Multiplex 的社区检测算法比较
摘要
Multiplex 是同一顶点集(即 )上的一组图。 它是一个广义图,用于对顶点之间具有平行边的多重关系进行建模。 本文对现有的 Multiplex 社区检测算法进行了文献综述并进行了比较分析。
PAC:
我简介
复杂性科学研究交互代理系统的集体行为,而图(网络)通常是可视化此类系统的恰当表示。 传统上,代理被表示为顶点,顶点对之间的边意味着它们之间存在交互。
然而,网络科学的现代观点是概括边缘以封装代理之间的多种类型的关系。 例如在社交网络中,人们通过工作、学校、家庭等方式认识。 这是为了保留数据的丰富性并揭示系统更深入的视角。 这称为多路复用。
Multiplex 是图的自然过渡,许多学科独立研究了这种数学模型,用于社区检测等各种应用。 社区是指行为与系统其他部分不同的一组顶点。 这是将复杂的系统模块化为更简单的表示形式,以形成信息流的更大图景。
本文的前半部分是对不同社区检测算法的文献综述以及图切割的一些理论界限。 接下来,我们提出了一套基准多路复用和相似性度量来确定各种社区检测算法的相似性。 最后我们提出本文的实证结果。
II 预赛
Definition II.1.
(多重) 多路复用是 图 的有限集合,其中每个图 都有一个不同的边集 。
Multiplex 有许多同义名称,有时它们同时出现在同一篇论文中。 这是为了帮助读者通过不同的描述来可视化系统。 例如,“多层网络”将多路复用描述为图形层,即层意味着。 以下列表是 Multiplex 的同义名称,本文的其余部分将避免使用: Multigraph Cormode 和 Muthukrishnan (2005); Gjoka 等人 (2011), 多维网络 Berlingerio 等人 (2011, 2012); Hossmann 等人 (2012); Kazienko 等人 (2011); Lerch 等人 (2006);罗塞蒂等人 (2011);唐 等人 , 多重关系网络 Cai 等人 (2005);戴维斯等人 (2011);罗德里格斯和希纳维尔 (2010); Szell 等人 (2010); Bry 等人 (2012); Louati等人(2012); Skvoretz 和 Agneessens (2007), 多层网络 Bródka 等人 (2012, 2011, 2013);李等人(2012); Cozzo 等人 (2012); Mucha 等人 (2010)、PolySocial Networks Applin 和 Fischer、多模态网络 Ambrosino 和 Sciomachen (2012) );勒布朗 (1988); Nagurney (2000)、异构网络 Dong 等人 (2012) 和多重网络0> Magnani 和 Rossi (2013) 1>。 但是,我们将使用 层、关系或维度来引用图表 。 这是为了帮助我们更具体地表达某些想法。
例如,当图层彼此堆叠时,将会存在边彼此“重叠”的顶点对(Def. II.2)。 重叠边数的分布是多路复用的一个重要特征,用于对不同的多路复用集成进行分类 Cellai 等人 (2013);李等人 (2012);陈等人(2012); Ranola 等人 (2010);比安科尼(2013)。
Definition II.2.
(重叠边缘) 令 中两个不同图的两条边为 和 ,其中 。 当且仅当 时,边 和 重叠,即 和 。
如果上下文出现歧义,我们将把 Multiplex 和 Monoplex(Multiplex 中的图形)之间的“社区”区分为 Multiplex-community 和 Monoplex-community分别。 当我们审查不同的 Multiplex 社区检测算法时,这将避免混淆。
许多这样的多路复用算法将多路复用问题划分为单工上的独立社区检测问题。 这些单工的解决方案称为辅助分区,为多路复用算法聚合提供补充信息。 聚合的主要解决方案形成了多路复用分区,它定义了多路复用中的社区。
III 多重社区的定义
社区被模糊地描述为一组交互的代理,它们的共同行为与其相邻代理不同。 然而,没有普遍接受的正式定义,因为社区的构造取决于问题领域。 Fortunato (2010) 按社区的本地定义、全局定义和顶点相似度对这种多样性进行分类。
III.1 本地定义
假设社区与其相邻顶点的交互较弱,社区的评估可以与网络的其余部分隔离。 因此,从社区成员的角度来看,建立一个社区就足够了。
将 Multiplex 中的每个图视为成员之间的独立通信模式,例如电子邮件、电话、邮政等。当其中一种通信方式失败时,高质量社区应在其成员之间恢复高信息流(少一张图)。 因此,Berlingerio 等人提出了社区 Berlingerio 等人 (2011) 的冗余作为衡量多重社区质量的指标。
Definition III.1.
(冗余) 令 为多路复用社区中的顶点集合, 为 中与 中相邻的顶点对集合> 关系。 冗余顶点对的集合是,其中中的顶点对在关系中相邻。 的冗余度由下式决定:
| (1) |
其中如果 ,则 (否则为零)。
等式。 1 计算多路复用社区中相应顶点对在两个或多个图中相邻的边的数量。 该总和通过所有相邻顶点对之间的理论最大边数(即 )进行归一化。 多路复用社区的质量取决于多路复用中各图中子图(由多路复用社区的顶点引起)的相同程度。
因此,冗余并不取决于多路复用社区中的边数,即不是其质量的必要条件。 这可能会导致一个不寻常的想法,即社区的密度可能较低。 例如,重叠边缘的循环形成与重叠边缘的完整集团相同质量的“社区”。
III.2 全局定义
分区的全局度量考虑了社区的质量以及社区之间的交互。 例如,Newman 和 Girvan 的模块化函数衡量单一社区与随机图的差异程度(Def. III.2)纽曼(2006)。
Definition III.2.
(模块化) 令 为具有 条边的图的邻接矩阵, 为顶点 的度数。如果和位于同一社区,则,否则。 模块化函数衡量社区与随机图的差异程度:
| (2) |
给定顶点集上的固定分区,多路复用中每个 图的模块化都不同。 因此,良好的多重社区表明图中的所有单一社区都具有高模块化性。
为了量化这个概念,Tang 等人。 al 声称,如果多路复用中存在潜在社区,则多路复用中图的子集 有足够的信息来找到这些社区 Tang 等人 。 如果假设成立,那么从 检测到的社区应该反映多路复用中其余图(即 )的高度模块化。
在机器学习的语言中,选择一个随机图作为测试数据,并让作为训练数据。 使用测试数据 上的模块化函数来评估 上的社区检测算法生成的多重分区 。如果图 上的分区 的模块性最大化,则 是一个很好的多路复用分区。 这扩展了 Multiplex 的模块化度量。
III.3 顶点相似度
如果两个顶点在某种程度上相似,则它们属于顶点相似度社区。 例如,图中顶点对的边聚类系数 Radicchi 等人 (2004) 衡量它们之间公共邻居的(归一化)数量。 高的边聚类系数意味着顶点对之间有许多共同的邻居,从而表明这两个顶点应该属于同一社区。 在多路复用的扩展中,Brodka 等人。 al 介绍了跨层边缘聚类系数(CLECC)Bródka 等人(2012)。
Definition III.3.
(跨层边缘聚类系数) 给定参数 ,顶点 、 的 MIN-Neighbors 是在 at 中与 相邻的顶点集至少 个图表。 两个顶点的跨层边缘聚类系数衡量它们的公共邻居与所有邻居的比率。
| (3) |
具有低 CLECC 的多重社交网络中的一对顶点表明,个体至少不通过 个社交网络共享共同的朋友集团。 因此,他们不太可能一起形成一个社区。
III.4紧密联系的社区核心
社区检测是对顶点进行分区的过程,使得每个顶点至少属于一个社区。 然而,在某些情况下,人们只需要多路复用中的某些子结构具有某些属性。 例如,密集连接社区核心是一组顶点,对于所有辅助分区Yin 和 Khaing (2013),它们位于同一社区中。
IV 理论界限
最大割问题找到图的分区,使得跨簇产生的边数最大化。 因此,补图上的相同划分最大限度地减少了簇之间的边数。 这被称为平衡最小割问题,它与我们的社区检测问题密切相关,其中社区之间产生的边数被最小化。
因此,为了扩展我们对多路复用的理解,我们从最大割问题的已知结果开始。 它使我们能够证明多路复用上平衡最小切割问题的推论。
IV.1 复用上的最大切割问题
Theorem IV.1.
考虑同一顶点集 上的图 。存在 到 社区 的 k 分区,这样对于所有 :
| (4) |
证明。
通过施加额外的条件对界限进行了进一步的发展,其中最大度有界 Kühn 和 Osthus (2007) 以及 Patel (2008) 的情况。 t2>。 由于图上的最大切割的解决方案是 NP 完全的,因此同时对多路复用中的所有图进行最大切割的扩展自然也是 NP 完全的。 因此,这也意味着平衡最小二分也是 NP 完全的Garey 和 Johnson (1990)。
IV.2 复用上的平衡最小切割问题
Corollary IV.1.
考虑同一顶点集 上的图 。存在将 划分为 个大小相等的社区 (即 )的 k 分区,这样对于所有 :
| (5) |
其中
V Multiplex 社区检测算法
现有多路复用社区检测算法的一般策略是从多路复用中提取特征并将问题简化为熟悉的表示。 在求解简化表示时,然后从简化问题的辅助解中推导出多重社区。
因此,许多多重算法依赖于现有的单重社区检测算法来获取临时步骤的辅助分区。 算法的选择通常与其对复用的扩展无关,因此理论上可以选择任何社区检测算法来解决中间步骤。 在本文中,我们的实验使用 Louvain 算法来生成辅助分区。
V.1投影
最简单的方法是将多重投影到加权图中。 IE。设为的邻接矩阵。 的加权投影的邻接矩阵由 给出。 我们将其称为多路复用的“投影平均”。
它被独立提议作为更复杂的多路复用算法的基准,因为性能通常“低于标准”Berlingerio 等人 (2011); Kazienko 等人 (2011);内费多夫(2011);戴维斯等人 (2011);罗塞蒂等人(2011)。 在我们的实验中,我们将其与未加权的变体进行比较,即多路复用的“投影二进制”,即 。
顶点对之间的另一种权重分配是考虑其邻居的连通性,其中共同邻居的高比例意味着更强的联系 Berlingerio 等人 (2011)。 这是基于同一社区的成员倾向于在同一关系子集上进行交互的想法,这是由 Brodka 等人独立提出的。 等人在Def。 III.3 Bródka 等人 (2012)。 这种替代方案将被称为“投影邻居”。
V.2 共识聚类
之前的策略首先聚合图,然后对结果图执行社区检测算法。 这是一个糟糕的策略,因为它忽略了维度 Tang 等人 的丰富信息。 因此,共识聚类策略是首先在图上单独应用社区检测算法作为辅助分区,然后通过以有意义的方式聚合这些辅助分区来导出主聚类(多重社区)。
共识聚类背后的关键概念是测量在辅助分区中的同一社区中找到两个顶点的频率。 经常位于同一单工社区中的顶点更有可能位于同一多路复用社区中。 因此,多路复用上各个图上的社区检测算法决定了多路复用社区的结构属性,而共识聚类则确定了多路复用社区的关系属性。
V.2.1 频繁关闭项集挖掘
数据挖掘是寻找在一系列事务中经常一起出现的一组项目。 例如,根据一系列销售交易,牛奶、谷物和水果等物品经常在超市一起购买。 这些集合称为项集。 柏林杰里奥等。 al 将辅助分区的共识聚类转化为一个数据挖掘问题,以发现多重社区Berlingerio 等人 (2013)。
多路复用中的顶点定义了用于数据挖掘的 交易,而项是元组 ,其中各顶点属于维度 中的单路社区 。例如,假设顶点 分别属于维度 和 中的单群体 和 。 事务是项目 的集合。 因此,当我们使用频繁关闭项集挖掘等数据挖掘方法时,我们能够将频繁(相对于预定义阈值)项集识别为多重社区。
例如,每个顶点是超市中客户的交易,社区是超市想要发现的目标市场。 只有当目标市场足够大时才有意义,因此我们需要定义最小社区规模(例如 10)。 在这种情况下,客户的交易就是他的辅助社区成员资格。 因此,频繁关闭项集挖掘将至少在例如每个客户的交易都是目标市场项目集的子集的 10 个顶点。
V.2.2 基于簇的相似度划分算法
基于簇的相似度划分算法对位于相同辅助社区的实例顶点对的数量进行平均。 例如,在一个 5 维的复数中,如果有 3 个顶点 和 在同一个辅助社区中,那么顶点对 的相似度值就是 。
一旦测量了所有顶点对的相似性,就可以通过 k 均值聚类来确定主簇——每次迭代中具有最接近相似性的顶点被分组在一起。 因此,频繁出现在相同辅助社区中的顶点对将具有较高的相似度值,因此更有可能聚集在相同的主要社区中。 Tang 等人将这称为分区集成。 al 唐等人 .
V.2.3 广义典型相关性
每个辅助分区将顶点映射为 维(该维独立于复用的维)欧几里得空间中的点。 这些点的定位方式是两个顶点之间的最短路径越短,它们在欧几里得空间中越接近。 其中一种映射可以通过连接邻接矩阵的顶部特征向量来实现。 因此,给定多路复用中的 图,存在大小为 的 结构特征矩阵 ,其中每个矩阵中的列是 维欧几里得空间中顶点的位置。
唐等。 al 希望将结构特征矩阵聚合为主结构特征矩阵 ,以便可以根据 Tang 等人 确定主分区。 然而,“平均” 不会产生合理的主要结构特征矩阵,因为 和 之间的矩阵元素是独立的。
解决此问题的一个解决方案是转换 ,使它们位于同一空间,并且它们的“平均值”是合理的。 即不同欧几里得空间中的同一顶点在欧几里得空间中的同一点上对齐。 具体来说,我们需要一组线性变换,以便它们最大化的成对相关性,而广义典型相关分析就是此类标准统计工具之一Kettenring(1971) )。 这使我们能够以更合理的方式“平均”结构:
| (6) |
最后通过主特征矩阵的k均值聚类确定主分区。
V.3桥接检测
图中的桥梁指的是信息流较高的边缘,就像两个城市之间繁忙的道路一样,如果没有这些道路,城市就会被分割成孤立的社区。 实现此目的的一种方法是将多路复用 投影到加权网络并根据投影确定桥。 或者,可以通过多路复用桥的定义删除它们以获得所需的分区。
V.4 张量分解
代数图论是图论的一个分支,其中使用线性代数等代数方法来解决图问题。 因此,多路复用的自然表示是 阶张量(作为多维数组)而不是矩阵( 阶张量)。 Multiplex 中的 图集是一组 邻接矩阵,可以表示为 多维数组(张量)Rodriguez 和 Shinavier (2010)。 这使我们能够利用可用的张量算术,例如张量分解。
张量分解类似于矩阵中的奇异值分解和“下上”分解,它们将张量表示为更简单的分量。 例如,PARAFAC 张量分解 Harshman (1970) 是张量 的 k 级近似,作为一级张量(向量 、 和 ),即:
| (7) |
其中 表示向量外积。 因素中的组成部分,、 和 表明存在很强的联系(可能是集群/社区)通过 中顶部组件中的尺寸在 和 中的元素之间。
例如,假设 中的 元素是最大的元素。 这表明在 社区中, 中的前 10 个(或任何预定义阈值)元素与 中的前 10 个元素位于同一集群中通过维度/关系Dunlavy等人(2011); Leginus 等人 (2012);米尔扎尔和古川(2010); Papalexakis 等人 (2013)。
VI 基准多重
Erdös-Rényi 图 是顶点对以固定概率 Erdös 和 Rényi (1960) 连接的图。 这种结构的随机性通常不具有任何有意义的社区结构。 因此,用作社区检测算法的基准图并不理想。
因此,基准图应该类似于格文和纽曼模型,其中在一组密集子图(作为社区)之间引入一些随机边以形成单个连接的组件/图。 这组密集子图充当社区检测算法要发现的图的“真实”社区,因此成为社区检测算法的基准。 本节的目标是为 Multiplex 设计类似的基准。
主要挑战是,对于良好的多元化社区,目前还没有一个普遍接受的定义。 因此,我们没有办法构建一个不支持某些算法的基准。 因此,以下基准图的目的是研究这些多重社区检测算法之间的关系。 这使我们能够使用一组高度不相关的算法来研究多重社区的不同视角。
VI.1 非结构化合成随机多重
随机多路复用的最简单构造是在同一顶点集上生成一组独立图。 然而,许多社区检测算法都是基于对现实世界多路复用的一些观察,并且这些算法不会在这种随机构造上产生有趣的结果。 我们将此类随机多路复用表示为非结构化合成随机多路复用 (USRM),它们类似于 Erdős-Rényi 图,其中社区检测算法不应在其中找到任何有意义的社区。
为了简化数值实验,多路复用中只有二维,这样我们就可以轻松生成 Erdős-Rényi、Watts Strogatz Watts 和 Strogatz (1998) 和 Barabási-Albert 图 阿尔伯特和巴拉巴西 (2002)。 这种结构的统计特性可以在Loe and Jensen (2013)中找到。
| Name | Graph 1 | Graph 2 |
|---|---|---|
| USRM1 | Erdős-Rényi | Erdős-Rényi |
| USRM2 | Erdős-Rényi | Watts Strogatz |
| USRM3 | Erdős-Rényi | Barabási-Albert |
| USRM4 | Watts Strogatz | Watts Strogatz |
| USRM5 | Watts Strogatz | Barabási-Albert |
| USRM6 | Barabási-Albert | Barabási-Albert |
实验中顶点集的大小为128。 重要的是,两个图中的边数相等,以便两者都不会主导多路复用的交互。 为了确保 Erdős-Rényi 图以高概率连接,顶点对连接的概率必须为 。 因此,Erdős-Rényi 图(以及多路复用中的其他图)中的边数为 。
VI.2 结构化合成随机多重
这种结构类似于格文和纽曼模型,其中独立生成的社区以保留“真实”社区的方式连接。 然而,我们在上面看到 Multiplex 社区有不同的观点,我们希望将这些想法封装到 Multiplex 基准中。
结构化合成随机多路复用 (SSRM) 是一种结构,其中不同的多路复用分区提供由不同定义定义的高质量多路复用社区。 然而,与此同时,从多重社区的其他定义的角度来看,分区的质量必须“不太理想”。
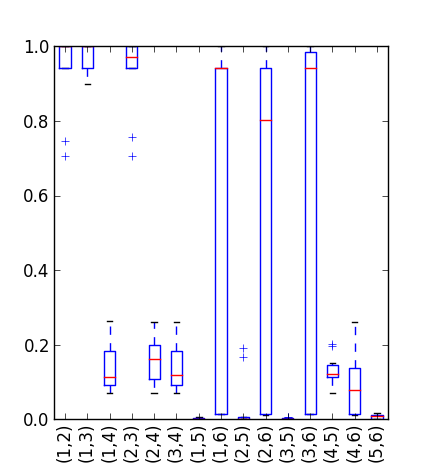
我们首先生成多重社区,每个社区对于社区的不同独立定义而言都是高质量的。 接下来,我们修改这些多路复用社区,使其在三个多路复用社区定义之一中保持良好质量,而在其他定义中保持较差质量。 最后一步是将这些 Multiplex 社区合并为一个 Multiplex,作为我们的 SSRM 基准(图 1)。
图 1 将 显示为具有 2 个社区的分区,其中集群 1 和 2 形成一个社区,集群 3 和 4 形成第二个社区。 该分区具有高冗余、低模块化和低CLECC复用社区。 还有另一个分区 ,其中社区具有较高的模块化程度,但其余指标较低。 最后 是社区具有高 CLECC 顶点对的最终分区。 这种综合多重表达了多重社区的多视角性质。
VI.2.1高模块化、低冗余和低 CLECC 复用社区
为了创建一个高度模块化的多重社区,我们从集群 1 和集群 3 开始,在两个维度上都作为一个类似派系的结构。 为了使这些集群的冗余度较低,我们必须删除两个集群中的一些边,以便集群中很少有重叠的边,同时保持高模块化性。 这可以通过使两个簇中的第一维图成为第二维图的补集来完成。
下一步是在簇 1 和簇 3 之间添加边,使生成的簇成为单个连接组件。 我们将 表示为由集群 1 和集群 3 连接的组件。 为了保持低冗余,新边不能重叠。
最后,我们需要调整簇,使得簇 1 和簇 3 的组合组件中大量顶点对之间的 CLECC 分数较低。 具体来说,我们希望上一步中新边连接的顶点对具有较低的 CLECC 分数。 如果簇 1 在第一维度中具有更多边缘,而簇 3 在第二维度中具有更多边缘,则这是可能的。 这样做时,簇 1 中顶点的邻居将与簇 3 中顶点的邻居显着不同,因此 CLECC 分数较低。
相同的构造适用于集群 2 和集群 4,其中集群 2 与集群 3 相似,集群 4 与集群 1 相似。
VI.2.2 高 CLECC、低模块化和低冗余复用社区
由于所有 4 个簇都不具有重叠边缘,因此多路复用上的任何分区的冗余度仍然较低。 因此,第一步是使聚类 1 和 4 的 CLECC 分数较高,并对聚类 2 和 3 应用相同的构造。
由于簇 1 和 4 类似地基于上一小节的构造,因此每个簇中任何给定顶点的邻居也将相似。 因此,在簇 1 和簇 4 之间添加新边不会影响 CLECC 分数。 然而,这些新边应该仅在第一维中绘制,因为它是中的主要维度。 这同时降低了第二维中 的模块化,因为簇没有连接并且第二维中的图是稀疏的。 这为多元化社区提供了较低的模块化,同时保持了较高的 CLECC 分数。
簇 2 和簇 3 的构造类似,但只有第二维中的边将两个簇连接在一起。
VI.2.3 高冗余、低模块化和 CLECC 多重社区
鉴于 的 CLECC 分数较低,因此相同的分数应适用于 ,因为聚类 2 和聚类 3 相似。 主要目标是连接集群 1 和集群 2,使得 的冗余度较高。 冗余度由等式测量。 1,计算重叠边的数量。 由于此时的构造没有重叠边,因此增加冗余的最简单方法是在簇之间添加新的重叠边以形成组件 和 。
虽然和与多路复用中的其他分区相比具有相对较高的冗余,但它仍然比USRM1中的随机社区具有较低的冗余。 为了提高冗余度,有必要添加新的边,使得四个簇中存在重叠。 然而,这可能会增加我们想要避免的 的模块化。 因此,最后一步必须逐步完成。
VI.2.4 不同地面实况分区的评估
有 3 个不同的“ground-truth”分区 、 和 ,它们各自代表一个不同的“ideal-partition”。 然而,同时从其他指标的角度来看,它们“不太理想”。 尽管其中一些指标总体上是相关的(来自我们的实验),但 SSRM 的这些真实划分表明这些指标都能够捕获社区结构的基本方面。
| Redundancy | *CLECC | **Modularity | |
| 0.0492 | 0.1142 | -0.0287 | |
| 0.0537 | 0.1087 | -0.0332 | |
| 0 | 0.1541 | 0.007 | |
| 0 | 0.1642 | 0.012 | |
| 0 | 0.1113 | 0.0317 | |
| 0 | 0.1083 | 0.0245 | |
| Random | 0.0217 | 0.1056 | 0.0033 |
例如表1显示分区具有最大冗余的社区。 然而,它具有多模块化性,并且 CLECC 得分与随机分区相似,这表明它相对于其他指标“不太理想”。
VI.3现实世界多路复用
合成多重的问题在于它不能正确反映现实世界的系统。 顶点之间的关系是人为强加的,以便我们可以区分不同的社区检测算法。 然而,现实世界的社区不会以如此系统的方式运作,即使它们是由不同的动力创建的,也可能会接近类似的结构和关系。 因此,我们将多重社区检测算法与开放数据集中的真实世界多重进行比较。
VI.3.1 Youtube 社交网络
YouTube 是一个视频共享网站,允许视频创作者和观众之间进行互动。 Tang 等人收集了 15,088 个活跃用户,形成一个具有 5 个关系的多路复用,其中两个用户连接,如果 Tang 等人 :
-
1.
他们在彼此的联系人列表中;
-
2.
他们的联系人列表重叠;
-
3.
他们订阅同一用户的频道;
-
4.
他们有普通用户的订阅;
-
5.
他们分享共同喜爱的视频。
VI.3.2交通网络
交通网络中的广义图被称为多式联运网络,其中公交车站、车站和终点站是转乘不同交通工具的不可区分的位置(顶点)。 Cardillo等人根据欧洲航空运输(EAT)网络的数据构建了一个以450个机场为顶点的空中交通复合交通Cardillo等人(2013)。 如果两个顶点之间存在直接飞行,则在两个顶点之间绘制一条边。 EAT 网络中的 37 家不同航空公司中的每家都在机场之间形成了关系。
由于航空公司的基地往往位于老旧的大型机场,因此存在“富者愈富”的现象,新机场往往有直飞主要机场的航班。 因此Cardillo等人通过确保度分布遵循幂律分布来验证这一现象,这意味着无标度系统。
VII 比较分区
归一化互信息 (NMI) Manning 等人 (2008) 是网络分区的一种流行的相似性度量,其中 之间的实值分数与分数 1 表示相同的分区。 然而,我们无法简单地将 NMI 指标应用于所有算法的所有成对比较。
与其他算法不同,频繁闭合项集挖掘和张量分解会产生重叠社区,而 NMI 并非旨在测量重叠社区。 此外,这些算法也不能确保所有顶点都属于至少一个社区,即可能存在没有社区成员资格的“孤立”顶点。 因此,即使是重叠社区的 NMI Lancichinetti 等人 (2009) 的变体也不适用于我们的研究。
调整兰德指数是分类研究中 NMI 的替代指标Hubert 和 Rabie (1985)。 它用于测量重叠社区的扩展被称为 Omega 指数 Collins 和 Dent (1988),并且能够测量具有孤立顶点的分区。 与 NMI 的重叠变体不同,两个非重叠分区与 Omega 指数的比较可简化为调整兰德指数。
VII.1 归一化互信息
互信息在给定中的社区成员资格的情况下测量中所有顶点对的社区成员资格信息,反之亦然。 粗略地说,给定 ,我们能在多大程度上猜测 中的顶点对位于同一社区中? 正式定义为 ,其中 是香农熵:
| (8) |
其中是随机顶点位于分区的社区中的概率,即的大小的比率> 社区的顶点总数。 类似地, 表示分区 的情况。 互信息也可以表示为:
| (9) |
其中 是随机顶点同时位于 和 社区中的概率。 基本上,和的和社区的交集越大,互信息就越高。 最后标准化互信息分数:
| (10) |
VII.2 欧米茄指数
未经调整的 Omega 指数对相同数量社区中的顶点对数量进行平均。 已知此类顶点对一致。 考虑有两个分区和的情况,其中社区的数量分别为和。 函数返回恰好出现在中的重叠社区中的顶点对集合。 因此,未经调整的欧米茄指数:
| (11) |
为了考虑偶然分配到相同社区的顶点对,我们必须从空模型的预期 omega 索引中减去它:
| (12) |
最后,欧米茄指数由下式给出:
| (13) |
欧米茄指数有可能为负值,其一致性低于纯粹随机巧合的预期。 它被认为是无趣的,因为它除了表明分区不相似这一事实之外没有任何暗示。 相同分区的 Omega 指数为 1。
VII.3 经验结果的符号
为了简化展示实验结果的图,我们将使用一些简写来表示算法和分区。 对于社区检测算法,我们使用和分别表示“算法”和“SSRM分区”(表2)。
| Notation | Description |
|---|---|
| Projection-Binary | |
| Projection-Average | |
| Projection-Neighbors | |
| Cluster-based Similarity Partition Algorithm | |
| Generalized Canonical Correlations | |
| CLECC Bridge Detection | |
| Frequent Closed Itemsets Mining | |
| PARAFAC, Tensor Decomposition | |
| of SSRM | |
| of SSRM | |
| of SSRM |
VIII多重社区检测算法的实证比较
VIII.1 非结构化合成随机多重
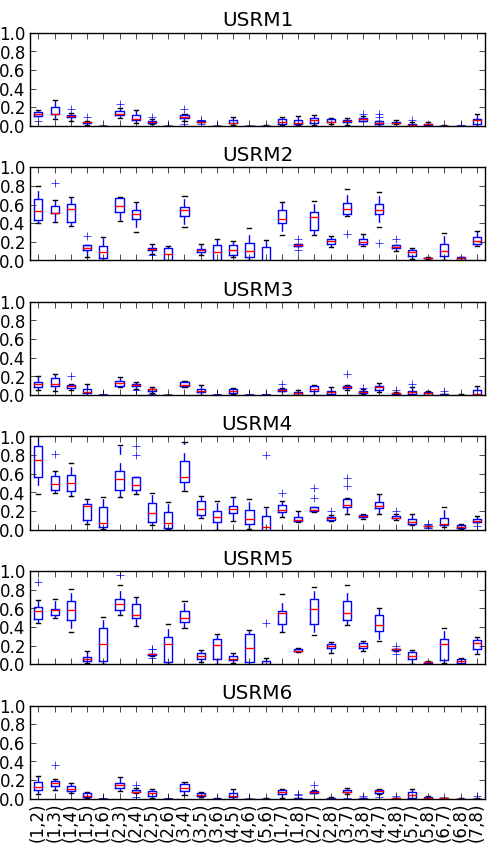
图2显示了USRM基准的所有成对多重社区检测算法的Omega指数。 右侧最后 13 个箱线图是与重叠社区算法的成对比较,即 和 。
第一个观察结果是 (PARAFAC) 与任何算法都不相似。 原因之一是很难为 PARAFAC 选择正确的参数,即方程 (1) 的 近似值。 7 以及一阶张量的前几个元素的预定义阈值。 对于给定的图,除了手动实验外,没有系统的方法 Dunlavy 等人 (2011); Leginus 等人 (2012);米尔扎尔和古川(2010); Papalexakis 等人 (2013)。
然而,重叠社区算法(频繁关闭项集挖掘)类似于一类非重叠算法,即到。 具体来说,频繁闭项集挖掘类似于投影算法到类。 事实上,算法系列 的所有成对比较的 Omega 指数通常大于其他算法对。 图 3 中的 NMI 分数支持了这一点。
然而,算法系列 对于 USRM 1、3 和 6 的成对 Omega 指数和 NMI 分数较低。 没有根本原因说明为什么投影算法类( 到 )应该产生非相似社区,因此我们可以推断 USRM 1、3 和 6 不是好的多路复用为基准。
原因是USRM1是两个Erdős-Rényi图的组合,因此不存在社区结构。 而 USRM 3 和 6 分别是 Barabási-Albert 图与 Erdős-Rényi 和 Barabási-Albert 的组合。 尽管 Barabási-Albert 具有结构特性,但它具有较低的聚类系数(类似于 Erdős-Rényi),该系数衡量顶点聚类在一起的趋势。 因此,USRM 3 和 6 中的顶点不形成社区。
为了增加多路复用的聚类系数,我们可以在系统中引入 Watts Strogatz 图。 我们可以近似这种多重投影的聚类系数Loe and Jensen (2013)并推断社区存在的趋势。 这使我们能够从 USRM 2、4 和 5 等基准多路复用中观察算法之间有趣的关系。
例如图3中的USRM 5表明与(CLECC桥检测)的相似性范围很宽。 当我们研究它们与 SSRM 基准的关系时,这一点更加明显。
VIII.2 结构化合成随机多重
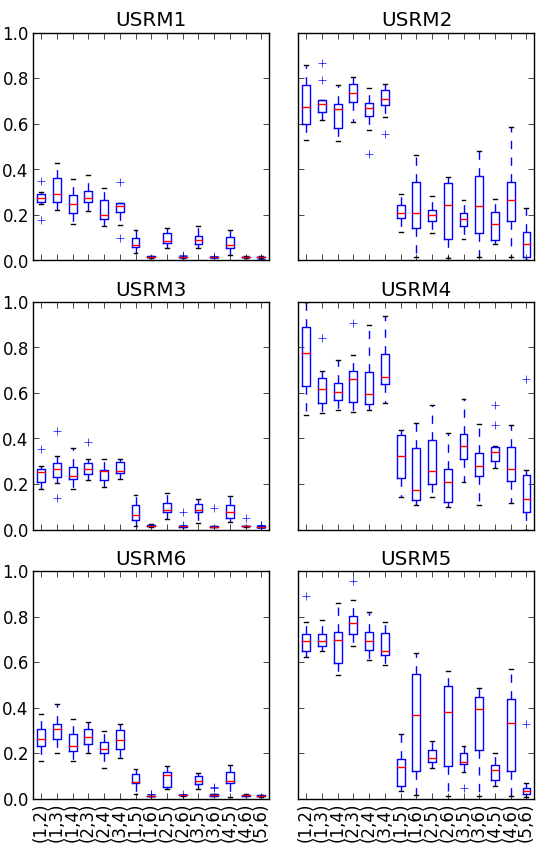
在上一节中,USRM 基准表明 会产生类似的社区。 然而,图 4 显示,(基于聚类的相似性划分算法)中的 SSRM 社区与投影算法类( 到 )。 因此我们可以得出结论,基于簇的相似度划分算法为多重社区提供了另一种视角,并且它不能简化为投影算法类。
回想一下上一节中的最后观察,(CLECC 桥检测)与投影算法的相似性范围很广。 图4显示,存在它们非常不同的情况(接近NMI=0),并且存在NMI的情况。 通过这种方式,我们的实验凸显了 CLECC 桥检测算法的弱点。
CLECC 有时会过早地产生单独的组件,其中一个组件是一小群顶点,甚至是作为一个社区的单个顶点。 因此,CLECC 似乎产生了显着不同的社区,因为其余算法倾向于产生平衡大小的社区。 因此,如果我们排除 CLECC 的此类情况, 与 SSRM 的投影算法类似。
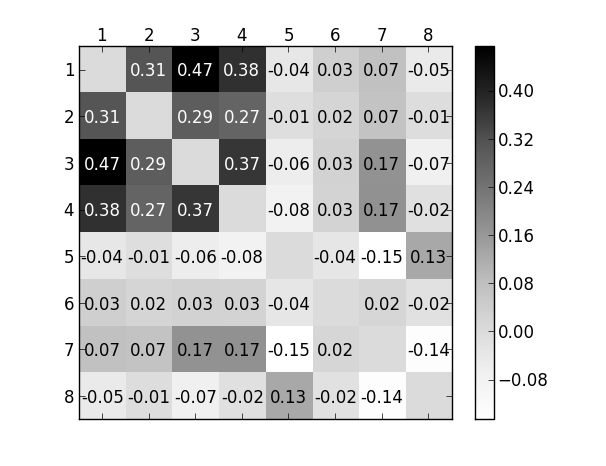
最后,我们将算法与“ground-truth”分区 、 和 进行比较。 表3显示,没有一种算法能够捕获,即具有高冗余的分区。 (Projection-Neighbors)被提出来提取高冗余社区Berlingerio等人(2011)。
相反,(CLECC 桥检测)能够找到高 CLECC 分区。 然而,与任何投影算法( 到 )相比,它没有任何优势。 这进一步支持 与投影算法类相似。
Tang 等人的结果。 al 表明,(广义规范相关性)往往比 (基于聚类的相似性划分算法)更好地捕获像 这样的高模块化社区唐等人 . 本实验中也观察到了这一点。
| 0 | 0.983 | 0 | |
| 0.002 | 0.94 | 0.017 | |
| 0 | 0.978 | 0 | |
| 0.019 | 0.14 | 0.083 | |
| 0.004 | 0.002 | 0.158 | |
| 0.006 | 0.964 | 0.006 |
VIII.3现实世界多路复用
不幸的是,尽管参数选择不同,(CLECC 桥检测)往往会过早停止。 因此,我们在此实验中未能获得有关 CLECC 桥检测的任何见解。
VIII.4总结
算法、和中的参数需要手动微调才能产生有意义的社区进行比较。 因此,详尽地测试这些算法的所有配置是不切实际的。 然而,当选择不同的参数时,分析结果不会发生任何本质的变化。
从 USRM 基准和现实世界的多路复用来看, 组中的算法往往会生成相对相似的分区。 然而,SSRM 基准测试表明 能够捕获高冗余社区,并且执行方式与投影算法类别不同。
我们对 USRM 和 SSRM 基准进行的实验表明,当算法不将小顶点簇推断为社区时,(CLECC 桥检测)与投影算法类 类似。 因此,如果不仔细分析,CLECC 桥接检测不是很稳定。
最后我们必须强调,对于大多数成对比较来说,绝对 Omega 指数和 NMI 指数通常较低 ()。 这意味着算法在技术上以不同的方式感知不太理想的多重社区。 然而,我们的结果表明,社区内的一些顶点簇比其他算法更有可能被某些算法捕获。
九讨论与结论
文献综述和 SSRM 基准强调了定义多重社区的额外复杂性。 它是社区的结构拓扑及其关系之间的平衡。 SSRM 是一个有用的基准,可以揭示这些算法之间的根本差异。 因此,需要进行进一步的研究来改进 SSRM,以使社区的不同定义更加明显。
本文的主要贡献是巩固和比较所有现有的多重社区检测算法。 多路复用的一长串同义名称导致许多研究人员不知道多路复用的相关工作,因此倾向于使这项研究变得分散和分散Mikko Kivela (2013)。 因此,我们希望本文能让人们认识到多重社区检测算法的进一步发展,以便研究人员能够在现有想法的基础上继续发展。
参考
- Cormode and Muthukrishnan (2005) G. Cormode and S. Muthukrishnan, in Proceedings of the twenty-fourth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, PODS ’05 (ACM, New York, NY, USA, 2005) pp. 271–282.
- Gjoka et al. (2011) M. Gjoka, C. T. Butts, M. Kurant, and A. Markopoulou, IEEE J. Sel. Areas Commun. on Measurement of Internet Topologies (2011).
- Berlingerio et al. (2011) M. Berlingerio, M. Coscia, and F. Giannotti, in ASONAM (IEEE Computer Society, 2011) pp. 490–494.
- Berlingerio et al. (2012) M. Berlingerio, M. Coscia, F. Giannotti, A. Monreale, and D. Pedreschi, World Wide Web , 1 (2012).
- Hossmann et al. (2012) T. Hossmann, G. Nomikos, T. Spyropoulos, and F. Legendre, Computer Communications 35, 1613 (2012).
- Kazienko et al. (2011) P. Kazienko, K. Musial, E. Kukla, T. Kajdanowicz, and P. Bródka, in Computational Collective Intelligence. Technologies and Applications (Springer, 2011) pp. 378–387.
- Lerch et al. (2006) F. Lerch, J. Sydow, and K. G. Provan, in annual colloquium of the European Group for Organizational Studies, Bergen, Norway (2006).
- Rossetti et al. (2011) G. Rossetti, M. Berlingerio, and F. Giannotti, in ICDM Workshops, edited by M. Spiliopoulou, H. Wang, D. J. Cook, J. Pei, W. W. 0010, O. R. Zaïane, and X. Wu (IEEE, 2011) pp. 979–986.
- (9) L. Tang, X. Wang, and H. Liu, in ICDM ’09: Proceedings of IEEE International Conference on Data Mining.
- Cai et al. (2005) D. Cai, Z. Shao, X. He, X. Yan, and J. Han, in Proceedings of the 9th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD) (Porto, Portugal, 2005).
- Davis et al. (2011) D. A. Davis, R. Lichtenwalter, and N. V. Chawla, in ASONAM (IEEE Computer Society, 2011) pp. 281–288.
- Rodriguez and Shinavier (2010) M. A. Rodriguez and J. Shinavier, Journal of Informetrics 4, 29 (2010).
- Szell et al. (2010) M. Szell, R. Lambiotte, and S. Thurner, Proceedings of the National Academy of Sciences 107, 13636 (2010), http://www.pnas.org/content/107/31/13636.full.pdf+html .
- Bry et al. (2012) F. Bry, F. Kneißl, K. A. Weiand, and T. Furche, IJSNM 1, 141 (2012).
- Louati et al. (2012) A. Louati, J. E. Haddad, and S. Pinson, in ICSOC, Lecture Notes in Computer Science, Vol. 7636, edited by C. Liu, H. Ludwig, F. Toumani, and Q. Yu (Springer, 2012) pp. 664–671.
- Skvoretz and Agneessens (2007) J. Skvoretz and F. Agneessens, Quality & Quantity 41, 341 (2007).
- Bródka et al. (2012) P. Bródka, T. Filipowski, and P. Kazienko, CoRR abs/1209.6050 (2012).
- Bródka et al. (2011) P. Bródka, K. Skibicki, P. Kazienko, and K. Musial, in Computational Aspects of Social Networks (CASoN), 2011 International Conference on (IEEE, 2011) pp. 237–242.
- Bródka et al. (2013) P. Bródka, T. Filipowski, and P. Kazienko, in Information Systems, E-learning, and Knowledge Management Research (Springer, 2013) pp. 185–190.
- Li et al. (2012) C. Li, J. Luo, J. Huang, and J. Fan, in Intelligence and Security Informatics, Lecture Notes in Computer Science, Vol. 7299, edited by M. Chau, G. Wang, W. Yue, and H. Chen (Springer Berlin Heidelberg, 2012) pp. 60–72.
- Cozzo et al. (2012) E. Cozzo, A. Arenas, and Y. Moreno, Physical Review E 86 (2012), 10.1103/physreve.86.036115, arXiv:1205.3111 .
- Mucha et al. (2010) P. J. Mucha, T. Richardson, K. Macon, M. A. Porter, and J.-P. Onnela, Science 328, 876 (2010).
- (23) S. A. Applin and M. Fischer, The 111th Annual Meeting of the American Anthropological Association (AAA) .
- Ambrosino and Sciomachen (2012) D. Ambrosino and A. Sciomachen, European Transport Trasporti Europei (2012).
- LeBlanc (1988) L. J. LeBlanc, Transportation Research Part B: Methodological 22, 383 (1988).
- Nagurney (2000) A. Nagurney, Mathematical and Computer Modelling 32, 393 (2000).
- Dong et al. (2012) Y. Dong, J. Tang, S. Wu, J. Tian, N. V. Chawla, J. Rao, and H. Cao, in Data Mining (ICDM), 2012 IEEE 12th International Conference on (IEEE, 2012) pp. 181–190.
- Magnani and Rossi (2013) M. Magnani and L. Rossi, in Social Computing, Behavioral-Cultural Modeling and Prediction (Springer, 2013) pp. 257–264.
- Cellai et al. (2013) D. Cellai, E. López, J. Zhou, J. P. Gleeson, and G. Bianconi, arXiv preprint arXiv:1307.6359 (2013).
- Lee et al. (2012) K.-M. Lee, J. Y. Kim, W. kuk Cho, K.-I. Goh, and I.-M. Kim, New Journal of Physics 14, 033027 (2012).
- Chen et al. (2012) A. L. Chen, F. J. Zhang, and H. Li, Acta Mathematica Sinica, English Series 28, 941 (2012).
- Ranola et al. (2010) J. M. O. Ranola, S. Ahn, M. E. Sehl, D. J. Smith, and K. Lange, Bioinformatics 26, 2004 (2010).
- Bianconi (2013) G. Bianconi, Phys. Rev. E 87, 062806 (2013).
- Fortunato (2010) S. Fortunato, Physics Reports 486, 75 (2010).
- Newman (2006) M. E. Newman, Proceedings of the National Academy of Sciences 103, 8577 (2006).
- Radicchi et al. (2004) F. Radicchi, C. Castellano, F. Cecconi, V. Loreto, and D. Parisi, Proceedings of the National Academy of Sciences 101, 2658 (2004).
- Yin and Khaing (2013) Z. M. Yin and S. S. Khaing, International Journal of Advanced Research in Computer Engineering & Technology 2 (2013).
- Kühn and Osthus (2007) D. Kühn and D. Osthus, Combinatorics, Probability & Computing 16, 277 (2007).
- Patel (2008) V. Patel, Journal of Graph Theory 57, 19 (2008).
- Garey and Johnson (1990) M. R. Garey and D. S. Johnson, Computers and Intractability; A Guide to the Theory of NP-Completeness (W. H. Freeman & Co., New York, NY, USA, 1990).
- Nefedov (2011) N. Nefedov, in WIMS, edited by R. Akerkar (ACM, 2011) p. 64.
- Berlingerio et al. (2013) M. Berlingerio, F. Pinelli, and F. Calabrese, Data Mining and Knowledge Discovery 27, 294 (2013).
- Kettenring (1971) J. R. Kettenring, Biometrika 58, pp. 433 (1971).
- Girvan and Newman (2002) M. Girvan and M. E. Newman, Proceedings of the National Academy of Sciences 99, 7821 (2002).
- Harshman (1970) R. A. Harshman, UCLA Working Papers in Phonetics 16, 84 (1970).
- Dunlavy et al. (2011) D. M. Dunlavy, T. G. Kolda, and W. P. Kegelmeyer, Graph Algorithms in the Language of Linear Algebra, J. Kepner and J. Gilbert, eds., Fundamentals of Algorithms, SIAM, Philadelphia , 85 (2011).
- Leginus et al. (2012) M. Leginus, P. Dolog, and V. Žemaitis, in User Modeling, Adaptation, and Personalization, Lecture Notes in Computer Science, Vol. 7379, edited by J. Masthoff, B. Mobasher, M. Desmarais, and R. Nkambou (Springer Berlin Heidelberg, 2012) pp. 151–163.
- Mirzal and Furukawa (2010) A. Mirzal and M. Furukawa, “Node-Context Network Clustering using PARAFAC Tensor Decomposition,” (2010), arXiv:1005.0268 .
- Papalexakis et al. (2013) E. E. Papalexakis, L. Akoglu, and D. Ienco, in 16th International Conference on Information Fusion (2013).
- Erdös and Rényi (1960) P. Erdös and A. Rényi, in PUBLICATION OF THE MATHEMATICAL INSTITUTE OF THE HUNGARIAN ACADEMY OF SCIENCES (1960) pp. 17–61.
- Watts and Strogatz (1998) D. J. Watts and S. H. Strogatz, nature 393, 440 (1998).
- Albert and Barabási (2002) R. Albert and A.-L. Barabási, Reviews of modern physics 74, 47 (2002).
- Loe and Jensen (2013) C. W. Loe and H. J. Jensen, Journal of Physics A: Mathematical and Theoretical 46, 245002 (2013).
- Cardillo et al. (2013) A. Cardillo, J. Gómez-Gardeñes, M. Zanin, M. Romance, D. Papo, F. del Pozo, and S. Boccaletti, Scientific reports 3 (2013).
- Manning et al. (2008) C. D. Manning, P. Raghavan, and H. Schütze, Introduction to information retrieval, Vol. 1 (Cambridge university press Cambridge, 2008).
- Lancichinetti et al. (2009) A. Lancichinetti, S. Fortunato, and J. Kertész, New Journal of Physics 11, 033015 (2009).
- Hubert and Arabie (1985) L. Hubert and P. Arabie, Journal of classification 2, 193 (1985).
- Collins and Dent (1988) L. M. Collins and C. W. Dent, Multivariate Behavioral Research 23, 231 (1988).
- Mikko Kivela (2013) M. B. J. P. G. Y. M. M. A. P. Mikko Kivela, Alexandre Arenas, arXiv:1309.7233 (2013).