14There is a subtle difference in how we retrieve alignments
for the different alignment functions. At time step t in which
we receive yt-1 as input and then compute ht,at,ct, and
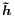 t before predicting yt, the alignment vector at is used
as alignment weights for (a) the predicted word yt in the
location-based alignment functions and (b) the input word yt-1
in the content-based functions.
t before predicting yt, the alignment vector at is used
as alignment weights for (a) the predicted word yt in the
location-based alignment functions and (b) the input word yt-1
in the content-based functions.