使用神经网络进行序列到序列学习
摘要
深度神经网络 (DNN) 是强大的模型,在困难的学习任务上取得了优异的性能。 尽管只要有大型标记训练集可用,DNN 就能很好地工作,但它们不能用于将序列映射到序列。 在本文中,我们提出了一种通用的端到端序列学习方法,该方法对序列结构做出最少的假设。 我们的方法使用多层长短期记忆 (LSTM) 将输入序列映射到固定维度的向量,然后使用另一个深度 LSTM 从向量解码目标序列。 我们的主要结果是,在 WMT'14 数据集的英语到法语翻译任务中,LSTM 生成的翻译在整个测试集上的 BLEU 得分为 34.8,其中 LSTM 的 BLEU 得分因词汇外问题而受到惩罚字。 此外,LSTM 在处理长句子时没有困难。 作为比较,基于短语的 SMT 系统在同一数据集上的 BLEU 得分为 33.3。 当我们使用 LSTM 对上述 SMT 系统产生的 1000 个假设进行重新排序时,其 BLEU 分数增加到 36.5,这接近于之前该任务的最佳结果。 LSTM 还学习了对词序敏感且对主动语态和被动语态相对不变的敏感短语和句子表示。 最后,我们发现反转所有源句子(但不是目标句子)中的单词顺序可以显着提高 LSTM 的性能,因为这样做会在源句子和目标句子之间引入许多短期依赖关系,从而使优化问题变得更容易。
1简介
深度神经网络 (DNN) 是极其强大的机器学习模型,可在语音识别 [13, 7] 和视觉对象识别 [19, 6, 21, 20 等难题上取得优异的性能]。 DNN 非常强大,因为它们可以以适度的步骤执行任意并行计算。 DNN 强大功能的一个令人惊讶的例子是它们能够仅使用 2 个二次大小的隐藏层对 位数字进行排序 [27] 。 因此,虽然神经网络与传统的统计模型相关,但它们学习复杂的计算。 此外,只要标记集有足够的信息来指定网络参数,就可以通过有监督的反向传播来训练大型 DNN。 因此,如果存在一个大型 DNN 的参数设置可以取得良好的结果(例如,因为人类可以非常快速地解决任务),有监督反向传播将找到这些参数并解决问题。
尽管 DNN 具有灵活性和强大功能,但它只能应用于输入和目标可以用固定维度的向量进行合理编码的问题。 这是一个很大的限制,因为许多重要的问题最好用长度未知的序列来表达。 例如,语音识别和机器翻译是顺序问题。 同样,问答也可以被视为将表示问题的单词序列映射到表示答案的单词序列。 因此,很明显,学习将序列映射到序列的独立于域的方法将是有用的。
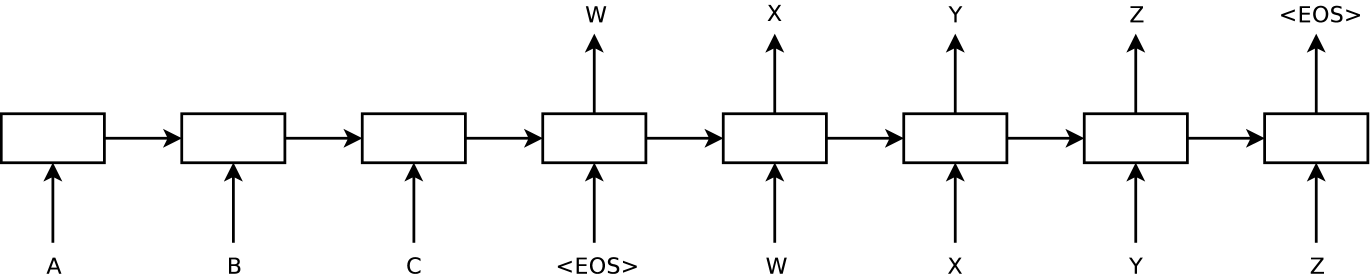
序列对 DNN 提出了挑战,因为它们要求输入和输出的维数已知且固定。 在本文中,我们展示了长短期记忆(LSTM)架构[16]的直接应用可以解决一般的序列到序列问题。 这个想法是使用一个 LSTM 读取输入序列,一次一个时间步,以获得大的固定维向量表示,然后使用另一个 LSTM 从该向量中提取输出序列(图 1)。 第二个 LSTM 本质上是一个循环神经网络语言模型[28,23,30],只不过它以输入序列为条件。 由于输入与其相应输出之间存在相当大的时间滞后,LSTM 能够成功学习具有长范围时间依赖性的数据,使其成为此应用程序的自然选择(图 1)。
已经进行了许多相关尝试来解决神经网络的一般序列到序列学习问题。 我们的方法与 Kalchbrenner 和 Blunsom [18] 密切相关,他们是第一个将整个输入句子映射到向量的人,并且与 Cho 等人 [5] 相关,尽管后者仅用于对基于短语的系统产生的假设进行重新评分。 Graves [10] 引入了一种新颖的可微分注意力机制,允许神经网络关注其输入的不同部分,并且这个想法的一个优雅变体被 Bahdanau 等人成功应用于机器翻译 [2]。 连接序列分类是另一种使用神经网络将序列映射到序列的流行技术,但它假设输入和输出之间是单调对齐的[11]。
这项工作的主要结果如下。 在 WMT'14 英语到法语翻译任务中,我们通过使用简单的左模型直接从 5 个深度 LSTM(每个具有 384M 个参数和 8,000 维状态)的集合中提取翻译,获得了 34.81 的 BLEU 分数-向右波束搜索解码器。 这是迄今为止通过大型神经网络直接翻译实现的最佳结果。 为了进行比较,该数据集上 SMT 基线的 BLEU 得分为 33.30 [29]。 34.81 BLEU 分数是由词汇量为 80k 单词的 LSTM 获得的,因此只要参考翻译包含这 80k 单词未涵盖的单词,分数就会受到惩罚。 这一结果表明,相对未优化的小词汇量神经网络架构有很大的改进空间,其性能优于基于短语的 SMT 系统。
最后,我们使用 LSTM 对同一任务 [29] 上公开的 SMT 基线 1000 个最佳列表进行重新评分。 通过这样做,我们获得了 36.5 的 BLEU 分数,这将基线提高了 3.2 BLEU 分,接近之前发布的该任务的最佳结果(37.0 [9])。
令人惊讶的是,尽管其他研究人员最近在相关架构方面取得了经验[26],但 LSTM 在处理很长的句子时并没有受到影响。 我们能够在长句子上做得很好,因为我们颠倒了源句子中的单词顺序,但没有颠倒训练和测试集中的目标句子。 通过这样做,我们引入了许多短期依赖关系,使优化问题变得更加简单(参见第 2 和 3.3 节)。 因此,SGD 可以学习处理长句子的 LSTM。 颠倒源句子中单词的简单技巧是这项工作的关键技术贡献之一。
LSTM 的一个有用特性是它能够学习将可变长度的输入句子映射到固定维度的向量表示。 鉴于翻译往往是源句子的释义,翻译目标鼓励 LSTM 找到捕获其含义的句子表示,因为具有相似含义的句子彼此接近,而不同句子含义则相距较远。 定性评估支持了这一说法,表明我们的模型能够识别词序,并且对于主动语态和被动语态相当不变。
2模型
循环神经网络 (RNN) [31, 28] 是前馈神经网络对序列的自然推广。 给定输入序列 ,一个标准 RNN 计算输出序列
只要提前知道输入和输出之间的对齐情况,RNN 就可以轻松地将序列映射到序列。 然而,目前尚不清楚如何将 RNN 应用于输入和输出序列长度不同且关系复杂且非单调的问题。
一般序列学习最简单的策略是使用一个 RNN 将输入序列映射到固定大小的向量,然后使用另一个 RNN 将向量映射到目标序列(Cho 等人 也采用了这种方法) [5])。 虽然原则上它可以工作,因为 RNN 提供了所有相关信息,但由于产生的长期依赖性,训练 RNN 会很困难(图 1)[14, 4 , 16, 15]。 然而,众所周知,长短期记忆 (LSTM) [16] 可以学习具有长范围时间依赖性的问题,因此 LSTM 在这种情况下可能会成功。
LSTM 的目的是估计条件概率 ,其中 是一个输入序列, 是它相应的输出序列,输出序列长度 可以与输入序列长度 不同。 LSTM 计算这个条件概率的方法是首先获取输入序列 固定维度的表示 ,并通过 LSMT 最后的隐藏层给出,然后使用标准的 LSTM-LM 公式计算 的概率,它的初始隐藏层设置为 的表示 :
| (1) |
在此等式中,每个 分布用词汇表中所有单词的 softmax 表示。 我们使用 Graves [10] 的 LSTM 公式。 请注意,我们要求每个句子以特殊的句尾符号“EOS”结尾,这使得模型能够定义所有可能的序列上的分布长度。 整体方案如图1所示,其中所示的LSTM计算“A”、“B”、“C”、“EOS”,然后使用这个表示来计算“W”、“X”、“Y”、“Z”、“EOS”。
我们的实际模型在三个重要方面与上述描述不同。 首先,我们使用了两种不同的 LSTM:一种用于输入序列,另一种用于输出序列,因为这样做以可忽略的计算成本增加了模型参数的数量,并且可以很自然地同时在多个语言对上训练 LSTM[18 ]。 其次,我们发现深层 LSTM 的性能明显优于浅层 LSTM,因此我们选择了四层 LSTM。 第三,我们发现颠倒输入句子的单词顺序非常有价值。 因此,举例来说,LSTM 不会将句子 映射到句子 ,要求 LSTM 映射 to , where 是 的译文。 这样, 非常接近 , 非常接近 ,依此类推,这一事实使得 SGD 可以轻松地在输入和输出之间“建立通信”。 我们发现这种简单的数据转换可以极大地提高 LSTM 的性能。
3实验
我们通过两种方式将我们的方法应用于 WMT’14 英语到法语 MT 任务。 我们用它来直接翻译输入句子,而不使用参考 SMT 系统,并用它来重新评分 SMT 基线的 n 个最佳列表。 我们报告这些翻译方法的准确性,提供示例翻译,并将生成的句子表示可视化。
3.1 数据集详细信息
我们使用 WMT’14 英语到法语数据集。 我们在由 348M 法语单词和 304M 英语单词组成的 12M 句子子集上训练模型,这是从 [29] 中“选择”的干净子集。 我们选择这个翻译任务和这个特定的训练集子集是因为标记化训练和测试集以及来自基线 SMT [29] 的 1000 个最佳列表是公开可用的。
由于典型的神经语言模型依赖于每个单词的向量表示,因此我们对两种语言都使用了固定的词汇表。 我们使用了 160,000 个源语言最常用单词和 80,000 个目标语言最常用单词。 每个词汇表之外的单词都被替换为特殊的“UNK”词符。
3.2 解码和重新评分
我们实验的核心涉及在许多句子对上训练一个大型深度 LSTM。 我们通过在给定源句子 的情况下最大化正确翻译 的对数概率来训练它,因此训练目标是
其中 是训练集。 训练完成后,我们通过根据 LSTM 查找最有可能的翻译来生成翻译:
| (2) |
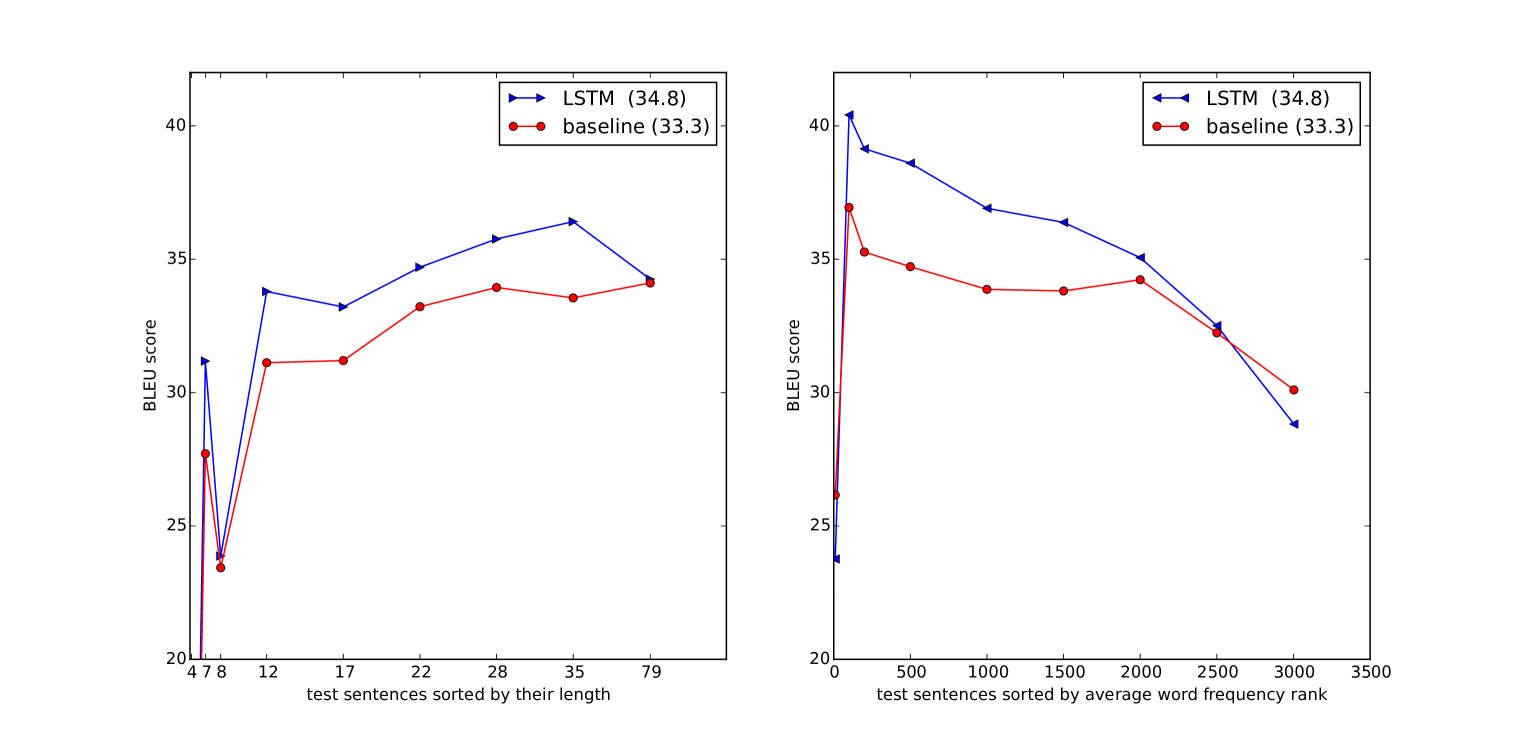
我们使用简单的从左到右波束搜索解码器来搜索最可能的翻译,该解码器维护少量 部分假设,其中部分假设是某些翻译的前缀。 在每个时间步,我们用词汇表中的每个可能的单词扩展光束中的每个部分假设。 这大大增加了假设的数量,因此我们根据模型的对数概率丢弃除 最可能的假设之外的所有假设。 一旦“EOS”符号被附加到假设中,它就会从光束中删除并添加到完整假设集中。 虽然该解码器是近似的,但实现起来很简单。 有趣的是,即使波束尺寸为 1,我们的系统也能表现良好,而尺寸为 2 的波束提供了波束搜索的大部分优点(表 1)。
我们还使用 LSTM 对基线系统 [29] 生成的 1000 个最佳列表进行重新评分。 为了重新评分 n-best 列表,我们使用 LSTM 计算每个假设的对数概率,并用它们的分数和 LSTM 的分数取平均数。
3.3 颠倒源句
虽然 LSTM 能够解决具有长期依赖关系的问题,但我们发现,当源句子反转(目标句子不反转)时,LSTM 学得更好。 通过这样做,LSTM 的测试困惑度从 5.8 下降到 4.7,解码翻译的测试 BLEU 分数从 25.9 增加到 30.6。
虽然我们对这种现象没有完整的解释,但我们认为这是由于向数据集引入了许多短期依赖性造成的。 通常,当我们将源句子与目标句子连接时,源句子中的每个单词与目标句子中对应的单词相距甚远。 因此,该问题具有较大的“最小时间滞后”[17]。 通过颠倒源句子中的单词,源语言和目标语言中对应单词之间的平均距离保持不变。 然而,源语言中的前几个单词现在与目标语言中的前几个单词非常接近,因此问题的最小时间滞后大大减少。 因此,反向传播可以更轻松地在源句子和目标句子之间“建立通信”,从而显着提高整体性能。
最初,我们认为颠倒输入句子只会导致目标句子的前半部分的预测更自信,而后半部分的预测更不自信。 然而,在反向源句子上训练的 LSTM 在长句子上的表现比在原始源句子上训练的 LSTM 好得多(参见第 3.7 节),这表明反转输入句子会导致 LSTM 具有更好的内存利用率。
3.4训练细节
我们发现 LSTM 模型相当容易训练。 我们使用 4 层的深度 LSTM,每层有 1000 个单元和 1000 维词嵌入,输入词汇量为 160,000,输出词汇量为 80,000。 因此深度LSTM使用8000个实数来表示一个句子。 我们发现深层 LSTM 的性能明显优于浅层 LSTM,其中每增加一层,困惑度就会降低近 10%,这可能是因为它们的隐藏状态要大得多。 我们在每个输出中使用了超过 80,000 个单词的朴素 softmax。 由此产生的 LSTM 有 384M 个参数,其中 64M 是纯循环连接(32M 用于“编码器”LSTM,32M 用于“解码器”LSTM)。 完整的训练细节如下:
-
•
我们初始化了 LSTM 的所有参数,使其均匀分布在 -0.08 到 0.08 之间
-
•
我们使用无动量的随机梯度下降,固定学习率为 0.7。 5 个 epoch 后,我们开始每半个 epoch 将学习率减半。 我们总共训练了 7.5 个时期的模型。
-
•
我们使用 128 个序列的批次作为梯度,并将其划分为批次的大小(即 128)。
-
•
尽管 LSTM 往往不会遇到梯度消失问题,但它们可能会出现梯度爆炸。 因此,当梯度 [10, 25] 的范数超过阈值时,我们通过对其进行缩放来对梯度的范数施加硬约束。 对于每个训练批次,我们计算 ,其中 如果 ,我们设置 .
-
•
不同的句子有不同的长度。 大多数句子都很短(例如,长度 20-30),但有些句子很长(例如,长度 100),因此由 128 个随机选择的训练句子组成的小批量将有许多短句子和很少的长句子,因此,小批量中的大部分计算都被浪费了。 为了解决这个问题,我们确保小批量中的所有句子的长度大致相同,从而实现 2 倍的加速。
3.5并行化
深度 LSTM 的 C++ 实现(采用上一节中的配置)在单个 GPU 上的处理速度约为每秒 1,700 个字。 这对于我们的目的来说太慢了,因此我们使用 8-GPU 机器并行化我们的模型。 LSTM 的每一层都在不同的 GPU 上执行,并在计算后立即将其激活传递给下一个 GPU/层。 我们的模型有 4 层 LSTM,每层都驻留在单独的 GPU 上。 剩下的4个GPU用于并行化softmax,因此每个GPU负责乘以 矩阵。 最终的实现实现了每秒 6,300 个单词(英语和法语)的速度,小批量大小为 128。 此实施的训练大约花费了十天的时间。
3.6实验结果
我们使用大小写的 BLEU 分数 [24] 来评估我们翻译的质量。 我们使用以下方法计算 BLEU 分数 多蓝.pl111 BLEU 分数有多种变体,每种变体都是用 perl 脚本定义的。 关于标记化预测和真实情况。 这种评估BELU分数的方式与[5]和[2]一致,并再现了[29]的33.3分数。 然而,如果我们以这种方式评估最好的 WMT'14 系统[9](其预测可以从statmt.org\matrix下载),我们得到 37.0,大于 statmt.org\matrix 报告的 35.8。
结果显示在表1和2中。 我们的最佳结果是通过一组 LSTM 获得的,这些 LSTM 的随机初始化和小批量的随机顺序有所不同。 虽然 LSTM 集成的解码翻译并没有优于最好的 WMT'14 系统,但纯神经翻译系统首次在大规模 MT 任务上以相当大的幅度优于基于短语的 SMT 基线,尽管它无法做到这一点处理词汇表之外的单词。 如果使用 LSTM 对基线系统的 1000 个最佳列表进行重新评分,则 LSTM 与最佳 WMT’14 结果的 BLEU 点相差不超过 0.5 分。
| Method | test BLEU score (ntst14) |
|---|---|
| Bahdanau et al. [2] | 28.45 |
| Baseline System [29] | 33.30 |
| Single forward LSTM, beam size 12 | 26.17 |
| Single reversed LSTM, beam size 12 | 30.59 |
| Ensemble of 5 reversed LSTMs, beam size 1 | 33.00 |
| Ensemble of 2 reversed LSTMs, beam size 12 | 33.27 |
| Ensemble of 5 reversed LSTMs, beam size 2 | 34.50 |
| Ensemble of 5 reversed LSTMs, beam size 12 | 34.81 |
| Method | test BLEU score (ntst14) |
|---|---|
| Baseline System [29] | 33.30 |
| Cho et al. [5] | 34.54 |
| Best WMT’14 result [9] | 37.0 |
| Rescoring the baseline 1000-best with a single forward LSTM | 35.61 |
| Rescoring the baseline 1000-best with a single reversed LSTM | 35.85 |
| Rescoring the baseline 1000-best with an ensemble of 5 reversed LSTMs | 36.5 |
| Oracle Rescoring of the Baseline 1000-best lists | 45 |
3.7 长句子的表现
| Type | Sentence |
|---|---|
| Our model | Ulrich UNK , membre du conseil d’ administration du constructeur automobile Audi , |
| affirme qu’ il s’ agit d’ une pratique courante depuis des années pour que les téléphones | |
| portables puissent être collectés avant les réunions du conseil d’ administration afin qu’ ils | |
| ne soient pas utilisés comme appareils d’ écoute à distance . | |
| Truth | Ulrich Hackenberg , membre du conseil d’ administration du constructeur automobile Audi , |
| déclare que la collecte des téléphones portables avant les réunions du conseil , afin qu’ ils | |
| ne puissent pas être utilisés comme appareils d’ écoute à distance , est une pratique courante | |
| depuis des années . | |
| Our model | “ Les téléphones cellulaires , qui sont vraiment une question , non seulement parce qu’ ils |
| pourraient potentiellement causer des interférences avec les appareils de navigation , mais | |
| nous savons , selon la FCC , qu’ ils pourraient interférer avec les tours de téléphone cellulaire | |
| lorsqu’ ils sont dans l’ air ” , dit UNK . | |
| Truth | “ Les téléphones portables sont véritablement un problème , non seulement parce qu’ ils |
| pourraient éventuellement créer des interférences avec les instruments de navigation , mais | |
| parce que nous savons , d’ après la FCC , qu’ ils pourraient perturber les antennes-relais de | |
| téléphonie mobile s’ ils sont utilisés à bord ” , a déclaré Rosenker . | |
| Our model | Avec la crémation , il y a un “ sentiment de violence contre le corps d’ un être cher ” , |
| qui sera “ réduit à une pile de cendres ” en très peu de temps au lieu d’ un processus de | |
| décomposition “ qui accompagnera les étapes du deuil ” . | |
| Truth | Il y a , avec la crémation , “ une violence faite au corps aimé ” , |
| qui va être “ réduit à un tas de cendres ” en très peu de temps , et non après un processus de | |
| décomposition , qui “ accompagnerait les phases du deuil ” . |
3.8模型分析
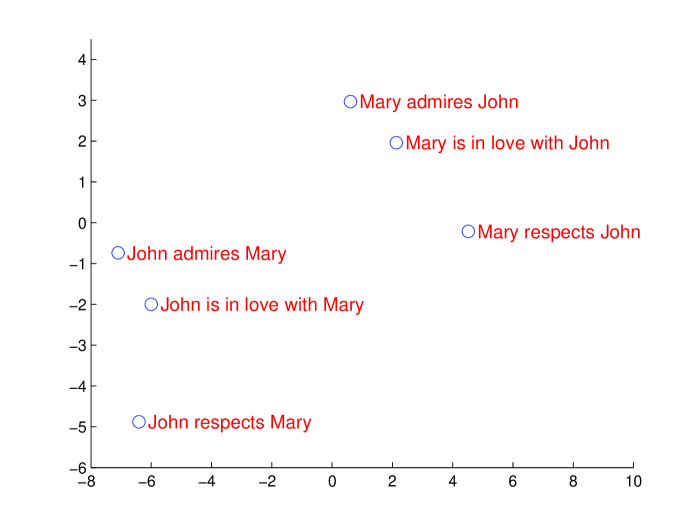
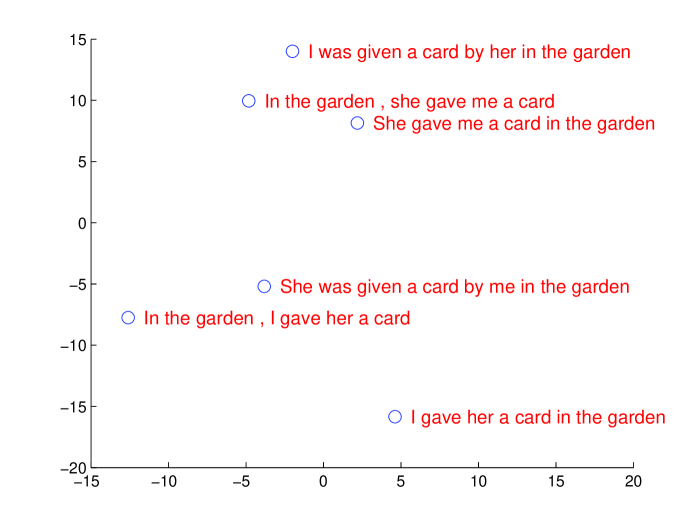
我们模型的一个吸引人的特征是它能够将单词序列转换为固定维度的向量。 图2可视化了一些学习到的表示。 该图清楚地表明,这些表示对单词的顺序很敏感,而对用被动语态替换主动语态相当不敏感。 二维投影是使用 PCA 获得的。
4相关工作
关于神经网络在机器翻译中的应用有大量的工作。 到目前为止,应用 RNN 语言模型 (RNNLM) [23] 或前馈神经网络语言模型 (NNLM) [3] 的最简单、最有效的方法MT 任务是通过对强 MT 基线 [22] 的 n 个最佳列表进行重新评分,从而可靠地提高翻译质量。
最近,研究人员开始研究将源语言信息纳入 NNLM 的方法。 这项工作的例子包括 Auli 等人 [1],他们将 NNLM 与输入句子的主题模型结合起来,从而提高了重新评分性能。 Devlin 等人[8]遵循了类似的方法,但他们将 NNLM 合并到 MT 系统的解码器中,并使用解码器的对齐信息为 NNLM 提供输入句子中最有用的单词。 他们的方法非常成功,并且比他们的基线取得了巨大的进步。
我们的工作与 Kalchbrenner 和 Blunsom [18] 密切相关,他们是第一个将输入句子映射到向量然后再映射回句子的人,尽管他们使用卷积神经网络将句子映射到向量,这会失去单词的顺序。 与这项工作类似,Cho 等人 [5] 使用类似 LSTM 的 RNN 架构将句子映射到向量并映射回来,尽管他们的主要重点是将神经网络集成到 SMT 系统中。 Bahdanau 等人 [2] 还尝试使用神经网络进行直接翻译,该神经网络使用注意力机制来克服 Cho 等人 [5] 在长句子上表现不佳的问题,以及取得了令人鼓舞的成果。 同样,Pouget-Abadie 等人 [26] 尝试通过以产生流畅翻译的方式翻译源句子片段来解决 Cho 等人 [5] 的记忆问题,这类似于基于短语的方法。 我们怀疑他们可以通过简单地在反向源句子上训练他们的网络来实现类似的改进。
端到端训练也是 Hermann 等人[12]的重点,其模型通过前馈网络表示输入和输出,并将它们映射到空间中的相似点。 然而,他们的方法无法直接生成翻译:为了获得翻译,他们需要在预先计算的句子数据库中查找最接近的向量,或者重新评分句子。
5结论
在这项工作中,我们证明了词汇量有限且几乎不对问题结构做出任何假设的大型深度 LSTM 在大规模 MT 任务中的表现优于词汇量不受限制的基于标准 SMT 的系统。 我们基于 LSTM 的简单方法在 MT 上的成功表明,只要有足够的训练数据,它应该可以在许多其他序列学习问题上表现良好。
我们对通过颠倒源句子中的单词所获得的改进程度感到惊讶。 我们的结论是,找到具有最多短期依赖性的问题编码非常重要,因为它们使学习问题变得更加简单。 特别是,虽然我们无法在非反向翻译问题上训练标准 RNN(如图 1 所示),但我们相信当源句子反向时,标准 RNN 应该很容易训练(虽然我们没有通过实验验证)。
我们还对 LSTM 正确翻译很长句子的能力感到惊讶。 我们最初确信 LSTM 由于其有限的记忆力会在长句子上失败,而其他研究人员报告说,使用与我们的模型类似的模型 [5, 2, 26] 在长句子上表现不佳。 然而,在反向数据集上训练的 LSTM 翻译长句子几乎没有困难。
最重要的是,我们证明了一种简单、直接且相对未优化的方法可以优于 SMT 系统,因此进一步的工作可能会带来更高的翻译准确性。 这些结果表明我们的方法可能会在其他具有挑战性的序列到序列问题上表现良好。
6致谢
我们感谢 Samy Bengio、Jeff Dean、Matthieu Devin、Geoffrey Hinton、Nal Kalchbrenner、Thang Luong、Wolfgang Macherey、Rajat Monga、Vincent Vanhoucke、Peng Xu、Wojciech Zaremba 以及 Google Brain 团队提供的有用评论和讨论。
参考
- [1] M. Auli, M. Galley, C. Quirk, and G. Zweig. Joint language and translation modeling with recurrent neural networks. In EMNLP, 2013.
- [2] D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- [3] Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin. A neural probabilistic language model. In Journal of Machine Learning Research, pages 1137–1155, 2003.
- [4] Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2):157–166, 1994.
- [5] K. Cho, B. Merrienboer, C. Gulcehre, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Arxiv preprint arXiv:1406.1078, 2014.
- [6] D. Ciresan, U. Meier, and J. Schmidhuber. Multi-column deep neural networks for image classification. In CVPR, 2012.
- [7] G. E. Dahl, D. Yu, L. Deng, and A. Acero. Context-dependent pre-trained deep neural networks for large vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing - Special Issue on Deep Learning for Speech and Language Processing, 2012.
- [8] J. Devlin, R. Zbib, Z. Huang, T. Lamar, R. Schwartz, and J. Makhoul. Fast and robust neural network joint models for statistical machine translation. In ACL, 2014.
- [9] Nadir Durrani, Barry Haddow, Philipp Koehn, and Kenneth Heafield. Edinburgh’s phrase-based machine translation systems for wmt-14. In WMT, 2014.
- [10] A. Graves. Generating sequences with recurrent neural networks. In Arxiv preprint arXiv:1308.0850, 2013.
- [11] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In ICML, 2006.
- [12] K. M. Hermann and P. Blunsom. Multilingual distributed representations without word alignment. In ICLR, 2014.
- [13] G. Hinton, L. Deng, D. Yu, G. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath, and B. Kingsbury. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 2012.
- [14] S. Hochreiter. Untersuchungen zu dynamischen neuronalen netzen. Master’s thesis, Institut fur Informatik, Technische Universitat, Munchen, 1991.
- [15] S. Hochreiter, Y. Bengio, P. Frasconi, and J. Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001.
- [16] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 1997.
- [17] S. Hochreiter and J. Schmidhuber. LSTM can solve hard long time lag problems. 1997.
- [18] N. Kalchbrenner and P. Blunsom. Recurrent continuous translation models. In EMNLP, 2013.
- [19] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
- [20] Q.V. Le, M.A. Ranzato, R. Monga, M. Devin, K. Chen, G.S. Corrado, J. Dean, and A.Y. Ng. Building high-level features using large scale unsupervised learning. In ICML, 2012.
- [21] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998.
- [22] T. Mikolov. Statistical Language Models based on Neural Networks. PhD thesis, Brno University of Technology, 2012.
- [23] T. Mikolov, M. Karafiát, L. Burget, J. Cernockỳ, and S. Khudanpur. Recurrent neural network based language model. In INTERSPEECH, pages 1045–1048, 2010.
- [24] K. Papineni, S. Roukos, T. Ward, and W. J. Zhu. BLEU: a method for automatic evaluation of machine translation. In ACL, 2002.
- [25] R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. arXiv preprint arXiv:1211.5063, 2012.
- [26] J. Pouget-Abadie, D. Bahdanau, B. van Merrienboer, K. Cho, and Y. Bengio. Overcoming the curse of sentence length for neural machine translation using automatic segmentation. arXiv preprint arXiv:1409.1257, 2014.
- [27] A. Razborov. On small depth threshold circuits. In Proc. 3rd Scandinavian Workshop on Algorithm Theory, 1992.
- [28] D. Rumelhart, G. E. Hinton, and R. J. Williams. Learning representations by back-propagating errors. Nature, 323(6088):533–536, 1986.
- [29] H. Schwenk. University le mans. http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/, 2014. [Online; accessed 03-September-2014].
- [30] M. Sundermeyer, R. Schluter, and H. Ney. LSTM neural networks for language modeling. In INTERSPEECH, 2010.
- [31] P. Werbos. Backpropagation through time: what it does and how to do it. Proceedings of IEEE, 1990.