R-FCN:通过基于
区域的全卷积网络进行物体检测
摘要
我们提出了基于区域的全卷积网络,用于准确有效的目标检测。 与之前的基于区域的检测器(例如 Fast/Faster R-CNN [6, 18])相比,它应用了数百次昂贵的每区域子网络,我们的基于区域的检测器是完全卷积的,几乎所有计算都在整个图像上共享。 为了实现这一目标,我们提出了位置敏感的分数图来解决图像分类中的平移不变性和对象检测中的平移方差之间的困境。 因此,我们的方法可以自然地采用完全卷积图像分类器主干,例如最新的残差网络(ResNets)[9],用于对象检测。 我们使用 101 层 ResNet 在 PASCAL VOC 数据集上展示了具有竞争力的结果(例如,2007 年数据集的 mAP 为 83.6%)。 同时,我们的结果是在每张图像 170ms 的测试速度下实现的,比 Faster R-CNN 快 2.5-20。 代码公开于:https://github.com/daijifeng001/r-fcn。
1简介
用于对象检测的流行的深度网络系列[8,6,18]可以通过感兴趣区域(RoI)池层[6]分为两个子网络>:(i) 一个独立于 RoI 的共享的“完全卷积”子网络,以及 (ii) 不共享计算的 RoI-wise 子网络。 这种分解[8]在历史上是由开创性的分类架构产生的,例如AlexNet [10]和VGG Nets [23],其中包括设计上由两个子网络组成——一个以空间池层结尾的卷积子网络,后面是几个全连接(fc)层。 因此,图像分类网络中的(最后一个)空间池化层自然地变成了目标检测网络中的 RoI 池化层[8,6,18]。
但最近最先进的图像分类网络,例如 Residual Nets (ResNets) [9] 和 GoogLeNets [24, 26] 在设计上完全是卷积111只有最后一层是全连接的,在微调对象检测时被删除并替换。. 以此类推,在目标检测架构中使用所有卷积层来构建共享的卷积子网络似乎很自然,而 RoI-wise 子网络没有隐藏层。 然而,根据本工作的实证研究,这种简单的解决方案的检测精度较低,与网络的优越的分类精度不匹配。 为了解决这个问题,在 ResNet 论文 [9] 中,Faster R-CNN 检测器 [18] 的 RoI 池化层被不自然地插入在两组卷积层之间 - 这创建了一个更深的 RoI 子网络,可以提高准确性,但由于不共享每个 RoI 计算而导致速度降低。
我们认为,上述不自然的设计是由图像分类与增加平移不变性的困境引起的。尊重对象检测的翻译方差。 一方面,图像级分类任务有利于平移不变性——图像内对象的移动应该是不加区别的。 因此,正如 ImageNet 分类[9,24,26]的领先结果所证明的那样,尽可能具有平移不变性的深度(完全)卷积架构是更可取的。 另一方面,对象检测任务需要在一定程度上具有平移变体的本地化表示。 例如,候选框内对象的平移应该产生有意义的响应,以描述候选框与对象的重叠程度。 我们假设图像分类网络中更深的卷积层对平移不太敏感。 为了解决这个困境,ResNet 论文的检测管道[9]将 RoI 池化层插入到卷积中 - 这种区域特定操作打破了平移不变性,并且后 RoI当跨不同区域进行评估时,卷积层不再是平移不变的。 然而,这种设计牺牲了训练和测试效率,因为它引入了大量的区域层(表1)。
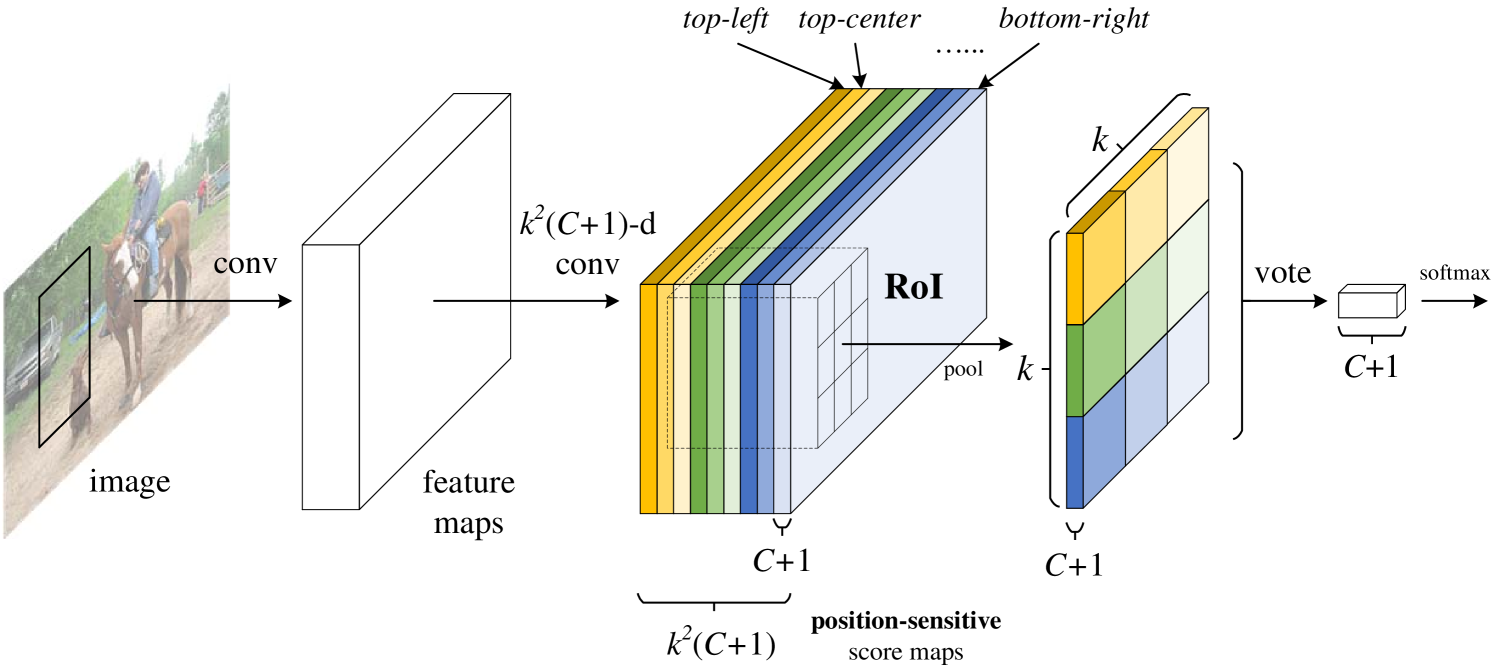
在本文中,我们开发了一个名为基于区域的全卷积网络(R-FCN)的框架,用于对象检测。 我们的网络由共享、完全卷积架构组成,就像 FCN [15] 的情况一样。 为了将平移方差合并到FCN中,我们通过使用一组专门的卷积层作为FCN输出来构建一组位置敏感分数图。 这些分数图中的每一个都对相对空间位置(例如,“对象的左侧”)的位置信息进行编码。 在此 FCN 之上,我们附加了一个位置敏感的 RoI 池化层,用于管理这些分数图中的信息,后面没有权重(卷积/fc)层。 整个架构是端到端学习的。 所有可学习层都是卷积层并在整个图像上共享,但对对象检测所需的空间信息进行编码。 图1说明了关键思想,表1比较了基于区域的检测器的方法。
使用 101 层残差网络 (ResNet-101) [9] 作为主干,我们的 R-FCN 在 PASCAL VOC 2007 集上产生了 83.6% mAP,在 2012 集上产生了 82.0% 的竞争结果。 同时,我们的结果是使用 ResNet-101 在每张图像 170ms 的测试速度下取得的,这比 Faster R-CNN + ResNet 快 2.5 到 20。 [9] 中的 101 个对应项。 这些实验表明,我们的方法成功地解决了平移不变性/方差之间的困境,并且 ResNet 等全卷积图像级分类器可以有效地转换为全卷积目标检测器。 代码公开于:https://github.com/daijifeng001/r-fcn。
| R-CNN [7] | Faster R-CNN [19, 9] | R-FCN [ours] | |
|---|---|---|---|
| depth of shared convolutional subnetwork | 0 | 91 | 101 |
| depth of RoI-wise subnetwork | 101 | 10 | 0 |
2 我们的方法
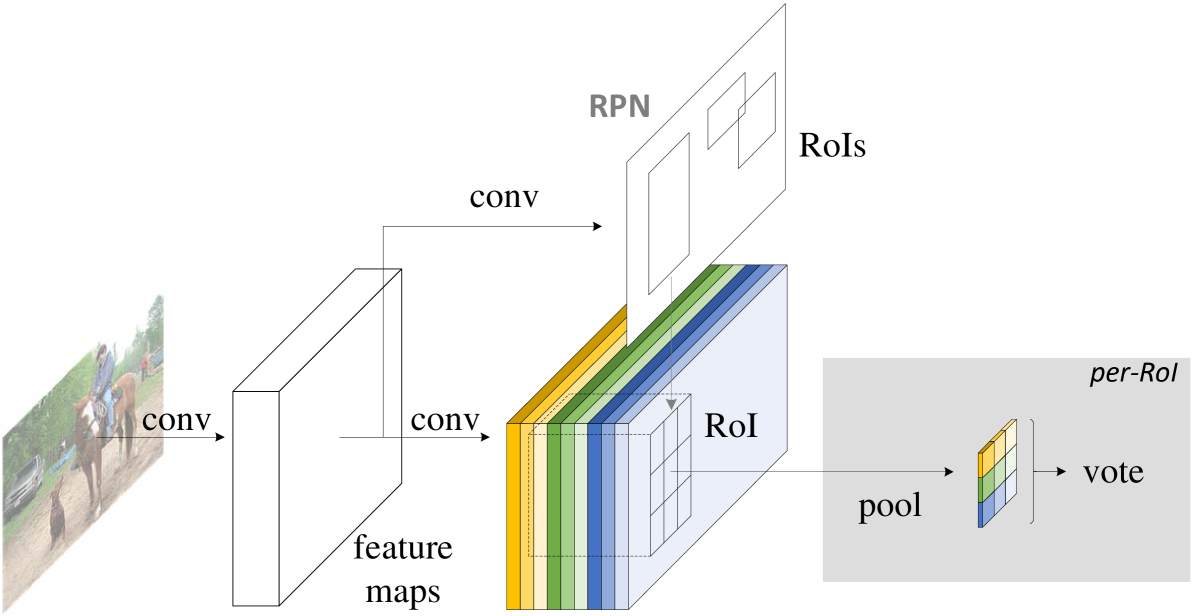
概述。 继 R-CNN [7] 之后,我们采用流行的两阶段目标检测策略 [7, 8, 6, 18, 1, 22],其中包括: ( i) 区域提议,以及 (ii) 区域分类。 尽管不依赖区域提议的方法确实存在(例如、[17, 14]),但基于区域的系统仍然具有领先的准确性在多个基准测试中[5,13,20]。 我们通过区域提议网络(RPN)[18]提取候选区域,它本身就是一个完全卷积的架构。 继[18]之后,我们分享RPN和R-FCN之间的特性。 图2显示了系统的概述。
给定提议区域 (RoIs),R-FCN 架构旨在将 RoIs 分类为对象类别和背景。 在 R-FCN 中,所有可学习权重层都是卷积层,并且是在整个图像上计算的。 最后一个卷积层为每个类别生成一组 位置敏感分数图,因此有一个 通道输出层,其中有 个对象类别( 个背景类别)。 分数图库对应于描述相对位置的 空间网格。 例如,对于 ,9 个分数图对 {左上、中上、右上、...、右下} 对象类别。
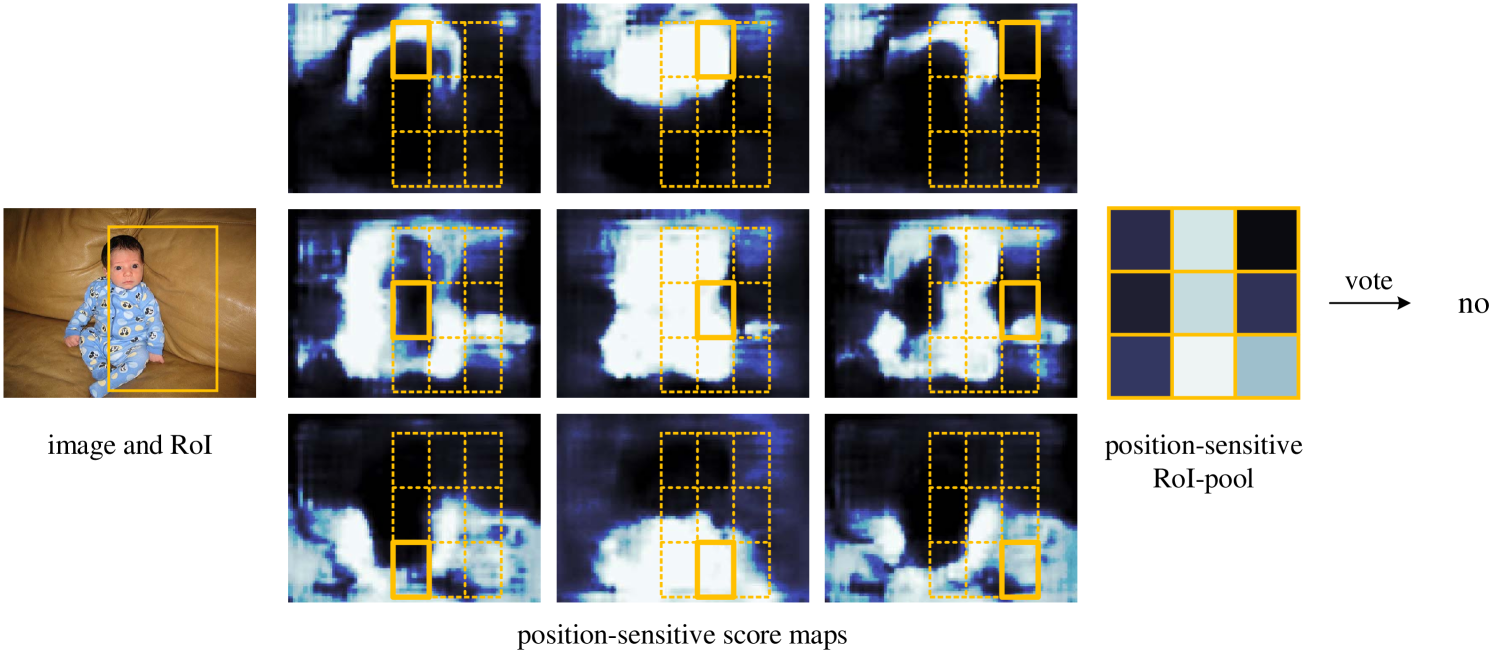
R-FCN 以位置敏感的 RoI 池化层结束。 该层聚合最后一个卷积层的输出并为每个 RoI 生成分数。 与[8, 6]不同,我们的位置敏感RoI层进行选择性池化,并且每个 bin仅聚合来自的响应从 组得分图中选出一个 得分图。 通过端到端训练,该 RoI 层引导最后一个卷积层来学习专门的位置敏感得分图。 图1说明了这个想法。 图 4 和 4 展示了一个示例。 详细介绍如下。
骨干架构。 本文中的 R-FCN 的化身基于 ResNet-101 [9],但其他网络 [10, 23] 也适用。 ResNet-101 有 100 个卷积层,后面是全局平均池化和 1000 类 fc 层。 我们删除了平均池化层和fc层,仅使用卷积层来计算特征图。 我们使用[9]作者发布的ResNet-101,在ImageNet [20]上进行预训练。 ResNet-101中的最后一个卷积块是2048-d,我们附加了一个随机初始化的1024-d 11卷积层来减少维度(准确地说,这增加了表1 乘 1)。 然后我们应用通道卷积层来生成分数图,如下所述。
位置敏感的得分图和位置敏感的 RoI 池化。 为了将位置信息显式编码到每个 RoI 中,我们通过规则网格将每个 RoI 矩形划分为 bin。 对于大小为 的 RoI 矩形,bin 的大小为 [8, 6]。 在我们的方法中,构造最后一个卷积层来为每个类别生成 分数图。 在第 个 bin () 内,我们定义了一个位置敏感的 RoI 池化操作,该操作仅在第 个分数图上进行池化:
| (1) |
这里 是第 个类别的第 个 bin 中的汇总响应, 是一个分数图 分数图, 表示 RoI 的左上角, 是 bin 中的像素数,表示网络的所有可学习参数。 第 个 bin 跨越 和 。 方程的运算。(1)如图1所示,其中一种颜色代表一对。 方程。(1) 执行平均池化(正如我们在本文中使用的那样),但也可以进行最大池化。
然后, 位置敏感分数对 RoI 进行投票。 在本文中,我们简单地通过平均分数进行投票,为每个 RoI 生成一个 维向量:。 然后我们计算跨类别的 softmax 响应:。 它们用于评估训练期间的交叉熵损失以及在推理期间对 RoI 进行排名。
我们以类似的方式进一步解决边界框回归[7, 6]。 除了上面的 -d 卷积层之外,我们还附加了一个兄弟 -d 卷积层用于边界框回归。 位置敏感的 RoI 池化在这组 地图上执行,为每个 RoI 生成一个 -d 向量。 然后通过平均投票聚合成-d向量。 此 -d 向量将边界框参数化为 ,遵循 [6] 中的参数化。 我们注意到,为了简单起见,我们执行了与类无关的边界框回归,但特定于类的对应部分(即,具有 -d 输出层)是适用的。
位置敏感得分图的概念部分受到 [3] 的启发,后者开发了用于实例级语义分割的 FCN。 我们进一步介绍了位置敏感的 RoI 池化层,该层引导学习目标检测的分数图。 RoI 层之后没有可学习层,从而实现几乎无成本区域计算并加速训练和推理。
训练。 通过预先计算的区域建议,可以轻松地端到端训练 R-FCN 架构。 在[6]之后,我们在每个RoI上定义的损失函数是交叉熵损失和框回归损失的总和:。 这里 是 RoI 的真实标签( 表示背景)。 是分类的交叉熵损失,是[6]中定义的边界框回归损失, 代表地面实况框。 是一个指示符,如果参数为 true,则等于 1,否则等于 0。 我们将平衡重量设置为[6]。 我们将正例定义为与真实框的交集(IoU)重叠至少为 0.5 的 RoI,否则为负例。
我们的方法在训练过程中很容易采用在线困难示例挖掘(OHEM)[22]。 我们的每 RoI 计算量可以忽略不计,几乎可以实现无成本示例挖掘。 假设每个图像有 个提案,在前向传递中,我们评估所有 个提案的损失。 然后,我们按损失对所有 RoI(正和负)进行排序,并选择损失最高的 RoI。 根据所选示例执行反向传播[11]。 因为我们的 per-RoI 计算可以忽略不计,所以前向时间几乎不受 的影响,而 [22] 中的 OHEM Fast R-CNN 可能会使训练时间加倍。 我们在下一节的表5中提供了全面的时序统计数据。
我们使用 0.0005 的权重衰减和 0.9 的动量。 默认情况下,我们使用单尺度训练:调整图像大小,使比例(图像的短边)为 600 像素[6, 18]。 每个 GPU 保存 1 个图像并选择 RoIs 进行反向传播。 我们使用 8 个 GPU 训练模型(因此有效的小批量大小为 )。 我们在 VOC 上对 R-FCN 使用 20k 小批量的学习率为 0.001,对于 10k 小批量的学习率为 0.0001。 为了让 R-FCN 与 RPN 共享特征(图 2),我们采用 4 步交替训练222虽然联合训练[18]是适用的,但联合执行示例挖掘并不简单。 在[18]中,在训练RPN和训练R-FCN之间交替。
推断。 如图2所示,计算了RPN和R-FCN之间共享的特征图(在单尺度为600的图像上)。 然后 RPN 部分提出 RoIs,R-FCN 部分在此基础上评估类别分数并回归边界框。 在推理过程中,我们评估 300 个 RoI,如 [18] 中所示,以进行公平比较。 作为标准做法,结果使用 0.3 IoU [7] 阈值通过非极大值抑制 (NMS) 进行后处理。
À 特鲁斯 并大步迈进。 我们的全卷积架构享有 FCN 广泛用于语义分割的网络修改的好处[15, 2]。 特别是,我们将 ResNet-101 的有效步幅从 32 像素减少到 16 像素,从而提高了分数图分辨率。 conv阶段[9](stride=16)之前和之上的所有层均保持不变;第一个 conv 块中的 stride=2 操作被修改为 stride=1,并且 conv 阶段上的所有卷积滤波器均通过“空洞算法”[15, 2] (“Algorithme à trous” [16]) 来补偿减少的步幅。 为了公平比较,RPN 是在 conv 阶段(与 R-FCN 共享)之上计算的,就像 Faster R 的 [9] 中的情况一样CNN,因此 RPN 不受 à trous 技巧的影响。 下表展示了R-FCN的消融结果(,无硬例挖掘)。 à trous 技巧将 mAP 提高了 2.6 点。
| R-FCN with ResNet-101 on: | conv, stride=16 | conv, stride=32 | conv, à trous, stride=16 |
|---|---|---|---|
| mAP (%) on VOC 07 test | 72.5 | 74.0 | 76.6 |

3相关工作
R-CNN [7] 证明了在深度网络中使用区域提议 [27, 28] 的有效性。 R-CNN 在裁剪和扭曲区域上评估卷积网络,并且计算不在区域之间共享(表1)。 SPPnet [8]、Fast R-CNN [6] 和 Faster R-CNN [18] 是“半卷积”,其中卷积子网络对整个图像执行共享计算,另一个子网络评估各个区域。
有些物体检测器可以被认为是“完全卷积”模型。 OverFeat [21] 通过在共享卷积特征图上滑动多尺度窗口来检测对象;类似地,在 Fast R-CNN [6] 和 [12] 中,研究了替代区域提案的滑动窗口。 在这些情况下,可以将单个尺度的滑动窗口重新构建为单个卷积层。 Faster R-CNN [18] 中的 RPN 组件是一个全卷积检测器,可预测多个尺寸的参考框(锚点)的边界框。 原始 RPN 在 [18] 中与类无关,但其特定于类的对应项是适用的(另请参见 [14]),正如我们在下面进行评估的那样。
另一系列物体检测器采用全连接 (fc) 层来在整个图像上生成整体物体检测结果,例如 [25, 4, 17]。
4实验
| method | RoI output size () | mAP on VOC 07 (%) |
|---|---|---|
| naïve Faster R-CNN | 61.7 | |
| 68.9 | ||
| class-specific RPN | - | 67.6 |
| R-FCN (w/o position-sensitivity) | fail | |
| R-FCN | 75.5 | |
| 76.6 |
4.1PASCAL VOC实验
我们在具有 20 个对象类别的 PASCAL VOC [5] 上进行实验。 我们在[6]之后的VOC 2007 trainval和VOC 2012 trainval(“07+12”)的联合集上训练模型,并且在 VOC 2007 测试集上进行评估。 对象检测精度通过平均精度 (mAP) 来衡量。
与其他全卷积策略的比较
尽管可以使用全卷积检测器,但实验表明它们要达到良好的精度并非易事。 我们使用 ResNet-101 研究以下完全卷积策略(或“几乎”完全卷积策略,每个 RoI 只有一个分类器 fc 层):
Naïve Faster R-CNN。 正如简介中所讨论的,可以使用 ResNet-101 中的所有个卷积层来计算共享特征图,并在最后一个卷积层之后(在 conv 之后)采用 RoI 池化。 在每个 RoI 上评估一个廉价的 21 级 fc 层(因此这个变体“几乎”是完全卷积的)。 à trous 技巧用于公平比较。
特定于类别的 RPN。 该 RPN 是按照[18]进行训练的,只不过 2 类(对象或非对象)卷积分类器层被替换为 21 类卷积分类器层。 为了公平比较,对于这个特定于类的 RPN,我们使用 ResNet-101 的 conv 层和 à trous 技巧。
无位置敏感性的 R-FCN。 通过设置,我们消除了 R-FCN 的位置敏感性。 这相当于每个 RoI 内的全局池化。
|
|
|
|
mAP (%) on VOC07 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | 10 | 1.2 | 0.42 | 76.4 | |||||||||
| R-FCN | 0 | 0.45 | 0.17 | 76.6 | |||||||||
| Faster R-CNN | 10 | ✓(300 RoIs) | 1.5 | 0.42 | 79.3 | ||||||||
| R-FCN | 0 | ✓(300 RoIs) | 0.45 | 0.17 | 79.5 | ||||||||
| Faster R-CNN | 10 | ✓(2000 RoIs) | 2.9 | 0.42 | N/A | ||||||||
| R-FCN | 0 | ✓(2000 RoIs) | 0.46 | 0.17 | 79.3 |
| training data | mAP (%) | test time (sec/img) | |
|---|---|---|---|
| Faster R-CNN [9] | 07+12 | 76.4 | 0.42 |
| Faster R-CNN +++ [9] | 07+12+COCO | 85.6 | 3.36 |
| R-FCN | 07+12 | 79.5 | 0.17 |
| R-FCN multi-sc train | 07+12 | 80.5 | 0.17 |
| R-FCN multi-sc train | 07+12+COCO | 83.6 | 0.17 |
| training data | mAP (%) | test time (sec/img) | |
|---|---|---|---|
| Faster R-CNN [9] | 07++12 | 73.8 | 0.42 |
| Faster R-CNN +++ [9] | 07++12+COCO | 83.8 | 3.36 |
| R-FCN multi-sc train | 07++12 | 77.6 | 0.17 |
| R-FCN multi-sc train | 07++12+COCO | 82.0 | 0.17 |
分析。 表2显示了结果。 我们注意到,ResNet 论文 [9] 中的标准(并非幼稚)Faster R-CNN 使用 ResNet-101 实现了 76.4% mAP(另请参见表 5),它在 conv 和 conv [9] 之间插入 RoI 池化层。 作为比较,naïve Faster R-CNN(在 conv之后应用 RoI 池化)的 mAP 大大降低,为 68.9%(表 2)。 这种比较从经验上证明了通过在 Faster R-CNN 系统的层之间插入 RoI 池来尊重空间信息的重要性。 [19] 中报告了类似的观察结果。
特定类别 RPN 的 mAP 为 67.6%(表2),比标准 Faster R-CNN 的 76.4% 低约 9 个百分点。 这种比较与 [6, 12] 中的观察结果一致——事实上,特定于类的 RPN 类似于 Fast R-CNN [6] 的特殊形式> 使用密集滑动窗口作为提案,其结果较差,如 [6, 12] 中报告的那样。
另一方面,我们的 R-FCN 系统具有明显更好的精度(表2)。 其 mAP (76.6%) 与标准 Faster R-CNN (76.4%,表 5) 相当。 这些结果表明,我们的位置敏感策略能够对用于定位对象的有用空间信息进行编码,而无需在 RoI 池化后使用任何可学习层。
通过设置进一步证明了位置敏感性的重要性,对此R-FCN无法收敛。 在这种降级情况下,无法在 RoI 内明确捕获任何空间信息。 此外,我们报告说,如果 RoI 池化输出分辨率为 ,naïve Faster R-CNN 就能够收敛,但 mAP 进一步大幅下降至 61.7%(表 2) >)。
与使用 ResNet-101 的 Faster R-CNN 的比较
接下来我们与标准“Faster R-CNN + ResNet-101”[9]进行比较,它是PASCAL VOC上最强的竞争对手和表现最好的,MS COCO,和 ImageNet 基准测试。 我们在下面使用。 表5显示了比较。 Faster R-CNN 评估每个区域的 10 层子网络以实现良好的精度,但 R-FCN 的每区域成本可以忽略不计。 测试时有 300 个 RoI,Faster R-CNN 每个图像需要 0.42 秒,比我们的 R-FCN 慢 2.5,每个图像需要 0.17 秒(在 K40 GPU 上;这个数字在 GPU 上为 0.11 秒)。泰坦 X GPU)。 R-FCN 的训练速度也比 Faster R-CNN 更快。 此外,困难示例挖掘[22]不会增加R-FCN训练的成本(表5)。 从 2000 个 RoI 开始挖掘时训练 R-FCN 是可行的,在这种情况下 Faster R-CNN 慢 6(2.9s vs. 0.46s)。 但实验表明,从更大的候选集(例如,2000)中挖掘没有任何好处(表5)。 因此,我们在本文的其他部分使用 300 个 RoI 进行训练和推理。
表5显示了更多比较。 在[8]中的多尺度训练之后,我们在每次迭代中调整图像大小,以便从{400,500,600,700,800}像素中随机采样尺度。 我们仍然测试 600 像素的单个比例,因此不增加测试时间成本。 mAP 为 80.5%。 此外,我们在 MS COCO [13] trainval 集上训练我们的模型,然后在 PASCAL VOC 集上对其进行调节。 R-FCN 达到 83.6% mAP(表 5),接近 [9] 中也使用 ResNet-101 的“Faster R-CNN +++”系统。 我们注意到,我们的竞争结果是在每张图像 0.17 秒的测试速度下获得的,比 Faster R-CNN +++ 快 20,后者需要 3.36 秒,因为它进一步结合了迭代框回归、上下文和多尺度测试[9]。 这些比较也在 PASCAL VOC 2012 测试集上观察到(表5)。
关于深度的影响
下表显示了使用不同深度的ResNets[9]的R-FCN结果。 当深度从 50 增加到 101 时,我们的检测精度会提高,但在深度为 152 时会达到饱和。
| training data | test data | ResNet-50 | ResNet-101 | ResNet-152 | |
|---|---|---|---|---|---|
| R-FCN | 07+12 | 07 | 77.0 | 79.5 | 79.6 |
| R-FCN multi-sc train | 07+12 | 07 | 78.7 | 80.5 | 80.4 |
论区域提案的影响
R-FCN 可以轻松地与其他区域提议方法一起应用,例如选择性搜索(SS)[27] 和边缘框(EB)[28]。 下表显示了不同提案的结果(使用 ResNet-101)。 R-FCN 使用 SS 或 EB 进行竞争,显示了我们方法的通用性。
| training data | test data | RPN [18] | SS [27] | EB [28] | |
|---|---|---|---|---|---|
| R-FCN | 07+12 | 07 | 79.5 | 77.2 | 77.8 |
4.2MS COCO上的实验
接下来,我们对具有 80 个对象类别的 MS COCO 数据集 [13] 进行评估。 我们的实验涉及 80k train 集、40k val 集和 20k test-dev 集。 我们将 90k 次迭代的学习率设置为 0.001,接下来的 30k 次迭代的学习率设置为 0.0001,有效小批量大小为 8。 我们将交替训练 [18] 从 4 步扩展到 5 步(即,在再一个 RPN 训练步骤后停止),这在以下情况下稍微提高了该数据集的准确性:功能是共享的;我们还报告说,2 步训练足以实现相对较高的准确度,但功能并未共享。
结果见表6。 我们经过单尺度训练的 R-FCN 基线的 val 结果为 48.9%/27.6%。 这与 Faster R-CNN 基线 (48.4%/27.2%) 相当,但我们的测试速度快了 2.5。 值得注意的是,我们的方法在小尺寸的对象(由[13]定义)上表现更好。 我们经过多尺度训练(尚未进行单尺度测试)的 R-FCN 在 val 集上的结果为 49.1%/27.8%,在 test-dev< 上的结果为 51.5%/29.2% /t1> 设置。 考虑到COCO广泛的对象尺度,我们进一步评估了[9]之后的多尺度测试变体,并使用测试尺度{200,400,600,800,1000}。 mAP 为 53.2%/31.5%。 这一结果接近 MS COCO 2015 竞赛中的第一名成绩(Faster R-CNN +++ with ResNet-101,55.7%/34.9%)。 尽管如此,我们的方法更简单,并且没有添加 [9] 使用的上下文或迭代框回归等花哨的训练,并且对于 和 测试来说都更快。
|
|
|
|
|
|
|
|
|||||||||||||||
| Faster R-CNN [9] | train | val | 48.4 | 27.2 | 6.6 | 28.6 | 45.0 | 0.42 | ||||||||||||||
| R-FCN | train | val | 48.9 | 27.6 | 8.9 | 30.5 | 42.0 | 0.17 | ||||||||||||||
| R-FCN multi-sc train | train | val | 49.1 | 27.8 | 8.8 | 30.8 | 42.2 | 0.17 | ||||||||||||||
| Faster R-CNN +++ [9] | trainval | test-dev | 55.7 | 34.9 | 15.6 | 38.7 | 50.9 | 3.36 | ||||||||||||||
| R-FCN | trainval | test-dev | 51.5 | 29.2 | 10.3 | 32.4 | 43.3 | 0.17 | ||||||||||||||
| R-FCN multi-sc train | trainval | test-dev | 51.9 | 29.9 | 10.8 | 32.8 | 45.0 | 0.17 | ||||||||||||||
| R-FCN multi-sc train, test | trainval | test-dev | 53.2 | 31.5 | 14.3 | 35.5 | 44.2 | 1.00 |
5 结论和未来工作
我们提出了基于区域的全卷积网络,这是一种简单但准确且高效的目标检测框架。 我们的系统自然地采用了最先进的图像分类主干网,例如 ResNet,它们在设计上是完全卷积的。 我们的方法实现了与 Faster R-CNN 同类方法相媲美的准确率,但在训练和推理过程中速度更快。
我们有意保持论文中提出的 R-FCN 系统简单。 已经有一系列针对语义分割而开发的 FCN 正交扩展(例如,请参阅[2]),以及基于区域的对象方法的扩展检测(例如,请参阅[9, 1, 22])。 我们希望我们的系统能够轻松享受该领域进步的好处。


参考
- [1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016.
- [2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015.
- [3] J. Dai, K. He, Y. Li, S. Ren, and J. Sun. Instance-sensitive fully convolutional networks. arXiv:1603.08678, 2016.
- [4] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.
- [5] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes (VOC) Challenge. IJCV, 2010.
- [6] R. Girshick. Fast R-CNN. In ICCV, 2015.
- [7] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
- [8] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
- [9] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [10] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- [11] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989.
- [12] K. Lenc and A. Vedaldi. R-CNN minus R. In BMVC, 2015.
- [13] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
- [14] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. SSD: Single shot multibox detector. arXiv:1512.02325v2, 2015.
- [15] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
- [16] S. Mallat. A wavelet tour of signal processing. Academic press, 1999.
- [17] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016.
- [18] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
- [19] S. Ren, K. He, R. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. arXiv:1504.06066, 2015.
- [20] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015.
- [21] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
- [22] A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016.
- [23] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- [24] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015.
- [25] C. Szegedy, A. Toshev, and D. Erhan. Deep neural networks for object detection. In NIPS, 2013.
- [26] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016.
- [27] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013.
- [28] C. L. Zitnick and P. Dollár. Edge boxes: Locating object proposals from edges. In ECCV, 2014.
| method |
data |
mAP |
areo |
bike |
bird |
boat |
bottle |
bus |
car |
cat |
chair |
cow |
table |
dog |
horse |
mbike |
person |
plant |
sheep |
sofa |
train |
tv |
| Faster R-CNN |
07+12 |
76.4 |
79.8 |
80.7 |
76.2 |
68.3 |
55.9 |
85.1 |
85.3 |
89.8 |
56.7 |
87.8 |
69.4 |
88.3 |
88.9 |
80.9 |
78.4 |
41.7 |
78.6 |
79.8 |
85.3 |
72.0 |
| Faster R-CNN+++ |
07+12+CO |
85.6 |
90.0 |
89.6 |
87.8 |
80.8 |
76.1 |
89.9 |
89.9 |
89.6 |
75.5 |
90.0 |
80.7 |
89.6 |
90.3 |
89.1 |
88.7 |
65.4 |
88.1 |
85.6 |
89.0 |
86.8 |
| R-FCN |
07+12 |
79.5 |
82.5 |
83.7 |
80.3 |
69.0 |
69.2 |
87.5 |
88.4 |
88.4 |
65.4 |
87.3 |
72.1 |
87.9 |
88.3 |
81.3 |
79.8 |
54.1 |
79.6 |
78.8 |
87.1 |
79.5 |
| R-FCN ms train |
07+12 |
80.5 |
79.9 |
87.2 |
81.5 |
72.0 |
69.8 |
86.8 |
88.5 |
89.8 |
67.0 |
88.1 |
74.5 |
89.8 |
90.6 |
79.9 |
81.2 |
53.7 |
81.8 |
81.5 |
85.9 |
79.9 |
| R-FCN ms train |
07+12+CO |
83.6 |
88.1 |
88.4 |
81.5 |
76.2 |
73.8 |
88.7 |
89.7 |
89.6 |
71.1 |
89.9 |
76.6 |
90.0 |
90.4 |
88.7 |
86.6 |
59.7 |
87.4 |
84.1 |
88.7 |
82.4 |
| method |
data |
mAP |
areo |
bike |
bird |
boat |
bottle |
bus |
car |
cat |
chair |
cow |
table |
dog |
horse |
mbike |
person |
plant |
sheep |
sofa |
train |
tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN |
07++12 |
73.8 |
86.5 |
81.6 |
77.2 |
58.0 |
51.0 |
78.6 |
76.6 |
93.2 |
48.6 |
80.4 |
59.0 |
92.1 |
85.3 |
84.8 |
80.7 |
48.1 |
77.3 |
66.5 |
84.7 |
65.6 |
| Faster R-CNN+++ |
07++12+CO |
83.8 |
92.1 |
88.4 |
84.8 |
75.9 |
71.4 |
86.3 |
87.8 |
94.2 |
66.8 |
89.4 |
69.2 |
93.9 |
91.9 |
90.9 |
89.6 |
67.9 |
88.2 |
76.8 |
90.3 |
80.0 |
| R-FCN ms train |
07++12 |
77.6 |
86.9 |
83.4 |
81.5 |
63.8 |
62.4 |
81.6 |
81.1 |
93.1 |
58.0 |
83.8 |
60.8 |
92.7 |
86.0 |
84.6 |
84.4 |
59.0 |
80.8 |
68.6 |
86.1 |
72.9 |
| R-FCN ms train |
07++12+CO |
82.0 |
89.5 |
88.3 |
83.5 |
70.8 |
70.7 |
85.5 |
86.3 |
94.2 |
64.7 |
87.6 |
65.8 |
92.7 |
90.5 |
89.4 |
87.8 |
65.6 |
85.6 |
74.5 |
88.9 |
77.4 |