使用自适应实例归一化实现实时任意风格迁移
摘要
Gatys 等人最近提出了一种神经算法,该算法以另一种图像的风格渲染内容图像,实现了所谓的风格迁移。 然而,他们的框架需要缓慢的迭代优化过程,这限制了其实际应用。 已经提出了使用前馈神经网络进行快速近似来加速神经风格迁移。 不幸的是,速度的提高是有代价的:网络通常绑定到一组固定的风格,无法适应任意新的风格。 在本文中,我们提出了一种简单而有效的方法,它首次实现了实时的任意风格迁移。 我们方法的核心是新颖的自适应实例归一化 (AdaIN) 层,该层将内容特征的均值和方差与风格特征的均值和方差对齐。 我们的方法实现了与最快的现有方法相当的速度,而没有对预定义风格集的限制。 此外,我们的方法允许灵活的用户控制,例如内容风格权衡、风格插值、颜色和空间控制,所有这些都使用单个前馈神经网络。
1 介绍
Gatys 等人et al. [16] 的开创性工作表明,深度神经网络 (DNN) 不仅编码图像的内容信息,还编码图像的风格 信息。 此外,图像风格和内容在某种程度上是可分离的:可以改变图像的风格,同时保持其内容。 [16] 的风格迁移方法足够灵活,可以组合任意图像的内容和风格。 然而,它依赖于一个过于缓慢的优化过程。
已经投入了大量的努力来加速神经风格迁移。 [24, 51, 31] 尝试训练前馈神经网络,以便通过单次前向传递来执行风格化。 大多数前馈方法的主要限制是每个网络仅限于一种风格。 有些最近的工作解决了这个问题,但它们要么仍然局限于有限的风格集 [11, 32, 55, 5], 要么比单风格迁移方法 [6] 慢得多。
在这项工作中,我们提出了第一个解决这种基本灵活性-速度困境的神经风格迁移算法。 我们的方法可以实时迁移任意新的风格,将基于优化的框架的灵活性 [16] 与最快的 前馈方法类似的速度 [24, 52] 相结合。 我们的方法受到 实例归一化 (IN) [52, 11] 层的启发,该层在 前馈风格迁移中令人惊讶地有效。 为了解释实例归一化的成功,我们提出了一种新的解释,即实例归一化通过归一化特征 统计信息来执行风格归一化,而特征统计信息被发现承载了图像的风格信息 [16, 30, 33]。 受我们解释的启发,我们引入了 IN 的一个简单扩展,即 自适应实例归一化 (AdaIN)。 给定一个内容输入和一个风格输入,AdaIN 只需调整内容输入的均值和方差以匹配 风格输入的均值和方差。 通过实验,我们发现 AdaIN 通过迁移特征统计信息有效地将前者的内容与后者的风格 相结合。 然后训练一个解码器网络,通过将 AdaIN 输出反转回图像空间来生成最终的风格化 图像。 我们的方法比 [16] 快近三个数量级,而不会牺牲将输入迁移到任意新风格的 灵活性。 此外,我们的方法在运行时提供了丰富的用户控制,而无需对训练过程进行任何修改。
2 相关工作
风格迁移。 风格迁移问题起源于非真实感渲染 [28],并且与纹理合成和迁移密切相关 [13, 12, 14]。 一些早期的方法包括线性滤波器响应的直方图匹配 [19] 和非参数采样 [12, 15]。 这些方法通常依赖于低级统计信息,并且经常无法捕获语义结构。 Gatys 等人. [16] 首次通过匹配深度神经网络卷积层中的特征统计信息,展示了令人印象深刻的风格迁移结果。 近年来,对 [16] 的一些改进已被提出。 Li 和 Wand [30] 在深度特征空间中引入了一个基于马尔可夫随机场 (MRF) 的框架来强制执行局部模式。 Gatys 等人. [17] 提出了控制风格迁移的颜色保留、空间位置和尺度的方法。 Ruder 等人. [45] 通过施加时间约束,提高了视频风格迁移的质量。
Gatys 等人. [16] 的框架基于一个缓慢的优化过程,该过程迭代地更新图像以最小化由损失网络计算的内容损失和风格损失。 即使使用现代 GPU,也可能需要几分钟才能收敛。 因此,移动应用程序中的设备内处理速度太慢,不切实际。 一种常见的变通方法是用一个前馈神经网络来代替优化过程,该神经网络经过训练以最小化相同的目标 [24, 51, 31]。 这些前馈风格迁移方法的速度比基于优化的替代方法快大约三个数量级,为实时应用打开了大门。 Wang 等人. [53] 使用多分辨率架构增强了前馈风格迁移的粒度。 Ulyanov 等人. [52] 提出了提高生成样本质量和多样性的方法。 但是,上述前馈方法的局限性在于,每个网络都与一种固定风格绑定在一起。 为了解决这个问题,Dumoulin 等人. [11] 引入了一个能够编码 风格及其插值的单个网络。 与我们的工作同时,Li et al. [32] 提出了一种前馈架构,可以合成多达 种纹理并迁移 风格。 然而,以上两种方法无法适应训练过程中未观察到的任意风格。
最近,Chen 和 Schmidt [6] 提出了一种前馈方法,该方法可以通过风格交换层迁移任意风格。 给定内容图像和风格图像的特征激活,风格交换层以逐块的方式用最匹配的风格特征替换内容特征。 然而,它们的风格交换层创建了一个新的计算瓶颈:对于 输入图像,超过 的计算量用于风格交换。 我们的方法也允许任意风格迁移,同时比 [6] 快 - 个数量级。
风格迁移的另一个核心问题是使用哪种风格损失函数。 Gatys et al. [16] 的原始框架通过匹配特征激活之间的二阶统计量来匹配风格,这些统计量由 Gram 矩阵捕获。 还提出了其他有效的损失函数,例如 MRF 损失 [30]、对抗损失 [31]、直方图损失 [54]、CORAL 损失 [41]、MMD 损失 [33] 以及通道级均值和方差之间的距离 [33]。 请注意,所有上述损失函数都旨在匹配风格图像和合成图像之间的一些特征统计量。
深度生成式图像建模。 有几种用于图像生成的替代框架,包括变分自动编码器 [27]、自回归模型 [40] 和生成式对抗网络 (GAN) [18]。 值得注意的是,GAN 在视觉质量方面取得了最令人印象深刻的成就。 已针对 GAN 框架提出了各种改进,例如条件生成 [43, 23]、多阶段处理 [9, 20] 以及更好的训练目标 [46, 1]。 GAN 也已应用于风格迁移 [31] 和跨域图像生成 [50, 3, 23, 38, 37, 25]。
3 背景
3.1 批量归一化
Ioffe 和 Szegedy [22] 的开创性工作介绍了一种批量归一化 (BN) 层,通过规范化特征统计信息显著简化了前馈网络的训练。 BN 层最初被设计用于加速判别网络的训练,但也发现它们在生成式图像建模中有效 [42]。 给定一个输入批次 ,BN 规范化每个单独特征通道的均值和标准差:
| (1) |
其中 是从数据中学习到的仿射参数; 是均值和标准差,分别针对每个特征通道跨批次大小和空间维度计算得出:
| (2) |
| (3) |
BN 在训练期间使用小批量统计信息,并在推理期间用流行的统计信息替换它们,这导致训练和推理之间存在差异。 批量重归一化 [21] 最近被提出以解决这个问题,方法是在训练期间逐渐使用流行的统计信息。 作为 BN 另一个有趣的应用,Li 等人. [34] 发现 BN 可以通过在目标域中重新计算流行的统计信息来缓解域偏移。 最近,已经提出了几种替代规范化方案,以将 BN 的有效性扩展到循环架构 [35, 2, 47, 8, 29, 44]。
3.2 实例归一化
在原始的前馈风格化方法 [51] 中,风格迁移网络在每个卷积层之后包含一个 BN 层。 令人惊讶的是,Ulyanov 等人. [52] 发现,简单地用 IN 层替换 BN 层就可以实现显著的改进:
| (4) |
与 BN 层不同的是,这里 和 是针对每个通道 和每个样本 在空间维度上独立计算的:
| (5) |
| (6) |
另一个区别是,IN 层在测试时保持不变,而 BN 层通常用总体统计量替换小批量统计量。
3.3 条件实例归一化
Dumoulin 等人. [11] 提出了一个 条件实例归一化 (CIN) 层,它学习了每个风格 的不同参数集 和 ,而不是学习单一组仿射参数 和 :
| (7) |
在训练过程中,从一个固定的风格集 ( 在他们的实验中) 中随机选择一个风格图像及其索引 。 然后,内容图像被风格迁移网络处理,在该网络中,相应的 和 被用于 CIN 层。 令人惊讶的是,该网络可以通过使用 相同 的卷积参数,但在 IN 层中使用 不同 的仿射参数来生成完全不同风格的图像。
与没有归一化层的网络相比,具有 CIN 层的网络需要 个额外的参数,其中 是网络中特征图的总数 [11]。 由于额外参数的数量随着风格数量线性增长,因此将他们的方法扩展到对大量风格 (例如,数万种) 进行建模具有挑战性。 此外,他们的方法无法在不重新训练网络的情况下适应任意新的风格。
4 解读实例归一化
尽管(条件)实例归一化取得了巨大成功,但它们为何在风格迁移方面表现特别出色仍然难以捉摸。 Ulyanov 等人. [52] 将 IN 的成功归因于其对内容图像对比度的不变性。 但是,IN 发生在特征空间中,因此它应该比像素空间中简单的对比度归一化具有更深远的影响。 也许更令人惊讶的是,IN 中的仿射参数可以完全改变输出图像的风格。
众所周知,DNN 的卷积特征统计可以捕捉图像的风格 [16, 30, 33]。 虽然 Gatys 等人. [16] 使用二阶统计量作为他们的优化目标,但 Li 等人. [33] 最近表明,匹配许多其他统计量,包括通道级均值和方差,对于风格迁移也是有效的。 受这些观察结果的启发,我们认为实例归一化通过归一化特征统计量,即均值和方差,来执行一种形式的风格归一化。 尽管 DNN 在 [16, 33] 中充当图像描述符,但我们认为生成器 网络的特征统计量也可以控制生成的图像的风格。
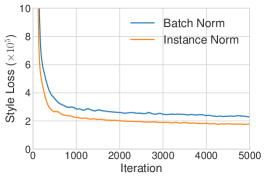
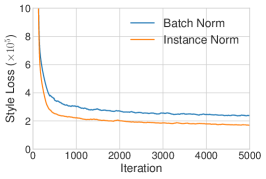
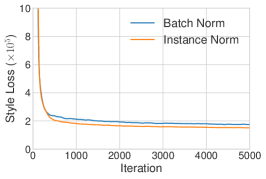
我们运行改进纹理网络的代码 [52] 以执行单风格迁移,使用 IN 或 BN 层。 正如预期的那样,使用 IN 的模型比 BN 模型收敛更快 (图 1 (a))。 为了测试 [52] 中的解释,我们随后通过对亮度通道执行直方图均衡化,将所有训练图像归一化为相同的对比度。 如图 1 (b) 所示,IN 仍然有效,表明 [52] 中的解释并不完整。 为了验证我们的假设,我们使用 [24] 提供的预训练风格迁移网络将所有训练图像归一化为相同的风格(不同于目标风格)。 根据图 1 (c),当图像已经被风格归一化时,IN 带来的改进变得更小。 剩余的差距可以用 [24] 的风格归一化并不完美这一事实来解释。 此外,在风格归一化图像上训练的具有 BN 的模型可以像在原始图像上训练的具有 IN 的模型一样快地收敛。 我们的结果表明 IN 确实执行了一种风格归一化。
由于 BN 对一批样本的特征统计进行归一化,而不是单个样本,因此可以直观地理解为将一批样本归一化为以单一风格为中心。 然而,每个单个样本可能仍然具有不同的风格。 当我们想要将所有图像转换为相同的风格时,这是不可取的,正如原始的前馈风格转换算法 [51] 中所做的那样。 虽然卷积层可能会学习补偿批内风格差异,但这对训练提出了额外的挑战。 另一方面,IN 可以将每个单个样本的风格归一化为目标风格。 训练得到简化,因为网络的其余部分可以专注于内容操作,同时丢弃原始风格信息。 CIN 成功背后的原因也变得清晰:不同的仿射参数可以将特征统计归一化为不同的值,从而将输出图像归一化为不同的风格。
5 自适应实例归一化
如果 IN 将输入归一化为仿射参数指定的单一风格,那么是否可以通过使用自适应仿射变换将其适应任意给定的风格? 在这里,我们提出了对 IN 的一个简单扩展,我们称之为自适应实例归一化 (AdaIN)。 AdaIN 接收一个内容输入 和一个风格输入 ,并简单地将 的通道级均值和方差对齐以匹配 的那些。 与 BN、IN 或 CIN 不同,AdaIN 没有可学习的仿射参数。 相反,它从风格输入自适应地计算仿射参数:
| (8) |
其中我们只是用 缩放归一化后的内容输入,并用 平移它。 与 IN 类似,这些统计信息是在空间位置上计算的。
直观地,让我们考虑一个检测特定风格笔触的特征通道。 具有这种笔触的风格图像将为该特征产生一个较高的平均激活值。 AdaIN 生成的输出将对该特征具有相同的高平均激活值,同时保留内容图像的空间结构。 笔触特征可以使用前馈解码器反转到图像空间,类似于 [10]。 该特征通道的方差可以编码更微妙的风格信息,这些信息也转移到 AdaIN 输出和最终输出图像。
简而言之,AdaIN 通过转移特征统计信息(特别是逐通道的均值和方差)在特征空间中执行风格迁移。 我们的 AdaIN 层与 [6] 中提出的风格交换层具有类似的作用。 虽然风格交换操作非常耗时且占内存,但我们的 AdaIN 层与 IN 层一样简单,几乎没有计算成本。
6 实验设置
图 2 显示了基于提出的 AdaIN 层的风格迁移网络的概述。 代码和预训练模型 (在 Torch [7] 中) 可在以下地址获取:https://github.com/xunhuang1995/AdaIN-style
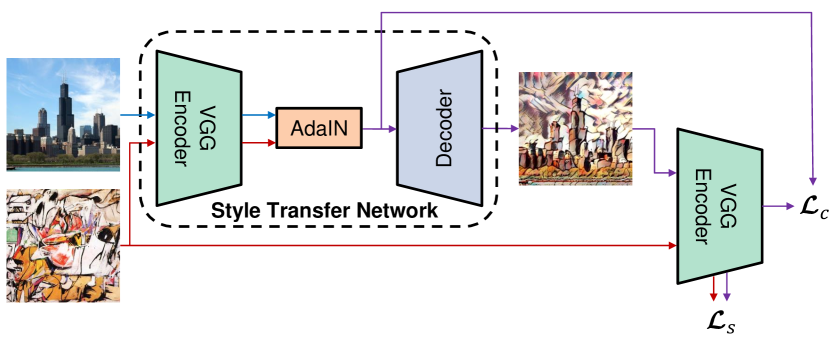
6.1 架构
我们的风格迁移网络 以内容图像 和任意风格图像 作为输入,并合成一个输出图像,该图像重新组合了前者的内容和后者的风格。 我们采用一个简单的编码器-解码器架构,其中编码器 被固定为预训练的 VGG-19 [48] 的前几层(直到 relu4_1)。 在特征空间中编码内容和风格图像之后,我们将两个特征图都馈送到一个 AdaIN 层,该层将内容特征图的均值和方差与风格特征图的均值和方差对齐,生成目标特征图 :
| (9) |
随机初始化的解码器 被训练为将 映射回图像空间,生成风格化的图像 :
| (10) |
6.2 训练
我们使用 MS-COCO [36] 作为内容图像,并使用主要从 WikiArt [39] 收集的绘画数据集作为样式图像来训练我们的网络,遵循 [6] 的设置。 每个数据集包含大约 个训练样本。 我们使用 adam 优化器 [26] 和 内容-样式图像对的批次大小。 在训练过程中,我们首先将两个图像的最小维度调整为 ,同时保持纵横比,然后随机裁剪大小为 的区域。 由于我们的网络是全卷积的,因此它可以在测试期间应用于任何大小的图像。
与 [51, 11, 52] 相似,我们使用预训练的 VGG-19 [48] 来计算损失函数以训练解码器:
| (11) |
这是一个内容损失 和样式损失 的加权组合,样式损失权重为 。 内容损失是目标特征与输出图像特征之间的欧几里得距离。 我们使用 AdaIN 输出 作为内容目标,而不是常用的内容图像特征响应。 我们发现这导致收敛速度略快,也与我们反转 AdaIN 输出 的目标相一致。
| (12) |
由于我们的 AdaIN 层只传递样式特征的均值和标准差,因此我们的样式损失只匹配这些统计数据。 虽然我们发现常用的 Gram 矩阵损失可以产生类似的结果,但我们匹配 IN 统计数据,因为它在概念上更简洁。 此样式损失也已被 Li et al. [33] 研究。
| (13) |
其中每个 表示 VGG-19 中用于计算样式损失的层。 在我们的实验中,我们使用 relu1_1、relu2_1、relu3_1、relu4_1 层,权重相同。
7 结果
7.1 与其他方法的比较
在本小节中,我们将我们的方法与三种类型的风格迁移方法进行比较:1)灵活但速度较慢的基于优化的方法 [16],2)仅限于单一风格的快速前馈方法 [52],以及 3)速度中等灵活的基于补丁的方法 [6]。 除非另有说明,否则比较方法的结果是通过使用默认配置运行其代码获得的。 111We run iterations of [16] using Johnson’s public implementation: https://github.com/jcjohnson/neural-style 对于 [6],我们使用作者提供的预训练逆网络。 所有测试图像的大小为 。
定性示例。 在图 4 中,我们展示了比较方法生成的示例风格迁移结果。 请注意,所有测试风格图像在我们的模型训练过程中都 从未 出现过,而 [52] 的结果是通过将一个网络拟合到每个测试风格获得的。 即使如此,我们风格化图像的质量对于许多图像来说 (e.g.,行 ) 与 [52] 和 [16] 相当有竞争力。 在其他一些情况下 (e.g.,行 ),我们的方法略微落后于 [52] 和 [16] 的质量。 这并不意外,因为我们认为速度、灵活性和质量之间存在三方权衡。 与 [6] 相比,对于大多数比较图像,我们的方法似乎更忠实地传递了风格。 最后一个例子清楚地说明了 [6] 的一个主要局限性,它试图将每个内容补丁与最匹配的风格补丁匹配。 但是,如果大多数内容补丁与几个不代表目标风格的风格补丁匹配,则风格迁移将失败。 因此,我们认为匹配全局特征统计量是一个更通用的解决方案,尽管在某些情况下 (e.g.,行 ) [6] 的方法也能产生吸引人的结果。











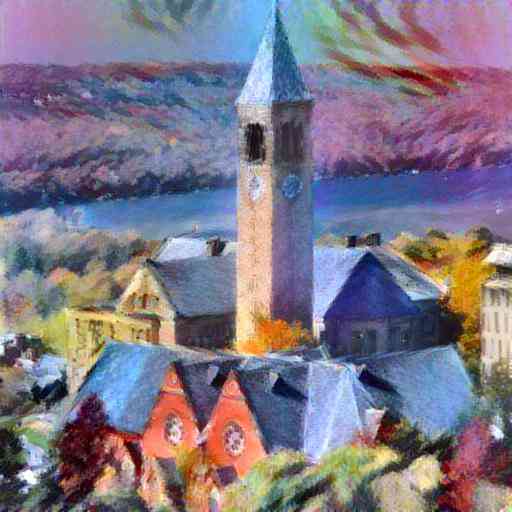












[5pt] 风格
[5pt]
风格
[5pt] 内容
[5pt]
内容
[5pt] 我们
[5pt]
我们
[5pt] Chen 和 Schmidt
[5pt]
Chen 和 Schmidt
[5pt] Ulyanov et al.
[5pt]
Ulyanov et al.
[5pt] Gatys et al.
Gatys et al.
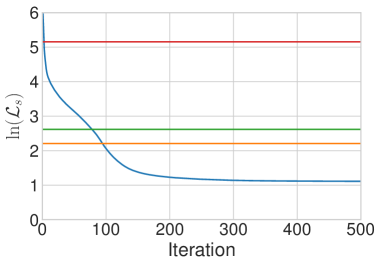
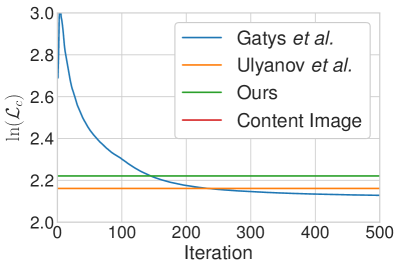
定量评估。 我们的算法是否以牺牲一定质量为代价来换取更高的速度和灵活性,如果是,程度如何? 为了定量回答这个问题,我们根据内容损失和风格损失,将我们的方法与基于优化的 [16] 方法和快速单风格迁移方法 [52] 进行比较。 由于我们的方法使用基于 IN 统计量的风格损失,我们也相应地修改了 [16] 和 [52] 中的损失函数,以便进行公平比较(图 4 中的结果仍然使用默认的 Gram 矩阵损失获得)。 这里显示的内容损失与 [52, 16] 中的相同。 报告的数字是在 风格图像和 内容图像上取平均值,这些图像是从 WikiArt 数据集 [39] 和 MS-COCO [36] 的测试集中随机选择的。
如图 3 所示,我们合成图像的平均内容和风格损失略高,但与 Ulyanov et al. [52] 的单风格迁移方法相当。 特别是,我们的方法和 [52] 在 50 到 100 次优化迭代中获得了与 [16] 相似的风格损失。 这证明了我们方法的强大泛化能力,考虑到我们的网络在训练期间从未见过测试风格,而 [52] 的每个网络都针对一个测试风格进行了专门的训练。 此外,请注意,我们的风格损失远小于原始内容图像的风格损失。
速度分析。 我们的大部分计算都花费在内容编码、风格编码和解码上,每项大约占时间的 1/3。 在某些应用场景中(例如视频处理),风格图像只需要编码一次,AdaIN 可以使用存储的风格统计信息来处理所有后续图像。 在其他一些情况下(e.g.,将相同的内容转移到不同的风格),用于内容编码的计算可以共享。
在表 1 中,我们将我们的方法的速度与以前的方法 [16, 52, 11, 6] 进行了比较。 不包括风格编码的时间,我们的算法针对 和 图像分别以 和 FPS 运行,使得能够实时处理任意用户上传的风格。 在适用于任意风格的算法中,我们的方法比 [16] 快近 个数量级,比 [6] 快 - 个数量级。 对 [6] 的速度改进对于更高分辨率的图像尤其显著,因为 [6] 中的风格交换层不能很好地扩展到高分辨率风格图像。 此外,我们的方法实现了与仅限于少数风格的前馈方法 [52, 11] 相当的速度。 我们方法的处理时间略长主要是由于我们更大的基于 VGG 的网络,而不是方法上的限制。 通过更有效的架构,可以进一步提高我们的速度。
| Method | Time (px) | Time (px) | # Styles |
| Gatys et al. | () | () | |
| Chen and Schmidt | () | () | |
| Ulyanov et al. | 0.011 (N/A) | 0.038 (N/A) | 1 |
| Dumoulin et al. | 0.011 (N/A) | 0.038 (N/A) | 32 |
| Ours | 0.018 () | 0.065 () |
7.2 其他实验。
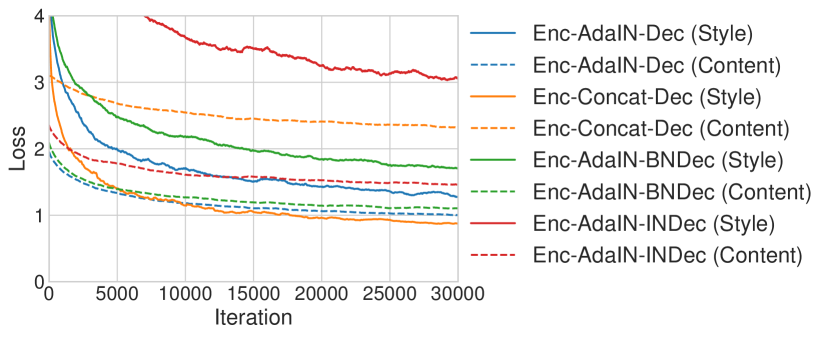
在本小节中,我们进行实验以证明我们重要的架构选择。 我们将第 6 节中描述的方法称为 Enc-AdaIN-Dec。我们实验了一个名为 Enc-Concat-Dec 的模型,该模型用串联替换了 AdaIN,这是一种将内容和风格图像信息结合起来的自然基线策略。 此外,我们在解码器中运行带有 BN/IN 层的模型,分别称为 Enc-AdaIN-BNDec 和 Enc-AdaIN-INDec。 其他训练设置保持不变。
在图 5 和 6 中,我们展示了比较方法的示例和训练曲线。 在 Enc-Concat-Dec 基线生成的图像中(图 5(d)),可以清楚地观察到风格图像的物体轮廓,表明网络未能将风格信息从风格图像的内容中分离出来。 这也与图 6 相符,其中 Enc-Concat-Dec 可以达到较低的风格损失,但未能降低内容损失。 带有 BN/IN 层的模型也获得了定性上更差的结果和始终更高的损失。 带有 IN 层的结果特别差。 这再次验证了我们的断言,即 IN 层倾向于将输出归一化为单一风格,因此当我们想要生成不同风格的图像时应避免使用它们。






7.3 运行时控制
为了进一步突出我们方法的灵活性,我们展示了我们的风格迁移网络允许用户控制风格化的程度,在不同风格之间插值,在保留颜色的同时迁移风格,以及在不同的空间区域使用不同的风格。 请注意,所有这些控制仅在运行时使用同一个网络应用,而无需对训练过程进行任何修改。
内容-风格权衡。 风格迁移的程度可以通过在训练过程中调整风格权重 在 Eqa. 11 中来控制。 此外,我们的方法允许在测试时通过在馈送到解码器的特征图之间插值来进行内容-风格权衡。 请注意,这等同于在 AdaIN 的仿射参数之间插值。
| (14) |
当 时,网络试图忠实地重建内容图像,当 时,网络试图合成最具风格化的图像。 如图 7 所示,通过将 从 更改为 ,可以观察到内容相似度和风格相似度之间的平滑过渡。
风格插值。 为了在 风格图像 集之间插值,这些图像具有相应的权重 ,使得 ,我们类似地在特征图之间插值(结果如图 8 所示):
| (15) |
[5pt] [5pt]
[5pt] [5pt]
[5pt] [5pt]
[5pt] [5pt]
[5pt] [5pt]
[5pt] 风格
风格
空间和颜色控制。 Gatys 等人. [17] 最近引入了对风格迁移的颜色信息和空间位置的用户控制,这些控制可以轻松地融入我们的框架。 为了保留内容图像的颜色,我们首先将风格图像的颜色分布与内容图像的颜色分布匹配(类似于 [17]),然后使用颜色对齐的风格图像作为风格输入执行正常的风格迁移。 图 9 中显示了示例结果。
在图 10 中,我们证明了我们的方法可以将内容图像的不同区域迁移到不同的风格。 这是通过使用来自不同风格输入的统计数据对内容特征图中的不同区域分别执行 AdaIN 来实现的,类似于 [4, 17],但完全是前馈方式。 虽然我们的解码器只在具有同质风格的输入上进行训练,但它自然地泛化到不同区域具有不同风格的输入。
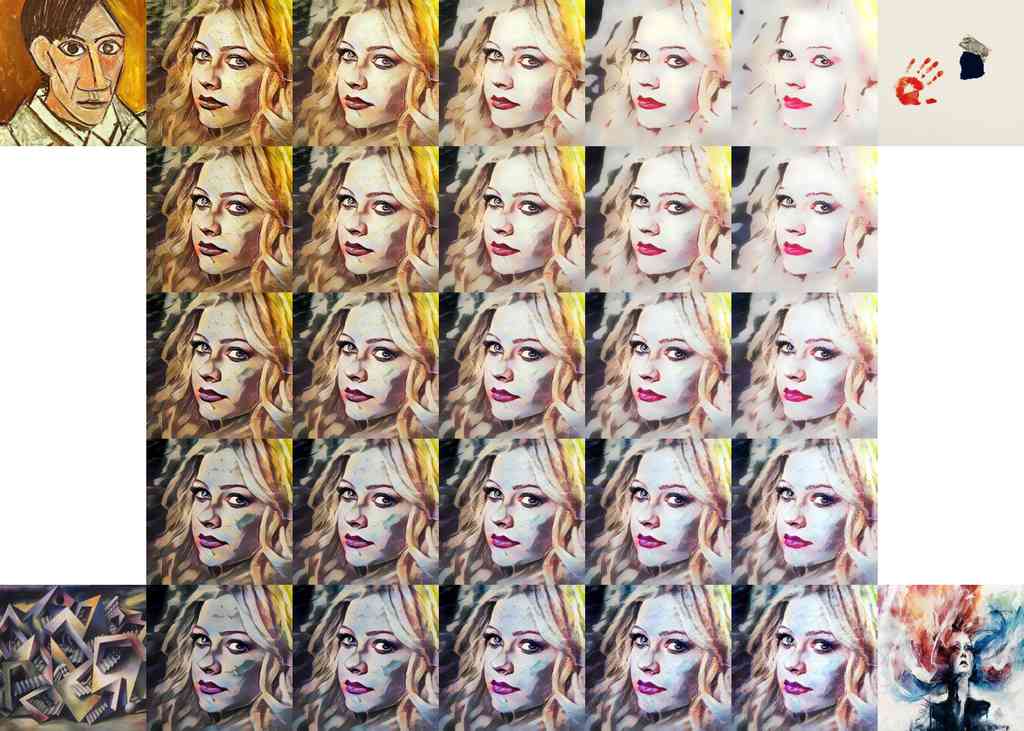
8 讨论和结论
在本文中,我们提出了一种简单的自适应实例归一化 (AdaIN) 层,它首次实现了实时任意风格迁移。 除了迷人的应用之外,我们相信这项工作也为我们对深度图像表示的理解提供了启示。
考虑我们的方法与基于特征统计的先前神经风格迁移方法之间的概念差异很有趣。 Gatys 等人. [16] 使用优化过程来操作像素值以匹配特征统计信息。 在 [24, 51, 52] 中,优化过程被前馈神经网络取代。 然而,网络被训练来修改像素值以 间接地 匹配特征统计信息。 我们采用了一种截然不同的方法,该方法 直接 在特征空间中对齐统计信息 一次性,然后将特征反转回像素空间。


鉴于我们方法的简洁性,我们相信仍有很大的改进空间。 在未来的工作中,我们计划探索更先进的网络架构,例如残差架构 [24] 或具有来自编码器附加跳跃连接的架构 [23]。 我们还计划研究更复杂的训练方案,例如增量训练 [32]。 此外,我们的 AdaIN 层仅对齐最基本特征统计(均值和方差)。 有可能用相关性对齐 [49] 或直方图匹配 [54] 替换 AdaIN 可以通过转移更高阶统计信息来进一步提高质量。 另一个有趣的方向是将 AdaIN 应用于纹理合成。






































致谢
我们感谢 Andreas Veit 的宝贵讨论。 这项工作部分得到了谷歌聚焦研究奖、AWS 云研究积分和 Facebook 设备捐赠的支持。
参考文献
- [1] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017.
- [2] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [3] K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. arXiv preprint arXiv:1612.05424, 2016.
- [4] A. J. Champandard. Semantic style transfer and turning two-bit doodles into fine artworks. arXiv preprint arXiv:1603.01768, 2016.
- [5] D. Chen, L. Yuan, J. Liao, N. Yu, and G. Hua. Stylebank: An explicit representation for neural image style transfer. In CVPR, 2017.
- [6] T. Q. Chen and M. Schmidt. Fast patch-based style transfer of arbitrary style. arXiv preprint arXiv:1612.04337, 2016.
- [7] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In NIPS Workshop, 2011.
- [8] T. Cooijmans, N. Ballas, C. Laurent, Ç. Gülçehre, and A. Courville. Recurrent batch normalization. In ICLR, 2017.
- [9] E. L. Denton, S. Chintala, R. Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In NIPS, 2015.
- [10] A. Dosovitskiy and T. Brox. Inverting visual representations with convolutional networks. In CVPR, 2016.
- [11] V. Dumoulin, J. Shlens, and M. Kudlur. A learned representation for artistic style. In ICLR, 2017.
- [12] A. A. Efros and W. T. Freeman. Image quilting for texture synthesis and transfer. In SIGGRAPH, 2001.
- [13] A. A. Efros and T. K. Leung. Texture synthesis by non-parametric sampling. In ICCV, 1999.
- [14] M. Elad and P. Milanfar. Style-transfer via texture-synthesis. arXiv preprint arXiv:1609.03057, 2016.
- [15] O. Frigo, N. Sabater, J. Delon, and P. Hellier. Split and match: example-based adaptive patch sampling for unsupervised style transfer. In CVPR, 2016.
- [16] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016.
- [17] L. A. Gatys, A. S. Ecker, M. Bethge, A. Hertzmann, and E. Shechtman. Controlling perceptual factors in neural style transfer. In CVPR, 2017.
- [18] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014.
- [19] D. J. Heeger and J. R. Bergen. Pyramid-based texture analysis/synthesis. In SIGGRAPH, 1995.
- [20] X. Huang, Y. Li, O. Poursaeed, J. Hopcroft, and S. Belongie. Stacked generative adversarial networks. In CVPR, 2017.
- [21] S. Ioffe. Batch renormalization: Towards reducing minibatch dependence in batch-normalized models. arXiv preprint arXiv:1702.03275, 2017.
- [22] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In JMLR, 2015.
- [23] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017.
- [24] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.
- [25] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim. Learning to discover cross-domain relations with generative adversarial networks. arXiv preprint arXiv:1703.05192, 2017.
- [26] D. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [27] D. P. Kingma and M. Welling. Auto-encoding variational bayes. In ICLR, 2014.
- [28] J. E. Kyprianidis, J. Collomosse, T. Wang, and T. Isenberg. State of the” art”: A taxonomy of artistic stylization techniques for images and video. TVCG, 2013.
- [29] C. Laurent, G. Pereyra, P. Brakel, Y. Zhang, and Y. Bengio. Batch normalized recurrent neural networks. In ICASSP, 2016.
- [30] C. Li and M. Wand. Combining markov random fields and convolutional neural networks for image synthesis. In CVPR, 2016.
- [31] C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. In ECCV, 2016.
- [32] Y. Li, C. Fang, J. Yang, Z. Wang, X. Lu, and M.-H. Yang. Diversified texture synthesis with feed-forward networks. In CVPR, 2017.
- [33] Y. Li, N. Wang, J. Liu, and X. Hou. Demystifying neural style transfer. arXiv preprint arXiv:1701.01036, 2017.
- [34] Y. Li, N. Wang, J. Shi, J. Liu, and X. Hou. Revisiting batch normalization for practical domain adaptation. arXiv preprint arXiv:1603.04779, 2016.
- [35] Q. Liao, K. Kawaguchi, and T. Poggio. Streaming normalization: Towards simpler and more biologically-plausible normalizations for online and recurrent learning. arXiv preprint arXiv:1610.06160, 2016.
- [36] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- [37] M.-Y. Liu, T. Breuel, and J. Kautz. Unsupervised image-to-image translation networks. arXiv preprint arXiv:1703.00848, 2017.
- [38] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In NIPS, 2016.
- [39] K. Nichol. Painter by numbers, wikiart. https://www.kaggle.com/c/painter-by-numbers, 2016.
- [40] A. v. d. Oord, N. Kalchbrenner, and K. Kavukcuoglu. Pixel recurrent neural networks. In ICML, 2016.
- [41] X. Peng and K. Saenko. Synthetic to real adaptation with deep generative correlation alignment networks. arXiv preprint arXiv:1701.05524, 2017.
- [42] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016.
- [43] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. In ICML, 2016.
- [44] M. Ren, R. Liao, R. Urtasun, F. H. Sinz, and R. S. Zemel. Normalizing the normalizers: Comparing and extending network normalization schemes. In ICLR, 2017.
- [45] M. Ruder, A. Dosovitskiy, and T. Brox. Artistic style transfer for videos. In GCPR, 2016.
- [46] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training gans. In NIPS, 2016.
- [47] T. Salimans and D. P. Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In NIPS, 2016.
- [48] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- [49] B. Sun, J. Feng, and K. Saenko. Return of frustratingly easy domain adaptation. In AAAI, 2016.
- [50] Y. Taigman, A. Polyak, and L. Wolf. Unsupervised cross-domain image generation. In ICLR, 2017.
- [51] D. Ulyanov, V. Lebedev, A. Vedaldi, and V. Lempitsky. Texture networks: Feed-forward synthesis of textures and stylized images. In ICML, 2016.
- [52] D. Ulyanov, A. Vedaldi, and V. Lempitsky. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In CVPR, 2017.
- [53] X. Wang, G. Oxholm, D. Zhang, and Y.-F. Wang. Multimodal transfer: A hierarchical deep convolutional neural network for fast artistic style transfer. arXiv preprint arXiv:1612.01895, 2016.
- [54] P. Wilmot, E. Risser, and C. Barnes. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv preprint arXiv:1701.08893, 2017.
- [55] H. Zhang and K. Dana. Multi-style generative network for real-time transfer. arXiv preprint arXiv:1703.06953, 2017.