Dropout 作为贝叶斯近似:
表示深度学习中的模型不确定性
摘要
深度学习工具在应用机器学习领域获得了极大的关注。 然而,此类回归和分类工具无法捕获模型的不确定性。 相比之下,贝叶斯模型提供了一个以数学为基础的框架来推理模型的不确定性,但通常会带来高昂的计算成本。 在本文中,我们开发了一个新的理论框架,将深度神经网络(NN)中的 dropout 训练转换为深度高斯过程中的近似贝叶斯推理。 该理论的直接结果为我们提供了使用 dropout NN 来对不确定性进行建模的工具——从迄今为止已被丢弃的现有模型中提取信息。 这减轻了深度学习中表示不确定性的问题,而不会牺牲计算复杂性或测试准确性。 我们对辍学不确定性的特性进行了广泛的研究。 以 MNIST 为例,在回归和分类任务上评估各种网络架构和非线性。 与现有最先进的方法相比,我们在预测对数似然和 RMSE 方面取得了相当大的进步,并通过在深度强化学习中使用 dropout 的不确定性来完成。
1简介
深度学习引起了物理、生物学、制造等领域研究人员的极大关注(Baldi等人,2014;Anjos等人,2015;Bergmann等人,2014)。 神经网络 (NN)、dropout、卷积神经网络 (convnet) 等工具被广泛使用。 然而,在这些领域中,表示模型不确定性至关重要(Krzywinski & Altman,2013;Ghahramani,2015)。 随着最近许多领域转向使用贝叶斯不确定性(Herzog & Ostwald,2013;Trafimow & Marks,2015;Nuzzo,2014),深度学习工具产生了新的需求。
用于回归和分类的标准深度学习工具无法捕获模型的不确定性。 在分类中,在管道末端获得的预测概率(softmax 输出)经常被错误地解释为模型置信度。 即使 softmax 输出较高,模型的预测也可能不确定(图 1)。 通过 softmax(实线 1(b))传递函数的点估计(实线 1(a))会导致对远点的置信度不合理的外推从训练数据来看。 例如, 将被分类为类别 1,概率为 。 然而,将分布(阴影区域1(a))传递给softmax(阴影区域1(b))可以更好地反映远离训练数据的分类不确定性。
模型不确定性对于深度学习从业者来说也是不可或缺的。 有了模型的置信度,我们就可以明确地处理不确定的输入和特殊情况。 例如,在分类的情况下,模型可能返回具有高度不确定性的结果。 在这种情况下,我们可能决定将输入传递给人类进行分类。 这可能发生在邮局,根据邮政编码对信件进行分类,或者发生在拥有负责关键基础设施的系统的核电站(Linda等人,2009)。 不确定性在强化学习 (RL) 中也很重要(Szepesvári,2010)。 利用不确定性信息,智能体可以决定何时利用以及何时探索其环境。 RL 的最新进展利用神经网络进行 Q 值函数逼近。 这些函数用于估计代理可以采取的不同操作的质量。 Epsilon 贪婪搜索通常用于代理以一定概率选择最佳操作并探索其他操作的情况。 通过对代理 Q 值函数的不确定性估计,汤普森采样(Thompson,1933)等技术可用于更快地学习。
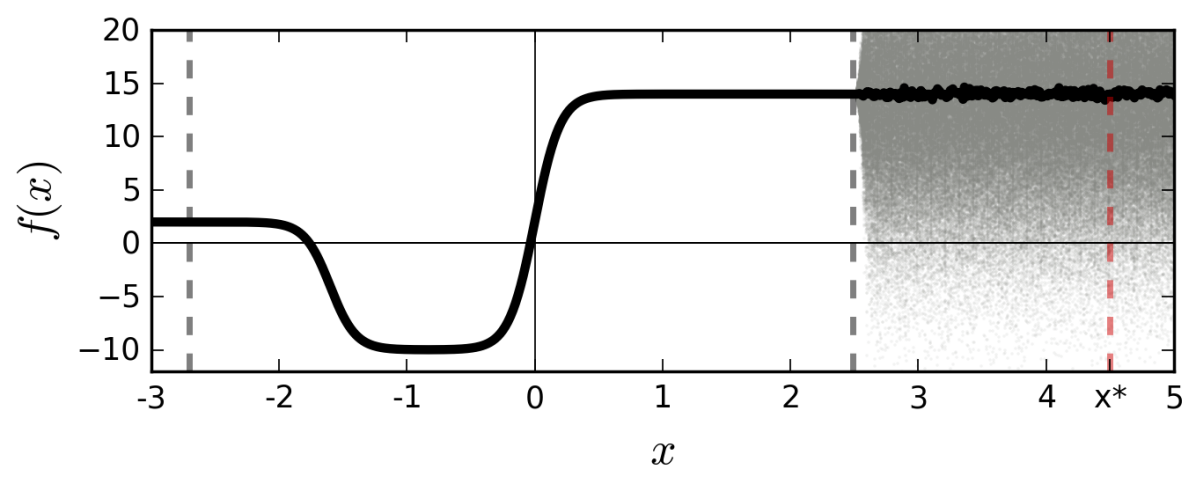
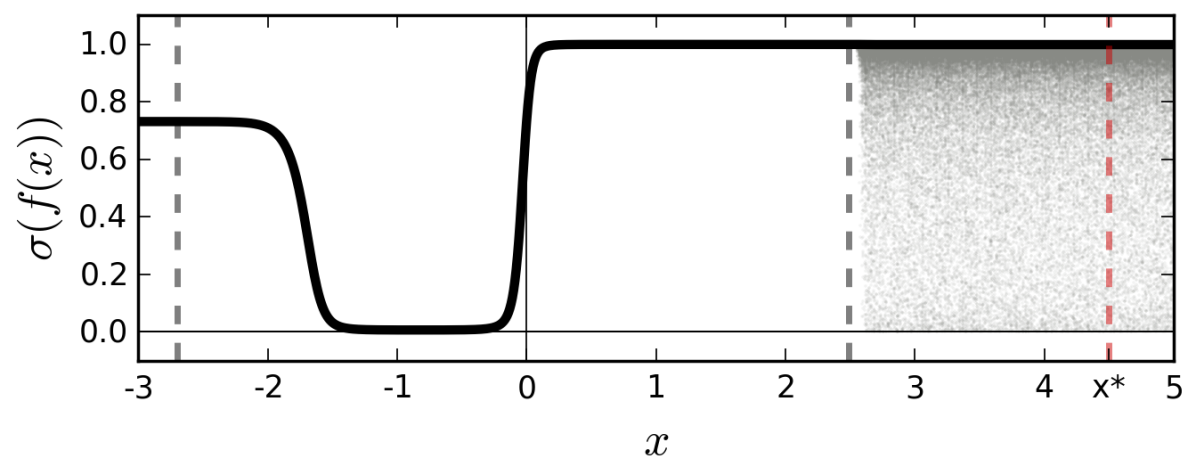
贝叶斯概率论为我们提供了基于数学的工具来推理模型的不确定性,但这些工具通常会带来高昂的计算成本。 也许令人惊讶的是,可以将最新的深度学习工具转换为贝叶斯模型——而不改变模型或优化。 我们证明,在神经网络中使用 dropout(及其变体)可以解释为众所周知的概率模型的贝叶斯近似:高斯过程 (GP)(Rasmussen & Williams,2006)。 Dropout 在深度学习的许多模型中被用作避免过度拟合的一种方式(Srivastava 等人,2014),我们的解释表明 Dropout 近似整合了模型的权重。 我们开发了用于表示现有 dropout NN 的模型不确定性的工具 - 提取迄今为止已被丢弃的信息。 这减轻了深度学习中表示模型不确定性的问题,而无需牺牲计算复杂性或测试准确性。
在本文中,我们对高斯过程和 dropout 之间的联系进行了完整的理论处理,并开发了表示深度学习中的不确定性所需的工具。 我们对回归和分类任务中的 dropout 神经网络和卷积网络获得的不确定性的特性进行了广泛的探索性评估。 我们比较了从不同模型架构获得的不确定性和回归中的非线性,并以 MNIST 作为具体示例表明模型不确定性对于分类任务是不可或缺的。 然后,与现有最先进的方法相比,我们在预测对数似然和 RMSE 方面展示了相当大的改进。 最后,我们在类似于深度强化学习中使用的实际任务(Mnih等人,2015)中对强化学习设置中的模型不确定性进行了定量评估。111代码和演示可从 http://yarin.co 获取。
2相关研究
人们早就知道,权重分布的无限宽(单隐藏层)神经网络会收敛于高斯过程(Neal,1995;Williams,1997)。 这种已知关系是通过极限参数实现的,该极限参数不允许我们轻松地将属性从高斯过程转换为有限神经网络。 权重分布的有限神经网络已被广泛研究为贝叶斯神经网络(Neal,1995;MacKay,1992)。 这些也提供了对过度拟合的鲁棒性,但具有挑战性的推理和额外的计算成本。 变分推理已应用于这些模型,但取得的成功有限(Hinton & Van Camp,1993;Barber & Bishop,1998;Graves,2011)。 变分推理的最新进展将新技术引入该领域,例如基于采样变分推理和随机变分推理(Blei 等人,2012;Kingma & Welling, 2013; Rezende 等人, 2014; Titsias & Lázaro-Gredilla, 2014; Hoffman 等人, 2013)。 这些已用于获得贝叶斯神经网络的新近似值,其性能与 dropout 一样(Blundell 等人,2015)。 然而,这些模型的计算成本令人望而却步。 为了表示不确定性,对于相同的网络大小,这些模型中的参数数量加倍。 此外,它们需要更多时间来收敛并且不会改进现有技术。 鉴于可以从常见的 dropout 模型中廉价地获得良好的不确定性估计,这可能会导致不必要的额外计算。 变分推理的另一种方法利用期望传播(Hernández-Lobato & Adams,2015),并且在 RMSE 和 VI 方法的不确定性估计方面有了显着改进,例如(Graves,2011). 在结果部分,我们将 dropout 与这些方法进行比较,并显示 RMSE 和不确定性估计都有显着改进。
3 作为贝叶斯近似的 Dropout
我们证明,具有任意深度和非线性的神经网络,在每个权重层之前应用 dropout,在数学上等价于概率深度高斯过程的近似(Damianou & Lawrence,2013)(边缘化)其协方差函数参数)。 我们想强调的是,文献中没有对 dropout 的使用做出简化假设,并且得出的结果适用于任何使用 dropout 的网络架构,就像实际应用中出现的那样。 此外,我们的结果也适用于 dropout 的其他变体(例如 drop-connect (Wan 等人, 2013)、乘性高斯噪声 (Srivastava 等人, 2014) , ETC。)。 我们表明,dropout 目标实际上最小化了近似分布与深度高斯过程的后验之间的 Kullback-Leibler 散度(在其有限秩协方差函数参数上边缘化)。 由于篇幅限制,我们建议读者参阅附录,深入回顾 dropout、高斯过程和变分推理(第 2 节),以及 dropout 及其变体的主要推导(第 3 节)。 这里总结了结果,在下一节中我们获得了 dropout NN 的不确定性估计。
令 为具有 层和损失函数 的 NN 模型的输出,例如 softmax 损失或欧几里得损失(平方损失)。 我们用 表示 NN 的权重矩阵,维数为 ;用 表示每层的偏置向量,维数为 ,维数为 。 我们用 表示 数据点的输入 对应的观察到的输出,输入和输出设置为 。 在神经网络优化期间,经常添加正则化项。 我们经常使用正则化,通过一些权重衰减进行加权,从而实现最小化目标(通常称为成本),
| (1) |
通过 dropout,我们对每个输入点和每一层中的每个网络单元(除了最后一层)进行二进制变量采样。 对于层 ,每个二元变量取值 1,概率为 。 对于给定输入,如果其相应的二进制变量值为 0,则该单位将被删除(即,其值设置为零)。 我们在向后传递中使用相同的值将导数传播到参数。
与非概率神经网络相比,深度高斯过程是统计学中的一个强大工具,它允许我们对函数的分布进行建模。 假设我们给出了形式的协方差函数
具有一些元素方面的非线性和分布。 在附录的第 3 节和第 4 节中,我们展示了具有 层和协方差函数 的深层高斯过程,可以通过在谱分解的每个分量上放置变分分布来近似GP 的协方差函数。 这种谱分解将深度 GP 的每一层映射到显式表示的隐藏单元层,如下文将简要解释的那样。
令 为每层 的维度为 的(现在是随机的)矩阵,并写入 。 先验,我们让的每一行按照上面的分布。 此外,假设每个 GP 层的向量 的维度为 。 深度 GP 模型的预测概率(积分 w.r.t. 给定一些精度参数,有限秩协方差函数参数)可以参数化为
| (2) | ||||
等式中的后验分布 (2) 很棘手。 我们使用 (列随机设置为零的矩阵分布)来近似难以处理的后验。 我们将 定义为:
给定一些概率 和矩阵 作为变分参数。 二进制变量 对应于层 中的单元 ,作为层 的输入被丢弃。 变分分布 是高度多模态的,在矩阵 的行(对应于稀疏频谱 GP 近似中的频率)上产生强联合相关性。
我们最小化上面的近似后验 和全深 GP 的后验 之间的 KL 散度。 这个KL就是我们的最小化目标
| (3) |
我们将第一项重写为总和
并通过蒙特卡罗积分与单个样本 近似求和中的每一项,以获得无偏估计 。 我们进一步近似等式中的第二项。 (3) 并获得具有先前长度尺度 的 (参见附录中的第 4.2 节)。 给定模型精度 ,我们将结果按常数 缩放以获得目标:
| (4) | ||||
环境
我们恢复方程。 (1) 用于正确设置精度超参数 和长度尺度 。采样的 结果是伯努利分布 的实现,相当于 dropout 情况下的二进制变量222在附录(第 4.1 节)中,我们将此推导扩展到分类。 定义为softmax损失,设置为1。.
4 获取模型不确定度
接下来我们得出的结果扩展了上述结果,表明模型不确定性可以从 dropout NN 模型中获得。
根据附录 2.3 节,我们的近似预测分布由下式给出
| (5) |
其中 是具有 层的模型的随机变量集。
我们将进行矩匹配并凭经验估计预测分布的前两个矩。 更具体地说,我们从伯努利分布 和 中采样 组实现向量,得到 。 我们估计
| (6) |
遵循附录中的命题 C。 我们将此蒙特卡洛估计称为MC dropout。 实际上,这相当于在网络中执行随机前向传递并对结果求平均值。
该结果之前已在文献中作为模型平均提出。 我们对此结果给出了新的推导,这使我们能够得出基于数学的不确定性估计。 Srivastava 等人(2014,第 7.5 节) 根据经验推断,MC dropout 可以通过平均网络权重(将每个 乘以 来近似)在测试时,称为标准 dropout)。
我们以同样的方式估计第二个原始时刻:
遵循附录中的命题 D。 为了获得模型的预测方差,我们有:
它等于通过神经网络的随机前向传递的样本方差加上逆模型精度。 请注意, 是行向量,因此总和超过外积。 给定权重衰减 (以及我们之前的长度尺度 ),我们可以从恒等式中找到模型精度
| (7) |
我们可以通过等式的蒙特卡罗积分来估计我们的预测对数似然。 (2)。 这是对模型对均值和不确定性的拟合程度的估计(请参阅附录中的第 4.4 节)。 对于回归,由下式给出:
| (8) |
具有 项的 log-sum-exp 和 随机前向传递通过网络。
我们的预测分布 预计将是高度多模态的,并且上述近似值仅给出了其属性的一瞥。 这是因为每个权重矩阵列上的近似变分分布是双模态的,因此每层权重上的联合分布是多模态的(附录中的第 3.2 节)。
请注意,dropout NN 模型本身并没有改变。 为了估计预测平均值和预测不确定性,我们只需收集模型的随机前向传递的结果。 因此,这些信息可以与使用 dropout 训练的现有 NN 模型一起使用。 此外,前向传递可以同时进行,从而产生与标准 dropout 相同的恒定运行时间。
5实验
接下来,我们对回归和分类任务中从 dropout NN 和卷积网络获得的不确定性估计的属性进行广泛的评估。 我们比较了在外推任务上从不同模型架构和非线性获得的不确定性,并以 MNIST (LeCun & Cortes,1998) 为例表明模型不确定性对于分类任务很重要。 然后我们证明,与现有的最先进方法相比,利用 dropout 的不确定性,我们可以在预测对数似然和 RMSE 方面获得相当大的改进。 最后,我们以贝叶斯管道中模型不确定性的示例使用为例。 我们对模型在强化学习设置中的性能进行了定量评估,该任务类似于深度强化学习中使用的任务(Mnih等人,2015)。
使用上一节的结果,我们首先定性评估两个回归任务的 dropout NN 不确定性。 我们使用两个回归数据集和易于可视化的模型标量函数。 这些是人们在现实世界的数据分析中经常遇到的任务。 我们使用从夏威夷莫纳罗亚天文台采集的原位空气样本中获得的大气 CO2 浓度数据集的子集(Keeling 等人,2004 年)(称为CO2)来评估模型外推。 在附录(D.1 节)中,我们给出了第二个数据集(重建的太阳辐照度数据集(Lean,2004))的进一步结果,以评估模型插值。 数据集相当小,每个数据集由大约 200 个数据点组成。 我们对两个数据集进行了居中和标准化。
5.1 回归任务中的模型不确定性
我们在 CO2 数据集上训练了多个模型。 我们使用具有 4 或 5 个隐藏层和 1024 个隐藏单元的神经网络。 我们在每个网络中使用 ReLU 非线性或 TanH 非线性,并使用 或 的丢失概率。 附录 E.1 节给出了确切的实验设置。
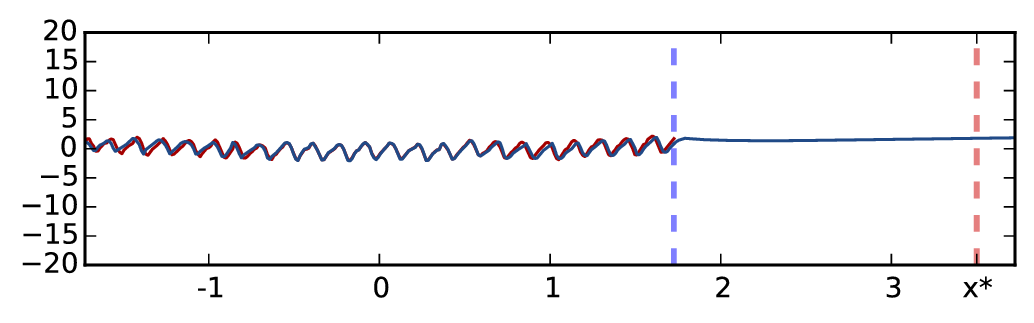
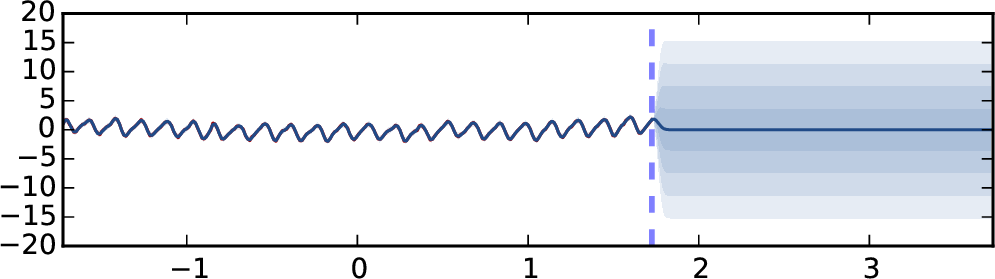
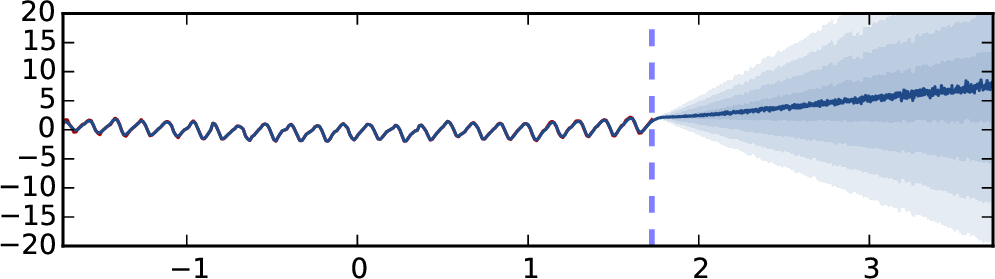
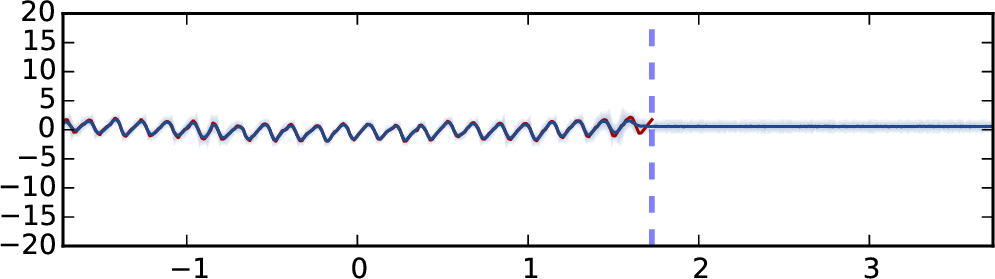
外推结果如图2所示。 该模型在训练数据(蓝色虚线左侧)上进行训练,并在整个数据集上进行测试。 图2(a)显示了5层ReLU模型的标准dropout(即权重平均且不评估模型不确定性)的结果。 图2(b)显示了使用平方指数协方差函数的高斯过程获得的结果以进行比较。 图2(c)显示了与图2相同的网络的结果。 2(a),但使用 MC dropout 来评估训练集和测试集的预测平均值和不确定性。 最后,如图。 2(d) 使用具有 5 层的 TanH 网络显示相同的结果(出于可视化目的,使用 8 倍标准差绘制)。 蓝色阴影代表模型不确定性:每个颜色梯度代表一半标准差(总共显示预测平均值加/减 2 个标准差,代表 95% 的置信度)。 没有绘制 4 层模型,因为它们收敛到相同的结果。
推断观察到的数据,没有一个模型可以捕获周期性(尽管使用合适的协方差函数,GP 可以很好地捕获它)。 标准 dropout NN 模型(图 2(a))以高置信度预测点 (用红色虚线标记)的值为 0,尽管它显然不是一个明智的预测。 GP 模型通过增加其预测不确定性来体现这一点——实际上声明预测值可能为 0,但模型是不确定的。 MC dropout 中也捕获了这种行为。 尽管图 2 中的模型具有不正确的预测平均值,但增加的标准差表示模型对该点的不确定性。

请注意,对于 ReLU 模型,不确定性的增加与数据相差甚远,而对于 TanH 模型,不确定性则保持有界。


这并不奇怪,因为 dropout 的不确定性从 GP 中汲取了其属性,其中不同的协方差函数对应于不同的不确定性估计。 ReLU 和 TanH 近似不同的 GP 协方差函数(附录中的第 3.1 节),TanH 饱和,而 ReLU 不会。 对于 TanH 模型,我们使用丢失概率 和丢失概率 评估不确定性。 使用 dropout 概率 初始化的模型最初表现出比使用 dropout 概率 初始化的模型更小的不确定性,但在优化结束时,当模型收敛时,不确定性几乎无法区分。 看起来 dropout 模型的矩收敛于近似 GP 模型的矩——它的均值和不确定性。 值得一提的是,我们尝试将数据与层数较少的模型进行拟合,但没有成功。
出于绘图目的,用于估计不确定性 () 的前向迭代次数为 。 可以使用更小的数字来获得对预测平均值和不确定性的合理估计(例如,参见图 3 和 )。
5.2分类任务中的模型不确定性
为了评估实际示例中的模型分类置信度,我们测试了在完整 MNIST 数据集(LeCun & Cortes,1998)上训练的卷积神经网络。 我们训练 LeNet 卷积神经网络模型(LeCun 等人,1998),并在最后一个完全连接的内积层之前应用 dropout(这是卷积网络中使用 dropout 的常用方式)。 我们使用的丢失概率。 我们使用与之前 和 相同的学习率策略对模型进行 迭代训练。 我们使用 Caffe (Jia 等人, 2014) 参考实现来进行此实验。
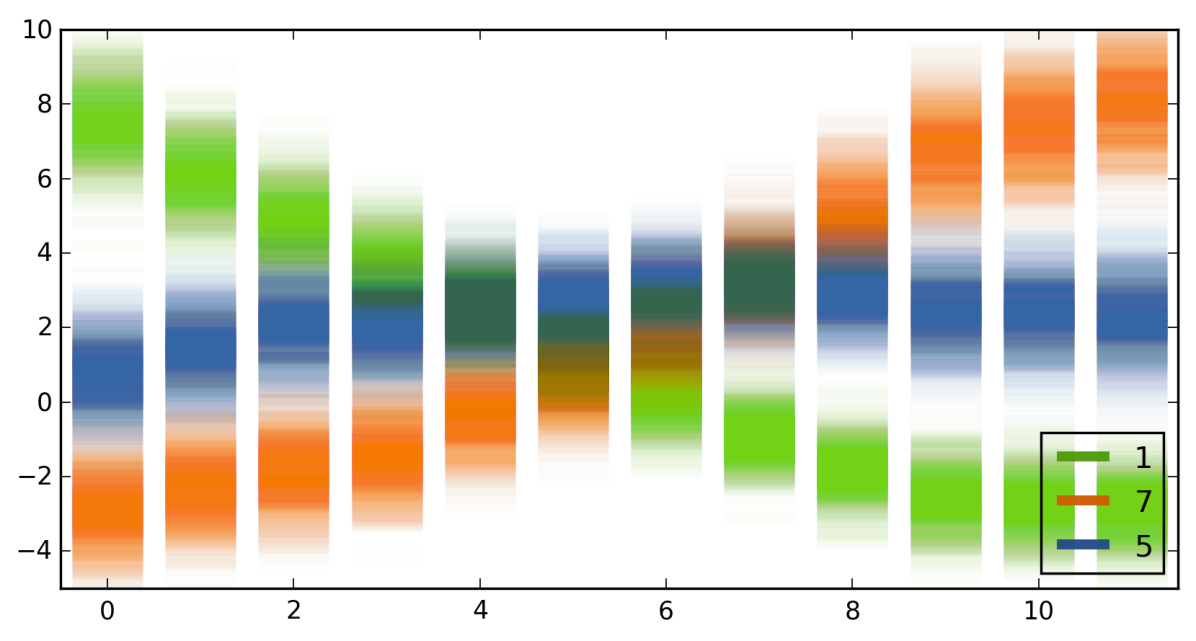
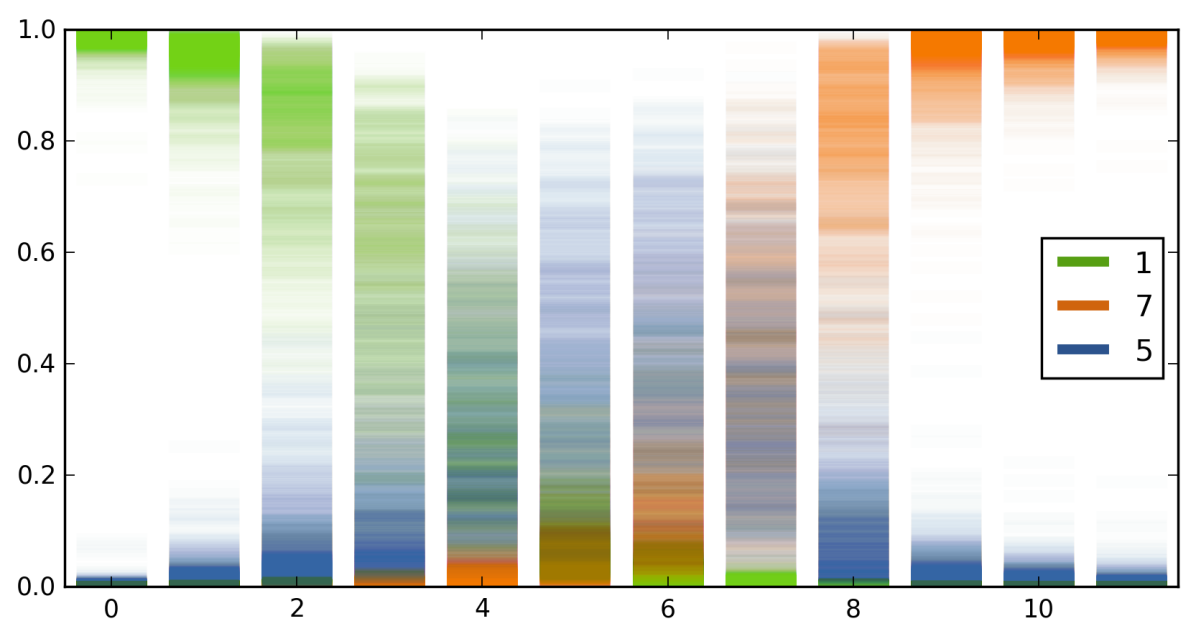
我们在数字 1 的连续旋转图像上评估训练模型(如图 4 的 轴所示)。 我们分散了 softmax 输入(最后一个全连接层的输出,图 4(a))以及每个顶级类的 softmax 输出(图4(b))。 对于 12 张图像,模型预测类别 [1 1 1 1 1 5 5 7 7 7 7 7]。
| Avg. Test RMSE and Std. Errors | Avg. Test LL and Std. Errors | |||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | VI | PBP | Dropout | VI | PBP | Dropout | ||
| Boston Housing | 506 | 13 | 4.32 0.29 | 3.01 0.18 | 2.97 0.19 | -2.90 0.07 | -2.57 0.09 | -2.46 0.06 |
| Concrete Strength | 1,030 | 8 | 7.19 0.12 | 5.67 0.09 | 5.23 0.12 | -3.39 0.02 | -3.16 0.02 | -3.04 0.02 |
| Energy Efficiency | 768 | 8 | 2.65 0.08 | 1.80 0.05 | 1.66 0.04 | -2.39 0.03 | -2.04 0.02 | -1.99 0.02 |
| Kin8nm | 8,192 | 8 | 0.10 0.00 | 0.10 0.00 | 0.10 0.00 | 0.90 0.01 | 0.90 0.01 | 0.95 0.01 |
| Naval Propulsion | 11,934 | 16 | 0.01 0.00 | 0.01 0.00 | 0.01 0.00 | 3.73 0.12 | 3.73 0.01 | 3.80 0.01 |
| Power Plant | 9,568 | 4 | 4.33 0.04 | 4.12 0.03 | 4.02 0.04 | -2.89 0.01 | -2.84 0.01 | -2.80 0.01 |
| Protein Structure | 45,730 | 9 | 4.84 0.03 | 4.73 0.01 | 4.36 0.01 | -2.99 0.01 | -2.97 0.00 | -2.89 0.00 |
| Wine Quality Red | 1,599 | 11 | 0.65 0.01 | 0.64 0.01 | 0.62 0.01 | -0.98 0.01 | -0.97 0.01 | -0.93 0.01 |
| Yacht Hydrodynamics | 308 | 6 | 6.89 0.67 | 1.02 0.05 | 1.11 0.09 | -3.43 0.16 | -1.63 0.02 | -1.55 0.03 |
| Year Prediction MSD | 515,345 | 90 | 9.034 NA | 8.879 NA | 8.849 NA | -3.622 NA | -3.603 NA | -3.588 NA |
该图显示了 3 位数字的 softmax 输入值和 softmax 输出值,以及每个相应输入的最大值。 当某个类的 softmax 输入大于所有其他类的输入时(图 4(a) 中前 5 个图像为类 1,接下来 2 个图像为类 5,其余图像为类 7) >),模型预测对应的类别。 查看 softmax 输入值,如果一个类的不确定性包络与其他类的不确定性包络相差甚远(例如最左边的图像),则输入的分类具有高置信度。 另一方面,如果不确定性包络与其他类的不确定性包络相交(例如在中间输入图像的情况下),那么即使 softmax 输出可以任意高(如果均值远离均值,则可达 1)其他类别的),softmax 输出不确定性可以与整个空间一样大。 这表明模型的 softmax 输出值(即预测)存在不确定性。 在这种情况下,当不确定性如此之高时,使用概率为中间图像返回 5 类是不合理的。 人们会期望模型向外部注释器询问该输入的标签。 这种情况下的模型不确定性可以通过查看模型预测的熵或变化比来量化。
5.3预测性能
预测对数似然捕获模型对数据的拟合程度,值越大表明模型拟合效果越好。 不确定性质量也可以根据该数量来确定(参见附录中的第 4.4 节)。 我们复制了 Hernández-Lobato & Adams (2015) 中的实验设置,并将 Dropout(在实验中称为“Dropout”)的 RMSE 和预测对数似然与 Probabilistic Back 进行比较-传播(称为“PBP”,(Hernández-Lobato & Adams,2015))以及贝叶斯神经网络中流行的变分推理技术(称为“VI”,(Graves) ,2011))。 本实验的目的是比较在 NN 中 nnaive 滤波的应用与为捕捉不确定性而开发的专门方法所获得的不确定性质量。
根据我们对 dropout 的贝叶斯解释(eq. (4)),我们需要定义一个先前的长度尺度,并找到一个最佳模型精度参数 ,这将使我们能够评估预测对数似然(eq. (4))。 与(Hernández-Lobato & Adams,2015)类似,我们在验证日志上使用贝叶斯优化(BO,(Snoek等人,2012;Snoek&authors,2015))找到最佳的可能性,并根据数据范围将大多数数据集的先验长度尺度设置为。 请注意,这是一个标准的 dropout NN,其中先前的长度尺度 和模型精度 仅用于通过等式定义模型的权重衰减: (7)。 我们使用概率为 和 的 dropout,因为网络规模非常小( 之后有 50 个单元(Hernández-Lobato & Adams,2015))并且数据集也相当小。 BO 运行在原始设置后使用了 40 次迭代,但在找到最佳参数值后,我们使用了 10 倍以上的迭代,因为 dropout 需要更长的时间才能收敛。 尽管模型在 40 次迭代内没有收敛,但它为 BO 提供了参数是否良好的良好指示。 最后,我们使用了大小为 32 的小批量和 Adam 优化器(Kingma & Ba,2014)。 有关各种数据集的更多详细信息,请参阅(Hernández-Lobato & Adams,2015)。
结果见表333更新 [2016 年 10 月]:请注意,在本文的早期版本中,我们报告的 dropout 标准误差被错误地按比例放大了因子为 4.5(例如,对于波士顿 RMSE,我们报告的标准误差为 0.85,而不是 0.19)。 1. Dropout 在 RMSE 以及除 Yacht 之外的所有数据集上的测试对数似然性方面都显着优于所有其他模型,其中 PBP 获得了更好的 RMSE。 所有实验均对 20 个随机数据分割进行平均(除了仅使用 5 个分割的蛋白质和使用 1 个分割的年份)。 大多数数据集的中位数比平均值提供更好的性能。 例如,在波士顿住房数据集上,辍学学生的 RMSE 中位数为 2.68,IQR 区间为 [2.45, 3.35],预测对数似然中位数为 -2.34,IQR [-2.54, -2.29]。 在混凝土强度数据集中,dropout 的 RMSE 中值达到 5.15。
为了实现该模型,我们使用了 Keras (Chollet,2015),这是一个基于 Theano (Bergstra 等人,2010) 的开源深度学习包。 在(Hernández-Lobato & Adams,2015)中,与 PBP 相比,VI 的 BO 似乎需要大量的额外时间。 然而我们模型的运行时间(包括 BO)与 PBP 的 Theano 实现相当444 更新 [2016 年 10 月]:在上面的结果中,我们尝试匹配 PBP 的运行时间(因此与 PBP 相比,只使用了 10 倍多的 epoch) 40 个纪元)。 与 PBP 相比,实验的历时增加了 100 倍(与表 1 中的结果相比,实验的历时增加了 10 倍),与表 1 中的结果相比,测试 RMSE 和测试对数似然均有显著改善。 我们进一步评估了具有两个隐藏层而不是一个隐藏层的模型(第二层使用相同数量的单元)。 这两个实验均显示在本文档末尾的表 2 中。 . 例如,在海军推进领域,我们的模型每次分段平均需要 276 秒(从开始到结束,除以分段数量)。 找到最佳参数 BO 后,模型训练耗时 95 秒。 这是与 PBP 的 220 秒相比。 对于 Kin8nm,我们的模型平均需要 188 秒(包括 BO),不包括 BO 需要 65 秒,而 PBP 需要 156 秒。
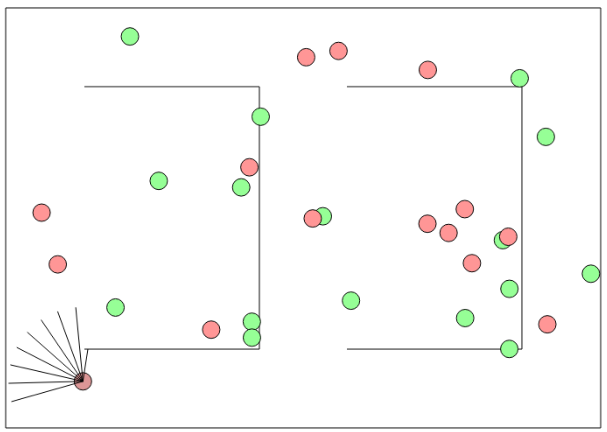
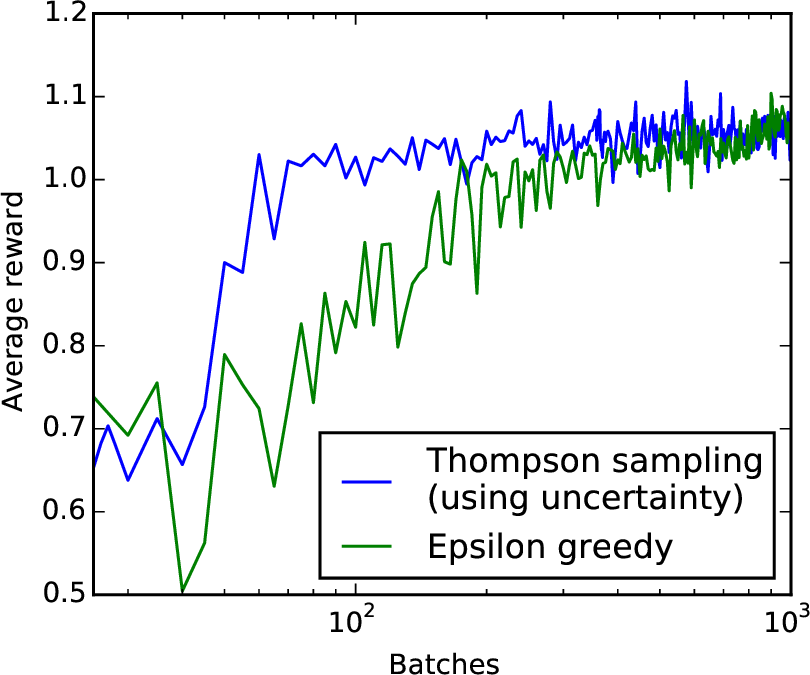
表 1 中 Dropout 的 RMSE 是通过对网络中的随机前向传播进行平均得出的,如下式: (6)(MC 丢失)。 与标准辍学权重平均相比,以及与小得多的辍学概率(接近零)相比,我们观察到使用此估计的改进。 例如,对于波士顿住房数据集,以退出概率 0 重复相同的实验会导致 RMSE 为 3.07,预测对数似然为 -2.59。 这表明,即使 dropout 概率相当小,dropout 也会显着影响预测对数似然和 RMSE。
我们使用 dropout 的方式与当前研究中使用的方法相同——无需调整模型结构。 这是为了证明在使用 MC dropout 进行评估时可以从现有模型中获得的结果。 通过尝试不同的网络架构,我们期望该方法能够给出更好的不确定性估计。
5.4强化学习中的模型不确定性
在强化学习中,代理从不同状态接收各种奖励,其目标是随着时间的推移最大化其预期奖励。 代理试图学习避免过渡到低奖励状态,并选择导致更好状态的行动。 不确定性在这项任务中非常重要——利用不确定性信息,智能体可以决定何时利用它所知道的奖励,以及何时探索其环境。
RL 的最新进展利用神经网络来估计智能体的 Q 值函数(称为 Q 网络),该函数用于估计智能体在不同状态下可以采取的不同动作的质量。 这在 Atari 游戏模拟中取得了令人印象深刻的结果,智能体在各种游戏中取代了人类的表现(Mnih 等人,2015)。 在此设置中使用了 Epsilon 贪婪搜索,其中代理以一定的概率根据当前 Q 函数估计选择最佳操作,并探索其他操作。 通过 dropout Q 网络给出的不确定性估计,我们可以使用 Thompson 采样(Thompson,1933) 等技术来比 epsilon 贪婪更快地收敛,同时避免过度拟合。
我们使用 (Karpathy &authors, 2014–2015) 的代码,该代码通过更简单的 2D 设置复制了 (Mnih 等人, 2015) 的结果。 我们模拟 2D 世界中的代理,其 9 只眼睛指向前方的不同角度(如图 6 所示)。 每只眼睛可以感知 3 种颜色的单个像素强度。 该代理通过使用 5 个动作之一控制其底部的两个电机来进行导航。 一个动作使电机以不同的角度和不同的速度转动。 环境由红色圆圈和绿色圆圈组成,红色圆圈给予代理到达时的正奖励,绿色圆圈则给予负奖励。 智能体因不看(白)墙并沿直线行走而获得进一步奖励。
我们训练了原始模型,并在每个权重层之前应用了概率为 0.1 的 dropout 的附加模型。 请注意,出于比较目的,两个代理在本实验中使用相同的网络结构。 在使用 dropout 的现实场景中,我们将使用更大的模型(因为原始模型被特意选择得很小以避免过度拟合)。 为了利用 dropout Q 网络的不确定性估计,我们使用 Thompson 采样而不是 epsilon 贪婪采样。 实际上,这意味着每次我们需要采取行动时,我们都会通过网络执行一次随机前向传递。 在重播中,我们执行一次随机前向传播,然后使用采样的伯努利随机变量进行反向传播。 附录 E.2 节给出了精确的实验设置。
在图中。 6 我们展示了原始实现(绿色)和我们的方法(蓝色)获得的平均奖励的对数图,作为批次数量的函数。 未绘制 25 个批次(随机移动)的预烧间隔。 汤普森采样在预烧后的 25 个批次内获得大于 的奖励。 Epsilon 贪婪需要 175 个批次才能达到相同的性能。 有趣的是,我们的方法似乎在 1K 批次之后停止改进。 这是因为我们仍在对随机动作进行采样,而 epsilon 贪婪仅在这个阶段进行利用。
6 结论和未来研究
我们建立了 dropout 的概率解释,这使我们能够从现有的深度学习模型中获得模型不确定性。 我们详细研究了这种不确定性的特性,并演示了可能的应用,将贝叶斯模型和深度学习模型交织在一起。 这延伸了从贝叶斯角度研究辍学的初步研究(Wang & Manning,2013;Maeda,2014)。
伯努利丢失只是与导致不确定性估计的近似变分分布相对应的正则化技术的一个示例。 Dropout 的其他变体也遵循我们的解释,并对应于替代的近似分布。 这些将导致不同的不确定性估计,权衡不确定性质量与计算复杂性。 我们将在后续工作中探索这些。
此外,每个 GP 协方差函数与 NN 非线性和权重正则化的组合具有一一对应的关系。 这提出了根据我们对数据的先验假设来选择适当的神经网络结构和正则化的技术。 例如,如果预期函数是平滑的并且不确定性会增加得远离数据,则余弦非线性和 正则化可能是合适的。 非线性正则化组合以及相应的预测均值和方差的研究是当前研究的主题。
致谢
作者要感谢 Yutian Chen 博士、Christof Angermueller 先生、Roger Frigola 先生、Rowan McAllister 先生、Gabriel Synnaeve 博士、Mark van der Wilk 先生、Yan Wu 先生以及许多其他审稿人的有益评论。 Yarin Gal 得到了谷歌欧洲机器学习奖学金的支持。
参考
- Anjos et al. (2015) Anjos, O, Iglesias, C, Peres, F, Martínez, J, García, Á, and Taboada, J. Neural networks applied to discriminate botanical origin of honeys. Food chemistry, 175:128–136, 2015.
- Baldi et al. (2014) Baldi, P, Sadowski, P, and Whiteson, D. Searching for exotic particles in high-energy physics with deep learning. Nature communications, 5, 2014.
- Barber & Bishop (1998) Barber, D and Bishop, C M. Ensemble learning in Bayesian neural networks. NATO ASI SERIES F COMPUTER AND SYSTEMS SCIENCES, 168:215–238, 1998.
- Bergmann et al. (2014) Bergmann, S, Stelzer, S, and Strassburger, S. On the use of artificial neural networks in simulation-based manufacturing control. Journal of Simulation, 8(1):76–90, 2014.
- Bergstra et al. (2010) Bergstra, James, Breuleux, Olivier, Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Desjardins, Guillaume, Turian, Joseph, Warde-Farley, David, and Bengio, Yoshua. Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy), June 2010. Oral Presentation.
- Blei et al. (2012) Blei, D M, Jordan, M I, and Paisley, J W. Variational Bayesian inference with stochastic search. In ICML, 2012.
- Blundell et al. (2015) Blundell, C, Cornebise, J, Kavukcuoglu, K, and Wierstra, D. Weight uncertainty in neural networks. ICML, 2015.
- Chen et al. (2015) Chen, W, Wilson, J T, Tyree, S, Weinberger, K Q, and Chen, Y. Compressing neural networks with the hashing trick. In ICML-15, 2015.
- Chollet (2015) Chollet, François. Keras. https://github.com/fchollet/keras, 2015.
- Damianou & Lawrence (2013) Damianou, A and Lawrence, N. Deep Gaussian processes. In AISTATS, 2013.
- Ghahramani (2015) Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature, 521(7553), 2015.
- Graves (2011) Graves, A. Practical variational inference for neural networks. In NIPS, 2011.
- Hernández-Lobato & Adams (2015) Hernández-Lobato, J M and Adams, R P. Probabilistic backpropagation for scalable learning of bayesian neural networks. In ICML-15, 2015.
- Herzog & Ostwald (2013) Herzog, S and Ostwald, D. Experimental biology: Sometimes Bayesian statistics are better. Nature, 494, 2013.
- Hinton & Van Camp (1993) Hinton, G E and Van Camp, D. Keeping the neural networks simple by minimizing the description length of the weights. In Proceedings of the sixth annual conference on Computational learning theory, 1993.
- Hoffman et al. (2013) Hoffman, M D, Blei, D M, Wang, C, and Paisley, J. Stochastic variational inference. The Journal of Machine Learning Research, 14(1):1303–1347, 2013.
- Jia et al. (2014) Jia, Y, Shelhamer, E, Donahue, J, Karayev, S, Long, J, Girshick, R, Guadarrama, S, and Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093, 2014.
- Karpathy & authors (2014–2015) Karpathy, A and authors. A Javascript implementation of neural networks. https://github.com/karpathy/convnetjs, 2014–2015.
- Keeling et al. (2004) Keeling, C D, Whorf, T P, and the Carbon Dioxide Research Group. Atmospheric CO2 concentrations (ppmv) derived from in situ air samples collected at Mauna Loa Observatory, Hawaii, 2004.
- Kingma & Welling (2013) Kingma, D P and Welling, M. Auto-encoding variational Bayes. arXiv preprint arXiv:1312.6114, 2013.
- Kingma & Ba (2014) Kingma, Diederik and Ba, Jimmy. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Krzywinski & Altman (2013) Krzywinski, M and Altman, N. Points of significance: Importance of being uncertain. Nature methods, 10(9), 2013.
- Lean (2004) Lean, J. Solar irradiance reconstruction. NOAA/NGDC Paleoclimatology Program, USA, 2004.
- LeCun & Cortes (1998) LeCun, Y and Cortes, C. The mnist database of handwritten digits, 1998.
- LeCun et al. (1998) LeCun, Y, Bottou, L, Bengio, Y, and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Linda et al. (2009) Linda, O, Vollmer, T, and Manic, M. Neural network based intrusion detection system for critical infrastructures. In Neural Networks, 2009. IJCNN 2009. International Joint Conference on. IEEE, 2009.
- MacKay (1992) MacKay, D J C. A practical Bayesian framework for backpropagation networks. Neural computation, 4(3), 1992.
- Maeda (2014) Maeda, S. A Bayesian encourages dropout. arXiv preprint arXiv:1412.7003, 2014.
- Mnih et al. (2015) Mnih, V, Kavukcuoglu, K, Silver, D, Rusu, A A, Veness, J, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
- Neal (1995) Neal, R M. Bayesian learning for neural networks. PhD thesis, University of Toronto, 1995.
- Nuzzo (2014) Nuzzo, Regina. Statistical errors. Nature, 506(13):150–152, 2014.
- Rasmussen & Williams (2006) Rasmussen, C E and Williams, C K I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning). The MIT Press, 2006.
- Rezende et al. (2014) Rezende, D J, Mohamed, S, and Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In ICML, 2014.
- Snoek & authors (2015) Snoek, Jasper and authors. Spearmint. https://github.com/JasperSnoek/spearmint, 2015.
- Snoek et al. (2012) Snoek, Jasper, Larochelle, Hugo, and Adams, Ryan P. Practical Bayesian optimization of machine learning algorithms. In Advances in neural information processing systems, pp. 2951–2959, 2012.
- Srivastava et al. (2014) Srivastava, N, Hinton, G, Krizhevsky, A, Sutskever, I, and Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 2014.
- Szepesvári (2010) Szepesvári, C. Algorithms for reinforcement learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 4(1), 2010.
- Thompson (1933) Thompson, W R. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 1933.
- Titsias & Lázaro-Gredilla (2014) Titsias, M and Lázaro-Gredilla, M. Doubly stochastic variational Bayes for non-conjugate inference. In ICML, 2014.
- Trafimow & Marks (2015) Trafimow, D and Marks, M. Editorial. Basic and Applied Social Psychology, 37(1), 2015.
- Wan et al. (2013) Wan, L, Zeiler, M, Zhang, S, LeCun, Y, and Fergus, R. Regularization of neural networks using dropconnect. In ICML-13, 2013.
- Wang & Manning (2013) Wang, S and Manning, C. Fast dropout training. ICML, 2013.
- Williams (1997) Williams, C K I. Computing with infinite networks. NIPS, 1997.
附录A附录
该论文的附录位于http://arxiv.org/abs/1506.02157。
| Avg. Test RMSE and Std. Errors | Avg. Test LL and Std. Errors | |||||
|---|---|---|---|---|---|---|
| Dataset | Dropout | 10x Epochs | 2 Layers | Dropout | 10x Epochs | 2 Layers |
| Boston Housing | 2.97 0.19 | 2.80 0.19 | 2.80 0.13 | -2.46 0.06 | -2.39 0.05 | -2.34 0.02 |
| Concrete Strength | 5.23 0.12 | 4.81 0.14 | 4.50 0.18 | -3.04 0.02 | -2.94 0.02 | -2.82 0.02 |
| Energy Efficiency | 1.66 0.04 | 1.09 0.05 | 0.47 0.01 | -1.99 0.02 | -1.72 0.02 | -1.48 0.00 |
| Kin8nm | 0.10 0.00 | 0.09 0.00 | 0.08 0.00 | 0.95 0.01 | 0.97 0.01 | 1.10 0.00 |
| Naval Propulsion | 0.01 0.00 | 0.00 0.00 | 0.00 0.00 | 3.80 0.01 | 3.92 0.01 | 4.32 0.00 |
| Power Plant | 4.02 0.04 | 4.00 0.04 | 3.63 0.04 | -2.80 0.01 | -2.79 0.01 | -2.67 0.01 |
| Protein Structure | 4.36 0.01 | 4.27 0.01 | 3.62 0.01 | -2.89 0.00 | -2.87 0.00 | -2.70 0.00 |
| Wine Quality Red | 0.62 0.01 | 0.61 0.01 | 0.60 0.01 | -0.93 0.01 | -0.92 0.01 | -0.90 0.01 |
| Yacht Hydrodynamics | 1.11 0.09 | 0.72 0.06 | 0.66 0.06 | -1.55 0.03 | -1.38 0.01 | -1.37 0.02 |