


Note
Click here to download the full example code
Text Classification with TorchText¶
This tutorial shows how to use the text classification datasets
in torchtext, including
- AG_NEWS,
- SogouNews,
- DBpedia,
- YelpReviewPolarity,
- YelpReviewFull,
- YahooAnswers,
- AmazonReviewPolarity,
- AmazonReviewFull
This example shows how to train a supervised learning algorithm for
classification using one of these TextClassification datasets.
Load data with ngrams¶
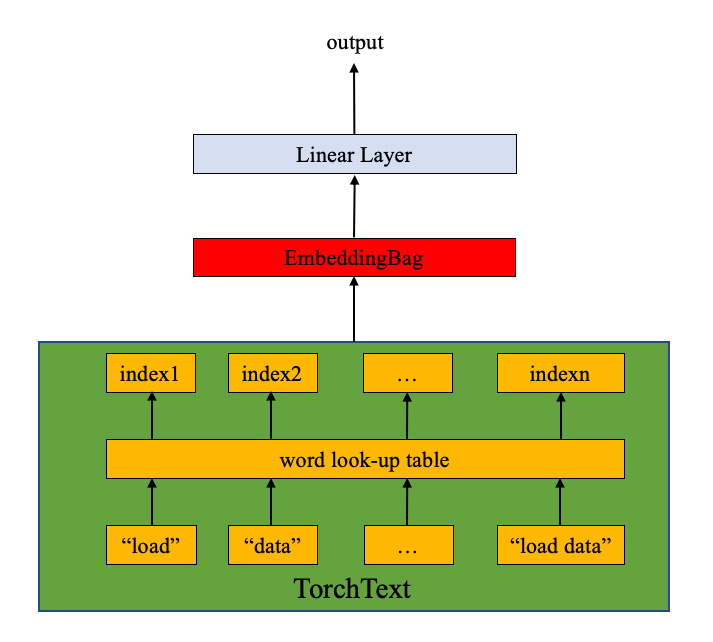
A bag of ngrams feature is applied to capture some partial information about the local word order. In practice, bi-gram or tri-gram are applied to provide more benefits as word groups than only one word. An example:
"load data with ngrams"
Bi-grams results: "load data", "data with", "with ngrams"
Tri-grams results: "load data with", "data with ngrams"
TextClassification Dataset supports the ngrams method. By setting
ngrams to 2, the example text in the dataset will be a list of single
words plus bi-grams string.
import torch
import torchtext
from torchtext.datasets import text_classification
NGRAMS = 2
import os
if not os.path.isdir('./.data'):
os.mkdir('./.data')
train_dataset, test_dataset = text_classification.DATASETS['AG_NEWS'](
root='./.data', ngrams=NGRAMS, vocab=None)
BATCH_SIZE = 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Define the model¶
The model is composed of the
EmbeddingBag
layer and the linear layer (see the figure below). nn.EmbeddingBag
computes the mean value of a “bag” of embeddings. The text entries here
have different lengths. nn.EmbeddingBag requires no padding here
since the text lengths are saved in offsets.
Additionally, since nn.EmbeddingBag accumulates the average across
the embeddings on the fly, nn.EmbeddingBag can enhance the
performance and memory efficiency to process a sequence of tensors.
import torch.nn as nn
import torch.nn.functional as F
class TextSentiment(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
Initiate an instance¶
The AG_NEWS dataset has four labels and therefore the number of classes is four.
1 : World
2 : Sports
3 : Business
4 : Sci/Tec
The vocab size is equal to the length of vocab (including single word and ngrams). The number of classes is equal to the number of labels, which is four in AG_NEWS case.
VOCAB_SIZE = len(train_dataset.get_vocab())
EMBED_DIM = 32
NUN_CLASS = len(train_dataset.get_labels())
model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device)
Functions used to generate batch¶
Since the text entries have different lengths, a custom function
generate_batch() is used to generate data batches and offsets. The
function is passed to collate_fn in torch.utils.data.DataLoader.
The input to collate_fn is a list of tensors with the size of
batch_size, and the collate_fn function packs them into a
mini-batch. Pay attention here and make sure that collate_fn is
declared as a top level def. This ensures that the function is available
in each worker.
The text entries in the original data batch input are packed into a list
and concatenated as a single tensor as the input of nn.EmbeddingBag.
The offsets is a tensor of delimiters to represent the beginning index
of the individual sequence in the text tensor. Label is a tensor saving
the labels of individual text entries.
def generate_batch(batch):
label = torch.tensor([entry[0] for entry in batch])
text = [entry[1] for entry in batch]
offsets = [0] + [len(entry) for entry in text]
# torch.Tensor.cumsum returns the cumulative sum
# of elements in the dimension dim.
# torch.Tensor([1.0, 2.0, 3.0]).cumsum(dim=0)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text = torch.cat(text)
return text, offsets, label
Define functions to train the model and evaluate results.¶
torch.utils.data.DataLoader
is recommended for PyTorch users, and it makes data loading in parallel
easily (a tutorial is
here).
We use DataLoader here to load AG_NEWS datasets and send it to the
model for training/validation.
from torch.utils.data import DataLoader
def train_func(sub_train_):
# Train the model
train_loss = 0
train_acc = 0
data = DataLoader(sub_train_, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=generate_batch)
for i, (text, offsets, cls) in enumerate(data):
optimizer.zero_grad()
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
output = model(text, offsets)
loss = criterion(output, cls)
train_loss += loss.item()
loss.backward()
optimizer.step()
train_acc += (output.argmax(1) == cls).sum().item()
# Adjust the learning rate
scheduler.step()
return train_loss / len(sub_train_), train_acc / len(sub_train_)
def test(data_):
loss = 0
acc = 0
data = DataLoader(data_, batch_size=BATCH_SIZE, collate_fn=generate_batch)
for text, offsets, cls in data:
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
with torch.no_grad():
output = model(text, offsets)
loss = criterion(output, cls)
loss += loss.item()
acc += (output.argmax(1) == cls).sum().item()
return loss / len(data_), acc / len(data_)
Split the dataset and run the model¶
Since the original AG_NEWS has no valid dataset, we split the training dataset into train/valid sets with a split ratio of 0.95 (train) and 0.05 (valid). Here we use torch.utils.data.dataset.random_split function in PyTorch core library.
CrossEntropyLoss criterion combines nn.LogSoftmax() and nn.NLLLoss() in a single class. It is useful when training a classification problem with C classes. SGD implements stochastic gradient descent method as optimizer. The initial learning rate is set to 4.0. StepLR is used here to adjust the learning rate through epochs.
import time
from torch.utils.data.dataset import random_split
N_EPOCHS = 5
min_valid_loss = float('inf')
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=4.0)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)
train_len = int(len(train_dataset) * 0.95)
sub_train_, sub_valid_ = \
random_split(train_dataset, [train_len, len(train_dataset) - train_len])
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train_func(sub_train_)
valid_loss, valid_acc = test(sub_valid_)
secs = int(time.time() - start_time)
mins = secs / 60
secs = secs % 60
print('Epoch: %d' %(epoch + 1), " | time in %d minutes, %d seconds" %(mins, secs))
print(f'\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)')
print(f'\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)')
Running the model on GPU with the following information:
Epoch: 1 | time in 0 minutes, 11 seconds
Loss: 0.0263(train) | Acc: 84.5%(train)
Loss: 0.0001(valid) | Acc: 89.0%(valid)
Epoch: 2 | time in 0 minutes, 10 seconds
Loss: 0.0119(train) | Acc: 93.6%(train)
Loss: 0.0000(valid) | Acc: 89.6%(valid)
Epoch: 3 | time in 0 minutes, 9 seconds
Loss: 0.0069(train) | Acc: 96.4%(train)
Loss: 0.0000(valid) | Acc: 90.5%(valid)
Epoch: 4 | time in 0 minutes, 11 seconds
Loss: 0.0038(train) | Acc: 98.2%(train)
Loss: 0.0000(valid) | Acc: 90.4%(valid)
Epoch: 5 | time in 0 minutes, 11 seconds
Loss: 0.0022(train) | Acc: 99.0%(train)
Loss: 0.0000(valid) | Acc: 91.0%(valid)
Evaluate the model with test dataset¶
print('Checking the results of test dataset...')
test_loss, test_acc = test(test_dataset)
print(f'\tLoss: {test_loss:.4f}(test)\t|\tAcc: {test_acc * 100:.1f}%(test)')
Checking the results of test dataset…
Loss: 0.0237(test) | Acc: 90.5%(test)
Test on a random news¶
Use the best model so far and test a golf news. The label information is available here.
import re
from torchtext.data.utils import ngrams_iterator
from torchtext.data.utils import get_tokenizer
ag_news_label = {1 : "World",
2 : "Sports",
3 : "Business",
4 : "Sci/Tec"}
def predict(text, model, vocab, ngrams):
tokenizer = get_tokenizer("basic_english")
with torch.no_grad():
text = torch.tensor([vocab[token]
for token in ngrams_iterator(tokenizer(text), ngrams)])
output = model(text, torch.tensor([0]))
return output.argmax(1).item() + 1
ex_text_str = "MEMPHIS, Tenn. – Four days ago, Jon Rahm was \
enduring the season’s worst weather conditions on Sunday at The \
Open on his way to a closing 75 at Royal Portrush, which \
considering the wind and the rain was a respectable showing. \
Thursday’s first round at the WGC-FedEx St. Jude Invitational \
was another story. With temperatures in the mid-80s and hardly any \
wind, the Spaniard was 13 strokes better in a flawless round. \
Thanks to his best putting performance on the PGA Tour, Rahm \
finished with an 8-under 62 for a three-stroke lead, which \
was even more impressive considering he’d never played the \
front nine at TPC Southwind."
vocab = train_dataset.get_vocab()
model = model.to("cpu")
print("This is a %s news" %ag_news_label[predict(ex_text_str, model, vocab, 2)])
This is a Sports news
You can find the code examples displayed in this note here.
Total running time of the script: ( 2 minutes 7.283 seconds)