DriveDreamer4D: World Models Are Effective Data Machines
for 4D Driving Scene Representation
Abstract
Closed-loop simulation is essential for advancing end-to-end autonomous driving systems. Contemporary sensor simulation methods, such as NeRF and 3DGS, rely predominantly on conditions closely aligned with training data distributions, which are largely confined to forward-driving scenarios. Consequently, these methods face limitations when rendering complex maneuvers (e.g., lane change, acceleration, deceleration). Recent advancements in autonomous-driving world models have demonstrated the potential to generate diverse driving videos. However, these approaches remain constrained to 2D video generation, inherently lacking the spatiotemporal coherence required to capture intricacies of dynamic driving environments. In this paper, we introduce DriveDreamer4D, which enhances 4D driving scene representation leveraging world model priors. Specifically, we utilize the world model as a data machine to synthesize novel trajectory videos based on real-world driving data. Notably, we explicitly leverage structured conditions to control the spatial-temporal consistency of foreground and background elements, thus the generated data adheres closely to traffic constraints. To our knowledge, DriveDreamer4D is the first to utilize video generation models for improving 4D reconstruction in driving scenarios. Experimental results reveal that DriveDreamer4D significantly enhances generation quality under novel trajectory views, achieving a relative improvement in FID by 24.5%, 39.0%, and 10.5% compared to PVG, Gaussian, and Deformable-GS. Moreover, DriveDreamer4D markedly enhances the spatiotemporal coherence of driving agents, which is verified by a comprehensive user study and the relative increases of 20.3%, 42.0%, and 13.7% in the NTA-IoU metric.
![[Uncaptioned image]](x1.png)
1 Introduction
End-to-end planning [24, 25, 28], which directly maps sensor inputs to control signals, is among the most critical and promising tasks in autonomous driving. However, current open-loop evaluations are inadequate for accurately assessing end-to-end planning algorithms, highlighting an urgent need for enhanced evaluation methods [36, 75]. A compelling solution lies in closed-loop evaluations within real-world scenarios, which require retrieving sensor data from arbitrarily specified viewpoints. This necessitates constructing a 4D driving scene representation capable of reconstructing complex, dynamic driving environments.
Closed-loop simulation in driving environments predominantly relies on scene reconstruction techniques such as Neural Radiance Fields (NeRF) [41, 66, 68, 16] and 3D Gaussian Splatting (3DGS) [30, 65, 26, 10], which are inherently limited by the density of input data. Specifically, these methods can render scenes effectively only under conditions closely aligned with their training data distributions—primarily forward-driving scenarios—and struggle to perform accurately during complex maneuvers (see Fig. 1). To mitigate these limitations, methods like SGD [73] and GGS [18] leverage generative models to extend the range of training viewpoints. However, these approaches primarily supplement sparse image data or static background elements, falling short of modeling the intricacies of dynamic, interactive driving scenes. Recently, advancements in autonomous driving world models [57, 76, 58, 23, 59, 14] have introduced the capability to generate diverse, command-aligned video viewpoints, offering renewed promise for closed-loop simulation in autonomous driving. Nonetheless, these models remain constrained to 2D videos, lacking the spatial-temporal coherence essential for accurately modeling complex driving scenarios.
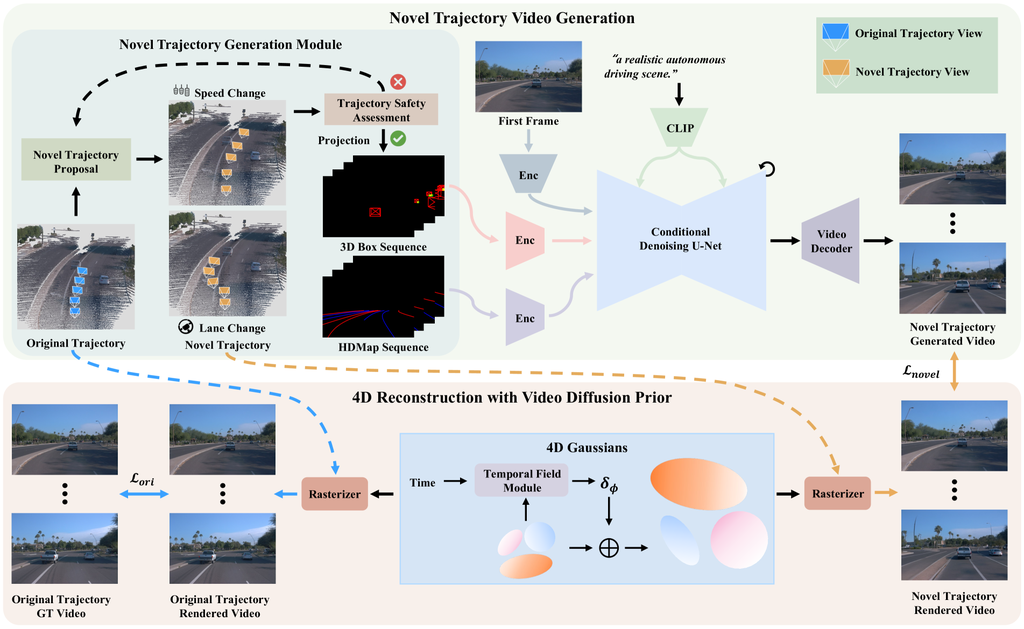
In this paper, we introduce DriveDreamer4D, which improves 4D driving scene representation by integrating priors from autonomous driving world models. Our approach utilizes an autonomous driving world model [57, 76] as a generative engine, synthesizing novel trajectory video data that densifies real-world driving datasets for enhanced training. Notably, we propose the Novel Trajectory Generation Module (NTGM) to generate diverse structured traffic conditions, and DriveDreamer4D applies these conditions to independently regulate the motion dynamics of foreground and background elements in complex driving environments. These conditions undergo view projection synchronized with vehicle maneuvers, ensuring that the synthesized data rigorously adheres to the spatiotemporal constraints of 4D driving scenarios. To the best of our knowledge, DriveDreamer4D is the first framework to harness video generation models for elevating 4D scene reconstruction quality in autonomous driving, providing richly varied viewpoint data for scenarios including lane change, acceleration, and deceleration. As shown in Fig. 1, experiment results demonstrate that DriveDreamer4D significantly enhances generation fidelity for novel trajectory viewpoints, achieving a relative improvement in FID by 24.5%, 39.0%, and 10.5% compared to PVG [8], Gaussian [26], and Deformable-GS [69]. Besides, DriveDreamer4D fortifies the spatiotemporal coherence between foreground and background elements, with respective increases of 20.3%, 42.0%, and 13.7% in the NTA-IoU metric. Furthermore, a comprehensive user study confirms that the average win rate of DriveDreamer4D exceeds 80%, compared to three baselines.
The primary contributions of this work are as follows: (1) We present DriveDreamer4D, the first framework to leverage world model priors for advancing 4D scene reconstruction in autonomous driving. (2) The NTGM is proposed to automate the generation of diverse structured conditions, enabling DriveDreamer4D to produce novel trajectory videos with complex maneuvers. By explicitly incorporating structured conditions, DriveDreamer4D ensures spatial-temporal consistency across both foreground and background elements. (3) We perform comprehensive experiments to validate that DriveDreamer4D notably enhances generation quality across novel trajectory viewpoints, as well as the spatiotemporal coherence of driving scene elements.
2 Related Work
2.1 Driving Scene Representation
NeRF and 3DGS have emerged as leading approaches for 3D scene representation. NeRF models [41, 2, 3, 42] continuous volumetric scenes using multi-layer perceptron (MLP) networks, enabling highly detailed scene reconstructions with remarkable rendering quality. More recently, 3DGS [30, 72] introduces an innovative method by defining a set of anisotropic Gaussians in 3D space, leveraging adaptive density control to achieve high-quality renderings from sparse point cloud inputs. Several works have extended NeRF [68, 66, 27, 39, 48, 54, 16] or 3DGS [65, 77, 8, 73, 26, 10] to autonomous driving scenarios. Given the dynamic nature of driving environments, there has also been significant effort in modeling 4D driving scene representations. Some approaches encode time as an additional input to parameterize 4D scenes [1, 11, 35, 38, 44, 52, 26], while others represent scenes as a composition of moving object models alongside a static background model [68, 33, 43, 55, 61, 63]. Despite these advancements, methods based on NeRF and 3DGS face limitations tied to the density of input data. These techniques can only render scenes effectively when sensor data closely matches the training data distribution, which is typically confined to forward-driving scenarios.
2.2 World Models
The world model module predicts possible future world states as a function of imagined action sequences proposed by the actor [34, 78]. Approaches such as [58, 64, 74, 15, 17, 4, 20, 40, 21, 5, 32, 70, 22, 62] simulate environments through video generation controlled by free-text actions. At the forefront of this evolution is Sora [6], which leverages advanced generative techniques to produce intricate visual sequences that respect the fundamental laws of physics. This ability to deeply understand and simulate the environment not only improves video generation quality but also has substantial implications for real-world driving scenarios. Autonomous driving world models [57, 76, 59, 23, 14, 67] employ predictive methodologies to interpret driving environments, thereby generating realistic driving scenarios and learning key driving elements and policies from video data. Although these models successfully produce diverse driving video data conditioned on complex driving actions, they remain limited to 2D outputs and lack the spatial-temporal coherence needed to accurately capture the complexities of dynamic driving environments.
2.3 Diffusion Prior for 3D Representation
Constructing comprehensive 3D scenes from limited observations demands generative prior, particularly for unseen areas. Earlier studies distill the knowledge from text-to-image diffusion models [49, 45, 50, 47] into a 3D representation model. Specifically, the Score Distillation Sampling (SDS) [46, 37, 60] is adopted to synthesize a 3D object from the text prompt. Furthermore, to enhance 3D consistency, several approaches extend the multi-view diffusion models [51, 13] and video diffusion models [4, 56, 9] to 3D scene generation. To extend the diffusion prior to complex, dynamic, large-scale driving scenes for 3D reconstruction, methods such as SGD [73], GGS [18] and MagicDrive3D [12] employ generative models to broaden the range of training viewpoints. Nonetheless, these approaches mainly address sparse image data or static background elements, lacking the capacity to fully capture the complexities inherent in the 4D driving environments.
3 Method
In this section, we first elaborate on the preliminaries of 4D driving scene representation and world models for driving video generation. Then we present the details of DriveDreamer4D, which enhances 4D driving scene representation leveraging priors from driving world models.
3.1 Preliminary
3.1.1 4D Driving Scene Representation
4DGS models the driving scene with a collection of 3DGS and a temporal field module. Each 3DGS [30] is parameterized by its center position , opacity , covariance , and view-dependent RGB color , controlled via spherical harmonics. For stability, each covariance matrix is decomposed by:
| (1) |
where scaling matrix and a rotation matrix are learnable parameters, represented by scaling and quaternion . All trainable parameters of a single 3D Gaussian are collectively denoted as . The temporal field takes and a time step as input, outputting the offset for each Gaussian relative to canonical space. The 4D Gaussian is then computed by:
| (2) |
Following [71], a differentiable Gaussian Splatting renderer is employed to project 4D Gaussians into camera coordinates, yielding the covariance matrix , where is the Jacobian matrix of the perspective projection, and is the transform matrix. The color of each pixel is calculated by ordered points using -blending:
| (3) |
where is the transmittance defined by , denotes the color of each point, is given by evaluating a 2D Gaussian with covariance multiplied with a learned per-point opacity . The trainable parameters can be optimized by a combination of RGB loss, depth loss and SSIM loss:
| (4) | ||||
where and represent the rendered image and the ground truth image. and are the rendered depth and the ground truth LiDAR depth map. refers to the operation of the Structural Similarity Index Measure, and are the loss weights.
3.1.2 World Models for Controllable Driving Video Generation
The world model module predicts possible future world states based on imagined action sequences [34]. Autonomous-driving world models [57, 76, 59, 14], typically based on diffusion models, leverage structured driving information or action controls to guide future video prediction. During training, these models first encode videos into a lower-dimensional latent space using a variational encoder . After adding noise to the latent, the diffusion model learns a denoising process. This diffusion process is optimized by:
| (5) |
where is a parameterized denoising network, denotes the time step, representing the level of noise added or removed at each stage. Additionally, to improve the controllability of the generated data, conditional features (e.g., reference images, speed, steering angle, scene layouts, camera poses and textual information) can be introduced into the reverse diffusion process, ensuring that the generated outputs adhere to the input control signals. During inference, the world models can be conditioned on a reference image to control the style of the output scene, while predicting the future world states contingent upon the other input actions.
3.2 DriveDreamer4D
The overall pipeline of DriveDreamer4D is depicted in Fig. 2. In the upper part, the Novel Trajectory Generation Module (NTGM) is proposed to adjust original trajectory actions such as steering angle and speed to generate new trajectories. These novel trajectories provide fresh perspectives for extracting structured information like 3D boxes and HDMap details. Subsequently, a controllable video diffusion model synthesizes videos from these updated viewpoints, incorporating specific priors associated with the modified trajectories. In the lower part, both original and novel trajectory videos are integrated to optimize the 4DGS model. In the following sections, we delve into the details of novel trajectories video generation and then introduce 4D reconstruction with video diffusion priors.
3.2.1 Novel Trajectory Video Generation
As previously mentioned, traditional 4DGS methods are limited in rendering complex maneuvers, largely due to the training data being dominated by straightforward driving scenarios. To overcome this, DriveDreamer4D leverages world models priors to generate diverse viewpoint data, enhancing the 4D scene representation. To achieve this, we propose the NTGM, which is designed to create new trajectories that serve as input for the world model, enabling the automated generation of complex maneuver data. NTGM comprises two main components: (1) novel trajectory proposal, (2) trajectory safety assessment. In the novel trajectory proposal stage, text-to-trajectory [76] can be adopted to automatically generate diverse complex trajectories. Additionally, trajectories can be custom-designed to meet specific requirements, allowing for tailored data generation based on precise needs. The overview of the custom-designed trajectory proposal (e.g., lane change) and trajectory safety assessment is shown in the Algo. 1. In a specific driving scenario, the original trajectory in the world coordinate system can be readily acquired as , where denotes the number of frames and refers to the position of the ego-vehicle at the -th frame. To propose novel trajectories, the original trajectory is transformed into the ego-vehicle coordinate system of the first frame, denoted as and computed as:
| (6) |
where represents the transformation matrix from the ego-vehicle coordinate system of the first frame to the world coordinate system, denotes the operation of the concat. In the ego-vehicle coordinate system, the vehicle’s heading is aligned with the positive -axis, the -axis points to the left side of the vehicle, and the -axis is oriented vertically upwards, perpendicular to the plane of the vehicle. Consequently, changes in the vehicle’s velocity and direction can be respectively represented by adjusting the value along the -axis and -axis. A final safety assessment is conducted for the newly generated trajectory points, which includes verifying whether the vehicle trajectories remain within drivable areas and ensuring that no collisions occur with pedestrians or other vehicles .
| (7) |
where is the minimal distance between different agents. Once a novel trajectory that complies with traffic regulations is generated, the road structure and 3D bounding boxes can be projected onto the camera view from the perspective of the new trajectory, thereby generating structured information relative to the updated trajectory. This structured information, along with the initial frame and text, is fed into a world model [76] to produce the videos that follow the novel trajectories.
3.2.2 4D Reconstruction with Video Diffusion Prior
Based on the video diffusion prior, we can generate novel videos with diverse trajectories, enhancing the 4D reconstruction capabilities across different baselines [8, 26, 69]. Specifically, to train the 4DGS with video diffusion prior, it is essential to construct a hybrid dataset , which combines the original trajectory dataset with the novel trajectory dataset . The balance between these datasets can be adjusted through the hyper-parameter , allowing us to control the 4DGS scene reconstruction performance for both original and novel trajectories. This relationship is formulated as . The loss function for optimizing the 4DGS with generated data is akin to [8, 26], defined as follows:
| (8) | ||||
where represents the generated images corresponding to the novel trajectories as described in Sec. 3.2.1, and denotes the rendered images under the novel trajectories via differentiable splatting [71]. Notably, different from [8, 26], depth maps are not employed as constraints in the optimization of 4DGS when using the generated dataset . The limitation arises from the fact that LiDAR point cloud data is exclusively collected for the original trajectory. When these LiDAR points are projected onto a new trajectory, it cannot produce a complete depth map for the new perspective, as something visible in the novel trajectory may have been occluded in the original view. Consequently, the incorporation of such depth maps does not facilitate the optimization of the 4DGS model. The more details are described in Sec. 4.3. The overall loss function for mixed training is defined as follows:
| (9) |
| Method | Lane Change | Acceleration | Deceleration | Average | ||||
| NTA-IoU | NTL-IoU | NTA-IoU | NTL-IoU | NTA-IoU | NTL-IoU | NTA-IoU | NTL-IoU | |
| PVG [8] | 0.256 | 50.70 | 0.396 | 53.08 | 0.394 | 53.65 | 0.349 | 52.48 |
| DriveDreamer4D with PVG | 0.428 | 53.00 | 0.411 | 53.10 | 0.421 | 53.78 | 0.420 | 53.29 |
| Gaussian [26] | 0.175 | 49.05 | 0.434 | 51.93 | 0.384 | 52.14 | 0.331 | 51.04 |
| DriveDreamer4D with Gaussian | 0.491 | 53.36 | 0.474 | 52.60 | 0.445 | 52.57 | 0.470 | 52.84 |
| Deformable-GS [69] | 0.240 | 51.62 | 0.346 | 52.17 | 0.377 | 53.21 | 0.321 | 52.33 |
| DriveDreamer4D with Deformable-GS | 0.322 | 52.90 | 0.370 | 52.50 | 0.404 | 53.79 | 0.365 | 53.06 |
4 Experiments
In this section, we first outline the experimental setup, detailing the dataset, implementation details, and evaluation metrics. We then provide both quantitative and qualitative evidence demonstrating that the proposed DriveDreamer4D significantly enhances generation quality for novel trajectory viewpoints and improves the spatiotemporal coherence of foreground and background components.
4.1 Experiment Setup
Dataset. We conduct experiments using the Waymo dataset [53], known for its comprehensive real-world driving logs. However, most logs capture scenes with relatively straightforward dynamics, lacking focus on scenarios with dense, complex vehicle interactions. To address this gap, we specifically select eight scenes characterized by highly dynamic interactions, featuring numerous vehicles with diverse relative positions and intricate driving trajectories. Each selected segment contains approximately 40 frames, with segment IDs detailed in the supplement.
Implementation Details. To demonstrate the versatility and robustness of DriveDreamer4D, we incorporate various 4DGS baselines into our pipeline, including Deformable-GS [69], Gaussian [26], and PVG [8]. For a fair comparison, LiDAR supervision is introduced to Deformable-GS. During training, scenes are segmented into multiple clips, each containing 40 frames, aligned with the generative model’s output length. We use only forward-facing camera data and standardize the resolution across methods to . Our model is trained for 50,000 iterations using the Adam optimizer [31], following the learning rate schedule used for 3D Gaussian Splatting. Training strategies and hyperparameters align with each baseline’s original setup, with each model trained for 50,000 iterations.
Metrics. Traditional 3D reconstruction tasks typically employ PSNR and SSIM metrics for evaluation, with validation sets that closely match the training data distribution (i.e., uniformly sampling frames from video sequences for validation, with the remainder used for training). However, in closed-loop driving simulation, the focus shifts to evaluating model rendering performance under novel trajectories, where corresponding sensor data are unavailable, making metrics like PSNR and SSIM inapplicable for evaluation. Therefore, we propose Novel Trajectory Agent IoU (NTA-IoU) and Novel Trajectory Lane IoU (NTL-IoU), which assess the spatiotemporal coherence of foreground and background traffic components in novel trajectory viewpoints.
| Method | FID |
| PVG | 105.29 |
| DriveDreamer4D with PVG | 79.54 |
| Gaussian | 124.90 |
| DriveDreamer4D with Gaussian | 76.24 |
| Deformable-GS | 92.34 |
| DriveDreamer4D with Deformable-GS | 82.67 |
For NTA-IoU, we use YOLO11 [29] to identify vehicles in images rendered from novel trajectory views, yielding 2D bounding boxes. Simultaneously, geometric transformations are applied to the original 3D bounding boxes, projecting them onto the new viewpoints to generate corresponding 2D bounding boxes. For each projected 2D box, we then identify the closest detector-generated 2D box and compute their Intersection over Union (IoU). To ensure accurate matching, a distance threshold is introduced: when the center-to-center distance between the nearest detected box and the correctly projected box surpasses this threshold, their NTA-IoU is assigned a value of zero:
| (10) |
For NTL-IoU, we employ TwinLiteNet [7] to extract 2D lanes from rendered images. Ground truth lanes are also projected onto the 2D image plane. We then compute the mean Intersection-over-Union (mIoU) between the rendered and ground truth lanes and :
| (11) |

Additionally, in lane change scenarios, we observe inaccuracies in relative positioning, as well as frequent occurrences of artifacts such as flying points and ghosting, which notably degrade image quality. To assess this, we employ the FID metric [19], which quantifies differences in feature distribution between rendered novel trajectory images and original trajectory images. This metric effectively reflects visual quality and is particularly sensitive to artifacts like flying points and ghosting, providing a robust measure of image fidelity in these complex scenes. Finally, we conduct a user study to evaluate the generation quality. Specifically, we compare the visual results of each baseline method with its DriveDreamer4D enhanced version across three distinct novel trajectories. The evaluation criteria focus on overall video quality, with particular attention to foreground objects like vehicles. For each comparison, participants were asked to select the option they found most favorable. Further details are provided in the supplement.

4.2 Comparison with Different 4DGS Baselines
Quantitative Results. As demonstrated in Tab. 1, integrating DriveDreamer4D with different 4DGS algorithms consistently yields superior NTA-IoU and NTL-IoU scores across diverse, complex maneuvers (e.g., lane changes, acceleration, and deceleration), significantly outperforming the baseline methods. Specifically, with DriveDreamer4D, the average NTL-IoU scores across three baselines (PVG [8], Gaussian [26], Deformable-GS [69]) are relatively enhanced by 1.5%, 3.5%, and 1.4%, underscoring DriveDreamer4D’s capability to significantly improve the spatiotemporal coherence of background lanes. Moreover, rendering dynamic foreground agents in intricate driving scenarios presents substantial challenges. However, DriveDreamer4D facilitates a relative improvement in average NTA-IoU for these baselines by 20.3%, 42.0%, and 13.7%, thereby markedly enhancing the spatiotemporal coherence of foreground agents in 4D rendering of driving scenarios.
In addition to verifying the spatiotemporal consistency of rendered novel trajectory views, we leverage the FID metric to assess rendering quality under novel trajectories. Given that acceleration and deceleration scenarios yield rendered views with distributional similarities to ground truth, limiting FID’s discriminative capability across algorithms, our FID comparisons focus specifically on lane change scenarios. Experiment results, as presented in Tab. 2, indicate that our method substantially outperforms the baseline methods (PVG [8], Gaussian [26], Deformable-GS [69]), with FID relative improvements of 24.5%, 39.0%, and 10.5%. These results highlight DriveDreamer4D’s capability to enhance generation quality for novel trajectory viewpoints.
Finally, we conducted a user study to evaluate the rendering quality of different methods on novel trajectories, with a specific focus on foreground agents. For each method, we generated three novel trajectory views—lane change, acceleration, and deceleration—across eight scenes from the Waymo dataset. Participants were then asked to select the renderings they found most visually favorable in each comparison. The DriveDreamer4D win rates from this study, shown in Tab. 3, reveal a significant user preference for our method’s renderings.
| Counterpart Method | DriveDreamer4D Win Rate | |||
| Lane Change | Acceleration | Deceleration | Average | |
| PVG [8] | 100.0% | 85.7% | 79.4% | 88.6% |
| Gaussian [26] | 100.0% | 96.9% | 90.6% | 95.8% |
| Deformable-GS [69] | 93.8% | 81.2% | 65.6% | 80.2% |
Qualitative Results. In addition to quantitative comparisons, we provide a qualitative analysis of novel trajectory view renderings, as shown in Fig. 3, focusing on speed change scenarios. Our method significantly enhances the positional accuracy of foreground vehicles and background elements under acceleration viewpoints. Specifically, baseline algorithm results (PVG [8], Gaussian [26], Deformable-GS [69]) are displayed in rows 1, 3, and 5. It is clear that the baseline methods struggle with perspective synthesis under acceleration, leading to inaccurate positional shifts of surrounding vehicles during ego-car acceleration. In contrast, with the integration of DriveDreamer4D, the 4DGS algorithms achieve both enhanced spatial consistency and noticeably improved rendering quality. Especially noticeable in the last frame (rightmost column of Fig. 3), the baseline algorithms lead to blurring or disappearance of foreground vehicles. In contrast, our method significantly improves image rendering quality, as highlighted by the orange boxes. In Fig. 4, we present the novel trajectory view synthesis during lane change. Images rendered by the baseline algorithms exhibit issues where foreground vehicles incorrectly change lanes in sync with the camera’s motion, and some vehicles are incompletely rendered. Additionally, the background is filled with speckles and ghosting. Especially shown in the last frame (rightmost column of Fig. 4), baseline algorithms often produce blurred, ghosted foreground vehicles and background speckles in the sky, alongside blurred lane markings. Our method, however, significantly improves rendering quality, as highlighted by the orange boxes. Vehicle contours are sharper, and background artifacts such as speckles and ghosting are substantially reduced.
4.3 Ablation Studies
We conduct an ablation study based on PVG [8] to determine the optimal mixing ratio for combining real and synthetic data. As shown in Tab. 5, our results indicate that increasing the proportion of generated data () significantly improves both NTA-IoU and FID metrics compared to using only real data (). To balance the FID and NTA-IoU metrics, we ultimately selected . Additionally, an ablation study is performed to identify the appropriate training loss weight for the novel trajectory view. Results presented in Tab. 5 demonstrate that incorporating the loss for the novel trajectory view while optimizing 4DGS algorithms effectively enhances the NTA-IoU and FID metrics. Taking into account the balance between the FID and NTA-IoU scores, the is set to 1. Finally, as shown in Table 6, the experiment confirms that the depth loss should not be included when optimizing novel trajectory views, since LiDAR depth maps are incomplete due to occlusions.
| NTA-IoU | FID | |
| 0 | 0.351 | 105.29 |
| 0.2 | 0.413 | 82.37 |
| 0.3 | 0.417 | 80.68 |
| 0.4 | 0.420 | 79.54 |
| 0.5 | 0.425 | 83.19 |
| NTA-IoU | FID | |
| 0 | 0.351 | 105.29 |
| 0.5 | 0.405 | 82.84 |
| 0.7 | 0.411 | 80.61 |
| 1 | 0.420 | 79.54 |
| 1.5 | 0.417 | 82.10 |
| depth loss | NTA-IoU | FID |
| 0.401 | 82.63 | |
| 0.420 | 79.54 |
5 Discussion and Conclusion
In this paper, we presented DriveDreamer4D, a novel framework designed to advance 4D driving scene representations by harnessing priors from world models. Addressing key limitations of current sensor simulation methods—namely, their dependence on forward-driving training data distributions and inability to model complex maneuvers—DriveDreamer4D leverages a world model to generate novel trajectory videos that complement real-world driving data. By explicitly employing structured conditions, our framework maintains spatial-temporal consistency across foreground and background elements, ensuring that generated data adheres closely to the dynamics of real-world traffic scenarios. Our experiments demonstrate that DriveDreamer4D achieves superior quality in generating diverse simulation viewpoints, with significant improvements in both the rendering fidelity and spatiotemporal coherence of scene components. Notably, these results highlight DriveDreamer4D’s potential as a foundation for closed-loop simulations that require high-fidelity reconstructions of dynamic driving scenes.
Acknowledgments
The authors would like to thank Chen Liu, Yuyin Chen, Kun Zhan, Peng Jia, Yifei Zhan, and Fu Liu at Li Auto Inc. for the fruitful discussions, related implementation, and the contributed computational resources for this work.
References
- [1] Benjamin Attal, Jia-Bin Huang, Christian Richardt, Michael Zollhoefer, Johannes Kopf, Matthew O’Toole, and Changil Kim. Hyperreel: High-fidelity 6-dof video with ray-conditioned sampling. In CVPR, 2023.
- [2] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In CVPR, 2022.
- [3] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid-based neural radiance fields. In ICCV, 2023.
- [4] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
- [5] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In CVPR, 2023.
- [6] Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024.
- [7] Quang-Huy Che, Dinh-Phuc Nguyen, Minh-Quan Pham, and Duc-Khai Lam. Twinlitenet: An efficient and lightweight model for driveable area and lane segmentation in self-driving cars. In MAPR, 2023.
- [8] Yurui Chen, Chun Gu, Junzhe Jiang, Xiatian Zhu, and Li Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering. arXiv preprint arXiv:2311.18561, 2023.
- [9] Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, and Huaping Liu. V3d: Video diffusion models are effective 3d generators. arXiv preprint arXiv:2403.06738, 2024.
- [10] Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. Omnire: Omni urban scene reconstruction. arXiv preprint arXiv:2408.16760, 2024.
- [11] Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. In CVPR, 2023.
- [12] Ruiyuan Gao, Kai Chen, Zhihao Li, Lanqing Hong, Zhenguo Li, and Qiang Xu. Magicdrive3d: Controllable 3d generation for any-view rendering in street scenes. arXiv preprint arXiv:2405.14475, 2024.
- [13] Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314, 2024.
- [14] Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. arXiv preprint arXiv:2405.17398, 2024.
- [15] Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023.
- [16] Jianfei Guo, Nianchen Deng, Xinyang Li, Yeqi Bai, Botian Shi, Chiyu Wang, Chenjing Ding, Dongliang Wang, and Yikang Li. Streetsurf: Extending multi-view implicit surface reconstruction to street views. arXiv preprint arXiv:2306.04988, 2023.
- [17] Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Li Fei-Fei, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. arXiv preprint arXiv:2312.06662, 2023.
- [18] Huasong Han, Kaixuan Zhou, Xiaoxiao Long, Yusen Wang, and Chunxia Xiao. Ggs: Generalizable gaussian splatting for lane switching in autonomous driving. arXiv preprint arXiv:2409.02382, 2024.
- [19] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS, 2017.
- [20] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022.
- [21] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. NeurIPS, 2022.
- [22] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
- [23] Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023.
- [24] Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In ECCV, 2022.
- [25] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In CVPR, 2023.
- [26] Nan Huang, Xiaobao Wei, Wenzhao Zheng, Pengju An, Ming Lu, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. gaussian: Self-supervised street gaussians for autonomous driving. arXiv preprint arXiv:2405.20323, 2024.
- [27] Muhammad Zubair Irshad, Sergey Zakharov, Katherine Liu, Vitor Guizilini, Thomas Kollar, Adrien Gaidon, Zsolt Kira, and Rares Ambrus. Neo 360: Neural fields for sparse view synthesis of outdoor scenes. In ICCV, 2023.
- [28] Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. In ICCV, 2023.
- [29] Glenn Jocher and Jing Qiu. Ultralytics yolo11, 2024.
- [30] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM ToG, 2023.
- [31] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [32] Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, et al. Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125, 2023.
- [33] Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Caroline Pantofaru, Leonidas J Guibas, Andrea Tagliasacchi, Frank Dellaert, and Thomas Funkhouser. Panoptic neural fields: A semantic object-aware neural scene representation. In CVPR, pages 12871–12881, 2022.
- [34] Yann LeCun and Courant. A path towards autonomous machine intelligence version 0.9.2, 2022-06-27. 2022.
- [35] Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. In CVPR, 2021.
- [36] Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? In CVPR, 2024.
- [37] Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In CVPR, 2023.
- [38] Haotong Lin, Sida Peng, Zhen Xu, Yunzhi Yan, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Efficient neural radiance fields for interactive free-viewpoint video. In SIGGRAPH Asia, 2022.
- [39] Fan Lu, Yan Xu, Guang Chen, Hongsheng Li, Kwan-Yee Lin, and Changjun Jiang. Urban radiance field representation with deformable neural mesh primitives. In ICCV, 2023.
- [40] Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation. arXiv preprint arXiv:2401.03048, 2024.
- [41] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 2021.
- [42] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM ToG, 2022.
- [43] Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. Neural scene graphs for dynamic scenes. In CVPR, pages 2856–2865, 2021.
- [44] Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M Seitz. Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields. arXiv preprint arXiv:2106.13228, 2021.
- [45] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023.
- [46] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
- [47] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- [48] Konstantinos Rematas, Andrew Liu, Pratul P Srinivasan, Jonathan T Barron, Andrea Tagliasacchi, Thomas Funkhouser, and Vittorio Ferrari. Urban radiance fields. In CVPR, 2022.
- [49] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- [50] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS, 2022.
- [51] Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, et al. Zeronvs: Zero-shot 360-degree view synthesis from a single real image. arXiv preprint arXiv:2310.17994, 2023.
- [52] Liangchen Song, Anpei Chen, Zhong Li, Zhang Chen, Lele Chen, Junsong Yuan, Yi Xu, and Andreas Geiger. Nerfplayer: A streamable dynamic scene representation with decomposed neural radiance fields. IEEE Transactions on Visualization and Computer Graphics, 2023.
- [53] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. In CVPR, 2020.
- [54] Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. In CVPR, 2022.
- [55] Adam Tonderski, Carl Lindström, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. Neurad: Neural rendering for autonomous driving. In CVPR, 2024.
- [56] Vikram Voleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion. arXiv preprint arXiv:2403.12008, 2024.
- [57] Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-driven world models for autonomous driving. arXiv preprint arXiv:2309.09777, 2023.
- [58] Xiaofeng Wang, Zheng Zhu, Guan Huang, Boyuan Wang, Xinze Chen, and Jiwen Lu. Worlddreamer: Towards general world models for video generation via predicting masked tokens. arXiv preprint arXiv:2401.09985, 2024.
- [59] Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. In CVPR, 2024.
- [60] Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P Srinivasan, Dor Verbin, Jonathan T Barron, Ben Poole, et al. Reconfusion: 3d reconstruction with diffusion priors. In CVPR, 2024.
- [61] Zirui Wu, Tianyu Liu, Liyi Luo, Zhide Zhong, Jianteng Chen, Hongmin Xiao, Chao Hou, Haozhe Lou, Yuantao Chen, Runyi Yang, et al. Mars: An instance-aware, modular and realistic simulator for autonomous driving. In ICAI, 2023.
- [62] Jiannan Xiang, Guangyi Liu, Yi Gu, Qiyue Gao, Yuting Ning, Yuheng Zha, Zeyu Feng, Tianhua Tao, Shibo Hao, Yemin Shi, et al. Pandora: Towards general world model with natural language actions and video states. arXiv preprint arXiv:2406.09455, 2024.
- [63] Ziyang Xie, Junge Zhang, Wenye Li, Feihu Zhang, and Li Zhang. S-nerf: Neural radiance fields for street views. arXiv preprint arXiv:2303.00749, 2023.
- [64] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
- [65] Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians for modeling dynamic urban scenes. arXiv preprint arXiv:2401.01339, 2024.
- [66] Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision. arXiv preprint arXiv:2311.02077, 2023.
- [67] Xuemeng Yang, Licheng Wen, Yukai Ma, Jianbiao Mei, Xin Li, Tiantian Wei, Wenjie Lei, Daocheng Fu, Pinlong Cai, Min Dou, Botian Shi, Liang He, Yong Liu, and Yu Qiao. Drivearena: A closed-loop generative simulation platform for autonomous driving. arXiv preprint arXiv:2408.00415, 2024.
- [68] Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. In CVPR, 2023.
- [69] Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. In CVPR, 2024.
- [70] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024.
- [71] Wang Yifan, Felice Serena, Shihao Wu, Cengiz Öztireli, and Olga Sorkine-Hornung. Differentiable surface splatting for point-based geometry processing. ACM TOG, 2019.
- [72] Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splatting. In CVPR, 2024.
- [73] Zhongrui Yu, Haoran Wang, Jinze Yang, Hanzhang Wang, Zeke Xie, Yunfeng Cai, Jiale Cao, Zhong Ji, and Mingming Sun. Sgd: Street view synthesis with gaussian splatting and diffusion prior. arXiv preprint arXiv:2403.20079, 2024.
- [74] Yan Zeng, Guoqiang Wei, Jiani Zheng, Jiaxin Zou, Yang Wei, Yuchen Zhang, and Hang Li. Make pixels dance: High-dynamic video generation. arXiv preprint arXiv:2311.10982, 2023.
- [75] Jiang-Tian Zhai, Ze Feng, Jinhao Du, Yongqiang Mao, Jiang-Jiang Liu, Zichang Tan, Yifu Zhang, Xiaoqing Ye, and Jingdong Wang. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes. arXiv preprint arXiv:2305.10430, 2023.
- [76] Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. Drivedreamer-2: Llm-enhanced world models for diverse driving video generation. arXiv preprint arXiv:2403.06845, 2024.
- [77] Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. In CVPR, pages 21634–21643, 2024.
- [78] Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, et al. Is sora a world simulator? a comprehensive survey on general world models and beyond. arXiv preprint arXiv:2405.03520, 2024.