capbtabbox表[][]
层归一化
摘要
训练最先进的深度神经网络的计算成本很高。 减少训练时间的一种方法是使神经元的活动正常化。 最近引入的一种称为批量归一化的技术,使用小批量训练案例中神经元的输入总和的分布来计算均值和方差,然后使用它们对每个训练案例上该神经元的输入总和进行归一化。 这显着减少了前馈神经网络的训练时间。 然而,批量归一化的效果取决于小批量大小,如何将其应用于循环神经网络并不明显。 在本文中,我们通过计算单个训练案例中层中神经元的所有总输入的均值和方差来进行归一化,从而将批量归一化转换为层归一化。 与批量归一化一样,我们还为每个神经元提供了自己的自适应偏差和增益,这些偏差和增益在归一化之后但在非线性之前应用。 与批量归一化不同,层归一化在训练和测试时执行完全相同的计算。 通过在每个时间步分别计算归一化统计数据,也可以直接应用于循环神经网络。 层归一化对于稳定循环网络中的隐藏状态动态非常有效。 根据经验,我们表明与之前发布的技术相比,层归一化可以大大减少训练时间。
1简介
使用某种版本的随机梯度下降训练的深度神经网络已被证明在计算机视觉[Krizhevsky 等人,2012]和语音处理[Hinton 等中的各种监督学习任务上远远优于以前的方法。人,2012]。 但最先进的深度神经网络通常需要很多天的训练。 可以通过计算不同机器上案例的不同子集的梯度或将神经网络本身拆分到许多机器上来加速学习[Dean 等人, 2012],但这可能需要大量的通信和复杂的软件。 随着并行化程度的增加,它也往往会导致收益迅速递减。 正交方法是修改神经网络前向传递中执行的计算,以使学习更容易。 最近,提出了批标准化[Ioffe and Szegedy, 2015],通过在深度神经网络中包含额外的标准化阶段来减少训练时间。 归一化使用数据中的训练平均值和标准差对每个求和输入进行标准化。 即使使用简单的 SGD,使用批量归一化训练的前馈神经网络也能更快地收敛。 除了训练时间的改进之外,批量统计数据的随机性还可以在训练期间充当正则化器。
尽管批量归一化很简单,但它需要对输入统计数据求和的运行平均值。 在具有固定深度的前馈网络中,单独存储每个隐藏层的统计数据是很简单的。 然而,循环神经网络 (RNN) 中循环神经元的输入总和通常随序列长度的变化而变化,因此对 RNN 应用批量归一化似乎需要针对不同时间步长进行不同的统计。 此外,批量归一化不能应用于在线学习任务或小批量必须很小的极大分布式模型。
本文介绍了层归一化,这是一种简单的归一化方法,可以提高各种神经网络模型的训练速度。 与批量归一化不同,所提出的方法直接根据隐藏层内神经元的输入求和来估计归一化统计数据,因此归一化不会在训练案例之间引入任何新的依赖关系。 我们证明了层归一化对于 RNN 效果很好,并且提高了几个现有 RNN 模型的训练时间和泛化性能。
2 背景
前馈神经网络是从输入模式 到输出向量 的非线性映射。 考虑深度前馈神经网络中的 隐藏层,并令 为该层神经元输入总和的向量表示。 输入求和是通过线性投影计算的,权重矩阵 和自下而上的输入 如下:
| (1) |
其中 是逐元素非线性函数, 是 隐藏单元的传入权重, 是标量偏差参数。 神经网络中的参数是使用基于梯度的优化算法来学习的,梯度是通过反向传播计算的。
深度学习的挑战之一是,一层中权重的梯度高度依赖于前一层神经元的输出,特别是当这些输出以高度相关的方式变化时。 批量归一化[Ioffe and Szegedy, 2015]被提出来减少这种不良的“协变量偏移”。 该方法对训练案例中每个隐藏单元的输入总和进行标准化。 具体来说,对于 层中的 求和输入,批量归一化方法根据求和输入在数据分布下的方差重新缩放求和输入
| (2) |
其中 是 层中 隐藏单元的归一化总输入, 是缩放之前归一化激活的增益参数非线性激活函数。 请注意,期望是在整个训练数据分布下的。 计算方程式中的期望通常是不切实际的。 (2) 准确地说,因为它需要使用当前的权重集向前传递整个训练数据集。 相反, 和 使用当前小批量的经验样本进行估计。 这对小批量的大小造成了限制,并且很难应用于循环神经网络。
3 层标准化
我们现在考虑层归一化方法,该方法旨在克服批量归一化的缺点。
请注意,一层输出的变化往往会导致下一层的总输入发生高度相关的变化,尤其是对于输出可能发生很大变化的 ReLU 单元。 这表明可以通过固定每层内输入总和的均值和方差来减少“协变量偏移”问题。 因此,我们计算同一层中所有隐藏单元的层归一化统计量,如下所示:
| (3) |
其中表示层中隐藏单元的数量。 等式之间的差异。 (2) 和等式。 (3)是在层归一化下,层中的所有隐藏单元共享相同的归一化项和,但不同的训练情况具有不同的归一化项。 与批量归一化不同,层归一化不会对小批量的大小施加任何限制,并且可以在批量大小为 1 的纯在线机制中使用。
3.1 层归一化循环神经网络
最近的序列到序列模型[Sutskever等人, 2014]利用紧凑的循环神经网络来解决自然语言处理中的序列预测问题。 在 NLP 任务中,不同的训练案例有不同的句子长度是很常见的。 这在 RNN 中很容易处理,因为每个时间步都使用相同的权重。 但是,当我们以明显的方式将批量归一化应用于 RNN 时,我们需要为序列中的每个时间步计算并存储单独的统计数据。 如果测试序列比任何训练序列都长,这就会出现问题。 层归一化不存在这样的问题,因为它的归一化项仅取决于当前时间步的层输入总和。 它还只有一组在所有时间步长上共享的增益和偏置参数。
在标准 RNN 中,循环层中的输入求和是根据当前输入 和先前的隐藏状态向量 计算得出的,计算结果为 。 层归一化循环层使用类似于等式 1 的额外归一化项重新居中并重新缩放其激活。 (3):
| (4) |
其中 是隐藏权重的循环隐藏, 是隐藏权重的自下而上输入。 是两个向量之间的逐元素乘法。 和被定义为与相同维度的偏置和增益参数。
在标准 RNN 中,循环单元的总输入的平均幅度有在每个时间步增长或收缩的趋势,从而导致梯度爆炸或消失。 在层归一化 RNN 中,归一化项使其在重新缩放层的所有总输入时不变,从而产生更稳定的隐藏到隐藏动态。
4相关工作
批量标准化之前已扩展到循环神经网络[Laurent 等人, 2015, Amodei 等人, 2015, Cooijmans 等人, 2016]。 之前的工作[Cooijmans等人, 2016]建议通过为每个时间步保持独立的标准化统计来获得循环批量归一化的最佳性能。 作者表明,将循环批量归一化层中的增益参数初始化为 0.1 会对模型的最终性能产生显着影响。 我们的工作也与体重归一化相关[Salimans and Kingma, 2016]。 在权重归一化中,使用输入权重的 L2 范数代替方差来归一化神经元的总输入。 使用预期统计量应用权重归一化或批量归一化相当于对原始前馈神经网络进行不同的参数化。 Path-normalized SGD [Neyshabur 等人, 2015] 研究了 ReLU 网络中的重新参数化。 然而,我们提出的层归一化方法并不是原始神经网络的重新参数化。 因此,层归一化模型具有与其他方法不同的不变性,我们将在下一节中研究。
5分析
在本节中,我们研究不同归一化方案的不变性。
5.1 权重和数据变换下的不变性
所提出的层归一化与批量归一化和权重归一化相关。 尽管它们的归一化标量的计算方式不同,但这些方法可以概括为通过两个标量 和 对神经元的总输入 进行归一化。 他们还在标准化后为每个神经元学习自适应偏差 和增益 。
| (5) |
表 1 突出显示了三种归一化方法的以下不变性结果。
| Weight matrix | Weight matrix | Weight vector | Dataset | Dataset | Single training case | |
|---|---|---|---|---|---|---|
| re-scaling | re-centering | re-scaling | re-scaling | re-centering | re-scaling | |
| Batch norm | Invariant | No | Invariant | Invariant | Invariant | No |
| Weight norm | Invariant | No | Invariant | No | No | No |
| Layer norm | Invariant | Invariant | No | Invariant | No | Invariant |
权重重新缩放和重新居中: 首先,观察到在批量归一化和权重归一化下,对单个神经元的传入权重 的任何重新缩放对神经元的归一化总输入没有影响。 准确地说,在批量和权重归一化下,如果权重向量按 缩放,则两个标量 和 也会按 。 归一化求和输入在缩放之前和之后保持相同。 因此,批量和权重归一化对于权重的重新缩放是不变的。 另一方面,层归一化对于单个权重向量的单独缩放并不是不变的。 相反,层归一化对于整个权重矩阵的缩放是不变的,并且对于权重矩阵中所有传入权重的移位也是不变的。 假设有两组模型参数 、,其权重矩阵 和 相差比例因子 和 中的所有传入权重也被移动一个常数向量 ,即 。 在层归一化下,两个模型有效地计算相同的输出:
| (6) |
请注意,如果归一化仅应用于权重之前的输入,则模型对于权重的重新缩放和重新居中不会保持不变。
数据重新缩放和重新居中: 我们可以通过验证神经元的输入总和在变化下保持不变来证明所有归一化方法对于重新缩放数据集都是不变的。 此外,层归一化对于单个训练案例的重新缩放是不变的,因为等式中的归一化标量 和 。 (3)仅依赖于当前输入数据。 令 为通过 重新缩放 获得的新数据点。 然后我们有,
| (7) |
很容易看出,重新缩放各个数据点不会改变层归一化下模型的预测。 与层归一化中权重矩阵的重新居中类似,我们还可以证明批量归一化对于数据集的重新居中是不变的。
5.2 学习过程中参数空间的几何
我们研究了在参数重新居中和重新缩放下模型预测的不变性。 然而,即使模型表达相同的底层函数,学习在不同的参数化下也会表现得非常不同。 在本节中,我们通过参数空间的几何和流形来分析学习行为。 我们表明,归一化标量可以隐式降低学习率并使学习更加稳定。
5.2.1 黎曼度量
统计模型中的可学习参数形成一个平滑流形,由模型所有可能的输入输出关系组成。 对于输出为概率分布的模型,测量流形上两点分离的自然方法是模型输出分布之间的 Kullback-Leibler 散度。 在KL散度度量下,参数空间是黎曼流形。
黎曼流形的曲率完全由其黎曼度量来捕获,其二次形式表示为。 这是参数空间中一点在切空间中的无穷小距离。 直观地,它测量参数空间沿切线方向模型输出的变化。 之前研究过 KL 下的黎曼度量[Amari, 1998],并且证明在使用 Fisher 信息矩阵的二阶泰勒展开下可以很好地近似:
| (8) | ||||
| (9) |
其中, 是对参数的微小更改。 上面的黎曼度量呈现了参数空间的几何视图。 以下对黎曼度量的分析提供了一些关于归一化方法如何帮助训练神经网络的见解。
5.2.2 归一化广义线性模型的几何
我们将几何分析重点放在广义线性模型上。 以下分析的结果可以轻松地应用于理解具有费舍尔信息矩阵的块对角近似的深度神经网络,其中每个块对应于单个神经元的参数。
广义线性模型 (GLM) 可以被视为使用权重向量 和偏差标量 对指数族的输出分布进行参数化。 为了与前面的部分保持一致,可以使用求和输入 来编写 GLM 的对数似然,如下所示:
| (10) | ||||
| (11) |
其中,是传递函数,类似于神经网络中的非线性,是传递函数的导数,是实值函数, 是对数分区函数。 是一个缩放输出方差的常数。 假设使用 独立 GLM 和 对 维输出向量 进行建模。 令 为权重矩阵,其行为各个 GLM 的权重向量, 表示长度为 和 的偏差向量> 表示克罗内克向量算子。 多维 GLM 相对于其参数 的 Fisher 信息矩阵只是数据特征和输出协方差矩阵的预期 Kronecker 乘积:
| (12) |
我们通过将归一化方法应用于原始模型中通过 和 求和的输入 来获得归一化 GLM。 不失一般性,我们将 表示为具有附加增益参数 的归一化多维 GLM 下的 Fisher 信息矩阵:
| (13) | ||||
| (14) |
通过权重向量的增长隐式学习率降低: 请注意,与标准 GLM 相比,沿权重向量 方向的块 由增益参数和归一化标量 缩放。 如果权重向量的范数增长两倍,即使模型的输出保持不变,Fisher信息矩阵也会不同。 沿 方向的曲率将改变 倍,因为 也将变为原来的两倍。 因此,对于归一化模型中相同的参数更新,权重向量的范数有效地控制了权重向量的学习速率。 在学习过程中,范数较大的权重向量的方向很难改变。 因此,归一化方法对权重向量具有隐含的“提前停止”效果,有助于稳定学习以实现收敛。
学习传入权重的大小: 在归一化模型中,输入权重的大小由增益参数明确参数化。 我们比较了学习过程中更新归一化 GLM 中的增益参数和更新原始参数化下的等效权重大小之间模型输出的变化情况。 中增益参数的方向捕获传入权重大小的几何形状。 我们表明,标准 GLM 的输入权重大小的黎曼度量是按其输入范数缩放的,而学习批量归一化和层归一化模型的增益参数仅取决于预测误差的大小。 因此,与标准模型相比,在归一化模型中学习输入权重的大小对于输入及其参数的缩放更加稳健。 详细推导请参见附录。
6实验结果
我们对 6 个任务进行了层归一化实验,重点是循环神经网络:图像句子排序、问答、上下文语言建模、生成建模、手写序列生成和 MNIST 分类。 除非另有说明,实验中层归一化的默认初始化是将自适应增益设置为,将偏差设置为。
6.1 图像和语言的嵌入顺序

| MSCOCO | ||||||||
|---|---|---|---|---|---|---|---|---|
| Caption Retrieval | Image Retrieval | |||||||
| Model | R@1 | R@5 | R@10 | Mean r | R@1 | R@5 | R@10 | Mean r |
| Sym [Vendrov et al., 2016] | 45.4 | 88.7 | 5.8 | 36.3 | 85.8 | 9.0 | ||
| OE [Vendrov et al., 2016] | 46.7 | 88.9 | 5.7 | 37.9 | 85.9 | 8.1 | ||
| OE (ours) | 46.6 | 79.3 | 89.1 | 5.2 | 37.8 | 73.6 | 85.7 | 7.9 |
| OE + LN | 48.5 | 80.6 | 89.8 | 5.1 | 38.9 | 74.3 | 86.3 | 7.6 |
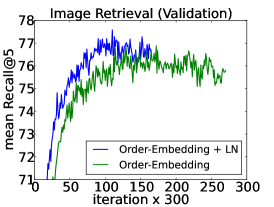
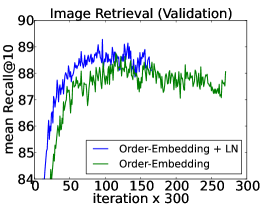
在这个实验中,我们将层归一化应用于Vendrov等人[2016]最近提出的顺序嵌入模型,以学习图像和句子的联合嵌入空间。 我们遵循与 Vendrov 等人 [2016] 相同的实验协议,并修改他们的公开可用代码以合并层归一化 111https://github.com/ivendrov/order-embedding,它利用 Theano [团队等人,2016 ]。 将 Microsoft COCO 数据集 [Lin 等人, 2014] 中的图像和句子嵌入到公共向量空间中,其中使用 GRU [Cho 等人, 2014]对句子进行编码,并使用预训练的 VGG ConvNet [Simonyan 和 Zisserman,2015](10-crop)的输出对图像进行编码。 顺序嵌入模型将图像和句子表示为 2 级偏序,并用非对称函数替换 Kiros 等人 [2014] 中使用的余弦相似度评分函数。
我们训练了两个模型:基线顺序嵌入模型以及应用于 GRU 的层归一化的相同模型。 每 300 次迭代后,我们在保留的验证集上计算 Recall@K (R@K) 值,并在 R@K 改进时保存模型。 然后,在 5 个单独的测试集上评估表现最佳的模型,每个测试集包含 1000 张图像和 5000 个标题,并报告平均结果。 两个模型都使用 Adam [Kingma and Ba, 2014] 和相同的初始超参数,并且两个模型都使用与 Vendrov 等人 [2016] 中使用的相同架构选择进行训练。 我们建议读者参阅附录,了解如何将层归一化应用于 GRU。
6.2 教机器阅读和理解
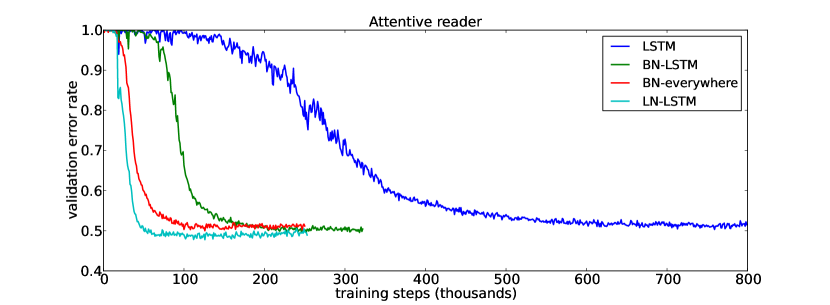
为了将层归一化与最近提出的循环批量归一化[Cooijmans等人,2016]进行比较,我们在CNN语料库上训练了一个单向注意力阅读器模型,两者均由Hermann等人[2015]引入]。 这是一项问答任务,必须通过填空来回答有关段落的查询描述。 数据是匿名的,以便为实体提供随机 Token 以防止退化解决方案,这些解决方案在训练和评估期间一致排列。 我们遵循与 Cooijmans 等人 [2016] 相同的实验协议,并修改他们的公共代码以合并层归一化 222https://github.com/cooijmanstim/Attentive_reader/tree/bn 使用 Theano [团队等人, 2016]。 我们获得了Cooijmans等人[2016]使用的预处理数据集,它与Hermann等人[2015]原始实验的不同之处在于每个通道限制为4句子。 在 Cooijmans 等人 [2016] 中,使用了两种循环批量归一化变体:一种是 BN 仅应用于 LSTM,另一种是在整个模型的各处应用 BN。 在我们的实验中,我们仅在 LSTM 内应用层归一化。
本实验结果如图2所示。 我们观察到,层归一化不仅训练速度更快,而且在基线和 BN 变体上收敛到更好的验证结果。 在Cooijmans等人[2016]中,认为BN中的尺度参数必须仔细选择,并在他们的实验中设置为0.1。 我们对 1.0 和 0.1 尺度初始化进行了层归一化实验,发现前一个模型的性能明显更好。 这表明层归一化不像循环 BN 那样对初始尺度敏感。 333We only produce results on the validation set, as in the case of Cooijmans et al. [2016]
6.3 跳过思维向量
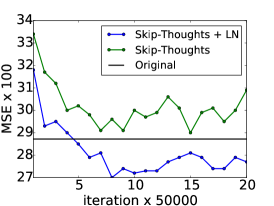
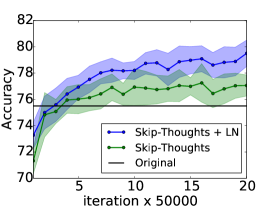
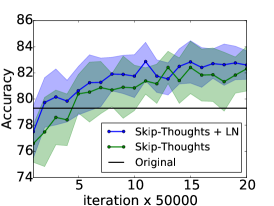
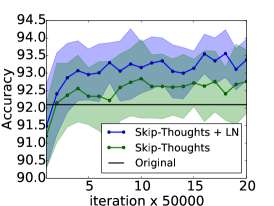
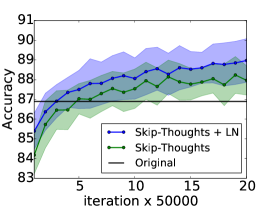
Skip-thoughts [Kiros 等人, 2015] 是 Skip-gram 模型 [Mikolov 等人, 2013] 的推广,用于学习无监督分布式句子表示。 给定连续文本,使用编码器 RNN 对句子进行编码,并使用解码器 RNN 来预测周围的句子。 Kiros 等人 [2015] 表明该模型可以生成通用的句子表示,无需进行微调即可在多个任务上表现良好。 然而,训练这个模型非常耗时,需要几天的训练才能产生有意义的结果。
| Method | SICK() | SICK() | SICK(MSE) | MR | CR | SUBJ | MPQA |
|---|---|---|---|---|---|---|---|
| Original [Kiros et al., 2015] | 0.848 | 0.778 | 0.287 | 75.5 | 79.3 | 92.1 | 86.9 |
| Ours | 0.842 | 0.767 | 0.298 | 77.3 | 81.8 | 92.6 | 87.9 |
| Ours + LN | 0.854 | 0.785 | 0.277 | 79.5 | 82.6 | 93.4 | 89.0 |
| Ours + LN | 0.858 | 0.788 | 0.270 | 79.4 | 83.1 | 93.7 | 89.3 |
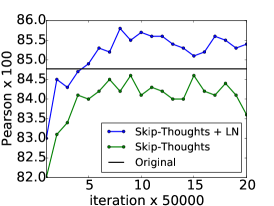
在这个实验中,我们确定层标准化可以加速训练的效果。 使用Kiros等人[2015]的公开代码444https://github.com/ryankiros/skip-thoughts,我们在 BookCorpus 数据集上训练了两个模型[Zhu 等人, 2015] :一个有层归一化,一个没有层归一化。 这些实验是使用 Theano [Team 等人, 2016] 进行的。 我们遵循Kiros等人[2015]中使用的实验设置,训练具有相同超参数的2400维句子编码器。 考虑到所使用的状态的大小,可以想象,层标准化会产生比没有更慢的每次迭代更新。 但是,我们发现提供了 CNMeM 555https://github.com/NVIDIA/cnmem,两个模型没有显着差异。 我们每 50,000 次迭代后检查两个模型,并评估它们在五个任务上的性能:语义相关性 (SICK) [Marelli 等人, 2014]、电影评论情绪 (MR) [Pang 和 Lee ,2005],客户产品评论(CR)[Hu and Liu,2004],主观/客观分类(SUBJ)[Pang and Lee,2004]和意见极性(MPQA)[Wiebe 等人,2005]。 我们绘制了所有任务上每个检查点的两个模型的性能,以确定 LN 是否可以提高性能率。
6.4使用 DRAW 对二值化 MNIST 进行建模
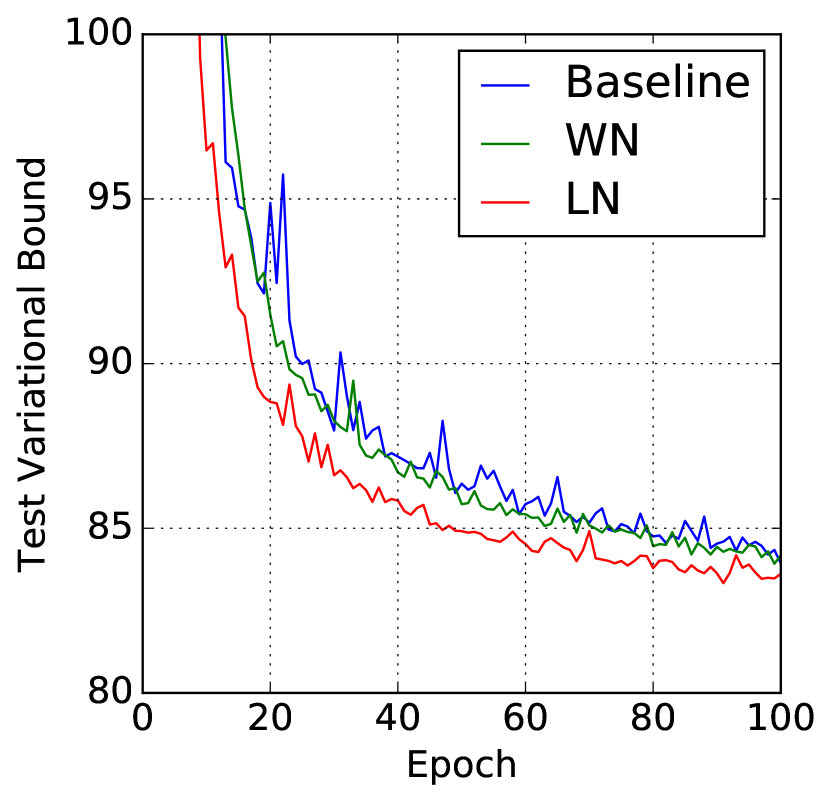
我们还在 MNIST 数据集上尝试了生成模型。 Deep Recurrent Attention Writer (DRAW) [Gregor 等人, 2015] 之前已经在 MNIST 数字分布建模方面取得了最先进的性能。 该模型使用差分注意机制和循环神经网络来顺序生成图像片段。 我们使用 64 个预览和 256 个 LSTM 隐藏单元评估 DRAW 模型上层归一化的效果。 该模型使用 Adam [Kingma and Ba, 2014] 优化器的默认设置和 128 的小批量大小进行训练。 之前关于二值化 MNIST 的出版物使用了各种训练协议来生成数据集。 在本实验中,我们使用了 Larochelle 和 Murray [2011] 的固定二值化。 数据集已分为 50,000 个训练图像、10,000 个验证图像和 10,000 个测试图像。
图 4 显示前 100 个时期的测试变分界限。 它强调了应用层归一化的加速优势,即层归一化 DRAW 的收敛速度几乎是基线模型的两倍。 200 个 epoch 后,基线模型在测试数据上收敛到变分对数似然为 82.36 nat,层归一化模型获得 82.09 nat。
6.5 手写序列生成
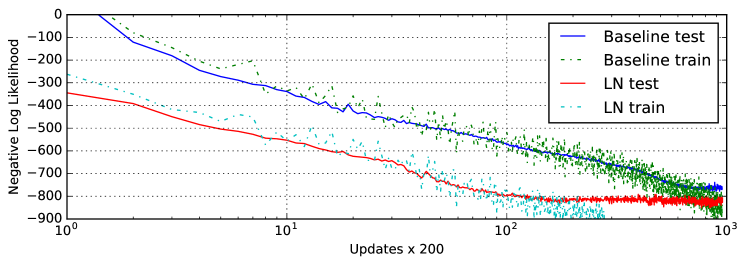
之前的实验主要检查长度在 10 到 40 范围内的 NLP 任务上的 RNN。 为了展示层标准化对较长序列的有效性,我们使用 IAM 在线手写数据库[Liwicki 和 Bunke,2005] 执行手写生成任务。 IAM-OnDB 由从 221 位不同作家收集的手写线条组成。 当给定输入字符串时,目标是预测白板上相应手写线的 x 和 y 笔坐标序列。 总共有 12179 个手写行序列。 输入字符串通常超过 25 个字符,平均手写行长度约为 700。
我们使用与 Graves [2013] 的第 (5.2) 节相同的模型架构。 该模型架构由 3 个包含 400 个 LSTM 单元的隐藏层组成,它们在输出层产生 20 个二元高斯混合分量,以及一个大小为 3 的输入层。 字符序列使用 one-hot 向量进行编码,因此窗口向量的大小为 57。 窗口参数使用了 10 个高斯函数的混合,需要大小为 30 的参数向量。 权重总数增加至约3.7M。 该模型使用大小为 8 的小批量和 Adam [Kingma 和 Ba,2014] 优化器进行训练。
小批量大小和非常长的序列的结合使得拥有非常稳定的隐藏动态变得非常重要。 图 5 显示层归一化收敛到与基线模型相当的对数似然,但速度要快得多。
6.6排列不变 MNIST
除了 RNN 之外,我们还研究了前馈网络中的层归一化。 我们展示了在经过充分研究的排列不变 MNIST 分类问题上,层归一化与批量归一化的比较。 根据之前的分析,层归一化对于输入重新缩放是不变的,这对于内部隐藏层来说是理想的。 但这对于 logit 输出来说是不必要的,因为预测置信度由 logit 的尺度决定。 我们仅将层归一化应用于不包括最后一个 softmax 层的全连接隐藏层。
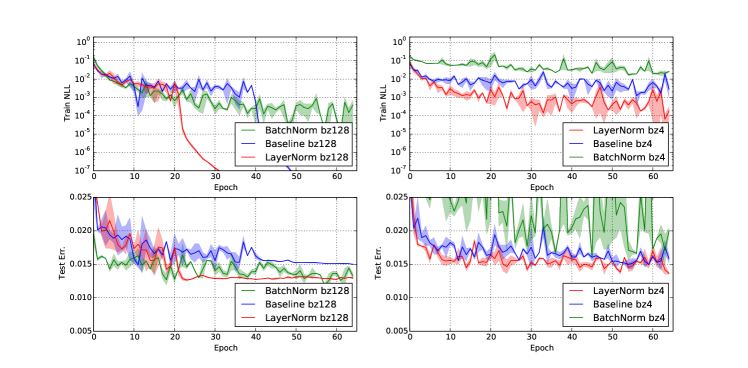
所有模型均使用 55000 个训练数据点和 Adam [Kingma and Ba, 2014] 优化器进行训练。 对于较小的批量大小,批量归一化的方差项是使用无偏估计器计算的。 图 6 的实验结果强调,层归一化对于批量大小具有鲁棒性,并且与应用于所有层的批量归一化相比,表现出更快的训练收敛。
6.7卷积网络
我们还尝试了卷积神经网络。 在我们的基础知识实验中,我们观察到层归一化比没有归一化的基线模型提供了加速,但批量归一化优于其他方法。 对于完全连接的层,层中的所有隐藏单元往往会对最终预测做出类似的贡献,并且重新居中和重新缩放层的总输入效果很好。 然而,对于卷积神经网络来说,类似贡献的假设不再成立。 感受野位于图像边界附近的大量隐藏单元很少被打开,因此与同一层内的其余隐藏单元具有非常不同的统计数据。 我们认为需要进一步研究才能使层归一化在卷积网络中发挥良好作用。
7结论
在本文中,我们引入了层归一化来加速神经网络的训练。 我们提供了理论分析,比较了层归一化与批量归一化和权重归一化的不变性。 我们表明,层归一化对于每个训练案例的特征移位和缩放是不变的。
根据经验,我们表明循环神经网络从所提出的方法中获益最多,特别是对于长序列和小批量。
致谢
这项研究由 NSERC、CFI 和 Google 资助。
参考
- Krizhevsky et al. [2012] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- Hinton et al. [2012] Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE, 2012.
- Dean et al. [2012] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior, Paul Tucker, Ke Yang, Quoc V Le, et al. Large scale distributed deep networks. In NIPS, 2012.
- Ioffe and Szegedy [2015] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ICML, 2015.
- Sutskever et al. [2014] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104–3112, 2014.
- Laurent et al. [2015] César Laurent, Gabriel Pereyra, Philémon Brakel, Ying Zhang, and Yoshua Bengio. Batch normalized recurrent neural networks. arXiv preprint arXiv:1510.01378, 2015.
- Amodei et al. [2015] Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, et al. Deep speech 2: End-to-end speech recognition in english and mandarin. arXiv preprint arXiv:1512.02595, 2015.
- Cooijmans et al. [2016] Tim Cooijmans, Nicolas Ballas, César Laurent, and Aaron Courville. Recurrent batch normalization. arXiv preprint arXiv:1603.09025, 2016.
- Salimans and Kingma [2016] Tim Salimans and Diederik P Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. arXiv preprint arXiv:1602.07868, 2016.
- Neyshabur et al. [2015] Behnam Neyshabur, Ruslan R Salakhutdinov, and Nati Srebro. Path-sgd: Path-normalized optimization in deep neural networks. In Advances in Neural Information Processing Systems, pages 2413–2421, 2015.
- Amari [1998] Shun-Ichi Amari. Natural gradient works efficiently in learning. Neural computation, 1998.
- Vendrov et al. [2016] Ivan Vendrov, Ryan Kiros, Sanja Fidler, and Raquel Urtasun. Order-embeddings of images and language. ICLR, 2016.
- Team et al. [2016] The Theano Development Team, Rami Al-Rfou, Guillaume Alain, Amjad Almahairi, Christof Angermueller, Dzmitry Bahdanau, Nicolas Ballas, Frédéric Bastien, Justin Bayer, Anatoly Belikov, et al. Theano: A python framework for fast computation of mathematical expressions. arXiv preprint arXiv:1605.02688, 2016.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. ECCV, 2014.
- Cho et al. [2014] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. EMNLP, 2014.
- Simonyan and Zisserman [2015] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. ICLR, 2015.
- Kiros et al. [2014] Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. Unifying visual-semantic embeddings with multimodal neural language models. arXiv preprint arXiv:1411.2539, 2014.
- Kingma and Ba [2014] D. Kingma and J. L. Ba. Adam: a method for stochastic optimization. ICLR, 2014. arXiv:1412.6980.
- Wang et al. [2016] Liwei Wang, Yin Li, and Svetlana Lazebnik. Learning deep structure-preserving image-text embeddings. CVPR, 2016.
- Hermann et al. [2015] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In NIPS, 2015.
- Kiros et al. [2015] Ryan Kiros, Yukun Zhu, Ruslan R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Skip-thought vectors. In NIPS, 2015.
- Mikolov et al. [2013] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- Zhu et al. [2015] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In ICCV, 2015.
- Marelli et al. [2014] Marco Marelli, Luisa Bentivogli, Marco Baroni, Raffaella Bernardi, Stefano Menini, and Roberto Zamparelli. Semeval-2014 task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment. SemEval-2014, 2014.
- Pang and Lee [2005] Bo Pang and Lillian Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In ACL, pages 115–124, 2005.
- Hu and Liu [2004] Minqing Hu and Bing Liu. Mining and summarizing customer reviews. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 2004.
- Pang and Lee [2004] Bo Pang and Lillian Lee. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In ACL, 2004.
- Wiebe et al. [2005] Janyce Wiebe, Theresa Wilson, and Claire Cardie. Annotating expressions of opinions and emotions in language. Language resources and evaluation, 2005.
- Gregor et al. [2015] K. Gregor, I. Danihelka, A. Graves, and D. Wierstra. DRAW: a recurrent neural network for image generation. arXiv:1502.04623, 2015.
- Larochelle and Murray [2011] Hugo Larochelle and Iain Murray. The neural autoregressive distribution estimator. In AISTATS, volume 6, page 622, 2011.
- Liwicki and Bunke [2005] Marcus Liwicki and Horst Bunke. Iam-ondb-an on-line english sentence database acquired from handwritten text on a whiteboard. In ICDAR, 2005.
- Graves [2013] Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013.
补充材料
将层归一化应用于每个实验
本节介绍如何将层归一化应用于每篇论文的实验。 为了符号方便,我们将层归一化定义为具有两组自适应参数(增益 和偏差 )的函数映射 :
| (15) | |||
| (16) |
其中, 是向量 的 元素。
教学机器阅读理解以及手写序列生成
用于这些实验的基本 LSTM 方程由下式给出:
| (17) | |||||
| (18) | |||||
| (19) |
合并层归一化的版本修改如下:
| (20) | |||||
| (21) | |||||
| (22) |
其中 分别是加法参数和乘法参数。 每个 都初始化为一个由 0 组成的向量,每个 都被初始化为一个由 1 组成的向量。
顺序嵌入和跳过思想
这些实验利用门控循环单元的变体,其定义如下:
| (23) | |||||
| (24) | |||||
| (25) |
层归一化的应用如下:
| (26) | |||||
| (27) | |||||
| (28) |
就像以前一样, 被初始化为一个由 0 组成的向量,每个 被初始化为一个由 1 组成的向量。
使用 DRAW 对二值化 MNIST 进行建模
本实验中层范数仅应用于 LSTM 隐藏状态的输出:
合并层归一化的版本修改如下:
| (29) | |||||
| (30) | |||||
| (31) |
其中 分别是加法参数和乘法参数。 初始化为 0 向量, 初始化为 1 向量。
学习传入权重的大小
我们现在比较梯度下降如何更新归一化 GLM 和原始参数化之间等效权重的变化幅度。 使用归一化模型中的增益参数来明确地参数化权重的大小。 假设有一个梯度更新将权重向量的范数改变。 我们可以将梯度更新投影到普通 GLM 的权重向量上。 KL 度量,即梯度更新改变模型预测的程度,对于归一化模型仅取决于预测误差的大小。 具体来说,
在批量归一化下:
| (32) |
层归一化下:
| (33) |
体重标准化下:
| (34) |
而标准 GLM 中的 KL 度量与其活动 相关,即取决于其当前权重和输入数据。 我们将 神经元的增益参数 的梯度更新投影到其权重向量,如标准 GLM 模型中的 :
| (35) |
因此,批量归一化模型和层归一化模型对于输入及其参数的缩放比标准模型更加稳健。