is generally not publicly available, so one can only infer its type through interactions with the model. Understanding this behavior is crucial because when adapting an LLM to the telecom domain, specific trends emerge based on this behavior.
To illustrate this, let us consider two models: Gemma-2B and Gemma-2B-it999https://huggingface.co/google/gemma-2b-it. The latter is an instruct version of the former that has been post-trained on instruction-following data, which includes tasks like question answering and summarization. As Table 5 shows, instruct models outperform their base counterparts on Tele-Eval. This is because the additional instruction-focused training allows the LLM to better handle questions, follow instructions, and leverage its internalized knowledge to effectively answer queries. This advantage is significant enough that Gemma-2B-it is able to outperform our telecommunications-adapted LLM, Gemma-2B-Tele. However, since Gemma-2B-Tele has been enriched with telecommunications knowledge, we can surpass the performance of Gemma-2B-it by applying a similar post-training instruction-following adaptation using a dataset like Alpaca101010https://huggingface.co/datasets/tatsu-lab/alpaca and utilizing the same training settings previously detailed, thus creating Gemma-2B-Tele-Alpaca.
| Tele-Eval | |||
|---|---|---|---|
| Original | Tele | Tele-Alpaca | |
| Gemma-2B | 13.59 | 17.07 | 25.31 |
| Gemma-2B-it | 19.84 | 18.05 | 24.83 |
| Phi-1.5 | 14.87 | 13.06 | 18.84 |
The significance of the above observation is that some base models have been trained on instruct-like data during their pretraining stage. An example of this is Microsoft Phi-1.5. In their paper (et al., 2023), the authors specify that Phi-1.5 can be prompted as an instruct model because the pretraining data included a large portion of question-answer formats. This leads to noticeable behavioral differences between Gemma-2B and Phi-1.5, as illustrated in Fig. 7. One can see that Phi-1.5 behaves more like a chatbot, following the instructions of the prompt, while Gemma-2B fills in sentences without treating the input prompt as an instruction to follow.
Given the above, when applying the training recipe described in our paper to Phi-1.5, the performance on Tele-Eval declines for Phi-1.5-Tele, similar to what occurred for Gemma-2B-it. However, by post-training Phi-1.5-Tele on Alpaca using the same training settings, the performance significantly improves beyond that of the base model. This is because, by doing so, we align the model back to its original behavior. With this in mind, it is crucial to be mindful of the model’s behavior before proceeding with the adaptation process, in order to anticipate its dynamics accordingly.
Given the above observations and the special behavior of the Phi-1.5 model, we only release the Alpaca fine-tuned version of Phi-1.5 as part of our Tele-LLM series. It is worth noting that its performance on general knowledge datasets is 0.3965 on MMLU, 0.4680 on HellaSWAG, and 0.1107 on GSM8K, compared to 0.4072, 0.4798, and 0.0576, respectively, for the original Phi-1.5. This demonstrates that our model performs better in telecom while still retaining its general knowledge and even gaining in mathematical performance.
| Tele-Eval | ||||
|---|---|---|---|---|
| Base | Instruct | Tele | Tele-Instruct | |
| Tinyllama-1.1B | 8.26 | 15.42 | 11.37 | 17.40 |
| Gemma-2B | 13.59 | 19.84 | 17.07 | 27.78 |
| LLama-3-8B | 24.60 | 30.65 | 29.60 | 34.51 |
8.3. Instructions Fine-tuning
Although base models are essential, as they contain the raw LLM’s knowledge and are best suited for fine-tuning for specific telecommunications applications, it is common for users to interact with these models as chatbots. Therefore, in this section, we proceed to fine-tune our telecom-adapted models to follow instructions through instructions fine-tuning.
Training Settings. We maintain the training settings from Section 7 with minor adjustments. Specifically, we decrease the batch size to 128k tokens, set the context length to 2048, and limit the number of epochs to 1. For this stage, we use two datasets: Alpaca and Open-Instruct111111https://huggingface.co/datasets/VMware/open-instruct. The combined datasets provide approximately 200k samples for training.
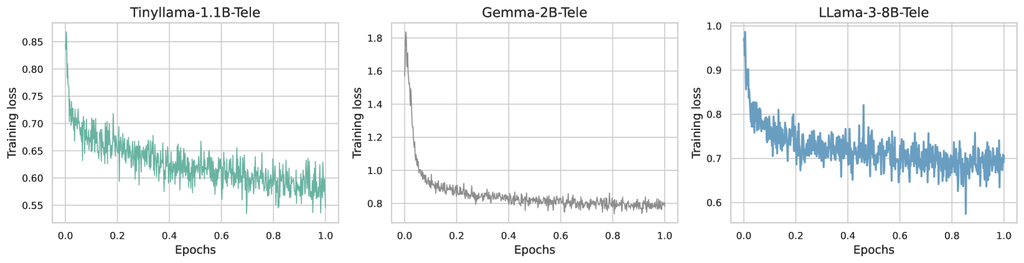
Results. As seen in Fig. 8, the training loss consistently decreases as the model becomes more adept at following instructions. Next, in Table 6, we compare the Tele-Instruct versions of our models to their general instruct counterparts. Our instruction-tuned series outperforms the general instruct models, thereby showcasing their superior knowledge in telecom compared to their general-purpose counterparts.
9. Conclusions
In this paper, we addressed the challenge of adapting LLMs for specialized use in telecommunications. In our endeavor, we created and released Tele-Data and Tele-Eval, a comprehensive telecommunications training and evaluation datasets. Through extensive experimentation, we identified the most suitable training strategies for adapting LLMs to this domain. The culmination of our work is Tele-LLMs, a series of open-source models ranging from 1B to 8B parameters, specifically designed for the telecommunications domain. These models outperform their general-purpose counterparts on Tele-Eval while retaining their broader capabilities. Beyond this culmination, our work also investigated various adaptation strategies, such as the division of expertise, and explored the dynamics that arise during the adaptation process depending on the models involved. As a future direction, our work will aim to leverage Tele-LLMs and augment them with multi-modal capabilities to understand and reason about wireless measurements and signals.
References
- (1)
- Aynetdinov and Akbik (2024) Ansar Aynetdinov and Alan Akbik. 2024. SemScore: Automated Evaluation of Instruction-Tuned LLMs based on Semantic Textual Similarity. arXiv:2401.17072 [cs.CL] https://arxiv.org/abs/2401.17072
- Bariah et al. (2023a) Lina Bariah, Qiyang Zhao, Hang Zou, Yu Tian, Faouzi Bader, and Merouane Debbah. 2023a. Large Language Models for Telecom: The Next Big Thing? arXiv preprint arXiv:2306.10249 (2023). arXiv:2306.10249 [cs.CL]
- Bariah et al. (2023b) Lina Bariah, Hang Zou, Qiyang Zhao, Belkacem Mouhouche, Faouzi Bader, and Merouane Debbah. 2023b. Understanding Telecom Language Through Large Language Models. arXiv preprint arXiv:2306.07933 (2023). arXiv:2306.07933 [cs.CL]
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems. arXiv:2110.14168 [cs.LG] https://arxiv.org/abs/2110.14168
- Colombo et al. (2024) Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, and Michael Desa. 2024. SaulLM-7B: A pioneering Large Language Model for Law. arXiv:2403.03883 [cs.CL] https://arxiv.org/abs/2403.03883
- Du et al. (2023) Yuyang Du, Soung Chang Liew, Kexin Chen, and Yulin Shao. 2023. The Power of Large Language Models for Wireless Communication System Development: A Case Study on FPGA Platforms. arXiv preprint arXiv:2307.07319 (2023). arXiv:2307.07319 [eess.SP]
- et al. (2024) Abhimanyu Dubey et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
- et al. (2023) Suriya Gunasekar et al. 2023. Textbooks Are All You Need. arXiv:2306.11644 [cs.CL] https://arxiv.org/abs/2306.11644
- Griot et al. (2024) Maxime Griot, Jean Vanderdonckt, Demet Yuksel, and Coralie Hemptinne. 2024. Multiple Choice Questions and Large Languages Models: A Case Study with Fictional Medical Data. arXiv:2406.02394 [cs.CL] https://arxiv.org/abs/2406.02394
- Gupta et al. (2023) Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats Leon Richter, Quentin Gregory Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort. 2023. Continual Pre-Training of Large Language Models: How to re-warm your model?. In Workshop on Efficient Systems for Foundation Models @ ICML2023. https://openreview.net/forum?id=pg7PUJe0Tl
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 8342–8360. https://doi.org/10.18653/v1/2020.acl-main.740
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding. In International Conference on Learning Representations. https://openreview.net/forum?id=d7KBjmI3GmQ
- Holm (2021) H. Holm. 2021. Bidirectional Encoder Representations from Transformers (BERT) for Question Answering in the Telecom Domain: Adapting a BERT-like language model to the telecom domain using the ELECTRA pre-training approach. (2021).
- Hu et al. (2022) Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations. https://openreview.net/forum?id=nZeVKeeFYf9
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Regina Barzilay and Min-Yen Kan (Eds.). Association for Computational Linguistics, Vancouver, Canada, 1601–1611. https://doi.org/10.18653/v1/P17-1147
- Kotaru (2023) Manikanta Kotaru. 2023. Adapting Foundation Models for Information Synthesis of Wireless Communication Specifications. arXiv preprint arXiv:2308.04033 (August 2023). arXiv:2308.04033 [cs.NI]
- Krell et al. (2022) Mario Michael Krell, Matej Kosec, Sergio P. Perez, and Andrew Fitzgibbon. 2022. Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance. arXiv:2107.02027 [cs.CL] https://arxiv.org/abs/2107.02027
- Labrak et al. (2024) Yanis Labrak, Adrien Bazoge, Emmanuel Morin, Pierre-Antoine Gourraud, Mickael Rouvier, and Richard Dufour. 2024. BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. arXiv:2402.10373 [cs.CL] https://arxiv.org/abs/2402.10373
- Lewis et al. (2021) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https://arxiv.org/abs/2005.11401
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013
- Luo et al. (2024) Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2024. An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning. arXiv:2308.08747 [cs.CL] https://arxiv.org/abs/2308.08747
- Maatouk et al. (2023) Ali Maatouk, Fadhel Ayed, Nicola Piovesan, Antonio De Domenico, Merouane Debbah, and Zhi-Quan Luo. 2023. TeleQnA: A Benchmark Dataset to Assess Large Language Models Telecommunications Knowledge. arXiv:2310.15051 [cs.IT] https://arxiv.org/abs/2310.15051
- Maatouk et al. (2024) Ali Maatouk, Nicola Piovesan, Fadhel Ayed, Antonio De Domenico, and Merouane Debbah. 2024. Large Language Models for Telecom: Forthcoming Impact on the Industry. IEEE Communications Magazine (2024), 1–7. https://doi.org/10.1109/MCOM.001.2300473
- OpenAI (2024) OpenAI. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (Philadelphia, Pennsylvania) (ACL ’02). Association for Computational Linguistics, USA, 311–318. https://doi.org/10.3115/1073083.1073135
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116 (2023). arXiv:2306.01116 https://arxiv.org/abs/2306.01116
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. https://api.semanticscholar.org/CorpusID:160025533
- Reimers and Gurevych (2020) Nils Reimers and Iryna Gurevych. 2020. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/2004.09813
- Team (2024) Gemma Team. 2024. Gemma: Open Models Based on Gemini Research and Technology. arXiv:2403.08295 [cs.CL] https://arxiv.org/abs/2403.08295
- Xie et al. (2023) Yong Xie, Karan Aggarwal, and Aitzaz Ahmad. 2023. Efficient Continual Pre-training for Building Domain Specific Large Language Models. arXiv:2311.08545 [cs.CL] https://arxiv.org/abs/2311.08545
- Xu et al. (2024) Shengzhe Xu, Christo Kurisummoottil Thomas, Omar Hashash, Nikhil Muralidhar, Walid Saad, and Naren Ramakrishnan. 2024. Large Multi-Modal Models (LMMs) as Universal Foundation Models for AI-Native Wireless Systems. arXiv:2402.01748
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a Machine Really Finish Your Sentence?. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 4791–4800. https://doi.org/10.18653/v1/P19-1472
- Zheng et al. (2024) Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. 2024. Large Language Models Are Not Robust Multiple Choice Selectors. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=shr9PXz7T0
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685 [cs.CL] https://arxiv.org/abs/2306.05685
- Zhou et al. (2024) Hao Zhou, Chengming Hu, Dun Yuan, Ye Yuan, Di Wu, Xue Liu, Zhu Han, and Charlie Zhang. 2024. Generative AI as a Service in 6G Edge-Cloud: Generation Task Offloading by In-context Learning. arXiv:2408.02549 [eess.SY] https://arxiv.org/abs/2408.02549
- Çağatay Yıldız et al. (2024) Çağatay Yıldız, Nishaanth Kanna Ravichandran, Prishruit Punia, Matthias Bethge, and Beyza Ermis. 2024. Investigating Continual Pretraining in Large Language Models: Insights and Implications. arXiv:2402.17400 [cs.CL] https://arxiv.org/abs/2402.17400
Appendices
Appendix A Manuscripts Cleaning Procedure
Given the importance of ensuring that the arXiv papers are clean for training, we employ a rigorous cleaning process on these sources. Our process begins with the removal of all comments written in the LaTeX files. For this, we leverage Google’s arXiv LaTeX Cleaner121212https://github.com/google-research/arxiv-latex-cleaner.
Next, because LaTeX sources can include multiple LaTeX files, we start by unifying the LaTeX commands used for importing these files. Particularly, we ensure that imports use the \input{} command. By creating a directed graph that maps these relationships, we identify the main LaTeX file of the paper. We then use the Latexpand Perl script131313We tested fatex (https://ctan.org/pkg/fatex) and fap (https://github.com/fchauvel/fap), but achieved the best results with latexpand ( https://ctan.org/pkg/latexpand). to flatten the document, ensuring the main file contains all material.
In the subsequent step, we address the author’s custom commands by ‘de-macoring’ them. To do so, we unify all custom commands—from \def{} and \DeclareMathOperator{} to \newcommand{}—before using the Python library de-macro (https://ctan.org/pkg/de-macro) to replace these macros with their native LaTeX equivalents. Afterwards, we target the removal of figures and tables, as our focus is on the in-line text and equations. We also compile a list of over a hundred LaTeX commands and environments that are not informative, which we remove using regular expression matching. This ensures that the final LaTeX files contain only the text and equations without any LaTeX residue.
Additionally, given the many forms that citations can take, along with the wide variety of text within their brackets, we unify all citation, label, and reference commands. This standardization helps the LLM to avoid dealing with heterogeneity during training. Lastly, we remove all preambles of the LaTeX files and ensure that the title of the manuscript is retained. This provides a unified format for these sources, thus facilitating the LLM training in the next stage.
Appendix B Samples of Tele-Data
We provide below an example of each category of Tele-Data. The […] symbol is inserted below to reduce the size of the strings.
ID: arxiv_14326
Category: arxiv
Content: Flexible-Position MIMO for Wireless Communications: Fundamentals, Challenges, and Future Directions\n \n Abstract\n \n The flexible-position multiple-input multiple-output (FLP-MIMO), such as fluid antennas and movable antennas, is a promising technology for future wireless communications […]
Metadata:
Arxiv_id: 2308.14578
Title: Flexible-Position MIMO for Wireless Communications: Fundamentals, Challenges, and Future Directions
Abstract: The flexible-position multiple-input multiple-output (FLP-MIMO), such as […]
ID: standard_2413
Category: standards
Content: 3rd Generation Partnership Project; \n Technical Specification Group Core Network and Terminals;\n Interworking between the Public Land Mobile Network (PLMN)\n supporting packet based services with\n Wireless Local Area Network (WLAN) Access and\n Packet Data Networks (PDN)\n (Release 12)\n Foreword\n This Technical Specification (TS) has been produced […]
Metadata:
Series: 29
Release: 12
File_name: 29161-c00
ID: wiki_5438
Category: wiki
Content:A backbone or core network is a part of a computer network which interconnects networks, providing a path for the exchange of information between different LANs or subnetworks. A backbone can tie together diverse networks […]
Metadata:
Title: Backbone network
Url: https://en.wikipedia.org/wiki/Backbone%20network
ID: web_71187
Category: web
Content:1. Field of the Invention\n The present invention relates generally to methods of addressing data packets destined to a host in a communications network, and particularly to a method of defining an address for a mobile terminal/host […]
Metadata:
Url: http://www.google.com/patents/US6147986
Appendix C LLM Prompts
The following prompts were utilized throughout our framework to develop and evaluate various areas. In summary, and in order, the prompts were used for the following tasks:
-
(1)
Prompt 1: Used to find arXiv papers related to the telecommunications and networking domains.
-
(2)
Prompt 2: Used to find websites and Wikipedia pages related to the telecommunications and networking domains.
-
(3)
Prompt 3: Leveraged to generate the QnAs that form the initial Tele-eval dataset.
-
(4)
Prompt 4: Leveraged to filter out locally relevant QnAs, resulting in the filtered Tele-eval dataset.
-
(5)
Prompt 5: Used to instruct the base model to complete the answer based on the provided question.
-
(6)
Prompt 6: Utilized as a prompt for LLM-Eval.
Appendix D Qualitative Examples
Below, we present examples that illustrate the qualitative differences between the base Gemma-2B model and Gemma-2B-Tele. These examples include telecommunications-related questions from Tele-Eval (Question), and simple string prompts (Prompt).