使用 Match-LSTM 和答案指针的机器理解
摘要
文本的机器理解是自然语言处理中的一个重要问题。 最近发布的数据集斯坦福问答数据集(SQuAD)提供了大量由人类通过众包创建的真实问题及其答案。 SQuAD 为评估机器理解算法提供了一个具有挑战性的测试平台,部分原因是与以前的数据集相比,SQuAD 中的答案不是来自一小部分候选答案,而且它们的长度是可变的。 我们为该任务提出了一种端到端的神经架构。 该架构基于 match-LSTM(我们之前提出的用于文本蕴涵的模型)和 Pointer Net(由Vinyals 等人(2015)提出的序列到序列模型,用于将输出标记约束为来自输入序列。 我们提出了两种使用 Pointer Net 来完成我们的任务的方法。 我们的实验表明,我们的两个模型都远远优于 Rajpurkar 等人 (2016) 使用逻辑回归和手工制作的特征获得的最佳结果。
1简介
机器理解文本是自然语言处理的最终目标之一。 虽然机器理解文本的能力可以通过多种不同的方式进行评估,但近年来,已经创建了几个基准数据集来专注于回答问题,以此作为评估机器理解的方式(Richardson 等人,2013;Hermann等人,2015;Hill 等人,2016;Weston 等人,2016;。 在此设置中,通常首先向机器呈现一段文本,例如新闻文章或故事。 然后,机器将回答一个或多个与文本相关的问题。
在大多数基准数据集中,一个问题可以被视为多项选择题,其正确答案是从一组提供的候选答案中选择的(Richardson等人,2013;Hill等人,2016). 据推测,候选人给出的答案越多的问题就越具有挑战性。 Rajpurkar 等人 (2016) 最近引入的斯坦福问答数据集 (SQuAD) 包含此类更具挑战性的问题,其正确答案可以是给定文本中的任何标记序列。 此外,与其他一些以完形填空方式自动创建问题和答案的数据集(Hermann等人,2015;Hill等人,2016)不同,SQuAD中的问题和答案是由人类通过众包创建的,这使得数据集更加真实。 鉴于 SQuAD 数据集的这些优势,在本文中,我们重点关注这个新数据集来研究机器对文本的理解。 表 1 中显示了一段示例文本及其三个相关问题。
此类问答任务的传统解决方案依赖于 NLP 管道,涉及语言分析和特征工程的多个步骤,包括句法解析、命名实体识别、问题分类、语义解析等。 最近,随着神经网络模型在 NLP 中应用的进展,人们对为各种 NLP 任务构建端到端神经架构产生了浓厚的兴趣,其中包括一些关于机器理解的工作(Hermann 等人,2015; Hill 等人, 2016; Yin 等人, 2016; Kadlec 等人, 2016; Cui 等人, 2016)。 然而,考虑到先前机器理解数据集的属性,该任务的现有端到端神经架构要么依赖于候选答案(Hill 等人,2016;Yin 等人,2016),要么假设答案是单个词符(Hermann 等人, 2015; Kadlec 等人, 2016; Cui 等人, 2016),这使得这些方法不适合 SQuAD 数据集。 在本文中,我们提出了一种新的端到端神经架构来解决 SQuAD 数据集中定义的机器理解问题。
具体来说,观察到 SQuAD 数据集中的许多问题都是原文句子的释义,我们采用了我们之前为文本蕴涵开发的匹配 LSTM 模型(Wang & Jiang,2016)。 我们进一步采用了 Vinyals 等人 (2015) 开发的 Pointer Net (Ptr-Net) 模型,该模型能够仅根据输入序列而不是根据更大的固定词汇表来预测标记,从而使我们能够生成由原始文本中的多个标记组成的答案。 我们提出了两种将 Ptr-Net 模型应用于我们的任务的方法:序列模型和边界模型。 我们还通过搜索机制进一步扩展边界模型。 在 SQuAD 数据集上的实验表明,我们的两个模型均优于 Rajpurkar 等人 (2016) 报告的最佳性能。 此外,通过使用我们的多个模型的集成,我们可以在 SQuAD 上实现非常有竞争力的性能。
我们的贡献可以概括如下:(1)我们提出了两种新的用于机器理解的端到端神经网络模型,它们结合了 match-LSTM 和 Ptr-Net 来处理 SQuAD 数据集的特殊属性。 (2) 我们在未见过的测试数据集上取得了 67.9% 的精确匹配分数和 77.0% 的 F1 分数的性能,这比特征工程解决方案(Rajpurkar 等人,2016). 我们的表现也接近 SQuAD 上的最新水平,根据 Salesforce Research 的精确匹配率为 71.6%,F1 为 80.4%。 (3)我们对模型的进一步分析揭示了一些进一步改进该方法的有用见解。 另外,我们还在线提供了代码 111 https://github.com/shuohangwang/SeqMatchSeq。
| In 1870, Tesla moved to Karlovac, to attend school at the Higher Real Gymnasium, where he was profoundly influenced by a math teacher Martin Sekulić. The classes were held in German, as it was a school within the Austro-Hungarian Military Frontier. Tesla was able to perform integral calculus in his head, which prompted his teachers to believe that he was cheating. He finished a four-year term in three years, graduating in 1873. | |
| 1. In what language were the classes given? | German |
| 2. Who was Tesla’s main influence in Karlovac? | Martin Sekulić |
| 3. Why did Tesla go to Karlovac? | attend school at the Higher Real Gymnasium |
2方法
在本节中,我们首先简要回顾一下 match-LSTM 和 Pointer Net。 这两项现有工作奠定了我们方法的基础。 然后,我们提出用于机器理解的端到端神经架构。
2.1匹配LSTM
在最近关于学习自然语言推理的工作中,我们提出了一种用于预测文本蕴涵的匹配 LSTM 模型(Wang & Jiang,2016)。 在文本蕴涵中,给出两个句子,其中一个是前提,另一个是假设。 为了预测前提是否蕴涵假设,match-LSTM 模型会依次遍历假设的标记。 在假设的每个位置,使用注意力机制来获得前提的加权向量表示。 然后,这个加权前提将与假设当前词符的向量表示相结合,并输入到 LSTM 中,我们将其称为匹配 LSTM。 match-LSTM本质上是按顺序聚合注意力加权前提与假设的每个词符的匹配,并使用聚合的匹配结果做出最终预测。
2.2指针网
Vinyals 等人 (2015) 提出了一种指针网络(Ptr-Net)模型来解决一类特殊的问题,即我们想要生成一个输出序列,其标记必须来自输入序列。 Ptr-Net 不是从固定词汇中挑选输出词符,而是使用注意力机制作为指针,从输入序列中选择一个位置作为输出符号。 指针机制启发了最近一些语言处理方面的工作(Gu等人,2016;Kadlec等人,2016)。 在这里,我们采用 Ptr-Net 来使用输入文本中的标记构建答案。
2.3 我们的方法
形式上,我们试图解决的问题可以表述如下。 我们得到一段文本(我们称之为段落)和一个与该段落相关的问题。 段落由矩阵 表示,其中 是段落的长度(标记数量), 是词嵌入的维度。 类似地,问题由矩阵 表示,其中 是问题的长度。 我们的目标是从文章中找出一个子序列作为问题的答案。
如前所述,由于输出标记来自输入,因此我们希望采用指针网络来解决此问题。 在这里应用 Ptr-Net 的一种直接方法是将答案视为来自输入段落的标记序列,但忽略这些标记在原始段落中是连续的事实,因为 Ptr-Net 没有做出连续性假设。 具体来说,我们将答案表示为整数序列,其中每个是1到之间的整数,指示段落中的某个位置。
或者,如果我们想确保连续性,也就是说,如果我们想确保我们确实从段落中选择了一个子序列作为答案,我们可以使用 Ptr-Net 来仅预测答案的开始和结束。 在这种情况下,Ptr-Net只需要从输入段落中选择两个token,并且段落中这两个token之间的所有token都被视为答案。 具体来说,我们可以将要预测的答案表示为两个整数,其中和是1到之间的整数。
我们将上面的第一个设置称为序列模型,将上面的第二个设置称为边界模型。 对于任一模型,我们假设给出了三元组 形式的一组训练示例。
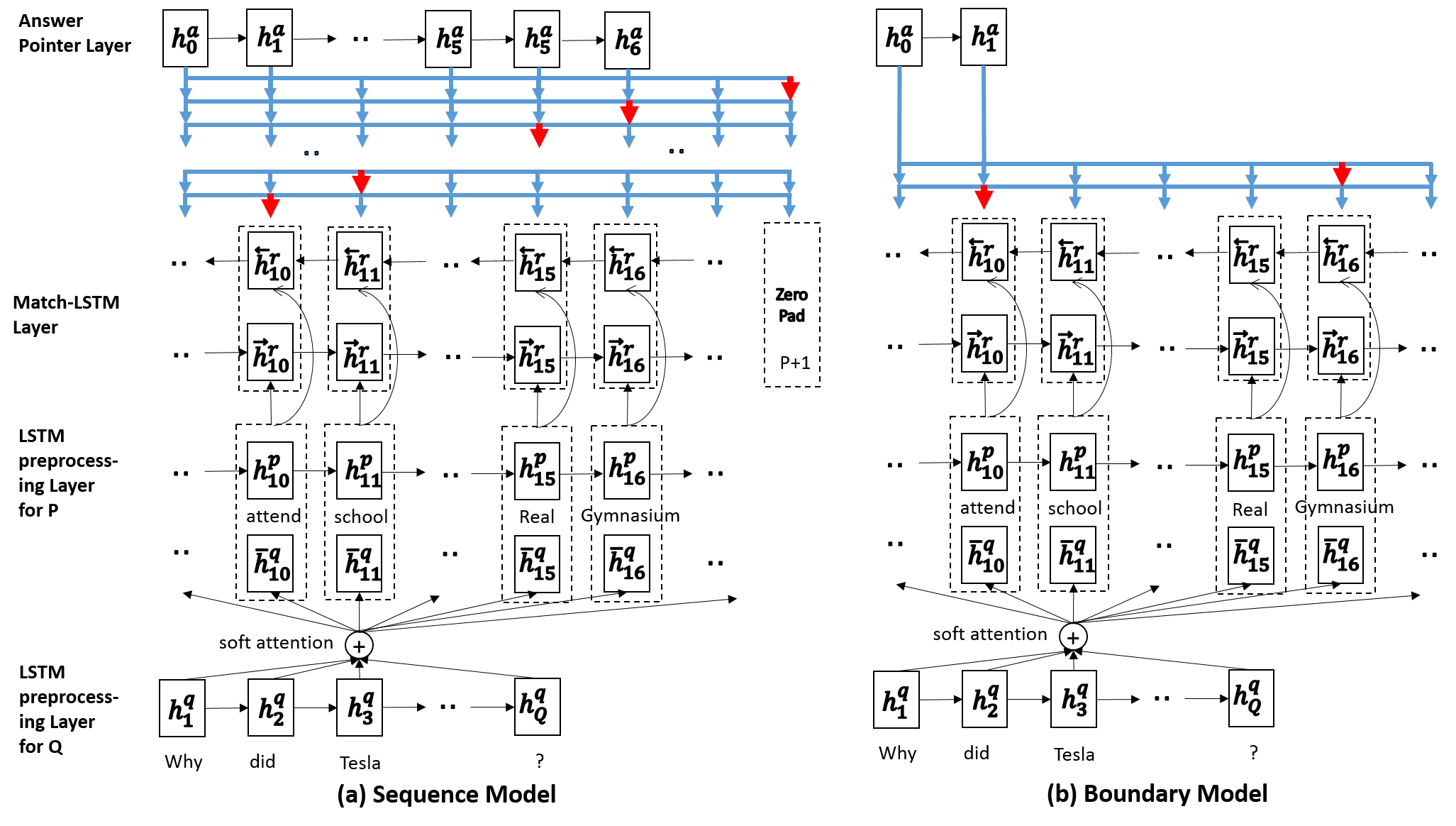
两种神经网络模型的概述如图1所示。 两个模型都由三层组成:(1)LSTM 预处理层,使用 LSTM 对文章和问题进行预处理。 (2) 匹配 LSTM 层,尝试将段落与问题进行匹配。 (3) 答案指针 (Ans-Ptr) 层,使用 Ptr-Net 从段落中选择一组标记作为答案。 两个模型的区别仅在于第三层。
LSTM预处理层
LSTM 预处理层的目的是将上下文信息合并到段落和问题中每个词符的表示中。 我们使用标准的单向 LSTM (Hochreiter & Schmidhuber,1997) 222由于预处理层中的输出门对最终性能影响很小,因此我们在实验中将其删除。 分别处理短文和问题,如下图:
| (1) |
生成的矩阵 和 是段落和问题的隐藏表示,其中 是隐藏向量的维度。 换句话说,(或)中的列向量(或)代表文章(或问题)中的词符以及左侧的一些上下文信息。
匹配LSTM层
我们将针对文本蕴涵提出的匹配 LSTM 模型(Wang & Jiang,2016)应用于我们的机器理解问题,将问题视为前提,将段落视为假设。 match-LSTM 按顺序遍历该段落。 在段落的位置处,它首先使用标准的逐字注意力机制来获得注意力权重向量,如下所示:
| (2) |
其中,和是要学习的参数,是单向匹配LSTM的隐藏向量(如下所述)在位置 处,外积 通过将左侧的向量或标量重复 次来生成矩阵或行向量。
本质上,上面得到的注意力权重表示了段落中的词符与问题中的词符之间的匹配程度。 接下来,我们使用注意力权重向量 获得问题的加权版本,并将其与段落当前词符组合形成向量 :
| (3) |
该向量 被输入到标准的单向 LSTM 中,形成我们所谓的 match-LSTM:
| (4) |
其中。
我们进一步在相反方向构建一个类似的 match-LSTM。 目的是获得对段落中每个词符的两个方向的上下文进行编码的表示。 为了构建这个反向匹配 LSTM,我们首先定义
| (5) |
请注意,这里的参数(、、、、 和 ) 与等式中使用的相同。 (2)。 然后我们以类似的方式定义 ,最后将 定义为由 match-LSTM 在相反方向产生的位置 处的隐藏表示。
让代表隐藏状态,代表。 我们将 定义为两者的串联:
| (6) |
应答指针层
顶层,即答案指针(Ans-Ptr)层,是由Vinyals等人(2015)引入的指针网络驱动的。 该层使用序列 作为输入。 回想一下,我们有两个不同的模型: sequence 模型生成一系列答案标记,但这些标记在原始段落中可能不是连续的。 boundary模型只产生答案的起始词符和结束词符,然后原始段落中这两者之间的所有标记都被认为是答案。 我们现在分别解释这两个模型。
序列模型: 回想一下,在序列模型中,答案由整数序列 表示,指示所选标记在原始段落中的位置。 Ans-Ptr 层以顺序方式对这些整数的生成进行建模。 由于答案的长度不固定,为了在某个点停止生成答案标记,我们允许每个 占用 1 到 之间的整数值,其中 是一个特殊值,表示答案的结束。 一旦设置为,答案的生成就会停止。
为了生成表示的答案词符,首先再次使用注意力机制获得注意力权重向量,其中 () 是从文章中选择词符作为答案中词符的概率, 是在位置 处停止生成答案的概率。 建模如下:
| (7) | |||||
| (8) |
其中 是 与零向量的串联,定义为 、、 和是要学习的参数,遵循与之前相同的定义,是位置的隐藏向量回答 LSTM 定义如下:
| (9) |
然后我们可以将生成答案序列的概率建模为
| (10) |
和
| (11) |
为了训练模型,我们根据训练示例最小化以下损失函数:
| (12) |
边界模型: 边界模型的工作方式与上面的序列模型非常相似,只不过我们不需要预测索引序列 ,而是只需要预测两个索引 和 。 所以与上面的序列模型的主要区别在于,在边界模型中我们不需要为添加零填充,生成答案的概率简单地建模为
| (13) |
我们通过结合搜索机制进一步扩展边界模型。 具体来说,在预测过程中,我们尝试限制跨度的长度,并全局搜索由计算出的概率最高的跨度。 此外,由于边界具有固定数量的值序列,因此可以简单地组合双向Ans-Ptr来调整正确的跨度。
3实验
在本节中,我们将展示我们的实验结果并进行一些分析,以更好地了解我们的模型是如何工作的。
3.1数据
我们使用斯坦福问答数据集 (SQuAD) v1.1 来进行实验。 SQuAD 中的段落来自维基百科的 536 篇文章,涵盖广泛的主题。 每个段落都是维基百科文章中的一个段落,每个段落都有大约 5 个与之相关的问题。 总共有 23,215 篇文章和 107,785 个问题。 数据已分为训练集(包含 87,599 个问答对)、开发集(包含 10,570 个问答对)和隐藏测试集。
3.2实验设置
我们首先标记所有的段落、问题和答案。 生成的词汇表包含 117K 个独特单词。 我们使用 GloVe (Pennington 等人, 2014) 中的词嵌入来初始化模型。 GloVe 中未找到的单词将被初始化为零向量。 在模型训练期间,词嵌入不会更新。
隐藏层的维度设置为150或300。 我们使用 ADAMAX (Kingma & Ba, 2015) 以及系数 和 来优化模型。 每次更新都是通过 30 个实例的小批量计算的。 我们不使用 L2 正则化。
性能通过两个指标来衡量:与真实答案完全匹配的百分比,以及将预测答案中的标记与真实答案中的标记进行比较时的单词级 F1 分数。 请注意,在开发集和测试集中,每个问题都有大约三个真实答案。 具有最佳匹配答案的 F1 分数用于计算平均 F1 分数。
3.3结果
| Exact Match | F1 | |||||
| Dev | Test | Dev | Test | |||
| Random Guess | - | 0 | 1.1 | 1.3 | 4.1 | 4.3 |
| Logistic Regression | - | - | 40.0 | 40.4 | 51.0 | 51.0 |
| DCR | - | - | 62.5 | 62.5 | 71.2 | 71.0 |
| Match-LSTM with Ans-Ptr (Sequence) | 150 | 882K | 54.4 | - | 68.2 | - |
| Match-LSTM with Ans-Ptr (Boundary) | 150 | 882K | 61.1 | - | 71.2 | - |
| Match-LSTM with Ans-Ptr (Boundary+Search) | 150 | 882K | 63.0 | - | 72.7 | - |
| Match-LSTM with Ans-Ptr (Boundary+Search) | 300 | 3.2M | 63.1 | - | 72.7 | - |
| Match-LSTM with Ans-Ptr (Boundary+Search+b) | 150 | 1.1M | 63.4 | - | 73.0 | - |
| Match-LSTM with Bi-Ans-Ptr (Boundary+Search+b) | 150 | 1.4M | 64.1 | 64.7 | 73.9 | 73.7 |
| Match-LSTM with Ans-Ptr (Boundary+Search+en) | 150 | 882K | 67.6 | 67.9 | 76.8 | 77.0 |
我们的模型结果以及 Rajpurkar 等人 (2016) 和 Yu 等人 (2016) 给出的基线结果如表 2。 我们可以看到,我们的两个模型都明显优于 Rajpurkar 等人 (2016) 的逻辑回归模型,该模型依赖于精心设计的特征。 此外,我们的边界模型优于序列模型,精确匹配分数为 61.1%,F1 分数为 71.2%。 特别是在精确匹配分数方面,边界模型比序列模型具有明显的优势。 我们的模型相对于逻辑回归模型的改进表明,我们的端到端神经网络模型在没有太多特征工程的情况下对于这个任务和这个数据集非常有效。 考虑到边界模型的有效性,我们进一步探索了该模型。 观察到大多数答案都是尺寸相对较小的跨度,我们简单地将最大预测跨度限制为不超过 15 个标记,并进行跨度搜索实验。这导致 F1 在开发数据上提高了 1.5%,并且优于DCR模型(Yu等人,2016),该模型还在模型中引入了一些语言特征,例如POS和NE。 此外,我们尝试增加模型中的内存维度或添加双向预处理LSTM或添加双向Ans-Ptr。 使用前两种方法对开发数据的改进相当小。 而通过添加 Bi-Ans-Ptr 和双向预处理 LSTM,我们可以在 F1 上获得 1.2% 的提升。 最后,我们通过简单地计算从 5 个边界模型收集的边界概率的乘积,然后搜索不超过 15 个标记的最可能的跨度来探索集成方法。 如表所示,该集成方法取得了最佳性能。
3.4进一步分析
为了更好地了解我们模型的优点和缺点,我们对下面的结果进行了一些进一步的分析。
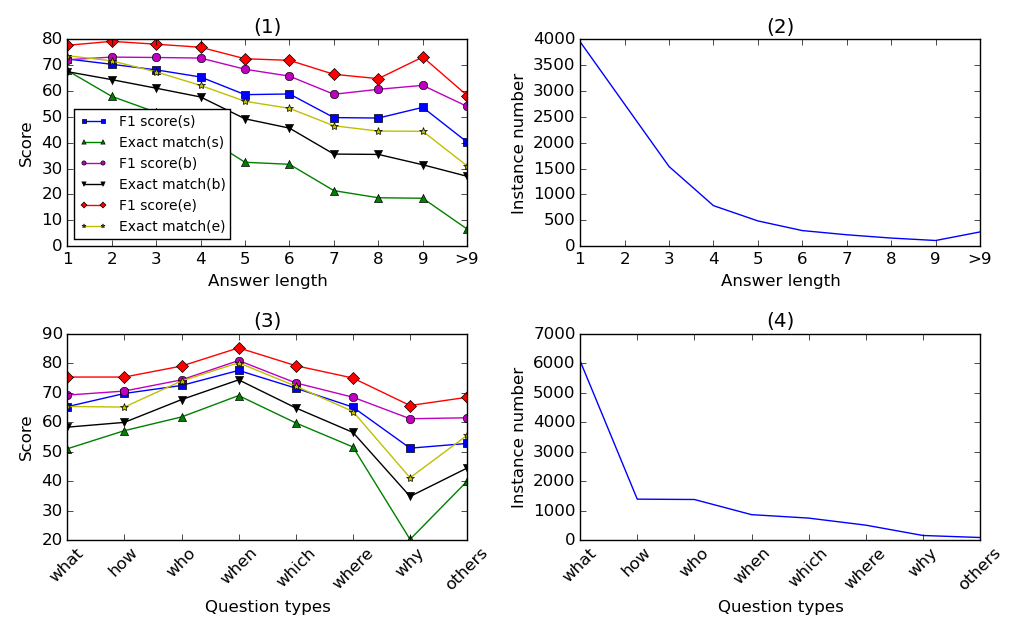
首先,我们怀疑较长的答案更难预测。 为了验证这一假设,我们分析了开发集上答案长度的精确匹配和 F1 分数方面的性能。 例如,对于答案包含超过 9 个 token 的问题,边界模型的 F1 分数下降到 55% 左右,精确匹配分数下降到只有 30% 左右,而 F1 分数和精确匹配分数接近 72对于具有单标记答案的问题,分别为 % 和 67%。 这支持了我们的假设。
接下来,我们分析模型在不同问题组上的表现。 我们使用一种粗略的方法,根据我们定义的一组问题词将问题分成不同的组,包括“什么”、“如何”、“谁”、“何时”、“哪个”、“哪里”和“为什么。”这些不同的疑问词大致指的是具有不同类型答案的问题。 例如,“何时”问题寻找时间表达式作为答案,而“何处”问题寻找位置作为答案。 根据开发数据集的表现,我们的模型对于“何时”问题最有效。 这可能是因为在这个数据集中时间表达式相对更容易识别。 其他答案为名词短语的问题组,例如“what”问题、“which”问题和“where”问题,也获得相对较好的结果。 另一方面,“为什么”问题是最难回答的。 这并不奇怪,因为“为什么”问题的答案可能非常多样化,并且不限于任何特定类型的短语。
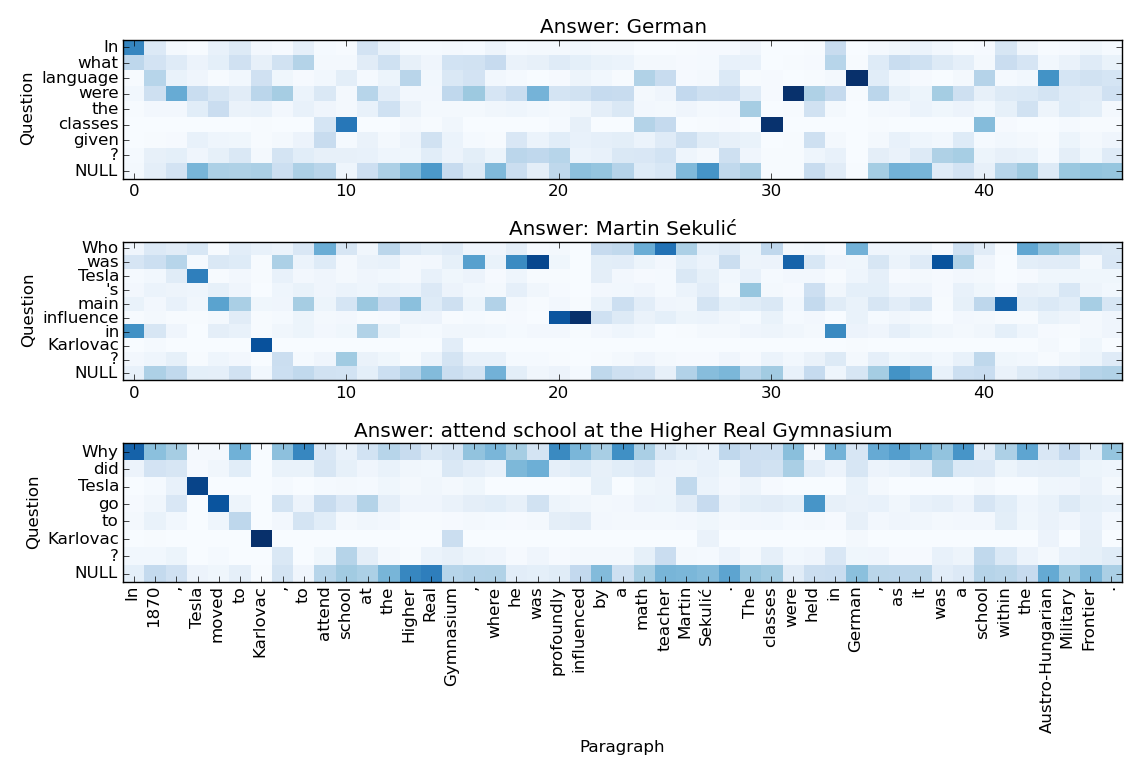
最后,我们想检查 match-LSTM 层中使用的注意力机制是否能有效帮助模型找到答案。 我们在图2中显示了注意力权重。 图中颜色越深权重越高。 我们可以看到一些单词根据注意力权重已经很好地对齐了。 例如,文章中的“德语”一词与第一个问题中的“语言”一词很好地对齐,并且模型成功预测“德语”作为问题的答案。 对于第二个问题中的问题词“谁”,“老师”一词实际上受到了相对较高的注意力权重,并且模型预测了其后的短语“Martin Sekulic”作为答案,这是正确的。 对于以“为什么”开头的最后一个问题,注意力权重分布更加均匀,并且不清楚哪些单词与“为什么”对齐。
4相关工作
近年来,文本的机器理解引起了广泛关注,越来越多的研究人员正在为该任务构建数据驱动的端到端神经网络模型。 我们将首先回顾最近发布的数据集,然后回顾该任务的一些端到端模型。
4.1 数据集
通过从原始语料库中的句子中删除单个词符,以完型填空的方式创建了许多用于研究机器理解的数据集,其任务是预测丢失的单词。 例如,Hermann 等人 (2015) 根据 CNN 和《每日邮报》的精彩集锦,以完形填空的形式提出了问题。 Hill 等人 (2016) 创建了儿童图书测试数据集,该数据集基于儿童故事。 崔等人(2016)发布了两个类似的中文数据集:人民日报数据集和儿童童话数据集。
许多其他数据集不是以完形填空的方式创建问题,而是依靠人工注释者来创建真实的问题。 Richardson 等人 (2013) 创建了著名的 MCTest 数据集,Tapaswi 等人 (2016) 创建了 MovieQA 数据集。 在这些数据集中,为每个问题提供了候选答案。 与这两个数据集类似,SQuAD 数据集(Rajpurkar 等人,2016) 也是由人类注释者创建的。 然而,与前两个不同的是,SQuAD 数据集不提供候选答案,因此给定段落中的所有可能的子序列都必须被视为候选答案。
除了上述数据集之外,还有一些其他为机器理解而创建的数据集,例如 WikiReading 数据集 (Hewlett 等人, 2016) 和 bAbI 数据集 (Weston 等人, 2016) t1>,但它们本质上与上面的数据集有很大不同。
4.2 用于机器理解的端到端神经网络模型
已经有许多研究提出了用于机器理解的端到端神经网络模型。 一种常见的方法是使用递归神经网络(RNN)来处理给定的文本和问题,以预测或生成答案(Hermann等人,2015)。 注意力机制也广泛应用于 RNN 之上,以便将问题与给定的段落进行匹配(Hermann 等人,2015;Chen 等人,2016)。 鉴于答案通常来自给定的段落,一些研究采用了指针网络,以便从给定的段落中复制标记作为答案(Kadlec等人,2016;Trischler等人,2016) 。 与现有工作相比,我们使用 match-LSTM 来匹配问题和给定段落,并且以不同的方式使用指针网络,以便我们可以生成包含给定段落中的多个标记的答案。
记忆网络(Weston等人,2015)也已应用于机器理解(Sukhbaatar等人,2015;Kumar等人,2016;Hill等人,2016),但其应用于大型数据集时的可扩展性仍然是一个问题。 在这项工作中,我们没有考虑 SQuAD 数据集的内存网络。
5结论
在本文中,我们针对斯坦福问答(SQuAD)数据集中定义的机器理解问题开发了两个模型,均使用匹配 LSTM 和指针网络。 在 SQuAD 数据集上的实验表明,我们的第二个模型,即边界模型,在测试数据集上可以达到 67.6% 的精确匹配分数和 77% 的 F1 分数,这优于我们的序列模型和 Rajpurkar 等人(2016) 的特征工程模型。
未来,我们计划进一步研究不同类型的问题,并重点关注那些目前表现不佳的问题,例如“为什么”问题。 我们还计划测试如何将我们的模型应用于其他机器理解数据集。
6致谢
我们感谢 Pranav Rajpurkar 在隐藏的测试数据集上测试我们的模型,感谢 Percy Liang 帮助我们使用 Codalab 的 Dockerfile。
参考
- Chen et al. (2016) Danqi Chen, Jason Bolton, and Christopher D. Manning. A thorough examination of the CNN/Daily Mail reading comprehension task. In Proceedings of the Conference on Association for Computational Linguistics, 2016.
- Cui et al. (2016) Yiming Cui, Ting Liu, Zhipeng Chen, Shijin Wang, and Guoping Hu. Consensus attention-based neural networks for chinese reading comprehension. In arXiv preprint arXiv:1607.02250, 2016.
- Gu et al. (2016) Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the Conference on Association for Computational Linguistics, 2016.
- Hermann et al. (2015) Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In Proceedings of the Conference on Advances in Neural Information Processing Systems, pp. 1693–1701, 2015.
- Hewlett et al. (2016) Daniel Hewlett, Alexandre Lacoste, Llion Jones, Illia Polosukhin, Andrew Fandrianto, Jay Han, Matthew Kelcey, and David Berthelot. WIKIREADING: A novel large-scale language understanding task over wikipedia. In Proceedings of the Conference on Association for Computational Linguistics, 2016.
- Hill et al. (2016) Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston. The Goldilocks principle: Reading children’s books with explicit memory representations. In Proceedings of the International Conference on Learning Representations, 2016.
- Hochreiter & Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Kadlec et al. (2016) Rudolf Kadlec, Martin Schmid, Ondrej Bajgar, and Jan Kleindienst. Text understanding with the attention sum reader network. In Proceedings of the Conference on Association for Computational Linguistics, 2016.
- Kingma & Ba (2015) Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, 2015.
- Kumar et al. (2016) Ankit Kumar, Ozan Irsoy, Jonathan Su, James Bradbury, Robert English, Brian Pierce, Peter Ondruska, Ishaan Gulrajani, and Richard Socher. Ask me anything: Dynamic memory networks for natural language processing. In Proceedings of the International Conference on Machine Learning, 2016.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher D Manning. GloVe: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2014.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2016.
- Richardson et al. (2013) Matthew Richardson, Christopher JC Burges, and Erin Renshaw. MCTest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2013.
- Sukhbaatar et al. (2015) Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. In Proceedings of the Conference on Advances in neural information processing systems, 2015.
- Tapaswi et al. (2016) Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, and Sanja Fidler. MovieQA: Understanding stories in movies through question-answering. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016.
- Trischler et al. (2016) Adam Trischler, Zheng Ye, Xingdi Yuan, and Kaheer Suleman. Natural language comprehension with the EpiReader. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2016.
- Vinyals et al. (2015) Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In Proceedings of the Conference on Advances in Neural Information Processing Systems, 2015.
- Wang & Jiang (2016) Shuohang Wang and Jing Jiang. Learning natural language inference with LSTM. In Proceedings of the Conference on the North American Chapter of the Association for Computational Linguistics, 2016.
- Weston et al. (2015) Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. In Proceedings of the International Conference on Learning Representations, 2015.
- Weston et al. (2016) Jason Weston, Antoine Bordes, Sumit Chopra, Alexander M Rush, Bart van Merriënboer, Armand Joulin, and Tomas Mikolov. Towards AI-complete question answering: A set of prerequisite toy tasks. In Proceedings of the International Conference on Learning Representations, 2016.
- Yin et al. (2016) Wenpeng Yin, Sebastian Ebert, and Hinrich Schütze. Attention-based convolutional neural network for machine comprehension. arXiv preprint arXiv:1602.04341, 2016.
- Yu et al. (2016) Yang Yu, Wei Zhang, Kazi Hasan, Mo Yu, Bing Xiang, and Bowen Zhou. End-to-end answer chunk extraction and ranking for reading comprehension. arXiv preprint arXiv:1610.09996, 2016.
附录A附录
我们在图 3 中按答案长度和问题类型显示了序列模型、边界模型和集成模型的性能细分。