Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models
Abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks but their performance in complex logical reasoning tasks remains unsatisfactory. Although some prompting methods, such as Chain-of-Thought, can improve the reasoning ability of LLMs to some extent, they suffer from an unfaithful issue where derived conclusions may not align with the generated reasoning chain. To address this issue, some studies employ the approach of propositional logic to further enhance logical reasoning abilities of LLMs. However, the potential omissions in the extraction of logical expressions in these methods can cause information loss in the logical reasoning process, thereby generating incorrect results. To this end, we propose Logic-of-Thought (LoT) prompting which employs propositional logic to generate expanded logical information from input context, and utilizes the generated logical information as an additional augmentation to the input prompts, thereby enhancing the capability of logical reasoning. The LoT is orthogonal to existing prompting methods and can be seamlessly integrated with them. Extensive experiments demonstrate that LoT boosts the performance of various prompting methods with a striking margin across five logical reasoning tasks. In particular, the LoT enhances Chain-of-Thought’s performance on the ReClor dataset by +4.35%; moreover, it improves Chain-of-Thought with Self-Consistency’s performance on LogiQA by +5%; additionally, it boosts performance of Tree-of-Thoughts on ProofWriter dataset by +8%.
1 Introduction
In recent years, Large Language Models (LLMs) have demonstrated excellent capabilities across various NLP tasks openai2024gpt4 ; anil2023palm ; touvron2023llama2 . However, even the most advanced LLMs exhibit limited performance in mathematics and complex logical reasoning tasks arkoudas2023gpt ; liu2023evaluating . Chain-of-Thought (CoT) prompting kojima2022large ; wei2023chainofthought ; nye2021show has emerged as a promising approach to improve logical reasoning capabilities, which enhances reasoning abilities by adding intermediate steps in the reasoning process. Subsequent research, such as besta2024graph ; besta2024topologies ; yao2024tree , has sought to simulate human reasoning processes by expanding the Chain-of-Thought into more complex reasoning topology. Tree-of-Thoughts (ToT) yao2024tree extends into a tree-like reasoning topology, exploring more reasoning branches at each step and supporting backtracking. Graph-of-Thoughts (GoT) besta2024graph supports a graph reasoning topology, allowing for the aggregation of multiple thoughts into new ones. STaR eric2022star and Chain-of-Thought with Self-Consistency (CoT-SC) wang2022self generate multiple chains of thought or reasoning paths, selecting the most optimized and consistent answers from these. However, bao2024llms ; lanham2023measuring ; lyu2023faithful ; turpin2024language observe that LLMs occasionally exhibit unfaithful reasoning, wherein the derived conclusions do not adhere to the previously generated reasoning chain.
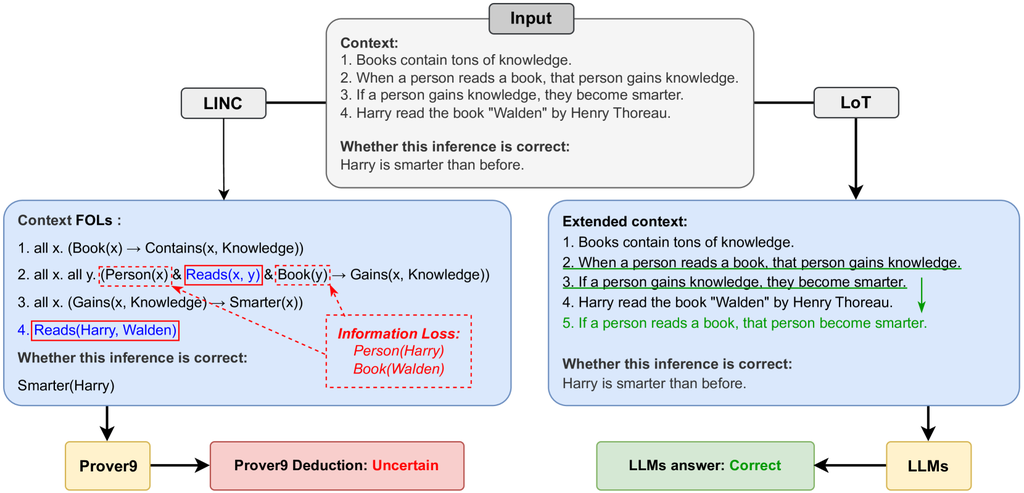
To tackle the challenge of the unfaithfulness in the reasoning process, researchers have proposed many neuro-symbolic methods that integrate LLMs with symbolic reasoning, such as Faithful Chain-of-Thought lyu2023faithful , LINC olausson2023linc , Logic-LM pan2023logic and SatLM ye2024satlm . These methods follow a similar process: Initially, the problem and objectives are translated into symbolic expressions. Subsequently, symbolic results are derived through external tools such as symbolic solvers. Finally, it’s optional to explain symbolic results using LLMs or interpreters. However, these existing neuro-symbolic methods inevitably suffer from the issue of information loss, which results from omissions in the extraction of logical expressions and directly leads to incorrect intermediate reasoning processes. As illustrated in the Figure 1, in the extraction process of logical expressions in LINC, two key pieces of hidden information "Harry is a person" and "Walden is a book" are lost, which makes it impossible for the symbolic solver Prover9 to obtain the correct reasoning result.
To address the issue of information loss, in this paper, we propose a novel Logic-of-Thought (LoT) prompting method. Specifically, LoT extracts propositions and logical expressions from the input context, expands these expressions according to logical reasoning laws, translates the expanded logical expressions back into natural language, and utilizes the extended logical descriptions as additional augmentation to the input prompts for LLMs. The LoT prompting preserves the original input prompt while appending logical information described in natural language to guide the LLM’s reasoning. Thus, LoT prompting prevents complete dependence on the symbolic solver and also avoids the potential issue of information loss inherent in existing methods’ symbolic extraction processes. Additionally, the LoT prompting approach is compatible and orthogonal to existing prompting methods, enabling seamless integration of these methods. To validate the effectiveness of LoT, we conduct extensive experiments to evaluate its capability in boosting various prompting methods such as CoT, SC, CoT-SC and ToT across five logical reasoning datasets. Experimental results demonstrate that LoT prompting can seamlessly integrate with existing prompting methods and significantly boost their performance in logical reasoning. Specifically, LoT significantly enhances the performance of CoT on the ReClor dataset, achieving an improvement in accuracy up to +4.35%. Furthermore, LoT improves the SC’s performance on the ReClor dataset by a remarkable +6.52%. Moreover, LoT boost the accuracy of CoT-SC on LogiQA by +5%. Additionally, LoT effectively elevates the performance of ToT on the ProofWriter dataset, resulting in a significant improvement of +8%.
The main contributions of this paper are as follows:
-
1.
We propose a novel prompting method Logic-of-Thought (LoT) to address the issue of information loss in existing neuro-symbolic methods by generating logical proposition descriptions as augmentations for original prompts.
-
2.
We integrate LoT with a variety of distinct prompting techniques, including Chain-of-Thought (CoT), Self-Consistency (SC), Chain-of-Thought with Self-Consistency (CoT-SC), Tree-of-Thoughts (ToT), by leveraging the orthogonal capabilities of LoT.
-
3.
We conduct extensive experiments to evaluate the effectiveness of LoT in enhancing the capabilities of different prompting techniques across diverse logical reasoning tasks. The results demonstrate the significant effectiveness of LoT in boosting the performance of various prompting methods.
2 Preliminary
As this study focuses on logical reasoning tasks, we first provide some definitions and symbols about the propositional logic system, which will be used throughout the paper.
-
•
Propositions are defined as declarative sentences that have clear truth-value characteristic and cannot be simultaneously true and false. In this context, propositions are considered fundamental elements of logical expressions. We use standard uppercase letters such as , , to symbolize specific propositions, exemplified by statements like "you have keyboarding skills", and lowercase letters such as , , to refer to any proposition.
-
•
Connectives are defined as operators on propositions, which can operate on a single proposition or link propositions together to form a new logical expression, which is defined as a single proposition or a combination of propositions through connectives. In this study, We mainly focus on three connectives: , and . Herein, negative denotes the negation operation for a specific logical symbol (e.g., represents the negation of ). Implication signifies a sufficient condition or causal relationship between two propositions (e.g., indicates that is a sufficient condition for ). Conjunction also operates on two propositions, which represents that the entire expression is true only if both propositions are true (e.g., indicates and ).
-
•
Logical reasoning laws are defined as the deducing relation between two logical expressions. Meanwhile, signifies that a certain logical expression can infer another logical expression. signifies that two logical expressions can be mutually inferred. In this study, we utilize three basic logical reasoning laws: the Double Negation Law , the Contraposition Law , and the Transitive Law , which all align with human intuition and are fundamental and widely used in propositional logic buning1999propositional .
With these basic symbols and definitions, we can construct a propositional logic system and analyze complex logical reasoning processes. While the logic system setting presented here is straightforward, our paper primarily concentrates on introducing a new prompting paradigm to address information loss in existing neuro-symbolic methods. Moreover, notable enhancements have already been achieved within this setting (See Section 4.4). Therefore, we leave the exploration of incorporating more diverse connectives and laws to strengthen the logic system in our method to future work.
3 Methodology
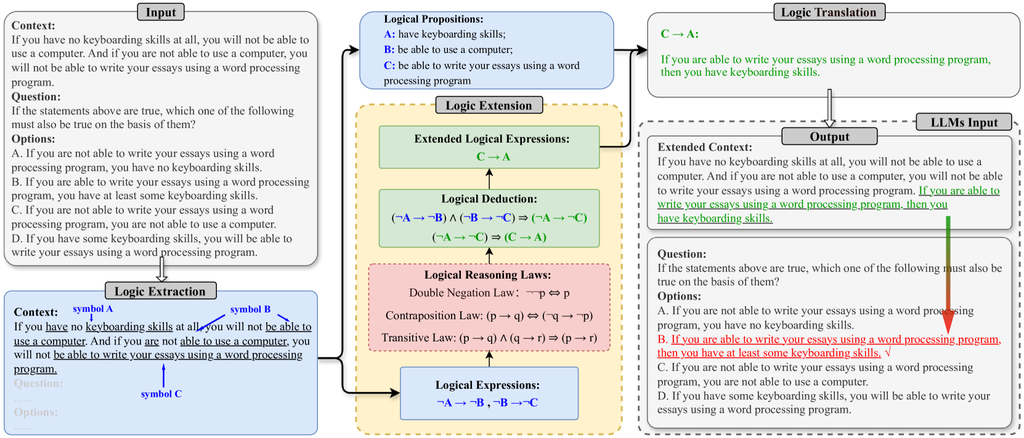
Overview.
Figure 2 presents an overview of LoT, which consists of three phases. Firstly, in the Logic Extraction phase, propositions and logical relations are extracted from the input context using LLMs to output logical expressions. Secondly, in the Logic Extension phase, the logical expressions are expanded through Python-implemented logical rules. Thirdly, in the Logic Translation phase, the expanded logical expressions are translated into natural language descriptions of logical information through LLMs. And then, the logical information is incorporated into the input prompt, forming a comprehensive and novel input prompt for LLMs. The following sections provide detailed introduction to the phases of Logic Extraction, Logic Extension, and Logic Translation.
Logic Extraction.
In the Logic Extraction phase, we use LLMs to extract formal logic expressions from the input context through two stages. Firstly, we instruct LLMs to select sentences containing conditional reasoning relationships from the input context to generate collection of sentences with logical relationships. Subsequently, we use LLMs to extract the set of propositional symbols and the set of logical expressions from the collection. During the process of Logic Extraction, LLMs identify propositions with similar meanings and represent them using identical propositional symbols. Furthermore, LLMs analyze the logical relationships between propositions from their natural language descriptions. For propositions expressing opposite meanings, the negation is added. When a conditional relationship exists between two propositions, the implication is used to connect their corresponding propositional symbols. For example, as depicted in Figure 2, LLMs extract the same meaning description "be able to use a computer" from two different sentences, symbolized as . Then, through analyzing its logical relationship with other propositions, LLMs apply to and another proposition and add between them, which results in a new logical expression .
Logic Extension.
During the Logic Extension phase, we apply logical reasoning laws to the collection of logical expressions from the Logic Extraction phase. These logical expressions can be further expanded using a Python program to implement logical deduction. As illustrated in the Figure 2, the extracted logical expressions and serve as inputs for our logical deduction program. Through expansion based on Transitive Law and Contraposition Law, we finally obtain the new expression , which will be used in the next phase.
Logic Translation.
During the Logic Translation phase, we use LLMs to translate the generated extended logical expressions into natural language descriptions. Subsequently, we combine the natural language descriptions of propositional symbols according to the extended logical expressions to form a new part of the original input prompt. Through this approach, we inject the deduced logical information as additional augmentation into the original prompt, thus avoiding information loss. As shown in Figure 2, by associating with its description "be able to write your essays using a word processing program", with its description "have keyboarding skills", and with the logical description "if…then…", we can translate the aforementioned logical expression back to its natural language description and add it to original prompts as new input prompts.
4 Experiments
4.1 Tasks and Datasets
In the experiment, we employ five logical reasoning datasets: ReClor yu2020reclor , LogiQA liu2020logiqa , RuleTaker clark2021transformers , ProofWriter tafjord2021proofwriter , and FOLIO han2022folio .
-
•
The ReClor dataset is collected from standardized test logical reasoning questions, including the Law School Admission Test (LSAT) and the Graduate Management Admission Test (GMAT). Each question is composed of a context, a question, and four answer options, with only one correct answer.
-
•
The LogiQA dataset is derived from expert-written questions for testing human logical reasoning, specifically the reading comprehension section, which is designed by domain experts to evaluate the logical reasoning ability of test participants.
-
•
The RuleTaker dataset is automatically generated via programming, utilizing connectives such as conjunction , negation , and implication . Each question comprises a context and a conclusion.
-
•
The ProofWriter dataset comprises numerous small rulebases composed of facts and rules, and contains RuleTaker-style datasets with 500k questions, answers and proofs over natural-language rulebases.
-
•
The FOLIO dataset is a comprehensive and diverse dataset designed for reasoning in natural language, which is characterized by its human annotations, open-domain nature, and logical complexity. It boasts first-order logic (FOL) annotations, comprising 1,435 unique examples of conclusions.
4.2 Baselines
We consider five prompting approaches and one neuro-symbolic method, including: (1) Direct prompting, which simply answers the question without any reasoning process; (2) Self-Consistency (SC) wang2022self , which employs majority voting to aggregate responses from multiple Direct prompting, represented as SC(5) when it involves 5 reasoning paths; (3) CoT kojima2022large ; wei2023chainofthought ; nye2021show , which utilizes a progressive thinking approach for reasoning; (4) CoT-SC wang2022self , which applies majority voting to aggregate multiple Chain-of-Thought, represented as CoT-SC(5) when involving 5 reasoning paths; (5) ToT yao2024tree , which models the reasoning process as a thought search tree; (6) SatLM ye2024satlm , which leverages automated theorem provers to assist LLMs in reasoning. We conduct an evaluation of our LoT and all of the above baselines, and assess the integration of four prompting methods with LoT: CoT, SC, CoT-SC and ToT.
4.3 Experiment Setup
We utilize three pre-trained models: GPT-3.5-turbo-instruct, GPT-3.5-turbo ouyang2022training , and GPT-4 openai2024gpt4 and conduct three types of experiments for comparison:
Main experiments.
Main experiments employ four prompting methods including Direct, CoT, SC, CoT-SC and combination of these prompting methods with LoT on GPT-3.5-turbo and GPT-4 across five datasets. The experiments conduct here utilize the zero-shot prompt, employing default values for temperature, top_p, and top_k. For ReClor, we select 46 data entries from the dataset that examine deductive reasoning abilities in the implementation section. Regarding LogiQA, we randomly extract 200 data entries within the dataset. As for RuleTaker, we randomly select 200 data entries from the test set of the dataset, with the depth of reasoning randomly distributed between 1-5 layers. Concerning ProofWriter, we randomly extract 200 data entries with a depth of 5 from the validation set of the dataset. In relation to FOLIO, we extract 100 data entries from the validation set of the dataset.
Comparison between LoT and SatLM.
We conduct a comparative analysis of SatLM’s performance, benchmarking it against LoT, LoT+CoT, and LoT+CoT-SC using the ReClor dataset. Consistent with the approach outlined in ye2024satlm , we utilize the GPT-3.5-turbo-instruct to leverage the SatLM implementation. To ensure compatibility with our experimental setup, we select a subset of the ReClor datasets, specifically a subset containing 46 data entries, as they closely mirror the LSAT dataset previously tested in ye2024satlm .
Comparison between LoT and ToT.
In this study, we evaluate the performance enhancement achieved by LoT under the guidance of ToT on the ProofWriter dataset, leveraging GPT-4. The ToT prompt employed in our analysis is based on the work presented in zhang2024cumulative . In the experiments, the Direct, ToT, and LoT+ToT approaches are all implemented using few-shot prompting. For the ToT-related experiments, each successful state explores up to five new states. The success or failure of a state is verified by assessing its compliance with the established rules. The exploration process terminates either after achieving four successful state explorations or when no new states are available for exploration. The experiment utilizes 100 randomly selected data entries with a depth of 5 from the ProofWriter validation set.
A detailed description of the prompts used in all experiments can be found in the Appendix E.
| Method | GPT-3.5-turbo | GPT-4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ReClor | LogiQA | RuleTaker | ProofWriter | FOLIO | ReClor | LogiQA | RuleTaker | ProofWriter | FOLIO | |
| Direct | 46.20 | 34.60 | 58.80 | 54.50 | 74.20 | 72.17 | 54.80 | 62.60 | 64.70 | 83.00 |
| LoT | 56.02 9.82 | 35.30 0.70 | 61.40 2.60 | 59.50 5.00 | 75.00 0.80 | 77.98 5.81 | 57.60 2.80 | 65.30 2.70 | 66.70 2.00 | 86.00 3.00 |
| CoT | 52.17 | 34.00 | 60.70 | 58.80 | 78.00 | 77.39 | 55.40 | 62.40 | 75.90 | 84.40 |
| LoT + CoT | 56.52 4.35 | 36.50 2.50 | 61.60 0.90 | 61.50 2.70 | 78.00 0.00 | 79.13 1.74 | 57.50 2.10 | 65.60 3.20 | 76.80 0.90 | 84.80 0.40 |
| SC(5) | 56.52 | 36.60 | 59.00 | 57.50 | 76.00 | 73.91 | 55.50 | 65.50 | 67.50 | 85.00 |
| LoT + SC(5) | 58.70 2.18 | 38.00 1.40 | 60.00 1.00 | 60.00 2.50 | 78.60 2.60 | 80.43 6.52 | 58.50 3.00 | 64.50 1.00 | 66.00 1.50 | 88.00 3.00 |
| CoT-SC(5) | 58.70 | 34.50 | 65.50 | 61.50 | 80.00 | 80.43 | 56.50 | 63.50 | 80.50 | 84.00 |
| LoT + CoT-SC(5) | 60.87 2.17 | 39.50 5.00 | 65.50 0.00 | 67.50 6.00 | 83.00 3.00 | 82.61 2.18 | 61.00 4.50 | 66.50 3.00 | 80.50 0.00 | 86.00 2.00 |
4.4 Main Results
In this section, we integrate LoT prompting with four baseline prompting methods, namely Direct, CoT, SC and CoT-SC, to conduct a comparative analysis of whether LoT enhances logical reasoning abilities across five distinct datasets. The results presented in Table 1 reveal some key observations:
-
•
Combining LoT with existing prompting methods consistently achieves best performance, which highlights the superiority of our methods. Specifically, LoT+CoT-SC(5) outperforms all other methods across all five datasets with GPT-3.5-turbo and four datasets with GPT-4. LoT+SC achieves the highest accuracy rate in the FOLIO dataset with GPT-4.
-
•
LoT prompting enhances the performance of four baseline prompting methods in most experiments, suggesting that LoT can be seamlessly integrated into existing prompting methods to further improve the logical reasoning ability of LLMs. Among total 40 comparisons (including four baseline prompting methods across five datasets with two LLMs), LoT significantly enhances the performance of baseline prompting methods in 35 instances. For example, in comparison to CoT using GPT-4, LoT+CoT can achieve great improvements in accuracy on five datasets, ReClor(+1.74%), LogiQA(+2.10%), RuleTaker(+3.20%), ProofWriter(+0.90%) and FOLIO(+0.40%), respectively.
-
•
We find that a few negligible improvements all occur when CoT or CoT-SC is integrated with LoT. We conduct an analysis of specific examples of CoT and CoT+LoT on the dataset and observe that this is attributed to CoT’s capacity to gradually deduce concealed information, which interestingly overlaps with the capabilities of LoT. (The Appendix D illustrates an example of the overlap in capabilities between CoT and LoT.)
-
•
Upon utilizing GPT-4 exclusively on the RuleTaker and ProofWriter datasets, we observe that LoT+SC marginally trailed behind SC, recording a decline of 1% and 1.5% respectively. We find that the primary factor contributing to this issue within the LoT framework is the deviation in logical information extracted during the Logic Extraction process. To illustrate this, we provide an example in the Appendix C, analyzing a failure case where LoT’s information extraction during the Logic Extraction phase is flawed. This example demonstrates how the information bias during this phase leads to an erroneous final result.
-
•
LoT achieves significant enhancements in the accuracy of Direct across all datasets and outperforms CoT in eight out of ten sets of comparative data. Thus, this provides compelling evidence that the standalone utilization of LoT can achieve or even exceed the logical reasoning capability exhibited by CoT.

4.5 Comparative Study of LoT and SatLM
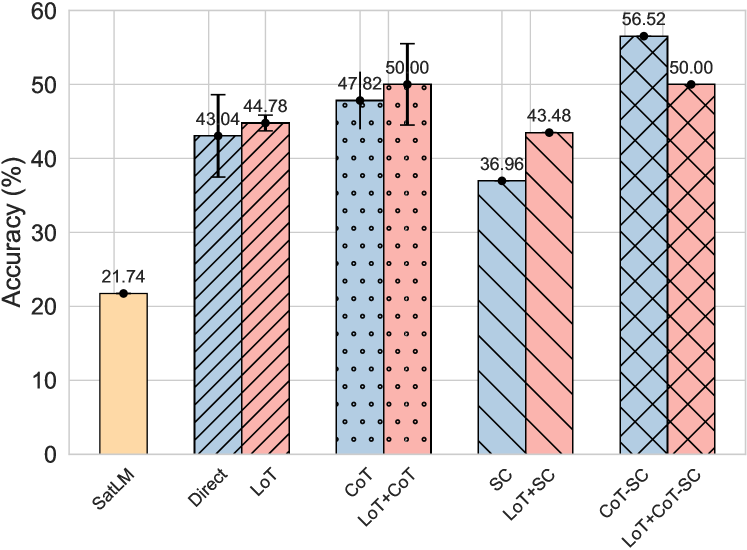
In this section, we conduct a comprehensive comparison and analysis of LoT with a neuro-symbolic approach SatLM to delve deeper into their respective capabilities and potential differences.
Performance Study.
From Figure 4, it can be first observed that LoT significantly outperforms SatLM in terms of accuracy on the Reclor dataset as well as obtains notable improvements across various prompting methods, including Direct (+1.74%), CoT (+2.18%), and SC (+6.52%), which also shows LoT’s effectiveness. But we observe that in this set of experiments, the performance of LoT+CoT-SC is inferior to that of CoT-SC. We speculate that this is due to a bias in the extraction of logical information, which is also discussed in Section 4.4.
Furthermore, SatLM exhibits poor performance under our setup compared to prompting methods. This is in line with our motivation that neuro-symbolic methods like SatLM, are more likely to encounter the issue of information loss when extracting logical symbolic expressions, significantly compromising their overall performance. Conversely, LoT maintains the original context, ensuring that possible minor information loss during the Logic Extraction phase may not necessarily exert a critical impact on the final results.
Case Study.
We provide a comparative case study between SatLM and LoT based on our experiments. As depicted in Figure 3, SatLM induces information mistakes and loss. Specifically, during logical extraction, SatLM erroneously employs "abilities" to represent "can", leading to semantic errors in constraints. Additionally, SatLM confuses "has a sense of self" with "has a sense of the minds of others" and only utilizes "possesses" to represent them together. In contrast to SatLM, LoT successfully extracts logical proposition descriptions and symbolizes them. Here, we have a very interesting finding: when directly examining the extracted logical expressions, a small mistake in results in an incorrect (i.e., we cannot infer general "animal" from specific "great ape"). However, when translating the deduced logical expressions into natural language, LLMs recognize the subordinate relationship between "ape" and "animal" and correct this error, resulting in correct augmentation to prompts and right answers. This reflects that LoT fully leverages the LLM’s understanding of natural language descriptions, enabling it to correct errors from earlier phases in the three-phase process. This avoids the pitfalls of neuro-symbolic methods, which rely entirely on the accuracy of logical symbol extraction, where errors in intermediate results directly propagate to errors in the final outcome.
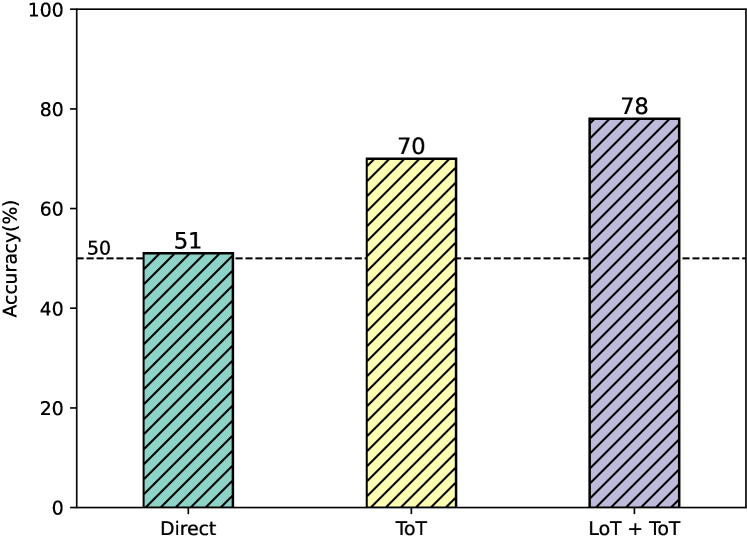
4.6 In-depth Analysis of LoT and ToT
In this experiment, we assess the enhancing effect of LoT on ToT, which is a prompting method characterized by its complex reasoning topology. As shown in Figure 5, we can observe that under the complex reasoning scenario with a deduction depth of 5 in the ProofWriter dataset, Direct only achieves an accuracy rate of 51%, which is nearly the same as random guessing (50%). The accuracy rate of ToT is +19% higher than the Direct prompting, reaching 70%, which shows that ToT can assist LLMs in better solving multi-step reasoning. The accuracy rate of LoT+ToT reaches 78%, an +8% increase in accuracy compared to ToT, indicating that LoT can effectively enhance the ability of ToT in complex logical reasoning.
| Method | Total States | Successful States | Full Reasoning() |
|---|---|---|---|
| ToT | 18.70 | 7.70 | 90 |
| LoT+ToT | 19.10 2.13% | 8.09 5.06% | 92 2% |
To further investigate the influence of LoT on ToT, we have carefully analyze a range of indices within ToT, including the total count of states, full reasoning (wherein four successful states explorations are achieved), and the tally of successful states. Firstly, as shown in Table 2, we observe a notable +2.14% increase in the overall states of LoT+ToT compared to ToT. This suggests that LoT facilitates an expanded exploration scope for ToT. Moreover, a higher level of full reasoning indicates a more comprehensively explored space and it is evident that LoT has augmented ToT’s full reasoning by +2%. Furthermore, compared to ToT, LoT+ToT exhibits a +2.59% increase in the average number of successful states, indicating that the LoT can significantly enhance the effectiveness of ToT’s exploratory states. In the Appendix B, we present a thorough analysis of an example, comparing the exploration of states when using ToT, and LoT+ToT respectively.
5 Related Work
5.1 Prompting Approaches for LLMs Reasoning
Numerous studies are dedicated to exploring enhancements in the logical reasoning capabilities of LLMs. CoT prompting wei2023chainofthought , which breaks down a multi-step reasoning problem into multiple intermediate steps to gradually generate answers, has significantly improved logical reasoning, mathematical logic, and interpretability. Zero-shot CoT kojima2022large integrates zero-shot learning with CoT, controlling LLMs to generate thought chains for answering questions through prompting. CoT-SC wang2022self generates multiple thought chains, and the final answer is obtained through majority voting, which significantly enhances the performance of the thought chain method. Least-To-Most zhou2022least prompting deconstructs a problem into multiple sub-questions, addressing them step by step, with the answer to the previous sub-question serving as the input for the next. Similar decomposition methods of sub-problems include Lambada kazemi2022lambada and the Divide-and-Conquer zhang2024guiding . lightman2023lets employs a process-supervised method, providing feedback on the intermediate reasoning process to enhance logical reasoning capabilities. shum2023automatic ; eric2022star ; zhou2022large select optimal candidates from multiple chains of thought. ToT yao2024tree and GoT besta2024graph achieve logical branching and the aggregation of multiple thoughts by utilizing more complex reasoning topologies.
5.2 Neuro-symbolic Approaches for LLMs Reasoning
The neuro-symbolic methods, which combine LLMs with symbolic reasoning, are considered an effective approach to address the issue of unfaithful reasoning and enhance the logical reasoning ability of LLMs. LReasoner wang2022logic proposes a framework for context extension that expands the logical information contained in the context by applying logical reasoning laws. Additionally, it utilizes data augmentation algorithms to better capture logical information. LogicAsker wan2024b proposes an enhancement of LLMs’ logical reasoning capabilities, which are based on a set of propositions and collections of predicate logic. Logic-LM pan2023logic initially utilizes LLMs to transform natural language problems into symbolic formulas. Subsequently, a symbolic solver is determined to reason about the formalized problems. Moreover, a self-refinement module is introduced, which utilizes error messages from the symbolic solver to modify the symbolic formalization. The SatLM ye2024satlm utilizes LLMs to generate declarative task specifications rather than imperative programs, and leverages readily available automated theorem solver to derive the final answers. In LINC olausson2023linc , LLMs acts as a semantic parser, translating premises and conclusions from natural language into first-order logic expressions. These expressions are then offloaded to an external theorem solver for deductive reasoning.
6 Limitations
Although our proposed LoT has achieved excellent performance in various logical reasoning tasks, there are still some limitations in LoT. Firstly, current LoT supports a limited set of connectives and logical reasoning laws. More connectives and logical reasoning laws in LoT means more complex prompt design in the Logic Extraction and Logic Translation phase, and increased difficulty in logical deducing in the Logic Extension phase. In the future, we will try to include additional connectives and logical reasoning laws in LoT to further enhance the logical reasoning capabilities.
Additionally, LoT employs LLMs to extract logical symbols and expressions but illusion issues inherent in LLMs can lead to problems such as repetition of expressions, omission of logical relationships, and deviations in logical propositions and expressions. (In Appendix C, we conduct a comprehensive analysis of an example illustrating a failure in Logic Extraction using LoT, resulting from deviations in extracting logical expressions.)
7 Conclusion
In this paper, we introduce a symbolic-enhancement prompting approach, named Logic-of-Thought (LoT), designed to address the challenge of information loss inherent in existing neuro-symbolic methods. LoT leverages propositional logic to derive expanded logical information from input context, serving as a supplementary augmentation to the original prompts, to enhance logical reasoning capabilities of LLMs. Notably, LoT exhibits compatibility with widely used prompting techniques, including Chain-of-Thought (CoT), Self-Consistency (SC), Chain-of-Thought with Self-Consistency (CoT-SC), Tree-of-Thoughts (ToT), and can be seamlessly integrated with them. In the experiments, we demonstrate that LoT prompting significantly boosts the performance of various existing prompting methods across multiple logical reasoning datasets. In the future, we will explore more logical relationships and logical reasoning laws and support additional prompting methods to further enhance LoT’s logical reasoning capabilities.
References
- [1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [2] Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- [3] Konstantine Arkoudas. Gpt-4 can’t reason. arXiv preprint arXiv:2308.03762, 2023.
- [4] Guangsheng Bao, Hongbo Zhang, Linyi Yang, Cunxiang Wang, and Yue Zhang. Llms with chain-of-thought are non-causal reasoners. arXiv preprint arXiv:2402.16048, 2024.
- [5] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690, 2024.
- [6] Maciej Besta, Florim Memedi, Zhenyu Zhang, Robert Gerstenberger, Nils Blach, Piotr Nyczyk, Marcin Copik, Grzegorz Kwaśniewski, Jürgen Müller, Lukas Gianinazzi, et al. Topologies of reasoning: Demystifying chains, trees, and graphs of thoughts. arXiv preprint arXiv:2401.14295, 2024.
- [7] Hans Kleine Büning and Theodor Lettmann. Propositional logic: deduction and algorithms, volume 48. Cambridge University Press, 1999.
- [8] Peter Clark, Oyvind Tafjord, and Kyle Richardson. Transformers as soft reasoners over language. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 3882–3890, 2021.
- [9] Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Luke Benson, Lucy Sun, Ekaterina Zubova, Yujie Qiao, Matthew Burtell, et al. Folio: Natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840, 2022.
- [10] Mehran Kazemi, Najoung Kim, Deepti Bhatia, Xin Xu, and Deepak Ramachandran. Lambada: Backward chaining for automated reasoning in natural language. arXiv preprint arXiv:2212.13894, 2022.
- [11] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- [12] Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702, 2023.
- [13] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- [14] Hanmeng Liu, Ruoxi Ning, Zhiyang Teng, Jian Liu, Qiji Zhou, and Yue Zhang. Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv preprint arXiv:2304.03439, 2023.
- [15] Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. arXiv preprint arXiv:2007.08124, 2020.
- [16] Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. arXiv preprint arXiv:2301.13379, 2023.
- [17] Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021.
- [18] Theo X Olausson, Alex Gu, Benjamin Lipkin, Cedegao E Zhang, Armando Solar-Lezama, Joshua B Tenenbaum, and Roger Levy. Linc: A neurosymbolic approach for logical reasoning by combining language models with first-order logic provers. arXiv preprint arXiv:2310.15164, 2023.
- [19] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- [20] Liangming Pan, Alon Albalak, Xinyi Wang, and William Yang Wang. Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
- [21] KaShun Shum, Shizhe Diao, and Tong Zhang. Automatic prompt augmentation and selection with chain-of-thought from labeled data. arXiv preprint arXiv:2302.12822, 2023.
- [22] Oyvind Tafjord, Bhavana Dalvi, and Peter Clark. Proofwriter: Generating implications, proofs, and abductive statements over natural language. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 3621–3634, 2021.
- [23] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [24] Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36, 2024.
- [25] Yuxuan Wan, Wenxuan Wang, Yiliu Yang, Youliang Yuan, Jen-tse Huang, Pinjia He, Wenxiang Jiao, and Michael R Lyu. A & b== b & a: Triggering logical reasoning failures in large language models. arXiv preprint arXiv:2401.00757, 2024.
- [26] Siyuan Wang, Wanjun Zhong, Duyu Tang, Zhongyu Wei, Zhihao Fan, Daxin Jiang, Ming Zhou, and Nan Duan. Logic-driven context extension and data augmentation for logical reasoning of text. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1619–1629, 2022.
- [27] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2022.
- [28] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [29] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- [30] Xi Ye, Qiaochu Chen, Isil Dillig, and Greg Durrett. Satlm: Satisfiability-aided language models using declarative prompting. Advances in Neural Information Processing Systems, 36, 2024.
- [31] Zhang Yifan, Yang Jingqin, Yuan Yang, and Yao Andrew, Chi-Chih. Cumulative reasoning with large language models. arXiv preprint arXiv:2308.04371, 2024.
- [32] Weihao Yu, Zihang Jiang, Yanfei Dong, and Jiashi Feng. Reclor: A reading comprehension dataset requiring logical reasoning. arXiv preprint arXiv:2002.04326, 2020.
- [33] Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:15476–15488, 2022.
- [34] Yizhou Zhang, Lun Du, Defu Cao, Qiang Fu, and Yan Liu. Guiding large language models with divide-and-conquer program for discerning problem solving. arXiv preprint arXiv:2402.05359, 2024.
- [35] Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- [36] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910, 2022.
Appendix A More Details of Main Results
In Table 1, we present the experimental results of integrating LoT with various prompting methods. Table 3 and 4 further provide detailed results including standard deviations using GPT-3.5-turbo and GPT-4, respectively. The results demonstrate the effectiveness of our LoT.
| Method | GPT-3.5-turbo | ||||
| ReClor | LogiQA | RuleTaker | ProofWriter | FOLIO | |
| Direct | 46.202.68 | 34.601.83 | 58.802.58 | 54.502.35 | 74.202.14 |
| CoT | 52.174.56 | 34.001.50 | 60.702.69 | 58.802.06 | 78.003.85 |
| SC(5) | 56.520.00 | 36.600.00 | 59.000.00 | 57.500.00 | 76.000.00 |
| CoT-SC(5) | 58.700.00 | 34.500.00 | 65.500.00 | 61.500.00 | 80.000.00 |
| LoT | 56.023.20 | 35.301.44 | 61.401.07 | 59.502.12 | 75.002.83 |
| LoT + CoT | 56.522.71 | 36.501.92 | 61.601.53 | 61.501.21 | 78.002.15 |
| LoT + SC(5) | 58.700.00 | 38.000.00 | 60.000.00 | 60.000.00 | 78.600.00 |
| LoT + CoT-SC(5) | 60.870.00 | 39.500.00 | 65.500.00 | 67.500.00 | 83.000.00 |
| Method | GPT-4 | ||||
| ReClor | LogiQA | RuleTaker | ProofWriter | FOLIO | |
| Direct | 74.202.14 | 72.172.24 | 54.800.93 | 62.601.02 | 64.701.21 |
| CoT | 77.392.94 | 55.401.88 | 62.401.43 | 75.901.24 | 84.401.85 |
| SC(5) | 73.910.00 | 55.500.00 | 65.500.00 | 67.500.00 | 85.000.00 |
| CoT-SC(5) | 80.430.00 | 56.500.00 | 63.500.00 | 80.500.00 | 84.000.00 |
| LoT | 77.983.88 | 57.601.22 | 65.300.51 | 66.701.50 | 86.001.26 |
| LoT + CoT | 79.133.98 | 57.501.05 | 65.601.24 | 76.802.11 | 84.800.40 |
| LoT + SC(5) | 80.430.00 | 58.500.00 | 64.500.00 | 66.000.00 | 88.000.00 |
| LoT + CoT-SC(5) | 82.610.00 | 61.000.00 | 66.500.00 | 80.500.00 | 86.000.00 |
Appendix B Comparative Study of States in ToT and LoT+ToT
We present a comprehensive analysis of an illustrative example, comparing the exploration of states when utilizing ToT and LoT+ToT. In Figure 6, we can observe that in LoT+ToT, LoT generates the logical description "If things are rough, then things are round", from which ToT further generates 4 successful states. The corresponding premises are: (1)"If Charlie is round, then Charlie is young and nice", (2)"Charlie is not young", (3)"If Charlie is quiet and round, then Charlie is young", (4)"If Charlie is round and rough, then Charlie is white". Subsequently, the generated information by the LoT and ToT serves as an enhancement to the input prompt, enabling LLMs to produce correct results. Compared to using ToT alone, the logical description generated by LoT enables ToT to generate an additional four successful states, which leads to the correct results. This indicates that LoT enhances the total number of states as well as the number of successful states, thereby expanding the reasoning space and improving the accuracy of ToT reasoning.

Appendix C An Error Case of LoT
Figure 7 illustrates an instance of inaccuracies in extracting logical information during the Logic Extraction process, leading to erroneous logical expressions and errors in the final outcome. When LoT selects sentences with logical relationships, there are biases in the information extracted by LLMs. The sentences "Today is Easter, but Cindy’s hair is still braided", "Cindy’s hair is braided, which means it must be a special occasion", and "If it’s a holiday, Cindy will most likely have her hair braided" all exhibit inaccuracies. Subsequently, extracted logical expressions, such as , , exhibit errors. These accumulated errors result in erroneous generated logical descriptions and incorrect final outcomes.

Appendix D An Example of Overlap Capabilities between CoT and LoT
The following example illustrates the overlap in capabilities between CoT and LoT. In the example, LoT first extracts propositions , , and from the context and identifies the relationships and . Then, it extends to a new expression . This new expression is translated into additional logical information "If a person reads a book, that person becomes smarter". This logical information directly links "Harry read the book" and "become smarter" in the context, helping LLMs correctly infer the answer. CoT’s reasoning process involves first deriving proposition from proposition based on the second sentence, then deriving proposition from proposition based on the third sentence, ultimately arriving at the answer. We can see that both CoT and LoT handle this problem by linking conditional statements and reasoning step by step, indicating that CoT and LoT sometimes have overlapping capabilities.