顺序很重要:集合的顺序
摘要
由于循环神经网络的复兴,序列已成为监督学习中的一等公民。 现在可以使用序列到序列 (seq2seq) 框架来制定许多需要从观察序列进行映射或映射到观察序列的复杂任务,该框架采用链式法则来有效表示序列的联合概率。 然而,在许多情况下,可变大小的输入和/或输出可能不会自然地表达为序列。 例如,尚不清楚如何将一组数字输入到模型中,而模型的任务是对它们进行排序;同样,当输出对应于随机变量时,我们不知道如何组织输出,而任务是对它们的未知联合概率进行建模。 在本文中,我们首先使用各种示例表明,在学习基础模型时,组织输入和/或输出数据的顺序非常重要。 然后我们讨论 seq2seq 框架的扩展,它超越了序列并以原则性的方式处理输入集。 此外,我们提出了一种损失,通过在训练期间搜索可能的顺序,处理输出集结构的缺乏。 我们展示了我们关于排序的主张的经验证据,以及对基准语言建模和解析任务的 seq2seq 框架的修改,以及两个人工任务——对数字进行排序和估计未知图形模型的联合概率。
1简介
过去几年中,深度架构已经表明,它们通常在多项任务上都能产生最先进的性能,从图像分类(Ioffe & Szegedy,2015)到语音识别( Hinton 等人,2012)。 最近,循环神经网络 (RNN) 和变体,例如 Hochreiter 和 Schmidhuber (1997) 提出的长短期记忆网络 (LSTM),在几个固有的顺序任务上表现出了类似的令人印象深刻的性能。 此类示例涵盖从机器翻译 (Sutskever 等人, 2014; Bahdanau 等人, 2015a) 到图像字幕 (Vinyals 等人, 2015c; Mao 等人, 2015; Donahue 等人, 2015)、语音识别(Chan 等人, 2015; Bahdanau 等人, 2015b)、选区解析(Vinyals 等人, 2015b)和学习计算(Zaremba & Sutskever,2014;Vinyals 等人,2015a)。 这些方法都遵循一个简单的架构,称为序列到序列(seq2seq),其中使用编码器完全读取输入,当输入是序列时,编码器可以是 LSTM,或者是卷积编码器。图像网络。 然后编码器的最终状态被馈送到解码器 LSTM,其目的是生成目标序列,一次一个词符。
当数据自然地组织为序列时,序列到序列框架非常适合。 例如,链式法则用于分解单词序列的联合概率,并且可以通过LSTM来实现,而无需做任何条件独立性假设。 但是,对于无法确定明显顺序的问题,我们应该如何表示数据(输入或输出)? 例如,当任务是对一组数字进行排序时,我们应该如何对它们进行编码? 或者,当图像中检测到的一组对象之间没有特定的已知顺序时,我们应该如何输出它们? 呈现给模型的数据顺序的先验选择重要吗?
本文的目的是双重的。 首先,我们表明,即使输入或输出对象之间不知道自然顺序,仍然可能有一个可以产生更好的性能,因此,顺序很重要。 其次,我们提出了两种方法来将集合视为模型中的输入和/或输出,并评估它们在各种人工和真实数据集上的表现。
2相关工作
自从序列到序列模型被提出用于机器翻译(Sutskever 等人,2014;Cho 等人,2014;Kalchbrenner & Blunsom,2013),研究界已经提出了这些模型的几种应用可以执行来自和/或到序列的映射。 例如,图像字幕从图像映射到句子 (Vinyals 等人, 2015c; Mao 等人, 2015; Donahue 等人, 2015),解析从句子映射到(线性化)解析树(Vinyals等人,2015b),以及从问题陈述(例如Python程序或平面上的一组点)到其解决方案(程序的答案)的计算模型(Zaremba & Sutskever, 2014),或者点集的旅行商问题游览(Vinyals 等人, 2015a))。 回顾 seq2seq 的所有成功应用超出了本文的范围,但上面的列表已经包含了一些映射到对象或从对象映射的重要示例,这些对象不一定是序列。
最近,人们提出了许多利用外部记忆概念的相关模型和关键贡献,包括 RNNSearch (Bahdanau 等人, 2015a)、Memory Networks (Weston 等人, 2015) 和神经图灵机(Graves 等人,2014)。 这些模型利用的关键要素是读取(或注意)机制,以完全可微分的方式读取这些外部记忆(尽管也有离散读取机制的工作,最著名的是 RL-NTM (Zaremba & Sutskever, 2015))。
与传统的结构化预测算法(Bakir等人,2007)不同,我们的方法依靠链式规则通过LSTM网络的强大能力来序列化输出随机变量来建模长期相关性。 同样,我们不想假设已知的结构化输入,例如递归神经网络(Socher等人,2010)将句子递归编码为(给定)树。
3 序列和集合的神经网络
让我们考虑一个通用的监督任务,它具有给定的训练集 对 ,其中 是输入的 对,其对应的目标。 sequence-to-sequence 范式对应于其中 和 均由可能不同长度的序列表示的任务: 和。 在这种情况下,使用条件概率 对每个示例进行建模并使用链式法则将其分解如下是合理的(我们在其余部分中删除示例索引 为了便于阅读,本节):
并将其实现为编码器递归神经网络 (RNN),以按顺序读取每个 ,如下所示:
| (1) |
其中, 是编码器在 时刻的状态,接下来是解码器 RNN,在给定当前状态 和前一个 符号的情况下,一次生成每个 :
| (2) |
链式法则的使用使得这种方法无需假设,因此当输入 对应于一个序列(如句子)时,将其按顺序读入 RNN 是合理的,如式(1)所示。 (1)。 但是,如果 不自然地对应于序列,我们应该如何编码呢? 例如,如果它对应于一组无序元素怎么办?
类似地,当目标 对应于一个序列时,使用 RNN 顺序生成它是合理的,如式(1)所示。 (2),但是如果 不自然地对应于序列,我们应该如何生成它呢?
请注意,序列可以编码为集合。 事实上,如果我们将序列中的每个元素与它在序列中占据的索引相关联,形成一个元组,我们就可以有效地将这个序列转换为集合。 例如,序列“I like cats”变成集合{(I,1),(like,2),(cats,3)}(注意,我们可以排列集合中的元素,但仍然恢复原始序列)。 尽管这在某些情况下可能是不必要的,但我们认为,即使对于序列,以不同的顺序输入和/或输出它们也可能是有益的。 例如,在排序中,我们可能希望采用分而治之的策略,首先找到中值元素(即,我们可以既不按递增顺序也不按递减顺序输出解决方案)。
4 输入集
我们首先研究编码(读取)集的扩展。 正如我们在上一节中讨论的,可以使用循环神经网络读取序列,该网络可以将其内容压缩为向量。 当输入是一个集合时(即顺序并不重要),必须满足的一个重要不变性属性是,在集合 中交换两个元素 和 不应改变其编码。
满足这一点的一种简单方法是词袋方法,实际上它已常用于编码句子。 在这种情况下,表示只是计数、词嵌入或类似嵌入函数的减少(例如,加法),并且自然是排列不变的。 对于自然顺序的语言和其他领域,这被更复杂的编码器所取代,例如考虑顺序并对数据的高阶统计建模的循环神经网络。
使用归约运算(例如加法)的一个令人不满意的特性是,它使表示效率非常低:无论集合的长度如何,模型都在固定维度的嵌入上进行操作。 这种表示不太可能成功,因为编码长度 集(或序列)所需的内存量应该作为 的函数而增加。因此,我们认为即使是深度卷积架构也会受到这种限制——尽管存在一些修改(Maas等人,2012)。
在我们的工作中,我们很大程度上依赖注意力机制来整合来自可变长度结构的信息,我们在 4.2 节中对此进行了描述。
4.1 输入顺序很重要
在本节中,我们重点介绍之前的工作,我们观察到输入的顺序会影响以序列作为输入的 seq2seq 模型的性能。 原则上,当使用复杂的编码器(例如循环神经网络)时,顺序并不重要,因为它们是通用逼近器,可以从输入序列(例如,任何顺序的 n 元模型)中编码复杂的特征。 我们认为顺序似乎很重要的原因是由于底层的非凸优化和更合适的先验。
我们实验的第一个例子是在机器翻译的背景下改变序列的顺序。 在机器翻译中,映射函数对源语言(例如英语)的句子进行编码,并将其解码为目标语言(例如法语)的翻译。 通过反转输入英语句子的顺序,Sutskever 等人 (2014) 的 BLEU 分数提高了 5.0,这使他们能够缩小模型之间的差距 - 机器的完全端到端模型翻译——以及经过精心设计的最先进的模型。 类似地,对于选区解析,其中映射是从英语句子到其选区解析树的扁平化版本,当反转英语句子 时,观察到 F1 分数绝对增加了 0.5%(Vinyals 等人,2015b) 。
此外,如果我们通过按角度对点进行排序来预处理数据,例如 Vinyals 等人 (2015a) 中提出的凸包计算,则任务会变得更简单(来自 到 ),因此获得的模型训练速度更快、效果更好(在最具挑战性的情况下,准确率绝对提高了 10%)。
所有这些实证研究结果都指向同一个故事:通常出于优化目的,向模型显示输入数据的顺序会对学习性能产生影响。
请注意,我们可以定义一个独立于输入序列或集合 的排序(例如,始终反转翻译任务中的单词),但也可以定义一个依赖于输入的排序(例如,对输入进行排序)凸包情况下的点)。 这种区别也适用于 5.1 节中有关输出序列和集合的讨论。
最近的方法通过向这些模型添加内存和计算来进一步推动 seq2seq 范式,使我们能够定义一个模型,该模型不对输入排序做出任何假设,同时保留我们刚刚讨论的正确属性:随集合大小而增加的内存,并且是顺序不变的。 在接下来的章节中,我们将解释这样的修改,它也可以被视为记忆网络(Weston等人,2015)或神经图灵机(Graves等人, 2014) – 计算流程如图1所示。
4.2 注意力机制
具有记忆与可微分寻址机制耦合的神经模型已成功应用于手写体生成和识别(Graves,2012)、机器翻译(Bahdanau等人,2015a)等通用计算机(Graves等人,2014;Weston等人,2015)。 由于我们对联想记忆感兴趣,因此我们采用了基于“内容”的注意力。 它具有这样的特性:如果我们随机打乱内存,从内存中检索到的向量不会改变。 这对于正确处理输入集 至关重要。 特别是,我们基于注意力机制的流程块使用以下内容:
| (3) | |||||
| (4) | |||||
| (5) | |||||
| (6) | |||||
| (7) |
![[Uncaptioned image]](x1.png)
其中 通过每个内存向量 进行索引(通常等于 的基数), 是一个查询向量,它允许我们要从内存中读取 , 是一个从 和 计算单个标量的函数(例如,点积), 是一个 LSTM,它计算循环状态,但不接受任何输入。 是此 LSTM 演化的状态,由查询 与结果注意力读出 连接而成。 是指示正在执行多少个“处理步骤”来计算要馈送到解码器的状态的索引。 请注意,排列 和 对读取向量 没有影响。
4.3 读取、处理、写入
我们的模型自然地处理输入集,具有三个组成部分(确切的方程和实现将在出版前的附录中发布):
-
•
一个 reading 块,它简单地使用一个小型神经网络将每个元素 嵌入到内存向量 中(相同的神经网络用于所有 )。
- •
-
•
一个 write 块,它是一个 LSTM 指针网络 (Vinyals 等人, 2015a),它接收 (作为它需要的上下文)从输入集中产生输出),并指向 的元素(隐式地,),一次一步。 Vinyals 等人 (2015a) 中的原始工作使用了指针机制,该机制不是通过软指针的加权和来发出内存读出(参见等式6 ),它使用指针作为损失的一部分。 我们通过在指针之前添加额外的注意步骤来扩展这一点(我们称之为一瞥)。 这与上述过程块相关,但不同之处在于注意力读取在每个指针输出之间交错发生。 正如后面的结果所述,我们发现这两种机制是相辅相成的。
该架构如图1所示,可以视为神经图灵机或内存网络的特例。 它的关键特性是对 中元素的顺序保持不变,从而有效地将输入作为一个集合进行处理。 另请注意,如果输出来自固定字典,则 write 组件可以只是一个 LSTM。 不过,对于这个模型,我们研究组合问题,其中输出是指向输入的指针,因此我们使用指针网络。
4.4排序实验
为了验证我们的模型是否比普通的 seq2seq 方法更有效地处理集合,我们对用于数字排序任务的人工数据进行了以下实验:给定 0 到 1 之间的无序随机浮点数,我们按排序顺序返回它们。 请注意,这个问题是 set2seq 的一个实例。 我们使用图1中定义的架构,其中Read模块是每个数字的小型多层感知器,Process模块是一个注意力机制读取的数字,实现为 在没有输入和输出的 LSTM 上进行步骤,但参与输入嵌入,然后使用 LSTM 通过指针网络在输入数字中生成索引 (Vinyals等人,2015a),按正确的排序顺序。 我们还将该架构与普通 seq2seq 架构进行了比较,该架构由输入 LSTM 连接到输出 LSTM,输出 LSTM 通过指针网络 (Ptr-Net) 在输入数字中生成索引。 请注意,这两个模型之间的唯一区别是使用 LSTM(如之前的工作)或上一节中提出的架构对集合进行编码。 我们运行了多个实验,改变要排序的数字的数量 以及读取、处理、写入模型的处理步骤的数量 。
这些实验的样本外准确率(无论我们是否成功对所有数字进行排序)总结在表1中。 我们可以看到,当不使用处理步骤(步骤)时,基线指针网络 LSTM 输入模型优于 Read-Process-and-Write 模型,但只要至少有一个处理步骤如果允许,读处理和写模型的性能会变得更好,并随着处理步骤的数量而增加。 我们还可以看到,随着任务大小(以要排序 的元素数量表示)的增长,性能会变得更差,正如预期的那样。 另请注意,通过 0 个处理步骤和 0 个瞥见,写入模块实际上不受 的限制,并且必须“盲目”指向 的元素。 因此,看到它的性能比表 1 中考虑的任何其他模型更差也就不足为奇了。 最后,为写作模块配备一瞥(即,在“指向”之前添加注意机制)可以显着改善基线模型(Ptr-Net)和我们提出的修改(在最具挑战性的情况下,它的准确性提高了一倍以上) )。
| Length | Ptr-Net | step | step | steps | steps | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| glimpses | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 81% | 90% | 65% | 84% | 84% | 92% | 88% | 94% | 90% | 94% | |
| 8% | 28% | 7% | 30% | 14% | 44% | 17% | 57% | 19% | 50% | |
| 0% | 4% | 1% | 2% | 0% | 5% | 2% | 4% | 0% | 10% | |
5 输出集
到目前为止,我们已经考虑了输入集的编码问题;现在让我们将注意力转向输出表示。 描述随机变量集 上的联合概率的链式法则也许是联合概率最简单的分解,它不会产生任意限制(例如条件独立性)。 因此,只要存在可训练的强大模型(可以处理长范围相关性),任何顺序都应该在没有生成 的基础问题的任何先验顺序信息的情况下工作。 尽管如此,即使使用像 LSTM 这样非常强大的模型(在建模能力和对长期梯度消失的恢复能力方面),输出排序仍然在成功的模型中发挥着关键作用。
在下一小节中,我们将描述应用链式法则的顺序如何影响各种任务的性能。
5.1 输出顺序很重要
令 为集合(或序列)。 在本节中,我们将研究排序对 seq2seq 模型在多个任务上的性能的影响。 也就是说,我们将考虑 中变量的任意(和非任意)顺序,并为所有训练示例按照该顺序对条件概率分布 进行建模。 正如我们将看到的,顺序很重要(即使考虑到无论的顺序如何,通过链式法则的公式都有效,至少原则上如此)。
5.1.1 语言建模
在本实验中,我们使用 PennTree Bank,它是标准语言建模基准。 对于语言建模标准来说,这个数据集非常小,因此大多数模型都缺乏数据。 我们训练了具有大量正则化的中型 LSTM(参见 Zaremba 等人 (2014) 的中型模型)来估计单词序列的概率。 我们考虑具有三种排序的数据集的三个版本:自然、反向和固定的 3 字反转:
自然:“这是一句话。”
反转:“. 句子 a is This”
3-word: “a is This pad 。 句子”
请注意,3 词反转破坏了句子的基础结构,并且使联合概率建模变得更加困难,因为许多高阶 n 元模型被打乱。 对于每个订单,我们训练了不同的模型。 自然和反向的结果在开发集上的复杂度为 86 时相互匹配(使用与 Zaremba 等人 (2014) 相同的设置)。 令人惊讶的是,3 个词的反转仅降低了 10 个困惑点,在该语料库中仍然以 96 个困惑度取得了令人印象深刻的结果。 然而,我们注意到,训练困惑度也高出了 10 个百分点,这表明该模型在处理尴尬的排序时遇到了困难。 因此,即使考虑到链式法则仍然正确地模拟了联合概率,当选择混杂排序时,仍会观察到一些退化。
5.1.2解析
选区解析的任务在于根据给定的句子生成解析树。 Vinyals 等人 (2015b) 提出的模型是一个句子编码器 LSTM,后跟一个解码器 LSTM,经过训练,使用注意力机制生成解析树的深度优先遍历编码。 这种方法与该任务的最新结果相匹配。
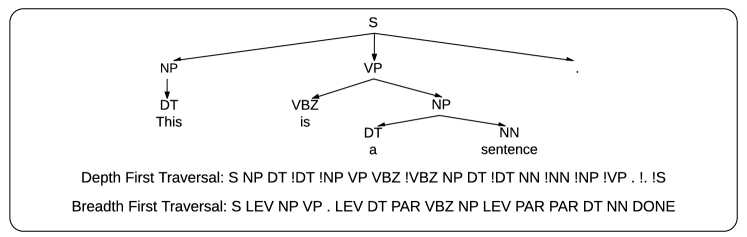
尽管深度优先遍历看起来更明智,但它只是将树唯一编码到序列上的多种方法之一。 因此,我们尝试使用深度优先遍历(与 Vinyals 等人 (2015b) 的基线匹配)训练一个小型模型,并使用广度优先遍历训练另一个模型(请注意,这些排序取决于输入)。 有关树如何在两种遍历方案下线性化的示例,请参见图 2。 经过训练生成深度优先遍历线性化树的模型获得了 89.5% 的 F1 分数(如 Vinyals 等人 (2015b) 报道),而生成广度优先遍历树的模型的 F1 分数要低得多,为 81.5 %,111事实上,在很多情况下解码器无法生成有效的树,因此真正的 F1 分数可能会更低。 再次显示了选择正确输出顺序的重要性。
5.1.3 组合问题
与前两个示例不同,当我们尝试表示非序列数据(如游览、三角测量等,(Vinyals 等人, 2015a) 讨论过)时,更常见的问题是,事实上,可能存在大量等价类的解。
以输出一组随机数 的排序输入的索引为例。 事实上,这是一个确定性函数。 我们可以选择以某种顺序输出这些索引(例如,增加、减少或使用任意固定排列),或者将它们视为一个集合(具有相应排名的 argsort 索引的元组)。 结果有 给定 的可能输出,所有这些都完全有效。 如果我们的训练集是使用随机均匀选择的任何排列生成的,则我们的映射(经过完美训练后)将必须在 上放置相同的概率 相同输入的输出配置。 因此,该公式在统计上的效率要低得多。
在之前的工作(Vinyals等人,2015a)中,发现尽可能限制输出的等价类总是更好。 例如,为了输出一次旅行(即为解决旅行推销员问题而必须访问的一系列城市),我们从索引较低的城市(即我们输入的第一个城市)开始,并遵循逆时针顺序。 类似地,为了输出一组三角形(对一组输入点进行三角测量),我们按字典顺序对它们进行排序,并从左到右移动。 在所有情况下,我们都观察到绝对准确度提高了 5% 或更多。
未能限制输出等价类通常意味着收敛速度要慢得多(因此需要更多的训练数据)。 例如,对于排序,如果将输出视为我们在任何可能的 中输出的集合 排序、 小至 5 的收敛从未达到相同的性能。
5.1.4图形模型
让我们考虑一组随机变量的联合概率。 由于事先不知道这些随机变量如何相互作用,对它们的联合概率进行建模的一种方法是使用链式法则,如下所示:
| (8) |
并使用 RNN 对此进行建模,类似于 RNN 语言模型。
对于句子来说,单词的自然顺序提供了如何对模型中的随机变量进行排序的良好线索,但对于其他类型的数据,可能更难做出决定。 此外,从理论上讲,顺序并不重要,因为贝叶斯规则允许我们根据需要对所有条件概率进行重新排序。 然而在实践中,正如我们在本文中所示,一种订单可能比另一种订单更容易建模。
本实验的目的是通过受控玩具实验来证明这一点。 我们在随机变量上生成了类星图形模型,其中一个变量(头部)遵循无条件分布,而其他变量则遵循基于头部变量值的条件分布。 我们期望通过选择以头变量开始的任何顺序,可以更容易地对联合分布进行建模。 我们通过改变要建模的随机变量的数量(10 到 50 之间,每个变量都是超过 10 个符号的多项式)、训练集大小(200 到 20000 个训练样本之间)以及 随机性来创建几个人工数据集 边际分布,或者它们的确定性或峰值程度。 对于每个问题,我们训练了两个 LSTM,进行 10,000 次小批量迭代,以对联合概率进行建模,其中一个首先显示头部随机变量,另一个最后显示。
结果如下:
-
•
当训练集大小足够大(20000)时,LSTM能够以任意顺序学习联合概率;
-
•
当边缘分布非常尖峰(因此几乎是确定性的)时,LSTM 还能够独立于阶数来学习联合概率;
-
•
在所有其他情况下(小训练集大小、少量或大量随机变量以及边缘分布中的一定程度的随机性),学习具有最佳随机顺序的 LSTM 总是更容易变量比任何其他顺序。
5.2 训练时寻找最佳排序
回想一下我们提出的用于处理输入集的模型:给定每个输入的嵌入,我们有一个能够以任何顺序处理其输入的通用模块。 这产生的嵌入满足重新排序不变的关键属性,同时在对输入集进行的计算类型中具有通用性。
不幸的是,当联合概率函数的结构未知时,将联合概率置于一组随机变量上是一个难题。 幸运的是,得益于循环神经网络,我们可以应用链式法则来顺序分解这个联合概率(参见等式8),而无需独立性假设。 在这项工作中,我们专注于使用链式法则,丢弃具有强烈且不切实际的假设(例如条件独立性)的更朴素的分解。
链式法则的一个明显缺点违反了将 视为集合的论点,那就是我们以特定顺序调节这些随机变量。 尽管原则上顺序不重要,但在上一节中我们已经证明事实并非如此,并且在各种任务中某些顺序比其他顺序更好——很可能是由于关节的参数化概率(使用 LSTM),以及优化问题的非凸性质。
我们提出的解决上述缺点的解决方案非常简单:在训练时,我们让模型决定应用链式法则的最佳顺序。 更正式地,假设存在一个最大限度地简化任务的排序 (其中 是输入序列或集合,可以为空)。 我们希望将模型训练为 。 可能的订购数量很大 – 其中 是输出的长度,最佳顺序是先验未知的。
自 可能非常大,我们可以尝试在训练模型时进行(不精确)搜索。 我们不是最大化每个示例对的 对数概率,而是最大化排序,如下所示:
| (9) |
其中 是简单地计算的,或者是通过不精确的搜索计算的。 请注意,由于非凸性,方程(9)可能不会严格改进常规最大似然框架,但我们发现这在实践中不是问题。
除了不可扩展之外,我们发现,如果天真地完成并在训练时选择最大排序,模型将选择随机排序(作为初始参数的函数),并且将永久卡在它上(因为它会通过学习强化)。 我们添加了两种方法来探索所有排序的空间,如下所示:
-
•
我们使用 的统一先验预训练模型 1000 步,相当于替换等式中的 。 (9) 由。
-
•
然后,我们根据与 成比例的分布对 进行采样来选择排序。 这需要 模型评估(相对于朴素搜索,其成本为 )。
至关重要的是,采样 可以非常高效地完成,因为我们可以使用祖先采样(从左到右),这需要评估 仅一次而不是 。
5.2.15-gram建模
在我们最初尝试解决 (9) 问题时,我们考虑了 5.1.1 节中描述的语言建模任务的简化版本。 简化的任务包括在没有任何进一步上下文(即没有输入 )的情况下对 5-gram 的联合概率进行建模。 这种选择使我们能够拥有足够小的 ,因为最初我们试图从 中准确找到最佳排序。 可能的。 因此,我们忽略了不精确搜索可能产生的影响,并专注于训练动态的本质,其中正在优化的模型选择最佳排序 ,从而在当前参数下最大化 ,并且通过对 w.r.t 的梯度应用更新来强化这种排序。 参数。 最终,如 5.2 节所述,我们发现采样在收敛性方面具有优越性,同时简化了 的复杂性 一直到 ,这是我们在本节其余部分中使用的首选解决方案。
为了测试这个框架,我们通过以下方式将 5-gram(即单词序列)转换为集合:
5 克(序列):=This、=is、=a、= Five、=gram
5-gram(集合):=(This,1), =(is,2), =(a,3), =(5,4),
请注意,在单词旁边添加原始位置会使 成为一个集合。 这样,我们就可以任意打乱,而不会丢失序列的原始结构。 第一个实验强化了我们在 5.1.1 节中的结果,再次检验了顺序很重要的假设。 训练一个遵循自然顺序的模型(即,生成 (This,1),然后生成以 (This,1) 为条件的 (is,2),等等),验证困惑度达到 225。222这比 5.1.1 节中报告的结果要糟糕得多,因为在没有上下文的情况下对 5-gram 进行建模比标准语言建模要困难得多。 如果我们不选择 ,而是使用 ,困惑度会降至 280。
然后我们测试方程的优化。 (9) 在两种设置中:
简单:训练集包含来自 和 的示例,统一采样。
Hard:训练集包含来自的示例 可能的订购,统一抽样。
我们的结果如表2所示。 请注意,在简单的情况下,我们将排序的搜索空间限制为仅 2,其中一个顺序明显优于另一个顺序。 我们注意到,在预训练阶段之后,我们决定两种排序中的哪一种更能代表正在训练的模型下的数据。 很快,模型就确定了自然的 顺序,产生了 225 的困惑度。 在最困难的情况下,任何顺序都是可能的,模型会采用 、 等顺序以及它们的微小变化。 在所有情况下,最终的困惑度都是 225。 因此,我们提出的框架能够在没有任何先验知识的情况下找到良好的排序。 我们计划不仅恢复最佳排序,而且还找到我们在天真的应用 seq2seq 框架时未知的排序。
| Task | Orders considered | Perplexity |
|---|---|---|
| 1 | 225 | |
| 1 | 280 | |
| Easy | 2 | 225 |
| Hard | 225 |
6结论
LSTM 已被证明是表示可变长度序列数据的强大模型,因为它们能够处理合理的长期依赖性,并使用链式法则有效分解联合分布。 另一方面,一些问题用无序的元素集来表达,或者作为输入,或者作为输出;在其他一些情况下,数据由某种需要线性化才能输入 LSTM 的结构表示,并且可能有不止一种方法可以实现这一点。 本文的第一个目标是阐明这些问题:事实上,我们表明顺序很重要以获得最佳性能。 然后,我们考虑了无序输入数据的情况,针对这种情况,我们提出了读取处理和写入架构,以及无序输出数据的情况,针对这种情况,我们提出了一种高效的训练算法,其中包括在训练和训练过程中搜索可能的顺序。推理。 我们通过各种实验(例如排序、图形模型、语言建模和解析)说明了我们提出的输入和输出集方法。
致谢
我们要感谢 Ilya Sutskever、Navdeep Jaitly、Rafal Jozefowicz、Quoc Le、Lukasz Kaiser、Geoffrey Hinton、Jeff Dean、Shane Gu 和 Google Brain 团队就此主题进行的有益讨论。 我们还要感谢帮助改进我们论文的匿名审稿人。
参考
- Bahdanau et al. (2015a) Bahdanau, D., Cho, K., and Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proc. ICLR, 2015a.
- Bahdanau et al. (2015b) Bahdanau, D., Chorowski, J., Serdyuk, D., Brakel, P., and Bengio, Y. End-to-end attention-based large vocabulary speech recognition. arXiv preprint arXiv:1508.04395, 2015b.
- Bakir et al. (2007) Bakir, G., Hofmann, T., Scholkopf, B., Smola, A. J., Taskar, B., and Vishwanathan, S.V.N. (eds.). Predicting Structured Data. MIT Press, 2007.
- Chan et al. (2015) Chan, W., Jaitly, N., Le, Q. V., and Vinyals, O. Listen, attend and spell. arXiv, abs/1508.01211, 2015. URL http://arxiv.org/abs/1508.01211.
- Cho et al. (2014) Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proc. EMNLP, 2014.
- Donahue et al. (2015) Donahue, J., Hendricks, L. A., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., and Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proc. CVPR, 2015.
- Graves (2012) Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks. Springer, 2012.
- Graves et al. (2014) Graves, A., Wayne, G., and Danihelka, I. Neural turing machines. In arXiv preprint arXiv:1410.5401, 2014.
- Hinton et al. (2012) Hinton, G., Deng, L., Yu, D., Dahl, G., Mohamed, A., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T. N., and Kingsbury, B. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 29:82–97, 2012.
- Hochreiter & Schmidhuber (1997) Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural Computation, 9(8), 1997.
- Ioffe & Szegedy (2015) Ioffe, S. and Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML, 2015.
- Kalchbrenner & Blunsom (2013) Kalchbrenner, N. and Blunsom, P. Recurrent continuous translation models. In Proc. EMNLP, 2013.
- Maas et al. (2012) Maas, A. L., Miller, S. D., O’Neil, T. M., and Ng, A. Y. Word-level acoustic modeling with convolutional vector regression. In ICML 2012 Workshop on Representation Learning, 2012.
- Mao et al. (2015) Mao, J., Xu, W., Yang, Y., Wang, J., Huang, Z., and Yuille, A. L. Deep captioning with multimodal recurrent neural networks (m-RNN). In International Conference on Learning Representations, 2015.
- Socher et al. (2010) Socher, R., Manning, C. D., and Ng, A. Y. Learning continuous phrase representations and syntactic parsing with recursive neural networks. In Advances in Neural Information Processing Systems, 2010.
- Sutskever et al. (2014) Sutskever, Ilya, Vinyals, Oriol, and Le, Quoc V. Sequence to sequence learning with neural networks. In Proc. NIPS, 2014.
- Vinyals et al. (2015a) Vinyals, O., Fortunato, M., and Jaitly, N. Pointer networks. In Advances in Neural Information Processing Systems, NIPS, 2015a.
- Vinyals et al. (2015b) Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I., and Hinton, G. Grammar as a foreign language. In Advances in Neural Information Processing Systems, 2015b.
- Vinyals et al. (2015c) Vinyals, O., Toshev, A., Bengio, S., and Erhan, D. Show and tell: A neural image caption generator. In Proc. CVPR, 2015c.
- Weston et al. (2015) Weston, J., Chopra, S., and Bordes, A. Memory networks. In International Conference on Learning Representations, ICLR, 2015.
- Zaremba & Sutskever (2014) Zaremba, W. and Sutskever, I. Learning to execute. arXiv, abs/1410.4615, 2014.
- Zaremba & Sutskever (2015) Zaremba, W. and Sutskever, I. Reinforcement learning neural turing machines. arXiv, abs/1505.00521, 2015.
- Zaremba et al. (2014) Zaremba, W., Sutskever, I., and Vinyals, O. Recurrent neural network regularization. arXiv, abs/1409.2329, 2014.