Measuring and Enhancing Trustworthiness of LLMs in RAG
through Grounded Attributions and Learning to Refuse
Abstract
LLMs are an integral part of retrieval-augmented generation (RAG) systems. While many studies focus on evaluating the quality of end-to-end RAG systems, there is a lack of research on understanding the appropriateness of an LLM for the RAG task. Thus, we introduce a new metric, Trust-Score, that provides a holistic evaluation of the trustworthiness of LLMs in an RAG framework. We show that various prompting methods, such as in-context learning, fail to adapt LLMs effectively to the RAG task. Thus, we propose Trust-Align, a framework to align LLMs for higher Trust-Score. LLaMA-3-8b, aligned with our method, significantly outperforms open-source LLMs of comparable sizes on ASQA (10.7), QAMPARI (29.2) and ELI5 (14.9). We release our code at: https://github.com/declare-lab/trust-align.
Measuring and Enhancing Trustworthiness of LLMs in RAG
through Grounded Attributions and Learning to Refuse
Maojia Song1††thanks: These authors contributed equally. Shang Hong Sim111footnotemark: 1 Rishabh Bhardwaj1, Hai Leong Chieu2 Navonil Majumder1 Soujanya Poria1 1 Singapore University of Technology and Design, 2 DSO National Laboratories, Singapore {maojia_song, shanghong_sim, rishabh_bhardwaj}@mymail.sutd.edu.sg chaileon@dso.org.sg {navonil_majumder, sporia}@sutd.edu.sg
1 Introduction
Hallucination in Large Language Models (LLMs) is a significant concern in generative AI, where the models produce information that appears plausible but is factually incorrect Ji et al. (2023). Examples include falsely accusing individuals of crimes The Independent (2023), generating fictitious judicial cases Bohannon (2023), and creating historically inaccurate images Business Insider (2023). Such instances raise concerns about the reliability of LLMs as tools for accessing accurate information.
Rather than directly using LLMs as an information source, incorporating them into a Retrieval-Augmented Generation (RAG) framework has become a popular approach to enhance the credibility of generated information. A typical RAG system, thus, consists of a large corpus of documents, a retriever that finds the top-K reference documents relevant to a query, and an LLM that composes the response and presents it to the user in a well-formatted manner. Notably, the role of the LLM shifts from being a source of information (in a non-RAG setup) to a consolidator of the information supplied by the retriever, with consolidation conditioned on the question asked.
There has been a significant amount of research on studying and reducing hallucinations in LLMs. For instance, Bai et al. (2024) examines hallucinations due to incorrect access to parametric knowledge. However, there is a lack of understanding of how these LLMs behave when they are required to rely solely on external (non-parametric) knowledge provided to them. An early work by Gao et al. (2023b) focuses on evaluating the RAG system in an end-to-end fashion, thereby, entangling the shortcomings of the retrieval with the errors in the final LLM output. Naturally, such an evaluation scheme is inconducive to isolating the role of LLMs under RAG setup.
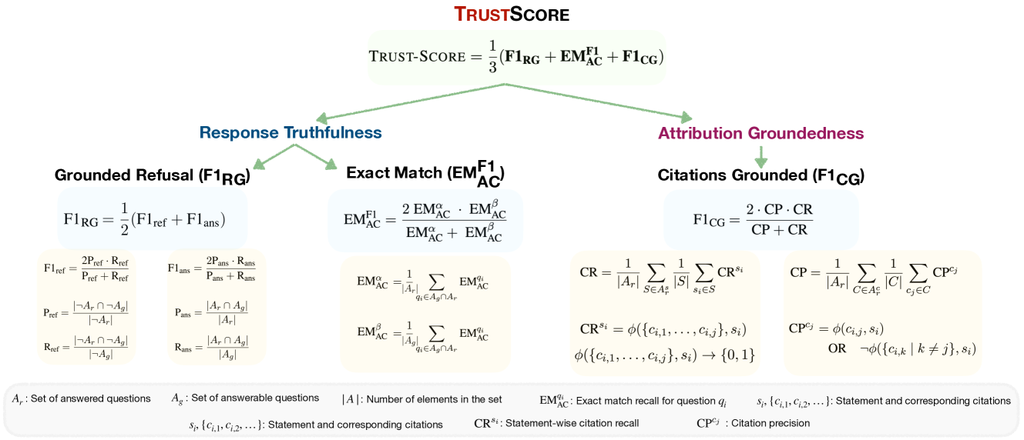
In this work, we propose Trust-Score—a novel holistic metric to exclusively evaluate the trustworthiness of LLMs for RAG. Trust-Score assesses an LLM across multiple dimensions: 1) The ability to discern which questions can be answered or refused based on the provided documents (Grounded Refusals); 2) Gold claim recall scores for the answerable responses (Exact Match Recall); 3) The extent to which generated claims are supported by the corresponding citations (Citation Recall); and 4) The relevance of the citations (Citation Precision).
Our investigation shows that many state-of-the-art systems, including GPT-4 and Claude-3.5-Sonnet, heavily rely on their internal parametric knowledge acquired during parameter tuning phases to answer questions OpenAI (2023); Anthropic (2024). This limits their suitability for RAG tasks, where models should base responses solely on provided documents, leading to a low Trust-Score. Moreover, prompting approaches intended to enhance model trustworthiness have been found ineffective, as the responsiveness of the models becomes overly sensitive to the prompt. This leads to extreme Answered Ratio (AR%) values, indicating indiscriminate answering or refusal.
Thus, we propose an alignment framework, Trust-Align, to tune LLMs towards generating document-grounded responses and achieving higher Trust-Score. The framework aims to build an alignment dataset consisting of 19K questions, documents, positive (preferred) responses , and negative (unpreferred) responses . This dataset was created to address the five hallucinations types found - Inaccurate Answer, Over Responsveness, Excessive Refusal, OverCitation and Improper Citation. First, we collect a diverse and high-quality seed set of questions , followed by gathering the relevant (oracle) documents , and then perform extensive data augmentation. Positive responses are generated by stitching the gold claims together using GPT-4, while negative responses are derived from high-ranked hallucinations of a generic RAG fine-tuned model.
Evaluation on the benchmark datasets shows that the models trained with Trust-Align outperform the competitive baselines w.r.t. Trust-Score: 10.73%, 29.24%, and 14.88% on ASQA, QAMPARI, and ELI5, respectively. TRUST-ALIGN significantly enhances the ability of models to correctly refuse or provide answers as compared to the baselines with refusal metric scores increased by 9.87% for ASQA, 22.53% for QAMPARI, and 5.32% for ELI5. Moreover, Trust-Align improves citation quality, with citation groundedness scores increasing by 26.67% for ASQA, 31.96% for QAM- PARI, and 29.30% for ELI5. Due to gamification, we observe mixed scores on exact match recall. We observe a notable increase in recall scores for QAMPARI (33.23%) and ELI5 (10.04%), but a decrease of 4.34% for ASQA.
We show that Trust-Align combined with DPO improves trustworthiness more effectively than prompting or SFT methods. Our augmented data leads to significant gains in Trust-Score, with an increase of 1.50% on ASQA, 1.78% on QAMPARI, and 2.23% on ELI5. Additionally, ablation studies highlight the importance of using data specific to each hallucination subtype. Removing subsegments of data for any subtype results in a measurable decrease in Trust-Score. Moreover, we find that aligning with refusal samples in Trust-Align produces the highest Trust-Score scores, emphasizing the critical role of including refusal samples during training. Our key contributions to this work are as follows:
-
•
We are the first to study hallucinations of LLMs in a RAG setup, where model responses should be exclusively grounded in retrieved documents rather than the model’s parametric knowledge.
-
•
We define answerability—a crucial concept for determining if the provided documents are sufficient to answer the question.
-
•
To measure LLM performance under RAG, we introduce Trust-Score, a holistic metric for quantifying LLM hallucinations in the RAG setup.
-
•
We propose Trust-Align, an alignment framework designed to improve the trustworthiness of LLMs in RAG. It first creates an alignment dataset of 19K samples with positive (gold) and negative (unpreferred) responses, followed by applying the DPO algorithm on the model.
2 Problem Description
2.1 Task Setup
Given a question and a set of retrieved documents as input, the LLM is instructed to generate a response which consists of a set of citation-grounded statements ; each statement follows a set of citations referring to the documents in 111For QAMPARI, we treat each entity in the response list as a statement.. If is not sufficient to answer , the gold response would be a refusal statement, such as, “I apologize, but I couldn’t find an answer to your question in the search results”.
2.2 When is refusal expected?
To label a sample as a ground truth refusal, we first define the notion of answerability:
A refusal response contains no claims or citations but provides a generic message conveying the LLM’s inability to respond to .
Nuances of answerability.
Determining answerability can be challenging. To determine answerability, we use a system that evaluates the entailment of gold claims against provided documents, referred to as the Natural Language Inference (NLI) system. An NLI system can range from a simple exact match (EM) identifier to an LLM or even a human evaluator, with answerability determined based on and biases of the NLI222For EM, the bias is that a is answerable if exact match fo claims is present in .. These biases can be useful in specific RAG applications, such as solving mathematical problems where the documents provide a formula and the question assigns values to variables. The choice of NLI depends on whether the RAG system requires the LLM to have mathematical understanding. Ideally, to prevent improper evaluations, the NLI model used to construct the gold claims should also be used to evaluate the LLM responses.
In this paper, our focus is on evaluating the generic comprehension capabilities of LLMs without specialized knowledge. Thus, we use two NLI mechanisms: 1) identifying whether an exact match of claims is present in the gold claims, and 2) using a Machine Learning (ML) model to determine if the documents can entail the gold claims. The ML-based NLI model is used for multiple purposes, such as alignment dataset construction (data/training) and evaluating generated responses (metric/testing). For this, we adopt the NLI model from Rashkin et al. (2022). if (premise) entails (hypothesis); otherwise, 0. To determine answerability, we employ the TRUE-based method Honovich et al. (2022) to assess whether a gold claim can be entailed by a given document.
The knowledge grounding problem.
Typically, LLMs are designed to perform question-answering tasks, where response generation heavily relies on the parametric (internal) knowledge acquired during their pre-training, tuning, and alignment phases OpenAI (2023); Anthropic (2024). Thus, most of their knowledge is grounded in parametric memory. This makes them inherently less suitable for RAG applications, where the knowledge generated by the LLM is expected to be grounded in input documents. RAG is analogous to a reading comprehension task, where the answers must come from the provided passage (documents in RAG) rather than the prior knowledge of the person taking the test. Thus, any reliance on parametric knowledge can result in statements that are not fully grounded in the documents, including providing answers to unanswerable questions. Our investigation shows that state-of-the-art models, such as GPT-4 and Claude-3.5-Sonnet, overtly rely on parametric knowledge even when used in a RAG setting.333We show a detailed analysis in Sections D.1 and D.2.
2.3 Hallucination in LLM in RAG
For the task of RAG, we define hallucination in an LLM as any error where the generated response is not grounded on the provided documents. We categorize hallucination into five types: (1) Inaccurate Answer - The generated statements fail to cover claims in the gold response, (2) Over Responsiveness - The model answers an unanswerable (refusal) question, (3) Excessive Refusal - The model refuses to answer an answerable question, (4) Overcitation - The model generates redundant citations, (5) Improper Citation - The model’s citation(s) do not support the statement.
Next, we introduce a comprehensive metric to effectively measure hallucinations in LLMs.
3 Metrics for LLM-in-RAG
Given a question and the corresponding ground truth response consisting of gold claims, we define the claims obtainable from the provided documents as and the claims generated in the response as . We aim to measure two aspects of an LLM in RAG: 1) the Correctness of the generated claims (Response Truthfulness); and 2) the Correctness of citations generated (Attribution Groundedness).
Insufficiency of the existing metrics.
The existing metric measures Response Truthfulness by first computing the per-sample exact match recall (EMr) score for gold claims Gao et al. (2023b), disregarding how many of these claims are obtainable from . This is followed by averaging the recall scores across samples to obtain a single score for the dataset. This method introduces inconsistencies: models that rely on parametric knowledge () may generate gold claims not found in , leading to an artificially inflated recall value. In contrast, an ideal LLM () would rely solely on to generate responses (a desired trait) and would be constrained by an upper recall limit of , which varies depending on the question. This approach presents two key problems: (1) Recall Consolidation: Since the measurement range depends on the claims present in , it is infeasible to provide a consistent, consolidated EMr score across the dataset, (2) Recall Gamification: may have a higher upper limit on EMr (up to 1) because they can generate gold claims not present in (an undesirable trait), unlike that depend entirely on .
Answer Calibration.
To address the challenges of recall consolidation and gamification in existing evaluation metrics, we propose new metrics that measure sample-wise recall score based on the fraction of gold claims that can be obtained from . Specifically, this involves computing , which measures the exact match (EM) recall after calibrating the gold claims. This approach sets a maximum recall limit of 1 for all models. For dataset-wide scoring, we consolidate per-sample EM recall scores using two methods: 1) EM: The average recall score across samples answered by the LLM, i.e., samples where ; 2) EM: The average recall score across samples that are answerable, i.e., samples where 444Notably, both EM and EM sum over samples that are both answered and answerable, differing primarily in their normalization values.. These metrics, illustrated in Fig. 1, are then combined into a single score, EM, which serves as a comprehensive measure of how well the LLM grounds its claims on the document . This combined metric not only facilitates the consolidation of recall but also addresses issues related to recall gamification.
Scoring Refusals.
An important capability of an LLM in RAG is its ability to identify when a response is unanswerable based on the provided documents . To measure this, we introduce a metric called Grounded Refusals. This metric evaluates the model’s refusal performance by calculating dataset-wide precision and recall for both ground-truth answerable cases and refusals. These values are then combined into their respective F1 scores, F1ref for refusals and F1ans for answerable cases. The final score, F1, is the average of these two F1 scores, as shown in Fig. 1.
Measuring Attribution Groundedness.
While Response Truthfulness metrics like EM and F1 evaluate the quality of generated claims, it is equally important to measure how well these statements are supported by relevant citations—what we call Attribution Groundedness. To this end, we adopt two sub-metrics from Gao et al. (2023b): Citation Recall (CR) and Citation Precision (CP). To compute CR, we first determine if a generated statement is supported by its cited documents using an NLI model555An NLI model checks if the cited document entails the statement., thus obtaining sample-wise recall scores CR. Then we take the mean across all samples to obtain the final CR score (Figure 1). To compute CP, we first score each citation of a statement , followed by computing the average across citations in a response (sample-wise score). The dataset-wide citation score is computed by averaging the citation scores across all the samples. To provide a single metric for Attribution Groundedness, we calculate the harmonic mean of CP and CR, resulting in the final score, F1.
Thus, we define a new metric, Trust-Score, as follows:
Responsiveness.
To measure the answering tendency of an LLM, we define Responsiveness. It is the fraction of answered questions, denoted by the Answered Ratio (AR %), which is calculated as . A model is expected to show a high AR% for answerable questions and a low AR% for unanswerable ones, with the scores expected to align with the dataset distribution.
4 The Trust-Align Framework
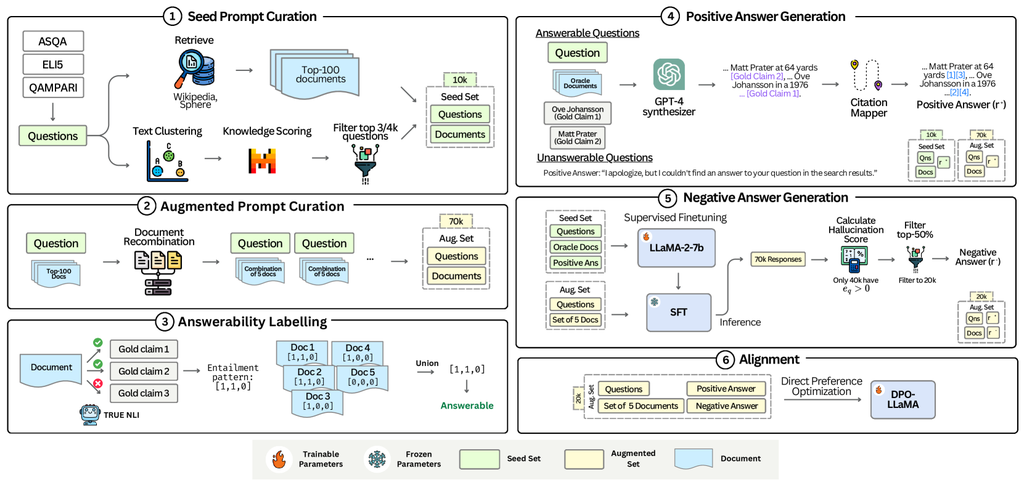
To align LLMs towards trustworthiness, we propose a new framework, Trust-Align. The framework constructs an LLM trustworthiness alignment dataset, where each sample in the dataset consists of a question , a set of retrieved documents , and a pair of positive (preferred) and negative (unpreferred) responses (, ). The positive response corresponds to an answer that encompasses expected gold claims for and corresponding citations referring to the documents. If is not sufficient to answer , is assigned a refusal response, while is its non-refusal counterpart. We build the dataset in multiple steps: 1) Obtain a set of high quality and diverse questions, 2) Obtain documents for each question, 3) Augmenting pairs that cover diverse hallucination types, 4) Construct positive responses entailing gold claims, and 5) Construct negative (unpreferred) responses by prompting a fine-tuned model and observing its hallucinations.
Collecting Quality Questions.
The dataset construction begins by collecting a set of high-quality (challenging) and diverse questions from source datasets i.e. ASQA, QAMPARI, and ELI5—referred to as seed samples. To collect such samples, we first divide the questions in a dataset into clusters. After identifying the diverse clusters, we assign each a quality score ranging from 1 to 7. The quality of a cluster is determined by how difficult it is to answer the questions without requiring additional information i.e. a higher score corresponds to a high difficulty. We then select clusters with a quality score of 4 or higher and sample the desired number of questions from these top clusters. Suppose we have three clusters, , with respective sizes , where . To sample questions from the clusters, we sample questions from cluster . If this number exceeds the available questions in the cluster, we randomly sample the remaining questions from the filtered-out clusters (those with a quality score below 4). This process ensures that the seed set prioritizes both high quality and diversity. For this paper, we set to 3K, 3K, and 4K for ASQA, QAMPARI, and ELI5, respectively, resulting in approximately 10K questions in the seed set.
Collecting D’s.
Next, we collect documents relevant to each question in the seed set. To do this, we query Wikipedia and Common Crawl to retrieve the 100 most relevant documents. We filter seed question for which the retriever fails to retrieve relevant documents. Furthermore, we identify 5 documents that are equally effective for the model as the 100 documents in terms of achieving the EM recall value); we refer to such documents as oracle documents for question .666We provide clustering and document retrieval detials in Appendix B. Notably, to compute EM, gold claims are obtained from respective source datasets.
Augmenting (q,D) set.
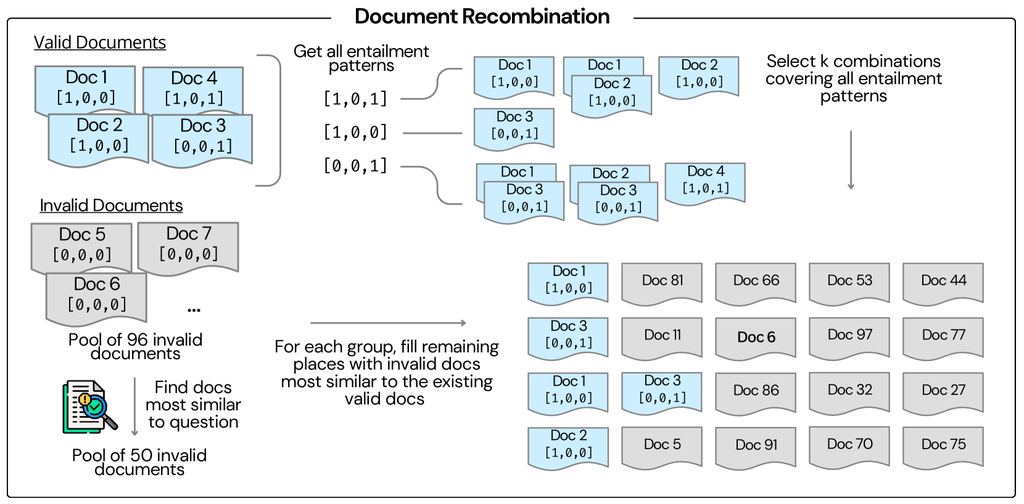
Now that we have the questions and the most relevant (oracle) documents, our goal is to create samples of diverse types (i.e., different proportions of relevant documents for the same question) that can trigger multiple hallucinations from LLMs (Section 2.3). As illustrated in Fig. 3, for answerable questions, we first utilize the identified entailment patterns to generate all possible combinations of documents, then select combinations that cover diverse patterns. To create samples with unanswerable questions, we select documents that are similar to gold-claim-entailing documents but do not entail any gold claims. To minimize the risk of introducing bias in citation indices, we shuffle the order of documents in each sample. As a result, we generate approximately 70K question-document pairs.
After obtaining pairs for the alignment dataset, we obtain positive and negative responses () for each pair—an essential component of the dataset signaling the model’s preferred and unpreferred responses. To achieve this, we introduce a response generation pipeline.
Obtaining .
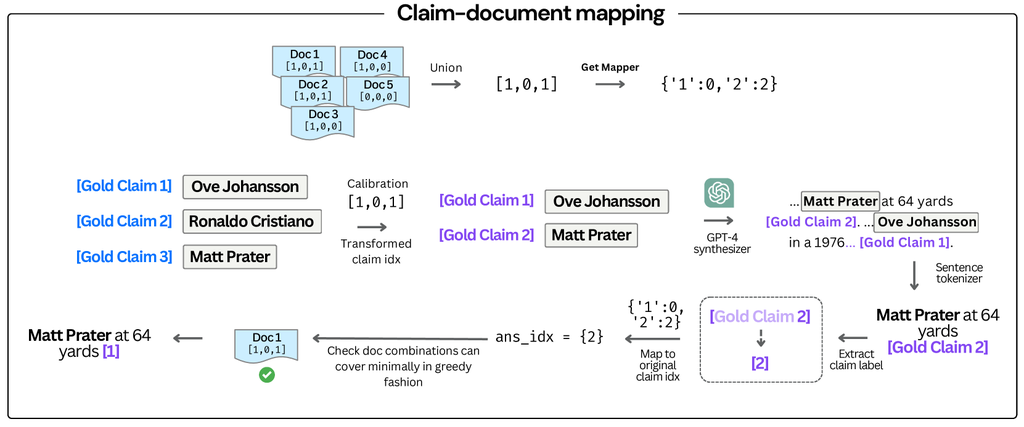
We develop an automated data labeling pipeline that synthesizes natural responses from gold claims and maps each statement to the corresponding documents for embedded in-line citations. The gold claims are obtained from the source datasets (ASQA, QAMPARI, ELI5) and calibrated to the provided documents, i.e., filtering out claims that cannot be derived from . We first split the questions into answerable and unanswerable samples based on whether the provided documents entail the gold claims. For an answerable sample, consisting of a question , a set of documents , and a list of (calibrated) gold claims, we prompt GPT-4 to generate a natural response by stitching together the gold claims using a template (Table 6). The prompt template asks GPT-4 to label each gold claim used with its index from the provided list (e.g., "[Gold Claim X]"), allowing for later matching of claims to documents. For unanswerable questions, a refusal response is assigned. Additional details are provided in Section B.1. To generate citations corresponding to each statement generated, we map the "[Gold Claim X]" labels to the appropriate documents. First, we extract all such labels from a sentence (which may contain multiple claims and labels). Then, we greedily identify the smallest combination of documents that covers these claims, minimizing over-citation. Details of this process is illustrated in Fig. 4.
Obtaining .
To create high-quality preference data, we aim to obtain quality negative (unpreferred) responses. We first fine-tune LLaMA-2-7b on the training set of the source datasets, creating (details in Section B.1). We then test on the above-obtained dataset with approximately 70K questions and identify that 40K responses exhibit hallucinations. Table 1 shows the severity computation () and the frequency of each hallucination type (). Thus, we can compute hallucination severity for each sample:
| (1) |
| Hallucination type | Frequency () | Severity () | |
|---|---|---|---|
| Unwarranted Refusal | 8,786 | 0.50 | |
| Over Responsiveness | 13,067 | 0.50 | |
| Overcitation | 12,656 | 0.34 | 1 - CP |
| Improper Citation | 9,592 | 0.26 | 1 - CR |
| Inaccurate Claims | 14,783 | 0.40 | 1 - EM |
To obtain good negative samples, we first rank each of the 40K responses according to their severity score . We then select the top 50% of the corresponding samples for both answerable and unanswerable responses. Thus, we demonstrate the alignment data construction phase of Trust-Align, i.e., obtaining 19K samples with all the desired attributes .
5 Experimental Setup
Evaluation datasets.
We evaluate on the test-set of attributable factoid and long-form question-answering tasks from ASQA Stelmakh et al. (2023), QAMPARI Amouyal et al. (2023), and ELI5 Fan et al. (2019). Additionally, we include ExpertQA Malaviya et al. (2024) for generalization evaluation. For each question, we append the top 5 documents obtained using retriever. For ELI5 and ExpertQA, the ground truth answers are decomposed into three claims. The dataset statistics are shown on top of Section 6.
Baselines.
We evaluate the effectiveness of Trust-Align framework under two settings — default prompting and refusal prompting as shown in Table 15. We compare our models trained with Trust-Align framework against five competitive baseline methods — In-Context Learning (ICLCite) Gao et al. (2023b), Post-hoc Attribute Gao et al. (2023a), Post-hoc Search Gao et al. (2023b), Self-RAG Asai et al. (2024), and FRONT Huang et al. (2024b). The details of these baselines are given in Section G.3.
6 Results and Analysis
| ASQA (610 answerable, 338 unanswerable) | QAMPARI (295 answerable, 705 unanswerable) | ELI5 (207 answerable, 793 unanswerable) | ||||||||||||||
| Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | |||||||||||
| AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | |||||
| Prompt | EM | F1 | F1 | EM | F1 | F1 | EM | F1 | F1 | |||||||
| LLaMA-2-7b | ||||||||||||||||
| ICL | R | 0.00 | 0.00 | 26.28 | 0.00 | 8.76 | 0.00 | 0.00 | 41.35 | 0.00 | 13.78 | 0.50 | 0.00 | 46.71 | 0.00 | 15.57 |
| PostCite | R | 10.44 | 0.07 | 35.23 | 0.00 | 11.77 | 34.40 | 0.00 | 57.34 | 9.50 | 22.28 | 0.90 | 1.86 | 44.98 | 5.04 | 17.29 |
| PostAttr | R | 10.44 | 0.07 | 35.23 | 0.00 | 11.77 | 34.40 | 0.00 | 57.34 | 3.78 | 20.37 | 0.90 | 1.86 | 44.98 | 0.00 | 15.61 |
| Self-RAG | R | 100.00 | 45.19 | 39.15 | 63.49 | 49.28 | 96.00 | 6.81 | 28.23 | 19.95 | 18.33 | 73.50 | 14.94 | 40.20 | 13.80 | 22.98 |
| FRONT | R | 100.00 | 60.47 | 39.15 | 68.86 | 56.16 | 100.00 | 17.27 | 22.78 | 24.26 | 21.44 | 100.00 | 21.66 | 17.15 | 52.72 | 30.51 |
| ICL | D | 94.30 | 50.38 | 49.51 | 43.67 | 47.85 | 93.60 | 8.36 | 31.02 | 3.88 | 14.42 | 95.30 | 19.83 | 22.82 | 16.30 | 19.65 |
| PostCite | D | 88.71 | 2.30 | 50.82 | 0.98 | 18.03 | 56.30 | 0.00 | 49.18 | 7.73 | 18.97 | 83.90 | 11.95 | 30.05 | 4.90 | 15.63 |
| PostAttr | D | 87.24 | 2.32 | 51.56 | 0.43 | 18.10 | 51.10 | 0.00 | 49.50 | 4.70 | 18.07 | 84.00 | 11.94 | 29.74 | 0.93 | 14.20 |
| Self-RAG | D | 98.00 | 46.82 | 41.16 | 56.59 | 48.19 | 96.20 | 7.72 | 27.08 | 15.44 | 16.75 | 97.90 | 13.16 | 19.62 | 10.31 | 14.36 |
| LLaMA-2-13b | ||||||||||||||||
| ICL | R | 17.41 | 21.52 | 41.40 | 13.83 | 25.58 | 26.50 | 0.44 | 59.57 | 0.00 | 20.00 | 46.40 | 19.97 | 54.81 | 4.73 | 26.50 |
| PostCite | R | 90.51 | 2.21 | 49.91 | 1.53 | 17.88 | 100.00 | 0.00 | 22.78 | 8.05 | 10.28 | 76.60 | 2.27 | 38.05 | 0.72 | 13.68 |
| PostAttr | R | 90.51 | 2.21 | 49.91 | 0.17 | 17.43 | 100.00 | 0.00 | 22.78 | 2.95 | 8.58 | 76.60 | 2.27 | 38.05 | 0.09 | 13.47 |
| Self-RAG | R | 100.00 | 48.52 | 39.15 | 69.79 | 52.49 | 72.70 | 2.71 | 48.58 | 26.91 | 26.07 | 22.10 | 12.77 | 58.68 | 24.54 | 32.00 |
| ICL | D | 97.57 | 49.16 | 44.06 | 9.35 | 34.19 | 97.80 | 0.00 | 26.20 | 0.00 | 8.73 | 96.50 | 20.93 | 21.06 | 2.80 | 14.93 |
| PostCite | D | 89.77 | 0.04 | 50.33 | 0.00 | 16.79 | 63.00 | 0.00 | 47.20 | 7.14 | 18.11 | 7.00 | 3.62 | 45.31 | 4.73 | 17.89 |
| PostAttr | D | 89.24 | 0.04 | 51.46 | 0.00 | 17.17 | 58.50 | 0.00 | 48.86 | 4.56 | 17.81 | 6.70 | 3.66 | 48.41 | 0.71 | 17.59 |
| Self-RAG | D | 97.68 | 48.93 | 42.74 | 63.39 | 51.69 | 96.30 | 3.66 | 27.15 | 21.06 | 17.29 | 98.00 | 12.19 | 19.07 | 6.68 | 12.65 |
| LLaMA-3-8b | ||||||||||||||||
| ICL | R | 1.48 | 3.01 | 28.58 | 86.50 | 39.36 | 3.90 | 5.92 | 48.60 | 20.24 | 24.92 | 0.00 | 0.00 | 44.23 | 0.00 | 14.74 |
| PostCite | R | 77.53 | 32.98 | 53.31 | 28.01 | 38.10 | 87.00 | 6.10 | 34.52 | 8.42 | 16.35 | 62.00 | 20.80 | 45.88 | 8.06 | 24.91 |
| PostAttr | R | 77.53 | 32.98 | 53.31 | 5.95 | 30.75 | 87.00 | 6.10 | 34.52 | 1.64 | 14.09 | 62.00 | 20.80 | 45.88 | 1.25 | 22.64 |
| ICL | D | 89.66 | 58.28 | 55.62 | 61.59 | 58.50 | 70.80 | 5.82 | 50.50 | 4.81 | 20.38 | 84.60 | 23.69 | 33.11 | 31.03 | 29.28 |
| PostCite | D | 97.26 | 34.80 | 43.56 | 17.89 | 32.08 | 92.00 | 2.45 | 30.07 | 11.14 | 14.55 | 98.90 | 19.00 | 18.47 | 6.33 | 14.60 |
| PostAttr | D | 97.47 | 34.75 | 42.98 | 3.18 | 26.97 | 93.00 | 2.43 | 29.95 | 5.65 | 12.68 | 98.90 | 19.00 | 18.26 | 1.02 | 12.76 |
| Our Models | ||||||||||||||||
| SFT-LLaMA-2-7b | R | 80.17 | 53.21 | 63.43 | 79.61 | 65.42 | 31.60 | 33.76 | 71.13 | 46.37 | 50.42 | 29.50 | 21.58 | 63.30 | 39.59 | 41.49 |
| SFT-LLaMA-3-8b | R | 68.99 | 52.35 | 66.06 | 80.95 | 66.45 | 24.20 | 33.85 | 71.11 | 48.01 | 50.99 | 23.60 | 22.57 | 65.06 | 46.85 | 44.83 |
| DPO-LLaMA-2-7b | R | 65.30 | 52.48 | 66.12 | 83.94 | 67.51 | 31.10 | 32.09 | 71.83 | 51.33 | 51.75 | 21.60 | 22.54 | 63.27 | 48.43 | 44.75 |
| DPO-LLaMA-3-8b | R | 56.43 | 53.94 | 65.49 | 88.26 | 69.23 | 23.10 | 35.94 | 71.11 | 58.87 | 55.31 | 15.50 | 22.81 | 64.00 | 53.84 | 46.88 |
| 3-17 | 4.34 | 9.87 | 26.67 | 10.73 | 33.23 | 22.53 | 31.96 | 29.24 | 10.04 | 5.32 | 29.30 | 14.88 | ||||
In Section 6, we present the summarized results and articulate the core takeaways below.
Trust-Align boosts trustworthiness compared to baseline methods.
Using the Trust-Align framework, our models significantly outperform the best baselines on Trust-Score by 10.73%, 29.24%, and 14.88% for ASQA, ELI5, and QAMPARI, respectively (see row in Section 6). This improvement suggests that our models are more capable of generating responses grounded in the documents. Since Trust-Score is an average of EM, F1, and F1, we now examine the impact of Trust-Align on each score below.
Trust-Align improves models’ refusal capability.
Trust-Align significantly enhances the ability of models to correctly refuse or provide answers, compared to the best baseline ranked by Trust-Score. This is demonstrated by the increases in F1 scores: 9.87% for ASQA, 22.53% for QAMPARI, and 5.32% for ELI5.
Trust-Align enhances models’ citation quality.
Aligning with Trust-Align improves the model’s ability to provide citations that fully support claims, outperforming the best baseline ranked by Trust-Score in each dataset. This is reflected in the significant increases in F1 scores: 26.67% for ASQA, 31.96% for QAMPARI, and 29.30% for ELI5.
Trust-Align has mixed effects on EM.
We observe a notable increase in EM for QAMPARI (33.23%) and ELI5 (10.04%), but a decrease of 4.34% for ASQA. This mixed performance in ASQA can be explained by the composition of EM, which is derived from EM and EM (Eq. 10).
As shown in Table 20, our models achieve higher EM compared to the ICL with LLaMA-3-8b and FRONT (52.72% vs. 49.83% and 49.69%) despite having a lower AR% (56.43% vs. 89.66% and 100%). This suggests that our models have a higher expected value for EMAC (per-sample EM recall), as the denominator depends on the number of answered questions. A similar trend is observed for QAMPARI and ELI5 in Table 21 and Table 22.
However, in ASQA, our models underperform in EM due to the overwhelmingly adverse impact of EM. The recall of answerable questions () is lower for our model compared to baselines (68.20% vs. 95.25% and 100%), which rarely refuse questions. As a result, fewer terms are summed in the numerator of EM, while the denominator remains constant (the number of answerable questions). This leads to a lower overall EM score.
To further analyze the baseline models’ performance, we investigated how much of their answering ability relies on parametric knowledge versus document-based information, as discussed in Section D.1 and Section D.2.
Models aligned with DPO outperform those trained with SFT.
DPO models outperform SFT models in Trust-Score across all datasets, with improvements of 2.09% (LLaMA-2-7b) and 2.78% (LLaMA-3-8b) for ASQA, 1.33% (LLaMA-2-7b) and 4.32% (LLaMA-3-8b) for QAMPARI, and 3.26% (LLaMA-2-7b) and 2.05% (LLaMA-3-8b) for ELI5.
SFT fine-tuning also improves all key metrics: EM, F1, and F1. On the ASQA dataset with LLaMA-3-8b, we see increases of 30.8% in EM, 24.6% in F1, and 67.1% in F1. However, F1 decreased by 5.55% due to the base model’s tendency to decline answering (AR% dropped from 68.99% to 1.48%), yielding a high F1 on a limited set of responses, which artificially inflated its citation quality score.
DPO further improves F1 compared to SFT, as seen on ASQA with LLaMA-3-8b (88.26% vs. 80.95%), indicating better citation quality. However, DPO shows smaller gains on EM and F1. Despite some variability on sub metrics, DPO models achieve better overall Trust-Score scores.
Trust-Align enhances trustworthiness more robustly than prompting.
Aligning with Trust-Align leads to more significant improvements in Trust-Score compared to using prompting alone. While adding a refusal prompt has inconsistent effects on Trust-Score and its subcomponents, it tends to be more beneficial in more capable models, such as LLaMA-2-13b and LLaMA-3-8b.
Relying solely on prompting to teach refusal is ineffective, as models’ responsiveness becomes overly sensitive to the prompt. Under the default prompt, models rarely refuse (AR% close to 100), while adding a refusal prompt in ICL drastically reduces AR%, often to near zero, indicating indiscriminate refusal. This lack of nuanced refusal ability is also seen in post hoc methods. At both extremes, Trust-Score scores suffer due to errors in correctly refusing questions and lower citation groundedness scores. In contrast, Trust-Align enables models to identify and correctly answer appropriate questions, resulting in AR% closer to the maximum answerable percentage and improvements in F1.
It’s important to note that responsiveness should not be the primary metric for comparing RAG systems when the retrieved documents are the same. The TRUST score rewards accurate answers, appropriate refusals, and correct citations while penalizing failures. Systems with low responsiveness will score poorly on TRUST, regardless of their overall response rate.
In PostCite, PostAttr, and Self-RAG, adding a refusal prompt results in minimal changes in Trust-Score (e.g., ASQA Self-RAG with LLaMA-2-13b: 51.69% vs. 52.49%). Subcomponent analysis shows little difference in F1 (42.74% vs. 39.15%), indicating that the refusal prompt does not effectively help models distinguish between answerable and unanswerable questions. These findings highlight the instability of relying on prompting to enhance trustworthiness and underscore the robustness of our system in achieving this goal.
6.1 Analysis
6.1.1 Different Data Synthesis Techniques
Table 3 demonstrates the effectiveness of our data construction approach. Adding augmented prompts targeting five error types improves Trust-Score scores across ASQA, QAMPARI, and ELI5 by 1.50%, 1.78%, and 2.23%, respectively, highlighting the value of our synthetic data in improving trustworthiness and reducing hallucinations. When data for specific hallucination types is omitted, Trust-Score scores drop, emphasizing the importance of each subtype. In particular, removing refusal-related hallucinations significantly affects F1, with decreases of 2.79% for ASQA, 0.46% for QAMPARI, and 2.03% for ELI5, showing that refusal-related data is critical for improving a model’s ability to decide when to answer, thereby enhancing trustworthiness.
To validate our approach, we compared it against a strong baseline: the GPT-4 critic pipeline Huang et al. (2024a); Li et al. (2024a); Huang et al. (2024b), an automated data collection method that uses advanced prompts to iteratively identify and correct errors (details in Appendix F). Our data pipeline outperformed GPT-4, particularly in ELI5 (with a 4.12% improvement), further demonstrating the effectiveness of our method.
| ASQA | QAMPARI | ELI5 | |||||||||||||
| Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | ||||||||||
| AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | ||||
| EM | F1 | F1 | EM | F1 | F1 | EM | F1 | F1 | |||||||
| DPO-LLaMA-2-7b | 65.30 | 52.48 | 66.12 | 83.94 | 67.51 | 31.10 | 32.09 | 71.83 | 51.33 | 51.75 | 21.60 | 22.54 | 63.27 | 48.43 | 44.75 |
| Trust-Align w/o. augmented instructions | 79.43 | 53.54 | 63.33 | 81.15 | 66.01 | 32.20 | 33.14 | 70.82 | 45.94 | 49.97 | 29.50 | 23.98 | 63.30 | 40.28 | 42.52 |
| Trust-Align w/o. answer HT | 77.74 | 53.29 | 63.7 | 81.2 | 66.06 | 33.40 | 33.56 | 71.36 | 46.17 | 50.36 | 27.60 | 23.47 | 63.56 | 38.28 | 41.77 |
| Trust-Align w/o. citation HT | 77.32 | 52.55 | 63.88 | 81.51 | 65.98 | 33.10 | 34.13 | 71.40 | 46.91 | 50.81 | 26.70 | 22.65 | 64.33 | 42.81 | 43.26 |
| Trust-Align w/o. refusal HT | 79.11 | 53.55 | 63.33 | 81.85 | 66.24 | 31.10 | 34.40 | 71.35 | 48.12 | 51.29 | 28.30 | 22.93 | 64.05 | 41.18 | 42.72 |
| GPT-4 as critic | 70.36 | 54.91 | 65.29 | 78.47 | 66.22 | 25.90 | 30.77 | 70.29 | 48.87 | 49.98 | 23.50 | 17.27 | 62.24 | 42.38 | 40.63 |
6.1.2 Effect of Adding Refusal Samples in Trust-Align
Table 4 underscores the importance of including refusal samples during fine-tuning in ASQA. Training with refusal samples in Trust-Align achieves the highest Trust-Score score of 69.23%. Removing all unanswerable questions from the training set creates a set without refusals or refusal-related hallucination types. Without refusal samples, Trust-Score scores drop significantly—by 10.2% for LLaMA-3-8b and 11.41% for LLaMA-2-7b. This decline is particularly pronounced in F1 (down 26.34% for LLaMA-3-8b and 26.97% for LLaMA-2-7b) and F1 (down 6.87% for LLaMA-3-8b and 6.57% for LLaMA-2-7b).
We also observe that EM is higher for LLaMA-3-8b in the answerable-only set compared to the set with refusals. As discussed in main results, this is because EM favors over-responsive models, which artificially inflates EM. When refusal samples are excluded, responsiveness (AR%) reaches 100%, meaning the models answer all questions, even without supporting documents. This suggests that the models rely more on ungrounded parametric knowledge, as discussed in Section D.1.
| Model | Responsiveness (AR%) | EM | F1 | F1 | TRUST | |
|---|---|---|---|---|---|---|
| Only Answerable | DPO-LLaMA-2-7b | 100 | 51.79 | 39.15 | 77.37 | 56.10 |
| DPO-LLaMA-3-8b | 100 | 56.54 | 39.15 | 81.39 | 59.03 | |
| With Refusal | DPO-LLaMA-2-7b | 65.30 | 52.48 | 66.12 | 83.94 | 67.51 |
| DPO-LLaMA-3-8b | 56.43 | 53.94 | 65.49 | 88.26 | 69.23 |
6.1.3 Generalizability Analysis
Following Huang et al. (2024a), we use ExpertQA Malaviya et al. (2024) to assess our model’s generalizability. As shown in Table 5, the open-source ICL models perform significantly worse on Trust-Score compared to proprietary models, with a 16.35% gap between ICL-LLaMA-3-8b and ICL-GPT-4. Trust-Align not only closes this gap but establishes a lead: the tuned LLaMA-3-8b model achieves the highest TRUST score of 54.85, surpassing GPT-4’s score of 52.32.
Using Trust-Align results in a 28.61% improvement in grounded refusal judgment (F1) and significantly outperforms GPT-3.5 and Claude 3.5 in both grounded citation generation (F1) and refusal judgment (F1). Although GPT-3.5 and GPT-4 achieve higher EM scores, indicating better document understanding and answer extraction, they rely heavily on parametric knowledge (Section D.1 and Section D.2). This leads to higher responsiveness, which can result in less precise and trustworthy responses, as reflected in their Trust-Score scores. In contrast, our model’s superior performance in F1 and F1 demonstrates its strength in refusal and grounding, making it more reliable.
| Model | AR (%) | EM | F1 | F1 | TRUST |
|---|---|---|---|---|---|
| In-Context Learning Models | |||||
| ICL-LLaMA-2 7B | 0.51 | 0.00 | 41.01 | 9.52 | 16.84 |
| ICL-LLaMA-3 8B | 0.65 | 2.82 | 42.50 | 69.46 | 38.26 |
| ICL-GPT-3.5 | 59.47 | 36.65 | 56.39 | 63.91 | 52.32 |
| ICL-GPT-4 | 72.20 | 41.21 | 52.91 | 69.70 | 54.61 |
| ICL-Claude 3.5 | 73.95 | 11.68 | 51.91 | 10.70 | 24.76 |
| Direct Preference Optimization Models | |||||
| DPO-LLaMA-2-7B | 17.75 | 23.99 | 66.63 | 64.96 | 51.86 |
| DPO-LLaMA-3-8B | 16.41 | 27.36 | 68.05 | 70.11 | 54.85 |
7 Related Works
7.1 Attributable Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) has been widely studied for reducing the knowledge gap and providing more referenced information to enhance answer generation Karpukhin et al. (2020); Lewis et al. (2021); Gao et al. (2023c). However, LLMs are prone to being misled by irrelevant information, leading to hallucinations and less factual outputs Shi et al. (2023); Yoran et al. (2024); Xu et al. (2023). This challenge has spurred research into attributable RAG, which aims to verify model outputs by identifying supporting sources. Rashkin et al. (2022) first introduced the concept of Attributable to Identified Sources (AIS) to evaluate attribution abilities. Subsequently, Gao et al. (2023b) adapted this approach to verify generated content with citations, improving the reliability of RAG systems. Simultaneously, Press et al. (2024) and Song et al. (2024) explored related aspects: citation attribution for paper identification and the verifiability of long-form generated text, respectively. Further fine-grained evaluations have been examined, such as assessing the degree of support Zhang et al. (2024b) and the granularity of claims Xu et al. (2024). Recent studies Buchmann et al. (2024); Hsu et al. (2024) have also investigated attribution ability by disentangling the confounding effects of retrievers and LLMs. Unlike existing work, we prioritize trustworthiness in LLMs, ensuring that generated responses are derived solely from the provided documents and refrain from producing unverifiable content.
7.2 Enhance grounded text generation in attributed Large Language Models
To enhance grounded text generation, various attributed LLMs have been proposed, falling into two main paradigms: training-free and training-based. For training-free methods: 1) In-context learning Gao et al. (2023b) is used to generate in-line citations with few-shot demonstrations. 2) Post-hoc attribution Gao et al. (2023a); Li et al. (2024b) first generates an initial response and then retrieves evidence as attribution. 3) Ji et al. (2024) demonstrate that using chain-of-thought reasoning improves the quality of text generated with citations. For training-based methods: 1) Asai et al. (2024); Slobodkin et al. (2024); Xia et al. (2024); Ye et al. (2024) apply supervised fine-tuning (SFT) to LLMs, training them to identify useful information from documents and guide cited text generation with them. 2) Beyond simple SFT, recent studies model the task as preference learning, employing Reinforcement Learning with Human Feedback (RLHF) Ouyang et al. (2022) and Direct Preference Optimization (DPO) Rafailov et al. (2024). Huang et al. (2024a) proposed a method to improve attribution generation using fine-grained rewards and Proximal Policy Optimization (PPO) Schulman et al. (2017), while Li et al. (2024a); Huang et al. (2024b) introduced the modified DPO framework to enhance fine-grained attribution abilities. 3) While many approaches rely on external documents provided by the user or retrieved during generation, Khalifa et al. (2024); Zhang et al. (2024a) focus on tuning LLMs to cite sources from pre-training data using learned parametric knowledge.
8 Conclusion
In this study, we investigated the hallucination issues present in Large Language Models (LLMs) within a Retrieval-Augmented Generation (RAG) context. We categorized various types of hallucinations and used these insights to develop a dataset specifically aimed at addressing these challenges. Two notable examples include the model’s failure to refuse to answer when given insufficient information and its inability to properly attribute responses to source documents. We applied Direct Preference Optimization (DPO) alignment techniques to train LLaMA-2-7b and LLaMA-3-8b on this dataset, which significantly reduced hallucinations in an RAG environment. Our approach, Trust-Align, demonstrates performance comparable to major closed-source language models like GPT-4. To effectively evaluate hallucinations, we introduced a new metric, Trust-Score, which assesses not only answer accuracy but also the model’s ability to ground responses, refuse questions when the provided information is inadequate, and avoid unnecessary refusals. To our knowledge, this metric represents the first comprehensive attempt to quantify LLM hallucinations in an RAG setting. Our ongoing research will explore more fundamental modifications to alignment methods to further minimize hallucinations.
References
- Amouyal et al. (2023) Samuel Joseph Amouyal, Tomer Wolfson, Ohad Rubin, Ori Yoran, Jonathan Herzig, and Jonathan Berant. 2023. Qampari: An open-domain question answering benchmark for questions with many answers from multiple paragraphs. Preprint, arXiv:2205.12665.
- Anthropic (2024) Anthropic. 2024. Introducing claude 3.5 sonnet. Anthropic News.
- Asai et al. (2024) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations.
- Bai et al. (2024) Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930.
- Bohannon (2023) Molly Bohannon. 2023. Lawyer used chatgpt in court—and cited fake cases. a judge is considering sanctions. Forbes. Accessed: 2024-08-17.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. Preprint, arXiv:2005.14165.
- Buchmann et al. (2024) Jan Buchmann, Xiao Liu, and Iryna Gurevych. 2024. Attribute or abstain: Large language models as long document assistants. Preprint, arXiv:2407.07799.
- Business Insider (2023) Business Insider. 2023. Google’s bard ai gives inaccurate answer in ad, causing concern about its chatgpt rival. https://www.businessinsider.com/google-ad-ai-chatgpt-rival-bard-gives- {}inaccurate-answer-2023-2. Accessed: 2024-08-17.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, et al. 2024. The llama 3 herd of models. Preprint, arXiv:2407.21783.
- Ester et al. (1996) Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. In Knowledge Discovery and Data Mining.
- Fan et al. (2019) Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. 2019. Eli5: Long form question answering. Preprint, arXiv:1907.09190.
- Gao et al. (2023a) Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. 2023a. RARR: Researching and revising what language models say, using language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16477–16508, Toronto, Canada. Association for Computational Linguistics.
- Gao et al. (2023b) Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023b. Enabling large language models to generate text with citations. Preprint, arXiv:2305.14627.
- Gao et al. (2023c) Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023c. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
- Honovich et al. (2022) Or Honovich, Roee Aharoni, Jonathan Herzig, Hagai Taitelbaum, Doron Kukliansy, Vered Cohen, Thomas Scialom, Idan Szpektor, Avinatan Hassidim, and Yossi Matias. 2022. TRUE: Re-evaluating factual consistency evaluation. In Proceedings of the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering, pages 161–175, Dublin, Ireland. Association for Computational Linguistics.
- Hsu et al. (2024) I-Hung Hsu, Zifeng Wang, Long T. Le, Lesly Miculicich, Nanyun Peng, Chen-Yu Lee, and Tomas Pfister. 2024. Calm: Contrasting large and small language models to verify grounded generation. Preprint, arXiv:2406.05365.
- Huang et al. (2024a) Chengyu Huang, Zeqiu Wu, Yushi Hu, and Wenya Wang. 2024a. Training language models to generate text with citations via fine-grained rewards. Preprint, arXiv:2402.04315.
- Huang et al. (2024b) Lei Huang, Xiaocheng Feng, Weitao Ma, Yuxuan Gu, Weihong Zhong, Xiachong Feng, Weijiang Yu, Weihua Peng, Duyu Tang, Dandan Tu, and Bing Qin. 2024b. Learning fine-grained grounded citations for attributed large language models. In Findings of the Association for Computational Linguistics ACL 2024, pages 14095–14113, Bangkok, Thailand and virtual meeting. Association for Computational Linguistics.
- Ji et al. (2024) Bin Ji, Huijun Liu, Mingzhe Du, and See-Kiong Ng. 2024. Chain-of-thought improves text generation with citations in large language models. Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):18345–18353.
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- Jiang et al. (2023) Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
- Khalifa et al. (2024) Muhammad Khalifa, David Wadden, Emma Strubell, Honglak Lee, Lu Wang, Iz Beltagy, and Hao Peng. 2024. Source-aware training enables knowledge attribution in language models. Preprint, arXiv:2404.01019.
- Lewis et al. (2021) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-augmented generation for knowledge-intensive nlp tasks. Preprint, arXiv:2005.11401.
- Li et al. (2024a) Dongfang Li, Zetian Sun, Baotian Hu, Zhenyu Liu, Xinshuo Hu, Xuebo Liu, and Min Zhang. 2024a. Improving attributed text generation of large language models via preference learning. In Findings of the Association for Computational Linguistics ACL 2024, pages 5079–5101, Bangkok, Thailand and virtual meeting. Association for Computational Linguistics.
- Li et al. (2023) Dongfang Li, Zetian Sun, Xinshuo Hu, Zhenyu Liu, Ziyang Chen, Baotian Hu, Aiguo Wu, and Min Zhang. 2023. A survey of large language models attribution. arXiv preprint arXiv:2311.03731.
- Li et al. (2024b) Weitao Li, Junkai Li, Weizhi Ma, and Yang Liu. 2024b. Citation-enhanced generation for llm-based chatbots. Preprint, arXiv:2402.16063.
- Liu et al. (2023) Nelson Liu, Tianyi Zhang, and Percy Liang. 2023. Evaluating verifiability in generative search engines. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7001–7025, Singapore. Association for Computational Linguistics.
- Malaviya et al. (2024) Chaitanya Malaviya, Subin Lee, Sihao Chen, Elizabeth Sieber, Mark Yatskar, and Dan Roth. 2024. Expertqa: Expert-curated questions and attributed answers. Preprint, arXiv:2309.07852.
- McInnes et al. (2018) Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426.
- Meng et al. (2024) Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. SimPO: Simple preference optimization with a reference-free reward. arXiv preprint arXiv:2405.14734.
- Menick et al. (2022) Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. 2022. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. 2021. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332.
- Ni et al. (2022) Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, and Yinfei Yang. 2022. Large dual encoders are generalizable retrievers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9844–9855, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- OpenAI (2023) OpenAI. 2023. Chatgpt. Accessed: 2024-09-01.
- OpenAI et al. (2024) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, et al. 2024. Gpt-4 technical report. Preprint, arXiv:2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. Preprint, arXiv:2203.02155.
- Piktus et al. (2021) Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Dmytro Okhonko, Samuel Broscheit, Gautier Izacard, Patrick Lewis, Barlas Oğuz, Edouard Grave, Wen-tau Yih, et al. 2021. The web is your oyster-knowledge-intensive nlp against a very large web corpus. arXiv preprint arXiv:2112.09924.
- Press et al. (2024) Ori Press, Andreas Hochlehnert, Ameya Prabhu, Vishaal Udandarao, Ofir Press, and Matthias Bethge. 2024. Citeme: Can language models accurately cite scientific claims? Preprint, arXiv:2407.12861.
- Rafailov et al. (2024) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. Direct preference optimization: Your language model is secretly a reward model. Preprint, arXiv:2305.18290.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67.
- Rashkin et al. (2022) Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter. 2022. Measuring attribution in natural language generation models. Preprint, arXiv:2112.12870.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. Preprint, arXiv:1707.06347.
- Shi et al. (2023) Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 31210–31227. PMLR.
- Slobodkin et al. (2024) Aviv Slobodkin, Eran Hirsch, Arie Cattan, Tal Schuster, and Ido Dagan. 2024. Attribute first, then generate: Locally-attributable grounded text generation. Preprint, arXiv:2403.17104.
- Song et al. (2024) Yixiao Song, Yekyung Kim, and Mohit Iyyer. 2024. Veriscore: Evaluating the factuality of verifiable claims in long-form text generation. Preprint, arXiv:2406.19276.
- Stelmakh et al. (2023) Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. 2023. Asqa: Factoid questions meet long-form answers. Preprint, arXiv:2204.06092.
- The Independent (2023) The Independent. 2023. Chatgpt could be used to commit sexual harassment, law professor warns. https://www.independent.co.uk/tech/chatgpt-sexual-harassment-law-professor-b2315160.html. Accessed: 2024-08-17.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models. Preprint, arXiv:2307.09288.
- Xia et al. (2024) Sirui Xia, Xintao Wang, Jiaqing Liang, Yifei Zhang, Weikang Zhou, Jiaji Deng, Fei Yu, and Yanghua Xiao. 2024. Ground every sentence: Improving retrieval-augmented llms with interleaved reference-claim generation. Preprint, arXiv:2407.01796.
- Xu et al. (2023) Fangyuan Xu, Weijia Shi, and Eunsol Choi. 2023. Recomp: Improving retrieval-augmented lms with compression and selective augmentation. Preprint, arXiv:2310.04408.
- Xu et al. (2024) Yilong Xu, Jinhua Gao, Xiaoming Yu, Baolong Bi, Huawei Shen, and Xueqi Cheng. 2024. Aliice: Evaluating positional fine-grained citation generation. Preprint, arXiv:2406.13375.
- Ye et al. (2024) Xi Ye, Ruoxi Sun, Sercan Ö. Arik, and Tomas Pfister. 2024. Effective large language model adaptation for improved grounding and citation generation. Preprint, arXiv:2311.09533.
- Yoran et al. (2024) Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. 2024. Making retrieval-augmented language models robust to irrelevant context. Preprint, arXiv:2310.01558.
- Zhang et al. (2024a) Jingyu Zhang, Marc Marone, Tianjian Li, Benjamin Van Durme, and Daniel Khashabi. 2024a. Verifiable by design: Aligning language models to quote from pre-training data. Preprint, arXiv:2404.03862.
- Zhang et al. (2024b) Weijia Zhang, Mohammad Aliannejadi, Yifei Yuan, Jiahuan Pei, Jia-Hong Huang, and Evangelos Kanoulas. 2024b. Towards fine-grained citation evaluation in generated text: A comparative analysis of faithfulness metrics. Preprint, arXiv:2406.15264.
Appendix A Metrics
In this section, we elaborate on how we compute metrics that are components of Trust-Score.
A.1 Response Truthfulness
Truthfulness captures the model’s ability to answer or refuse a question correctly by computing the grounded refusal (F1RG) and the factual accuracy by computing the answer-calibrated exact match score (EMAC).
Grounded Refusal []:
A macro-averaged F1 score that measures the LLM’s ability in correctly refusing to answer a question () and correctly providing an answer when required ().
-
•
: This metric evaluates a model’s ability to correctly refuse unanswerable questions. We calculate it based on how accurately the model identifies and refuses these questions. Let and represent the sets of ground truth answerable and unanswerable questions, respectively, and and denote the sets of questions where the model provided an answer and refused to answer, respectively. is computed from precision and recall :
(2) (3) (4) where measures the proportion of correctly refused unanswerable questions among all refused questions, and measures the proportion of correctly refused unanswerable questions out of all unanswerable questions. Here, denote the cardinality of the set, thus , , and are scalar values.
-
•
: This metric evaluates a model’s ability to correctly answer answerable questions. It is computed based on the precision and recall for non-refusal responses to answerable questions:
(5) (6) (7)
F1RG (Grounded Refusals) provides an overall assessment of the model’s refusal capabilities by computing the macro-average of and :
| (8) |
evaluates the model’s ability to correctly refuse unanswerable questions, while assesses its ability to correctly answer answerable ones. By penalizing both incorrect refusals and incorrect non-refusals, offers a balanced evaluation of the model’s over-responsiveness and under-responsiveness
Exact Match (Answer Calibrated) [EMF1AC]:
Given a question and the corresponding gold claims , we define the claims obtainable from the provided documents as and the claims generated in the response as . disregards the claims that cannot be inferred from (answer calibration), and the exact match recall scores is computed on the remaining claims, i.e., :
| (9) |
For the whole dataset with multiple questions , one can compute the average:
| (10) |
Where denote the set of questions that are answerable using the provided documents, fully or partially; denote the set of questions that are answered by the model (non-refusal). There are two variants of EMAC we study— first EM with denominator (number of answered questions). Second variant EM with denominator (number of answerable questions). Here denotes the cardinality of the set. We denote the aggregated score by
| (11) |
The primary reason for adjusting the conventional Exact Match (EM) metric to account for the presence of answers in retrieved documents is to avoid rewarding models for generating correct answers without locating them in the provided documents. This approach discourages models from relying solely on their pre-trained knowledge to answer questions, instead encouraging them to find and ground their answers within the provided documents.
A.2 Attribution Groundedness
Attribution or citation groundedness measures the relevance of generated citations to their corresponding statements, both individually and collectively. A citation is deemed "relevant" when the statement it cites can be inferred from the cited document. The collective importance of citations is assessed using a statement-wise recall metric, while the individual importance of each citation is evaluated using a precision metric. Given that a generated response consists of multiple statements and their corresponding citations , we first compute statement-wise citation recall and per-citation precision. These scores are then averaged to obtain sample-wise scores, which are finally averaged to produce dataset-wide scores.
Citation Grounded F1 [F1CG]:
For a given statement , statement-wise citation recall is computed by:
| (12) |
where is a function that determines whether the concatenation of all cited documents fully supports the statement . Next, we compute precision for a generated citation for statement as:
| (13) | ||||
Thus, citation precision is 0 if and only if the cited document does not entail the statement , while all other citations collectively entail without .
As an aggregate measure, we report F1CG, which computes the F1 score using cumulative precision and recall over the answered questions only (non-refusals):
| CR | (14) | |||
| CP | (15) | |||
| F1CG | (16) |
Where denotes the number of samples answered by the model, denotes the set of statements in a generated response, and denotes the set of responses (including only statements, ignoring citations) in the dataset. Similarly, denotes the set of citations in a generated response, and denotes the set of responses (including only citations, ignoring statements) in the dataset.
Trust-Score:
Finally, we combine the metrics to produce a single trustworthiness score, which allows us to rank models based on their trustworthiness. This score is calculated as the average of each component metric.
| (17) |
Appendix B Details on Trust-Align Framework
B.1 Seed Prompt Curation Detials
Clustering Questions.
For text clustering, we embed the questions into vector space using sentence-transformers Reimers and Gurevych (2019). The high-dimensional vectors are then mapped to a lower-dimensional space using UMAP McInnes et al. (2018), followed by DBSCAN Ester et al. (1996) to find clusters in the low-dimensional representations.
Cluster Quality.
To score each cluster’s quality, we select 30 questions nearest to the centroid of each cluster. Using Mixtral-8x7B, we assign each question a knowledge-demanding score (from 1 to 7) depending on how hard it is to provide an answer without extra information. The prompt for this is shown in Table 14.
Obtaining D for q.
For each seed question that is obtained from ASQA and QAMPARI, we used gtr-t5-xxl Ni et al. (2022) to retrieve the top 100 relevant documents from the 2018-12-20 Wikipedia snapshot 777In practice, we only prompt the LLMs with top 5 documents due to the context length limitation. For the ELI5 dataset, we employed BM25 in conjunction with Sphere Piktus et al. (2021), a filtered version of Common Crawl, as it better encompasses the wide range of topics present in ELI5.
We utilize TRUE-NLI to derive the entailment pattern for each document. This pattern represents the set of gold claims that the document supports. The TRUE model takes as input a concatenation of a premise and a hypothesis, producing an entailment score (0 or 1) that indicates whether the premise entails the hypothesis. In our approach, the documents serve as the premise, while the hypothesis is formed by combining the relevant question with each corresponding gold claim to reduce ambiguity. We take the union of the entailment patterns across documents to assess the answerability of each question—if the pattern contains at least one supporting claim, the question is considered answerable.
Following Gao et al. (2023b), we further retrieve 5 documents from the initial pool of top 100 documents that achieve similar recall scores as the top 100 documents. This set is referred to as the oracle documents.
Obtaining .
In Fig. 4 shows the process by which we obtain cited gold responses. We provide the template by which each answerable sample is fitted in Table 6.
For ASQA, we include the question , a list of (calibrated) gold claims, and their corresponding supporting documents as additional context. For ELI5, we follow Gao et al. (2023b) by decomposing each labeled response into three claims, which serve as a set of ground truth answers. For QAMPARI, since its response format aligns with its labeled ground truth format (a list of entities), no additional action is required.
Since the claim labels already provide sufficient context, we only fit the question and calibrated claims into the template.
Obtaining .
To generate quality unpreferred responses, we first fine-tune (SFT) LLaMA-2-7b using the seed questions, corresponding oracle documents, and the gold answers ().
| Type | Template |
|---|---|
| ASQA | Please provide a high-quality answer to the given question using the provided document. The answer must include all the answer labels, and each answer label used should be marked with its index immediately after it in the format [Answer Label X], where X is the index of the answer label in the provided list starting from 1. For example, [Answer Label 1]. Ensure the answer is coherent and natural, and does not exceed four statements. You cannot make up any factual information based on your imagination: The additional information added from the given document should be relevant to the question and grounded by the document, but must not contain any factual information that cannot be inferred from the given answer labels. (e.g., if the answer label does not mention a specific year, you cannot introduce a specific year in the final answer). Question: {question} Document: {passage} {answers} Output: |
| ELI5 | Given a problem and some claims as answer tags, please generate a high-quality response. The response needs to follow the following requirements: 1. Use only all of the claims: Ensure that the response contains and only contains information from the given claims, without introducing any new information. Guarantee covering all claims in the response. 2. Each statement must contain valuable information: Every statement must either directly originate from the claims or infer from the claims, avoiding any irrelevant and unuseful information included in the response. You can use each claim only for one time. 3. Condense and combine: If there are similarities between claims, merge them into a comprehensive statement to make the response more concise. For example, if two claims both mention similar aspect of health benefits, they can be merged into one statement. 4. Fluent and natural: Ensure that the statements in the response are coherent and natural, using connecting words and maintaining logical order between statements. 5. Answer tags in response: Indicate each claim immediately after the corresponding content in the response with the format [Claim X], where X is the index of the claim in the provided list starting from 1. For example, [Claim 1]. Question: {question} {claims} Generated Response: |
B.2 Dataset Statistics
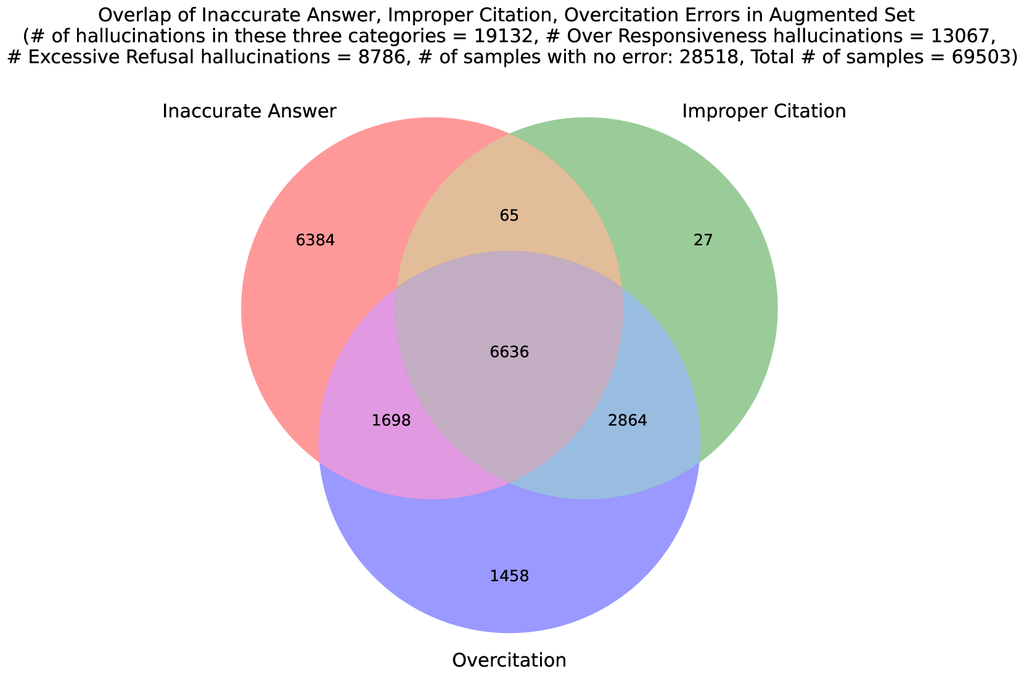
The statistics of different types of hallucinations in our constructed data are shown Fig. 2.
Appendix C Answerability: A Case Study
Prior works Liu et al. (2023); Gao et al. (2023b); Ye et al. (2024); Huang et al. (2024a); Li et al. (2024a) have employed substring matching to indicate entailment. While this syntactic approach is fast, it often proves inadequate in complex, long contexts. A case study is presented in Table 7. To address the limitations of this superficial entailment, we adopt a TRUE-based method Honovich et al. (2022), which combines the strengths of both syntactic and semantic approaches. Specifically, we enhance the process by using the TRUE model, a T5-11B model Raffel et al. (2020) fine-tuned for the NLI task, to verify, from a semantic perspective, whether a substring match corresponds to meaningful entailment within document passages. The input to the TRUE model is the concatenation of a premise and a hypothesis, and the output is an entailment score between 0 and 1, indicating the degree to which the premise entails the hypothesis. We treat the corresponding documents as the premise, and to minimize ambiguity, the associated question is concatenated with each gold answer as the hypothesis. In cases where the TRUE model does not yield a positive entailment score despite a substring match, we rely on the TRUE judgment as the final label. However, if the substring match fails, we bypass TRUE calculation, thus reducing the computational cost of relying solely on TRUE for semantic entailment.
| Question | How many state parks are there in Virginia? |
|---|---|
| Gold Answer | 38 |
| Retrieved document | Virginia has 30 National Park Service units, such as Great Falls Park and the Appalachian Trail, and one national park, the Shenandoah National Park. With over 500 miles of trails, including 38 miles of the iconic Appalachian Trail, it’s a paradise for hikers, nature lovers, and those seeking serene mountain landscapes. |
| Substring match | Substring is matched and as such the question is answerable. |
| TRUE Judgement | Not entailed as such the question is unanswerable given the document. |
Appendix D Additional Analysis
D.1 Utilization of Parametric Knowledge
For an LLM used for RAG task, it is important to study the tendency of LLM towards grownding its knowledge on the provided documents. To partially quantify this, we compute EM uncalibrated score for questions that are unanswerable by the provided documents; thus but ,
| (18) |
Where, , , and are claims in the ground truth answer, claims present in the documents, and the claims generated in the response, respectively. is the number of answered questions.
In Table 8, our analysis reveals that responsive models tend to rely on parametric knowledge more frequently. Notably, closed-source models like GPT-4 exhibit higher parametric knowledge usage compared to our models. However, this metric only partially captures the models’ utilization of parametric knowledge. For instance, cases where models correctly generate gold claims without proper grounding may also indicate reliance on parametric knowledge. This phenomenon is evident in Table 10, where on ASQA, GPT-4 achieves a significantly higher EM than our models, yet its attribution groundedness score F1CG is five points lower.
| Model | ASQA | QAMPRARI | ELI5 | |||
|---|---|---|---|---|---|---|
| AR (%) | AR (%) | AR (%) | ||||
| ICL-LLaMA-2 7B | 0.00 | 0.00 | 0.00 | 0.00 | 0.50 | 0.00 |
| ICL-LLaMA-3 8B | 1.48 | 1.79 | 3.90 | 16.92 | 0.00 | 0.00 |
| ICL-GPT-3.5 | 71.20 | 9.74 | 65.30 | 11.45 | 49.00 | 7.89 |
| ICL-GPT-4 | 86.81 | 12.71 | 73.40 | 13.05 | 61.50 | 9.05 |
| ICL-Claude-3.5 | 84.60 | 12.99 | 69.80 | 12.55 | 59.00 | 1.76 |
| DPO-LLaMA-2-7B | 65.30 | 8.15 | 31.10 | 8.45 | 21.60 | 5.56 |
| DPO-LLaMA-3-8B | 56.42 | 8.65 | 23.10 | 8.97 | 15.50 | 7.26 |
D.2 The Source of LLM Hallucinations
Model errors can be categorized into two primary sources:
-
1.
Parametric knowledge-based hallucination: Errors arising from the model’s internal knowledge representation.
-
2.
Information extraction failures: Inability to accurately extract relevant information from provided documents.
To quantify these error types, we employ the following methodology:
-
•
For the non-refused questions with errors, calculate the proportion of the incorrect answers that are:
-
Present in the provided documents
-
Absent from the provided documents
-
For answers absent from the documents, we can attribute the error to parametric knowledge-based hallucination. For answers present in the documents, the specific source of the error remains indeterminate as it can be attributed to both.
The substring matching Gao et al. (2023b) is used here for searching for the existence of incorrect answers in the documents. As the model’s response only on QAMPARI can be decomposed into atomic facts, we chose to perform this analysis on it. Specifically, for every answered question, we calculate the proportion of incorrect answers present in or absent from the documents using the equations below:
| Presence | (19) | |||
| Absence | (20) |
Where denotes the set of answerable questions that answered by the model with one or more incorrect answers; , are facts present in the documents and erroneous facts generated in the response, respectively.
The findings are presented in Table 9. Our analysis reveals that, with the exception of LLaMA-2 7B which provides no responses, all other ICL-based models exhibit a higher tendency to produce erroneous answers based on their parametric knowledge compared to our models. Notably, Claude-3.5 demonstrates a more frequent reliance on its parametric knowledge, which elucidates its significantly lower Trust-Score score in Table 10.
In summary, our investigation indicates that baseline models, including GPT-4 and GPT-3.5, are more susceptible to hallucinations stemming from their parametric knowledge.
| Model | QAMPARI | |
|---|---|---|
| Presence (%) | Absence (%) | |
| ICL-LLaMA-2 7B | 0.00 | 0.00 |
| ICL-LLaMA-3 8B | 84.41 | 15.59 |
| ICL-GPT-3.5 | 85.04 | 14.96 |
| ICL-GPT-4 | 89.3 | 10.7 |
| ICL-Claude-3.5 | 72.18 | 27.82 |
| DPO-LLaMA-2-7B | 93.26 | 6.74 |
| DPO-LLaMA-3-8B | 95.63 | 4.37 |
D.3 Comparison with Closed-source Models
We continue our comparison of trustworthiness against competitive closed-source models utilizing in-context learning techniques. As shown in Table 10, our aligned models outperform GPT-3.5 ( vs. ) and Claude-3.5 ( vs. ) on the ASQA dataset, and substantially outperform GPT-3.5 ( vs. ), GPT-4 ( vs. ), and Claude-3.5 ( vs. ) on QAMPARI. However, the responsiveness of current closed-source models remains much higher than that of our models: even with a refusal prompt, ICL-GPT-4 still answers a significant fraction of questions (86.81% on ASQA, 73.40% on QAMPARI). As discussed in Section 6, this tendency allows GPT-4 to achieve higher EM scores on ASQA, but it negatively impacts its attribution groundedness: its F1 scores on both datasets are lower than those of our models. Similarly, GPT-4’s F1 scores on both datasets are also lower. On QAMPARI, the EM scores of all closed-source models are lower than those of our models.
Moreover, there still remains a gap between our models and the closed-source models on the ELI5 dataset. Our models’ Trust-Score is 2.45 points lower than that of the advanced ICL-GPT-4, and specifically, the EM and F1 scores are lower. For higher EM, as discussed in Section 6, it is due to a higher number of its answered answerable questions with comparable EM. As for higher F1, We hypothesize that this gap could be attributed to the information density of the extracted claims utilized in constructing the alignment data (Section 4). Specifically, the three claims derived from the decomposition process may either be redundant or inadequate to fully encapsulate the information inherent in the original labelled response. In some cases, the decomposed claims may even fail to align with the original facts. First, insufficient information can lead the model to learn to extract fewer facts from the document, thereby reducing the answerability by covering fewer correct answers after training. Second, redundant information can impair grounded citation learning, as it repeats the same information across different claims, making the model less capable of performing precise citations from the corresponding documents. This issue is illustrated in the case study presented in Table 11.
| ASQA | QAMPARI | ELI5 | ||||||||||||||
| Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | |||||||||||
| AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | |||||
| Prompt | EM | F1 | F1 | EM | F1 | F1 | EM | F1 | F1 | |||||||
| Closed-source Models | ||||||||||||||||
| ICL-GPT-3.5 | R | 71.20 | 52.91 | 66.07 | 83.94 | 67.64 | 65.30 | 26.57 | 58.49 | 31.80 | 38.95 | 49.00 | 32.38 | 58.27 | 57.29 | 49.31 |
| ICL-GPT-4 | R | 86.81 | 62.96 | 61.85 | 84.35 | 69.72 | 73.40 | 30.13 | 55.46 | 35.45 | 40.35 | 61.50 | 33.05 | 53.11 | 61.84 | 49.33 |
| ICL-Claude-3.5 | R | 84.60 | 59.97 | 64.77 | 68.35 | 64.36 | 69.80 | 28.40 | 58.10 | 32.83 | 39.78 | 59.00 | 11.34 | 54.00 | 12.43 | 25.92 |
| ICL-GPT-3.5 | D | 94.41 | 55.03 | 52.48 | 78.04 | 61.85 | 94.50 | 20.30 | 29.54 | 21.22 | 23.69 | 93.50 | 23.88 | 24.68 | 46.28 | 31.61 |
| ICL-GPT-4 | D | 92.72 | 62.37 | 54.17 | 79.70 | 65.41 | 87.70 | 26.19 | 40.03 | 30.02 | 32.08 | 82.80 | 29.09 | 37.02 | 48.33 | 38.15 |
| ICL-Claude-3.5 | D | 82.49 | 54.20 | 66.49 | 58.88 | 59.86 | 69.90 | 0.00 | 57.40 | 0.00 | 19.13 | 56.60 | 11.56 | 56.03 | 11.22 | 26.27 |
| Our Models | ||||||||||||||||
| DPO-LLaMA-2-7b | R | 65.30 | 52.48 | 66.12 | 83.94 | 67.51 | 31.10 | 32.09 | 71.83 | 51.33 | 51.75 | 21.60 | 22.54 | 63.27 | 48.43 | 44.75 |
| DPO-LLaMA-3-8b | R | 56.43 | 53.94 | 65.49 | 88.26 | 69.23 | 23.10 | 35.94 | 71.11 | 58.87 | 55.31 | 15.50 | 22.81 | 64.00 | 53.84 | 46.88 |
| Insufficient case |
|---|
| Question: Why do burns blister and why do burn wounds remain warm long after the injury occurred? |
| Label: Burn blisters occur when the second layer of the skin is damaged, they occur to protect the underlying skin layers from more damage and infection. You could see it as the bodys/skins natural bandage, so never pop them. The skin remain warm because of the increased blood in the area to repair and replace the damaged skin. |
| Decomposed claims: 1. Burn blisters occur when the second layer of skin is damaged. 2. Burn wounds remain warm due to increased blood flow to the area to repair and replace damaged skin. |
| Missing points: 1. Protection and Infection: The first claim does not mention that the blisters protect the underlying skin from more damage and infection, which is a significant part of the explanation in the answer. 2. Never Pop Them: The answer advises against popping blisters, which is a preventive measure not mentioned in the claims. |
| Redundant case |
| Question: How do fitness trackers know that you actually sleeping but not just laying there resting, being awake? |
| Label: Your heart beats slows down when you sleep, they will use a mixture of heart rate and how long you haven’t moved to determine how you’ve slept |
| Decomposed claims: 1. The combined factors of heart rate and inactivity determine sleep assessment. 2. Fitness trackers consider the duration of inactivity to assess sleep. 3. A slowed heart rate is an indicator of sleep that fitness trackers monitor. |
| Redundant point: The first claim has already summarised the core statement, and the last two claims just expand it and give more details |
D.4 Adaptability with Different Alignment Techniques
To demonstrate the robustness of our synthesized alignment data across different training methods, Table 12 also includes the performance of SFT and SIMPO Meng et al. (2024) methods. Compared to the SFT baseline, which only utilizes the positive data points in the alignment pairs to fine-tune the base model, preference optimization methods, such as DPO and SIMPO, consistently show performance improvements, highlighting the versatility of our data pipeline. Unlike the SFT approach, DPO and SIMPO demonstrate improved TRUST scores, albeit with a reduction in responsiveness. This decrease in responsiveness is actually a favorable outcome, as it indicates that the models are less likely to attempt to answer questions for which they lack sufficient information.
| Alignment | Model | Responsiveness (AR%) | EM | F1 | F1 | TRUST |
|---|---|---|---|---|---|---|
| DPO | LLaMA-2-7b | 65.30 | 52.48 | 66.12 | 83.94 | 67.51 |
| LLaMA-3-8b | 56.43 | 53.94 | 65.49 | 88.26 | 69.23 | |
| SIMPO | LLaMA-2-7b | 72.47 | 53.19 | 66.44 | 82.21 | 67.28 |
| LLaMA-3-8b | 57.38 | 49.84 | 64.13 | 86.86 | 66.94 |
D.5 Evaluation Data Creation Without Using TRUE
The determination of question answerability in our dataset is based on a combination of substring matching and TRUE criteria, as detailed in Section 2. Additionally, we developed an alternative version of the evaluation data that relies solely on substring matching, disregarding the TRUE criterion. This relaxation of answerability constraints results in an increased number of answerable questions. The findings from this analysis are presented in Table 13. It is worth noting that the overall trends observed in this analysis align with those reported in Section 6, which employs the combined approach of substring matching followed by TRUE verification.
| ASQA (779 answerable, 169 unanswerable) | QAMPARI (586 answerable, 414 unanswerable) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Responsiveness | Trustworthiness | Responsiveness | Trustworthiness | ||||||||
| AR (%) | Truthfullness | Attr. Grdness | TRUST | AR (%) | Truthfullness | Attr. Grdness | TRUST | ||||
| Prompt | EM | F1 | F1 | EM | F1 | F1 | |||||
| LLaMA-2-7b | |||||||||||
| ICL | R | 0.00 | 0.00 | 15.13 | 0.00 | 5.04 | 0.00 | 0.00 | 29.28 | 0.00 | 9.76 |
| PostCite | R | 10.44 | 0.13 | 24.91 | 0.00 | 8.35 | 34.40 | 0.00 | 52.57 | 9.50 | 20.69 |
| PostAttr | R | 10.44 | 0.13 | 24.91 | 0.00 | 8.35 | 34.40 | 0.00 | 52.57 | 3.78 | 18.78 |
| Self-RAG | R | 100.00 | 44.40 | 45.11 | 63.49 | 51.00 | 96.00 | 9.64 | 44.15 | 19.95 | 24.58 |
| ICL | D | 94.30 | 51.13 | 54.01 | 44.86 | 50.00 | 93.60 | 13.31 | 43.37 | 3.88 | 20.19 |
| PostCite | D | 88.71 | 2.64 | 54.63 | 0.98 | 19.42 | 56.30 | 0.00 | 52.85 | 7.73 | 20.19 |
| PostAttr | D | 87.24 | 2.71 | 55.63 | 0.43 | 19.59 | 51.10 | 0.00 | 52.45 | 4.70 | 19.05 |
| Self-RAG | D | 98.00 | 47.22 | 46.27 | 56.59 | 50.03 | 96.20 | 12.13 | 40.83 | 15.44 | 22.80 |
| LLaMA-2-13b | |||||||||||
| ICL | R | 17.41 | 19.29 | 31.22 | 14.14 | 21.55 | 26.50 | 0.63 | 53.67 | 0.00 | 18.10 |
| PostCite | R | 90.51 | 2.04 | 56.40 | 1.53 | 19.99 | 100.00 | 0.00 | 36.95 | 8.05 | 15.00 |
| PostAttr | R | 90.51 | 2.04 | 56.40 | 0.17 | 19.54 | 100.00 | 0.00 | 36.95 | 2.95 | 13.30 |
| Self-RAG | R | 100.00 | 48.10 | 45.11 | 69.79 | 54.33 | 72.70 | 4.90 | 60.20 | 26.91 | 30.67 |
| ICL | D | 97.57 | 51.18 | 50.16 | 9.40 | 36.91 | 97.80 | 0.05 | 41.05 | 0.00 | 13.70 |
| PostCite | D | 89.77 | 0.07 | 54.96 | 0.00 | 18.34 | 63.00 | 0.00 | 53.22 | 7.14 | 20.12 |
| PostAttr | D | 89.24 | 0.07 | 55.01 | 0.00 | 18.36 | 58.50 | 0.00 | 52.31 | 4.56 | 18.96 |
| Self-RAG | D | 97.68 | 49.10 | 48.47 | 63.39 | 53.65 | 96.30 | 6.04 | 41.17 | 21.06 | 22.76 |
| LLaMA-3-8b | |||||||||||
| ICL | R | 1.48 | 2.12 | 17.09 | 89.14 | 36.12 | 3.90 | 4.77 | 35.42 | 20.24 | 20.14 |
| PostCite | R | 77.53 | 34.32 | 54.76 | 28.01 | 39.03 | 87.00 | 9.90 | 47.98 | 8.42 | 22.10 |
| PostAttr | R | 77.53 | 34.32 | 54.76 | 5.95 | 31.68 | 87.00 | 9.90 | 47.98 | 1.64 | 19.84 |
| ICL | D | 89.66 | 58.83 | 64.47 | 62.12 | 61.81 | 70.80 | 7.48 | 61.03 | 4.81 | 24.44 |
| PostCite | D | 97.26 | 37.48 | 49.41 | 17.89 | 34.93 | 92.00 | 3.35 | 45.43 | 11.14 | 19.97 |
| PostAttr | D | 97.47 | 37.44 | 48.95 | 3.18 | 29.86 | 93.00 | 3.32 | 46.03 | 5.65 | 18.33 |
| Our Models | |||||||||||
| DPO-LLaMA-2-7b | R | 65.30 | 47.85 | 61.60 | 84.95 | 64.80 | 32.30 | 27.80 | 63.60 | 49.42 | 46.94 |
| DPO-LLaMA-3-8b | R | 56.43 | 48.18 | 57.60 | 88.84 | 64.87 | 22.40 | 26.57 | 56.84 | 58.77 | 47.39 |
Appendix E Prompt Templates
Table 14 details the prompt given to Mixtral-8x7B to acquire domain labels and knowledge demanding score. Table 15 details prompts used during evaluation.
| Prompt |
| The examples below are questions from the same cluster. Identify a single short topic they share in common, for example: Philosophy, Lifestyle, Linear Algebra, Biochemistry, Economics, etc. Additionally, evaluate if the topics in the examples are broadly suitable as knowledge-demanding questions that require additional research or grounding. Exclude any sensitive, inappropriate, or irrelevant content, such as sex, explicit violence, ads & scams, and other NSFW subjects. Consider a wide range of content, including scientific, educational, historical, cultural, and practical applications. Provide a rating from 1 to 7 based on the topic’s dependence on additional knowledge or search materials: a score of 1 indicates the question can be answered with common sense alone, without needing any additional information lookup; a score of 5 means the topic requires a combination of common sense and additional lookup, roughly an equal split between the two; a score of 7 indicates that answering the question directly would be difficult, and without additional information, the answer would likely be incorrect. The output format should be like this: Topic: the_topic, Demanding value rating: score. |
| Type | Prompt |
|---|---|
| Default | Write an accurate, engaging, and concise answer for the given question using only the provided search results (some of which might be irrelevant) and cite them properly. Use an unbiased and journalistic tone. Always cite for any factual claim. When citing several search results, use [1][2][3]. Cite at least one document and at most three documents in each statement. If multiple documents support the statement, only cite a minimum sufficient subset of the documents. |
| Refusal | {Default} + If none of the provided documents contains the answer, only respond with ‘‘I apologize, but I couldn’t find an answer to your question in the search results.’’ Do not add further explanation as to why an answer cannot be provided; just state the response above as-is |
Appendix F GPT-4 based Data Pipeline
For the GPT-4 data pipeline, we employ GPT-4 to simulate a critic that performs two key tasks in succession. First, it identifies and revises mistakes or supplements missing information in the given response based on correct answers. Second, it validates the attribution of statement-level citations and corrects them accordingly. The detailed instruction is provided in Table 16.
Coverage critiques.
To ensure that the correct answers are accurately reflected in the given response, we prompt GPT-4 with the corresponding question, correct answers, and reference facts (documents that support the provided correct answers) as context. GPT-4 is then asked to locate specific mistakes or identify any missing correct answers in the given response. After identifying coverage-related issues, GPT-4 is instructed to minimally revise the original response to correct these issues based on the detected problems. This minimal revision approach is intended to generate more precise data for alignment learning.
Citation critiques.
Based on the revised content, we further tokenize it into individual statements to enable a more fine-grained citation check in later stages. We format all documents in the instruction as holistic facts and instruct GPT-4 to determine the attribution of each statement relative to these facts. We define three levels of attribution: SUPPORT, OPPOSE, and IRRELEVANT. We then compare GPT-4’s attribution results to the original attributions in the response, modifying the original attributions wherever they do not align with GPT-4’s critiques. Finally, we concatenate all citation-revised statements to form the final revised response.
| Coverage Critic Prompt |
|---|
| [INSTRUCTION] You will be given Question and the corresponding correct answers, along with a candidate answer and reference facts. Please follow these steps to process the candidate answer: 1. Carefully read and understand the given Question, the list of correct answers, and the candidate answer. 2. For each given correct answer, first determine if there is a conflict with the candidate answer: - If there is no conflict, and it is included in the candidate answer, extract the matched term from the candidate answer and classify them as "upvote". - If there is a conflict, identify the specific conflicting span within the candidate answer (accurately pinpoint the details), classify it as "downvote", then only minimally modify the conflicting part of the candidate answer to correct it according to the corresponding correct answer (using context from the reference fact). Classify the modified span as "revise". - If there is a conflict, but it is not included in the candidate answer, extend the candidate answer to include the correct answer (using material from the corresponding part of the reference facts), and classify the extended portion as "revise". 3. At the end of your response, provide the following: - The final revised candidate answer that includes all correct answers and has no conflicts (if no modification is needed, output the original one). [TASK] Question: {QUESTION} Correct Answers: {SHORT_ANS} Candidate Answer: {CANDIDATE} Reference Facts: {FACT} |
| Citation Critic Prompt |
| [INSTRUCTION] Given a question and a list of CLAIMs, use the provided FACTs to determine which numbered FACTs togeter SUPPORT, OPPOSE, or are IRRELEVANT to each CLAIM. Follow these to give your judgement: 1. "SUPPORT" means the FACT directly participates in supporting the factuality of the CLAIM. The CLAIM should be strongly implied by the FACT. 2. "OPPOSE" means the FACT contributes to prove the CLAIM contains at least one factual error. 3. "IRRELEVANT" means the FACT does not contribute directly to either SUPPORT or OPPOSE the given CLAIM. 4. Carefully read the given question and FACTs to ensure you have a clear understanding of them. 5. For each CLAIM, analyze its content to show all factual arguments and assertions. 6. Look into the details of each FACT, and find factual-related points of each FACT. 7. Before determining your final judgement for all CLAIMs at the end, state your reasoning and evidence first. 8. In your final judgement, give a numbered list with each line corresponding to a CLAIM. Then, for each CLAIM, separately list the index of each FACT for "SUPPORT", "OPPOSE", and "IRRELEVANT", with the format [FACT X], where X is the index of the FACT starting from 1. For example, suppose we have two CLAIMs and three FACTs in total: "/n/n1. SUPPORT: [FACT 1][FACT 3], OPPOSE: NONE, IRRELEVANT: [FACT 2]/n/n2. SUPPORT: NONE, OPPOSE: [FACT 2], IRRELEVANT: [FACT 1][FACT 3]". If no FACT, then just give "NONE". [TASK] Question: {QUESTION} CLAIM: {CLAIM_PLACEHOLDER} FACTs: {FACT_PLACEHOLDER} |
| ASQA | QAMPARI | ELI5 | ExpertQA | |
|---|---|---|---|---|
| Total # of Samples | 948 | 1000 | 1000 | 2169 |
| # Answerable Samples | 610 | 295 | 207 | 682 |
| # Unanswerable Samples | 338 | 705 | 793 | 1487 |
Appendix G Experimental Setup
G.1 Implementation details
For all experiments involving our tuned models and baselines, we provided the top 5 retrieved documents as context and used decoding temperatures of 0.1 and 0.5, respectively, with other settings consistent with those in Gao et al. (2023b). We benchmarked against three open-source models—LLaMA-2-7b, LLaMA-2-13b Touvron et al. (2023), and LLaMA-3-8b Dubey et al. (2024)—and three closed-source models—GPT-4 OpenAI et al. (2024), GPT-3.5 Brown et al. (2020) 888We utilize the latest version on the AzureOpenAI Service: https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/models, and Claude-3.5-Sonnet 999https://www.anthropic.com/news/claude-3-5-sonnet. LLaMA-2-7b and LLaMA-3-8b were used as base models for fine-tuning. For supervised fine-tuning (SFT), we trained the models for 2 epochs with a learning rate of 2e-5. For direct preference optimization (DPO) alignment, we trained the models for 2 epochs with a beta value of 0.5. All experiments were conducted on NVIDIA A40 40G GPUs.
G.2 Dataset details
Following Liu et al. (2023); Gao et al. (2023b), to form , we divide large text documents into 100-word passages and limit the number of citations for each claim to a maximum of three. If the response is empty, it is excluded from evaluation. We provide dataset statistics in Table 17.
ASQA Stelmakh et al. (2023)
This long-form factoid dataset features ambiguous queries from AmbigQA Li et al. (2023), requiring multiple short answers to address different aspects. It includes comprehensive long-form answers that combine these short responses.
QAMPARI Amouyal et al. (2023)
This factoid QA dataset is derived from Wikipedia, with answers consisting of lists of entities gathered from various passages.
ELI5 Fan et al. (2019)
This dataset is a long-form QA collection based on the Reddit forum “Explain Like I’m Five” (ELI5). Most ELI5 questions require the model to utilize knowledge from multiple passages to formulate a complete answer. The ELI5 dataset is frequently used in related research due to its challenging nature Nakano et al. (2021); Menick et al. (2022); Jiang et al. (2023).
ExpertQA Malaviya et al. (2024)
This dataset spans various topics and requires domain-specific knowledge to solve long-form questions. To further verify the generalizability of our framework, we test our best model and some of the baselines on this unseen dataset.
G.3 Baselines
G.3.1 In-Context Learning (ICLCite)
Following Gao et al. (2023b), we prepend with two demonstrations, each consisting of a query, top-5 retrieved passages, and an answer with inline citations.
G.3.2 Post-hoc Search Gao et al. (2023b) (PostCite)
Following Gao et al. (2023b), we first prompt the model under a closed book setting i.e. without any retrieved passages, to obtain an uncited answer. Then, GTR is used to find the best matching citation among the top-5 retrieved passages for every statement.
G.3.3 Post-hoc Attribute Gao et al. (2023a) (PostAttr)
Similar to PostCite, we first obtain model response under a closed book setting. Then we use the TRUE NLI model to find the best matching citation among top-5 retrieved passages.
G.3.4 Self-RAG Asai et al. (2024)
Self-RAG trains the LLM to retrieve documents on demand using special reflection tokens and enhances generation quality through self-reflection. We compare our results against the 7b and 13b models released, using the default settings as described in Asai et al. (2024).
G.3.5 FRONT Huang et al. (2024b)
FRONT utilizes a fine-grained attribution training framework that first grounds specific supporting quotes, and then generates responses with citations based on those quotes. It tunes the LLM with automatically collected data based on ChatGPT and quality filtering. We reproduce its 7b model for the evaluation.
G.4 Refusal Detection
We employed two methods to measure refusals robustly. In a refusal prompt, models were explicitly instructed to respond only with the phrase: "I apologize, but I couldn’t find an answer to your question in the search results." without providing any further explanation. As the models generally complied with this pattern, we were able to apply fuzzy matching101010Fuzz Partial Ratio was used to mitigate the impact of string length. to detect the phrase above indicating refusal. For models responding to a default prompt, refusals did not adhere to a fixed pattern, making detection more challenging. Two human annotators verified that fuzzy matching yielded poor performance Table 19. Hence, GPT-4o was employed as an evaluator to classify whether an answer should be considered a refusal. The specific prompt used is provided in Table 18.
| GPT Evaluator Prompt |
| Instruction: You are an intelligent evaluator. Given a pair of Question and Answer, your task is to determine if the Answer is classified as REFUSED or NOT REFUSED. Please follow these steps to produce your judgement: 1. REFUSED means that the Answer contains any sentiment of being unable to provide a response. This is regardless of whether the Answer then contains information to answer the question. 2. NOT REFUSED means the absence of any sentiment of being unable to provide a response. The Answer attempts to address the Question. 3. Carefully read and understand the Question and Answer. 4. Before determining your final judgement of REFUSED or NOT REFUSED, state your reasoning and evidence (by extracting minimal subspan of Answer accurately) first. 5. For each Answer, determine if it is REFUSED or NOT REFUSED. 6. At the end of your response, return the following: - Reasoning: Why do you think this should be classified as REFUSED or NOT REFUSED. - Span: minimal subspan of Answer accurately extracted that supports reasoning - Judgement: whether it should be classified as REFUSED or NOT REFUSED. Question: Who set the record for longest field goal? Answer: I apologize, but I couldn’t find an answer to your question in the search results. Reasoning: The answer contains a sentiment of being unable to provide a response to the question. Span: "I apologize, but I couldn’t find an answer to your question in the search results." Judgement: REFUSED Question: Who killed the man in thelma and louise? Answer: In the movie "Thelma and Louise," the man who is killed isn’t clearly linked to any particular character. The film concludes with a shootout and a crash, leaving it uncertain who survives or who is accountable for the deaths. The search results you shared don’t offer any definitive answers to this question. Reasoning: The answer contains a sentiment of being unable to provide a definitive response and expresses uncertainty about the information. Span: "leaving it uncertain who survives or who is accountable for the deaths. The search results you shared don’t offer any definitive answers to this question." Judgement: REFUSED Question: When did the us break away from England? Answer: When the US left England is not explicitly stated. Hence I cannot provide an answer to your question. Question: Who played galen in planet of the apes? Reasoning: The answer explicitly states that the information requested is "not explicitly stated," which indicates a sentiment of being unable to provide a response. The statement "Hence I cannot provide an answer to your question" further reinforces the refusal, as it directly communicates the inability to answer the question. Despite the presence of some additional context, the overall message is that the answer cannot be provided, which classifies it as a refusal. Span: "When the US left England is not explicitly stated. Hence I cannot provide an answer to your question." Judgement: REFUSED Question: Which is the most rainy place on earth? Answer: Several places on Earth claim to be the most rainy, such as Lloró, Colombia, which reported an average annual rainfall of 12,717 mm between 1952 and 1989, and López de Micay, Colombia, which reported an annual 12,892 mm between 1960 and 2012 [3]. However, the official record is held by Mawsynram, India with an average annual rainfall of 11,872 mm [3], although nearby town Sohra, India, also known as Cherrapunji, holds the record for most rain in a calendar month for July 1861 and most rain in a year from August 1860 to July 1861 [1]. Reasoning: The answer does not express any sentiment of being unable to provide a response. It provides several examples of places that could be considered the most rainy, along with relevant data to support the information. Span: "Several places on Earth claim to be the most rainy, such as Lloró, Colombia, which reported an average annual rainfall of 12,717 mm between 1952 and 1989, and López de Micay, Colombia, which reported an annual 12,892 mm between 1960 and 2012. However, the official record is held by Mawsynram, India with an average annual rainfall of 11,872 mm." Judgement: NOT REFUSED Question: {Q} Answer: {A} Return the following: Reasoning: Span: Judgement: |
| Question: Who killed the man in thelma and louise? |
| Answer: "In the movie T̈helma and Louise,ẗhe man who is killed is not explicitly identified as being killed by any specific character. The movie ends with a shootout and a crash, and it is unclear who survives or who is responsible for the deaths. The search results you provided do not provide any clear answers to this question. |
| Fuzzy match judgement: Not refusal |
| Human judgement: Refusal |
| GPT-4o judgement: Refusal |
Appendix H Detailed Results
| Prompt | AR% | EMreg | EM | EM | EMF1AC | F1 | CR | CP | F1CG | Trust-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-2-7b | |||||||||||||||||
| ICL | R | 0.00 | 12.78 | 0.00 | 0.00 | 0.00 | 100.00 | 35.65 | 52.57 | 0.00 | 0.00 | 0.00 | 26.28 | 0.00 | 0.00 | 0.00 | 8.76 |
| PostCite | R | 10.44 | 8.49 | 0.25 | 0.04 | 0.07 | 90.53 | 36.04 | 51.56 | 10.98 | 67.68 | 18.90 | 35.23 | 0.00 | 0.00 | 0.00 | 11.77 |
| PostAttr | R | 10.44 | 8.49 | 0.25 | 0.04 | 0.07 | 90.53 | 36.04 | 51.56 | 10.98 | 67.68 | 18.90 | 35.23 | 0.00 | 0.00 | 0.00 | 11.77 |
| Self-RAG | R | 100.00 | 28.87 | 37.13 | 57.71 | 45.19 | 0.00 | 0.00 | 0.00 | 100.00 | 64.35 | 78.31 | 39.15 | 59.27 | 68.35 | 63.49 | 49.28 |
| FRONT | D | 100.00 | 40.72 | 49.69 | 77.22 | 60.47 | 0.00 | 0.00 | 0.00 | 100.00 | 64.35 | 78.31 | 39.15 | 68.45 | 69.27 | 68.86 | 56.16 |
| ICL | D | 94.30 | 32.29 | 42.06 | 62.79 | 50.38 | 11.54 | 72.22 | 19.90 | 97.54 | 66.55 | 79.12 | 49.51 | 44.21 | 43.14 | 43.67 | 47.85 |
| PostCite | D | 88.71 | 1.91 | 1.98 | 2.73 | 2.30 | 16.27 | 51.40 | 24.72 | 91.48 | 66.35 | 76.91 | 50.82 | 0.98 | 0.98 | 0.98 | 18.03 |
| PostAttr | D | 87.24 | 1.91 | 2.01 | 2.73 | 2.32 | 18.05 | 50.41 | 26.58 | 90.16 | 66.51 | 76.55 | 51.56 | 0.43 | 0.43 | 0.43 | 18.10 |
| Self-RAG | D | 98.00 | 30.11 | 38.63 | 59.41 | 46.82 | 2.37 | 42.11 | 4.48 | 98.20 | 64.48 | 77.84 | 41.16 | 50.69 | 64.05 | 56.59 | 48.19 |
| LLaMA-2-13b | |||||||||||||||||
| ICL | R | 17.41 | 9.17 | 50.54 | 13.67 | 21.52 | 86.39 | 37.29 | 52.10 | 19.51 | 72.12 | 30.71 | 41.40 | 10.94 | 18.81 | 13.83 | 25.58 |
| PostCite | R | 90.51 | 1.88 | 1.89 | 2.66 | 2.21 | 14.20 | 53.33 | 22.43 | 93.11 | 66.20 | 77.38 | 49.91 | 1.53 | 1.53 | 1.53 | 17.88 |
| PostAttr | R | 90.51 | 1.88 | 1.89 | 2.66 | 2.21 | 14.20 | 53.33 | 22.43 | 93.11 | 66.20 | 77.38 | 49.91 | 0.17 | 0.17 | 0.17 | 17.43 |
| Self-RAG | R | 100.00 | 30.82 | 39.87 | 61.96 | 48.52 | 0.00 | 0.00 | 0.00 | 100.00 | 64.35 | 78.31 | 39.15 | 66.42 | 73.52 | 69.79 | 52.49 |
| ICL | D | 97.57 | 33.31 | 40.57 | 62.35 | 49.16 | 5.03 | 73.91 | 9.42 | 99.02 | 65.30 | 78.70 | 44.06 | 7.22 | 13.25 | 9.35 | 34.19 |
| PostCite | D | 89.77 | 0.06 | 0.03 | 0.04 | 0.04 | 15.09 | 52.58 | 23.45 | 92.46 | 66.27 | 77.21 | 50.33 | 0.00 | 0.00 | 0.00 | 16.79 |
| PostAttr | D | 89.24 | 0.06 | 0.03 | 0.04 | 0.04 | 16.57 | 54.90 | 25.45 | 92.46 | 66.67 | 77.47 | 51.46 | 0.00 | 0.00 | 0.00 | 17.17 |
| Self-RAG | D | 97.68 | 31.36 | 40.53 | 61.73 | 48.93 | 3.85 | 59.09 | 7.22 | 98.52 | 64.90 | 78.26 | 42.74 | 58.31 | 69.44 | 63.39 | 51.69 |
| LLaMA-3-8b | |||||||||||||||||
| ICL | R | 1.48 | 0.69 | 67.14 | 1.54 | 3.01 | 99.70 | 36.08 | 52.99 | 2.13 | 92.86 | 4.17 | 28.58 | 92.86 | 80.95 | 86.50 | 39.36 |
| PostCite | R | 77.53 | 22.15 | 30.17 | 36.36 | 32.98 | 27.51 | 43.66 | 33.76 | 80.33 | 66.67 | 72.86 | 53.31 | 28.01 | 28.01 | 28.01 | 38.10 |
| PostAttr | R | 77.53 | 22.15 | 30.17 | 36.36 | 32.98 | 27.51 | 43.66 | 33.76 | 80.33 | 66.67 | 72.86 | 53.31 | 5.95 | 5.95 | 5.95 | 30.75 |
| ICL | D | 89.66 | 36.41 | 49.83 | 70.17 | 58.28 | 20.41 | 70.41 | 31.65 | 95.25 | 68.35 | 79.59 | 55.62 | 61.40 | 61.77 | 61.59 | 58.50 |
| PostCite | D | 97.26 | 27.65 | 28.91 | 43.69 | 34.80 | 4.73 | 61.54 | 8.79 | 98.36 | 65.08 | 78.33 | 43.56 | 17.89 | 17.89 | 17.89 | 32.08 |
| PostAttr | D | 97.47 | 27.65 | 28.84 | 43.69 | 34.75 | 4.14 | 58.33 | 7.73 | 98.36 | 64.94 | 78.23 | 42.98 | 3.18 | 3.18 | 3.18 | 26.97 |
| Closed-source Models | |||||||||||||||||
| GPT-3.5 | R | 71.20 | 27.30 | 50.36 | 55.72 | 52.91 | 48.82 | 60.44 | 54.01 | 82.30 | 74.37 | 78.13 | 66.07 | 84.66 | 83.24 | 83.94 | 67.64 |
| GPT-4 | R | 86.81 | 37.93 | 54.81 | 73.95 | 62.96 | 28.99 | 78.40 | 42.33 | 95.57 | 70.84 | 81.37 | 61.85 | 85.82 | 82.93 | 84.35 | 69.72 |
| Claude-3.5 | R | 84.60 | 36.29 | 52.79 | 69.41 | 59.97 | 34.02 | 78.77 | 47.52 | 94.92 | 72.19 | 82.01 | 64.77 | 67.29 | 69.43 | 68.35 | 64.36 |
| GPT-3.5 | D | 94.41 | 34.67 | 46.27 | 67.88 | 55.03 | 14.20 | 90.57 | 24.55 | 99.18 | 67.60 | 80.40 | 52.48 | 78.13 | 77.95 | 78.04 | 61.85 |
| GPT-4 | D | 92.72 | 41.13 | 52.58 | 76.65 | 62.37 | 16.86 | 82.61 | 28.01 | 98.03 | 68.03 | 80.32 | 54.17 | 79.48 | 79.92 | 79.70 | 65.41 |
| Claude-3.5 | D | 82.49 | 32.68 | 47.64 | 62.86 | 54.20 | 37.87 | 77.11 | 50.79 | 93.77 | 73.15 | 82.18 | 66.49 | 57.41 | 60.44 | 58.88 | 59.86 |
| Our Models | |||||||||||||||||
| SFT-LLaMA-2-7b | R | 80.17 | 29.21 | 47.96 | 59.76 | 53.21 | 36.69 | 65.96 | 47.15 | 89.51 | 71.84 | 79.71 | 63.43 | 83.36 | 76.18 | 79.61 | 65.42 |
| SFT-LLaMA-3-8b | R | 68.99 | 25.22 | 50.59 | 54.24 | 52.35 | 51.18 | 58.84 | 54.75 | 80.16 | 74.77 | 77.37 | 66.06 | 86.09 | 76.38 | 80.95 | 66.45 |
| DPO-LLaMA-2-7b | R | 65.30 | 25.04 | 52.10 | 52.87 | 52.48 | 55.33 | 56.84 | 56.07 | 76.72 | 75.61 | 76.16 | 66.12 | 85.35 | 82.57 | 83.94 | 67.51 |
| DPO-LLaMA-3-8b | R | 56.43 | 23.53 | 57.72 | 50.63 | 53.94 | 64.79 | 53.03 | 58.32 | 68.20 | 77.76 | 72.66 | 65.49 | 88.93 | 87.60 | 88.26 | 69.23 |
| Prompt | AR% | EM | EM | EMF1AC | F1 | CR | CP | F1CG | Trust-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-2-7b | ||||||||||||||||
| ICL | R | 0.00 | 0.00 | 0.00 | 0.00 | 100.00 | 70.50 | 82.70 | 0.00 | 0.00 | 0.00 | 41.35 | 0.00 | 0.00 | 0.00 | 13.78 |
| PostCite | R | 34.40 | 0.00 | 0.00 | 0.00 | 70.21 | 75.46 | 72.74 | 45.42 | 38.95 | 41.94 | 57.34 | 9.50 | 9.50 | 9.50 | 22.28 |
| PostAttr | R | 34.40 | 0.00 | 0.00 | 0.00 | 70.21 | 75.46 | 72.74 | 45.42 | 38.95 | 41.94 | 57.34 | 3.78 | 3.78 | 3.78 | 20.37 |
| Self-RAG | R | 96.00 | 4.45 | 14.49 | 6.81 | 5.25 | 92.50 | 9.93 | 98.98 | 30.42 | 46.53 | 28.23 | 17.92 | 22.50 | 19.95 | 18.33 |
| FRONT | D | 100.00 | 11.18 | 37.89 | 17.27 | 0.00 | 0.00 | 0.00 | 100.00 | 29.50 | 45.56 | 22.78 | 24.20 | 24.32 | 24.26 | 21.44 |
| ICL | D | 93.60 | 5.49 | 17.51 | 8.36 | 8.23 | 90.63 | 15.08 | 97.97 | 30.88 | 46.95 | 31.02 | 3.83 | 3.93 | 3.88 | 14.42 |
| PostCite | D | 56.30 | 0.00 | 0.00 | 0.00 | 45.67 | 73.68 | 56.39 | 61.02 | 31.97 | 41.96 | 49.18 | 7.73 | 7.73 | 7.73 | 18.97 |
| PostAttr | D | 51.10 | 0.00 | 0.00 | 0.00 | 50.21 | 72.39 | 59.30 | 54.24 | 31.31 | 39.70 | 49.50 | 4.70 | 4.70 | 4.70 | 18.07 |
| Self-RAG | D | 96.20 | 5.04 | 16.45 | 7.72 | 4.40 | 81.58 | 8.34 | 97.63 | 29.94 | 45.82 | 27.08 | 13.25 | 18.50 | 15.44 | 16.75 |
| LLaMA-2-13b | ||||||||||||||||
| ICL | R | 26.50 | 0.47 | 0.42 | 0.44 | 79.01 | 75.78 | 77.36 | 39.66 | 44.15 | 41.79 | 59.57 | 0.00 | 0.00 | 0.00 | 20.00 |
| PostCite | R | 100.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100.00 | 29.50 | 45.56 | 22.78 | 8.05 | 8.05 | 8.05 | 10.28 |
| PostAttr | R | 100.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100.00 | 29.50 | 45.56 | 22.78 | 2.95 | 2.95 | 2.95 | 8.58 |
| Self-RAG | R | 72.70 | 1.90 | 4.69 | 2.71 | 32.91 | 84.98 | 47.44 | 86.10 | 34.94 | 49.71 | 48.58 | 25.73 | 28.20 | 26.91 | 26.07 |
| ICL | D | 97.80 | 0.00 | 0.00 | 0.00 | 3.12 | 100.00 | 6.05 | 100.00 | 30.16 | 46.35 | 26.20 | 0.00 | 0.00 | 0.00 | 8.73 |
| PostCite | D | 63.00 | 0.00 | 0.00 | 0.00 | 39.01 | 74.32 | 51.16 | 67.80 | 31.75 | 43.24 | 47.20 | 7.14 | 7.14 | 7.14 | 18.11 |
| PostAttr | D | 58.50 | 0.00 | 0.00 | 0.00 | 43.69 | 74.22 | 55.00 | 63.73 | 32.14 | 42.73 | 48.86 | 4.56 | 4.56 | 4.56 | 17.81 |
| Self-RAG | D | 96.30 | 2.39 | 7.80 | 3.66 | 4.40 | 83.78 | 8.36 | 97.97 | 30.01 | 45.95 | 27.15 | 19.46 | 22.95 | 21.06 | 17.29 |
| LLaMA-3-8b | ||||||||||||||||
| ICL | R | 3.90 | 25.36 | 3.35 | 5.92 | 97.87 | 71.80 | 82.83 | 8.14 | 61.54 | 14.37 | 48.60 | 17.22 | 24.53 | 20.24 | 24.92 |
| PostCite | R | 87.00 | 4.08 | 12.05 | 6.10 | 14.04 | 76.15 | 23.71 | 89.49 | 30.34 | 45.32 | 34.52 | 8.42 | 8.42 | 8.42 | 16.35 |
| PostAttr | R | 87.00 | 4.08 | 12.05 | 6.10 | 14.04 | 76.15 | 23.71 | 89.49 | 30.34 | 45.32 | 34.52 | 1.64 | 1.64 | 1.64 | 14.09 |
| ICL | D | 70.80 | 4.12 | 9.89 | 5.82 | 35.60 | 85.96 | 50.35 | 86.10 | 35.88 | 50.65 | 50.50 | 4.45 | 5.23 | 4.81 | 20.38 |
| PostCite | D | 92.00 | 1.60 | 5.24 | 2.45 | 8.37 | 73.75 | 15.03 | 92.88 | 29.78 | 45.10 | 30.07 | 11.14 | 11.14 | 11.14 | 14.55 |
| PostAttr | D | 93.00 | 1.58 | 5.24 | 2.43 | 7.80 | 78.57 | 14.19 | 94.92 | 30.11 | 45.71 | 29.95 | 5.65 | 5.65 | 5.65 | 12.68 |
| Closed-source Models | ||||||||||||||||
| GPT-3.5 | R | 65.30 | 19.29 | 42.69 | 26.57 | 45.25 | 91.93 | 60.65 | 90.51 | 40.89 | 56.33 | 58.49 | 30.75 | 32.92 | 31.80 | 38.95 |
| GPT-4 | R | 73.40 | 21.12 | 52.55 | 30.13 | 37.30 | 98.87 | 54.17 | 98.98 | 39.78 | 56.75 | 55.46 | 34.44 | 36.51 | 35.45 | 40.35 |
| Claude-3.5 | R | 69.80 | 20.20 | 47.79 | 28.40 | 41.70 | 97.35 | 58.39 | 97.29 | 41.12 | 57.80 | 58.10 | 32.23 | 33.46 | 32.83 | 39.78 |
| GPT-3.5 | D | 94.50 | 13.32 | 42.68 | 20.30 | 6.81 | 87.27 | 12.63 | 97.63 | 30.48 | 46.45 | 29.54 | 20.97 | 21.47 | 21.22 | 23.69 |
| GPT-4 | D | 87.70 | 17.50 | 52.01 | 26.19 | 17.45 | 100.00 | 29.71 | 100.00 | 33.64 | 50.34 | 40.03 | 29.66 | 30.39 | 30.02 | 32.08 |
| Claude-3.5 | D | 69.90 | 0.00 | 0.00 | 0.00 | 41.13 | 96.35 | 57.65 | 96.27 | 40.63 | 57.14 | 57.40 | 0.00 | 0.00 | 0.00 | 19.13 |
| Our Models | ||||||||||||||||
| SFT-LLaMA-2-7b | R | 31.60 | 32.63 | 34.96 | 33.76 | 81.13 | 83.63 | 82.36 | 62.03 | 57.91 | 59.90 | 71.13 | 46.25 | 46.49 | 46.37 | 50.42 |
| SFT-LLaMA-3-8b | R | 24.20 | 37.56 | 30.81 | 33.85 | 87.66 | 81.53 | 84.48 | 52.54 | 64.05 | 57.73 | 71.11 | 47.78 | 48.24 | 48.01 | 50.99 |
| DPO-LLaMA-2-7b | R | 32.30 | 30.64 | 33.55 | 32.03 | 80.85 | 84.19 | 82.49 | 63.73 | 58.20 | 60.84 | 71.67 | 49.34 | 49.50 | 49.42 | 51.04 |
| DPO-LLaMA-3-8b | R | 22.40 | 40.95 | 31.09 | 35.35 | 89.08 | 80.93 | 84.81 | 49.83 | 65.63 | 56.65 | 70.73 | 58.58 | 58.96 | 58.77 | 54.95 |
| Prompt | AR% | EMreg | EM | EM | EMF1AC | F1 | CR | CP | F1CG | Trust-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-2-7b | |||||||||||||||||
| ICL | R | 0.50 | 2.63 | 0.00 | 0.00 | 0.00 | 100.00 | 79.70 | 88.70 | 2.42 | 100.00 | 4.72 | 46.71 | 0.00 | 0.00 | 0.00 | 15.57 |
| PostCite | R | 0.90 | 6.33 | 22.22 | 0.97 | 1.86 | 99.12 | 79.31 | 88.12 | 0.97 | 22.22 | 1.85 | 44.98 | 5.04 | 5.04 | 5.04 | 17.29 |
| PostAttr | R | 0.90 | 6.33 | 22.22 | 0.97 | 1.86 | 99.12 | 79.31 | 88.12 | 0.97 | 22.22 | 1.85 | 44.98 | 0.00 | 0.00 | 0.00 | 15.61 |
| Self-RAG | R | 73.50 | 6.80 | 9.57 | 33.98 | 14.94 | 29.13 | 87.17 | 43.67 | 83.57 | 23.54 | 36.73 | 40.20 | 12.34 | 15.65 | 13.80 | 22.98 |
| FRONT | D | 100.00 | 9.57 | 13.07 | 63.12 | 21.66 | 0.00 | 0.00 | 0.00 | 100.00 | 20.70 | 34.30 | 17.15 | 52.44 | 53.01 | 52.72 | 30.51 |
| ICL | D | 95.30 | 12.03 | 12.07 | 55.56 | 19.83 | 5.55 | 93.62 | 10.48 | 98.55 | 21.41 | 35.17 | 22.82 | 15.73 | 16.92 | 16.30 | 19.65 |
| PostCite | D | 83.90 | 8.13 | 7.45 | 30.19 | 11.95 | 16.14 | 79.50 | 26.83 | 84.06 | 20.74 | 33.27 | 30.05 | 4.90 | 4.90 | 4.90 | 15.63 |
| PostAtr | D | 84.00 | 8.13 | 7.44 | 30.19 | 11.94 | 15.89 | 78.75 | 26.44 | 83.57 | 20.60 | 33.05 | 29.74 | 0.93 | 0.93 | 0.93 | 14.20 |
| Self-RAG | D | 97.90 | 8.13 | 7.97 | 37.68 | 13.16 | 2.40 | 90.48 | 4.67 | 99.03 | 20.94 | 34.57 | 19.62 | 9.01 | 12.05 | 10.31 | 14.36 |
| LLaMA-2-13b | |||||||||||||||||
| ICL | R | 46.40 | 6.90 | 14.44 | 32.37 | 19.97 | 58.39 | 86.38 | 69.68 | 64.73 | 28.88 | 39.94 | 54.81 | 3.79 | 6.28 | 4.73 | 26.50 |
| PostCite | R | 76.60 | 2.27 | 1.44 | 5.31 | 2.27 | 25.73 | 87.18 | 39.73 | 85.51 | 23.11 | 36.38 | 38.05 | 0.72 | 0.72 | 0.72 | 13.68 |
| PostAttr | R | 76.60 | 2.27 | 1.44 | 5.31 | 2.27 | 25.73 | 87.18 | 39.73 | 85.51 | 23.11 | 36.38 | 38.05 | 0.09 | 0.09 | 0.09 | 13.47 |
| Self-RAG | R | 22.10 | 2.40 | 12.37 | 13.20 | 12.77 | 81.59 | 83.06 | 82.32 | 36.23 | 33.94 | 35.05 | 58.68 | 22.09 | 27.60 | 24.54 | 32.00 |
| ICL | D | 96.50 | 13.07 | 12.71 | 59.26 | 20.93 | 3.91 | 88.57 | 7.49 | 98.07 | 21.04 | 34.64 | 21.06 | 2.45 | 3.25 | 2.80 | 14.93 |
| PostCite | D | 7.00 | 0.57 | 7.14 | 2.42 | 3.62 | 92.18 | 78.60 | 84.85 | 3.86 | 11.43 | 5.78 | 45.31 | 4.73 | 4.73 | 4.73 | 17.89 |
| PostAttr | D | 6.70 | 0.57 | 7.46 | 2.42 | 3.66 | 93.44 | 79.42 | 85.86 | 7.25 | 22.39 | 10.95 | 48.41 | 0.71 | 0.71 | 0.71 | 17.59 |
| Self-RAG | D | 98.00 | 9.73 | 7.38 | 34.94 | 12.19 | 2.02 | 80.00 | 3.94 | 98.07 | 20.71 | 34.20 | 19.07 | 5.71 | 8.06 | 6.68 | 12.65 |
| LLaMA-3-8b | |||||||||||||||||
| ICL | R | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100.00 | 79.30 | 88.46 | 0.00 | 0.00 | 0.00 | 44.23 | 0.00 | 0.00 | 0.00 | 14.74 |
| PostCite | R | 62.00 | 10.80 | 13.87 | 41.55 | 20.80 | 40.86 | 85.26 | 55.24 | 72.95 | 24.35 | 36.52 | 45.88 | 8.06 | 8.06 | 8.06 | 24.91 |
| PostAttr | R | 62.00 | 10.80 | 13.87 | 41.55 | 20.80 | 40.86 | 85.26 | 55.24 | 72.95 | 24.35 | 36.52 | 45.88 | 1.25 | 1.25 | 1.25 | 22.64 |
| ICL | D | 84.60 | 11.90 | 14.74 | 60.23 | 23.69 | 17.65 | 90.91 | 29.57 | 93.24 | 22.81 | 36.66 | 33.11 | 31.32 | 30.74 | 31.03 | 29.28 |
| PostCite | D | 98.90 | 17.40 | 11.49 | 54.91 | 19.00 | 1.26 | 90.91 | 2.49 | 99.52 | 20.83 | 34.45 | 18.47 | 6.33 | 6.33 | 6.33 | 14.60 |
| PostAttr | D | 98.90 | 17.40 | 11.49 | 54.91 | 19.00 | 1.13 | 81.82 | 2.24 | 99.03 | 20.73 | 34.28 | 18.26 | 1.02 | 1.02 | 1.02 | 12.76 |
| Closed-source Models | |||||||||||||||||
| GPT-3.5 | R | 49.00 | 8.47 | 23.03 | 54.51 | 32.38 | 58.26 | 90.59 | 70.91 | 76.81 | 32.45 | 45.62 | 58.27 | 56.57 | 58.03 | 57.29 | 49.31 |
| GPT-4 | R | 61.50 | 10.50 | 22.09 | 65.62 | 33.05 | 45.65 | 94.03 | 61.46 | 88.89 | 29.92 | 44.77 | 53.11 | 61.33 | 62.35 | 61.84 | 49.33 |
| Claude-3.5 | R | 59.00 | 2.87 | 7.66 | 21.82 | 11.34 | 48.05 | 92.93 | 63.34 | 85.99 | 30.17 | 44.67 | 54.00 | 11.64 | 13.34 | 12.43 | 25.92 |
| GPT-3.5 | D | 93.50 | 14.33 | 14.58 | 65.86 | 23.88 | 7.57 | 92.31 | 13.99 | 97.58 | 21.60 | 35.38 | 24.68 | 46.46 | 46.10 | 46.28 | 31.61 |
| GPT-4 | D | 82.80 | 15.00 | 18.18 | 72.71 | 29.09 | 21.19 | 97.67 | 34.82 | 98.07 | 24.52 | 39.23 | 37.02 | 48.20 | 48.47 | 48.33 | 38.15 |
| Claude-3.5 | D | 56.60 | 3.40 | 7.89 | 21.58 | 11.56 | 51.07 | 93.32 | 66.01 | 85.99 | 31.45 | 46.05 | 56.03 | 10.22 | 12.43 | 11.22 | 26.27 |
| Our Models | |||||||||||||||||
| SFT-LLaMA-2-7b | R | 29.50 | 3.80 | 18.36 | 26.17 | 21.58 | 77.05 | 86.67 | 81.58 | 54.59 | 38.31 | 45.02 | 63.30 | 45.25 | 35.19 | 39.59 | 41.49 |
| SFT-LLaMA-3-8b | R | 23.60 | 3.27 | 21.19 | 24.15 | 22.57 | 82.98 | 86.13 | 84.52 | 48.79 | 42.80 | 45.60 | 65.06 | 51.77 | 42.79 | 46.85 | 44.83 |
| DPO-LLaMA-2-7b | R | 21.60 | 3.30 | 22.07 | 23.03 | 22.54 | 83.98 | 84.95 | 84.46 | 43.00 | 41.20 | 42.08 | 63.27 | 48.46 | 46.29 | 47.35 | 44.39 |
| DPO-LLaMA-3-8b | R | 15.50 | 2.77 | 24.30 | 18.20 | 20.81 | 89.66 | 84.14 | 86.81 | 35.27 | 47.10 | 40.33 | 63.57 | 50.75 | 49.74 | 50.24 | 44.87 |