用于回归的**高斯过程**:
快速介绍
M. Ebden, 2008年8月
评论发送至 mebden@gmail.com
1 动机
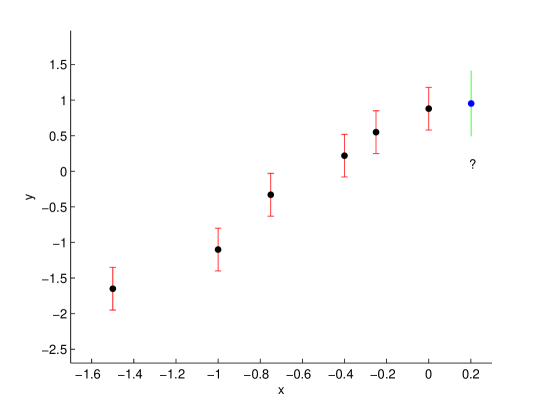
图 1 说明了一个典型的预测问题: 给定在自变量 的某些值处对因变量的一些噪声观察结果,我们对自变量在新的值 处的最佳估计是什么?
如果我们期望底层函数 是线性的,并且可以对输入数据做一些假设,我们可以使用最小二乘法来拟合一条直线(线性回归)。 此外,如果我们怀疑 也可能是二次、三次甚至非多项式的,我们可以使用模型选择原则在各种可能性之间进行选择。
高斯过程回归(GPR)比这更精细。 与声称 与某些特定模型相关联(例如 )不同,高斯过程可以通过让数据更清晰地“说话”来倾斜地、但严格地表示 。 GPR 仍然是一种监督学习的形式,但训练数据以更微妙的方式被利用。
因此,GPR 是一种不太“参数化”的工具。 然而,它并不完全是自由形式的,如果我们不愿意对 做出任何基本假设,那么应该考虑更通用的技术,包括那些以最大熵原理为基础的技术;Sivia 和 Skilling (2006) 的第 6 章提供了一个介绍。
2 高斯过程的定义
高斯过程(GP)将多元高斯分布扩展到无限维。 正式地,高斯过程在某个域中生成数据,使得范围的任何有限子集都遵循多元高斯分布。 现在,, 因此,反向推理,这个数据集可以与一个GP配对。 因此,GP既普遍又简单。
很多时候,假设这个配对GP的均值在任何地方都为零。 在这种情况下,将一个观察结果与另一个观察结果联系起来的就是协方差函数,。 一个流行的选择是“平方指数”,
| (1) |
其中最大允许协方差被定义为 - 对于在轴上覆盖广泛范围的函数,这应该很高。 如果,那么接近这个最大值,这意味着与几乎完全相关。 这是好的:为了使我们的函数看起来平滑,邻居必须相似。 现在如果距离很远,我们反而有,即这两个点无法“看到”彼此。 因此,例如,在新的值上的插值期间,距离较远的观察结果将具有可以忽略的影响。 这种分离的影响程度将取决于长度参数,因此在(1)中内置了很大的灵活性。
尽管如此,灵活性还不够:数据通常也很嘈杂,例如来自测量误差。 每个观察结果可以被认为是通过高斯噪声模型与基础函数相关的:
| (2) |
对于那些以前做过回归的人来说,这应该看起来很熟悉。 回归是寻找。 纯粹是为了简化下一页的说明,我们采用了将噪声折叠到 中的新颖方法,通过编写
| (3) |
其中 是克罗内克德尔塔函数。 (当大多数人使用高斯过程时,他们将 与 分开。 然而,我们对 的重新定义同样适合于处理图 1 中提出的问题。 因此,给定 观测值 ,我们的目标是预测 ,而不是“实际”;根据 (2),它们的期望值是相同的,但由于观测噪声过程,它们的方差有所不同。 例如在图 1 中, 和 的预期值是 处的点。)
3 如何使用高斯过程进行回归
由于 GP 建模的关键假设是我们的数据可以表示为多元高斯分布的样本,因此我们有
| (6) |
其中表示矩阵转置。 我们当然对条件概率 感兴趣:“给定数据, 的某个预测的可能性有多大?”。 正如附录中更慢地解释的那样,概率遵循高斯分布:
| (7) |
我们对 的最佳估计是该分布的平均值:
| (8) |
我们估计的不确定性体现在其方差中:
| (9) |
现在我们已准备好处理图 1 中的数据。
- 1.
- 2.
-
3.
图 1 展示了一个带有问号的数据点, 代表在 处对因变量的估计。
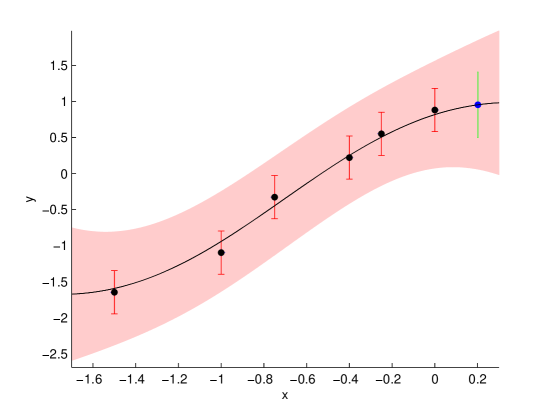
我们可以在 轴上的某些部分重复上述过程,如 图 2 所示。 (实际上,等效地,我们可以通过一次执行上述过程来避免重复, 使用适当更大的 和 矩阵。 在这种情况下,由于有 1,000 个测试点分布在 轴上, 的大小将为 1,000 1,000。) 与绘制简单的误差范围相比,我们决定绘制 ,给出 95% 的置信区间。
4 GPR 在现实世界中的应用
我们回归的可靠性取决于我们选择协方差函数的程度。 显然,如果它的参数——我们称之为 ——没有被明智地选择,结果就是无稽之谈。 我们对 的最大后验估计发生在 最大时。 贝叶斯定理告诉我们,假设我们对 应该是什么几乎没有先验知识,这对应于最大化 ,由
| (10) |
只需对该方程运行你最喜欢的多元优化算法(例如共轭梯度、Nelder-Mead单纯形等),你就会找到一个相当不错的 的选择;在我们的例子中, 和 。
它只是“相当不错”,因为当然,托马斯·贝叶斯正在他的坟墓里翻滚。 当你可以对 的许多不同可能选择进行积分时,为什么只推荐一个 的答案? Rasmussen 和 Williams (2006) 的第 5 章介绍了这种情况下必要的方程。
最后,如果你觉得你已经掌握了图 2 中的玩具问题,接下来的两个例子将处理更复杂的情况。 图 3(a),除了长期下降趋势,还有一些波动,因此我们可能会使用更复杂的协方差函数:
| (11) |
第一项考虑了因变量的小波动,第二项具有更长的长度参数 () 来表示其长期趋势。 协方差函数可以通过这种方式无限增长,以适应特定数据的复杂性。
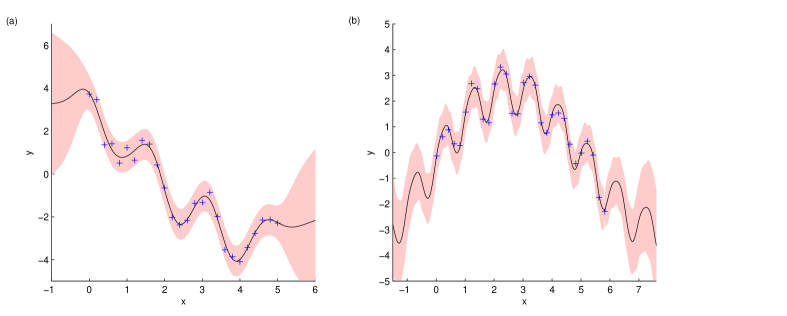
该函数看起来好像可能包含一个周期性元素,但很难确定。 让我们考虑另一个函数,我们被告知它有一个周期性元素。 图 3(b) 中的实线是用以下协方差函数回归的:
| (12) |
第一项表示长期内的类似山丘的趋势,第二项以频率 给出周期性。 这是我们第一次遇到 和 距离很远,但仍然可以“看到”彼此的情况(即 对于 )。
如果因变量有其他动态,先验地,您预计会出现的? 可以变得多么复杂都没有限制,只要 是正定的。 Rasmussen 和 Williams (2006) 的第 4 章概述了您应该在工具箱中保留的协方差函数范围。
“等等,”你问道,“从工具箱中选择一个协方差函数,是否很像选择模型类型,例如线性与立方——我们在开始时讨论过?”好吧,确实存在相似之处。 事实上,如果没有对数据集施加至少一点结构,就无法执行回归;这是生成模型的本质。 然而,值得重复的是,高斯过程确实允许数据非常清晰地表达。 例如,在许多环境中使用 (1) 存在着良好的理论依据 (Rasmussen 和 Williams (2006),第 4.3 节)。 您仍然需要仔细调查哪些协方差函数适合您的数据集。 本质上,在替代函数之间进行选择是反映对正在研究的 物理过程 的各种先验知识的一种方式。
5 讨论
我们已经简要概述了 GPR 的数学原理,但上述想法的实际实现需要解决一些算法障碍,而不是数据分析的障碍。 如果您不是优秀的计算机程序员,那么图 1 和 2 的代码位于 github.com/mebden/GPtutorial,更通用的代码可以在 www.gaussianprocess.org/gpml 找到。
我们仅仅触及了一种强大技术的表面 (MacKay, 1998)。 首先,虽然重点是一维输入,但接受更高维度的输入很简单。 其中 将从标量变为向量, 将保持为标量,因此总体数学运算几乎不会改变。 其次,表示 (6) 中多元高斯分布均值的零向量可以替换为 的函数。 第三,除了在回归中的应用之外,GP 还适用于积分、全局优化、混合专家模型、无监督学习模型等等——参见 Rasmussen 和 Williams (2006) 的第 9 章。 下一个教程将重点介绍它们在 分类 中的应用。
参考文献
- MacKay (1998) MacKay, D. (1998). In C.M. Bishop (Ed.), Neural networks and machine learning. (NATO ASI Series, Series F, Computer and Systems Sciences, Vol. 168, pp. 133-166.) Dordrecht: Kluwer Academic Press.
- Rasmussen and Williams (2006) Rasmussen, C. and C. Williams (2006). Gaussian Processes for Machine Learning. MIT Press.
- Sivia and Skilling (2006) Sivia, D. and J. Skilling (2006). Data Analysis: A Bayesian Tutorial (second ed.). Oxford Science Publications.
附录
想象一个从某些具有零均值和由矩阵 给出的协方差的多元高斯分布中取出的数据样本 。现在任意地将 分解为两个连续的子向量 和 ——换句话说,写 等同于写
| (13) |
其中 、 和 是构成 的相应部分。
有趣的是,给定 的 的条件分布本身是高斯分布的。 如果协方差矩阵 是对角线甚至是对角线块,那么知道 不会告诉我们关于 的任何信息:具体来说,。 另一方面,如果 不为零,那么一些矩阵代数将引导我们得到
| (14) |
均值,,被称为“回归系数矩阵”,而方差,,是“ 在 中的 Schur 补”。
总之,如果我们知道 的一部分,我们可以利用它来推断我们对 的其余部分的估计,这要归功于 的揭示性的非对角元素。
用于分类的高斯过程:
快速入门
M. Ebden,2008 年 8 月
前提阅读:用于回归的高斯过程
1 概述
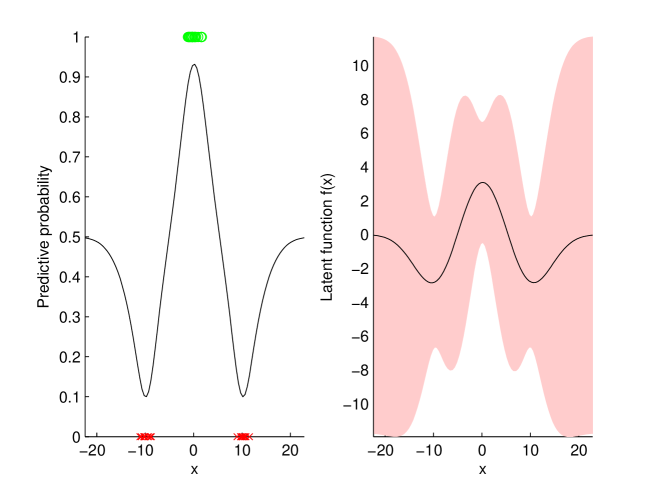
如前文所述,GP 可以应用于回归以外的问题。 例如,如果 GP 的输出被压缩到范围 内,它可以表示数据点属于两个类型之一的 概率,瞧,我们可以确定分类。 这就是 本文的主题。
GPR 和 GPC 之间的最大区别在于输出数据 如何与底层函数 输出 相关联。 它们不再像前文中 (2) 中那样通过噪声过程简单地连接,而是 现在是离散的:对于一个类别来说精确地是 ,而对于另一个类别来说则是 。 原则上,我们可以尝试拟合一个 GP,它在 的某些值下产生大约为 的输出,而在 其他值下则产生大约为 的输出,模拟这种离散化。 相反,我们在数据和 压缩函数之间插入 GP;然后,对新数据点 的分类需要两个步骤而不是一个步骤:
-
1.
评估一个“潜在函数” ,它对一个类别与另一个类别在 轴上的可能性如何变化进行定性建模。 这就是 GP。
-
2.
使用任何 S 型函数 将此潜在函数的输出压缩到 。
用图表表示这两个步骤,
数据, 潜在函数, 类别概率, 。
下一节将逐步详细地向您介绍这种分类器是如何工作的。 第 3 节解释了 如何训练分类器,因此我们可能是在反向顺序介绍内容! 第 4 节处理 当有超过两个类别时的分类。
在我们开始之前,关于 的一个快速说明。 虽然其他形式也可以,但这里我们将规定它是累积高斯分布,。 这个形的函数满足了我们的需求,将高映射到,将低映射到。
2 使用分类器
假设我们已经从输入数据及其对应的专家标注的输出数据训练了一个分类器。 并假设在这个过程中我们形成了一些与这些数据对应的GP输出,这些数据有一些不确定性,但平均值由给出。 我们现在准备输入一个新的数据点,在我们示意图的左侧,以便在另一端确定其类别成员资格的概率。
在第一步中,找到概率类似于GPR,即我们调整(2):
| (3) |
(将很快解释,但现在把它看作与非常相似。) 在第二步中,我们将压缩以找到类别成员资格的概率。 预期值是
| (4) |
这是一个累积高斯与高斯的积分,可以解析求解。 根据Rasmussen and Williams (2006)的第3.9节,解为:
| (5) |
图1展示了一个示例。
3 在分类器中训练 GP
我们的目标现在是找到 和 ,这样我们就知道关于生成 (3) 的 GP 的一切信息,这是分类器的第一步。 分类器的第二步不需要训练,因为它是一个固定的 S 型函数。
在与我们的数据集配对的众多 GP 中,自然地,我们希望定量地比较它们的效用。 考虑到某个 GP 的输出 ,它们对于训练数据是否合适的可能性可以使用贝叶斯定理分解:
| (6) |
让我们关注分子中的两个因素。 假设数据集是 i.i.d.,
| (7) |
丢弃乘积中的下标, 由我们的 S 型函数 提供信息。 具体来说, 按定义等于 ,为了完整起见,。 结合这两种情况的简洁方式是写 。
分子中的第二个因素是 。 这与我们示意图的第一步的输出有关,但首先我们对最大化后验概率 的 值感兴趣。 当 (6) 对 的导数为零时,或者等效地更简单地说,当它的对数的导数为零时,就会发生这种情况。 做到这一点,并使用与上一篇文档中产生 (10) 相同的逻辑,我们发现
| (8) |
其中 是我们问题中最好的 。 不幸的是, 出现在等式两侧,因此我们先做一个初始猜测(零是可以的)并进行几次迭代。 (8) 的答案可以直接用于 (3),因此我们找到了其中我们寻求的两个量之一。
的方差由 (6) 的对数的负二阶导数给出,结果为 ,其中 。 进行 拉普拉斯近似,我们假装 服从高斯分布,即
| (9) |
(这个假设有时不准确,因此如果它产生较差的分类,应该考虑表征 中不确定性的更好方法,例如通过期望传播。)
现在谈到一个微妙的点。 可以变化的事实意味着直接使用 (2) 是不合适的:特别是,它的平均值是正确的,但它的方差不再能说明全部情况。 这就是我们使用自适应版本 (3) 的原因,其中 代替 。 由于 (2) 中变化的量 被 乘以,因此我们将 添加到 (2) 中的方差。 简化后得到 (3),其中 。
现在 GP 已完全指定,我们已准备好使用上一节中描述的分类器。
现实世界中的 GPC
与 GPR 一样,我们分类的可靠性取决于我们在第一步中选择 GP 中协方差函数的程度。 参数为 ,现在少了一个,因为 。
但是,像往常一样, 通过最大化 来优化,或者(省略等式右侧的 ),
| (10) |
这可以使用拉普拉斯近似进行简化,得到
| (11) |
这是在 GPR 中执行时运行您最喜欢的优化器的方程。
4 多类别GPC
我们已经描述了二元分类,其中可能的类别数,,只有两个。 在类的情况下, 一种方法是为每个类拟合一个。 在分类的两个步骤中的第一步,我们的GP值被串联起来作为
| (12) |
令为与长度相同的向量,对于每个,它对于类别标签为,对于其他项为。 令在矩阵中增长为块对角线。 因此,对于我们看到的第一个 变化是GP的延长。 Rasmussen和 Williams(2006)的第3.5节提供了关于如何使计算可管理的提示。
第二个变化是,(仅仅是一维的)累积高斯分布不再足以描述我们分类器中挤压 函数;相反,我们使用softmax函数。 对于第个数据点,
| (13) |
其中是的非连续子集,即。 我们可以用总结我们的结果。
5 讨论
与 GPR 一样,分类可以扩展为接受具有多个维度的 值,同时保持大部分数学不变。 其他可能的扩展包括使用期望传播方法代替前面提到的拉普拉斯近似, 对分类概率设置置信区间,计算 (16) 的导数以帮助优化器,或者 使用 MacKay (1998) 中描述的变分高斯过程分类器,仅举四种扩展为例。
其次,我们重复之前文档中的贝叶斯调用,以对一系列可能的协方差函数进行积分 参数。 无论有多少先验知识都应该这样做——例如,参见 Sivia 和 Skilling (2006) 的第 5 章,了解如何在最不透明的情况下选择先验。
第三,我们再次为您省去了一些实用的算法细节;计算机代码可在 www.gaussianprocess.org/gpml 找到, 并附有示例。
致谢
感谢 Stephen Roberts 教授和模式分析研究小组的成员,以及 ALADDIN 项目 (www.aladdinproject.org)。
参考文献
- MacKay (1998) MacKay, D. (1998). In C.M. Bishop (Ed.), Neural networks and machine learning. (NATO ASI Series, Series F, Computer and Systems Sciences, Vol. 168, pp. 133-166.) Dordrecht: Kluwer Academic Press.
- Rasmussen and Williams (2006) Rasmussen, C. and C. Williams (2006). Gaussian Processes for Machine Learning. MIT Press.
- Sivia and Skilling (2006) Sivia, D. and J. Skilling (2006). Data Analysis: A Bayesian Tutorial (second ed.). Oxford Science Publications.
用于降维的高斯过程:
快速入门
M. Ebden,2015 年 8 月
预备阅读:用于回归的高斯过程
假设您想学习一个数据集的低维表示,以便于解释,就像您的影子是对三维物体的简化二维表示一样。 令原始数据为矩阵 ,其中包含 行(观测值),每行有 个维度,令新的表示为 ,其中包含 行,每行有 个维度 ()。
为了学习这种低维表示,我们假设对于 的 维度, 中的 个元素是基于低维空间的高斯过程的样本。 具体来说,我们将使用一个零均值高斯过程,,为 的每个维度保留相同的模型。我们将为 选择平方指数核(又称 RBF 核),以确保 中接近的点在 中也会接近。将噪声方差从 (在第一份报告中)重命名为 ,则核为:
此 GP 的协方差矩阵 按照第一份报告中的 (4) 构建,我们不需要 (5) 中的 或 ,因为 中没有要预测的点。 这次的核参数元组是 。
我们进一步假设每个 维度背后的 GP 是独立采样的。 因此, 中观测值的似然是 个独立 GP 的乘积:
然后我们可以调整 和 以最大化此似然。 如果我们只调整 ,它就类似于确定最有可能对应您身体形状的阴影。 因为我们也调整了 ,所以想象一下操控光源和阴影出现的表面。
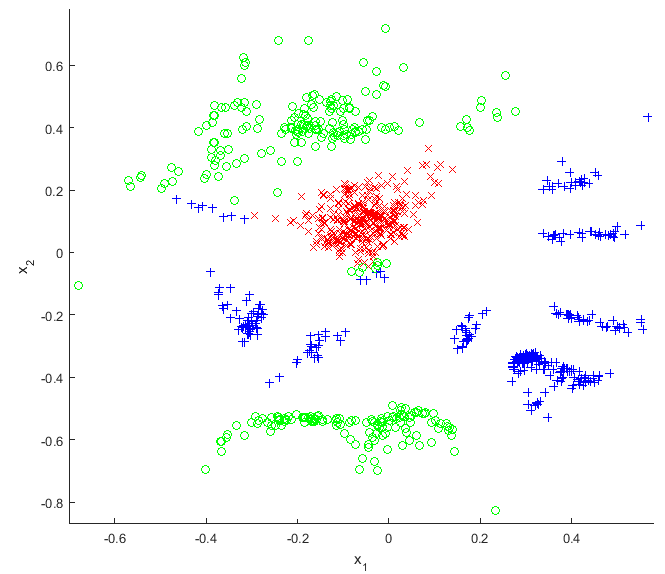
图 1 给出了对于某个 的最可能 的示例结果,其中 、 和 。 已预处理为每个维度均值为零且方差相同。 使用基于缩放共轭梯度的优化器,随后找到了最优的 和 。 前者是 ,后者在图 1(b) 中给出。 在这个例子中, 不仅仅是 的“阴影”(简单投影):上述降维方法足够强大,可以了解到图 1(a) 中左侧曲线的点应该组合在一起,而右侧曲线的点形成一个独立的组;没有简单的灯光投影可以实现这一点。 我们为这种灵活性付出的代价是大量参数需要拟合:总数为 ,即 加上 中的一维值。 通常 被称为潜在变量而不是参数,我们的整体设置被称为“高斯过程潜在变量模型”(GP-LVM)。 该技术最初由 Neil Lawrence 于 2004 年提出;他检查了一组油流数据,其中 和 ,我们将它们简化为图 2 中的 。
本 GP-LVM 教程由牛津大学的技术衍生公司 Mind Foundry 提供。
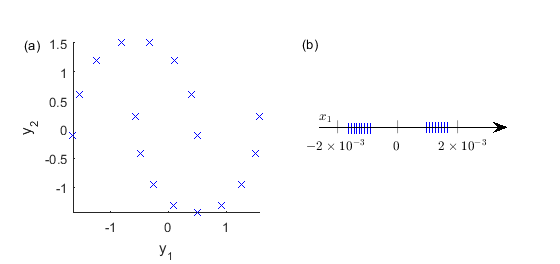
d (b) 这些点的 一维投影。