指针网络
摘要
我们引入了一种新的神经架构来学习输出序列的条件概率,其中的元素是与输入序列中的位置相对应的离散标记。 此类问题无法通过序列到序列[1]和神经图灵机[2]等现有方法轻松解决,因为每个步骤中目标类的数量输出的长度取决于输入的长度,输入的长度是可变的。 诸如对可变大小序列进行排序的问题以及各种组合优化问题都属于此类。 我们的模型使用最近提出的神经注意力机制解决了可变大小输出字典的问题。 它与之前的注意力尝试的不同之处在于,它不是使用注意力在每个解码器步骤将编码器的隐藏单元混合到上下文向量,而是使用注意力作为指针来选择输入序列的成员作为输出。 我们将此架构称为指针网络(Ptr-Net)。 我们展示了 Ptr-Nets 可用于学习三个具有挑战性的几何问题的近似解决方案——寻找平面凸包、计算 Delaunay 三角剖分和平面旅行商问题——仅使用训练示例。 Ptr-Net 不仅通过输入注意力改进了序列到序列,而且还允许我们泛化到可变大小的输出字典。 我们表明,学习到的模型的泛化能力超出了它们训练的最大长度。 我们希望这些任务的结果能够鼓励对离散问题的神经学习进行更广泛的探索。
1简介
三十多年来,循环神经网络 (RNN) 一直用于学习示例序列上的函数[3]。 然而,他们的架构将其限制为输入和输出以固定帧速率可用的设置(例如[4])。 最近引入的序列到序列范式 [1] 通过使用一个 RNN 将输入序列映射到嵌入,并使用另一个(可能相同)RNN 将嵌入映射到输出序列,消除了这些约束。 巴达瑙等。 等人。通过使用基于内容的注意力机制[5,2,6]从输入传播额外的上下文信息来增强解码器。 这些进展使得 RNN 应用于新领域成为可能,在自然语言处理的核心问题上取得了最先进的结果,例如翻译 [1, 5] 和解析 [ 7],图像和视频字幕[8, 9],甚至学习执行小程序[2, 10]。
不过,这些方法仍然要求输出字典的大小先验固定。 由于这个限制,我们不能直接将该框架应用于组合问题,其中输出字典的大小取决于输入序列的长度。 在本文中,我们通过重新利用 [5] 的注意力机制来创建指向输入元素的指针来解决此限制。 我们展示了所得到的架构,我们将其命名为指针网络(Ptr-Nets),经过训练后可以为三个组合优化问题输出令人满意的解决方案——计算平面凸包、Delaunay 三角剖分和对称平面旅行商问题(TSP)。 由此产生的模型以纯粹数据驱动的方式(即,当我们只有输入和所需输出的示例时)产生这些问题的近似解决方案。 所提出的方法如图1所示。
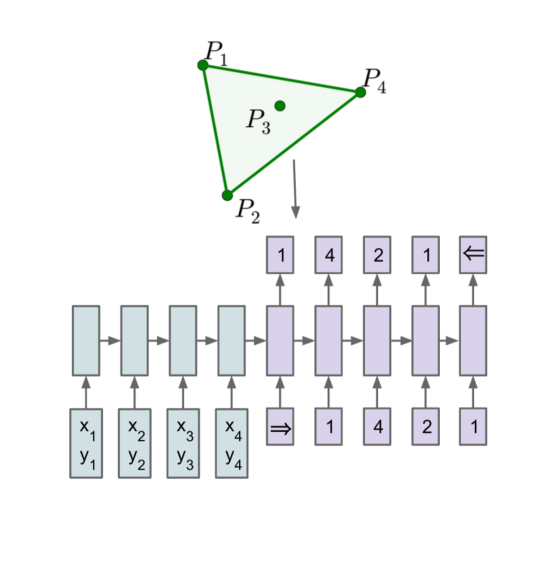
我们工作的主要贡献如下:
-
•
我们提出了一种新的架构,我们称之为Pointer Net,它简单而有效。 它通过使用 softmax 概率分布作为“指针”来解决表示可变长度字典的基本问题。
-
•
我们将指针网络模型应用于涉及几何的三个不同的非平凡算法问题。 我们表明,学习的模型可以推广到比训练问题具有更多分数的测试问题。
-
•
我们的 Pointer Net 模型学习有竞争力的小规模 () TSP 近似求解器。 我们的结果表明,纯粹的数据驱动方法可以学习计算上难以解决的问题的近似解决方案。
2型号
2.1序列到序列模型
模型的参数是通过最大化集合的训练条件概率来学习的,即
| (2) |
其中总和超过训练示例。
与 [1] 一样,我们使用长短期记忆 (LSTM) [11] 来建模 。 RNN 在每个时间步 馈送 ,直到到达输入序列的末尾,此时输入一个特殊符号 到模型。 然后模型切换到生成模式,直到网络遇到特殊符号,它表示输出序列的终止。
请注意,该模型没有做出统计独立性假设。 我们使用两个独立的 RNN(一个用于编码向量序列 ,另一个用于生成或解码输出符号 )。 我们将前者称为编码器,后者称为解码器或生成式 RNN。
在推理过程中,给定一个序列,学习到的参数用于选择概率最高的序列,即 由于可能的输出序列的组合数量,寻找最佳序列在计算上是不切实际的。 相反,我们使用波束搜索过程来找到给定波束大小的最佳可能序列。
在此序列到序列模型中,所有符号 的输出字典大小都是固定的且等于 ,因为输出是从输入中选择的。 因此,我们需要为每个 训练一个单独的模型。这使得我们无法学习输出字典大小取决于输入序列长度的问题的解决方案。
假设输出数量为 ,该模型的计算复杂度为 。 然而,针对我们正在处理的问题的精确算法成本更高。 例如,凸包问题的复杂度为。 注意力机制(参见第 2.2 节)为该模型添加了更多“计算能力”。
2.2 基于内容的输入注意力
普通的序列到序列模型使用输入序列 末尾的识别 RNN 的固定维度状态生成整个输出序列 。 这限制了可以流向生成模型的信息量和计算量。 [5] 的注意力模型通过在编码器 RNN 状态的整个序列上使用注意力机制的附加神经网络来增强编码器和解码器 RNN,从而改善了这个问题。
出于符号目的,我们将编码器和解码器隐藏状态分别定义为 和 。 对于 LSTM RNN,我们使用输出门按分量乘以单元激活后的状态。 我们计算每个输出时间 的注意力向量,如下所示:
| (3) | |||||
其中,softmax 将向量 (长度为 )标准化为输入上的“注意力”掩码,以及 、和 是模型的可学习参数。 在我们所有的实验中,我们在编码器和解码器处使用相同的隐藏维度(通常为 512),因此 是向量, 和 是平方矩阵。 最后, 和 连接起来并用作隐藏状态,我们从中进行预测并将其提供给循环模型中的下一个时间步骤。
请注意,对于每个输出,我们必须执行 操作,因此推理时的计算复杂度变为 。
该模型在凸包问题上的表现明显优于序列到序列模型,但它不适用于输出字典大小取决于输入的问题。
尽管如此,模型的一个非常简单的扩展(或者更确切地说是简化)使我们能够轻松地做到这一点。
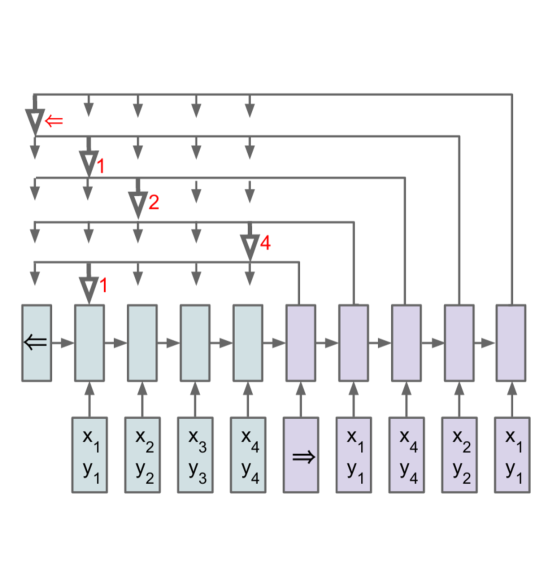
2.3Ptr-Net
我们现在描述注意力模型的一个非常简单的修改,它允许我们应用该方法来解决组合优化问题,其中输出字典的大小取决于输入序列中元素的数量。
第2.1节的序列到序列模型使用固定大小输出字典上的softmax分布来计算方程1中的。 因此,它不能用于输出字典的大小等于输入序列的长度的问题。 为了解决这个问题,我们使用方程 3 的注意力机制对 进行建模,如下所示:
其中,softmax 将向量 (长度为 )标准化为输入字典上的输出分布,以及 、和 是输出模型的可学习参数。 在这里,我们不混合编码器状态 以将额外信息传播到解码器,而是使用 作为指向输入元素的指针。 以类似的方式,为了以方程 1 中的 为条件,我们只需复制相应的 作为输入。 我们的方法和注意力模型都可以看作是[6,5,2]中提出的基于内容的注意力机制的应用。
我们还注意到,我们的方法专门针对输出离散且与输入中的位置相对应的问题。 这些问题可以通过人为方式解决——例如我们可以学习使用 RNN 直接输出目标点的坐标。 然而,从推断来看,该解决方案不遵守输出准确映射回输入的约束。 如果没有约束,预测在较长的序列上必然会变得模糊,如视频 [12] 的序列到序列模型所示。
3 动机和数据集结构
在以下部分中,我们将回顾我们考虑的三个问题以及我们的数据生成协议。111我们在http://goo.gl/NDcOIG上发布了所有数据集。
在训练数据中,输入是平面点集 ,每个点都有 元素,其中 是我们找到凸点的笛卡尔坐标船体、Delaunay 三角剖分或相应的旅行商问题的解决方案。 在所有情况下,我们都从 中的均匀分布中采样。 输出是表示与点集相关联的解的序列。 在图 2 中,我们找到了凸包和 Delaunay 问题的输入/输出对 的图示。
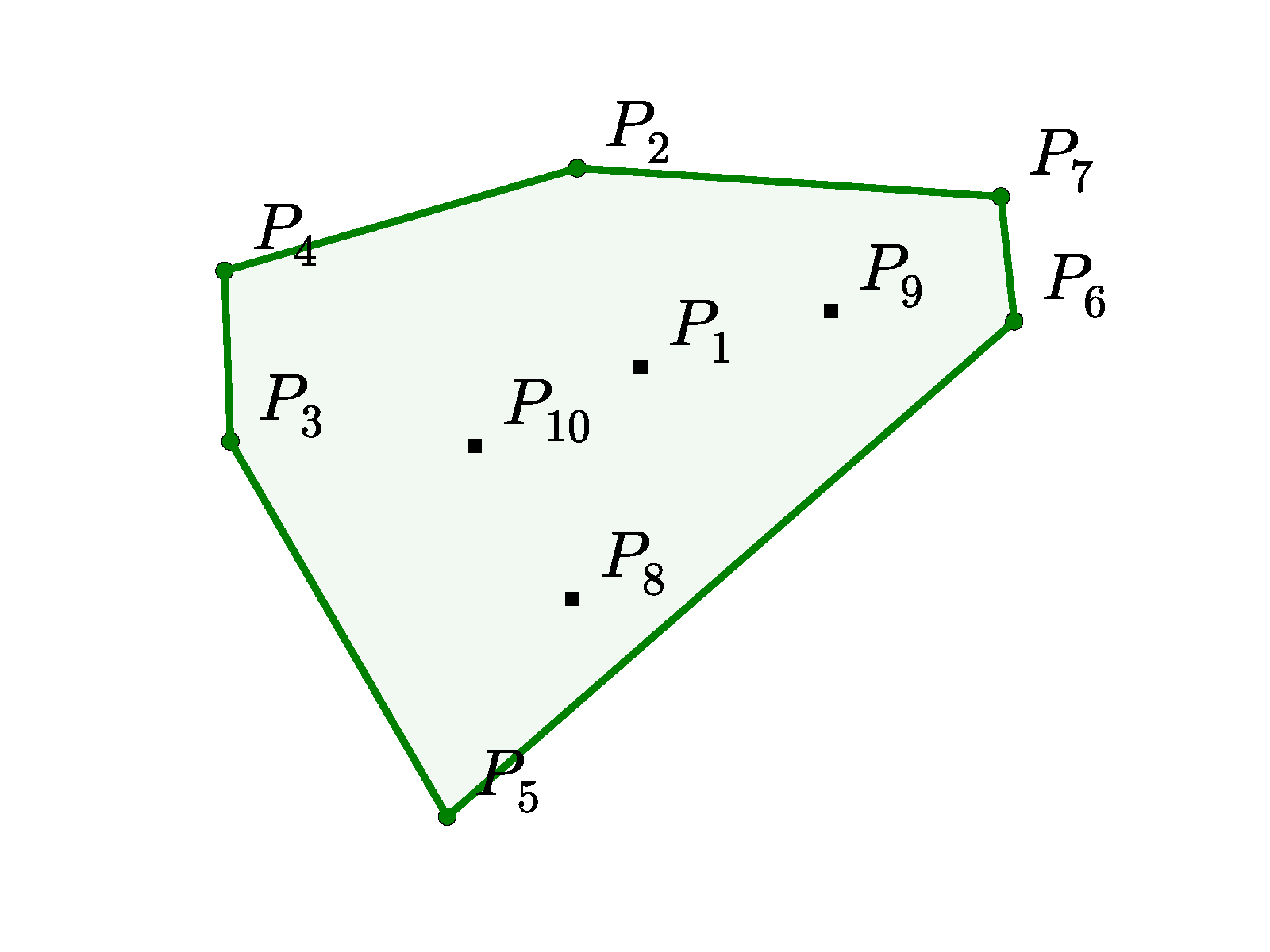
(a) Input , and the output sequence representing its convex hull.
(b) Input , and the output representing its Delaunay Triangulation.
3.1 凸包
我们使用这个例子作为基线来开发我们的模型并了解使用数据驱动方法解决组合问题的难度。 查找有限数量点的凸包是计算几何中一项众所周知的任务,并且有几种可用的精确解决方案(请参阅[13,14,15])。 一般来说,找到(通常是唯一的)解决方案具有复杂性,其中是考虑的点数。
向量是从中均匀采样的。 元素 是 1 和 之间的索引,对应于序列 中的位置,或者表示序列开始或结束的特殊标记。 请参见图2 (a) 进行说明。 为了将输出表示为序列,我们从索引最低的点开始,逆时针旋转——这是一个任意选择,但有助于减少训练过程中的歧义。
3.2 德洛内三角剖分
平面上一组 点的 Delaunay 三角剖分是这样的三角剖分:每个三角形的每个外接圆都是空的,即,其内部不存在来自 的点。 精确的 解可用 [16],其中 是 中的点数。
在此示例中,输出 是表示点集 三角测量的相应序列。 每个是从1到的整数三元组,对应于中三角形顶点的位置或序列标记的开始/结束。 参见图2(b)。
我们注意到序列 的任何排列都表示 的相同三角剖分,此外三个整数的每个三角形表示 也可以排列。 在不失一般性的情况下,与我们在训练时对凸包所做的类似,我们按三角形的中心坐标(字典顺序)对三角形 进行排序,并选择递增的三角形表示222我们选择而不是(2,4,1)或任何其他排列。. 如果没有排序,学习到的模型就不会那么好,找到 Ptr-Net 可以更好利用的更好的排序是未来工作的一部分。
3.3 旅行商问题(TSP)
TSP 出现在理论计算机科学的许多领域,是用于微芯片设计或 DNA 测序的重要算法。 在我们的工作中,我们专注于平面对称 TSP:给定一个城市列表,我们希望找到最短路线,该路线恰好访问每个城市一次并返回起点。 此外,我们假设两个城市之间的距离在每个相反方向上都相同。 这是一个 NP 难题,它允许我们测试模型的能力和局限性。
输入/输出对 具有与 3.1 节中描述的凸包问题类似的格式。 将是代表城市的笛卡尔坐标,在 方块中随机选择。 将是从 1 到 的整数排列,表示最佳路径(或游览)。 为了保持一致性,在训练数据集中,我们总是从第一个城市开始,而不失通用性。
为了生成精确的数据,我们实现了 Held-Karp 算法 [17],该算法在 中找到最佳解决方案(我们一直使用它到 )。 对于较大的 ,生成精确解的成本极高,因此我们还考虑了生成近似解的算法:A1 [18] 和 A2 [19] ,它们都是 和实现 Christofides 算法的 A3 [20]。 后一种算法保证找到最佳长度 1.5 倍以内的解。 表 2 显示了它们在我们的测试集中的表现。
4实证结果
4.1 架构和超参数
这里介绍的工作中没有对 Ptr-Net 进行广泛的架构或超参数搜索,并且我们在所有实验和数据集中使用了几乎相同的架构。 尽管通过调整模型可能会获得一些收益,但我们认为对所有问题使用相同的模型超参数将使论文的主要信息更加有力。
因此,我们所有的模型都使用具有 256 或 512 个隐藏单元的单层 LSTM,并使用随机梯度下降进行训练,学习率为 1.0,批量大小为 128,随机均匀权重初始化为 -0.08 到 0.08,L2 梯度2.0 的剪辑。 我们生成了 1M 个训练示例对,并且在某些任务较简单的情况下(即,对于较小的 ),我们确实观察到了过度拟合。
4.2 凸包
我们使用凸包作为指导任务,这使我们能够了解标准模型(例如序列到序列方法)的缺陷,并建立我们对纯数据驱动模型能够实现的期望一个精确的解决方案。
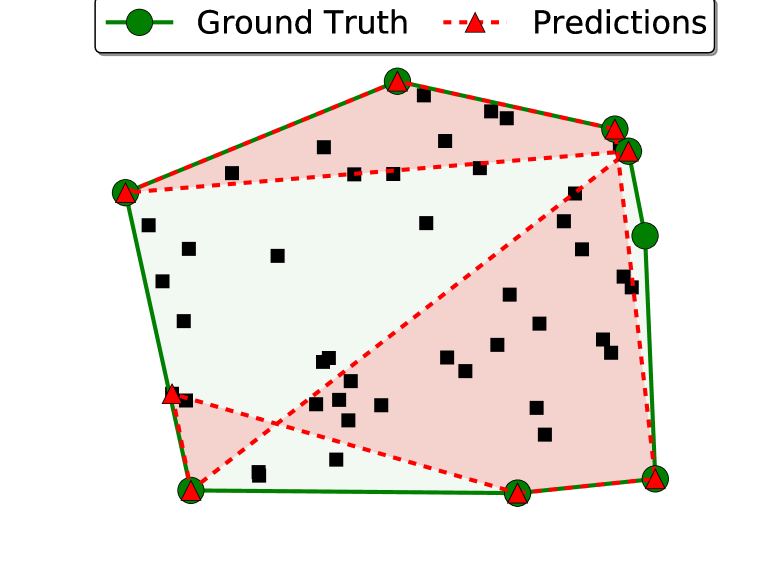
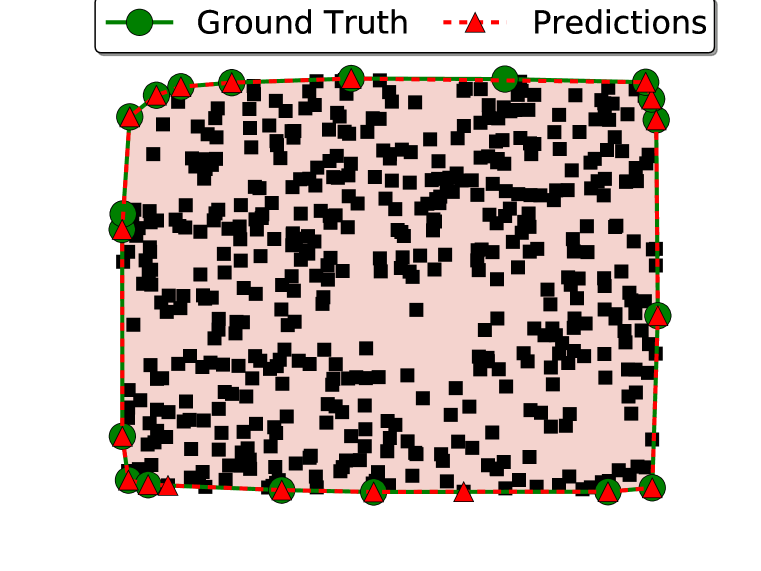
我们报告了两个指标:准确性和真实凸包覆盖的面积(请注意,任何简单的多边形都将与真实凸包完全相交)。 为了计算准确性,如果两个输出序列 和 表示相同的多边形,我们认为它们是相同的。 为简单起见,我们仅计算测试示例的区域覆盖范围,其中输出表示简单的多边形(即没有自相交)。 如果算法在超过 1% 的情况下无法生成简单多边形,我们只会报告失败。
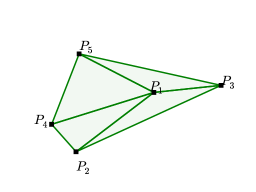
结果如表1所示。 我们注意到 Ptr-Net 实现的区域覆盖率接近 100%。 看看错误的例子,我们发现大多数问题都来自于对齐的点(参见图3(d)中的错误)——这是一个常见的来源大多数求解凸包的算法都会出现错误。
可以看出,在推理过程中输入呈现给编码器的顺序会影响其性能。 当真实凸包上的点在输入序列中出现“较晚”时,精度会降低。 这可能是网络没有足够的处理步骤来“更新”它计算的凸包,直到看到最新的点。 为了克服这个问题,我们使用了2.2节中描述的注意力机制,它允许解码器随时查看整个输入。 这一修改显着提高了模型性能。 我们检查了注意力所关注的内容,我们发现它“指向”输入端的正确答案。 这启发我们创建了 2.3 节中描述的 Ptr-Net 模型。
我们的模型不仅优于 LSTM 和具有注意力的 LSTM,还具有本质上可变长度的关键优势。 表 1 的下半部分显示,当我们的模型在 5 到 50 的各种长度上进行训练时(均匀采样,因为我们发现其他形式的课程学习并不有效),单个模型能够在其训练过的所有长度上表现得很好(但是可以观察到 的一些退化)。 该模型仅在长度为 50 个实例上进行训练)。 更令人印象深刻的是,该模型确实推断出了训练期间从未见过的长度。 即使对于 ,我们的结果也是令人满意的,间接表明模型学到的不仅仅是简单的查找。 LSTM 或具有注意力的 LSTM 都不能用于任何给定的 ,而无需在 上训练新模型。
| Method | trained | Accuracy | Area | |
| LSTM [1] | 50 | 50 | 1.9% | FAIL |
| +attention [5] | 50 | 50 | 38.9% | 99.7% |
| Ptr-Net | 50 | 50 | 72.6% | 99.9% |
| LSTM [1] | 5 | 5 | 87.7% | 99.6% |
| Ptr-Net | 5-50 | 5 | 92.0% | 99.6% |
| LSTM [1] | 10 | 10 | 29.9% | FAIL |
| Ptr-Net | 5-50 | 10 | 87.0% | 99.8% |
| Ptr-Net | 5-50 | 50 | 69.6% | 99.9% |
| Ptr-Net | 5-50 | 100 | 50.3% | 99.9% |
| Ptr-Net | 5-50 | 200 | 22.1% | 99.9% |
| Ptr-Net | 5-50 | 500 | 1.3% | 99.2% |
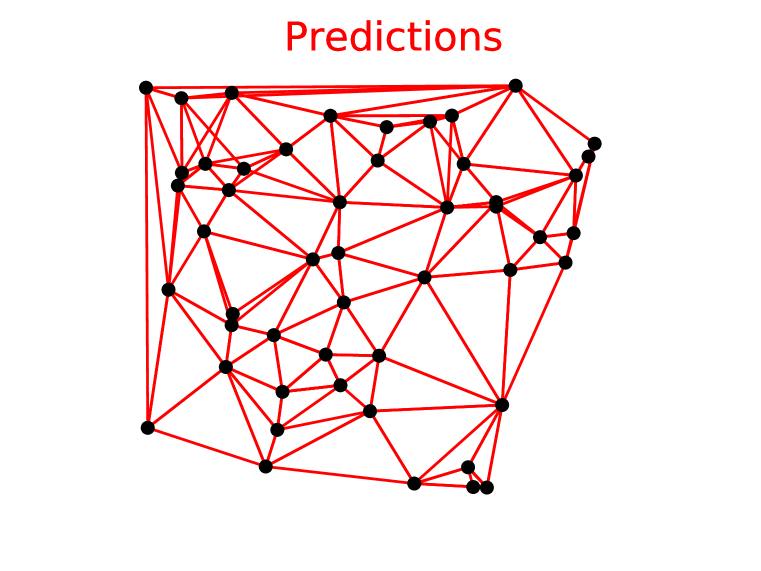
4.3 德洛内三角剖分
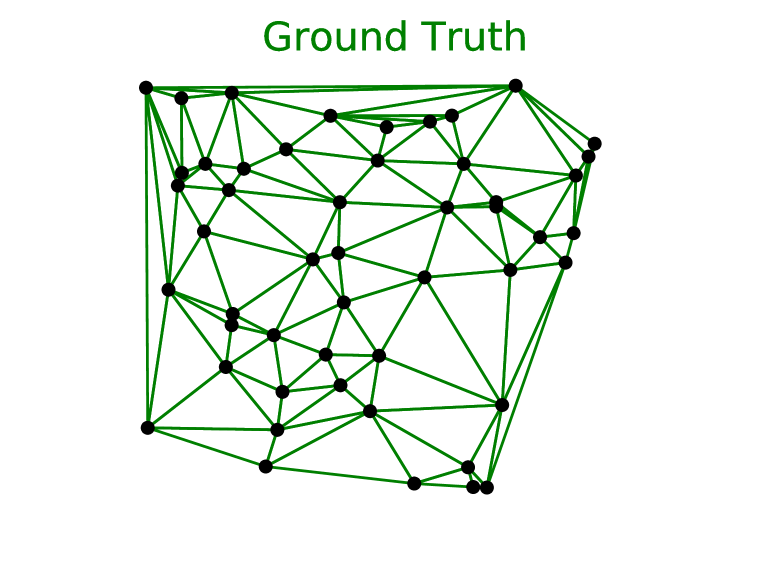
Delaunay 三角剖分测试用例与我们寻找凸包的第一个问题相关。 事实上,给定点集的 Delaunay 三角剖分对这些点的凸包进行了三角剖分。
我们报告了两个指标:准确性和三角形覆盖率(模型正确预测的三角形的百分比)。 请注意,在这种情况下,对于输入点集,输出序列实际上是一个集合。 因此,其元素的任何排列都将表示相同的三角剖分。
使用的Ptr-Net模型,我们获得了80.7%的准确率和93.0%的三角形覆盖率。 对于,准确率为22.6%,三角形覆盖率为81.3%。 对于,我们没有产生任何精确正确的三角测量,但获得了 52.8% 的三角形覆盖率。 有关 的示例,请参见图 3 的中间列。
4.4 旅行商问题
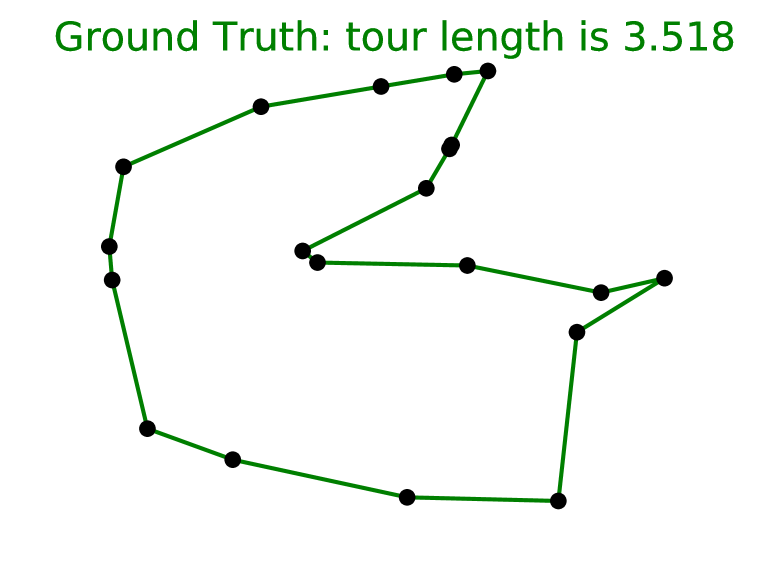
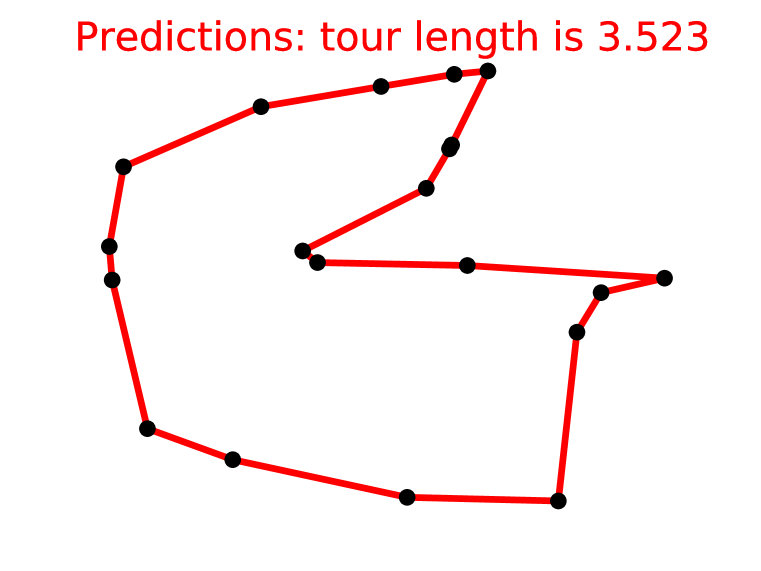
我们考虑平面对称旅行商问题(TSP),这是第三个问题,它是 NP 困难的。 与寻找凸包类似,它也有顺序输出。 鉴于 Ptr-Net 实现了 算法,尚不清楚它是否有足够的能力仅从数据中学习有用的算法。
正如 3.3 节中所讨论的,可以为相对较小的 值生成精确解以用作训练数据。 对于较大的,由于TSP的重要性,存在提供合理近似解的良好且高效的算法。 我们在实验中使用了三种不同的算法 - A1、A2 和 A3(参考文献请参见 3.3 节)。
表 2 显示了我们在 TSP 上的所有结果。 报告的数字是拟议旅行的长度。 与解码器不受约束的凸包和 Delaunay 三角剖分情况不同,在本示例中,我们将波束搜索过程设置为仅考虑有效的旅行。 否则,Ptr-Net 模型有时会输出无效的旅行 - 例如,它会重复两个城市或决定忽略目的地。 此过程与 相关,其中至少 10% 的实例不会产生任何有效的游览。
表中的第一组行显示了在最佳数据上训练的 Ptr-Net,但 除外,因为这在计算上不可行(我们为每个 训练了一个单独的模型) 。 有趣的是,当使用最差算法(A1)数据来训练 Ptr-Net 时,我们的模型优于试图模仿的算法。
表中的第二组行显示了 Ptr-Net 在 5 到 20 个城市的最佳数据上进行训练后如何进行泛化。 的结果几乎是完美的, 的结果也很好,但 40 及以上的结果似乎会崩溃(尽管如此,结果还是远远好于偶然)。 这与凸包情况形成对比,我们能够将其概括为 10 倍。 然而,底层算法比复杂得多,这可以解释这种现象。
| Optimal | A1 | A2 | A3 | Ptr-Net | |
| 5 | 2.12 | 2.18 | 2.12 | 2.12 | 2.12 |
| 10 | 2.87 | 3.07 | 2.87 | 2.87 | 2.88 |
| 50 (A1 trained) | N/A | 6.46 | 5.84 | 5.79 | 6.42 |
| 50 (A3 trained) | N/A | 6.46 | 5.84 | 5.79 | 6.09 |
| 5 (5-20 trained) | 2.12 | 2.18 | 2.12 | 2.12 | 2.12 |
| 10 (5-20 trained) | 2.87 | 3.07 | 2.87 | 2.87 | 2.87 |
| 20 (5-20 trained) | 3.83 | 4.24 | 3.86 | 3.85 | 3.88 |
| 25 (5-20 trained) | N/A | 4.71 | 4.27 | 4.24 | 4.30 |
| 30 (5-20 trained) | N/A | 5.11 | 4.63 | 4.60 | 4.72 |
| 40 (5-20 trained) | N/A | 5.82 | 5.27 | 5.23 | 5.91 |
| 50 (5-20 trained) | N/A | 6.46 | 5.84 | 5.79 | 7.66 |
5结论
在本文中,我们描述了 Ptr-Net,这是一种新的架构,它允许我们在给定另一个序列 的情况下学习一个序列 的条件概率,其中 是与 中的位置相对应的离散标记序列。 我们证明 Ptr-Nets 可用于学习三种不同组合优化问题的解决方案。 我们的方法适用于可变大小的输入(产生可变大小的输出字典),这是基线模型(有或没有注意的序列到序列)无法直接做到的。 更令人印象深刻的是,它们在固定输入大小问题上的表现优于基线——这两个模型都可以应用。
先前的方法,例如 RNNSearch、记忆网络和神经图灵机[5,6,2],都使用注意力机制来处理输入。 然而,这些方法并不能直接解决可变输出字典出现的问题。 我们已经证明,可以将注意力机制应用于输出来解决此类问题。 通过这样做,我们开辟了一类新的问题,无需人为假设即可应用神经网络。 在本文中,我们将此扩展应用于 RNNSearch,但这些方法同样适用于记忆网络和神经图灵机。
未来的工作将尝试展示其对其他问题的适用性,例如从输入中选择输出的排序。 我们也对使用这种方法解决其他组合优化问题的可能性感到兴奋。
致谢
我们要感谢 Rafal Jozefowicz、Ilya Sutskever、Quoc Le 和 Samy Bengio 就该主题进行的有益讨论。 我们还要感谢丹尼尔·吉利克 (Daniel Gillick) 对最终手稿的帮助。
参考
- [1] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems, pages 3104–3112, 2014.
- [2] Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014.
- [3] David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning internal representations by error propagation. Technical report, DTIC Document, 1985.
- [4] Anthony J Robinson. An application of recurrent nets to phone probability estimation. Neural Networks, IEEE Transactions on, 5(2):298–305, 1994.
- [5] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In ICLR 2015, arXiv preprint arXiv:1409.0473, 2014.
- [6] Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. In ICLEAR 2015, arXiv preprint arXiv:1410.3916, 2014.
- [7] Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, and Geoffrey Hinton. Grammar as a foreign language. arXiv preprint arXiv:1412.7449, 2014.
- [8] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. In CVPR 2015, arXiv preprint arXiv:1411.4555, 2014.
- [9] Jeff Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. In CVPR 2015, arXiv preprint arXiv:1411.4389, 2014.
- [10] Wojciech Zaremba and Ilya Sutskever. Learning to execute. arXiv preprint arXiv:1410.4615, 2014.
- [11] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [12] Nitish Srivastava, Elman Mansimov, and Ruslan Salakhutdinov. Unsupervised learning of video representations using lstms. In ICML 2015, arXiv preprint arXiv:1502.04681, 2015.
- [13] Ray A Jarvis. On the identification of the convex hull of a finite set of points in the plane. Information Processing Letters, 2(1):18–21, 1973.
- [14] Ronald L. Graham. An efficient algorith for determining the convex hull of a finite planar set. Information processing letters, 1(4):132–133, 1972.
- [15] Franco P. Preparata and Se June Hong. Convex hulls of finite sets of points in two and three dimensions. Communications of the ACM, 20(2):87–93, 1977.
- [16] S1 Rebay. Efficient unstructured mesh generation by means of delaunay triangulation and bowyer-watson algorithm. Journal of computational physics, 106(1):125–138, 1993.
- [17] Richard Bellman. Dynamic programming treatment of the travelling salesman problem. Journal of the ACM (JACM), 9(1):61–63, 1962.
- [18] Suboptimal travelling salesman problem (tsp) solver, 2015. Available at https://github.com/dmishin/tsp-solver.
- [19] Traveling salesman problem c++ implementation, 2015. Available at https://github.com/samlbest/traveling-salesman.
- [20] C++ implementation of traveling salesman problem using christofides and 2-opt, 2015. Available at https://github.com/beckysag/traveling-salesman.