深度学习中的身份很重要
摘要
深度学习中的一个新兴设计原则是深度人工神经网络的每一层都应该能够轻松地表达恒等变换。 这个想法不仅激发了各种标准化技术,例如批量标准化,而且也是残差网络取得巨大成功的关键。
在这项工作中,我们将身份参数化的原理置于更坚实的理论基础上,同时取得了进一步的实证进展。 我们首先给出一个非常简单的证明,证明任意深度的线性残差网络没有虚假的局部最优值。 线性前馈网络在其标准参数化中的相同结果要微妙得多。 其次,我们表明,具有 ReLu 激活的残差网络具有通用的有限样本表达能力,只要模型的参数多于样本大小,网络就可以表示其样本的任何函数。
直接受到我们理论的启发,我们尝试了一种极其简单的残差架构,仅包含残差卷积层和 ReLu 激活,但没有批量归一化、dropout 或最大池。 我们的模型在 CIFAR10、CIFAR100 和 ImageNet 分类基准上比之前的全卷积网络有了显着改进。
1简介
用于图像分类的传统卷积神经网络,例如 AlexNet ([13]),其参数化方式为:当所有可训练权重均为 时,卷积层表示 -映射。 此外,权重围绕 对称初始化 这种标准参数化使得使用随机梯度方法训练的卷积层保留已经很好的特征变得非常重要。 换句话说,这样的卷积层在训练时不能轻易收敛到恒等变换。
[9] 通过批量归一化观察到并部分解决了这个缺点,即使用学习的均值和协方差对输入进行逐层白化。 但这个想法仍然有些隐含,直到残差网络([6];[7])明确引入了卷积层的重新参数化,这样当所有可训练的权重都是层代表恒等函数。 形式上,对于输入 ,每个残差层的形式为 而不是 这种简单的重新参数化允许更深层次的架构,很大程度上避免了梯度消失(或爆炸)的问题。 从那时起,残差网络以及使用相同参数化的后续架构在各种计算机视觉基准(例如 CIFAR10 和 ImageNet)上始终取得了最先进的结果。
1.1 我们的贡献
在这项工作中,我们从理论角度考虑恒等参数化,同时将我们的一些理论见解转化为实验。 宽松地说,我们的第一个结果强调了身份参数化如何使优化变得更容易,而我们的第二个结果表明对于表示来说也是如此。
线性残差网络。
由于一般的非线性神经网络超出了当前优化理论方法的范围,因此我们将深度线性网络的情况视为简化模型。 线性网络将任意线性映射表示为矩阵序列 目标函数为 ,其中 用于某些未知的线性变换, 和 是从分布中得出的。 近年来,人们对这种线性网络进行了积极的研究,作为通向一般非线性情况的垫脚石(参见1.2节)。 尽管 只是一个线性映射,但因子变量 的优化问题是非凸的。
与残差网络类似,我们将目标函数参数化为
| (1.1) |
直观地说,当深度 足够大时,我们可以希望目标函数 具有因子表示,其中每个矩阵 具有较小的矩阵规范。 例如,任何对称正半inite 矩阵 都可以写成乘积 ,其中每个 对于大的 都非常接近同一性,因此 具有较小的谱规范。 我们首先证明类似的主张对于所有具有正行列式的线性变换 都是正确的111正如下面将要讨论的定理2.1,不失一般性地假设的行列式是积极的。 . 具体来说,我们证明对于每个具有 的线性变换 ,都存在一个 (1.1) 的全局优化器 ,使得足够大的深度
| (1.2) |
这里,表示的谱范数 常数因子取决于的条件。我们在定理2.1中给出了正式的陈述。 该定理有一个有趣的结果,即随着深度的增加,存在较小的范数解,因此正则化可能会抵消参数的增加。
通用有限样本表达能力。
回到具有 ReLU 激活的非线性残差网络,我们可以问:仅基于具有 ReLU 激活的残差层的深度神经网络的表达能力如何? 为了回答这个问题,我们给出了一个非常简单的结构,表明这种残差网络具有完美的有限样本表达能力。 换句话说,具有 ReLU 激活的残差网络可以轻松表达大小为 的样本的任何函数,只要它具有足够多于 的参数。 请注意,这个要求在实践中很容易满足。 例如,在 CIFAR 10 () 上,成功的残差网络通常具有多个 个参数。 更正式地说,对于大小为 且具有 类的数据集,我们的构造需要 参数。 定理3.2给出了正式的陈述。
我们构造中的每个残差层的形式为 ,其中 和 是线性变换。 这些层比标准残差层简单得多,标准残差层通常具有两个 ReLU 激活以及两个批量归一化实例。
全卷积残差网络的强大功能。
直接受到我们表达性结果的简单性的启发,我们在 CIFAR10、CIFAR100 和 ImageNet 数据集上尝试了非常相似的架构。 我们的架构只是一系列卷积残差层,每个层都有一个 ReLU 激活,但没有标准架构中常见的批量归一化、丢失或最大池化。 最后一层是未经训练的固定随机投影。 根据我们的理论,卷积权重在 附近初始化,主要使用高斯噪声作为对称破坏器。 唯一的正则化器是标准权重衰减(-正则化),并且不需要 dropout。 尽管很简单,我们的架构在 CIFAR10 基准(使用标准数据增强)上达到了 top- 分类错误。 这与[6]中报告的最佳残差网络具有竞争力,后者实现了。 此外,它还改进了之前由 [15] 实现的最佳全卷积网络 的性能。 与我们的不同,之前的全卷积架构还需要对整个数据集进行 dropout 和非标准预处理(ZCA)。 我们的架构还显着改进了 Cifar100 和 ImageNet 上的 [15]。
1.2相关工作
自从残差网络([6];[7])出现以来,大多数最先进的图像分类网络都采用了卷积网络的残差参数化层。 [8] 报告了残差网络变体(称为密集网络)的进一步令人印象深刻的改进。 这些网络不是将原始输入添加到卷积层的输出,而是直接通过串联保留原始特征。 在此过程中,密集网络还能够轻松地在更高维空间中对身份嵌入进行编码。 看看我们的理论结果是否也适用于这种残差网络变体将会很有趣。
尽管全面的答案仍然难以捉摸,但在理解神经网络的优化领域方面最近取得了进展。 [5]和[4]中的实验表明,训练目标具有有限数量的具有较大函数值的不良局部最小值。 [3] 的工作在神经网络的优化景观与物理学中的自旋玻璃模型的优化景观之间进行了类比 ([1])。 [14]表明层神经网络没有不好的可微局部最小值,但他们没有证明一个好的可微局部最小值确实存在。 [2]和[12]表明线性神经网络没有坏的局部极小值。 相比之下,我们表明深度线性残差网络的优化景观没有坏的临界点,这是一个更强、更理想的特性。 我们的证明也明显更简单,说明了重新参数化优化的力量。 我们的结果还表明,与较浅的网络相比,更深的网络可能具有更理想的优化景观。
2 线性残差网络的优化景观
考虑从噪声测量 学习线性变换 的问题,其中 是 维球形高斯向量。 用表示输入数据的分布,令为其协方差矩阵。
当然,有很多方法可以解决这个经典问题,但我们的目标是深入了解神经网络,特别是残差网络的优化领域。 因此,我们通过一系列权重矩阵 来参数化我们的学习模型,
| (2.1) |
这里 是 隐藏层, 是学习模型对输入 的预测 更简洁地说,我们有
很容易看出这个模型可以表达任何线性变换我们将使用作为所有权重矩阵的简写,即 维张量,包含 作为切片。 我们的目标函数是最大似然估计,
| (2.2) |
我们将分析人口风险的情况,定义为:
回想一下, 是 的谱范数。 我们将张量 的范数 定义为其切片的谱范数的最大值,
本节第一个定理指出,目标函数具有较小范数的最优解,其与层数成反比 。 因此,当架构很深时,我们可以寻找相当小的范数解决方案。 我们定义。 这里分别表示的最小和最大奇异值。
Theorem 2.1.
假设和。 那么,存在一个具有范数的群体风险的全局最优解
我们首先注意到条件在以下意义上不失一般性。 给定任何具有负行列式的线性变换 ,我们可以通过使用附加维度增强数据和标签来有效地翻转行列式:让 和 ,其中是一个独立的随机变量(例如,来自标准正态分布),并让。 然后,我们有 和 。222当维度为奇数时,有一个更简单的方法可以看到这一点 - 翻转标签对应于翻转 ,我们有 。
其次,我们注意到这里 应该被认为是一个常量,因为如果 太大(或太小),我们可以适当缩放数据,以便 . 具体来说,如果,那么我们可以正确缩放输出,以便和。 在本例中,我们有 ,对于相当大的条件数 ,它将保持一个小常数。 我们还指出,我们在分析中没有尝试优化常量因素。 定理2.1的证明比较复杂,推迟到A节。
鉴于对定理 2.1 的观察,我们将注意力限制在分析 与 集合中的 的景观 -范数小于,
这里使用定理2.1,半径应该被认为是的量级。 我们在本节中的主要定理声称,对于任何 ,域 中不存在坏临界点。 回想一下,临界点具有消失梯度。
Theorem 2.2.
对于任何,我们有域内目标函数的任何临界点也必须是全局最小值。
定理2.2表明优化器足以收敛到总体风险的临界点,因为所有临界点也是全局最小值。
为了证明定理2.2,我们从一个简化群体风险的简单主张开始。 我们用表示矩阵的Frobenius范数,表示标准基中和的内积(即 ,其中 表示矩阵的迹。)
断言 2.3。
在本节的设置中,我们有,
| (2.4) |
这里是一个不依赖于的常数,表示的平方根,即满足的唯一对称矩阵。
接下来,我们通过简单的矩阵演算计算目标函数 的梯度。 我们将完整的证明推迟到 A 部分。
Lemma 2.4.
的梯度可以写为,
| (2.5) |
其中 。
3 残差网络的表征能力
在本节中,我们描述残差网络的有限样本表达能力。 我们考虑具有单个 ReLU 激活且没有批量归一化的残差层。 基本残差构建块是一个函数 ,它由两个权重矩阵 和一个偏差向量 参数化,
| (3.1) |
残差网络由一系列此类残差块组成。 与[7]中的完整预激活架构相比,我们在每个构建块中删除了两个批量归一化层和一个ReLU层。
我们假设数据具有 标签,编码为 中的 标准基向量,用 表示。 我们有 训练示例 ,其中 表示第 数据, 表示 -第一个标签。 不失一般性,我们假设数据已标准化,因此 我们还做出温和的假设,即没有两个数据点彼此非常接近。
Assumption 3.1.
我们假设对于每个 ,我们都有 对于某个绝对常数
例如,图像总是可以在像素空间中受到难以察觉的扰动,从而满足小但恒定的 的假设
在这个温和的假设下,我们证明只要参数数量是大于 的对数因子,残差网络就有能力表达数据的任何可能的标签。
Theorem 3.2.
假设训练示例满足假设3.1。 然后,存在一个残差网络(如下指定),其参数完美地表达了训练数据,即对于所有网络 将 映射到
在实践中, 很常见,例如 Imagenet 数据集的情况,其中 和
我们使用等式 (3.1) 中定义的 形式的构建块构建以下残差网络。 该网络由隐藏层组成,输出由表示。 第一层权重矩阵将维输入映射到维隐藏变量。 然后我们应用带有权重矩阵的构建块的层。 最后,我们应用另一个层将隐藏变量 映射到 中的标签 。 从数学上来说,我们有
我们注意这里的和以便维度兼容。 我们假设标签数 和输入维度 都小于 ,这在实际应用中是安全的。444In computer vision, typically is less than and is less than while is larger than 超参数 将选择为 ,层数选择为 。 因此,第一层具有 参数,中间的每个 构建块包含 参数,最终构建块具有 参数。 因此,参数总数为。
为了构建适合数据的上述形式的网络 ,我们首先采用一个随机矩阵 将所有数据点 映射到向量 。 这里我们将使用 来表示第 示例的第 层隐藏变量。 根据 Johnson-Lindenstrauss 定理([10],或参见 [17]),很有可能,结果向量 仍然满足假设3.1(缩放比例略有不同,常数较大),即任意两个向量和不是很相关的。
然后我们构造 中间层,将每个 的 映射到 。 这些向量 将根据标签聚集到 组中,尽管它们位于 中,而不是所需的 中。 具体来说,我们通过在中挑选随机单位向量来设计这个聚类中心。 我们将它们视为维度 中的代理标签向量(请注意, 可能比 小得多)。 在高维度(技术上,如果)随机单位向量与小于的内积成对不相关。 我们将第 个示例与定义如下的目标代理标签向量 相关联,
| (3.2) |
然后,我们将构造矩阵 ,以便网络的前 层将向量 映射到代理标签向量 。 从数学上讲,我们将构造 使得
| (3.3) |
最后,我们将构造最后一层 ,以便它将向量 映射到 ,
| (3.4) |
将它们放在一起,通过定义 (3.2) 和方程 (3.3),对于每个 ,如果标签为 是 ,那么 将是 。 然后通过方程(3.4),我们得到。 因此我们得到。 该计划的关键部分是构建中间层权重矩阵,以便。 我们将其封装到以下非正式引理中。 正式声明和完整证明推迟到B节。
Lemma 3.3 (引理B.2的非正式版本)。
在上面的设置中,对于(几乎)任意向量 和 ,存在权重矩阵 ,这样,
我们简要地概述引理的证明以提供直觉,并将完整的证明推迟到 B 节。 每个残差块应用于隐藏变量的操作可以抽象地写为:
| (3.5) |
其中 对应于块之前的隐藏变量, 对应于块之后的隐藏变量。 我们声称,对于(几乎)任意的向量序列,存在,使得操作(3.5)变换 的向量到我们可以自由选择的任意一组其他 向量,并保持其余 向量的值。 具体来说,对于任何大小为 的子集 和任何所需的向量 ,都存在 使得
| (3.6) |
该主张在引理 B.1 中得到了形式化。 我们可以重复使用它来构建 层构建块,每个构建块将 中的 向量子集转换为 ,并维护他人的价值观。 回想一下,我们有 层,因此在 层之后,所有向量 都会转换为 的,这完成校样草图。 ∎
4 全卷积残差网络的功效
受我们理论的启发,我们在标准图像分类基准上尝试了全卷积残差网络。
4.1 CIFAR10 和 CIFAR100
我们的 CIFAR10 和 CIFAR100 架构是相同的,除了最终维度分别对应于类 和 的数量。 在表 1 中,我们概述了我们的架构。 每个残差块的形式为,其中是指定维度的卷积(内核宽度、内核高度、输入通道数、输出通道数) )。 每个块中的第二个卷积始终具有步幅 ,而第一个卷积可能具有指定的步幅 。 在变换不保持维度的情况下,原始输入 使用平均池化和填充进行调整,这是残差层中的标准。
我们使用 Tensorflow 框架训练模型,使用动量优化器,动量为 ,批量大小为 。 所有卷积权重均通过权重衰减进行训练 初始学习率为 ,下降了 、 和 步长。 该模型在大约 步时达到峰值性能,在单个 NVIDIA Tesla K40 GPU 上大约需要 步。 我们的代码可以轻松地从开源实现555https://github.com/tensorflow/models/tree/master/resnet 通过删除批量归一化,调整剩余组件和模型架构。 与代码的一个重要区别是,我们使用标准差 的随机正态初始化器来初始化内核大小 和 输出通道的残差卷积层,而不是比用于标准卷积层的 更好。 这种小得多的权重初始化有助于训练,同时不影响表示。
与标准模型的一个显着区别是最后一层没有经过训练,而只是一个固定的随机投影。 一方面,这稍微改善了测试误差(可能是由于正则化效应)。 另一方面,这意味着我们模型中唯一可训练的权重是卷积的权重,使我们的架构成为“全卷积”。
| variable dimensions | initial stride | description |
| 1 standard conv | ||
| 9 residual blocks | ||
| 9 residual blocks | ||
| 9 residual blocks | ||
| – | – | global average pool |
| – | random projection (not trained) |
我们模型的一个有趣的方面是,尽管其大小为 万个可训练参数,但即使数据集大小为 ,模型似乎也不会过快过拟合。 相比之下,我们发现很难在 CIFAR10 上训练具有这种大小的批量归一化的模型而不会出现明显的过度拟合。
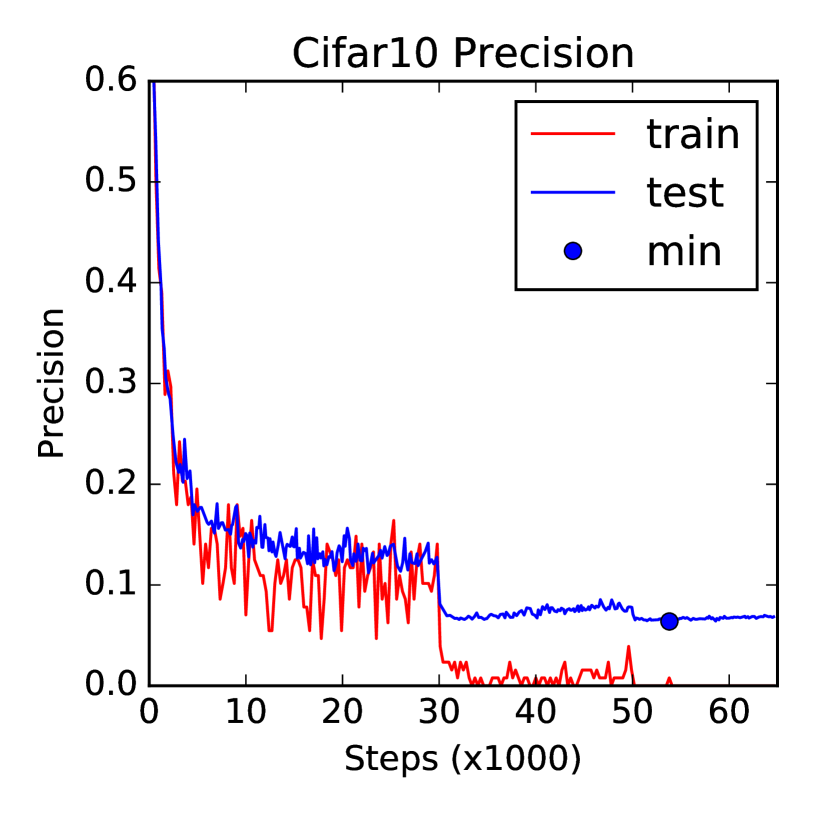
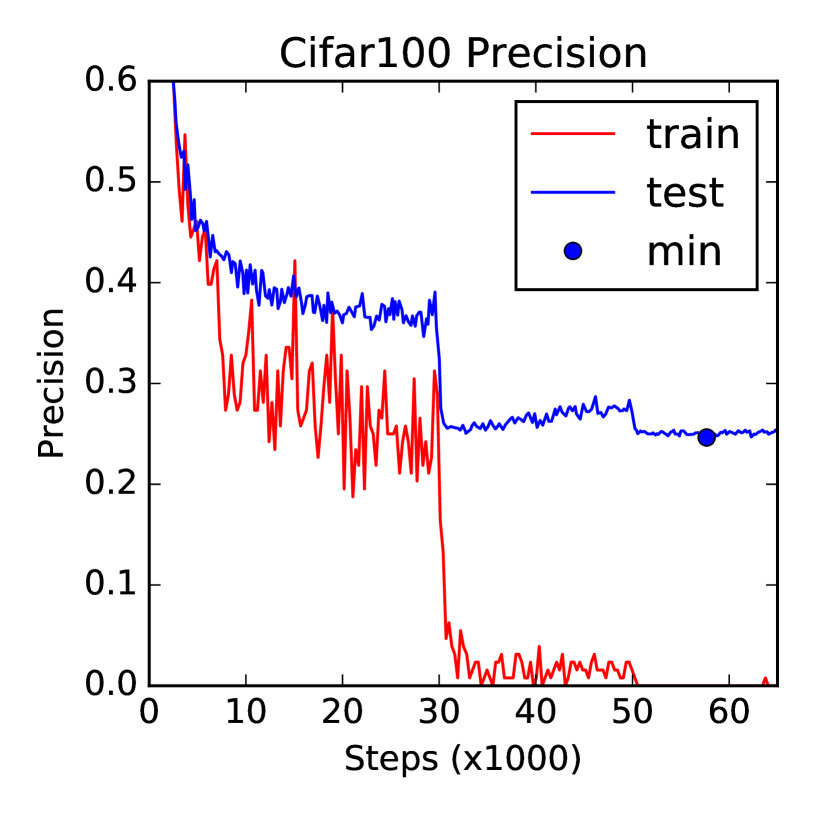
表 2 总结了我们的模型与之前工作的非详尽列表相比的 top- 分类误差,仅限于 之前的最佳全卷积结果[ 15],第一个残差结果[6],以及[8]在CIFAR上的最新结果。 所有结果均采用标准数据增强。
| Method | CIFAR10 | CIFAR100 | ImageNet |
remarks |
| All-CNN |
all-convolutional, dropout
|
|||
| Ours |
all-convolutional |
|||
| ResNet | ||||
| DenseNet | N/A |
4.2ImageNet
ImageNet ILSVRC 2012 数据集具有 个数据点和 类。 每个图像的大小都调整为具有 通道的 像素。 我们在 [6] 中尝试了 层网络的全卷积变体。 原始模型实现了分类错误。 我们的派生模型具有 可训练参数。 我们使用动量优化器(动量为 )和学习率时间表对模型进行训练,学习率时间表从初始学习率 开始,每两个历时衰减 倍。 训练分布在 机器上,异步更新。 每台机器都配备了 GPU (NVIDIA Tesla K40),并使用批量大小 分割在 GPU 上,以便每个 GPU 更新的批量大小
与 CIFAR10 和 CIFAR100 的情况相比,在 ImageNet 上,我们的全卷积模型的表现明显比其原始模型差。 具体来说,我们经历了大量的欠拟合,这表明较大的模型可能会表现更好。
尽管存在这个问题,我们的模型在测试集( 数据点)上仍然达到了 top- 分类错误,并且 top- 在 步骤后测试训练错误(大约一周)。 虽然不再是最先进的,但这种性能明显优于 [13] 报告的 以及 [15]。 我们相信,我们模型的更好的学习率计划和超参数设置很可能可以大大提高此处报告的初步性能。
5结论
我们的理论强调了训练深度人工神经网络时身份参数化的重要性。 一个突出的开放问题是将我们的优化结果扩展到非线性情况,其中每个残差都有一个 ReLU 激活,就像我们的表达结果一样。 我们推测类似于定理2.2的结果对于一般非线性情况是正确的。 与标准参数化不同,我们认为获得这样的结果没有根本障碍。
我们希望我们的理论和实验共同帮助简化深度学习的状态,旨在用一些基本原理来解释深度学习的成功,而不是需要巧妙组合的大量技巧。 我们相信,图像识别方面的大部分进步可以仅通过残差卷积层和 ReLU 激活来实现。 这可能会导致极其简单(尽管很深)的架构,与所有图像分类基准的最新技术相匹配。
致谢:我们感谢 Jason D. Lee、Qixing Huang 和 Jonathan Shewchuk 进行了有益的讨论,并善意地指出了本文早期版本中的错误。 我们还感谢 Jonathan Shewchuk 建议改进方程 (2.3),并将其纳入当前版本。 马腾宇感谢Dodds Fellowship和Siebel奖学金的支持。
参考
- [1] Antonio Auffinger, Gérard Ben Arous, and Jiří Černỳ. Random matrices and complexity of spin glasses. Communications on Pure and Applied Mathematics, 66(2):165–201, 2013.
- [2] P. Baldi and K. Hornik. Neural networks and principal component analysis: Learning from examples without local minima. Neural Netw., 2(1):53–58, January 1989.
- [3] Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks. In AISTATS, 2015.
- [4] Yann N Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In Advances in neural information processing systems, pages 2933–2941, 2014.
- [5] I. J. Goodfellow, O. Vinyals, and A. M. Saxe. Qualitatively characterizing neural network optimization problems. ArXiv e-prints, December 2014.
- [6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In arXiv prepring arXiv:1506.01497, 2015.
- [7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV, pages 630–645, 2016.
- [8] Gao Huang, Zhuang Liu, and Kilian Q. Weinberger. Densely connected convolutional networks. CoRR, abs/1608.06993, 2016.
- [9] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, pages 448–456, 2015.
- [10] William B Johnson and Joram Lindenstrauss. Extensions of lipschitz mappings into a hilbert space. Contemporary mathematics, 26(189-206):1, 1984.
- [11] H. Karimi, J. Nutini, and M. Schmidt. Linear Convergence of Gradient and Proximal-Gradient Methods Under the Polyak-Lojasiewicz Condition. ArXiv e-prints, August 2016.
- [12] K. Kawaguchi. Deep Learning without Poor Local Minima. ArXiv e-prints, May 2016.
- [13] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [14] D. Soudry and Y. Carmon. No bad local minima: Data independent training error guarantees for multilayer neural networks. ArXiv e-prints, May 2016.
- [15] J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller. Striving for Simplicity: The All Convolutional Net. ArXiv e-prints, December 2014.
- [16] Eric W. Weisstein. Normal matrix, from mathworld–a wolfram web resource., 2016.
- [17] Wikipedia. Johnson–lindenstrauss lemma — wikipedia, the free encyclopedia, 2016.
附录 A 第 2 部分缺少证明
A.1 定理证明2.1
事实证明,如果假设是一个对称正半定(PSD)矩阵,或者如果我们允许变量是复矩阵,那么证明会容易得多。 这里我们首先给出第一个特殊情况的证明草图。 读者可以跳过它并跳转到下面的完整证明。 对于特殊情况,我们还将证明更强的结果,即 。
当是PSD时,它可以通过正交矩阵进行对角化,在的意义上,其中是对角矩阵非负对角线条目。 让,然后我们有
| (since ) | ||||
我们看到由 定义的网络重建了变换 ,因此它是总体风险的全局最小值(正式参见下面的声明 2.3)。 接下来,我们验证每个 具有较小的谱范数:
| (since is orthonormal) | ||||
| (A.1) |
从开始,我们有。 它遵循
| (since for all ) |
然后使用方程 (A.1) 和上面的方程,我们得到 ,它完成了特殊情况的证明。
为了充分证明定理2.1,我们从以下声明开始:
Claim A.1.
假设 是正交矩阵。 那么对于任意整数,存在矩阵和对角矩阵满足(a)和,(b) 是一个对角矩阵,对角线上有 ,并且 (c) 如果 是旋转,则 .
证明。
我们首先考虑是旋转的情况。 每个旋转矩阵可以写为。 假设。 然后我们可以取和。 我们可以验证
接下来,我们考虑 是反射的情况。 那么我们可以将 写为 ,其中 是相对于 轴的反射。 然后我们就可以取和来完成证明。 ∎
接下来给出定理2.1的正式完整证明。 主要思想是减少块对角线情况并应用上述权利要求。
定理证明2.1。
令 为 的奇异值分解,其中 、 为两个正交矩阵,是对角线上具有非负项的对角矩阵。 由于和,我们可以适当翻转,以便。 由于 是一个正矩阵(即 满足 ),根据权利要求 C.1,我们可以将 通过正交矩阵 分块对角化为 ,其中 是一个实数分块对角矩阵,每个分块 的大小最多为 。 使用声明A.1,我们可以得出对于任何,都存在,使得
| (A.2) |
和。 让 和 。 我们可以将方程 (A.2) 重写为
| (A.3) |
此外,我们有 是一个对角矩阵,对角线上有 。 由于 是行列式为 1 的正交矩阵,因此我们有 。 也就是说, 在对角线上有偶数个 。 然后我们可以将 分组为 块。 请注意, 是旋转矩阵。 因此,我们可以将 写为对角线上的 和块 的串联。 然后应用声明A.1(在每个块上),我们得到使得
| (A.4) |
其中。 因此,使用方程 (A.3) 和 (2.3),我们得到
此外,对于每个 、,我们都有它,因为 是正交矩阵。 对于也可以证明同样的道理。 因此让 代表 和 ,我们可以重写,
我们可以通过将 分解为 矩阵(与单位矩阵 接近)来类似地处理 ,
最后,我们处理对角矩阵。让。 我们有。 然后,我们可以写,其中和是稍后选择的整数。 我们有 。 当 时,我们有
| (since for ) |
让,然后我们有。 最后,我们选择和, 666这里为了符号方便,不选择为整数。 但是将它们四舍五入到最接近的整数将会以小的常数因子改变范数的最终界限。 并让。 我们有 和
此外,根据需要,我们还有 。 ∎
A.2 引理证明2.4
附录B第3部分缺少证明
在本节中,我们提供定理3.2的完整证明。 我们从以下引理开始,构建一个构建块 ,将任意 向量序列的 向量转换为任意向量集,并且 main他人的价值。 为了更好的抽象,我们使用 , 来表示向量序列。
Lemma B.1.
令 的大小为 。假设 是 向量的序列,对于每个 满足 a),我们有 ,并且 b) 如果 和 至少包含 之一,然后是 。 令 为任意向量序列。 那么,存在,这样对于每个,我们有,此外,对于每个,我们有。
引理B.1的证明。
不失一般性,假设。 我们构造 如下。 令 的第 行为 的 ,并令 其中 表示全1的向量。 令 的 列为 的 。 接下来我们验证一下构造的正确性。 我们首先考虑。 我们知道 是一个向量,其 坐标等于 。 的第 坐标等于 ,可以使用引理假设将其上限设置为
| (B.1) |
因此,这意味着 包含单个正条目(其值至少为 ),而所有其他条目均为非正条目。 这意味着 其中 是第 个自然基向量。 由此可见。 最后,考虑。那么与式(B.1)中的计算类似,是所有坐标都小于的向量。 因此 是一个具有负项的向量。 因此我们有 ,这意味着 。 ∎
现在我们准备好声明引理 3.3 的正式版本。
Lemma B.2.
假设 向量 的序列满足假设 3.1 的宽松版本:a) 对于每个 , b) 对于每个 ,我们有 。 让 被定义在上面。 然后存在权重矩阵,这样给定,我们有,
我们将重复使用引理B.1来构造积木,从而证明引理B.2。 每个构建块 获取 中 向量的子集,并将它们转换为 的,同时将所有其他向量保持为固定的。 由于它们完全是 层,因此我们最终将所有 映射到目标向量 。
引理B.2的证明。
我们重复使用引理B.1。 让。 然后使用引理B.1与和对于,我们得到存在这样对于,它保持,对于,它保持。 现在我们归纳构建其他层。 我们将构建这样的图层:图层 的隐藏变量满足 中的每一个 ,以及 中的每一个 。 假设我们已经构造了第一个 层,接下来我们使用引理 B.1 构造 层。 然后我们认为、和的选择满足引理B.1的假设。 事实上,因为 是均匀随机选择的,所以我们对每个 和 、 都有 w.h.p。 因此,从 开始,我们就知道 也与任何 都不相关。 然后我们应用引理B.1并得出结论,存在使得对于, 代表 , 代表 。这些意味着
因此,我们构建了满足层 归纳假设的 层。 因此,通过归纳我们得到了所有层,最后一层对于每个示例都满足。 ∎
定理证明3.2。
我们使用形式化下面讨论的直觉定理3.2。 First, take for sufficiently large absolute constant (for example, works), by Johnson-Lindenstrauss Theorem ([10], or see [17]) we have that when is a random matrix with standard normal entires, with high probability, all the pairwise distance between the the set of vectors are preserved up to factor. 也就是说,我们对每个 、 和每个 、 都有它。 让 和 。 那么我们就有 满足 Lemam B.2 的条件。 我们在中选择个随机向量。 让定义为等式(3.2)。 然后通过引理 B.2,我们可以构造矩阵 使得
| (B.2) |
请注意, 和 是随机单位向量。 因此,选择、,并且满足引理B.1的条件,并使用引理B.1 我们得出结论,存在 使得
| (B.3) |
附录C工具箱
在本节中,我们将陈述两个民间传说的线性代数陈述。 下面的声明应该是已知的,但我们在文献中找不到它。 为了完整性,我们在这里提供证明。
Claim C.1。
令为实数正规矩阵(即满足)。 那么,存在一个正交矩阵 使得
其中是一个真正的块对角矩阵,由大小最多为的块组成。
证明。
由于 是正规矩阵,因此它可酉对角化(有关背景,请参阅 [16])。 因此,中存在酉矩阵,中存在对角矩阵,使得具有特征分解。 由于 本身是一个实数矩阵,因此特征值( 的对角线条目)以共轭对的形式出现,特征向量()。 也就是说,我们可以将的列分组为对,并令相应的特征值为。 这里。 然后我们就得到了。 令,则我们有是一个2阶实数矩阵。 令 为 列跨度的正交基,然后我们可以将 写为 ,其中 是一个 矩阵。 最后让和我们完成证明。 ∎
下面的权利要求用于证明定理2.2。 我们在这里提供完整性证明。
Claim C.2 (民间传说)。
对于任意两个矩阵 ,我们有
证明。
由于 是 的最小特征值,因此我们有
因此,可以得出
两边取平方根完成证明。 ∎